
Abstract
Process industry suffers from production management in terms of efficiency promotion and waste reduction in large scale manufacturing due to poor organization of the intricate relational databases. In order to enhance the suitability of intelligent manufacturing systems in process industry, this study proposed an innovative top-down structure Knowledge Graph (KG) for process fault diagnosis, and papermaking was taken as a case study. The KG consists of a normalized seven-step-built ontology, which extracted instances of papermaking knowledge via Protégé software. The exported OWL file was imported into Neo4j software for visualization of the KG. The application in papermaking drying process for fault diagnosis shows that it can depict the material and energy flows throughout the process with a clearer relationship visualization than traditional measures. They also enable rationale search for faults and identification of their potential causes. The built KG efficiently manages the vast knowledge of the process, stores unstructured data, and promotes the intelligent development of process with high reusability and dynamicity that can rapidly import new production knowledge as well as flexibly self-updating.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Human activities have inflicted irreparable harm on the natural environment since the Industrial Revolution has been polluting water and air resources, exacerbating global warming and eroding biodiversity. One major culprit is process industry which consumes massive amounts of resources and energy while generating copious pollutants such as waste gas and water [1]. In order to cope with the escalating environmental challenges, people have strived to optimize resource utilization and energy consumption, rather than constantly pursuing industrial growth on the expense of ecological well-being. Sustainable development has thus increasingly emerged as a guiding principle for various countries’ industrial policies. Industry 4.0 heralds an era of intelligence that leverages information technology to transform traditional manufacturing radically. Amidst global environmental pressures, the development of Industry 4.0 technologies such as artificial intelligence, big data, cloud computing, internet of things etc., tend to enhance production efficiency and quality while curbing energy use and carbon emissions thereby paving the way for a greener future of the industry [2].
The full digitization of industry remains nascent and is challenged by the heterogeneity and multiplicity of industrial data as well as its unstructured nature [3]. Process industry constitutes a vital segment of the manufacturing industry whose product lifecycle entails copious amounts of data and knowledge. However, most of the factories rely on conventional relational databases to store these informational assets. The limitations of such databases comprise their inability to accommodate unstructured data resulting in weak associations among data items, as well as lack of semantic analysis, thus impairing cognitive and reasoning skills for knowledge extraction [4]. It can be noted that the process industry is suffering from a paradox where technological advancement and complexity outstrip knowledge management capacity thereby impeding intelligent development [5].
Knowledge graphs have garnered considerable interest from the industry in the last decades owing totheir remarkable abilities to represent relationships supporting knowledge inference, query enhancement, andenable intuitive knowledge visualization [6]. It have been witnessed their advances in many applications infields such as healthcare [7, 8], education [9, 10] and finance [11, 12], where knowledge is well-structured andreadily available [4]. However, constructing a knowledge graph in the industrial domain poses greaterchallenges than others due to fragmented knowledge distribution, complex data acquisition, and variedequipment processes etc. Therefore, devising an appropriate method for building industrial domain-specificknowledge graphs is imperative.
Some scholars have recently endeavored to create Knowledge Graphs for the industrial applications in areas such as machinery electric power and aerospace [13]. They adopted a top-down method to construct a special mechanical processing Knowledge Graph which resolved professional terminology conflicts [14]. The development of Knowledge Graph in the domain of electric power has enhanced intelligent applications throughout the power generation life cycle offering assistance for operation optimization, technical overhaul, and equipment maintenance [15] etc. The spacecraft launch Knowledge Graph enabled automatic question answering based on semantic search of fault detection based on machine learning and profiles of equipment or information systems. It boosted intelligent data engineering at the launch site, and expedited its intelligence process [16]. Nevertheless, most of these studies remain within their own fields without finding a generalizable method for building Knowledge Graphs, whose outcomes are also hard to be reproduced. Hence this paper will target the process industry’s distinctive features of knowledge along with the expressive power of Knowledge Graphs, to devise a comprehensive framework for depicting and summarizing process industry knowledge effectively, and integrating the production process-related information that can be reused across various industries.
Papermaking is among the traditional process industries that one of the most vital ones closely linked with socio-economic growth. It supplies foundational materials for various areas such as agriculture, defense, as well as consumable items for people’s cultural and daily needs. It constitutes an essential part of the socio-economic chain [17]. Nonetheless, papermaking is also commonly perceived as a highly polluting and emitting industry that requires massive water and power resources during production while discharging copious wastes. As conventional industries, most of the paper mills have enhanced their automation levels, but many are still adopting extensive management methods, causing considerable resource squander and environmental contamination. These paper mills are at a critical juncture for intelligent transformation yet their lagging capacities of knowledge management impede this progress and their prospects on sustainability. Novel knowledge management approaches are urgently needed to rectify this issue. Accordingly, this study exemplifies constructing a Knowledge Graph of the papermaking industry presenting a generic framework for Knowledge Graph development of process industries addressing the aforementioned specific challenges. It will be investigated of creating a Knowledge Graph and discussing its real-world implications via a case study.
2 Methods
2.1 The general approach and framework for domain knowledge graph building
There are two main approaches of building Knowledge Graphs in general, namely bottom-up and top-down [18]. The bottom-up approach uses various techniques to extract diverse data from different public databases and incorporate them into a knowledge base. After transforming all the data into a structured format, it is added data with high confidence to the Knowledge Graph. This approach is common for general-purpose Knowledge Graphs, such as Microsoft’s Satori and Google’s Knowledge Vault [19]. The advantage of this approach is that it leverages many intelligent algorithms for knowledge extraction, and enhances the efficiency of the process. However, the drawback of this approach is that it compromises the accuracy of the Knowledge Graph and obscures its hierarchical structure.
The top-down method, by contrast, starts from extracting the domain ontology from a large amount of data based on expert knowledge, and then complement the knowledge instances to the Knowledge Graph following the ontology constraints [20]. It is mainly used for domain-specific Knowledge Graphs. There are many associated examples of domain ontologies built. For instance, Citespace analysis method can be used to construct a precise and clear ontology of product manufacturing, and then a Knowledge Graph has been built based on it [21]. Similarly, an ontology for the traditional Chinese medicine domain has been constructed to capture the relational knowledge among various medicals, and it has been employed to establish a traditional Chinese medicine Knowledge Graph [22]. These top-down built Knowledge Graphs have a well-defined hierarchical structure, with clear boundaries and relationships among different entities, so that pose fewer errors and ambiguities. However, the quality of the top-down built Knowledge Graphs relies heavily on ontologies which require a lot of human expertise to design, resulting in a very challenging task.
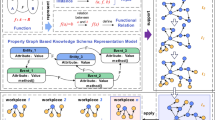
The top-down Knowledge Graph has a two-layer logical structure, consisting of the schema layer and the data layer [23]. The schema layer defines the ontology that governs the Knowledge Graph, while the data layer contains the concrete knowledge instances that populate the Knowledge Graph. Figure 1 illustrates the framework for building a domain-specific Knowledge Graph. The schema layer involves the ontology created by domain experts based on their domain knowledge. The data layer involves the processing of a large amount of knowledge. The steps are as follow:
-
(1). Data: Collect a data set of domain-relevant information from various sources and formats, such as text, tables, images, etc.
-
Ontology definition: Define the key concepts and relationships in the domain, along with their hierarchy and rules, and create an ontology model to serve as the schema layer of the Knowledge Graph.
-
Knowledge extraction: This process mainly includes three parts, entity extraction, attribute extraction and relationship extraction from a data set for constructing a Knowledge Graph.
-
Knowledge Graph construction: Store all extracted knowledge in a graph after integrating them, and then establish an application mechanism for the Knowledge Graph.
-
Knowledge application: With its strong visualization and search features, the Knowledge Graph can provide different applications for different scenarios and needs. These include question answering systems, recommendation systems, and search engines.

A General framework for Domain Knowledge Graph Construction
2.2 Characteristics of process industry knowledge graph construction
The process industry aims to obtain products with specific properties or uses by changing the physical and chemical properties of raw materials through a series of processing and modification. The characteristic of this industry is that various raw materials form a material flow that undergoes heat transfer, mass transfer and momentum transfer processes under energy input, resulting in physical, chemical or biochemical reactions according to a unique process flow [24].
The construction of process industry Knowledge Graphs requires describing how material and energy flows of raw materials change, starting from the raw materials themselves. This leads to a process that alters the properties of raw materials in various aspects to create desired products.
The difficulties in constructing process industry Knowledge Graphs lie in the complexity of knowledge, the lack of relevant data and the difficulty of knowledge management, as shown in Table 1. It is especially important to build a well-performed ontology framework for these problems. A well-performed ontology framework can greatly reduce the dependence on domain experts’ knowledge. You can create a Knowledge Graph by adding knowledge instances under the framework with some basic knowledge. This also lowers the experts’ workload and increases data utilization. Some existing methods for building ontologies are: (1) Skeleton method [25] (2) IDEF5 method [26]; (3) TOVE method [27]; (4) KACTUS engineering method [28]; (5) Methontology method [29]; and (6) Seven-step method [30]. The first four methods are common for business ontologies, while the last two are typical for domain ontologies. The most popular method for domain ontologies now is the seven-step method, which was developed by Stanford University in the US and first applied to medical ontologies. It is very practical and versatile.
2.3 The construction of paper process knowledge graph and fault knowledge graph
2.3.1 Construction of paper process ontology
The seven-step procedure for ontology construction in this study is shown in Fig. 2. The first step is to define the domain scope of the ontology, which is designed for representing the papermaking process. As a typical process industry, paper production involves mainly heat and mass transfer from pulp to paper. Most of the reactions are physical rather than chemical. Therefore, the Knowledge Graph of paper production requires tracing both material and energy flows along the entire process.

Specific steps of the seven-step ontology construction method
Considering the reuse of ontology, OntoCAPE is the result of nearly twenty years of research by a group led by Wolfgang Marquardt. It aims to establish a reusable chemical engineering process ontology for knowledge representation and information modeling in chemical engineering. This ontology covers almost all concepts in the chemical engineering domain and spans the entire life cycle of chemical process and plant design. It also provides good guidance for the construction of ontologies in other domains. The papermaking process differs significantly from the chemical process in terms of reaction types, but they have in common that they both focus on the material and energy flows of raw materials. Therefore, some descriptions of OntoCAPE for chemical processes, such as “Heat exchange”, “Material flow”, etc., can be reused in the construction of papermaking process ontology.
The next step is to identify the important terms in the domain and define them as classes, and then determine the hierarchy of classes. Some of the professional terms and hierarchies involved are shown in Fig. 3, which describe the papermaking process from three aspects: the “reactions” that occur, the “phenomena” that form, and how to “implement” them. From these three aspects, they are further divided until they reach a direct description of the material changes. The ontology includes reactions and parameters that are common to general physical and chemical processes, such as “Vaporization”, “Liquidation”, “Temperature”, “Pressure” etc. There are also some descriptions unique to the papermaking process, such as “Dryness”, “Strength”, “Bulk” and various papermaking process equipment.

The hierarchy of the paper process ontology and a part of the technical terms
The last step is to define the attributes of the classes and the relationships between the ontologies. Figure 4 shows a schematic diagram of some of the relationships in the pulp drying process. The raw materials are “Paper Pulp” and “Steam”. The “Paper Pulp” flows into the “Cylinder”, and the “Steam” is fed into the “Cylinder”. The main components of the “Paper Pulp” are “Water” and “Fiber”, which correspond to two attributes: “Moisture” and “Dryness”. The “Water” in the “Paper Pulp” enters the “Cylinder” and undergoes a process of “Vaporization”. The phenomenon in terms of parameters is that the “Temperature” changes. The raw material temperature and dryer cylinder temperature are both phenomena of this process, and their specific values are attributes of temperature [31, 32] After all these steps, the papermaking process ontology is constructed.

Examples of the paper page drying process ontology and its relationships
2.3.2 Construction of fault ontology
For the process industry, normal operation is only part of the operating state, and there are many abnormal operating states. And because most of them are continuous production processes, that is, they operate continuously from inputting raw materials to outputting finished products, and any problem in any link will affect the production performance of the entire industrial chain. These abnormal operating states will greatly affect the economic benefits of the process industry and sometimes even affect safety. In order to describe the process more comprehensively and better play the role of Knowledge Graph, this paper establishes not only a Knowledge Graph of normal operating state, but also a fault Knowledge Graph of abnormal state.
The construction of fault ontology also chooses the seven-step method, and the fault domain terms are determined by combining FMEA [33] (Failure Mode and Effects Analysis) fault analysis method. Its analysis content mainly includes “Fault Mode”, “Fault occurrence location”, “Fault cause”, “Fault symptom”, “Fault impact” and “Fault handling measures” and so on, and these analysis contents are conceptualized into corresponding classes. The hierarchy of classes is determined according to the fault tree analysis method combined with the characteristics of papermaking faults, as shown in Fig. 5.

The hierarchy of the paper fault ontology and a part of the technical terms
The relationship between class attributes and ontology is shown in Table 2. Fault refer to(referTo) “Technological process”, has warning (hasWarning) “Fault symptom”, is related to (isRelatedTo) “Apparatus parameter”, happen in (happenIn) “Equipment structure”, has fault cause (hasFaultCause) “Fault cause”, lead to (leadTo) “Fault impact”, and has maintenance method (hasMaintenanceMethod) “Fault handling measures” after fault occur.
2.4 Importing knowledge
The last step of the seven-step method for ontology construction is to create instances, which is actually the process of building the data layer of the Knowledge Graph. It extracts triples from structured, semi-structured and unstructured data, and then imports them into the framework of the ontology. The specific operation is to extract named entities from the data first. The extraction method chosen in this paper is a heuristic method, which is to construct a large number of entity recognition rules by experts in a specific domain and then match the rules with text characters to extract entities. This method can automatically extract entities more accurately in small-scale extraction, but the disadvantage is that constructing rules consumes a lot of manpower and has poor portability. This paper aims to construct a single-domain Knowledge Graph for papermaking process, which does not require high generality, so it chooses this method to establish a Knowledge Graph with higher accuracy.
The process of importing after entity extraction is shown in Fig. 6. The entities are aligned with the ontology classes and imported into the ontology framework. Then, the relevant ontology relations are linked to construct the data layer of the Knowledge Graph.

Schematic of the import process after entity extraction
2.5 Word vectorization model
In order to apply the constructed Knowledge Graph for fault diagnosis, a word vectorization model is introduced using word embedding techniques of Word2vec to compute the entities and paths numerically. A preprocess of the text using regular expressions is firstly needed to delete all numbers, letters, and nonsensical verbs such as "ah", "um", etc. Then the Skip-gram model of Word2vec is developed to vectorize the texts of Knowledge Graph for further computations. Where Word2vec is a widely used word vector generation model based on neural networks, which can learn distributed representations of words from a large number of text corpora. Skip-gram word vectorization model fits to the scenarios of seeking similar words, which is assumed more applicable for fault diagnosis in this study, so that is constructed. In order to characterize the similarity of texts and verify the constructed vectorization model, the Cosine Similarity of word vectors are used based on Eq. (1):
where A and B denote word vectors, i implies the number of words in vectors.
In order to exploit the Knowledge Graph more efficiently, Euclidean Distance is employed to calculate the distances of vectors to recognize the synonyms:
The constructed vectorization model is applied to complement the Knowledge Graph, where Principal Component Analysis (PCA) [2] was used to reduce the dimension of the word vectors, and then Translating Embedding (TransE) [34] was utilized to complement the Knowledge Graph with the dimension-reduced vectors.
2.6 Fault diagnosis with knowledge graphs path search and word vector distance
In order to diagnose the papermaking fault such as paper breaks, it is proposed to probabilize the distance between the fault entity and other entity word vectors, and find out the probability of failure caused by the fault cause, then search the Knowledge Graph paths to find the transmission relationship of which causes lead to faults. As aforementioned, Euclidean Distance can be used to estimate the relationship of the fault entity and other entities, which means that converting Euclidean distance into probability through a discrete probability density function, it can be quantified the relationship between a fault and its cause. Therefore, it is converted Euclidean distances between the fault entity word vector and other entity word vectors into a discretized Gaussian-like distribution, namely a Gaussian distribution with μ = 0. Subsequently, substitute the distances between the word vectors into the probability density function of the discretized Gaussian-like distribution, as shown in Eq. (3):
where \(PX_{a,\,b}\) represents the probability that fault b is caused by reason a, \(d_{a,\,b}\) denotes the word vector distance between fault b and reason a, \(d_{i,\,b}\) represents the distance from the i-th reason to fault b, σ stands for the standard deviation of all distances.
Searching the relationship path in Knowledge Graph from the entities of starting point to the ending point can reveal the potential causes of the fault and induce diagnosis results. In this study, Dijkstra is used to search the shortest distance of path of entities. It is applied the Neo4j embedded function Cypher to search the relationship path in Knowledge Graph. Three examples of Cypher language application are given below (results refer to Fig. 7.) for searching the shortest path of two entities, all the paths of two entities and all the paths shorter than n for certain entity:

Examples of three search patterns (a) Shortest path from entity “Steam” to “Hood”, (b) all paths from entity “secondary steam” to “secondary steam reuse”, and (c) All the paths shorter than 5 for entities “steam” and “hood”
Shortest path of two entities: match p = shortestpath((a)-[r*0..n]-(b)).
All the paths of two entities: match p = (a)-[r*..n]-(b) where a and b.
All the paths shorter than n for certain entity: match p = (a)-[r*..n]-(b) where a.
With the constructed Knowledge Graph, word vectorization model and path search methods, it can be inferenced the fault causes through the process displayed in Fig. 8. So, when a fault occurs, the fault could be input into the models. The input model calculates the word vector distance to find entities that are close to the failure entity, then applies a Gaussian distribution analysis to obtain the probability of the cause of these entities on the fault. Utilize the two fault path search methods of Dijkstra and Cypher obtain the shortest distance and the shortest path of the fault cause, respectively. With which, the transmission path of the fault could be determined.

Flowchart of fault diagnosis based on Knowledge Graph
3 Results and discussion
3.1 Knowledge graph of the drying process of papermaking: case study
This paper generally takes the drying process of papermaking as a case study to illustrate the establishment of the Knowledge Graph. Protégé is a free and open-source ontology editing tool based on java language. Protégé has a clear operation interface, simple ontology imports steps, and supports the construction of Chinese ontology. The storage file supports multiple formats, including Rdf, Turtle, Owl and other formats. Combined with the specific application scenario of this paper, Protégé is selected as the ontology construction tool. It is imported the previously built ontology framework into Protégé and show its schematic diagrams for both drying process and fault ontologies in Fig. 9. It is also imported and defined their relations with value domains and definition domains in Protégé’s “Object properties” interface. Finally, it is imported instances in Protégé’s “Individual by class” interface.

Schematic of the drying process ontology and the fault ontology
After adding instances, the ontology forms a Knowledge Graph, and the visualization display chooses the same open-source graph database software Neo4j based on Java implementation. Neo4j graph database is a kind of directed Knowledge Graph with attributes, which expresses and stores knowledge through nodes and relationships between nodes. The correspondence between ontology model and Knowledge Graph is shown in Table 3. The class in ontology model is the label in Knowledge Graph and the instance corresponds to the entity in Knowledge Graph. The relationship between ontologies is the relationship in the triple “Entity-Relation-Entity”, and the data attribute of class is the attribute in the triple “Entity-Attribute-Attribute value”. Through Py2Neo transformation, Protégé saved OWL file can be imported into Neo4j graph database. The Knowledge Graph of papermaking drying process contains 156 entities and 304 relationships. The fault Knowledge Graph uses the same method to import, which currently contains five faults of papermaking drying process shown in Table 4.
3.2 Content and structure of knowledge graphs
The papermaking process Knowledge Graph describes in detail the processes of paper sheet drying and dehydration, hood ventilation and material energy recovery in the papermaking drying process. The completed process Knowledge Graph is shown in Fig. 10, which mainly includes three levels, namely equipment description, qualitative description and quantitative description. Equipment description mainly describes the physical properties of the equipment, including shape, size, design specifications, instruments, etc., such as the size and model of the dryer cylinder. Qualitative description mainly describes the reactions of raw materials, such as the evaporation and endothermic process of water in pulp and the condensation and exothermic process of steam in dryer cylinder. Quantitative description mainly describes what parameters have changed when raw materials undergo these reactions, such as the specific change value of water content in pulp during evaporation process, the power of supply and exhaust fan and the specific change value of temperature and humidity in hood.

Partial sketch of the paper drying process
It is used a Knowledge Graph to represent different types of faults in papermaking drying process. Our Knowledge Graph covers five aspects: mode, location, cause, impact and solution. Figure 11 shows our Knowledge Graph for dripping faults. Dripping faults occur when water vapor condenses inside hoods and drops onto paper sheets. The main causes are high humidity and low temperature inside hoods; low power of supply and exhaust fans; etc. The impacts are visible drip marks on paper; high moisture content or paper breakage; etc. The solutions are increasing temperature and power of supply and exhaust fans; reducing speed and production rate; etc.

Schematic representation of the Knowledge Graph of the fault dripping phenomenon
3.3 Word vectorization for complementing knowledge
In a collection of texts (over 200k words) describing the papermaking process, including device, measures, simulation, optimization etc., especially, the fault description and related information of drying section collected from equipment instructions, factory operation logs, maintenance records and similar ways, are used to build the word vectorization model. Taking “Window size”and “Vector size”as 5 and 100 respectively for the Skip-gram model. In the training process of the model, stochastically divide the texts two sets of which have the same number of certain keywords, switching the keyword in one of the sets to the words neither nonexistent, observing the similarity of the keyword to the switched word in the formulated vectors. In Fig. 12, it is found that the word vectors have a growing similarity when the frequency of occurrence of the word raises in a text. As the determined keyword and switched word are assumed identical leading to the Cosine Similarity of it stably close to 1 and the standard error close to 0, which indicates that the model has a high degree of fitting.

The Cosine Similarity and standard error of vectorization model following the number of keywords in the vectorized texts
It is also conducted a comparison of the Euclidean Distance of entities to recognize the synonyms. From the text, it is calculated the Euclidean Distance of word vectors to find the potential synonyms of “moisture”, and the top 20 of them are listed in Table 5. It is note that through the calculation of word vector similarity and Euclidean Distance, it can be found the synonyms words of moisture, such as “wet” and “water content”, but there are many interfering words remaining, so we need to carry out a further recognition or screening manually. The words that appear in the Knowledge Graph are replaced according to the description in the KG, for the other words that do not appear in the KG would be replaced according to the description of words with the highest frequency.
After dimension-reduction with PCA from 100 to 20D, the dimension-reduced vectors are feed to the TransE model to complement the Knowledge Graph, in which, the hyperparameters of TransE are given by λ = 0.01, γ = , k = 20, and estimation function E is calculated by L2 norm, realized by Python. In this process, the first entity in the Knowledge Graph is taken as the head entity, and then traverse all the relationships and combined them with this head entity in triad, and their corresponding word vectors are added together afterward, search the word vectors that mostly close to the added ones. Repeat this process until all entities in the Knowledge Graph have been treated as head entities. From the most top-ranked combinations of word vectors, manually filter out the complemented entities. In the explored texts and constructed Knowledge Graph, it is complemented 13 new entities, taking Fig. 13 as an example, one of the entities is complemented in the Knowledge Graph of “Fiber” and its corresponding process parameter of “Fiber ratio”.

Schematic diagram of the Knowledge Graph complementation
3.4 Application of knowledge graphs for fault diagnosis
Knowledge Graphs can represent and store knowledge effectively, and they are widely used for fault diagnosis. In this section it is leveraged the path search feature of Knowledge Graphs to explore the root causes of known faults.
We import the Knowledge Graph of drying process and the Knowledge Graph of fault that have been established in the previous section into Neo4j at the same time. The fault Knowledge Graph contains direct relationships. After importing the two graphs at the same time, because the two graphs contain some same nodes, there will be some overlap between the two graphs. It can be found the indirect causes of faults by searching for relationship paths. Figure 14 shows all nodes within three relationship paths of dripping phenomenon. In the increasingly complex process industry environment, when faults occur, it can be found quickly all the potential causes of faults by searching for relationship paths, and make more targeted analysis of faults, improving the efficiency and accuracy of fault diagnosis [35,36,37].

All nodes within the three relations of the dropper phenomenon
Dripping could lead to a series of other failures such as paper break and inadequate drying, so this study takes dripping phenomenon as an example to estimate the fault diagnosis capability of constructed Knowledge Graph and the corresponding models. As aforementioned, it is firstly vectorized the words of the texts of Knowledge Graph, and calculated the vector Euclidean Distance, obtained the top 20 closest entities (as illustrated in Table 6). The standard errorσof them is 0.53, so it can be achieved the probability distribution of these entities based on Eq. (3), as displayed in Fig. 15. It is worth noted that only the top 7 entities have relatively high probability for causing dripping fault, starting from web, probability for the rest of them are nearly 0. Depending on relationship path search, the Dijkstra model and Cypher model are used to gain the closest path, where Fig. 16 are the shortest relationship paths from fresh air and steam-water separator to dripping fault respectively. According to the shortest relationship path, it can be deduced the fault propagation path. For example, the relationship between dripping phenomenon and fresh air is that fresh air with high humidity passes through waste heat recovery device and becomes medium temperature air, then passes through air heater and enters gas hood. Due to the high humidity of air, it is difficult to take away enough water vapor from gas hood, which eventually leads to dripping phenomenon.

Probability distribution of the 20 entities with the closest distance to the entity of “Dripping”

The shortest relationship path from fresh air to the dripping fault
4 Conclusions and future works
The process industry is rapidly developing towards intelligent manufacturing. However, most of its information management still remain in the use of traditional relational databases which are difficult to represent the versatile information of unstructured knowledge in the production process. This has resulted in mismatching of many mills of their production management with their advanced equipment, technology and other intelligent applications, leading to inefficiency, dramatic waste of resources, frequent failures and other issues. It not only arouses economic pressure on enterprises but also violates the sustainable prospects of the industrial development. Upon which, this article takes the papermaking industry as an example, and proposed to construct the industrial Knowledge Graph to manage the production process. Based on a top-down measure, it is divided the papermaking industry Knowledge Graph into a process Knowledge Graph for normal production status and a fault Knowledge Graph for abnormal production status. A search application for potential fault relationships is further proposed on the basis of the constructed Knowledge Graph. The main research conclusions include:
-
(1)
The construction method of general domain Knowledge Graph and the characteristics of process industry were analyzed. The difficulties of constructing Knowledge Graphs in three aspects of process industry knowledge complexity, data lack and knowledge management difficulty were analyzed, and a top-down process industry Knowledge Graph construction method was proposed accordingly. Starting from the raw materials of the process industry, the process is decomposed, and the Knowledge Graph construction is realized by following the changes of raw materials, which provides a more comprehensive description of the process industry.
-
(2)
According to the characteristics of the papermaking industry, its process ontology and fault ontology were constructed, and a reusable ontology was constructed. The ontology can be applied to different sections of papermaking, reducing the dependence on expert knowledge when building a new process Knowledge Graph. The results show that the Knowledge Graph constructed based on the two ontologies contains richer knowledge and more comprehensive relationships, which can efficiently manage a large amount of knowledge in the papermaking production process.
-
(3)
Taking the paper drying section as an example, the Knowledge Graph construction process proposed was specifically demonstrated, and the graph visualization was implemented in the open-source ontology software Protégé and the Knowledge Graph software Neo4j. The final constructed drying process Knowledge Graph contains 156 entities and 304 relationships, and the fault Knowledge Graph contains five common faults of drying sections.
-
(4)
Finally, this article proposes a fault potential relationship mining method based on Knowledge Graph relationship path search. According to the relationship path between the fault entity and other entities, the potential cause and propagation path of the fault are found. Taking the search of “Dew” and “Fresh air” relationship path as a case, the effectiveness of this method is validated.
It is obvious that Knowledge Graph has a range of relative advantages than the existing methods or technologies to promote the sustainability of the process industry. It integrates and correlate multiple aspects of sustainable development, including resource utilization, environmental protection, technological innovation, and policy formulation, forms a comprehensive and systematic knowledge network to support decision-makers to gain a more holistic understanding of sustainable development and formulate more comprehensive and effective strategies. It can reveal potential relationships between different concepts and entities, leading to new knowledge and insights, and visually represent the relationships between knowledge, making complex information more intuitive and easier to understand. More importantly, Knowledge Graphs can be continuously updated and expanded as new data and knowledge emerge, keeping them up-to-date, which can reflect these changes in a timely manner, providing the latest support for sustainable development.
Though the overall focus of this article is on the analysis of the characteristics of the papermaking industry, and the papermaking industry Knowledge Graph is constructed based on the ontology, the accuracy and efficiency of the imported knowledge in the knowledge import stage remain low. It is because the construction of knowledge graphs relies heavily on versatile expert experience and numerous data. It has high technical barriers and cost for constructing and maintaining the knowledge graphs, which may prevent smaller enterprises to develop. Also, as mentioned above, as the industry, the enterprise, and the process evolve, knowledge graphs need to be regularly updated and maintained to retain their effectiveness and accuracy, which could be very time-consuming and resource-intensive, that poses a challenge for certain studies and enterprises. Therefore, it is essential to weigh the pros and cons based on specific situations, and in necessity, combine knowledge graphs with other methods and technologies to jointly drive the sustainable development of the industry.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Man Y, Yan Y, Wang X, Ren J, Xiong Q, He Z. Overestimated carbon emission of the pulp and paper industry in China. Energy. 2023;273:127279. https://doi.org/10.1016/j.energy.2023.127279].
He Z, Xu J, Tran KP, Thomassey S, Zeng X, Yi C. Modeling of textile manufacturing processes using intelligent techniques: a review. Int J Adv Manuf Technol. 2021;116:39–67.
He Z, Qian J, Li J, Hong M, Man Y. Data-driven soft sensors of papermaking process and its application to cleaner production with multi-objective optimization. J Clean Prod. 2022;372:133803. https://doi.org/10.1016/j.jclepro.2022.133803.
Zhang D, Liu Z, Jia WQ, et al. Survey on the research status and application prospect of knowledge graph in intelligent manufacturing. J Mech Eng. 2021;57(5):24–32. https://doi.org/10.3901/JME.2021.05.090].
Shi M. Knowledge graph question and answer system for mechanical intelligent manufacturing based on deep learning. Math Probl Eng. 2021;2021(2):1–8. https://doi.org/10.1155/2021/6627114.
Wang Q, Mao Z, Wang B, et al. Knowledge graph embedding: a survey of approaches and applications. IEEE Trans Knowl Data Eng. 2019;29(12):2724–43. https://doi.org/10.1109/TKDE.2017.2754499.
Qu J. A review on the application of knowledge graph technology in the medical field. Sci Program. 2022;3:12–23. https://doi.org/10.1155/2022/3212370.
Cheng B, Zhang J, Liu H, et al. Research on medical knowledge graph for stroke. J Healthcare Eng. 2021;2021(6):1–10. https://doi.org/10.1155/2021/5531327.
Zheng W, Wang ZC, Sun MC, et al. Building a large-scale knowledge graph for elementary education in China. Sem Technol. 2020;1157:1–12. https://doi.org/10.1007/978-981-15-3412-6_1.
Lang Y, Wang G. Personalized knowledge point recommendation system based on course knowledge graph. J Phys: Conf Ser. 2020;1634:65–73. https://doi.org/10.1088/1742-6596/1634/1/012073.
Wang W, Xu Y, Du C, et al. Data set and evaluation of automated construction of financial knowledge graph. Data Intell. 2021;5:1–21. https://doi.org/10.1162/dint_a_00108.
Tang XB, Fu WG, Liu Y. Knowledge big graph fusing ontology with property graph: a case study of financial ownership network. Knowl Organ: KO. 2021;1:48–53. https://doi.org/10.5771/0943-7444-2021-1-55.
Buchgeher G, Gabauer D, Martinez-Gil J, et al. Knowledge graphs in manufacturing and production: a systematic literature review. IEEE Access. 2021;5(99):55537–54. https://doi.org/10.1109/ACCESS.2021.3070395.
Mou T, Li S. Knowledge graph construction for process industry control systems. J Intell Sci Technol. 2022;4(1):129–41. https://doi.org/10.1195/j.issn.2096-6652.202216.
Guo L, Yan F, Li T, et al. An automatic method for constructing machining process knowledge base from knowledge graph. Robotics Comput-Integr Manuf. 2022;73:102–9. https://doi.org/10.1016/j.rcim.2021.102222.
Li J, Liu S, Liu A, et al. Knowledge graph construction for SOFL formal specifications. Int J Software Eng Knowl Eng. 2022;4:32–9. https://doi.org/10.1142/S0218194022500279.
Kou C, Liu T, Ma L, et al. Construction and application research of knowledge graph in spacecraft launch. J Phys: Conf Ser. 2021;1754(1):12–8. https://doi.org/10.1088/1742-6596/1754/1/012180.
He Z, Chen G, Hong M, Xiong Q, Zeng X, Man Y. Process monitoring and fault prediction of papermaking by learning from imperfect data. IEEE Trans Automat Sci Eng. 2023. https://doi.org/10.1109/TASE.2023.3290552.
Karimi S, Iordanova I. St-Onge D. Ontology-based approach to data exchanges for robot navigation on construction sites. J Inform Technol Constr. 2021;26:546–65. https://doi.org/10.36680/j.itcon.2021.029.
Dong X, Gabrilovich E, Heitz G, et al. Knowledge vault: a web-scale app-roach to probabilistic knowledge fusion. ACM. 2014;12:601–10. https://doi.org/10.1145/2623330.2623623.
Liu Q, Li Y, Duan H, et al. Knowledge graph construction techniques. J Comput Res Dev. 2019;118(19):1869–83. https://doi.org/10.7544/issn1000-1239.2016.20148228.
Zhang S, Zou H, Sun J. Knowledge mapping analysis of manufacturing product innovation based on CiteSpace. J Circ Syst Comput. 2022;7:31–42. https://doi.org/10.1142/S0218126622501213.
Tong Y, Li J, Qi Y, Tian Y, Shun X, Lili X, Zhu L, Gao H, et al. Knowledge graph for TCM health preservation: design, construction, and applications. Artif Intell Med. 2017;77(6):48–52. https://doi.org/10.1016/j.artmed.2017.04.001.
Huang YQ, Yu J, Liao X, et al. A survey of knowledge graphs. Comput Syst Appl. 2019;28(6):12–7.
He Z, Hong M, Zheng H, Wang J, Xiong Q, Man Y. Towards low-carbon papermaking wastewater treatment process based on Kriging surrogate predictive model. J Clean Prod. 2023;425:139039. https://doi.org/10.1016/j.jclepro.2023.139039.
Silva-López RB, Méndez-Gurrola II, Pablo-Leyva H. Comparative methodologies for evaluation of ontology design. In: Martínez-Villaseñor L, Herrera-Alcántara O, Ponce H, Castro-Espinoza FA, editors. Advances in computational intelligence: 19th Mexican international conference on artificial intelligence, MICAI 2020, Mexico City, Mexico, October 12–17, 2020, Proceedings, Part II. Cham: Springer International Publishing; 2020.
Brahimi M. An agents’ model using ontologies and web services for creating and managing virtual enterprises. IJCDS J. 2019;08(1):9–15. https://doi.org/10.12785/ijcds/080101.
Yi LT, Zhou SQ, Ding CS. Research on domain ontology modeling in information extraction. Comput Technol Dev. 2011;21(10):5. https://doi.org/10.3969/j.issn.1673-629X.2011.10.006.
Martinez-Garcia J, Castillo-Barrera FE, Palacio R, et al. An ontology for knowledge condensation to support expertise location in the code phase during software development process. IET Softw. 2020;18:22–31. https://doi.org/10.1049/iet-sen.2019.0272.
Zhang B, Qian P, Li C, et al. Research on the construction method of knowledge ontology facing the field of substation maintenance. J Phys: Conf Ser. 2021;1971(1):62–75. https://doi.org/10.1088/1742-6596/1971/1/012062.
Zhang H, Li J, Hong M, Man Y, He Z. Cost optimal production-scheduling model based on VNS-NSGA-II hybrid algorithm—study on tissue paper mill. Processes. 2022;10(10):1–18. https://doi.org/10.3390/pr10102072.
Zhang Z, He X, Man Y, He Z. Multi-objective scheduling in dynamic of household paper workshop considering energy consumption in. J Smart Environ Green Comput. 2023;3:87–105. https://doi.org/10.20517/jsegc.2023.05.
Reda H, Dvivedi A. Decision-making on the selection of lean tools using fuzzy QFD and FMEA approach in the manufacturing industry. Expert Syst Appl. 2022;192:116–26. https://doi.org/10.1016/j.eswa.2021.116416.
Nayyeri M, Vahdati S, Lehmann J, et al. Soft marginal transe for scholarly knowledge graph completion[J]. IEICE Trans Fundam Electron. 2019;18:298–309.
He Z, Tran KP, Thomassey S, Zeng X, Xu J, Yi C. A deep reinforcement learning based multi-criteria decision support system for optimizing textile chemical process. Comput Ind. 2021;125:103373. https://doi.org/10.1016/j.compind.2020.103373.
He Z, Tran KP, Thomassey S, Zeng X, Xu J, Yi C. Multi-objective optimization of the textile manufacturing process using deep-Q-network based multi-agent reinforcement learning. J Manuf Syst. 2021. https://doi.org/10.1016/j.jmsy.2021.03.017.
He Z, Liu C, Wang Y, Wang X, Man Y. Optimal operation of wind-solar-thermal collaborative power system considering carbon trading and energy storage. Appl Energy. 2023;352:121993. https://doi.org/10.1016/j.apenergy.2023.121993.
Author information
Authors and Affiliations
Contributions
X. Liang and Q. Zhang wrote the main manuscript text and Y. Man supervised the study, Z. He conceptalize the work and review the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This work is supported by the Science and Technology Program of Guangzhou, China (2023A04J1367), the young scholar research project of Pazhou Lab (PZL2021KF0019), and the State Key Laboratory of Pulp and Paper Engineering (2022ZD02), Fundamental Research Funds for the Central Universities (x2qsD2231000).
Competing interests
All authors declared that there are no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liang, X., Zhang, Q., Man, Y. et al. Toward sustainable process industry based on knowledge graph: a case study of papermaking process fault diagnosis. Discov Sustain 5, 93 (2024). https://doi.org/10.1007/s43621-024-00259-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43621-024-00259-6