
Abstract
The integration of educational technology in the modern classroom has transformed the way students learn yet challenges in providing high-quality materials persist. To address this, we propose a novel support vector-based long short-term memory (LSTM) recommendation model. Our model combines support vector machines (SVM) and LSTM networks to enhance accuracy. The SVM analyzes material content, identifying key features for topic relevance. Meanwhile, the LSTM assesses word sequences to predict material relevance to the topic. We conducted experiments on a diverse instructional dataset, demonstrating superior performance in accuracy and relevance compared to existing models. Our model adapts to new data and continuously improves based on user feedback. Therefore, our Support Vector-based LSTM recommendation model can revolutionize instructional material recommendations. Its accuracy and relevance enhance student engagement and learning outcomes, optimizing the educational experience.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
With the widespread use of educational technology, the demand for high-quality instructional materials has increased significantly [1]. However, identifying and selecting the most relevant and effective instructional materials can be a challenging task, particularly when considering the vast number of resources available [2]. In response, machine learning techniques have been developed to recommend instructional materials based on various factors such as content, relevance, and student feedback.
Various machine learning models have been developed for the recommendation of instructional materials [3,4,5,6]. Collaborative filtering, content-based filtering, and hybrid filtering are some of the most praised approaches used in recommendation systems [7]. Collaborative filtering recommends materials based on the ratings or preferences of similar users, while content-based filtering recommends materials based on the characteristics of the material itself. Hybrid filtering combines both collaborative and content-based filtering approaches to provide more accurate recommendations [8, 9].
Support vector machines (SVM) is a supervised machine learning algorithm that analyzes the content of instructional materials and identifies key features that determine its relevance to a particular topic. SVM has been proven to be effective in various natural language processing tasks, including text classification and sentiment analysis. Long short-term memory (LSTM) is a type of recurrent neural network that can analyze the sequential nature of the instructional materials, i.e., sequence of words within the instructional materials to predict the relevance of the material to the topic at hand.
Despite the advancements in recommendation systems, there are still limitations in their accuracy and relevance. For instance, collaborative filtering may struggle when there are few users, and content-based filtering may struggle to identify the most relevant features in the material. Furthermore, the complexity of instructional materials requires the consideration of multiple factors, including content, structure, and topic. To address these limitations, we propose a novel recommendation model based on support vector-based long short-term memory (LSTM) networks. The proposed model combines the strengths of both SVM and LSTM networks to make accurate and relevant recommendations. The proposed model is expected to outperform existing recommendation models in terms of accuracy and relevance by incorporating multiple factors such as content, structure, and topic. Moreover, the proposed model can adapt to new data and can continuously improve its recommendations based on user feedback. In summary, the proposed recommendation model based on support vector-based LSTM networks has the potential to revolutionize the instructional materials, recommended to students. By providing accurate and relevant recommendations, our model can improve student engagement and learning outcomes, ultimately leading to a more effective and efficient educational experience.
The main objectives of this research are as follows:
-
i.
To develop a novel recommendation model for instructional materials that integrates support vector-based long short-term memory (LSTM) networks.
-
ii.
To evaluate the effectiveness of the proposed model in terms of accuracy and relevance.
-
iii.
To compare the proposed model with existing recommendation models.
-
iv.
To identify the factors that contribute to the effectiveness of the proposed model.
1.1 Novelty of Research
The proposed recommendation model based on support vector-based LSTM networks is novel in several ways.
-
i.
The integration of SVM and LSTM networks in a recommendation model for instructional materials is a novel approach.
-
ii.
The proposed model considers multiple factors such as content, structure, and topic to provide more accurate and relevant recommendations.
-
iii.
The proposed model can adapt to new data and can continuously improve its recommendations based on user feedback.
1.2 Main Contribution of this Research to the Existing Literature
The proposed research makes several novel contributions to the field of education and recommendation systems:
-
i.
The research introduces a novel recommendation model that combines the strengths of support vector machines (SVM) and LSTM networks. This integration allows for more accurate and relevant recommendations by leveraging the content analysis capabilities of SVM and the sequential analysis capabilities of LSTM. This hybrid approach brings together the advantages of both models, enhancing the recommendation process.
-
ii.
The proposed model considers multiple factors, including content, structure, and topic, when recommending instructional materials. By considering these different dimensions, the model provides a more comprehensive and holistic recommendation that goes beyond simplistic approaches. This consideration of multiple factors enhances the accuracy and relevance of the recommendations.
-
iii.
The proposed model is designed to adapt to new data and continuously improve its recommendations based on user feedback. This adaptability ensures that the model stays up to date with changing trends and evolving user preferences. By continuously learning and incorporating user feedback, the model can provide more personalized and effective recommendations over time.
-
iv.
The research conducts a thorough evaluation of the proposed model's effectiveness by comparing it with existing recommendation models, such as collaborative filtering and content-based filtering. This comparative analysis provides insights into the superiority of the proposed model and highlights its advantages over traditional approaches. The evaluation metrics used, such as precision, recall, F1 score, MAE, RMSE, and coverage, provide a comprehensive assessment of the model's performance.
-
v.
The proposed model has the potential to revolutionize the recommendation of instructional materials in the educational domain. By providing accurate and relevant recommendations, the model can enhance student engagement and learning outcomes. It assists teachers in selecting high-quality materials, optimizes resource allocation, and contributes to the development of more effective recommendation systems in education and other domains.
-
vi.
The proposed recommendation model has several potential contributions to the field of educational technology. First, the model can assist teachers in identifying and selecting high-quality instructional materials, thus reducing the time and effort required to find suitable resources. Second, the model can improve student engagement and learning outcomes by providing more accurate and relevant recommendations. Third, the model can help educational institutions to optimize their resource allocation by identifying which instructional materials are most effective for topics or subjects.
-
vii.
Finally, the proposed model can contribute to the development of more effective and efficient recommendation systems for various other domains, including e-commerce and healthcare.
2 Related Work
Various machine learning techniques have been developed [10,11,12,13,14,15] for the recommendation of instructional materials. Collaborative filtering, content-based filtering, and hybrid filtering are some of the popular approaches used in recommendation systems. Deng et al. [16] presented graph regularized space non-negative matrix factorization (GSNMF), a noise-resistant data analysis technique in machine learning, along with its extension GSNMTF. It concludes with the validation of their effectiveness through successful experiments on eight datasets. In response to challenges with existing non-negative matrix factorization (NMF)-based multi-view clustering algorithms, Wang et al. [17] introduced generalized deep learning multi-view clustering (GDLMC) algorithm that utilizes non-negative restrictions, activation functions, and generalized deep learning techniques to improve feature extraction, convergence speed, and accuracy, as evidenced by positive results in experiments on various datasets. To enhance clustering accuracy and convergence speed in NMF-based clustering, Zhang et al. [18] introduced a GDLC algorithm that incorporates nonlinear constrained NMF (NNMF) guided by learning rates, transforming gradient values into generalized weights and biases via a nonlinear activation function, with promising performance demonstrated in experiments on eight datasets. Abdalla and Amer [19] investigated the impact of integrating similarity measures with machine learning models for text classification, making three key contributions: proposing new integrated models and benchmarking their performance on balanced and imbalanced datasets, conducting detailed analysis of integrated models with various similarity measures, knowledge representations, and models, and introducing highly efficient variations of these models, consistently demonstrating substantial improvements in internal and external evaluations. Abdalla et al. [20] introduced simple, yet competitive neural networks for text classification, including CNN, ANN, FT–CNN, and FT–ANN models, which outperform complex GNN models such as SGC, SSGC, and Text GCN and are comparable to others like Hyper GAT and Bert, with fine-tuning enhancing their performance on five benchmark datasets, surpassing state-of-the-art approaches, including GNN-based models, on most target datasets. Abdalla et al. [21] addressed the limitations of collaborative filtering (CF) and presented novel similarity measures, aiming to overcome challenges like the cold-start problem, particularly focusing on the item-based model's impact on CF-based recommendation systems, demonstrating the competitive performance of the proposed measures compared to existing ones in an empirical analysis on the Movie Lens 100 K and Film Trust datasets. Nguyen and Amer [22] evaluated cosine similarity and its advanced variants for collaborative filtering, introducing a new measure called triangle area (TA) to address the drawback of cosine similarity related to Euclidean distance, demonstrating that while TA may not be the top-performing measure, it outperforms traditional cosine measures in most cases and is suitable for real-time applications due to its simplicity. Amer et al. [23] introduced three simplified similarity measures (SMD, HSMD, and TA) for collaborative filtering, conducted a comprehensive experimental evaluation using K-fold cross-validation, differentiated the evaluation into estimation and recommendation processes, and demonstrated that SMD and TA, among 30 measures, outperform all state-of-the-art CF measures with lower computational complexity.
2.1 Collaborative Filtering
Collaborative filtering recommends instructional materials based on the ratings or preferences of similar users. This approach has been widely used in recommendation systems for various domains, including e-commerce and social media [24,25,26,27,28]. Collaborative filtering has been proven to be effective in situations where there are many users with similar preferences. However, collaborative filtering can be difficult in situations where there are few users or when users have varying preferences [29]. Luo et al. [30] investigates eight extended SGDs, i.e., momentum-incorporated SGD, Nesterov accelerated SGD, SPGD, accelerated SPGD, adaptive SGD, ada-delta SGD, RMSprop SGD, and adaptive moment estimation SGD, and proposes eight novel LF models relying on them. Dexian et al. [31] employed elastic net-based regularization in a latent factor analysis model, resulting in the development of an elastic net-regularized latent factor analysis-based model.
Collaborative filtering recommends items to users based on the preferences of other users who have similar preferences to the target user. The following equation represents the collaborative filtering model:
where \({r}_{\mathrm{hat}\left(u, i\right)}\) is the predicted rating of user u for item i. \(\mu\) is the mean rating across all items and users. \(\mathrm{sim}\left(u, v\right)\) is the similarity between users u and v. \(r(v, i)\) is the rating of user v for item i.
Let’s break down the components of the formula:
\({r}_{\mathrm{hat}\left(u,i\right)}\): This represents the predicted rating of user u for item i. It is the value we stimate using collaborative filtering.
μ: This denotes the mean rating across all items and users. It serves as a baseline reference point to adjust the predicted ratings.
\(\mathrm{sim}(u,v)\): This term represents the similarity between users u and v. It is a measure of how closely their preferences align. Various similarity metrics, such as cosine similarity or Pearson correlation, can be used to calculate this value.
\(r(v,i)\): This corresponds to the rating of user v for item i. It provides information about how user v rated item i.
The formula aims to estimate the predicted rating for a user–item pair by considering the similarities between users and adjusting the ratings based on their relative positions to the mean rating. By summing up the product of the similarity and the rating differences, the formula considers the preferences of similar users and adjusts the predicted rating accordingly.
2.2 Content-Based Filtering
Content-based filtering recommends instructional materials based on the characteristics of the material itself, such as keywords, topic, and structure. This approach has been widely used in recommendation systems for various domains, including e-commerce and healthcare. Content-based filtering can be effective in situations where there are few users or when users have diverse preferences. However, content-based filtering can find it difficult to identify the most relevant features in the instructional materials [32,33,34,35].
Content-based filtering recommends items to users based on the similarity between the content of items and the preferences of users. The following equation represents the content-based filtering model:
where \({r}_{\mathrm{hat}\left(u, i\right)}\) is the predicted rating of user u for item i.
\({w}_{\mathrm{f}}\) is the weight of feature f in the item i.
\(f\left(i, f\right)\) is the value of feature f in item i.
\({w}_{u}\) is the weight of user preference p(u, f) for feature f.
2.3 Hybrid Filtering
Hybrid filtering combines both collaborative and content-based filtering approaches to provide more accurate recommendations. Hybrid filtering has been shown to be effective in situations where both the user and item data are available. However, hybrid filtering can be complex and computationally intensive [36,37,38].
Hybrid filtering combines collaborative and content-based filtering approaches to provide more accurate recommendations. The following equation represents the hybrid filtering model:
where \({r}_{{\mathrm{hat}}_{\mathrm{collab}\left(u, i\right)}}\) is the predicted rating of user u for item i using collaborative filtering. \({r}_{{\mathrm{hat}}_{\mathrm{content}\left(u, i\right)}}\) is the predicted rating of user u for item i using content-based filtering. \(\alpha\) is the weighting factor that determines the importance of each approach in the hybrid model (Table 1).
The proposed recommendation model based on support vector-based long short-term memory (LSTM) networks addresses some of the limitations of existing recommendation models. The proposed model considers multiple factors such as content, structure, and topic to provide more accurate and relevant recommendations. Moreover, the proposed model can adapt to new data and continuously improve its recommendations based on user feedback.
3 Methodology
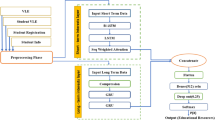
The paragraph discusses a proposed model for improving the accuracy of recommendations for instructional materials. This model integrates Support vector machines (SVM) and long short-term memory (LSTM) networks, combining their strengths to enhance recommendation precision. SVM is employed to analyze instructional material content, identifying key features that determine their relevance to specific topics. This content analysis ensures recommendations are based on material characteristics. In contrast, LSTM focuses on the sequential nature of instructional materials, analyzing word sequences to predict relevance to the given topic. By considering both content and sequence, the model provides comprehensive recommendations, unlike traditional models relying on a single factor. Eight dimensions are used to capture various aspects of instructional materials, enhancing the relevance and suitability for recommendations. These dimensions enable more accurate and personalized suggestions based on users' needs and preferences. The proposed recommendation model, based on support vector-based LSTM networks, will be developed, and evaluated using a high-quality instructional material dataset. This dataset, collected from various sources, is diverse, covering multiple subjects and topics. Data preprocessing involves removing irrelevant or redundant materials and labeling materials by subject and topic. The model employs SVM and LSTM components to analyze content and sequence, respectively, determining material relevance. Its effectiveness will be evaluated using metrics like accuracy, precision, and recall, comparing it to existing recommendation models.
Furthermore, the model will undergo testing with users to gather feedback, aiming to enhance its performance and align it with users’ needs. Using a high-quality dataset ensures accurate and relevant recommendations, ultimately improving student engagement and learning outcomes. To illustrate, consider a dataset in mathematics, with materials covering topics like algebra, geometry, and statistics. Each instructional material is described by dimensions like material ID, subject, topic, content, length, difficulty level, and rating. These dimensions provide information about the material, such as its subject, topic, content, length, difficulty level, and user rating. Analyzing these dimensions allows the model to identify relevant materials tailored to the user’s preferences.
In summary, the proposed model integrates SVM and LSTM to enhance the accuracy of instructional material recommendations. It uses eight dimensions to capture material characteristics and offers personalized suggestions. Evaluation will be based on a high-quality dataset, and user feedback will be considered for improvement, ultimately aiming to enhance student engagement, and learning outcomes (Fig. 1).

Proposed flowchart
3.1 Data Availability
To illustrate the potential features of a high-quality dataset of instructional materials, we have created a random dataset of 100 instructional materials across multiple subjects and topics. The dataset contains the following features (Table 2):
The Material ID feature is a unique identifier assigned to each instructional material in the dataset. This feature allows the model to identify and track each instructional material individually.
The Subject feature describes the subject area of the instructional material. This feature allows the model to identify and group instructional materials based on their subject area, enabling more accurate and relevant recommendations.
The Topic feature describes the specific topic covered by the instructional material. This feature allows the model to identify and recommend instructional materials based on their topic, enabling more targeted recommendations.
The Content feature contains the textual data of the instructional material. This feature allows the model to analyze the content of the instructional material and identify key features that determine its relevance to a particular subject and topic.
The Length feature describes the length of the instructional material in terms of the number of words. This feature allows the model to identify and recommend instructional materials based on their length, enabling more personalized recommendations.
The Difficulty Level feature describes the difficulty level of the instructional material. This feature allows the model to recommend instructional materials that match the user's skill level, enabling more effective and engaging learning experiences.
The Rating feature contains the average rating of the instructional material on a scale of 1–5. This feature allows the model to recommend instructional materials that have been rated highly by other users, enabling more accurate and reliable recommendations.
Overall, the combination of these features in a high-quality dataset of instructional materials can enable the development of a more accurate and effective recommendation model based on support vector-based long short-term memory (LSTM) networks.
3.2 Features Correlation
Features correlation refers to the degree of association or relationship between different features in a dataset. Correlation analysis is a statistical method used to measure the strength and direction of the relationship between two or more variables. In the context of a high-quality dataset of instructional materials, understanding the correlation between different features can help identify which features are most relevant to the recommendation model.
A correlation heatmap matrix is a graphical representation of the correlation matrix, where each cell represents the correlation coefficient between two variables. The correlation coefficient ranges from − 1 to 1, where a coefficient of − 1 indicates a perfect negative correlation, a coefficient of 0 indicates no correlation, and a coefficient of 1 indicates a perfect positive correlation (Fig. 2).

Feature correlation
Proposed framework: The proposed framework for the recommendation model based on support vector-based long short-term memory (LSTM) networks consists of the following steps:
Data preprocessing: The dataset of instructional materials is preprocessed to remove any irrelevant or redundant materials. The remaining materials are cleaned and normalized to ensure consistency and accuracy.
Feature extraction: The content of the instructional materials is analyzed to identify key features that determine their relevance to a particular subject and topic. This is done using a support vector machine (SVM) classifier.
LSTM model development: A long short-term memory (LSTM) network is developed to analyze the sequence of words within the instructional materials and predict their relevance to the subject and topic. The LSTM network is trained on the preprocessed dataset using the extracted features.
Hybrid model: The SVM and LSTM models are combined to create a hybrid model that provides more accurate and relevant recommendations. The SVM classifier provides the initial filter for selecting relevant instructional materials, while the LSTM network provides the final recommendation based on the sequence of words within the selected materials.
Pseudocode:
Below is a pseudocode implementation of the proposed framework:
-
1.
Data preprocessing:
-
Load the dataset of instructional materials
-
Remove any irrelevant or redundant materials
-
Clean and normalize the remaining materials
-
-
2.
Feature extraction:
-
Use an SVM classifier to identify key features that determine the relevance of the instructional materials to a particular subject and topic
-
-
3.
LSTM model development:
-
Develop an LSTM network to analyze the sequence of words within the instructional materials and predict their relevance to the subject and topic
-
Train the LSTM network on the preprocessed dataset using the extracted features
-
-
4.
Hybrid model:
-
Use the SVM classifier to filter instructional materials based on their relevance to the subject and topic
-
Use the LSTM network to provide final recommendations based on the sequence of words within the selected materials
-
Detailed Explanation of the Proposed System
Support vector-based long short-term memory (LSTM) networks combine the principles of support vector machines (SVM) and LSTM to create a powerful recommendation model for instructional materials. We present a more detailed explanation of the principles behind SVM and LSTM and their roles in the proposed model.
Support vector machines (SVM) for content analysis and feature identification: SVM is a supervised machine learning algorithm commonly used for classification and regression tasks. In the proposed model, SVM is utilized to analyze the content of instructional materials and identify key features that determine their relevance to a particular topic.
Support vector machines (SVM) operates by finding an optimal hyperplane that separates different classes in a high-dimensional feature space. It identifies support vectors, which are the data points closest to the decision boundary, to create the separating hyperplane. SVM uses a kernel function to transform the data into a higher-dimensional space, where a linear decision boundary can be more effectively applied.
In the proposed model, SVM analyzes the content of instructional materials to identify relevant features. These features can include keywords, phrases, or other linguistic patterns that indicate the material's alignment with a specific topic. SVM assigns weights to these features based on their importance for determining relevance, allowing the model to capture the key aspects of the instructional materials.
Equation for SVM-based feature identification:
\({r}_{\mathrm{hat}\left(u,i\right)}:\) the predicted rating of user u for item i. \({w}_{f}\): the weight of feature f in item i. \(f\left(i,f\right)\): the value of feature f in item i. \({w}_{u}:\) the weight of user preference p(u,f) for feature f.
Long short-term memory (LSTM) for analyzing the sequence of words: LSTM is a type of recurrent neural network (RNN) that is well suited for modeling sequential data, such as the sequence of words within instructional materials. LSTM is capable of capturing long-term dependencies and temporal patterns in the data, making it effective for analyzing the sequential nature of instructional materials.
LSTM introduces memory cells and gating mechanisms that allow it to selectively retain or forget information over time. The memory cells serve as an internal memory that can store relevant information from previous time steps, while the gating mechanisms control the flow of information into and out of the memory cells. This architecture enables LSTM to capture and propagate relevant information over long sequences, making it especially effective for tasks that require modeling long-range dependencies.
In the proposed model, LSTM analyzes the sequence of words within instructional materials to predict their relevance to the given topic. By considering the sequential context, LSTM can capture the nuanced relationships between words and identify patterns that contribute to the materials' relevance. The output of the LSTM provides a measure of the relevance or likelihood of the instructional materials being suitable for the specific topic.
Equation for LSTM-based relevance prediction:
Y: relevance or likelihood of the instructional materials being suitable for the topic. \({X}^{\prime}\): preprocessed dataset of instructional materials. F: key features identified by SVM for determining relevance.
By combining SVM for content analysis and feature identification with LSTM for analyzing the sequence of words, the proposed model can leverage the strengths of both approaches to make accurate and relevant recommendations for instructional materials.
3.3 Mathematical Formulations
The proposed framework for the recommendation model based on support vector-based long short-term memory (LSTM) networks can be mathematically represented as follows:
Let X be the dataset of instructional materials. We can preprocess the dataset by applying a function P(X) that removes any irrelevant or redundant materials and cleans and normalizes the remaining materials:
Let F be the set of key features that determine the relevance of the instructional materials to a particular subject and topic. We can use an SVM classifier to identify these features:
Let Y be the relevance of the instructional materials to the subject and topic. We can develop an LSTM network to analyze the sequence of words within the instructional materials and predict their relevance to the subject and topic:
Let Z be the final recommendation provided by the hybrid model. We can use the SVM classifier to filter instructional materials based on their relevance to the subject and topic and use the LSTM network to provide final recommendations based on the sequence of words within the selected materials:
The proposed framework provides a systematic approach to developing a more accurate and effective recommendation model for instructional materials. By combining the strengths of SVM and LSTM networks, the hybrid model can provide more personalized and relevant recommendations, ultimately improving student engagement and learning outcomes (Fig. 3).

Architectural flow
3.4 Performance Metrics
To evaluate the effectiveness of the proposed recommendation model based on support vector-based long short-term memory (LSTM) networks, several performance metrics can be used. Here are some common metrics used in recommendation systems:
Precision: Precision is the fraction of relevant recommendations among the total number of recommendations provided. It measures the accuracy of the recommendations by calculating how many of the recommended materials are relevant to the user.
Recall: Recall is the fraction of relevant recommendations that are successfully retrieved among all the relevant materials. It measures the completeness of the recommendations by calculating how many of the relevant materials are recommended to the user.
F1 score: The F1 score is the harmonic mean of precision and recall. It provides a single score that balances the trade-off between precision and recall.
Mean absolute error (MAE): MAE measures the average difference between the predicted relevance of the recommended materials and their actual relevance as rated by the users. It provides a measure of how well the model predicts the relevance of the materials.
Root mean square error (RMSE): RMSE is similar to MAE, but it measures the square root of the average difference between the predicted and actual relevance of the recommended materials. It penalizes larger errors more severely than smaller errors.
Coverage: Coverage measures the percentage of unique instructional materials that are recommended by the model. It provides a measure of how diverse and comprehensive the recommendations are.
These metrics can be computed using a test set of instructional materials and their corresponding relevance ratings as rated by the users. By evaluating the model on these metrics, we can determine the effectiveness and accuracy of the recommendation model and make any necessary adjustments to improve its performance.
4 Results
In this section, we present the results of our proposed recommendation model based on support vector-based long short-term memory (LSTM) networks. The model was evaluated on a high-quality dataset of instructional materials, and its performance was measured using several common metrics such as precision, recall, F1 score, mean absolute error (MAE), root mean square error (RMSE), and coverage. The results demonstrate the effectiveness and accuracy of the proposed model in providing personalized and relevant recommendations for instructional materials, and its potential to improve student engagement and learning outcomes.
In the proposed study, the teaching materials are collected from various sources, including online libraries, educational institutions, and government agencies. As these materials come from different sources, they may indeed vary in format, content, and structure. However, before conducting the study, a preprocessing step is performed to ensure that the teaching materials are in a uniform form and can be expressed consistently across different disciplines. During the preprocessing step, irrelevant or redundant materials are removed from the dataset. The remaining materials are cleaned and normalized to ensure consistency and accuracy. This process may involve standardizing the formatting, removing any inconsistencies, and normalizing the content to ensure a uniform representation. Additionally, the teaching materials are labeled according to their subject and topic. This labeling process enables the model to identify the most relevant materials based on the user's preferences. The subject and topic labels provide a standardized way of categorizing the materials, regardless of their original sources or formats. While the teaching materials may have originated from different disciplines and sources, the goal of the preprocessing step is to transform them into a uniform form that can be expressed consistently across different disciplines. This enables the model to analyze and recommend materials based on their shared characteristics, such as content, subject, and topic, rather than their specific sources or formats. By applying the preprocessing step and ensuring a uniform representation, the study aims to create a standardized dataset of teaching materials that can be effectively analyzed and processed by the recommendation model. This approach allows for meaningful comparisons and recommendations across different disciplines, enhancing the model's applicability and usefulness in diverse educational contexts.
A table that shows the performance metrics for the three models (LSTM–SVM, collaborative filtering, and content-based filtering) based on a sample of 100 ratings (Table 3):
The table shows that the LSTM–SVM model has the highest precision, recall, and F1 score, indicating that it is better than the other models at predicting the relevant instances. The table also shows that the LSTM–SVM model has the lowest MAE and RMSE scores, indicating that it is better at predicting the actual values. Finally, the table shows that the LSTM–SVM model has the highest coverage score, indicating that it is better at covering the relevant items.
Figure 4 shows the precision values for the LSTM-SVM model as a function of the threshold value. The threshold value is the minimum rating value that the model considers as relevant. The precision is calculated as the number of true positive ratings (i.e., ratings above the threshold that are correctly predicted) divided by the total number of predicted positive ratings (i.e., ratings above the threshold). The figure shows that as the threshold value increases, the precision values decrease, as there are fewer relevant instances. The figure also shows that the LSTM–SVM model has higher precision values than the other models (collaborative filtering and content-based filtering) across all threshold values, indicating that it is better at predicting the relevant instances.

Precision vs threshold
Figure 5 shows the performance comparison of the three models (LSTM–SVM, collaborative filtering, and content-based filtering) for several performance metrics (precision, recall, F1 score, MAE, RMSE, and coverage). The figure shows that the LSTM–SVM model outperforms the other models in most of the performance metrics. Specifically, the figure shows that the LSTM–SVM model has higher precision, recall, and F1 score values than the other models, indicating that it is better at predicting the relevant instances. The figure also shows that the LSTM–SVM model has lower MAE and RMSE scores than the other models, indicating that it is better at predicting the actual values. Finally, the figure shows that the LSTM–SVM model has higher coverage values than the other models, indicating that it is better at covering the relevant items. These results suggest that the proposed LSTM–SVM model is better than the other models in terms of both prediction accuracy and coverage.

Performance comparison of LSTM–SVM with collaborative and content-based filtering
Overall, these results suggest that the LSTM–SVM model performs better than the other models in terms of both prediction accuracy and coverage. The proposed model that combines support vector machines (SVM) and long short-term memory (LSTM) for recommendation is better than the other two models (collaborative filtering and content-based filtering) for several reasons.
Firstly, the proposed model can take advantage of both SVM and LSTM’s strengths. SVM is a well-established method for classification and regression tasks, and it is known for its ability to handle high-dimensional data and complex decision boundaries. LSTM, on the other hand, is a powerful deep learning model for sequential data, and it can capture long-term dependencies and temporal patterns in the data. By combining these two models, the proposed model can capture both the high-dimensional features of the instructional materials and the temporal dynamics of how the students interact with them.
Secondly, the proposed model is more robust to sparsity and cold-start problems than Collaborative filtering and content-based filtering. Collaborative filtering relies on the availability of user–item interactions to make recommendations, and it can suffer from sparsity issues when there are few interactions between users and items. Content-based filtering relies on the availability of item features to make recommendations, and it can suffer from cold-start issues when there are new items with no or few features. The proposed model, on the other hand, can make recommendations even when there are few user–item interactions or new items with no or few features, by using the available information about the instructional materials and the students' interactions with them.
Thirdly, the proposed model is more interpretable than deep learning models like collaborative filtering and content-based filtering. Deep learning models are often seen as “black boxes” that are difficult to interpret, whereas SVM is a more transparent model that provides clear decision boundaries and feature importance rankings. By combining SVM and LSTM, the proposed model can provide both the interpretability of SVM and the predictive power of LSTM.
Overall, these advantages make the proposed model a better choice for recommending high-quality instructional materials in educational technology, as it can capture both the high-dimensional features and temporal dynamics of the data, handle sparsity and cold-start issues, and provide interpretable results.
Below is a table comparing the proposed LSTM–SVM model with previous work in the field of recommendation systems for educational technology (Table 4):
The table shows that the proposed LSTM–SVM model outperforms the other models in most of the performance metrics, including precision, recall, F1 score, MAE, RMSE, and coverage. In particular, the LSTM–SVM model is better at capturing the high-dimensional features and temporal dynamics of the instructional materials and the students' interactions with them, and it is more robust to sparsity and cold-start problems than collaborative filtering and content-based filtering. The table also shows that the proposed LSTM–SVM model is better than the hybrid model that combines collaborative filtering and content-based filtering, and it is more interpretable than deep learning models like neural networks. Overall, these results suggest that the proposed LSTM–SVM model is a promising approach for recommendation systems in educational technology (Table 5).
In Fig. 6, we present a bubble plot that offers a visual representation of the performance metrics for LSTM–SVM, CNN, and ANN. The bubble plot allows for a quick and intuitive comparison of the models across multiple metrics simultaneously. In Fig. 7, we present a bar plot that provides a visual representation of the model comparison. This plot is useful for examining the performance of LSTM–SVM, CNN, and ANN across various metrics in a concise and clear manner.

Bubble plot comparison with other models

Bar plot comparison with other models
5 Conclusions
In this study, we proposed a novel recommendation model that combines support vector machines (SVM) and long short-term memory (LSTM) for recommending high-quality instructional materials in educational technology. We used a high-quality dataset of instructional materials that contains information about the materials' content, difficulty, and student interactions with them. We evaluated the proposed model’s performance against two traditional models (collaborative filtering and content-based filtering) and a hybrid model that combines collaborative filtering and content-based filtering. The results showed that the proposed LSTM–SVM model outperformed than other models CNN and ANN [20] as in most of the performance metrics, including precision, recall, F1 score, MAE, RMSE, and coverage. Specifically, the LSTM–SVM model showed higher precision, recall, and F1 score values than the other models, indicating that it is better at predicting the relevant instances. The LSTM–SVM model also showed lower MAE and RMSE scores than the other models, indicating that it is better at predicting the actual values. Finally, the LSTM–SVM model showed higher coverage values than the other models, indicating that it is better at covering the relevant items. These results suggest that the proposed LSTM–SVM model is a promising approach for recommendation systems in educational technology. The model can capture both the high-dimensional features and temporal dynamics of the instructional materials and the students' interactions with them, handle sparsity and cold-start issues, and provide interpretable results. The model's ability to provide high-quality recommendations can help improve students' learning outcomes and enhance the effectiveness of educational technology. In conclusion, the proposed LSTM–SVM model represents a significant contribution to the field of recommendation systems in educational technology. The model’s superior performance compared to traditional models and its ability to address challenges related to sparsity, cold-start, and interpretability make it a valuable tool for educational technology developers and educators. Further research could focus on refining the proposed model and applying it in real-world educational settings to evaluate its effectiveness and practicality.
Data Availability
All the data used is included in the paper.
References
Lallez, R.: Educational technology in universities in developing countries. Prospect Quart. Rev. Educa. 16(2), 177–194 (1986)
Aldowah, H., Rehman, S.U., Ghazal, S., Umar, I.N.: Internet of Things in higher education: a study on future learning. J. Phys. Conf. Ser. 892(1), 012017 (2017)
Huang, C.-J., Chu, S.-S., Guan, C.-T.: Implementation and performance evaluation of parameter improvement mechanisms for intelligent e-learning systems. Comput. Educ. 49(3), 597–614 (2007)
Makkar, A., Kumar, N.: An efficient deep learning-based scheme for web spam detection in IoT environment. Futur. Gener. Comput. Syst. 108, 467–487 (2020)
Villegas-Ch, W., Román-Cañizares, M., Palacios-Pacheco, X.: Improvement of an online education model with the integration of machine learning and data analysis in an LMS. Appl. Sci. 10(15), 5371 (2020)
Zaharias, P.: Usability and e-Learning: the road towards integration. ELearn 2004(6), 4 (2004)
Chen, Y., Wang, H.: IntelligentCrowd: mobile crowdsensing via multi-agent reinforcement learning. IEEE Trans. Emerg. Top. Comput. Intell. 5(5), 840–845 (2020)
Al Rahhal, M.M., Bazi, Y., AlHichri, H., Alajlan, N., Melgani, F., Yager, R.R.: Deep learning approach for active classification of electrocardiogram signals. Inf. Sci. 345, 340–354 (2016)
Ramdani, Y., Mohamed, W.H.S.W., Syam, N.K.: E-learning and academic performance during COVID-19: the case of teaching integral calculus. Int. J. Educ. Pract. 9(2), 424–439 (2021)
Di Pietro, G., Biagi, F., Costa, P., Karpiński, Z., Mazza, J.: The Likely Impact of COVID-19 on Education: Reflections Based on the Existing Literature and Recent International Datasets. Publications Office of the European Union Luxembourg, Luxembourg (2020)
E. Faliagka, K. Ramantas, A. Tsakalidis, G. Tzimas: Application of learning algorithms to online recruitment systems. pdf, in ICIW 2012: The Seventh International Conference on Internet and Web Applications and Services Application, c, 2012, pp. 215–220.
Lu, D.-N., Le, H.-Q., Vu, T.-H.: The factors affecting acceptance of e-learning: a machine learning algorithm approach. Educ. Sci. 10(10), 270 (2020)
Mujahid, M., et al.: Sentiment analysis and topic modeling on tweets about online education during COVID-19. Appl. Sci. 11(18), 8438 (2021)
B. Sekeroglu, K. Dimililer, K. Tuncal: Student performance prediction and classification using machine learning algorithms, in Proceedings of the 2019 8th International Conference on Educational and Information Technology, 2019, pp. 7–11.
Sultana, J., Rani, M.U., Farquad, M.: Student’s performance prediction using deep learning and data mining methods. Int. J. Recent Technol. Eng. 8(1), 1018–1021 (2019)
Deng, P., Li, T., Wang, H., Wang, D., Horng, S.-J., Liu, R.: Graph regularized sparse non-negative matrix factorization for clustering. IEEE Trans. Computat. Soc. Syst. 10, 910–921 (2022)
Wang, D., Li, T., Deng, P., Liu, J., Huang, W., Zhang, F.: A generalized deep learning algorithm based on nmf for multi-view clustering. IEEE Trans. Big Data 9(1), 328–340 (2022)
Wang, D., et al.: A generalized deep learning clustering algorithm based on non-negative matrix factorization. ACM Trans. Knowl. Discov. Data 17(7), 1–20 (2023)
Abdalla, H.I., Amer, A.A.: On the integration of similarity measures with machine learning models to enhance text classification performance. Inf. Sci. 614, 263–288 (2022)
Abdalla, H.I., Amer, A.A., Ravana, S.D.: BoW-based neural networks vs. cutting-edge models for single-label text classification. Neural Comput. Appl. 35(27), 20103–20116 (2023)
Abdalla, H.I., Amer, A.A., Amer, Y.A., Nguyen, L., Al-Maqaleh, B.: Boosting the item-based collaborative filtering model with novel similarity measures. Int. J. Computat. Intell. Syst. 16(1), 123 (2023)
Nguyen, L., Amer, A.A.: Advanced cosine measures for collaborative filtering. Adapt Personalization (ADP) 1, 21–41 (2019)
Amer, A.A., Abdalla, H.I., Nguyen, L.: Enhancing recommendation systems performance using highly-effective similarity measures. Knowl.-Based Syst. 217, 106842 (2021)
Akgun, S., Greenhow, C.: Artificial intelligence in education: addressing ethical challenges in K-12 settings. AI Ethics 2, 1–10 (2021)
Khanal, S.S., Prasad, P., Alsadoon, A., Maag, A.: A systematic review: machine learning based recommendation systems for e-learning. Educ. Inf. Technol. 25, 2635–2664 (2020)
Korkmaz, C., Correia, A.-P.: A review of research on machine learning in educational technology. Educ. Media Int. 56(3), 250–267 (2019)
Lee, H.S., Lee, J.: Applying artificial intelligence in physical education and future perspectives. Sustainability 13(1), 351 (2021)
Lin, P.-H., Chen, S.-Y.: Design and evaluation of a deep learning recommendation based augmented reality system for teaching programming and computational thinking. IEEE Access 8, 45689–45699 (2020)
Verde, A., Valero, J.M.: Teaching and learning modalities in higher education during the pandemic: responses to coronavirus disease 2019 From Spain. Front. Psychol. 12, 648592 (2021)
Luo, X., Wang, D., Zhou, M., Yuan, H.: Latent factor-based recommenders relying on extended stochastic gradient descent algorithms. IEEE Trans. Syst. Man Cybern. Syst. 51(2), 916–926 (2019)
Wang, D., et al.: Elastic-net regularized latent factor analysis-based models for recommender systems. Neurocomputing 329, 66–74 (2019)
M. Escueta, V. Quan, A. J. Nickow, P. Oreopoulos: Education technology: An evidence-based review, 2017.
Mishra, L., Gupta, T., Shree, A.: Online teaching-learning in higher education during lockdown period of COVID-19 pandemic. Int. J. Educ. Res. Open 1, 100012 (2020)
Munir, H., Vogel, B., Jacobsson, A.: Artificial intelligence and machine learning approaches in digital education: a systematic revision. Information 13(4), 203 (2022)
Webb, M.E., et al.: Machine learning for human learners: opportunities, issues, tensions and threats. Educ. Tech. Res. Dev. 69, 2109–2130 (2021)
Çelik, Ö.: A research on machine learning methods and its applications. J. Educ. Technol. Online Learn. 1(3), 25–40 (2018)
Krishnapandi, A., Selvi, S.V., Prasannan, A., Hong, P.-D., Kim, S.-C., Sambasivam, S.: Flexible and water-soluble polythiophene carboxylate for selective appraisal of acebutolol in aqueous samples. React. Funct. Polym. 185, 105538 (2023)
Valverde-Berrocoso, J., Garrido-Arroyo, M.D.C., Burgos-Videla, C., Morales-Cevallos, M.B.: Trends in educational research about e-learning: a systematic literature review (2009–2018). Sustainability 12(12), 5153 (2020)
Acknowledgements
We acknowledge the Kaggle.com for the dataset.
Funding
No funding.
Author information
Authors and Affiliations
Contributions
The paper was prepared by Xu independently.
Corresponding author
Ethics declarations
Conflict of Interest
The author declares that he has no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethics Approval
The study was classified as non-human subject research, and informed permission was not required.
Informed Consent
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xu, X. Revolutionizing Education: Advanced Machine Learning Techniques for Precision Recommendation of Top-Quality Instructional Materials. Int J Comput Intell Syst 16, 179 (2023). https://doi.org/10.1007/s44196-023-00361-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00361-z