
Abstract
Horizon scanning for innovative technologies that might be applied to medical products and requires new assessment approaches to prepare regulators, allowing earlier access to the product for patients and an improved benefit/risk ratio. The purpose of this study is to confirm that citation network analysis and text mining for bibliographic information analysis can be used for horizon scanning of the rapidly developing field of AI-based medical technologies and extract the latest research trend information from the field. We classified 119,553 publications obtained from SCI constructed with the keywords “conventional,” “machine-learning,” or “deep-learning" and grouped them into 36 clusters, which demonstrated the academic landscape of AI applications. We also confirmed that one or two close clusters included the key articles on AI-based medical image analysis, suggesting that clusters specific to the technology were appropriately formed. Significant research progress could be detected as a quick increase in constituent papers and the number of citations of hub papers in the cluster. Then we tracked recent research trends by re-analyzing “young” clusters based on the average publication year of the constituent papers of each cluster. The latest topics in AI-based medical technologies include electrocardiograms and electroencephalograms (ECG/EEG), human activity recognition, natural language processing of clinical records, and drug discovery. We could detect rapid increase in research activity of AI-based ECG/EEG a few years prior to the issuance of the draft guidance by US-FDA. Our study showed that a citation network analysis and text mining of scientific papers can be a useful objective tool for horizon scanning of rapidly developing AI-based medical technologies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The application of innovative technologies to the development of medical products is expected as a potential new treatment or diagnostic tool for various diseases. Conversely, in some cases, the application of conventional development and evaluation concepts and/or regulatory frameworks to innovative technologies is inappropriate. In some cases in the past, a guidance document was issued when the clinical development is about to begin, the development of companion diagnostics in Japan, the U.S., and the EU. However, the guidance must be provided earlier, such as before starting clinical development planning. Therefore, the early identification of innovative technologies with a potential application to medical products through horizon scanning would encourage regulatory authorities to establish new approaches to assess their quality, efficacy, and safety to advice developers and revise their regulations if necessary. Doing so contributes to timely patient access and improve the benefit/risk ratio of the product [1].
The International Coalition of Medicines Regulatory Authorities (ICMRA), consisting of regulatory authorities, has recognized the need to respond quickly to innovative technologies and promotes the use of “horizon scanning” to identify such technologies [2]. The ICMRA Innovation concept note [3] describes horizon scanning as a broad-reaching information-gathering monitoring activity to anticipate emerging products and technologies and potentially disruptive research avenues. Two major methods exist for acquiring the data needed to create high-quality horizon scanning [4]. The expert-based approach mainly uses the tacit knowledge of domain experts, such as the Delphi method. Traditionally, horizon scanning has been conducted predominantly in Europe for policy making, scientific research funding, and health-care budgeting purposes, by surveying a variety of sources such as the Internet, government, international organizations and companies, databases, and journals [5, 6]. This type of expert-based approach is very difficult to implement in the current information explosion. Moreover, individual experts must subdivide their domain of expertise to keep up with the growth of their respective domains, which makes their perception of the big picture extremely subjective [7]. Computer-based approaches collect and analyze vast amounts of formal knowledge, such as articles, patents, and newspapers. Recently, the European Commission (EC) published reports, such as “Weak signals in Science and Technologies 2019 Report” based on Tools for Innovation Monitoring (TIM) [8] that use text mining and keywords in the scientific literature. The Japanese National Institute of Science and Technology Policy (NISTEP) also uses a digital tool to analyze academic papers; the top 1% of citations contributes to science and innovation policy planning.
These cover the medical field as a sub-survey of the overall science survey and are used in efforts to identify and evaluate advanced technologies.
Hines et al. reported that, in the medical and health-care field, most horizon-scanning methods used manual or semi-automated, with relatively few automated aspects, which may be resolved in the not-too-distant future via the rapidly evolving fields of machine learning and artificial intelligence [6]. To solve this challenge, a computer-based approach can complement the expert-based approach as it fits the scale of the information [9, 10] because they are compatible with the scale of the information. The two types of computer-based approaches are citation mining and text mining.
The citation-based approach assumes that the cited papers and their research topics are similar. Analyzing this citation network allows us to understand the structure of the research areas constituting the large volume of papers that we can read. These methods have been widely used as powerful tools to visualize and understand the structure of a research field and to identify new trends and research directions; they also have been proven effective in various studies [11,12,13]. For example, Kajikawa et al. [7] used citation network analysis to track emerging research areas in the field of sustainable science effectively and efficiently. Many fields have applied similar approaches, including energy research [14], regenerative medicine [15], robotics, and gerontology [16]. Sakata et al. [17] proposed a meta-structure of academic knowledge on patent and innovation research to effectively assist policy discussions on intellectual property system reform. They have shown that network analysis and machine learning methods are useful for understanding and predicting the development of technologies such as solar cells [18] and nanocarbons [19].
Many fields have used also text mining to analyze technology trends; Kostoff et.al. (2004) analyzed multi-word phrase frequencies and phrase proximity to extract energy-related taxonomic structures [20]. Another study discussed the trend in the field of information security by creating a network of co-occurring words and focusing on clusters with network centralities [21]. Ohniwa et al. (2010) focused on the MeSH terms included in the top 5% of the increase rate in a given year in the field of life science [22]. A study to discuss a community’s the future prospects by calculating the cosine similarity of terms in the session content from the data of conference proceedings focused on the field related to the World Wide Web [23].
R&D strategists and policymakers in many fields find citation network analysis and text mining useful to understand the broad scope of scientific and technological research.
It is difficult to understand the semantics of clusters based on citation relations alone. Text mining can reveal subject relationships across citations and provide insights into the diffusion of knowledge into interdisciplinary research and development. The addition of text mining to citation-based bibliometrics makes accessible the large-scale multigenerational citation studies necessary to display the full impact of research [24].
Text mining is extremely sensitive to certain terms. When only text mining is used, the problem of terminological distortions cannot be ignored. In addition, it is difficult to separate homonyms that are used in different fields with different meanings. Hao et al. (2018) attempted to identify research fronts using only text mining in the medical field [25]. They highlighted the challenges of clustering by text similarity, which makes the results vulnerable to the method selection. At the same time, they observed that citation relationships are highly valuable in explaining relationships in scientific knowledge.
Therefore, there are challenges in analyzing trends using only one citation network and text mining. The associations between papers in citation networks reflect authors' background knowledge which cannot be extracted by simple text mining.
Our study proposes an objective methodology for horizon scanning that identifies innovative technologies to be applied to medical products from entire research papers in the target field using citation network analysis methods and text mining. The three types of citation network analysis are direct citation, bibliographic merging, and co-citation. Existing studies have shown that direct citation is the most appropriate for obtaining leading-edge information on trends [26]. Other fields have widely used the approach of clustering the subject area into subcategories by direct citation networks and interpreting the contents of the clusters by text mining [7, 14,15,16,17], but insufficient examples exist of the application of advanced technologies in medical-related fields. We focus on AI-based medical image analysis as a retrospective example of AI-based medical devices that have been developed in recent years, applied in many fields, and selected for consideration in ICMRA [1].
Methods
Extraction of Paper Data for Analysis
We used “convolutional” OR “deep learning” in the review article of medical image analysis [27]; we used “machine-learning” to include a wide range of conventional studies. As a result, we obtained 140,794 papers that contain “convolutional*” OR “machine-learning” OR “deep-learning” from the SCI (Science Citation Index) and SSCI (Social Sciences Citation Index) indexed by Web of Science Core Collection (WoS, Clarivate analytics), between January 1, 1900, and December 31, 2020, (1900–2020). This database has the longest history of containing bibliographic information from academic papers. It is also used for many bibliometric analyses because of its excellent searchability and comprehensiveness as a database platform [7, 14,15,16,17]. In addition to the data in 1900–2020, we created datasets for 1900–2012, 1900–2013, 1900–2014, 1900–2015, 1900–2016, 1900–2017, 1900–2018, and 1900–2019 and identified the cluster that contains key articles for each year.
To track the development history of AI-based medical image analysis and to select keywords for the extraction of the papers for citation network analysis, we selected 13 key articles [28,29,30,31,32,33,34,35,36,37,38,39] (Table 1 presents eight articles included in the analysis data), including several papers cited in the review article [28] on the application of deep learning in medical image analysis and a study [39] that led to the clinical development of IDx-DR, a retinal imaging software approved as a medical device by the US Food and Drug Administration (FDA) in 2018.
Citation Network Analysis
In this study, we converted the citation network into an unweighted network with papers as nodes and citation relationships as links. Papers with no citations as the largest component were considered digressional and were ignored in this study (Step 2 in Fig. 1). The core paper with the highest number of citations appears at the center of the citation relations. Papers with no citation relationships with other papers were considered deviant and ignored in this study. The network was then divided into several clusters using the topological clustering method. Topological clustering is a clustering method based on the graph structure of a network; here, we use modularity maximization. A cluster module in a citation network is a group of papers in which the citation relations are divided by using a modularity (Q value) maximization method and are densely aggregated (Louvain method) [19, 40]. The modularity maximization method appreciates network partitioning so that the intracluster is dense and the inter-cluster is sparse. The modularity maximization method determines an optimal partitioning pattern by extracting the partitioning pattern that maximizes the modularity using a greedy algorithm. Q is an evaluation function of the degree of coupling within a cluster and between clusters, as follows:

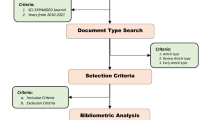
Steps of clustering and making Academic Landscape based on citation network. This figure has been published in reference [10]. The procedure of the citation network is as follows: (1) Extract the dataset of academic papers for analysis. (2) To extract the data, convert the citation network into an unweighted network with papers as nodes and citation relationships as links. (3) Divide the network into several clusters by using the topological clustering method. (4) Use a large graph layout (LGL), based on a force-direct layout algorithm, to display the largest connected component of the network to generate coordinates for the nodes in two dimensions and to visualize the citation network by expressing inter-cluster links with the same color.
where \({A}_{ij}\) represents the weight of the edge between \(i\) and \(j\), \({k}_{i}={\sum }_{j}{A}_{ij}\) is the sum of the weights of the edges attached to vertex i, ci is the community to which vertex i is assigned, δ-function δ(u, v) is 1 if \(u=v\) and 0 otherwise, and \(m=\frac{1}{2}{\sum }_{ij}{A}_{ij}\).
The clusters are assigned labels corresponding to the size of the number of papers included. The characteristics of each cluster were confirmed by extracting a summary of frequently cited academic papers in the cluster and the characteristic keywords in the cluster.
Moreover, we computed the term frequency-inverse cluster frequency (TF-ICF) to extract the characteristic keywords of each cluster. The TF gives a measure of the importance of a term in a particular sentence, whereas the ICF provides a measure of the general importance of a term. The TF-ICF of a given term i in a given cluster j is given by
where N is the total number of sentences. Each cluster was labeled based on the resulting keywords and sentences.
To confirm the trends in the research field, we extracted the mean or median year of publication of papers in each cluster, as well as information on journals, authors, and affiliated institutions.
After clustering the network, visualization is converted to intuitively infer relationships among these clusters. We used a large graph layout (LGL) based on a force-direct layout algorithm [41, 42]. This layout can display the largest connected component of the network to generate coordinates for nodes in two dimensions. We visualize the citation network by expressing inter-cluster links with the same color (Step 4 in Fig. 1). However, the position of the clusters and the distance between clusters did not indicate an approximation of the content. Figure 1 shows an overview of this process.
For the extracted dataset, we converted the citation network into an unweighted network with papers as nodes and citation relationships as links (Step 2). The network was then divided into several clusters using the topological clustering method (Step 3). Moreover, a LGL, based on a force-direct layout algorithm, displayed the largest connected component of the network to generate coordinates for the nodes in two dimensions, visualizing the citation network by expressing inter-cluster links with the same color (Step 4).
Results
Results of Citation Network Analysis
We analyzed 140,794 papers and found that 119,553 (85%) formed a citation network. We divided this network into 36 clusters by extracting the largest linkage component from all linkage components via direct citation of papers (excluding the gray linkage not involved in cluster formation shown in Figs. 1, 2). The contents of the top 10 clusters, which contain approximately 75% of the papers in a citation network, were estimated from the characteristic keywords appearing in each cluster and the titles and abstracts of the papers with the highest number of citations. The cluster numbers (number of papers) and their contents are as follows:

Tracking clusters containing key articles. We analyzed papers obtained from WoS published up to the indicated years. We plotted the cluster numbers that contained the eight key articles shown in Table 1, with the circle sizes representing the approximate number of citations in the cluster for each paper
Cluster 1 (14,033): Basic studies on deep learning and convolutional neural networks (CNNs), including geographic information system (GIS) image analysis using remote sensing.
Cluster 2 (13,309): Drug discovery technologies related to proteins, peptides, etc., using machine learning.
Cluster 3 (10,992): Applied research in medical image analysis.
Cluster 4 (9867): Feature classification using ensemble methods to increase accuracy by combination.
Cluster 5 (7829): Natural language processing of clinical records.
Cluster 6 (7412): Application of deep learning to fault diagnosis, for example, motor condition monitoring for machines running on electric motors.
Cluster 7 (6571): Machine learning (ML) and data mining (DM) methods for cyber analysis.
Cluster 8 (5815): Application to traffic flow information analysis for the implementation of intelligent transport systems.
Cluster 9 (4371): Single-image super-resolution (SR) to reconstruct high-quality data.
Cluster 10 (4333): Classification of individuals based on the analysis of text information from social media, such as emotions and behavior.
Table 1 presents the clusters in which key articles were included. Three papers (labeled A, B, and C) based on image recognition were found in clusters 1 and 5 (labeled D, E, F, G, and H) on image diagnosis in cluster 3, including the review article “Deep Learning” [34] (labeled D), which is often cited in medical field papers. This indicates that we appropriately formed clusters related to medical imaging in cluster 3.
Tracking the Time Series of Key Articles
We analyzed papers published each year and identified the cluster containing the key papers in Table 1 and the number of citations within the cluster to assess the position of the research on medical imaging in the past. As shown in Fig. 2, all the papers were included in the same cluster until 2015 and the rank of cluster number increased by one until 2014. In 2015, the number of papers in this field increased rapidly and the rank of cluster numbers rose from 13th in 2014 to 6th, suggesting that great scientific attention has increased. In 2016, a key paper on the imaging diagnosis of diabetic retinopathy (F in Table 1) was in cluster 7, which comprised papers on medical image analysis, and the other seven key articles were in cluster 3. Subsequently, in 2017, cluster 1 contained all the key articles, but from 2018 onward, a new separate cluster containing papers on image analysis using deep learning was formed. It should be noted that the number of citations of key articles also increased.
Thus, most key articles were in one or two clusters, suggesting that we properly formed the clusters related to the targeted AI-based medical image analysis. The research status of the clusters can also be confirmed by the cluster numbers, which reflect the number of papers comprising the cluster and the number of citations of the key articles.
Recent Research Trends in AI-Based Medical Products
To detect the latest research trends in AI-based medical products, we focused on “younger” clusters with an average publication year later than 2017 as research progress could be observed over three years for AI-based medical image analysis (Fig. 3). We re-analyzed clusters 3, 15, 12, 5, 13, and 2, which we considered to be closely related to AI-based medical technologies. We listed these clusters in order of average publication year. Table 2 lists the sub-clusters formed by re-analysis of the most cited articles (hub-paper) [34, 43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74] in each subcluster, suggesting recent research trends in this field as follows:

Tracking clusters related to ECG and EEG. We analyzed papers obtained from WoS published up to the indicated years. A cluster number indicates the cluster on ECG and EEG. The circle sizes indicate the approximate citation frequency of the key article, [73] and the number in each circle represents the number of citations in the cluster. Clusters on ECG and EGG were first detected in 2015 as cluster number 10 and were classified into cluster numbers 11, 21, 1, 15, and 15 for 2016, 2017, 2018, 2019, and 2020, respectively
Cluster 3 Applied research in medical image analysis.
Cluster 15 Electrocardiogram, electroencephalogram, and other electrical biosignals of human activity.
Cluster 12 Human activity recognition.
Cluster 5 Natural language processing of clinical records. Cluster 13: Neuroimaging analysis.
Cluster 2 Drug discovery with machine learning related to proteins, peptides, etc.
Among these AI-based medical technologies, EEG analysis was identified for applications in epileptic seizure prediction, emotional analysis, and brain–computer interfaces, for which the FDA issued draft guidance on non-clinical and clinical trials in 2019.
Electrocardiograms (ECGs) and electroencephalograms (EEGs) in cluster 15 are most likely to be applied to new medical devices; therefore, we tried to follow the cluster containing a key paper on the application of deep learning to EEG analysis [75], which was one of the triggers for the development of this field. During 2015–2016, the article was included in the same cluster as other neuroimaging techniques, such as MRI (MEG, fNIRS, etc.). In 2017, the key article was found in a separate cluster numbered 20 from other neuroimaging techniques, suggesting that a new cluster specific to the application of deep learning to EEG was formed. Then, in 2018, we included the article in cluster 1 of the applications of deep learning in various fields but was included in specific clusters re-formed, numbered 14 and 15 in 2019 and 2020, respectively; the number of citations of the article increased. This suggests that research in this field has developed rapidly since 2017.
Discussion
In this study, we examined the possibility of using this analysis method for horizon-scanning targeting AI-based medical image analysis. IDx-DR, an image-analysis software for the automatic diagnosis of diabetic retinopathy, received FDA certification in 2018. The AI characteristics are self-learning, the algorithm for learning data during the development of a medical product is in a black box, and performance changes as the product continues learning during clinical use. This has become an interesting dilemma for regulators [76].
We assessed the feasibility of using citation network analysis and text mining to identify trend history in AI-based medical image analysis research and development as follows: Research on convolutional neural networks (CNNs), the current leading technology in deep learning that arose in the 1970s, renewed interest in neural networks was Werbos's multi-layer networks [77]. LeNet [54], a CNN-based handwritten number recognition system—was developed and succeeded by a CNN called AlexNet [30], which is a key trigger for renewed interest in neural networks. Later, the U-net [33] architecture was proposed, which consists of an upsampling section that uses "up" convolution to increase the image size. Furthermore, the combination of CNNs and recurrent neural networks (RNNs), represented by long short-term memory (LSTM), has been applied to analysis involving time-series data [28, 54].
We evaluated 13 key articles, including these milestones in the development of AI-based medical image analysis, to determine how citation network analysis can capture key articles. We identified eight articles in one or two clusters (Table 1), with a concentration of the characteristic keywords of the clusters, and the titles and abstracts of the articles with the highest number of citations confirmed that the clusters were related to AI-based medical image analysis and that identifying actual research trends was possible. Moreover, we analyzed the papers reported each year and found that the number of constituent papers of the cluster containing the key articles increased dramatically after 2014, with the rank rising from 13 to 6th, suggesting that the technology related to diagnostic imaging has progressed dramatically. This might have led to a major clinical trial of IDx-DR in 2017. Since then, research activity has increased in this field, as can be seen from the rank of cluster numbers and number of citations in the key articles.
We did not include five of the 13 selected articles in the analysis: three papers were not included in the WoS and the other two [31, 39] on clinical evaluation were not found with the set query, because there was no mention of the underlying technology in the abstract or title, and the methods were mainly described as product names or computer detection in either paper.
Next, we explored trends in the development of new medical products using AI by re-analyzing “young” clusters with a late average of the publication year of constituent papers to identify more specific topics by sub-clustering (Table 2). This allowed us to objectively look at the landscape of AI-based medical technology. We focused on EEG and ECG, which have the potential to lead to the development of new medical devices, and followed the cluster containing the key article on this topic. As shown in Fig. 3, the increase in constituent papers and citations of key articles suggested that this topic developed significantly between 2017 and 2018, a couple of years before the FDA issued a guidance draft on brain–computer interfaces in 2019, which was finalized in 2021 [78]. Regarding the FDA’s activity, a public workshop was held on November 21, 2014, to promote open discussion of scientific and clinical considerations related to the development of BCI devices, suggesting that the FDA might consult public on product development. The ECG is already at the stage of realization in smartwatches and other devices and was judged to be of low novelty. The FDA has already approved the app for the Apple Watch®.
This study also showed that analysis every several months might allow us to identify the candidate topics for further investigation through the rapid rise of the rank of cluster number, i.e., a sharp increase in constituent papers (2014–2015 in Fig. 2 and 2017–2018 in Fig. 3), or the emergence of a new cluster spun out of the original one (2017–2018 in Fig. 2 and 2016–2017 in Fig. 3), which may be a signal of significant research progress.
This analysis has the following limitations. Which would be detected by this method as well. Therefore, it is necessary to determine whether the candidate topic is a good idea or We included papers in major journals in WoS relatively quickly after publication, but there might be a delay of approximately six months for almost all journals and some research areas may not be reflected in WoS sufficiently quickly, which may delay the identification of research trends. Until the birth of Scopus and Google Scholar in 2004, WoS was the only tool for citation analysis [79]. Even today, WoS is known to have a longer record period than Scopus and is one of the most effective databases in the field of history. In addition to WoS, Scopus and PubMed have also become powerful databases, and future studies are needed to evaluate the robustness of those databases. Although this paper does not show these data, we also analyzed the papers obtained from PubMed; however, approximately 30% of the papers formed a citation network and only five of the 13 key articles were included. One possible reason for not being able to extract appropriate research papers from PubMed was that many papers did not use terminology related to AI-based technologies. This suggests that the choice of the literature database according to the target technology is also critical. Furthermore, research results in the field of machine learning, which covers basic technologies in the field of AI and other informatics fields, tends to be published as proceedings of international conference or arXiv.com as preprints than peer-reviewed journals, where researchers can directly exchange papers with each other via the Internet; therefore, the latest results cannot be covered by databases of academic papers, such as WoS or PubMed. A comparison of peer-reviewed journal-based analysis and proceeding—or preprints-based analysis—needs to be conducted in the future.
Experts who have a deep understanding of innovative technologies would be able to predict the development of medical products based on the technology. However, it might sometimes be inappropriate to narrow the scope of consideration based solely on experts’ opinions [80]. Extracting a limited number of novel topics that may affect pharmaceutical regulations from a vast amount of information on a human basis is difficult and using a computer-based method (such as this study) is reasonable and appropriate. This study assumes that the ultimate users are regulators who evaluate technologies in the mid to long term. Because policymakers and decision makers are not always experts in their fields, providing the status of the academic field in a systematic method supports decision making that can be reproduced by anyone. In our study, we used citation network analysis and text mining to classify the entire papers in the target field in terms of research topic. Furthermore, we identified the topics of the clusters based on the characteristic cluster keywords and titles of the most cited papers. We objectively evaluated the popularity and novelty of a topic based on the number of papers and the median year of publication. We consider that the feature of the method is suitable for a primary screening by regulators to pick up candidate topics from wide range of scientific fields, and the topics would be further evaluated based on the opinion of experts of the topic and other sources such as patents.
We considered that limiting the search to papers in the clinical development stage was rather inappropriate because the purpose of horizon scanning is to detect technologies that have the potential to reach clinical development in the pre-clinical stage. When searching for papers on clinical development, papers on related technologies in the earlier stages are less likely to not include in the analysis, which involves the risks that do not reflect the overall picture of the field. The overall landscape of R&D can be grasped more objectively by analyzing a wide range of papers, for example and then target cluster, the cluster on clinical development is obtained by clustering and re-clustering. Information on the clinical development stage can be directly and timely obtained from clinical trial registries such as ClinicalTrials.gov. The information provided by these other tools from analysis such as “Tools for Innovation Monitoring (TIM)” is useful for determining the query for the papers data in our method.
Another possible bias, as mentioned [81], is that researchers mainly check and cite papers written in their native language or journals they contribute to, or that they tend to search and cite papers using the same terminology and not others, even when the technological meaning is the same.
Considering the opinions of experts in the field regarding candidate topics to be investigated will help in overcoming the aforementioned limitations. Our method provides information about the median and average year of publication of the papers in the cluster and the newness of the Hub paper, but prioritization requires the perspective of an expert in the field. Academic size and speed of discussion do not necessarily determine prioritization; however, depending on the social demands and feasibility of the technologies included in the individual topics. Hence, a content-based evaluation is necessary.
Conclusion
This study showed that citation network analysis and text mining for bibliographic information analysis of the rapidly developing field of AI-based medicine can be used for horizon scanning for medical products that require new assessment approaches. We detected recent research developments, including AI-based ECG/EEG. We suggest that this method be used as a primary screening tool for horizon scanning, and that the analysis results be used more effectively and appropriately by incorporating the opinions of experts.
References
ICMRA. Innovation Strategic Priority Project Report. 2019. http://www.icmra.info/drupal/sites/default/files/2019-04/Innovation%20Strategic%20Priority%20Final%20Report.pdf2020.
ICMRA. Innovation | International Coalition of Medicines Regulatory Authorities (ICMRA). http://www.icmra.info/drupal/en/strategicinitiatives/innovation. Accessed 12 Jan 2021.
ICMRA. ICMRA Strategic Priority on Innovation Concept Notes. 2017. http://www.icmra.info/drupal/sites/default/files/2017-12/ICMRA%20Innovation%20Concept%20Note_0.pdf.
Kostoff RN, Schaller RR. Science and technology roadmaps. IEEE Trans Eng Manag. 2001;48(2):132–43.
OECD. Overview of Methodologies. https://www.oecd.org/site/schoolingfortomorrowknowledgebase/futuresthinking/overviewofmethodologies.htm. Accessed 6 Jan 2021.
Hines P, Yu LH, Guy RH, et al. Scanning the horizon: a systematic literature review of methodologies. BMJ Open. 2019;9(5):e026764. https://doi.org/10.1136/bmjopen-2018-026764.
Kajikawa Y, Ohno J, Takeda Y, et al. Creating an academic landscape of sustainability science: an analysis of the citation network. Sustain Sci. 2007;2(2):221–31.
Commission. ESH-E. Tools for Innovation Monitoring. 2017. https://ec.europa.eu/jrc/en/scientific-tool/tools-innovation-monitoring.
Börner K, Chen C, Boyack KW. Visualizing knowledge domains. Annu Rev Inf Sci Technol. 2003;37(1):179–255.
Boyack KW, Klavans R, Börner K. Mapping the backbone of science. Scientometrics. 2005;64(3):351–74.
Chen C. Visualising semantic spaces and author co-citation networks in digital libraries. Inf Process Manag. 1999;35(3):401–20.
Chen C, Cribbin T, Macredie R, et al. Visualizing and tracking the growth of competing paradigms: two case studies. J Am Soc Inf Sci Technol. 2002;53(8):678–89.
Small H. Visualizing science by citation mapping. J Am Soc Inf Sci. 1999;50(9):799–813.
Kajikawa Y, Yoshikawa J, Takeda Y, et al. Tracking emerging technologies in energy research: toward a roadmap for sustainable energy. Technol Forecast Soc Change. 2008;75(6):771–82.
Shibata, N, Kajikawa, Y, Takeda, et al. Detecting emerging research fronts in regenerative medicine by citation network analysis of scientific publications. PICMET'09–2009 Portland International Conference on Management of Engineering & Technology. IEEE; 2009.
Ittipanuvat V, Fujita K, Sakata I, et al. Finding linkage between technology and social issue: a literature based discovery approach. J Eng Technol Manag. 2014;32:160–84.
Sakata I, Sasaki H, Kajikawa Y. Identifying knowledge structure of patent and innovation research. J Intellect Prop Assoc Jpn. 2012;8(2):56–67.
Sasaki H, Hara T, Sakata I. Identifying emerging research related to solar cells field using a machine learning approach. J Sustain Dev Energy Water Environ Syst-JSDEWES. 2016;4(4):418–29. https://doi.org/10.13044/j.sdewes.2016.04.0032.
Sasaki H, Fugetsu B, Sakata I. Emerging scientific field detection using citation networks and topic models: a case study of the nanocarbon field. Appl Syst Innov. 2020;3(3):40.
Kostoff RN, Tshiteya R, Pfeil KM, Humenik JA, Karypis G. Science and technology text mining: electric power sources. Arlington: Office of Naval Research; 2004.
Lee W. How to identify emerging research fields using scientometrics: an example in the field of information security. Scientometrics. 2008;76(3):503–25.
Ohniwa RL, Hibino A, Takeyasu K. Trends in research foci in life science fields over the last 30 years monitored by emerging topics. Scientometrics. 2010;85(1):111–27.
Furukawa T, Mori K, Arino K, Hayashi K, Shirakawa N. Identifying the evolutionary process of emerging technologies: a chronological network analysis of World Wide Web conference sessions. Technol Forecast Soc Change. 2015;91:280–94.
Kostoff RN, del Rio JA, Humenik JA, Garcia EO, Ramirez AM. Citation mining: integrating text mining and bibliometrics for research user profiling. J Am Soc Inf Sci Technol. 2001;52(13):1148–56.
Hao T, Chen X, Li G, Yan J. A bibliometric analysis of text mining in medical research. Soft Comput. 2018;22(23):7875–92.
Boyack KW, Klavans R. Co-citation analysis, bibliographic coupling, and direct citation: which citation approach represents the research front most accurately? J Am Soc Inf Sci Technol. 2010;61(12):2389–404.
Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Proc IEEE. 1998;86(11):2278–324. https://doi.org/10.1109/5.726791.
Litjens G, Kooi T, Bejnordi BE, et al. A survey on deep learning in medical image analysis. Med Image Anal. 2017;42:60–88. https://doi.org/10.1016/j.media.2017.07.005.
Farabet C, Couprie C, Najman L, et al. Learning hierarchical features for scene labeling. IEEE Trans Pattern Anal Mach Intell. 2013;35(8):1915–29. https://doi.org/10.1109/tpami.2012.231.
Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. Commun ACM. 2017;60(6):84–90. https://doi.org/10.1145/3065386.
Abramoff MD, Folk JC, Han DP, et al. Automated analysis of retinal images for detection of referable diabetic retinopathy. JAMA Ophthalmol. 2013;131(3):351–7. https://doi.org/10.1001/jamaophthalmol.2013.1743.
Prasoon A, Petersen K, Igel C, et al. Deep feature learning for knee cartilage segmentation using a triplanar convolutional neural network. International conference on medical image computing and computer-assisted intervention. Springer; 2013.
Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation. International Conference on Medical image computing and computer-assisted intervention. Springer; 2015.
LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436–44.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition; 2016.
Setio AAA, Ciompi F, Litjens G, et al. Pulmonary nodule detection in CT images: false positive reduction using multi-view convolutional networks. IEEE Trans Med Imaging. 2016;35(5):1160–9. https://doi.org/10.1109/tmi.2016.2536809.
Abramoff MD, Lou YY, Erginay A, et al. Improved automated detection of diabetic retinopathy on a publicly available dataset through integration of deep learning. Investig Ophthalmol Vis Sci. 2016;57(13):5200–6. https://doi.org/10.1167/iovs.16-19964.
Esteva A, Kuprel B, Novoa RA, et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature. 2017;542(7639):115. https://doi.org/10.1038/nature21056.
van der Heijden AA, Abramoff MD, Verbraak F, et al. Validation of automated screening for referable diabetic retinopathy with the IDx-DR device in the hoorn diabetes care system. Acta Ophthalmol. 2018;96(1):63–8. https://doi.org/10.1111/aos.13613.
Blondel VD, Guillaume JL, Lambiotte R, et al. Fast unfolding of communities in large networks. J Stat Mech-Theory Exp. 2008. https://doi.org/10.1088/1742-5468/2008/10/p10008.
Adai AT, Date SV, Wieland S, et al. LGL: creating a map of protein function with an algorithm for visualizing very large biological networks. J Mol Biol. 2004;340(1):179–90.
Sasaki H, Zhidong L, Sakata I. Academic landscape of hydropower: citation-analysis-based method and its application. Int J Energy Technol Policy. 2016;12(1):84–102.
Gulshan V, Peng L, Coram M, et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA-J Am Med Assoc. 2016;316(22):2402–10. https://doi.org/10.1001/jama.2016.17216.
Kamnitsas K, Ledig C, Newcombe VFJ, et al. Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Med Image Anal. 2017;36:61–78. https://doi.org/10.1016/j.media.2016.10.004.
Bejnordi BE, Veta M, van Diest PJ, et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. JAMA-J Am Med Assoc. 2017;318(22):2199–210. https://doi.org/10.1001/jama.2017.14585.
Lakhani P, Sundaram B. Deep learning at chest radiography: automated classification of pulmonary tuberculosis by using convolutional neural networks. Radiology. 2017;284(2):574–82. https://doi.org/10.1148/radiol.2017162326.
Parmar C, Grossmann P, Bussink J, et al. Machine learning methods for quantitative radiomic biomarkers. Sci Rep. 2015. https://doi.org/10.1038/srep13087.
Kiranyaz S, Ince T, Gabbouj M. Real-time patient-specific ECG classification by 1-D convolutional neural networks. IEEE Trans Biomed Eng. 2016;63(3):664–75. https://doi.org/10.1109/tbme.2015.2468589.
Tabar YR, Halici U. A novel deep learning approach for classification of EEG motor imagery signals. J Neural Eng. 2016;14(1):016003.
Acharya UR, Oh SL, Hagiwara Y, et al. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput Biol Med. 2018;100:270–8. https://doi.org/10.1016/j.compbiomed.2017.09.017.
Lin YP, Wang CH, Jung TP, et al. EEG-based emotion recognition in music listening. IEEE Trans Biomed Eng. 2010;57(7):1798–806. https://doi.org/10.1109/tbme.2010.2048568.
Atzori M, Gijsberts A, Castellini C, et al. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci Data. 2014. https://doi.org/10.1038/sdata.2014.53.
Ji SW, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition. IEEE Trans Pattern Anal Mach Intell. 2013;35(1):221–31. https://doi.org/10.1109/tpami.2012.59.
Ordonez FJ, Roggen D. Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition. Sensors. 2016;16(1):115. https://doi.org/10.3390/s16010115.
Shan CF, Gong SG, McOwan PW. Facial expression recognition based on local binary patterns: a comprehensive study. Image Vis Comput. 2009;27(6):803–16. https://doi.org/10.1016/j.imavis.2008.08.005.
Begg R, Kamruzzaman J. A machine learning approach for automated recognition of movement patterns using basic, kinetic and kinematic gait data. J Biomech. 2005;38(3):401–8. https://doi.org/10.1016/j.jbiomech.2004.05.002.
Tompson J, Stein M, Lecun Y, et al. Real-time continuous pose recovery of human hands using convolutional networks. ACM Trans Graph. 2014;33(5):1–10. https://doi.org/10.1145/2629500.
Obermeyer Z, Emanuel EJ. Predicting the future - big data, machine learning, and clinical medicine. N Engl J Med. 2016;375(13):1216–9. https://doi.org/10.1056/NEJMp1606181.
Uzuner O, South BR, Shen SY, et al. 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text. J Am Med Inf Assoc. 2011;18(5):552–6. https://doi.org/10.1136/amiajnl-2011-000203.
Mullainathan S, Spiess J. Machine learning: an applied econometric approach. J Econ Perspect. 2017;31(2):87–106. https://doi.org/10.1257/jep.31.2.87.
Rajkomar A, Oren E, Chen K, et al. Scalable and accurate deep learning with electronic health records. NPJ Dig Med. 2018. https://doi.org/10.1038/s41746-018-0029-1.
Nemati S, Holder A, Razmi F, et al. An interpretable machine learning model for accurate prediction of sepsis in the ICU. Crit Care Med. 2018;46(4):547–53. https://doi.org/10.1097/ccm.0000000000002936.
Avendi M, Kheradvar A, Jafarkhani H. A combined deep-learning and deformable-model approach to fully automatic segmentation of the left ventricle in cardiac MRI. Med Image Anal. 2016;30:108–19.
Arbabshirani MR, Plis S, Sui J, et al. Single subject prediction of brain disorders in neuroimaging: promises and pitfalls. Neuroimage. 2017;145:137–65. https://doi.org/10.1016/j.neuroimage.2016.02.079.
Orru G, Pettersson-Yeo W, Marquand AF, et al. Using support vector machine to identify imaging biomarkers of neurological and psychiatric disease: a critical review. Neurosci Biobehav Rev. 2012;36(4):1140–52. https://doi.org/10.1016/j.neubiorev.2012.01.004.
Suk HI, Lee SW, Shen DG, et al. Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis. Neuroimage. 2014;101:569–82. https://doi.org/10.1016/j.neuroimage.2014.06.077.
Rathore S, Habes M, Iftikhar MA, et al. A review on neuroimaging-based classification studies and associated feature extraction methods for Alzheimer’s disease and its prodromal stages. Neuroimage. 2017;155:530–48. https://doi.org/10.1016/j.neuroimage.2017.03.057.
Walsh CG, Ribeiro JD, Franklin JC. Predicting risk of suicide attempts over time through machine learning. Clin Psychol Sci. 2017;5(3):457–69. https://doi.org/10.1177/2167702617691560.
Heinsfeld AS, Franco AR, Craddock RC, et al. Identification of autism spectrum disorder using deep learning and the ABIDE dataset. Neuroimage-Clin. 2018;17:16–23. https://doi.org/10.1016/j.nicl.2017.08.017.
Breiman L. Random forests. Mach Learn. 2001;45(1):5–32. https://doi.org/10.1023/a:1010933404324.
Ma JS, Sheridan RP, Liaw A, et al. Deep neural nets as a method for quantitative structure-activity relationships. J Chem Inf Model. 2015;55(2):263–74. https://doi.org/10.1021/ci500747n.
Alipanahi B, Delong A, Weirauch MT, et al. Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Nat Biotechnol. 2015;33(8):831. https://doi.org/10.1038/nbt.3300.
Pedregosa F, Varoquaux G, Gramfort A, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–30.
Zhu XJ, Feng CQ, Lai HY, et al. Predicting protein structural classes for low-similarity sequences by evaluating different features. Knowl-Based Syst. 2019;163:787–93. https://doi.org/10.1016/j.knosys.2018.10.007.
Cecotti H, Graser A. Convolutional neural networks for P300 detection with application to brain-computer interfaces. IEEE Trans Pattern Anal Mach Intell. 2010;33(3):433–45.
Ratner M. FDA backs clinician-free AI imaging diagnostic tools. Nat Biotechnol. 2018;36(8):673–4. https://doi.org/10.1038/nbt0818-673a.
Werbos PJ. Beyond regression: new tools for prediction and analysis in the behavioral sciences; 1975.
Administration FDA. Implanted brain-computer interface (BCI) devices for patients with paralysis or amputation---Non-clinical testing and clinical considerations. US Food and Drug Administration May 20 2021.
Mongeon P, Paul-Hus A. The journal coverage of web of science and scopus: a comparative analysis. Scientometrics. 2016;106:213–28.
Beretta R. A critical review of the Delphi technique. Nurse Res. 1996;3(4):79–89.
Takano Y, Kajikawa Y, Ando M. Trends and typology of emerging antenna propagation technologies: citation network analysis. Int J Innov Technol Manag. 2017;14(01):1740005.
Acknowledgements
We want to thank Dr. Hidefumi Kobatake for his advice on the history of AI technology development. We also want to thank Dr. Rika Wakao, Dr. Masafumi Shimokawa, and Ms. Ai Fukaya for their help.
Funding
This research was supported by AMED (Japan Agency for Medical Research and Development) under Grant Number JP20mk0101155.
Author information
Authors and Affiliations
Contributions
MS obtained developed the research design and interpreted the results. TT investigated the literature, analyzed the data, and interpreted the results. HS and HY designed the methodology and software and interpreted the results. MH designed the data-editing process. TT and MS drafted the manuscript. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
All authors have completed the ICMJE uniform disclosure form at coi_disclosure.pdf and declare: no support from any organization for the submitted work; no financial relationships with any organizations that might have an interest in the submitted work in the previous three years; no other relationships or activities that could appear to have influenced the submitted work.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Takata, T., Sasaki, H., Yamano, H. et al. Study on Horizon Scanning with a Focus on the Development of AI-Based Medical Products: Citation Network Analysis. Ther Innov Regul Sci 56, 263–275 (2022). https://doi.org/10.1007/s43441-021-00355-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s43441-021-00355-z