
Abstract
Decision-making environment often encounters complexity along its processes, especially in the context of multidisciplinary scientific research. This can commonly be seen in engineering, computing, finance, astrology and other different areas. It is of great restriction in dealing with the practical problems which have diverse demands and properties. There is a growing body of literature that recognizes the importance of dealing with the complexity in decision making environment. The reliability and the transparency are the dominant feature of the integration of fuzzy network and Z-numbers. However, much of the research up to now has been descriptive in nature of the features. Hence, this proposed method is unique and novel because it offers some interesting insight of dealing with reliability and transparency of information in Z-hesitant fuzzy network decision-making environment. The fuzzy networks have the functionality under rule bases of fuzzy systems where it is recognized by its transparency and precision. The proposed method makes use of fuzzy network with the incorporation of hesitant fuzzy sets to assimilate decision information towards alternatives. For the validation and applicability purposes of the proposed method, the case study of stock evaluation assessed by a number of decision makers has been utilized as a real-world problem. The performance of the proposed method is evaluated respectively by applying the Spearman’s rho correlation. The result shows that the proposed method performs as the established method with the consideration of additional dominant features.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The fuzzy network approach has been introduced by Gegov [1] to infuse transparency in decision making. A structure of fuzzy system without considering the intermediate variables will affect the level of trust and certainty of the alternatives. This is proven as the precision of single rule base and multiple rule base in the fuzzy system serves a moderate level of transparency and accuracy in countering multiplex procedures of problem solving [2]. Fuzzy network considers the benefit and cost subsystems of the demonstrating network. Because it analyses benefit and cost factors individually, a fuzzy network is more transparent than a single rule based and multiple rules based fuzzy system for decision making. By expressing each set of criteria as a node and the interactions between them as links, this network accounts for the internal structure of the represented process. Fuzzy network has the capacity of being straightforward and exact, which is extremely crucial to settle on better choices [1].
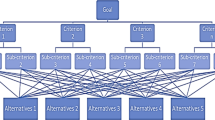
Interpretable Artificial Intelligence (AI) as a part of explainable AI model, can be discovered from the transparency delivered by fuzzy network. As claimed by Loyola-Gonzalez [3], interpretable model capable of providing information to decision makers independently. Fuzzy network also capable of serving the final decisions well as it carries the importance of criteria and decision makers expertise throughout the formulation. This statement can best demonstrate as white-box models in a fuzzy network where rule-based approach is used in order to describe the collection of intermediate variables in the process of decision making as illustrate in Fig. 1. In this situation, because of unequivocal and sufficient information of the inner structure of the modelling process present, the white-box interpretation further enhances the description of transparency in the model [2].

Black box and white box illustration
The extension of fuzzy sets introduced by Vicenc Torra [4] can be utilized in deciding the allocation or standards of alternatives engaged with the decision-making issues confronted [5]. As proposed by [6], hesitant fuzzy sets permits several possible membership degrees to be included in a component of a set within a range [0,1] [7]. As it manages vulnerability, hesitant fuzzy sets have been demonstrated in previous studies to show proficiency in decision making. The authors in [8] incorporate hesitant fuzzy set in Technique for Order Preferences by Similarity to Ideal Solution (TOPSIS) in order to select the most appropriate energy policy with the incorporation of maximizing deviation method. On the other hand, Xu et al. [9] provided and overview of a decision support process for incomplete hesitant fuzzy preference relations (HFPRs).
Human encounters issues in settling for right choices depending on the inadequate, loss or questionable data. Thus, Zadeh introduced Z-number as a fuzzy set that can capture the reliability of decisions made through the confidence level of decision makers [10]. Z-numbers prove to be useful in putting forward questionable data as it is an idea worked together in fuzzy theory which portrays the information on individual through the unwavering reliability of decision making. As Z-number holds two elements in an ordered pair fuzzy number, the first element represents the ratings and the second element represents the confidence level of decision makers on the ratings. This new concept is broadly applied in the process involves uncertain information, as the knowledge of human beings is more closely described [11]. Based on the Fuzzy Expectation of the fuzzy set, Z-numbers can be implied as classical fuzzy sets as demonstrated by Kang et al. [10]. Other than the application of Z-number in TOPSIS as carried by Yaakob and Gegov in the enhanced fuzzy rule-based approach in MCDM using Z-number on TOPSIS [12], Aliev and Memmedova [13] applied Z-numbers in modeling the effect of Pilates exercises on psychological of human beings. To conclude, Z-numbers are flexible to be implied in several possible approaches as reliability is assigned to the ratings.
It is crucial for decision makers are aware on the performance of criteria in multicriteria in decision making. However, established TOPSIS methods disclose the performance of benefit and cost criteria due to low transparency inherited [2]. In real situation, experts encounter hesitancy in making decision, for instance, when they have hesitancy to decide whether the alternative is good or very good. Thus, if less information is adapted in the decision making, the end result could be misleading without considering different opinions. Even though there are increasing number of research on the reliability of decision information, but it still in need of better incorporation into modelling complex decision-making processes. For example, how sure the decision makers are in their opinions about their alternatives. The drawbacks mentioned above bring the motivation of this study.
This paper describes the transparency through fuzzy network approach in the formulation proposed. The incorporation of Z-numbers in fuzzy network contributes to reliability in the transparency of decision making and hesitant fuzzy set overcomes the vagueness of decisions inherit in the process. Z-numbers are evaluated by the decision makers as they decide the confidence level towards the ratings made, thus making a more reliable decision. In addition, hesitant fuzzy set is subsumed in fuzzy network to allow decision makers incorporate several possible evaluations out of doubts. When compared with the established research on fuzzy decision making, the proposed Z-HFN has the following interesting advantages and characteristics:
-
1.
This proposed method allows decision makers to give several possible opinions in their evaluations on alternatives.
-
2.
This proposed method allows decision makers to access the performance of alternatives in terms of benefit and cost criteria, thus, increase the level of transparency in the process of decision making.
-
3.
This proposed method also considers the reliability of information which represent the confidence level of decisions.
The proposed method is verified through the comparison of the proposed method to established fuzzy methods under the Spearman’s rho correlation method. This paper presents the theoretical preliminaries in Sect. 2, method formulation in Sect. 3 and case study that testify this method through stocks ranking in Sect. 4. The analysis of results are presented in Sect. 5 with the conclusion of this paper in Sect. 6.
2 Theoretical Preliminaries
2.1 Fuzzy Numbers
A fuzzy number is defined as a fuzzy set that forms a normal convex graph with a single point on a single line [14]. A fuzzy set must represent a normal and convex graph. A fuzzy set is normal if there is only one element, \(x\) in which the membership degree is one through the universe as shown in Fig. 2. A convex fuzzy set is represented by a membership function whose membership values are increasing linearly, or whose membership values are decreasing linearly, or whose membership values are increasing linearly, then decreasing rigidly linear with increasing values for elements in the universe. Convex fuzzy set can be derived mathematically when there exists a relation between element a, b and c in fuzzy set \(\mathop D\limits_{\sim }\) as
when \(a<b<c\).

Membership function of fuzzy number
2.2 Hesitant Fuzzy Numbers
In 2009, Vicenc Torra [4] originated the concept of Hesitant Fuzzy Set (HFS) where every possible evaluation made by decision makers are permitted as the membership degree values of HFS which is defined as:
Definition 1
Hesitant fuzzy set (HFS) returns a subset of [0, 1] when fixed set, X receives HFS as a function [15].
\(h_{Z} \left( x \right)\) is the possible membership degree of the element \(x \in X\) as it stands as a set of values ranging from [0, 1] to the \(HFS\).
2.3 Z-numbers
Z-numbers are a concept that incorporates rating and reliability in computations as shown in Figs. 3 and 4. It is represented in the form of type-1 fuzzy number. \(\tilde{D}\) represents the evaluations in real-valued fuzzy numbers. \(\tilde{E }\) signifies the confidence of decision makers towards the rating of \(\tilde{D }\).

Membership function of ratings in Z-numbers

Membership function of reliability in Z-numbers
2.4 Fuzzy Network
This paper is incorporated with if-then rules and Boolean matrices that are infused through fuzzy rules in the fuzzy network, FN. The choice is demonstrated by the ability of such structured models to operate with any number of nodes in FNs. With these links, these structures can depict nodes in an FN and are used as a bridge between fuzzy systems and FNs. A fuzzy system of fuzzy network is formed through if-then rules before converting it to Boolean matrices. The established Boolean matrix is then formed through nodes that are created from the if-then rules earlier. A Boolean matrix contains information that are derived from the outputs and inputs assigned through rules that are established from if-then rules. Binary values of 1 are applied in the Boolean matrix to show the presence of rules between inputs and outputs and 0 indicates no rules presence [16].
Horizontal merging is an operation in fuzzy network that carries binary values into serial nodes in the same level of the fuzzy network. Referring to Gegov et al. [17], this method can be implied as the output from the first operand nodes and the second operand nodes are merged as the final nodes in the Boolean matrix while the intermediate nodes do not arise in the final product. In comparison to horizontal merging, vertical merging carries a pair of parallel nodes in the operation that carries the binary values. Gegov [1] presents vertical merging as a method that carries the output from the second operand nodes and input from the first operand nodes to be merged in the final product.
3 Method Formulation
A proposed method is presented in this section in the systematic manner, where evaluations made by decision makers are collected independently due to different backgrounds in the field, which contributes to a different level of expertise. The criteria assigned in the evaluation are classified as benefit and cost criteria as output generated from each subsystem will be depicted as Benefit Level (BL) and Cost Level (CL). The proposed method of Z-Hesitant Fuzzy Network (Z-HFN) can be interpreted where inputs are classified firstly into each benefit and cost subsystem before implying as output to the alternative system. The outer frame of the model represents the vertical merging carried out under rule bases and the inner frame which consists of benefit and cost subsystems represents the horizontal merging of rule bases carried in the fuzzy network.
Step 1:
Construct decision matrices where decisions, \({x}_{vy,z}\) and \({w}_{ty,z}\), made by decision makers, \(z\), are converted to Hesitant Fuzzy Sets (HFS). The decisions made by decision makers are represented by the linguistic terms in the rating in Figs. 5 and 6. As \(z = 1, 2, 3,\dots , Z\), these matrices are then categorized according to the criteria determined in the Benefit System and Cost System, which are the Benefit Criteria and Cost Criteria.
for \(z=\mathrm{ 1,2},\dots ,Z\)

Linguistic terms for the ratings of alternatives

Linguistic terms for the importance weight of each criterion
The matrices \({D}_{z}^{B}\) represents the decision matrix of the benefits and \({D}_{z}^{C}\) represents the decision matrix of the costs. \({x}_{vy,z}\) represents the alternative’s rating with respect to the benefit criteria, \({B}_{v}(v=\mathrm{1,2},\dots ,V)\) and \({w}_{ty,z}\) is denoted as the rating of alternatives to the cost criteria, \({C}_{t}(t=\mathrm{1,2},\dots ,T)\)
Step 2:
The reliability of decisions, \(\tilde{E }\), in Z-numbers as shown in Eq. (6), is represented by linguistic terms in Fig. 7. Then, merge both elements in Z-numbers into Type-1 fuzzy number.

Linguistic terms for the reliability of experts
As Z number holds the rating, \(\tilde{D }\) as \(\left\{\tilde{D }=\left(x, {\varphi }_{\tilde{D }}\right)\left|x\in \left[\mathrm{0,1}\right]\right.\right\}\) and the reliability, \(\tilde{E }\) as \(\left\{\tilde{E }=\left(x, {\varphi }_{\tilde{E }}\right)\left|x\in \left[\mathrm{0,1}\right]\right.\right\}\) where the \({\varphi }_{\tilde{D }}\) and \({\varphi }_{\tilde{E }}\) are the membership functions. The method to convert Z-number into Type-1 fuzzy number has been adopted from [10]:
-
(a)
Conversion of the second element (reliability) using Eq. 7
$$\Phi =\frac{\int x{\varphi }_{\tilde{E }}\left(x\right)dx}{\int {\varphi }_{\tilde{E }}\left(x\right)dx}$$(7) -
(b)
Multiply the reliability into the rating in \(\tilde{D }\) thus representing a weighted Z-number. Referring to [10], we can signify weighted Z-number as
$${Z}^{\Phi }=\left\{\langle x, {\varphi }_{{\tilde{D }}^{\Phi }}(x)\rangle \left|{\varphi }_{{\tilde{D }}^{\Phi }}\left(x\right)=\Phi {\varphi }_{{\tilde{D }}^{\Phi }}\left(x\right),x\in \left[\mathrm{0,1}\right]\right.\right\}$$(8)
Theorem 1
\({F}_{{\tilde{D }}^{\Phi }}\left(x\right)=\Phi {F}_{\tilde{D }}\left(x\right), x\in X\)
Proof
-
(c)
Convert the weighted Z-fuzzy number into Type 1 fuzzy number as referred to the Fuzzy Expectation theory [10]. Type-1 fuzzy number can be depicted as
$${\tilde{Z }}^{{{\prime}}}=\left\{\langle x, {\varphi }_{{\tilde{Z }}^{{^{\prime}}}}(x)\rangle \left|{\varphi }_{{\tilde{Z }}^{{^{\prime}}}}\left(x\right)={\varphi }_{\tilde{D }}\left(\frac{x}{\sqrt{\Phi }}\right),x\in \left[{0,1}\right]\right.\right\}$$(11)
Theorem 2
\({F}_{{\tilde{Z }}^{{^{\prime}}}}\left(x\right)=\Phi {F}_{\tilde{D }}\left(x\right), x\in \sqrt{\Phi }X\)
Proof
Theorem 3
Proof
This method concludes that under fuzzy expectation, \({\tilde{Z }}^{{^{\prime}}}\) is equal to \({\tilde{D }}^{\Phi }\).
Step 3:
The hesitant fuzzy positive initial solution (PIS) A+ and hesitant fuzzy negative fuzzy initial solution (NIS) A are derived as follows:
A+ = \(\left\{{{x}}_{v},{ max} \langle {x}_{vy}^{\sigma (\lambda )}\rangle ,{ v }={ 1,2},\dots .{v}\right\}\)
A− = \(\left\{{{x}}_{v},\mathrm{ max} \langle {x}_{vy}^{\sigma (\lambda )}\rangle ,{ v }={ 1,2},\dots .{v}\right\}\)
Step 4:
Determine the distance of alternatives, \({\delta }_{i}^{+}\) and \({\delta }_{i}^{-}\) from the hesitant fuzzy PIS \({A}^{+}\) and NIS \({A}^{-}\) by incorporating the hesitant fuzzy Euclidean distance presented by Xu and Xia [18].
Step 5:
Calculate the relative closeness coefficient, \({C}_{i}\) of alternatives with respect to hesitant fuzzy PIS A+ separately, according to the level of criteria, benefit, and cost criteria, using Eq. (20).
Step 6:
Referring to Yaakob [2], find the Influence Closeness Coefficient (ICC) by adopting the influence degree of decision makers to each of the stock measured. This method is then continued by normalizing the ICC (NICC) by assigning the maximum value of ICC to be divided to each ICC according to the stocks.
\(\theta\) is denoted as the influence degree of decision maker k where the value is between 0 i.e. verified as not influential to 10 i.e. signified as most influential [2]. \(\sigma\) resembles the normalized influence degree of kth decision makers. This method is carried on by assigning the normalized influence degree to each correlation coefficient of stocks accordingly. According to j = 1, 2, … m and k = 1, 2, …, K,
\({ICC}_{j,k}^{B}\) and \({ICC}_{j,k}^{C}\) are then normalized in the equations shown below to obtain values between 0 to 1.
as j = 1, 2, … m and k = 1, 2, …, K.
The normalized influenced closeness coefficient is then converted into linguistic terms that are determined from Fig. 8 to evaluate the level of alternative performances.

Linguistic terms for the level of alternatives
Step 7:
By referring to the NICC values calculated previously and evaluations made earlier by decision makers, build the antecedent and consequent matrices that depict the system of benefit and cost. Build the antecedent matrices of BS and CS with respect to groups, \(k\):
for \(k=\mathrm{1,2}, \dots , K\)\({x}_{em,k}\) and \({y}_{el,k}\) are linguistic terms that reflect the views of decision makers. Consequent matrices are built complementary to the previous antecedent matrices. \({\lambda }_{m,k}\) and \({\psi }_{m,k}\) represent the coefficients in consequent matrices for the benefit system, BS and cost system, CS, respectively.
as \(k=\mathrm{1,2},\dots , K\). where \({\Lambda }_{k}\) and \({\Psi }_{k}\) are linguistic terms representing the output of the BS and CS systems, reflecting the values of \({NICC}_{j.k}^{B}\) and \({NICC}_{j.k}^{C}\).
The benefit system consists of K matrix decision rules presented in Eq. (30).
The previous matrices can best be interpreted in rule bases as
where \(BL\) is the benefit level of alternatives, for \(j=1,\dots ,m\) and for \(k=1,\dots ,K\). The same formulation is implied on the cost system of K matrix decision rules where:
as matrices k = 1, 2, …, K.
The previous matrices can best be interpreted in rule bases as
With the cost level of alternatives represented by \(CL\), for \(j=1,\dots ,m\) and, for \(k=1,\dots ,K\)
Step 8:
Define the alternative system (AS), \({M}_{k}\). AS can be constructed based on the antecedent and consequent matrices built. As k = 1,2,…..K,
The measured levels of the same alternative \(j\) is represented by each row of inputs for this case. Hence, the AS antecedent matrices, \({M}_{k}\), are developed as the size of \(m\times 2\) as in Eq. (35).
To complement the antecedent matrices of AS, the AS consequent matrices are retrieved accordingly:
-
(i)
Calculate the aggregation, \({\xi }_{j,k}\) of the weighted \({NICC}_{j.k}^{B}\) and \({NICC}_{j.k}^{C}\) as in Eq. (36).
$${\xi }_{j,k}=\frac{ {NICC}_{j.k}^{B}\times \left(\frac{e}{e+f}\right)+{NICC}_{j.k}^{C}\times \left(\frac{f}{e+f}\right)}{2}$$(36)According to \(j = 1, 2, \dots m\) and \(k = 1, 2, \dots , K\).
-
(ii)
Normalizing the values of \({\xi }_{j,k}\) to confirm their values lie in between [0,1].
$${N\xi }_{j,k}= {\xi }_{j,k}/{\mathrm{max}}_{j}{\xi }_{j,k}$$(37)as \(j = 1, 2, \dots m\) and \(k = 1, 2, \dots , K\).
-
(iii)
The normalized value of \({\xi }_{j,k}\) is then translated into linguistic terms as listed in Fig. 8 which represent the alternative levels. Then, the K for AS consequent matrices, in this case of size \(1\times m\) rather than \(1 \times m\cdot m\), are described in Eq. (38).
$${N}_{k}=AL\left[{N\xi }_{1,k}, {N\xi }_{2,k}\cdots {N\xi }_{m,k}\right] \,{\rm for}\, k=1,\dots ,K$$(38)
Alternative levels are categorised as AL. Thus, decision rules in \(K\) matrices, represents the system of alternatives:
If \({M}_{k}= \begin{array}{c}BL\\ CL\end{array}\left[\begin{array}{ccc}{\lambda }_{1,k}& ,& \begin{array}{ccc}{\lambda }_{2,k}& ,& \begin{array}{ccc}{\lambda }_{3,k}& \cdots & {\lambda }_{m,k}\end{array}\end{array}\\ {\psi }_{1,k}& ,& \begin{array}{ccc}{\psi }_{2,k}& ,& \begin{array}{ccc}{\psi }_{3,k}& \cdots & {\psi }_{m,k}\end{array}\end{array}\end{array}\right]\),
for \(k=1,\dots ,K\)and can best be interpreted in rule bases
as \(k=1,\dots ,K\).
Step 9:
Derived rules are interpreted into generalised Boolean matrix. Generalised Boolean matrix depict the overall system represented by \(BS\), \(CS\) and \(AS\) systems. Referring to the evaluations of decision makers,
The possible transposition of the benefit system rule base is depicted by the rows and columns of the previous Boolean matrix. The transposition implements linguistic terms from Figs. 5 and 6 to represent the input and the linguistic terms in Fig. 8 to represent the end result.
as \(j=\mathrm{1,2}, \dots , m\).
The same method is applied on CS where similar linguistic terms are also implied as BS. To form a generalized Boolean matrix that includes BS generalized Boolean matrices and CS generalized Boolean matrices, vertical merging is applied in the form of Eq. (43).
for \(j = 1, 2, \dots , m\)
AS generalized Boolean matrix are constructed based on \(j\) alternatives accordingly as in Eq. (44)
The resultant generalized Boolean matrix is then formed as in Eq. (45).
Step 10:
Generalized Boolean matrix from Eq. (45) is constructed to form the rules of alternatives as referred below for \(j = 1 , 2, ... m\)
Step 11:
Derive a final score for each alternative. The final score for each alternative, \({\Omega }_{j}\) can be derived by multiplying the aggregate membership value of the consequent part of the \({n}_{j}\) rules,\({N\xi }_{j,k}\), to the summation of benefit and cost NICC, \({NICC}_{j,k}^{B}\) and \({NICC}_{j,k}^{C}\). Then, averaging in accordance to the number of rules and decision makers are performed. Thus, every alternative is ranked accordingly based on the final score attained. To evaluate its performance, we consider implementing this method in stock evaluation using 30 stocks.
as \(j=1, 2, \dots , m\).
4 Case Study: Stock Evaluation
This case study involves 30 stocks as alternatives to be evaluated by decision makers from 3 groups. The decisions from decision makers were merged according to groups into HFEs. Six criteria were categorised into four benefit system and two cost system. The process of ranking these stocks followed the proposed methods presented in Sect. 3.
Step 1:
The rating from 3 groups of experts were applied in the form of Z-HFS after converted to fuzzy number based on Figs. 5, 6 and 7. Here, the reliability of experts is taken into consideration during the decision-making process. The experts are advised to use the linguistic terms in Fig. 7 to evaluate the confidence in their decision. Decision makers are not supposed to use negative weight to represent their opinion. Otherwise, this would imply the use of unreliable information which is undesirable. Decision matrices were constructed afterwards according to the benefit and cost systems as Eqs. (4) (5).
Step 2:
Equations (6) and (7) were utilized in determining the hesitant fuzzy PIS (A+) and NIS (A−) according to decision makers separately:
A+ = {〈 0.745, 0.927, 0.927, 1, 〈 0.343, 0.519, 0.519, 0.716, 〈 0.025, 0.142, 0.142, 0.319, 〈 0.32, 0.522, 0.522, 0.702,〈 0.588, 0.777, 0.777, 0.928, 〈 0.089, 0.17, 0.17, 0.273}.
A- = {〈 0, 0.078, 0.078, 0.251, 〈 0, 0.016, 0.016, 0.106, 〈 0.72, 0.896, 0.896, 0.96, 〈 0, 0.016, 0.016, 0.097,〈 0, 0.026, 0.026, 0.141,〈 0.263, 0.361, 0.361, 0.43}
Step 3:
The distance, \({\delta }^{+}\) and \({\delta }^{-}\) were calculated according to each cost and benefit criteria. Alternatives, \({A}_{i}\) from the \({A}^{+}\) and A− using the Eqs. (8) and (9) as shown in Table 1.
Step 4:
The relative closeness coefficient \(Ci\) of each alternative Ai to the hesitant fuzzy PIS, A+ were calculated in Table 2.
Step 5:
The Influence Closeness Coefficient (ICC) and Normalized Influence Closeness Coefficient (NICC) were calculated by referring to Eq. (11) to Eq. (15). To exemplify, influence degree of G1 is \({\theta }_{1}=5\). Influence degree is determined by the groups themselves via linguistic terms in Fig. 2 which was then interpreted into a numerical value according to the level of linguistic terms in Fig. 2. The influence degree of G1 is calculated as Table 3.
To generate ICC, the influence degree of each group to the closeness coefficient of alternatives were calculated accordingly as in Eqs. (12) and (13). Then in accordance to Eqs. (14) and (15), the NICC of each alternative with respect to the criteria divided were determined.
Step 6:
The rule base for the benefit System (BS) and Cost System (CS) were constructed based on the NICC calculated.
The NICC obtained was converted into linguistic terms referring to Fig. 2 in order to form the antecedent and consequent matrices of both BS and CS as performed in Eq. (16–23).
Step 7:
The antecedent matrices, \({M}_{k}\), of the Alternatives System (AS) of each DM \(k\) are constructed based on the Benefit Level (BL) and Cost Level (CL), which are the outputs of the benefit system BS and cost system CS, respectively. Based on the opinion of G1,
The AS consequent matrices are derived as follows:
-
i.
Calculation of the aggregation \({\xi }_{j,1}\) of weighted \({NICC}_{j.1}^{B}\) and \({NICC}_{j.1}^{C}\)
$${\xi }_{1,1}=\frac{ {NICC}_{\mathrm{1,1}}^{B}\times \left(\frac{e}{e+f}\right)+{NICC}_{\mathrm{1,1}}^{C}\times \left(\frac{f}{e+f}\right)}{2}$$$$= \frac{0.484789\times \left(\frac{4}{2+4}\right)+0.631889\times \left(\frac{2}{2+4}\right)}{2}$$$$=0.291428$$ -
ii.
Normalization of the values of \({\xi }_{j,k}\) to confirm their values lie in between [0,1].
$${N\xi }_{1,1}= {\xi }_{1,1}/{\mathrm{max}}_{j}{\xi }_{j,1}.=0.291428 /0.5=0.582856= R$$ -
iii.
The value of \({N\xi }_{1,1}\) were converted to linguistic terms as listed in Fig. 8.
The AS consequent matrix \({N}_{1}\) for DM1 is constructed based on the values of \({N\xi }_{j,1}\) or each alternative,\(j\).
The alternatives system of G1 is presented as:
If \({M}_{1}= \begin{array}{c}BL\\ CL\end{array}\left[\begin{array}{ccc}R& ,& \begin{array}{ccc}G& ,\cdots ,& G\end{array}\\ G& ,& \begin{array}{ccc}B& ,\cdots , & R\end{array}\end{array}\right]\), then \({N}_{1}=AL\left[R, B\cdots R\right]\)
can best be interpreted in rule bases as follows.
Step 8:
BS, CS and AS derived rules are presented in Boolean matrix form. The Boolean benefit system matrix for S1 is generated as shown below.
1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
1111 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : |
2222 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : |
3333 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : |
4444 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : |
5 1 1 2 | 0 | 0 | 1 | 0 | 0 |
5 1 1 3 | 0 | 0 | 0 | 1 | 0 |
5555 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : |
6666 | 0 | 0 | 0 | 0 | 0 |
7 2 2 4 | 0 | 0 | 1 | 0 | 0 |
The Boolean cost system matrix for S1 is generated as shown below.
1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
11 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : |
22 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : |
33 | 0 | 0 | 0 | 0 | 0 |
3 5 | 0 | 1 | 0 | 0 | 0 |
3 6 | 0 | 1 | 0 | 0 | 0 |
: | : | : | : | : | : |
44 | 0 | 0 | 0 | 0 | 0 |
4 7 | 0 | 0 | 0 | 1 | 1 |
: | : | : | : | : | : |
55 | 0 | 0 | 0 | 0 | 0 |
In order to form a generalized Boolean matrix that includes BS generalized Boolean matrices and CS generalized Boolean matrices, vertical merging was implied.
11 | 22 | 23 | 24 | 25 | 33 | 34 | 35 | 42 | 44 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
4444/44 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : | : | : | : | : | : | : | : |
5555/55 | : | : | : | : | : | : | 0 | 0 | : | 0 | : | 0 |
5 1 1 2/35 | : | : | : | 1 | : | : | 0 | 0 | : | 0 | : | 0 |
5 1 1 2/36 | : | : | : | 1 | : | : | 0 | 0 | : | 0 | : | 0 |
5 1 1 2/47 | : | : | : | : | : | 1 | 0 | 0 | : | 0 | : | 0 |
5 1 1 3/35 | : | : | : | : | : | : | 1 | 0 | : | 0 | : | 0 |
5 1 1 3/36 | : | : | : | : | : | : | 1 | 0 | : | : | : | 0 |
5 1 1 3/47 | : | : | : | : | : | : | 0 | 0 | 1 | 0 | : | 0 |
7 2 2 4/35 | : | : | : | : | : | : | 1 | 0 | : | 0 | : | 0 |
7 2 2 4/35 | : | : | : | : | : | : | 1 | 0 | : | 0 | : | 0 |
7 2 2 4/47 | : | : | : | : | : | : | 0 | : | 1 | 0 | : | 0 |
The AS Boolean matrix for S1 is evaluated as follows:
1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
11 | 0 | 0 | 0 | 0 | 0 |
: | : | : | : | : | : |
23 | : | 0 | 1 | : | : |
24 | : | 0 | 0 | : | : |
32 | : | 0 | 0 | : | : |
33 | : | 0 | 1 | : | : |
34 | : | 0 | 0 | : | : |
3 5 | : | 0 | 0 | 1 | : |
: | : | : | : | : | : |
42 | : | 0 | : | : | : |
44 | : | 0 | : | : | : |
The resulting Boolean matrix generated to represent the overall system is as shown below.
1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
1111/11 | 0 | 0 | 0 | 0 | 0 |
5555/55 | 0 | 0 | 0 | 0 | 0 |
5 1 1 2/35 | : | 0 | 1 | : | : |
5 1 1 2/36 | : | 0 | 1 | : | : |
5 1 1 2/47/NA | : | 0 | : | : | : |
5 1 1 3/35 | : | 0 | 1 | : | : |
5113/36 | : | 0 | 1 | : | : |
: | : | 0 | : | 0 | : |
5 1 1 3/47 | : | 0 | : | 1 | : |
7224/35/3 | : | : | 1 | 0 | : |
7224/36/3 | : | : | 1 | 0 | : |
7224/47 | : | : | 0 | 1 | : |
7777/77/5 | : | : | 0 | : | : |
From the Boolean matrix generated previously, the rule basis for stock S1 was derived as follows:
Rule 1: | 5 1 1 2/35/3 | 5112 | 35 | 3 | R |
|---|---|---|---|---|---|
Rule 2: | 5 1 1 2/36/3 | 5112 | 36 | 3 | R |
Rule 3: | 5 1 1 3/35/3 | 5113 | 35 | 3 | R |
Rule 4: | 5 1 1 3/36/3 | 5113 | 36 | 3 | R |
Rule 5: | 5 1 1 3/47/4 | 5113 | 47 | 4 | G |
Five rules were obtained that can be interpreted according to the linguistic terms on the level of rating as:
Rule 1: If \({B}_{1}\) is VG and \({B}_{2}\) is VP and \({B}_{3}\) is VP and \({B}_{4}\) is P and \({C}_{1}\) is MP and \({C}_{2}\) is MG then \({S}_{1}\) is R.
Rule 2: If \({B}_{1}\) is VG and \({B}_{2}\) is VP and \({B}_{3}\) is VP and \({B}_{4}\) is P and \({C}_{1}\) is MP and \({C}_{2}\) is G then \({S}_{1}\) is R.
Rule 3: If \({B}_{1}\) is VG and \({B}_{2}\) is VP and \({B}_{3}\) is VP and \({B}_{4}\) is MP and \({C}_{1}\) is MP and \({C}_{2}\) is MG then \({S}_{1}\) is R.
Rule 4: If \({B}_{1}\) is MG and \({B}_{2}\) is VP and \({B}_{3}\) is VP and \({B}_{4}\) is MP and \({C}_{1}\) is MP and \({C}_{2}\) is G then \({S}_{1}\) is R.
Rule 5: If \({B}_{1}\) is VG and \({B}_{2}\) is VP and \({B}_{3}\) is VP and \({B}_{4}\) is F and \({C}_{1}\) is MG and \({C}_{2}\) is VG then \({S}_{1}\) is G.
Step 9:
For each alternative, the final score was derived from Eq. (47). There were 5 active rules formulated for S1 as the end result and the final score for S1 was obtained by implementing the equation. Then, the calculation proceeded to find the average aggregate membership value in order to be infused to the influence multiplier.
A better ranking position is defined by the highest final score attained. Thus, Stock 14 was ranked the highest as compared to other stocks due to its highest final score. As proposed earlier, the Spearman’rho correlation was adapted in order to evaluate the performance of the proposed method to compare to its actual rank.
5 Analysis of Result
For the purpose of validation for the proposed method, the comparison to established Fuzzy TOPSIS methods is considered in Table 4. It is shown that Z-numbers could assist in determining better result with the merging in reliability of decisions to the ratings.
Table 5 presents the comparison between the proposed method and three established methods based on transparency, reliability and hesitancy. Utilizing the Spearman’s rho correlation coefficient, the rankings of stocks obtained by the methods considered are compared, where the strength of relationship between variables are measured [21]. Owing to anomalies, this statistical significance is instinctively comprehensible and less bias. It is observed that the proposed method performed as well as [22] and [20]. The proposed method offers hesitancy in comparison to Yaakob et al. [12], which scored 0.712 and 0.697 in Spearman’s rho, respectively. Thus, the proposed method proves that hesitant fuzzy set helps in solving vulnerability in decision making. In addition, both the proposed method and Wang & Mao [19] incorporated Z-numbers, but the proposed method promotes fuzzy network which contributes to improve the transparency of decisions, thus resulting in a higher score of Spearman’s rho as compared to Wang & Mao.
Chen & Lee scored the highest Spearman’s rho which was 0.715. In comparison to the proposed method, they implied a type-2 fuzzy number which offers the minimization of uncertainties effects in a rule-based fuzzy system. As highlighted in [23], type-2 fuzzy sets serve an additional degree of freedom due to its three-dimensional membership function. Thus, type-2 fuzzy set offers a membership degree with higher accuracy and precision in fuzziness. As shown in Fig. 9, it is observed that stocks ranked using Z-HFN are almost similar to the ranking of actual stocks and the rankings in the established methods. This paper proposed a novel method of Z-Hesitant Fuzzy Network TOPSIS (Z-HFN TOPSIS), in which the fuzzy network has improvised the transparency of decision making by thoroughly evaluate all subsystems and dynamical communication between them. The method is then enhanced by incorporating the Z-numbers in cooperating reliability which can depict the confidence level of ratings made by decision makers.

Ranking of stocks
Considering the six criteria used in the case study of stock selection described in Sect. 4, the proposed model Z-HFN TOPSIS perform as well as the other established TOPSIS methods, as shown in the last row of Table 5.
6 Conclusion
This paper proposed novel decision making method using fuzzy network approach that incorporates Z- numbers with hesitant fuzzy sets. The advantages of the proposed method not only contribute to solving hesitancy in decision making, but also incorporates the expertise level of decision makers. Another contribution of proposed method is the incorporation of fuzzy network that increase the level of transparency in the process of decision making by allowing decision makers to access the performance of alternatives in terms of benefit and cost criteria. The limitation of proposed method is the attention given to the subject is only in small scale of group decision making. Hence, for the future, this research can be conducted for large scale group decision making. Moreover, it is also interesting to check relation of this research with R-sets.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Gegov, A.: Fuzzy Networks for Complex Systems. Springer, Berlin (2010)
Yaakob, A.M., Serguieva, A., Gegov, A.: FN-TOPSIS: Fuzzy networks for ranking traded equities. IEEE Trans. Fuzzy Syst. 2, 3 (2017)
Loyola-Gonzalez, O.: Black-box vs. white-box: Understanding their advantages and weaknesses from a practical point of view. IEEE Access 7, 154096–154113 (2019)
V. Torra and Y. Narukawa, "On Hesitant Fuzzy Sets and Decision," in IEEE International Conference on Fuzzy Systems , Korea, 2009.
Wang, L., Rodriguez, R.M., Wang, Y.-M.: A dynamic multi-attribute group emergency decision making method considering experts’ hesitation. Int. J. Comput. Intell. Syst. 11, 163–182 (2018)
Chen, N., Xu, Z., Xia, M.: The ELECTRE I multi-criteria decision-making method based on hesitant fuzzy sets. Int. J. Inf. Technol. Decis. Mak. 14(03), 621–657 (2015)
Xia, M., Xu, Z.: Hesitant fuzzy information aggregation in decision making. Int. J. Approx. Reason. 52, 395–407 (2011)
Xu, Z., Zhang, X.: Hesitant fuzzy multi-attribute decision making based on TOPSIS with incomplete weight information. Knowl.-Based Syst. 52, 53–64 (2013)
Xu, Y., Li, C., Wen, X.: Missing values estimation and consensus building for incomplete hesitant fuzzy preference relations with multiplicative consistency. Int. J. Comput. Intell. Syst. 11, 101–119 (2018)
Kang, B., Wei, D., Li, Y., Deng, Y.: A method of converting Z-number to classical fuzzy number. J. Inf. Comput. Sci. 9(3), 703–709 (2012)
Bahrami, S., Yaakob, R., Azman, A., Atan, R.: A review on Z-numbers. Int J Eng Technol 7(4), 487–490 (2018)
Yaakob, A.M., Gegov, A., Abdul Rahman, S.F.: Selection of alternatives using fuzzy networks with rule base aggregation. Fuzzy Set Syst. 341, 1–8 (2018)
Aliev, R., Memmedova, K.: Application of Z-number based modelling in psychological research. Comput. Intell. Neurosci. 2015, 1–7 (2015)
T. J. Ross, "Properties of Membership Function, Fuzzification and Defuzzification," in Fuzzy Logic with Engineering Applications, Third Edition, University of New Mexico, USA, John Wiley & Sons, Ltd. , pp. 89–92, 2010
Xu, Z.: Hesitant Fuzzy Sets Theory, vol. 314. Springer International Publishing, Cham (2014)
Latinovic, M., Dragovic, I., Arsic, V.B., Petrovic, B.: A fuzzy inference system for credit scoring using Boolean consistent fuzzy logic. Int. J. Comput. Intell. Syst. 11(1), 414–427 (2018)
Gegov, A., Arabikhan, F., Petrov, N.: Linguistic composition based modelling by fuzzy networks with modular rule bases. Fuzzy Sets Syst 2, 1–29 (2014)
Xu, Z., Xia, M.: Distance and similarity measures for hesitant fuzzy sets. Inf. Sci. 181(11), 2128–2138 (2011)
Wang, F., Mao, J.: Approach to multicriteria group decision making with Z-numbers based on TOPSIS and power aggregation operators. Math. Probl. Eng. 2019, 1–18 (2019)
Chen, S.M., Lee, L.W.: Fuzzy multiple attributes group decision-making based on the interval type-2 TOPSIS method. Expert Syst. Appl. 37(4), 2790–2798 (2010)
Sedgwick, P.: Spearman’s rank correlation coefficient. BMJ 349, 1–3 (2014)
Chen, C.-T.: Extensions of the TOPSIS for group decision-making under fuzzy environment. Fuzzy Sets Syst. 114(1), 1–9 (2000)
Mendel, J.M., John, R.: Type-2 fuzzy sets made simple. IEEE Trans. Fuzzy Syst. 10(2), 117–127 (2002)
Acknowledgements
This work was funded by Ministry of Higher Education, Malaysia (Grant no.: S/O Code:14392).
Funding
This research was support by Ministry of Higher Education (MOHE) of Malaysia through Fundamental Research Grant Scheme (FRGS/1/2019/STG06/UUM/02/6). We also want to thank to Government of Malaysia which provide MyBrain15 program for sponsoring this work under the self-fund research grant and L00022 from Ministry of Science, Technology and Innovation (MOSTI).
Author information
Authors and Affiliations
Contributions
The authors confirm same responsibility of the authors on contribution to the research and preparation of articles. All authors reviewed the results and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors can confirm that there are no relevant financial or non-financial competing interests to report.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yaakob, A.M., Shafie, S., Gegov, A. et al. Z-Hesitant Fuzzy Network Model with Reliability and Transparency of Information for Decision Systems. Int J Comput Intell Syst 14, 176 (2021). https://doi.org/10.1007/s44196-021-00029-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-021-00029-6