
Abstract
Gestational diabetes mellitus (GDM) is the most common disease in pregnancy and can cause a series of maternal and infant complications. A new study shows that GDM affects one in six deliveries. Identifying and screening for risk factors for GDM can effectively help intervene and improve the condition of women and their children. Therefore, the aim of this paper is to determine the risk factors for GDM and to use the ensemble learning method to judge whether pregnant women suffer from GDM more accurately. First, this study involves six commonly used machine learning algorithms to analyze the GDM data from the Tianchi competition, selects the risk factors according to the ranking of each model, and uses the Shapley additive interpreter method to determine the importance of the selected risk factors. Second, the combined weighting method was used to analyze and evaluate the risk factors for gestational diabetes and to determine a group of important factors. Lastly, a new integrated light gradient-boosting machine-extreme gradient boosting-gradient boosting tree (LightGBM-Xgboost-GB) learning method is proposed to determine whether pregnant women have gestational diabetes mellitus. We used the gray correlation degree to calculate the weight and used a genetic algorithm for optimization. In terms of prediction accuracy and comprehensive effects, the final model is better than the commonly used machine learning model. The ensemble learning model is comprehensive and flexible and can be used to determine whether pregnant women suffer from GDM. In addition to disease prediction, the model can also be extended for use to many other areas of research.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
This research was motivated by a maternal and child health care institution that is engaged in providing prenatal care to pregnant women. The agency found that with the opening up of the second-child policy and an increasing number of older pregnant women coupled with substantial improvements in standards of living and continuous improvement of the dietary structure, the incidence of gestational diabetes is increasing every year. Therefore, the medical team at this institution must detect and determine the risk of gestational diabetes in pregnant women as soon as possible and intervene early to change the pregnancy outcome. For the sake of confidentiality, the institution is referred to using the fictitious name Maternal and Child Health Hospital (MCH).
According to research surveys, in 2019, the total number of births in China was 14.65 million, and the annual birth rate was 1.048% [1]. China’s fertility rate is significantly lower than it was in the past. It is currently not only well below the global average of 2.45% but also below the level of 1.67% in developed countries [2]. With the opening up of the second-child policy and an increasing number of older pregnant women, coupled with substantial improvements in standards of living and continuous improvement of the dietary structure, the incidence of gestational diabetes is increasing year by year.
Gestational diabetes mellitus (GDM), which is defined as carbohydrate intolerance of a variable degree with onset or recognition during pregnancy, has recently been identified as a potential risk factor for type II diabetes mellitus (T2DM) [3,4,5]. Compared with normal women, women diagnosed with GDM are 10 times more likely to develop type 2 diabetes, 2.5 times more likely to have ischemic heart disease, and twice as likely to have hypertension during their later years [6, 7]. According to International Diabetes Federation (IDF) statistics, in 2019, one in six births was affected by GDM [8, 9]. A total of 15.8% (20.4 million) of live births were by women with hyperglycemia in pregnancy (HIP). China now has 116.4 million people with diabetes (excluding Hong Kong, Macao and Taiwan), the highest number in the world [8]. The development of GDM has been very severe, and GDM will not only harm pregnant women but also newborns.
GDM can cause severe complications such as excessive amniotic fluid, ketoacidosis, preeclampsia, spontaneous abortion, stillbirth, and secondary infection in pregnant women as well as fetal malformation hypoglycemia, hyperbilirubinemia, and hypocalcemia [3]. Women who develop gestational diabetes are at higher risk of developing type 2 diabetes later in life. Children exposed in utero are at higher risk of macrosomia at birth, or of being significantly larger than average, and of having obesity and type 2 diabetes in childhood and adulthood. The impact of diabetes on pregnant women can be greatly reduced if the risk can be predicted during the first trimester and timely interventions are made [10]. It is very important to identify the risk factors for GDM to predict the risk of pregnant women developing and suffering from gestational diabetes accurately; moreover, timely control measures can effectively improve maternal and infant outcomes. Therefore, the motivation of this study is to support MCH in identifying GDM risk factors among pregnant women seeking prenatal care and to predict whether the mother will develop gestational diabetes accurately.
In research on the pathogenic factors associated with gestational diabetes, researchers found that the pathogenesis of gestational diabetes is complicated and caused by many factors. The classic explanation of the pathogenic mechanism is that pregnant women have an increased need for glucose during pregnancy, but insulin resistance and insulin secretion are relatively insufficient. Rissanen [11] et al. study of insulin secretion levels in GDM and patients with type 2 diabetes found that the deletion of individual gene loci can trigger GDM and type 2 diabetes. Bao [12] et al. proposed that body mass index (BMI) values are closely related to pregnant women suffering from gestational diabetes and found that GDM patients have a significant increase in the incidence of T2DM in the future. Minooee [13] et al. found that factors such as prepregnancy BMI, age, family history of GDM, weight gain during pregnancy and other factors were risk factors for the occurrence of GDM. Research by Li and Hu et al. found that advanced age, overweight prepregnancy BMI, history of diabetes mellitus in first-degree relatives and a positive rate of thyroid peroxidase antibody are associated with an increased risk of GDM [14]. Kuzmicki [15] et al. found that low-grade inflammation can affect the pathogenesis of GDM. A study by Rezvan [16] et al. showed that the low plasma adhesin concentration in the patient's body is related to the blood glucose regulation ability of hemoglobin A1c (HbA1c). Shaat [17] et al. showed that polymorphisms of certain alleles affect the disease. There are many factors that affect diabetes, and it is necessary to rank the importance of these factors because it is possible to determine whether a pregnant woman has gestational diabetes according to the size of the top factors. Early diagnosis of pregnant women with disease factors, improved GDM screening, and early intervention and management can improve pregnancy outcomes and improve the health status of newborns.
Many studies have been performed on disease prediction, such as diagnosis, prediction, classification, and therapy. Recent research shows that various machine learning algorithms have been used for disease identification and prediction. They have resulted in remarkable efficiency and improvements in profound conventional and machine learning [18, 19]. For example, Wu used a tree model and neural network model algorithm for modeling and data mining analysis for maternal physical examination indicators [10, 20]. Saloni used the idea of voting integration to predict diabetes mellitus [21]. Wang used the basic idea of stacking ensemble learning and then adopted three basic models, namely, random forests, Xgboost and CatBoost, as the basic learning device and constructed a novel integrated model for predicting and analyzing gestational diabetes mellitus [22].
Our main contribution is to use a new integrated LightGBM-Xgboost-GB ensemble learning method for maternal and child health care providers to analyze the risk factors for GDM. This method uses a group of the most important influencing factors selected through learning algorithms to identify GDM risk factors accurately and to predict the possibility of gestational diabetes precisely. In response to the research problem, the proposed model improves the existing methodology. This model provides a comprehensive, practical and flexible method for use by medical staff during early prenatal care and disease prediction. Therefore, our model was suggested to be very useful for medical staff to assess pregnant women with gestational diabetes.
The paper is organized as follows. In Sect. 2, we will review some basic knowledge. Section 3 lays the theoretical foundation for the proposed method. Section 4 describes a new integrated LightGBM-Xgboost-GB method. In Sect. 5, we first select and analyze the influencing factors, then analyze the acquired data by applying the model, and summarize the calculation results to verify the model. We then provide the study conclusions in Sect. 6
2 Preliminary
2.1 Machine Learning Methods
Disease prediction models are closely linked to epidemiological research and clinical practice. In establishing disease prediction models, the risk factors for disease onset are linked to the incidence of disease. Some prediction model studies divide the population into low-risk, medium-risk and high-risk groups according to the probability of disease to provide a basis and direction for personalized diagnosis and treatment and comprehensive intervention in clinical practice. At present, big data management is not only widely used in the public domain but has also provided many studies on the association between big data and disease prediction and uses deep learning, transfer learning and other algorithms to establish the association between pathogenic factors and disease probability. With improvements in the parallel computing ability of big data and the in-depth study of machine learning models, research using machine learning models to improve the accuracy of disease prediction is gradually deepening. With the improvement of data dimensions, making full use of multisource and multidimensional data has become a trend in disease prediction.
In a study on gestational diabetes prediction models at home and abroad, Anna Patrick Nomb [20] and other researchers used the multivariate logistic model in 2018 to model the probability of GDM risk and concluded that a family history of stillbirth and type 2 diabetes increased the prevalence of GDM. Wu [10] et al. established a prediction model for gestational diabetes mellitus in 2017 by using a decision tree algorithm. According to the classification and regression trees (CART) algorithm, we obtained a set of rule characteristics for the GDM high-risk group. In 2018, Zhang [23] made the extreme gradient boosting (Xgboost) algorithm an accurate prediction model for the pathogenic factors of type two diabetes mellitus. Wang [24] and other researchers studied the application of the deep learning model for predicting the risk of type two diabetes in 2017. With the development of machine learning and big data, using machine learning algorithms to design diagnosis-aided decision-making systems provides a prerequisite to meeting this objective. Therefore, in recent years, many researchers have used machine learning algorithms to build disease prediction reasoning models to assist doctors in diagnosis.
A decision tree (DT) is a basic classifier for which the two steps are learning and classification [25]. As a machine learning method, decision trees create an effective model for data classification and regression [26, 27]. Random forest (RF) is an algorithm developed by Breimen and Cutler in 2001. It runs by constructing multiple decision trees while training and outputting the class. It has improved performance over single decision trees, and it is much more efficient than traditional machine learning techniques, especially when the dataset is large [28, 29]. The gradient boosting tree (GB) is a combination of regression and classification tree models. GB improves prediction power results by progressively improving estimations. Additionally, GB employs a nonlinear regression procedure that helps improve the accuracy of the trees [30, 31]. Xgboost implements a gradient boosting framework based on decision trees, which was proposed by Chen2016 [32]. The library of Xgboost is designed to be highly efficient, flexible and portable [33]. The light gradient boosting machine (LightGBM) algorithm is an efficient distributed gradient boosting tree algorithm [34, 35]. Due to its fast speed, low memory consumption and relatively high accuracy, it is widely used in classification and regression problems [36]. A multilayer perceptron (MLP), also known as an artificial neural network (ANN), is a forward structure of artificial neural networks. MLP is one of the most popular networks and possesses a powerful ability to solve nonlinear problems and is highly efficient at calculation [37,38,39].
These models have become commonly used machine learning algorithms for predicting gestational diabetes mellitus in recent years. In addition, the selection of important factors in the follow-up research and the base model of the integration model are from this group of common models.
2.2 Model Fusion Based on Ensemble Learning
In terms of gestational diabetes prediction, research on gestational diabetes was conducted on a single model prediction until 2019. Later, Yu [40] applied an ensemble learning algorithm in the diagnosis and prediction of gestational diabetes mellitus for the first time by using a multi-model fusion method based on the cascading classifier method. This paper is focused on the use of three learning algorithms to predict the prevalence of gestational diabetes mellitus. These three models are capable of handling small sample sizes, high missing values, and classification features. On this basis, while aiming at the optimization problem of model evaluation index and threshold selection, we are the first to propose that applying the gray correlation method can be used to calculate the weight value to integrate the three learning models, optimize the prediction model and improve the success rate of diagnosis, which provides a solution for future research on disease prediction models with poor data quality.
The ensemble learning algorithm is good at addressing defective data by building multiple classifiers to prevent over fitting and improving the performance of the prediction model. In addition to its stability and generalization ability, the ensemble learning model performs better than traditional models, and the final prediction accuracy is also relatively high. At present, some integrated learning models are applied in other disease predictions, and the effect is remarkable. Therefore, it is possible to use an integrated learning algorithm to study the relationship between various indicators and the prediction model of the gestational diabetes mellitus incidence rate.
3 Theoretical Foundation of the Main Model
3.1 Ensemble Learning Methods
In traditional machine learning algorithms, since the modeling process of each single prediction model and the method of data preprocessing are different, the prediction results of each single prediction model are different, and the prediction accuracy is also different [28]. A single learner may not achieve very good results, but if the results of multiple weak learners are combined, the performance of the model may be improved to some extent. Therefore, ensemble learning methods combine a series of different individual learners through a specific strategy to achieve better learning results. Ensemble learning methods are divided into stacking, blending and voting, which are powerful prediction techniques since they can increase the diversity of algorithms and reduce generalization errors to improve the accuracy of the results.
Ensemble learning methods have two basic elements: one is that the correlation between single models should be as small as possible, and the other is that the performance between single models is not too different. In practice, it is often the case that a single model with a low correlation coefficient and good performance can significantly improve the final prediction result. In the research for this article, the overall model was constructed using the idea of the blending ensemble method, and the equation is as follows:
where \(n\) is the number of learners and \(w_{i}\) is the weight of individual learner \(g_{i} (x)\), usually required \(~~w_{i} \ge 0,\sum\nolimits_{{i\, = \,1}}^{n} {w_{i} = 1}\). When \(w_{i} = \frac{1}{n}\), the weighted average becomes a simple average. In fact, the weighted average method can be regarded as the basic starting point of ensemble learning research. For a given base learner, different ensemble learning methods can be regarded as different ways to determine the weight of the base learner in the weighted average method.
3.2 Traditional Gray Relational Analysis
Gray system theory is a relational analysis method for system analysis. By comparing the shapes of several curves, it is concluded that the more similar the shapes are, the closer the relation they have [41]. Gray relational analysis (GRA) is a very important part of gray system theory; it uses the similarity and nearness of the sequences to determine the relations among the factors of the system. The original gray relational analysis model was constructed by Deng Julong [42], and Liu Sifeng developed the classic gray absolute degree of gray incidence [43, 44]. Gray relational analysis is useful for managing poor, incomplete, and uncertain information, so it has been widely used in decision-making and evaluation problems.
Because the extent of each model that contributes to the construction of the ensemble model is different, it was better to estimate the relative weight for each model. In model fusion, theoretically, the higher the prediction accuracy of a single model is, the greater its contribution to the integrated model should be. If a simple weighted average is adopted, the contribution of different models to the integration model is not taken into account. The higher the relative weight was, the greater the model contribution to the ensemble model construction. In fact, GRA is a very useful technique for preference analysis; it effectively measures the relationships between one reference sequence and the other comparative sequences. We were motivated to use GRA to estimate the relative weight for each model.
The weighting steps based on gray relational analysis are as follows:
-
(a)
Determine the analysis sequence. We use the true value of the data as the reference sequence (also known as the mother sequence) as \(Y = Y(k)\left| {k = 1,2, \ldots n;} \right.\) the predicted value of the model as the comparison sequence (also known as the subsequence) is \(X_{i} = X_{i} (k)\left| {k = 1,2, \ldots n,\begin{array}{*{20}c} {} \\ \end{array} i = 1,2, \ldots ,m;} \right.\) where \(k\) is the number of samples and \(i\) is the number of models.
-
(b)
Nondimensionalization. Since the parent column and the child column are 0, 1 label data, no dimensionless processing is required.
-
(c)
Calculate the correlation coefficient. The formula is as follows:
$$\xi_{i} (k) = \frac{{\mathop {\min }\limits_{i} \mathop {\min }\limits_{k} \left| {x_{0} (k) - x_{i} (k)} \right| + \rho \times \mathop {\max }\limits_{i} \mathop {\max }\limits_{k} \left| {x_{0} (k) - x_{i} (k)} \right|}}{{\left| {x_{0} (k) - x_{i} (k)} \right| + \rho \times \mathop {\max }\limits_{i} \mathop {\max }\limits_{k} \left| {x_{0} (k) - x_{i} (k)} \right|}}$$(2) -
(d)
\(\rho \in (0,\infty )\) is called the resolution coefficient. The smaller \(\uprho\) is, the greater the resolution. Generally, the value interval of \(\rho\) is (0, 1), and the specific value depends on the situation. When \(\rho \le 0.5463\), the resolution is best, usually \(\rho = 0.5\).
-
(e)
Calculate the degree of association. The correlation coefficient at each time is concentrated into one value; that is, the average value is calculated as the quantitative expression of the correlation degree between the comparison series and the reference series. The correlation degree formula is
$$r_{i} = \frac{1}{N}\sum\limits_{k = 1}^{N} {\xi_{i} (k)} ,k = 1,2,...,N$$(3) -
(f)
The correlation between the comparison series and the reference series can be regarded as the contribution of a single prediction model to the prediction accuracy. Then, calculating the proportion of the single model's correlation degree in the total of all the model's correlation degrees is the contribution rate of the single model to the integrated model, that is, the weight of the integrated model. The weight coefficient of the integrated model can be expressed as:
$$w_{i} \, = \,\frac{{r_{i} }}{{\mathop \sum \nolimits_{i\, = \,1}^{n} r_{i} }}$$(4)
Then, the expression of the ensemble model is changed to:
where, \(\frac{{r_{i} }}{{\mathop \sum \nolimits_{i = 1}^{n} r_{i} }} \ge 0,\mathop {\begin{array}{*{20}c} {} \\ \end{array} \sum }\limits_{i\, = \,1}^{n} \frac{{r_{i} }}{{\mathop \sum \nolimits_{i\, = \,1}^{n} r_{i} }}\, = \,1\).
3.3 Genetic Algorithm
The gray correlation analysis obtains the relative weight of each model, which improves the overall performance of the integrated model and can significantly overcome the defects of a single model, which is due to the large hypothesis space of the learning task, resulting in poor generalization performance and falling into local minima. However, the prediction performance of the integrated model still has room for improvement.
The genetic algorithm (GA) was developed using the evolutionary theory of biology and genetics. It is a type of self-organizing and adaptive artificial intelligence technology that simulates the evolution process and mechanism of natural organisms to solve problems. The GA is a random search algorithm that can better improve the optimization of discrete data [45]. Goldberg summarized a unified and most basic genetic algorithm that uses a selection operator, crossover operator and mutation operator [45]. The GA has three unique characteristics: adaptability and versatility, implicit parallelism, and scalability.
Our goal is to minimize the relative error between the predicted value and the real value of a single prediction model and the relative error between the predicted value and the real value of an integrated model. That is, the average relative error between the overall predicted value and the real value is the minimum. Therefore, we propose an ensemble learning model for target optimization based on genetic calculations:
where \(i = 1,2, \ldots ,n\) is the number of samples, \(j = 1,2, \ldots ,N\) is the number of models, \(g_{j}^{i} (x)\) is the predicted value of a single model at the sample point, \(G^{i} (x)\) is the predicted value of the ensemble model at the sample point, and \(y_{i}\) is the true value of the sample point.
4 Model Development for GDM Prediction
4.1 Problem Description of GDM
Maternal and child health care is related not only to the health of mothers and babies but also to the health status of the birth population and to the prosperity of the country and the future of the nation. MCH medical staff are committed to basic medical services that are closely related to the health of women and children. Gestational diabetes is a common phenomenon in female pregnancy, but it has very negative effects on both women and children, and it must be detected and controlled early. The pathogenesis of gestational diabetes is complicated and caused by a variety of factors. Among them, a classic explanation of the pathogenic mechanism is that pregnant women have an increased need for glucose during pregnancy, but insulin resistance and insulin secretion are relatively insufficient. Therefore, the medical staff of MCH urgently need to know the risk factors for gestational diabetes and to focus on detection and control to avoid adverse pregnancy outcomes.
The identification of key factors has important clinical significance in GDM risk assessment. Most previous studies have used prospective controlled cases to study risk factors for gestational diabetes. However, case studies may have some particularities, and there may be no association between cases. In this study, we solved this dilemma. We studied a set of the most commonly used machine learning algorithms to predict gestational diabetes. After comparing their prediction accuracy, we used various classifiers and Shapley additive interpreters to identify a set of important risk factors to obtain a more objective and reasonable set of routine features for the GDM population. We analyzed and explained the impact of this group of important factors on the development of gestational diabetes. Then, we used ensemble learning methods in machine learning to build ensemble models and to train predictions. The result of the ensemble learning model is better than that of each individual machine learning model.
4.2 The Ensemble Learning Model
The ensemble learning model may bring benefits in three parts. First, from a statistical perspective, by considering several models and averaging their predictions, we can reduce the risk of choosing a very poor model; second, the integration of multiple models brings the final result closer to the true value; finally, from the perspective of representation, the hypothesis space can be expanded, and it is possible to learn a better approximation.
Ensemble learning methods have two basic elements: one is that the correlation between single models should be as small as possible, and the other is that the performance between single models is not too different. In practice, it is often the case that a single model with a low correlation coefficient and good performance can significantly improve the final prediction result. The GB model is a combination of regression and classification tree models. Xgboost implements a gradient boosting framework based on decision trees. The LightGBM algorithm is an efficient distributed gradient boosting tree algorithm. In addition, these three methods are based on the improved tree model. Therefore, the three classes of algorithms satisfy the diversity, correlation, and performance requirements.
Therefore, we chose GB, Xgboost, and LightGBM as the base learners and propose a new integrated LightGBM-Xgboost-GB method, which uses gray correlation to calculate weights and genetic algorithms to optimize them. Therefore, the n of the final formula for the model is 3.
The specific steps are as follows:
Step 1. Data preprocessing: the original data are preprocessed and divided into a training set and a testing set.
Step 2. First, a single model is trained with the training set, and then the trained model is used to predict the predicted value of the sample set. Second, the gray correlation coefficient between the predicted value of the \(j{ - }th\) prediction model and the observed value of the \(i{ - }th\) predicted sample point is calculated. Lastly, the gray correlation degree between the predicted value of the model and the observed value is calculated, and the weight coefficient is calculated.
Step 3. Determine the fitness function. Calculate the fitness of each individual and determine whether it meets the optimization criteria. Calculate the average relative error between the predicted value and the true value, so the fitness function is:
If it is satisfied, output the best individual and the optimal solution represented by it, and end the algorithm; if not, go to the next step.
Step 4. Initialize the parameters of the genetic algorithm, such as the population size, crossover probability, and mutation probability. Parameter optimizations: first, decode the chromosomes in the population; then, calculate the fitness value of each generation of the population and perform the survival of the fittest. Lastly, determine whether the population performance satisfies the maximum number of genetics, and if so, the optimal parameter is output; otherwise, according to the genetic strategy, the selection, crossover and mutation operations are used to obtain the offspring.
Step 5. Result judgment: if the objective function is satisfied, then the optimizations are finished. Otherwise, repeat step (3).
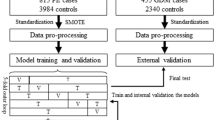
Step 6. Input the test sample to obtain the best prediction result. The detailed process is shown in (Fig. 1).

Calculation steps of the ensemble model
5 Applying the LightGBM-Xgboost-GB Model to Objective Data
5.1 Data Collection
5.1.1 Research Data
The data came from the Tianchi precision medicine competition on artificial intelligence-assisted genetic risk prediction of diabetes, which was held by Aliyun United Qingwutong Health Technology Co. LTD. The first line of the data is the field name, and each line represents an individual. Some field names have been identified. The data contain a total of 85 fields and 1200 pieces of data. The data do not include the time of physical examination and relevant geographic information. Some field contents are missing for some individuals, among which the first column is the individual ID number. The last column of the data is a label column, with 0 indicating no disease and 1 indicating disease, both of which require a prediction of gestational diabetes. (https://tianchi.aliyun.com/).
Among the 83 original features, only 2 features have no missing values, and the remaining 81 features are missing to varying degrees. The general method for addressing missing values is to delete the missing features, but it cannot be applied in this sample. The reason is that more than 97% of the features in this sample are missing, which indicates that the missing values here have a specific meaning and should be regarded as information rather than noise. Therefore, we use the mean to fill it in, since the mean will not affect the overall situation but will also solve the problem of missing values.
5.1.2 Basic Characteristics
The data contain a total of 85 fields and 1,200 pieces of data. “Id” is the patient code, and “label” is the classification label. Among the 83 variables, there were 55 genetic variables, all of which were discrete variables, and 28 conventional variables. Of the 28 regular variables, there are 3 discrete variables and 25 continuous variables. Discrete variables are single nucleotide polymorphism (SNP) gene site information. SNP genes are widely present in the existing human genome library, and the average probability is 1/500–1000 base pairs. Amniocentesis during pregnancy extracts the baby's deoxyribonucleic acid (DNA) and SNP corresponding gene sites for detection. The physiological index of a continuous variable indicates that TG represents triglyceride, which is an index to measure hyperlipidemia; RBP4 represents retinol binding protein-4. As an adipocytokine, RBP4 participates in obesity and insulin resistance and affects glucose and lipid metabolism in pregnant women; the BMI index is often used to study whether the patient is obese or not. In China, 24 and 28 are regarded as the thresholds of overweight and obesity; HsCRP represents high-sensitivity C-reactive protein. It is a plasma protein produced by the liver and is primarily used as a marker of inflammation. White blood cells (WBCs) are a common indicator of inflammation during routine blood examination. Apolipoproteins a1 (ApoA1) and b (ApoB) are apolipoproteins that are of great value in the diagnosis of diabetes mellitus complicated with lipid metabolism disorders. HDLC is high-density lipoprotein cholesterol, and LDLC is low-density lipoprotein cholesterol. Alanine aminotransferase (ALT) and aspartate aminotransferase (AST) are two types of aminotransferase. They are essential catalysts for human metabolism. They are the two clinical indicators of liver function testing and play a specific role in the occurrence and development of gestational diabetes mellitus. Cr is creatinine, and CHO is total cholesterol, which are routine physical examination indices.
We analyzed and compared the basic characteristics of 25 general variables, and the results are shown in (Table 1). Continuous variables are expressed as the mean ± standard deviation (SD), and the characteristic differences between the GMD group and the non-GMD group were tested by using the T test. Compared with patients who did not have gestational diabetes, gestational diabetes patients had a higher age, gestational age, prepregnancy weight, prepregnancy BMI, diastolic blood pressure, systolic blood pressure, VAR00007, wbc, ALT, CHO, TG, ApoB, and hsCRP. By contrast, a higher RBP4, BUN, Cr, HDLC, and LDLC were more common in those without gestational diabetes.
5.2 Collection of Important Variables
5.2.1 Comparison of the Individual Learning Model
We used the accuracy, area under the receiver operating characteristic curve (AUC), precision, recall and f1-score to evaluate the performance of the individual models.
The accuracy is the percentage of the data sample that predicts the correct category.
The accuracy reflects the correct ability of the model's category prediction, including two situations: a positive example is predicted as a positive example, and a negative example is predicted as a negative example. When we pay the same attention to category 1 and category 0 (the category is symmetric), the accuracy is a good evaluation index.
The area under the receiver operating characteristic curve (AUC); as the name implies, the AUC value is the area under the receiver operating characteristic curve. Typically, AUC values range from 0.5 to 1.0, and a larger AUC represents a better performance.
The precision rate is the proportion of the actual positive examples in the sample predicted to be positive examples.
The precision rate reflects the prediction ability of the model on the positive case, which focuses on the positive case. If we pay attention to the prediction accuracy of the positive case, the precision rate is a good indicator.
The recall rate is the proportion of the predicted positive sample in the real positive sample.
The recall rate reflects the coverage of the model in the correct prediction of positive examples, which is a little like “no fish is allowed to escape the net”. If we focus on the comprehensiveness of the prediction of positive samples, the recall rate is a good indicator. The recall rate is not affected by the sample proportion imbalance because it only focuses on the prediction of the positive sample.
The F1-score is a model evaluation index that takes into account both the accuracy and recall rate, which is defined as
When there is no special requirement for the precision or recall rate, it is necessary to consider both the precision rate and recall rate when evaluating a model, and the F1-score can be considered.
Here, the data sample can be binarily classified into positive and negative categories. Then, there are 4 combinations of the predicted results and the real tags TP, FP, FN, and TN, as shown in (Fig. 2).

The confusion matrix
Table 2 shows the comparison results for individual machine learning algorithms. As indicated by the output results, the Xgboost model has high scores in terms of accuracy, AUC value, recall rate, recall accuracy and f1-score, making it the best prediction model. When we pay the same attention to category 1 and category 0 (the category is symmetric), the accuracy is a good evaluation index. When there is no special requirement for the precision or recall rate, it is necessary to consider both the precision rate and recall rate when evaluating a model, and the f1-score can be considered. Thus, we use the accuracy and the F1-score as the main evaluation indicators of the model, as shown in (Fig. 3), for a comparison of the accuracy and the F1-score of each model.

Comparison of the accuracy and the F1-score of each model
5.2.2 Risk Factor Selection of GDM
Table 3 shows the top 20 variables in the ranking of importance for each algorithm variable. Variable VAR00007 appears many times at the top of the list, in addition to other factors, such as SNP34, TG, and SNP37. Pregestational weight and pregestational BMI were listed as important influencing factors of GDM in most models, which may reflect the relationship between obesity and GDM. Systolic blood pressure and diastolic blood pressure were also listed as important factors in GDM in most models, indicating that hypertension has a specific influence on the development of GDM.
We use the principle underlying the Shapley value method and use the ranking value of different factors in different models as the contribution value of a factor in different models, and then the weighting factor is one-sixth. The important factors from each model were re-ranked, and the final ranking results of importance were obtained, as shown in (Table 3). The risk factors for the GDM risk score include age, genetic factors, prepregnancy body mass index, number of pregnancies, blood pressure and other factors, which are also listed as important variables in our study.
To study the importance of the risk factor variables in gestational diabetes, we projected twenty important variables that were selected by the machine learning algorithm onto a four-quadrant matrix. Figure 4 shows the quadrants of four important variables based on Shapley’s ranking of the importance of variables (higher rankings are at the bottom) and comprehensive weighting (smaller weights are on the left). The ranking of the Shapley method on the importance of variables is shown in (Table 4). The comprehensive weight is shown in (Table 5) (the comprehensive weight obtained by the expert scoring method, where 0 is unimportant, 5 is generally important and 10 is very important). The horizontal line dividing the upper and lower quadrants is based on the median value of Shapley's ranking, while the vertical line is the median value of the weight. The lower right quadrant is the quadrant with the highest rankings and highest weights. The factors in this quadrant are very important for the development of gestational diabetes. By contrast, the upper left quadrant contains factors with low rankings and low weights. Comparatively speaking, these factors are related to the development of gestational diabetes. The remaining two quadrants correspond to abnormal points with high ranking and low weight or low ranking and high weight.

Quadrant distribution of 20 variables
5.2.3 Attractive Variables (First Quadrant)
We found that ApoA1, ApoB, and the number of pregnancies were present in the first quadrant with high weight and low ranking. Recent studies have shown that ApoA1 and ApoB are apolipoproteins. Apolipoproteins can play a role in stabilizing the structure of lipoproteins by binding and transporting lipids, regulating the activities of key lipoprotein enzymes and participating in the key link of lipoprotein metabolism. The combined detection of apolipoprotein ApoA1 and ApoB is of great value in diagnosing diabetes mellitus complicated with lipid metabolism disorders and helps guide the treatment and prognosis of diabetes. Studies have also shown that pregnant women have a greater risk of having a higher prepregnancy BMI, and the interaction caused by the parity of pregnant women cannot be ignored. Body mass index (BMI) and parity are the main risk factors for pregnant women to develop gestational diabetes [46]. Second, overweight or obesity is a risk factor for gestational diabetes [47]. In addition, parity can increase the impact of overweight and obesity on gestational diabetes. Pregnant women with more recent last pregnancies will have relatively weak physical function and a relatively low metabolic rate, thus impairing glucose tolerance. The incidence of diabetes and other diseases is relatively high. The predictability of these three factors on machine learning algorithms may not be as good as other factors, but their impact on gestational diabetes has received more attention from scholars in recent years.
5.2.4 Least Preferred Variables (Second Quadrant)
Women who are obese are not choosing a good time to become pregnant. Cholesterol is a common clinical lipid metabolism hormone that can reflect abnormal lipid metabolism. If the body’s lipid metabolism is disordered, it will lead to abnormal glucose metabolism. The reason is that the serum cholesterol level may cause the progression of insulin resistance. RBP4 is a new type of adipocytokine and a type of secreted retinol binding protein that transports retinol through the liver and blood circulation. Studies have shown that improving serum RBP4 levels is essential for improving insulin sensitivity and maintaining blood sugar stability. HDLC can control glucose homeostasis through insulin secretion and direct glucose uptake by amp-activated protein kinase in the muscles and possibly enhance insulin sensitivity. Studies have shown that the higher the HDLC is, the lower the risk of gestational diabetes. Through a literature search, we found that ALT, AST, diastolic blood pressure and systolic blood pressure also play a role in the development of gestational diabetes (for details about the literature, please refer to Appendix Tables 6, 7).
5.2.5 Potential Variables (Third Quadrant)
There was only one factor in the third quadrant, Cr (creatinine). Previous studies have shown that Cr is susceptible to interference from external stimuli. As long as the kidney has a strong compensatory function, the Cr level can be maintained in the normal range. Therefore, this indicator can only be used as an auxiliary indicator and has little significance for early diagnosis. However, machine learning algorithm prediction research has shown that Cr has important predictive value in predicting gestational diabetes [48]. In addition, recent studies by scholars have shown and believed that the combined detection of serum albumin, beta-2-microglobulin, non-esterified fatty acids and Cr, four indicators, has a significant effect on GDM disease in addition to high diagnostic efficiency, especially for the early diagnosis of disease, dynamic monitoring of index factor expression differences and the sustainable monitoring of disease progression.
5.2.6 Important Variables (Fourth Quadrant)
Factors such as the prepregnancy BMI, TG, age, VAR00007, hsCRP, wbc, SNP34 and SNP37 belong to the fourth quadrant, which is a group of factors with higher weight and higher ranking. From the data, we found that the higher the value of the factors, the greater the risk of disease, as shown in (Fig. 5). Through the study of previous research literature, we have indeed found that these factors play an important role in the development of gestational diabetes (for details about the literature, please refer to Appendix Tables 6, 7). In other words, obese pregnant women, older pregnant women and pregnant women with lower physical fitness have a higher risk of gestational diabetes.

a Monotonicity of Prepregnancy, TG, Age and VAR00007. b Monotonicity of hsCRP, wbc, SNP34 and SNP37
Therefore, the variables VAR00007, SNP34, TG, age, SNP37, wbc, hsCRP, and prepregnancy BMI were the factors that had the greatest impact on pregnant women suffering from gestational diabetes. In addition, Cr is a latent variable that requires more attention. Although scholars have recently believed that ApoA1, ApoB and the number of pregnancies also have an important impact on gestational diabetes, their importance is far less than that of VAR00007, SNP34, TG and other factors. When SNP34 and SNP37 were 2, the incidence of GDM was relatively high, and the higher the VAR00007 was, the more prone to gestational diabetes the woman was; through reading the literature, we suspect that VAR00007 is an insulin resistance index.
5.3 Analysis of Predicted Results
5.3.1 Result of the Ensemble LightGBM-Xgboost-GB Model
We calculated the gray correlation coefficient between the predicted value of the \(j{ - }th\) prediction model and the observed value of the \(i{ - }th\) predicted sample point, thereby calculating the gray correlation degree between the predicted value of the model and the observed value.
The correlations between the predicted value and the true value of the LightGBM, Xgboost, and GB models calculated by gray correlation analysis are \(r_{1} = 0.631407\), \(r_{2} = 0.631814\), and \(r_{3} = 0.631407\), respectively. In using the normalized value of the gray correlation degree as the coefficient value of the combined model,\(w_{1} = 0.33262\), \(w_{2} = 0.33476\), and \(w_{3} = 0.33262\) are obtained. Then, a genetic algorithm is used to optimize the integrated model coefficient parameters, and the final weight values are \(w_{1} = 0.2130\), \(w_{2} = 0.5320\) and \(w_{3} = 0.2550\).
After the combined model coefficients are obtained, the test sample is input to obtain the best prediction result. Table 8 compares the prediction correctness of the ensemble learning model with each individual learning algorithm. The comparison results are shown in (Fig. 6).

Comparison results on the index accuracy and F1-score
Compared with the LightGBM, Xgboost and GB algorithms, the proposed ensemble blending learning method has the best performance.
5.3.2 Comparative Analysis Using Other Ensemble Methods
Ensemble learning methods are divided into stacking, blending and voting, which are powerful prediction techniques since they can increase the diversity of algorithms and reduce generalization errors to improve the accuracy of the results. We refer to other methods about the ensemble model of pregnancy diabetes prediction [21, 22]. Unlike our ensemble blending method, other articles use the voting method and the stacking method. Therefore, to show that the method for the ensemble blending model is better, we ensemble LightGBM, Xgboost and GB models with the voting method and stacking method and then predict the same dataset again. The final prediction results are shown in (Table 9 and Fig. 7).

Radar map showing a comparative analysis of different methods
5.4 Conclusion
From the results of Table 9 and Fig. 7, we can conclude that the result of the ensemble model obtained by the mixed mode is better than the other two methods. Therefore, we believe that the new integrated model has a good effect in predicting gestational diabetes mellitus. Although the prediction accuracy of the new integrated model is 2.56 percentage points higher than that of a single best model, the prediction accuracy of the new integrated model is of great benefit to the prediction of gestational diabetes mellitus. It is possible to improve the accuracy of the diagnosis of the disease to improve maternal and infant outcomes as early as possible.
Gestational diabetes mellitus is a common disease during pregnancy. Therefore, it is necessary to identify this disease as soon as possible. This research primarily verifies the accuracy of the commonly used machine learning algorithms used in several gestational diabetes mellitus cases in the past and obtains the best ensemble prediction method for predicting diabetes mellitus. The results also show that our proposed ensemble method is better.
6 Discussion
This paper proposes a new integrated LightGBM-Xgboost-GB method to help MCH detect and determine the risk of GDM in pregnant women and to take measures to control pregnancy outcomes. We analyzed and compared several risk prediction models for characterizing the risk of developing GDM. To predict gestational diabetes, we paid more attention to determining whether a pregnant woman has gestational diabetes according to the examination results. To our knowledge, this is the first study to assess the importance of variables and to characterize the risk of developing GDM using different machine learning methods. Our results were consistent with previous findings. From the research conclusions of many scholars, the age, BMI, WBC, hsCRP, RBP4, weight, calpain-10 gene, and TG were important risk factors. Our results also revealed their prominent presence on the top 10 key factors for GDM.
The identification of key factors has important clinical significance in GDM risk assessment. We used Shapley's idea to rank the importance of the feature variables of each model comprehensively to obtain a more objective and reasonable set of routine features for the GDM population. In the past ten years, the detection of various indicators has matured very rapidly. Therefore, when assessing the risk of gestational diabetes, MCH medical staff need to pay more attention to these important factors.
Most importantly, we propose a new integrated model that uses gray correlation to calculate weights and a genetic algorithm to optimize them. Using an ensemble model composed of the Xgboost, GB and LightGBM algorithms, the results are encouraging. In terms of prediction accuracy and comprehensive effects, the final model is better than the commonly used machine learning models. Our main contribution is reflected in two parts. First, some scholars have used the traditional regression tree analysis method to study the prediction model of gestational diabetes mellitus, but few studies have integrated multiple models to predict gestational diabetes mellitus. Therefore, this research focuses on the integration of LightGBM, Xgboost and GB algorithms. These three models have strong processing abilities for small samples, many missing values and classification features. It provides a solution for disease prediction models with poor data quality. Second, some scholars have established a model explanation for gestational diabetes mellitus based on physiological indicators but have not accounted for genetic factors. Some studies have shown that genetic factors are also the cause of gestational diabetes mellitus. In practice, we hope to improve the diagnostic accuracy and work efficiency of doctors and reduce the negative impact of missed diagnosis and misdiagnosis. Second, this research idea provides a research case in the direction of disease prediction, enriches the application of artificial intelligence in the medical field, and provides ideas for disease diagnosis and prediction research.
However, several limitations should be mentioned. First, the examination time and region of the patients in these data were unknown, and the analysis results may be different by time and region. Second, we must perform future research with external validation and other machine learning methods to assess the important characteristic variables. In addition, it is difficult to explain the inherent complexity of variable interactions and their impacts on outcomes because of the “black box” nature of machine learning methods.
In conclusion, this study is based on machine learning methods that were used to predict the early occurrence of gestational diabetes, which will help MCH staff diagnose the risk of diabetes in pregnant women in a timely manner and provide a basis for preventive intervention and treatment of GDM. By using a series of machine learning models, we used Shapley's idea to rank the importance of the feature variables of each model comprehensively to obtain a rule feature set of GDM high-risk groups with higher objectivity and rationality. We analyzed and explained the impact of this group of important factors on the development of gestational diabetes. Our results demonstrate the excellent ability of machine learning to identify risk factors and to predict the results of multidimensional data, which enables us to have a deeper understanding of disease risk factors without causation. This paper verifies the feasibility and effectiveness of the multimodal combination prediction model for the accurate diagnosis of gestational diabetes through theoretical research and experimental analysis. It has made practical contributions to the study of intelligent recognition models for gestational diabetes, but there are still deficiencies in the research or some issues that are not well considered. In today's medical industry, the digitalization of hospitals is gradually increasing. The popularity of electronic medical records and the digitization of medical equipment have further increased the amount and scope of medical data. With their rapid accumulation and scale growth, the era of medical big data has arrived. In this case, the artificial intelligence method represented by machine learning studied in this article can provide support for scientific medical decision-making and promote the healthy development of China's medical service industry.
Data availability
The data came from the Tianchi precision medicine competition, artificial intelligence-assisted genetic risk prediction of diabetes, which was held by Aliyun United Qingwutong Health Technology Co. LTD. (https://tianchi.aliyun.com/).
Abbreviations
- GDM:
-
Gestational diabetes mellitus
- MCH:
-
Maternal and child health hospital
- T2DM:
-
Type II diabetes mellitus
- IDF:
-
International diabetes federation
- HIP:
-
Hyperglycemia in pregnancy
- DT:
-
Decision tree
- CART:
-
Classification and regression trees
- Xgboost:
-
Extreme gradient boosting
- RF:
-
Random forest
- GB:
-
Gradient boosting tree
- LightGBM:
-
Light gradient boosting machine
- MLP:
-
Multilayer perceptron
- ANN:
-
Artificial neural network
- GRA:
-
Gray relational network
- GA:
-
Genetic algorithm
- BMI:
-
Body mass index
- HbA1c:
-
Hemoglobin a1c
- SNP:
-
Single nucleotide polymorphism
- DNA:
-
Deoxyribonucleic acid
- RBP4:
-
Retinol binding protein 4
- wbc:
-
White blood cell
- ALT:
-
Alanine aminotransferase
- AST:
-
Alanine aminotransferase
- Cr:
-
Creatinine
- BUN:
-
Blood urea nitrogen
- CHO:
-
Cholesterol
- TG:
-
Triglyceride
- HDLC:
-
High density cholesterol
- LDLC:
-
Low density cholesterol
- ApoA1:
-
Apolipoprotein a1
- ApoB:
-
Apolipoprotein
- Lpa:
-
Lipoprotein a
- hsCRP:
-
High-sensitivity C-reactive protein
- AUC:
-
Area under the receiver characteristic curve
- TP:
-
True positive-it was originally a positive example, but it is classified as a positive example
- FP:
-
False positive-it was originally a positive example, but it is classified as a positive example
- FN:
-
False negative-it was originally a positive example, but it is classified as a negative example
- TN:
-
False negative-it was originally a positive example, but it is classified as a negative example
- VAR00007:
-
Physical examination indexes after desensitization treatment through reading the literature, we suspect that VAR00007 is an insulin resistance index
References
National Bureau of Statistics. Birth Rate[DB/OL]. http://www.stats.gov.cn/2021. Accessed 2021
OCED.Global fertility in developed countries[DB/OL]. https://www.oecd.org/.2021. Accessed 2021
Stewart, Z.A.: Gestational diabetes[J]. Obstet. Gynaecol. Reprod. Med. 30(3), 79–83 (2020)
Wang, X., Chen, M., Xia, W., Zhu, K., et al.: Improving the risk management of Type 2 diabetes mellitus in China from the perspective of social relationships[J]. Expert. Syst. 37(2), 1–18 (2020)
Wang, X., Gong, W., Zhu, K., et al.: Sequential prediction of glycosylated hemoglobin based on long short-term memory with self-attention mechanism[J]. Int. J. Comput. Intell. Syst. 13(1), 1578–1589 (2020)
Vounzoulaki, E., Khunti, K., Abner, S.C., et al.: Progression to type 2 diabetes in women with a known history of gestational diabetes: Systematic review and meta-analysis[J]. Br. Med. J. 369(1361), 1–11 (2020)
Zheng, W.: Case control study of gestational diabetes mellitus influential factors and maternal and fetal outcomes[D]. Master thesis. China Medical University, pp. 1–10 (2009)
Care, D., Suppl, S.: Classification and diagnosis of diabetes: Standards of medical care in diabetesd-2019[J]. Diabetes. Care. 42(1), 13–28 (2019)
Cheruku, R., Edla, D.R., Kuppili, V.: Diabetes classification using radial basis function network by combining cluster validity index and BAT optimization with novel fitness function[J]. Int. J. Comput. Intell. Syst. 10(1), 247–265 (2017)
Wu, B., Huang, H., Yao, Q., et al.: The application of big data and artificial intelligence methods in prediction of GDM[J]. Chin J. Health. Inform. Manag. 114(6), 832–837 (2017)
Rissanen, J., Markkanen, A., et al.: Sulfonylurea receptor 1 gene variants are associated with gestational diabetes and type 2 diabetes but not with altered secretion of insulin[J]. Diabetes. Care. 23(1), 70–73 (2000)
Bao, W., Yeung, E., Tobias, D.K., et al.: Long-term risk of type 2 diabetes mellitus in relation to BMI and weight change among women with a history of gestational diabetes mellitus: a prospective cohort study[J]. Diabetologia 58(6), 1212–1219 (2015)
Minooee, S., Ramezani Tehrani, F., et al.: Diabetes incidence and influencing factors in women with and without gestational diabetes mellitus: A 15 year population-based follow-up cohort study[J]. Diabetes Res. Clin. Pract. 128(1), 24–31 (2017)
Li, F., Hu, Y., Zeng, J., et al.: Analysis of risk factors related to gestational diabetes mellitus[J]. Taiwan. J. Obstet. Gynecol. 59(5), 718–722 (2020)
Kuzmicki, M., Telejko, B., Szamatowicz, J., et al.: High resistin and interleukin-6 levels are associated with gestational diabetes mellitus[J]. Gynecol. Endocrinol 25(4), 258–263 (2009)
Rezvan, N., Hosseinzadeh Attar, M.J., Masoudkabir, F., et al.: Serum visfatin concentrations in gestational diabetes mellitus and normal pregnancy[J]. Arch. Gynecol. Obstet. 285(5), 1257–1262 (2011)
Shaat, N., Karlsson, E., Lernmark, A., et al.: Common variants in MODY genes increase the risk of gestational diabetes mellitus[J]. Diabetologia 49(7), 1545–1551 (2006)
Kumar, D., Jain, N., Khurana, A., et al.: Automatic detection of white blood cancer from bone marrow microscopic images using convolutional neural networks[J]. IEEE Access 8(1), 142521–142531 (2020)
Mittal, M., Arora, M., Pandey, T., Goyal, L.M.: Image segmentation using deep learning techniques in medical images[M]. Algor. Intell. Syst. (2019). https://doi.org/10.1007/978-981-15-1100-4_3
Nombo, A.P., Mwanri, A.W., et al.: Gestational diabetes mellitus risk score: a practical tool to predict gestational diabetes mellitus risk in Tanzania[J]. Diabetes Res. Clin. Pract. 145(8), 130–137 (2018)
Kumari, S., Kumar, D., Mittal, M.: An ensemble approach for classification and prediction of diabetes mellitus using soft voting classifier[J]. Int. J. Cognitive Comput. Eng. 2(1), 40–46 (2021)
Wang X.: Application of integrated learning in gestational diabetes mellitus prediction[D]. Master thesis. Chongqing Normal University, pp. 14–25 (2020)
Zhang, H., He, G., Wang, J.: Research on type 2 diabetes mellitus precise prediction models based on XGBoost algorithm[J]. China. Exp. Diagn. 22(3), 408–412 (2018)
Wang, X., Wang, X., Li, L.: Application of deep learning model in predicting the risk of type 2 diabetes mellitus[J]. Elect. J. Clin. Med. Liter. 4(84), 16460–16461 (2017)
Lan, T., Hu, H., Jiang, C., et al.: A comparative study of decision tree, random forest, and convolutional neural network for spread-F identification[J]. Adv. Space Res. 65(8), 2052–2061 (2020)
Begenova, S., Avdeenko, T.: Building of fuzzy decision trees using ID3 algorithm[J]. J. Phys: Conf. Ser. 1015(2), 22002–22009 (2018)
Qiao, W., Tian, W., Tian, Y., et al.: The forecasting of PM2.5 using a hybrid model based on wavelet transform and an improved deep learning algorithm[J]. IEEE Access 7(7), 142814–142825 (2019)
Lu, Y., Fu, X., Chen, F., et al.: Prediction of fetal weight at varying gestational age in the absence of ultrasound examination using ensemble learning[J]. Artif. Intell. Med. 102(101748), 1–10 (2020)
Li, X.: Using, “ random forest ” for classification and regression[J]. Chin. J. Appl. Entomol 50(4), 1190–1197 (2013)
Lombardo, L., Cama, M., Conoscenti, C., et al.: Binary logistic regression versus stochastic gradient boosted decision trees in assessing landslide susceptibility for multiple-occurring landslide events: application to the 2009 storm event in Messina (Sicily, southern Italy)[J]. Nat. Hazards 79(3), 1621–1648 (2015)
Ye, J, Chow, J-H, Chen, J.: Stochastic Gradient Boosted Distributed Decision Trees[C]. Proceedings of the 18th ACM Conference on Information and Knowledge Management, 2061–2064 (2009)
Chen, T, Guestrin, C.: XGBoost: A scalable tree boosting system[C]. International Conference on Knowledge Discovery and Data Mining, 785–794 (2016)
Yue, L., Yi, Z., Pan, J., et al.: Identify M Subdwarfs from M-type Spectra using XGBoost[J]. Optik 225(2), 165535.1-165535.6 (2021)
Sharma, V., Mir, R.N.: An enhanced time efficient technique for image watermarking using ant colony optimization and light gradient boosting algorithm[J]. J. King Saud Univ – Comput. Inf. Sci. 34(3), 615–626 (2019)
Ke, G, Meng, Q, Finley, T.: LightGBM: A Highly Efficient Gradient Boosting Decision Tree[C]. Adv Neural Inf Process Syst, 3146–3154 (2017)
Del Ser, J., Rokach, L., Herrera, F., et al.: A practical tutorial on bagging and boosting based ensembles for machine learning: Algorithms, software tools, performance study, practical perspectives and opportunities[J]. Inf. Fusion. 64(1), 205–237 (2020)
Zeng, X., Yeung, D.S.: Hidden neuron pruning of multilayer perceptrons using a quantified sensitivity measure[J]. Neurocomputing 69(4), 825–837 (2006)
Shadkani, S., Abbaspour, A., Samadianfard, S., et al.: Comparative study of multilayer perceptron-stochastic gradient descent and gradient boosted trees for predicting daily suspended sediment load: The case study of the Mississippi River, U.S.[J]. Int. J. Sediment. Res. 36(4), 512–523 (2021)
Wang, X., Wang, J., Zhang, K., et al.: Convergence and objective functions of noise-injected multilayer perceptrons with hidden multipliers[J]. Neurocomputing 452(7), 796–812 (2020)
Jianyu Y.: Research on Predictive Model of Gestational Diabetes Based on Integrated Learning Algorithm[D]. Master thesis. Harbin Institute of Technology, pp. 37–46 (2019)
Yang, M., Deng, M.H., et al.: (2010) Research on index weight based on improved grey relational analysis[J]. Int. Conf. Mach. Learning Cybern. 4(1), 1967–1970 (2010)
Deng, J.: Grey information space[J]. J. Grey. Syst. 1(2), 103–117 (1989)
Fang, Z., Liu, S., Forrest, J.: A new definition for the degree of grey incidence[J]. Sci. Inq. 7(2), 111–124 (2006)
Jana, C., Pal, M.: A dynamical hybrid method to design decision making process based on GRA approach for multiple attributes problem[J]. Eng. Appl. Artif. Intell. 100(82), 104203.1-104203.10 (2021)
Dong, X., Zhang, H., et al.: Hybrid genetic algorithm with variable neighborhood search for multi-scale multiple bottleneck traveling salesmen problem[J]. Futur. Gener. Comput. Syst. 114(3), 229–242 (2021)
Huo, Z., Li, H., Du, W.: The effect of pre-pregnancy BMI and parity on gestational diabetes mellitus among pregnant women[J]. J. Clin. Pathol. Res. 36(2), 161–167 (2016)
Paula Bertoli, J.P., Schulz, M.A., et al.: Obesity in patients with gestational diabetes: Impact on newborn outcomes[J]. Obes. Med. 20(1), 100296.1-100296.5 (2020)
Mishra, S., Shetty, A., Rao, C.R., et al.: Risk factors for gestational diabetes mellitus: A prospective case-control study from coastal Karnataka[J]. Clin. Epidemiol. Glob. Health. 8(4), 1082–1088 (2020)
Acknowledgements
This work was supported by a grant from the Key Disease of Diabetes Mellitus Study Center at the National Chinese Medicine Clinical Research Base, the National Natural Science Foundation of China grant Nos. U2001201 and 61876055 and National Steering Committee for Graduate Education of Chinese Medicine and Traditional Chinese Medicine grant No. 20190723-FJ-B39.
Author information
Authors and Affiliations
Contributions
XW, YW, SZ, LY, and SX: contributed to the conception of the study; YW: performed the simulation experiment; XW: contributed significantly to the model; SX, YW, and SZ: performed the data analyses and wrote the manuscript; and LY and SX: helped perform the analysis with constructive discussions.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Ethical Approval and Consent to Participate
The data used in this paper is a public data set without ethical experiments.
Consent for Publication
The authors involved in this paper agree to publish this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, X., Wang, Y., Zhang, S. et al. Analysis and Prediction of Gestational Diabetes Mellitus by the Ensemble Learning Method. Int J Comput Intell Syst 15, 72 (2022). https://doi.org/10.1007/s44196-022-00110-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-022-00110-8