
Abstract
Retinal issues are crucial because they result in visual loss. Early diagnosis can aid physicians in initiating treatment and preventing visual loss. Optical coherence tomography (OCT), which portrays retinal morphology cross-sectionally and noninvasively, is used to identify retinal abnormalities. The process of analyzing OCT images, on the other hand, takes time. This study has proposed a hybrid approach based on a fully dense fusion neural network (FD-CNN) and dual preprocessing to identify retinal diseases, such as choroidal neovascularization, diabetic macular edema, drusen from OCT images. A dual preprocessing methodology, in other words, a hybrid speckle reduction filter was initially used to diminish speckle noise present in OCT images. Secondly, the FD-CNN architecture was trained, and the features obtained from this architecture were extracted. Then Deep Support Vector Machine (D-SVM) and Deep K-Nearest Neighbor (D-KNN) classifiers were proposed to reclassify those features and tested on University of California San Diego (UCSD) and Duke OCT datasets. D-SVM demonstrated the best performance in both datasets. D-SVM achieved 99.60% accuracy, 99.60% sensitivity, 99.87% specificity, 99.60% precision and 99.60% F1 score in the UCSD dataset. It achieved 97.50% accuracy, 97.64% sensitivity, 98.91% specificity, 96.61% precision, and 97.03% F1 score in Duke dataset. Additionally, the results were compared to state-of-the-art works on the both datasets. The D-SVM was demonstrated to be an efficient and productive strategy for improving the robustness of automatic retinal disease classification. Also, in this study, it is shown that the unboxing of how AI systems' black-box choices is made by generating heat maps using the local interpretable model-agnostic explanation method, which is an explainable artificial intelligence (XAI) technique. Heat maps, in particular, may contribute to the development of more stable deep learning-based systems, as well as enhancing the confidence in the diagnosis of retinal disease in the analysis of OCT image for ophthalmologists.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The retina is a light-sensitive optical nerve tissue layer that covers the inner surface of the eyeball and converts into brain messages light acquired by the lens [1]. The macula, which contains photoreceptor nerve cells that assist sense light, its intensity, and visual details, is at the heart of this structure. As a result, the retina interprets the information retrieved by the macula and communicates it to the brain for visual perception through optical nerve channels [2].
Age-related macular degeneration (AMD), choroidal neovascularization (CNV), drusen, and diabetic macular edema (DME) are only a few of the eye illnesses that impact the retina. At 65 years of age or older, AMD is one of the primary causes of blindness [1]. Dry AMD and wet AMD are the two kinds of AMD. Drusen corresponds to dry AMD, whereas choroidal neovascularization, or CNV, alludes to wet AMD. Fluid and protein buildup in the macula promote DME, which deteriorates the retinal neurovascular anatomy. The prevalence of DME in diabetic patients is estimated to be around 25% [3]. Macular edema and associated neurovascular conditions are chronic diseases that can culminate in irreversible vision loss if left misdiagnosed and untreated. To ensure visual acuity, retinal disorders should be recognized and treated early. Surgical intervention is not required for early-stage retinal disorders. In a nutshell, the retina is a critical structure that has an impact on human life. Retinal illnesses result in vision issues, which can be very catastrophic. In order to stop or delay the progression of retinal illnesses, it is vital to recognize and treat them immediately.
OCT is an imaging technique used to view retinal morphology noninvasively and cross-sectionally [4]. Direct cross-sectional imaging of retinal anatomy can differentiate the cross-sectional morphological features of the retinal fovea and optic disc, the layered retinal structure, normal anatomical variations in the retinal nerve fiber layer, and retinal thickness [5]. Because it delivers noninvasive and non-contact high-resolution imaging, OCT is effective in the early diagnosis and follow-up of AMD and DME [6, 7]. OCT presents a diagnostic superiority in retinal disorders; however, interpreting OCT images appears to take ophthalmologists far too long [8] because they consist of multiple retinal sections from diverse angles. Each component is crucial and thus should be thoroughly investigated. Automatically examining OCT images for retinal illnesses enhances clinical practice by determining diagnostic accuracy and expediting access to expert knowledge, especially in cases when staffing is a constraint [9]. Analyzing OCT images via computer vision methods speeds up the clinical diagnosis process and automates the workflow [10].
Numerous academics are engaged in clinical decision support systems due to the current advancement of machine learning (ML) and deep learning (DL) algorithms in the field of artificial intelligence (AI) [11, 12]. Researchers have focused on retinal diseases [13] and proposed many ML and DL early detection and diagnosis systems [14, 15]. For image categorization and pattern recognition, DL has made a significant accomplishment in medical imaging. Ophthalmologists have been progressively using two-dimensional and three-dimensional OCT volumetric scan images to investigate DL and glaucoma in past few years, which has piqued the interest of researchers [16]. The convolutional neural network (CNN) is a standard DL technique that learns from image features such as X-ray images for the detection of diseases, especially eye diseases [17].
OCT image inherently has speckle noise. However, optimizing image quality of this image is just as essential as removing noise in image improvement. Advances in technology result in better image quality. Fine details can be detected using high-resolution images. The output of a neural network is disrupted by blurriness or other quality issues [18]. CNN is an ML algorithm that performs well in computer vision, image classification, and object recognition [19]. However, input image quality depends on some factors, such as layer structure and activation functions. According to research, ML approaches are just as susceptible to image quality degradation (blurriness or noise) as deep neural networks are [20, 21]. The CNN has a high capacity to learn because it involves multiple feature extraction stages that can automatically learn fine details from data [19]. However, traditional ML algorithms such as Support vector machine (SVM), k-nearest neighbor (KNN) need hand-crafted features for classification. CNN architecture, unlike previous algorithms, does not offer an external mechanism for feature extraction because it already has feature extraction functions. The strength of CNN over conventional ML approaches is that, because to its automatic feature extraction capacity, the features explaining the pattern in the best way may be learned directly from the raw data, rather than hand-crafted features. As a result, the capabilities of CNN are noteworthy since it bypasses the necessity for a separate feature extraction approach.
The use of CNN as a stand-alone decision maker has been exhibited that utilizing CNN as a feature extractor and employing it in a hybrid way with different ML algorithms enhances the classification performance in many distinct problems as glaucoma and hemorrhage determination from retinal images [22, 23].
This study addresses to eliminate noise in OCT images and solve the classification problem. In this direction, the main contributions of this study are as follows.
-
(1)
The study proposes a new FD-CNN architecture to use as an automatic feature extractor and classifier,
-
(2)
This study evaluates the effect of preprocessing methods that make up the Hybrid speckle filter on the FD-CNN architecture using ablation testing,
-
(3)
The study proposes the D-SVM and D-KNN models that include the classify of features obtained from the FD-CNN architecture,
-
(4)
The study generates the heat map showing what the proposed system focuses on in the decision-making process with the XAI technique,
-
(5)
The study evaluates the proposed method in UCSD and Duke OCT datasets, which are widely used in the literature, and comparison with state-of-art methods.
-
(6)
The study demonstrates that the D-SVM method, which is formed by FD-CNN architecture and SVM, is an effective and successful hybrid method for classification of retinal diseases in OCT images.
The rest of the article is organized as follows: Sect. 2 presents related works on the paper topic. Section 3 explains flow diagram of the proposed method, the OCT dataset, image preprocessing methods, CNN, ML methods, XAI technique, and ablation study. Section 4 describes the structure and details of the proposed method. Section 5 presents the results of ablation testing and experiments of preprocessing methods performed on the proposed method. Section 6 summarizes the findings and evaluates the proposed method. Finally, Sect. 7 provides the conclusion by presenting the main summary of the study.
2 Related Work
To characterize retina illnesses using OCT images, multiple DL technologies have been implemented. Kermany et al. used a pre-trained CNN architecture (Inception V3) [24] to classify OCT images to diagnose CNV, DME, drusen, and typical retinal diseases via transfer learning [1]. Li et al. used the ResNet50 [25] architecture to classify OCT images. They used four ResNet50 architectures and developed the Multi-ResNet50 ensembling architecture [26]. Islam et al. developed a method based on feature extraction using pre-trained CNN and feature classification via artificial neural network (ANN) to diagnose diabetic retinopathy. They compared the pre-trained CNN architectures, and they ended that DenseNet201 [27] exhibited the best performance. They also stated that the retraining of the features extracted from OCT images by DenseNet201 through ANN increased the performance [28]. Kim et al. used a fully convolutional neural network, a preprocessing technique, to remove the background from OCT images. After training them on multiple pre-trained CNN networks, they compared the performance of preprocessed OCT images. They reported that ResNet152 had performed the best. In another approach, they stated that they improved performance by training three ResNet152 via a learning method [29]. Paul et al. developed the Extended Optical Coherence Tomography (OCTx) model as an ensemble network based on VGG16, DenseNet, InceptionV3 and custom CNN architectures to diagnose retinal diseases. Before training the OCTx network, they conducted data augmentation (preprocessing) to balance the amount of retinal illness classes in the dataset [30]. Rastogi et al. looked into the effects of dense block translations on pre-trained DenseNet architecture and used the best performing model to classify OCT images [31]. Tsuji et al. used the Capsule Network [32] to improve the classification accuracy in OCT images. They added four more convolution layers and developed a new network of capsules with good performance in OCT images [33]. Li et al. developed a VGG-16 network based on deep transfer learning to detect retinal diseases [34]. Chetoui et al. used the EfficientNet [35] architecture to classify retinal diseases. They employed gradient-weighted class activation mapping (Grad-CAM) [36] to see on which region of the retinal images the proposed approach focused [37]. Saraiva et al. proposed a 12-layer CNN model for retinal classification in OCT images and used k-fold cross-validation to determine the model's performance [38]. Huang et al. focused on detecting retinal diseases based on lesions in the retinal layers. They used fully convolutional deep architecture, termed ReLayNet [39] to obtain two layers (i.e., inner limiting membrane-retinal pigment epithelium (ILM-RPE) layer and retinal pigment epithelium-Bruch’s membrane (RPE-BrM) layer) associated with lesions. They trained these layers on the created layer guided convolutional neural network (LGCNN) architecture and compared the performance of the model on two public datasets [40]. Rajagopalan et al. compared image denoising methods to improve classification efficiency in OCT images and used k-fold cross-validation on the proposed CNN architecture to evaluate the most effective method [41]. As seen in the above-mentioned literature, it seems that although the use of pre-trained CNN architectures in disease diagnosis from OCT images is quite common, it is not sufficient on its own. In addition to the classification approach in disease diagnosis from OCT images, the enhancement of the OCT images is an important step in improving the performance of computer-aided diagnosis systems. It is seen that the enhancement of the images in computer-aided systems also affects the system performance positively [20]. In this context, another difficulty with OCT images is speckle noise [42]. This may reveal details about the structure of retinal tissues as well as the nature of noise. It is induced by the instrument and the surface exchanging ongoing infrared waves. The mechanism sends waves to the surface that have a refractive index greater than the refractive index, generating an unexpected delay. Speckle noise appears all over the image as a result of many of the forward and backward waves [43]. Speckle noise that may occur in OCT images may prevent the physician from seeing the fine details in the retina during diagnosis, as well as it is an important problem that should be considered in terms of improving the performance of computer-aided diagnosis systems. The retinal layers should be carefully examined and decomposed to diagnose diseases on OCT images, and before doing that, speckle noise should be reduced to facilitate and speed up the diagnostic process. As a result, enhancing OCT images is a fundamental step toward improving the reliability of disease identification on retinal imaging. Therefore, researchers have concentrated on image preprocessing procedures to decrease speckle noise in recent years.
In one of these studies, Rajagopalan et al. employed image denoising methods (mean filter, Lee filter, Kuan filter, and wavelet filter) to remove natural speckle noise from OCT images. They calculated image quality parameters to compare the filters and reported that the Kuan filter performed the best [41]. Adler et al. used a spatially adaptive two-dimensional wavelet filter to remove speckle noise from time-domain OCT images. They argued that the filter would allow them to separate OCT images' edges from noise-induced discontinuity and attenuate it in the wavelet field without damaging the image sharpness [44]. Zaki et al. developed the noise adaptive wavelet thresholding (NAWT) algorithm to remove speckle noise from OCT images. They compared the values of signal noise ratio (SNR: an algorithm image quality measurement metric). They claimed that the NAWT could remove speckles from most pixels [45]. Chong et al. proposed a speckle noise reduction algorithm based on Morlet wavelet decomposition and modified block matching 3D filter. They tested the algorithm on the OCT image of a human index finger and then presented the signal-to-noise ratio values, the equivalent number of looks, contrast-to-noise ratio, edge preservation coefficient, and central processing unit time. They found out that the algorithm was an effective method for reducing speckle noise [46]. Koresh et al. developed a hybrid speckle reduction (HSR) technique to reduce speckle noise in corneal OCT images. The technique was based on the application of the Gaussian, anisotropic, and bilateral filters in order. The researchers calculated the correlation coefficient and peak signal–noise ratio values to compare the technique to other filters for speckle noise reduction. They found that the HSR reduced speckle noise more significantly and preserved edge information better than the other filters [47].
3 Material and Method
This study has proposed a hybrid FD-CNN architecture using D-SVM and D-KNN models to classify retinal diseases using OCT images. The greatest challenge of retinal disease classification is detecting deformation in retinal layers. Any information obtained from OCT images can be significant because they visualize the morphological structure of the retina. The OCT device emits infrared waves to capture the image of the retina structure, resulting in speckle noise spreading all over the image. This problem prevents experts from clearly seeing the retina layers and identifying their thickness. Therefore, firstly speckle noise should be reduced if the researchers are interested in using computer-assisted technology to detect retina diseases. To that end, in this proposed study, hybrid speckle reduction (HSR) technique, which has been proven to be successful before, was first applied to OCT images to remove speckle noise in OCT images. Also, an ablation study or test was applied on the FD-CNN architecture for the performance evaluation of the filters that make up the HSR and the obtained results were compared. In this test, the preprocessing method with the highest performance was used in FD-CNN, which forms part of the proposed method. Afterwards, D-SVM and D-KNN methods, which used traditional ML techniques, were applied separately to the FD-CNN architecture and their performances were compared.
The proposed method is depicted in Fig. 1 as a flow diagram. To eliminate noise from the OCT images, HSR was used firstly. The data was then trained in the FD-CNN architecture, and the impact of preprocessing on system performance was investigated. After that, features obtained from the dataset during training were retrieved using an activation function. In the next step, the features retrieved were trained in the D-SVM and D-KNN models seperately. At the end of the training, in order to quantify system performance, the features obtained from the test dataset were evaluated by applying these models. Finally, one of the highest performing D-SVM and D-KNN models were proposed.

Flow diagram of proposed method
In this study, the success of the proposed method was measured on two different OCT datasets and the results were reported. In addition, as can be seen in Fig. 1, the performance evaluation was made by applying the ablation test to the filters containing HSR, and the obtained results were also presented.
3.1 OCT Dataset
In this study, two different OCT datasets were used. One of them is the UCSD dataset [1], consisting of 84,484 OCT B-images of 4696 patients from the Shiley Eye Institute at the University of California San Diego and other medical organizations between 1 July 2013 and 1 March 2017. All UCSD images were carefully reviewed and classified by medical experts. The dataset consists of two parts: training (n = 83,484) and test (n = 1000). The training dataset consisted of four classes of images: CNV (n = 37,205), DME (n = 11,348), drusen (n = 8616), and normal (n = 26,315). The test dataset involved four classes of images (n = 250 images in each class): CNV, DME, drusen, and normal.
Another used dataset is the Duke dataset [48], which includes 3231 OCT images collected by Srinivasan et al. [48] from 45 different subjects in three different categories: normal (n = 1407), AMD (n = 723) and DME (n = 1101). This dataset is not separated as training and testing. Therefore, in this study, Duke dataset is divided into 90% training and 10% testing to evaluate the proposed method. Figure 2 illustrates some OCT images from the Duke and UCSD datasets. The details of these datasets are documented in full in Table 1.

Sample images in OCT datasets: a UCSD and b Duke
3.2 Image Preprocessing
In recent years, digital filters for image enhancement have grown prevalent in a variety of disciplines. Filters are used by medical professionals to strengthen the interpretation of images [49]. Filtering is a technique for improving image quality by eliminating noise or interference. In the medical industry, image preprocessing is done with a myriad of filters. Filters are used to reduce image noise, but they can also be used to highlight or remove features.
In this study, the HSR [47] method, which has proposed effective ways in order to prevent speckle noise on OCT images in earlier studies, was used as a preprocessing on OCT images to remove speckle noise. The HSR involves gaussian, anisotropic diffusion, and bilateral filters combined with expanded operand decomposition. In addition, the effects of the HSR on the FD-CNN architecture were examined.
A Gaussian filter is used to filter the noise from various sources (medical, satellite images, etc.). The Gaussian filter is also known as the Gaussian blur or Gaussian smoothing. The Gaussian filter employs a Gaussian function to calculate the transformation for each pixel of an image. The one-dimensional equation of the Gaussian function is given in Eq. (1):
The two-dimensional equation of the Gaussian function is given in Eq. (2), and it was used to calculate a Gaussian function on both axes \((x, y)\).
where x is the distance to the origin on the horizontal axis, \(y\) is the distance to the origin on the vertical axis, and σ is the standard deviation of the Gaussian distribution. The smoothness of an image depends on the \(\sigma\) value. Figure 3 provides an example of the effect of the Gaussian filter on an OCT image. As seen in Fig. 3, the Gaussian filter reduces and smoothens the noise. A standard Gaussian filtering technique was used within the HSR.

a Raw OCT image b post-Gaussian OCT image
The anisotropic diffusion filter is another preprocessing method employed to enhance medical images (Lung, breast, brain, knee, etc.) [50]. The primary purpose of diffusion algorithms in image processing is to reduce noise through a partial differential equation. Perona et al. [51] used an anisotropic coefficient to stop the diffusion at the edges of images.
where \(\nabla\) is the gradient operator, div is the divergence operator, \(| |\) is the magnitude operator, \(c(x)\) is the diffusion coefficient function, and Io is the input image. Two diffusion coefficients developed by Perona et al. [51] are given in Eqs. (4) and (5).
where k is the edge magnitude parameter. Anisotropic diffusion uses the gradient magnitude to identify the edge areas or intensity discontinuities [52]. At pixels where \(|\nabla |> k\), the value of \(c (|\nabla |)\) becomes 0. At pixels where \(|\nabla |< k\), the value of \(c (|\nabla |)\) becomes 1. Equation (3) can be written in discrete form as in Eq. (6).
where \({I}_{s}^{t}\) is the discretized image, s is the location of the pixel in a discrete 2-D image, \({\Delta }^{t}\) is the time step size, \({n}_{s}\) is the spatial neighborhood of \(s\), and \(\left|{n}_{s}\right|\) is the number of pixels in the window. Anisotropic diffusion filter involves intraregional-smoothing and edge-preserving [52]. Figure 4 provides an example of an anisotropic diffusion filter applied to a post-Gaussian OCT image.

a Gaussian filter b Gaussian filter and Anisotropic diffusion filter
Bilateral filter was used after anisotropic diffusion filter to preserve the edges of the OCT image. One of the filters used to remove speckle noise, bilateral filter is widely made use of to improve the boundaries of the object on the image and to remove speckle noise without destroying the image features [53]. The bilateral filter is becoming more and more popular in image processing nowadays because it is also able to enhance images [54].
The bilateral filter replaces the pixel intensity value with the weighted average intensity values of the neighbor pixels. The mathematical presentation of the bilateral filter is given in Eq. (7). Mathematically, at a pixel location m, the output of a bilateral filter is calculated as follows:
where \({\sigma }_{d}\) and \({\sigma }_{t}\) are parameters controlling the fall-off of weights in spatial and density domains and are also known as smoothing parameters. \(N(x)\) is a spatial neighborhood of \(E(m)\), and \(K\) is the normalization constant. \({E}_{bi}\) refers to the pixel density obtained by applying a bilateral filter to \(m\) pixel positions. Figure 5 provides an example of a bilateral filter applied to a post-anisotropic OCT image.

a Anisotropic diffusion filter b Anisotropic diffusion filter and Bilateral filter
3.3 Deep Learning
DL is a sub-branch of ML that has been increasingly popular in recent years for solving complex issues. DL is exemplified by ANNs. Although ANN goes back to the 1950s, technological advancements have vastly expanded hardware capacity and computer capability since then. As a result, we can now leverage big datasets to train deeper structures using ANN. ANNs have multi-layered structure and they solve the complex structure in large data sets using the backpropagation algorithm in this structure. ANNs have achieved remarkable developments in a broad range of subjects, including speech and object recognition, as well as drug development [17].
The convolution neural network is a popular DL technique used to perform unsupervised deep feature extraction from input images in multi-computer vision operations. Utilizing a multilayer structure to process data with grid-like topology, CNNs are advanced neural networks inspired by living creatures' visual cortex [17]. Images are known as 2D grid-type structures. The CNN structure containing the multilayer structure may be seen in Fig. 6. One of the basic layers of CNN is the convolution layer. This layer extracts features by traversing the convolution kernel on the input image step by step. These features are located sequentially in feature maps. When the convolution operations are complete, the bias and weight are calculated. Convolution processes are followed by bias and weight calculations. This neural network is referred to as a "convolution neural network" [55] because it involves dense convolution processes (Fig. 6). In CNN terminology, the input and convolution are defined as the first and second arguments, respectively, while the feature map is defined as the output [56].

A typical CNN architecture
DL is based on learning its representations by extracting features from input data through the interactions among multiple abstract layers. When a neural network is stimulated, the convolution kernel creates a feature map. As seen in Fig. 6, the output of a layer is the input of the next one. The CNN continues its operation until the last layer, resulting in a ConvNet with low and high quality features regarding the input data.
The convolution layer extracts the basic features and groups them in a feature map (see Eq. 8 for its mathematical presentation).
where \(l\) is the convolution layer, and \({kb}_{1}^{l-1}\) is the feature map of the previous convolution layer (input). Where \(l=1\), it represents the input layer. \({kb}_{2}^{l-1}\) is the channel size of the image input (1-dimensional etc.), and \({kb}_{3}^{l-1}\) is the dimensions of the input image. \({Y}_{i}^{l-1}\) is the input, \({Y}_{i}^{l}\) is the feature matrix, \(i\) is the sequence of the extracted feature, \({B}_{\mathrm{I}}^{l}\) is the bias matrix, \({K}_{i,j}^{l}\) is the convolution function, and \((i, j)\) is the size of the convolution.
The attributes from the convolution layer are filtered from a non-linear activation function. In the next step, the pooling layer (see Eq. 9 for its mathematical presentation) takes the attributes as input. The importance of the pooling layer is that it combines the attributes extracted by the convolution layer with those near it to create a statistical summary [56].
\({Z}_{l}^{k}\) is the pooled feature map, \({F}_{l}^{k}\) is the input feature map, l-th is the layer, k-th is the feature map, and \({g}_{p}(.)\) is the pooling process type [19]. Nonlinear functions in CNN can be used to help it learn complex structures. The most common activation function, ReLU, is denoted in Eq. (10).
The last step of the CNN process including the last fully connected layer combines the extracted features to reduce their size and it uses the backpropagation method to determine the most accurate weight. In the last decade, many CNN architectures have been developed, such as CiFarNet [57], AlexNet [58], GoogLeNet [59], ResNet50 [25], and DenseNet201 [27], the most common of which are AlexNet and CiFarNet. AlexNet architecture was the winner of the ImageNet Large-Scale Visual Recognition Competition (ILSVRC) held in 2012, and it manages to reduce the error rate significantly compared to other proposed DL methods in the competition.
3.4 Machine Learning Methods
Support vector machine (SVM) is a guided learning-based ML approach for classifying data. Object detection, document categorization, bioinformatics, medicine, and chemistry are some of the domains where it is employed in engineering. Its ultimate aim is to make calculations easier by decomposing hyperplanes in a high-dimensional feature space [60]. Every part of a medical image is critical for pathology, lesion, or tumor detection. ANNs and CNNs can extract meaningful features from every region of an image because they have a multilayer structure. Popular in tumor detection or breast cancer diagnosis, a SVM can effectively classify features extracted by CNN [61]. The KNN is one of the simplest and most effective ML methods used to solve data classification problems in the medical field [62]. In a nutshell, the KNN is founded on the idea that items which are close to each other should have similar characteristics. In big datasets, the KNN classifier can be utilized in computer-aided systems to improve automatic diagnosis of many diseases with overlapping symptoms.
In this study, SVM and KNN classifiers in the proposed method focused on the features of the last fully connected layer. In the proposed method, the properties formed on the last connected fully connected layer will be extracted with the help of the activation function. After the extracted features were modeled with SVM and KNN methods, D-SVM and D-KNN models based on FD-CNN architecture were proposed. The newly created models were used to improve performance on the proposed method.
3.5 Explainable Artificial Intelligence
Technologies of ML and AI are more like black boxes in that they don't reveal how they end up creating predictions. Human intelligence includes the ability to rationalize decisions. One downside of AI in medical applications is that its estimates are not transparent. As a result, scientists have recently concentrated their efforts on inventing new ways for visualizing, explaining, and interpreting DL models [63]. Ribeiro et al. proposed the Local Interpretable Model-agnostic Explanations (LIME) method to make ML and AI predictions interpretable [64]. LIME helps experts in the medical field use XAI methods and explain and interpret ML and AI predictions. Such methods express the commitment of XAI methods to their decisions by detecting where they focus on.
The retinal morphology is represented by OCT images. Even minor aberrations in the retina layers in OCT images can indicate the presence of a wide range of illnesses. Experts spend far too much time by analyzing OCT images in order to diagnose diseases. Every detail counts in OCT pictures. On OCT images, the XAI was used to assess the reliability of FD-CNN-based diagnoses. Experts may be shown the FD-CNN-based diagnoses and OCT images to measure the FD-CNN architecture's reliability.
3.6 An Ablation Study/Test
In this study, as seen in Fig. 1, HSR filter was firstly applied to the OCT images as a preprocess to reduce speckle noise. HSR involves the combined use of gaussian, anisotropic and bilateral filters. In order to determine the effect of these filters, which make up the HSR filter, on the performance, an ablation test was performed on the FD-CNN architecture. This test was evaluated in the Duke and UCSD datasets used in the study. The effects of filters used in ablation test on performance were compared with each other. As a result of this test, the preprocess or filter application with the highest performance was determined to be used in the proposed method.
4 Proposed Hybrid FD-CNN Architecture
This study, which is a new hybrid method based on FD-CNN architecture, image processing technique, D-SVM and D-KNN models (a combination of CNN and ML methods), and XAI is presented to diagnose retinal diseases on OCT images. The proposed method generally consists of three stages: image preprocessing, feature extraction with FD-CNN and classification with D-SVM and D-KNN models.
In the proposed method first the speckle noise on the OCT images were reduced. For this purpose, the HSR approach was utilized to minimize speckle noise in the OCT images from the UCSD and Duke datasets. The HSR approach relies on sequentially applying gaussian, anisotropic diffusion, and bilateral filtering. The original-size images were preprocessed with a Gaussian filter. The Gaussian filter employed a two-dimensional function (Eq. 2). The σ parameter of the Gaussian filter was 2 and it was used to determine the standard deviation to filter the OCT images. In the second step, the anisotropic diffusion filter at standard values were applied. The third and final step of the preprocessing was the bilateral filter. The bilateral filter enhances image edges using neighboring pixel values. As mentioned above, the HSR method was applied to the OCT datasets for speckle noise reduction. Then the images were resized to 227 × 227 pixels and rendered three-dimensional using an image combining function. After the images were made ready for the proposed architecture, the feature extraction phase with FD-CNN was started. After feature extraction, the extracted features were classified with D-SVM and D-KNN models. Finally, according to the classification results, the model with the highest performance was determined and then the XAI method was also applied to this model to visualize the classification stability.
4.1 Feature Extraction with FD-CNN Architecture
The FD-CNN architecture was based on AlexNet architecture with five convolution layers, three pooling layers, and two fully connected layers (Fc6 and Fc7) with about 60 million free parameters. It was created by revising the last layers of AlexNet, adding two new fully connected layers (FC_1000 and FC_256), as well as a fully connected layer with 4 neurons for the classification output. FD-CNN’s general structure and layer details are given in Figs. 7 and 8, respectively. In the proposed method, FD-CNN was used as a feature extractor (except for the output layer layer in Fig. 7), but it was also used as a classifier to examine the effect of preprocessing methods.

FD-CNN architecture

A detailed representation of the layers of the FD-CNN architecture
While Fig. 7 shows the general structure of the FD-CNN architecture, Fig. 8 shows the details of the parameters of the layers of this architecture. ‘Conv’ is the convolution layer, ‘Pool’ is the pooling layer, ‘Norm’ is the normalization layer, and ‘Fc’ is the fully connected layer. The FD-CNN architecture was convoluted in the first convolution layer (Conv1), consisting of 96 filters with 11 × 11. Afterward, the ReLU activation function was used, and a cross channel normalization layer was added to the end of the output. In Conv1 convolution, a 3 × 3 maximum pooling (Pool1) in two strides was used as the subsample. The second convolution layer (Conv2) consisted of 256 filters of 5 × 5. After the Conv2 layer, the ReLU activation function was used, and a cross channel normalization layer was added to the end of the output. In Conv2 convolution, a 3 × 3 maximum pooling (Pool1) in two strides was used as the subsample. The third convolution layer (Conv3) consisted of 384 filters of 3 × 3. After the Conv3 layer, the ReLU activation function was used. The fourth convolution layer (Conv4) consisted of 384 filters of 3 × 3. After the Conv4 layer, the ReLU activation function was used. The fifth convolution layer (Conv5) consisted of 256 filters of 3 × 3. After the Conv5 layer, the ReLU activation function was used. In Conv5 convolution, a 3 × 3 maximum pooling (Pool5) in two strides was used as the subsample. In another procedure, a fully connected layer (Fc6) providing 4096 neuron outputs was applied, and then the ReLU activation function was used. Next, parameter reduction was carried out, and a dropout layer was applied with a possibility of 0.5. Neuron outputs (n = 4096) were iterated using a fully connected layer (Fc7), and then the ReLU activation function was used. The layers in AlexNet architecture were applied using the transfer learning method until this stage. In another step, fully connected layers (‘FC_1000’ and ‘FC_256’) were created. The FC_1000 and FC_256 had a new dense layer structure of 1000 and a neuron output of 256. The SoftMax function was administered to the neurons of the origin of the last fully connected layer. Finally, the scalar score of the classes was calculated in the classification layer just as the output was shown in Fig. 7.
By decreasing the divergence between actual and output values, the CNN is optimized. In the CNN, gradient-based modifications are commonly used. Adam optimization [65] was used based on the stochastic optimization method, which is effective in large parameters. The backpropagation method, which measures the difference between real and predicted values, is also used to update the weights and biases of neurons in CNNs. The learning rate is one of the hyperparameters that greatly affect the network's training in CNNs. The higher the learning rate, the more the input data affects the network, whereas the lower the learning rate, the more long-term learning is achieved on the network. Thus, when constructing the neural network, learning rate may be the most pertinent hyperparameter. The impacts of learning rate on model performance in the FD-CNN architecture were researched using a range of learning rates, and their results were compared. Another hyperparameter used in CNNs is the mini-batch size, which is the number of training iterations at the beginning of the CNN. The mini-batch size is generally 32, 64, or 128. The training of a CNN in each data group is calculated as an iteration. The completion of the training of all groups in a dataset is referred to as Epoch. In this study, the mini-batch size was 64, and the network completed the training with 6520 iterations in five epochs. Since learning rate is one of the important hyperparameters of CNN, multiple attempts were made to find the most appropriate value in the FD-CNN architecture.
At the end of the training of FD-CNN, the feature maps obtained from convolution layers gradually are given in Fig. 9. All the features obtained from FD-CNN were extracted by activation from the last fully connected layer for classification in the proposed method. Also, the effects of the preprocessing methods used in this study were investigated on FD-CNN. For this purpose, OCT images with and without preprocessing were used on FD-CNN’s training and the results were examined.

Feature maps extracted from convolution layers of FD-CNN architecture, respectively a Conv 1 b Conv2 c Conv3 d Conv4, and e Conv5
4.2 Classification with D-SVM and D-KNN
After feature extraction, D-SVM and D-KNN models based on the use of SVM and KNN were used to classify features obtained from FD-CNN. SVM and KNN can perform effectively by providing an understandable distinction and computational simplicity between non-linear high-dimensional data [65], and it has been reported that high performances are obtained when these methods are used in a hybrid way with deep learning methods such as CNN [22, 23]. Therefore, SVM and KNN classifiers can be used as alternative classifiers instead of CNN's original classification layer.
D-SVM and D-KNN models in this study were connected as classifiers before the classification layer of FD-CNN. In this way, features obtained from FD-CNN were classified with these models. Gaussian kernel function was used in D-SVM model. In addition, \(\sigma\) and C values were determined as 1 in D-SVM. On the other hand, in order to determine the most suitable \(k\) value for the D-KNN model, four different \(k\) values, such as 3, 4, 5 and 6 were tried and the most appropriate \(k\) value was used. Finally, the performances obtained from D-SVM and D-KNN models were compared with FD-CNN and the most suitable model was determined for the proposed method.
5 Experimental Results
In this study, all experiments related to the proposed method and FD-CNN architecture were performed in MATLAB 2020a software environment on a PC running Windows 10 with 16 GB RAM, Nvidia GTX 1650Ti graphics processing unit and Intel Core i7 & 2.6 GHz processor.
5.1 Performance Evaluation
Confusion matrix performance metrics [accuracy (Eq. 11), specificity (Eq. 12), sensitivity, also known as recall (Eq. 13), precision (Eq. 14), and F1 score (Eq. 15)] were deployed in this study to evaluate performance. In addition to those, another performance metric used to evaluate classifications is the area under the receiver operating characteristic (ROC) curve, which is produced by calculating and plotting the true positive rate (TPR) against the false positive rate (FPR) for a classifier at distinct thresholds. The FPR and TPR equal to specificity and sensitivity, respectively.
As used in the equations above, there are four potential outcomes here: True Positive (TP) indicates that data that is actually in the positive class is predicted to be positive as a result of classification, True Negative (TN) indicates that data that is actually in the negative class is predicted as negative as a result of classification, False Negative (FN) indicates that data that is actually in the positive class is predicted as negative as a result of classification, and False Positive (FP) indicates that data that is actually in the negative class is predicted as positive as a result of classification.
While calculating performance metrics in multiple classification problems, in the confusion matrix, the target class is determined as positive while the others are determined as negative. The number of successfully categorized samples in the classifier's test class divided by the total number of samples is the accuracy. Accuracy is commonly utilized since it determines a classifier's performance characteristics. A model's specificity is its capacity to recognize negative classes. A network's sensitivity is its potential to recognize affirmative classes. The number of accurately predicted positive samples divided by the total number of projected positive samples is known as precision. F1 score is the weighted average of precision and sensitivity. The area under the curve (AUC), a graph of sensitivity and specificity, is known as the average of each point above the ROC curve. The area under the curve should range from 0 and 1 for the performance of a model. The higher the AUC, the better the classifier is at classifying. AUC metric is widely used in medical diagnostic systems to evaluate models.
5.2 FD-CNN's Training at Different Learning Rates
First of all, the best learning rate was investigated by training with FD-CNN at different learning rates on the UCSD dataset, and the learning rate with the highest success was determined for FD-CNN. Table 2 shows the performance rates of the FD-CNN architecture according to the separate learning rates (the best value is shown in bold style). The results indicate that the highest accuracy rate was obtained via a learning rate of 10−5. Figure 9 shows the feature maps extracted from the FD-CNN architecture providing the highest accuracy.
5.3 Performance Evaluation of FD-CNN and AlexNet Architectures
The layer structure of the AlexNet architecture was revised to construct the FD-CNN architecture adopted for this research. The performance of AlexNet and FD-CNN architectures with and without HSR was scrutinized on UCSD and Duke datasets, and the findings have been presented in Table 3 (The best values for each dataset are shown in bold style). When comparing the success rates of the FD-CNN architecture suggested in this study to AlexNet, the results in Table 3 imply that the FD-CNN design has a better success rate in both datasets. Also, using HSR as a preprocessing significantly improved the performance of the evaluation in UCSD and Duke datasets.
5.4 Evaluation of the Ablation Study/Test
Looking at Table 3, it clearly showed that HSR provides performance improvement in the FD-CNN and AlexNet architectures. Also, in this study, ablation test was applied to measure the efficiency of gaussian, anisotropic and bilateral filters forming HSR. Using various combinations of the three filters, the FD-CNN architecture was separately trained on Duke and UCSD datasets, and at the end of the training, confusion matrices for the classification report were generated. The accuracy metric was used for the evaluation of the ablation test and the results obtained are given in Table 4 (the best values are shown in bold style).
In comparison of ablation test, it was observed that the gaussian filter improved performance over the UCSD and Duke dataset compared to without preprocessing, and the combination of gaussian with anisotropic and bilateral filter further improved the performance. Moreover, the combination of these three filters, HSR, has been one of the most successful preprocessing methods as it shows the best performance on the UCSD and Duke dataset.
5.5 Evaluation of the Proposed Method on UCSD and Duke Datasets
The features obtained from the highest performing FD-CNN with HSR were extracted for use as inputs to the D-SVM and four D-KNN models (\(k=3\), 4, 5 and 6). In these models, the extracted features were classified and then, performance metrics were calculated by creating confusion matrices for performance evaluation. Table 5 shows the performance metrics of the FD-CNN, D-SVM, and four D-KNN (\(k=3\), 4,5 and 6) models (The best values are shown in bold style). Except for the D-KNN (\(k=3\)) model, other D-KNN and D-SVM models outperformed the FD-CNN. The D-KNN (\(k=4.5\) and 6) models increased the accuracy by 0.1%. However, since the double values for the \(k\) value in the KNN method can make the system unstable, in this study, the 5 neighbor \(k\) value with the highest accuracy in D-KNN was determined as the most appropriate value. As for the D-SVM, it showed the highest performance over the others, with an accuracy increase of 0.2%, and thus became a fundamental part of the proposed method. As seen in Table 5, D-SVM improved all performance metrics except AUC. The D-SVM had the same performance as FD-CNN at AUC and even achieved the highest rating in the drusen class with full accuracy, according to FD-CNN. Figure 10 also illustrates the detailed ROC curves of the CNV, DME, drusen and normal classes of the FD-CNN architecture and the D-SVM.

ROC curve: a FD-CNN architecture, b D-SVM
A different evaluation of the FD-CNN, D-SVM, and D-KNN (\(k=3\), 4, 5 and 6) models was also made on the Duke dataset. The features obtained from the highest performing FD-CNN in the Duke dataset were extracted and the extracted features were classified in the D-SVM and D-KNN models. The performance metrics obtained because of the classification are given in Table 6 (the best values are shown in bold style). D-SVM achieved the highest performance in Duke dataset compared to other classifiers.
5.6 XAI Visualization
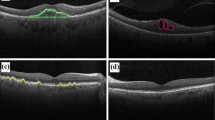
Explainable AI is one of the key requirements to ensure the explainability of proposed AI-based models and transparency in the decision-making process. In the use of the AI-based proposed systems, XAI techniques are used in order to trust the decisions taken by the system and to emphasize transparency in the decision-making process. In this context, this study used the LIME which is one of the XAI techniques. Visualization of heatmaps generated on features of test images using LIME demonstrates the classification stability of the FD-CNN used in the proposed method. The features were visualized and interpreted using LIME, which was applied to the SoftMax layer of the FD-CNN trained with the preprocessed UCSD dataset. The test images and heat maps for the categorization of the FD-CNN could be seen in Fig. 11. The FD-CNN concentrate on the regions highlighted in red above the successfully and inaccurately classified test images as seen Fig. 11. Retinal disorders seen in OCT images have several similarities. Therefore, it may be concluded that incorrectly classified test images may contain some retina diseases. In addition to the performance metrics obtained in this study, the heat maps of the proposed hybrid FD-CNN architecture are presented using the LIME method. According to the obtained heat maps, it was seen that the proposed method focuses on the relevant regions in the retina layer during the classification stage in OCT images.

Heatmaps of correct (a and b) and incorrect (c and d) classifications with LIME: a–c input test image, b–d superimposed heat map of test image
6 Discussion
In recent years, interest in CNN-based approaches and hybrid approaches has increased in the detection of retinal diseases. When the studies on the UCSD dataset containing OCT images are examined, it is seen that mostly pre-trained CNN architectures are used for retinal disease detection. In this study, first speckle noise was reduced by using HSR technique in OCT images. After this preprocessing step, D-SVM and D-KNN models including the use of CNN and ML methods together are proposed. According to the results obtained, the proposed D-SVM was found to be the most successful approach in the study. Performance indicators of D-SVM are compared to those reported in state-of-the-art on the UCSD dataset in Table 7 (the best values are shown in bold style).
Table 7 clearly demonstrate that the D-SVM outscored the DL approaches utilized in previous studies. The D-SVM performed the best in terms of sensitivity, precision, and AUC. From a different point of view, the D-SVM exhibited greater accuracy and specificity ratings than the average, indicating that it performed well in classification. Rajagopalan et al. ranked first in specificity but had a lower accuracy rate than the average.
Another evaluation of the proposed method was made on the Duke dataset, and the performance comparison of the D-SVM method, which achieved the highest performance, with previous studies is given in Table 8 (the best value is shown in bold style).
Looking at previous studies on the Duke dataset, overall accuracy metric was presented for performance evaluation, and therefore this was used for comparison in this study as well. Considering at the comparison in Table 8, D-SVM was one of the most successful methods compared to previous studies.
The results obtained from the UCSD and Duke datasets in this study suggest that the D-SVM may effectively detect retinal disorders on OCT images. After speckle noise reduction and training in the FD-CNN, the D-SVM outperformed significantly. The D-SVM correctly categorized the features retrieved by the FD-CNN from the OCT images, inferring that traditional ML approaches operate effectively on DL-based CNN models.
In this study, the classification effect of proposed hybrid method was analyzed using LIME. The findings (as seen in Fig. 11) have shown that proposed hybrid method focuses and classifies the fine details in retinal layers on OCT images. LIME was used to show the classification robustness and reliability of proposed hybrid method compared to state-of-art techniques, and the findings will play an important role in the development of new hybrid models for the detection of retinal diseases in the literature.
7 Conclusion
OCT is a noninvasive imaging technique allowing the experts to view the retinal morphology in cross-section and diagnose retinal diseases. The quality of the images and the accuracy with which they are comprehended are both significant factors in determining the definitive diagnosis of retinal disorders using OCT images. The displacement of the layers induces retinal disorders. Small deformations in the retinal layers could be a symptom or cause of an underlying cause. OCT depicts the shape of the retina, enabling experts to diagnose disorders relatively rapidly. However, uncovering and interpreting OCT images tends to take far too much time for professionals. Furthermore, due to wave transfer between the tissue surface and the instrument, the OCT device causes speckle noise throughout the image. Experts find it a challenge to determine retinal illnesses using OCT images because of speckle noise. Therefore, before using OCT images to identify retinal disorders, speckle noise needs to be eliminated. The construction of automatic diagnosis systems requires speckle noise-free OCT images. Experts deploy computer vision techniques (image processing and machine learning) to assist them diagnose diseases. CNNs are based on DL, a sub-branch of ML. They are becoming more and more popular in automatic diagnosis systems.
DL-based hybrid FD-CNN architecture for retinal disease classification using OCT images was proposed in this study. The hybrid FD-CNN architecture was based on image preprocessing technique, a combination of CNN and ML methods, and an XAI technique. To broaden the FD-CNN's performance and remove speckle noise from the images, an image preprocessing technique has been utilized. The FD-CNN was established using the AlexNet architecture, which was fine-tuned over time. The image preprocessing technique was a HSR method based on gaussian, anisotropic diffusion, and bilateral filters. The HSR removed the speckle noise from the images and enhanced the edges of the retinal layers. The HSR was applied to the FD-CNN architecture on the UCSD and Duke datasets. The FD-CNN architecture was trained with OCT images and then evaluated in the network test dataset. The results showed that the HSR significantly improved the performance of the FD-CNN on both datasets used in this study. In addition, ablation test was applied to the preprocessing combinations formed by gaussian, anisotropic and bilateral filters and the results were compared. According to the ablation test results, the combination of gaussian, anisotropic and bilateral filter, namely HSR, showed the best performance on the FD-CNN architecture and revealed that it is one of the most effective preprocessing methods.
This study has proposed another architecture based on feature extraction from the last fully connected layer of FD-CNN. The features were then retrained with the SVM and KNN classifiers to generate a hybrid system. The training resulted in two models: D-SVM and D-KNN. The models were evaluated on the preprocessed UCSD and Duke datasets and then compared to the FD-CNN. While D-KNN and D-SVM improved performance in UCSD dataset, only D-SVM improved performance in Duke dataset. The D-SVM, on the other hand, categorized the characteristics better and its performance is better than the D-KNN.
On OCT images, the FD-CNN architecture performed well in recognizing retina disorders. Nevertheless, the neural network's performance was significantly elevated by preprocessing and training the OCT images in the FD-CNN architecture. CNNs capture robust properties from images. Therefore, the D-SVM and D-KNN generated by connecting conventional ML algorithms to the last fully connected layer in the FD-CNN improved the performance slightly. The D-SVM has done much better than the other approaches in categorizing retinal disorders on OCT images, highlighting that traditional ML techniques are impactful in CNN-based DL models.
Retinal diseases may indicate comparable features residing in OCT images. Therefore, every detail of retinal layers in OCT images is critical for disease classification. The D-SVM was derived from FD-CNN features. LIME (an XAI technique) was also used to improve diagnostic reliability with the proposed hybrid FD-CNN architecture and to determine based on what the system diagnoses diseases. Heat maps were generated using the SoftMax function of the FD-CNN architecture. As seen in Fig. 11, the red regions on the heat maps indicate on which regions proposed hybrid method focuses to diagnose diseases. The heat maps show that the proposed hybrid method focuses mainly on the retinal layer structure. It's worth remembering that clinical decision support systems are not really diagnostic, but instead just supportive. As a result, the XAI-based proposed hybrid method is expected to aid physicians in evaluating systems' diagnosis in clinical settings. In medicine, XAI techniques are an important tool to assist the physicians in their decisions and develop more efficient and transparent classification methods. In this study, the effectiveness of the proposed hybrid method was supported by the LIME method. The results show that the proposed hybrid method can play an active role especially in the classification of OCT images and can be used as a computer-aided early diagnosis system to assist physicians in the field of ophthalmology. In addition, it is thought that the use of similar hybrid decision support systems with the use of XAI techniques that can be recommended for the medical field can make significant contributions to the literature.
Data Availability
The Duke and UCSD datasets used in this study are open access (available at https://www.kaggle.com/paultimothymooney/kermany2018 and https://www.duke.edu/~sf59/Srinivasan_BOE_2014_dataset.htm).
Abbreviations
- OCT:
-
Optical coherence tomography
- CNV:
-
Choroidal neovascularization
- DME:
-
Diabetic macular edema
- FD-CNN:
-
Fully dense fusion neural network
- D-SVM:
-
Deep support vector machine
- D-KNN:
-
Deep k-nearest neighbor
- UCSD:
-
University of California San Diego
- LIME:
-
Local interpretable model-agnostic explanations
- XAI:
-
Explainable artificial intelligence
- AMD:
-
Age-related macular degeneration
- ML:
-
Machine learning
- DL:
-
Deep learning
- AI:
-
Artificial intelligence
- CNN:
-
Convolutional neural network
- ANN:
-
Artificial neural network
- Grad-CAM:
-
Gradient-weighted class activation mapping
- HSR:
-
Hybrid speckle reduction
- CC:
-
Correlation coefficient
- SVM:
-
Support vector machine
- KNN:
-
K-nearest neighbor
- ILSVRC:
-
Imagenet large-scale visual recognition competition
- AUC:
-
Area under the curve
- ROC:
-
Receiver operating characteristic
- TP:
-
True pozitive
- TN:
-
True negative
- FP:
-
False pozitive
- FN:
-
False negative
References
Kermany, D.S., Goldbaum, M., Cai, W., et al.: Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 172(5), 1122–1131 (2018)
Farsiu, S., Chiu, S.J., O’Connell, R.V., et al.: Quantitative classification of eyes with and without intermediate age-related macular degeneration using optical coherence tomography. Ophthalmology 121(1), 162–172 (2014)
Cohen, S.R., Gardner, T.W.: Diabetic retinopathy and diabetic macular edema. Retinal Pharmacotherap. 55, 137–146 (2016)
Huang, D., Swanson, E.A., Lin, C.P., et al.: Optical coherence tomography. Science 254(5035), 1178–1181 (1991)
Hee, M.R., Izatt, J.A., Swanson, E.A., et al.: Optical coherence tomography of the human retina. Arch. Ophthalmol. 113(3), 325–332 (1995)
Keane, P.A., Patel, P.J., Liakopoulos, S., et al.: Evaluation of age-related macular degeneration with optical coherence tomography. Surv. Ophthalmol. 57(5), 389–414 (2012)
Drexler, W., Fujimoto, J.G.: State-of-the-art retinal optical coherence tomography. Prog. Retin. Eye Res. 27(1), 45–88 (2008)
Lo, Y.C., Lin, K.H., Bair, H., et al.: Epiretinal membrane detection at the ophthalmologist level using deep learning of optical coherence tomography. Sci. Rep. 10(1), 1–8 (2020)
Lu, W., Tong, Y., Yu, Y., et al.: Deep learning-based automated classification of multi-categorical abnormalities from optical coherence tomography images. Transl. Vision Sci. Technol. 7(6), 41–41 (2018)
Alqudah, A.M.: AOCT-NET: a convolutional network automated classification of multiclass retinal diseases using spectral-domain optical coherence tomography images. Med. Biol. Eng. Comput. 58(1), 41–53 (2020)
Kwasigroch, A., Jarzembinski, B., Grochowski, M.: Deep CNN based decision support system for detection and assessing the stage of diabetic retinopathy. In: 2018 International Interdisciplinary PhD Workshop (IIPhDW), 111–116 (2018)
Masood, A., Sheng, B., Li, P., et al.: Computer-assisted decision support system in pulmonary cancer detection and stage classification on CT images. J. Biomed. Inform. 79, 117–128 (2018)
Li, X., Shen, L., Shen, M., et al.: Deep learning based early stage diabetic retinopathy detection using optical coherence tomography. Neurocomputing 369, 134–144 (2019)
Lee, C.S., Baughman, D.M., Lee, A.Y.: Deep learning is effective for classifying normal versus age-related macular degeneration OCT images. Ophthalmol. Retina 1(4), 322–327 (2017)
Karri, S.P.K., Chakraborty, D., Chatterjee, J.: Transfer learning based classification of optical coherence tomography images with diabetic macular edema and dry age-related macular degeneration. Biomed. Opt. Express 8(2), 579–592 (2017)
Ran, A.R., Tham, C.C., Chan, P.P., et al.: Deep learning in glaucoma with optical coherence tomography: a review. Eye 35(1), 188–201 (2021)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521(7553), 436–444 (2015)
Yim, J., Sohn, K. A.: Enhancing the performance of convolutional neural networks on quality degraded datasets. In: 2017 International Conference on Digital Image Computing: Techniques and Applications (DICTA),1–8 (2017)
Khan, A., Sohail, A., Zahoora, U., et al.: A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 53(8), 5455–5516 (2020)
Uysal, E., Güraksin, G.E.: Computer-aided retinal vessel segmentation in retinal images: convolutional neural networks. Multimedia Tools Appl. 80(3), 3505–3528 (2021)
Dodge, S., Karam, L.: Understanding how image quality affects deep neural networks. In: 2016 eighth international conference on quality of multimedia experience (QoMEX), 1–6 (2016)
Mahum, R., Rehman, S.U., Okon, O.D., et al.: A novel hybrid approach based on deep CNN to detect glaucoma using fundus imaging. Electronics 11(1), 26 (2021)
Lahmiri, S.: Hybrid deep learning convolutional neural networks and optimal nonlinear support vector machine to detect presence of hemorrhage in retina. Biomed. Signal Process. Control 60, 101978 (2020)
Szegedy, C., Vanhoucke, V., Ioffe, S., et al.: Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2818–2826 (2016)
He, K., Zhang, X., Ren, S., et al.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016)
Li, F., Chen, H., Liu, Z., et al.: Deep learning-based automated detection of retinal diseases using optical coherence tomography images. Biomed. Opt. Express 10(12), 6204–6226 (2019)
Huang, G., Liu, Z., Van Der Maaten, L., et al.: Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 4700–4708 (2017)
Islam, K. T., Wijewickrema, S., O'Leary, S.: Identifying diabetic retinopathy from oct images using deep transfer learning with artificial neural networks. In: 2019 IEEE 32nd international symposium on computer-based medical systems (CBMS), 281–286 (2019)
Kim, J., Tran, L.: Ensemble learning based on convolutional neural networks for the classification of retinal diseases from optical coherence tomography ımages. In: 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), 532–537, (2020)
Paul, D., Tewari, A., Ghosh, S., et al.: Octx: Ensembled deep learning model to detect retinal disorders. In: 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), 526–531 (2020)
Rastogi, D., Padhy, R. P., Sa, P. K.: Detection of retinal disorders in optical coherence tomography using deep learning. In: 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), 1–7 (2019)
Sabour, S., Frosst, N., Hinton, G. E.: Dynamic routing between capsules. Adv. Neural İnform. Process. Syst. 30, 3856–3866 (2017)
Tsuji, T., Hirose, Y., Fujimori, K., et al.: Classification of optical coherence tomography images using a capsule network. BMC Ophthalmol. 20(1), 1–9 (2020)
Li, F., Chen, H., Liu, Z., et al.: Fully automated detection of retinal disorders by image-based deep learning. Graefes Arch. Clin. Exp. Ophthalmol. 257(3), 495–505 (2019)
Tan, M., Le, Q.: Efficientnet: Rethinking model scaling for convolutional neural networks. In: 36th International conference on machine learning, 6105–6114 (2019)
Selvaraju, R. R., Cogswell, M., Das, A., et al.: Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE international conference on computer vision, 618–626 (2017)
Chetoui, M., Akhloufi, M. A.: Deep retinal diseases detection and explainability using oct images. In: International Conference on Image Analysis and Recognition, 358–366 (2020)
Saraiva, A. A., Santos, D. B. S., Pimentel, P., et al.: Classification of Optical Coherence Tomography using Convolutional Neural Networks. In: Proceedings of the 13th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC), 168–175 (2020)
Roy, A.G., Conjeti, S., Karri, S.P.K., et al.: ReLayNet: retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomed. Opt. Express 8(8), 3627–3642 (2017)
Huang, L., He, X., Fang, L., et al.: Automatic classification of retinal optical coherence tomography images with layer guided convolutional neural network. IEEE Signal Process. Lett. 26(7), 1026–1030 (2019)
Rajagopalan, N., Narasimhan, V., KunnavakkamVinjimoor, S., et al.: Deep CNN framework for retinal disease diagnosis using optical coherence tomography images. J. Ambient. Intell. Humaniz. Comput. 12(7), 7569–7580 (2021)
Schmitt, J.M., Xiang, S.H., Yung, K.M.: Speckle in optical coherence tomography. J. Biomed. Opt. 4(1), 95–105 (1999)
Amini, Z., Kafieh, R., Rabbani, H.: Speckle noise reduction and enhancement for OCT images. Retinal Optical Coherence Tomogr. Image Analysis. (2019). https://doi.org/10.1007/978-981-13-1825-2_3
Adler, D.C., Ko, T.H., Fujimoto, J.G.: Speckle reduction in optical coherence tomography images by use of a spatially adaptive wavelet filter. Opt. Let. (2004). https://doi.org/10.1364/ol.29.002878
Zaki, F., Wang, Y., Su, H., et al.: Noise adaptive wavelet thresholding for speckle noise removal in optical coherence tomography. Biomed. Opt. Express 8(5), 2720–2731 (2017)
Chong, B., Zhu, Y.K.: Speckle reduction in optical coherence tomography images of human finger skin by wavelet modified BM3D filter. Opt. Commun. 291, 461–469 (2013)
Koresh, H.J.D, Chacko, S.: Hybrid speckle reduction filter for corneal OCT ımages. In: Chen, J.IZ., Tavares, J.M.R.S., Shakya, S., Iliyasu, A.M. (eds) Image Processing and Capsule Networks (2020). https://doi.org/10.1007/978-3-030-51859-2_9.
Srinivasan, P.P., Kim, L.A., Mettu, P.S., et al.: Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomed. Opt. Express 5(10), 3568–3577 (2014)
Cadena, L., Zotin, A., Cadena, F., et al.: Noise reduction techniques for processing of medical images. Proc. World Congress Eng. 1, 5–9 (2017)
Kurt, B., Nabiyev, V. V., Turhan, K.: Medical images enhancement by using anisotropic filter and clahe. In: 2012 International symposium on innovations in intelligent systems and applications,1–4 (2012)
Perona, P., Malik, J.: Scale-space and edge detection using anisotropic diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 12(7), 629–639 (1990)
Yu, Y., Acton, S.T.: Speckle reducing anisotropic diffusion. IEEE Trans. Image Process. 11(11), 1260–1270 (2002)
Balocco, S., Gatta, C., Pujol, O., et al.: SRBF: Speckle reducing bilateral filtering. Ultrasound Med. Biol. 36(8), 1353–1363 (2010)
Tomasi, C., Manduchi, R.: Bilateral filtering for gray and color images. In: Sixth international conference on computer vision (IEEE Cat. No. 98CH36271), 839–846 (1998)
LeCun, Y., Bottou, L., Bengio, Y., et al.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Bengio, Y., Goodfellow, I., Courville, A.: Deep learning, vol. 1. MIT Press, Cambridge (2017)
Krizhevsky, A., Hinton, G.: Learning multiple layers of features from tiny images. Technical report, Univ. of Toronto (2009).
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. Commun. ACM 60(6), 84–90 (2017)
Szegedy, C., Liu, W., Jia, Y., et al.: Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 1–9 (2015)
Gunn, S.R.: Support vector machines for classification and regression. ISIS Tech. Rep. 14(1), 5–16 (1998)
Ragab, D.A., Sharkas, M., Marshall, S., et al.: Breast cancer detection using deep convolutional neural networks and support vector machines. PeerJ 7, e6201 (2019)
Khamis, H.S.: Application of k-Nearest Neighbour classification in medical data mining in the context of Kenya. Sci. Conf. Proc. 4(December), 990–1000 (2014)
Samek, W., Wiegand, T., Müller, K. R.: Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv preprint arXiv:1708.08296 (2017)
Ribeiro, M. T., Singh, S., Guestrin, C.: "Why should i trust you?" Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 1135–1144 (2016)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR) (2015)
Thomas, A., Harikrishnan, P.M., Krishna, A.K., et al.: A novel multiscale convolutional neural network based age-related macular degeneration detection using OCT images. Biomed. Signal Process. Control 67, 102538 (2021)
Amaladevi, S., Jacob, G.: Classification of retinal pathologies using convolutional neural network. Int. J. Adv. Trends Comput. Sci. Eng. (2020). https://doi.org/10.30534/ijatcse/2020/205932020
Acknowledgements
The authors would like to thank the editor and anonymous referees of this manuscript.
Funding
No funds, grants, or other support was received.
Author information
Authors and Affiliations
Contributions
Methodology: GEG and IK; conceptualization: GEG and IK; software: IK; supervision: GEG; validation: GEG; writing—original draft: IK; writing—review and editing: GEG and IK. All authors have read and agreed to the final version of the manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no competing interests to declare that are relevant to the content of this article.
Ethics Approval and Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kayadibi, İ., Güraksın, G.E. An Explainable Fully Dense Fusion Neural Network with Deep Support Vector Machine for Retinal Disease Determination. Int J Comput Intell Syst 16, 28 (2023). https://doi.org/10.1007/s44196-023-00210-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00210-z