
Abstract
The fault diagnosis of cargo UAVs (Unmanned Aerial Vehicles) is crucial to ensure the safety of logistics distribution. In the context of smart logistics, the new trend of utilizing knowledge graph (KG) for fault diagnosis is gradually emerging, bringing new opportunities to improve the efficiency and accuracy of fault diagnosis in the era of Industry 4.0. The operating environment of cargo UAVs is complex, and their faults are typically closely related to it. However, the available data only considers faults and maintenance data, making it difficult to diagnose faults accurately. Moreover, the existing KG suffers from the problem of confusing entity boundaries during the extraction process, which leads to lower extraction efficiency. Therefore, a fault diagnosis knowledge graph (FDKG) for cargo UAVs constructed based on multi-domain fusion and incorporating an attention mechanism is proposed. Firstly, the multi-domain ontology modeling is realized based on the multi-domain fault diagnosis concept analysis expression model and multi-dimensional similarity calculation method for cargo UAVs. Secondly, a multi-head attention mechanism is added to the BERT-BILSTM-CRF network model for entity extraction, relationship extraction is performed through ERNIE, and the extracted triples are stored in the Neo4j graph database. Finally, the DJI cargo UAV failure is taken as an example for validation, and the results show that the new model based on multi-domain fusion data is better than the traditional model, and the precision rate, recall rate, and F1 value can reach 87.52%, 90.47%, and 88.97%, respectively.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the increasing development of the logistics industry, consumer demand for efficient and timely delivery is increasing, so it is crucial to open up the “last mile” logistics [1]. This segment is typically constrained by issues such as traffic congestion, delivery delays, and high labor costs [2], urgently requiring an innovative solution. As an important branch of intelligent logistics, UAV logistics utilizes its advantages of flexibility, efficiency, safety, and convenience to solve complex terrain and end transportation problems [3]. However, cargo UAVs face various complex situations during operation, such as urban environment, geographic climate, and extreme weather conditions, which are very likely to induce various types of failures, seriously threatening the safety of cargo distribution. Therefore, UAV fault diagnosis technology is needed to ensure the efficiency and safety of last-mile logistics distribution.
As of right now, using KG for UAV fault diagnosis is a novel and innovative technique. The KG is a semantic network structure that displays the links between items and efficiently organizes knowledge and presents it in the form of a graph [4]. Compared with traditional fault diagnosis methods, FDKG can integrate data from multiple sources, demonstrate complex entity relationships, and reveal potential correlations of fault patterns [5]. At the same time, FDKG can be dynamically updated and reasoned and is capable of logical reasoning to discover implied failure modes [6]. In addition, the intuitive visualization and explanatory nature of FDKG make the fault diagnosis process more transparent [7]. Therefore, constructing a fault diagnosis knowledge graph can improve the accuracy and timeliness of fault diagnosis.
However, the current FDKG for UAVs only takes into account information on faults and maintenance, which makes it difficult to cover diverse operational scenarios, limiting the global insights for fault diagnosis under different conditions [8–10]. Therefore, it is necessary to consider the data in each domain e.g., environment, fault, and maintenance, to construct a conceptual knowledge data corpus that integrates multiple domains to provide the required fault knowledge for the FDKG of cargo UAVs. The conceptual relationships and data knowledge structures of different domains are quite different, so multi-domain fusion becomes the primary problem in establishing FDKG.
The primary difficulty in building FDKG is extracting the entities. The knowledge graph’s quality will suffer if the entities are not appropriately extracted [11]. Deep learning has received a lot of attention lately in the field of entity extraction [12], and many deep learning algorithms have been researched, including BERT [13], BILSTM-CRF [14], BBiGRU-CRF [15], and D-CNN [16]. However, they still encounter problems such as entity overlapping and confusion in entity boundaries in practical applications, leading to reduced efficiency of entity extraction. Thus, accurate entity extraction is also a key element that affects the modeling of FDKG.
In this study, we aim to propose a multi-domain fusion-based KG construction method for cargo UAV fault diagnosis based on the introduction of an attention mechanism. The contribution of this paper is summarized as follows:
1) In the domain of cargo UAV fault diagnosis, there remains a scarcity of relevant research concerning KG construction. Compared to traditional fault diagnosis methods, we proposed to integrate KG and UAV fault diagnosis to guarantee the security and effectiveness of the last kilometer of logistics distribution.
2) To address the problem that a single distribution of UAV fault data, a multi-domain fusion method based on a multi-domain conceptual analysis expression model and multi-dimensional similarity calculation is proposed. Ontology concepts and attribute relationships are then clarified by analyzing the multi-domain corpus sentence information to achieve multi-domain fusion ontology modeling. This establishes a solid foundation for the construction of FDKG.
3) To address the problems of entity overlap and confusion regarding entity boundaries during entity extraction, we adopt the BERT-BILSTM-MHA-CRF model for entity extraction. The introduced multi-head attention mechanism can distinguish overlapping entities by simultaneously focusing on different semantic levels in parallel, which enhances the model’s ability and accuracy to recognize key entities.
The remainder of this paper is structured as follows. Section 2 reviews the related works on UAV fault diagnosis, multi-domain fusion, and knowledge graph construction. Section 3 details the fault KG construction methodology. Section 4 conducts a case analysis. Section 5 summarizes the important conclusions.
2 Related works
2.1 UAV fault diagnosis
The fault diagnosis technology for UAVs refers to the use of various measurements to quantify and analyze the effects caused by a malfunction in the event of a failure in a UAS to determine the type, location, and cause of the malfunction and to give an effective repair solution [17]. Model-based [18], knowledge-based [19], and signal-processing fault diagnosis [20] techniques are the three main types of current UAV fault diagnostic techniques.
Fault diagnostic procedures based on mathematical models need the construction of an accurate mathematical model of the system being tested, which mainly includes the parameter estimation method and the state estimation method. Cao et al. [21] introduced a fault detection system for UAV actuators based on interval and extended state observers that can identify different types of faults in the presence of rudder failure and limited disturbances. Knowledge-based methods are used to build diagnostic systems such as expert systems, fuzzy systems, etc. for fault diagnosis through a priori knowledge. Currently in the field of UAV fault diagnosis, the traditional rule-based expert system is gradually replaced by the fuzzy logic-based neural network expert system. Muhammad et al. [22] employed a neural network observer based on fuzzy-assisted sliding mode control to estimate and isolate quadcopter UAV sensor faults online. They achieved accurate fault diagnosis and isolation by integrating an adaptive technique with fuzzy-assisted sliding mode control. Signal-based approaches use wavelet transform and information fusion to evaluate quantifiable signals, and they handled time-domain, frequency-domain, and time-frequency signals to extract the associated features. Li et al. [23] used wavelet analysis to extract the frequency domain features of the data and then used a neural network on the signal to diagnose it. Based on this, data from a single sensor signal is used for self-diagnosis, and a joint information diagnosis method is proposed, which is capable of effectively diagnosing sensor faults in a multi-sensor system.
Existing fault diagnosis methods can solve the problem but still have some limitations. Model-based fault diagnosis methods still have issues regarding the sensitivity and practicality of algorithmic detection, and it is difficult to obtain an accurate mathematical diagnostic model. Fault diagnostic techniques based on expert systems rely excessively on professional expertise. Low fault diagnostic accuracy is caused by data sparsity constraints on signal processing-based fault diagnosis methods. In this context, fault diagnosis using KG presents a new approach to solving the problem, which is expected to bring new opportunities to improve the accuracy of fault diagnosis.
2.2 Multi-domain fusion
Over the last few years, a rising quantity of academics has begun to study how to explore ways to solve the problems of machine operation process, data, and knowledge separation from the three directions of data, knowledge, and model, and proposed the concept of multi-domain fusion [24]. Multi-domain fusion has previously been employed in the fields of biotechnology and healthcare. Mangesh et al. [25] the discovery of new multidomain truncated hemoglobins and their distinct structural arrangement, which expands on the development and uses of the trHb family. Liu and Zhong [26] utilized multi-channel access to heterogeneous data sources, combined with multi-domain fusion methods to construct a medical knowledge graph, and realized an intelligent questioning model based on a medical knowledge graph covering the whole range of diseases. Within the domain of fault diagnosis, multi-domain fusion also shows great potential for application. By fusing data, knowledge, and models from different domains, faults can be diagnosed more comprehensively and accurately. Hasan et al. [27] used multidomain vibration imaging and convolutional neural network (CNN)-assisted multitask learning to identify bearing fault problems under varying speed and health circumstances. Wu et al. [28] proposed a multi-domain feature fusion method based on a generalized learning system for variable-speed bearing diagnosis, which converts raw vibration data at different speeds into unified time and frequency-domain data to obtain more dynamic fault information. Xie et al. [29] built a gearbox fault diagnosis experimental platform and proposed a gearbox fault diagnosis method based on multi-domain information fusion CNN. It is verified that the method has high robustness and feasibility. However, multidomain fusion has not yet been applied to the level of UAV fault diagnosis, and most of them are fault diagnoses of mechanical parts. There are some problems in UAV fault diagnosis, such as single data and sparse data sources, so it is of great significance and value to apply multi-domain fusion to UAV fault diagnosis.
2.3 Knowledge graph construction
KG is a structured semantic repository capable of thoroughly and accurately describing the ideas and their interrelationships that exist in the physical world, as well as mining the implicit information that underpins knowledge. It is made up of a sequence of nodes, edges, and attributes, usually in the form of an “entity-relationship-entity” triad to effectively organize the scattered knowledge and present it in the form of a graph [30]. The building of KG involves several processes, including ontology modeling, named entity recognition, and relationship extraction.
Ontology modeling is the key to constructing KG, which provides a structured framework for knowledge units by conceptualizing the KG schema in the form of an ontology in a top-down manner. Recently there has been an increase in research and applications of ontology modeling. Tang et al. [31] developed an engineering-based technique that may improve traditional natural language processing to create a domain KG based on the oil exploration and development ontology. Taking the domain of fault diagnosis as an example, Jiang et al. [32] created a fault event ontology model to label the elements and relationships found in the CRDM fault event corpus. Wang et al. [33] proposed an ontology-based KG construction method for turbine generator fault diagnosis. The main concepts of the fault diagnosis domain include equipment name, fault diagnosis, operators, and overhaul cases, which realize the standardized expression and application of fault diagnosis knowledge.
One of the most important jobs in knowledge extraction and the cornerstone of KG creation is named entity recognition. During recent years, deep learning models and probabilistic graph models have combined to achieve significant results in named entity recognition tasks. For example, Deng et al. [34] employed stacked BILSTM to acquire deep contextual characteristics of the text. As a complement to stacked BILSTM, the self-attentive mechanism obtains character-dependent features from different subspaces and achieves entity recognition using CRF. Pre-trained language model embedding has now become a promising approach for entity recognition. As an illustration, Kameko et al. [35] proposed a named entity recognition model combining BERT-CRF and multi-task learning for performing factual analysis of Japanese events. Liu et al. [36] suggested a training model that uses Transformers’ bi-directional encoder representation of BERT, combining BILSTM and CRF to extract specified entity classes from unstructured citrus pest and disease data. Chen et al. [37] introduced the BERT-BILSTM-CRF model for extracting named entities from faulty text in power equipment.
The process of locating and expressing relationships between entities as entity-relationship triples from unstructured or semi-structured data is known as relationship extraction. In recent years, neural network models, the combination of neural network models and reinforcement learning, etc. have achieved better results in relation extraction tasks. Chen et al. [11] suggested a remotely supervised relationship extraction (RSRE) based approach to construct an FDKG for fault diagnosis that does not require large amounts of annotated data. Sun et al. [38] suggested a supervised relationship extraction approach using dependency paths in the inter-entity dependency tree, which successfully reduced the time for model training data. Abdurrahim et al. [39] proposed a paradigm for deep learning for relational extraction with BILSTM-CNN based on the attention mechanism, and the experiments demonstrated the accuracy and F1 value of the method compared to the traditional deep learning methods (RNN, CNN).
KG has now been introduced into the domain of equipment fault diagnosis and fault repair. Xiao et al. [30] proposed a bearing fault diagnosis framework based on a knowledge graph and a data accumulation strategy, and used the weighted random forest algorithm as the knowledge graph’s inference algorithm to fully exploit the correlation between features and faults, thereby improving bearing fault classification accuracy. Guo et al. [40] constructed KG for high-speed train repairability design based on multi-domain ontology fusion and a bi-directional coding Transformer model. Li et al. [41] proposed an analysis of design-oriented fault KG using maintenance text, which can feed back the fault knowledge recorded by maintenance into the next generation of product design to realize the closed loop of the product life cycle.
In summary, most of the existing research on using KG for fault diagnosis but few studies have modeled KG for cargo UAV failure domains. However, the operating environment of cargo UAVs is complex and variable, and traditional fault diagnosis methods are difficult to cope with multiple sources of heterogeneous data and complex causal relationships. KG is widely concerned because it can solve similar problems well [42]. Therefore, this work aims to provide a knowledge graph-based approach for modeling fault diagnosis information of cargo UAVs to fill the research gap. This research can not only improve the accuracy and timeliness of fault diagnosis of cargo UAVs but also enhance the safety and efficiency of cargo delivery.
3 Methodology
3.1 UAV fault diagnosis KG construction framework
The UAV Fault Diagnosis KG is used for fault analysis, fault knowledge query, fault detection, and repair scenarios when a UAV fault. It is primarily made up of a pattern layer and a data layer. The methods for building KG can be classified as bottom-up, top-down, or a hybrid of both. The bottom-up construction approach starts with building the data layer of the KG. The process involves extracting the relationships between entities, between entities and attributes, and between attributes to form the entity, attribute, and relationship triad. Subsequently, more entity layers are created and added to the data layer to complete the data model. In contrast, the top-down construction approach first builds an ontology conceptual model and then extracts knowledge instances from the data based on the ontology to add to the graph. Currently, there is a lack of corresponding technologies to support the effective retrieval of UAV fault repair knowledge for UAV fault diagnosis KG. The data source is single, making it difficult to abstract the ontology layer as well as build the graph from the bottom up directly through fault knowledge and data generalization. Moreover, the raw corpus of UAV failures is complex and specialized. As a result, this article uses a combination of top-down and bottom-up methodologies to construct KG for UAV fault diagnosis.
The model layer is first constructed using a top-down approach. By analyzing the data knowledge content of the three domains, the entity data model such as fault subject, fault content, and fault cause, and the relationship data model such as cause, association, and trigger are determined. After that, a bottom-up approach is used to build the data layer. Suitable extraction methods are designed for different fault information materials to perform the extraction of entities, relationships, and attributes. The extracted knowledge is then fused to form a series of high-quality factual representations. Finally, the KG is stored in the graph database Neo4j and visualized to display the KG. Its building process is depicted in Fig. 1.

UAV fault diagnosis KG construction process
3.2 Multi-domain ontology modeling
To address the issue of insufficient fault information in diverse operational settings during KG construction, we propose establishing a conceptual analytical expression model for the environment, fault, and maintenance domains, and employing multi-dimensional similarity calculation for multi-domain ontology modeling. Compared to the single-domain ontology modeling approach, the multi-domain fusion approach can more comprehensively cover the fault information of cargo UAVs in various operating environments. This approach achieves data interconnection and sharing, thereby enhancing the comprehensiveness and accuracy of the knowledge graph [40]. Additionally, multi-domain fusion helps to reveal the intrinsic connection between different domains, enhancing the logic and systematicity of knowledge representation, thus providing more reliable support for fault prediction and repair [43].
3.2.1 Multi-domain knowledge concept analysis modeling
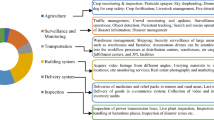
This paper proposes a conceptual analysis and expression model for multi-domain fault diagnosis of the cargo UAV as shown in Fig. 2. This analytical expression model focuses on the expression of knowledge concepts such as fault information appearing in various operating environments of cargo UAVs and the corresponding repair methods, which improves the flexibility of fault diagnosis knowledge expression in the field of cargo UAVs. Based on the expression model of concept analysis, the domain knowledge ontology of cargo UAV environment domain, fault domain, and maintenance domain is constructed, and the multi-domain ontology modeling of cargo UAV is realized through the conceptual semantic relationship of the three domains.

Conceptual analysis of cargo UAV failure knowledge expression model
Based on the expression model of concept analysis, the domain knowledge ontology of cargo UAV environment domain, fault domain, and maintenance domain is constructed, and the multi-domain ontology modeling of cargo UAV is realized through the conceptual semantic relationship of the three domains. The same semantic concepts contained in the environment, fault, and maintenance domains of cargo UAVs are bound to have different names in different domains, so it’s required to construct a mapping between the knowledge ontologies of the fault diagnosis system of cargo UAVs. The association of semantic concepts between two ontologies is realized through inter-ontology mapping relations, and instances of the source ontology are mapped to the target ontology.
3.2.2 Multi-dimensional similarity calculation
In this section, using the fault and maintenance domain knowledge ontologies as an example, a multi-dimensional similarity calculation is employed to establish a mapping relationship between them. Define the fault domain ontology \(O^{G} \) and the repair domain ontology \(O^{L}\), from which concepts \(C^{G}\) and \(C^{L}\) are selected to compute the conceptual similarity \(S_{N}\), attribute similarity \(S_{A}\), and full similarity \(S_{O}\), respectively. If the maximum similarity value of one or more of these three is greater than a given threshold \(\lambda _{i}\), this concept pair is stored in the result set. The similarity calculation of all concept pairs in the ontology is completed in the same way, and finally, the concept pair with the largest similarity value in the result set is selected to establish the mapping relationship.
1) Calculation of conceptual similarity
Determine the conceptual similarity between the fault domain ontology and the maintenance domain ontology after processing according to the string mapping method ISub mapping. Given two concepts \(C^{G}\) and \(C^{L}\) in the fault domain ontology and the maintenance domain ontology, respectively, where \(C^{G} \in O^{G} \) and \(C^{L} \in O^{L}\), the semantic similarity between the concepts \(C^{G}\) and \(C^{L}\) is calculated as follows:
where \(Sim_{G,L}^{name}\) denotes the named similarity; \(Sim_{G,L}^{syn}\) denotes the similarity of the same set of words.
In practical applications, consistent naming descriptions better represent the same concept, so the weight of \(Sim_{G,L}^{name} \) is higher than that of \(Sim_{G,L}^{syn}\). Naming similarity and the same-word similarity are calculated respectively:
where \(ID_{G} \) and \(ID_{L}\) denote the URIs of \(C^{G}\) and \(C^{L}\) in \(O^{G}\) and \(O^{L}\), respectively. \(Lb_{G}\) and \(Lb_{L}\) denote the names of \(C^{G}\) and \(C^{L}\) in \(O^{G}\) and \(O^{L}\), respectively. \(S_{G}\) and \(S_{L}\) denote the same set of words of \(C^{G}\) and \(C^{L}\) in \(O^{G}\) and \(O^{L}\); \(\omega _{G}\), \(\omega _{L}\) are the weights, which are given by experts.
The string mapping method ISub is:
where \(t_{G}\), \(t_{L}\) denote the strings of the conceptual pairs of fault and repair domains. \(comm ( t_{G}, t_{L} ) \) denotes the same part of the strings. \(diff ( t_{G}, t_{L} ) \) denotes the difference part of the strings. \(winkler ( t_{G}, t_{L} )\) denotes the correction factor.
2) Attribute similarity
In the Cargo UAV Failure Domain Ontology, if two concepts of the Failure Domain Ontology and the Maintenance Domain Ontology have a common attribute and the similarity values of the two attributes are close to each other, the two concepts can be determined to be the same or similar. Thus, the similarity of concepts can be determined based on the similarity of attributes. Let the set of attributes of the UAV fault domain ontology be \(C^{G} = \{ C_{1}^{G}, C_{2}^{G},\dots, C_{m}^{G} \}\), and the set of conceptual attributes of the repair domain ontology be \(C^{L} = \{ C_{1}^{L}, C_{2}^{L},\dots, C_{n}^{L} \}\), then the formula for the similarity of conceptual attributes is:
where \(\theta _{i}\) is the weight value of the conceptual attribute of the maintenance domain ontology.
3) Calculation of full similarity of concepts
As there will be cases of homonymy or heteronymy in reality, the degree of overlap between two concepts cannot be determined solely based on the similarity of the concepts or the similarity of the attributes. Given the weights of concept similarity and attribute similarity, respectively, the formula for concept full similarity is obtained as:
where \(\varphi _{i}\), \(\varphi _{j}\) are the weight values.
The condition for mapping is whether the concept similarity, attribute similarity, and concept full similarity are greater than their respective given thresholds. If one or more of them satisfy the conditions, they are stored in the result set for invocation during mapping.
After mapping between ontologies, multi-domain concepts, attributes, and relationships are determined after adjudication to determine the set of concepts of a multi-domain fusion ontology of knowledge on cargo UAV failures, as well as the definitions of relationships between concepts. Some of the inter-concept relationship definitions are shown in Table 1.
3.2.3 Ontology modeling
After clarifying the concepts and attribute relationships of the multi-domain ontology modeling on the fault diagnosis ontology for cargo UAVs, ontology modeling was performed using the Protégé tool. The constructed UAV fault knowledge ontology is shown in Fig. 3, including entities such as fault type, fault subject, fault source, fault content, fault phenomenon, fault cause, and repair measures. The ontology primarily focuses on the input and extraction of fault knowledge, delving into the intrinsic connections between fault information. At the same time, constraints have been imposed on the relationships between entities, specifying the domains and ranges of the head and tail entities. For example, regarding the relationship “associated,” the head entity can only be “fault content,” and the tail entity can only be “fault phenomenon.” If either the head entity or the tail entity fails to meet the conditions simultaneously, the relationship is not established.

Ontology modeling of UAV failure knowledge constructed in Protégé
3.3 BERT-BILSTM-MHA-CRF neural network
To tackle the problem of low efficiency in faulty entity extraction, we propose the BERT-BILSTM-MHA-CRF extraction model, which effectively addresses entity overlapping and accurately delineates entity boundaries. Specifically, BERT reduces the likelihood of entity overlap by capturing contextual information through its powerful linguistic representation capabilities, resulting in a more precise semantic representation of each word [44]. BILSTM captures forward and backward dependencies in sequences using a bidirectional long and short-term memory network to improve the recognition of continuous entities [45]. The Multiple-Head Attention (MHA) mechanism further enhances the model’s ability to perceive overlapping multiple entities in complex contexts by focusing on different semantic levels in parallel to distinguish overlapping entities [46]. Finally, CRF is used to globally optimize the label sequence to ensure that the model predicts continuous and reasonable entity boundaries, thus effectively eliminating entity overlap [45]. Through this series of steps, the BERT-BILSTM-MHA-CRF model can accurately identify and differentiate the fault entities, ensuring the accurate extraction of fault knowledge information.
In this paper, some data are selected to summarize the characteristics of the faulty text data, for these characteristics to BERT-BILSTM-MHA-CRF deep neural network as the basis, to construct the faulty text maintenance data information entity extraction model. The model structure is shown in Fig. 4.

BERT-BILSTM-MHA-CRF entity recognition model
1) BERT embedding layer
The BERT model is used as a feature extractor, which is pre-trained to obtain a deep linguistic representation on a large-scale fault knowledge corpus. As shown in Fig. 5, the BERT model acts as an embedding layer to encode each input character in the Named Entity Recognition (NER) task. It is based on the self-attention mechanism, which allows each character’s encoded information to merge with that of other characters in the context for improved semantic representation.

BERT embedded structure diagram
In using BERT for named entity extraction of UAV fault knowledge, the input layer of the BERT model consists of 3 parts: word vectors, sentence vectors, and position vectors. In this structure, [CLS] is the start flag of the text, and [SEP] is the inter-sentence separator or end flag of the text. Token is the process of encoding the input sequence word by word into a vector of fixed dimensions to represent the original word vector of the word. Segment is to differentiate between pairs of input sentences and perform a subsequent classification task based on the semantic similarity of the two sentences. Position is used to indicate the sequence position of the words in the input sequence in the fault knowledge.
2) BILSTM layer
BILSTM is a recurrent neural network structure suitable for sequence labeling tasks. The network consists of two LSTM layers that process the input along the forward and reverse sequences, respectively. The LSTM memory unit can perform UAV fault diagnosis quickly and accurately by selectively memorizing UAV fault knowledge and fully utilizing the vast majority of the information recorded in the fault repair data. The formula for each gating cell of the LSTM is:
where \(i_{t}\), \(f_{t}\), \(o_{t} \) are the input, forget, and output gate functions, respectively. \(x_{t}\) and \(h_{t}\) are the input vector and the hidden layer vector at moment t. tanh and σ are the Sigmoid activation function and hyperbolic tangent activation function. W denotes the weight matrix for different states. b denotes the bias vector. \(\tilde{c_{t}}\), \(c_{t}\) are the new state data candidate and the current cell state, respectively.
The forward LSTM model and the backward LSTM model are combined to create the BILSTM model. It has the ability to capture long-term dependencies and contextual information in sequences, and effectively encodes contextual information of words in sentences for effective learning of temporal features of text sequences. Therefore, BILSTM is chosen to extract the textual features of UAV fault repair logs, and its network structure is shown in Fig. 6, with \(L_{t}\) as the output data.

BILSTM network structure
3) Multi-head Attention
The multiple attention mechanism enables the model to pay attention to information at distinct places within the input sequence. It does this by linearly mapping the input dividing it into multiple heads and calculating the attention weight for each head. These heads enable the model to concentrate on various segments of the sequence in parallel, thus better capturing correlation information at different locations. In this study, the multiple attention mechanism layer is added to the BILSTM module to improve the model’s capacity to mine global information and sentence relevance, allowing the model to be more effectively applied to UAV fault information.
Within the multi-head attention mechanism layer, the Query, Key, and Value vector are each subjected to h independent linear mappings using different vector matrices, which are then fed into h parallel heads to perform attention operations. In this way, each parallel header can access the semantic information specific to each character in the input text sequence in separate presentation spaces. The final output is obtained by combining the results of the calculations on the h parallel heads and performing a linear mapping. The specific function formulae are given below:
where \(W_{i}^{Q}\), \(W_{i}^{K}\), \(W_{i}^{V}\), \(W^{O}\) are the weight matrices. \(h_{i} \) denotes the ith head in the multi-head attention module. \(Concat\) is the multiplication with the connection matrix after connecting each \(h_{i}\) matrix.
4) CRF layer
The Multi-head Attention Mechanism layer and the BILSTM layer though can discover local and global feature information from contexts and output labels with maximum probability values for pairs of words. However, it cannot learn the relationship between individual labels, resulting in an illogical output of consecutive labels. To fully learn the dependencies between neighboring labels, this paper employs CRF at the conclusion of the model to decode the fault fusion feature data generated by the multi-attention mechanism layer, obtains the transfer probability of each sequence through the feature function, and calculates the highest-scoring sequence labels using the Viterbi algorithm.
3.4 ERNIE relational extraction
In this paper, ERNIE [47] is used for fault relation extraction. ERNIE is an improvement on BERT, using a masking mechanism with a priori knowledge. The model semantic representation is enhanced by modeling semantic information such as words and phrases, and using entities and phrases as masking units. In this way, knowledge and longer semantically dependent information is learned implicitly. The masking strategy for the BERT and ERNIE models is shown in Fig. 7.

BERT model and ERNIE model masks
3.5 Knowledge integration
The knowledge obtained through knowledge extraction may have a large number of fuzzy and repetitive data. The purpose of knowledge fusion is to effectively fuse and unify them to improve the knowledge quality of the knowledge graph database [48]. The task of knowledge fusion mainly includes entity disambiguation and coreference resolution. Entity disambiguation techniques are employed to address the issue of multiple referents for the same named entity. For instance, “sensor” in some texts may refer to a “temperature sensor,” while in others, it may refer to a “pressure sensor.” Therefore, it is necessary to leverage the semantic context to clarify the accurate meaning of the same named entity. Coreference resolution techniques are used to address the issue of multiple expressions corresponding to the same entity object. For example, “motor,” “engine,” and “electric motor” all correspond to the entity “motor.” Especially in manually written fault reports and troubleshooting experiences, the phenomenon of non-standard language usage is quite common. Therefore, there is a need for standardized entity naming. In this paper, the cosine similarity algorithm is used for the extracted entities to calculate the similarity value between the candidate entities, the higher the similarity the closer the expression of the two. Assuming that the 2 phrase vectors are u and v, the cosine similarity \(\cos ( u,v ) = \frac{ ( u,v )}{\parallel u\parallel \times \parallel v\parallel} \), the closer the cosine value is to 1, the more similar the corresponding phrases are. The closer the cosine value is to 0, the more irrelevant the corresponding phrase is. The implementation is shown in Algorithm 1.

Fault knowledge fusion algorithm
The algorithm uses ‘CountVectorizer’from the ‘sklearn’ library to convert the text into a vector representation and the ‘cosine_similarity’function to calculate the cosine similarity between fault descriptions. It then groups similar descriptions into the same category based on a set similarity threshold.
4 Case study
4.1 Data analysis
The information in this document is derived from the flight simulation data of the cargo UAV provided by DJI Innovation Technology Co. Ltd, which records the fault repair data of the cargo UAV, and some of the fault data are shown in Table 2. During the flight simulation, a variety of flight environments and mission scenarios were simulated using the simulation system, including cargo flight missions in different geographic locations and meteorological conditions. Various fault-triggering mechanisms were also simulated to trigger fault events according to set fault models and rules, and the flight status and parameters at the time of the fault were recorded. All simulation flight data is recorded and stored in a database to ensure data integrity and accuracy. The dataset covers a wide range of cargo UAV failure data such as operating environment, failure content, failure causes, and repair measures. For data cleaning, some ambiguous fault data records were first eliminated, and missing data values were filled in. Subsequently, some important attribute data were integrated to optimize the model training results.
Data labeling before model training is then performed. The corpus of cargo drone failure data is divided into a training set with 678 sentences and 18,452 words, and a test set with 324 sentences and 7675 words. Based on the constructed ontology, entities from the original corpus are labeled using the BIO format. Under the BIO annotation system, the token at the beginning of each entity is labeled by the label B-x (beginning), the non-beginning tokens are labeled with the label I-x (inside), and other non-tokenized entity tokens are denoted by the label O (other). A total of 819 entities were labeled and the results of entity labeling are shown in Fig. 8.

Entity annotation visualization
4.2 Experimental environment and evaluation indicators
The experiment is based on the Windows 11 operating system, NVIDIAGeForceRTX4070GPU, Intel(R)Core (TM)i7-13700KF processor, 32G RAM, operating platform Ubuntu20.04, Pycharm2022.1.2, and building a model based on Pytoch neural network framework. The experimental parameter settings are displayed in Table 3.
To validate the efficacy of the entity extraction model built in this paper on the data, the Precision, Recall, and F1 values, which are common in the fields of machine learning and deep learning, are used as the evaluation criteria for the entity recognition effect. To determine the superiority of the entity recognition model, the assessment metrics against the model are still chosen as above, with the following formula.
where TP represents the number of correct predictions, FN represents the number of correct unpredicted forecasts, and FP represents the number of incorrect predictions.
4.3 Results
Based on the collected UAV fault analysis corpus, the Neo4j graph database is utilized to construct a UAV fault diagnosis KG based on the method described above. Currently, a total of 472 entity nodes and 497 relational attributes are constructed within the graph database. Due to the construction of the KG as a whole containing more content, to demonstrate the impact more clearly, this paper selects part of the KG content for visualization as shown in Fig. 9. Which can be based on the fault body to find the corresponding fault content description, fault detection methods, and fault repair countermeasures.

Partial demonstration of UAV fault diagnosis knowledge mapping
4.4 Discussion
4.4.1 Analysis of results of multi-domain fusion
In the knowledge extraction phase, we conducted experiments comparing single-domain and multi-domain data. Single-domain data refers primarily to data in the fault and maintenance domains, and these datasets typically focus on domain-specific textual content, such as fault information and maintenance records. Multi-domain data, on the other hand, includes data from the environmental, fault, and maintenance domains, which cover a wider range of domains and contexts, including environmental conditions, types of faults, and maintenance methods. We evaluated and compared the performance of the two datasets concerning precision, recall, and F1 values, respectively. The experimental findings are depicted in Fig. 10.

Performance analysis of single-multi-domain data extraction models
The experimental results show that the multi-domain dataset significantly outperforms the single-domain dataset in the knowledge extraction phase, with a 2.03% improvement in F1 value. The knowledge extraction accuracy of the multi-domain dataset reaches 84.25%, which is a 2.69% improvement over the single-domain dataset. The extraction efficiencies of single-domain datasets are all lower than those of multi-domain datasets, which fully demonstrates the superiority of multi-domain datasets in knowledge extraction tasks. In multi-domain datasets, models are more adaptable to the context and characteristics of different domains, which improve the ability to capture the accuracy and comprehensiveness of entities.
4.4.2 Comparative analysis of model performance
1) Performance comparison of different entity recognition models
The experimental results of recognizing entities of a class object by selecting BERT-CRF, BERT-LSTM-CRF, and BERT-BILSTM-CRF models as control are shown in Fig. 11. Cross-validation on the same dataset was performed, and accuracy, recall, and F1 scores were obtained to measure the model’s performance.

Performance comparison of entity recognition models
The results indicate that the F1 score of the BERT-LSTM-CRF model increased by 1.06% compared to the BERT-CRF model, which can be attributed to the LSTM’s superior capability in capturing long-range dependencies within sequences. Furthermore, the F1 score of the BERT-BiLSTM-CRF model is 0.89% higher than that of the BERT-LSTM-CRF model. This is because BiLSTM enhances the model’s contextual capture ability and prediction performance by utilizing bidirectional contextual information from the sequence. Compared to the BERT-BiLSTM-CRF model, the BERT-BiLSTM-MHA-CRF model demonstrates superior performance, with precision, recall, and F1 scores reaching 87.52%, 90.47%, and 88.97%, respectively. The addition of the multi-attention mechanism captures the correlation information of different positions in the sequence and addresses issues of entity overlap and boundary confusion, resulting in a 2.86% improvement in the F1 score. The addition of the multi-attention mechanism captures the correlation information of different positions in the sequence and addresses issues of entity overlap and boundary confusion, resulting in a 2.86% improvement in the F1 score. Among the entities in the category of solution measures, there are a large number of long sentences and words that express similar meanings. Due to the lack of an attention mechanism, the BERT-BiLSTM-CRF model performs poorly in capturing long-distance dependencies and handling complex contextual information, resulting in an F1 score that is 11.27% lower than that of the model presented in this paper. Therefore, the model incorporating the multi-head attention mechanism demonstrates superior experimental performance compared to the baseline model.
2) Comparison of different attention head counts
In previous experience, we have found that the quantity of attention heads in the attention mechanism affects the complexity of the model and the network performance. Therefore, we compared different attentional head counts several times in this experiment. Each parameter setting was executed 10 times and the average of the F1 values was calculated and obtained. The experimental findings are depicted in Fig. 12.

Comparison of different attention heads
The experimental findings suggest that the model performs better when there are eight attention heads, with an F1 value of 84.11%. In contrast, when there is just one attentional head, the model can only focus on one aspect of the input sequence and cannot fully capture the diverse information in the sequence, resulting in lower performance. In contrast, when there are five attention heads, the increase in the number of attention heads brings about an increase in model complexity, but it does not necessarily always bring about an increase in performance and still fails to adequately capture enough information, leading to a decrease in performance.
5 Conclusions
Given that the use of KG for fault diagnostics is still in its early stages, the low performance of the knowledge extraction model, and the single distribution of UAV fault data, a multi-domain fusion KG construction method for fault diagnosis of large-scale cargo UAVs is proposed, drawing on the experience of the successful application of KG technology in other fields. The methodology implements multi-domain fusion ontology modeling employing a multi-domain fault diagnosis concept analysis expression model for cargo UAVs and a multi-dimensional similarity calculation method; The UAV fault KG is created by combining the schema and data layers, including the processes of multi-domain heterogeneous knowledge extraction, knowledge fusion, and knowledge storage. From unstructured UAV data to structured fault diagnosis knowledge storage based on cargo UAV fault repair data records. It realizes the sharing and utilization of UAV fault expertise, assists UAV users in maintenance decisions as well as improves the safety of UAVs in logistics and distribution, and adds to the application of KG within the domain of fault diagnosis.
In the future, we will consider using joint entity-relation extraction methods based on recurrent neural networks or convolutional neural networks to rapidly enrich the corpus of UAV fault data and dynamically update the constructed knowledge graph in real-time. This approach aims to better serve the field of UAV fault diagnosis. Subsequent research will focus on the failure mechanisms of UAVs, combining the faults that occurred during test flights and knowledge of the entire UAV production process to conduct “knowledge reasoning” research. This research will explore the links between the production process and the faults that occur, and optimize the production process to improve product quality. Additionally, if the large language model can be integrated with the knowledge graph for freight UAV troubleshooting, it will result in a deeper enhancement of the knowledge graph in this field.
Availability of data and material
The data and material supporting the conclusions of this article will be made available by the authors on request.
References
T. Bosona, Urban freight last mile logistics—challenges and opportunities to improve sustainability. A literature review. Sustainability 12(21), 8769 (2020)
Y. Su, Q.M. Fan, The green vehicle routing problem from a smart logistics perspective. IEEE Access 8, 839–846 (2019)
H. He, H. Ye, C. Xu, X. Liao, Exploring the spatial heterogeneity and driving factors of uav logistics network: case study of Hangzhou, China. ISPRS Int.l J. Geo-Inf. 11(8), 419 (2022)
L. Xue, X.W. Yao, Q.M. Zheng, X. Wang, Research on the construction method of fault knowledge graph of CTCS on-board equipment. J. Railw. Sci. Eng. 1, 34–43 (2023)
X. Meng, S. Wang, J. Pan, Y. Huang, X. Jiao, Fault knowledge graph construction and platform development for aircraft PHM. Sensors 24(1), 231 (2023)
M. Farghaly, M. Mounir, M. Aref, S.M. Moussa, Investigating the challenges and prospects of construction models for dynamic knowledge graphs. IEEE Access 12, 40973–40988 (2024)
S. Munir, R.A.S. Malick, S. Ferretti, A network analysis-driven framework for factual explainability of knowledge graphs. IEEE Access 12, 28071–28082 (2024)
L. Qiu, A. Zhang, Y. Zhang, S. Li, C. Li, L. Yang, An application method of knowledge graph construction for UAV fault diagnosis. Comput. Eng. Appl. 59, 280–288 (2023)
T.P. Nie, J.Y. Zeng, Y.J. Cheng, L. Ma, Knowledge graph construction technology and its application in aircraft power system fault diagnosis. Acta Aeronaut. Astronaut. Sin. 43(8), 46–62 (2022)
Y. Fan, B. Mi, Y. Sun, L. Yin, Research on the intelligent construction of UAV knowledge graph based on attentive semantic representation. Drones 7(6), 360 (2023)
C. Chen, T. Wang, Y. Zheng, Y. Liu, H. Xie, J. Deng, L. Cheng, Reinforcement learning-based distant supervision relation extraction for fault diagnosis knowledge graph construction under industry 4.0. Adv. Eng. Inform. 55, 101900 (2023)
J. Li, A. Sun, J. Han, C. Li, A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 34(1), 50–70 (2020)
J. Devlin, M.W. Chang, K. Lee, K. Toutanova, Bert: pre-training of deep bidirectional transformers for language understanding (2018). arXiv preprint. arXiv:1810.04805
L. Liu, B. Wang, F. Ma, Q. Zheng, L. Yao, C. Zhang, M.A. Mohamed, A concurrent fault diagnosis method of transformer based on graph convolutional network and knowledge graph. Front. Energy Res. 10, 837553 (2022)
P. Liu, B. Tian, X. Liu, S. Gu, L. Yan, L. Bullock, W. Zhang, Construction of power fault knowledge graph based on deep learning. Appl. Sci. 12(14), 6993 (2022)
P. Zhou, S. Lai, J. Cui, B.M. Chen, Formation control of unmanned rotorcraft systems with state constraints and inter-agent collision avoidance. Auton. Intell. Syst. 3(1), 4 (2023)
P. Cheng, C. Cai, Y. Zou, Finite time fault tolerant control design for UAV attitude control systems with actuator fault and actuator saturation. IFAC-PapersOnLine 52(24), 53–58 (2019)
K. Lu, C. Chen, T. Wang, L. Cheng, J. Qin, Fault diagnosis of industrial robot based on dual-module attention convolutional neural network. Auton. Intell. Syst. 2(1), 12 (2022)
Y. Chi, Y. Dong, Z.J. Wang, F.R. Yu, V.C. Leung, Knowledge-based fault diagnosis in industrial Internet of things: a survey. IEEE Int. Things J. 9(15), 12886–12900 (2022)
J. Liu, Sensor fault analysis of aero-engine using ensemble SCNN and Bayesian interval estimation. Eng. Appl. Artif. Intell. 125, 106675 (2023)
L. Cao, X. Yang, G. Wang, Y. Liu, Y. Hu, Fault detection based on extended state observer and interval observer for UAVs. Aircr. Eng. Aerosp. Technol. 94(10), 1759–1771 (2022)
M. Taimoor, X. Lu, W. Shabbir, C. Sheng, Neural network observer based on fuzzy auxiliary sliding-mode-control for nonlinear systems. Expert Syst. Appl. 237, 121492 (2024)
D. Li, Z. Cai, B. Qin, L. Deng, Signal frequency domain analysis and sensor fault diagnosis based on artificial intelligence. Comput. Commun. 160, 71–80 (2020)
H. Eldardiry, E. Bart, J. Liu, J. Hanley, B. Price, O. Brdiczka, Multi-domain information fusion for insider threat detection, in 2013 IEEE Security and Privacy Workshops (IEEE, New York, 2013), pp. 45–51
M.D. Hade, J. Kaur, P.K. Chakraborti, K.L. Dikshit, Multidomain truncated hemoglobins: new members of the globin family exhibiting tandem repeats of globin units and domain fusion. IUBMB Life 69(7), 479–488 (2017)
X. Liu, Y. Zhong, Research on intelligent diagnosis model based on the medical knowledge graph of multi-source data fusion, in 2022 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS) (IEEE, New York, 2022), pp. 225–228
M.J. Hasan, M.M. Islam, J.M. Kim, Bearing fault diagnosis using multidomain fusion-based vibration imaging and multitask learning. Sensors 22(1), 56 (2021)
T. Wu, Y. Zhuang, B. Fan, H. Guo, W. Fan, C. Yi, K. Xu, Multidomain feature fusion for varying speed bearing diagnosis using broad learning system. Shock Vib. 2021, 1–8 (2021)
F. Xie, G. Wang, J. Shang, H. Liu, Q. Xiao, S. Xie, Gearbox fault diagnosis method based on multidomain information fusion. Sensors 23(10), 4921 (2023)
X. Xiao, C. Li, J. Huang, T. Yu, Fault diagnosis of rolling bearing based on knowledge graph with data accumulation strategy. IEEE Sens. J. 22(19), 18831–18840 (2022)
X. Tang, Z. Feng, Y. Xiao, M. Wang, T. Ye, Y. Zhou, D. Zhang et al., Construction and application of an ontology-based domain-specific knowledge graph for petroleum exploration and development. Geosci. Front. 14(5), 101426 (2023)
X.J. Jiang, W. Zhou, J. Hou, Construction of fault diagnosis system for control rod drive mechanism based on knowledge graph and Bayesian inference. Nucl. Sci. Tech. 34(2), 21 (2023)
J. Wang, C.F. Yan, Y.M. Zhang, Y.J. Li, H.B. Wang, Construction and application of knowledge graph for fault diagnosis of turbine generator set based on ontology. J. Phys. Conf. Ser. 2184(1), 012015. IOP Publishing (2022)
J. Deng, T. Wang, Z. Wang, J. Zhou, L. Cheng, Research on event logic knowledge graph construction method of robot transmission system fault diagnosis. IEEE Access 10, 17656 (2022)
H. Kameko, Y. Murawaki, S. Matsuyoshi, S. Mori, Japanese event factuality analysis in the era of BERT. IEEE Access 11, 93286–93292 (2023)
Y. Liu, S. Wei, H. Huang, Q. Lai, M. Li, L. Guan, Naming entity recognition of citrus pests and diseases based on the BERT-BiLSTM-CRF model. Expert Syst. Appl. 234, 121103 (2023)
P. Chen, B. Tai, Y. Shi, Y. Jin, L. Kong, J.F. Wang, Text entity extraction of power equipment defects based on BERT-BI-LSTM-CRF algorithm. Fluid Power Syst. Technol. 35(2), 123 (2023)
H. Sun, R. Grishman, Lexicalized dependency paths based supervised learning for relation extraction. Comput. Syst. Sci. Eng. 43(3), 861–870 (2022)
P. Abdurehim, T. Tohti, A. Hamdulla, An entity relation extraction method based on deep learning. Comput. Eng. Sci. 45(5), 895 (2023)
H. Guo, R. Li, H. Zhang, Y. Wei, Construction of knowledge graph of maintainability design based on multi-domain fusion of high-speed trains. China Mech. Eng. 33(24), 3015 (2022)
S. Li, J. Wang, J. Rong, Design-oriented product fault knowledge graph with frequency weight based on maintenance text. Adv. Eng. Inform. 58, 102229 (2023)
Y. Guo, L. Wang, Z. Zhang, J.X. Cao, Y. Liu, Integrated modeling for retired mechanical product genes in remanufacturing: a knowledge graph-based approach. Adv. Eng. Inform. 59, 102254 (2024)
J. Li, Z. Ye, J. Gao, Z. Meng, K. Tong, S. Yu, Fault transfer diagnosis of rolling bearings across different devices via multi-domain information fusion and multi-kernel maximum mean discrepancy. Appl. Soft Comput. 159, 111620 (2024)
L. Gorenstein, E. Konen, M. Green, E. Klang, BERT in radiology: a systematic review of natural language processing applications. J. Am. Coll. Radiol. 21, 914–941 (2024)
Y. Zhu, A knowledge graph and BiLSTM-CRF-enabled intelligent adaptive learning model and its potential application. Alex. Eng. J. 91, 305–320 (2024)
Y. Wang, K. Liu, Y. He, P. Wang, Y. Chen, H. Xue, L. Li et al., Enhancing air quality forecasting: a novel spatio-temporal model integrating graph convolution and multi-head attention mechanism. Atmosphere 15(4), 418 (2024)
Z. Zhang, X. Han, Z. Liu, X. Jiang, M. Sun, Q. Liu, ERNIE: enhanced language representation with informative entities (2019). arXiv preprint. arXiv:1905.07129
X. Zhao, Y. Jia, A. Li, A survey of the research on multi-source knowledge fusion technology. J. Yunnan Univ. Nat. Sci. 42(3), 459–473 (2020)
Acknowledgements
I would like to thank Dr. Yan, whose expertise was invaluable in formulating the research questions and methodology. His expertise has been instrumental in shaping this work.
Funding
This research was funded by the National Natural Science Foundation of China under Grant No. 52075396, 52375508 and “The 14th Five Year Plan” Hubei Provincial advantaged characteristic disciplines (groups) project of Wuhan University Science and Technology under Grant No. 2023B0405. the Logistics Education Reform and Research Project under Grant No. JZW2023252.
Author information
Authors and Affiliations
Contributions
All authors provided critical input that helped shape the research, analysis, and paper. AX: Writing-original graft, conceptualization, formal analysis, writing-review, editing, and software. WY: Conceptualization, writing-original graft, validation, and editing. XZ: Formal analysis and review. YL: Review and supervision. HZ: Supervision. QL: formatting. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Consent for publication
All authors have read and agreed to the published version of the manuscript.
Declaration of competing interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiao, A., Yan, W., Zhang, X. et al. Multi-domain fusion for cargo UAV fault diagnosis knowledge graph construction. Auton. Intell. Syst. 4, 10 (2024). https://doi.org/10.1007/s43684-024-00072-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43684-024-00072-y