
Abstract
The recent decade has seen an explosion in the e-commerce industry with the support of modern technologies (e.g., artificial intelligence) to maximize conversion rates. Many recommendation systems, therefore, have been developed to predict the customer behaviors to take appropriate actions. Customization of promotions or items for distinct groups of online customers considerably contributes to enhancing the sales. The purchasing records are essential information that can be used to investigate the customer behaviors. These kinds of information, however, are mainly expressed in tubular forms. Several computational models were developed using conventional machine learning algorithms to deal with that data type. However, these approaches struggle with large-volume and high-dimensional data, feature engineering, and high computational cost. In our study, we propose a deep learning model based on the Feature Tokenizer Transformer architecture to predict the customer purchasing intention. This novel architecture is a simplified adaptive version of the Transformer tabular data. The results demonstrated that our model showed better performance compared to conventional machine learning models. Furthermore, the model’s stability was also confirmed by the results of multiple repeated experiments.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In recent years, the growth in e-commerce has provided many promising opportunities in the market, while the conversion rates have not been elevated as expected [1, 2]. Therefore, using recommendation systems to customize promotions or items for distinct groups of online customers is one of the most applied solutions to enhance sales [1, 3,4,5]. In physical retailing, a diverse range of customized alternatives can be introduced to customers based on the experience or understanding of salespeople about products or customers’ needs [6]. This experience used to have a crucial impact on the effective use of time, purchase conversion rates, and sales figures until e-commerce appeared and started to invade the market. To support e-commerce, numerous information technologies have developed early detection and behavioral prediction systems serving as sales assistants in virtual shopping environments [7, 8]. Alongside these endeavors, several studies were conducted to address this issue from different standpoints using machine learning and deep learning approaches [9]. While some studies focused on classifying of potential visits based on the user’s navigational patterns [1, 6, 10, 11], others were designed to perform real-time prediction on customer behaviors and how they take actions consequently to maximize the shopping cart abandonment as well as purchase conversion rates [12, 13].
The customer’s clickstream and session-related data are considered major information in developing a framework for classifying visits. Clickstream is a sequential interaction by a user while navigating through an online platform. And a session refers to a period of continuous user activity on that application. It starts when a user initiates their interaction and closes when there the user explicitly logs out or times out due to inactivity. The duration of a session can vary depending on the platform and its settings. Clickstream and session data are valuable sources of information to understand the user’s behavior within short-term timeframe for recommendation systems. Analyzing these user behavior patterns helps create more accurate and personalized recommendations, e.g., during customer purchasing session, enhancing the overall user experience, and increasing the satisfaction [6, 14, 15].
A set of features were obtained from page-to-page clickstream data (of the visited item categories). The K-mean clustering algorithm was employed to create different clusters of visited categories. All obtained clusters were then analyzed to investigate the customer behaviors of each cluster, and they were termed “Directed Buying”, “Hedonic Browsing”, “Knowledge Building”, “Search/Deliberation”, and “Shallow”. The “Directed Buying” group is customers visiting e-commerce sites to order pre-determined items, whereas the “Shallow” group are passers-by that leave the sites’ several pageviews.
In another study, Mobasher et al. proposed two distinct models using clustering techniques in combination with customer profiles (e.g., transactions and pageviews) [10]. The recommendation system uses customer profiles as features to take particular actions in real time. Their findings demonstrate that customers’ clickstream data are useful in enabling successful customization at the early stages of customers’ visits in a virtual shopping environment. Suchacka and Chodak conducted a study aiming to explore e-customer behaviors using Web server log data gathered from an online bookshop [16]. The association rule mining was applied to the dataset to examine the purchasing probability of the customers as well as to gain a deeper understanding of the purchasing behavior from investigating diverse customer profiles. Suchacka and Potempa proposed another machine learning model to classify e-customer using Support Vector Machines [17]. In another study by Suchacka et al., they proposed using k-Nearest Neighbor to develop a classification model on the same dataset to achieve the same goal. However, k-NN is somehow not appropriate for real-time prediction due to lazy learning [18]. Sakar et al. developed a computational model to predict the customer purchasing intention using multilayer perceptron and long short-term memory to analyze real-time online customer behaviors [19].
Recently, deep learning (DL) has emerged as an effective computational method in numerous fields, revolutionizing various domains with its transformative capabilities [20,21,22,23]. In healthcare, DL has shown immense potential in medical imaging, assisting in the accurate detection and diagnosis of diseases like cancer [24,25,26,27]. It has also been leveraged in drug discovery and genomics research, accelerating the development of new therapies [28,29,30]. In finance, this computational advance was employed to develop fraud detection systems, improving security and reducing financial losses [31,32,33]. Besides, DL transformed object detection by significantly promoting detection accuracy, speed, and robustness [34,35,36,37]. DL architectures designed specifically for tubular data are motivated by the unique characteristics and challenges associated with this type of data [38,39,40]. In the past, DL has not been commonly used to address problems related to tubular data, because the previous DL model failed to capture highly distinct features from tubular data [41,42,43]. However, the prediction efficiency of DL has changed, since Transformer was introduced [44].
In our study, we propose an effective computational framework to predict the customer purchasing intention using Feature Tokenizer Transformer (FT-Transformer) architecture, a simplified adaptive version of the Transformer architecture to cope with tabular data [45]. Like other Transformer-based models, our model is specified by the self-attention mechanism that facilitates learning efficiency. Our model is bench-marked with several conventional machine learning models to fairly assess the model performance. Also, the experiments are repeated multiple times to examine its stability.
2 Materials and Methods
2.1 Dataset Description
In our study, the computational model for predicting purchasing behaviors was designed as a binary classification model evaluating the customer’s intention to complete the transaction. Hence, the model focuses on identifying potential customers (who are more likely to purchase items) and non-potential customers (who are less likely to purchase items). We use the dataset ”Online Shoppers” from UCI’s Machine Learning Library 5. The dataset contains 12,330 sessions (samples) in which each session represented a distinct customer in a 1-year period to avoid biases of any tendency to specific on-sale campaigns, customer profiles, special occasions, or personalities. The dataset has 10,422 negative samples (sessions ended with purchasing) and 1908 positive samples (sessions ended without purchasing) that account for 84.5% and 15.5%, respectively. The categorical and numerical variables which were used as features for modeling are shown in Tables 1 and 2.
Table 1 describes the numerical variables with their ranges of values. Among these numerical variables, ‘Administrative’, ‘Administrative Duration’, ‘Informational’, ‘Informational Duration’, ‘Product Related’, and ‘Product Related Duration’ variables give information on the number of distinct page’s types accessed by the customers in that session and the duration that the customers spent on each type of page. These variables’ values were retrieved from the URL information of the pages accessed by the customers. These recorded values were updated in real time when a customer took an action (e.g., clicking to transfer from one page to another one). The ‘Bounce Rate’, ‘Exit Rate’, and ‘Page Value’ variables are metrics calculated by Google Analytic on each page of the e-commerce sites. These values for all pages of the e-commerce sites were reserved in the database and automatically updated after a certain period of time. The ‘Bounce Rate’ variable of a web page indicates the ratio of the customers who access the sites from that page and then exit without activating any additional requests to the analytic server during that session. The ‘Exit Rate’ variable of a particular web page is evaluated based on all page views to the page in the session. The ‘Page Value’ variable refers to the mean value for a web page that a customer accessed before finalizing an e-commerce transaction. The ‘Special Day’ variables represent the time distance between the site accessing time to a special occasion (e.g., Father’s day, Valentine’s day) in which the customers have more tendency to complete their session with transactions. This variable’s values were computed by the dynamics of e-commerce such as the duration between the ordering date and the delivery date. For instance, for Valentine’s day, this variable takes a nonzero value in the period from February 2 to 12 while taking zero values in the pre-period. This variable reaches its maximum value of 1 on February 8.
Table 2 provides the categorical variables with their numbers of categorical levels. The ‘TrafficType’ variable contains the largest number of categorical levels, followed by ‘Browser’, ‘Month’, ‘Region’, ‘OperatingSystems’, ‘VisitorType’, and ‘Weekend’. The ‘Revenue’ variable is the class label for the binary classification problem. The labels show whether the session has been completed with a transaction.
2.2 Model Architecture
Figure 1 visualizes the model architecture used in our study. This architecture is derived from FT-Transformers—a simplified adaptive version of the Transformers architecture to deal with tabular data. The FT-Transformer is designed as a stack of Transformer layers to transform both numerical and categorical features into embeddings. Hence, all Transformer layer operates on the feature level of one sample. Generally, feature vectors are transformed by the Feature Tokenizer (FT) block to create corresponding embeddings that are then learned by the Transformer block. Eventually, the final representation of the [CLS] token is captured for prediction.
2.3 The Feature Tokenizer Block
The FT block transforms the input features x to embeddings FT \(\in \) \(\mathbb {R}^{k \times d}\) where k is the embedding dimension and d is the number of features. For a given feature \(x_j\), its embedding is transformed as follows:
where \(b_j\) is the jth feature bias, \(f^\mathrm{(num)}_j\) \(\in \) \(\mathbb {R}^{d}\) refers to the element-wise multiplication with the weight vector \(W^\mathrm{(num)}_j\) for numeric features, and \(f^\mathrm{(cat)}_j\) \(\in \) \(\mathbb {R}^{S_j \times d}\) is the multiplication with the lookup table’s weight vector \(W^\mathrm{(cat)}_j\) for categorical features
where \(e^{T}_j\) is a one-hot vector of the corresponding categorical feature.

The FT-Transformer architecture (the proposed architecture contains two major blocks, including the Feature Tokenizer and the Transformer)
2.4 The Transformer Block
Before entering the Transformer block, the embeddings T are stacked with the [CLS] token which is known as the ‘classification token’ or ‘output token’. The [CLS] has its own embedding to be loaded in L Transformer layers \(F_1,\ldots ,F_L\) for computation
The Transformer block is characterized by two Normalization layers applied before the Multi-Head Self-Attention and Feed Forward layers. The structures of these steps are illustrates in block Transformer of Fig. 1. The predicted outcome is computed based on the representation of the [CLS] token as
The Adam optimizer [46] was used to iterative update FT and Transformer blocks at a learning rate of 0.001. The optimal network was obtained at the epoch at which the validation loss reaches the minimum value. The loss function used is binary cross-entropy expressed as
where y is the actual label and \(\widehat{y}\) is the predicted probability. The inputs of the model are vectors sized 1\(\times \)75. In our study, all deep learning models were developed with PyTorch 1.12.0 and trained on an AMD Ryzen 7-5800X CPU equipped with 32GB RAM and one NVIDIA GeForce RTX 3060 GPU over 50 epochs. It took about 3.3 s and 0.2 s to finish training one epoch and testing models, respectively. The prediction threshold of 0.5 was set as the default.
3 Results and Discussion
3.1 Model Evaluation
To examine the performance of the models, we computed multiple metrics, including the area under the receiver-operating characteristic curve (AUCROC), the area under the precision–recall curve (AUCPR), balanced accuracy (BA), F1 score (F1), precision (PR), and Matthews’s correlation coefficient (MCC). The True Positive (TP), False Positive (FP), True Negative (TN), and False Negative (FN) data were used to compute these metrics. The evaluation metrics’ equations are provided below
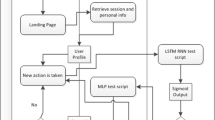
Figure 2 describes the workflow of developing our model. The training and test sets were formed using stratified random sampling with a ratio of 80:20. To develop our deep learning model, 15% of the training data were randomly sampled to create a validation set. The numbers of training, validation, and test samples are 8384, 1480, and 2466, respectively.

Development stages of our proposed model. (Original data were split into training data and test data with a ratio of 80:20. 15% of the training data was used as the validation set used for monitoring the training process. The rest of the training data was used as the training set. The test data were kept for model evaluation.)
We trained four models using four conventional machine learning algorithms: AdaBoost [47], Randomized Trees (ERT) [48], Random Forest (RF) [49], and (XGB) [50] to compare with ours. All models were tuned with selected parameters using the GridSearchCV method to obtain the optimal models. Table 3 provides the performance of conventional machine learning models and ours on the test set. The results indicate that our model works more effectively compared to other machine learning models. Our model achieves the AUCROC and AUCPR values of 0.9239 and 0.7410, respectively, followed by the RF model, XGB model, ERT model, and ABC model.
Based on achieved the AUCROC and AUCPR values, our model outperforms other conventional machine learning models. Additionally, conventional machine learning models are usually less efficient when dealing with large data volumes. Hence, their applicability to larger dataset is limited.
3.2 Model Stability
To investigate the model’s stability, we repeated our experiments ten times. The training, validation, and test sets of each trial were randomly sampled with the same ratio as mentioned above. Hence, we obtained ten different test sets for ten trials. The training process of one trial is independent of those of other trials. Table 4 compares the performance of our model on the test set over ten trials. The results show that our model obtains AUCROC and AUCPR values of over 0.92 and 0.70, respectively. The average AUCROC value of 0.93 and AUCPR value of 0.73 indicate the model performance is robust. Besides, the small standard deviation confirms the model’s stability with high repeatability.
4 Future Work
Predicting customer behavior in shopping is a challenging yet essential task for businesses seeking to enhance customer experiences and optimize their marketing strategies. The future of predicting customer behavior in shopping lies in the continued integration of deep learning techniques with contextual information, personalized recommendations, sequential patterns, multimodal data, uncertainty estimation, and ethical considerations. By exploring these avenues, businesses can gain valuable insights into customer preferences, optimize their marketing strategies, and deliver personalized shopping experiences that foster customer loyalty and satisfaction. The future scope of the paper can be extended to using more types of tubular data to improve prediction efficiency.
5 Conclusions
The experimental results demonstrate that our proposed method achieved higher performance than all conventional machine learning models. As most well-known deep learning models were supposed to be less efficient in dealing with tubular data compared to the conventional machine learning models, they have not been frequently selected for modeling tabular data despite their advantages in feature extraction and fast training. The advent of FT-Transformer architecture showed that deep learning now can achieve competitive performance on that data type. Additionally, the small variation in model performance over repeated experiments confirmed our model’s stability. In the future, the FT-Transformer can be further enhanced to apply to a broader variety of issues.
Data Availability Statement
The data used in this study are available at UCI Machine Learning Repository: https://www.kaggle.com/datasets/henrysue/online-shoppers-intention. Refer to file online_shoppers_intention.csv.
Code Availability
The code is available at Zenodo: khangntGH. (2023). khangntGH/purchasing-behavior-ft_transformer: v1.0 (1.0). Zenodo. https://doi.org/10.5281/zenodo.7687772.
Change history
02 April 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s44196-024-00493-w
References
Carmona, C.J., Ramírez-Gallego, S., Torres, F., Bernal, E., del José, J.M., García, S.: Web usage mining to improve the design of an e-commerce website: Orolivesur.com. Expert Syst. Appl. 39(12), 11243–11249 (2012)
Söderholm, P., Karim, R.: An enterprise risk management framework for evaluation of eMaintenance. Int. J. Syst. Assur. Eng. Manag. 1(3), 219–228 (2010)
Rajamma, R.K., Paswan, A.K., Hossain, M.M.: Why do shoppers abandon shopping cart? perceived waiting time, risk, and transaction inconvenience. J. Prod. Brand Manag. 18(3), 188–197 (2009)
Ding, A.W., Li, S., Chatterjee, P.: Learning user real-time intent for optimal dynamic web page transformation. Inf. Syst. Res. 26(2), 339–359 (2015)
Li, C.-W., Chao, Y.-Y.: The effect of auditing assurance levels on accounting conservatism: evidence from Taiwan. Int. J. Syst. Assur. Eng. Manag. 11(1), 64–76 (2019)
Moe, W.W.: Buying, searching, or browsing: differentiating between online shoppers using in-store navigational clickstream. J. Consum. Psychol. 13(1–2), 29–39 (2003)
Albert, T.C., Goes, P.B., Gupta, A.: GIST: a model for design and management of content and interactivity of customer-centric web sites. Mis Q. 1, 161–182 (2004)
Cho, C.-H., Kang, J., Cheon, H.J.: Online shopping hesitation. CyberPsychol. Behav. 9(3), 261–274 (2006)
Maayah, B., Arqub, O.A., Alnabulsi, S., Alsulami, H.: Numerical solutions and geometric attractors of a fractional model of the cancer-immune based on the atangana-baleanu-caputo derivative and the reproducing kernel scheme. Chin. J. Phys. 80, 463–483 (2022)
Mobasher, B., Dai, H., Luo, T., Nakagawa, M.: Discovery and evaluation of aggregate usage profiles for web personalization. Data Min. Knowl. Disc. 6, 61–82 (2002)
Kau, A.K., Tang, Y.E., Ghose, S.: Typology of online shoppers. J. Consum. Mark. 20(2), 139–156 (2003)
Awad, M.A., Khalil, I.: Prediction of user’s web-browsing behavior: application of Markov model. IEEE Trans. Syst. Man Cybernet. Part B (Cybernetics) 42(4), 1131–1142 (2012)
Budnikas, G.: Computerised recommendations on e-transaction finalisation by means of machine learning. Stat. Trans. New Ser. 16(2), 309–322 (2015)
Alrae, R., Nasir, Q., Talib, M.A.: Developing house of information quality framework for IoT systems. Int. J. Syst. Assur. Eng. Manag. 11(6), 1294–1313 (2020)
Selvam, P.K.P., Thangavelu, R.B.: The IMBES model for achieving excellence in manufacturing industry: an interpretive structural modeling approach. Int. J. Syst. Assur. Eng. Manag. 10(4), 602–622 (2019)
Suchacka, G., Chodak, G.: Using association rules to assess purchase probability in online stores. IseB 15, 751–780 (2017)
Suchacka, G., Skolimowska-Kulig, M., Potempa, A.: Classification of e-customer sessions based on support vector machine. ECMS 15, 594–600 (2015)
Suchacka, G., Skolimowska, M., Potempa, A.: A k-nearest neighbors method for classifying user sessions in e-commerce scenario. J. Telecommun. Inf. Technol. 2015, 64–69 (2015)
Sakar, C.O., Polat, S.O., Katircioglu, M., Kastro, Y.: Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and LSTM recurrent neural networks. Neural Comput. Appl. 31, 6893–6908 (2019)
Ubaid, A.M., Dweiri, F.T., Ojiako, U.: Organizational excellence methodologies (OEMs): a systematic literature review. Int. J. Syst. Assur. Eng. Manag. 11(6), 1395–1432 (2020)
Zhang, Z., Wang, Z.: Design of financial big data audit model based on artificial neural network, Int. J. Syst. Assur. Eng. Manag. (2021)
Arcos-Medina, G., Mauricio, D.: Aspects of software quality applied to the process of agile software development: a systematic literature review. Int. J. Syst. Assur. Eng. Manag. 10(5), 867–897 (2019)
Gupta, S., Gupta, P., Parida, A.: Modeling lean maintenance metric using incidence matrix approach. Int. J. Syst. Assur. Eng. Manag. (2017)
Gupta, V., Mittal, M., Mittal, V.: A novel FrWT based arrhythmia detection in ECG signal using YWARA and PCA. Wirel. Pers. Commun. 124(2), 1229–1246 (2021)
Gupta, V., Mittal, M., Mittal, V.: Frwt-ppca-based r-peak detection for improved management of healthcare system. IETE J. Res. 1–15 (2021)
Gupta, V., Saxena, N.K., Kanungo, A., Kumar, P., Diwania, S.: PCA as an effective tool for the detection of r-peaks in an ECG signal processing. Int. J. Syst. Assur. Eng. Manag. 13(5), 2391–2403 (2022)
Gupta, V., Mittal, M., Mittal, V., Gupta, A.: An efficient AR modelling-based electrocardiogram signal analysis for health informatics. Int. J. Med. Eng. Inform. 14(1), 74 (2022)
Gupta, V., Mittal, M., Mittal, V., Saxena, N.K., Chaturvedi, Y.: Nonlinear technique-based ECG signal analysis for improved healthcare systems. In: Algorithms for Intelligent Systems. Springer, Singapore, pp. 247–255 (2021)
Gupta, V.: Application of chaos theory for arrhythmia detection in pathological databases. Int. J. Med. Eng. Inform. 15(2), 191 (2023)
Gupta, V.: Wavelet transform and vector machines as emerging tools for computational medicine. J. Ambient. Intell. Humaniz. Comput. 14(4), 4595–4605 (2023)
Alketbi, A., Nasir, Q., Talib, M.A.: Novel blockchain reference model for government services: Dubai government case study. Int. J. Syst. Assur. Eng. Manag. 11(6), 1170–1191 (2020)
Ebad, S.A.: Lessons learned from offline assessment of security-critical systems: the case of Microsoft’s active directory. Int. J. Syst. Assur. Eng. Manag. 13(1), 535–545 (2021)
Ye, W., Wang, H., Zhong,Y.: Optimization of network security protection situation based on data clustering. Int. J. Syst. Assur. Eng. Manag. (2022)
Gupta, V., Rathi, N.: Various objects detection using Bayesian theory. In: Proceedings of the International Conference on Computer Applications—Computer Applications—II. Research Publishing Services (2010)
Gupta, V., Mittal, M., Mittal, V., Diwania, S., Saxena, N.K.: ECG signal analysis based on the spectrogram and spider monkey optimisation technique. J. Inst. Eng. (India) Ser. B 104(1), 153–164 (2023)
Gupta, V., Mittal, M., Mittal, V., Saxena, N.K.: Spectrogram as an emerging tool in ECG signal processing. In: Recent Advances in Manufacturing, Automation, Design and Energy Technologies. Springer, Singapore, pp. 407–414 (2021)
Gupta, V., Mittal, M., Mittal, V.: A simplistic and novel technique for ECG signal pre-processing. IETE J. Res. 1–12 (2022)
Xu, Q., Wu, D., Jiang, C., Wang, X.: A composite quantile regression long short-term memory network with group lasso for wind turbine anomaly detection. J. Ambient. Intell. Humaniz. Comput. 14(3), 2261–2274 (2022)
Son, Y., Zhang, X., Yoon, Y., Cho, J., Choi, S.: LSTM–GAN based cloud movement prediction in satellite images for PV forecast. J. Ambient Intell. Humaniz. Comput. (2022)
Gundu, V., Simon, S.P.: PSO–LSTM for short term forecast of heterogeneous time series electricity price signals. J. Ambient. Intell. Humaniz. Comput. 12(2), 2375–2385 (2020)
Amanbek, N., Mamayeva, L.A., Rakhimzhanova, G.M.: Results of a comprehensive assessment of the quality of services to the population with the use of statistical methods. Int. J. Syst. Assur. Eng. Manag. 12(6), 1322–1333 (2021)
Gupta, V., Mittal, M., Mittal, V., Gupta, A.: An efficient AR modelling-based electrocardiogram signal analysis for health informatics. Int. J. Med. Eng. Informat. 14(1), 74 (2022)
Gupta, V., Mittal, M., Mittal, V., Chaturvedi, Y.: Detection of r-peaks using fractional Fourier transform and principal component analysis. J. Ambient. Intell. Humaniz. Comput. 13(2), 961–972 (2021)
Amoiralis, E.I., Tsili, M.A., Kladas, A.G.: Transformer design and optimization: a literature survey. IEEE Trans. Power Deliv. 24(4), 1999–2024 (2009)
Gorishniy, Y., Rubachev, I., Khrulkov, V., Babenko, A.: Revisiting deep learning models for tabular data. Adv. Neural Inf. Process. Syst. 34, 18932–18943 (2021)
Kingma, B.J., Diederik, P.: Adam: A method for stochastic optimization (2014). arXiv preprint arXiv:1412.6980
Freund, Y., Schapire, R.E.: A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55(1), 119–139 (1997)
Geurts, P., Ernst, D., Wehenkel, L.: Extremely randomized trees. Mach. Learn. 63(1), 3–42 (2006)
Breiman, L.: Random forests. Mach. Learn. 45(1), 5–32 (2001)
Chen, T., Guestrin, C.: Xgboost: a scalable tree boosting system. In: Proceedings of the 22nd International Conference on Knowledge Discovery and Data Mining, pp. 785–794 (2016)
Acknowledgements
This paper is supported by project CSCL02.01/24-25, Institute of Information Technology, Vietnam Academy of Science and Technology. I would like to express my very great appreciation to my supervisor for his valuable and constructive suggestions during the planning and development of this research work. PhD. Ass. Professor. Nguyen Viet Anh, Institute of Information Technology, Vietnam Academy of Science and Technology.
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
All authors have contributed equally to this work.
Corresponding authors
Ethics declarations
Conflict of Interest
The authors declare no conflict of interest.
Additional information
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s44196-024-00493-w
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nguyen, K., Mai, T.N., Nguyen, H.A. et al. RETRACTED ARTICLE: A Computational Model for Predicting Customer Behaviors Using Transformer Adapted with Tabular Features. Int J Comput Intell Syst 16, 128 (2023). https://doi.org/10.1007/s44196-023-00307-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00307-5