
Abstract
As the core competitiveness of the national industry, large-scale equipment such as ships, high-speed rail and nuclear power equipment, their production process involves in-depth personalization. It includes complex processes and long manufacturing cycles. In addition, the equipment’s supply chain management is extremely complex. Therefore, the development of a supply chain management knowledge graph is of significant strategic significance. It not only enhances the synergistic effect of the supply chain management but also upgrades the level of intelligent management. This paper proposes a distant supervision knowledge extraction and knowledge graph construction method in the supply chain management of large equipment manufacturing, which achieves digital and structured management and efficient use of supply chain management knowledge in the industry. This paper presents an approach to extract entity-relation knowledge using limited samples. We achieve this by establishing a distant supervision model. Furthermore, we introduce a fusion gate mechanism and integrate ontology information, thereby enhancing the model’s capability to effectively discern sentence-level semantics. Subsequently, we promptly modify the weights of input features using the gate mechanism to strengthen the model’s resilience and address the issue of vector noise diffusion. Finally, an inter-bag sentence attention mechanism is introduced to integrate different sentence bag information at the sentence bag level, which achieves more accurate entity-relation knowledge extraction. The experimental results prove that compared with the latest distant supervision method, the accuracy of relation extraction is improved by 2.8%, and the AUC value is increased by 3.9%, effectively improving the quality of knowledge graph in supply chain management.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Large-scale equipment, including ships, high-speed railways, and nuclear power installations, are cornerstones of a nation’s strength and vital elements defining a robust manufacturing sector [1]. These industries are characterized by stringent customization needs, exacting quality standards, intricate production processes, and a multitude of critical components, which contribute to the complexity and challenges inherent in managing their extensive supply chain systems [2]. In recent times, there has been a persistent drive towards digital transformation and upgrading strategies; among these initiatives, the digitization and intellectualization of supply chains in manufacturing enterprises have emerged as a pivotal juncture [3]. Tasks such as supply chain performance assessment, supplier selection, and risk management heavily rely on knowledge-intensive decision-making. Thus, enhancing intelligent management in supply chains through data and knowledge is a crucial, urgent task that both academia and industry are actively researching [4]. At the core of this endeavor lies the construction of a dedicated knowledge graph for supply chain management. Such a knowledge graph is crucial since it facilitates the organization and representation of domain-specific knowledge encapsulated in unstructured textual data, making it more accessible for continuous augmentation and application [5]. Therefore, Advanced knowledge extraction methodologies are crucial, which should be tailored for supply chain management. Exploring knowledge graph construction methods is also essential. These steps are profoundly important. They underpin the intelligent transformation of supply chain management that is particularly critical within the equipment manufacturing sector.
The knowledge graph for large-scale equipment manufacturing supply chains predominantly comprises structured knowledge represented as entity-relation triples. Present research into automated extraction of domain-specific entity-relation knowledge primarily encompasses three paradigms: supervised learning, unsupervised learning, and distant supervision techniques [6]. While supervised learning for entity-relation extraction exhibits commendable effectiveness, it confronts a major hurdle in the supply chain management context – the reliance on ample labeled resources. On the other hand, unsupervised learning methods leverage clustering for entity-relation extraction, sidestepping the need for training data, yet they often yield less accurate results [7]. Distant supervision offers a promising solution by significantly reducing the expense of manual data labeling. It utilizes existing knowledge bases to automatically label a substantial volume of unlabeled text data, assuming that if two entities in a sentence bear a specific relation in the knowledge base, they likely express that same relation in the text [8]. Despite its potential for scaling up labeled data creation, the domain of supply chain management typically presents with small-sample and sparse-distribution characteristics for unstructured textual data [9]. There currently exists a gap for publicly accessible, large-scale, annotated entity-relation training datasets. This necessitates research into automatic annotation methods for unstructured text data in this domain. The aim is to alleviate dependency on manual labor for data annotation and to expedite the construction of training sample sets [10]. Moreover, achieving precise entity-relation knowledge extraction in the supply chain domain is critical. This is especially challenging when based on a small sample set. Overcoming this challenge is essential for constructing a high-quality domain knowledge graph [11]. This paper capitalizes on the untapped potential of distant supervision methods to diminish the reliance on annotation resources, effectively curtailing the time and cost associated with manual annotation of domain knowledge text data. Nonetheless, the distant supervision approach is plagued by overgeneralization and mislabeling due to considerable noise during the corpus construction process, which substantially hampers model performance [12].
In response to these challenges, this study proposes a novel distant supervision entity-relation knowledge extraction model specifically designed for the supply chain management domain. The primary contributions and ensuing work are as follows:
-
By conducting thorough case studies within the realm of supply chain management, we meticulously craft a holistic ontology model designed. This meticulously devised model then serves as a guiding principle, enabling us to thoughtfully annotate a subset of our data. In parallel, we leverage an advanced distant supervision relation extraction model, which automates the extraction of domain-specific knowledge, culminating in the efficient construction of a knowledge graph tailored for supply chain management applications.
-
To address the prevalent issue of overgeneralization and substantial noise in distant supervision techniques, we introduced an innovative integration methodology. It unites a gating mechanism with ontological feature inputs, finally enhancing sentence representation in sentence clusters via an inter-sentence attention mechanism. The integration of ontological information significantly bolsters the model’s feature extraction capabilities, thereby effectively seizing semantic information at the sentence level. The gating mechanism adjusts feature weights smartly which makes the model flexible and reduces noise problems. This novel approach has been highly effective in the realm of distant supervised relationship extraction, yielding remarkable outcomes.
-
We have meticulously carried out an extensive series of comparative and ablation experiments, which thoroughly evaluate and validate the effectiveness of our proposed model in extracting knowledge within the complex realm of supply chain management. These empirical evaluations serve as a testament to the practical utility and theoretical soundness of our contribution.
2 Related works
Over the last several years, the rapid advancements in artificial intelligence technologies have propelled knowledge graphs into a pivotal position in various domains such as information retrieval, data mining, and intelligent decision-making [13–15]. Within the realm of manufacturing supply chain management, knowledge graphs have emerged as a transformative tool to break down informational silos and foster intelligent, knowledge-driven supply chain management practices through the structured representation of information. However, the successful implementation of knowledge graphs hinges upon the development of effective knowledge extraction techniques.
Entity-relation knowledge extraction is a critical step in this process, directly influencing the overall performance and practical utility of knowledge graphs [16]. Distant supervision methods have gained significant traction due to their capability of automatically annotating large amounts of training data using pre-existing knowledge bases. This innovation dramatically reduces manual labeling efforts and has fueled advancements in relation extraction [17]. Despite its notable benefits, the distant supervision approach comes with inherent constraints, particularly concerning the noise introduced during the automatic annotation phase, which can undermine the precision and reliability of relation extraction [12].
Several researchers have endeavored to refine distant supervision methods to overcome these obstacles. For instance, Feng et al. [18] employed reinforcement learning to assign varying degrees of importance to different entities, thus mitigating the effects of mislabelling by focusing on more relation-relevant information. Riedel et al. [19] tackled the issue by adopting a multi-instance learning framework to lessen the repercussions of incorrect labels. Lin et al. [20] leveraged Piecewise Convolutional Neural Networks (PCNN) as sentence encoders, assigning dynamic weights to sentences featuring the same entity pair, prioritizing those that better convey the relation. Nevertheless, such models may overlook the significance of named entities in shaping sentence representations. Building on these progresses, Ji et al. [21] aimed to enhance the quality of entity vectors by utilizing textual descriptions of entities, proposing a high-level regularization approach to improve the original relation extraction task.
Wen et al. [22] tackled the inadequacy of selective attention when dealing with single-sentence contexts. To surmount this limitation, they introduced the Entity-Guided Enhancement Feature Neural Network (EGEFNet). This innovative method incorporates an entity-focused attention mechanism that effectively identifies and captures pivotal relational features from both discrete words and cohesive phrases. The entity representations thus augmented are subsequently transformed into a relation-centric representation and merged with other semantic aspects, such as the PCNN-encoded sentence representation, culminating in an enhanced sentence representation. Ultimately, the research pioneers a relation-guided gate pooling strategy, which adeptly manages the challenges posed by one-sentence bags.
Kastrati et al. [23] addressed the challenge of supervised learning’s heavy dependence on copious amounts of labeled data by implementing a distant supervision methodology that capitalizes on emojis within tweets to annotate them according to Ekman’s six foundational emotions. A systematic and exhaustive experimental campaign was launched, leveraging a broad array of conventional machine learning algorithms and state-of-the-art deep learning frameworks, including transformer-based models, to establish performance benchmarks in the field. This endeavor notably resulted in an F1-score of 70.92% for sentiment categorization and 54.85% for emotion detection.
Despite these advances, the challenge of effectively integrating ontological and sentence-level semantic information about entities in the complex landscape of manufacturing supply chain environments remains largely unresolved.
This paper addresses this gap by presenting a pioneering distant supervision relation extraction model uniquely tailored for manufacturing supply chain management. The proposed model incorporates a gate mechanism and an entity-to-ontology information-based strategy. Unlike prior studies, it not only fortifies the distant supervision method against noisy environments but also enhances relation extraction accuracy through a sentence bag level attention mechanism. This innovative approach provides a fresh technical pathway for the construction of knowledge graphs in the manufacturing supply chain management domain, thereby advancing the state-of-the-art by offering a robust, accurate, and contextually-aware solution for knowledge extraction and representation.
3 Supply chain management knowledge graph construction
This paper proposes a distant supervision knowledge extraction and knowledge graph construction method for the supply chain management domain to achieve automated knowledge acquisition and supply chain management knowledge graph construction. The overall process of supply chain knowledge graph construction in the supply chain management domain using the distant supervision method is shown in Fig. 1. Firstly, raw data related to supply chain management domain knowledge is screened and collected, including high-level technical literature, experience logs, management specification texts, etc., which contain supply chain management domain knowledge as the core data source to establish a supply chain management text data set mainly based on unstructured text data. Further, some of the collected unstructured text data is finely preprocessed, and manual annotation methods identify pairs of relation entities and their interrelations. Finally, the knowledge base with annotations for the supply chain management domain is constructed with multiple relations between entities labeled in detail to support the subsequent automated construction of the knowledge graph.

Supply chain management knowledge graph construction method based on distant supervision
3.1 Supply chain management ontology model construction
Based on the basic concepts and business logic of the supply chain management domain, the system constructs an ontology model of knowledge in the supply chain management domain from a structured ontology model. As shown in Fig. 2, the model covers 11 common entity types in supply chain management, which constitute the core components of the model. Subsequently, six relation types are defined for these entity types as well as for the actual needs of the supply chain management domain, which include “Belong_to”, “Contrapose”, “Have_attribute”, “Have_step”, “Lead_to” and “NA”. The model provides an essential semantic framework for distant supervision relation extraction. Through the distant supervision method, the annotated relation entity pairs are intelligently matched with a large-scale text set, and the relation instances containing relation entity pairs are automatically identified and extracted, which effectively extends the coverage of the supply chain knowledge corpus. Further, entity-relation knowledge extraction models are trained and constructed using these preprocessed and annotated training corpora to acquire supply chain management domain knowledge automatically.

Entity types in the field of supply chain management
3.2 Distant supervision dataset construction
Based on the established supply chain management domain knowledge ontology model, we selected more than 1200 representative supply chain management domain knowledge corpora. We annotated the selected knowledge corpora using the defined domain knowledge ontology model. In order to ensure the high accuracy of data annotation, the cross-annotation method is adopted [24], i.e., each data is independently completed by at least two annotators to verify the consistency and reliability of the annotation results. For example, for the text description “Large equipment procurement management mainly adopts two modes: traditional management mode and punctual management mode…”, its corresponding supply chain entity relation is expressed as a series of triples. For example, (Large Equipment Procurement Management, inclusion mode (Have_step), traditional management mode) and (Large Equipment Procurement Management, inclusion mode (Have_step), punctual management mode). Meanwhile, in this process, “large equipment procurement management” is classified as “Field”, while “traditional management mode” and “punctual management mode” are labelled as “Mode”. After cross-labelling and pre-processing, we can obtain a high-quality supply chain management domain knowledge base that matches the ontology model.
Subsequently, a training dataset for entity-relation knowledge extraction is further constructed using a distant supervision approach based on a manually annotated management domain knowledge base. This dataset is constructed as follows: firstly, each sentence is traversed in the corpus to identify the occurring entities using string matching and to filter out the sentences that do not contain entities or contain only a single entity. The sentences are then subjected to a segmentation process that removes generic terms while retaining the entities defined in the knowledge base, and the piecewise sentences are again subjected to entity filtering to exclude duplicates or entities with unclear relations. The entities are paired for the filtered set of entities, and the information in the knowledge base is used to determine whether there is a relation between them (if the relation is not defined in the knowledge base for the entity, it is marked as “no relation”). Eventually, the dataset was divided into a training set and a test set based on a ratio close to 3:1, and 24,961 training instances and 8325 test instances were obtained, respectively.
4 Entity relation knowledge extraction model incorporating ontology information and gate mechanism
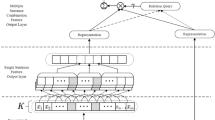
Due to the broad assumptions of the supply chain knowledge dataset constructed based on the distant supervision method, the automatically acquired instances sometimes need to describe the relations accurately, thus introducing a large amount of noisy data, seriously affecting the effect of relation extraction [25]. To solve this problem, this paper proposes a distant supervision model based on the ontology information gate mechanism; the network structure is shown in Fig. 3, which mainly consists of 3 parts: PCNN, ontology information gate layer, and bag-of-sentence level attention mechanism. The model uses a multi-instance learning approach, i.e., for a given bag (a collection of sentences containing the same entity pairs) B = \(\{ s_{1},s_{2}, \ldots , s_{n}\}\) and the entity pairs in the sentence, the probability of predicting the individual entity relation labels is predicted on Bag. The model can both automatically extract sentence features and reduce the influence of a large number of noisy sentences. Next, the semantic information of the sentence structure of the training instances is obtained through the PCNN network [16]. The ontology information of the entity pairs is fused through a gate mechanism, which is used to reduce the weight of the error information, and a sentence bag-level attention mechanism is introduced to calculate the relevance of the sentence bags to the corresponding relations among multiple training instances, in order to reduce the inter-sentence bag noise data and improve the performance of entity-relation extraction.

Entity Relation Extraction with the integration of Ontological Information and Gate Mechanisms
4.1 Piecewise convolutional neural networks
4.1.1 Word vector
The word vector technique converts each word into a low-dimensional numeric vector through a distributed representation designed to capture and express rich semantic information. Compared to traditional one-hot encoding, this representation can contain more semantic content as each character is mapped to a low-dimensional real number vector through model training [26].
Specifically, for an input sentence s containing n words, it can be expressed as s = \(\{ w_{1}, w_{2}, \ldots , w_{n}\}\). These words are first mapped to a numerical index number through a dictionary. Secondly, each index number is converted to a vector form through a mapping matrix \(W^{\mathrm{E}} \in R^{ \vert V \vert } \times d_{w}\), where \(d_{{w}}\) is the dimension of the word vector, and \(\vert V \vert \) is the dictionary size.
In particular, for the specific needs of distant supervision relation extraction tasks, the Glove model [21] is employed for word vector transformation to use global statistical information and local contextual information fully. In addition, in the Piecewise Convolutional Network layer and ontology fusion gate layer of the model, sentences are mapped to word vectors and combined with positional and ontology features to achieve in-depth semantic feature extraction of entity information.
4.1.2 Position vector
In sentence representation, words closer to the target entity word usually contribute more to the semantics of the sentence, a phenomenon that points to the importance of positional information in sentence comprehension [27]. In order to effectively encode such positional information, the present model incorporates positional vector features in sentence encoding, which effectively compensates for the deficiency of Convolutional Neural Networks (CNN) in positional information encoding. In the specific implementation for the text data in the field of supply chain management, the sentences are first preprocessed, including removing stop words and performing entity disambiguation so as to extract the entity sequences in the Chinese sentences.
The next steps of implementation are as follows: the relative distances between the i-th word in the sentence and the two key entities are denoted by \(P1_{i}(i = 1,2, \ldots n)\) and \(P2_{i}(i = 1,2, \ldots n)\) respectively. Then, the values are mapped into low-dimensional vectors \(p1_{i}(i = 1,2, \ldots ,n)\) and \(p2_{i}(i = 1,2, \ldots ,n)\) by two vector matrices \(PE_{1}\) and \(PE_{2}\), with the mapping dimensions of the position vectors being \({d}_{{p}}\). Finally, the position vector and sentence vector are concatenated to derive the composite vector, \({X}_{\mathrm{pos}}\), as illustrated below:
where \(X_{i}\) represents the sentence word vector, which is directly concatenated to obtain a vector that combines positional features \({X}_{\mathrm{pos}}\). Given the variability in sentence length, a maximum positional distance limit is set to normalize the processing of position vectors. At the Piecewise convolutional neural networks level, the model’s ability to encode positional information is significantly enhanced by fusing the positional features of entity pairs with the vectorial representations of sentences.
4.1.3 Piecewise feature extraction
Sentence vectors incorporating positional features are constructed by transforming word vectors and integrating position vectors. To mine the local structural features in the sentences deeply, PCNN is adopted as the core neural network architecture to automate the learning of textual features. Within the field of Natural Language Processing (NLP), the maximum pooling operation is widely used to extract salient features in sentence expressions. This process helps to reduce the number of parameters in the model [6].
However, in relation extraction tasks, standard maximum pooling often fails to accurately capture critical information related to entity pairs due to its large selection granularity. By introducing the piecewise maximum pooling mechanism, PCNN can deal with crucial information in the sentence in a more detailed manner, especially the semantic features that are neighboring to the target entity pairs, significantly improving the model’s ability to capture the deeper semantics of the sentence.
Specifically, \(X^{pos}\), which incorporates positional features, is taken as input and passed through a one-dimensional CNN to obtain the output result \(X_{p}\), a process that can be defined as:
where \(W^{c} \in R^{d_{c} \times \mathrm{m} \times d_{p}}\) is a CNN network matrix with a number of filters m, and f is the activation function ReLu. Next, in order to obtain sentence-level features, each sentence \(X_{p}\) is divided into \(\{ X_{p1},X_{p2},X_{p3}\}\), and the piecewise maximum pooling is defined as:
For each output sentence after the CNN network, a 3D vector \(P_{i} = \{ P_{i1},P_{i2},P_{i3} \}\) is obtained, and subsequently, \(P_{1}\) to \(P_{k}\) are concatenated to form a sentence vector \(P_{1:k}\) incorporating positional features.
4.2 Ontology information fusion gate layer
Traditional distant supervision models rely on the attention mechanism to identify the noise distribution of sentences within a sentence bag to cope with the noisy data problem. However, in supply chain management datasets, there are a large number of sentence bags containing only a single sentence, in which case the effectiveness of the attention mechanism is limited. To address this problem, a gate mechanism incorporating ontology information is introduced into the model. This mechanism can dynamically assign lower threshold values to mislabelled instances within the sentence bag, effectively filtering out noise signals that are interfering or useless to the model and playing a crucial role in mitigate the noise problem in the sentence bag.
4.2.1 Sentence vectors incorporating ontological features
The ontology information in the supply chain management dataset is attached to each class of entities by using the distant supervision method. The fusion of ontology information will enhance the model’s understanding of sentence structure and significantly improve the representation of distantly supervision word vectors. The positional features are incorporated into the sentence vectors through word vector techniques to form the base vectors of the piecewise convolutional neural network (PCNN); meanwhile, the fusion of ontology information also employs word vector techniques as a critical source for capturing semantic information. Given an entity pair with an ontology information pair vector \(( Ont^{i(h)}, Ont^{i(t)} )\) and a sentence word vector \(X^{i}\), the semantic information embedding of an entity pair is defined as:
where \(Ont^{i}\) denotes one of the ontology information vectors in the entity pair, \(W^{\mathrm{o}} \in R^{d_{w} \times d_{r}}\) is the vector matrix of ontology information, and \(b^{o}\) is the bias term to obtain the vectors \(X^{{o}^{{i}}} \in R^{d_{w}}\) for the front ontology and the back ontology in the entity pair, respectively, where \(d_{r}\) is the dimension of the ontology information word vector and \(d_{w}\) is the dimension of the word vector in Sect. 4.1.1, the vector \(O_{i} \in R^{d_{w} \times 3}\) incorporating the ontology information can be obtained by assembling the sentence word vector with the two target ontologies \(X^{{o}^{{i}({h})}}\) and \(X^{{o}^{{i}(\mathrm{t})}}\) in the sentence.
4.2.2 Gate convolutional layer
The self-attention mechanism in traditional distant supervision frameworks, while attempting to solve the noise problem by calculating the noise distribution of sentences in the sentence bag, is often limited by mislabelled sentences in the sentence bag.
In particular, in the supply chain management domain dataset, the large number of entity pair types leads to the existence of a large number of sentence bags containing only a single sentence, which broadly weakens the effectiveness of the self-attention mechanism. To address this problem, a gate mechanism incorporating ontology information is proposed, which can dynamically adjust the weights of the signals according to the features of the inputs, thus effectively filtering out the noisy signals that interfere with the model. For this purpose, each sentence’s ontological information vector \({O}_{i}\) is processed through a two-layer fully connected neural network to compute its gate weight values.
where the tanh activation function is used to introduce nonlinear features, and the function restricts the output of the tanh to values between 0 and 1, thus ensuring that the range of values is (0, 1).
To extract the ontological information features and positional features of the entity and get a more accurate representation of the sentence vectors, the next step will be obtained by fusing the weights with the positional feature vector vector \(x_{p}\) obtained in Sect. 4.1 as follows:
where \(\mathrm{O}_{i}\) is the ontological feature information of the entity pair, and \(x_{p}'\) is the sentence-level vector that combines the entity location information. The combined word vector \(c'\) combining ontological and positional information is computed for each sentence by precisely modulating ontological information gate weights.
Finally, as shown in Eq. 9, by ensembling such integrated word vectors \(c'\) for all sentences in the bag of sentences and calculating their average, a bag-of-sentence level vector representation b is obtained. This vector b integrates the ontological and positional information of all sentences in the bag of sentences, which provides a comprehensive and accurate feature representation for subsequent entity-relation classification, thus improving the accuracy of the relation extraction model.
4.3 Intersentential bag-of-attention mechanism
In Sect. 4.2, word vectors incorporating ontological features have been successfully obtained, and noise has been effectively removed by introducing a gate mechanism for external information to get accurate vector representations of sentence bags. However, there are still difficulties in matching these vector representations with the most relevant relational labels. Specifically, assuming that both Bag1 and Bag2 are labeled as having the same relation r, the next goal is to make them as close as possible in the vector space.
Therefore, a similarity-based inter-sentence bag attention mechanism is further introduced in the model. The core idea of this mechanism lies in grouping sentence bags labeled as having the same relation and assigning different weights based on their similarity. Higher weights are assigned to those sentence bags that are more similar to most sentence bags in the group [28]. The degree of similarity between sentence bag vectors can be accurately assessed by calculating the similarity between sentence bag vectors. The specific calculation formula is as follows:
where \(b_{r}^{i}\) represents the bag-of-sentences vector representation obtained from Sect. 4.2.2, and \(Sim_{ir}\) is the bag-of-sentences similarity calculated based on the bag-of-sentences vector itself, which in turn is used to represent the bag-of-sentences weights. Considering the diversity in the lengths of sentence bag vectors, all sentence bags vectors \(b_{r}^{i}\) are normalized for length before calculating the similarity to ensure consistency in the calculation:
The above method can calculate the similarity between sentence bags, i.e., the weight matrix between sentence bags and relation labels. Next, this matrix is utilized to determine the confidence level \(\omega _{{ir}}\) between the bag of sentences and a particular relation; each \(\omega _{{ir}}\) is defined as:
After obtaining the bag of sentences confidence level through Eq. 12, the bag of sentences vector \(\overline{b_{r}^{i}}\) obtained using Eq. 11 is dot-produced with the individual bag of sentences confidence levels and accumulated to obtain a composite vector representation of the bag group \(g_{r}\). Next, \(g_{r}\) is calculated by multiplying it with the embedding matrix of the entity relation to calculate the score \(s_{r}\) for which the bag group g has been classified into a particular relation r:
where \(d_{r}\) is involved in the calculation as a bias term. The score \(s_{r}\) is subsequently processed using the Softmax function to compute the probability that bag group g is classified into relation r:
The Dropout technique is employed in the bag-of-sentences representation \(\overline{b_{r}^{i}}\) to suppress the over-fitting phenomenon. Finally, the cross-entropy loss function combined with L2 regularisation is adopted as the optimization objective, as a way to ensure the robustness and effectiveness of model training:
where T represents the set of all training samples in the supply chain dataset, while θ contains the model parameters such as word vector matrix, CNN vector matrix, gate convolutional layer matrix, and relation embedding matrix. Through this approach, the relation classification of the supply chain management dataset is accurately performed, which also effectively improves the adaptability and accuracy of the model for the relation extraction task in the supply chain management domain.
5 Experiments and analysis
5.1 Datasets and evaluation criteria
In this paper, we employ a strategy based on distant supervised learning to construct a corpus of entity relations specific to the supply chain domain. The corpus serves as the core foundation for the experimental data, where we define in detail 11 key entity types and six primary inter-entity interaction relations within the supply chain management domain. Applying this systematic approach, the experiments successfully generated 33,286 high-quality instance data, including 24,961 carefully selected data instances for training and 8325 test set instances for evaluating model performance.
On the other hand, the word vector query dictionary \(D^{w}\) was constructed using the glove2word2vec tool provided by the gensim library in Python, based on the Glove model trained for the supply chain management dataset [29]. During training, the model was set with specific training parameters, as shown in Table 1, and the rest of the parameters were kept as default settings. The experiments were performed on a device equipped with an i7-9700K processor (3.6 GHz), 32 GB of RAM, and 12 GB of video memory.
5.2 Experimental settings
In terms of data noise reduction, we propose a model that incorporates an ontology information gate mechanism to optimise the quality of the data acquired by the distant supervision method. The specific hyperparameters for model training are shown in Table 2.
-
Where the positional features contain the maximum relative distance and the location feature dimension, the PCNN network layer parameters are the window size and the number of convolutional kernels.
5.3 Analysis of experimental results
This paper designs four comparison experiments to validate the distant supervision model’s effectiveness. It conducts three ablation experiments to deeply evaluate the practical effectiveness of each component of the model.
5.3.1 Comparative experiments
In this paper, a total of four comparative experiments are set up to test the performance of the proposed model for distant supervision relation extraction on the supply chain domain dataset, which validates the effectiveness of the proposed method in improving the performance of entity relation extraction:
-
1.
PCNN+BAG-ATT [30]: utilizes a piecewise convolutional neural network as a sentence encoder to add a bag-level attention mechanism for bag-level noise reduction.
-
2.
CNN+BAG-ATT [30]: using a bag-of-sentence-level attention mechanism but with a regular CNN as the sentence encoder.
-
3.
ENT-AWARE [31]: enhances the feature filtering of PCNN extraction with entity vector information to obtain features that are more relevant to the relational labels.
-
4.
PSAN-RE [32]: an attention mechanism model optimized by a pre-trained model incorporating information from entity relation patterns. For fairness and adaptability, the pre-trained model is replaced with a generic PCNN model for experiments.
-
5.
ONG+BAG-ATT: fuses the gate structure of ontology information with sentence bag-level attention mechanisms and uses this model for entity relation extraction testing.
In this paper, we experimentally use AUC and P@N [32] as evaluation parameters to measure the distant supervision model. Where AUC demonstrates precision and recall results by calculating the area under the PR curve in a combined manner. P@N reflects the precision rate of the model in selecting the first N instances in the packet for evaluation.
Within the realm of Multi-Instance Learning (MIL), where datasets are structured as bags comprising multiple instances, assessing model efficacy demands a nuanced methodology. Here, Precision at N (P@N) emerges as a pivotal metric, gauging the precision of a model’s leading N predictions when a predefined count of instances from each bag is examined. This assessment hinges upon validating the uppermost N instances per bag, thereby rigorously scrutinizing the model’s aptitude for highlighting the most pertinent information. We employ four distinct configuration settings to optimize the scrutiny of the model’s performance capabilities. Notably, the evaluation metrics P@100, P@200, and P@300 are deployed, corresponding to training scenarios involving the utilization of instances per bag. Additionally, P@Mean is calculated as the average of these three metrics, further enriching our evaluative scope. This methodology ensures an exhaustive examination of the model’s precision across a broad range of instances, thereby bolstering the reliability of our evaluative framework.
As shown in Table 3, the AUC value of the method in this paper is significantly improved, indicating that the overall robustness of the model is strengthened, and the ontology information feature helps to improve the model performance. The reasons for this are as follows:
-
1.
By incorporating ontology information, the model can understand the relations between entities more deeply, improving the accuracy and reliability of relation extraction.
-
2.
By combining the gate mechanism and the sentence bag-level attention mechanism, the model effectively copes with the noise problem in distantly supervised data and significantly improves its robustness when dealing with large-scale datasets.
-
3.
This comprehensive feature representation provides new perspectives for future distant supervision relation extraction tasks, especially showing potential in feature extraction efficiency and model optimization.
As shown in Fig. 4, the comparative analysis of the P-R curves further validates the significant advantage of the ontology fusion gate attention mechanism model over the other four mainstream models in terms of accuracy. It proves the effectiveness of the approach in enhancing the performance of distant supervision relation extraction tasks. This is attributed to the innovative structure of the model, i.e., by fusing the ontology information of entity pairs with the gate mechanism and the bag-of-sentences level attention mechanism, the model is not only able to extract key entity-relation semantic information but also effectively reduce the inter-bag-of-sentences noise, which improves the overall accuracy of relation extraction.

PR curves of different distant supervision models
5.3.2 Ablation experiment
In order to analyze in depth the contribution of the components of the proposed model to the experimental results, three ablation experiments are designed in this subsection:
-
w/o SEG: remove the gating mechanism and directly fuse the ontology information into the PCNN model for uniform feature extraction.
-
w/o ONG: the ontology information fusion step is removed and feature extraction of the gate mechanism is achieved through sentence features only.
-
w/o BAG-ATT: performed under conditions that do not employ sentence bag-level attention mechanisms.
As demonstrated in Fig. 5, the model with ontology information fusion removed (w/o ONG) has the worst experimental performance due to the lack of utilization of entity ontology information features, which emphasizes the importance of ontology information in distant supervision tasks. By comparing the model with the removal of the gate control mechanism (w/o SEG) with the bag-of-sentences level attention mechanism (w/o BAG-ATT), it is not difficult to find that there is a slight degradation in the model performance with the removal of the bag-of-sentences level attention mechanism. The decrease in accuracy is more pronounced significantly when the recall rate is increased. And after removing the gate-control mechanism, the model exhibits significant instability and rapidly decreasing accuracy, which further demonstrates that the combination of the gate-control mechanism and the sentence bag-level attention mechanism can significantly smooth out and improve the model’s accuracy and maintain a certain degree of accuracy even under high recall, thus enhancing the overall robustness of the model.

Comparison of ablation experiments
The ablation experiments not only validate the effectiveness of each module of the proposed model but also further demonstrate the crucial roles of the fusion of ontology information, the gate-control mechanism, and the sentence-bag-level attention mechanism in improving the performance of the distant supervision of the relation extraction task, showing the effectiveness and advancement of the methodology in this paper.
5.4 Visualisation of knowledge graph in supply chain management domain
After entity-relation extraction of a dataset in the supply chain management domain using a distant supervision model, a large amount of entity-relation triad information is obtained by identifying and extracting entities and their relations. The information is imported into the Neo4j graph database, which is a powerful and flexible graphical database management system for building and presenting manufacturing supply chain knowledge graphs.
As shown in Fig. 6, the knowledge graph is presented graphically, where the nodes (circles) represent entities such as suppliers, producers, supply chain methods, etc. The links between the nodes represent relations between entities in the supply chain. The lines between the nodes represent the relations between the entities, such as “Have_step”, “Used_for”, “belong_to” etc., which clearly reveal the complex interactions and dependencies between the entities in the supply chain. Dependencies between entities in the supply chain. Through this intuitive graphical display, key nodes and relations in the supply chain can be easily identified, providing robust support for decision-making in supply chain management.

Supply chain management realm knowledge graph
6 Conclusion
This paper focuses on the demand for intelligent transformation and upgrading supply chain management of large-scale equipment manufacturing. It proposes a distant supervision-driven domain knowledge extraction and knowledge graph construction method for supply chain management. To effectively alleviate the noise problem caused by distant supervision, a gate-control mechanism for ontology information fusion is introduced, and the positional features of entity pairs in sentences are extracted by piecewise maximum pooling technique. The gate control mechanism is then used to profoundly integrate the ontological and semantic information of the instances and figure out the sentence-level noise threshold. This makes noise reduction processing work well at the sentence level. The inter-bag attention mechanism reduces the weight of mislabelling in the sentence bags with the same relation. The experimental results demonstrate that the gated attention mechanism based on ontology information fusion proposed in this paper significantly reduces the impact of mislabeled instances and effectively improves the accuracy of knowledge extraction of distantly supervision entity relations.
This article has made significant progress in reducing the detrimental effects of noisy data. It skillfully incorporates ontology information gating mechanisms along with sentence bag-level attention mechanisms. Despite these advancements, some notable limitations of the model persist. One such shortcoming lies in the underutilization of the abundant graph feature information inherent within the knowledge graph, presenting an untapped potential for deeper insights [12]. Moreover, while the ontology model tailored to this specific domain demonstrates efficacy, its lack of generalizability across other disciplines signifies a gap in broad applicability, thereby underscoring the need for more versatile frameworks that transcend domain-specific boundaries [33]. In future work we will explore more advanced noise filtering mechanisms, such as graph neural network-based methods, to identify and reject noise instances more accurately. Meanwhile, how to extend the method of this paper for knowledge graph construction and relation extraction in other domains is also the direction of subsequent in-depth research.
Availability of data and materials
Not applicable
Code availability
Not applicable
References
J. Deng, C. Chen, X. Huang, W. Chen, L. Cheng, Research on the construction of event logic knowledge graph of supply chain management. Adv. Eng. Inform. 56, 101921 (2023)
X. Sheng, L. Chen, X. Yuan, Y. Tang, Q. Yuan, R. Chen, Q. Wang, Q. Ma, J. Zuo, H. Liu, Green supply chain management for a more sustainable manufacturing industry in China: a critical review. Environ. Dev. Sustain. 25(2), 1151–1183 (2023)
S. Wang, Q. Li, Remote collaborative process optimization in research and design of industrial manufacturing. Auton. Intell. Syst. 3(1), 10 (2023)
B. Bigliardi, S. Filippelli, A. Petroni, L. Tagliente, The digitalization of supply chain: a review. Proc. Comput. Sci. 200, 1806–1815 (2022)
X. Tang, Z. Feng, Y. Xiao, M. Wang, T. Ye, Y. Zhou, J. Meng, B. Zhang, D. Zhang, Construction and application of an ontology-based domain-specific knowledge graph for petroleum exploration and development. Geosci. Front. 14(5), 101426 (2023)
H. Wang, K. Qin, R.Y. Zakari, G. Lu, J. Yin, Deep neural network-based relation extraction: an overview. Neural Comput. Appl. 34(6), 4781–4801 (2022)
Z. Nasar, S.W. Jaffry, M.K. Malik, Named entity recognition and relation extraction: state-of-the-art. ACM Comput. Surv. 54(1), 1–39 (2021)
M. Mintz, S. Bills, R. Snow, D. Jurafsky, Distant supervision for relation extraction without labeled data, in Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP (2009), pp. 1003–1011
M. Schwieterman, C. Welter, Supply chain from start to finish: the implications of supply chain management for entrepreneurs. Int. J. Entrepreneurship Innov. Manag. 19(4), 1947–1964 (2023)
W.P. Wong, P.S. Saw, S. Jomthanachai, L.S. Wang, H.F. Ong, C.P. Lim, Digitalization enhancement in the pharmaceutical supply network using a supply chain risk management approach. Sci. Rep. 13(1), 22287 (2023)
Q.U. Ain, M.A. Chatti, K.G.C. Bakar, S. Joarder, R. Alatrash, Automatic construction of educational knowledge graphs: a word embedding-based approach. Information 14(10), 526 (2023)
Y. Shi, Y. Xiao, P. Quan, M. Lei, L. Niu, Distant supervision relation extraction via adaptive dependency-path and additional knowledge graph supervision. Neural Netw. 134, 42–53 (2021)
M. Arcan, S. Manjunath, C. Robin, G. Verma, D. Pillai, S. Sarkar, S. Dutta, H. Assem, J.P. McCrae, P. Buitelaar, Intent classification by the use of automatically generated knowledge graphs. Information 14(5), 288 (2023)
X. Hao, Z. Ji, X. Li, L. Yin, L. Liu, M. Sun, Q. Liu, R. Yang, Construction and application of a knowledge graph. Remote Sens. 13(13), 2511 (2021)
N. Zafeiropoulos, P. Bitilis, G.E. Tsekouras, K. Kotis, Evaluating ontology-based pd monitoring and alerting in personal health knowledge graphs and graph neural networks. Information 15(2), 100 (2024)
C. Peng, F. Xia, M. Naseriparsa, F. Osborne, Knowledge graphs: opportunities and challenges. Artif. Intell. Rev. 56(11), 13071–13102 (2023)
X. Chen, X. Huang, Eant: distant supervision for relation extraction with entity attributes via negative training. Appl. Sci. 12(17), 8821 (2022)
J. Feng, M. Huang, L. Zhao, Y. Yang, X. Zhu, Reinforcement learning for relation classification from noisy data. Proc. AAAI Conf. Artif. Intell. 32, 5779–5786 (2018)
S. Riedel, L. Yao, A. McCallum, Modeling relations and their mentions without labeled text, in Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, September 20-24, 2010. Proceedings, Part III, vol. 21 (Springer, 2010), pp. 148–163
Y. Lin, S. Shen, Z. Liu, H. Luan, M. Sun, Neural relation extraction with selective attention over instances, in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, vol. 1 (2016), pp. 2124–2133. Long Papers
G. Ji, K. Liu, S. He, J. Zhao, Distant supervision for relation extraction with sentence-level attention and entity descriptions. Proc. AAAI Conf. Artif. Intell. 31, 3060–3066 (2017)
H. Wen, X. Zhu, L. Zhang, Improving distant supervision relation extraction with entity-guided enhancement feature. Neural Comput. Appl. 35(10), 7547–7560 (2023)
M. Kastrati, Z. Kastrati, A. Shariq Imran, M. Biba, Leveraging distant supervision and deep learning for twitter sentiment and emotion classification. J. Intell. Inf. Syst., 1–26 (2024). https://doi.org/10.1007/s10844-024-00845-0.
A. Polenghi, I. Roda, M. Macchi, A. Pozzetti, An ontological modelling of multi-attribute criticality analysis to guide prognostics and health management program development. Auton. Intell. Syst. 2(1), 2 (2022)
C. Jinli, T. Liwei, D. Shijie et al., Distant supervision Chinese relation extraction based on dual attention mechanism. Comput. Eng. Appl. 55(20), 107–113 (2019)
T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space (2013). arXiv preprint. arXiv:1301.3781
J. Wang, Q. Liu, Distant supervised relation extraction with position feature attention and selective bag attention. Neurocomputing 461, 552–561 (2021)
Y. Liu, C. Chen, T. Wang, L. Cheng, An attention enhanced dilated cnn approach for cross-axis industrial robotics fault diagnosis. Auton. Intell. Syst. 2(1), 11 (2022)
J. Pennington, R. Socher, C.D. Manning, Glove: global vectors for word representation, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2014), pp. 1532–1543
Z.X. Ye, Z.H. Ling, Distant supervision relation extraction with intra-bag and inter-bag attentions (2019). arXiv preprint. arXiv:1904.00143
Y. Zhou, L. Pan, C. Bai, S. Luo, Z. Wu, Self-selective attention using correlation between instances for distant supervision relation extraction. Neural Netw. 142, 213–220 (2021)
Y.M. Shang, H. Huang, X. Sun, W. Wei, X.L. Mao, A pattern-aware self-attention network for distant supervised relation extraction. Inf. Sci. 584, 269–279 (2022)
N. Jain, Domain-specific knowledge graph construction for semantic analysis, in The Semantic Web: ESWC 2020 Satellite Events: ESWC 2020 Satellite Events: ESWC 2020 Satellite Events, Heraklion, Crete, Greece, May 31–June 4, 2020. Revised Selected Papers, vol. 17 (Springer, Berlin, 2020), pp. 250–260
Acknowledgements
We would like to extend our sincere appreciation to those who have made valuable contributions to this paper but do not meet the authorship criteria. Their professional insights, provision of essential materials, and continuous support have been pivotal to the fruition of this article.
Authors’ information
[Author details] Guangdong Provincial Key Laboratory of Cyber-Physical System, Guangdong University of Technology, Guangzhou 510006, China.
Funding
This work was supported in part by Key Project of Guangdong Joint Fund of National Natural Science Foundation of China under Grant No. U1801263, National Key Research and Development Programme of China under Grant No. 2019YFB1705503
Author information
Authors and Affiliations
Contributions
FH: Experiments, Writing & original draft. LC: Conceptualization, Methodology, review & editing. All authors read and approved the final manuscript. All authors contributed equally to the writing of this paper.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Huang, F., Cheng, L. Distant supervision knowledge extraction and knowledge graph construction method for supply chain management domain. Auton. Intell. Syst. 4, 7 (2024). https://doi.org/10.1007/s43684-024-00064-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43684-024-00064-y