
Abstract
With the development and application of Internet technology, the world has entered a new era of the Internet economy. Information resources worldwide are no longer limited by time or space, which significantly improves the operational efficiency of production and commerce. As an essential part of the digital economy, digital finance is developing rapidly. Compared with traditional finance, Internet finance and digital finance have the advantages of low informational and transactional costs, and efficient services, which bring more benefits to consumers and investors. In the traditional small and fragmented long-tail market, the availability of finance has been effectively improved through technology-driven development. However, the sound development of the financial digital industry is inseparable from the self-generated sense of innovation and the exploration of green and sustainable development within the industry. This paper shows the evolution of the innovation and development of the financial digital industry driven by information technology in recent years, summarizes and discusses the key technologies emerging in it, and analyzes its limitations and shortcomings. This work will provide some references for the green development of the current industry.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The information technology revolution, which started in the middle of the twentieth century, promoted the rapid adjustment and upgrading of industrial structures in various countries, and not only the information industry emerged as a new leading industrial group, but also led to the transformation of electronic technology and industrial integration of traditional industries [1]. At the beginning of the twenty-first century, a “new economy” based on the information revolution and global market, with continuous adjustment and optimization of industrial structure, namely the information economy [2], has emerged globally. Information technology has and will completely change the global production, circulation, and consumption methods.
1.1 Research Motivation
In recent years, the use of information technology to create new products, services, or operational models has become an important means of industrial innovation for many enterprises, and governments at all levels also see it as an important way to foster and develop new industries [3]. Information technology-driven new industries have assumed the new period of social production division of labor functions, representing the new market requirements for the overall output of the economic system and the new direction of industrial structure transformation relative to the region. However, since they are currently in the formation stage of their own life cycle, it remains to be seen whether these industrial innovations will eventually succeed and thus trigger the entire industrial transformation under specific industrial structure and internal and external conditions, and successfully promote the rapid development and industrial upgrading of the entire industry.
At present, China is in a critical period of strategic adjustment of economic structure, and facing the economic downturn and labor force employment tension brought by the financial crisis, vigorously cultivating and promoting the development of new industries have become an important way to realize the transformation of traditional industries, improve international competitiveness, expand domestic demand, and promote labor force employment [4]. In a sense, the speed and scale of the development of new industries will fundamentally determine the overall quality and dynamics of China's future economic development. The formation of emerging industries must have a certain potential market, effective driving mechanism, and suitable environmental conditions and the necessary foundation of relevant resource factors. Empirical analysis shows that, on the basis of existing industry, the use of information technology to create new products, services or operational models, for the formation of new industries and the rapid development of scale has an important role in promoting [5]. Therefore, the integration of informatization and industrialization has become one of the important ways to cultivate and develop new industries, and the cultivation and development of new industries has become an important goal of the integration of informatization and industrialization.
1.2 Research Objectives
The focus of building a modern socialist country is to develop the economy, and the focus of developing the economy is the real economy. Finance is the core of modern economy and is crucial to the development of real economy. In the context of diversification of financial institutions and financial products, industrial finance as a financial model to serve the industrial economy has an increasing impact on the development of the real economy. In the financing structure of key industries in China, the proportion of financing from finance ranks first in all kinds of financing sources, which fully proves that the development of key industries in China is inseparable from the support of the financial industry [6]. Making bigger industrial finance has a great impact on the development of the financial industry and is of great significance to promote the sustainable development of the real economy. In the era of digital economy, “digital technology + N” has become an effective remedy to solve the contradictions of social and economic development by technical means, digital finance has become a major trend in the development of the contemporary financial industry, industrial finance as a mode of the financial industry, and “digital technology + industrial finance” has also become a necessary option [7]. As the object of industrial financial services has certain specificity, it is of great practical significance to discuss the development mode of digital industrial finance and explore the new path of “digital technology + industrial finance” to promote the construction of healthy finance and develop high-quality industrial finance.
1.3 Research Contributions
The contribution of this paper is shown as follows:
For small and scattered long-tail data, reinforcement learning algorithms are used to train the decision-making subjects in the simulation environment with techniques to realize data-driven financial availability solutions.
The benign development of the financial digital industry cannot be separated from the spontaneous sense of innovation and the exploration of green and sustainable development within the industry. This paper demonstrates the evolution of IT-driven innovation and development of the financial digital industry in recent years, summarizes and discusses the key technologies that have emerged, and analyzes their limitations and shortcomings.
The experiments are trained differently in two datasets: in the Ciao DVD dataset, five cross-validations are used, multiple experiments are used, and the average of the results of multiple experiments is taken.
1.4 Organization of the Paper
The remaining deployment section of this paper is shown below: Sect. 2 describes related work; Sect. 3 describes the methodology of this paper, a reinforcement learning framework model using Monte Carlo methods; Sect. 4 describes the experimental content and the conclusion is drawn in Sect. 5.
2 Related Work
2.1 The Concept and Characteristics of Industrial Finance
Industrial finance is a general term for financial services provided with industry as the target. Based on industry, industrial finance is a financial form that achieves mutual integration between industry and finance through the enabling effects of finance on industry, such as capital financing, resource integration, and value appreciation. Therefore, the concept of industrial finance has two understanding dimensions: one is the service object dimension, such as science and technology finance, cultural finance, transportation finance, etc., i.e., the industrial finance mode with industry as the support object; the second is the property rights of the combination of industry and finance dimension.
As a mode of finance, industrial finance has attracted high attention from all walks of life because of the importance of its service objects and the special form of industrial finance operation system. Minfeng [7] believes that the industrial finance model is conducive to the use of the group's advantages and the application of financial resources to industry, especially to small- and medium-sized enterprises in the supply chain. Reig-Mullor et al. [8] believes that, from the current situation, industrial finance is basically based on the development mode of supply chain finance, so, in a certain sense, industrial finance is equal to supply chain finance.
2.2 The Development Path of Industrial Finance
High-quality industrial finance is the only way to provide high-quality services to the real economy, and the high relevance of industrial finance to the real economy makes all walks of life pay great attention to the development and trend of industrial finance. Scholars have proposed various development paths: first, we should strengthen industrial finance by vigorously developing supply chain economy. According to the research [9, 10], the establishment of the “double carbon” target has brought great changes to the existing supply chain economy, and the original supply chain system has been broken, while the modern industrial finance is based on various business circles and material circles of the supply chain economy. Second, the service mode of industrial finance is optimized to enhance the technological content of industrial finance, so as to improve the service capacity of industrial finance. Zhaobao and Minfeng and Butkus [11, 12] proposed that the current financial institutions should comprehensively promote digital transformation, and boldly introduce digital technology embedded in the various business processes of industrial finance, so that technological means become the operational gene of industrial finance. Third, the main contradiction in the development of industrial finance should be solved. Chahed and Santana et al. [13, 14] concluded that the current focus should be on the reform and development of rural finance. In China's industrial development, rural industrial development faces problems, such as low investment and low access to financial services, etc. Only when industrial development is coordinated and balanced, the development of industrial finance will have a better foundation.
2.3 Digital Technology and “Digital Technology + N”
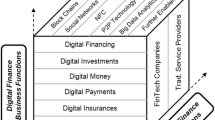
According to [15], digital technology is a branch of science and technology, which is the integration of the latest information technology such as big data, block chain, artificial intelligence, IoT, meta-universe, etc. Once such technology is used in the financial industry and served by the financial industry, it is collectively called financial technology. Digital technology has wide applicability and permeability, and many socio-economic problems can be solved by digital technology. At the same time, the digital economy as a trend, the impact on the market economic subjects is fundamental and decisive, digital finance and financial innovation (see Fig. 1), and therefore, all economic subjects must accept the baptism of digital technology, and constantly improve the level of digital applications.

Technology roadmap
The theoretical community generally believes that “digital technology + N” as the application model of digital economy has become the basic formula of digitalization, “digital technology + finance” that is, the concept of digital finance has become the unified paradigm of the financial industry, industrial finance belongs to the specific concept of finance, according to the aforementioned expression habits, “digital technology + finance” is the concept of the financial industry [16, 17]. Obviously, the reference to “industrial digital finance” is questionable, but it expresses the meaning of digital technology application in industrial finance. Goodell and Zetzsche et al. [18, 19] emphasize the role of digital technology in the development of industrial finance, and recognize the importance, necessity and practical feasibility of the comprehensive integration of digital technology with the real economy. Khalil et al. and Sharma et al. [20, 21] take blockchain technology as an example and proposes that the use of blockchain technology can effectively solve the problem of information sharing and decentralization of each subject in the industrial finance chain, and effectively realize the transformation from subject credit to transaction credit, while smart contracts can also bind the compliance and trustworthiness of each subject in the supply chain. Lee et al. [22] believe that the digital transformation of industrial finance will guide the extension of the digital economy from the consumer Internet to the industrial Internet, which is conducive to cultivating new dynamic energy for the development of the digital economy, optimizing industrial financial services as well as the structure of the real industry, etc.
From the existing research results, the academic community has fully recognized the great significance of the current vigorous development of industrial finance, and the practice is also exploring the ideas of developing and growing industrial finance, especially the application of digital technology in industrial finance has been explored. The shortcoming of the research is that the research on the theoretical logic and operation mode of digital industrial finance is still not systematic enough, and the operability needs to be strengthened. The innovation of this paper is that according to the historical logic of industrial finance development, based on the reality that industrial finance development is at the stage of supply chain ecosystem development, from the perspective of financial supply-side structural reform, it proposes to create a digital industrial finance model of platform, ecology, and content, which focuses on solving the pain points of industrial finance development and has strong operability, which is conducive to comprehensively improving the quality of industrial finance through the technical segment.
3 Method
In this paper, a reinforcement learning framework model using Monte Carlo methods is proposed for constructing the simulation environment described above [23], and the proposed model is a tuned improvement of the framework for this problem based on this approach. The reinforcement learning algorithm is used to train the decision-making agents in the simulation environment, so that the banks operated by the agents can make rational decisions and obtain higher overall bank returns when faced with different financial risk events compared to the rival banks operated by human experts. In the simulation environment, the basic information of the environment faced by each round of operators includes detailed asset and liability information of their own banks, public asset and liability information of the rival banks (operated by human experts), and the financial risks in the current environment. Trends in macroeconomic conditions and events. This environmental information is all the information that the agent refers to when making decisions.
Deep learning is a machine learning method, which can be roughly divided into three steps to achieve: first, establish the network architecture, then determine the goal of network learning, and finally, give the network learning algorithm and learn [24]. In the following, we will introduce deep learning through these three steps. The neural network is composed of a multilayer perceptron (multilayer perceptron, MLP for short) [25] (see Fig. 2).

Multilayer perceptron
The main feature of the multilayer perceptron is that it has multiple neuron layers. It is mainly used to receive the input training set, and multiple hidden layers in the middle of the multilayer perceptron belong to the middle layer. The middle layer mainly operates on the data received by the input layer, and the output layer mainly outputs the operation results. To understand the multilayer perceptron more clearly, the structure of a perceptron in Fig. 2 is expanded as shown in Fig. 3.

A single perceptron
In Fig. 3, a perceptron consists of a weight \(w\), a bias \(a\), and an input \(b\). The perceptors are connected by connecting the output of the perceptron. The value obtained by the linear operation of the parameters \(w\) and \(b\) is represented by \(Z\). In Fig. 3, the square brackets indicate the number of layers of the perceptron where the number is located, and the subscript \(i\) is the value of the \(i\) perceptron in a certain layer of perceptors. Assuming that the l − 1th layer has \(n\) outputs, the vector representation of the \(i\) rd \(Z_{i}^{[l]}\) value of the lth layer is
For the \(Z^{|l + 1|}\) value of the perceptron of the l + 1 layer, it can be expressed in the form of a matrix
If \(Z^{|l + 1|}\) is directly input into the next perceptron, the operation between the perceptrons adopts linear operation, which makes the approximation ability of the neural network has certain limitations. To improve the defects of linear operation and improve the learning ability and generalization ability of neural network, and \(Z_{i}^{[l]}\) is passed and then input to the next layer of perceptron. Common activation functions are: sigmoid, tanh, ReLU, etc. The activation function can be divided into saturated activation function and non-saturated activation function by judging whether its derivative is close to 0. Saturated activation functions include sigmoid and tanh, while a series of functions such as ReLU are unsaturated. Disappearance and speed up the convergence. The following are some commonly used activation functions: the sigmoid function is shown in Eq. (4):
Its definition domain is the whole real domain, and its value domain is [0, 1]. The advantage of using the sigmoid function as the activation function is that the output of the neuron is between 0 and 1, monotonically continuous, can be used in the output layer, and the derivation is relatively easy. The disadvantage is that the derivative value of the activation function is small due to function saturation. In the process of backpropagation, the result of the gradient multiplication will approach 0, resulting in no gradient signal being transmitted back to the gradient of the previous layer through neurons updating. As a result, the parameters such as weights are hardly updated, which leads to the problem of gradient disappearance, which causes the training model not to converge, and the optimization efficiency to be very low. The tanh function is shown in Eq. (5), and the tanh function can be transformed from the sigmoid function. However, its disadvantage is the same as that of the sigmoid function, and the problem of gradient disappearance still exists. Due to the use of exponential calculation, it will consume a lot of resources for exponential calculation
The linear rectification function (ReLU) is also called the modified linear unit, and its function expression is as shown in the following equation:
The ReLU function is a typical ramp function and is also a piecewise function. The advantage of the ReLU function is that the ReLU function, as a non-saturating function, avoids the problem of gradient disappearance, and does not require exponential calculation like the tanh function, which is more efficient and converges faster. The disadvantage is that when the model training learning rate is too large, most neurons in the neural network are not activated, resulting in poor model generalization ability, so a smaller learning rate needs to be selected. The different activation function are shown in Fig. 4.

Common activation functions
Reinforcement learning, as a branch of machine learning, focuses on how an algorithmic agent (Agent) learns actions (Actions) in different states (States) by interacting with it in a specific environment framework, so that it can obtain the most Cumulative return (Reward). The principle of reinforcement learning is shown in Fig. 5.

Schematic diagram of deep reinforcement learning
Currently, the development of reinforcement learning has entered the stage of integration with deep learning. As the neural network approach in deep learning has been widely used in computer vision in recent years with good results, similar approaches have been introduced into the framework of reinforcement learning. In China, the application of deep reinforcement learning is currently largely limited to the gaming domain. For example, Tencent’s deep reinforcement learning agent—“Jeuiwu” for “Glory of Kings”—won a professional player level test in 2019. But globally, there is no precedent for using deep reinforcement learning techniques to enable effective decision support for bank risk pricing. Having a game-like simulation environment is fundamental to the application of reinforcement learning, especially in conducting a customized simulation environment that sets up a reasonable reward approach to solve real-world problems. In other words, to study the risk pricing strategies of commercial banks, the existing risk pricing environment and mechanism must first be simulated and constructed to derive the expected returns of bank strategies in different market environments [26,27,28]. A simulation environment is constructed for commercial banks’ risk pricing. This environment integrates real historical risk scenarios, risk model simulations, bank regulatory indicators, and embedded formulas to derive the changes in core business indicators of commercial banks under different market conditions and business strategies based on international common quantitative models and regulatory rules, using common business measures of banks under Basel and other norms, as shown in Fig. 6.

Algorithm diagram
Due to the numerous scenarios and variables in banking business, it is impossible to rely on traditional regression analysis to model them one by one, and it is also difficult to obtain a large number of manually labeled samples for supervised approaches. Therefore, the simulation environment is built and the model is trained based on deep reinforcement learning algorithms to obtain intelligent models that can be applied to real banking scenarios and derive optimal risk pricing strategies for banks under different market conditions (e.g., systematic risk constraints), as shown in Fig. 7.

Schematic diagram of strategy neural network and evaluation neural network
In this paper, these parameterized environmental states are denoted as \(s_{t}\), where the subscript t is the environmental state obtained when the simulation proceeds to the \(t\) round. The decisions that banks operated by agents need to make are to make corresponding adjustments to business decisions such as pricing of different credit products according to the current market conditions. In this paper, these adjustments are defined as the decisions made by agents, represented by symbol \(a_{t}\). The subscript \(t\) is the decision made when the simulation reaches the \(t\) round. From the perspective of the specific algorithm implementation, a reinforcement learning problem can be abstracted as the optimal decision-making method under the environment framework obtained by the algorithm agent interacting with the environment in discrete multi-round simulation decision-making. In each round of risk event \(t\), the agent obtains the current environmental state information \(s_{t}\) from the environment, makes decisions \(a_{t}\) according to the environmental information, and obtains the corresponding return \(r_{t}\) of the current round of risk events. In the simulation framework of this paper, the decision-making return is the level of the bank’s “return on equity” (ROE) under the normal operating state of the bank. The higher its value, the better the decision-making return. The optimal decision-making method that reinforcement learning ultimately needs to obtain is that when a simulation ends, the total return after multiple rounds of decision-making is the highest, so the evaluation of the pros and cons of any round of agent decision-making can be done through an action-value function (Value-Based) Q to approximate
In the algorithm framework of this paper, the action-value function refers to: in the current round state, after taking a certain countermeasure, the expectation of the cumulative return in all subsequent rounds of decision-making. When calculating and updating such an action-value function neural network, it is necessary to calculate the cumulative reward of each round and all subsequent rounds of decision-making after completing each round of simulation, as the target criterion for network updating. To this end, the Temporal-Difference loss (TD loss) function needs to be used to update the parameters of the network. The loss function of the action-value function network is as follows:
where \(R_{t}\) is the single-round instant return obtained by the t decision-making round, and the variable with subscript t + 1 refers to the state and action of the next round of decision-making. The temporal difference method is a model-free reinforcement learning algorithm. It combines the traditional dynamic programming algorithm (Dynamic Programming) of reinforcement learning and the algorithm characteristics of Monte Carlo simulation (Monte Carlo Methods). The idea of iterative calculation of median function in planning method is combined with the principle of Monte Carlo method based on actual test sampling. Among model-free reinforcement learning algorithms, the temporal difference method can achieve faster convergence than the Monte Carlo method.
Based on the above principles, the improved deep deterministic gradient descent method in this paper is an algorithm structure similar to “actor-critic” (AC). This algorithm uses two neural networks to approximate the policy network and the evaluation network, respectively, and both neural networks use the accumulation of multiple linear layers (Linear Layer) and excitation functions (ReLU) as hidden layers; and to make the input data of different dimensions have a similar degree of importance in the network, in the input of the network A batch normalization layer (Batch Norm) is also added to normalize the data of different dimensions.
4 Experiment
To evaluate the proposed algorithm, this paper uses Film Trust and Ciao DVD datasets for experimental validation. The Film Trust dataset scores taken in the experiment range from 0.5 to 4, with 0.5 as an interval. The trust value in Film Trust ranges from 1 to 10, but the public data sets are mostly represented by binary types, that is, 1 means there is a trust relationship, and 0 means no trust relationship. We excluded 635 users from Film Trust who had no social connections and 133 who had no rating record. In the Ciao DVD dataset, movie ratings range from 1 to 5, and the ratings are integers with 1 as an interval. The trust relationship in this dataset is also represented by a binary type. It can be seen from the above analysis that the number of available users in the Film Trust dataset is much smaller than that in the Ciao DVD dataset
When conducting experiments on the Film Trust dataset, 80% for training and 20% for testing, repeat the experimental results. In the experiments on the Ciao DVD dataset, we use fivefold cross-validation to better calculate the dynamic change of the trust value, and we preprocess the trust value and map it to a continuous [0,1] interval, where 1 is used to represent complete trust, and 0 is used to represent complete distrust.
For a better and fairer algorithm comparison, we reviewed the hyperparameter settings of the original papers of the six comparison algorithms and adjusted them. Second, by consulting the papers and related reference materials, we set the discount factor of our algorithm γ = 0.8, and the settings of the rest of parameters are shown in Table 1.
The experiments discuss the influence of different embedding dimension d on the performance of algorithm. Then conduct experiments on Film Trust and Ciao DVD datasets×. The effect of embedding dimension d as shown in Fig. 8.

The effect of embedding dimension d on DDPG-TR
From the above graphs, we observe that the two algorithms have the same trend on both datasets, and observe that when d is small (for example, when d = 16), the algorithm obtains poorer performance, because the embedding dimension is small, the algorithm cannot adequately capture and represent the characteristic data of items and users. And when we gradually increase the embedding dimension, the performance indicators begin to gradually improve, especially when d = 100, the ndcg@10 indicators on both datasets reach the maximum value. Then, as d continues to increase, the performance drops slightly and remains stable. The reason for this trend is that the model. Therefore, when the recommendation accuracy reaches its peak, if the embedding dimension d continues to be expanded, the model capacity will not increase, and the performance of the recommendation system will gradually remain stable. He has actively interacted with before time step t. To verify the impact of different interaction lengths on the recommendation active l to be 5, 10, 15, 20, 25, and 30, respectively, and conduct experiments on two datasets. The experimental results corresponding to the two algorithms are shown in Fig. 9.

Influence of interaction length l on DDPG-TR algorithm
The two algorithms have the same trend on the Film Trust and Ciao DVD data sets, that is, the algorithm index interaction length l. When l = 5, the algorithms of the two data sets show a downward trend performance is at its maximum. Satisfy historical items with l active interactions. Therefore, when l increases, fewer users meet the conditions, the available data will become more sparse, and the performance of the algorithm will gradually deteriorate, as shown in Fig. 10.

Comparison on Film Trust dataset
The former is about 10% of the latter, and the number of corresponding experimental test sets also becomes larger. Next, we fine-tune the hyperparameters in the experiment when reproducing the comparison algorithm, and the training methods are different in the two datasets: in the Ciao DVD dataset, fivefold cross-validation is used, multiple experiments are used, and the average of the results of the multiple experiments is taken value. The last point is that the selected datasets do not have other attribute information other than the trust and ratings obtain the latent embedding vectors of other attributes of these, so it cannot provide high accuracy rate, so that its effect on the Ciao DVD dataset is also inferior to the WRMF algorithm. The performance of different algorithms is shown in Fig. 11.

Performance comparison on Ciao DVD dataset
To sum up, through the above experiments and analysis, our algorithm DDPG-TR performs better we refer to the hyperparameter settings in the original text of the five comparison algorithms. It is then fine-tuned to ensure fair comparisons across experiments. See Fig. 12. To sum up, our experiments are real and effective, and are better than the comparison algorithms. The experimental results of the Yelp dataset.

Comparison on the Yelp dataset
This paper outputs the final decision-making mode of the agent simulation bank. Under the tested financial scenario, the ratio of the agent strategy and the human expert strategy is shown in Fig. 3; the ratio of the agent strategy result to the human expert strategy result is shown in Fig. 4. From the financial perspective, analyze the strategy development process of the agent as follows. In the risk scenario, the core of the management strategy is to ensure sufficient liquidity and reasonable adjustment of asset allocation, that is, an asset pricing scheme. As shown in Fig. 3, the initial 0–10,000 training sessions are mainly about the influence of each factor on the cumulative return (ROE) and the relationship between each indicator. Between 1 and 20,000 times, the agent's strategy gradually approaches the preset human expert strategy and gradually converges. In the last 5000 times (i.e., 20,000–25,000 times), the agent finally optimizes its strategy and obtains a better strategy than the human expert. From the final result, this set of strategies has achieved higher Nim and roe on the basis of ensuring that the three business indicators (NPL, LCR, and total capital ratio) are equal to the return of human expert strategies. Therefore, the pricing strategy obtained by the model through training is superior to that of its human expert competitors in terms of at least five core business indicators. In conclusion, as the number of training rounds increases, the risk management pricing strategy of agents gradually approaches the management strategy of financial experts and the financial risk management experience in history; with the further increase of the training amount, the agent tries to gradually converge to a more mature pricing strategy, so that the output return gradually approaches and eventually exceeds the human expert strategy.
5 Conclusion
The development of digital finance improves investment in corporate innovation activities, and also pays attention to the actual output of corporate innovation. Digital finance and modern information technology coexist with each other and have the characteristics of rapid change and wide influence. This paper investigates the development of the financial digital industry from multiple dimensions, summarizes the innovation and development achievements of the industry, and helps to scientifically and comprehensively grasp and perceive the latest development process and future trends of China’s financial digital industry. At the same time, this paper conducts a discussion on the direction of green and healthy development of the industry, which is an important but currently ignored direction by most researchers.
In the future, we should start with the integration of green design, application of new technologies, lean management, and digital and intelligent transformation, and gradually promote the green and healthy development of the entire industry cycle.
Availability of Data and Materials
The experimental data used to support the findings of this study are available from the corresponding author upon request.
References
Yangyang, X., Minfeng, L.: Research on the practice and innovation path of digital transformation model of commercial banks–analysis based on the annual reports of some A-share listed banks in recent years. Southwest Finance 8, 23–32 (2022)
Li, W., Yüksel, S., Dinçer, H.: Understanding the financial innovation priorities for renewable energy investors via QFD-based picture fuzzy and rough numbers. Financ Innov 8(1), 1–30 (2022)
Gepp, A., Kumar, K., Bhattacharya, S.: Lifting the numbers game: identifying key input variables and a best-performing model to detect financial statement fraud. Account Finance 61(3), 4601–4638 (2021)
Banham, R.: Wrong numbers: the risks of inaccurate financial statements. Risk Manag 66(8), 32–35 (2019)
Wanke, P., Azad, M.A.K., Yazdi, A.K., Birau, F.R., Spulbar, C.M.: Revisiting CAMELS rating system and the performance of ASEAN banks: a comprehensive MCDM/Z-numbers approach. IEEE Access 10, 54098–54109 (2022)
Flayyih, H.H., Noorullah, A.S., Jari, A.S., Hasan, A.M.: Benford law: a fraud detection tool under financial numbers game: a literature review. Soc Sci Humanit J 18, 1909–1914 (2020)
Minfeng, L.: Digital technology enables high-quality development of real economy: integration advantages, operation mechanism and practice path. J Xinjiang Normal Univ (Philos Soc Sci Edn) 1, 136–144 (2023)
Reig-Mullor, J., Brotons-Martinez, J.M.: The evaluation performance for commercial banks by intuitionistic fuzzy numbers: the case of Spain. Soft. Comput. 25(14), 9061–9075 (2021)
Kumar, S.B., Goyal, V., Mitra, S.K.: Do Indian firms manage earning numbers? An empirical investigation. Acad Account Financ Stud J 22(1), 1–7 (2018)
Ouyang, W.J., Minfeng, L.: Research on the current situation, model comparison and innovative ideas of small and micro finance of commercial banks. Financ Theory Pract 10, 30–37 (2022)
Zhaobao, Z., Minfeng, L.: Research on the application of blockchain technology in supply chain finance–a perspective of supply chain finance with the construction of fintech platform as the core. Fintech Times 12, 7–13 (2022)
Butkus, S.: Use your numbers: what’s essential to private practice success? A solid financial plan that you tweak based on what your practice spends and earns. ASHA Lead 23(1), 42–49 (2018)
Chahed, Y.: Words and numbers: financialization and accounting standard setting in the United Kingdom. Contemp Account Res 38(1), 302–337 (2021)
Santana, S., Thomas, M., Morwitz, V.G.: The role of numbers in the customer journey. J Retail 96(1), 138–154 (2020)
Cobbin, P.E., Burrows, G.H.: The profession of arms and the profession of accounting numbers—accounting, the military and war: a review. Account Hist 23(4), 487–520 (2018)
Cao, L.: AI in finance: challenges, techniques, and opportunities. ACM Comput Surv (CSUR) 55(3), 1–38 (2022)
Egger, D.J., Gambella, C., Marecek, J., McFaddin, S., Mevissen, M., Raymond, R., Yndurain, E.: Quantum computing for finance: State-of-the-art and future prospects. IEEE Trans Quantum Eng 1, 1–24 (2020)
Goodell, J.W.: COVID-19 and finance: agendas for future research. Financ Res Lett 35, 101512 (2020)
Zetzsche, D.A., Arner, D.W., Buckley, R.P.: Decentralized finance. J Financ Regul 6(2), 172–203 (2020)
Khalil, M., Khawaja, K.F., Sarfraz, M.: The adoption of blockchain technology in the financial sector during the era of fourth industrial revolution: a moderated mediated model. Qual Quant 56(4), 2435–2452 (2022)
Sharma, A.P.A., Reddy. S.P., Patwal, P.S., Gowda, D.V.: Data analytics and cloud-based platform for internet of things applications in smart cities. 2022 international conference on industry 4.0 technology (I4Tech), pp 1–6. Pune, India (2022). https://doi.org/10.1109/I4Tech55392.2022.9952780
Lee, M., Yun, J.J., Pyka, A., Won, D., Kodama, F., Schiuma, G., Zhao, X.: How to respond to the fourth industrial revolution, or the second information technology revolution? Dynamic new combinations between technology, market, and society through open innovation. J Open Innov Technol Mark Complex 4(3), 21 (2018)
George, G., Merrill, R.K., Schillebeeckx, S.J.: Digital sustainability and entrepreneurship: how digital innovations are helping tackle climate change and sustainable development. Entrep Theory Pract 45(5), 999–1027 (2021)
Gil-Gomez, H., Guerola-Navarro, V., Oltra-Badenes, R., Lozano-Quilis, J.A.: Customer relationship management: digital transformation and sustainable business model innovation. Econ Res Ekonomska istraživanja 33(1), 2733–2750 (2020)
Nie, D., Panfilova, E., Samusenkov, V., Mikhaylov, A.: E-learning financing models in Russia for sustainable development. Sustainability 12(11), 4412 (2020)
ElMassah, S., Mohieldin, M.: Digital transformation and localizing the sustainable development goals (SDGs). Ecol Econ 169, 106490 (2020)
Xu, Y., Tao, Y., Zhang, C., Xie, M., Li, W., Tai, J.: Review of digital economy research in china: a framework analysis based on bibliometrics. Comput Intell Neurosci 2022, 2427034 (2022). https://doi.org/10.1155/2022/2427034
Wang, Z., Zhang, Q., Ong, Y.-S., Yao, S., Liu, H., Luo, J.: Choose appropriate subproblems for collaborative modeling in expensive multiobjective optimization. IEEE Trans Cybern 53(1), 483–496 (2023)
Acknowledgements
The author would like to show sincere thanks to those techniques who have contributed to this research.
Funding
There is no specific funding to support this research.
Author information
Authors and Affiliations
Contributions
Not applicable.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declared that they have no conflicts of interest regarding this work.
Consent for Publication
The author reviewed the results, approved the final version of the manuscript, and agreed to publish it.
Ethical Approval
Not applicable.
Consent to Participate
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, Y. Key Technologies of Financial Digital Industry Innovation and Green Development Driven by Information Technology. Int J Comput Intell Syst 16, 78 (2023). https://doi.org/10.1007/s44196-023-00262-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00262-1