
Abstract
With the formation of urban agglomerations, economic zones, and metropolitan areas, the supporting role of the regional logistics industry in economic development is becoming increasingly prominent. It is of great significance to study the spatiotemporal evolution and the coordinated development of regional logistics networks to realize regional integration. In this paper, we propose the weighted co-evolution model of regional logistics networks based on node attraction by introducing concepts such as logistics attractiveness, geographic space distance, and logistics node level, and we integrate the true regional situation into the evolution model. Taking the Chengdu–Chongqing region as an example, we analyze the co-evolution simulation of the area’s regional logistics network. The results show that (1) there are three node connections between new and original nodes, and 50 nodes are added per time interval, which is an ideal situation for studying the evolution of a regional logistics network; (2) the future evolution of the regional logistics network in the Chengdu–Chongqing region can be divided into three stages: the initial construction period from the initial state to the T2 stage, the slow maturity period from T2 to T3, and the coordinated development period from T3 to T4. This research serves as a reference for government managers to formulate logistics development plans.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Logistics networks are developed to achieve the systematization and the socialization of logistics, which is an inevitable trend in the development of the modern logistics industry [1]. Understanding the evolution process and the internal laws of regional logistics networks is an important way to effectively promote the regional economy and urban development.
Logistics networks have long been a popular research topic. Studies by Chinese and foreign scholars mainly focus on the construction of logistics networks [2,3,4], hub location and layout [5,6,7,8], and network design and optimization [9,10,11,12], among other subjects. With the development of regional integration and urban agglomerations, some scholars have carried out research on the structures of regional logistics networks in urban agglomerations [13, 14]. Li and Zhang [15] and Ma and Wang [16] studied the structural characteristics and spatial pattern of the logistics network in the Beijing–Tianjin–Hebei region based on the gravity model and social network analysis methods. Wang et al. [17] explored the evolution characteristics of the logistics network pattern in the Shandong Peninsula urban agglomeration and the mid-southern urban agglomeration before and after the construction of the Bohai Sea corridor. However, scholars have found that the typical small-world network model and the BA scale-free network model cannot accurately explain the characteristics of real network evolution in practical research, so the improved models based on the original network models have gradually become emphasized in the research. Through their analysis of real networks, Rui et al. [18] argued that individuals in a local area are more closely related; they proposed the nonlinear growth model of a weighted network based on the LC model. Wu et al. [19] proposed a new evolution model based on the BBV model and argued that the priority connection mechanism for adding nodes should be determined by the attractiveness index of existing nodes.
With in-depth research on logistics networks and the development of complex network theory, the integration of the two approaches has received increasing attention in the academic community [20, 21], and some scholars have shown a strong interest in the study of logistics networks evolution based on complex network theory. Considering the growth and the connection characteristics of nodes, Lu et al. [22] proposed three evolution models of regional logistics networks with optimal growth based on node degree, node attractiveness, and non-equilibrium weights of sides. Fu et al. [23] constructed a weighted local world evolution model based on the priority connection principle of agglomeration degree, and explored the characteristics and the evolution mechanism of the spatial structure of urban logistics networks through simulation. Zhang et al. [24] analyzed the evolution mechanism of international logistics networks from the perspective of the “Belt and Road”. Jia et al. [25] found that freight transport networks of Chinese cities with logistics hubs develop toward a small-world network with the steady growth of agglomeration, a stable network structure, and the weakening of scale-free network characteristics. Wu [26] constructed the co-evolution model of urban logistics networks in Beijing-Tianjin-Hebei from a macro perspective and suggested some corresponding co-development countermeasures. The use of complex network theory has led to many findings in the exploration of logistics network structures and evolution characteristics [27,28,29,30]. A summary of literature research on logistics network evolution is shown in Table 1. However, the research perspectives of most of these studies are limited to theoretical research and model construction; therefore, research that integrates real data into a model combined with geographic space and exploring the future evolution law of regional logistics networks needs to be enriched.
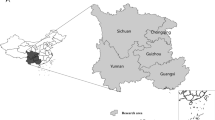
Based on complex network theory, this paper examines the related evolution mechanism of regional logistics networks and constructs the co-evolution model of weighted regional logistics networks based on node attraction. Taking the logistics network in the Chengdu–Chongqing Area Twin City Economic Circle in 2020 as a foundation, the simulation was carried out by setting the initial state of the network and the rules for adding nodes and adjusting parameters. Additionally, according to the characteristic analysis of the network structure, we discuss the future evolution laws and the evolution direction of the regional logistics network in the Chengdu–Chongqing region. The Chengdu–Chongqing Area Twin City Economic Circle is located in the Sichuan Basin and the upper reaches of the Yangtze River, which is an urbanization area with the highest development level and great development potential in western China. It is also an important part of the implementation of the Yangtze River Economic Belt and the “Belt and Road” strategy. In October 2021, the “Planning Outline of the Construction of the Chengdu–Chongqing Area Twin City Economic Circle” was issued. It is of great significance to the Chengdu–Chongqing region for coordinated development, improving the regional energy level, and accelerating the formation of new development patterns. To facilitate data collection and analysis, the research scope of the paper covers all areas of the 15 prefecture-level cities in Sichuan and all districts and counties in Chongqing that are listed in the Planning Outline. The central area of Chongqing, northeastern Chongqing, western Chongqing, and southeastern Chongqing are regarded as four units for the purposes of this study. In total, 19 research units are included in this study (Fig. 1).

Study area
The contributions of this paper are as follows. First, by introducing concepts such as logistics attractiveness, geographic space distance, and logistics node level into the model, we propose the co-evolution model of regional logistics networks based on node attraction, which combines theoretical research with regional realities, giving it scientific and practical significance. Second, in terms of node addition, we determine all nodes added in the evolution process through three methods: actual layout and related planning, big data extraction, and buffer inference. According to the specific order for adding nodes set by the paper, the obtained logistics nodes are added to the logistics network, which is very different from the random growth of nodes in the traditional sense. Third, based on our simulation analysis, the future evolution direction and the network characteristics of the regional logistics network in the Chengdu–Chongqing region are explored, and the evolution laws are summarized in stages.
The rest of this paper is structured as follows. In Sect. 2, the nodes’ growth mechanism, the edges’ connection mechanism, and the weight evolution mechanism are introduced, and the concept of node attraction is proposed. Section 3 describes the construction process and the evolution algorithm of the co-evolution model. Section 4 presents the empirical analysis of the co-evolution of the regional logistics network in Chengdu–Chongqing, and summarizes future evolution stages by simulation. Finally, the research conclusions and some additional issues to be addressed are presented in Sect. 5.
2 Evolution Mechanism
Regional logistics networks are composed of a variety of interconnected and interacting logistics elements [31,32,33], including the six main structural characteristics of globality, regionality, openness, hierarchy, complexity, and evolution. Against the background of regional integration, due to the continuous adjustment and development of regional strategic positioning, economic scale, industrial structure, transportation planning, and other factors, as well as the influence of the scale economy effect of the regional logistics network, the structure of the network is constantly changing. Thus, the growth of logistics nodes, the division of node levels, and the flow of materials between nodes are very complex throughout the evolution process.
2.1 Node Growth Mechanism
2.1.1 Determination of Adding Nodes
Regional logistics networks are formed based on urban logistics networks, so the growth of nodes should not only include the growth of urban internal network nodes but also cover the nodes that appear to support and connect global regional logistics activities. In the classic BA model and the BBV model, the random generation method is used to simulate the increase of nodes. However, the network structure considered in this paper is not a simple topology structure, and it is studied in combination with geographic space. Therefore, the new nodes added in the study are pre-set and stored based on the acquisition methods of the true layout and related planning, big data extraction, and buffer inference. Then these nodes are randomly added according to the specific addition order.
2.1.2 Node Level
Most studies divide the level of logistics nodes into three categories: logistics park, logistics center, and distribution center. However, different divisions can also be made according to research needs. Combined with “Logistics Terminology” (GB/T 18,354–2021) and the construction of real regional logistics nodes, we divide the node level into three categories: logistics hub, logistics park, and logistics center. These are also referred to as the primary, secondary, and tertiary logistics nodes, respectively. The division of each level of logistics nodes is defined according to the classification standard of a logistics park in the Fifth National Logistics Park Survey Report released in 2018. From the current distribution of logistics nodes at various levels in China, the number of nodes at each level is inversely proportional to its level. Studies have found that a reasonable quantitative ratio between logistics park and logistics center is about \(\beta { - }4\) [34]; that is, there are about four logistics centers within the geographical scope of one logistics park. For example, there were seven logistics parks and 29 logistics centers planned and constructed in Wuhan during the “13th Five-Year Plan” period, which roughly conforms to the quantitative relationship of \(\beta { - }4\). Based on existing research, we established the quantitative relationship of \(\beta {\text{ - m}}\left( {4 \le m \le 6} \right)\), which means that there are between four and six logistics centers around one logistics park.
2.2 Edge Connection Mechanism
The material flow process between logistics nodes in regional logistics networks is defined as the edge connection mechanism, thereby forming complex spatial structures of logistics networks, which are similar to the edge connections in a complex network. With the advancement of regional economic integration and urban agglomeration construction, logistics hubs and logistics parks will establish resource sharing and collaborative cooperation with logistics nodes in other cities while meeting local logistics needs. At this time, logistics nodes at all levels do not need to be connected strictly in a hierarchical order. Ultimately, the connection between logistics nodes in regional logistics networks will be more complex, and the network structure will be transformed from a simple network structure to a complex network structure, as shown in Fig. 2.

Change in regional logistics network structure
We improve the edge connection mechanism of the classic BA model and propose a priority connection mechanism based on node attraction. The relationships among the connection probability of the new node \(j\) and the node \(i\) and node degree, node attraction, logistics attractiveness, and the weight of each edge are shown in Eqs. (1)–(6). Among them, node attraction is related to logistics attractiveness and the weights of edges between the node and its neighbors. Logistics attractiveness represents the logistics capacity and the development potential of a node, and the weight of each edge refers to the capacity of the logistics channel. Equations (1)–(6) are as follows:
where the value 6371 refers to the average radius (km) of Earth. The implications of relevant parameters in the above-mentioned equations are given below:
\(P_{ij}\) | denotes the connection probability of the new node \(j\) and the node \(i\) |
|---|---|
\(k_{i}\) and \(k_{j}\) | denotes the node degree of node \(i\) and node \(j\), respectively |
\(F_{ij}\) | denotes the node attraction between node \(i\) and node \(j\) |
\(\alpha\) and \(\beta\) | are adjustment coefficients, which are used to adjust the weight of node degree and node attraction |
\(G\) | is the gravitational constant, which is taken as one here |
\(Z_{i}\) and \(Z_{j}\) | represents the sum of the node attractiveness of node \(i\) and node \(j\), and the weights of the edges connected to them, respectively; the calculation process is the same for each |
\(d_{ij}\) | is the geographic space distance between node \(i\) and node \(j\) |
\(a_{i}\) | is the logistics attractiveness of node \(i\) |
\(W_{i}\) | is the sum of the weights of the edges connected to node \(i\) |
\(n\) | is the number of edges connected to node \(i\) |
\(w_{in}\) | is the weight of the edge between node \(i\) and its neighbor, node \(n\) |
\(\gamma\) | is the adjustment factor for node level |
\(I\) | represents the central bearing region |
\(M_{I}\) | represents the development level of the logistics industry in the central bearing region |
\(d_{iI}\) | is the geographic space distance between node \(i\) and the central bearing region |
\(x_{i}\) and \(y_{i}\) | refers to the latitude and longitude of node \(i\) |
\(x_{j}\) and \(y_{j}\) | refers to the latitude and longitude of node \(j\) |
To avoid excessive node load and network inconsistency, the node saturation of \(K_{\max }\) should be set for nodes at different levels. This means that if the number of edges connected to a node reaches saturation, it will no longer establish connections with new nodes. Here, the saturation of the primary, secondary, and tertiary logistics nodes are 100, 50, and 10, respectively. In Eq. (1), \(\alpha\) is the value given according to the logistics node level; the higher the level, the larger the value [35, 36]. When the nodes are primary, secondary, and tertiary logistics node, \(\alpha\) takes the value of 1, 0.7, and 0.5, respectively. Furthermore, \(\beta\) depends on the topology of the regional logistics network. The setting rule is that: when the primary logistics nodes are connected to primary, secondary, and tertiary logistics nodes, \(\beta\) takes the value of 1, 2, and 1, respectively. When the secondary logistics nodes are connected to secondary and tertiary logistics nodes, \(\beta\) takes the value of 1.8 and 1.5, respectively. When the tertiary logistics nodes are connected to tertiary logistics nodes, \(\beta\) takes the value of 0.5. In Eq. (5), when the nodes are primary, secondary, and tertiary logistics nodes, \(\gamma\) takes the value of 1, 0.95, and 0.75, respectively.
2.3 Weight Evolution Mechanism
In the BBV model, the edge formed by the new node \(j\) and the original node \(i\) in the network corresponds to the true logistics channel, so the edge’s weight is used to represent the traffic capacity of the logistics channel. The newly added edge \(\left( {j,i} \right)\) will cause the weight of the edge between node \(i\) and its neighboring nodes to change. This change will affect the node attraction, thereby changing the connection probability between nodes; then, the evolution of the entire network will be realized. The specific weight evolution rules are as follows.
-
(1)
The initial weight of the initial edge in the initial network is set as the ratio of the sum of the logistics attractiveness of the two nodes to their distance. The initial weight of the newly added edge \(\left( {j,i} \right)\) is calculated as shown in Eq. (7). In fact, the initial weight of the initial edge is calculated in the same way as the initial weight of the newly added edge. In the real logistics network, the most reasonable indicator of the edge’s weight is logistics quantity. However, the logistics quantity between the new node and the old node cannot be directly obtained, so the initial assignment of the weight of the new edge is made using logistics attractiveness and the geographic space distance between the nodes.
$$w_{ij(0)} = \frac{{a_{i} + a_{j} }}{{d_{ij} }}.$$(7) -
(2)
When the new node is first connected to the node with the highest connection probability according to the priority connection principle, the weights of the edges in the network will be updated for the first time according to the weight evolution mechanism in the BBV model. Then, the node with the second-highest connection probability is connected, and the edges’ weights will be updated again. This will be repeated until the new node connects to m nodes. It is necessary to update the weights of all edges as new nodes join the network. The newly added edge \(\left( {j,i} \right)\) will cause the edge weights between node \(i\) and its neighboring nodes to be changed dynamically from \(w_{in}\) to \(w_{in} + \Delta w_{in}\).
$$\Delta w_{in} = \delta_{i} \frac{{w_{in} }}{{W_{i} }},$$(8)$$\delta_{i} = \frac{{a_{j} }}{m},$$(9)$$W_{i} = W_{i}^{\prime } + \delta_{i} + w_{ij(0)} ,$$(10)$$W_{n} = W_{n}^{\prime } + \Delta w_{in} .$$(11)where \(\Delta w_{in}\) is the change value in the edge’s weight between node \(i\) and its neighboring node \(n\), and \(\delta_{i}\) is the extra traffic burden created for node \(i\) after the new edge is added. The extra traffic burden will be borne by all nodes connected to node \(i\); this is calculated using the ratio of the logistics attractiveness of node \(j\) to the number m of connections between the new and old nodes. \(W_{i}\) and \(W_{n}\) denote the now sum of the weights of the edges connected to node \(i\) and its neighboring node \(n\), respectively. \(W_{i}^{\prime }\) and \(W_{n}^{\prime }\) represent the previous values of \(W_{i}\) and \(W_{n}\) before node \(i\) and node \(j\) are connected.
-
(3)
When the old node exits the network, it will cause the weights of all edges with its neighboring nodes to change. Similar to the weight evolution mechanism of adding new nodes, the edge weights of the neighboring nodes will be updated after the old node exits, and this network evolution will continue after all the updates are completed. The change rule is that: when the old node g exits, the edge’s weight of its neighboring node \(p\) is changed dynamically from \(w_{pd}\) to \(w_{pd} + \Delta w_{pd}\).
$$\Delta w_{pd} = \lambda_{p} \frac{{w_{pd} }}{{W_{p} }},$$(12)$$\lambda_{p} = \frac{{a_{g} }}{l},$$(13)$$W_{p} = W_{p}^{\prime } - w_{pg} + \lambda_{p} ,$$(14)$$W_{d} = W_{d}^{\prime } + \Delta w_{pd} ,$$(15)where g represents the node to be deleted, and \(p\) is the neighboring node of node g, and \(d\) is the neighboring node of node \(p\). \(w_{pd}\) is the edge’s weight between node \(p\) and node \(d\); and \(\Delta w_{pd}\) is the change value in the edge’s weight between node \(p\) and node \(d\). \(\lambda_{p}\) is the extra traffic burden created for node \(p\) after deleting node g, which is expressed by the ratio of the logistics attractiveness of node g to the number l of deleted edges. Furthermore, \(a_{g}\) denotes the logistics attractiveness of node g, and \(w_{pg}\) denotes the edge weight between node \(p\) and its neighboring node g. \(W_{p}\) and \(W_{d}\) refer to the now sum of the weights of the edges connected to node \(p\) and node \(d\), respectively. \(W_{p}^{\prime }\) and \(W_{d}^{\prime }\) represent the previous values of \(W_{p}\) and \(W_{d}\) before the node g is deleted.
3 Model and Evolution Algorithm
3.1 Model
The dynamic evolution process of the regional logistics network examined in this paper includes five aspects: the generation of the initial network, the addition of new nodes, the connection between old and new nodes, the exit of old nodes, and the evolution of the weights. Since the co-evolution mechanism of the real logistics network is more complicated. Because the theoretical model, the specific parameters, such as logistics attractiveness and geographic space distance, are added to characterize and explain the real network in the model’s construction. The co-evolution model of the weighted regional logistics network based on node attraction is established as follows.
-
(a)
Generation of the initial network. It is assumed that there are \(m_{0}\) nodes in the initial network. These are connected to form an incompletely connected network according to the actual situation, and the logistics attractiveness and edge weights are given.
-
(b)
Adding new nodes. Once a new node is added, it is connected with m \((m \le m_{0} )\) nodes in the initial network, and each of these new nodes cannot be connected to itself. The connection probability between the new node and the existing node can be calculated according to Eq. (1).
-
(c)
Priority connection of new nodes. For the new node \(j\), sort the connection probability \(P_{ij}\) in descending order, and take the first m nodes to connect with the new node preferentially. In doing so, the nodes that are preferentially connected are often the logistics nodes with the strongest development strength, a larger economic scale, and the best traffic location in the real network.
-
(d)
Exit of old nodes. During the evolution process, some nodes will exit the network. Affected by factors such as traffic location, policy changes, and the transfer of logistics supply and demand, some logistics nodes with a small scale, deteriorating logistics functions, a lack of processing capacity, and that are inconsistent with the layout of the urban logistics industry will withdraw from the network. That is, these nodes and the edges connected to them will be removed from the network.
-
e)
Weight evolution. The evolution of the edges in the network represents the change of the logistics channel, and the increase of edge weights indicates the growth of the passing capacity of the logistics channel. In the process of adding new nodes and old nodes exiting the network, the weights of edges will continue to change.
3.2 Evolution Algorithm
The evolution algorithm is designed based on the evolution model established in Sect. 3.1.
Step 1: Set the initial number \(m_{0}\) of network nodes, the connection status of the initial network, and the connected number of nodes m with priority connection probability. Calculate node degree \(k_{i}\), the logistics attractiveness \(a_{i}\), and the initial values of the edge weights.
Step 2: Select q nodes to join the network per interval. When the degree of a node is equal to \(K_{\max }\), it no longer establishes a connection relationship with new nodes.
Step 3: calculate the probability that the new node \(j\) connects to the existing node \(i\) in the network, and sort in descending order to obtain the priority connection sequence.
Step 4: Select the first m nodes from the priority connection sequence calculated in Step 3 to connect to the new node. Once a connection is completed, the weights of all edges and the node attraction of all nodes will be updated. The update process of the edge weights is shown in Eqs. (8)–(11), and the update process of node attraction is shown in Eqs. (2)–(3).
Step 5: When the network scale reaches a certain scale after two intervals, some nodes will start to exit the network. That is, starting from \(t = 3\), the node with the least logistics attractiveness and all the edges connected to it will be deleted in each subsequent interval, which will also cause the edge’s weight and node attraction to change. All the weights are updated using Eqs. (12)–(15), and node attraction is updated using Eqs. (2) and (3).
Step 6: Terminate the evolution. The remaining nodes are added to the network at each time interval. Evolution stops when all nodes have been added to the network, resulting in the final evolution network.
Step 7: Comparative analysis of results. Change some parameters, thereby calculating relevant statistical eigenvalues of the final evolution network, and conduct a comparative analysis of network characteristics.
4 Empirical Analysis
4.1 Node Acquisition and Logistics Attractiveness
4.1.1 Node Acquisition
Combined with the layout of national logistics hubs in Chengdu, Suining, Luzhou, Dazhou, and Chongqing, as well as the development plans and the status quo of the logistics industry in other cities, 21 primary logistics nodes were identified. Based on the Baidu Map API platform, and using keywords such as “logistics park”, “logistics base”, “logistics center”, “bonded center”, and “logistics port” to conduct Python web crawling, we obtained 369 secondary and tertiary logistics nodes within the research scope. By consulting the “14th Five-Year Plan” and the medium- and long-term planning documents of the logistics industry announced in 15 cities in Sichuan, Chongqing, and other districts and counties, the future planning of logistics nodes can be acquired; this includes 81 secondary logistics nodes and 11 tertiary logistics nodes. However, the quantitative relationship between secondary and tertiary logistics nodes obtained through the actual layout and related planning, as well as big data extraction, does not meet the condition of \(\beta {\text{ - m}}\left( {4 \le m \le 6} \right)\). Therefore, we used the core idea of “from disorder to order” in the synergy theory to reasonably add logistics nodes. The concrete method is as follows: with the help of the buffer analysis tool in ArcGIS, 207 circular buffer zones with a radius of 20 km were established according to the location of 207 secondary logistics nodes. We carried out the planning and layout of the tertiary logistics nodes within buffer zones until the quantitative relationship was satisfied. Finally, an additional 710 tertiary logistics nodes were added. This quantitative relationship will facilitate effective connections and interaction between secondary and tertiary logistics nodes, thereby promoting the coordinated development of the logistics network. The number of primary, secondary, and tertiary logistics nodes within the research scope are 21, 207, and 964, respectively, and the layout is shown in Fig. 3.

Distribution of logistics nodes
4.1.2 Logistics Attractiveness
The logistics attractiveness of the primary logistics nodes is expressed by a 100-fold magnification of the logistics industry development level of the cities where these nodes are located in 2020. The logistics attractiveness of the primary logistics nodes and the development level of the urban logistics industry are shown in Table 2. The logistics attractiveness of the secondary and tertiary logistics nodes can be calculated using Eqs. (5) and (6), but it is necessary to determine the central bearing region of each logistics node and its distance before calculation. The central area of Chongqing is set as the central bearing region for the logistics nodes in Chongqing, and Chengdu is set as the central bearing region for the logistics nodes within the rest of the research area. The development level of the logistics industry in the two central bearing regions can be found in Table 2. Combined with the conclusion that about 91.1% of logistics parks in China are mainly reached via land transportation (Fifth National Logistics Park Survey Report, 2018), this paper selected the locations of land port hubs in Chengdu and the central area of Chongqing to replace the positions of the two central bearing regions when calculating the distance between nodes and central bearing regions. The serial numbers of land port hubs in Table 2 are 1 and 17, respectively. If the distance is less than 1 km, then the logistics attractiveness is not affected by the geographic space distance between the central bearing region and the node, so it is regarded as 1 km uniformly.
4.2 Initial Network and Node Addition Process
4.2.1 Initial Network
The initial network is established based on the 15 strong connection relationships between the primary logistics nodes in the Chengdu–Chongqing region in 2020; that is, the network in its initial state is an undirected weighted network containing 13 primary logistics nodes and 15 edges (Fig. 4).

Initial network structure
4.2.2 Node Addition Process
The evolution of the regional logistics network is always accompanied by the addition of new nodes, and the order in which the nodes are added will affect the network structure in different periods. The logistics nodes obtained in the paper include the completed and operated logistics nodes, the logistics nodes planned to be constructed in the future, and the nodes inferred by the buffer zone. They are also divided into node levels. To ensure that the order of adding nodes reflects the real network’s evolution, the specific rules for node addition are the following:
-
(a)
First, the primary logistics nodes that have not been added to the initial network are randomly joined to the network.
-
(b)
Then the secondary and tertiary logistics nodes obtained through the Baidu API are added by generating random sequences, but the secondary logistics nodes are given priority to join in the early stage.
-
(c)
Third, the secondary and tertiary logistics nodes in future planning are randomly added to the network.
-
(d)
Finally, join the nodes obtained through buffer inference by generating random sequences until all nodes are added to the network.
4.3 Parameter Variation
4.3.1 Number of Node Connections
After determining the joining order of the nodes, we set the number of new nodes added to the network at each time interval to 50, according to the model and the evolution algorithm constructed in Sect. 3. The number of node connections signifies the number of connections between the new node and the original node after the new node is added, which is represented by m. Here, different values were assigned to the number of node connections, which are equal to 2, 3, 4, and 5. Network evolution and comparative analysis were carried out in MATLAB, and the final evolution network with different parameter values was obtained. Figure 5 shows that the network shapes after completing the evolution with different values of m are not very different, and there is no obvious difference intuitively. To further explore the internal structural differences of the logistics network after the evolution, it is necessary to analyze the characteristic parameters of the final evolution network. The calculation results of average node degree, average path length, and the average clustering coefficient are shown in Table 3. Moreover, the probability distribution of node degree of the final evolution network with different parameter values is displayed in Fig. 6.

The influence of parameter m on network evolution

Probability distribution of node degree
With different values of m, average node degree, average path length, and the average clustering coefficient in the network all change, but there are also similarities. As m becomes larger, the number of edges in the network increases accordingly after completing the evolution, so the average degree of the nodes also increases significantly, from 3.9812 to 9.9060. No matter how large m is, the node degree of nearly 70% of the logistics nodes is less than the average value, and all conform to the power-law distribution. This is mainly because the co-evolution model of the logistics network constructed in this paper is based on the BA scale-free network.
The average path length refers to the average number of intermediate nodes between two nodes in the network, which reflects the global efficiency of the network. When m increases from 2 to 5, the average path length of the network correspondingly decreases from 5.4845 to 4.5241, and the network efficiency gradually improves. However, when m changes from 2 to 3, the average path length of the network decreases the most, by 11.09%; meanwhile when m changes from 3 to 4 and from 4 to 5, the average path length decreases by 3.07% and 4.29%, respectively. This shows that as the number of node connections increases, the improvement of the global network efficiency slows. The average clustering coefficient of the network is the average value of the clustering coefficients of all nodes in the network. It represents the probability that the two neighboring nodes of a node are still neighboring nodes to each other, which reflects the local characteristics of the network. With the increase of m in the regional logistics network, the average clustering coefficient of the network experiences a process of decreasing and then increasing, but across the board, the average clustering coefficient is still increasing. This is because when the number of node connections gradually increases, the logistics connection between the nodes in the regional logistics network becomes closer and closer, and it gradually develops in the direction of the grouping.
4.3.2 Number of Nodes Added
Combined with the comparative analysis of the characteristic parameters of different values of m, the global efficiency of the regional logistics network in the Chengdu–Chongqing area improves the most when m = 3. Thus, the number of node connections is set to three to conduct the influence analysis of the number of new nodes added through evolution in this section. The number of nodes added is measured at each time interval, q, and it corresponds to the number of logistics nodes constructed in each period in real life. Here, q is set to 30, 40, and 60 for the network evolution, and the simulation results are compared with q = 50 in Sect. 4.3.1 (Fig. 5b). The results of the network evolution are shown in Fig. 7, and the characteristic parameters and the probability distributions of node degree are shown in Table 4 and Fig. 8.

The influence of parameter q on network evolution

Probability distribution of node degree
With the constant adjustment of the value of q, average node degree, average path length, and the average clustering coefficient in the network, the changing range of three characteristic parameters is much smaller than that of m. This shows that the planning and construction of new logistics channels have a greater impact on the future development of the regional logistics network in the Chengdu–Chongqing region compared with the number of logistics nodes constructed at each stage. Compared with q = 50, the average node degree in other cases decreases, but the range of decrease is very small, and the trend of the probability distribution of node degree is also similar. This is because the node degree is mainly related to the number of node connections, which means that the probability distribution of node degree is closely related to the value of m. Furthermore, the average path length increases by 4.56% and 2.79% when q is equal to 30 and 60, respectively. It reduces by 0.41% when q equals 40, indicating that the global network efficiency is improved, but the scope of improvement is still not large. In addition, the change of the average clustering coefficient of the regional logistics network is consistent with the variation of the average path length when the value of q is different. When q is 30 and 60, the average clustering coefficient increases, and the local efficiency of the network is improved, but the average clustering coefficient and the local efficiency of the network decreases when q equals 40.
4.4 Network Dynamic Evolution
From the analysis in Sect. 4.3, we find that the network is relatively better when m = 3 and q is unchanged. Compared with m = 3 and q = 50, although the global network efficiency is improved and the local efficiency is decreased when m = 3 and q = 40, the rate of decrease of 1.04% is bigger than the rate of increase of 0.41%. Therefore, we believe that when m = 3 and q = 50, the regional logistics network in the Chengdu–Chongqing area is ideal in the process of evolution.
To analyze the evolution characteristics from the initial network to the final network, we added all nodes to the network in the order of node addition. A total of 24 periods passed during the evolution process. The regional logistics network of each period is formed by adding nodes based on the previous stage. We filtered four key times to obtain the logistics network in different periods (Fig. 9). Among them, the average node degree, average path length, and network clustering coefficient of the regional logistics network in the Chengdu–Chongqing region in different periods were calculated (Table 5). Figure 10 shows the probability distribution of node degree at four key times.

Evolution process of the logistics network in the Chengdu–Chongqing region

Probability distribution of node degree of the regional logistics network
According to Table 5 and the probability distribution of node degree in different periods, the future evolution of the regional logistics network in Chengdu–Chongqing can be roughly divided into three stages.
-
(1)
Initial construction period. From the initial state to T2, with the addition of the secondary and tertiary logistics nodes, the average node degree and the average path length of the regional logistics network increase rapidly, the network clustering coefficient declines rapidly, and the distributions of node degree are different. During this period, the global and local efficiency of the network declined quickly. The period is the initial stage of the construction of the regional logistics network, and the coordinated development pattern of the entire regional logistics network has not yet been formed.
-
(2)
Slow maturity period. During the period from T2 to T3, secondary and tertiary nodes join and exit the network continuously. The regional logistics network has undergone a period of construction and development, and the network pattern that conforms to the development of the logistics industry in Chengdu–Chongqing has initially taken shape. In this stage, the average path length and the network clustering coefficient increase and decrease, respectively, indicating that the global and local efficiency of the network is still decreasing, but the rate of decrease is greatly slowed. Therefore, it is a slow maturity period, and the coordinated development pattern of the entire regional logistics network has formed.
-
(3)
Coordinated development period. During the period from T3 to T4, as the remaining nodes are added to the network, the average node degree further increases, and the decline of the global and local network efficiency gradually slows and stabilizes. After experiencing the initial construction period and the slow maturation, the structure of the regional logistics network has gradually transformed from its original disordered state to a methodical state, and it enters a stable period of coordinated development.
5 Conclusion
This study constructed the weighted co-evolution model of a regional logistics network based on node attraction, and the co-evolution of the regional logistics network in the Chengdu–Chongqing area was empirically analyzed. In terms of node growth, the added nodes needed to be pre-set and stored in combination with the true layout and related planning, big data extraction, and buffer inference, and then they were randomly selected to join the network according to the rules for adding nodes, which reflects reality. In the edge connection mechanism, we improved the priority connection mechanism of the classic BA model by introducing concepts such as logistics attractiveness, edge weight, geographic space distance, and the logistics node level. We then calculated the connection probability between newly added nodes and the original nodes. Here, the logistics attractiveness is closely related to the development level of the logistics industry in the central region. After exploring the influence of parameter changes on the network’s structure, we determined the number of node connections to be three and the number of nodes added per interval to be 50, thereby analyzing the laws that appear in the ideal evolution of the regional logistics network in Chengdu–Chongqing. The dynamic evolution results show that the future evolution of the regional logistics network in Chengdu–Chongqing can be roughly divided into three stages. The time from the initial state to T2 is the initial construction period, the time from T2 to T3 is the slow maturity period, and the time from T3 to T4 is the coordinated development period. These findings can provide some reference for government managers to formulate relevant plans.
Despite these conclusions, there are still some limitations. First, although there is a certain basis for the number and time of the future nodes to be added, the development of real logistics nodes is variable, resulting in different evolution results. Then, the node with the least logistics attractiveness is set to be deleted at each interval in the evolution process, but in fact the number of exiting nodes is not fixed. Finally, we used complex network theory to research the co-evolution of regional logistics networks. In the future, the spatial distribution characteristics and evolution laws of logistics nodes can be studied together with geospatial analysis methods, the research implications from the related conclusions should be further explored [37,38,39].
References
Ju, S., Xu, J., Bian, W., Geng, Y., Liu, R.: Proposition and exploration of logistics network theory. J. Beijing Jiaotong Univ. (Soc. Sci. Ed.) 8(02), 16–20 (2009)
Li, M., Wang, H.: Review of hub-and-spoke logistics network research. Logist. Technol. 37(09), 1–5 (2018)
Cao, B., Yin, D.: Research on the construction of regional logistics network in Yangtze River Delta based on the hub-and-spoke theory. Geograph. Geograph. Inf. Sci. 32(02), 105–110 (2016)
Cao, Z., Yang, Z., Ye, Z.: Research on the comprehensive evaluation of regional logistics system and the construction of hub and spoke network under “New Land-Sea Corridor”-Taking Guangxi as an example. J. Syst. Sci. 01, 119–124 (2022)
X. Chao, Research on logistics facilities location based on GIS. In: 2018 2nd international conference on data science and business analytics (ICDSBA), 2018, pp. 358–361.
Xin, X., Yu, N., Chao, X.: A study on location of logistics hubs of hub-and-spoke network in Beijing-Tianjin-Hebei region. J. Phys. Conf. Ser. 1187(05), 52063 (2019)
T.Y. Nguyen, T.A. Nguyen, J. Zhang, ASEAN logistics network model and algorithm, Asian J. Shipping Logist. (2021) (preprint)
Li, J., Yang, Y., Lei, H., Wang, G.: Solving logistics distribution center location with improved cuckoo search algorithm. Int. J. Comput. Intell. Syst. 14(1), 676 (2020)
Wang, Y., Shi, Q., Song, W., Hu, Q.: Multi-objective optimization model and solution algorithm of dynamic logistics network. Comput. Integr. Manuf. Syst. 26(04), 1142–1150 (2020)
Jiang, J., Zhang, D., Meng, Q., Liu, Y.: Regional multimodal logistics network design considering demand uncertainty and CO2 emission reduction target: a system-optimization approach. J Cleaner Prod 248, 119304 (2020)
Çalık, A., Pehlivan, N.Y., Paksoy, T., Weber, G.W.: A novel interactive fuzzy programming approach for optimization of allied closed-loop supply chains. Int. J. Comput. Intell. Syst. 11(1), 672 (2018)
Kwanjira, K., Veeris, A., Nam, H.V.: Multi-objective optimization of freight route choices in multimodal transportation. Int. J. Comput. Intell. Syst. 14(1), 794 (2021)
Liu, X., Yang, B., Huang, Z.: Optimization analysis on trade-logistics network structure along China Railway Express. Railway Transport Econ. 43(04), 54–60 (2021)
Ge, S., Yao, H., Lian, B.: Research on the aviation logistics network structure of “The Belt and Road” from the perspective of geographic space. Logist. Technol. 44(12), 86–92 (2021)
Li, Z., Zhang, C.: Research on the structure of logistics network in Beijing–Tianjin–Hebei region from the perspective of social network. Bus. Econ. Res. 17, 97–98 (2017)
Ma, X., Wang, H.: Research on the structure of logistics network in Beijing-Tianjin-Hebei region——Based on the perspective of social network analysis. J. Beijing Univ. Civ. Eng. Arch. 36(03), 95–102 (2020)
Wang, Z., Zhang, X., Sun, D., Sun, H.: The temporal and spatial evolution of logistics network structure of regional urban agglomeration before and after the construction of the cross-sea passage in Bohai Strait. Geograph. Res. 39(03), 585–600 (2020)
Rui, Y., Ban, Y.: Nonlinear growth in weighted networks with neighborhood preferential attachment. Phys. A Stat. Mech. Appl. 391(20), 4790–4797 (2012)
Wu, X., Zhu, J., Wu, W., Ge, W.: A weighted network evolving model with capacity constraints. Sci. China Phys. Mech. Astron. 56(9), 1619–1626 (2013)
Chen, T., Wu, S., Yang, J., Cong, G.: Risk propagation model and its simulation of emergency logistics network based on material reliability. Int. J. Environ. Res. Public Health 16(23), 4677 (2019)
L. Yan, Y. Wen, K.L. Teo, J. Liu, F. Xu, R. Rao, Construction of regional logistics weighted network model and its robust optimization: Evidence from China, Complexity, (2020).
Lu, H., Liu, K.: Research on evolution model of regional logistics network structure. J. Wuhan Univ. Technol. (Transport. Sci. Eng. Ed.) 39(04), 692–697 (2015)
Fu, J., Zhang, J., Xiong, J., Chen, Y.: Study on the weighted local world evolution model of the spatial structure of urban logistics network. Complex Syst. Complexity Sci. 12(03), 38–44 (2015)
Zhang, D., Zhang, F., Liang, Y.: An evolutionary model of the international logistics network based on the Belt and Road perspective. Phys. A Stat. Mech. Appl. 572(2), 125867 (2021)
Jia, P., Wu, J., Li, H., Kuang, H.: Spatial-temporal characteristics and driving mechanism of logistic pivotal bears the weight of city freight transport network in China. Sci. Geograph. Sin. 41(05), 759–767 (2021)
D. Wu, Research on the co-evolution of Beijing-Tianjin-Hebei urban logistics network, Beijing Univ. Civ. Eng. Arch. (2020)
Li, A., Wei, H.: Research on the logistics network of sea-rail intermodal transportation from the perspective of complex network. Softw. Guide 20(11), 57–64 (2021)
Lu, Y., Sun, X.: Research on invulnerability of cross-border e-commerce logistics network based on complex network. Sci. Technol. Manag. Res. 38(20), 195–200 (2018)
He, L.: Analysis on the construction of urban logistics network based on complex network. Chinese Business Theory 28, 6–7 (2018)
Ma, J., Wang, L., Jiang, Z., Yan, W., Zhou, W.: City logistics networks based on online freight orders in China. Phys. A Stat. Mech. Appl. 583, 126333 (2021)
Liang, C., Liu, X., Gong, Y., Zhao, K., Wen, W.: Construction of multi-hub hybrid hub-and-spoke logistics network in Beijing-Tianjin-Hebei. China Bus. Market 33(06), 118–126 (2019)
Liu, J.: Research on the regional logistics network structure facing the Maritime Silk Road strategy-Taking Fujian Province as an example. Logist. Technol. 42(03), 123–126 (2019)
Liu, H., Li, Y., Tian, L.: Analysis on regional logistics network structure based on spatio-temporal evolution model-Taking Yunnan Province as an Example. Logist. Eng. Manag. 34(12), 33–35 (2012)
Wang, G., Liu, J., Wang, G.: Quantity planning theory and application of three-level logistics nodes. Logist. Eng. Manag. 33(03), 40–42 (2011)
G. Tang, Research on dynamic evolution of the topology structure of urban freight network based on the attractiveness of logistics nodes, Huazhong Univ. Sci. Technol. (2017).
Mu, N., Wang, Y., Tian, P.: Spatio-temporal distribution characteristics of the cooperation between logistics industry and economy in southwest China. Int. J. Comput. Intell. Syst. 15(1), 1–12 (2022)
Chen, Z.S., Liu, X.L., Chin, K.S., Pedrycz, W., Tsui, K.L., Skibniewski, M.J.: Online-review analysis based large-scale group decision-making for determining passenger demands and evaluating passenger satisfaction: case study of high-speed rail system in China. Inf. Fus. 69, 22–39 (2021)
Chen, Z.S., Zhang, X., Govindan, K., Wang, X.J., Chin, K.S.: Third-party reverse logistics provider selection: a computational semantic analysis-based multi-perspective multi-attribute decision-making approach. Expert Syst. Appl. 166, 114051 (2021)
Rodríguez, R.M., Labella, Á., Nunez-Cacho, P., Molina-Moreno, V., Martínez, L.: A comprehensive minimum cost consensus model for large scale group decision making for circular economy measurement. Technol. Forecast. Soc. Change 175, 121391 (2022)
Acknowledgements
The authors would like to thank in advance the Editor-in-Chief, the Associate Editor, and the anonymous referees for their time and efforts in handling and reviewing this paper.
Funding
This work was supported by the Soft Science Research Program of Sichuan Province (No. 2021JDR0072) and the National Natural Science Foundation of China (No. 72171182).
Author information
Authors and Affiliations
Contributions
NYM: conceptualization, methodology, writing—original draft, and writing—review and editing. YSW: writing—original draft and writing—review and editing. MW: writing—review and editing. SJH: writing—review and editing. ZSC: funding acquisition and writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Availability of data and material
The data that support the findings of this study are available on request from the corresponding author Z. S. Chen.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mu, N., Wang, Y., Wang, M. et al. The Co-evolution of the Regional Logistics Network in the Chengdu–Chongqing Region Based on Node Attraction. Int J Comput Intell Syst 15, 25 (2022). https://doi.org/10.1007/s44196-022-00082-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-022-00082-9