
Abstract
SpatialHadoop could handle spatial data operations in a low partitioning execution time compared to the traditional Hadoop. However, developing an efficient and an accurate partitioning algorithm is still a research field opened to many researchers. Confidently, this paper proposes a Minimum Boundary Rectangle-aware Priority R-Tree (MBR-aware PR-Tree) as an enhanced partitioning algorithm applicable at SpatialHadoop. Compared to state-of-art partitioning algorithms, our proposed algorithm outperforms them in terms of query execution time, file size, number of partitions, indexing time, and number of returned objects. The experimental results show superiority of our algorithm which have been confirmed for both spatial range query and k-nearest-neighbour query through evaluating the performance in different scenarios using a real dataset.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Integrating cloud computing with GIS represents a new era for geospatial big data and its application for the geographic information systems (GISs) [1, 2]. Cloud computing is a new computing model of ‘pay for what you use’ [3]. In essence, one can say that it is a transition from clients owning personal computers (PCs) to clients only having access to computing resources preserved by service providers.
Recently, Hadoop [4], which released in 2007, is the most well-known open source cloud-computing platform. Hadoop has a distributed file system that enables to maintain a massive number of operations in a parallel and distributed processing Mode. Moreover, Hadoop with MapReduce programming paradigm is more robust and scalable than traditional programming. It could diverts work to another location and keeps processing even if a node has a failure [5]. In addition, new nodes could be added easily without changing the data formats, the loading mechanism, and the infrastructure.
The previous researchers work about using Hadoop to manipulate big geospatial data goes in two main trends:
1.1 Spatial-Operation Oriented
In this, researchers intended to develop a function for a particular spatial operation where the desired operations will be executed on traditional Hadoop clusters. For example: (1) R-tree construction [6], an R-tree allocates records as per their Z-values and, for each partition, it combines those R-trees under the same root [7]. (2) RQ [8,9,10], the records are scanned against the query range. (3) kNN query [11, 12], determines the k-nearest points, using distance metrics, from a given location using a brute force approach [9] [11]. (4) All nearest neighbour (ANN) query [13], the points are parcelled by their Z-values in order to find a result similar to kNN queries. (5) Reverse nearest neighbour (RNN) query [11], find all the objects for which query location has nearest neighbours. (6) Spatial join [9, 14,15,16,17], the map function converts data into cells and the reduce function joins data in each cell. (7) kNN join [18,19,20].
1.2 Full-System Oriented
Five main systems were proposed: (1) Parallel-Secondo [21] as a parallel spatial DBMS that utilizations Hadoop as a distributed task scheduler, (2) MD-HBase [22] expands HBase [23], (3) Hadoop-GIS [24]; and (4) GeoSpark [25, 26].
All these systems are an upper layer over classic Hadoop and hence they inherited all its limitations [27, 28]. Hadoop has confinements and execution bottlenecks and it does not support spatial data. Furthermore, the uniform grid index is the only index available, and so these systems only deal with a uniform distribution of data. In addition, the developed systems cannot access the constructed index or enhance new spatial operations.
In contrary to these systems, (5) SpatialHadoop [29, 30] is developed to guarantee spatial data operations in Hadoop [29, 31].
Until now, to the best of our knowledge, no one could make the original PR-Tree partitioning algorithm applicable at SpatialHadoop platforms. State-of-art partitioning algorithms are only confined to eight main algorithms namely: Grid, Quadtree, Z-curve, Hilbert curve, Sort-Tile-Recursive (STR), STR+, KD-Tree, and 2DPR-Tree [27, 32, 33]. Dependently, this paper proposes a number of novelties:
-
1.
State-of-art partitioning algorithms researches [27] only depend in their measurements on query execution time, file size, number of partitions, and indexing time. All of them do not pay any attention to the accuracy of objects retrieved. Hence, a new metric (accuracy of query results) for the assessment of different partitioning techniques is presented.
-
2.
All various SpatialHadoop partitioning techniques are based on a two-tier (2-tier) process for approximating all objects in the input spatial dataset into a set of two-dimensional (2D) points. By this way, it may lead to inaccurate results. The proposed MBR-aware PR-Tree, unlike other techniques [27], guarantees the desired number of partitions and a higher accuracy is well preserved. The accuracy is explored through depicting the graphical representation of the results and studying the number of objects retrieved.
-
3.
The proposed MBR-aware PR-Tree approach overcomes all other state-of-art techniques in terms of performance, functionality, and accuracy for both RQs and kNN queries.
The rest of this paper is organized as follows: Sect. 2 presents a glance on SpatialHadoop system architecture and related works that has been done on different partitioning techniques. Section 3 introduces the presented partitioning algorithm. Section 4 presents the results of the experimentations performed. Finally, Sect. 5 shows the conclusion and future work.
2 Related Works
In SpatialHadoop, spatial data are partitioned and disseminated to the cluster nodes. Thereafter, these data are aggregated into one partition according to their spatial closeness, which will be indexed later. a set of spatial index structures were developed based on a number of partitioning techniques such as grid [27], R-tree [34], R+-tree [35], Z-curve[36], Hilbert curve [37], Quadtree [38], KD-Tree [39, 40] and 2DPR-Tree [33].
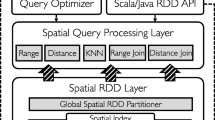
The core of SpatialHadoop consists of four layers as shown in Fig. 1: (1) the Language layer called Pigeon [41, 42]. It conceals all complexities of the framework by giving a simple high-level language. Pigeon is combatable with the Open Geospatial Consortium (OGC) standard [43]. PostGIS [44]and Oracle Spatial [45] both are adapted to OGC standard. Therefore, adaptation with the OGC standard makes it possible to integrate with these existing systems by exporting/importing data. (2) The Query Processing layer (operations layer) includes the spatial operations (range query, kNN and spatial join) upheld by SpatialHadoop. A set of basic computational geometry operations were developed in CG_Hadoop [46]. In addition, new spatial operations, that use different built indexes, can be developed based on SpatialHadoop query processing engine. (3) The MapReduce layer provides the MapReduce query engine with the access method to utilize the spatial constructed Indexes while processing a spatial query. In case of the absence of either SpatialFileSplitter or SpatialRecordReader, the query processing layer will scan the whole file and will not be able to access the constructed indexes. The SpatialFileSplitter accesses the global index to eliminate file partitions that do not participate into answering according to a user-defined filter function. Using the local index stored in each partition, the SpatialRecordReader could handle these partitions efficiently and reuse indexes effortlessly. (4) The Storage/Spatial Indexing layer employs a two-layer index structure consisting of one global index and many local indexes. The global index partitions data across the cluster nodes, and then each node indexes its partition separately using a local index. The separation of global and local indexes supports the MapReduce programming paradigm where the MapReduce job configured using the global index and map tasks processed using the local indexes. Adjusting the file into 64 MB partitions ensures load balancing, allows indexing each partition separately in memory and allows writing each partition to a one Hadoop Distributed File System (HDFS) block in an append-only manner.

SpatialHadoop system architecture [33]
The process of creating spatial index comprises three main stages: partitioning, local indexing, and global indexing [29]. In partitioning stage, the input file spatially fractioned into n partitions to satisfy that spatially, nearby objects are stored in the same partition. The size of partition is equal to the size of HDFS block (64 MB). After that, partitions boundaries are calculated differently based on the index algorithm being utilized. Towards the end, for each record r allocated to a partition p, the map function composes an intermediate pair < p, i > . Such pairs are then gathered by p and sent to the reduce function for the following stage. In local indexing stage, a local index structure is built upon the data contents of each partition. A reduce function stores the records assigned to each partition in a local index file. In Global Indexing stage, a global index that indexes all partitions is built. All local index files are concatenated into one file that represents the final indexed file. However, in SpatialHadoop indexing phase, all input shapes are approximated are converted into 2D points [27]. Therefore, all indexing techniques are designed to build the requested index structure based on abstracted layer of 2D points. Consequently, all partitioning techniques mentioned in the literature lacks the accuracy. MBR-aware PR-Tree is proposed as a new indexing and partitioning technique that based on the Priority R-tree [47] which presented in details in Sect. 3.
3 The Proposed PR-Tree Partitioning Approach
Objects saved in spatial datasets can be somewhat complicated. Therefore, it is approximated into more simplistic objects. After that, spatial indexes are based on these approximations. All previous SpatialHadoop partitioning techniques are based on a 2-tier process for approximating all objects found in the input dataset into a set of 2D points as shown in Fig. 2. In addition, all spatial operations are performed based on these 2D definitions.

Two-tier process for approximating a virtual spatial data into a set of 2D points
By this way, the input spatial geometries are mapped into a set of Minimum Boundary Rectangle. Then, the centroid point of each rectangle is calculated which treated as the final geometry representation. Too many spatial data of the original geometries are lost due to this 2-tier approximation process causing inaccurate results for the spatial operations. For instance, assume we have the shapes shown in Fig. 2. Figure 3 shows the process of performing RQ operation based on a randomly generated spatial dataset which is performed according to algorithm 2. Assume a query point (P) and a distance threshold (d). A spatial RQ should returns A and D objects which are fully located inside the search area. However, as all shapes are mapped into 2D points, the 2-tier process returns A, B, C, D, E, and F objects as depicted in Fig. 4. It noticeable that this way lacks the accuracy of spatial data retrieval.

Rang query operation over a virtual spatial input dataset

Rang query operation over the approximated point layer

For KNN query, as mentioned in Sect. 2, it determines the k-nearest points, using distance metrics, from a given location based on a brute force approach. For instance, assume we search for three most nearest neighbour of a query point (P) illustrated in Fig. 5. It is obviously that B, C, D objects is the most nearest neighbour to the specified query point. However, based on the approximated 2D point layer, the results return A, C, and D objects as the most nearest neighbour to the specified query point. Figure 6 illustrates these details.

KNN query operation over a virtual spatial input dataset

KNN query operation over the approximated 2D point layer

In contrast to other SpatialHadoop partitioning techniques, the proposed MBR-aware PR-Tree partitioning technique is based on a 1-tier process of approximating all objects in the input spatial dataset, as shown in Fig. 7. Such a 1-tier process is proceeded through calculating the MBR for each object in the input dataset. Thereafter, a spatial index is constructed based on these approximated set of rectangles. MBR-aware PR-Tree partitioning technique bypass the process of approximating the rectangles layer into a 2D points which is the main cause of wastage for many of the original geometries data.

One-tier process of approximating a virtual input spatial dataset into a set of Minimum Boundary Rectangles
If we again assume the same RQ with query point (p) and a distance threshold (d), for the 1-tier process, it returns only A and D objects as depicted in Fig. 8. Therefore, it is matched with our naked eyes, and therefore, it is more accurate than other techniques which based on 2-tier process. In addition, assume again that we need to retrieve the three most nearest neighbour of a query point P shown in Fig. 9. Hence, the query result returns B, C, and D objects as the most nearest neighbour to the specified query point, which is also matched with our naked eyes.

Rang query operation over the MBRs layer

KNN query operation over the MBRs layer
The idea of the MBR-aware PR-Tree is to deal with the MBRs of the input shapes as a 4D point (X_min, Y_min, X_max, Y_max), which is defined in SpatialHadoop as a new data type to store the MBR value for each input shape. Starting with identifying how many shapes can one partition (leaf) contains (B). Then, calculates the MBR for each input shape. Thereafter, the total number of available shapes is calculated to estimate if they are suitable to fit into one partition. Then, a scalar priority leaf \({\nu }_{\rho }\) should be generated to store the B minimal x-coordinates shapes. In the same way, the other three priority are produced. The previous steps are performed recursively until all shapes are fitted in partitions.
Algorithm 3 illustrates the steps of the proposed MBR-aware PR-Tree partitioning technique. It starts by calculating the maximum number of shapes that can be fit in one partition (leaf). Then, each input shape is converted to a 4D point. After that, a root node is created and the total number of shapes is checked. If it is less than or equal to the maximum number of shapes that can be fit in one partition (leaf), if so then the algorithm generates a scalar priority leaf ν_ρ. Unless, it generates a priority leaf V_p^(x_min) that stores a B shapes with minimal x-coordinates. Then, the algorithm is process in the same way to produce the other three priority. On the other hand, if the root node has a number of shapes higher than 4B, then a two sub PR-Trees and a four-priority leaves are produced. The algorithm recursively applies these calculations until no shapes remaining to be filled.

4 Experimentation and Discussion
Different SpatialHadoop partitioning techniques are experimented using the Amazon Hadoop cluster with ‘m.xlage’ servers. Real datasets extracted from OpenStreetMap: Buildings (28.2 GB), Roads (25.9 GB), Lakes (9.7 GB), Cities (1.4 GB), and Sports (590 MB) [29] are utilized in the testing process for all partitioning and indexing techniques.
It is cleared that plotting a non-indexed file is a time-consuming process as it takes too much time than the indexed one. On the other hand, the proposed MBR-aware PR-Tree has the shortest plotting time due to preserving spatial proximity of the spatial shapes. Table 1 demonstrates the partitions number generated by different partitioning techniques. All partitioning techniques (MBR-aware PR-Tree, 2DPR-Tree, KD-Tree, Z-curve, and Hilbert) take into consideration the desired number of partitions unless Quadtree, STR, and STR+. The highlighted numbers shown in Table 1 does not meet the desired number of partitions.
In Z-curve, Hilbert curve, STR, 2D PR-Tree and MBR-aware PR-Tree, boundary objects are assigned only to the partition with a maximal intersection. In contrast, Quadtree, STR+, and KD-Tree, the objects located on the boundaries between partitions are allocated to all of those overlapping partitions. This has its effect on the size of the indexed datasets as documented in Table 2. It illustrates the sizes of different indexed datasets in mega byte (MB). In addition, the proposed MBR-aware PR-Tree preserved spatial proximity of the spatial shapes and not only meets the required number of partitions but also guarantees that all partitions have the same number of objects, which in turn have roughly the same size. For all of these, it gives the minimum indexed datasets sizes, which marked in bold. Accordingly, the proposed algorithm has the advantage of highly load balancing when working on such partitions. Inversely, Quadtree, STR+, and KD-Tree have the maximum indexed datasets sizes compared with the others, which marked in green, due to generation of a big number of partitions. As a result, they waste too much storage space to save the generated partitions.
Figure 10 shows the indexing time for different real datasets (Sports, Cities, Lakes, Roads, and Buildings) for different partitioning techniques. It is noticeable that the proposed MBR-aware PR-Tree has the best indexing time. Figure 11a–d shows the range query execution time with different query window areas range from 0.01 to 50% of datasets. As noticed, as the query window area increases the Quadtree performance rapidly became better than the other techniques. The results shown in Fig. 11a–d confirm our earlier claims as the MBR-aware PR-Tree, 2DPR-Tree, and the KD-Tree answer the RQ with a query window area equal to 50% of the Buildings dataset area in 110, 111 and 120 s, respectively. On the other side, Quadtree takes approximately twice the time to answer the same query.

Indexing time for the real datasets (Sports, Cities, Lakes, Roads, and Buildings)

Range query execution time with for query window area 0.01%, 1%, 10%, and 50% on indexed real datasets a Sports, b Cities, c Lakes, and d Roads
As mentioned earlier, all SpatialHadoop partitioning techniques are based on a 2-tier process for approximating all objects in the input spatial datasets into a set of 2D points, which causes the loss of many original objects data, and in turn spatial indexes are constructed on these approximated set of 2D points. Consequently, all spatial operations are performed based on these indexes. Such 2-tier approximation process causes an inaccurate result for the spatial operations. In contrast, the proposed MBR-aware PR-Tree partitioning technique is based on a 1-tier process for approximating all objects in the input spatial dataset into their MBRs without any level of approximation or losing objects data. By the way, it guarantees more accurate query results. Figures 12 and 13 show, for instance, a RQ on Cities dataset with a query window area 0.00005% and 0.001%, respectively, for the proposed MBR-aware PR-Tree (on the right hand) and the other state-of-art techniques (on the left hand). The objects, marked in orange on the left hand, are not returned in the query using the proposed MBR-aware PR-Tree which is agreed with our dissertations.

Range query with a random query window area 0.00005% of Cities dataset

Range query with a random query window area 0.001% of Cities dataset
Figure 12b differs with Fig. 12a in only one object, whereas Fig. 13b differs in 10 objects. The reason behind that returns to the query window size. As long as the window size is enlarged, the more differentiations will be appeared. Table 3 comes to strengthen this meaning about the accuracy of returned objects. As illustrated in Table 3, the number of objects returned as a result for the execution of ten different rectangle areas (R1–R10) selected randomly for different RQ areas (0.01–50%) on different datasets. It is noticeable from Sports dataset, a small size file with a small number of objects; there are no major difference between the proposed MBR-aware PR-Tree and other techniques except only for RQ with query window area 50% in R10 the proposed algorithm returns 160,799 objects that is more accurate than the other techniques by 173 objects. However, for Roads and Buildings datasets (a big size file with a huge number of objects), it is noted that there are many differences in the number of retrieved objects for different range areas especially for quires with range area 10% and 50%.
Figure 14a–d shows the kNN query performance on different real datasets. It is noticeable that Quadtree outperforms the other techniques in performing the kNN queries, as it divides the input datasets into a big number of partitions with small sizes. However, the MBR-aware PR-Tree has the best performance compared to techniques that work on the desired number of partitions. In addition, the proposed MBR-aware PR-Tree not only meets the required number of partitions but also guarantees that all partitions have the same number of objects, which in turn have roughly the same size so the proposed MBR-aware PR-Tree has the advantage of highly load balancing when working on such partitions inversely with Quadtree which would be have a great decreasing effect on the Quadtree performance with the input dataset with huge sizes.

kNN query execution time for Sports, Cities, Lakes and Buildings
5 Conclusion
In this paper, an enhanced PR-Tree partitioning technique in SpatialHadoop is proposed for dealing with big spatial data operations. Various state-of-art SpatialHadoop partitioning techniques have been experimentally evaluated compared to our proposed MBR-aware PR-Tree. The experimental results show that Quadtree, STR, STR+ take long time in the index creation process than the other techniques. In addition, for RQ on a large size input dataset, all other techniques performance is highly decreased specially for large query window areas. In contrary, MBR-aware PR-Tree has a better time in the index creation process and generates the desired number of partitions. RQ based on MBR-aware PR-Tree index has the best Tree execution time for all datasets sizes since it could preserve the spatial proximity of the input objects. Moreover, kNN query-based MBR-aware PR-Tree index performance becomes better as the k values and the dataset size become larger. More importantly, the proposed MBR-aware PR-Tree guarantee a higher accuracy in terms of objects retrieved. In the future work, more experiments will be conducted on the kNN query with bigger k values with the goal of further enhancing query response time and query result accuracy.
Availability of Data and Materials
Data will be available upon reasonable request.
Abbreviations
- MBR:
-
Minimum Boundary Rectangle
- PR:
-
Priority R
- GISs:
-
Geographic information systems
- PCs:
-
Personal computers
- ANN:
-
All nearest neighbour
- RNN:
-
Reverse nearest neighbour
- STR:
-
Sort-tile-recursive
- 2-tier:
-
Two-tier
- 2D:
-
Two dimensional
- OGC:
-
Open Geospatial Consortium
- HDFS:
-
Hadoop distributed file system
- RQ:
-
Range query
- MB:
-
Mega byte
References
Haynes, D., Ray, S., Manson, S.: Terra populus: challenges and opportunities with heterogeneous big spatial data. In: Griffith, D.A., Chun, Y., Dean, D.J. (eds.) Advances in geocomputation: geocomputation 2015–The 13th International Conference, pp. 115–121. Springer International Publishing, Cham (2017)
Katzis, K., Efstathiades, C.: Resource management supporting big data for real-time applications in the 5G Era. In: Mavromoustakis, C.X., Mastorakis, G., Dobre, C. (eds.) Advances in mobile cloud computing and big data in the 5G era, pp. 289–307. Springer International Publishing, Cham (2017)
Rajaraman, V.: Toward a computing utility. Ann. Indian Natl. Acad. Eng. 3, 1–10 (2006)
Auradkar, P., et al.: Performance tuning analysis of spatial operations on Spatial Hadoop cluster with SSD. Procedia Comput. Sci. 167, 2253–2266 (2020)
Oussous, A., et al.: Big data technologies: a survey. J. King Saud Univ. Comput. Inform. Sci. 30, 431–448 (2017)
Cary, A. et al.: Experiences on Processing Spatial Data with MapReduce, in Scientific and Statistical Database Management. In: M. Winslett (ed) 21st International Conference, SSDBM 2009 New Orleans, LA, USA, June 2–4, 2009 Proceedings. Springer Berlin Heidelberg: Berlin, Heidelberg. p. 302–319 (2009)
Migliorini, S., Belussi, A.: A balanced solution for the partition-based spatial merge join in MapReduce. In: EDBT/ICDT Workshops (2020)
Aly, A. M. et al.: Kangaroo: Workload-Aware Processing of Range Data and Range Queries in Hadoop. In: Proceedings of the Ninth ACM International Conference on Web Search and Data Mining. ACM: San Francisco, California, USA. pp 397–406 (2016)
Zhang, S. et al.: Spatial queries evaluation with MapReduce. In: 2009 Eighth International Conference on Grid and Cooperative Computing (2009)
Ma, Q. et al.: Query processing of massive trajectory data based on MapReduce. In: Proceedings of the first international workshop on Cloud data management. ACM: Hong Kong, China. pp 9–16 (2009)
Akdogan, A. et al.: Voronoi-Based Geospatial Query Processing with MapReduce. In: 2010 IEEE Second International Conference on Cloud Computing Technology and Science (2010)
Nodarakis, N., et al.: (A)kNN query processing on the cloud: a survey. In: Sellis, T., Oikonomou, K. (eds.) Algorithmic aspects of cloud computing: second international workshop, ALGOCLOUD 2016, Aarhus, Denmark, August 22, 2016, revised selected papers, pp. 26–40. Springer International Publishing, Cham (2017)
Moutafis, P., et al.: Efficient processing of all-k-nearest-neighbor queries in the MapReduce programming framework. Data Knowl. Eng. 121, 42–70 (2019)
Ray, S. et al.: A parallel spatial data analysis infrastructure for the cloud, in Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. ACM: Orlando, Florida. pp 284–293 (2013)
Ray, S. et al.: Skew-resistant parallel in-memory spatial join. In: Proceedings of the 26th International Conference on Scientific and Statistical Database Management, ACM: Aalborg, Denmark. p. 1–12 (2014)
Vo, H., Aji, A., Wang, F.: SATO: a spatial data partitioning framework for scalable query processing. In: Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. ACM: Dallas, Texas. pp 545–548 (2014)
Patel, J.M., DeWitt, D.J.: Partition based spatial-merge join. SIGMOD Rec. 25(2), 259–270 (1996)
Lu, W., et al.: Efficient processing of k nearest neighbor joins using MapReduce. PVLDB 5, 1016–1027 (2012)
Zhang, C., Li, F., Jestes, J.: Efficient parallel kNN joins for large data in MapReduce. EDBT (2012)
García-García, F., et al.: Enhancing SpatialHadoop with closest pair queries. In: Pokorný, J., et al. (eds.) Advances in Databases and Information Systems: 20th East European Conference, ADBIS 2016, Prague, Czech Republic, August 28–31, 2016, Proceedings, pp. 212–225. Springer International Publishing, Cham (2016)
Lu, J., Guting, R.H.: Parallel secondo: boosting database engines with Hadoop. In: ICPADS (2012)
Nishimura, S., et al.: MD-HBase: design and implementation of an elastic data infrastructure for cloud scale location services. DAPD 31(2), 289–319 (2013)
HBase. Apache HBase. 2008 Apache HBase™ is the Hadoop database. Use it when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables—billions of rows X millions of columns—atop clusters of commodity hardware]. Available from: http://hbase.apache.org/. Cited 10 Jun 2017
Aji, A., et al.: Hadoop GIS: a high performance spatial data warehousing system over mapreduce. Proc. VLDB Endow. 6(11), 1009–1020 (2013)
You, S., Zhang, J., Gruenwald, L.: Large-scale spatial join query processing in cloud. ICDE Workshops, pp 34–41 (2015)
Yu, J., Wu, J., Sarwat, M.: GeoSpark: a cluster computing framework for processing large-scale spatial data. In: Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems. ACM: Seattle, Washington. pp 1–4 (2015)
Eldawy, A., Alarabi, L., Mokbel, M.F.: Spatial partitioning techniques in SpatialHadoop. In: International Conference on Very Large Databases. Kohala Coast, HI (2015)
Siddiqa, A., Karim, A., Chang, V.: Modeling SmallClient indexing framework for big data analytics. J. Supercomput. 74, 1–22 (2017)
Eldawy, A., Mokbel, M.F.: SpatialHadoop: a MapReduce framework for spatial data. In: ICDE Conference. pp 1352–1363 (2015)
Maleki, E.F., Azadani, M.N., Ghadiri, N.: Performance evaluation of SpatialHadoop for big web mapping data. In: 2016 Second International Conference on Web Research (ICWR) (2016)
Eldawy, A.: SpatialHadoop: towards flexible and scalable spatial processing using mapreduce. In: Proceedings of the 2014 SIGMOD PhD symposium. ACM: Snowbird, Utah, USA. pp 46–50 (2014)
Singh, H., Bawa, S.: A survey of traditional and MapReduce based spatial query processing approaches. SIGMOD Rec. 46(2), 18–29 (2017)
Elashry, A., et al.: 2DPR-Tree: two-dimensional priority R-Tree algorithm for spatial partitioning in SpatialHadoop. ISPRS Int. J. Geo Inf. 7(5), 179 (2018)
Guttman, A.: R-trees: a dynamic index structure for spatial searching. SIGMOD Rec. 14(2), 47–57 (1984)
Beckmann, N., et al.: The R*-tree: an efficient and robust access method for points and rectangles. SIGMOD Rec. 19(2), 322–331 (1990)
Kalyvas, C., Maragoudakis, M.: Skyline and reverse skyline query processing in SpatialHadoop. Data Knowl. Eng. 122, 55–80 (2019)
Meng, L., et al.: An improved Hilbert curve for parallel spatial data partitioning. Geo-Spatial Inform. Sci. 10(4), 282–286 (2007)
Zhang, J., You, S.: High-performance quadtree constructions on large-scale geospatial rasters using GPGPU parallel primitives. Int. J. Geogr. Inf. Sci. 27(11), 2207–2226 (2013)
Wei, H., et al.: A k-d tree-based algorithm to parallelize Kriging interpolation of big spatial data. GISci. Remote Sens. 52(1), 40–57 (2015)
Nandy, S.K., et al.: K-d tree based gridless maze routing on message passing multiprocessor systems. IETE J. Res. 36(3–4), 287–293 (1990)
Eldawy, A., Mokbel, M. F.: Pigeon: a spatial MapReduce language. pp 1242–1245 (2014)
de Carvalho-Castro, J.P., Chaves-Carniel, A., Dutra-de-Aguiar-Ciferri, C.: Analyzing spatial analytics systems based on Hadoop and Spark: a user perspective. Softw. Pract. Exp. 50(12), 2121–2144 (2020)
OGC: the Open Geospatial Consortium. 2017. Available from: http://www.opengeospatial.org/. Cited 18 Aug 2017
Wenkel, S.D.: Geospatial artificial intelligence (2019)
Ravi Kothuri, S.R.: Oracle spatial, geometries, pp. 821–826. Springer (2008)
Eldawy, A., et al.: CG_Hadoop: computational geometry in MapReduce. In: Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. ACM: Orlando, Florida. pp 294–303 (2013)
Arge, L., et al.: The priority r-tree: a practically efficient and worst-case optimal r-tree. ACM Trans. Algorithms 4(1), 1–30 (2008)
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
AS participated in the experimental studies and in the design of the study, and performed the results analysis. AE carried out the experimental studies, participated in the sequence alignment and drafted the manuscript. AA and AR conceived of the study, participated in its design and coordination, and helped to draft the manuscript. All the authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflicts of interest to report regarding the present study.
Ethical Approval and Consent to Participate
All the authors agree ethics approval.
Consent for Publication
All the authors agree to publish the paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shehab, A., Elashry, A., Aboul-Fotouh, A. et al. An Enhanced Partitioning Approach in SpatialHadoop for Handling Big Spatial Data. Int J Comput Intell Syst 16, 15 (2023). https://doi.org/10.1007/s44196-023-00188-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00188-8