
Abstract
Textual-based factors have been widely regarded as a promising feature that can be applied to financial issues. This study focuses on extracting both basic and semantic textual features to supplement the traditionally used financial indicators. The main is to improve Chinese listed companies’ financial distress prediction (FDP). A unique paradigm is proposed in this study that combines financial and multi-type textual predictive factors, feature selection methods, classifiers, and time spans to achieve the optimal FDP. The frequency counts, TF-IDF, TextRank, and word embedding approaches are employed to extract frequency count-based, keyword-based, sentiment, and readability indicators. The experimental results prove that financial domain sentiment lexicons, word embedding-based readability analysis approaches, and the basic textual features of Management Discussion and Analysis can be important elements of FDP. Moreover, the finding highlights the fact that incorporating financial and textual features can achieve optimal performance 4 or 5 years before the expected baseline year; applying the RF-GBDT combined model can also outperform other classifiers. This study makes an innovative contribution, since it expands the multiple text analysis method in the financial text mining field and provides new findings on how to provide early warning signs related to financial risk. The approaches developed in this research can serve as a template that can be used to resolve other financial issues.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Financial institutions and academic sectors have long regarded financial distress prediction (FDP) as a key research issue [1]. The output of FDP can, to a certain extent, prevent financial losses by giving stakeholders early warning indicators of potential financial risks [2]. In general, earlier studies have primarily used statistical and machine learning methods to accomplish FDP. The latter method has attracted more attention in recent years, due to its advanced predictive capability [3, 4]. In this research field, the predictive factors, feature selection algorithms, and classifiers can be regarded as key undertakings when attempting to achieve better performance in the FDP that is based on machine learning methods.
Predictive factors are the basis for FDP. As such, extracting effective factors can achieve better FDP performance. To date, researchers have mainly focused on two types of predictive factors, namely financial and non-financial factors [1, 5,6,7,8]. Traditional studies in this field have tended to place more emphasis on financial factors, which cover the quantitative information of companies, including companies’ profitability, financial structure, solvency, development capacity, operational capacity, and stock ratios [4, 9]. Over the past few years, researchers have proposed that non-financial factors, such as management, macroeconomics, and textual factors, may act as supplemental indicators in FDP studies, particularly textual factors. Specifically, annual reports, audit reports, financial news, and even financial-related social media content can cover the qualitative information that comprehensively describes the status of companies. Studies have applied text mining methods to extract textual factors, such as sentiment, topic, readability, etc., from financial texts. What is noticeable is that existing studies have paid more attention to extracting single types of textual features for FDP [1, 4]. Therefore, developing a framework for extracting both basic and semantic features from financial domain texts could play a substantial role in improving FDP.
After exhaustively collecting related factors, FDP performance can be improved by feature selection methods and, alternatively, classifiers. In other words, feature selection could select representative features from the original dataset, which in turn are the input of the classifiers. Thus, promoting the classifiers achieves better performance under conditions of a dimension-reduced dataset [10]. Moreover, by merging various machine learning algorithms, in this study, ensemble classifiers outperform single classifiers in terms of FDP in terms of their predictive power [1, 2, 4, 11, 12].
Although existing research has undoubtedly made contributions to extracting predictive factors and developing feature selection models and classifiers, very few studies have focused on all three of these aspects together for FDP, especially with regard to textual factors. To address this research gap, this study employs TF-IDF and TextRank-based methods to extract keyword features. Several sentiment dictionaries are employed to extract sentiment features. This study also proposes a word embedding-based approach to extract the readability features of annual reports from Chinese listed companies. Then, the predictive capability between different types of features is compared. As far as we are aware, this is the first research that concentrates on extracting all frequency count-based, keyword-based, sentiment, and readability factors for Chinese listed companies’ FDP. Moreover, in the real world, the number of financial distressed and healthy companies is imbalanced. In spite of this fact, some prior studies have applied balanced samples in FDP [1, 13]. Therefore, after collecting the financial distressed companies’ data, this study employs all the non-distressed listed companies as the healthy sample. Companies for which the data were either not available or incomplete have been excluded. This study also employs multiple feature selection methods and ensemble models to achieve better FDP performance. Thus, the purpose of this study is to address three research questions, including:
RQ1. Which are the significant features that influence Chinese listed companies’ FDP?
RQ2. Which combinations of models show satisfactory performance in Chinese listed companies’ FDP?
RQ3. How early can ensemble models achieve the optimal FDP for Chinese listed companies?
To achieve these research objectives, this study collects multiple financial and textual factors from 3, 4, 5 ,and 6 years before the expected financial distress baseline year. Then filter, wrapper, and ensemble-based feature selection methods are applied to reveal the key influencing features of four different years. After that, an over-sampling method is employed to address the class-imbalanced issue. Following that, multiple single and ensemble models are constructed to predict financial distress. This approach reveals how and to what degree predictive factors, feature selection algorithms, and classifiers influence Chinese listed companies’ FDP.
The key contributions of this study are: First, this research develops an innovative unbalanced FDP framework that includes multiple predictive features, feature selection algorithms, and ensemble classifiers under four different time spans. Second, this study proposes a comprehensive index of textual factors that covers frequency count-based, keyword-based, sentiment, and readability indicators. Finally, the findings of the experiment demonstrate that both basic and semantic textual elements might play a significant role in FDP, especially the basic textual indicators extracted from the Management Discussion and Analysis (MD&A) part of the annual reports, the sentiment features generated through financial domain sentiment lexicons, and the readability factor produced by a word embedding-based approach. The results also highlight the fact that these factors can achieve optimal performance 4 or 5 years before the expected baseline year. These findings mean that the methods proposed in this research could be utilized as a template to extract textual features from financial texts. This template can also be expanded to solve other financial issues, such as truthful reporting detection and business environmental analysis [14, 15].
The rest of the study is structured as follows: The related research that deals with the key elements of FDP is summarized in Sect. 2. In addition, Sect. 3 presents the research framework and details the analytical methods. In Sect. 4, the empirical findings are then explained. Section 5 discusses the findings and addresses the three research questions. The summary of this research and suggestions for additional research are provided in the concluding section.
2 Related Works
The text mining methods, feature selection algorithms, and classifiers that are relevant to this study are summarized in this section. The research relating to the FDP of Chinese listed companies is then particularly emphasized. Table 1 provides a summary of the related studies.
2.1 Text Mining-Based Approaches for Extracting Predictive Factors in FDP
As shown in Table 1, previous works have mainly emphasized on financial factors in FDP. Only a few studies have applied the textual indicators of financial domain texts. Existing studies have mainly employed one or two text mining approaches, such as frequency counts, keyword detection, sentiment analysis, and readability analysis [5, 19,20,21,22,23,24], to explore financial domain texts that contain annual reports, financial news, and user-generated content from social media [1, 4]. These text mining methods can convert the unstructured textual information into structured information. This structured information can, in turn, be regarded as the predictive factors for several financial research questions, including those related to FDP, fraud detection, bankruptcy prediction, stock market prediction, etc.
Specifically, frequency counts and keyword detection present the basic features of the texts. Frequency counts include the word counts and the total number of sentences in the financial documents. Previous studies have mainly applied TF-IDF or TextRank-based approaches to extract keywords from the original texts [25]. Readability and sentiment analysis methods reveal texts’ more semantic characteristics. Scholars have mainly employed readability indexes to extract the financial text’s readability. These index-based approaches calculate the degree of readability based on the average number of syllables, number of sentences, number of words, etc. [26, 27]. All these variables reveal the complexity of the text. Moreover, with the development of deep learning and text mining, several researchers have applied word embedding to extract the readability of texts [28, 29]. However, few studies have applied this approach to analyze financial text readability. For sentiment analysis methods, both dictionary and machine learning-based methods have been implemented to analyze financial texts. It is noticeable that creating a financial domain sentiment lexicon is significant in financial text mining [23, 30]. In light of these findings, this study attempts to explore the connection between the multiple textual indicators of listed companies’ annual reports and those companies’ financial difficulties.
2.2 Feature Selection Algorithms in Financial Distress Prediction
After generating feature sets, an important part of the entire FDP process is feature selection. Filter-based, wrapper-based, and embedded-based techniques can all be utilized to extract features [31]. Specifically, filter approaches identify features with better discriminative ability, based on feature ranking standards. Wrapper approaches assess the feature subset by employing the performance of the chosen classifier as the objective function. In addition, embedded approaches incorporate the feature selection phase into the model training process, causing feature selection to become a step in the creation of the prediction model. Many FDP studies have employed the three approaches mentioned above to extract valuable features, including the T test, information gain (IG), recursive feature elimination (RFE), and genetic algorithm (GA), as shown in Table 1.
Previous studies have also proved that feature selection methods are indispensable when selecting the most appropriate set of variables in FDP. Farooq and Qamar [2] revealed how several profitability and growth ratios are important to the FDP of Pakistani firms. Tang et al. [1] demonstrated that dissimilar features are meaningful in different time spans. The study highlighted the contribution of textual elements to the FDP of Chinese listed companies as a complement to the traditional financial factors. Given these results, this study applies the most appropriate feature selection approaches to extract meaningful indicators. The aim is to prove whether multiple types of textual features can assist in FDP.
2.3 Classifiers in Financial Distress Prediction
The feature subsets obtained from the feature selection process can be employed as inputs for machine learning algorithms. Machine learning algorithms have been widely adopted in the financial field. Applications include, fraud detection, empirical asset pricing, and stock market prediction [32,33,34]. In FDP studies, multiple classifiers, including single classifiers and ensemble classifiers, have been broadly utilized. As shown in Table 1, many researchers have applied single classifiers, including SVM, KNN, ANN, DT, CART, and NB, to predict financial distress in diverse datasets. Multiple studies have also employed ensemble classifiers in FDP. The purpose of such models is to derive each classifier's unique advantages and combine them to produce a better output [35]. There are four widely utilized ensemble learning methods, including voting, bagging, boosting, and stacking.
Existing research has demonstrated that ensemble classifiers can achieve better performance in FDP. Wang et al. [4] maintained that the random subspace method, which is a bagging-based algorithm, can achieve higher accuracy in FDP that involves unbalanced datasets. Tang et al. [1] proved that gradient boosting decision tree (GBDT) and stacking models outperform other types of classifiers in FDP, especially in terms of financial factors. Tsai et al. [10] applied bagging and boosting methods for four single classifiers, namely ANN, DT, LR, and SVM. The study proved that ensemble classifiers can obtain better results under different evaluation metrics. In addition, several studies have referred to the idea of time series analysis that applies the dynamic prediction method for FDP. Sun et al. [36] employed single classifiers (e.g., SVM, DT, KNN) that keep updating, with the time window sliding on to achieve FDP. Meanwhile, most mainstream FDP studies continued to adopt the above-mentioned static prediction approach and focused on optimizing the predictive indicators and classifiers. Considering previous findings, this study focuses on employing ensemble classifiers in the following experiment described below. The objective is to achieve the best possible performance in FDP with multiple types of predictive factors.
2.4 Applications of FDP in Listed Chinese Companies
Different accounting procedures and rules are used in different countries. Regarding the FDP of companies in China, the China Securities Regulatory Commission (CSRC's) presentation of "special treatment" (ST) has frequently been interpreted in previous studies as a sign of the financial distress of publicly traded Chinese enterprises [4, 8, 23]. The ST mark should be assigned to listed companies for the following three main reasons: (1) a company has a 2-year streak of negative earnings; (2) the net worth per share is less than the nominal value per share; (3) unusual financial behavior has been determined and claimed by the CSRC or stock exchanges [8, 23]. According to the ST warning system, the related authorities may apply a ST mark to a particular listed firm on the basis of that company’s financial situation during the 2 years prior to the appearance of the factual financial risk. This means that predicting financial distress 1 or 2 years before such a ST milestone is virtually worthless. Therefore, the most recent research has attempted to gather the relevant data 3, 4, and 5 (T-3, T-4, T-5) years prior to the ST assignment year [1, 4, 23, 37] for Chinese listed companies’ FDP.
The optimization of predictive features has received researchers’ attention in terms of addressing Chinese listed companies’ FDP. For that reason, it may be seen as significant to extract diverse factors (especially textual ones), and thereby improve the FDP model’s performance. Regarding textual predictive factors, only a few prior studies have focused on this aspect, and thus it is necessary to extract more textual factors, such as frequency counts, keywords, sentiment, and readability features. With regard to predictive methods, existing studies have contributed to the comparison and improvement of the performance of diverse machine learning models. However, few studies have applied multiple feature selection methods and ensemble classifiers in Chinese listed companies’ FDP. Therefore, it is important in this field of study to compare these feature selection and prediction models.
3 Methodology
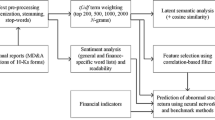
This study develops prediction models for the FDP of the listed Chinese firms. The models employ financial indicators and a multiple textual features (basic and semantic textual indicators) as predictive factors. Based on the FDP process proposed in previous studies [1, 4], this study proposes the conceptual framework shown in Fig. 1, which includes the following four steps: (1) samples’ selection and matching, (2) predictive factors collection and generation, (3) data preprocessing and feature selection, and (4) model creation and assessment.

The conceptual framework of this research
3.1 Samples’ Selection and Matching
This research obtained 1865 Chinese listed companies as experimental samples, all of which are listed in the Shanghai Stock Exchange and the Shenzhen Stock Exchange of China. Of these sampled firms, 214 have experienced instances of financial distress, and all of these companies received the ST label between 2012 and 2018. Specifically, 21 firms received the ST label in 2012, 16 in 2013, 26 in 2014, 31 in 2015, 43 in 2016, 38 in 2017, and 39 in 2018. The industry distribution of financial distress instances is shown in Table 2. Noticeably, companies in the manufacturing industry account for the largest number of financial distress samples. After eliminating companies for which the data were either not available or incomplete, this study chose 1651 non-distressed Chinese listed firms as samples of healthy firms in the benchmark year of 2018.
Additionally, to evaluate the effectiveness of financial and textual indicators in FDP, this research collected and extracted related information from 3, 4, 5, and 6 years (T-3, T-4, T-5, and T-6) before the firms were designated as the ST. These historical data can be employed to predict the financial situation of listed companies. This means that, if a certain listed firm was assigned the ST label in 2016, this study extracted the relevant factors related to this company in 2013 (T-3), 2012 (T-4), 2011 (T-5), and 2010 (T-6). Similarly, predictive factors from 2015 (T-3), 2014 (T-4), 2013 (T-5), and 2012 (T-6) were collected for healthy listed companies, which make up the control group.
3.2 Predictive Factors’ Collection and Generation
This study collected and extracted financial features (F1), basic textual features (F2), and semantic features (F3), for a total of 60 indicators. After all the predictive factors were obtained, the collected factors were stored separately in the T-3, T-4, T-5, and T-6 datasets. The following paragraphs that follow illustrate the predictive indicators utilized in this research.
3.2.1 Financial Factors of FDP
According to earlier works [2, 4, 37, 38], this study collected 34 financial factors, which were used for FDP. As shown in Table 3, these indicators cover six aspects of the listed companies, including profitability, solvency, operational capacity, financial structure, stock ratios, and development capacity. These structured indicators were collected from the China Stock Market and Accounting Research (CSMAR) database.
3.2.2 Basic Textual Factors of FDP
This study collected and extracted 12 basic textual features from annual reports for FDP, as illustrated in Table 4. Frequency count-based features were collected from the Chinese Research Data Services (CNRDS) database, which focuses on the features of the whole annual report, the MD&A part of the annual report, and the business discussion and analysis section of the MD&A.
An annual report’s “keywords” detail the evolution and business strategy of a corporation [4]. Following the work of Pröllochs and Feuerriegel, the process of extracting keyword-based features is shown in Fig. 2 [39]. To be specific, this study collected 2016–2018 Chinese listed companies’ annual reports (10,608 annual reports in total) as the domain corpora. After preprocessing, TF-IDF (term frequency–inverse document frequency) and TextRank were applied to separately generate the domain keywords list. Then the number of domain keywords contained in ST and health companies’ annual reports and MD&A parts could be calculated and matched, thereby obtaining four keyword-based features.

The process of keyword extraction
Specifically, the fundamental tenet of the TF-IDF approach is that if a particular phrase or word appears frequently in one article (the TF value is high) but infrequently in others (DF value is low, and the IDF value is high), it is believed that the word can serve as a good representation of the content and can be regarded as one of the keywords. The calculation formula is:
where \(TF\left(w\right)\) represents the frequency with which a given word \(w\) appears in the article, which can be calculated as follows:
where \(\mathrm{count}(w)\) denotes the number of times the word \(w\) appears in the text, and \(|{D}_{i}|\) indicates the number of all words in text \({D}_{i}\).
Next, \(IDF\left(w\right)\) represents the inverse document frequency of the word \(w\), which can be calculated as:
where \(N\) indicates the total number of texts, and \(DF(w)\) denotes the number of texts containing the word \(w\).
Moreover, TextRank is a graph-based sorting algorithm that calculates the similarity matrix between words and can be used for extracting text keywords. Assuming that the annual report text is \(T\), the set \(T=[{S}_{1},{S}_{2},\dots ,{S}_{m}]\) can be obtained by segmenting \(T.\) After that, an undirected weighted graph \(G=(V, E, W)\) of text \(T\) can be constructed, where \(V\) is the set of nodes, \(E\) is the non-empty finite set of edges between nodes, and \(W\) is the set of weights on each edge. The probability transition matrix \({SM}_{n\times n}\) between nodes in graph \(G\) is a symmetric similarity matrix, as:
According to \(G\) and \({SM}_{n\times n}\), the following formula can be applied to iteratively calculate the weights of each node:
where \(WS\left({V}_{i}\right)\) is the weight value of node \({V}_{i}\); \({V}_{i}\) and \({V}_{j}\) represent keywords, \({w}_{ji}\) denotes the similarity between \({V}_{i}\) and \({V}_{j}\), and \(d\) is the damping coefficient, usually taken as 0.85. Then \(\mathrm{ln}({V}_{i})\) represents all nodes connected to node \({V}_{i}\), and \(Out\left({V}_{j}\right)\) represents all nodes that can be reached from node \({V}_{j}\).
3.2.3 Semantic Textual Factors of FDP
As shown in Table 5, this study collected and generated 14 semantic textual factors. Sentiment features sen1 to sen8, were collected from CNRDS, which are L&M dictionary-based and National Taiwan University Sentiment Dictionary (NTUSD)-based indicators. Loughran and McDonald [30] produced the well-known financial emotion lexicon known as the L&M dictionary, which focuses on 10-K. The NTUSD is the general Chinese sentiment dictionary, without domain characteristics. Moreover, this study also followed the calculation process from CNRDS to generate the CFDSL-based sentiment features. This dictionary was created by Li et al. [23] and is the Chinese financial domain sentiment lexicon.
To extract the readability factor (rea1 and rea2), this study proposes a FastText and K-means combined (FTK) method, as shown in Fig. 3. To be specific, first, after collecting annual reports, the proposed preprocessing methods are employed. Then FastText is applied to train the word vectors, which can perform better than Word2Vec in terms of training word embeddings for long documents [40]. The pseudocode of FastText is as follows:

The FTK-based features extraction process
Pseudocode 1 Word vector training of FastText
Pseudocode 1: | Word vector training of FastText |
|---|---|
Input: | The corpus file F that requires training |
Output: | The output of FastText training includes model M and vector format model V |
1: | Read the input file F; |
2: | model = FastText (LineSentence(F), sg = 1, size = 100, window = 5, min_count = 5); |
3: | model.save(M); |
4: | model.save(V) |
After embedding all words in each annual report, this study employed K-means to cluster word vectors, and the contour coefficient method was utilized to determine the K value in the cluster. The calculation formula is as follows:
where \(a(i)\) denotes the average distance from the \(i\) vector to other samples in the same cluster. This could be viewed as the dissimilarity inside the cluster. Also, \(b(i)\) denotes the average distance from the \(i\) vector to all samples in the nearest cluster. This is referred to as the dissimilarity among clusters. Finally, the value of \(S(i)\) is between [− 1, 1], and a larger value of \(S(i)\) is more reasonable. This study fine-tuned K within the range of 10–200. The final output of clusters of the annual report is the FTK-based readability feature. This study believes that, the more clusters there are, the lower the readability of the annual report will be, and vice versa.
3.3 Data Preprocessing and Feature Selection
After gathering the original data, this research employed both data preprocessing and the feature selection to extract meaningful predictive indicators for the FDP. Then as inputs for the machine learning models, indicators were divided into three categories, namely F1, F2 + F3, and F1 + F2 + F3.
To be specific, the data preprocessing steps mainly cover two parts, namely removing missing data and normalizing the variables. After that, the processed T-3, T-4, T-5, and T-6 datasets are inputs for the feature selection models. This study applies T test (filter), RFE-SVM (wrapper), and RF (embedded) as feature selection approaches.
-
1.
T test: This method has the potential to assess the significance of the difference between the positive and negative samples. If a significant difference exists between the two samples, then the specific feature is retained; otherwise, that feature is removed.
-
2.
RFE-SVM: This greed algorithm first incorporates all the features into the SVM model. Then the coefficients (i.e., weights) that correspond to the features are obtained. Then those features (the removal of which leads to the largest margin of class separation in an iterative way) are eliminated.
-
3.
RF: Based on their variable importance, this algorithm can iteratively sort features in descending order, to generate feature sets. Based on each iteration, the associated out-of-bag error rate can be determined, and the feature set with the lowest out-of-bag error rate is chosen as the final one.
3.4 Model Creation and Assessment
3.4.1 Model Creation
This research compares the prediction abilities of multiple ensemble classifiers (bagging, boosting, and stacking), including RF, BaggingKNN, Xgboost, Adaboost, GBDT, and stacking. Single classifiers (SVM and DT) are also regarded as the baseline models.
-
1.
Bagging: This method can reduce the classifier's variance by creating numerous instances of a black-box estimator on diverse subsets of the initial training set. Then by combining each individual's predictions, a final prediction is generated.
-
2.
Boosting: This method trains different weak classifiers for the same training set. Then these classifiers are aggregated according to their weights, to generate a stronger final classifier.
-
3.
Stacking: This method stacks together the predictions of each individual classifier. This is followed by inputting to the final estimator, to obtain the prediction and thereby reduce each estimator’s biases.
Notably, so as to minimize the adverse effects of the training set's variability, in this research, tenfold cross-validation was applied ten times over. To be specific, first, the experiment dataset (T-3, T-4, T-5, and T-6) was randomly divided into ten subsets of the same size and distribution. More precisely, the test set consists of one subset, and the training set consists of the remaining nine subsets. Each subset can be utilized once as the test set. Then the test results were averaged to obtain the result of the tenfold cross-validation. After that, to address the impacts of the class-imbalanced issue, the training set was optimized with the SMOTE–Tomek algorithm. The testing set also adopts original class-imbalanced data to ensure the effectiveness of classifiers and, to some extent, avoid over-fitting [41, 42]. Specifically, the SMOTE–Tomek approach is a hybrid model that can benefit from both over-sampling and the filtering method. Initially, SMOTE is applied to the minority class, and the Tomek Links algorithm then eliminates ambiguous borderline instances that come from the majority class [43, 44]. Additionally, to minimize the impact of random partitions on the ten subsets, all steps are repeated ten times. Section 4 reveals the averaged results from this study.
The classifiers’ parameter settings applied in this study are shown in Table 6. Specifically, SVM and DT, as baseline models, both employ the default parameter settings. To optimize the ensemble classifiers, the grid search algorithm was also applied in this research [23].
3.4.2 Model Assessment
After the models are constructed, their performance needs to be evaluated. Specifically, area under the receiver operating characteristic curve (AUC), F-measure, Type I and Type II errors, and accuracy are some of the evaluation criteria used in this study [1, 4, 33]. Based on the outcomes of the prediction models, the samples are divided into four categories: true positive (TP), true negative (TN), false positive (FP), and false negative (FN). The ST samples are considered to be the positive class in this study, while the others are considered the negative class. The definition of the evaluation indexes is as follows:
4 Experimental Results
The steps proposed in Sect. 3 were utilized in this study to conduct the experiment. Both important and noteworthy is that feature selection and classifiers’ comparisons are the major tasks of this research. Thus, under different feature selection methods, this part first points out the meaningful factors of the T-3, T-4, T-5, and T-6 datasets. Then the predictive performance of multiple classifiers under diverse datasets is compared.
4.1 Feature Selection Results of Multiple Methods
This study applies three methods, namely T test, REF-SVM, and RF, to extract the valuable indicators of FDP in this study. Figure 4 presents the number of selected features in the T-3, T-4, T-5, and T-6 time spans using these three feature selection methods, and the panels inside Fig. 4 show different time spans presented by diverse colors. In general, T-4 datasets can be seen to retain more features across all approaches. Specifically, the T test retains more features (56 features in T-4, followed by 55 (T-5), 51 (T-3), and 49 (T-6)) in all time spans than do the other 2 methods. Since the T test method retains a large number of the original features, several studies have incorporated this method with other feature selection methods, to remove more meaningless indicators. Likewise, the RF method also extracted more features in T-4 (46), followed by T-3 (39), T-5 (38), and T-6 (34). The REF-SVM method selected 38 features in T-4, 32 in T-5, 30 in T-6, and 29 in T-3. Compared with other methods, it is clear that fewer textual features were selected by the REF-SVM method.

The number of selected features, based on different feature selection methods
The differences between the three methods are most noticeably reflected in the selection of financial factors. For the financial factors used in this study, profitability and solvency factors play the most significant role in diverse time spans. For basic textual factors, business discussion and analysis part-based and TextRank-based keywords factors, show advantages in this study. For semantic factors, sentiment features (especially those for CFDSL) were selected more times than the other two lexicon-based features. What is also noticeable is that readability features were selected by almost every method with four time spans. This finding demonstrates the value of the FTK approach developed in this study.
Moreover, so as to explore the key predictive factors of FDP, the features that were repeatedly selected by three different feature selection methods and over diverse time spans are illustrated in Table 7. The financial factors cover all six aspects of financial features, especially with regard to profitability. The factors also include quick ratio, total assets turnover, TCA ratio, net asset per share, and total assets turnover. Regarding basic textual factors, the number of words in the MD&A or business discussion and analysis part and the TextRank-based keywords in the MD&A, can all help with FDP. For semantic textual factors, L&M-based positive words, CFDSL-based negative words, and the FTK-based readability of annual reports all provide advantages in FDP.
4.2 Prediction Results of Ensemble Classifiers
This study employs 6 ensemble classifiers and 2 single classifiers as the baseline in FDP; this approach resulted in 288 combinations in total. The findings for accuracy (acc), F-measure (F), Type I error (T I), Type II error (T II), and AUC are used to describe the prediction performance of multiple classifiers under various feature selection techniques. The results are shown in Tables 8, 9, 10, 11, 12, 13. The models' greatest values for each time period and feature are presented in bold type. In general, the results indicate that ensemble models can achieve higher accuracy, F-measure, and AUC than can DT and SVM. Moreover, the number of Type II errors was noticeably lower than Type I errors under the majority of combinations. This finding means that this study’s experiment results can yield relatively low costs for failing to identify the financial distressed firms. This is significant for FDP.
Table 8 presents the predictive performance of the features selected by the T test. Notably, GBDT and Xgboost obtained better accuracy, F-measure and AUC for F1, F2 + F3, and F1 + F2 + F3 in all four time spans. Also, Xgboost achieved the highest accuracy (91.72%) and F-measure (91.35%) for F1 + F2 + F3 in time span T-5. This was followed by GBDT, which achieved 91.23% (accuracy) and 90.36% (F-measure) for F1 + F2 + F3 (T-4). In addition, the top two AUC were obtained by GBDT and stacking (90.73% and 90.55%), for F1 + F2 + F3 (T-5). Regarding Type I errors and Type II errors (shown in Table 9), with the F1 + F2 + F3 data, stacking achieved the minimum Type I error rate at 9.99% (T-5), and the lowest Type II error rate at 9.17% (Xgboost, T-5). Notably, GBDT, Adaboost, and RF also obtained the satisfactory minor Type I error and Type II error levels in several time spans with different feature sets.
Table 10 indicates that based on these REF-SVM selected features, GBDT, Xgboost, and stacking achieved better predictive performance than other models. For F1 + F2 + F3 (T-5), the highest degrees of accuracy (90.54%), F-measure (90.63%), and AUC (90.42%) were obtained by Xgboost. The second highest degrees of accuracy (90.42%), F-measure (90.32%), and AUC (90.36%) were reached by GBDT for F1 + F2 + F3 (T-3). For Type I errors, for all sample data, stacking achieved the minimum figure at 9.68% (F1 + F2 + F3, T-4), followed by the 10.27% obtained by stacking for F1 + F2 + F3 (T-6). Moreover, GBDT, Xgboost, RF, and Adaboost also achieved minor Type I error and Type II error levels (shown in Table 11) for F1, F2 + F3, F1 + F2 + F3 features in several time spans. In terms of Type II errors, GBDT achieved the best result for F1 + F2 + F3 across all time spans at 9.72% (T-4), followed by Adaboost at 10.03% (T-5).
Table 12 presents the experiment results that are based on RF selected indicators. Notably, GBDT and Xgboost yielded the maximum accuracy, F-measure, and AUC in all time spans for all datasets. The two exceptions were Adaboost, which reached the best AUC at T-4 (F2 + F3) and T-6 (F1). Stacking achieved the highest accuracy and F-measure at T-6 (F1 + F2 + F3). Also noteworthy is that the highest accuracy (92.12%) and F-measure (92.64%) were reached by GBDT for F1 + F2 + F3 (T-4). The best AUC (91.87%) was obtained by GBDT in the same feature combination and time spans. Regarding Type I errors and Type II errors (shown in Table 13), many models in this experiment were seen to obtain outstanding performances for F1, F2 + F3 and F1 + F2 + F3 across all four time spans. Specifically, the two lowest Type I error results were reached by Adaboost and Xgboost, at 9.63% and 9.68%, respectively, for F1 + F2 + F3 (T-5). Also, GBDT achieved the minimum Type II errors at 8.65% for F1 + F2 + F3 (T-4), followed by Xgboost, which yielded 9.13% Type II errors for F1 + F2 + F3 (T-6).
To clearly present the model effect, time spans, and features on FDP, this study calculates the average value of AUC and Type II errors under three feature selection methods, as shown in Fig. 5, and the panels inside Fig. 5 present the multiple combinations of time spans and feature sets can be shown as different colors. What is evident is that ensemble classifiers outperformed both SVM and DT, especially for GBDT and Xgboost. From the perspective of features, F1 + F2 + F3 feature sets showed advantages in all features’ combinations; F1 also outperformed F2 + F3. Therefore, one can conclude that basic and semantic textual features can supplement the traditional financial indicators to improve FDP. However, relying solely on textual features will make it hard to achieve efficient FDP. For the time spans, T-3 reached the best performance under F1, while T-4 and T-5 showed advantages under F2 + F3 and F1 + F2 + F3. This reflects the important influence of text features on the whole feature set.

The average value of AUC and Type II errors under three feature selection methods
To illustrate the best “feature selection methods–models–features–time spans” combinations of this study, the top ten combinations in terms of several vital evaluation metrics are listed. Table 14 shows the results for AUC and Type II errors, respectively.
These results indicate that the F1 + F2 + F3 feature sets all yielded the top ten evaluation metrics in Table 11. In addition, the other three factors—feature selection models, classifiers, and feature sets—can affect each other. The highest AUC (91.87%) and lowest Type II errors (8.65%) were yielded by the same combination, namely RF + GBDT + T-4. To be specific, for feature selection methods, RF accounted for the largest proportion of the top ten in terms of AUC and Type II errors, followed by T test. Also, REF-SVM only appears once in Table 14, achieving 10th in Type II errors. In terms of ensemble classifiers, GBDT and Xgboost obtained the most outstanding performances. With regard to time spans, these models can achieve better prediction results in T-4 and T-5.
4.3 Statistical Analysis Results
To conduct a more reliable analysis, this study applied a Friedman and Nemenyi test combined approach [45, 46]. This was done to separately rank and compare classifiers’ AUC and Type II errors for each dataset. The p values of the Friedman test for each model under the different features selection approaches and time spans are approximately equal to 0. Therefore, the null hypothesis is rejected. The ranks of multiple classifiers are shown in Table 15. Noticeably, the Friedman ranks on the AUC and Type II errors among classifiers are the same, meaning that, compared with other models, GBDT, Xgboost, and stacking can achieve better performance for FDP. In other words, the three ensemble models perform best in any feature sets and time spans.
Then all classifiers can be compared with one another using the Nemenyi test. Figure 6a and b present the Nemenyi test for AUC and illustrate the results of Type II error results, respectively; and the panels inside Fig. 6 illustrate the range of p values. It is noticeable that the p values between single classifiers (SVM and DT) and ensemble models (RF, BaggingKNN, GBDT, Adaboost, Xgboost, stacking) in Fig. 6a and b are less than 0.001. This finding means that the two types of classifiers have extremely significant statistical difference. Specifically, for AUC, the p < 0.001 for both GBDT vs. BaggingKNN, and GBDT vs. RF. Also, p < 0.05 for Xgboost vs. RF, and Xgboost vs. BaggingKNN. Similarly, for Type II errors, the p < 0.01 for GBDT vs. BaggingKNN, and p < 0.05 for GBDT vs. RF, and Xgboost vs. BaggingKNN.

The Nemenyi test results among different classifiers
This means that GBDT and Xgboost have statistical differences from several ensemble classifiers, especially compared to BaggingKNN and RF. The analysis in Sect. 4.2 also shows that GBDT and Xgboost achieved better performance under different combinations. One can also conclude that BaggingKNN and RF show fewer advantages than other ensemble classifiers.
5 Discussion and Implications
This study proposes an index that combines structured financial and multiple textual indicators to achieve FDP in four time spans. The FDP framework developed in this study incorporates three feature selection models and eight classifiers. Also, the prediction performance of various combinations can be compared. This study analyzes three research questions, as described in Sect. 1: (1) Which are the significant features that influence Chinese listed companies’ FDP? (2) Which combinations of models show satisfactory performance in Chinese listed companies’ FDP? (3) How early can ensemble models achieve the optimal FDP for Chinese listed companies?
To deal with the first research question, this study employed three feature selection procedures, namely T test, REF-SVM, and RF, to extract meaningful features. This approach can be regarded as an extension of prior studies [1, 10], which not only applied three feature selection methods, but also covered the filter, wrapper, and embedded method of feature selection. The results reveal that the T test approach retains more features than the other two methods. According to all three feature selection methods, the majority of the chosen features are financial ones. This finding is similar to those of prior studies [4, 8]. Both noteworthy and important is that profitability and solvency are significant in FDP for Chinese listed companies, since these features directly reflect the listed companies’ financial status, operating ability, and business performance.
With regard to textual factors, this is the first study to concentrate on various types of textual indicators for the FDP of Chinese listed firms. Notably, several frequency count-based, keyword-based, sentiment, and readability factors were selected by all methods in four time spans. This discovery shows that the multiple text mining approaches applied in this study are efficient for Chinese listed companies’ FDP. Specifically, the feature selection results indicate that the number of words in a MD&A (fc5), the number of words in the business discussion and analysis part of a MD&A (fc7), and the number of keywords in a MD&A based on the TextRank method (kb2) were repeatedly selected by different feature selection approaches under every time span. This finding means that the basic textual features of MD&As, which contain information that reveals the financial status of Chinese listed companies, can play an important role in FDP. This finding can be seen as an extension of Chen [47], which only analyzed MD&A sentiment features and found that a negative tone is effective for the FDP of listed Chinese firms.
For semantic features, the number of L&M dictionary-based positive vocabularies in an annual report (sen1), the number of CFDSL dictionary-based negative vocabularies in an annual report (sen10), and the FTK-based readability of an annual report (rea1) also show advantages in FDP. This finding proves that financial domain sentiment dictionaries (L&M and CFDSL) can achieve better performance than non-domain dictionaries. This result also proves that the positive word list of L&M and the negative word list of CFDSL are more likely to play a significant role in Chinese listed companies’ FDP. What is noticeable is that prior studies have mostly only employed L&M in Chinese listed companies’ FDP [1, 24]. This study, however, applies the CFDSL—a Chinese financial domain sentiment lexicon proposed by Li et al. [23]—and proves the efficiency and practicability of this dictionary. The feature selection results also reveal that the embedding-based readability analysis approach can be applied in FDP. This finding enriches the existing research that relies on index-based approaches to the readability analysis applied to financial risk prediction issues [48]. Moreover, the prediction that was based on F2 + F3 also reached acceptable results, particularly when compared with the FDP that only relied on sentiment features [23]. These results can be seen as the innovative findings of this study, particularly because previous FDP studies [1, 4] have focused more on sentiment features than on multiple textual features.
With regard to the second research question, this study combines three feature sets, three feature selection models, and eight classifiers for Chinese listed companies’ FDP. In general, the combinations, RF–GBDT or Xgboost–F1 + F2 + F3, achieved the best degrees of accuracy, F-measure, AUC, and Type II errors in this study. Compared with existing studies [1, 2, 4, 10], this is an FDP combination that has received little attention, but the results prove the effectiveness of the model proposed in this study. Apart from these groupings, the combinations of RF–Adaboost–F1 + F2 + F3 and REF-SVM–stacking–F1 + F2 + F3 also showed advantages for Type I errors. To be specific, F1 + F2 + F3 feature sets outperformed both the individual F1 and F2 + F3 sets. As expected, F1 achieved better predictive performance than F2 + F3, because F1 contains more indicators. This finding indicates that Chinese listed companies’ FDP is mainly based on financial characteristics and is supplemented by other non-financial features, especially textual features. Therefore, expanding and optimizing existing textual indicators and mainly applying sentiment indicators [1, 4, 23, 24] is a significant step in this research field. To achieve this objective, this study explores multiple types of textual features, including frequency count-based, keyword-based, sentiment, and readability features.
With regard to feature selection approaches, RF is more likely to extract valuable predictive features. However, in this study, the T test retained more features. This finding proves that employing multiple feature selection methods is more likely to distinguish the effective feature selection model and features for the specific problem. This is particularly true when compared to prior research that mainly applied the single feature selection approach [1, 2, 16]. Regarding ensemble classifiers, in this study, boosting-based algorithms showed advantages in this study for FDP, particularly when compared with bagging and stacking-based methods. Specifically, GBDT and Xgboost showed advantages in the top ten combinations; these two models also had statistical differences with more ensemble classifiers.
To address the third research question, this study collected T-3, T-4, T-5, and T-6 data in four time spans. To be specific, T-3 feature sets showed advantages when only employing financial features (F1) for FDP. This finding means that indicators of this type can predict financial distress more easily when the timeframe is closer to an official ST label years. Therefore, it is possible for one to conclude that financial indicators face the probability of poor prediction-making ability over a longer time. This is because these features only comprise quantitative information based on historical data [6]. This quantitative information makes predicting companies’ potential financial risk difficult. This is because the quantitative information does not contain environmental factors, such as business decisions, operations status, and external economic situations [49].
However, for textual features (F2 + F3) and the integration of all the feature sets (F1 + F2 + F3), as shown in Fig. 5, T-4 and T-5 achieved better predictive performance in Chinese listed companies’ FDP. This finding is partially similar to those of previous studies [1, 4] that incorporated financial and management features with sentiment factors. It takes a long time for healthy companies to become financially distressed ones, and for that reason, textual factors seem to cover the implicit information of financial distress earlier than do financial features. The basic and semantic textual features applied in this study not only involve valuable business strategies and companies’ development decisions, but they also have implications for the tone and emotion of managers [4]. One outstanding result of this study is that the T-4 and T-5 feature sets based on RF can achieve the best prediction results. Meanwhile, the T-3 and T-6 feature sets show fewer advantages. One can reasonably conclude that, since financial distress is a dynamic and long-term process, incorporating textual features can improve long-term prediction capability [4]. However, even textual financial features that are semantic and meaningful fail to infinitely capture such long-term trends; they can only obtain optimal performance over a certain duration. Accordingly, earlier textual factors (T-6) cannot absolutely maintain satisfactory FDP performance. This finding is supported by a previous study [1] that mainly explored the sentiment features for Chinese listed companies’ FDP. This, in turn, means that frequency count-based, keyword-based, and readability factors may have similar effects on FDP. Therefore, more types of textual features must be explored, to improve the prediction-making ability over a longer duration.
This study may be considered important, both theoretically and practically. From a theoretical aspect, to begin with, this study builds a framework for the unbalanced FDP of Chinese listed companies. The framework incorporates financial and textual factors in four time spans, based on three feature selection methods and eight classifiers. This integration framework, developed from previous studies, compares models or factors in almost every stage of the FDP process [1, 4, 8]. The hybrid approach proposed here has, until now, received little attention in FDP research. This proposed method can also be expanded to other financial supervision tasks, such as fraud detection, credit risk evaluation, and bankruptcy prediction. This research also designs a comprehensive index of textual factors that covers frequency count-based, keyword-based, sentiment, and readability indicators. This index is an innovative and theoretical contribution of this study for FDP. This is because prior studies have focused more on sentiment features, while ignoring other financial textual factors, especially the readability factors [1, 23, 49]. Regarding the practical aspect, this study suggests that textual features can complement financial features in the FDP of Chinese listed companies. This research also emphasizes the fact that textual indicators in a certain duration (T-4 and T-5) can provide a valuable warning signal. Therefore, the results of this research can be employed by stakeholders and even regulatory agencies to detect the early risks of financial distress. Early detection of such risk can help avoid financial losses, to some extent.
6 Conclusions and Future Work
A framework for FDP is proposed in this study that includes various predictive indicators, feature selection methods, classifiers, and time spans for Chinese listed companies’ FDP. The prediction index of this study contains 60 indicators covering the financial and textual indicators of listed companies. This is followed by applying T test, REF-SVM, and RF-based feature selection methods to extract valuable factors. Then these features are regarded as inputs for the eight classifiers. Finally, the experiment results are evaluated, and the three research questions are answered. In comparison to earlier research, the results of this study paint a quite different picture. Uniquely, this research mainly focuses on extracting basic and semantic indicators from annual reports for FDP. This approach is an expansion of prior studies [1, 4, 23], and the results prove that multiple textual features can supplement the traditional financial features used in FDP. This finding highlights the efficiency and practicability of financial domain sentiment dictionaries (L&M and CFDSL), the FTK-based readability analysis approach, and the basic textual features of MD&As. This study also finds that, in the FDP of Chinese listed companies, boosting-based models (GBDT and Xgboost) can yield better prediction results than other ensemble classifiers. Of particular note is the ability of GBDT and Xgboost to capture complex feature relationships. Moreover, the experiment conducted in this research indicates that earlier textual factors can achieve the best prediction results within a certain duration (T-4 or T-5). These novel findings extend those of previous studies in terms of generating textual features for FDP. These findings are hopefully significant with regard to extracting financial textual factors and analyzing related financial supervision tasks.
When generalizing the findings of this study, several limitations should be considered. This research extracts multiple textual features from annual reports but only applies the basic sentiment calculation strategy that refers to the CNRDS. With regard to this, future studies could collect and extract more textual features from more resources, such as news and social media. Extracting the semantic features from certain parts of MD&As will also be important in future work. Such studies could also employ the comprehensive lexicon-based sentiment analysis approach. This research was also limited by virtue of the fact that, for Chinese listed companies, ST samples were only collected for the years from 2014 to 2018. Future studies could potentially collect experiment samples over a longer duration of time and expand to other countries’ FDP issues. This study only applies a single over-sampling method to address the class-imbalanced problem. Future research will need to adopt and compare other approaches, to improve unbalanced FDP. Moreover, there are two types of FDP frameworks, as mentioned in Sect. 2, namely static and dynamic prediction. This study applies a static prediction framework in the FDP of Chinese listed companies that have achieved satisfactory performance. Future studies could also incorporate multiple textual features, feature selection models, and ensemble classifiers into a dynamic FDP study. Such a study could employ a rolling window strategy, which would help to achieve a more comprehensive and forward-looking analysis.
Availability of Data and Materials
The data that support the findings of this study are available in Chinese Research Data Services (CNRDS) database and China Security Market Accounting Research (CSMAR) database. These data were derived from the following resources available in the public domain: http://www.gtarsc.com, and http://www.cnrds.com.
References
Tang, X., Li, S., Tan, M., Shi, W.: Incorporating textual and management factors into financial distress prediction: a comparative study of machine learning methods. J. Forecast. 39, 769–787 (2020)
Farooq, U., Qamar, M.A.J.: Predicting multistage financial distress: reflections on sampling, feature and model selection criteria. J. Forecast. 38(7), 632–648 (2019)
Chen, N., Ribeiro, B., Chen, A.: Financial credit risk assessment: a recent review. Artif. Intell. Rev. 45(1), 1–23 (2016)
Wang, G., Chen, G., Chu, Y.: A new random subspace method incorporating sentiment and textual information for financial distress prediction. Electron. Commer. Res. Appl. 29, 30–49 (2018)
Hajek, P., Olej, V., Myskova, R.: Forecasting corporate financial performance using sentiment in annual reports for stakeholders’ decision-making. Technol. Econ. Dev. Econ. 20(4), 721–738 (2014)
du Jardin, P.: A two-stage classification technique for bankruptcy prediction. Eur. J. Oper. Res. 254(1), 236–252 (2016)
Liang, D., Lu, C.C., Tsai, C.F., Shih, G.A.: Financial ratios and corporate governance indicators in bankruptcy prediction: a comprehensive study. Eur. J. Oper. Res. 252(2), 561–572 (2016)
Jiang, Y., Jones, S.: Corporate distress prediction in China: a machine learning approach. Account. Finance 58(4), 1063–1109 (2018)
Lin, W.-C., Lu, Y.-H., Tsai, C.-F.: Feature selection in single and ensemble learning-based bankruptcy prediction models. Expert. Syst. 36(1), 1–8 (2019)
Tsai, C.F., Sue, K.L., Hu, Y.H., Chiu, A.: Combining feature selection, instance selection, and ensemble classification techniques for improved financial distress prediction. J. Bus. Res. 130, 200–209 (2021)
Fallahpour, S., Lakvan, E.N., Zadeh, M.H.: Using an ensemble classifier based on sequential floating forward selection for financial distress prediction problem. J. Retail. Consum. Serv. 34, 159–167 (2017)
Du, X., Li, W., Ruan, S., Li, L.: CUS-heterogeneous ensemble-based financial distress prediction for imbalanced dataset with ensemble feature selection. Appl. Soft Comput. 97, 106758 (2020)
Liu, J., Wu, C., Li, Y.: Improving financial distress prediction using financial network-based information and GA-based gradient boosting method. Comput. Econ. 53(2), 851–872 (2019)
Kim, Y.S., Rim, H.C., Lee, D.G.: Business environmental analysis for textual data using data mining and sentence-level classification. Ind. Manag. Data Syst. 119(1), 69–88 (2019)
Mohammadi, A., Hashemi Golpayegani, S.A.: A financial incentive mechanism for truthful reporting assurance in online crowdsourcing platforms. J. Theor. Appl. Electron. Commer. Res. 16(6), 2014–2030 (2021)
Zhou, L., Tam, K.P., Fujita, H.: Predicting the listing status of Chinese listed companies with multi-class classification models. Inf. Sci. 328, 222–236 (2016)
Liang, D., Tsai, C.F., Dai, A.J., Eberle, W.: A novel classifier ensemble approach for financial distress prediction. Knowl. Inf. Syst. 54(2), 437–462 (2018)
Huang, Y.P., Yen, M.F.: A new perspective of performance comparison among machine learning algorithms for financial distress prediction. Appl. Soft Comput. 83, 105663 (2019)
Loughran, T., McDonald, B.: Textual analysis in accounting and finance: a survey. J. Account. Res. 54(4), 1187–1230 (2016)
Myšková, R., Hájek, P.: Comprehensive assessment of firm financial performance using financial ratios and linguistic analysis of annual reports. J. Int. Stud. 10(4), 96–108 (2017)
Lewis, C., Young, S.: Fad or future? Automated analysis of financial text and its implications for corporate reporting. Account. Bus. Res. 49(5), 587–615 (2019)
Bacha, S., Ajina, A.: CSR performance and annual report readability: evidence from France. Corp. Gov. 20(2), 201–215 (2020)
Li, S., Shi, W., Wang, J., Zhou, H.: A deep learning-based approach to constructing a domain sentiment lexicon: a case study in financial distress prediction. Inf. Process. Manag. 58(5), 102673 (2021)
Zhao, S., Xu, K., Wang, Z., Liang, C., Lu, W., Chen, B.: Financial distress prediction by combining sentiment tone features. Econ. Model. 106, 105709 (2022)
Li, W., Zhao, J.: TextRank algorithm by exploiting Wikipedia for short text keywords extraction. In: 2016 3rd International Conference on Information Science and Control Engineering (ICISCE), IEEE (2016)
Lo, K., Ramos, F., Rogo, R.: Earnings management and annual report readability. J. Account. Econ. 63(1), 1–25 (2017)
Lim, E.K., Chalmers, K., Hanlon, D.: The influence of business strategy on annual report readability. J. Account. Public Policy 37(1), 65–81 (2018)
Tseng, H. C., Hung, H. T., Sung, Y. T., Chen, B.: Classification of text readability based on deep neural network and representation learning techniques. In: Processing In 28th Conference on Computational Linguistics and Speech Processing, ROCLING 2016, pp 255–270 (2016)
Cha, M., Gwon, Y., & Kung, H. T.: Language modeling by clustering with word embeddings for text readability assessment. In: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pp 2003–2006 (2017)
Loughran, T., McDonald, B.: When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. J. Financ. 66(1), 35–65 (2011)
Chandrashekar, G., Sahin, F.: A survey on feature selection methods. Comput. Electr. Eng. 40, 16–28 (2004)
Gandhmal, D.P., Kumar, K.: Systematic analysis and review of stock market prediction techniques. Comput. Sci. Rev. 34, 100190 (2019)
Bao, Y., Ke, B., Li, B., Yu, Y.J., Zhang, J.: Detecting accounting fraud in publicly traded US firms using a machine learning approach. J. Account. Res. 58(1), 199–235 (2020)
Gu, S., Kelly, B., Xiu, D.: Empirical asset pricing via machine learning. Rev. Financ. Stud. 33(5), 2223–2273 (2020)
Hajek, P., Henriques, R.: Mining corporate annual reports for intelligent detection of financial statement fraud: a comparative study of machine learning methods. Knowl. Based Syst. 128, 139–152 (2017)
Sun, J., Zhou, M., Ai, W., Li, H.: Dynamic prediction of relative financial distress based on imbalanced data stream: from the view of one industry. Risk Manag. 21(4), 215–242 (2019)
Geng, R., Bose, I., Chen, X.: Prediction of financial distress: an empirical study of listed Chinese companies using data mining. Eur. J. Oper. Res. 241(1), 236–247 (2015)
Fernández-Gámez, M.Á., Soria, J.A.C., Santos, J.A.C., Alaminos, D.: European country heterogeneity in financial distress prediction: an empirical analysis with macroeconomic and regulatory factors. Econ. Model. 88, 398–407 (2020)
Pröllochs, N., Feuerriegel, S.: Business analytics for strategic management: Identifying and assessing corporate challenges via topic modeling. Inf. Manag. 57(1), 103070 (2020)
Habib, A., Hasan, M.M.: Business strategies and annual report readability. Account. Financ. 60(3), 2513–2547 (2020)
Wang, L., Chen, Y., Jiang, H., Yao, J.: Imbalanced credit risk evaluation based on multiple sampling, multiple kernel fuzzy self-organizing map and local accuracy ensemble. Appl. Soft Comput. 91, 106262 (2020)
Sun, J., Lang, J., Fujita, H., Li, H.: Imbalanced enterprise credit evaluation with DTE-SBD: Decision tree ensemble based on SMOTE and bagging with differentiated sampling rates. Inf. Sci. 425, 76–91 (2018)
Jang, Y., Jeong, I.B., Cho, Y.K., Ahn, Y.: Predicting business failure of construction contractors using long short-term memory recurrent neural network. J. Constr. Eng. Manag. 145(11), 04019067 (2019)
Marso, S., El Merouani, M.: Predicting financial distress using hybrid feedforward neural network with cuckoo search algorithm. Proced. Comput. Sci. 170, 1134–1140 (2020)
Demšar, J.: Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 7, 1–30 (2006)
Zhou, L., Lu, D., Fujita, H.: The performance of corporate financial distress prediction models with features selection guided by domain knowledge and data mining approaches. Knowl.-Based Syst. 85, 52–61 (2015)
Chen, Y.: Forecasting financial distress of listed companies with textual content of the information disclosure: a study based on MD & A in Chinese annual reports. J. Manag. Sci. China 27, 23–34 (2019). (in Chinese)
Le Maux, J., Smaili, N.: Annual report readability and corporate bankruptcy. J. Appl. Bus. Res. 37(3), 73–80 (2021)
Jo, N.O., Shin, K.S.: Bankruptcy prediction modeling using qualitative information based on big data analytics. J. Intell. Inf. Syst. 22(2), 33–56 (2016)
Funding
This research was funded by grants from the National Natural Science Foundation of China (72204194), Opening Foundation of Early Warning and Emergency Linkage Technology Hubei Provincial Collaborative Innovation Center (AY2023-1-2).
Author information
Authors and Affiliations
Contributions
SL has made substantial contributions to the conception as well as analysis of the study, and the preparation of original draft. WS helped perform the analysis with constructive discussions.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, S., Shi, W. Incorporating Multiple Textual Factors into Unbalanced Financial Distress Prediction: A Feature Selection Methods and Ensemble Classifiers Combined Approach. Int J Comput Intell Syst 16, 162 (2023). https://doi.org/10.1007/s44196-023-00342-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00342-2