
Abstract
Graph convolutional network (GCN) is an effective tool for feature clustering. However, in the text classification task, the traditional TextGCN (GCN for Text Classification) ignores the context word order of the text. In addition, TextGCN constructs the text graph only according to the context relationship, so it is difficult for the word nodes to learn an effective semantic representation. Based on this, this paper proposes a text classification method that combines Transformer and GCN. To improve the semantic accuracy of word node features, we add a part of speech (POS) to the word-document graph and build edges between words based on POS. In the layer-to-layer of GCN, the Transformer is used to extract the contextual and sequential information of the text. We conducted the experiment on five representative datasets. The results show that our method can effectively improve the accuracy of text classification and is better than the comparison method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Text classification plays a pivotal role in natural language processing (NLP) [1]. It involves the automated categorization of text through computer technology, finding extensive application in sentiment analysis, document classification, and public opinion analysis, among other domains. Elevating the precision of text classification tasks holds the key to resolving pertinent real-world issues and enhancing the overall quality of life. Hence, the essence of this paper’s research lies in refining existing text classification techniques, focusing on improving the accuracy of text classification.
Existing text classification technologies are mainly based on machine learning and deep learning methods [2]. Common machine learning methods in text classification tasks include Support Vector Machine (SVM) [3], K-Nearest Neighbor (KNN) [4], and Random Forest (RF) [5], which have achieved excellent performance in simple classification tasks [5]. However, machine learning methods based on statistical techniques have difficulty in achieving the desired performance on complex tasks in real life, such as medical text diagnosis and sentiment analysis. With the breakthrough development of word vector technology in deep learning, words are given contextual semantics in the form of vectors [6]. Deep learning methods based on word vectors have achieved excellent NLP results and gradually become known as the mainstream method in the field of NLP [1]. In the field of text classification, the most commonly used deep learning methods are Convolutional Neural Network (CNN) [7], Recurrent Neural Network (RNN) [8], transformer [9], and Graph Convolutional Network (GCN) [10]. Due to the limitation of CNN convolutional kernel size, CNN focuses more on extracting local feature information of text. RNN takes into account the role of each token in text, so RNN focuses more on extracting global feature information of text, but there is a risk of gradient disappearance in RNN. Transformer is a powerful feature selection tool that combines attention mechanisms to obtain stronger contextual relationships for text, and is an innovative technique in NLP. TextGCN achieves text classification by constructing a word-document graph structure, and GCN focuses more on the spatial feature information of the text. Also, in the study [10], GCN achieves better text classification accuracy than CNN and RNN. Therefore, we believe that GCN has great potential for text classification tasks. We will combine Transformer to improve GCN to obtain higher performance for text classification.
Nodes in the GCN simultaneously assimilate information from their neighboring nodes. However, this approach implies that in a text classification task, document nodes consider all words within the document simultaneously, disregarding the text’s sequential order. Varied sentence structures convey nuanced meanings, underscoring the significance of preserving text order. Consequently, we posit that enhancing GCN’s efficacy in text classification necessitates imbibing knowledge about text sequences. Moreover, the scope of semantics attainable solely through contextual relationships in word-document graphs is inherently limited. Building upon this premise, our paper introduces a novel text classification approach that amalgamates Transformer and GCN. This fusion capitalizes on the strengths of both models. The principal contributions of our study encompass the following aspects:
-
To tackle the issue of GCN overlooking textual order, we seamlessly integrate the Transformer into the graph convolutional layers, forming what we refer to as a Graph Convolution Layer-Transformer-Graph Convolution Layer (GTG). The Transformer enhances the contextualization of textual information, considering the crucial textual order aspect. The resultant Transformer output is amalgamated with GCN to yield a more precise semantic representation of document nodes.
-
To address the issue of limited semantic information in word node vectors within GCN, we suggest constructing word-document graphs based on POS tagging. This approach imbues words with POS-related semantics, thereby enhancing the overall semantic quality of word node vectors.
2 Related Work
2.1 TextGCN
In the early days, GCN was mainly applied to tasks with obvious spatial structure, such as social networks and knowledge graphs. In 2019, Yao et al. [10] applied GCN to text classification tasks for the first time and achieved good document classification performance. TextGCN, a model based on semi-supervised learning, has enhanced the training difficulty to a certain extent. This enables TextGCN to achieve good fitting performance through only two layers of graph convolution. Moreover, in TextGCN, documents and words form a heterogeneous graph structure, allowing for the learning of information at the word and document levels. Since then, more and more researchers have applied GCN to text classification [11].
2.2 Recent Works
The proposal [12] proposes a document-level GCN-based text classification method. Unlike TextGCN, the proposal [12] constructs each document as a separate graph. The computational cost of GCN is optimized to achieve better classification performance than TextGCN and to support online classification of documents. A text classification method based on text graph tensor is proposed in the proposal [13]. The proposal [13] uses three different compositions, semantic, syntactic, and sequential, to coordinate the information between different types of graphs and achieve a better classification performance than TextGCN. A text classification method based on GCN with Bidirectional Long Short-Term Memory (BiLSTM) is proposed in the proposal [14], which is called IMGCN. The proposal [14] used Wordnet [15] with syntactic dependency composition method and used BERT to get the embedding representation of word nodes. Bidirectional LSTM with Attention was used to further extract the contextual relationship of the text and combined with residual concatenation to get the classification results. A text classification method combining BiGRU and GCN is proposed in the proposal [16]. The word embedding representation is obtained by Word2vec [17], the contextual information of the text is extracted by Bidirectional Gating Recurrent Unit (BiGRU) [18], and the spatial information of the text is extracted by the input GCN. A short text classification method based on GCN and BERT [19] was proposed in the proposal [20]. A word-document-topic graph structure was constructed using Biterm Topic Model (BTM) [21] to obtain the topics of documents. The word node features after GCN iteration are fused with the word features output from BERT and input to BiLSTM. BiLSTM will extract the contextual semantics of the text and finally fuse with the document node features to get the classification results. The proposal [22] proposed a text classification model based on BERT with GCN. They initialize the node vector of GCN by BERT and jointly train GCN and BERT to fully utilize the advantages of each model. A GCN text classification method based on inductive graphs was proposed in the proposal [23]. The original dataset was statistically summarized into small graphs, and good classification results were obtained based on the small graphs alone. In Table 1, we have briefly described the highlights and limitations of related work.
All of the aforementioned studies have built upon the foundation laid by TextGCN [10]. They have integrated additional networks or utilized diverse configurations as their primary focus, aligning closely with the direction of this research. Nevertheless, as indicated in Table 1, none of these approaches appear to have addressed the issue of textual ordering. Therefore, this paper aims to rectify the limitations of GCN concerning the aspect of text sequence.
3 Transformer and Graph Convolutional Network for Text Classification
3.1 Method Structure
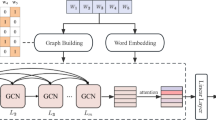
The text classification method based on Transformer and GCN including data pre-processing and GTG, and the model structure is shown in Fig. 1.

The text classification structure based on Transformer and GCN. In this figure, the term “doc” denotes a document, while “text” refers to the textual content within the dataset
Data pre-processing The initial step involves eliminating irrelevant words from the dataset, such as adverbs and adjectives, by referencing the list of stop words. In alignment with TextGCN [10], the identical stop words list is employed. Subsequently, the construction of the word-document global co-occurrence graph is rooted in contextual relationships. Further elaboration on this process can be found in Sect. 3.2.

Building graph based on POS. As shown in this figure, words of the same POS nature are linked by edges, allowing the words to obtain a POS-based semantic representation

Building graph based on context. Compute the relationships between words in the sliding window, so that the word nodes have context-based semantic representations
GTG After constructing a word-document graph, the graph node features undergo initial updates following the application of the first graph convolution layer (GCL). Subsequently, the word nodes are input into the Transformer to extract contextual semantics, along with the text’s semantic order information. Ultimately, the Transformer’s output is integrated with the document nodes to augment features, forming the input for the second GCL.
3.2 Data Preprocessing
Our data pre-processing methodology closely follows the approach outlined in [10], with a modification in the structure to enable the acquisition of POS-related information by words.
To begin, we segment the words within each document. Subsequently, we employ the Natural Language Toolkit (NLTK) [24] for POS tagging of the words. Upon analyzing each document, we establish connections between words sharing the same POS tag. All connections between words of identical POS nature are assigned equal significance, resulting in an edge weight of 1. A detailed illustration of this processing procedure is presented in Fig. 2.

Word-document graph based on POS and context. Using consistent colors to represent identical parts of speech, with D symbolizing the document node
Subsequently, we will establish word relationships grounded in context. Each document is scanned using a window of length 20, and we capture the frequency of occurrences for individual words within this window. Additionally, we tally the frequency of adjacent word pairs appearing within the same window. The detailed processing procedure is illustrated in Fig. 3.
After the processing illustrated in Fig. 3, we have successfully derived the word-to-word relationships. Subsequently, we proceed to establish word-to-word edges based on contextual information. The assignment of weights to these word-to-word edges is determined following Eqs. (1), (2), and (3)
In Eqs. (1), (2), and (3), \(N_\mathrm{{w}}\) represents the total number of sliding windows, \(N_i\) corresponds to the frequency of occurrence of term i across all sliding windows, and \(N_{ij}\) indicates the co-occurrence frequency of terms i and j within the same sliding windows. The Pointwise Mutual Information (PMI) [25] is employed to quantify the relationship between these two terms, with higher PMI values indicating a stronger association between them. Therefore, a PMI greater than 0 signifies a substantial correlation between the two words, leading to the establishment of edges with assigned weights.
Next, we establish connections between documents and words, treating each document as a node within the graph. Document nodes form connections with the words present in the respective documents. The weights assigned to these connections between documents and words are determined using Term Frequency-Inverse Document Frequency (TF-IDF) [26], with the corresponding formula presented in Eqs. (4), (5), and (6)
In the equations provided above, \(M_i\) represents the frequency of occurrence of term i within the current document, \(M_d\) signifies the total word count in the current document, \(M_D\) corresponds to the total number of documents, and \(M_{id}\) stands for the count of documents containing the term i. TF-IDF serves as a fundamental metric to assess word significance in the context of document classification, with higher TF-IDF values indicating greater word importance within documents. Following these initial steps, we constructed the word-document graph, and the comprehensive graph structure is visually depicted in Fig. 4.
At this point, our data pre-processing is complete, and the next step is to process the word-document graph via the GTG network, as detailed in the next section.
3.3 GTG
We integrated the Transformer between the GCN layers with the aim of not only extracting deeper contextual semantics from the word nodes but also capturing the semantic ordering information within the text. The specifics of this approach are illustrated in Fig. 5.

The GTG structure
In Fig. 5, the output of the Transformer is fused with the document node vector, which is shown in Eq. (7)
In the above equation, we fuse the output of the Transformer with the document vector of the first Graph Convolution Layer in a summation-averaging manner. We use a smoother Mish [27] to make \({\mathrm{{Out}}_\mathrm{{Transformer}}}\) and \({\mathrm{{Out}}_\mathrm{{1st-doc}}}\) blend better. The Mish function is defined as Eq. (8)
In Eq. (8), where x signifies the input features, tanh denotes the hyperbolic tangent function, and ln stands for the natural logarithm. Subsequently, we substitute the initial document features with \({\mathrm{{Out}}_\mathrm{{doc}}}\), followed by further convolving the refined graph using the second Graph Convolutional Layer to attain the classification outcome.
3.3.1 Transformer Encoder
Transformer is a powerful feature selection tool that incorporates an attention mechanism to give words context-based attention scores [28]. Transformer is based on an encoder to decoder structure; in this paper, we use only the encoder of Transformer. The Transformer encoder structure is shown in Fig. 6.

The Transformer encoder. It includes position embedding, multi-headed attention, residual connectivity, normalization, and feed-forward networks
In Fig. 6, the inclusion of position embedding introduces positional information to individual tokens, thus enabling the Transformer to consider the sequential order of tokens during training. The implementation of position embedding in the Transformer relies on trigonometric functions, as illustrated in Eqs. (9) and (10).
The periodic nature of trigonometric functions effectively captures the relative positions of words within a textual sequence. Additionally, the application of trigonometric formulas allows for the efficient calculation of positional information in a concise manner. Due to their representation as high-dimensional vectors, trigonometric functions align well with matrix multiplication operations in both the Transformer and GCN, enhancing overall efficiency
In the equations provided above, pos represents the index value of the word’s position within the original document, \(d_\mathrm{{model}}\) stands for the model’s dimensionality, and i corresponds to the positional embedding index. When two words exhibit strong trigonometric similarity, they are regarded as being in proximity within the sentence. Figure 7 visually depicts the fusion of the phrase “Natural language processing is an art” with positional embedding information.

An example of a word node with position embedding information
In Fig. 7, “pe” denotes the positional embedding information. Positional embedding is a vector that aligns with the dimensionality of the word nodes, obtained from Eqs. (9) and (10). Figure 8 illustrates the attention heatmap of the phrase "Natural language processing is an art" with the inclusion of positional embedding.
In Fig. 8, it is evident that word nodes in close proximity acquire higher attention scores following multiplication. This observation highlights that the incorporation of position embedding imbues the word nodes with valuable positional information. In multi-headed attention, the Transformer’s input is mapped into several Scaled Dot-Product Attention networks. The equation of Scaled Dot-Product Attention is Eq. (11)
In Eq. (11), Softmax is the normalization function, Q represents the query vector, K is the queried vector, V is the content vector, and d is the vector dimension. Here, Q, K, and V are text sequence vectors composed of word nodes that are multiplied by different parameter matrices. Therefore, what is being calculated here is the self-attention between words in the same context. Subsequent to the attention calculation, the output from each head is amalgamated to form the output of the multi-head attention. This multi-headed attention mechanism captures attention distributions from multiple perspectives, yielding superior outcomes compared to the singular attention approach. In this research, we employ a layer of the Transformer encoder. We concatenate the output tokens from each Transformer and standardize their dimensions before aligning them with the document node through a linear layer. The precise formulations are illustrated in Eqs. (12) and (13)
In the above formulas, Concat is the concatenation function and token is the word vector.
3.3.2 Graph Convolutional Network
GCN can be seamlessly employed to analyze graph data structures, effectively capturing spatial relationships among nodes and facilitating node classification [29]. Over the past years, the potential of GCN in text classification has garnered increasing attention from researchers, leading to its growing adoption in various text classification tasks.
To facilitate efficient computations, GCN employs matrix multiplication for all its operations, thereby representing and processing graph structures as adjacency matrices. In the initial graph convolutional layer (GCL), node updates are determined by the Eqs. (14) and (15)
where A is the adjacency matrix of the graph, \(\rho \) is the Relu function, D is the degree matrix of A, X is the node feature, and \(W_\mathrm{{o}}\) is the weight matrix.
After the initial GCL update, each node effectively assimilates information from its neighboring nodes, resulting in nodes possessing specific spatial characteristics and exhibiting a clustering effect. Subsequently, the textual nodes from the initial layer are inputted into the Transformer to additionally extract contextual and sequential textual information. The ensuing step involves dimensionality reduction through the second GCL, yielding the ultimate classification outcomes, as illustrated in Eq. (16)

The attention heat map of “Natural language processing is an art”. The coordinate axes represent the word nodes, and the depth of the matrix square color is positively correlated with the attention score of the word nodes
In Eq. (16), the feature input is refined as \(L^{(1)}\). Subsequently, an additional convolution operation is applied to \(L^{(1)}\) to extract more intricate word-document spatial information. This refinement aims to amplify the clustering impact of the document nodes, ultimately contributing to the accomplishment of the classification task. Consistent with the approach proposed in [10], we maintain a node dimension of 300 in this study.
4 Experimental Results
In this section, we will experimentally verify the effectiveness and superiority of the method in this paper.
4.1 Experimental Datasets
We selected R8, 20ng, MR, R52, and Ohsumed as experimental data sets, which are representative in this field. The information about the datasets is shown in Table 2.
As depicted in Table 2, these datasets encompass diverse domains including long text, short text, and sentiment analysis. These domains collectively provide a comprehensive representation of the text classification field. Given that the Transformer necessitates text inputs of fixed length, we adjust each document by either truncating or padding it based on the average length of the dataset.
4.2 Experimental Evaluation Index
Accuracy and f1 are used as experimental evaluation indicators. The calculation methods of accuracy and f1 are shown in Eqs. (17), (18), (19), and (20)
True Positives (TP) is the number of positive classes predicted; False Positives (FP) is the number of negative classes predicted to be positive classes; True Negatives (TN) is the number of negative classes predicted; False Negatives (FN) refers to the number of positive classes predicted to be negative [30].
4.3 Experimental Setting
Following the approach outlined in the proposal [10], we opt for a random selection of 10% of the documents from the training dataset to form the validation set. Our training process spans 200 epochs, employing a learning rate of 0.02, until the validation loss demonstrates no improvement for a span of ten epochs. A dropout rate of 0.5 is applied, accompanied by the utilization of the ReLU activation function.
4.4 Baselines
In this section, we will briefly introduce the baseline models of this paper.
Machine learning Machine learning-based methods have been widely used in the field of text classification. We choose SVM, KNN, and RF as machine learning methods, and their text features are initialized by TF-IDF.
Deep learning We choose BiLSTM, BiGRU, CNN, Transformer, and FastText [31] as the deep learning methods. The last output of BiLSTM and BiGRU is used as the classification token, and the classification token is fed into the linear layer to get the prediction. The CNN uses the version in TextCNN with convolution kernel of (2, 3, 4). In Transformer, all the output tokens are stitched to the same latitude and the prediction is obtained by a linear layer. The word vectors of RNN, Transformer, and CNN methods are initialized by the pre-trained GloVe [32]. In addition, FastText classification is performed by summing and averaging the word vectors obtained from training and obtaining predictions through a linear layer.
Recent related works We choose TextGCN [10], BiGRU+GCN [16], and BiLSTM+GCN [20] as the comparison methods. To compare the structural advantages and disadvantages of each method, we uniformly initialize the node features with one-hot.
4.5 Results
In this section, we present the pertinent experimental findings along with a concise analysis of these results. The test accuracies of each approach are displayed in Table 3. For the document classification task in this study, we evaluated test accuracy and F1 score through ten iterations across all models. The outcomes were reported as the mean value accompanied by the standard deviation. In Tables 3 and 4, the bolded results proved to be significantly better than the other methods in this dataset by t-test.
As indicated in Table 3, the proposed approach demonstrates optimal classification performance across three datasets. Specifically, the proposed method achieves a classification accuracy of 86.96% on 20NG, 94.46% accuracy on R52, and 69.72% accuracy on Ohsumed. In comparison, the proposed method outperforms BiGRU+GCN and BiLSTM+GCN by 0.19% and 0.41% on 20NG, surpasses BiGRU+GCN and BiLSTM+GCN by 0.58% and 0.26% on R52, and exceeds BiGRU+GCN and BiLSTM+GCN by 1.28% and 0.57% on Ohsumed. Furthermore, as detailed in Table 4, the proposed method also attains the highest F1 scores on 20NG, R52, and Ohsumed. These results underscore the superiority of the method presented in this paper for text classification tasks. They also affirm that the Transformer exhibits more robust feature extraction capabilities than the RNN structure and achieves a more precise semantic representation of tokens.
However, on the MR and R8 datasets, our classification performance lags behind the BiLSTM+GCN approach. This discrepancy suggests that the BTM within BiLSTM+GCN is more adept at capturing crucial information from shorter texts, revealing a limitation in our method’s performance with concise texts. Despite this, our method outperforms Transformer and TextGCN across all datasets, showcasing how the GTG structure effectively amalgamates the strengths of Transformer and GCN networks to enhance the model’s feature extraction prowess.
The inclusion of POS in TextGCN (POS) results in performance enhancements across four datasets, as word nodes encapsulate both contextual and POS-related semantics. Additionally, our observations demonstrate that SVM achieves commendable classification performance, often surpassing deep learning approaches. This underscores the effectiveness of machine learning in simpler tasks.
Next, we store the output of the second GCL post-training and proceed to visualize the two-dimensional embeddings of word nodes. Employing t-SNE [33], we condense the word embeddings into two dimensions, designating the highest value within the word vector dimension as the word label, as depicted in Fig. 9. Within the t-SNE visualization, the horizontal and vertical axes signify t-SNE values utilized for gauging point-to-point distances.

The embedding of word nodes from the second GCL in maximum value label. In the above figure, points with the same color represent the same document category
In Fig. 9, it is evident that words sharing the same label are closely clustered, aligning with the findings in the referenced proposal [10]. This indicates that words are predominantly situated within the document categories. Word nodes connected to document nodes are proximate to them. The semantic attributes of words are primarily molded by their immediate context, a distinctive trait of the GCN. To illustrate the embedding visualization of word nodes, we utilize POS as labels, as depicted in Fig. 10.

The embedding of word nodes from the second GCL in POS label. In the above figure, points with the same color represent the same POS tag
In Fig. 10, it is evident that nodes sharing the same POS are proximate within a limited span. This close proximity can be perceived as the immediate context of the word. Words within the same document naturally draw near, owing to their shared contextual surroundings. Building upon this premise, they are additionally influenced by their POS and tend to cluster around the corresponding POS within a given context. This observation underscores that the approach presented in this paper imbues the processed word nodes with both contextual and POS-related semantics.
5 Conclusion
In this study, we propose a new GCN structure called GTG, which combines the advantages of Transformer and GCN. By introducing positional embeddings, GTG considers the word node’s text sequence in GCN, and the introduction of Transformer further extracts context information from word nodes. In addition, we also propose a POS and context-based composition method to have the semantics of context and POS with word node vectors. The experimental results show that GTG effectively improves the text classification accuracy of TextGCN, and the POS-based construction graph method enables the word nodes to obtain POS clustering effect. The proposed method achieves state-of-the-art performance on three datasets compared to the comparison method. The proposed method provides a solution to improve the shortcomings of TextGCN in text classification tasks.
Availability of Data and Materials
Our experimental datasets from https://github.com/iworldtong/text_gcn.pytorch.
References
Kowsari, K., JafariMeimandi, K., Heidarysafa, M., et al.: Text classification algorithms: a survey. Information 10(4), 150 (2019)
Mirończuk, M.M., Protasiewicz, J.: A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 106, 36–54 (2018)
Goudjil, M., Koudil, M., Bedda, M., et al.: A novel active learning method using SVM for text classification. Int. J. Autom. Comput. 15, 290–298 (2018)
Trstenjak, B., Mikac, S., Donko, D.: KNN with TF-IDF based framework for text categorization. Procedia Eng. 69, 1356–1364 (2014)
Shah, K., Patel, H., Sanghvi, D., et al.: A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augment. Hum. Res. 5, 1–16 (2020)
Li, Y., Yang, T.: Word embedding for understanding natural language: a survey. Guide Big Data Appl. 26, 83–104 (2018)
Vieira, J.P.A., Moura, R.S., An analysis of convolutional neural networks for sentence classification. In: XLIII Latin American computer conference (CLEI), vol. 2017. IEEE, pp 1–5 (2017)
Liu, P., Qiu, X., Huang, X.: Recurrent neural network for text classification with multi-task learning. arXiv preprint arXiv:1605.05101 (2016)
Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 5988–5999 (2017)
Yao, L., Mao, C., Luo, Y.: Graph convolutional networks for text classification. Proc. AAAI Conf. Artif. Intell. 33(01), 7370–7377 (2019)
Malekzadeh, M., Hajibabaee, P., Heidari, M., Review of graph neural network in text classification. In: IEEE 12th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), 2021, pp, 0084–0091. IEEE (2021)
Huang, L., Ma, D., Li, S., et al.: Text level graph neural network for text classification. arXiv preprint arXiv:1910.02356 (2019)
Liu, X., You, X., Zhang, X., et al.: Tensor graph convolutional networks for text classification. Proc. AAAI Conf. Artif. Intell. 34(05), 8409–8416 (2020)
Xue, B., Zhu, C., Wang, X., et al.: The study on the text classification based on graph convolutional network and BiLSTM. In: Proceedings of the 8th International Conference on Computing and Artificial Intelligence, ACM, pp. 323–331(2022)
Fellbaum, C.: WordNet, Theory and Applications of Ontology: Computer Applications, pp. 231–243. Springer, Dordrecht (2010)
Dong, Y., Yang, Z., Cao, H.: A text classification model based on GCN and BiGRU fusion. In: Proceedings of the 8th International Conference on Computing and Artificial Intelligence, ACM, pp. 318–322 (2022)
Church, K.W.: Word2Vec. Nat. Lang. Eng. 23(1), 155–162 (2017)
Fang, F., Hu, X., Shu, J., et al.: Text classification model based on multi-head self-attention mechanism and BiGRU. In: 2021 IEEE Conference on Telecommunications, Optics and Computer Science (TOCS), pp. 357–361. IEEE (2021)
Devlin, J., Chang, M.W., Lee, K., et al.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
Ye, Z., Jiang, G., Liu, Y., et al.: Document and word representations generated by graph convolutional network and bert for short text classification. In: ECAI 2020, IOS Press, pp. 2275–2281 (2020)
Huang, J., Peng, M., Li, P., et al.: Improving biterm topic model with word embeddings. World Wide Web 23(6), 3099–3124 (2020)
Lin, Y., Meng, Y., Sun, X., et al.: Bertgcn: transductive text classification by combining gcn and bert. arXiv preprint arXiv:2105.05727 (2021)
Wang, K., Han, S.C., Poon, J.: InducT-GCN: inductive graph convolutional networks for text classification. In: 2022 26th International Conference on Pattern Recognition (ICPR), pp. 1243–1249. IEEE (2022)
Bird, S., Edward, L., et al.: Natural Language Processing with Python. O’Reilly Media Inc, Sebastopol (2009)
Bouma, G.: Normalized (pointwise) mutual information in collocation extraction. Proc. GSCL 30, 31–40 (2009)
Ramos, J.: Using tf-idf to determine word relevance in document queries. Proc. First Instr. Conf. Mach. Learn. 242(1), 29–48 (2003)
Misra, D.M.: A self regularized non-monotonic activation function. arXiv preprint arXiv:1908.08681 (2019)
Soyalp, G., Alar, A., Ozkanli, K., et al.: Improving Text Classification with Transformer. In: 2021 6th International Conference on Computer Science and Engineering (UBMK), pp. 707–712. IEEE (2021)
Zhang, S., Tong, H., Xu, J., et al.: Graph convolutional networks: a comprehensive review. Comput. Soc. Netw. 6(1), 1–23 (2019)
Feng, Y., Cheng, Y.: Short text sentiment analysis based on multi-channel CNN with multi-head attention mechanism. IEEE Access 9, 19854–19863 (2021)
Joulin, A., Grave, E., Bojanowski, P., et al.: Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759 (2016)
Pennington, J., Socher, R., Manning, C.D.: Glove: global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), ACL, pp. 1532–1543 (2014)
Van der Maaten, L., Hinton, G.: Visualizing high-dimensional data using t-SNE. J. Mach. Learn. Res. 9(11), 2579–2605 (2018)
Funding
This research was funded by the National Natural Science Foundation of China (No. 11864005), the Basic Ability Promotion Project for Yong Teachers in Guangxi (2023KY0017), and the Specific Research Project of Guangxi for Research Bases and Talents (AD23026105).
Author information
Authors and Affiliations
Contributions
Conceptualization, BL and WG; methodology, BL and WG; writing—original draft preparation, BL, ZL, and WG; experiment, BL, ZL, and CY; data, BL and CY; project administration, BL and ZF; visualization, BL and ZF; funding acquisition, ZF and ZL. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Conflict of Interest
The authors declare no competing interests.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, B., Guan, W., Yang, C. et al. Transformer and Graph Convolutional Network for Text Classification. Int J Comput Intell Syst 16, 161 (2023). https://doi.org/10.1007/s44196-023-00337-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00337-z