
Abstract
The creation and use of big data have driven the intelligent development of e-commerce. The information generated in e-commerce provides a good means to analyze the behavior of users. How to use this information to give customer recommendations, improve the accuracy of recommendations and protect information security is a topic worth studying. For improving the accuracy of recommendations, analysis of users and tagging of resources are key. The current popular session recommendation algorithms face many problems, such as user interest drift which is difficult to be handled by these algorithms, thus affecting the recommendation accuracy. Based on these problems, this paper proposes a recommendation model based on deep learning, applies it to the clustering analysis of user tagging system, and designs a personalized recommendation algorithm for the tagging system. The model proposed in this paper can effectively analyze not only the interests exhibited by users in the current session, but also their potential long-term interests. By comparing the different performances of different datasets, the experimental results of this paper show that the proposed algorithmic model in this paper helps to dig the interests of different users, thus improving the quality of the recommendation system.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the rapid development of the Internet, the gradual maturity and popularization of the mobile Internet and related ancillary technologies, the Internet has become an important platform for people to study, work and live. The rise of online shopping and other lifestyles has also driven a large number of e-commerce advertisements. As people's daily lives become more and more dependent on the convenience of the Internet, the data traffic on the network has exploded. Facing the information overload caused by the ever-increasing and complex commodity, news, and video data in the network, users spend more time and energy searching and filtering information to find effective information that meets their own needs. To ensure and improve the user experience, and to show the information that users are interested in or need accurately and quickly to users, so as to improve user stickiness and bring business benefits, has become the primary challenge of relevant enterprises and a major research hotspot at present. In previous works, how to understand the interests of users and the collection of information needed is the main limitation. By putting information into the recommendation system, the algorithm introduced in this paper can be better than the existing algorithm to deliver information to customers and meet their needs. Recommendation system is one of the most successful applications of data mining and machine learning technology in practice. As an effective technical means, it can help users find items related to their interests in a large set of objects in a personalized way [1]. Nowadays, with the continuous growth and enrichment of information in the network, such systems have been used in various application fields, including e-commerce or streaming media websites, and receiving different forms of automatic recommendation results has become a part of human daily online experience.
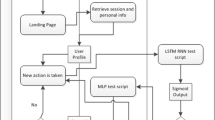
Tag system is a three-dimensional system composed of users, tags and resources. Tags are the link connecting users and resources. Aggregation analysis of the whole tag system can make tags with similar semantics form tag clusters, thus improving the personalized recommendation process. As shown in Fig. 1, user profile and tag clustering extracted from the tag system are first compared to generate personalized recommendations. In Fig. 1, R represents a resource, T represents a tag and RN and TN appear in pairs, representing a user's annotation of a resource.

Labeling system
The tag clustering in the tag system is very similar to the community structure in the social network, as shown in Fig. 2. The nodes in Fig. 2 can be regarded as members of a typical social network or labels in a label system; The edges in Fig. 2 can indicate that two members of a social network are closely related to each other, or that two labels of a label system are used to describe the same resource Tag clustering is a cluster formed by tags with close semantic links, which is very similar to the concept of community in social networks. The community discovery algorithm in social networks has been mature and successfully applied in the research of epidemiology, metabolic system and ecosystem.

A typical social network
Recommendation systems learn patterns in data by analyzing the historical behavior of individual users or entire groups of users. Most of the current online networks can record various types of user behaviors, including users viewing products or making purchases, etc., and there may be internal connections between multiple behaviors of a single user. The recommendation system uses these recorded behaviors and learned patterns to calculate recommendation results that match the preferences of individual users. Compared with search engines, recommendation systems can play a better role in fields that interact closely with users and when users have no specific needs and keywords that cannot accurately express the required information. The session recommendation studied in this paper is to recommend the items or content that the user is possibly interested in next, according to the click behavior sequence of the anonymous user in the current session. Many e-commerce platforms (especially those petty retailers) and most news and media sites typically do not track and record the historical behavior of users who visit their sites for long periods. While cookies and browser fingerprinting can provide some degree of user identifiability, these technologies are often unreliable and raise privacy concerns. Therefore, the problem commonly faced by today's real-life recommendation systems is that the recommendation must be based only on the short-term session data of the current user rather than the long-term history. In this case, classic and widely used recommendation algorithms such as matrix factorization, collaborative filtering, etc., may not work effectively in conversational recommendation scenarios due to the lack of user explicit feedback (user rating data). There are three main contributions of this paper: (1) we propose a deep learning-based short-term memory-first session recommendation algorithm; (2) we embed spatial attention and channel attention into the network to enhance the feature representation; (3) experiments show that our method far exceeds the baseline and can generalize to a variety of scenarios.
2 Related Work
2.1 Conversational Recommendation Algorithm Based on Traditional Machine Learning
By sorting out and summarizing the research ideas of related work modeling and learning user interests, this section divides traditional machine learning methods in the field of conversational recommendation systems into two categories according to the level of user interest concerned: (1) a global model that focuses on identifying users' long-term interests [2]; (2) local models with emphasis on short-term interests that change over time [3]. Based on the idea of collaborative filtering, the global model captures users' long-term interests by using historical data of user interactions (purchase/click) in all sessions. The idea of collaborative filtering is one of the earliest modeling ideas in the field of recommendation systems, and typical representatives include latent factor models and K-nearest neighbors. Among them, the latent factor model is mainly based on the matrix decomposition method [4], and the user latent vector representation and item representation representing long-term interests are obtained by matrix decomposition of the matrix formed by the interaction records between users and items. Similar to the K-nearest neighbor method [5] based on item similarity in the traditional recommendation system, the core idea of the K-nearest neighbor method in the session recommendation system is to use the similarity between sessions as the basis for recommendation [6]. The K-nearest neighbor model in the session recommendation task tries to find the K sessions that are most similar to the current session from the overall session data and then uses the session similarity as the score of each candidate item to indicate its interest in the current session. The correlation, that is, the prediction result of the user's next click is generated according to the items that appear in similar sessions. The calculation formula is shown in Eq. 1:
Among them, \(c\) represents the current user session, \(s_{nb}\) represents a similar session, \(1_{{s_{nb} }} (\hat{v})\) represents whether the candidate item appears in a similar session, 1 if it occurs, and 0 if it does not appear. Local models focus on short-term interests in the recent interaction behavior of users in modeling sessions, and Markov chain (MC), as a direct way to simulate continuous sequence data, was widely used in the early days of session recommendation research [7]. However, since the recommendation system is often faced with a huge number of candidate products and historical data, the state transition probability calculated by the Markov chain model is difficult to work effectively, and the Markov chain model only predicts the next record based on the last record in the sequence. It does not consider the previous context information in the sequence data, that is, in the session recommendation process, it only predicts based on the last item browsed by the user, and captures the short-term interests of the user represented by the local information in the sequence, which has certain limitations. The above methods have been proven to be able to effectively model the long-term or short-term interests of users in research work; however, there are still some key issues that remain unsolved. Although the global model can well perceive the user's usual long-term interest preference, it cannot give timely feedback on the recommendation results in line with the user's current interest due to the lack of consideration of the user's behavior in the current session, while the local model that pays attention to the user's current interest lacks the ability to model information between non-adjacent items [8, 9]. An ideal session recommendation system should take into account both the short-term interest in the session that changes with the user's behavior and the long-term interest in the overall information of the session when generating recommendations, because the user's next click behavior may be affected by these factors. Therefore, some researchers try to exploit both long-term interest and short-term interest information by fusing the features of global and local models. Ref. [10] proposed a Markov chain mixed model (FPMC), named personalized decomposition, which combines the advantages of both Markov chain and matrix factorization methods to model short-term behavior by the tensor representation of users’ sequential behaviors. By extracting user‘s behavior characteristics and decompose the user’s long-term interest representation, thus achieving a better recommendation effect than a single global model or a local model. Ref. [11] proposed a hybrid model based on representation learning, which adopts a hierarchical structure to separately model the sequential behavior of users in the current session and long-term interests in the full history. However, due to the limitation of the Markov chain model, the above hybrid models can only consider the local information of adjacent positions in the session, but cannot accurately model the overall information contained in the entire context of the session. Therefore, recent research work has begun to use deep neural network models to solve the problem of session-based recommendation.
2.2 Conversational Recommendation Algorithm Based on Deep Neural Network
In recent years, the ability of deep neural networks to effectively extract and utilize abstract features in data has been demonstrated in related research results and has attracted the attention of many researchers [12]. At the same time, with the proposal and promotion of a back-propagation algorithm, a cyclic neural network, which has advantages in modeling continuous dependencies, has become the preferred method for processing serialized data. The cyclic neural network is widely used in machine translation, intelligent question answering, and other fields to model sequences [13]. The latest research progress in deep learning in the field of natural language processing [14] has also inspired relevant researchers in the field of conversation recommendation, and several conversation recommendation algorithms based on deep neural networks have emerged, some of which represent more advanced technologies and cutting-edge development directions in the field of conversation recommendation research. This is the first attempt to use a recurrent neural network in the session recommendation task. Specifically, GRU4Rec considers the first item clicked by the user in the session as the initial input of the recurrent neural network and then predicts the next click based on this initial input. For each click in the input sequence, the model produces a recommendation that depends on the information of all previous clicks [15, 16]. The modeling method of the algorithm is simple and can be calculated in parallel. The experimental results show that the last hidden state of the recurrent neural network is represented as the session context information, which is used to predict the user's next interactive item with a high recommendation accuracy, so it has become a domestic leader. This is also the mainstream way for foreign researchers to model conversational contextual information. Based on the effectiveness of the GRU4Rec algorithm, many researchers continue to model sequence context information and propose a series of variants [17, 18]. Ref. [19] proposed a data augmentation technique and training set partitioning method to speed up the training process and alleviate model overfitting to improve the overall performance of deep neural network-based conversational recommendation algorithms. Based on the idea of GRU4Rec, Refs. [20, 21] proposed a multi-layer recurrent neural network model [22], which separately considered the user's dependencies and interest changes between different sessions to provide more reliable recommendation results. Among them, the GRU of the session layer is responsible for modeling the context information of the session and generating recommendations, while the GRU of the user layer is responsible for the information transfer across sessions, and the information representation of the previous session is used as the initial hidden state of modeling the next session. So then the user personalization information is considered in the conversational recommendation task. Another work similar to the modeling idea of GRU4Rec is that [23, 24] proposed a cyclic neural network model considering the user’s dynamic behavior. The model uses a basic recurrent neural network to continuously learn the user’s interest preferences for the items in his shopping basket to predict the user’s next item of interest. Although the above work has strengthened and optimized the modeling method of session context information from different perspectives, alleviating the problems of insufficient information utilization in the sequence existing in GRU4Rec, the way it captures information from the session is still mainly based on the modeling of sequential dependencies in the sequence by cyclic neural networks, and the same information extraction method is used for every user interaction in the session, Due to the lack of clear consideration of each interaction [25], important user behavior information and interest characteristics in the session may be lost during recommendation, resulting in the algorithm performance being affected by the diversity and variability of user interaction behavior in the session, and the accuracy of the recommendation system is the bottleneck.
3 Methodology
3.1 Session Recommendation Algorithm Based on Short-Term Memory
We propose the first baseline algorithm, called the short-term memory only model (STMO), whose main purposes include: first, by comparing this model with related work in experiments, in the conversational recommendation task, different from the general use of sequence overall information, only considering the user's recent behavior information for recommendation performance reflects the rationality of one of the modeling ideas in this chapter; second, the STMO model is proposed in this chapter. The short-term attention and memory-first conversational recommendation model, the simplest and most intuitive version of the short-term memory-first idea, which can be used to compare and evaluate the performance improvement of the final model proposed in this chapter. A baseline model STMP is compared to demonstrate the rationality of using both long-term memory and short-term memory proposed in the second model and the effectiveness of the proposed short-term memory-first information fusion approach. The model architecture of STMO is shown in Fig. 3.

Session recommendation model architecture based only on short-term memory
It can be seen from the model architecture diagram of STMO that the model takes the last click \(x_{t - 1}\) of the given session subsequence \(x_{t}\) as the model input and directly calculates with the candidate item after simple feature abstraction and extraction to predict the probability that the candidate item is the user's real next click item. It is mainly composed of a multi-layer perceptron and a softmax classifier. First, with the distributed vector expression \(x_{t - 1}\) corresponding to the item \(x_{t}\) clicked by the user for the last time in a given session as input, a simple multi-layer perceptron (MLP) without a hidden layer is used to characterize the short-term memory represented by the user's last click \(x_{t}\), and the output vector \(h_{t}\) is obtained, as shown in formula 2:
For each candidate item \(x_{i}\) in the item dictionary, we use the inner product to calculate the recommendation score with \(h_{t}\), and the probability distribution of all candidate items is obtained through the softmax classifier. The specific calculation process is:
3.2 Session Recommendation Algorithm with Short-Term Memory Priority
The structure of the STMO model is very simple. In the task of conversational recommendation in real scenarios, the model has the following obvious defects. First of all, in terms of modeling mechanism, the STMO model is actually a next click prediction algorithm based on a single click. When generating recommendation results, it does not consider any previous historical information in the current session, which is very important for correctly modeling users. Whether the next click is motivated by interest is so important that the model cannot effectively distinguish whether the user does not click or is out of curiosity about the displayed information. In addition, in terms of information utilization, the STMO model only extracts the user's current interest features from the short-term memory represented by the last click of the session. This design affects the model's generalization ability on longer-length sessions, because in shorter sessions, the user’s interest is less likely to change, and the last click can represent the user’s current interest, while in a longer session, the user’s behavior is more complex, so it is necessary to consider both the overall interest in the long-term behavior of the users and the current interest in the recent behavior of the users to generate a more comprehensive and accurate recommendation that satisfies the users. It alleviates the information loss problem that the STMO model does not consider the session history. The structure of the STMP model is shown in Fig. 4. As can be seen from the figure, compared with the STMO model, the biggest difference in the STMP model in terms of modeling ideas is that when calculating the candidate item score, the overall information of the session and the last click feature are taken into account, to alleviate the STMO model and the traditional Markov chain-based model that only calculate the item features of the latest click when making recommendations, ignoring that although the clicked item in the session context may contain features unrelated to the user's current interests, it still contains some features that can be more useful. It can accurately model important information of user interests. For example, it is known that the last click behavior in a user's session is about a certain model of mobile phone, and the user's preferences in terms of mobile phone brand or price can be clarified through the characteristics of items clicked before in the session. In this way, the interest range of the users under its jurisdiction produces more accurate recommendation results. Therefore, the STMP model uses two feature vectors (\(m_{s}\) and \(m_{t}\)) as the input of the trilinear feature fusion layer, where \(m_{s}\) represents the feature representation of the current session, which is considered in this chapter to contain the user's overall interest information, calculated by the external memory of the current session. The specific definition of the average income is shown in Eq. 4:

Short-term memory-first session recommendation model architecture
The so-called “external memory” refers to the vector sequence composed of the item vector representations in the current session subsequence \(x_{i}\). In this section, the average value of all historical click item vectors in the session is used as the session representation, so as to preserve the sequence information of the session itself. The effectiveness of this computationally simple way of representing sequence information has been proven in natural language processing and other related fields. At the same time, as can be seen from Fig. 3, since \(x_{t}\) is derived from the external memory of the session, it is called the short-term memory (current interest) representing the user's current preference in this chapter.
3.3 Session Recommendation Algorithm with Short-Term Attention and Short-Term Memory Priority
In the short-term attention memory priority (STAMP) model, the user’s next click in the session is predicted, where the weighted user interest is represented by a bilinear combination of long-term memory (the vector mean of the historically clicked items in the session) and short-term memory (the vector of the last clicked item). The importance of the contribution is the same, resulting in that, first, item information that was clicked many times in the session will occupy a larger proportion in the overall interest representation in the STMP model, and second, the overall interest representation in the STMP model will not. It changes because the order in which the items are clicked changes. This paper believes that there are some problems in this situation. First, for the first point, although the items that appear many times in the conversation occupy a large proportion of the overall interest, which can reflect some of the user's preference information. This method only considers the click frequency, but ignores the correlation between each historical click and the user’s re-click in the whole session, which is more important for the session recommendation task. Maybe only a part of the click behavior is highly related to the user's next click. In other words, the overall user interest representation based on the sum-average method is relatively rough and inflexible.
In addition, for the second point, since the interests of users in a session may be diverse, and the same item is clicked multiple times in a session, the contribution of this click behavior to modeling user interests will also occur depending on the location of the occurrence. Changes, especially in long sessions, are more likely to occur, because intuitively, when the session lasts for a long time, the user's interest is likely to have changed from the beginning and the items that the user has recently clicked in the session are related to information may be more reflective of the user's current interests. The results can be seen in Fig. 5. In short, this is a session recommendation algorithm for short-term attention and short-term memory, but users recommend the information they need in the short term.

Short-term attention and memory-prioritized conversational recommendation model architecture
4 Experiments
4.1 Experimental Dataset
This chapter uses two datasets from real websites, Yoochoose1 and Diginetica2, to conduct experiments on the proposed model. The former is a public dataset released in the RecSys Challenge 2015 competition. The data source is the e-commerce website Yoochoose.com. For months of historical click sequences (commodity browsing records), this chapter uses the part of the dataset that only contains session records as training and testing data. The latter Diginetica dataset is derived from another competition CIKM Cup 2016, and only transaction session data in this dataset is used in this study.
4.2 Implementation Details
The STAMP model proposed in this chapter mainly includes the following hyperparameters: vector expression dimension\(d\), learning rate \(\eta\), and learning rate attenuation \(\lambda\). Randomly divide 20% of the data in the training set as the validation set, and perform extensive grid optimization on the validation set to optimize all hyperparameters. According to the Recall@20, obtain the optimal model and determine the super parameter setting. The hyperparameter range of grid optimization is as follows: the value range of vector dimension \(d\) is {50,100, 200,300}, the value range of learning rate \(\eta\) is {0.001,0.005,0.01,0.1,1}, and the value range of learning rate attenuation \(\lambda\) is {0.75,0.8,0.85,0.9,0.95,1.0}. According to the comprehensive performance, in this research, the following super parameter combinations are used in three datasets for experiments: {100,0.005,1.0} \(d,\eta ,\lambda\). During training, the sample size of each batch is 512, and the Adam optimizer is used for 50 rounds of iterative training. In addition to the hyperparameters, the parameters of the neural network weight matrix of the model obey the normal distribution \(\eta^{2}\) (0,0.05) for initialization, and all bias vectors are initialized with zero vectors. The expression vectors of all items are randomly initialized by the normal distribution \(\eta^{2}\) (0,0.002) and are updated with the model training iteration together with other parameters of the model.
4.3 Validity Analysis Prioritizing the Last Clicked Item in a Session
Explicitly prioritizing the item information of the user's last click in the session when predicting the user's next click can strengthen the model to prioritize the user's current interests when making recommendations. This subsection designs a set of comparative experiments based on STAMP and STMP models on three datasets to further analyze the proposed role of the model in prioritizing the last click in a session as short-term memory. The following is a brief introduction to the model information involved in the comparison: STMP (without_lastclick): that is, the STMP model that does not use the last click item information for calculation in the trilinear combination calculation layer. STMP: that is, the STMP model that adds the final click item information for trilinear calculation. STAMP(without_lastclick): a STAMP model that does not use the last click item information to calculate in the trilinear combination calculation layer. STAMP: the STAMP model that adds the last clicked item information for trilinear calculation. Furthermore, the proposed method captures both long-term and short-term interests, considering that users' interests may change due to longer browsing during a session, and that the user's next click is more likely to be related to the last click that represents the current interest. A model that augments last click information is thought to be potentially very beneficial in handling long sessions. To further verify the effect of prioritizing the last clicked item in the session, this section analyzes the change of the Recall@20 indicator of the proposed model when faced with sessions of different lengths in the Yoochoose 1/64 dataset. The result is the line graph in Fig. 6.

Changes in model prediction accuracy over sessions of different lengths in Yoochoose 1/64
The graph shows the variation in prediction accuracy with increasing session length for three different models. It is observed from Fig. 6 (the upper figure) that the performance of the STMP and STAMP models proposed in this chapter weakens with the increase in the session length, but is still significantly higher than that of the NARM model. Interests are more important than just considering the main interests of users in a session. At the same time, from the performance changes of STMP and STAMP models and variant models (STMP and STAMP in the figure) with the session length shown in Fig. 6(the lower figure), it can be found that the model with short-term memory priority idea has better performance overall. The reason for the analysis may be that in a long session, the user's current interest is more likely to focus on the last click and its vicinity, so STMAP and STMP can more easily provide user-satisfied recommendation results. At the same time, the longer the session, the larger is the accuracy gap between STMP (without_lastclick) and STMP and between STAMP (without_lastclick) and STAMP. This further proves that prioritizing short-term memory is more in line with the general behavioral characteristics of users. Furthermore, STAMP (without_lastclick) also outperforms STMP (without_lastclick), which is due to the fact that the attention mechanism in STAMP (without_lastclick) captures mixed overall interest and current interest, while STMP (without_lastclick) only averages the information in a way Consider the overall information of the session: lack of enhanced utilization of the relatively important part of the click information in the session.
4.4 Validity Analysis of Attention Calculation Method
We highlight the information related to the user's overall (long-term) interest preference and current interest preference when modeling the expression of the session context, so as to alleviate the interest shift phenomenon caused by the change of user interests in the session, which is critical to the accuracy of the session recommendation algorithm. In the attention mechanism, the overall session information and the last click information are added to calculate the attention weight of each click in the session. This subsection designs comparative experiments based on the proposed STAMP model on Yoochoose 1/64 and Diginetica datasets to analyze the effectiveness of considering both the overall session information and the last click information for modeling session context. The descriptions of the three attention calculation methods General_Attention, Last_Attemtion, and Mixed_Attetnion appearing in the table are as follows—General_Attention: in the attention network, the degree of association between each click and the overall information of the session is calculated as the attention weight; Last_Attention: in the attention network, calculate the degree of association between each click and the last click in the session as the attention weight; Mixed_Attetnion: the attention network used in the STAMP model proposed in this chapter. It can be found from the table that the performances of General_Attention and Last_Attention have their own advantages and certain complementarities on different datasets, but they are generally comparable. This is due to the difference in the focus of the two when focusing on information, resulting in the lack of user interest captured from the context of the conversation, although effective. General_Attention pays attention to the overall information of the session (user's long-term behavior) and can extract items that the user is more concerned about under normal circumstances. Last_Attention pays attention to the short-term memory (user's recent behavior) in the session to accurately discover the user's current preferences. The former introduces noise because the user's next behavior in the session may only be related to some clicks in the session, while the latter is easily affected by the user's wrong click behavior and interest shift, which is shown in Fig. 7.

Model performance on session groups of different lengths. a Yoochoose 1/64 and b Diginetica
Mixed_Attention considers the user's long-term interest and short-term interest information in the session as comprehensively as possible when modeling the contextual representation of the session, so it achieves the best performance.
4.5 Performance and Efficiency Analysis of STAMP and NARM Algorithms in Actual Production Environment
Session-based recommendation systems have become an important means to help companies select suitable products from a large number of candidate products and recommend them to users in real time according to the interaction between users and e-commerce platforms. In fact, there are often more than six to ten items on e-commerce websites, and in reality, most users are only interested in the top-ranked recommendation results generated by the recommendation system on the homepage. Therefore, to compare whether the stamp model proposed in this chapter and the currently popular NARM model meet the actual use needs of the current industry, the experiment in this section stipulates that the recommendation system can only recommend a small number of items at a time and the user's real clicked items should appear at the top of the recommendation list. Therefore, when trying to simulate the actual situation, the setting in this section is based on Recall@5, MRR@5, Recall@10, and MRR@10 indicators to evaluate the quality of recommendations. To compare the match between the results recommended by an enterprise using both models and the desired results, we recorded the data using Table 1. Table 1 shows the experimental results to reflect the performance of the two models in actual use to a certain extent. It can be observed from the table that, when evaluated according to stricter evaluation indicators, the STAMP model can accurately meet user needs for recommendation to a certain extent and is more competitive than the NARM model. In experiments on three datasets, the STAMP model proposed in this chapter consistently outperforms the NARM model and consistently provides more accurate recommendation results. This demonstrates the effectiveness of considering both interests in a session in a session recommendation task. Combined with the experimental results in Sect. 3.3, it can be fully demonstrated that the STAMP model proposed in this chapter can provide more accurate recommendation results in the conversational recommendation task.
At the same time, during actual deployment, computing resources and training time consumption are also important factors to consider when the model is online and running. This subsection uses the same 100-dimensional item embedding vector as input for both models and also a GPU server for training and records the average training iteration time. The results are shown in Table 2. It can be found that the training time of NARM is about two to three times that of the STAMP model. Because the recurrent neural network structure GRU unit used in the encoding phase of the NARM model needs to perform the same repeated operation for each click in the session to encode the entire session, the STAMP model proposed in this chapter is implemented using a shallower neural network, without affecting the final performance which is based on processing sequence information without using a high model complexity recurrent neural network. Combining the above experimental results shows that because recommendation systems in real environments often deal with large-scale conversations and candidate items, computational efficiency and running time are critical for the system, so the STAMP model may be more applicable in real situations.
5 Conclusion
This paper analyzes the basic challenges faced by the recommendation task and the problems of the current mainstream session recommendation algorithm based on recurrent neural networks in modeling user interests. We put forward the core idea of the algorithm design: the long-term and current interests of users in the session are important for predicting the next click of the session, and the importance of different click information for session recommendation is not the same. Combined with the characteristics of human behavior, a short-term attention and memory-first session recommendation algorithm stamp model is proposed. The model can give priority to the impact of short-term memory on the user's next click when making recommendations and propose an attention mechanism to effectively capture the user's long-term interest and current interest characteristics in the session. In this way, it can achieve the user's accurate prediction for the next click in the session. Experiments show that our recommendation algorithm on the last click still can achieve the same or even better performance as the cyclic neural network model by using a complex computing structure. Therefore, the method in this paper can provide new modeling ideas and solutions for conversational recommendation research.
Data Availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Cui, Z., Xu, X., Fei, X.U.E., Cai, X., Cao, Y., Zhang, W., Chen, J.: Personalized recommendation system based on collaborative filtering for IoT scenarios. IEEE Trans. Serv. Comput. 13(4), 685–695 (2020)
Yao, J., Zhu, X., Jonnagaddala, J., Hawkins, N., Huang, J.: Whole slide images based cancer survival prediction using attention guided deep multiple instance learning networks. Med. Image Anal. 65, 101789 (2020)
Zhou, X., Li, Y., Liang, W.: CNN-RNN based intelligent recommendation for online medical pre-diagnosis support. IEEE/ACM Trans. Comput. Biol. Bioinf. 18(3), 912–921 (2020)
Huang, Z., Xu, X., Ni, J., Zhu, H., Wang, C.: Multimodal representation learning for recommendation in Internet of Things. IEEE Internet Things J. 6(6), 10675–10685 (2019)
Zhang, H., Li, Y., Lv, Z., Sangaiah, A.K., Huang, T.: A real-time and ubiquitous network attack detection based on deep belief network and support vector machine. IEEE/CAA J. Autom. Sin. 7(3), 790–799 (2020)
Lakshmanna, K., Subramani, N., Alotaibi, Y., Alghamdi, S., Khalafand, O.I., Nanda, A.K.: Improved metaheuristic-driven energy-aware cluster-based routing scheme for IoT-assisted wireless sensor networks. Sustainability 14(13), 7712 (2022)
Wang, W., Xia, F., Nie, H., Chen, Z., Gong, Z., Kong, X., Wei, W.: Vehicle trajectory clustering based on dynamic representation learning of internet of vehicles. IEEE Trans. Intell. Transp. Syst. 22(6), 3567–3576 (2020)
Gao, H., Xu, Y., Yin, Y., Zhang, W., Li, R., Wang, X.: Context-aware QoS prediction with neural collaborative filtering for Internet-of-Things services. IEEE Internet Things J. 7(5), 4532–4542 (2019)
Zhou, J., Cui, G., Hu, S., Zhang, Z., Yang, C., Liu, Z., Sun, M.: Graph neural networks: a review of methods and applications. AI Open 1, 57–81 (2020)
Xiao, Y., Tian, Z., Yu, J., Zhang, Y., Liu, S., Du, S., Lan, X.: A review of object detection based on deep learning. Multimed. Tools Appl. 79(33), 23729–23791 (2020)
Verma, S., Sharma, R., Deb, S., Maitra, D.: Artificial intelligence in marketing: Systematic review and future research direction. Int. J. Inform. Manag. Data Insights 1(1), 100002 (2021)
Zhou, Y., Huang, C., Hu, Q., Zhu, J., Tang, Y.: Personalized learning full-path recommendation model based on LSTM neural networks. Inf. Sci. 444, 135–152 (2018)
Zhang, Q., Lu, J., Jin, Y.: Artificial intelligence in recommender systems. Complex Intell. Syst. 7(1), 439–457 (2021)
Mu, R.: A survey of recommender systems based on deep learning. Ieee Access 6, 69009–69022 (2018)
Goh, G.D., Sing, S.L., Yeong, W.Y.: A review on machine learning in 3D printing: applications, potential, and challenges. Artif. Intell. Rev. 54(1), 63–94 (2021)
Li, X., Chen, W., Zhang, Q., Wu, L.: Building auto-encoder intrusion detection system based on random forest feature selection. Comput. Secur. 95, 101851 (2020)
Logesh, R., Subramaniyaswamy, V., Malathi, D., Sivaramakrishnan, N., Vijayakumar, V.: Enhancing recommendation stability of collaborative filtering recommender system through bio-inspired clustering ensemble method. Neural Comput. Appl. 32(7), 2141–2164 (2020)
Muessigmann, B., von der Gracht, H., Hartmann, E.: Blockchain technology in logistics and supply chain management—a bibliometric literature review from 2016 to January 2020. IEEE Trans. Eng. Manag. 67(4), 988–1007 (2020)
Meng, T., Jing, X., Yan, Z., Pedrycz, W.: A survey on machine learning for data fusion. Inform. Fusion 57, 115–129 (2020)
Quer, G., Arnaout, R., Henne, M., Arnaout, R.: Machine learning and the future of cardiovascular care: JACC state-of-the-art review. J. Am. Coll. Cardiol. 77(3), 300–313 (2021)
Liu, J., Chen, Y.: A personalized clustering-based and reliable trust-aware QoS prediction approach for cloud service recommendation in cloud manufacturing. Knowl.-Based Syst. 174, 43–56 (2019)
Ahmad, Z., Shahid Khan, A., Wai Shiang, C., Abdullah, J., Ahmad, F.: Network intrusion detection system: a systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 32(1), e4150 (2021)
Wang, H., Lei, Z., Zhang, X., Zhou, B., Peng, J.: A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 198, 111799 (2019)
Zhao, Z.Q., Zheng, P., Xu, S.T., Wu, X.: Object detection with deep learning: a review. IEEE Trans. Neural Netw. Learning. Syst. 30(11), 3212–3232 (2019)
Zhang, S., Tong, H., Xu, J., Maciejewski, R.: Graph convolutional networks: a comprehensive review. Comput. Soc. Netw. 6(1), 1–23 (2019)
Funding
This work was supported by the Innovative Research Team Project of Suzhou Institute of Industrial Technology (2021KYTD003).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The author declared no conflicts of interest regarding this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, W. Intelligent Recommendation System Based on the Infusion Algorithms with Deep Learning, Attention Network and Clustering. Int J Comput Intell Syst 16, 83 (2023). https://doi.org/10.1007/s44196-023-00264-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00264-z