
Abstract
Words representing individual preferences in group decision-making (GDM) are always associated with different meanings. Consequently, mining personalized semantics of decision-makers (DMs) hidden in preference expressions, and establishing a corresponding management mechanism, is an effective way to reach group consensus through computing with word methodology. However, the aforementioned consensus-reaching process may be hindered by self-confidence. To address this limitation, this study proposes a linguistic group decision model with self-confidence behavior. First, we identified the corresponding self-confidence levels for each DM. Next, we integrated different linguistic representation models into unified linguistic distribution-based models. We then obtained individual personalized semantics based on a consistency-driven optimization method, and designed a feedback-adjustment mechanism to improve the adjustment willingness of DMs and group consensus level. Finally, we conducted a quantitative experiment to demonstrate our model’s effectiveness and feasibility.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Linguistic group decision-making (GDM) is a field devoted to obtaining a set of alternatives to reach consensus within a group using possible linguistic values or rich expressions. The linguistic expression is the basic unit of human decision-making, as well as the carrier of preferences. Computing with word (CW) methods are a popular tool for representing and calculating linguistic information [1,2,3]. Herrera and Martinez [4] proposed a 2-tuple linguistic model to reflect expressions of opinions and information processing. However, DMs require more flexible expressions for complex and uncertain decision problems [5, 6]. Rodriguez et al. [7] proposed a hesitant fuzzy linguistic term set (HFLTS), whereas Zhang et al. [8] proposed linguistic distribution assessments (LDAs) to assign weights to linguistic terms, further improving the HFLTS model.
As one of the most widely used decision-making tools, HFLTS has experienced significant progress in recent years. Many researchers have extended the development of HFLTS into different directions for various applications. Chen et al. [9] designed a proportional HFLTS for linguistic distribution assessments, which includes the proportional information of each generalized linguistic term, as well as basic operations with closed properties based on t-norms and t-conorms. Unlike traditional assumptions that equate the possibility of being an expert’s assessment value, Wu and Xu [10] suggested the possibility that the alternative has an assessment value provided by the expert. In addition, linguistic distributions are a common tool that enables the assignment of symbolic proportions to all terms in a linguistic term set [8]. Accordingly, Zhang et al. [11] developed a hesitant linguistic distribution wherein the sum proportion for the HFLTS was provided by an expert. A clustering and management method for large-scale HFLTS was proposed and applied to group decision consensus, including the model designed by Chen et al. [12]. Chen et al. [13] further proposed a proportional interval type-2 hesitant fuzzy TOPSIS approach for linguistic decision-making under uncertainty.
In addition to hesitant fuzzy expressions, the individual emotional factors contained in an HFLTS are crucial to promoting consensus, as they serve as a window to accurately grasp individual decision-making behavior. Researchers refer to these personalized individual semantics (PIS) as the difference between the individual preference matrix provided by the decision-maker, and its corresponding perfect consistency preference matrix. Since PIS was first introduced in linguistic GDM [28], another approach for modeling PIS with the OWA operator and HFLTS has also been developed for decision-making. Chen et al. [14] proposed a novel computation structure for HFLTS possibility distributions based on the similarity measures of linguistic terms. Chen et al. [15] also designed a new framework model to address multiple-attribute GDM with hesitant fuzzy linguistic information, and proposed a weighted average operator, as well as an ordered weighted average operator, for such information. Labella et al. [16] developed an objective metric based on the cost of modifying expert opinions to evaluate CRPs in GDM problems. García-Zamora et al. [17] summarized the main methods and fields of large-group decision-making, and proposed potential directions for future research.
In real-life GDM, DMs do not always provide an absolutely reliable judgment between alternatives owing to time pressure or expertise restrictions. Reliability of information was therefore developed to evaluate the extent of knowledge in the decision-making context [18]. Generally, a DM explicitly adds reliability information to synthesize a linguistic triplet. Liu et al. [19] introduced a reliability measurement for self-confident decision problems.
Many previous studies have carried out relevant research on confident behavior in the consensus-reaching aspect of GDM.
-
1.
The detection and management of overconfidence behaviors [20]. Considering personalized semantics, Zhang et al. [21] proposed an individual semantic model in hesitant fuzzy linguistic preference relations with self-confidence.
-
2.
Consensus reaching process (CRP) in GDM with self-confidence. A feedback mechanism is the most common panel for preference modification. Such a mechanism may implement identification and direction rules [22, 23], as well as minimum adjustment or cost feedback [24,25,26,27,28] to minimize the adjustments or consensus cost.
Although many models have been developed for linguistic GDM with self-confidence behavior, their practical applicability remains a challenge due to the complex and diverse nature of real-world decision problems.
-
1.
Different people may understand the same word differently [29,30,31]. For example, in a speech, two judges may both evaluate the current participant’s performance as excellent, but whereas one judge gives 85 points, the other gives 90 points. Therefore, personalized individual semantics (PIS) must be investigated in various contexts.
-
2.
Multiple self-confidence levels in GDM exist because of the reliability of information provided by DMs. The combination of preference relations and self-confidence levels in the context of personalized semantics is unclear.
Motivated by the aforementioned real-life requirements, we propose a fuzzy linguistic GDM model that accounts for PIS and self-confidence behavior. First, we converted linguistic representation models into unified models. We then incorporated the dual information of preference values and associated self-confidence levels into our model to learn the PIS of the linguistic term set. Subsequently, we designed a consensus mechanism that considers underconfidence behavior. Finally, we conducted a quantitative experiment to demonstrate the effectiveness of our method.
As major contributions, this paper addresses the differences in individualized semantics of confident decision-makers in the HTLTS environment, and proposes a management method for PIS in the context of CRP in linguistic GDM.
The remainder of this paper is organized as follows. Section 2 provides an overview of relevant basic information. Section 3 establishes the linguistic GDM model and presents the solution process. We 4 further describes the linguistic GDM model in the context of PIS and confidence. Section 4 presents a numerical example and verifies the proposed method’s advantages. Section 5 summarizes the results of this study.
2 Preliminaries
In this section, we introduce the preliminary knowledge used in this study, including individual preference expression relationships, PIS, self-confidence, and the general consensus process.
2.1 Linguistic Representation Models
A linguistic symbolic computational model consists of ordinal scales on a linguistic term set.
Definition 1
[4, 32] Let \(S = \left\{ {S_{0} ,S_{1} ,...,S_{g} } \right\}\) be a linguistic term set and \(g + 1\) be odd. The linguistic symbolic computational model is defined as follows:
-
1.
The set is ordered: \(S_{i} \ge S_{j}\) if \(i \ge j\);
-
2.
A negation operator exists: \({\text{Neg}}(S_{i} ) = S_{g - i}\).
A 2-tuple linguistic model was proposed to compute the loss degree of information [36, 37].
Definition 2
[4] Let \(S = \left\{ {S_{0} ,S_{1} ,...,S_{g} } \right\}\) be as above, and \(\beta \in \left[ {0,g} \right]\) be a value representing the result of a symbolic aggregation operation. If \(\overline{S} = S \times \left[ { - 0.5,0.5} \right)\) and \(S_{i} \in S\), then the linguistic 2-tuple expresses assessment information equivalent to \(\beta\). This relationship can be described as
where \({\text{round}}( \cdot )\) is the usual rounding operation.
Correspondingly, \(\Delta^{ - 1}\), the inverse function of \(\Delta\), aims to transform a linguistic 2-tuple into the value \(\beta\). This transform function is expressed as
To describe the situation of a hesitant decision, HFLTS is defined as follows:
Definition 3
[7] Let \(S = \left\{ {S_{0} ,S_{1} ,...,S_{g} } \right\}\) be a linguistic term set. HFLTS \(H_{s}\) is an ordered finite subset of consecutive linguistic terms of \(S\).
Definition 4
[7] The upper bound \(H_{s}^{ + }\), lower bound \(H_{s}^{ - }\), envelope of, and complement \(H_{s}^{C}\) of \(H_{s}\) are denoted as follows:
Because the aforementioned linguistic terms are equally important fuzzy sets, Zhang et al. [8] used a probabilistic model, called the LDA model, to indicate the varying importance of linguistic terms.
Definition 5
[8] Let \(S = \left\{ {S_{0} ,S_{1} ,...,S_{g} } \right\}\) be defined as previously and \(P_{D}\) be the distribution assessment of \(S\). \(P_{D} = \{ (S_{i} ,\beta_{i} )\left| {i = 1,2,...,g} \right.\}\), where \(\beta_{i} \ge 0\) is a symbolic proportion of \(S_{i}\), \(S_{i} \in S\), or \(\sum\nolimits_{i = 1}^{g} {\beta_{i} } = 1\).
Zhang et al. [8] proposed the following negation operator of \(P_{D}\): \({\text{Neg(S}}_{i} {,}\beta_{i} {\text{) = (S}}_{i} {,}\beta_{g - i} {)}\).
2.2 Heterogeneous Preference Relation with Self-confidence
While confidence influences reasonable decision-making, it often leads to bias in the judgment of alternatives. A preference relation with self-confidence allows DMs to provide their preference values with self-confidence levels, as designed by Liu et al. [19].
Definition 6
[19] Let \(X = \{ x_{1} ,x_{2} ,...,x_{m} \} (m \ge 2)\) be a finite set of alternatives, and \(S = \{ S_{0} ,S_{1} ,...,S_{g} \}\) be a linguistic term set. \(F = (f_{ij} |c_{ij} )_{m \times m}\) is defined as a preference relation with self-confidence. Its elements have two components: \(f_{ij} \in [0,1]\) denotes the preference degree of alternative \(x_{i}\) over \(x_{j}\), and \(c_{ij} \in S\) denotes the self-confidence level related to \(f_{ij}\). The following conditions are satisfied: \(f_{ij} + f_{ji} = 1\),\(f_{ii} = 0.5\), \(c_{ii} = S_{g}\), and \(c_{ji} = c_{ij}\), for \(\forall i,j \in \{ 1,...,m\}\).
In linguistic GDM, we also introduce preference relations with self-confidence.
Definition 7
Let \(X = \{ x_{1} ,x_{2} ,...,x_{m} \}\), \(S = \{ S_{0} ,S_{1} ,...,S_{g} \}\) be equivalent to the above definitions. A heterogeneous preference relation with self-confidence (HPR-SC) \(L = (l_{ij} |c_{ij} )_{m \times m}\) is composed of two parts: \(l_{ij} \in S\) represents the preference value of alternatives \((x_{i} ,x_{j} )\), and \(c_{ij} \in S\) represents the self-confidence level associated with \(l_{ij}\). An HPR-SC also satisfies \(l_{ji} = {\text{Neg}} (l_{ij} )\), \(c_{ii} = S_{g}\), and \(c_{ji} = c_{ij}\)\(\forall i,j \in \{ 1,...,m\}\).
Remark
Preference values are expressed in linguistic terms—HFLTS or LDA—and the level of self-confidence is shown by a simple single linguistic term.
Example 1
Let \(S = \left\{ {S_{0} ,S_{1} ,...,S_{6} } \right\}\) be a set of seven linguistic terms and \(X = \{ x_{1} ,x_{2} ,...,x_{4} \}\) be a set of alternatives. For the evaluated linguistic preference values, the meaning of \(S\) can be expressed as
Assume that a DM expresses a preference relation with self-confidence using an HFLTS as follows:
In HPR-SC, \(l_{24} = \{ S_{2} ,S_{3} \}\) indicates that the preference degree of \(x_{2}\) over \(x_{4}\) is between \(S_{4}\) and \(S_{5}\) (i.e., between slightly good and good). Accordingly, \(c_{24} = S_{6}\) indicates that the DM’s self-confidence level associated with \(l_{24}\) is \(S_{6}\) (i.e., maybe absolutely confident).
2.3 PIS Model Based on Numerical Scale (NS)
Consistency measurement ensures that each judgment is logical based on a preference relation. Dong et al. [33] proposed the concept of NSs.
Definition 8
[33]. Let \(S = \{ S_{0} ,S_{1} ,...,S_{{\text{g}}} \}\) be a linguistic term set, and let \(R \in \Re\). A mapping function \({\text{NS}} :S \to R\) is a one-to-one injection, and \({\text{NS}} (S_{i} )\) is called the NS of \(S_{i} (i = 0,1,...,g)\). If \({\text{NS}} (S_{i} ) < {\text{NS}} (S_{i + 1} )\), then \({\text{NS}}\) is ordered.
On the basis of a balanced linguistic term set \(S\), the NSs satisfy \({\text{NS}} (S_{i} ) + {\text{NS}} (S_{g - i} ) = 1\).
Definition 9
[34, 35]. We assume that \(L^{*} = (l_{ij} )_{m \times m}\) is a linguistic preference relation. Based on NS, the consistency index of \(L^{*}\) is defined as
where \({\text{NS}}(l_{ij} ) \in [0,1],i,j = 1,2,...,n\). A larger value of \(CI(L^{*} )\) indicates better consistency of \(L^{*}\). If \({\text{CI}}(L^{*} ) = 1\), then the matrix \(L^{*}\) is completely consistent.
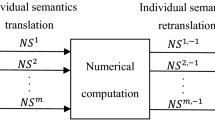
Words can have different meanings provided by different people. Accordingly, Li et al. [28] proposed a framework for handling preference information in linguistic GDM with a PIS. The individual semantic translation process converts linguistic input into corresponding personalized numerical scales (PNSs), and the individual semantic retranslation process converts the PNS output back into linguistic values.
Let \(S = \{ S_{0} ,S_{1} ,...,S_{{\text{g}}} \}\) be a linguistic term set, and \(D = \{ d_{1} ,d_{2} ,...,d_{n} \}\) be a set of DMs. \({\text{PNS}}^{k}\) represents the personalized numerical scale on \(S\) associated with DM \(d_{k}\). The function \(\Delta^{ - 1} ({\text{PNS}}^{k} )\) can transform a numerical scale into its equivalent linguistic values. This process is described in more detail in Li et al. [28].
3 Linguistic GDM Framework to Handle PIS and Self-confidence Behavior
In this section, we propose an HPR-SC model and a corresponding resolution framework.
Let \(X = \{ x_{1} ,x_{2} ,...,x_{m} \}\) be a set of alternatives, \(D = \{ d_{1} ,d_{2} ,...,d_{n} \}\) be a set of DMs, and \(S = \{ S_{0} ,S_{1} ,...,S_{g} \}\) be a linguistic term set. DM \(d_{k} (k = 1,2,...,n)\) pairwise compares alternatives \((x_{i} ,x_{j} )\) to generate an HPR-SC \(L^{k} = (l_{ij}^{k} |c_{ij}^{k} )_{m \times m}\), where \(l_{ij}^{k}\) represents the preference degree of \(x_{i}\) over \(x_{j}\), and \(c_{ij}^{k} \in S\) denotes the self-confidence level associated with preference value \(l_{ij}^{k}\). Each DM has personalized semantics for \(L^{k}\), and \(k = 1,2,...,n\).
Our model handles heterogeneous preference relations with self-confidence and reach consensus by accounting for PIS and confidence. The process comprises the following three consensus steps (Fig. 1).

Consensus framework
3.1 Transformation Process
LDAs are used to capture the maximum amount of information provided by DMs. We converted each HPR-SC into a linguistic distribution preference relation with self-confidence (LDPR-SC). The LDPR-SC represents the degree of affirmation of a linguistic distribution preference relation made by DMs for alternatives, and it expresses linguistic preferences under different confidence levels to improve the accuracy of linguistic representation. In our model, this confidence level is represented by linguistic preference. The following definitions and examples illustrate its transformation:
A single linguistic term can be regarded as a special LDA, obtained by converting an HFLTS.
Definition 10
Let \(S = \{ S_{0} ,S_{1} ,...,S_{g} \}\) be a linguistic term. For an HFLTS based on \(S\) and \(H_{S}\), we transform \(H_{S}\) into a distribution assessment \(P_{D} = \{ (S_{i} ,\beta_{i} )|i = 0,1,...,g\}\) by solving the following model:
where \(\# H_{S}\) denotes the number of linguistic terms in \(H_{S}\). We refer to Model (5) \(M1\).
Let \(X = \{ x_{1} ,x_{2} ,...,x_{m} \}\) be a set of alternatives, and \(D = \{ d_{1} ,d_{2} ,...,d_{n} \}\) be a set of DMs. After unification, each heterogeneous preference relation with self-confidence \(L^{{\text{k}}}\) can be transformed into an LDPR-SC
where \(p_{ij}^{k} = \{ (S_{t} ,\beta_{ij.t}^{k} )\left| {t = 0,1,...,g} \right.\} ,c_{ij}^{k} \in S,i,j = 1,2,...,m,k = 1,2,...,n\).
For example, the following preference relation with self-confidence \(L^{1}\)
can be transformed into a corresponding LDPR-SC \(P^{1}\):
Remark
In the above example, \(\left( {\left\{ {\left( {S_{1} ,0.5} \right),(S_{2} ,0.5)} \right\}\left| {S_{4} } \right.} \right)\) is a distribution assessment transformed from \(\left( {\{ S_{1} ,S_{2} \} \left| {S_{4} } \right.} \right)\). The credibility of group decision-making is precisely a result of the group opinion comprising the information of all decision-makers, so conflict may be reduced. If some decision-makers do not perceive a higher degree of confidence in the given preferences, the information will be identified, and guided adjustments will be applied in the consensus-reaching process in subsection C, thus reducing the impact of uncertainty. However, this information is not directly removed.
Self-confidence is a psychological expectation that exists in the process of making decisions or comparing preferences for every individual DM. In the supply chain inventory strategy, overconfident decisions are positively affected by the DMs’ psychological expectations of market demand, as market forecasts are published through annual financial reports or decision reports. In addition, in credit management, the risk preference type can be determined by answers to a questionnaire, which is a necessary link before credit is issued.
If the confidence level cannot be provided by experts, it can be determined by the decision-makers’ area of expertise.
3.2 PIS Model
We obtained each LDPR-SC and used a consistency-driven optimization method to test the PIS. We then transformed LDPR-SC into additive preference relations with self-confidence (APRs-SC).
Consistency is a metric used to ensure that a preference relation is reasonable and not random. Li et al. [19] proposed a consistency-driven optimization method that calculates NSs corresponding to the linguistic term set of each DM to reflect the PIS.
Definition 11
Let \(X = \{ x_{1} ,x_{2} ,...,x_{m} \}\) be a set of alternatives, and \(F = (f_{ij} |c_{ij}^{a} )_{m \times m}\) be an APR-SC,\(f_{ij} ,c_{ij}^{a} \in [0,1]\). \(f_{ij} = 0.5\) implies indifference between \(x_{i}\) and \(x_{j}\). For three alternatives,\(x_{i}\), \(x_{j}\), and \(x_{z}\), if their associated preference values \(f_{ij} ,f_{jz} ,f_{iz}\) fulfill \(f_{ij} + f_{jz} - f_{iz} = 0.5\), then the preference has additive transitivity at the self-confidence level \(c_{ijz}^{a}\), where \(c_{ijz}^{a} = \min \{ c_{ij}^{a} ,c_{jz}^{a} ,c_{iz}^{a} \}\).
If all elements in \(F\) satisfy \(f_{ij} + f_{jz} - f_{iz} = 0.5\), then \(F\) is considered completely consistent at the self-confidence level \(c^{a}\), where \(c^{a} = \min \{ c_{ij}^{a} \}\), and \(i,j = 1,2,...,m\).
Let \(S = \{ S_{0} ,S_{1} ,...,S_{{\text{g}}} \}\) be a linguistic term set, \(D = \{ d_{1} ,d_{2} ,...,d_{n} \}\) be a set of DMs, \(P^{k} = (p_{ij}^{k} |c_{ij}^{k} )_{m \times m}\) be an LDPR-SC provided by DM \(d_{k}\), and \({\text{PNS}}^{k}\) be the NSs associated with \(d_{k}\). To ensure that the preference relation \(P^{k}\) given by DM \(d_{k}\) is as consistent as possible, we maximize the consistency index using the objective function
In LDPR-SC \(P^{k} = (p_{ij}^{k} |c_{ij}^{k} )_{m \times m}\), each element \(p_{ij}^{k} = \{ (S_{t} ,\beta_{ij.t}^{k} )\left| {t = 0,1,...,g} \right.\}\) is a distribution assessment, and \(c_{ij}^{k}\) is the corresponding self-confidence level. Taking personalized semantics into account, we translate \(p_{ij}^{k}\), \(c_{ij}^{k}\) to corresponding numerical values \(f_{ij}^{k}\),\(c_{ij}^{ka}\). That is, the individual APR-SC \(F^{k} = (f_{ij}^{k} |c_{ij}^{ka} )_{m \times m}\) associated with \(P^{k}\) can be obtained as follows:
The consistency index \(CI(P^{k} )\) is calculated as
The range of \(PNS(S_{t} )\) for linguistic term \(S_{t}\) is
To make \({\rm PNS}^{k}\) ordered, a constraint value \(\sigma \in (0,1)\) is introduced
Based on Eqs. (6)–(11), we utilize a consistency-driven optimization method to determine the PIS as follows:
We call model (12) is denoted as \(M2\), and \({\text{PNS}}^{k} (S_{t} )\) refers to the decision variable. We can solve \(M2\) using traditional software such as Lingo. Subsequently, \({\text{PNS}}^{k}\) is performed.
3.3 Consensus Process
We gather member preferences to obtain group preferences, and subsequently calculate individual and group consensus levels. If the group consensus level is unacceptable, we enter the feedback-adjustment stage. Otherwise, the selection process can be entered to obtain the final decision result. In the feedback-adjustment phase, we detect underconfidence behaviors and provide preference modification advice based on identification and direction rules to improve group consensus.
We use a weighted operator to aggregate individual APR \((F^{k} )^{*} = (f_{ij}^{k} )_{m \times m}\) and obtain collective APR \(F^{c} = (f_{ij}^{c} )_{m \times m}\)
where \(w_{k} \in [0,1]\) is a weight vector of DMs, and \(\sum\nolimits_{k = 1}^{n} {w_{k} = 1}.\)
After obtaining collective opinions, we enter a consensus measurement and feedback-adjustment phase, which aims to coordinate and resolve conflicts among DMs.
Definition 12
Let \((F^{k} )^{*} = (f_{ij}^{k} )_{m \times m}\) be an individual APR, and let the collective opinion \(F^{c} = (f_{ij}^{c} )_{m \times m}\) be as defined previously. The individual consensus level of DM \(d_{k}\) is defined as follows:
The collective consensus level is calculated as
where \({\text{CL}} \in [0,1]\), and a larger value of \({\text{CL}}\) indicates a higher consensus level for all DMs.
If the consensus level obtained in Eq. (15) is acceptable, the priority vector of the alternatives is computed. Let \(O^{c} = (o_{1}^{c} ,o_{2}^{c} ,...,o_{m}^{c} )^{\rm T}\) be the priority vector generated to rank alternatives as follows:
When the collective consensus level is higher than a certain preset threshold, we assume that the group consensus level is acceptable; otherwise, we trigger a feedback mechanism to reach a higher consensus level. However, underconfidence hinders the achievement of a group consensus. We first define such underconfidence behavior.
Definition 13
Let \(F = (f_{ij} |c_{ij}^{a} )_{m \times m}\) be an APR-SC and \(f_{ij} ,c_{ij}^{a} \in [0,1]\).\(f_{ij}\) denotes the preference degree of alternative \(x_{i}\) over \(x_{j}\), and \(c_{ij}^{a}\) represents the self-confidence level associated with \(f_{ij}\). If \(c_{ij}^{a} = 0.5\), the DM is moderately confident. We then set a threshold \(\eta (\eta \le 0.5)\) for underconfidence behavior. If \(c_{ij}^{a} < \eta\), then they have underconfidence in evaluating alternatives \((x_{i} ,x_{j} )\). In this study, we used \(\eta = 0.5\).
Next, we detect underconfidence behaviors. Let \(D_{U}\) be a set of DMs with underconfidence behaviors. For individual APR-SC \(F^{k} = (f_{ij}^{k} |c_{ij}^{ka} )_{m \times m} (k = 1,2,...,n)\)
Some individuals may be unconfident regarding preference expressions because of their lack of access to background information or relevant professional knowledge. We can then provide additional supplementary knowledge for DMs to improve their self-confidence and consensus levels. Therefore, we propose the following feedback mechanism, which includes identification and direction rules.
Identification rule: Identify DM \(d_{z}\) which satisfies
Direction rule: The DM revises their preference values in accordance with the suggested direction.
Let matrix \((F^{z} )^{*} = (f_{ij}^{z} )_{m \times m}\) be the individual APR associated with the identified DM \(d_{z}\), matrix \(F^{c} = (f_{ij}^{c} )_{m \times m}\) be the collective APR, and \(X = \{ x_{1} ,x_{2} ,...,x_{m} \}\) be a set of alternatives. The adjustment direction of DM \(d_{z}\) conforms to the following rules:
-
1.
If \(f_{ij}^{z} < f_{ij}^{c}\), then DM \(d_{z}\) should increase the value of \(f_{ij}^{z}\) to be closer to \(f_{ij}^{c}\).
-
2.
If \(f_{ij}^{z} > f_{ij}^{c}\), then DM \(d_{z}\) should decrease the value of \(f_{ij}^{z}\) to be closer to \(f_{ij}^{c}\).
-
3.
Otherwise, \(f_{ij}^{z}\) should remain unchanged.
If the group reaches a consensus, we select the best alternatives.
3.4 Solution Algorithm
The solution and overall process are summarized in Table 1.
4 Numerical Example and Simulation Analysis
In this section, we present a quantitative example and simulation analysis to illustrate the effectiveness of the proposed model.
4.1 Numerical Example
We assume that in a real-life GDM issue, such as the green supplier selection in supply chain management, four alternatives need to be evaluated by six DMs. The expressions of FLPR-SC \(L^{k} = (l_{ij}^{k} |c_{ij}^{k} )_{m \times m} (k = 1,2,...,6)\) are as follows:
\(L^{4} = \left( {\begin{array}{*{20}c} {\left( {S_{3} |S_{6} } \right)} & {\left( {S_{3} |S_{4} } \right)} & {\left( {\left\{ {S_{3} ,S_{4} } \right\}|S_{3} } \right)} & {\left( {\left\{ {S_{4} ,S_{5} ,S_{6} } \right\}|S_{6} } \right)} \\ - & {\left( {S_{3} |S_{6} } \right)} & {\left( {\left\{ {S_{4} ,S_{5} } \right\}|S_{5} } \right)} & {\left( {S_{4} |S_{4} } \right)} \\ - & - & {\left( {S_{3} |S_{6} } \right)} & {\left( {\left\{ {S_{3} ,S_{4} } \right\}|S_{6} } \right)} \\ - & - & - & {\left( {S_{3} |S_{6} } \right)} \\ \end{array} } \right),\)
Based on the model \(M1\),we transform each HPR-SC \(L^{k}\) to a corresponding LDPR-SC \(P^{k}\).
We then obtain the personalized semantics of each DM on the basis of model \(M2\), as shown in Table 2.
After PIS management, we transform LDPR-SC into APR-SC based on Eqs. (7, 8)
We can then compute the collective APR \(F^{c}\) based on Eq. (13)
Next, we set the threshold of the consensus level as \(\varepsilon = 0.9\). On the basis of Eqs. (14, 15), we obtain an unaccepted collective consensus level \({\text{CL}} = 0.8878\). The individual consensus levels are \({\text{CL}}^{1} = 0.8818\), \({\text{CL}}^{2} = 0.8498\), \({\text{CL}}^{3} = 0.8602\), \({\text{CL}}^{4} = 0.9022\), \({\text{CL}}^{5} = 0.921\), and \({\text{CL}}^{6} = 0.9118\).
We developed a feedback mechanism with confidence to provide suggestions for adjustment. In accordance with the identification and directional rules, DM \(d_{2}\) should modify their preference relationship. The updated preference relation of \(d_{2}\) is
Because the updated collective consensus level \({\text{CL}} = 0.9006\) is acceptable, group consensus is reached. The final collective preference relationship is obtained as follows:
We obtain the priority vector of alternative \(x_{1} \succ x_{2} \succ x_{4} \succ x_{3}\), and \(x_{1}\) is chosen as the optimal alternative.
4.2 Simulation and Comparative Analysis
Individual self-confidence levels affect the decision-making process and selection of the final result [19, 37, 38]. This section presents a comparison between our proposed method and existing methods.
In linguistic GDM, fixed NSs are used to handle linguistic preference information in a process called the FNS-based method [39]. Specifically, each DM exhibits the same semantics as a linguistic term set. For example, in the linguistic term set \(S = \{ S_{1} ,S_{2} ,...,S_{6} \}\), the NSs corresponding to \(S\) of all DMs are \(NS = [0,\;0.17,\;0.33,\;0.5,\;0.67,\;0.83,\;1]\). Fuzzy linguistic preference relations indicate that DMs are fully confident in their evaluation information; that is, \(c_{ij} = S_{g}\) for \(\forall i,j \in \{ 1,2,...,m\}\).
The consistency index, which serves as the basis of a preference relation, is a metric used to evaluate the performance of different methods. We use the numerical example data in Sect. 3 to observe the consistency indices of six DMs under different methods in Fig. 2.
-
i.
HPR based on FNS, the preference relation without considering personalized semantics.
-
ii.
HPR based on PNS, the preference relation only considers personalized semantics.
-
iii.
HPR-SC based on PNS: the preference relation considers personalized semantics and confidence.

Consistency indexes of DMs under different approaches
Preference values are combined with multiple self-confidence levels to evaluate alternatives and obtain reliable evaluation information.
Figure 2 shows that the consistency index of the PNS-based method is higher than that of the FNS-based method, which indicates superior performance in the PNS-based method. Thus, the pairwise approach of preference expression (preference value and corresponding self-confidence level) can improve consistency.
A simulation experiment was conducted to illustrate the effectiveness of our model and analyze the effects of some parameters in the CRP. We randomly generated linguistic preference relations with self-confidence, and observed simulation results under different parameter settings.
In the feedback-adjustment stage, the identified DM must participate in the interaction. Thus, we replaced the adjustment direction rule in Sect. 4.3 with the following rules to automatically modify the DM’s preference values.
Simulation Experiment 1: Let \(m = 4\) and \(n \in \{ 5,6,7,8,9\}\), and then, let \(n = 6\) and \(m \in \{ 3,4,5,6,7\}\). We compared the average number of iterations in different contexts. The simulation results are shown in Fig. 3.

Average number of iterations under different settings
Simulation Experiment 2: We set different values of m and n to compare the consensus-reaching speed and average self-confidence level. Under each set of parameters, we obtained the average value of group consensus and self-confidence level 500 times to eliminate randomness. The simulation results are shown in Figs. 4 and 5.

Average consensus level under different iterations

Average self-confidence level under different iterations
The results in Figs. 3, 4 and 5 show that the proposed consensus process effectively improves the group consensus level. The number of iterations required to achieve full individual confidence is obviously less than that required for a complete consensus, as the latter requires time and effort within the group (Fig. 5). Therefore, we can set acceptable consensus and self-confidence levels to facilitate decision-making in accordance with actual situations, thus exploring the range of suitable alternatives in a specific scenario (Fig. 3).
5 Conclusions
In decision-making problems, preferences are generally expressed in words. We used multiple self-confidence levels to measure the reliability of preference information. In addition, due to the subjectivity associated with the understanding of words, we employed PIS management to reflect personalized semantics.
The results show that more DMs participate in decision-making, and more iterations are required to reach an acceptable consensus level. At the same time, a higher predefined acceptable consensus level necessitates more consensus rounds for CRP. The average self-confidence level of each DM varies similarly to the group consensus level. For a certain number of DMs, the number of consensus iterations increases with the number of alternatives; however, the rate of growth in the curve gradually decreases. A quantitative analysis was performed to verify our model’s advantages.
In future studies, we can incorporate DMs into a social network to explore the influence of group interaction on decision-making and consensus processes [40,41,42]. Focusing on the application of the GDM theory to practical decision-making problems is essential [43,44,45,46,47]. Therefore, we may also consider the GDM model using a data-driven method to achieve a more accurate degree of simulation.
Availability of Data and Materials
The datasets generated during the current study are available from the corresponding author on reasonable request.
Abbreviations
- GDM:
-
Linguistic group decision-making
- CW:
-
Computing with words
- DMs:
-
Decision-makers
- HFLTS:
-
Hesitant fuzzy linguistic term set
- LDAs:
-
Linguistic distribution assessments
- CRP:
-
Consensus reaching process
- PIS:
-
Personalized individual semantics
- HPR-SC:
-
Heterogeneous preference relation with self-confidence
- LDPR-SC:
-
Linguistic distribution preference relation with self-confidence
- APRs-SC:
-
Additive preference relations with self-confidence
- CL:
-
Consensus degree
References
Herrera, F., Alonso, S., Chiclana, F., Herrera-Viedma, E.: Computing with words in decision making: foundations, trends and prospects. Fuzzy Optim. Decis. Mak. 8(4), 337–364 (2009). https://doi.org/10.1007/s10700-009-9065-2
Martínez, L., Herrera, F.: An overview on the 2-tuple linguistic model for computing with words in decision making: extensions, applications and challenges. Inf. Sci. 207, 1–18 (2012). https://doi.org/10.1016/j.ins.2012.04.025
Herrera-Viedma, E., Palomares, I., Li, C.C., Cabrerizo, F.J., Dong, Y., Chiclana, F., Herrera, F.: Revisiting fuzzy and linguistic decision making: scenarios and challenges for making wiser decisions in a better way. IEEE Trans. Syst. Man Cybern. Syst. 51(1), 191–208 (2021). https://doi.org/10.1109/TSMC.2020.3043016
Herrera, F., Martínez, L.: A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy Syst. 8(6), 746–752 (2000). https://doi.org/10.1109/91.890332
Rodríguez, R.M., Labella, A., Martínez, L.: An overview on fuzzy modeling of complex linguistic preferences in decision making. Int. J. Comput. Int. Syst. 9(sup1), 81–94 (2016). https://doi.org/10.1080/18756891.2016.1180821
Wang, H., Xu, Z., Zeng, X.J.: Modeling complex linguistic expressions in qualitative decision making: an overview. Knowl. Based Syst. 144, 174–187 (2018). https://doi.org/10.1016/j.knosys.2017.12.030
Rodríguez, R.M., Martínez, L., Herrera, F.: Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 20(1), 109–119 (2011). https://doi.org/10.1109/TFUZZ.2011.2170076
Zhang, G., Dong, Y., Xu, Y.: Consistency and consensus measures for linguistic preference relations based on distribution assessments. Inf. Fusion 17, 46–55 (2014). https://doi.org/10.1016/j.inffus.2012.01.006
Chen, Z.S., Chin, K.S., Li, Y.L., Yang, Y.: Proportional hesitant fuzzy linguistic term set for multiple criteria group decision making. Inf. Sci. 357, 61–87 (2016)
Wu, Z., Xu, J.: Possibility distribution-based approach for MAGDM with hesitant fuzzy linguistic information. IEEE Trans. Cybern. 46(3), 694–705 (2015)
Zhang, G., Wu, Y., Dong, Y.: Generalizing linguistic distributions in hesitant decision context. Int. J. Comput. Int. Syst. 10(1), 970–985 (2017)
Chen, Z.S., Zhang, X., Pedrycz, W., Wang, X.J., Chin, K.S., Martínez, L.: K-means clustering for the aggregation of HFLTS possibility distributions: N-two-stage algorithmic paradigm. Knowl. Based Syst. 227, 107230 (2021)
Chen, Z.S., Yang, Y., Wang, X.J., Chin, K.S., Tsui, K.L.: Fostering linguistic decision-making under uncertainty: a proportional interval type-2 hesitant fuzzy TOPSIS approach based on Hamacher aggregation operators and andness optimization models. Inf. Sci. 500, 229–258 (2019)
Chen, Z.S., Chin, K.S., Martinez, L., Tsui, K.L.: Customizing semantics for individuals with attitudinal HFLTS possibility distributions. IEEE Trans. Fuzzy Syst. 26(6), 3452–3466 (2018)
Chen, Z.S., Xu, M., Wang, X.J., Chin, K.S., Tsui, K.L., Martinez, L.: Individual semantics building for HFLTS possibility distribution with applications in domain-specific collaborative decision making. IEEE Access 6, 78803–78828 (2018)
Labella, Á., et al.: A cost consensus metric for consensus reaching processes based on a comprehensive minimum cost model. Eur. J. Oper. Res. 281, 316–331 (2020)
García-Zamora, D., et al.: Large-scale group decision making: a systematic review and a critical analysis. IEEE/CAA J. Autom. Sin. 9, 949–966 (2022)
Zadeh, L.A.: A note on z-numbers. Inf. Sci. 181(14), 2923–2932 (2011). https://doi.org/10.1016/j.ins.2011.02.022
Liu, W., Dong, Y., Chiclana, F., Cabrerizo, F.J., Herrera-Viedma, E.: Group decision-making based on heterogeneous preference relations with self-confidence. Fuzzy Optim. Decis. Mak. 16(4), 429–447 (2017). https://doi.org/10.1007/s10700-016-9254-8
Liu, X., Xu, Y., Montes, R., Dong, Y., Herrera, F.: Analysis of self-confidence indices-based additive consistency for fuzzy preference relations with self-confidence and its application in group decision making. Int. J. Intell. Syst. 34(5), 920–946 (2019). https://doi.org/10.1002/int.22081
Zhang, H., Li, C.C., Liu, Y., Dong, Y.: Modeling personalized individual semantics and consensus in comparative linguistic expression preference relations with self-confidence: an optimisation-based approach. IEEE Trans. Fuzzy Syst. 29(3), 627–640 (2021). https://doi.org/10.1109/TFUZZ.2019.2957259
Herrera-Viedma, E., Cabrerizo, F.J., Kacprzyk, J., Pedrycz, W.: A review of soft consensus models in a fuzzy environment. Inf. Fusion 17, 4–13 (2014). https://doi.org/10.1016/j.inffus.2013.04.002
Chao, X., Kou, G., Peng, Y., Viedma, E.H.: Large-scale group decision-making with non-cooperative behaviors and heterogeneous preferences: an application in financial inclusion. Eur. J. Oper. Res. 288(1), 271–293 (2021). https://doi.org/10.1016/j.ejor.2020.05.047
Ben-Arieh, D., Easton, T.: Multi-criteria group consensus under linear cost opinion elasticity. Decis. Support Syst. 43(3), 713–721 (2007). https://doi.org/10.1016/j.dss.2006.11.009
Zhang, G., Dong, Y., Xu, Y., Li, H.: Minimum-cost consensus models under aggregation operators. IEEE Trans. Syst. Man Cybern. A 41(6), 1253–1261 (2011). https://doi.org/10.1109/TSMCA.2011.2113336
Zhang, H., Zhao, S., Kou, G., Li, C.C., Dong, Y., Herrera, F.: An overview on feedback mechanisms with minimum adjustment or cost in consensus reaching in group decision making: research paradigms and challenges. Inf. Fusion 60, 65–79 (2020). https://doi.org/10.1016/j.inffus.2020.03.001
Jing, F., Chao, X.: Fairness concern: an equilibrium mechanism for consensus-reaching game in group decision-making. Inf. Fusion 72, 147–160 (2021). https://doi.org/10.1016/j.inffus.2021.02.024
Li, C.C., Dong, Y., Herrera, F., Herrera-Viedma, E., Martínez, L.: Personalized individual semantics in computing with words for supporting linguistic group decision making. An application on consensus reaching. Inf. Fusion 33, 29–40 (2017). https://doi.org/10.1016/j.inffus.2016.04.005
Zhang, Z., Yu, W., Martínez, L., Gao, Y.: Managing multigranular unbalanced hesitant fuzzy linguistic information in multiattribute large-scale group decision making: a linguistic distribution-based approach. IEEE Trans. Fuzzy Syst. 28(11), 2875–2889 (2019). https://doi.org/10.1109/TFUZZ.2019.2949758
Liang, H., Li, C.C., Dong, Y., Herrera, F.: Linguistic opinions dynamics based on personalized individual semantics. IEEE Trans. Fuzzy Syst. 29(9), 2453–2466 (2020). https://doi.org/10.1109/TFUZZ.2020.2999742
Li, C.C., Liang, H., Dong, Y., Chiclana, F., Herrera-Viedma, E.: Consistency improvement with a feedback recommendation in personalized linguistic group decision making. IEEE Trans. Cybern. (2021). https://doi.org/10.1109/TCYB.2021.3085760
Yager, R.R.: A new methodology for ordinal multiobjective decisions based on fuzzy sets. In: Readings in Fuzzy Sets for Intelligent Systems, pp. 751–756. Morgan Kaufmann (1993). https://doi.org/10.1016/B978-1-4832-1450-4.50080-8
Dong, Y., Xu, Y., Yu, S.: Computing the numerical scale of the linguistic term set for the 2-tuple fuzzy linguistic representation model. IEEE Trans. Fuzzy Syst. 17(6), 1366–1378 (2009). https://doi.org/10.1109/TFUZZ.2009.2032172
Herrera-Viedma, E., Chiclana, F., Herrera, F., Alonso, S.: Group decision-making model with incomplete fuzzy preference relations based on additive consistency. IEEE Trans. Syst. Man Cybern. B 37(1), 176–189 (2007). https://doi.org/10.1109/TSMCB.2006.875872
Wu, Y., Zhang, Z., Kou, G., Zhang, H., Chao, X., Li, C.C., Herrera, F.: Distributed linguistic representations in decision making: taxonomy, key elements and applications, and challenges in data science and explainable artificial intelligence. Inf. Fusion 65, 165–178 (2021). https://doi.org/10.1016/j.inffus.2020.08.018
Zhang, Z., Kou, X., Yu, W., Gao, Y.: Consistency improvement for fuzzy preference relations with self-confidence: an application in two-sided matching decision making. J. Oper. Res. Soc. 72(8), 1914–1927 (2021). https://doi.org/10.1080/01605682.2020.1748529
Liu, W., Zhang, H., Chen, X., Yu, S.: Managing consensus and self-confidence in multiplicative preference relations in group decision making. Knowl. Based Syst. 162, 62–73 (2018). https://doi.org/10.1016/j.knosys.2018.05.031
Xiao, J., Wang, X., Zhang, H.: Managing personalized individual semantics and consensus in linguistic distribution large-scale group decision making. Inf. Fusion 53, 20–34 (2020). https://doi.org/10.1016/j.inffus.2019.06.003
Wu, J., Chiclana, F.: A social network analysis trust—consensus based approach to group decision-making problems with interval-valued fuzzy reciprocal preference relations. Knowl. Based Syst. 59, 97–107 (2014). https://doi.org/10.1016/j.knosys.2014.01.017
Hsu, W.C.J., Liou, J.J., Lo, H.W.: A group decision-making approach for exploring trends in the development of the healthcare industry in Taiwan. Decis. Support Syst. 141, 113447 (2021). https://doi.org/10.1016/j.dss.2020.113447
Liu, J., Kadziński, M., Liao, X., Mao, X.: Data-driven preference learning methods for value-driven multiple criteria sorting with interacting criteria. INFORMS J. Comput. 33(2), 586–606 (2021). https://doi.org/10.1287/ijoc.2020.0977
Chao, X., Kou, G., Peng, Y., Herrera-Viedma, E., Herrera, F.: An efficient consensus reaching framework for large-scale social network group decision making and its application in urban resettlement. Inf. Sci. 575, 499–527 (2021). https://doi.org/10.1016/j.ins.2021.06.047
Zhu, G.J., Cai, C.G., Pan, B., Wang, P.: A multi-agent linguistic-style large group decision-making method considering public expectations. Int. J. Comput. Int. Syst. 14(1), 1–13 (2021). https://doi.org/10.1007/s44196-021-00037-6
Xiong, K., Dong, Y., Zhao, S.: A clustering method with historical data to support large-scale consensus-reaching process in group decision-making. Int. J. Comput. Int. Syst. 15(1), 1–21 (2022). https://doi.org/10.1007/s44196-022-00072-x
Wang, H., Liu, Y., Liu, F., Lin, J.: Multiple attribute decision-making method based upon intuitionistic fuzzy partitioned dual maclaurin symmetric mean operators. Int. J. Comput. Int. Syst. 14(1), 1–20 (2021). https://doi.org/10.1007/s44196-021-00002-3
Liu, Y., Rodriguez, R.M., Qin, J., Martinez, L.: Type-2 fuzzy envelope of extended hesitant fuzzy linguistic term set: application to multi-criteria group decision making. Comput. Ind. Eng. (2022). https://doi.org/10.1016/j.cie.2022.108208
Rodríguez, R.M., Labella, Á., Nunez-Cacho, P., Molina-Moreno, V., Martínez, L.: A comprehensive minimum cost consensus model for large scale group decision making for circular economy measurement. Technol. Forecast. Soc. Change 175, 121391 (2022). https://doi.org/10.1016/j.techfore.2021.121391
Funding
This work was supported by the National Natural Science Foundation of China (Grant Number [71874023, 72274132]).
Author information
Authors and Affiliations
Contributions
Conceptualization, methodology, writing—original draft, software, and data curation were performed by LJ. Conceptualization, methodology and writing—review, funding acquisition, and editing were performed by XC.
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no competing interests to declare that are relevant to the content of this article.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jing, L., Chao, X. Mining Personalized Individual Semantics of Self-confidence Participants in Linguistic Group Decision-Making. Int J Comput Intell Syst 15, 82 (2022). https://doi.org/10.1007/s44196-022-00136-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-022-00136-y