
Abstract
AI applications bear inherent risks in various risk dimensions, such as insufficient reliability, robustness, fairness or data protection. It is well-known that trade-offs between these dimensions can arise, for example, a highly accurate AI application may reflect unfairness and bias of the real-world data, or may provide hard-to-explain outcomes because of its internal complexity. AI risk assessment frameworks aim to provide systematic approaches to risk assessment in various dimensions. The overall trustworthiness assessment is then generated by some form of risk aggregation among the risk dimensions. This paper provides a systematic overview on risk aggregation schemes used in existing AI risk assessment frameworks, focusing on the question how potential trade-offs among the risk dimensions are incorporated. To this end, we examine how the general risk notion, the application context, the extent of risk quantification, and specific instructions for evaluation may influence overall risk aggregation. We discuss our findings in the current frameworks in terms of whether they provide meaningful and practicable guidance. Lastly, we derive recommendations for the further operationalization of risk aggregation both from horizontal and vertical perspectives.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Recognized as a fundamental obligation, the trustworthiness of AI is globally emphasized by governmental and non-governmental organizations, companies, and leading AI experts [29, 44]. It is considered a key prerequisite particularly for critical applications, and also serves as differentiating factor between AI systems in non-critical domains. Accordingly, ongoing regulatory and standardization activities aim to ensure the quality of AI systems and avoid potential negative impacts on society and individuals. Given that AI technologies are (mostly) probabilistic and not fully verifiable, operators and users must adopt an approach to safeguard against uncertainties and unknowns of AI applications in a responsible manner [8, 30]. Risk assessment plays a crucial role in this regard [31]. It typically involves analyzing and evaluating risks and determining mitigation measures [38, 42], and thus has an essential part in how organizations take decisions and deal with uncertainty. Notably, (internal) AI risk assessment procedures are required for certain providers in upcoming AI regulationFootnote 1 (e.g., Article 9 [15]). In addition, many of the established testing and approval procedures do, in fact, address the subject of risk but need to be expanded to machines or products that now include AI components (e.g., IT security [14, 49], data protection [26], and functional safety [37, 39]).
Trustworthy AI has emerged as a concept that encompasses multiple dimensions,Footnote 2 each related to distinct risks and requiring distinct mitigation measures [32, 62]. In a structured AI assessment, different risk dimensions are therefore aggregated to some extent [42, 45, 59]. This offers the advantage that the “overall risk” of the AI system can be evaluated,Footnote 3 providing a manageable and organized summary of the different types of existing risks. Furthermore, risk aggregation becomes necessary in applications where conflicting requirements exist or where mitigation measures have varying effects across different quality dimensions. For instance, increasing the accuracy of an AI application may have the effect that it reflects real-world biases more strongly or that its outcomes are harder to explain because of internal complexity. In such cases, it may be impossible to bring each identified risk to the same low level.Footnote 4 Instead, prioritization and, accordingly, trade-offs must be made for selecting suitable mitigation measures (see [65] and, for worked out examples, [63]). This requires an aggregate view and comparison of the given risk dimensions. A simple example of a quantitative aggregation rule is a function that takes the scores (assessments) of all risk dimensions as input and forms a weighted sum of them. In this way, the assessments of the various dimensions are summarized, e.g. as an average, if uniform weights are used. In addition, a context-specific weighting of the individual risk dimensions can be applied.Footnote 5 For instance, stakeholders of an AI-based chatbot might assign a high weighting to the dimensions of reliability and bias and a low weighting to transparency, as discriminatory or harmful outputs are considered more critical in the use case than a lack of explainability. The impact of this weighting on aggregation is that transparency risks can be tolerated more than reliability or bias risks when it comes to bringing the overall risk to a certain level. Another possible consideration for determining the weighting could be the benefit or utility associated with the individual dimensions. For instance, one could argue that reliability offers the greatest societal benefit in a medical image-processing application and weight this dimension relatively heavily accordingly. As a result, adjustments to the model that may yield significantly greater improvements for some user groups than for others (and thus generate a bias) could be acceptable, provided that the reliability of the model does not deteriorate for any user group. Overall, the way risks are defined, weighted, and aggregated significantly affects the prioritization of mitigation measures in the development and operation of AI systems, as well as the final evaluation of a specific AI application.
Still, the interconnectedness of the various specific risk dimensions is one of the biggest challenges in AI quality standards today. Several operationalization approaches are currently being developed (e.g., at the national level and within specific domains such as the public sector, see Sect. 4). Especially, the European Commission has issued ten standardization requests in support of various requirements of the AI Act [17], that are currently being addressed by CEN-CENELEC [9]. However, there is no universally accepted AI risk aggregation scheme yet. In particular, the existing frameworks show that formalizing risk aggregation concisely is not trivial. First, there actually exist different notions of risks. While some risk concepts may allow for intentionally accepting or tolerating negative impacts in order to realize positive impacts, other concepts exclusively associate risks with negative effects that need to be mitigated (see Sect. 3). In addition, AI applications usually have an impact on various stakeholders, and the identification and evaluation of risks may differ depending on whether the risk notion focuses, for example, on individuals and society or on business goals. Second, risk aggregation requires that the different types of risks (e.g., safety risks and the risk of the violation of personal rights) be made commensurable in some way, which is a major challenge also in terms of theoretical foundation (see Sect. 2). Third, if a comparison of different risk dimensions is possible or feasible in principle, determining aggregation weights that are meaningful for specific AI systems is another key challenge given the wide range of potential AI applications. On the one hand, there is no comprehensive or agreed-upon list of AI hazards or threats that would be generally applicable to all types of AI systems. On the other hand, the current frameworks do not achieve the level of detail yet to describe AI use cases (this is being planned in some areas e.g., [35, 56]). In summary, there are several challenges to operationalizing risk aggregation and no definitive approach to solving them.
Given the widespread use and globally extended value chain of AI applications, efforts are underway to establish international AI quality standards. As discussed earlier, risk aggregation is an important aspect of emerging quality standards. It forms the basis for prioritizing risk mitigation measures for AI systems and thus significantly influences their final assessment. Notably, procedures and minimum requirements related to AI risk management have been defined [41, 42], but there is a need for more concrete guidance on their implementation, including risk aggregation. Currently, there is a lot of uncertainty about how to implement risk assessment”properly,” i.e., in a way that is acceptable to stakeholders such as regulators. Certainly, the specific risk assessment may depend on local socio-economic factors, so that a uniform risk assessment scheme applicable worldwide does not seem feasible. Nevertheless, the circumstances described indicate that an understanding of the various existing frameworks and their compatibility among each other is essential.
Overall, comprehending the potential agreements and discrepancies in existing approaches to risk aggregation is a crucial next step for promoting the operationalization of trustworthy AI on a global scale. We address this gap by creating a snapshot of twelve AI risk assessment frameworks in terms of how these systematize the aggregation of different AI risks. Section 2 surveys related work on risk aggregation and existing comparisons of assessment frameworks. Section 3 describes our methodology in detail, including the specific characteristics we use to structure the analysis. In Sect. 4, we first provide an overview of all twelve frameworks. Then, we discuss our findings and recommendations which we developed on the basis of in-depth analyses of selected frameworks. A description of these frameworks is provided in the appendix. Section 5 summarizes our main findings and provides an outlook on further operationalizing risk aggregation.
2 Related work
In recent years, numerous works that present and categorize AI risks have been published (e.g., [66, 69]). However, there is few research on the aggregation of individual AI risks. While several practical proposals have been made for AI assessment (see the frameworks in Sect. 4), theoretically founded approaches are lacking. In the context of social choice and preferences, formal theory of aggregation has been established as outlined below, as well as some empirical approaches, but we are not aware of any research works that analyze in-depth the relevance or transferability of respective aggregation rules to AI risks. We rather identified contributions that survey and compare existing AI assessment frameworks, as described further below. Similar to the analysis presented in this paper, they take a pragmatic approach, providing an overview of existing frameworks in terms of aspects relevant to application and practicality.
Independent of AI, a formal theory of aggregation has been developed in the social sciences and economics with applications in public policy, among others [48]. In social choice theory, for example, an aggregation rule is formalized as a function that maps an output to a so-called “profile” of inputs, such as a collection of individual votes, preferences, or judgements. A simple example of an aggregation rule is to calculate a weighted sum of the inputs and apply a threshold to it. In addition, more complex methods have been developed, for example aggregators that incorporate the correlation between the different inputs from the profile (e.g., for aggregating the utility of social policy outcomes, while the outcomes for individuals are dependent from each other) [3]. Theoretical research formalizes properties of such aggregation rules and examines under which conditions they are fulfilled or unfeasible [48]. While basic settings, for instance the aggregation of “yes/no”-votes, deal with the same type of quantifiable inputs, challenges arise when it comes to more complex aggregation objects such as individual judgements or individual welfare. This complicates empirical studies in particular (e.g., to investigate how the utility of different consequences influences an individual’s decision [7]). Assumptions need to be made regarding the measurability and comparability of the aggregation objects, similar to the aggregation of distinct AI risks (see Sect. 1). Lastly, another related area is that of preference theory, which refers to individuals’ aversion or willingness to take risk. In economics, there is empirical research investigating the impact of exogenous shocks (e.g., economic crises, violent conflicts) on risk preferences, and evidence has been found of systematic changes in preferences over the life cycle, particularly with respect to financial risk [64]. These results suggest that aggregation and evaluation standards may also be subject to dynamics with respect to AI risks. However, further research is needed to explore the connections between theoretical findings from these disciplines and AI assessment.
In the engineering literature, we identified two related studies that follow a pragmatic approach. First, Xia et al. identify 16 concrete AI risk assessment frameworks from the industry, governments, and non-government organizations and represents them in an overview table based on certain characteristics [71]. These characteristics include, among others, sector and region of the framework, the AI principles and lifecycle stages covered, the stakeholders involved (i.e., as assessors or assessees), and the types of risk factors considered (e.g., hazard, vulnerability, mitigation risk). Based on the overview, they also discuss “trivialized concreteness” and deficiencies of the existing frameworks given that many questionnaires, for example, lack a standardized way of completing and evaluating them, and potential solutions such as mitigation strategies are barely provided by the frameworks [71]. Second, Chia et al. specifically focus on autonomous driving and compare existing risk assessment methodologies in view of the requirements of specific safety standards [10]. However, the reference methods HARA (for determining ASIL at system level) and FMEA (for risk priority numbers at component level) originate from the classical engineering context, and the paper does not further discuss AI-specific methods or the application of these classical methods to AI components.
From a legal background, Kaminski compares current risk regulation approaches in the US and EU (incl. NIST AI RMF, GDPR impact assessment, draft AI Act) in terms of the regulatory tools used, as well as their underlying risk concept and goals (e.g., precautionary, or cost–benefit analysis) [45]. In addition, she questions the suitability of risk regulation for AI [45]. To this end, Kaminski refers to the predominantly quantitative and aggregate notion of AI risk, where quantification regarding the violation of fundamental rights is not possible and risk aggregation would lead to societal trade-offs where individual harms and their compensation might be neglected.
Lastly, there are some contributions from the non-academic literature that survey AI risk assessment methodologies [25], as well as frameworks for responsible AI in general [53]. Overall, these works provide a broad overview of existing frameworks, however the criteria for categorizing or comparing them are rather high-level and do not consider the specific risk aggregation method used in the frameworks.
3 Methodology
The analysis presented in this paper is motivated by the need for specific risk assessment methods that arises in the context of the development of international AI quality standards and regulation. A significant, but so far little exposed aspect in this respect is risk aggregation, for which there is as yet no universally accepted method. In order to work towards consistency or, at least, compatibility when further operationalizing existing aggregation approaches, it is therefore important to understand the agreements and discrepancies among them. The following subsections describe the methodologyFootnote 6 we use to perform such an analysis. First our selection of AI risk assessment frameworks is explained. Then the characteristics are introduced that we use to establish and structure the comparative analysis.
3.1 Selection of AI risk assessment frameworks
As motivated above, the scope of our comparative analysis encompasses representative AI risk assessment frameworks from different countries and regions worldwide that provide guidance, or at the very least, some direction for aggregating individual AI risks. To this end, we create a snapshot of approaches from national standardization, governments, industry associations and AI institutes, thus excluding purely academic contributions as well as publications from companies. Some of these frameworks are procedural (e.g., as part of management standards), while others take the form of templates or scoring schemes. Documents that solely describe AI principles or provide prompts/questionnaires for risk analysis without a discernible evaluation framework, however, are not in considered in this analysis.
In our search for existing AI assessment frameworks at the scope described above, we firstly filtered the OECD database [58] for countries (and the EU) that are particularly active in regulating AI, meaning they have at least five “laws, rules, directives or other policies made by a public authority on the development or use of new technologies” [ibid.]. For these countries, we reviewed the entries in the database against the aforementioned criteria and selected suitable frameworks. Furthermore, we conducted a keyword search for “AI assessment” on the websites of the EU Commission, Parliament, and Council respectively, which are the responsible institutions for AI regulation in the European Union. In addition, we investigated the frameworks discussed in other systematic literature reviews (see related work, Sect. 2), especially [71]. Eventually, from the frameworks we found both on the EU websites and in related work, we selected those for our comparative analysis that, as described above, provide direction for risk aggregation.
In a subsequent step, based on the overview of the twelve frameworks selected in this way (see Sect. 4.1), we in turn selected a subset of them for in-depth analyses (provided in the appendix). As explained further below (see Sect. 4.2A), this subset was chosen in a way that different approaches are covered in relation to the four analysis characteristics which are described in the following.
3.2 Structure of the comparative analysis
In the comparative analysis of the selected AI risk assessment frameworks, we focus on how they systematize the aggregation of different risks. We specifically identified four characteristics of a risk assessment framework that particularly influence how risk aggregation is performed for a given AI system: (i) risk notion, (ii) consideration of application context, (iii) risk quantification (of individual risks), and (iv) guidance on aggregation or trade-offs. They result from the four phases that precede risk aggregation in a standard risk management process (i.e., establishing the scope, context and criteria, risk identification, risk analysis, and risk evaluation [38, 42]). Each characteristic is chosen so that it represents exactly the aspect of a phase that can have the greatest methodical influence on subsequent aggregation. We therefore use these four characteristics to further substantiate and structure the comparative analysis. The following paragraphs explain the meaning and rationale for the choice of the characteristics in more detail.
First, under the risk notion, we subsume the objectives and potential impacts of AI systems subject to the assessment, as well as the “risk appetite” with which high risks or trade-offs between different objectives are tolerated in principle. As outlined in the introduction, these aspects clearly influence how risks are perceived in an aggregated manner. According to the international standard on risk management, the risk notion as described above is typically established in the initial phase of the risk management process by the organization (i.e., as part of establishing the scope, context and criteria) [38]. While this standard leaves open how organizations define their notion of risk,Footnote 7 some assessment frameworks contain specific instructions on which objectives are to be considered for risk assessment or they indicate a stance on trade-offs and risk acceptance. For example, in European AI policymaking, risk is mainly associated with negative impact or harm to individuals and society.Footnote 8 Moreover, even within European (draft) regulation, different risk appetites can be found e.g., when comparing vertical and horizontal frameworks. Namely, the MDR introduces the concept of a “benefit-risk determination” (Art. 2, [24]), which allows a medical device to be placed on the market if its benefits exceed its associated risks. This is a major difference from the European Commission’s draft AI Act, as this follows an “as low as possible” approach that does not primarily aim for outweighing risks with the potential benefits of an AI application [13]. While the Parliament Amendments eventually loosens this perspective,Footnote 9 the European example still suggests that international operationalization approaches for risk assessment might differ in these aspects as well. Under the characteristic risk notion, we therefore examine,
-
whether the risk notion is defined in the frameworks (i.e., if a definition of risk is given directly or by reference to a standard),
-
to which extent benefits are part of the risk notion in the selected frameworks, i.e., whether
-
a.
risk is negative (risk in the framework is mainly associated with the occurrence of negative impact, harm or damage; benefits are not explicitly considered in the framework)
-
b.
risk is neutral (potential benefits or positive impacts are included in the risk notion)
-
c.
risk and benefits are considered separately (the risk notion is negative but positive impacts or benefits are still explicitly considered in the framework – in distinction from risk)
-
and how the selected frameworks predefine or provide indications as to which general risk appetite the aggregation should be based on, i.e., whether a
-
a.
low risk appetite (the framework aims at flagging or mitigating any potential negative outcome as far as possible)
-
b.
medium risk appetite (the framework includes making trade-offs and prioritization to a certain extent, where necessary)
-
c.
high risk appetite (maximization of benefits and positive impacts is specifically part of the framework, and it allows to proceed with high risk if positive impacts predominate).
Second, the application context of an AI system has a major influence on which risks exist at all and need to be aggregated. This is particularly clear from the fact that risk identification in a standard risk assessment process relies on an analysis of the application context and environment in order to detect factors that might cause uncertainty regarding the achievement of objectives [38, 42]. In addition, the application context determines which risks are particularly relevant for a given AI system [59, 62]. Risk-based regulation and assessment approaches are founded on exactly this principle. They consider the specific application (context) when deriving requirements or evaluation criteria. In terms of compatibility of frameworks, we therefore investigate in Sect. 4, whether in the selected frameworks the application context
-
a.
influences aggregation (i.e., it influences the way how individual risk dimensions are aggregated; for example, the weight of a risk dimension, when determining the overall risk, differs depending on the application context),
-
b.
has no impact on aggregation (i.e., risk aggregation always follows the same rules independently of the specific application context).
Third, risk quantification affects the leeway (or subjectivity, on the other hand) a framework allows in the risk assessment of a specific AI application, and, consequently, to what extent comparability and reproducibility are ensured in multiple executions. Certainly, risk analysis can be quantitative or qualitative, as highly uncertain events and intangible harms are typically difficult to quantify [38, 45]. Since the results of the risk analysis serve as direct input for risk aggregation, in either way, the description of the existing risks shapes the assumptions when beginning risk aggregation. For example, the means of quantification chosen, or even qualitative scales, influence the extent to which the various risks have already been given a comparable format. Under the third characteristic we thus investigate whether the selected frameworks guide towards assigning a score or number to some risks or risk factors, i.e., whether they provide (multiple options are possible)
-
a.
objectively measurable indicators (e.g., the number of people using an AI system or being affected by it [47])
-
b.
quantified scales (i.e., evaluations scales that are described qualitatively in the first place and assigned a score)
-
c.
advocacy of quantification (suggestion to use KPIs or measurable indicators in general, without specifying any metrics to be used)
-
d.
no guidance (i.e., quantification is not required or included at all in the framework).
Lastly, risk aggregation typically occurs during risk evaluation which is the final phase of risk assessment [38, 42]. With respect to this phase, the way how risk aggregation is performed for a given AI system is apparently most influenced/shaped by the framework giving specific guidance. Therefore, we examine under the fourth characteristic, whether guidance is
-
a.
detailed (e.g., aggregation formula with specified weights or instructions for making trade-offs; in case of detailed guidance, a brief summary is given in Table 1 below)
-
b.
high-level (i.e., aggregation is recommended as a final step of the assessment without any more specific instructions).
4 Results and discussion
In this section, we first provide the results of the comparative analysis of the twelve frameworks (Sect. 4.1). Subsequently, we deepen relevant aspects of the analysis in a discussion and outline recommendations for the further operationalization of risk aggregation (Sect. 4.2). The discussion and recommendations derived from it are based on the in-depth analyses of selected frameworks, which are provided in the appendix.
4.1 Comparative analysis
Table 1 summarizes the findings from the comparative analysis. In addition, the most important trends and discrepancies resulting from the comparison are described in more detail at the end of this section. In the table, each line presents the findings regarding a framework. The first two columns provide general information about the framework. First, the name, country or region of origin, and risk dimensions covered in the framework are listed. The latter illustrates once again the starting point for the analysis: the frameworks all acknowledge that different dimensions have to be considered when assessing the risk, and these must be aggregated for an overall assessment result. Second, the type of guidance provided by the framework is described. Based on the review of all frameworks, we identified the following types:
-
Process-guidance (that describes the steps required for the assessment, without necessarily specifying how exactly they should be carried out in practice),
-
Templates (i.e., a form or table that typically includes a prompting question or exercise),
-
Questionnaire (that might be complemented with an answer scoring system which assigns scores to individual answer options of the questionnaire that may be used at a later stage for aggregation),
-
Evaluation scales (that describe a range of different risk levels or categories, possibly qualitative, where a risk type, factor or intermediate aspect can be classified; this might also include an overall assessment scale which describes different result categories or levels for the overall/aggregated risk),
-
Risk mitigation (i.e., the framework provides guidance on mitigation measures with respect to a specified risk).
Lastly, the subsequent four columns correspond to the characteristics described in Sect. 3.2. Here, also an explanation of the possible manifestations of these characteristics is given, which are used in the table to describe the risk assessment frameworks.
Regarding the risk notion, the table shows that most frameworks mainly associate risk with the occurrence of negative effects, harm or damage. Only one framework [54] explicitly includes positive impact and benefits in its underlying risk notion. Furthermore, there is often no precise definition of risk given in the frameworks, and the terms „impact“ and „risk“ are used interchangeably. In equal proportions, on the other hand, are the indications among the frameworks for a general intention to minimize risk (Low risk appetite) and for the encouragement of trade-offs and risk tolerance to realize benefits (High risk appetite). Thus, trade-offs appear to be mostly accepted but there is no clear trend to promote compromise in case of conflicting trustworthiness requirements or objectives. Heterogeneous indications can especially be found among frameworks which serve the purpose to identify the need for regulation or supervisory approval [11, 57], and among frameworks that aim to assess an AI application including its residual risks [27, 57, 62]. Still, one trend apparent from the table is that frameworks, which explicitly guide towards analyzing benefits or advantages of an AI application, tend to include or encourage trade-offs, compared with frameworks that focus on potential negative impacts.
With respect to the context, we observe in all frameworks with high-level aggregation guidance that it depends on the specific AI application how individual risk dimensions are aggregated or weighed against each other. However, the table shows that frameworks which provide complete and detailed aggregation rules lack a way to incorporate the application context in their aggregation approach. For instance, where aggregation is based on the maximum level of all risk dimensions, the overall result may certainly depend on the application context as this influences the distinct risks [11, 47]. Nevertheless, solely aggregating by maximum does not allow for trade-offs or acceptance of high-risk dimensions based on the specific context (i.e., the way of aggregation itself is fixed), which is especially consistent with a low risk appetite. Regarding frameworks based on a questionnaire with an answer scoring system, [27] is an interesting example where the context is scored and used as a summand in the aggregation formula. Still, the scores for the distinct impacts of the AI application are not adapted or weighted depending on the application context (e.g., there is no interaction with the context scores), and thus the aggregation formula itself is fixed. Another example is [68] which does not even require to specify the application context as part of the assessment. Overall, concrete rules that use the application context for determining weights or trade-offs of different risk dimensions have not yet been specified. It remains a challenge how to address the wide range of AI applications by more concise evaluation rules.
The table also indicates that quantification of individual risks or risk factors is encouraged in most frameworks. In half of the sample, guidance is given for assigning numbers to some types or dimensions of risks, and only four frameworks fully rely on qualitative scales for the classification/evaluation of risks. This finding is surprising given that various aspects of AI systems are not readily quantifiable by metrics or key performance indicators [54, 65]. Especially, it is to a large extent unclear how to calculate meaningful (real) probabilities for the occurrence of technical malfunction or undesired system behavior [61]. An important note regarding the frameworks considered is therefore, that their quantification approaches are mainly based on assigning scores to qualitative rating scales. For example, in [27], classifying the impacts of an AI-based decision on the rights or freedoms of individuals as “little to no impact” scores 1 point and as “moderate” 2 points (see also [68] for more examples). Naturally, calculating an assessment score in this way involves human interpretation and self-assessment. Only a few frameworks propose objectively measurable parameters for analyzing some risks or risk factors, such as the number of affected rights-holders [47] or the degree of anonymization achieved in the data when considering privacy risks [62]. Overall, risk quantification in the current state might lead to uncertain results if based on qualitative scales, or it might result in oversimplification if based on approximation through simpler (calculable) factors.
Lastly, compared with the number of frameworks that propose risk quantification, significantly fewer provide specific quantitative guidance on the aggregation of different risk dimensions. Overall, we observe three types of quantitative aggregation rules in our sample: (i) the rule of taking the maximum of all dimension scores [11, 47], (ii) the rule of averaging scores [68], and (iii) the rule of summarizing and subtracting certain score sets [27]. However, none of the three approaches uses weights to adapt the aggregation to the specific application context of the AI system under consideration. In addition, even many frameworks that encourage quantification of risks lack an evaluation scale for the overall assessment. This shows that, while quantification may be possible or suggested for certain risk types, there is currently no mature methodology for comparing different risk dimensions or aggregating their scores.
In this section, we presented the findings from the overview of all twelve frameworks in relation to the four characteristics derived in Sect. 3.2. In order to interpret these findings and draw conclusions from them, we carried out additional in-depth analyses of selected frameworks (see appendix). On the basis of these analyses, the following section discusses the findings from the comparative overview in detail and explores challenges of risk aggregation as well as solution approaches.
4.2 Discussion on the basis of in-depth analyses
A. Outline of the in-depth analyses (see appendix)
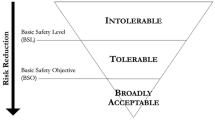
Based on the overview in the previous section, we conducted in-depth analyses of a reduced sample of frameworks. Some approaches clearly stand out from the table, such as the NIST AI Risk Management Framework [54] (see appendix A.4), which is the only approach with “neutral” risk notion. Also, [11, 28, 33, 35] set themselves apart as they do not require or include risk quantification, and we decided to look in detail into the first one, the Criticality Pyramid by the German Data Ethics Commission [11], due to its connection with the European AI regulation (see appendix A.1). In addition, we chose the Human Rights, Democracy, and the Rule of Law Framework by the Alan Turing Institute [47] (see appendix A.2), as well as the Fraunhofer IAIS AI Assessment Catalog [62] (see appendix A.5), since they contain different types of comprehensive guidance for risk mitigation and quantification, particularly including objectively measurable risk indicators. While the first covers impacts on individual rights and societal risks, the latter has a stronger focus on the AI system itself i.e., regarding the emergence of undesirable system properties. Finally, we completed our sample with the VCIO based Description for AI Trustworthiness Characterization [68] (see appendix A.3), which provides a scoring system and concise aggregation rules while barely considering the application context for evaluation. For each of these frameworks, we provide a detailed description in view of the four characteristics (risk notion, application context, quantification, aggregation guidance, see Sect. 3.2) in the appendix. In the following, we discuss our key learnings from the deep-dive and outline recommendations for the further operationalization of risk aggregation.
B. Findings
One finding from looking at the frameworks in more detail is that risks are analyzed and assessed at different levels of discourse, starting from a baseline assessmentFootnote 10 of possible impacts of a use case, up to the in-depth examinationFootnote 11 of the (technical) risk sources or triggers for the specific AI system. Figure 1 illustrates the possible reference points of these levels in terms of two stages of risk materialization: first, the occurrence of technical malfunction or undesired system properties/behavior, and second, the occurrence of impact such as material and immaterial damage (or realization of benefits, depending on the risk notion subject to the assessment). This general distinction between technical failures in the first place and their (potential) propagation to further effects in the second stage is inspired from safety engineering [39]. Notably, it enables taking into account mitigation measures and safeguards (in the embedding) of a system component when assessing the residual risks. Extending this safety concept to a broader notion of impact (compared with physical harm),Footnote 12 the two stages shown in Fig. 1 generally differentiate the depth and scope of system-specific analysis required for the assessment of trustworthy AI. In particular, potential (negative) impacts at the second stage can be evaluated on a use case-level i.e., without looking at the specific design and development of the AI system but rather on its context of use. Assessment methodologies that consider the first stage must, in contrast, involve detailed technical examinations. For example, risk factors or indicators may depend on the type of data and model used, the interaction of different components within the AI system, and the potential disturbances in the application environment. Certainly, an assessment at the second stage can still become arbitrarily complex, as the impact of AI systems can relate to various stakeholders and objectives (as indicated by the different risk dimensions of the current frameworks, see Table 1). In fact, the impacts we summarize under the second stage in Fig. 1 are neither on the same level nor equally important in each AI application. For example, damage to individuals can in turn have repercussions for the organization. Such interrelationships must be recognized by the responsible organization and the relevant risk layers addressed, ideally through dedicated roles (e.g., safety engineer, financial controller, etc.). Lastly, in addition to technical precautions, organizational measures can also be taken to mitigate or prevent undesired system behavior from materializing. Overall, analysis of the first stage, particularly metrics or testing methods, depend more strongly on the specific design, implementation, and application environment of the AI system (in terms of factors that influence or may be reflected in the input data), while an assessment of the second stage needs to be technically less deep but requires a thorough understanding of the AI application context and stakeholders.

Two stages of risk materialization. Given a technical malfunction, its propagation to negative impact can still be mitigated or prevented by technical and organizational measures
From the in-depth analysis, we also recognized that there is a trade-off between (i) including the application context and the specific design and development of the AI system in the assessment vs. (ii) objectivity and effort reduction. This trade-off is particularly reflected in the extent of quantification as well as the granularity of the assessment methodology. As mentioned in Sect. 4.1, none of the considered frameworks achieves a complete, holistic mathematical risk-modeling off all aspects related to trustworthy AI, which is also consistent with current literature [61]. Instead, the approaches considered are on a spectrum between classic “cost-utility analysis" (with fixed categories, weights, and aggregation schemes) on the one hand, and a totally individual assessment on the other which must be newly determined for each specific AI application. The VCIO model (see appendix A.3) and the AI Assessment Catalog (see appendix A.5) are two examples from each end of this spectrum. A comparison reveals similarities in their top-down approaches. At the highest level, the division into ethically relevant values in the VCIO model is similar to the six dimensions of trustworthiness in the AI Assessment Catalog. In addition, the subdivision into criteria and indicators in the VCIO model is comparable to the risk areas, objectives, and criteria of each trustworthiness dimension in the AI Assessment Catalog. Still, a direct mapping is not possible. The bottom-up approaches both start with documenting measures and then gradually evaluate and aggregate them across the various levels. In the AI Assessment Catalog, a structured definition of measures takes place at the lowest level. Then, an application-specific safeguarding argumentation is developed, where the Catalog provides potential metrics for certain aspects, but the assessor needs to select the metrics and argue their suitability with respect to the specific application. In the VCIO model, the measures and their effects are captured rather superficially by the observables which are assigned fixed scores. From then on, the evaluation is completely determined by aggregation rules – independent from potential trade-offs or priorities in the specific application. While such a static aggregation is of course in the interest of comparable results, feasibility and reasonable effort, it does not do justice to the dynamics of AI applications as illustrated in the following paragraph. This might explain why the VCIO model is labeled as a „value compliance model” and does not claim to assess the specific risk of an AI system. Process-level frameworks, on the other hand, are more strongly influenced by the individual interpretation and weighting of the assessors and require a lot of effort in each application (e.g., [54, 62]).
As mentioned, the range and variety of possible AI-based applications pose a challenge when it comes to defining uniform metrics that would allow to compare the degree of risk among all use cases in a standardized way. In the following, we exemplarily consider the transparency dimension to further explain this issue. Although a uniform structuring of different risk dimensions is not yet achieved, we can see from Table 1 that AI risk assessment frameworks mostly take this dimension into account. For example, there are well known-risks of blind trust or emotional bindings between humans and AI-systems, lack of appropriate ways to interrupt and control systems operations, and of insight into the system’s functioning. With respect to these risk types, the frameworks provide guidance by systematically listing risk indicators (e.g., in the form of questionnaires or templates) or qualitative evaluation scales, rather than specifying metrics or standardized schemata for measuring the risk. In addition, evaluation standards (e.g., standards specifying when an AI system is “transparent enough”) are still missing that may enable generally recognized and comparable assessments. One major reason is that transparency requires by its very nature human evaluation, as it refer to the way humans interact with or understand the AI system. Regarding the extent to which people are “being made aware”, for example, there may be applications in which a visible alert sticker is appropriate (e.g., “the estimated charging time for a full charge is based on an AI-model” in the case of a public charging station for an electrical car). Here, the size, color, and positioning of the alert sticker could be the basis of a metric. In contrast, considering an AI application that supports doctors in classifying cerebral strokes based on MRT results, at least a detailed documentation of the operational domain and limitations of the system should be provided. Here, length of documentation could be a metric, which, however, might be of limited expressiveness. In summary, we conclude that human- and context-related aspects of the use of AI-systems are particularly ill-suited for quantification. A solely quantitative and mathematical modeling of AI risk may even lead to over-simplification and misinterpretation. Therefore, the assessment of transparency-related risks should use qualitative evidence in addition. Lastly, also in the overall assessment of an AI system that aggregates individual risk dimensions, context and purpose play an important role. As explained in the introduction (see Sect. 1), different dimensions can have different weights and priorities in different contexts. There can be trade-offs between distinct risk dimensions [63] and often, (negative) impacts have to be balanced and weighted against benefits, again depending on the context and purpose of the application. These varying and complex interdependencies cannot be reflected in a once-fixed static aggregation scheme that attempts to be valid for all kinds of applications.
C. Recommendations
Overall, we conclude that a combination of horizontal (i.e., application-independent) and vertical (i.e., domain-specific) operationalization approaches is needed (see Fig. 2), given the trade-off between application-specific assessment vs. objectivity and practicality described above.

Recommendations for further operationalizing risk aggregation, from both horizontal and vertical perspectives
Since we have argued that both the application context and the specific AI system need to be considered in a holistic risk assessment, the only way to specify evaluation or aggregation standards at a more concrete level is to further restrict their scope i.e., focus on certain domains or AI use cases (e.g., the ISO/IEC technical report on AI use cases may serve as a starting point [40]). This approach can also be found in European legislation [15] and some national activities [35, 56], which initially provide horizontal frameworks that will be complemented by compatible vertical guidance or “use case profiles”. Using the two stages of risk materialization (see Fig. 1), we can distinguish a baseline impact assessment (stage 2) from the in-depth analysis of an AI application (stage 1). As the former is mostly independent of the specific technical design or implementation of the AI system, we consider it suitable to be determined from a vertical perspective e.g., by an interdisciplinary team of ethical, legal and domain experts. For instance, starting from the list of high-risk systems specified in the European AI Act [18, 19, 22], the general risk classification of these use cases could be broken further down to individual risk dimensions (i.e., in the sense of a specified protection requirement for the dimensions fairness, reliability, explainability, etc.) for each domain. Inspired from [54], we also recommend including potential benefits in such a baseline assessment (e.g., as one dimension), since these have a decisive impact on the acceptance of trade-offs. For example, benefits realized in medical use cases might lead to different trade-offs than benefits by solely commercial applications. In summary, a specified assessment of each dimension (e.g., in the form of fixed weights for a particular use case) provides indication for prioritizing mitigation measures and influences trade-offs and the overall assessment of the AI system. We therefore consider vertical operationalization at this level of abstraction to be a promising way to increase the objectivity and comparability of assessments of different AI systems used for the same purpose and domain. Of course, deviations from the specified baseline assessments/prioritizations may be permitted, but these would have to be justified.
Independently of the specific AI use case, in contrast, the deep dive shows that more granular guidance is needed on the identification and analysis of technical malfunction or failure of the AI system (see stage 1 in Fig. 1). This can be approached from a horizontal perspective by developing standardized lists of risk sources and indicators (e.g., metrics and tests), among others, specifically by AI functions or even for each ML model class (e.g., transformer models, decision trees). Clearly, breaking high-level risk dimensions and respective quantification and implementation guidance down to distinct AI functions or models requires further research. In addition, the effectiveness of technical mitigation measures needs to be further investigated that might prevent certain behavior or failures of AI components (e.g., an ML model) from propagating through the entire AI system. As outlined in the appendix, the risk areas described in the AI Assessment Catalog [62] (which in its current stage aims to be broadly applicable for different ML techniques and application contexts) provide a potential starting point for further operationalization. Each risk area bundles such (possibly undesirable) system properties within a dimension that can be addressed by a similar safeguarding approach. In addition, the lifecycle of an AI application is an important reference for identifying potential threats, and respective safeguarding approaches in the AI Assessment Catalog are structured along a simplified version of the AI lifecycle. Notably, there are further and more detailed lifecycle models available [43, 47]. The potential of lifecycle-assessment, among other risk management techniques, has not been fully harnessed yet [5] and breaking down the methodology described in the AI Assessment Catalog further along the AI lifecycle might be a promising next step. In our view, horizontal operationalization in this way is complementary to the vertical approach, in the sense that it works towards a standardized input to risk aggregation, where the individual inputs can be weighted using the vertical baseline assessment.
5 Conclusion and outlook
In this paper, we argued that aggregation of individual risk dimensions is a major challenge in evolving AI quality standards. We presented a comparative analysis of twelve internationally representative risk assessment frameworks, focusing on their respective risk aggregation schemes. For structuring the comparison, we derived the risk notion, application context, extent of risk quantification, and instructions on aggregation and trade-offs as four distinctive characteristics of AI risk aggregation. Our comparison of the specific aggregation approaches in the selected frameworks yields two key findings. Firstly, current frameworks predominantly provide high-level guidance on risk aggregation and mostly support consideration of the application context. In particular, the AI Assessment Catalog [62] (see detailed discussion in appendix A.5) uses a protection requirements analysis that allows for a basic weighting of the individual dimensions, though this does not lead to a fully quantitative aggregation formula. In the in-depth analysis, we additionally found that detailed guidance on risk aggregation (e.g., through specific rules or calculation schemes) within a general framework cannot sufficiently take into account the dynamics and application-dependency of AI risk assessment. Secondly, we have seen that risk quantification is widely advocated, but there is a lack of objectively measurable risk indicators that could approximate a mathematical risk modeling and aggregation of technical failures or hazards. A weighted risk aggregation formula that takes application-specific dependencies into account needs further research. Therefore, it is currently not practicable to dispense with qualitative evidence and assessment criteria. At the same time, it is desirable to have a standardized procedure for risk aggregation in order to make the assessment of different use cases comparable and reduce the effort of individual consideration (particularly in terms of practicability and scalability). We therefore propose that further operationalization be performed using a combination of vertical and horizontal approaches. On a vertical level, we recommend the development of use case profiles that define the domain-specific relevance of the individual risk dimensions of an AI application. On a horizontal level, there is a need for further research into the systematic recording of AI properties and behavior. This can be substantiated by a finer subdivision, for example between different model classes or functionalities (see [13] and Sect. 4.1.2.1 in [12]), along which potential (negative) effects can be broken down into more specific risk indicators. These could then be used as a basis for standardized system analysis and specifically weighted and evaluated based on their use case-specific relevance.
These findings and recommendations are particularly relevant with regard to current AI standardization needs. A major challenge in the near future will be the successful implementation of harmonized standards in support of the European AI Act. However, guidance is currently still missing for several aspects of risk and conformity procedures along the AI lifecycle. Among others, quality standards concerning the design, development, testing, deployment, and monitoring of trustworthy AI systems will be needed, as well as guidance on how to resolve tensions between conflicting mitigation objectives [51]. Moreover, it should be noted that the pre-market evaluation may include different stakeholders in different roles, ranging from a simple self-evaluation (and declaration) to a certification process including accredited third-party auditing bodies. (Contextual) conditions and the evaluation of risks can change over time, so that monitoring and re-assessments during operation are important elements of an organization’s risk management, as well as third-party audits schemes. Scope, tools and timeframes of AI (re-)assessment along the lifecycle still need to be determined, and, as possible, harmonized with international standards and future developments regarding AI assessment (e.g., from ISO/IEC SC 42). Correspondingly, the European Commission issued a Standardization Request to CEN-CENELEC that lists ten standardization deliverables to be drafted (e.g., on transparency, robustness, data quality) [17]. According to our findings, an overall trustworthiness assessment cannot be achieved if these would be developed independently from each other. Remarkably, a conformity assessment deliverable is requested separately from the other nine deliverables [17]. According to our analysis, it is important that the AI risk aggregation scheme should be part of the conformity deliverable standard and be applied consistently in the other nine standards. In addition, while defined in a horizontal approach, the risk aggregation scheme should interact with the requested standards in a way that enables the integration of domain-specific weighting. Only this way the current dynamics and trade-offs between different dimensions can be taken account of, and compatibility with upcoming vertical standards facilitated.
Another major challenge is posed by so-called “general purpose” systems i.e., large language and foundation models. These are typically not designed for a specific task or domain but can be used in a wide range of application areas, bearing systemic risks that might manifest in various downstream uses. The European AI Act imposes regulatory requirements on respective providers, including the assessment of systemic risks for certain “high-impact” foundation models [18, 19, 22]. Our analysis shows, however, that the specific application context has a major influence on risk analysis and aggregation in state-of-the-art frameworks. Especially given that the application of a general-purpose AI system is undefined in the first place, the necessity for novel, application-agnostic assessment standards becomes evident. By their very nature, risk assessment of general-purpose systems focuses on the (technical) capabilities and limitations of the underlying ML model (see stage 1 in Fig. 1) and, possibly, additional safeguards for alignment. Recent works on generative AI and large language models show that benchmarking, evaluation of generally dangerous capabilities (e.g., deception, AI development, self-proliferation [67]), and adversarial testing may serve as main approaches for application-independent assessment at the current stage [52, 70]. At the same time, it points out gaps and a need for research in the availability and implementation of corresponding methods. Overall, general capability tests are only one layer of risk assessment and are insufficient in themselves for a complete evaluation, since only the specific application context determines whether a risk of harm actually exists [52, 70]. In our recent work [50], we present an approach for risk assessment of AI applications that are based on foundation models. Regarding systemic risks of general-purpose models on the other hand, further clarification is needed on how various general capabilities can be aggregated for an overall evaluation and how such an assessment is connected to the risks of downstream applications.
Data availability
A data availability statement is not applicable in this case.
Notes
The European AI Act is the first comprehensive regulation of artificial intelligence worldwide, which is about to be formally adopted at the time of writing this paper [18, 19, 22]. As the technical details of the Act are currently being worked out, this paper refers to the European Commission’s initial draft [15] and the European Parliament’s compromise text of June 2023 [21].
For example, an evaluation of the “overall residual risk “ is required in the draft AI Act for providers of high-risk AI systems (see Article 9 [15]). But also vertical regulation covers risk aggregation. For instance, banks typically perform internal risk aggregation and their respective methods are reviewed as part of sectoral supervision procedures [60]. Another example is the proposal for a directive on consumer credits. It requires that, where creditworthiness assessment involves the use of automated processing, consumers can obtain a “clear and comprehensible explanation of the assessment (…), including on the logic and risks involved in the automated processing (…) as well as its significance and effects on the decision”, see Art. 18(6), [16]. Certainly, the AI relevance of existing aggregation methods in the financial sector needs to be further explored, as it is still in the process of developing best practices for AI risk management [6].
Correspondingly, the draft AI Act requires that “risk management measures (…) shall give due consideration to the effects and possible interactions resulting from the combined application of [trustworthiness] requirements (…)”, see Article 9 [15].
In this paper, we use the term “individual risk“ to distinguish it from an aggregated risk. Notably, the term does not mean that the risk refers to persons.
The methodology followed and the resulting analysis certainly have natural limitations. Firstly, we had to make a finite selection of frameworks and can therefore only provide a "snapshot" of current approaches (as representative as possible). Also, risk aggregation as the object of the analysis is primarily a concept which can be designed very differently, so that the characteristics considered are correspondingly abstract and are not represented by objectively measurable criteria. Lastly, we are not aware of any comparable work on this topic (see related work), with whose approach we can compare ourselves. Through the explanations in this section, we intend to make our methodology and the analysis criteria as comprehensible as possible.
International standardization on (AI) risk management and AI terminology defines risk as the “effect of uncertainty on objectives” [38, 41, 42], noting that “[a]n effect is a deviation from the expected [which] can be positive, negative or both, and can address, create or result in opportunities and threats” [ibid.]. In addition, the AI risk management standard states that risks need to be prioritized against risk criteria and objectives relevant to the organization (see clauses 4 and 6.4.1 in [42]). It should be noted that this is not the notion of risk used in the context of safety, compare further [4], [37].
The draft AIA defines “high risk” as “significant risk to health and safety or fundamental rights of persons” [15]. Also negatively associated but neutral with respect to the objectives involved, the European Medical Device Regulation defines risk as “the combination of the probability of occurrence of harm and the severity of that harm” (see [24], Art. 2 23, adopted in [21]). Another example is the definition of “model risk” in the European Capital Requirements Directive as “the potential loss an institution may incur, as a consequence of decisions that could be principally based on the output of internal models, due to errors in the development, implementation or use of such models “ [23].
Specifically, they propose that “relevant residual risks associated with each hazard as well as the overall residual risk of the high-risk AI system” shall be brought to an acceptable level through risk management measures (see Amendment 268, [21]), rather than “any residual risk” as proposed in the Commission’s draft [15].
AI systems are classified as high-risk, for example due to their “significant potential harm to health, safety, fundamental rights, environment, democracy and the rule of law” [22]. See also Article 7(2) of the initial draft of the European Commission which provides eight criteria for this classification [15].
In this context, the notion of “Rights-Holder” is as follows: “All individuals are human rights-holders. In the impact assessment, the primary focus is on rights-holders who are, or may be, adversely affected by the project.” (p. 20, [47]).
For example, the document states that “The standardised description is independent of the risk posed by the product and does not define any minimum requirements in the context of this.” p.1 [68]. See also the preface of the document.
Following the AI RMF, a trustworthy AI system is characterized as (1) valid and reliable, (2) safe, (3) secure and resilient, (4) accountable and transparent, (5) explainable and interpretable, (6) privacy-enhanced, and (7) fair with harmful bias managed. Notably, the characteristic “valid and reliable” is seen as a foundation for the other trustworthiness characteristics. The characteristic “accountable and transparent” is described as interacting with all other characteristics.
Among other challenges, NIST also describes the inscrutability of AI systems resulting from their opaque nature, as well as the difficulty of a defining a metric to compare how AI systems and humans perform on the same task.
It is important to note that in the risk analysis, the hazards and risks that may occur in principle for the AI system are recorded and evaluated. This procedure does not mean that the risks will actually occur in the concrete implementation of the AI system at the level indicated. Rather, in the subsequent steps of the approach, it should be shown that the relevant risks have been sufficiently mitigated.
Furthermore, it is noteworthy that the dimensions or risk areas in the AI Assessment Catalog which have similar objectives (e.g., reliability and functional safety), are partly focused on different structural elements of the AI system. For example, risk sources and measures in the reliability dimension refer to the ML model, and in the functional safety risk area to the embedding. The same holds for data protection (focused on the ML model) and integrity & availability (focused on classical embedding measures). Still, an entire separation is not possible and there are numerous cross-references between dimensions and risk areas.
References
AI Ethics Impact Group: From Principles to Practice: An interdisciplinary Framework to operationalize AI ethics. https://www.ai-ethics-impact.org/en (2019). Accessed 19 January 2024
AIST (National Institute of Advanced Industrial Science and Technology): Machine Learning Quality Management Guideline, 3rd English Edition. Technical Report, Digital Architecture Research Center / Cyber Physical Security Research Center / Artificial Intelligence Research Center, Digiarc-TR-2023–01 / CPSEC-TR-2023002 (2023)
Al-Najjar, N. I., Pomatto, L.: Aggregate risk and the Pareto principle. J. Econ. Theory. 189 (2020)
Avizienis, A., Laprie, J.C., Randell, B., Landwehr, C.: Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Depend. Secure Comput. 1(1), 11–33 (2004)
Ayling, J., Chapman, A.: Putting AI ethics to work: are the tools fit for purpose? AI and Ethics. 2(3), 405–429 (2022)
Basel Committee on Banking Supervision: Newsletter on artificial intelligence and machine learning. https://www.bis.org/publ/bcbs_nl27.htm (16 March 2022). Accessed 20 October 2023
Best, H.: Die Messung von Nutzen und subjektiven Wahrscheinlichkeiten: ein Vorschlag zur Operationalisierung der Rational Choice Theorie. (engl.: Measuring utility and subjective probabilities: a proposal for operationalization of Rational Choice Theory). Methoden, Daten, Analysen (mda), 1(2), 183–212 (2007)
Braunschweig, B., Buijsman, S., Chamroukhi, F., Heintz, F., Khomh, F., Mattioli, J., Poretschkin, M.: AITA: AI trustworthiness assessment: AAAI spring symposium 2023. AI and Ethics, 1–3 (2024) https://doi.org/10.1007/s43681-023-00397-z
CEN-CENELEC: ETUC’s position on the draft standardization request in support of safe and trustworthy AI. https://www.cencenelec.eu/news-and-events/news/2022/newsletter/issue-34-etuc-s-position-on-the-draft-standardization-request-in-support-of-safe-and-trustworthy-ai/ (2022). Accessed 19 January 2024
Chia, W. M. D., Keoh, S. L., Goh, C., Johnson, C.: Risk assessment methodologies for autonomous driving: A survey. IEEE Trans. Intellig. Transport. Syst. 23(10) (2022)
Datenethikkommission: Gutachten der Datenethikkommission. (engl.: Report of the German Data Ethics Commission). https://www.bmj.de/SharedDocs/Downloads/DE/Themen/Fokusthemen/Gutachten_DEK_DE.pdf?__blob=publicationFile&v=2 (2019). Accessed 06 December 2022
DIN & DKE: German Standardization Roadmap on Artificial Intelligence (1st edition). https://www.din.de/resource/blob/772610/e96c34dd6b12900ea75b460538805349/normungsroadmap-en-data.pdf (2020). Accessed 04 January 2024
DIN & DKE: German Standardization Roadmap on Artificial Intelligence (2nd edition). www.din.de/go/roadmap-ai (2022). Accessed 02 January 2024
Djeffal, C.: IT-Sicherheit 3.0: Der neue IT-Grundschutz: Grundlagen und Neuerungen unter Berücksichtigung des Internets der Dinge und Künstlicher Intelligenz (engl.: IT security 3.0: The new IT baseline protection: basics and innovations taking into account the Internet of Things and Artificial Intelligence). Multimedia und Recht, 289–294 (2019)
European Commission: Proposal for a Regulation of the European Parliament and of the Council laying down Harmonized Rules on Artificial Intelligence (Artificial Intelligence Act) and amending certain Union Legislative Acts. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52021PC0206 (2021). Accessed 07 December 2022
European Commission: Proposal for a Directive of the European Parliament and of the Council on consumer credits, COM(2021) 347 final 2021/0171(COD). https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:52021PC0347 (2021). Accessed 24 October 2023
European Commission: Draft standardisation request to the European Standardisation Organisations in support of safe and trustworthy artificial intelligence. https://ec.europa.eu/docsroom/documents/52376 (2022). Accessed 30 September 2023
European Commission: Commission welcomes political agreement on Artificial Intelligence Act. Press release, 9 December 2023. https://ec.europa.eu/commission/presscorner/detail/en/ip_23_6473 (2023). Accessed 22 December 2023
European Council: Artificial intelligence act: Council and Parliament strike a deal on the first rules for AI in the world. Press release, 9 December 2023. https://www.consilium.europa.eu/en/press/press-releases/2023/12/09/artificial-intelligence-act-council-and-parliament-strike-a-deal-on-the-first-worldwide-rules-for-ai/ (2023). Accessed 22 December 2023
European Law Institute: Model Rules on Impact Assessment of Algorithmic Decision-Making Systems Used by Public Administration. https://www.europeanlawinstitute.eu/fileadmin/user_upload/p_eli/Publications/ELI_Model_Rules_on_Impact_Assessment_of_ADMSs_Used_by_Public_Administration.pdf (2022). Accessed 19 January 2024
European Parliament: Amendments adopted by the European Parliament on 14 June 2023 on the proposal for a regulation of the European Parliament and of the Council on laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) and amending certain Union legislative acts (COM(2021)0206 – C9–0146/2021 – 2021/0106(COD)). https://www.europarl.europa.eu/doceo/document/TA-9-2023-0236_EN.html (2023). Accessed 31 August 2023
European Parliament: Artificial Intelligence Act: deal on comprehensive rules for trustworthy AI. Press release, 9 December 2023. https://www.europarl.europa.eu/news/en/press-room/20231206IPR15699/artificial-intelligence-act-deal-on-comprehensive-rules-for-trustworthy-ai (2023). Accessed 22 December 2023
European Parliament and Council: Directive 2013/36/EU of the European Parliament and of the Council of 26 June 2013 on access to the activity of credit institutions and the prudential supervision of credit institutions and investment firms, amending Directive 2002/87/EC and repealing Directives 2006/48/EC and 2006/49/EC Text with EEA relevance, 2013. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A32013L0036 (2013). Accessed 26 October 2023
European Parliament and Council: Regulation (EU) 2017/745 of the European Parliament and of the Council of 5 April 2017 on medical devices, amending Directive 2001/83/EC, Regulation (EC) No 178/2002 and Regulation (EC) No 1223/2009 and repealing Council Directives 90/385/EEC and 93/42/EEC, 2017. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32017R0745 (2017). Accessed 31 August 2023
Ezeani, G., Koene, A., Santiago, N., Kumar, R., Wright, D.: A survey of artificial intelligence risk assessment methodologies: The global state of play and leading practices identified. Ernest & Young LLP and Trilateral Research, London (2021)
Gellert, R.: Understanding the notion of risk in the General Data Protection Regulation. Comput. Law Secur. Rev. 34(2), 279–288 (2018)
Government of Canada: Algorithmic Impact Assessment tool. https://www.canada.ca/en/government/system/digital-government/digital-government-innovations/responsible-use-ai/algorithmic-impact-assessment.html (2023). Accessed 24 November 2023
Government of the Netherlands, Ministry of the Interior and Kingdom Relations: Impact Assessment Fundamental Rights and Algorithms (2022)
Hagendorff, T.: The ethics of AI ethics: An evaluation of guidelines. Minds Mach. 30(1) (2020)
Hanson, B., Stall, S., Cutcher-Gershenfeld, J., Vrouwenvelder, K., Wirz, C., Rao, Y., Peng, G.: Garbage in, garbage out: mitigating risks and maximizing benefits of AI in research. Nature 623(7985), 28–31 (2023)
Hendrycks, D., Carlini, N., Schulman, J., Steinhardt, J.: Unsolved problems in ml safety. arXiv preprint arXiv:2109.13916 (2021)
High-level Expert Group on AI: Ethics Guidelines on Trustworthy AI (2019)
Info-communications Media Development Authority (IMDA) and Personal Data Protection Commission (PDPC): Model AI Governance Framework, 2nd Edition (2020)
Info-communications Media Development Authority of Singapore and World Economic Forum’s Centre for the Fourth Industrial Revolution: Companion to the Model AI Governance Framework – Implementation and Self-Assessment Guide for Organizations. World Economic Forum, Geneva (2020)
Information Commissioner’s Office: AI and data protection risk toolkit. https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/artificial-intelligence/guidance-on-ai-and-data-protection/ai-and-data-protection-risk-toolkit/ (2023). Accessed 17 November 2023
Information Commissioner’s Office: Guidance on AI and Data Protection. https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/artificial-intelligence/guidance-on-ai-and-data-protection/what-are-the-accountability-and-governance-implications-of-ai/ (2023). Accessed 28 November 2023
International Electrotechnical Commission (IEC): IEC 61508–1:2010, Functional safety of electrical/electronic/programmable electronic safety-related systems - Part 1: General requirements (2010)
International Organization for Standardization: ISO 31000:2018, Risk management — Guidelines (2018)
International Organization for Standardization: ISO 26262–1:2018 – Road vehicles – Functional safety, Part 1: Vocabulary (2018)
International Organization for Standardization: ISO/IEC TR 24030:202, Information technology — Artificial Intelligence — Use Cases (2021)
International Organization for Standardization: ISO/IEC 22989:2022, Information Technology — Artificial Intelligence — Artificial Intelligence Concepts and Terminology (2022)
International Organization for Standardization: ISO/IEC 23894:2023, AI Risk Management (2023)
International Organization for Standardization: ISO/IEC DIS 5338, Information technology — Artificial intelligence — AI system life cycle processes (2023)
Jobin, A., Ienca, M., Vayena, E.: The global landscape of AI ethics guidelines. Nature machine intelligence 1(9), 389–399 (2019)
Kaminski, M. E.: Regulating the Risks of AI. Forthcoming, Boston University Law Review, 103 (2023)
Krafft, T. D., Zweig, K. A.: Transparenz und Nachvollziehbarkeit algorithmenbasierter Entscheidungsprozesse, Ein Regulierungsvorschlag aus sozioinformatischer Perspektive (vzbv). (engl.: Transparency and traceability of algorithm-based decision processes, A regulatory proposal from a socio-informatic perspective). https://www.vzbv.de/sites/default/files/downloads/2019/05/02/19-01-22_zweig_krafft_transparenz_adm-neu.pdf (2019). Accessed 06 February 2022
Leslie, D., Burr, C., Aitken, M., Katell, M., Briggs, M., Rincon, C.: Human rights, democracy, and the rule of law assurance framework for AI systems: A proposal. The Alan Turing Institute (2021). https://doi.org/10.5281/zenodo.5981676
List, C.: Social Choice Theory. The Stanford Encyclopedia of Philosophy (Winter 2022 Edition), Edward N. Zalta & Uri Nodelman (eds.), https://plato.stanford.edu/archives/win2022/entries/social-choice/ (2022). Accessed 20 October 2023
Mauri, L., Damiani, E.: Modeling threats to AI-ML systems using STRIDE. Sensors, 22(17) (2022)
Mock, M., Schmidt, S., Müller, F., Görge, R., Schmitz, A., Haedecke, E., Voss, A., Hecker, D., Poretschkin, M.: Vertrauenswürdige KI-Anwendungen mit Foundation-Modellen entwickeln (engl.: Developing trustworthy AI applications with foundation models). Fraunhofer-Institute for Intelligent Analysis- and Information Systems, Sankt Augustin, Germany (2024). https://www.iais.fraunhofer.de/content/dam/iais/publikationen/studien-und-whitepaper/Fraunhofer_IAIS_Whitepaper_Vertrauenswuerdige_KI-Anwendungen.pdf (an English version will be published soon)
Mökander, J., Floridi, L.: Operationalising AI governance through ethics-based auditing: an industry case study. AI and Ethics 3(2), 451–468 (2023)
Mökander, J., Schuett, J., Kirk, H. R., Floridi, L.: Auditing large language models: a three-layered approach. AI and Ethics, 1–31 (2023)
Narayanan, M., Schoeberl, C.: A Matrix for Selecting Responsible AI Frameworks. Issue Brief, Center for Security and Emerging Technology (2023). https://doi.org/10.51593/20220029
National Institute of Standards and Technology (U.S. Department of Commerce): Artificial Intelligence Risk Management Framework (AI RMF 1.0). https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf (2023). Accessed 14 February 2023
National Institute of Standards and Technology (U.S. Department of Commerce): NIST AI Risk Management Framework Playbook. https://pages.nist.gov/AIRMF/ (2023). Accessed 14 February 2023
National Institute of Standards and Technology (U.S. Department of Commerce): AI RMF Profiles. https://airc.nist.gov/AI_RMF_Knowledge_Base/AI_RMF/Core_And_Profiles/6-sec-profile (2023). Accessed 18 December 2023
NSW Government: NSW AI Assurance Framework. https://www.digital.nsw.gov.au/policy/artificial-intelligence/nsw-artificial-intelligence-assurance-framework (2022). Accessed 24 November 2023
OECD: AI Policy observatory, powered by EC/OECD. Database on Emerging AI-related regulation. https://oecd.ai/en/dashboards/policy-instruments/Emerging_technology_regulation (2021). Accessed 06 December 2022
OECD: Advancing accountability in AI: Governing and managing risks throughout the lifecycle for trustworthy AI. OECD Digital Economy Papers, No. 349, OECD Publishing, Paris (2023). https://doi.org/10.1787/2448f04b-en
Open Risk (2023) [Online]. Available: https://www.openriskmanual.org/wiki/Risk_Aggregation#cite_ref-1. Accessed 18 October 2023
Piorkowski, D., Hind, M., Richards, J.: Quantitative AI Risk Assessments: Opportunities and Challenges. arXiv preprint arXiv:2209.06317 (2022)
Poretschkin, M., Schmitz, A., Akila, M., Adilova, L., Becker, D., Cremers, A., Hecker, D., Houben, S., Mock, M., Rosenzweig, J., Sicking, J., Schulz, E., Voss, A., Wrobel, S.: Guideline for Trustworthy Artificial Intelligence - AI Assessment Catalog. Fraunhofer IAIS. arXiv preprint arXiv:2307.03681 (2023)
Sanderson, C., Douglas, D., Lu, Q.: Implementing Responsible AI: Tensions and Trade-Offs Between Ethics Aspects. International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 1–7 (2023). https://doi.org/10.1109/IJCNN54540.2023.10191274
Schildberg-Hörisch, H.: Are risk preferences stable? J. Econ. Perspect. 32(2), 135–154 (2018)
Schmitz, A., Akila, M., Hecker, D., Poretschkin, M., Wrobel, S.: The why and how of trustworthy AI. at-Automatisierungstechnik. 70(9), 793–804 (2022)
Schwartz, R., Vassilev, A., Greene, K., Perine, L., Burt, A., Hall, P.: Towards a standard for identifying and managing bias in artificial intelligence. NIST special publication 1270(10.6028) (2022)
Shevlane, T., Farquhar, S., Garfinkel, B., Phuong, M., Whittlestone, J., Leung, J., Dafoe, A.: Model evaluation for extreme risks. arXiv preprint arXiv:2305.15324 (2023)
VDE: VCIO based description of systems for AI trustworthiness, VDE SPEC 90012 V1.0 (en)characterization. https://www.vde.com/resource/blob/2176686/a24b13db01773747e6b7bba4ce20ea60/vde-spec-vcio-based-description-of-systems-for-ai-trustworthiness-characterisation-data.pdf (2022). Accessed 08 December 2022
Weidinger, L., Uesato, J., Rauh, M., Griffin, C., Huang, P. S., Mellor, J., Gabriel, I.: Taxonomy of risks posed by language models. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 214–229 (2022)
Weidinger, L., Rauh, M., Marchal, N., Manzini, A., Hendricks, L. A., Mateos-Garcia, J., Isaac, W.: Sociotechnical Safety Evaluation of Generative AI Systems. arXiv preprint arXiv:2310.11986 (2023)
Xia, B., Lu, Q., Perera, H., Zhu, L., Xing, Z., Liu, Y., Whittle, J.: Towards Concrete and Connected AI Risk Assessment (C2AIRA): A Systematic Mapping Study. IEEE/ACM 2nd International Conference on AI Engineering–Software Engineering for AI (CAIN), 104–116 (2023)
Acknowledgements
This research has been funded by the Ministry of Economic Affairs, Industry, Climate Action and Energy of the State of North Rhine-Westphalia as part of the flagship project ZERTIFIZIERTE KI, as well as by the Federal Ministry of Education and Research of Germany and the state of North Rhine-Westphalia as part of the Lamarr Institute for Machine Learning and Artificial Intelligence. The authors would like to thank both consortia for the successful cooperation.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix
The following in-depth analyses are listed in chronological order by the year of the frameworks’ publication.
A.1 Criticality pyramid
One purpose of risk assessment is to classify AI systems according to their need for regulation. Specifically, risk-based regulation approaches allow for requirements to be established solely in critical cases, rather than universally, and thus reduce the regulatory burden. The German Data Ethics Commission (DEK), set up by the German government, published a report on algorithmic decision making in 2019 [11] which proposes a “criticality pyramid” to define regulatory requirements depending on the damage potential of an algorithmic system. The risk-based approach of the EU AI Act resembles the “criticality pyramid” of the DEK in many aspects, as explained below. Both build on the view that as the damage potential of algorithmic systems increases, so do the need and depth of regulatory intervention.
The criticality pyramid consists of five levels (see Table 2), ranging from low to unacceptable. The criticality level of an AI system is determined by estimating the severity and probability of occurrence of damage. For determining the severity, material (e.g., financial) as well as immaterial impacts (e.g., fundamental rights violations) are considered, as well as the impacts on ecological, social, psychological, cultural, economic, and legal dimensions. The probability, as opposed to its mathematical calculation, is qualitatively approximated by several factors such as the relevance of the algorithm in the decision process, its complexity, consequences, and reversibility. Technical factors that might cause the occurrence of harmful system behavior are not considered in this estimation. An important feature of this approach is that the different impacts are not considered separately, but the severity is already determined in aggregated form over all possible impacts. Similarly, the estimation of the probability does not differentiate according to the type of damage, but the factors to be considered are partly even independent of it (e.g., relevance of the system in the decision process). Therefore, we interpret this framework in such a way that the aggregation follows the maximum, i.e., the most severe potential impact and the most likely damage determine the criticality level.
Notably, the structure of the DEK’s approach partly overlaps with the risk matrix by Krafft and Zweig [46]. Krafft and Zweig propose a two-dimensional risk matrix to classify algorithmic decision systems with respect to their damage potential. On the horizontal axis, a system is evaluated regarding the intensity of potential damage, while on the vertical axis it is assessed to which extent the system affects a person’s agency. Krafft and Zweig propose a division into five classes based on the area spanned (diagonally) by the two axes. Class 0 comprises systems with a low value on each axis that have a low risk of harm and do not require any regulation. Class 4 systems, on the other hand, have a high value on each axis and should be prohibited or strictly regulated. Regarding the aggregation of different risks, it should also be noted that Krafft and Zweig distinguish between two parts of the damage potential: the consequences for consumers and for society. In particular, it is not possible to derive societal harm from the sum of individual harms (p.10 and 27 [46]), but these must be evaluated differently depending on the application context (p. 18 [46]).
Legal requirements are also proposed by the DEK, that are increasing along the five levels of the “criticality pyramid”. While level 1, with lowest damage potential, does not need to be specifically regulated, the DEK suggests regulation for systems in levels 2, 3, and 4, and at least partial prohibition for level 5. They propose three areas of regulatory tools: (i) tools for correction and control, (ii) obligations regarding transparency, explainability, and traceability of results, and (iii) regulation on the allocation of responsibility and liability in connection with the development and use of algorithmic systems. Following the DEK, the task of legal regulation should be to avoid harmful effects on individuals and society, while regulating only as much as necessary to sustain technological innovation. Still, it should be noted that the approach for determining the criticality level of an AI system does not provide for a trade-off between possible damages and benefits.
Compared to the risk-based approach of the European AI Act, besides the supplementary fifth level of the “criticality pyramid” there is a lot of intersection. Levels 1 and 5 of the “criticality pyramid” are largely consistent with the lowest (AI systems with minimal or no risk) and the highest (prohibited AI systems) risk category of the AI Act. Furthermore, in both approaches the remaining levels are subject to specific regulation. Here, the AI Act only distinguishes between AI systems with limited and high risk, whereby the requirements for high-risk AI systems are much stricter [18, 19]. Lastly, while the European regulators are consistent with the DEK in terms of describing only high-level criteria for classifying an AI application as “high-risk”,Footnote 13 they reduce legal uncertainty by additionally providing the results of their classification. Specifically, the AI Act includes a list that determines which AI applications are regulated as high-risk systems (see [18], see also [15] for the initial version of the list). This list may be adapted over time by the regulators. Overall, it is important to note that the European risk-based legislation takes into account the specific application context when classifying a system as high-risk, and the AI Act therefore only lists specific AI use cases under this class. Lastly, a central extension of this approach, which the DEK does not cover in its risk classification, is the regulation of so-called "general purpose" AI systems or foundation models. The AI Act also makes a distinction here: while all providers of foundation models are subject to general transparency obligations, additional requirements are placed on so-called high-impact foundation models that pose a systemic risk [18, 22]. For example, risk management requirements (assessment and mitigation of systemic risk) are imposed on providers of high-impact foundation models [18, 22]. The European Commission is planning to develop codes of practices together with stakeholders from industry and science, for example, in order to operationalize these new obligations with respect to foundation models [18].
A.2 Human Rights, Democracy, and the Rule of Law Assurance Framework
The “HUDERAF” Human Rights, Democracy, and the Rule of Law Assurance Framework [47] was published by the Alan Turing Institute in 2021 in response to a request of the Council of Europe’s Ad Hoc Committee on Artificial Intelligence. It aims to operationalize a methodology to carry out impact assessments of AI applications from the perspective of human rights, democracy, and the rule of law. HUDERAF consists of four major parts: i) preliminary context-based risk analysis (PCRA), ii) stakeholder engagement process (SEP), iii) impact assessment (HUDERIA), and iv) assurance case (HUDERAC). Across these parts, it combines procedural guidance with templates and prompting questions.
The goal of the preliminary context-based risk analysis is to identify and flag issues for further (in-depth) analysis in HUDERIA. Similar to the “criticality pyramid”, the PCRA focuses on the potential adverse impacts of an AI system. However, in contrast to the previous approach, a risk index number is calculated for various predefined “harm events”. The risk index number (RIN) is additively combined from likelihood and severity for each event (see Fig. 3). While a qualitative scale is provided to determine the likelihood score (see Fig. 4), the severity is broken down further into the gravity of the impact and the number of affected rights-holders.Footnote 14 Gravity is classified according to the extent to which human rights may be violated (see Fig. 5). For the number of affected Rights-Holders, a score is assigned depending on the range in which the number of affected Rights-Holders lies (Fig. 6).

AI risk matrix to determine the RIN from HUDERAF, taken from [47]

Score for qualitative likelihood levels in HUDERAF, taken from [47]

Scores for Gravity Levels in HUDERAF, taken from [47]

Scores for number of Rights-Holders in HUDERAF, taken from [47]
At the end of the PCRA, an aggregate risk index number is determined as the maximum of all individual RINs. In addition, general recommendations for proportionate risk management practices, stakeholder engagement, and public transparency and accountability are provided depending on the aggregate risk index (see p. 231 [47]). Notably, the low weighting of the scores for the number of Rights-holders implies that an AI application, even if it can create “catastrophic harm”, might receive a “moderate” risk index (i.e., if the harm is limited to less than 10.000 Rights-holders and unlikely). Correspondingly, one example of a recommendation given an overall “moderate” risk index, is to check low risk probability through expert and stakeholder consultation (see p. 231 [47]). Still, considering highly specialized applications such as in the medical domain, which are only used in a limited number of cases, a different scaling of “severity” may be more appropriate.
Lastly, the HUDERIA part of the framework provides guidance on conducting a thorough analysis of the previously identified impacts to assess or corroborate the previous risk estimations more accurately and comprehensively. In this part, mainly process guidance and elaborate templates are provided as opposed to a fixed quantification and evaluation scheme. In particular, the process requires to evaluate the severity of human rights impacts by taking into account the three factors scale, scope and remediability (p. 238, [47]), that were as such not addressed in the PCRA. Moreover, in HUDERIA, stakeholders must decide whether to accept or mitigate risks, but specific recommendations on how to prioritize mitigation measures or when risks can/should be tolerated are not provided in this part of the framework.
A.3 VCIO based description for AI trustworthiness characterization
In April 2022, the VDE published the specification “VCIO based description of systems for AI trustworthiness characterization” [68] which builds on the works of the “AI Ethics Impact Group” [1]. It provides a structured scoring system for assessing an AI system’s compliance/adherence to the values transparency, accountability, privacy, fairness, and reliability. The VCIO model breaks down successively these values into criteria, indicators, and observables for scoring them (V = value, C = criteria, I = indicator, O = observable). As a result of the assessment, the fulfillment of each value is rated ranging from “A” (best) to “G” (worst).
A key characteristic is that the VCIO model does not follow a “risk-based” approachFootnote 15 for assessing and safeguarding an AI system, but it starts from values that are predefined (independently from a risk analysis) and provides a scoring scheme to evaluate compliance with these. In particular, it does not identify or evaluate the potential impacts/consequences that might arise if an AI system is not compliant with any of the values, nor does it foresee identification or analysis of any additional values that might be important (e.g., in order to prevent harm or maximize benefits of the AI system). As such, the VDE SPEC proceeds without defining “risk” or “impact”. At the same time, it is clear that fulfilling the values mentioned can contribute to the mitigation of potentially adverse impacts on individuals and society (e.g., privacy and fairness) and improve the positive impact of an AI system (e.g., reliability). For evaluating compliance with these values, the VCIO thus covers many potential sources/factors concerning the occurrence of undesired system properties that might propagate to adverse impacts. Overall, the VCIO approach includes elements of a risk assessment scheme regarding the first stage depicted in Fig. 7 and is therefore considered in this analysis.
The VCIO model provides a tree-based structure for the assessment (see Fig. 7) which consists of four hierarchical levels. The highest level are the values. The second level consists of several criteria for each value, against which the fulfillment or violation of the corresponding value can be measured. Each criterion in turn is subdivided on the third level into indicators, which are expressed as questions. Some indicators address system properties, for example, whether the system is robust (R1.4), to what extent the data is anonymized (P2.1), and whether personal data can be extracted from the system (P2.2). Most indicators, however, deal with the organization's handling of the AI system (in terms implementing specific actions or processes). For instance, having a channel for giving feedback and obtaining information about system characteristics (A2.1), monitoring the supply chain (F2.2), and analyzing the data for bias (F1.6) are indicators as well. Notably, there are process-level indicators that refer to the analysis of risks and trade-offs (e.g., F1.7 and P2.3) but an analysis of the benefits or advantages of an AI system is not considered in the framework. Lastly, on the lowest level, up to seven different possible manifestations are described for each indicator that are called observables. The observables are ranked on a scale from “A”, best fulfilled, to “G”, worst fulfilled (for some indicators there are less than seven observables which means that not all levels can be achieved, but there are always observables provided for levels “A” and “G”). However, since the descriptions are purely qualitative (e.g., “the AI application is globally interpretable “, T3.2, A, or it is asked whether certain documentation is provided, see R1.1–R1.3) and lack quantification guidance, the assignment to a specific observable is not unambiguous.

Composition of the VCIO model with examples, taken from [68]
The assessment aggregation of the VCIO model is based on averaging the scores bottom-up across the four hierarchical levels. Starting from the lowest level, the most applicable observable for each indicator is selected based on a self-assessment. Next, each level “A” to “G” is turned to a numeric score from zero to six. Subsequently, for each criterion, a score is assigned by averaging (and rounding) the scores of all indicators under this criterion (with one exception, where a “positive anchor” indicator exists which implies that the corresponding criterion is ranked “A” if this indicator is ranked “A”). In the same manner, the scores of the criteria are aggregated to the value level. Finally, the numeric scores at the value level are reassigned the corresponding rank from “A” to “G”.
The design of the bottom-up aggregation distinguishes the VCIO approach from the above frameworks in one major aspect: the AI application context is hardly reflected in the assessment results. On the lowest level, the ranking of observables already provides fixed preferences. For instance, global interpretability is always ranked “A” and low explainability ranked”G” (see T3.2), independent of whether explainability is relevant for the specific use case. Similarly, it is always ranked best if everyone can see certain documentation (see T4.3, T4.4) and if there is commitment to a fairness definition and metrics (see F1.4, F1.5), even if personal data might not be part of the AI application. While there are some exceptions where indicators can be skipped if they are not applicable to an AI system, the otherwise fixed list of indicators and ranking of observables confirm the intention of the framework to assess compliance with predefined values, rather than AI risks. Besides, trade-offs between different indicators and the opportunity to outweigh benefits and weaknesses of an AI system are not considered in the framework. For example, model interpretability and public documentation are always ranked best, as mentioned, while this might bear trade-offs with the reliability of the model and its security. Lastly, also the averaging of scores shows that in general all indicators and criteria are considered equally important, independent of the specific application context. In this aspect, the VDE specification differs from the previous works of the AI Ethics Impact Group. Specifically, [1] suggests a combination of the VCIO model with a classification of the application context (see Fig. 8). Depending on the application context, an AI system should be classified into one of five different classes derived from the risk matrix of Krafft and Zweig [46]. Based on this, a minimum score that needs to be achieved on value level can be derived for each class.

AI Ethics label derived from the VCIO approach in combination with classification of the application context, taken from [1]
A.4 Artificial intelligence risk management framework
Following the National Artificial Intelligence Initiative Act from the Congress, the U.S. Department of Commerce’s National Institute of Standards and Technology (NIST) released an initial version of an “Artificial Intelligence Risk Management Framework (AI RMF 1.0)” [54] in January 2023. The AI RMF document provides process-guidance on managing AI specific risks and developing, deploying, and using AI in a trustworthy and responsible way. It is intended for voluntary use by “AI actors” who are in some way involved in the AI application (e.g., organizations that develop, deploy, or use an AI system). The framework is non-sector specific and use case agnostic. Divided in two parts, the document firstly gives an overview of the notion of risk, AI specific challenges, and trustworthy AI characteristics. The second part comprises an approach for an AI risk management framework that is fundamentally based on the four functions govern, map, measure, and manage. Additional explanations, guidance, and actions regarding these functions are provided in the AI RMF playbook [55], an online companion resource to the framework.
The AI RMF denotes risk as the “composite measure of an event’s probability of occurring and the magnitude or degree of the consequences of the corresponding event” ([54], p.4). Additionally, it references ISO 31000:2018 which provides an equally neutral risk definition. Thus, as opposed to the frameworks described above, it particularly includes positive impacts and opportunities in its notion of risk ([54], p.4). This setting enables the AI RMF to consider risk management as the task of minimizing anticipated negative consequences and maximizing the positive impacts ([54], p.4). Especially, it takes the perspective that negative impacts can be reduced by enhancing the trustworthiness of AI systems.Footnote 16 This requires technical analysis of the system, and the AI RMF highlights the importance of testing, evaluation, verification and validation processes throughout the AI lifecycle accordingly ([54], p.9).
NIST proposes the four functions govern, map, measure and manage to be iteratively applied as an underlying structure for a risk management system (see Fig. 9). The “govern” function takes an organizational perspective and aims to establish an effective AI risk management culture covering the full AI lifecycle with appropriate structures, policies and processes. The following three functions are on a lower level and jointly steer the risk assessment. First, the “map” function operates from a product perspective in order to establish the AI system’s context ([54], p.24). This is the basis to identify potential use case-specific harm as well as benefits, independently from the AI trustworthiness characteristics (in contrast to other approaches such as the AI assessment catalog and the VCIO model). At the end of this phase, a qualitative, high-level assessment is made on whether to proceed with the development or use of the AI system. Second, the “measure” function analyzes and measures the identified use case-specific risks in the AI system. However, NIST points out the difficulty of measuring individual AI risks quantitatively and qualitatively, given that metrics are not yet available for all types of AI riskFootnote 17 ([54], p.30). Correspondingly, the AI RMF does not provide for specific metrics that must be used for measuring certain trustworthiness characteristics. It rather gives high-level procedural guidance such as “measurement methodologies should adhere to scientific, legal, and ethical norms and be carried out in an open and transparent process” ([54], p.28, see also p.30). The same holds for the AI RMF playbook (e.g., “Measure AI systems prior to deployment in conditions similar to expected scenarios.”, see Measure 2.3 [55]). Lastly, the “manage” function uses the contextual and empirical information collected by the previous functions in order to prioritize risk treatment and monitoring within the lifespan of an AI system ([54], p.31). The AI RMF states that “not all AI risks are the same, and resources can be allocated purposefully" ([54], p.7), indicating that risks should be weighted to focus risk mitigation on relevant or urgent negative impacts. While it additionally highlights the challenge of determining specific risk tolerance levels, it admits that a certain level of risk needs to be borne by an AI actor in order to achieve its objective, as not all AI incidents and failures can be eliminated ([54], p.7).

Four core functions of the AI RMF, taken from [54]
Besides the AI RMF, NIST presents the idea of use-case profiles which should illustrate an exemplary implementation of the framework adapted to specific application areas e.g., an “AI RMF fair housing profile”. Since the AI RMF will be further developed, NIST has published an AI RMF Roadmap to provide a platform for further research and guidance associated to the AI RMF activities. Although the AI RMF is still in an early stage and until now in many respects less concrete than various European approaches, its release is an important contribution of the U.S. to establish a foundation for reliable and trustworthy AI. In terms of risk notion, NIST refers in many definitions to international ISO standards and does not create inconsistency with the European approach. Noteworthy compared to other approaches is that the AI RMF does not focus on the minimization of negative impacts but also considers the maximization of AI benefits, which might be a motivation for the voluntary use of the framework.
A.5 AI Assessment Catalog
The Fraunhofer IAIS AI Assessment Catalog was published in 2021 (German version), followed by an English translation in 2023 [62]. It provides a structured approach for risk-based evaluation of AI systems with respect to six dimensions of trustworthiness [65]. The approach consists of a top-down phase serving to break down high-level risks into specific criteria for the AI system, and a bottom-up phase which encompasses the (likewise specific) measures taken in each dimension to argue for their fulfillment (see Fig. 10). The approach concludes with an overall assessment across the six dimensions. Here, the remaining residual risks are analyzed in relation to the application context and the protection requirement determined in advance for each dimension (see below). Ideally, all risks from dimensions with a “high” or “medium” protection requirement should be at an acceptable risk level. However, if it can be plausibly shown that possible measures to reduce risk in one dimension would inevitably increase the risks in another dimension that may have an even higher protection requirement, exceptions are possible, so that the developer can include trade-offs between dimensions in the final assessment. The following paragraphs describe the top-down and bottom-up phases which are conducted for each dimension more in detail. Subsequently, the Catalog’s structuring of the dimensions into risk areas is explained, which provides a starting point for further operationalizing granular AI risk analysis and aggregation schemes.

Top-down (lhs) and bottom-up (rhs) phases of the Fraunhofer IAIS AI Assessment Catalog
A key feature of the top-down and bottom-up phases in the AI Assessment Catalog is their consideration of the application context (see [65] for a more detailed description of this approach). In particular, evaluation criteria as well as safeguarding measures developed and applied within the two phases are tailored to the specific risks of the AI system. In the beginning of the top-down phase (see l.h.s., Fig. 10), the developers of the AI system are requested to fill an “AI Profile” that consists of questions about the system’s major characteristics and application context. The AI Profile can be used for an initial analysis of possible damage that could be caused by the AI system. The goal is to determine the protection requirement in a structured form for each dimension as “low”, “medium”, or “high”, similar to the “IT-Grundschutz” procedure. For example, in the case of an AI-based image recognition system designed to detect cracks or other damage for quality assurance in steel production processes, it could be argued that there is a low protection requirement in the dimensions of fairness and data protection, as the system does not process personal or particularly sensitive data. Reliability, on the other hand, should have a high protection requirement, as overlooking cracks could result in reputational damage or financial losses for the operators/users. The autonomy & control dimension could also be classified as high as it is crucial to ensure that the AI system is integrated into work processes in a trustworthy manner and that human supervision is provided to a sufficient extent. The last two dimensions could be classified as "medium" in this example. In terms of transparency, certain sub-requirements are helpful; for instance, explanations for individual detections, e.g. which image area they are based on, can make it easier to validate the results. On the other hand, however, there is no stakeholder group involved for whom a lack of transparency would be associated with greater harm or restriction. Security could also be classified as "medium" here, as the AI system should be investigated with respect to new attack vectors or communication channels, but overall no significant, AI-specific extensions to the existing "classic" IT security concepts are to be expected. Following the top-down phase of the AI Assessment Catalog, if a dimension is classified with “medium” or “high” protection requirement, a formalized in-depth risk analysis must be performed for each risk area in this dimension.Footnote 18 The Catalog’s structuring of a dimension into risk areas brings the high-level goals associated with the dimension down to the system-level (see next paragraph). This means that the core focus of the risk areas is on the risk sources that stem from the Machine Learning technique implemented in the AI application or that are at least directly related to its functionality (see Sect. 2.2 in [62]). The next step after the risk analysis is to derive specific safeguarding objectives and criteria for the given AI application. These criteria should reflect and accord to the protection requirement of the dimension (e.g., for dimensions with medium protection requirement, residual risks are more acceptable than for dimensions with high protection requirement). The bottom-up phase begins with implementing and documenting measures to mitigate the relevant risks in each risk area (see r.h.s., Fig. 10). A distinction is made between measures relating to the data, the development and modeling of the AI component, the embedding of the AI component, and the operation. For each category, the AI Assessment Catalog provides suggestions of measures commonly used and corresponding to the state of the art. Lastly, evaluation is conducted bottom-up, whereby reference must be made to the criteria and objectives set, as well as to the respective risk-reducing measures. While the overall objective is to bring residual risks to an acceptable level, it may be permissible to accept higher risks, as mentioned, which can be argued in the overall evaluation. Coming back to the example of the AI-based image recognition system, the protection requirements of the dimensions thus serve a similar purpose to the weights in a quantitative aggregation formula. For example, for this use case one could imagine mapping a "high" protection requirement (reliability, autonomy & control) to the weight "1", "medium" (transparency, security) to the weight "0.5" and "low" (fairness, data protection) to the weight "0". However, a general formula with context-specific weights for the individual dimensions requires further research. The aggregation in the AI Assessment Catalog is therefore described at a qualitative level.

Structuring of trustworthiness dimensions into risk areas in the AI Assessment Catalog
The six dimensions of trustworthiness are further distinguished into risk areas (see Fig. 11) in order to enable a granular risk assessment at system-level. Each risk area bundles risks related to malfunctions or undesirable system properties that would violate the high-level objective of the dimension. Specifically, the logic for classification/bundling of risk areas is based on two aspects. First, malfunctions or undesirable system properties are split into different risk areas, if respective safeguarding or risk mitigation approaches would significantly differ. The idea behind this is that the analysis of their risk sources as well as their evaluation (which, in the AI Assessment Catalog, are both conducted in the context of developing a safeguarding argumentation) would need to consider different aspects of the system or require different measures and tests. Thus, to keep the assessment approach clear and structured, guidance on risk assessment is provided in separate risk areas. In particular, this aspect of the classification logic leads to a general splitting of the risk areas „Control of dynamics “ for almost all dimensions, each of which bundling monitoring measures for the risk sources and system requirements associated with the dimension, aiming to ensure risk control over time.Footnote 19 As a final remark on the first aspect, it should be noted that safeguarding or mitigation measures usually have multiple effects and contribute to the mitigation of different risks, so that they cannot be mapped one-to-one to the mitigation of a single risk source. By bundling malfunctions with similar mitigation methods, the Assessment Catalog addresses these multiple effects, yet there are still many cross-references between different risk areas and dimensions in the catalog (e.g., between reliability and safety & security, or between transparency and autonomy & control). The second aspect of the classification logic is, that malfunctions and undesirable system properties are divided into distinct risk areas, if significantly different stakeholders or goals are affected. The underlying idea is that risks might be evaluated differently, depending on the affected stakeholder considered (e.g., the type and severity of impact could differ). For example, the technical analysis in the risk areas “Protection of personal data” and “Protection of business-relevant information” may be similar in principle (e.g., whether an ML model might leak sensitive training data). Still, although similar safeguarding or risk mitigation approaches might be available, a more comprehensive or reduced safeguarding argumentation may be developed depending on the goal/context, so that a separate risk analysis and assessment in distinct risk areas is more structured here as well.
Lastly, the approach to group system-level malfunctions/behavior in a risk area, for which similar safeguarding approaches may be used, also enables to provide more granular guidance on evaluation criteria. In the AI Assessment Catalog, criteria for the achievement of objectives are determined at the level of each risk area as an important prerequisite for evaluating the effectiveness of mitigation measures taken. While the protection requirement is classified on a qualitative scale and the overall assessment is described high-level, the criteria at risk level are the only aspect of the assessment approach where quantitative guidance is partially provided. For example, in the field of AI system development, there are a number of metrics (Key Performance Indicators, KPIs) that describe the quality of data or models. Certainly, the choice of evaluation metric often depends on the application but is not arbitrary. In addition, the Assessment Catalog lists possible testing requirements for the dimensions and enables the developer to justify which of the measures is suitable for the AI system under consideration and which measurable goal is to be achieved by the measures. Still, for certain dimensions such as transparency or autonomy & control, quantitative criteria are less suitable and it is also possible to rely on purely qualitative KPIs.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Schmitz, A., Mock, M., Görge, R. et al. A global scale comparison of risk aggregation in AI assessment frameworks. AI Ethics (2024). https://doi.org/10.1007/s43681-024-00479-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43681-024-00479-6