
Abstract
Machine learning algorithms can be used to detect Alzheimer disease with RMI-images. One of the challenges of these algorithms is to clearly extract image features that show small variants of brain cells changes, which reveal the condition of dementia at the intermediate stages of mild cognitive impairment. In this article, we explore the abilities of two approaches to diagnose Alzheimer’s disease with MRI. In the first approach, after noise reduction and correction of alterations was conducted by a non-linear filter size 3*3, a kmeans algorithm is used for segmentation of cells showing white and grey matters of brain images. A Convolutional neural network (CNN) model is trained to indicate variations on these cells and the presence of Alzheimer Disease. The second approach performs image feature reduction using principal component analysis (PCA) to extract white and grey matters, and the cerebrospinal fluid as the three relevant features for Alzheimer diagnosis. A multilayer perceptron algorithm is trained to classify Alzheimer cases. Experiments are conducted on both approaches to compare accuracy and processing time using a real dataset of 602 images from the Alzheimer’s disease Neuroimaging Initiative (ADNI) of cognitively normal and Alzheimer’s disease patients. Results show that the accuracy can be enhanced when PCA is used to extract relevant features on RMI images; and with relatively low processing time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Alzheimer is a neurodegenerative disease characterized by progressive memory problems such as reduced cognitive activity; loss of motor functions; and sometimes even loss of reason leading to dementia and death. It is the most common cause of dementia and is considered to be the cause of 60–70% of cases [1]. Until 2021, around 45 million people of third age were reported to be suffering from Alzheimer disease (AD). These figures are expected to double in Europe and triple worldwide by 2050 [2]. The main causes of AD are not clear in medicine. As results, there are no effective treatments or medication that can heal, prevent, or reverse AD progression. To date, early diagnosis remains the best way to control this pathology. It consists in conducting detection at its earlier stages of the transitional condition between normal aging and dementia called mild cognitive impairment (MCI) [3]; given that the disease affects mostly people at their third age. When dementia is confirmed at that stage, proactive action on the patients can slow down its progression and avoid total dementia. In most cases, failing to effectively diagnose AD at MCI will transition to defective brain cells and death [4]. In general, the diagnosis of Alzheimer can only be made by histological examination, which is an examination of tiny volume of tissue in the internal organs, extracted from the body at post-mortem [4]. Meanwhile, some techniques such as neuropsychology and neuroimaging can help to follow-up the condition of AD suspected people. These techniques aim to identify patients with dementia and the possible causes with satisfactory results [5]. Furthermore, similar research conducted by clinicians have reported an atrophy of the hippocampus in the brain of patients suffering from AD [3, 4, and 6]. They claim that this region of the brain is the first to be affected by the disease, revealing small variants of brain changes at the intermediate stages of mild cognitive impairment (MCI). In fact, their studies show that, the hippocampus shrinks when the disease is present, and by measuring this area at the MCI one can detect AD. This diagnosis method is possible through neuroimaging techniques which can help to evaluate partial or global atrophy of the brain. The cerebral atrophies and dysfunctions revealed by neuroimaging are characteristics of degenerative dementias, and thereby favours positive diagnosis of related pathologies.
In the same realm, medical imaging and machine learning algorithms are conjointly used in computer aided diagnosis to automatically detect certain pathologies including Alzheimer’s disease (AD). Alongside, various techniques have been designed and applied in extracting knowledge and building intelligence in data bases for diagnosis and treatment of diseases [7]. All these technologies have collaboratively contributed in the development of automatic and intelligent methods for analysing magnetic resonance imaging (MRI) images; in order to enhance the detection of AD. MRI stands for Magnetic Resonance Imaging; it is the most popular technique for detecting abnormalities of tissue composition via images obtained after scanning. This technique is predominantly used over other techniques because it provides rich information; high spatial resolution with cross-section image for soft tissue diagnosis; high quality anatomical image structure for the diagnosis of clinical suspected disease. However, image exploration requires experienced clinicians because RMI structure is very complex. RMI data contain very high dimensionality, therefore unexperienced clinicians can be assisted by computer aided diagnosis systems (CAD). Computer aided diagnosis (CAD) is a medical decision support system that help clinicians to diagnose certain diseases such as AD. Related systems use advanced information technology and machine learning as suitable tools to achieve cutting-edge techniques for early diagnosis of Alzheimer’s disease using MRI data. It has been proved that Machine learning (ML) models can improve CAD capabilities on undiagnosed samples. Consequently, researchers have set up diagnostic systems for Alzheimer's disease based on models trained to analyse MRI data, using deep learning and other machine learning algorithms [8], with hope of grasping the whole structure of images during analysis for an effective and accurate diagnosis. In most cases, although the detection methods can effectively analyse functional and structural characteristics of RMI, their results show a relatively low accuracy and long processing time due to irregular shapes and alterations of important regions in images, and the resulting extraction of important features at the pre-processing step.
In this research, we explore and compare the abilities of two approaches of image segmentation and classification to diagnose Alzheimer's disease using MRI data. In the first approach, simpler image representation is obtained in the pre-processing stage, where the method performs a segmentation of images using Kmeans-clustering algorithm. This well-known partitioning based clustering technique attempts to find centroids by which distinct regions containing sets of pixels of images will be regrouped in a same cluster. A convolutional neural network is then applied for classification. In the second approach, the pre-processing stage performs image feature reduction. PCA is used to allow the huge amount of information enclosed in initially correlated pixels-set to be converted into a set new orthogonal image components, enhancing visualisation. A Multilayer perceptron algorithm is applied for classification afterward. Experiments are carried out on both approaches with the same dataset to compare the accuracy and computation abilities of the two approaches. The two models are trained and evaluated with a real dataset that includes 602 MRI images (396 NC and 206 AD) from Alzheimer's disease Neuroimaging Initiative (ADNI) databases.
In this paper Sect. 2 reviews the works done by other researchers in Alzheimer’s disease detection using RMI, Sect. 3 presents material, data and explains methods used in this study; Sect. 4 describes and discuss experimental results; while Sect. 5 concludes the study and suggests possible direction for future works.
2 Related work
Alzheimer’s disease (AD) is a neurodegerative disease that can cause mental disorder and dementia, the resulting gradual loss of memory observed in patients leads to death [3]. AD patients usually exhibit progressive brain atrophy and widespread neurologic deterioration. It is reported that the first related neuropathological changes appear in the medial temporal lobe (MTL) of the memory structures years prior to the manifestation of clinical dementia [4]. The principle of AD diagnosis is based on neuropsychology and historical examination by analysis of microscopic tissue of the brain [4, 9]. Brain images are obtained by neuroimaging techniques developed to exploit the brain function and structure, including: Magnetic resonance spectroscopy; Electroencephalography; and Magnetic resonance imaging (MRI). The atrophy of the medial temporal lobe structure as revealed by the structural magnetic resonance imaging is nowadays considered to be a valid diagnosis marker at the mild cognitive impairment stage (MCI) [7, 10]. The detection and analysis of regions of interest are essential in computer-assisted diagnosis. A bad analysis of a region of interest leads to a bad diagnosis [6]; and semi-automatic or automatic segmentation is generally used to achieve these objectives. Consistently, image segmentation represents a key step that determines the efficiency of a detection model. It aims to divide the image into pieces or regions; and these chunks or regions correspond to objects in the image. The main purpose of segmentation is to extract (or separate) the entities of an image by applying a specific processing method and to interpret the contents of the image. In that axis many researches have been conducted to enhance RMI image segmentation in disease detection.
Hanane Allioui et Al. [8] used the U-NET algorithm to segment brain images. The method proposed is an automatic segmentation model of brain lesions that will allow the diagnosis of Alzheimer's disease. Indeed, the architecture of UNET algorithm is an auto-encoder where the input image passes through the contraction path to generate feature maps, then the expansion path to obtain the segmented image. Manhua Liu and al [11] opted to analyze the hippocampus which is one of the first regions of the brain affected, in order to make an early diagnosis of AD. They argue that many existing methods of hippocampus analysis still pose several problems. The first problem being the fact that both the hippocampal volumetric and shape analyses depend on an accurate hippocampal segmentation; and that an accurate segmentation of the hippocampus remains a challenging task due to its irregular shape and blurred boundaries in MRI scans. The second problem is that the characteristics of the volumes and shapes of the hippocampus created by hand may not be optimal for later analysis, which may affect classification performance. In order to address those limits, they proposed a fully convolutional multi-model method. The first model is a multi-task deep CNN that performs hippocampal segmentation, and thereafter a classification from the hippocampal binary masks obtained during the segmentation. The second model is a 3D convolutional network model with dense connections (3D DenseNet). It receives as input a 3D patch covering the hippocampus extracted on the basis of the centroid of the mask and the characteristics learned by the first model. The DenseNet 3D model will therefore learn features that are more relevant for disease classification. They obtained a similarity coefficient of 87.0% for the segmentation of the hippocampus. D. Holilah et al. proposed two approaches for the segmentation of the hippocampal region in [12]. The first approach is based on the Kmeans clustering algorithm which consists of dividing the pixels into regions according to a homogeneity criterion. The second approach is a segmentation method based on regions and contours called watershed. In that study the image is considered as a topographic surface through which the value of each pixel represents the height of the surface. The water flowing at the bottom surface will become the target object of the segmentation. The purpose of that segmentation was to find the boundary of the watershed that will separate the objects. At the end of the work, the authors claim that both approaches can effectively segment the hippocampus; except that the k-means algorithm produces more segmented objects. Table 1 shows a summary of some disease detection techniques using RMI.
3 Material and methods
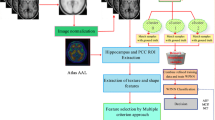
Our motivation is to address the accuracy and processing time of AD diagnosis models based ML. In this article, we explore the abilities of two approaches to diagnose Alzheimer's disease with MRI. In the first approach, a k-means algorithm is used for segmentation of cells showing white and grey matters of brain images, this segmentation is done after reduction and correction of alterations observed in images by a non-linear filter size 3*3, we have applied a convolutional neural network (CNN) trained to indicate variations on these white and grey cells. In the second approach features extraction was performed for reduction of image using principal component analysis (PCA) to extract white and grey matters, and the cerebrospinal fluid as the three relevant features for Alzheimer diagnosis. A multilayer perceptron algorithm is trained to classify Alzheimer cases with ADNI database. An overview of Alzheimer detection using our proposed scheme is presented in this section (see 7).
3.1 Dataset
The dataset used is real data as collection of labelled instances of patients who have gone through examinations using neuroimaging and whose diagnostic have attested by expert clinicians (Table 2 and Fig. 1). Database is from the Alzheimer's disease Neuroimaging Initiative (ADNI) of cognitively normal and Alzheimer’s disease patients. Images are 2D MRIs of coronal sections of the brain in T1 sequence. The images are grey-scale as shown in the sample presented in Fig. 1 of this section. Our dataset includes 602 MRI images (396 NC and 206 AD). CN (cognitively normal): for subjects with normal age-related physiological decline but without risk of progression to dementia. AD (Alzheimer Disease): for Demented Subjects. 332 images were used to train the models, 59 were used for validation and 211 have been used for testing.

Sample of RMI of the dataset
3.2 Proposed models
3.2.1 Image filtering
MRI images are marred by many artefacts due to imperfections in the acquisition system. These artefacts must be corrected in order to obtain quantitative information with acceptable precision [13]. Our research uses the nonlinear median-filter with window size 3 × 3 to correct these alterations. The principle is that, an operator replaces the value of each pixel by a nonlinear combination of the values of its neighbouring pixels. In general, averaging filters (linear) tend to blur the image and therefore lose information on edges characterized by strong variations of intensity. This effect is reduced in this research as median value in the neighbourhood is used over average value. Figure 2 shows the architecture of this median filtering.

Median filtering architecture
3.2.2 Image segmentation
3.2.2.1 K-means clustering
K-means clustering is an unsupervised non-hierarchical clustering algorithm. It is a widely used clustering algorithm to partition data into k clusters. The principle of clustering is to group data points with similar feature vectors into a single cluster and to group data points with dissimilar feature vectors into different clusters. Thus, the k-means algorithm aims to separate the data into homogeneous groups with common characteristics. It is generally used in data analysis for market segmentation and customer segmentation. It is also used for image segmentation as in Hossam M. Moftah et al. [14] where a comparative study between the standard kmeans clustering algorithm and an adaptive kmeans algorithm was conducted in order to improve accuracy in the prediction of breast cancer using RMI. They obtained an accuracy of 89.47% for the proposed approach and 69.19% for the standard Kmeans.
K-means algorithm creates clusters as follows:
Given a set of observations (x1, x2, …, xn), where each observation is a d-dimensional real vector, k-means clustering aims to partition the n observations into k (≤ n) sets S = {S1, S2, …, Sk} or C = {C1, C2, …, Ck}so as to minimize the within-cluster sum of squares or variances. Formally, the objective is to find the intra-class variance:
where μi is the mean (also called centroid) of points in cluster \({C}_{i}\). Also equivalent to the intra-class variance
Although there are other variants of K-means, we used the standard approach of K-means clustering to segment the MRIs of the brain in order to reveal the white matter and the grey matter of the brain which does not require the use of an optimized k-means algorithm. Figure 3 shows the Kmeans organisation chart.

Kmeans organisation chart
The k-means algorithm is non-deterministic. This means that the result of the clustering can be different each time the algorithm is run, even on the same dataset. Having an effective clustering algorithm primarily involves seeking an optimal number of clusters k, followed by a good evaluation metric. To find an optimal k, we employed a statistical method known as the "Elbow Method." In most cases, the number of clusters K is determined heuristically. In this method it involves running the k-means algorithm on the dataset (the pixels of an image) for a range of k values (e.g., from 1 to 10) in order to plot the curve of intra-class inertia evolution against k. The idea is to visualize the "elbow." The elbow point indicates the number of clusters for our clustering algorithm. The results are represented on the Figs. 4, 5. The elbow point is at k = 3, indicating that the optimal k for this dataset is 3. Therefore, we will use K = 3 clusters for segmenting the brain MRIs. The resulting segmentation represents the cerebrospinal fluid (in white), the white matter (in black) and the grey matter (in grey) comprising the hippocampus and the amygdala (Fig. 6) as the predictive markers of the AD. Since we do not have an available ground truth, evaluating the clustering performance becomes more challenging as there is no reference for comparing the obtained clusters. In this case, we utilized the silhouette index, which is an intrinsic evaluation measure for assessing intra-cluster cohesion and inter-cluster separation. After calculating the score for each segmented image, we obtained a minimum score of 0.77. It is important to note that the silhouette index ranges from -1 to 1. A score closer to 1 indicates better separation between clusters, while a score closer to -1 indicates significant overlap between clusters.

Evolution Curve for Diseased Images

Evolution Curve for Non-sick Images

MRI segmentation of the coronal slice brain using standard Kmeans clustering
3.2.2.2 Feature reduction using PCA
Principal component analysis (PCA) is part of the group of multidimensional descriptive methods called factorial methods [15] and Factorial methods consist of looking for factors in a limited number and summarizing the best possible data considered [16]. Figure 7 shows the dimension reduction algorithm. The general principle of PCA is to reduce the dimension of the initial data (which is p if we consider p quantitative variables), by replacing the p initial variables by q appropriate factors (q < p). The q factors sought are weighted averages of the initial variables. Their choice is done by maximizing the dispersion of individuals according to these factors (in other words, the factors retained must be of maximum variance) [17]. The variance–covariance matrix will produce the relevant components. In [20] PCA was used with deep learning networks in cough detection model using sound data. PCA was used to extract features in an acoustic signal. They could enhance the accuracy of their model from 94.4% up to 99.9%. In [21] PCA was used to remove insignificant features from diabetic retinopathy images to improve accuracy up to 96% when training an artificial neural network that will detect diabetes. In general, manipulating images means manipulating a large amount of variables called pixels; these variables must be reduced without distorting reality to extract information. In our study we manipulate images of dimensions 256*256 which is huge in terms of explanatory variables. We use PCA to return to a space of reduced dimension by distorting reality as little as possible. It consists of obtaining the most relevant summary of the initial data. With PCA we could reduce the image features to 50 components to preserve 90% variances. Figure 8 illustrates the results obtained after dimensionality reduction.

Dimension Reduction by PCA Model

MRI of feature-reduced brain using principal component analysis (PCA)
The features we aim to extract using Principal Component Analysis are the areas containing grey matter and white matter. After dimensionality reduction, we obtain three brain regions:
Region 1: white pixels corresponding to white matter.
Region 2: grey pixels corresponding to grey matter.
Region 3: black pixels corresponding to cerebrospinal fluid.
The analysis of grey matter and white matter from MRI provides crucial information about the anatomical and structural alterations occurring in the brains of Alzheimer's disease patients. This not only enables the diagnosis of the disease but also facilitates the monitoring of its progression and assessing the effectiveness of treatments [4, 5]. Indeed, Alzheimer's disease leads to a progressive brain atrophy, meaning that brain tissues decrease in size. This atrophy is particularly pronounced in grey matter, which contains the cell bodies of neurons. The trade-off between dimensionality reduction and image reconstruction quality is crucial when employing techniques such as Principal Component Analysis (PCA) or other dimensionality reduction methods. After dimensionality reduction, we observed that some reconstructed images have lost a significant amount of information regarding the brain's structure. This is due to the fact that our dataset contains a few MRIs in which the coronal slices are not taken in a plane perpendicular to the antero-posterior axis of the brain. The loss of anatomical coherence is explained by the disruption in the spatial relationships between different regions of the brain. This loss is noticeable in the reconstructed image in Fig. 8 (C). Instances of information loss do not affect significantly the accuracy the model but rather allows the model to avoid quick adjustment and thus prevents bias or overfitting.
3.2.3 Classification
For the classification, our model use two artificial neural networks, consistently with the output data after segmentation; namely multilayer perceptron and convolution neural networks.
3.2.3.1 Multilayer perceptron
A Perceptron is an artificial neuron, or a neural network unit. It performs calculations to detect patterns or trends in the input data. The multilayer perceptron is a network of perceptron organized in several layers within which information flows from the input layer to the output layer. It is a network architecture without loop, known as direct propagation (feedforward). A multilayer perceptron was used in our model after segmentation with PCA.
3.2.3.2 Convolutional neural network
Convolutional neural networks, also called CNNs, are a particular form of the multilayer perceptron (which consists of a set of formal neurons). These networks are capable of performing relatively complex tasks by exploiting data such as image, sound, text, video, etc. The architecture of a convolutional neural network is formed by a succession of processing blocks called “layers” to extract the characteristics that discriminate the class to which the image belongs. A processing block consists of one to many Convolution layers (CONV); Correction layers (ReLU); Pooling layers (POOL). The processing blocks are linked up to the final layers of the network which carry out the classification of the image and the calculation of the error between the prediction and the target value: “Fully connected” layer called fully connected (FC), Loss layer (LOSS). The way in which the convolution, correction and pooling layers are linked in the processing blocks, as well as the processing blocks between them, make the particularity of the architecture of the network. In our study, CNN was used for classification of Kmeans-based segmented images. The model architecture of the two approaches is shown in Fig. 9.

Kmeans + CNN Model architecture on left and PCA + ANN Model Architecture on right
4 Results and discussion
The presence of Alzheimer’s disease causes atrophy of the grey matter and alteration of the white matter. These parts of the brain can be detected by magnetic resonance imaging (MRI). To this end, two methods have been developed (notably kmeans clustering and principal component analysis) to segment these two regions, which are considered biomarkers for diagnosing and monitoring the disease, as well as for understanding the neurodegenerative mechanisms involved. It should be noted that, white matter ensures communication between different brain regions, while grey matter is responsible for information processing.
The confusion matrices (Fig. 10) obtained after training and testing the models show that the first model (Kmeans + CNN) has 173 good predictions against 38 bad predictions with the test data which gives us an accuracy of 82%. The second model (ACP + ANN) had 193 good predictions against 18 bad predictions with the test data which gives us an accuracy of 91% for the test data. These results are presented in Table 3 Accordingly, the metrics obtained in Fig. 11 shows that the difference in the areas under the curve (AUC) of the two models with the test data is considerable; and in addition the AUC are well above 0.8 which means that these two models have a good measure of class-separability.

Confusion matrix for the two models developed to detect Alzheimer’s disease

ROC curves of the two models with test data and train data
We can say that our two models can generalize. Consistently, this experience shows that the ACP + ANN model is more efficient (AUC = 0.941) than the Kmeans clustering + CNN model (AUC = 0.887). We argue that the performance of the ACP + ANN model over Kmeans + CNN model is due to the use of a factorial method (principal component analysis) for the reduction of dimensions in brain MRIs. Indeed, PCA can be used as a feature extractor compared to convolutional layers of convolutional neural networks (CNNs). In addition, this method is less greedy (106.70 s for 500 epochs) in CPU time compared to our CNN architecture which made 41413.04 s (i.e. 11.50 h for 60 epochs) of learning. Experiments were conducted on a laptop computer with the following characteristics (Brands: Lenovo Ideapad 110, Processor: Intel celeron CPU N3060 Dual core,
Processor frequency: 1.60 Ghz, Ram: 4 GB, HDD: 500 GB, Graphics card: Intel HD GRAPHIC, Total graphics memory: 2132 MB, Dedicated vacuum memory: 128 MB).
We can say that our two models can generalize. Consistently, this experience shows that the ACP + ANN model is more efficient (AUC = 0.941) than the Kmeans clustering + CNN model (AUC = 0.887). We argue that the performance of the ACP + ANN model over Kmeans + CNN model is due to the use of a factorial method (principal component analysis) for the reduction of dimensions in brain MRIs. Indeed, PCA can be used as a feature extractor compared to convolutional layers of convolutional neural networks (CNNs). In addition, this method is less greedy (106.70 s for 500 epochs) in CPU time compared to our CNN architecture which made 41413.04 s (i.e. 11.50 h for 60 epochs) of learning. Experiments were conducted on a laptop computer with the following characteristics (Brands: Lenovo Ideapad 110, Processor: Intel celeron CPU N3060 Dual core,
Processor frequency: 1.60 Ghz, Ram: 4 GB, HDD: 500 GB, Graphics card: Intel HD GRAPHIC, Total graphics memory: 2132 MB, Dedicated vacuum memory: 128 MB).
5 Conclusion and future works
The main aim of the study is to predict Alzheimer disease with ML algorithm. We have explored and compared the capability of two approaches of RMI image segmentation. In the first approach we used the k-means clustering algorithm to group the pixels of the images into 3 clusters then the data obtained at the output were loaded into a convolutional neural network (3 layers of convolutions) inspired by the vgg16 architecture. In the second approach, we used the PCA factorial method to summarize the dimensions of the images (256*256) into 50 components and then loaded the result into a neural network. We obtained an AUC of 0.887, accuracy of 82.0% for the first method and for the second method an AUC of 0.941, accuracy 91.0% with test data. Although all these results are satisfactory, in this study the second method has the best performance and shows that factorial methods for RMI image segmentation permits a better extraction of features. Approaches based on K-means and Principal Component Analysis (PCA) are useful tools for certain image analysis tasks, including in the field of neuroimaging. However, it is important to recognize some of their limitations including sensitivity to hyperparameters, as it can be challenging to determine the optimal k, especially in the absence of prior information. Futhermore, MRI images may contain artifacts and noise, which can affect the quality of segmentation. Methods based on K-means and PCA can be sensitive to these imperfections. Added to that is the loss of spatial information. PCA reduces dimensionality by focusing on the principal components, which can lead to a loss of fine spatial information.
In future works, we aim to explore the ability of deep learning algorithms hoping to extract complex features in order to consider spatial information; and Region of Interest (ROI)-based segmentation that can be efficient in focusing on specific regions of the brain associated with Alzheimer’s disease, instead of the whole image. We believe they can improve the Alzheimer's disease detection using MRI.
Data availability
All the experimental data used and that support the findings of this study are available in Alzheimer's disease Neuroimaging Initiative (ADNI) opened database via the link https://adni.loni.usc.edu/data-samples/access-data., with respect of the use agreement.
References
Jindal H, Bhatt B, Sk S, Singh Malik J. Alzheimer disease immunotherapeutics: then and now. Hum Vaccin Immunother. 2014;10(9):2741–3.
Bari Antor M, Jamil AHM, Mamtaz M, Monirujjaman Khan M, Aljahdali S, Kaur M, Masud M. A comparative analysis of machine learning algorithms to predict alzheimer’s disease. J Healthcare Eng. 2021. https://doi.org/10.1155/2021/9917919.
Islam J, Zhang Y. A novel deep learning based multi-class classification method for Alzheimer’s disease detection using brain MRI data. In Brain Informatics: International Conference, BI 2017, Beijing, China, November 16–18, 2017, Proceedings (pp. 213–222). Springer International Publishing. 2017.
Salehi AW, Baglat P, Gupta G. Alzheimer’s disease diagnosis using deep learning techniques. Int J Eng Adv Technol. 2020;9(3):874–80.
Symms M, Jäger HR, Schmierer K, Yousry TA. A review of structural magnetic resonance neuroimaging. J Neurol Neurosurg Psychiatry. 2004;75(9):1235–44.
Neelaveni J, Devasana MG. Alzheimer disease prediction using machine learning algorithms. In 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS) (pp. 101–104). IEEE. 2020.
Tanveer M, Richhariya B, Khan RU, Rashid AH, Khanna P, Prasad M, Lin CT. Machine learning techniques for the diagnosis of Alzheimer’s disease: a review. ACM Trans Multimedia Comput Commun Appl. 2020;16(1):1–35.
Allioui H, Sadgal M, Elfazziki A. A convolutional method applied to Alzheimer disease detection. Int J Adv Comput Sci Appl IJACSA. 2019;10(11):11.
Trambaiolli LR, Lorena AC, Fraga FJ, Kanda PA, Anghinah R, Nitrini R. Improving Alzheimer’s disease diagnosis with machine learning techniques. Clin EEG Neurosci. 2011;42(3):160–5.
Frisoni GB, Fox NC, Jack CR Jr, Scheltens P, Thompson PM. The clinical use of structural MRI in Alzheimer disease. Nat Rev Neurol. 2010;6(2):67–77.
Liu M, Li F, Yan H, Wang K, Ma Y, Shen L, Alzheimer’s Disease Neuroimaging Initiative. A multi-model deep convolutional neural network for automatic hippocampus segmentation and classification in Alzheimer’s disease. Neuroimage. 2020;208: 116459.
Holilah D, Bustamam A, Sarwinda D. Detection of Alzheimer’s disease with segmentation approach using K-means clustering and watershed method of MRI image. J Phys. 2021;1725(1):012009.
Collewet G, Idier J. Débruitage et correction du biais non multiplicatif en IRM pondérée T1. In 16ème Congrès Francophone AFRIF-AFIA Reconnaissance des Formes et Intelligence Artificielle (pp. 286–294). Laboratoire Modélisation, Information et Systèmes (MIS). 2008.
Moftah HM, Azar AT, Al-Shammari ET, Ghali NI, Hassanien AE, Shoman M. Adaptive k-means clustering algorithm for MR breast image segmentation. Neural Comput Appl. 2014;24(7–8):1917–28.
Celik T. Unsupervised change detection in satellite images using principal component analysis and k -means clustering. IEEE Geosci Remote Sens Lett. 2009;6(4):772–6.
Varshney SS, Rajpal N, Purwar R. Comparative study of image segmentation techniques and object matching using segmentation. In 2009 Proceeding of International Conference on Methods and Models in Computer Science (ICM2CS) (pp. 1–6). IEEE. 2019.
Islam MK, Ali MS, Miah MS, Rahman MM, Alam MS, Hossain MA. Brain tumor detection in MR image using superpixels, principal component analysis and template based K-means clustering algorithm. Mach Learn Appl. 2021;5: 100044.
Shaikh TA, Ali R. Enhanced computerised diagnosis of Alzheimer’s disease from brain MRI images using a classifier merger strategy. Int J Inf Technol. 1–13. 2021.
Shastry KA, Sattar SA. Logistic random forest boosting technique for Alzheimer’s diagnosis. Int J Inf Technol. 2023;15(3):1719–31.
Khomsay S, Vanijjirattikhan R, Suwatthikul J. (2019, October). Cough detection using PCA and Deep Learning. In 2019 International Conference on Information and Communication Technology Convergence (ICTC) (pp. 101–106). IEEE.
Gadekallu TR, Khare N, Bhattacharya S, Singh S, Maddikunta PKR, Ra IH, Alazab M. Early detection of diabetic retinopathy using PCA-firefly based deep learning model. Electronics. 2020;9(2):274.
Author information
Authors and Affiliations
Contributions
DGOO wrote the main manuscript text, and suggested model architecture and algorithm used in the research; Julien ZOOBO BISSE implemented the algorithms and provided related figures. and AAG also contributed to the algorithms implementation and reviewed computer aided diagnosis techniques and analysis of results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known conflict of interest associated with this publication and there has been no significant financial support for this work that could have influenced its outcome.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Olle Olle, D.G., Zoobo Bisse, J. & Abessolo Alo’o, G. Application and comparison of K-means and PCA based segmentation models for Alzheimer disease detection using MRI. Discov Artif Intell 4, 11 (2024). https://doi.org/10.1007/s44163-024-00106-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44163-024-00106-7