
Abstract
In the big data era, promising telecom companies need to develop their user strategies when facing large-scale data. For this purpose, we considered a typical strategy decision problem like market segmentation using a novel group sorting method based on FlowSort and applied it to a real case in the telecom market. A novel Group-FlowSort procedure based on stochastic multi-criteria acceptability analysis (SMAA) was developed for sorting large-scale problems. This method could process and integrate multiple expert opinions to reach a consensus by using the Clustering In QUEst (CLIQUE) algorithm and an improved Jaya algorithm. Furthermore, Group-FlowSort based on SMAA-2 is proposed to eliminate the impact of incomplete preference information and several main characteristics and properties are discussed. In addition, a real case study including 8000 customers and 25 experts is used to illustrate the feasibility of the proposed method for telecom market segmentation. Finally, a comparative analysis with FlowSort-GDSS and sensitivity analysis using SMAA-2 are demonstrated to verify the effectiveness and robustness of the method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Market segmentation is a strategy to divide a large market into homogenous segments of consumers with common needs, characteristics, or behaviors (Beane and Ennis 2013). The firm could understand customers’ preferences and needs using target market strategies and tailor different strategies for targeted segments. As a result, consumer satisfaction is improved and the revenue of the firm increases (Liu et al. 2018). In this study, we use a multi-criteria sorting technique to examine the market segmentation of telecom customers to help enterprises make reasonable packages based on customers’ performance. Considering the overall framework, the key point of the telecom market segmentation is accounting for customers’ preferences based on the combination of all criteria describing customers’ consumption performance. Once groups with similar preferences are distinguished, telecoms can provide targeted information, products, and services according to the needs of the groups. In this process, diverse criteria for telecom user characteristics are vital in telecom market segmentation. Thus, it can be regarded as a multi-criteria sorting (MCS) problem, and the customers in market can be seen as alternatives to be classified.
It is commonly acknowledged that MCS methods provide a set of powerful decision-support tools and methods to address decision problems. Preference Ranking Organization Methods For Enrichment Evaluations (PROMETHEE) (Angilella and Pappalardo 2021; Behzadian et al. 2010) is one of the most commonly used multi-criteria decision analysis (MCDA) methods. Based on PROMETHEE, the FlowSort (Nemery and Lamboray 2008) method, an MCDA sorting method for independent assignments and completely ordered categories, was proposed.
FlowSort is rapidly becoming a key instrument for sorting problems with three different assignment rules based on positive flow, negative flow, and net flow. With its advantages of accurate classification and computational simplicity, FlowSort and its variants have been used extensively in MCDA problems (Pelissari et al. 2019). However, three essential obstacles in FlowSort that require further study.
-
It is difficult to determine the precise weights of the criteria using incomplete or inaccurate information provided by experts.
-
Existing FlowSort-based models fail to focus on large-scale problems, which refers to the problem with numerous alternatives. In large-scale problems with practical significance, identifying the number of categories is technically challenging.
-
As the number of decision makers (DMs) increase and the amount of information become correspondingly larger for group decision-making problems, it is difficult to obtain a high-consensus solution to develop limiting profiles or central profiles. Moreover, existing MCDA sorting methods often lead to inconsistent sorting results for the same problem (Chang et al. 2013).
In this study, we introduce a novel group sorting method based on FlowSort for large-scale problems with inaccurate information to address the problems mentioned above.
In general, several contributions of this study could be summarized as follows:
-
First, a novel Group-FlowSort was developed. Integrated with stochastic multi-criteria acceptability analysis 2 (SMAA-2) (Lahdelma and Salminen 2001), a multi-criteria decision aid method suitable for problems with inaccurate and uncertain input data, can deal with imprecise information by Monte Carlo simulation. With the advantages of SMAA-2 and FlowSort, the proposed method can satisfy the requirements of facility and objectivity in sorting problems with uncertain preference information.
-
Second, in practical large-scale problems, there may be contradictions among experts in the number of classes, and this problem could be objectively solved using the CLIQUE algorithm (Agrawal et al. 1998), a clustering method based on density and grid. From an optimizing perspective, we improve the Jaya algorithm (Rao 2016) in terms of the objective function and termination condition to tackle the consensus-reaching process in large-scale problems, reaching a compromise solution of the optimal reference profile for each category.
-
Third, a real large-scale case concerning the market segmentation of the telecom industry is provided. In the case study, the existing market is divided into sub-markets with different consumption levels, providing meaningful references for telecom companies to focus more on high-value customers’ demand.
The remainder of this paper is organized as follows. Some preliminaries, including market segmentation, consensus-reaching process, FlowSort and SMAA, are reviewed in Sect. 2. Section 3 presents the novel Group-FlowSort method for sorting large-scale problems. In Sect. 4, a case study of a telecom market segmentation is detailed to clarify the proposed method. Section 5 presents a comparative analysis with the FlowSort-GDSS method and a sensitivity analysis to demonstrate the applicability and robustness of the proposed method. Finally, conclusions and recommendations for future studies are presented in Sect. 6.
2 Literature review
2.1 Market segmentation
Market segmentation (Smith 1956) divides a large market into several segments of customers who have common demands and applications for the products or services provided in the market (Huerta-Muñoz et al. 2017). The pertinent concepts of market segmentation have been applied in many research fields, including the women’s clothing market (Dowling and Midgley 1988), chain convenience store management (Han et al. 2014), the telephone and telegraph market (Kiang et al. 2006), the mobile service market (Liu et al. 2010), the electricity generation industry (Zheng et al. 2021), the trial-offer markets (Berbeglia et al. 2021) and so forth. Market segmentation has become increasingly critical, especially after deregulation (Teichert et al. 2008).
There are two main streams of market segmentation: a priori approach and a post-hoc approach. When the variables used as criteria are known in advance, a priori segmentation is applied. In contrast, in post-hoc segmentation, segments are specified in view of empirical results. In other words, post-hoc approaches are based on group of variables (Liu et al. 2018). There are many methods that use post-hoc approaches, including category management (Han et al. 2014), classification and regression trees (CART) (Fan and Zhang 2009) and clustering (Balakrishnan et al. 2011).
2.2 Consensus-reaching process
Consensus-reaching process is undoubtedly an essential part of group decision making problem, which aims to make optimal decision considering various opinions of a group of experts (Patrik et al. 2007; Song et al. 2022; Sun and Ma 2015). Due to the different experience and knowledge of experts, there are great differences in their preferences. Therefore, consensus-reaching process has been proposed to eliminate preference conflicts, integrate different opinions and choose the best alternative (Pérez et al. 2018; Song et al. 2021).
Consensus-reaching process is an iterative process, in which opinions of experts are constantly updated. After each iteration, it is necessary to check whether the value of group consensus level reaches the given consensus threshold, and then decide whether to start the next iteration or make the final decision (Herrera et al. 2001), which can be seen as a feedback mechanism to promote consensus (Wu and Xu 2018).
In recent years, consensus-reaching process has received extensive attention due to its practical value. There are two primary methods to solve this challenging problem. The first method is to distinguish the experts whose preference is quite different from the collective preference and persuade them to change their opinions (Tian et al. 2019; Wu and Xu 2018). In addition, in order to increase efficiency of consensus-reaching process, clustering method has been used to divide experts into several subgroups, integrating the opinions step by step (Kamis et al. 2018; Zhong and Xu 2020). In this study, we use CLIQUE algorithm and an improved Jaya algorithm to cluster experts.
2.3 FlowSort
FlowSort (Nemery and Lamboray 2008) is a PROMETHEE-based sorting method developed for assigning alternatives to predefined classes with either limiting or central profiles. With the ease of computation, FlowSort has been extensively applied to sorting problems in various fields ranging from economy and enterprise management to applications in evaluating industrial production (Lolli et al. 2015; Rahmanimanesh et al. 2018; Verheyden and Moor 2014).
FlowSort has experienced several improvements, most of which focus on information imperfection. For instance, FlowSort was combined with interval theory (Nemery and Janssen 2013), making it feasible to define imprecise input data by intervals rather than a single value. In 2015, fuzzy set theory was introduced to the original FlowSort method, and the fuzzy FlowSort (F-FlowSort) method (Campos et al. 2015) was developed for decision-making problems with some imperfect data types. Afterwards, to deal with the elicitation of criteria weights with imperfect preference information, a FlowSort-based method was integrated with SMAA (Pelissari et al. 2019, 2020).
FlowSort has great potential to manage large-scale problems considering its flexibility and computational simplicity; however, research on it is quite rare. In 2015, a novel integrated method, FlowSort-GDSS (Lolli et al. 2015) was proposed based on the integration of FlowSort and group decision-support systems (GDSS). However, the calculations in FlowSort-GDSS would become far more complicated and time-consuming when applied to a large-scale problem. To overcome these challenges, we propose a new Group-FlowSort-based method for large-scale problems with imprecise information.
2.4 Stochastic multi-criteria acceptability analysis (SMAA)
SMAA (Tervonen and Figueira 2008) is a family that includes a series of MCDA methods applied to problems with incompleteness, imprecision, or uncertainty preference information (Smets 1991). By using Monte Carlo simulation, SMAA variant methods could provide each alternative’s possibilities of being classified into all ranks or classes instead of a single exact result.
The SMAA was developed in 1998 (Lahdelma et al. 1998) by introducing three descriptive measures, including the acceptability index, the central weight vector, and the confidence factor. In 2001, SMAA-2 (Lahdelma and Salminen 2001) was proposed to extend the SMAA by considering all ranks with the rank acceptability index, three k-best rank-type measures, and the holistic acceptability index. In 2003, SMAA-O (Lahdelma et al. 2003) which considers ordinal criteria, was proposed. Subsequently, SMAA-A (Lahdelma et al. 2005) improved the deficiency of traditional goal programming with achievement functions and integrated it with prospect theory. Then, SMAA-P (Lahdelma and Salminen 2009) allows for the risk-averse behavior of decision makers. Besides, SMAA-3 (Hokkanen et al. 1998), SMAA-PROMETHEE (Corrente et al. 2014), SMAA‐ELECTRE (Zhou et al. 2019), SMAA-TODIM (Zhang et al. 2017), SMAA-M (García-Cáceres 2020; García-Cáceres et al. 2022) and other variants of the SMAA family were exploited to handle different problems (Wang et al. 2020). In this study, we used SMAA-2 to consider all ranks more holistically.
3 The proposed model: Group-FlowSort
In this section, Group-FlowSort is proposed to solve large-scale problems. The scheme of the proposed method is shown in Fig. 1. In phase 1, we define the decision problem including the set of alternatives, the system of criteria, the number of DMs, and so on. In phase 2, a consensus-reaching process based on reference profiles was conducted using the CLIQUE algorithm and an improved Jaya algorithm. In phase 3, using FlowSort and SMAA-2, we sort alternatives with imprecise information. This sorting process can be applied to market segmentation, which can be regarded as the sorting of customers.

The flowchart of the Group-FlowSort
3.1 Problem definition
In a large-scale group sorting problem, the fundamental notations are as follows.
-
1.
We define \(A=\{{a}_{1},{a}_{2},\dots ,{{a}_{i},\dots ,a}_{n}\}\) as the large-scale set of \(n\) alternatives that need to be sorted, and let \(G=\{{g}_{1},{g}_{2},\dots ,{g}_{j},{\dots ,g}_{m}\}\) be the set of \(m\) criteria, among which \({g}_{j}\) is considered as the \(j\)th criterion.
-
2.
Denote the set of weights \(W=\{{w}_{1},w,\dots ,{w}_{j},{\dots ,w}_{m}\}\) as the weights of the \(m\) criteria.
-
3.
Define \(E=\left\{{e}_{1},{e}_{2},\dots ,{{e}_{t},\dots ,e}_{s}\right\}\), which represents \(s\) experts whose opinions are input in the method.
-
4.
Determining and characterizing the classes. \(R\) is the set of reference profiles that characterize the \(k\) categories \(C=\left\{{C}_{1}, {C}_{2},\dots .,{C}_{h},\dots ,{C}_{k}\right\}\), where \({C}_{1}\) is the best category and \({C}_{k}\) is the worst \(\left( {C_{k} \triangleleft C_{k - 1} \triangleleft \ldots \triangleleft C_{1} } \right)\), where \(C_{l} \triangleleft C_{h}\) with \(h<l\) denotes that the class \({C}_{h}\) is preferred to \({C}_{l}\).
To describe the classes with reference profiles, both lps \({R}_{lp}=\{{lp}_{1},{lp}_{2},\dots ,{lp}_{h},\dots ,{lp}_{k+1}\}\) and cps \({R}_{cp}=\{{cp}_{1},{cp}_{2},\dots ,{cp}_{h},\dots ,{cp}_{k}\}\) are considered. The former represents the worst or best performance of the corresponding class, and the latter represents the typical performance.
3.2 A novel Group-FlowSort for sorting large-scale problems
In this subsection, a novel Group-FlowSort method applicable to large-scale problems is developed. First, the CLIQUE algorithm and an improved Jaya algorithm are provided to reach a consensus among the DMs. Then, we use FlowSort to allocate alternatives to completely ordered classes. Finally, the sorting results are presented. Four descriptive measures were obtained based on SMAA-2.
3.2.1 CLIQUE algorithm
In large-scale problems with a large number of alternatives and several criteria, experts’ opinions on the appropriate number of classes differ. In this study, the number of categories is objectively defined by CLIQUE (Agrawal et al. 1998) based on the original opinions of experts.
CLIQUE is a clustering method in terms of density and grid, obtaining the low-dimensional clusters that exist in the high-dimensional space step by step. Hence, the final clustering results exist not only in the full-dimensional space but also in its subspace. In addition, the result is independent of the order of the alternatives. Therefore, CLIQUE is suitable for processing high-dimensional and large-scale data. After the CLIQUE process, we derive the adjusted experts’ opinions on market segmentation with the same number of categories.
3.2.2 An improved Jaya algorithm
In the traditional Jaya algorithm (Rao 2016), after generating the initial solution stochastically according to the upper and lower bounds of the process variables, the \(t\)th expert’s opinion of the iteration function value in \((l+1)\)th iteration is updated randomly using Eq. (1):
where \(t\) represents the index of the \(t\)th expert of the objective function among the criteria. \(b\) and \(w\) are the indices of the maximum and minimum values of the objective function among the criteria, respectively. \(l\) and \(j\) represent the index of iteration and the criterion, respectively. Therefore, \(A(l,j,b)\) means the \(j\)th expert’s opinion with the maximum objective function value in the lth iteration. \(rd (l,j,1)\) and \(rd (l,j,2),\) ensure that the diversification is random within the scope of \([\mathrm{0,1}]\) (Rao, 2016).
However, since the goal is integrating the experts’ opinions to reach a consensus, there is no need to modify the values of each variable of every solution in each iteration. Consequently, the formula is altered as follows:
The improved Jaya algorithm adjusts the maximum and minimum values of the objective function among the criteria to bring them closer to each other. When the number of iterations is sufficient, that is, when the termination condition is reached, the algorithm can make all experts' opinions converge. The algorithm procedure is as follows:
Step 1 Obtain the decision matrix
The first step in the improved Jaya algorithm is to input the original reference profiles’ decision matrix \(X\left(o\right)={({r}_{tj}^{o})}_{sm}\) as follows:
where \({r}_{tj}^{o}\) is the rating of the \(t\)-th expert under the \(j\)-th criterion. If the limiting profiles are used, then \(o=\mathrm{1,2},\dots ,k+1\). Similarly, if the central profiles are used, then \(o=\mathrm{1,2},\dots ,k\).
Step 2 Define the objective function
In our paper, we define the objective function as:
Compared with the general Jaya, we set \(E\left(t\right)<0.001\) as the termination symbol to ensure that all experts reach a consensus. This means that for each expert, \(E\left(t\right)\) is calculated through each iteration. Simultaneously, the ratings with the maximum and minimum values of the objective function are changed by the calculation of Eqs. (1) and (2), respectively; The process continued until at least one \(E\left(t\right)\) was less than 0.001. This means that the sum of the errors of each expert opinion reaches the target value. After the above iteration process for all reference profiles, we obtain their final values as the input data for Group-FlowSort.
3.3 Group-FlowSort based on SMAA-2
Step 1 Evaluate the performance of alternatives
The evaluation of alternatives can be defined in a stochastic manner using random variables defined by any probability distribution. For these cases, we represent the evaluation of alternatives using the random variables \(\xi\) with a probability density function \({f}_{X}\left(\xi \right)\) in space \(X\), which is defined as follows:
Step 2 Acquire the criteria weights
Weights are defined as non-negative and normalized by a weight distribution with a joint density function \({f}_{W}\left(w\right)\) in the feasible weight vector space \(W\), a \(\left(n-1\right)\)-dimensional simplex.
Step 3 Establish the preference function
In the FlowSort method, the preference degrees can be obtained in the same manner as the PROMETHEE method. There are six types of functions used to obtain the preference degrees, some of which have several shortcomings.
-
1.
Preference degrees depend highly on preference and indifference thresholds in most functions.
-
2.
Suitable parameters need to be selected, which are difficult to determine, especially in group decision problems.
In this study, we use a new preference function, called Boltzmann, proposed in PROMETHEE (Nassereddine et al. 2019) to solve this problem. It considers both the degree of preference of the decision-maker and the criteria weights of this degree. As a user-friendly function, it is more suitable for real cases because no parameters need to be defined by the DMs.
For \({g}_{j}\), the preference degree can be calculated by:
where \({R}_{j}\) is the range of the criterion, and \({D}_{j}\) is the distance between the two evaluated alternatives \(a\) and \(b\) under criterion \({g}_{j}\).
Then the global result of the preference index \(\pi (a,b)\) is:
The outranking degree \(\pi \left(a,b\right)\) satisfies the following conditions 1–4:
Condition 1: \(0\le \pi \left(a,b\right)\le 1\);
Condition 2: \(\pi \left(a,a\right)=0\);
Condition 3: \(\pi \left(a,b\right)+\pi \left(b,a\right)\le 1\);
Condition 4: \(\forall {a}^{\mathrm{^{\prime}}},{b}^{\mathrm{^{\prime}}}\epsilon {R}_{i}, if {g}_{j}\left(a\right)-{g}_{j}\left(b\right)\le {g}_{j}\left({a}^{\mathrm{^{\prime}}}\right)-{g}_{j}\left({b}^{\mathrm{^{\prime}}}\right), \forall j=1, 2,\cdots ,m, then \pi \left(a,b\right)\le \pi \left({a}^{\mathrm{^{\prime}}},{b}^{\mathrm{^{\prime}}}\right).\)
Step 4 Calculate the net flow
According to the preference functions, we can compute the positive flow, negative flow, and net flow of alternative \({a}_{i}\) of \({R}_{i}=R\cup \left\{{a}_{i}\right\}\) as:
where \(\left|{R}_{i}\right|\) is the number of sets \({R}_{i}\). The order of the reference profiles and alternatives in \({R}_{i}\) is independent of the results.
We then calculate the net outranking flow \({\mathrm{\varnothing }}_{{R}_{i}}\left({a}_{i}\right)\) based on the positive and negative flows. Obviously, the higher the net flow \({\mathrm{\varnothing }}_{{R}_{i}}\left({a}_{i}\right)\), the better the alternative \({a}_{i}\).
Step 5 Assign alternatives to classes with lps or cps
-
1.
If the limiting profiles are chosen, then there are two assignment rules based on the positive and negative flows:
-
If \({\varnothing }_{{R}_{i}}^{+}\left({lp}_{h}\right)>{\varnothing }_{{R}_{i}}^{+}\left({a}_{i}\right)>{\varnothing }_{{R}_{i}}^{+}\left({lp}_{h+1}\right),\) then \(C\left({a}_{i}\right)={C}_{h}\);
-
If \({\varnothing }_{{R}_{i}}^{-}\left({lp}_{h}\right)>{\varnothing }_{{R}_{i}}^{-}\left({a}_{i}\right)>{\varnothing }_{{R}_{i}}^{-}\left({lp}_{h+1}\right),\) then \(C\left({a}_{i}\right)={C}_{h}\).
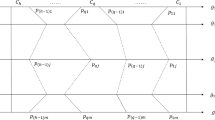
Using these two rules, alternative \({a}_{i}\) may be assigned to two different classes. Notably, DMs prefer assignment to one category strictly, so we define three assignment rules via the net flows (see Fig. 2):
-
If \({\varnothing }_{{R}_{i}}\left({lp}_{h}\right)>{\varnothing }_{{R}_{i}}\left({a}_{i}\right)>{\varnothing }_{{R}_{i}}\left({lp}_{h+1}\right), h\in \left[1,k\right]\) then \(C\left({a}_{i}\right)={C}_{h}\).
-
If \({\varnothing }_{{R}_{i}}\left({a}_{i}\right)\ge\) \({\varnothing }_{{R}_{i}}\left({lp}_{1}\right)\), then \(C\left({a}_{i}\right)={C}_{1}\).
-
If \({\mathrm{\varnothing }}_{{R}_{i}}\left({a}_{i}\right)\le\) \({\mathrm{\varnothing }}_{{R}_{i}}\left({lp}_{k+1}\right)\), then \(C\left({a}_{i}\right)={C}_{k}\).
-
-
2.
If we adopt central profiles to describe classes, then alternative \({a}_{i}\) is allocated to the class whose flow of the central profile is closest. There are two principles for allocating.
-
If \(\left|{\mathrm{\varnothing }}_{{R}_{i}}^{+}\left({a}_{i}\right)-{\mathrm{\varnothing }}_{{R}_{i}}^{+}\left({cp}_{h}\right)\right|\le \left|{\mathrm{\varnothing }}_{{R}_{i}}^{+}\left({a}_{i}\right)-{\mathrm{\varnothing }}_{{R}_{i}}^{+}\left({cp}_{l}\right)\right|,\forall l=\mathrm{1,2},\cdots ,k,\) then \(C\left({a}_{i}\right)={C}_{h}\).
-
If \(\left|{\mathrm{\varnothing }}_{{R}_{i}}^{-}\left({a}_{i}\right)-{\mathrm{\varnothing }}_{{R}_{i}}^{+}\left({cp}_{h}\right)\right|\le \left|{\mathrm{\varnothing }}_{{R}_{i}}^{-}\left({a}_{i}\right)-{\mathrm{\varnothing }}_{{R}_{i}}^{+}\left({cp}_{l}\right)\right|,\forall l=\mathrm{1,2},\cdots ,k,\) then \(C\left({a}_{i}\right)={C}_{h}\).
Similarly, two different classes can be obtained, and we define \({C}_{B}\left({a}_{i}\right)\) as the better class and \({C}_{w}\left({a}_{i}\right)\) as the worse. Then, to acquire a unique class, the rule in view of the net flow should be considered (see Fig. 2).
-
If \(\left|{\mathrm{\varnothing }}_{{R}_{i}}\left({a}_{i}\right)-{\mathrm{\varnothing }}_{{R}_{i}}\left({cp}_{h}\right)\right|\le \left|{\mathrm{\varnothing }}_{{R}_{i}}\left({a}_{i}\right)-{\mathrm{\varnothing }}_{{R}_{i}}\left({cp}_{l}\right)\right|,\forall l=\mathrm{1,2},\cdots ,k,\) then \(C\left({a}_{i}\right)={C}_{h}\).
It can easily be proven that \(C_{w} \left( {a_{i} } \right) \triangleleft C\left( {a_{i} } \right) \triangleleft C_{B} \left( {a_{i} } \right)\).
If the net flow of \({a}_{i}\) is exactly between two consecutive net flows of the central profiles, \({a}_{i}\) can be assigned to the upper class with an optimistic view, or assigned to the lower class with a pessimistic view.
-
If \({\mathrm{\varnothing }}_{{R}_{i}}\left({cp}_{h+1}\right)<{\mathrm{\varnothing }}_{{R}_{i}}\left({a}_{i}\right)<{\mathrm{\varnothing }}_{{R}_{i}}\left({cp}_{h}\right)\) and \(\left|{\mathrm{\varnothing }}_{{R}_{i}}\left({a}_{i}\right)-{\mathrm{\varnothing }}_{{R}_{i}}\left({cp}_{h}\right)\right|=\left|{\mathrm{\varnothing }}_{{R}_{i}}\left({a}_{i}\right)-{\mathrm{\varnothing }}_{{R}_{i}}\left({cp}_{h+1}\right)\right|\)
$$then\left\{\begin{array}{c}C\left({a}_{i}\right)={C}_{h}, with an optimisitic view\\ C\left({a}_{i}\right)={C}_{h+1}, with a pessimistic view\end{array}\right.$$
-

Sorting with limiting profiles or central profiles
Step 6 Next, we calculate descriptive measures in SMAA-2
-
1.
Category acceptability index \({c}_{i}^{h}\)
The category acceptability index \({c}_{i}^{h}\) measures the probability of alternative \({a}_{i}\) being assigned to category \({C}_{h}\). In order to define \({c}_{i}^{h}\), we first define a categorization function h \(=K\left(i,\xi ,w\right)\) that gives the category \({C}_{h}\) to which an alternative \({a}_{i}\) is distributed, where \(\mathrm{stochastic variable }\xi\) denotes the imprecise criteria value. The category membership function \({m}_{i}^{h}\) is defined as follows:
$${m}_{i}^{h}\left(\xi ,w\right)=\left\{\begin{array}{c}1, if K\left(i,\xi ,w\right)=h\\ 0, otherwise\end{array}\right.$$(13)The category acceptability index \({c}_{i}^{h}\in \left[\mathrm{0,1}\right]\) is computed numerically as a multidimensional integral over the spaces of feasible weight space \(W=\left\{w\in {\mathbb{R}}^{m}|{w}_{j}\ge 0 and {\sum }_{j=1}^{m}{w}_{j}=1\right\}\).
$${c}_{i}^{h}={\int }_{\xi \in X}{f}_{X}\left(\xi \right){d\xi \int }_{w\in W}{f}_{W}\left(w\right){m}_{i}^{h}\left(\xi ,w\right)dw$$(14) -
2.
Central weight vector \({w}_{i}^{h}\)
The central weight vector \({w}_{i}^{h}\) indicates the center of gravity of the space \({W}_{i}^{h}\left(\xi \right)=\left\{w\in W|{m}_{i}^{h}\left(\xi ,w\right)=1\right\}\), which can assign \({a}_{i}\) to the best category.
$${w}_{i}^{h}=\frac{1}{{c}_{i}^{h}}{\int }_{\xi \in X}{f}_{X}\left(\xi \right){d\xi \int }_{w\in {W}_{i}^{h}\left(\xi \right)}{f}_{W}\left(w\right){m}_{i}^{h}\left(\xi ,w\right)dw$$(15) -
3.
Confidence factor \({p}_{i}^{h}\)
The confidence factor \({p}_{i}^{h}\) denotes the probability that \({a}_{i}\) is assigned to the class with the calculated central weight vector \({w}_{i}^{h}\) calculated.
$${p}_{i}^{h}={\int }_{\xi \in X:{m}_{i}^{h}\left(\xi ,w\right)=1}{f}_{X}\left(\xi \right)d\xi$$(16) -
4.
Holistic acceptability index \({u}_{i}^{H}\)
The holistic acceptability index \({u}_{i}^{H}\) is a combination of category acceptability indices for each alternative, which can describe the performance of alternatives more intuitively.
$${u}_{i}^{H}=\sum_{h}{u}^{h}{c}_{i}^{h}\left({u}^{1}\ge {u}^{2}\ge \cdots \ge {u}^{h}\ge 0\right)$$(17)There are multiple ways to determine the meta-weights \({u}^{h}\). In this study, liner weights were chosen as follows:
$${u}^{h}=(k-h)/(k-1)$$(18)Using the four descriptive measures, the sorting results can be presented in a probabilistic manner.
4 Case study
In this section, we illustrate the viability and practicability of the designed model by describing its application to market segmentation in the telecom industry. Market segmentation has received growing attention with the increasingly stiff competition in the telecommunications market. The aim of this case study is to provide scientific decision-support for developing suitable prices, promotion strategies, and personalized services for each market segment, which can help enterprises improve operational efficiency.
4.1 Problem description
Confronted with an extremely large amount of telecom user data, fine market segmentation that considers many traits is computationally complex and practically unnecessary. To simplify it, this study focuses on implementing an individual layered service based on market segmentation to attract or retain high-value users. A criteria system (see Table 1) covering frequency, monetary, and duration of users is constructed to classify customers from the perspective of user value, and 8000 telecom users’ consumption information is selected as a sample after data desensitization. (Data source: https://www.kaggle.com/abhinav89/telecom-customer).
4.2 Market segmentation of telecom users
4.2.1 Determine the reference profiles of classes
In this subsection, we use the CLIQUE algorithm and an improved Jaya algorithm to determine the final number of categories. First, we collected the opinions of 25 market segmentation decision experts on the numerical settings for each lp using a questionnaire survey (see Fig. 3). Through the questionnaire survey method, expert opinion collection was more authoritative and persuasive. We use the CLIQUE algorithm to reach a consensus since different experts hold disparate opinions on the data classification.

The questionnaire for limiting profiles
After placing the matrix into the CLIQUE algorithm, we derive a seven-dimensional space visualization, which demonstrates the clustering results. Here, we choose three dimensions of the result with respect to the collected lps data of \({g}_{4}\) (see Fig. 4).

Some dimensions in CLIQUE algorithm
If a point deviates from the clustering center in a certain dimension, it will not be in the same class as other points, who hold the opinion that the number of classes is five. Hence, the opinions of the 2nd and 13th experts deviate from most experts, which mean that their views must be rejected. After the rejection, experts’ opinions on the lps of \({g}_{4}\) were derived.
To date, the number of classes (\(k\)) has been determined to be five. Then, we use the improved Jaya algorithm to synthesize 25 experts’ opinions and obtain their consensus on lps. In each iteration, the improved Jaya algorithm calculates the objective function once. Here, we show the lps in the first iteration in Table 2.
After calculating the objective function, the maximum and minimum values of lps under each criterion were corrected using Eqs. (1) and (2), respectively:
For example, the maximum value of \({lp}_{1}\) in \({c}_{1}\) is 57.0053, whereas the minimum value of \({lp}_{1}\) in \({c}_{1}\) is 47.7698. Assuming that \(rd(l,j,1)\) and \(rd(l,j,2)\) are all 0.1, these two values would be changed to 56.0818 and 48.6933.
The iteration continues until at least one E(t) is less than 0.001, and the expert opinion with this E(t) is taken as the final consensus.
The iteration continues until at least one E(t) is less than 0.001. When \(E(t)\) is less than 0.001, that is, the error reaches below the specified value, it means that all expert opinions have been agreed upon through the clustering algorithm.
Ultimately, we obtain the result of lps (see Table 3).
4.2.2 Sorting results analysis
In this subsection, the probability of each alternative assigned to each category is determined. By virtue of SMAA-2, we can access the sets of criteria weights \({W}_{g}=\{{w}_{g1},{w}_{g2},\dots ,{w}_{gj},{\dots ,w}_{gm}\}\) using the Monte Carlo simulation technique. The exact number \(N\) of iterations can be determined based on a confidence degree of 95% and the error limit \(d\) of the result.
To achieve a balance between the calculated quantity and the accuracy degree, the error limit \(d\) was set to 0.01, and the required number of iterations was 9604. Therefore, we obtained 10,000 sets of weights for each alternative to meet demand.
To achieve a balance between the calculated quantity and the accuracy degree, the error limit \(d\) was set to 0.01, and the required number of iterations was 9604. Therefore, we obtained 10,000 sets of weights for each alternative to meet demand.
With the local profiles acquired, the net flows of alternatives can be calculated based on the positive and negative flows using Eqs. (7)–(11). Subsequently, we can obtain the assignment of \({a}_{i}\) with each set of criteria weights, and the category acceptability indices \({c}_{i}^{h}\) of 8000 alternatives is obtained using Eq. (13). Due to the large number of alternatives, we take 50 as an example, and the results are shown in Fig. 5, where the height of the cylinder or the color of the block describes the size of the corresponding category acceptability index.

Category acceptability indices of 50 alternatives
To simplify the sorting results, the final exact assignments can be achieved based on the highest category acceptability index. The lps (black dotted lines) and typical alternatives (colored solid lines) assigned to different categories are depicted in Fig. 6. For dimensional inconsistencies among criteria and to show the performance of lps and alternatives, the data must be normalized ranging in \([0, 1]\).

Limiting profiles and the representative alternatives to be assigned
4.3 Further discussions
According to Pareto’s principle, also known as the 80-20 rule, a small share of high-value customers can bring a huge share of profits to an enterprise. In our case, it is reasonable to speculate that the users assigned to \({C}_{1}\) (the best category) with the higher customer loyalty would be more important for telecom, while those allocated to \({C}_{5}\) (the worst category) would play less significant roles in business operation management.
In Table 4, the number of users in each category and their consumption amounts are illustrated in the forms of both numerical and ratio values. The sorting results show the variance in customer value, demonstrating the practicality and availability of the proposed method. If the enterprise makes efforts to retain the customers categorized in \({C}_{1}\), \({C}_{2}\), \({C}_{3}\) and the churn probability of those customers is negligibly small, almost 83.494% of revenue could be ensured. Furthermore, if customers in \({C}_{4}\) are also considered, sales as high as 97.254% would be stable.
In this way, enterprises can provide targeted services to improve customer relationships, enhance customer loyalty, and enhance competitiveness.
5 Comparative and sensitivity analysis
5.1 Comparative analysis
In this subsection, the Group-FlowSort is compared with FlowSort-GDSS (Lolli et al. 2015) a sorting method for group decision-making problems. Multiple assignment results of a single alternative are obtained using FlowSort-GDSS according to the reference profiles of each DM, and the final sorting result is defined in accordance with the smallest distance to the reference profiles.
The improved Jaya algorithm in our model is computationally more complex than FlowSort-GDSS because the computation requirements of the former are only related to the reference profiles of DMs and are independent of the number of alternatives. To further verify the effectiveness of the Group-FlowSort, FlowSort-GDSS was applied to the case in Sect. 4 to compare the sorting results of the two models.
The assignment error of the two methods for \({a}_{i}\) is defined as \({\upvarepsilon }_{i}\).
where \({category}_{1}\left({a}_{i}\right)\) and \({category}_{2}\left({a}_{i}\right)\) refer to the sorting results using Group-FlowSort and FlowSort-GDSS, respectively.
We can observe that 42.563% of alternatives will be assigned to the same category as the Group-FlowSort and FlowSort-GDSS (Table 5), and 89.475% of deviations are no more than 1. Thus, the results of FlowSort-GDSS are roughly consistent with those of the proposed method.
In conclusion, there are three distinctive advantages of Group-FlowSort over FlowSort-GDSS. First, less computation is required during the process of consensus-reaching in large-scale problems; second, it can be applied to problems without reference information and third, the sorting result can be presented as probabilities, which is more reliable and precise.
5.2 Sensitivity analysis
In this subsection, the sensitivity analysis is performed by fluctuating the index values of each alternative and the reference profiles. To present the results clearer, we use the holistic acceptability index calculated using Eq. (16). In our case, \(k=5\), the values of the mate weight \({u}^{h}\) are listed in Table 6.
Regarding the index value, 1000 groups with a 30% fluctuation of each alternative are generated randomly, with which the alternative can be allocated to different classes based on the fluctuant net flow. The sensitivity analysis results of users in each category are visualized in Fig. 7, illustrating that a slight fluctuation of index value does not make much difference in the holistic acceptability index and the sorting result.

Sensitivity analysis with index value changed (\({C}_{1}\) to \({C}_{5}\))
Similarly, the results of 1000 sets of reference profiles with a 30% fluctuation can also indicate that small variations do not have a great impact on the ultimate result (see Fig. 8). Therefore, it reveals the reliability and stability of the proposed model.

Sensitivity analysis with reference profiles changed (\({C}_{1}\) to \({C}_{5}\))
6 Conclusions, limitations, and future works
This paper proposes a novel multiple criteria sorting procedure, the Group-FlowSort method, which is suitable for solving large-scale problems. To deal with the divergence of preference profiles in group decision-making, the CLIQUE algorithm and the improved Jaya algorithm are adopted to reach the consensus among DMs efficiently. In addition, based on the integration of SMAA-2, the proposed method can be used extensively for problems with imprecise input data.
To validate the practicability and availability of Group-FlowSort, we describe its application to a real large-scale case without reference information, in which 25 experts’ opinions are considered and 8000 customers are allocated according to user information. The sorting results indicates that the customers categorized in \({C}_{1}\), \({C}_{2}\), \({C}_{3}\) and \({C}_{4}\) account for as high as 97.254% sales. Therefore, in order to improve profits efficiently, the company should pay more attention on high-value customers. Subsequently, a comparison analysis with FlowSort-GDSS was implemented to demonstrate its superiority in large-scale problems, and a sensitivity analysis conducted to verify its robustness.
However, the proposed model had some limitations. First, it is difficult to ensure that the preference information of DMs was collected accurately, based on the questionnaire survey only. Second, the process of achieving a consensus is time-consuming and not sufficiently accurate if there is a great difference in the opinions of DMs. Third, owing to the large computational quantity of the Monte Carlo simulation technique, SMAA-2 only works on large-scale problems within a certain size. The practicability of SMAA-2 for ultra-large-scale questions leaves something to be desired.
There are several research directions for enlarging the applicable area of the Group-FlowSort in the future. As for the reference profiles, an objective determination method can be considered to enhance the accuracy and rationality of the existing sorting method. In addition, instead of obtaining weights of criteria completely at random, some imprecise preference information can be considered based on the combination of Choquet integral and robust ordinal regression. Moreover, to settle more complicated group decision cases, Group-FlowSort is expected to be extended with a minimum cost consensus model and robust optimization.
References
Agrawal, R., J. Gehrke, D. Gunopulos, and P. Raghavan. 1998. Automatic subspace clustering of high dimensional data for data mining applications. Paper Presented at the International Conference on Management of Data. https://doi.org/10.1145/276304.276314.
Angilella, S., and M.R. Pappalardo. 2021. Assessment of a failure prediction model in the European energy sector: A multicriteria discrimination approach with a PROMETHEE based classification. Expert Systems with Applications 184: 115513. https://doi.org/10.1016/j.eswa.2021.115513.
Balakrishnan, P., S. Kumar, and P. Han. 2011. Dual objective segmentation to improve targetability: An evolutionary algorithm approach. Decision Sciences 42 (4): 831–857. https://doi.org/10.1111/j.1540-5915.2011.00333.x.
Beane, T.P., and D.M. Ennis. 2013. Market Segmentation: A Review. European Journal of Marketing 21 (5): 20–42. https://doi.org/10.1108/EUM0000000004695.
Behzadian, M., R. Kazemzadeh, A. Albadvi, and M. Aghdassi. 2010. PROMETHEE: A comprehensive literature review on methodologies and applications. European Journal of Operational Research 200: 198–215. https://doi.org/10.1016/j.ejor.2009.01.021.
Berbeglia, F., G. Berbeglia, and P. Van Hentenryck. 2021. Market segmentation in online platforms. European Journal of Operational Research 295 (3): 1025–1041. https://doi.org/10.1016/j.ejor.2021.03.056.
Campos, S.M., A. Carolina, Bertrand Mareschal, D. Almeida, and A. Teixeira. 2015. Fuzzy FlowSort: An integration of the FlowSort method and Fuzzy Set Theory for decision making on the basis of inaccurate quantitative data. Information Sciences 293: 115–124. https://doi.org/10.1016/j.ins.2014.09.024.
Chang, Y., C. Yeh, and Y. Chang. 2013. A new method selection approach for fuzzy group multicriteria decision making. Applied Soft Computing 13: 2179–2187. https://doi.org/10.1016/j.asoc.2012.12.009.
Corrente, S., J.R. Figueira, and S. Greco. 2014. The SMAA-PROMETHEE method. European Journal of Operational Research 239 (2): 514–522. https://doi.org/10.1016/J.EJOR.2014.05.026.
Dowling, G.R., and D.F. Midgley. 1988. Identifying the coarse and fine structures of market segments. Decision Sciences 19 (4): 830–847. https://doi.org/10.1111/j.1540-5915.1988.tb00306.x.
Fan, B., and P. Zhang. 2009. Spatially enabled customer segmentation using a data classification method with uncertain predicates. Decision Support Systems 47 (4): 343–353. https://doi.org/10.1016/j.dss.2009.03.002.
García-Cáceres, R.G. 2020. Stochastic Multicriteria Acceptability Analysis—Matching (SMAA-M). Operations Research Perspectives 7: 100145. https://doi.org/10.1016/j.orp.2020.100145.
García-Cáceres, R.G., A.E. Delgado-Tobón, and J.W. Escobar-Velásquez. 2022. Selection of learning strategies supported on SMAA-M. Heliyon 8 (2): e08978. https://doi.org/10.1016/j.heliyon.2022.e08978.
Han, S., Y. Ye, F. Xin, and Z. Chen. 2014. Category role aided market segmentation approach to convenience store chain category management. Decision Support Systems 57: 296–308. https://doi.org/10.1016/j.dss.2013.09.017.
Herrera, F., E. Herrera-Viedma, and F. Chiclana. 2001. Multiperson decision-making based on multiplicative preference relations. European Journal of Operational Research 129 (2): 372–385. https://doi.org/10.1016/S0377-2217(99)00197-6.
Hokkanen, J., R. Lahdelma, K. Miettinen, and P. Salminen. 1998. Determining the implementation order of a general plan by using a multicriteria method. Journal of Multi Criteria Decision Analysis 7 (5): 273–284. https://doi.org/10.1002/(SICI)1099-1360(199809)7:53.0.CO;2-1.
Huerta-Muñoz, D.L., R.Z. Ríos-Mercado, and R. Ruiz. 2017. An iterated greedy heuristic for a market segmentation problem with multiple attributes. European Journal of Operational Research 261 (1): 75–87. https://doi.org/10.1016/j.ejor.2017.02.013.
Kamis, N.H., F. Chiclana, and J. Levesley. 2018. Preference similarity network structural equivalence clustering based consensus group decision making model. Applied Soft Computing 67: 706–720. https://doi.org/10.1016/j.asoc.2017.11.022.
Kiang, M.Y., M.Y. Hu, and D.M. Fisher. 2006. An extended self-organizing map network for market segmentation—A telecommunication example. Decision Support Systems 42 (1): 36–47. https://doi.org/10.1016/j.dss.2004.09.012.
Lahdelma, R., and P. Salminen. 2001. SMAA-2: Stochastic Multicriteria Acceptability Analysis for Group Decision Making. Operations Research 49: 444–454. https://doi.org/10.1287/opre.49.3.444.11220.
Lahdelma, R., and P. Salminen. 2009. Prospect theory and stochastic multicriteria acceptability analysis (SMAA). Omega 37 (5): 961–971. https://doi.org/10.1016/j.omega.2008.09.001.
Lahdelma, R., J. Hokkanen, and P. Salminen. 1998. SMAA—Stochastic multiobjective acceptability analysis. European Journal of Operational Research 106: 137–143. https://doi.org/10.1016/S0377-2217(97)00163-X.
Lahdelma, R., K. Miettinen, and P. Salminen. 2003. Ordinal Criteria in Stochastic Multicriteria Acceptability Analysis (SMAA). European Journal of Operational Research 147: 117–127. https://doi.org/10.1016/S0377-2217(02)00267-9.
Lahdelma, R., K. Miettinen, and P. Salminen. 2005. Reference point approach for multiple decision makers. European Journal of Operational Research 164: 785–791. https://doi.org/10.1016/j.ejor.2004.01.030.
Liu, Y., S. Ram, R.F. Lusch, and M. Brusco. 2010. Multicriterion market segmentation: A new model, implementation, and evaluation. Marketing Science 29 (5): 880–894. https://doi.org/10.1287/mksc.1100.0565.
Liu, J., X. Liao, W. Huang, and X. Liao. 2018. Market segmentation: A multiple criteria approach combining preference analysis and segmentation decision. Omega 83: 1–13. https://doi.org/10.1016/j.omega.2018.01.008.
Lolli, F., A. Ishizaka, R. Gamberini, B. Rimini, and M. Messori. 2015. FlowSort-GDSS—A novel group multi-criteria decision support system for sorting problems with application to FMEA. Expert Systems with Applications 42: 6342–6349. https://doi.org/10.1016/j.eswa.2015.04.028.
Nassereddine, M., A. Azar, A. Rajabzadeh, and A. Afsar. 2019. Decision making application in collaborative emergency response: A new PROMETHEE preference function. International Journal of Disaster Risk Reduction 38: 101221. https://doi.org/10.1016/j.ijdrr.2019.101221.
Nemery, P., and P. Janssen. 2013. An extension of the FlowSort sorting method to deal with imprecision. 4OR Quarterly Journal of the Belgian French and Italian Operations Research Societies 2013: 171–193. https://doi.org/10.1007/s10288-012-0219-7.
Nemery, P., and C. Lamboray. 2008. FLOWSORT: A flow-based sorting method with limiting or central profiles. TOP an Official Journal of the Spanish Society of Statistics and Operations Research 16: 90–113. https://doi.org/10.1007/s11750-007-0036-x.
Patrik, E., R. Agnieszka, and D.S. Harrie. 2007. Consensus reaching in committees. European Journal of Operational Research 178 (1): 185–193. https://doi.org/10.1016/j.ejor.2005.11.012.
Pelissari, R., M. Oliveira, S. Ben Amor, and A. Abackerli. 2019. A new FlowSort-based method to deal with information imperfections in sorting decision-making problems. European Journal of Operational Research 276 (1): 235–246. https://doi.org/10.1016/j.ejor.2019.01.006.
Pelissari, R., A.J. Abackerli, S.B. Amor, M.C. Oliveira, and K.M. Infante. 2020. Multiple criteria hierarchy process for sorting problems under uncertainty applied to the evaluation of the operational maturity of research institutions. Omega International Journal of Management Science. https://doi.org/10.1016/J.OMEGA.2020.102381.
Pérez, I.J., F.J. Cabrerizo, S. Alonso, Y.C. Dong, F. Chiclana, and E. Herrera-Viedma. 2018. On dynamic consensus processes in group decision making problems. Information Sciences 459: 20–35. https://doi.org/10.1016/j.ins.2018.05.017.
Rahmanimanesh, M., M. Nikabadi, F. Pourkarim, and G. Davoodifar. 2018. Using fuzzy flowsort inference system to rank the factors leading to failure for ERP projects among Iranian enterprises. Journal of Information Technology Management 9: 787–808. https://doi.org/10.22059/jitm.2017.232070.2019.
Rao, R. 2016. Jaya: A simple and new optimization algorithm for solving constrained and unconstrained optimization problems. International Journal of Industrial Engineering Computations 7 (1): 19–34. https://doi.org/10.5267/J.IJIEC.2015.8.004.
Smets, P. 1991. Varieties of ignorance and the need for well-founded theories. Information Sciences 57–58: 135–144. https://doi.org/10.1016/0020-0255(91)90073-4.
Smith, W.R. 1956. Product Differentiation and Market Segmentation as Alternative Marketing Strategies. Journal of Marketing 21 (1): 3–8. https://doi.org/10.1177/002224295602100102.
Song, Y., G. Li, T. Li, and Y. Li. 2021. A purchase decision support model considering consumer personalization about aspirations and risk attitudes. Journal of Retailing and Consumer Services 63: 102728. https://doi.org/10.1016/j.jretconser.2021.102728.
Song, Y., G. Li, D. Ergu, and N. Liu. 2022. An optimisation-based method to conduct consistency and consensus in group decision making under probabilistic uncertain linguistic preference relations. Journal of the Operational Research Society 73 (4): 840–854. https://doi.org/10.1080/01605682.2021.1873079.
Sun, B., and W. Ma. 2015. An approach to consensus measurement of linguistic preference relations in multi-attribute group decision making and application. Omega 51: 83–92. https://doi.org/10.1016/j.omega.2014.09.006.
Teichert, T., E. Shehu, and I. von Wartburg. 2008. Customer segmentation revisited: The case of the airline industry. Transportation Research Part: A Policy and Practice 42 (1): 227–242. https://doi.org/10.1016/j.tra.2007.08.003.
Tervonen, T., and J.R. Figueira. 2008. A survey on stochastic multicriteria acceptability analysis methods. Journal of Multi Criteria Decision Analysis 15: 1–14. https://doi.org/10.1002/MCDA.407.
Tian, Z.-P., R.-X. Nie, and J.-Q. Wang. 2019. Social network analysis-based consensus-supporting framework for large-scale group decision-making with incomplete interval type-2 fuzzy information. Information Sciences 502: 446–471. https://doi.org/10.1016/j.ins.2019.06.053.
Verheyden, T., and L. Moor. 2014. Sorting mutual funds with respect to process-oriented social responsibility: A FLOWSORT application. SSRN Electronic Journal 3 (4): 551–562. https://doi.org/10.2139/ssrn.2394467.
Wang, T., Y. Fu, H. Luo, and J. Yen. 2020. measuring olympics achievements via stochastic multicriteria acceptability analysis. Asia Pacific Journal of Operational Research 37 (6): 1–20. https://doi.org/10.1142/S021759592050030X.
Wu, Z., and J. Xu. 2018. A consensus model for large-scale group decision making with hesitant fuzzy information and changeable clusters. Information Fusion 41: 217–231. https://doi.org/10.1016/j.inffus.2017.09.011.
Zhang, W., Y. Ju, and L.F.A.M. Gomes. 2017. The SMAA-TODIM approach: Modeling of preferences and a robustness analysis framework. Computers & Industrial Engineering 114: 130–141. https://doi.org/10.1016/j.cie.2017.10.006.
Zheng, X., C. Wu, and S. He. 2021. Impacts of market segmentation on the over-capacity of the thermal electricity generation industry in China. Journal of Environmental Management 279: 111761. https://doi.org/10.1016/j.jenvman.2020.111761.
Zhong, X., and X. Xu. 2020. Clustering-based method for large group decision making with hesitant fuzzy linguistic information: Integrating correlation and consensus. Applied Soft Computing 87: 105973. https://doi.org/10.1016/j.asoc.2019.105973.
Zhou, H., J. Wang, and H. Zhang. 2019. Stochastic multicriteria decision-making approach based on SMAA-ELECTRE with extended gray numbers. International Transactions in Operational Research 26 (5): 2032–2052. https://doi.org/10.1111/ITOR.12380.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (NSFC) under Project 71701158 and 72071151, MOE (Ministry of Education in China) Project of Humanities and Social Sciences (17YJC630114), Fundamental Research Funds for the Central Universities under the Projects 2019GYZX015 and 2020GYZX003, and the Natural Science Foundation of Hubei Province (2020CFB773).
Author information
Authors and Affiliations
Contributions
All authors equally contributed to the study conception and design. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the work submitted.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Qin, J., Guo, Q. & Qu, C. A novel Group-FlowSort method for sorting large-scale problems with application to market segmentation. MSE 1, 2 (2022). https://doi.org/10.1007/s44176-022-00001-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44176-022-00001-4