
Abstract
An industrial robot is a complex mechatronics system, whose failure is hard to diagnose based on monitoring data. Previous studies have reported various methods with deep network models to improve the accuracy of fault diagnosis, which can get an accurate prediction model when the amount of data sample is sufficient. However, the failure data is hard to obtain, which leads to the few-shot issue and the bad generalization ability of the model. Therefore, this paper proposes an attention enhanced dilated convolutional neural network (D-CNN) approach for the cross-axis industrial robotics fault diagnosis method. Firstly, key feature extraction and sliding window are adopted to pre-process the monitoring data of industrial robots before D-CNN is introduced to extract data features. And self-attention is used to enhance feature attention capability. Finally, the pre-trained model is used for transfer learning, and a small number of the dataset from another axis of the multi-axis industrial robot are used for fine-tuning experiments. The experimental results show that the proposed method can reach satisfactory fault diagnosis accuracy in both the source domain and target domain.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the rapid development of automation and industrial production, the industrial robot system has attracted considerable attention [1]. The rise of industrial robots has promoted the development of modernization, changed the mode of production, and replaced some monotonous, harsh and dangerous jobs. An industrial robot consists of three parts, namely the main body, drive system and control system. Industrial robots, the highly integrated devices of mechanical, automated and electrical technologies, have been increasingly accepted and recognized by the industry [2]. However, the unexpected failure of the industrial robot will lead to the stagnation of the production line, casualty and economic loss [3, 4], which poses great challenges to the development of the modern manufacturing industry. Therefore, it is very important to develop an effective and advanced fault diagnosis method to detect the working state of multi-axis industrial robots.
The fault diagnosis of industrial robots highly depends on regular inspection by the technician. With the development of the Internet of Things, artificial intelligence and big data analytics, data-driven approaches have been widely investigated for fault diagnosis. Traditional models of the prevailing algorithms such as support vector machine [5], random forest [6], logistic regression [7], and artificial neural network [8] have made certain achievements. However, when handling the complex equipment monitoring data, such traditional shallow learning algorithms are difficult to mine useful features and achieve accurate fault diagnosis. Recently deep learning has been widely applied in the field of fault diagnosis in the industrial robot with its powerful learning ability and feature extraction ability [9–11]. Such as deep neural network [12], deep autoencoder [13], deep belief network [14], convolutional neural network (CNN) [15] and recursive neural network [16]. To be specific, Jaber and Bicker [17] measured vibration signals on robot joints and used discrete wavelet transform and artificial neural network to identify clearance recoil faults. Brambilla et al. [18] proposed a model-based robot fault diagnosis method, which detected sensor faults through a generalized observer scheme. However, model-based robot fault diagnosis is difficult to be applied in practical applications because the state of the robot is difficult to estimate. Kim et al. [19] proposed a time-domain average method for fault detection of a gearbox in an industrial robot using vibration signals. In addition, deep learning has also received a lot of attention in other electrical equipment such as bearings and circuits. Janssens et al. [20] proposed a three-layer CNN structure that can be used for bearing fault detection. The discrete Fourier transform time-frequency transformation of the original signal is needed before training. Chen et al. [21] proposed a CNN fault classification method combined with Extreme Learning Machine, which can effectively achieve fault classification, but it does not take into account the multi-channel original signals measured by multiple sensors. With the research of deep learning, many scholars pay more and more attention to the features related to faults, and attention mechanism has been applied. Gong and Du [22] proposed an analogue circuit fault diagnosis method based on attention mechanism and CNN, which effectively solved the problems of difficulty in extracting analogue circuit fault features, complex model calculation and poor accuracy. Hao et al. [23] proposed a CNN based on multi-scale and attention mechanisms to automatically diagnose the health status of rolling bearings. Yang et al. [24] proposed deep multiple autoencoders with an attention mechanism network for fault diagnosis under different working conditions. Zhang et al. [25] proposed a novel fault diagnosis method with global multi-attention deep residual shrinkage networks, which used an attention mechanism to dynamically infer self-adaptive parameters, to achieve fault diagnosis of vibration signals.
Through the attention mechanism, the model is able to pay more attention to features with a strong correlation of faults, thereby reducing the dependence on external information. Compared with CNN, recurrent neural networks and other models, it has fewer parameters and lower computation force requirements. However, attention bias exists for recurrent neural network algorithms, and the training process still needs a large number of data samples, while the actual industrial robot data has the following characteristics: 1) The collected signal is noisy. The electro-mechanical coupling of industrial robots makes the signals between different parts interfere with each other, making the collected data noisy. 2) The imbalance of normal and failure data. Its failure time is far less than the uptime, which causes the data imbalance issue.
When the failure samples are insufficient, the deep learning model is difficult to train, resulting in poor fault diagnosis accuracy of the model. In order to improve the generalization performance of fault diagnosis methods in different diagnosis scenarios, some fault diagnosis algorithms based on deep transfer learning have been developed [26]. Liu et al. [27] proposed adaptive transfer learning in the adversarial discriminant domain for fault diagnosis of gas turbines in different fields. Tian et al. [28] proposed a multi-source information transfer learning method for cross-domain fault diagnosis with subdomain adaptive, using a multi-branch structure to align the spatial distribution of elements in each source domain and target domain. Han et al. [29] proposed a generative adversarial network diagnosis model, introduced adversarial learning as a cross-domain regularization term, and took data under different load conditions as the source domain and target domain, respectively, to achieve an accurate diagnosis of rolling bearing faults under few-shot conditions through transfer learning. Pang and Yang [30] realized cross-domain rolling bearing fault diagnosis by using a cross-domain stacked denoising autoencoder. Zheng et al. [31] proposed an intelligent fault identification method based on multi-source domain generalization, which effectively reduced the risk of negative transfer. Hasan et al. [32] proposed a transfer learning method based on one-dimensional CNN and frequency domain analysis of vibration signals because of the influence of reliability of signal extraction on results, enabling the model to diagnose faults under other working conditions using information obtained under given working conditions.
Great achievements have been made in transfer learning, but few studies have explored the effect of sample imbalance in the source domain on transfer performance. As a result, this paper proposes an attention enhanced dilated CNN(D-CNN) approach for cross-domain industrial robotics fault diagnosis to realize the classification and diagnosis of industrial robot faults in the case of the issue of few-shot. The transfer performance under different proportions of normal failure data in the source domain is studied. The main contributions of this study are listed as follows:
-
1)
We designed a D-CNN to reduce the loss of spatial features without reducing the receptive field and can obtain long-ranged information. By introducing the dilation rate, the convolutional degradation problem is solved and the fault diagnosis of the low-parameter network is realized.
-
2)
Based on the D-CNN model, a self-attention mechanism is further introduced to enhance the fault-related features extraction, which does not need a large number of model parameters to improve the accuracy of fault diagnosis.
-
3)
Aiming at the problem that it is difficult to collect fault samples of industrial robots in practice, the transfer learning method is investigated. Through pre-trained models, cross-axis fault diagnosis of industrial robots can be realized with fewer failure data, which solves the problem of limited industrial robot fault data.
Experimental results show that the model has strong learning ability and better performance in processing sequence data, and is more suitable for multi-axis industrial robots fault diagnosis. Besides, accurate classification results can be achieved even when the amount of data in the target domain is limited.
The rest of the paper is organized as follows. Section 2 details the proposed method. A series of experimental steps and an analysis of the experimental results are presented in Sects. 3 and 4, respectively. Finally, the discussions and future works are given in Sect. 5, and the conclusions are made in Sect. 6.
2 Methodology
The flow of the fault diagnosis method of transfer learning proposed in this paper is shown in Fig. 1, which mainly includes three modules: data processing module, source domain processing module and target domain processing module. The details are as follows:

The general flow chart of fault diagnosis based on transfer learning
1) Data processing module. All parameter data during the normal operation of the industrial robot and the failure of the industrial robot reducer are collected to construct the dataset, and all the data are preprocessed. In order to respond to the trend of the dataset, the step length for the \(S_{1}\) average sampling needs to be considered. The mean value and the variance of \(S_{1}\) step sampling variation degree can reveal the pattern relevant to the healthy stage of the reducer. The indicators of mean and variance are multidimensional, and they still need through the \(S_{1}\) step sampling kurtosis such as non-dimensional indicators which are used to describe the steep or smooth of the data distribution. Kurtosis is calculated as shown in formula (1). The mean, variance and kurtosis collected from the above feature engineering are used to form a new dataset. The normal data and fault data are labelled respectively and then merged and scrambled. The data after feature engineering processing is processed according to the sliding window mechanism shown in Fig. 2, where the sliding window step is \(S_{2}\).

The sliding window approach
2) Source domain processing module. Firstly, in this module, the data in the source domain is divided into the training set and testing set to ensure the accuracy of the pre-training model. Secondly, the CNN model is constructed, and the dilation rate is introduced after the parameters are optimized to complete the construction of the D-CNN. In order to make the model pay more attention to the fault information, the self-attention mechanism is introduced to fuse the features extracted by the constructed D-CNN. Next, the testing set is input to observe different evaluation indicators. Finally, the final model is obtained through the testing set.
3) Target domain processing module. In this module, transfer learning is used to realize the fault diagnosis of the target domain data to solve the problem of few-shot. Firstly, an improved neural network pre-trained on the source domain is introduced. Transfer the network structure and network parameters to the target domain. Fixing shallow convolutional layer no longer training (frozen convolutional layer), and adding specific full connection layer and classifier; Then fine-tune the deep network using the target domain data on the target domain, and finally perform predictive classification on the testing set of the target domain.
Finally, the proposed method model combining the attention mechanism and the D-CNN model is shown in Fig. 3, in which the attention layer is located after the fourth convolutional layer.

Network diagram
2.1 Dilated convolutional neural network
Traditional CNN has been widely used in image classification, speech recognition, natural language processing and other fields. Due to the strong feature extraction capability, it can also be applied to fault diagnosis. CNN is mainly extracted by features within the convolution check range. In the convolution layer, the weight of each neuron connected to the data window is fixed, and each neuron only focuses on one feature. The sliding of the convolution kernel enables the integration of global-local features to obtain the information of the whole sample. When the convolution kernel is working, it will regularly sweep the input ground features, multiply and sum the matrix elements of the input features in the receptive field, and add the deviation amount, as shown in formula (2):
In (2), \((i, j) \subset \{ 0, 1, \dots , L_{i+1} \}\), \(L_{i+1} = \frac{L_{l +2p-f}}{s_{0}}+1\). The sum part is equivalent to solving the cross-correlation once, where b is the deviation, \(Z^{l}\) and \(Z^{l+1}\) represent the convolution input and output of the drop \(L_{i+1}\) layer, and \(L_{i+1}\) is the size of \(Z^{l+1}\). It is assumed that the length and width of the feature graph are the same, \(Z{ ( i,j )}\) corresponds to the pixel of the feature graph, K is the number of channels of the feature graph; f, \(s_{0}\) and p are convolution layer parameters which correspond to the size of the convolution kernel, the convolution step and the number of filling layers.
The dilated convolution method was studied by [33] which is often applied to semantic segmentation. Dilated convolution is a kind of CNN that can increase the receptive field without increasing the number of parameters. Its realization method is to add the dilation rate between elements inside the convolution kernel, which is equivalent to adding zero elements between adjacent elements of the convolution kernel. The number of inserted dilations is called dilation rate. Take \(3 \times 3\) convolutions as an example in Fig. 4. Figure 4(a) is a common convolution process, which is calculated by sliding on the feature graph of closely arranged convolution kernels. Figure 4(b) represents convolution calculation with dilation rate is 1. Similarly, Fig. 4(c) represents convolution calculation with dilation rate is 2.

Comparison between ordinary convolution and dilated convolution
The dilation rate should meet the criteria of formula (3), where \(r_{i}\) is the dilation rate of layer i, and \(M_{i}\) is the maximum dilation rate of layer i.
2.2 Self-attention mechanism
The principle of the attention mechanism is to adjust the direction of attention and the weighting model according to the specific task objective, increase the weighting of the attention mechanism in the hidden layer of the neural network, and neglect the information that is not essential to the attention mechanism. Its essence is to obtain more effective information by placing higher weights on the focused area. Its main functions are as follows: assign different weights to different parts of the input sequence; then the different parts of the input sequence are multiplied by the weight value, and the local feature vector is extracted to realize the amplification and reduction of different local weights of the input sequence.
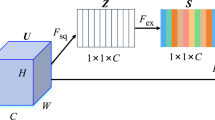
After the dilated convolution, it is inserted into the self-attention layer, and the input of the self-attention layer is the output of the fourth dilated convolution. In Fig. 3, the input is transformed into feature space \(F (x)\) and \(H (x)\) after passing through a \(1\times 1\) convolution layer to calculate the attention map, namely, the correlation of feature space 2:
In the above formulas, \(W_{f}\), \(W_{h}\) and \(W_{g}\) are the weight matrices obtained by training, \(s_{ij}\) is the correlation matrix, and \(\beta _{j, i}\) indicates the influence degree of i region on the resultant j region, that is, the correlation degree of the two. Finally, o is output through the feature map of self-attention transportation:
In order to make the network rely on local information at the beginning and gradually train to be able to assign more weight to the global elements, the weight coefficient γ, whose initial value is 0, is introduced and increases with the increase of this iterative process. The final output of the fault sub-attention module is shown in formula (10):
2.3 Transfer learning for cross-axis fault diagnosis of industrial robots
Transfer learning is an essential part of machine learning, including sample transfer, feature transfer, relational transfer, model transfer and other methods. Generally speaking, deep learning based on feature extraction of massive data is based on the training of historical data, and then it is applied to the data under the same or similar task for fitting in the originally trained network. However, transfer learning can be trained from the data samples in the source domain. When applied to new scenarios, the knowledge learned in the source domain can be used to achieve the classification of the target domain. In this case, the source domain and the target domain need not strictly meet the assumption of independent and identically distributed. In particular, given a marked the source domain \(D_{s} = \{ x_{i},y_{i} \}_{i=1}^{n}\) and a target domain unmarked \(D_{t} = \{ x_{j} \}_{j=n+1}^{n+m}\). Data distributions \(P ( x_{s} )\) and \(P ( x_{t} )\) in these two domains are different, that is \(P ( x_{s} ) \neq P ( x_{t} )\). The purpose of transfer learning is to learn the knowledge (label) of the target domain by utilizing the knowledge of \(D_{s}\).
In this paper, the model transfer is adopted, and model parameters are shared between the source domain and the target domain. Specifically, the model trained by a large amount of data in the 6th axis (source domain) is applied to the 4th axis (target domain) for prediction, so that the target domain can achieve a good prediction effect even with a small amount of data. In this paper, the industrial robot data collected offline are used as the experimental dataset, and the results are compared in the case of different data amounts in the source domain and target domain. The transfer learning process is shown in Fig. 5.

Schematic diagram of transfer learning
3 Experimental setup
The monitoring data was collected from an actual industrial robot through the fault injection experiment. In the experiment, a faulty reducer was used to replace a normal reducer in an industrial robot, then ran the machine to collect data. The experimental data of the 4th axis and the 6th axis were collected, in which the failure data and normal data of the 4th axis were 21,777 and 19,105 respectively, and the failure data and normal data of the 6th axis were 189,749 and 44,796 respectively. The sampling frequency was 25 Hz. Firstly, features were extracted from the data, and the sampling step was \(S_{1}\), and the sliding window step was \(S_{2}\). Mean, standard deviation and kurtosis were extracted and normalized. 80% of the processed dataset were used as training samples and 20% as testing samples.
As shown in Fig. 3, the proposed model mainly has two modules in the source task part, namely the D-CNN module and the self-attention mechanism module. The D-CNN used a 2D feature graph as input, and the size of the feature graph was \(N_{t} \times N_{f}\), where \(N_{t}\) represents the length of input time series processed by time window, and \(N_{f}\) represents the number of input features. The first layer was used for feature extraction. Each layer was equipped with \(F_{N}\) filters. The dilation rate was \(( D_{t}, D_{f} )\), and the convolution step was \((2,2)\). In order to ensure that the size of each layer’s feature map remains unchanged, the experiment used the zero-filling method. After the first layer of dilated convolution, the data dimension become \(N_{f} \times N_{t} \times N_{f}\). The remaining layers were similar, with the same input size as the output size. Secondly, the output of the self-attention layer was connected through two full connection layers, and the final classification confidence of each category was obtained by the SoftMax function. Before training, random samples were divided into multiple small batches, each of which contains 256 samples, with a learning rate of 0.01 and a training cycle of 150. Adam algorithm was used as the optimizer, and the above parameters are shown in Table 1.
In order to evaluate the effectiveness of the model and the impact of transfer learning in few-shot scenarios, Accuracy, Precision, Recall and F1 were used as metrics to evaluate the model. Among these metrics, the accuracy can judge the total correct rate, but it cannot reveal the actual algorithm performance in the case of unbalanced data classification task. Therefore, introducing the precision for prediction results and the recall for the original sample. While the F1 takes the advantage of accuracy and recall, which is the reconciliation average of both metrics. In addition, mean and standard deviation were taken to measure its stability under multiple cycles to make the model more convincing. The calculation method of each indicator is as follows:
In order to verify the superiority of the method proposed in this paper, relevant comparative experiments were designed under the above evaluation indicators. First, traditional long-short term memory (LSTM), full convolution neural network (FCNN), CNN and D-CNN were compared based on the 6th axis data. Second, in the case of transfer learning, the model obtained from the 6th axis is transferred to the 4th axis. Comparing the fine-tuning effects of transfer learning under different data volumes, so as to compare the impact of data volumes on model performance.
4 Experimental results
4.1 Benchmarking experiments for different algorithm models
This experiment uses the 6th axis data set and obtains four indicator data in different algorithm models through the same data preprocessing. The experimental results are shown in Fig. 6, where line segments on each column are error bars.

Comparison diagram of four indicators under different models
Figure 6(a) shows the changes in the accuracy of the five models under the same data processing. It is obvious that the method proposed in this paper has the highest accuracy and low error in the source task. Based on the comparative analysis of Figs. 6(b), (c) and (d), it can be found that the accuracy is higher than other benchmarking algorithms, while the recall rate of the CNN model is only 0.7. Therefore, from the perspective of these indicators, the confidence is low and the results are not very ideal.
In comparison, D-CNN performs better than the above models, with the accuracy and the precision being close to 0.95, the recall and F1 are more than 0.85. Based on this, the method proposed in this paper uses self-attention mechanism to make the network pay more attention to the fault point in the scenario with a larger field of view. In the end, no matter the accuracy, precision, and recall rate or F1 indicator, the proposed model performed best and the error rate is low.
4.2 Experiment on cross-axis fault diagnosis diagnostic
In this experiment, the model is transferred to the 4th axis dataset for fine-tuning and fault diagnosis for the 4th axis. Before transfer the model, in order to comprehensively compare the effectiveness of transfer learning, the experimental results of 4th axis with different data volumes are firstly compared. As shown in Fig. 7, among 6th axis fault data with different data volumes, the source domain model is established based on 6th axis data, so the accuracy can reach 0.9108 even when the data volume is small. However, with the increase in data volume,the accuracy gradually tends to be stable, and the average accuracy is 0.9616 after taking the mean value of multiple experiments. By applying the attention enhanced D-CNN model to the fault diagnosis of manipulator 4th axis data, it can be found that: with the increase of data volume, the overall effect of the model is getting better and better, and the diagnosis accuracy can reach 0.9269 even with a small error.

Comparison diagram of fault diagnosis results of the 4th axis before transfer learning
Then save the source domain task model to transfer to the 4th axis fault diagnosis, the results are shown in Fig. 8, the horizontal axis represents takes the 6th axis data of shaft according to the ratio of the amount in the total number of the vertical axis represents the different indicators, the curve represents different obtained the 4th axis data volume accounted for the 4th axis according to the ratio of the amount applied to the transfer learning, through the experiment discovers:

the 4th axis fault diagnosis accuracy under transfer learning
1) The amount of data in the source domain affects the model accuracy before transfer learning: For any curve in Fig. 8(a), with the increase of the horizontal axis (the increase of the amount of the 6th axis data), the overall accuracy of the model shows a rising trend; 2) The amount of data in the target domain affects the fine-tuning effect of the model after transfer learning: the amount of data in the source domain is fixed, and the obtained model is determined. When the amount of data in the target domain is larger after the transfer, the fine-tuning effect is more obvious and the accuracy is higher; 3) After the transfer learning, the overall fault diagnosis accuracy is on the rise: all source domain dataset and target domain dataset are used for experiments and combined with the experimental results in Fig. 7, it can be seen that: before the transfer learning, the accuracy of the 4th axis is only about 0.92 at best, but after the transfer learning, it can reach about 0.96 through data fine-tuning, as shown in Fig. 8(a). The transfer learning effect is obvious; 4) Few-shot issue can be solved: when the 4th axis data in Fig. 7 is small, if it only accounts for 10% of the total data, the accuracy of the model without transfer learning is less than 0.7; Under the condition of the same amount of data, the transfer learning can reach above 0.9, which greatly solves the problem of few-shot in the target domain; 5) According to Figs. 8(b), (c), (d), the proposed model has high accuracy, high accuracy, high recall rate and high F1 score.
5 Discussion
The increase or decrease of source domain data amount or target domain data amount will affect the final experimental results, while the source domain data amount affects the transfer learning model, and the target domain data amount affects the fine-tuning effect of the model after the transfer learning. Through further experiments, it is found that the effect is worse when the data amount is further reduced. However, it can also be found in Fig. 8 that the effect of increasing the amount of data in a certain area becomes worse, which is due to the data imbalance caused by random value, that is to say, certain correctly predicted data are just taken. As the data volume grows, the accuracy tends to increase, so it is acceptable.
The experiment is also worthy to be further investigated, such as the source domain, which did not use the best model for transfer learning. At the time of data pre-processing adjusting the larger sampling step length and the length of the sliding window can make the model own higher accuracy, and can be represented under the larger cycle averaged model accuracy in order to guarantee the experimental accuracy. Secondly, the source domain and target domain can be switched to make the results more convincing. Finally, the experiment only moved to the 4th axis, while industrial robots have the 6 axes in total, namely, six-axis industrial robots.
Therefore, the model does not consider the impact of data distribution, and the experimental results are obtained by inputting randomly sampled data into the model, which has certain specificity and has a certain impact on fault diagnosis. However, the long time series data problem can be solved effectively by simple feature engineering and introducing dilation rate, and good fault diagnosis results can also be obtained. And the average value of each indicator of the model is obtained through multiple cycles, which reduces the specificity of the model to a certain extent and improves its generality. In addition, the gearbox vibration signal is not easy to obtain, through the motor signal instead, the motor signal is received in real-time and input to the model, which can quickly and accurately carry out fault diagnosis. This provides a new idea for fault diagnosis of industrial equipment, which is of practical meaning.
6 Conclusion
This paper proposes a fault diagnosis model based on big data analysis of real-time operation of multi-axis industrial robots. The dataset is from real industrial robot equipment, and the feedback torque, feedback current and position of different coaxial data are collected. Since it is difficult to collect fault data, the data amount is small, so this paper adopts the transfer learning method to implement cross-axis fault diagnosis to solve the problem of insufficient data amount. The experimental results show that the proposed method can effectively diagnose the fault diagnosis of industrial robots by constructing the D-CNN,which provides a new idea for real-time fault diagnosis and cross-axis prediction of industrial robots. In future research, we will collect the data of other robotic axis and obtain a more general model through transfer learning, so as to solve the problem of few-shot in fault diagnosis modelling.
Availability of data and materials
Not applicable.
Code availability
Not applicable.
References
I. Eski, S. Erkaya, S. Savas, S. Yildirim, Fault detection on robot manipulators using artificial neural networks. Robot. Comput.-Integr. Manuf. 27(1), 115–123 (2011)
L.D. Evjemo, T. Gjerstad, E.I. Grtli, G. Sziebig, Trends in smart manufacturing: role of humans and industrial robots in smart factories. Curr. Robot. Rep. 1(2), 35–41 (2020)
H. Li, X. Lian, C. Guo, P. Zhao, Investigation on early fault classification for rolling element bearing based on the optimal frequency band determination. J. Intell. Manuf. 26(1), 189–198 (2015)
C. Chen, Y. Liu, X. Sun, S. Wang, C.D. Cairano-Gilfedder, S. Titmus, A.A. Syntetos, Reliability analysis using deep learning, in ASME IDETC-CIE (ASME, Quebec, 2018)
A. Tavakoli, L.D. Maria, B. Valecillos, D. Bartalesi, S. Bittanti, A machine learning approach to fault detection in transformers by using vibration data. IFAC-PapersOnLine 53(2), 13656–13661 (2020)
C. Yan, M. Li, W. Liu, Transformer fault diagnosis based on BP-AdaBoost and PNN series connection. Math. Probl. Eng. 2019, Article ID 1019845 (2019)
A. Science, Aircraft engine health prognostics based on logistic regression with penalization regularization and state-space-based degradation framework. Aerosp. Sci. Technol. 68, 345–361 (2017)
N. Khera, S.A. Khan, Prognostics of aluminum electrolytic capacitors using artificial neural network approach. Microelectron. Reliab. 81, 328–336 (2018)
D. Zhu, X. Song, J. Yang, Y. Cong, L. Wang, A bearing fault diagnosis method based on L1 regularization transfer learning and LSTM deep learning, in 2021 IEEE International Conference on Information Communication and Software Engineering (ICICSE) (IEEE, 2021)
D. Yang, K. Sun, A CAE-based deep learning methodology for rotating machinery fault diagnosis, in 2021 7th International Conference on Control, Automation and Robotics (ICCAR) (IEEE, 2021)
C. Zhang, L. Xu, X. Li, H. Wang, A method of fault diagnosis for rotary equipment based on deep learning, in 2018 Prognostics and System Health Management Conference (PHM-Chongqing) (IEEE, 2018)
Z. Dongzhu, Z. Hua, D. Shiqiang, S. Yafei, Aero-engine bearing fault diagnosis based on deep neural networks, in 2020 11th International Conference on Mechanical and Aerospace Engineering (ICMAE) (IEEE, 2020)
Z. Xu, W. Mo, Y. Wang, S. Luo, T. Liu, Transformer fault diagnosis based on deep brief sparse autoencoder, in 2019 Chinese Control Conference (CCC) (IEEE, 2019)
J. Jinghai, C. Weidong, Research on EMU cable fault diagnosis based on deep belief network and signal domain conversion, in 2021 4th International Conference on Electron Device and Mechanical Engineering (ICEDME) (IEEE, 2021)
W. Lihao, D. Yanni, A fault diagnosis method of tread production line based on convolutional neural network, in 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS) (IEEE, 2018)
G. Niu, S. Tang, B. Zhang, Machine condition prediction based on long short term memory and particle filtering, in IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society (IEEE, 2018)
A.A. Jaber, R. Bicker, Industrial robot backlash fault diagnosis based on discrete wavelet transform and artificial neural network. Am. J. Mech. Eng. 4(1), 21–31 (2016)
D. Brambilla, L.M. Capisani, A. Ferrara, P. Pisu, Fault detection for robot manipulators via second-order sliding modes. IEEE Trans. Ind. Electron. 55(11), 3954–3963 (2008)
Y. Kim, J. Park, K. Na, H. Yuan, B.D. Youn, C.-S. Kang, Phase-based time domain averaging (PTDA) for fault detection of a gearbox in an industrial robot using vibration signals. Mech. Syst. Signal Process. 138, 106544 (2020)
O. Janssens, V. Slavkovikj, B. Vervisch, K. Stockman, M. Loccufier, S. Verstockt, R. Van de Walle, S. Van Hoecke, Convolutional neural network based fault detection for rotating machinery. J. Sound Vib. 377, 331–345 (2016)
Z. Chen, K. Gryllias, W. Li, Mechanical fault diagnosis using convolutional neural networks and extreme learning machine. Mech. Syst. Signal Process. 133, 106272 (2019)
B. Gong, X. Du, Research on analog circuit fault diagnosis based on CBAM-CNN, in 2021 IEEE International Conference on Electronic Technology, Communication and Information (ICETCI) (IEEE, 2021)
Y. Hao, H. Wang, Z. Liu, H. Han, Multi-scale CNN based on attention mechanism for rolling bearing fault diagnosis, in 2020 Asia-Pacific International Symposium on Advanced Reliability and Maintenance Modeling (APARM) (IEEE, 2020)
S. Yang, X. Kong, Q. Wang, Z. Li, H. Cheng, K. Xu, Deep multiple auto-encoder with attention mechanism network: a dynamic domain adaptation method for rotary machine fault diagnosis under different working conditions. Knowl.-Based Syst. 249, 108639 (2022)
Z. Zhang, L. Chen, C. Zhang, H. Shi, H. Li, GMA-DRSNs: a novel fault diagnosis method with global multi-attention deep residual shrinkage networks. Measurement 196, 111203 (2022)
C. Qian, J. Zhu, Y. Shen, Q. Jiang, Q. Zhang, Deep transfer learning in mechanical intelligent fault diagnosis: application and challenge. Neural Process. Lett., 1–23 (2022). https://doi.org/10.1007/s11063-021-10719-z
S. Liu, H. Wang, J. Tang, X. Zhang, Research on fault diagnosis of gas turbine rotor based on adversarial discriminative domain adaption transfer learning. Measurement 196, 111174 (2022)
J. Tian, D. Han, M. Li, P. Shi, A multi-source information transfer learning method with subdomain adaptation for cross-domain fault diagnosis. Knowl.-Based Syst. 243, 108466 (2022)
T. Han, C. Liu, W. Yang, D. Jiang, A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowl.-Based Syst. 165, 474–487 (2019)
S. Pang, X. Yang, A cross-domain stacked denoising autoencoders for rotating machinery fault diagnosis under different working conditions. IEEE Access 7, 77277–77292 (2019)
H. Zheng, R. Wang, Y. Yang, Y. Li, M. Xu, Intelligent fault identification based on multisource domain generalization towards actual diagnosis scenario. IEEE Trans. Ind. Electron. 67(2), 1293–1304 (2019)
M.J. Hasan, M. Sohaib, J.-M. Kim, 1D CNN-based transfer learning model for bearing fault diagnosis under variable working conditions, in International Conference on Computational Intelligence in Information System (Springer, Berlin, 2019)
Y. Xu, Z. Li, S. Wang, W. Li, T. Sarkodie-Gyan, S. Feng, A hybrid deep-learning model for fault diagnosis of rolling bearings. Measurement 169, 108502 (2021)
Funding
Our work is supported by multiple funds in China, including the Key Program of NSFC-Guangdong Joint Funds (U1801263), the Natural Science Foundation of Guangdong Province (2020A1515010890, 2020B1515120010), the Dedicated Fund for Promoting High-Quality Economic Development in Guangdong Province (Marine Economic Development Project) GDNRC[2021]44, and the Major project of science and technology plan of Foshan City (1920001001367). Our work is also supported by Guangdong Provincial Key Laboratory of Cyber-Physical System (2020B1212060069).
Author information
Authors and Affiliations
Contributions
YL: Conceptualization, Methodology, Writing—original draft and Validation. CC: Conceptualization, Methodology, Review & Editing. TW: Conceptualization, Resources. LC: Supervision. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, Y., Chen, C., Wang, T. et al. An attention enhanced dilated CNN approach for cross-axis industrial robotics fault diagnosis. Auton. Intell. Syst. 2, 11 (2022). https://doi.org/10.1007/s43684-022-00030-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43684-022-00030-6