
Abstract
In the paper, the generalisation of the well-known “secretary problem” is considered. The aim of the paper is to give a generalised model in such a way that the chosen set of the possible best k elements have to be independent of all previously rejected elements. The independence is formulated using the theory of greedoids and in their special cases—matroids and antimatroids. Examples of some special cases of greedoids (uniform, graphical matroids and binary trees) are considered. Applications in cloud computing are discussed.
Similar content being viewed by others

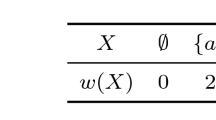

Avoid common mistakes on your manuscript.
1 Introduction
The secretary problem relies on a choice of the best candidate in such a way that only the relation to the previously interviewed candidates is known and the rejected candidates are definitively lost. The number of candidates is also known before the interview starts. After the interview we have to decide whether to accept the candidate or not. Our goal is to choose the best candidate, i.e. we have to decide when the process of recruitment should be stopped. In a more general situation we want to choose not only one, the best candidate, but we want to choose the best k members who form a team.
In the simplest case there is no constraint on recruitment process or the relationships inside the team. In this paper we focus on limited recruitment process on which we can only choose candidates that are not dependent on the candidates already rejected.
For example, using the terminology of secretary problem let us consider candidates from some organisation with hierarchical structure. Then if we reject the boss we must not employ the his/her subordinate even if he/she has better professional qualification.
Such an idea of a recruitment process requires a precise explanation of the meaning of the sentence “independent of previously rejected candidates”. As the next step we have to determine the stopping rule to obtain the optimal stopping time. The main aim of this paper is to formulate a sufficiently general but practicably useful structure of dependence.
Finding the optimal solution of the problem described above in the general case has very low probability of success in general cases. Therefore, we study optimal algorithms for finding the best solution only in some particular, but apparently useful cases.
The paper is organised as follows. In Sect. 2 the classical secretary problem is reviewed. Next, we present the variant of the problem in which the accepted candidates must be independent from the already rejected ones. Therefore, we have to introduce combinatorial structures with independence structure. The most known independence structures are matroids and antimatroids. Their generalisation are greedoids—less known, but more useful in our problem. Such structures are presented in the last part of Sect. 2. In Sect. 3 the problem in the general greedoid case is presented. Next, some particular, selected models are introduced. In the simplest models, the solutions are given. In the more complicated models, only some connections between known results (for example, from random graph theory) and problems of optimal stopping in such models are discussed. In Sect. 4 the models presented in the previous sections are proposed as a description of a model of cloud computing systems.
2 Preliminaries and Problems
2.1 Classical Secretary Problem
In the classical secretary problem there are n linearly ordered elements \(\{1,2,\dots ,n\}\). They are being observed in random order \((e_1, e_2,\dots ,e_n)\). At the moment t the observer knows only the relative ranks of the elements \(e_1,\dots e_t\) examined so far. Once rejected, an element cannot be recalled. The aim of the observer is to choose the currently examined object in such a way that the probability \(\Pr (e_t = n)\) will be maximal.
This problem is well known and solved. Dynkin in [6] shows that for large n, it is approximately optimal to wait until a fraction 1/e of the elements appears and then to select the next relatively best one. The probability of success is also 1/e. More strictly, we can present this result as follows. Let w(e) denote the rank of e and \(w(A)=\max _{e\in A}w(e)\).
Theorem 1
Let us assume that an algorithm of choices has the following form.
-
1.
Reject all elements \(e_t\) for subsequent \(t\le v\) for some v.
-
2.
If \(t>v\) then we accept \(e_t\) if \(w(e_t)\ge w({A_{t-1}})\) where \(A_k=\left\{ e_1,\dots ,e_k\right\}\) or reject it in the opposite case. The rejection is irrevocable.
-
3.
The process is stopped if the element is accepted or \(t=n\).
If \(v\sim n/e\) with \(n\rightarrow \infty\) then the \(\Pr (e_t = n)\) is maximal and is equal to 1/e.
The easy proof of Theorem 1 (see [8], also for a brief historical review of this classical secretary problem ) is a good pattern for considerations which will be used in more general models given in the next parts of this article.
The first \(v-1\) elements are rejected because of Item 1 of Theorem 1 and element m has the highest rank among these \(v-1\) elements. Next, select the first subsequent element that is better than element m. For an arbitrary v, the probability that the element with the highest rank is selected is
Therefore, the best choice is with probability:
Finally, the maximum is achieved for \(v\approx n/e\).
An important generalisation of this problem is known as the multiple choice secretary problem (see [10, 12, 14]). The objective of this problem is to select a group of at most k secretaries from a pool of n applicants having a combined value as large as possible.
2.2 Secretary Problem and Independence
Our generalisation leaves a linear order but assumes an additional combinatorial structure in the set of elements \(e_i\). Using the language of the optimal choice of the candidate to a position (secretary problem), our problem can be described as follows.
The subsequent candidates arrive. We can reject the candidate and then we consider a new candidate. The rejected candidate is irretrievably lost. Every new candidate is compared to the previously rejected candidates. If a new candidate is dependent on the previously rejected ones, such a candidate is also rejected. If the candidate is not dependent, then as a result of the comparison we can reject or accept him/her.
The main aim of the article is the research of stopping criteria if the random variables are indexed by elements of a finite structure and the permissible choice is limited by such a structure. Assume tentatively that an element e is independent on the set A if it does not belong to the closure of A. The name ‘closure’ needs defining which will be done in the next sections. Our basic assumptions are:
-
in the structure, a closure operator and a family of closed sets are specified,
-
if a new element belongs to the closure of previously rejected elements, then it also has to be rejected,
-
if it does not belong to the closure, the new element can be accepted.
Let us consider a simple, but illustrative example. The structure in this example is known as “linear structure” which is a special case of “strictly hierarchical structure” (see [15], p. 46). At first we have to formulate the following simple combinatorial result.
Lemma 1 Denote \(\left[ n\right] =\left\{ 1,2,\dots ,n\right\}\) and let \(j\in \left[ n\right]\) be fixed. The number P(j, n) of permutations \(\pi :\left[ n\right] \rightarrow \left[ n\right]\) such that
is equal to
Proof
For \(i=\pi (j)\) the number of permutations fulfilling (1) is equal to
For all \(i\le j\) we obtain
which completes the proof. \(\square\)
Example 1
Let \(S=\left[ n\right] =\{1,2,\dots ,n\}\). We will make the following assumptions: every secretary \(s\in S\) has two features—qualification (weight) w(s) and position in the hierarchical organisation (i.e. rank) r(s). Let all weights w(s) and ranks r(s) will be different. Let
and
If S is the set of candidates rejected so far, then if \(r(t)<r(S)\) for a new \(t\notin S\), t has to be rejected even if \(w(t)>w(S)\). More formally, the element t is independent of S if \(r(t)>r(S)\). Note, however, that at the moment t we do not know the values r(t) and w(t) but we can only verify if the inequalities \(r(t)>r(S)\) and \(w(t)>w(S)\) are fulfilled.
In this example we consider two completely different cases. The first ideal case:
Then we can assume that \(r(i)=w(i)=i\). This case coincides with the classical secretary problem.
The second is the most haphazard case: weight and rank are independent random variablesFootnote 1. Then we can assume that \(r(i)=i\) but \(w(i)=\pi (i)\) where \(\pi\) is random permutation of \(\left[ n\right]\).
In this case let us try to pick the best candidates in the same way as in the classic problem. First we examine and reject a fraction \(\alpha\) of n candidates (say \(S_{\alpha }\)) and at the next steps \(k>n/\alpha\) we pick the first candidate \(s_k\) with the rank and weight higher of the candidates rejected so far, i.e. \(r(s_k)>r(S_{k-1})\) and \(w(s_k)>w(S_{k-1})\).
Let us denote the most valuable candidate by \(z_1\) and the second most valuable by \(z_2\). If \(z_2\in S_{\alpha }\), \(z_1\notin S_{\alpha }\) and moreover \(r(z_1)>r(S_{\alpha })\), the selected candidate is the best. Therefore, the probability that the randomly chosen permutation fulfils (1) for given n and \(j>k_0\) for some fixed \(k_0\) is equal
where \(\gamma =0.5772156649\dots\) is an Euler constant.
Continuing this example for the second, haphazard case, let us assume that \(\alpha =1/2\). In such the case, let \(z_1\in S_{1/2}\) and \(z_2\notin S_{1/2}\). The candidate \(z_1\) is selected if \(r(j)<r(z_1)\) for all \(j<z_1\). From
and from Equation (3) we obtain
It seems that a better way is to take as \(\alpha\) the value other than 1/2. Then we have
and instead of (5) we obtain
Nevertheless, the difference between the right side of (5) and the maximal value of the right side of (7) is very small, less than 1%—see Table 1.
Note that in the ludicrous situationFootnote 2
for any pair \(e_1,e_2\), the optimal strategy is to choose the first candidate. Every next candidate will be either worse or dependent. This situation leads of course, with high probability \((n-1)/n\), to the lack of choice, so it can be neglected.
As the third case in this example we can consider such a situation that the correlation between ranks and weights is positive (usually essentially greater than zero), but smaller than one. Such a case needs more precise assumptions and probabilistic considerations; hence, it will be omitted in this paper.
2.3 Matroids
As it was mentioned previously we need a precise definition of the words ‘closure’ of A and ‘independent’ element e from the set A. The useful tool to give such the definitions are structures known as matroids and more generally—greedoids. In the next two sections we provide the necessary definitions and results from the matroid and greedoid theory.
Let E be a finite set. A family \(\mathcal {I}\) of subsets of E is the family of independent sets if the following conditions hold:
-
\((i_1)\) \(\emptyset \in \mathcal {I}\),
-
\((i_2)\) if \(I_1\subseteq I_2\in \mathcal {I}\), then \(I_1\in \mathcal {I}\),
-
\((i_3)\) if \(I_1,I_2\in \mathcal {I}\), \(|I_1|<|I_2|\), then there exists \(e\in I_2\setminus I_1\), such that \(I_1\cup \{e\}\in \mathcal {I}\).
A pair \((E,\mathcal {I})\) is a matroid (see, for example, [20, 24, 25]).
A basis is a maximal independent set. All bases have the same number of elements. The rank \(\rho (A)\) of any set \(A\subseteq E\) is the number of elements of any maximal independent set \(I\subseteq A\). The closure \(\sigma (A)\) of a set A is the maximal set with the same rank as A. The set A is closed if \(\sigma (A)=A\). The operator \(\sigma\) for matroids fulfils the following properties:
-
\((s_1)\) \(A\subseteq \sigma (A)\),
-
\((s_2)\) if \(A\subseteq B\) then \(\sigma (A)\subseteq \sigma (B)\),
-
\((s_3)\) \(\sigma (\sigma (A))=\sigma (A)\),
Using the definition of matroid, we can interpret “an independence” of element e of the set A in such a way that \(e\notin \sigma (A)\). Comparing this interpretation with the example in Sect. 2.2, we can remark that such a meaning of independence is not fortunate because the closure \(\sigma (A)\) has the exchange property:
-
(ex) if \(f\notin \sigma (A)\), \(f\in \sigma (A\cup \left\{ e\right\} )\) then \(e\in \sigma (A\cup \left\{ f\right\} )\).
A structure \((E,\mathcal {I})\) is a matroid if and only if \(\sigma\) fulfils the conditions \((s_1)\) and \((s_2)\) and the condition (ex). Note that \((s_3)\) follows from \((s_1)\) and \((s_2)\) and the condition (ex) but \((s_1)\) – \((s_3)\) does not give (ex). Therefore, the set of conditions \((s_1)\) – \((s_3)\) is not a characterisation of a matroid.
2.4 Greedoids
2.4.1 Basic Definitions and Properties
The hierarchical structure of dependence in Example 1 does not fulfil the condition (ex). Therefore, we have to use more a general structure than matroids.
A greedoid (a greedy structure) is the family \(\mathcal {F}\) of subsets of the set E which fulfils the following conditions (see, for example, [17, 18]):
-
\((f_1)\) \(\emptyset \in \mathcal {F}\),
-
\((f_2)\) if \(F_1,F_2\in \mathcal {F}\), \(|F_1|<|F_2|\), then there exists \(e\in F_2\setminus F_1\), such that \(F_1\cup \{e\}\in \mathcal {F}\).
Note that the conditions for greedoids are the conditions for matroids with the exception of \((i_2)\). The elements of family \(\mathcal {F}\) are called feasible sets. A family \(\mathcal {F}\) is called accessible if the following condition holds:
-
\((a_1)\) if \(F\in \mathcal {F}\setminus \{\emptyset \}\) then there exist \(e\in F\) such that \(F\setminus \{e\}\in \mathcal {F}\).
A pair \((E,\mathcal {F})\) where \(\mathcal {F}\) is accessible is called an accessible system. Every greedoid is an accessible system. Matroids are also greedoids with independent sets as feasible sets. Clearly, the property \((a_1)\) is weaker than the property \((i_2)\)—does not every subset of an independent set is independent, but at least one subset of a feasible set is also feasible.
A basis is a maximal feasible set. All bases have the same number of elements. The rank \(\rho (A)\) of any set \(A\subseteq E\) is the number of elements of maximal feasible set \(F\subseteq A\). A closure \(\tau (A)\) of a set A is the maximal set with the same rank as A, i.e. (see [16] or [18])
The closure \(\tau (A)\) defined by (8) fulfils the conditions \((s_1)\) and \((s_3)\) but not necessarily the condition \((s_2)\), i.e. closure operator is not necessarily monotone (see [18], Example on p. 69, fig. 6). However, one can define the monotone closure operator \(\sigma (A)\):
It is easy to see that the monotone closure \(\sigma (A)\) satisfies all conditions \((s_1)\) – \((s_3)\), but greedoids are not uniquely determined by its monotone closure operator (see [18], p. 63).
If a greedoid fulfils the antiexchange property
-
(aex) if \(f\notin \sigma (A)\), \(f\in \sigma (A\cup \left\{ e\right\} )\), \(f\ne e\) then \(e\notin \sigma (A\cup \left\{ f\right\} )\)
then we call such a greedoid an antimatroid.
Theorem 2
[17], Th. 14.4] If \((E,\mathcal {F})\) is an antimatroid then
is a closure operator, i.e. it satisfies conditions \((s_1)\)– \((s_3)\).
The structure of the Example 1 is an antimatroid if we take as closed sets all the sets of the form \(\left[ k\right]\), where \(\left[ k\right] =\left\{ 1,\dots ,k\right\}\) for \(1\le k\le n\) and \(\left[ 0\right] =\emptyset\). The feasible sets have the form \(\left[ n\right] \setminus \left[ k\right]\) for \(0\le k\le n\).
Lemma 2
Let \((E,\sigma )\) be an antimatroid. Suppose that the sequence \(e_1,\dots ,e_n\) is such that
for every pair \(i<j\). Then the sequence \(e_1\dots ,e_n\) is linearly ordered.
In the next parts of this section we give some examples of greedoids. The exhaustive review of examples of greedoids can be found in [11]. In our article we give only some simplified examples, useful for our aim.
2.4.2 Trees
Let T be a tree with the root r and the set of vertices V. The distance from the root r to a vertex v is denoted as the height \(h\left( v\right)\) of v, \(h(r)=0\). The height \(h=h(T)\) of the tree T is the maximum height of the leaf.
Let \(\mathcal {F}\) be the family of all vertex sets such that \(U\in \mathcal {F}\) if U is a subtree of T and \(r\in U\) or \(F=\emptyset\). Let
Then \(\mathcal {T}=(V,\mathcal {F})\) is a greedoid of feasible sets and \(\sigma\) defined by (12) is the closure operator, which fulfils the property (aex). Therefore, \(\mathcal {T}\) is an antimatroid. Note that \(\sigma (\left\{ r\right\} )=E\).
Such an antimatroid can be considered as an example of a hierarchical organisation. Note that the hierarchical structure of dependence in Example 1 is the trivial example of a tree (with the element n as a root), and it is a very simple example of antimatroid.

Rooted tree—greedoid of hierarchical organisation
From Theorem 2 and equation (12) we have the following result.
Lemma 3
Every closed set A in the given greedoid \(\mathcal {T}\) is a sum of k disjoint maximal subtrees \(T_i\subseteq T\), \(i=1,\dots ,k\), with the set of their roots \(H=\left\{ e_1,\dots ,e_k\right\}\) where \(e_i\in T_i\) has the lowest height in T.
The set \(H=H(A)\) is the unique spanning set of the set A, i.e. is the unique H such that \(\sigma (H)=A=\sigma (A)\).
In Fig. 1, for example, the sets of vertices \(\left\{ r,a,d,e\right\}\) and \(\left\{ r,c,f,g,h\right\}\) belong to \(\mathcal {F}\) (they are subtrees rooted in r) but the sets \(\left\{ d,e\right\}\), \(\left\{ a,d,e\right\}\) and \(\left\{ c,g,h,j\right\}\) do not belong to \(\mathcal {F}\) (they are not subtrees or they are subtrees do not rooted in r). The set
is closed and with the minimal spanning set \(H=\left\{ a,f\right\}\). A is the sum of the disjoint subtrees \(T_1\cup T_2\): \(T_1=\left\{ a,b,d\right\}\), \(T_2=\left\{ f,g,h,i,j\right\}\) where a is the root of \(T_1\), \(h(a)=1\) and f is the root of \(T_2\), h(f)=2.
2.4.3 Acyclic Digraphs
Let D be a rooted directed acyclic digraph with root r and the set of arcs E. A rooted subgraph of D is connected (directionally connected) if for its every vertex v there exist a path from r to v. Let \(\mathcal {F}\) be the family of all sets of arcs F of connected subgraphs rooted at r or \(F=\emptyset\).

Rooted acyclic digraph—greedoid of hierarchical organisation with multiply dependence
Let
Then \(\mathcal {D}=(V,\mathcal {F})\) is a greedoid of feasible sets and \(\sigma\) defined by (13) is the closure operator (see [18], p. 26). Such a greedoid can be considered as an example of a hierarchical organisation with multiple dependencies.
Let \(\mathcal D^+\) be the acyclic graph D with an additional arc \((r_0,r)\). Note that if every vertex \(v\ne r_0\) in D has indegree \(d^-(v)=1\), then the linegraph of \(\mathcal D^+\) is a tree. Therefore, in such a case, a greedoid \(\mathcal D^+\) is isomorphic to a greedoid \(\mathcal {T}\) presented in 2.4.2.
In Fig. 2, for example, the set of arcs \(\left\{ a,b,c\right\}\), \(\left\{ a,b,c,d\right\}\) and \(\left\{ a,c,e\right\}\) belong to \(\mathcal {F}\) (they are connected and rooted in r) but \(\left\{ b,d,f\right\}\) does not belong to \(\mathcal {F}\) (it is not rooted in r) and \(\left\{ b,e,j\right\}\) does not belong to \(\mathcal {F}\) either (it is not connected, so it is not rooted in r).
2.5 Secretary Problem in Greedoids
Now we formulate the problem in the most general way, for any greedoid. Let \((E,\mathcal {F})\), \(|E|=n\), be a greedoid with closure operator \(\sigma\). On the set E a weight function \(w:E\rightarrow \mathbb {N}\) is defined. We want to choose the element with the greatest weight under the following conditions.
-
1.
The structure \((E,\mathcal {F})\) and the function \(w:E\rightarrow \mathbb {R}\), \(w(e)>0\) for all \(e\in E\), is defined but can be unknown.
-
2.
The elements of E arrive sequentially at the moments \(t=1,2,\dots ,n\).
-
3.
At the moment t we know which element arrives (say the element \(e_t\)) and we can observe its weight \(w(e_t)\) and the closure of \(A_{t-1}\) restricted to \(A_t\), i.e. \(\sigma (A_{t-1})\cap A_t\,\).
-
4.
For any two subsets \(A',A''\subseteq A\) the possible inclusion \(\sigma (A')\subseteq \sigma (A'')\) is known.
-
5.
Let \(A_{t-1}\) be the set of elements which arrived before the moment t. If \(e_t\in \sigma (A_{t-1})\) then \(e_t\) is rejected irrevocably.
-
6.
If \(e_t\notin \sigma (A_{t-1})\) then we can accept \(e_t\) if \(w(e_t)\ge w({A_{t-1}})\) or reject it. The rejection is irrevocable.
-
7.
The process is stopped if the element is accepted or if there are no next elements to observe.
-
8.
Until the process stops the structure \((E,\mathcal {F})\) remains unchanged.
Condition 8 means that the structure is exactly the same at each step of the algorithm. It is tacit (seems evident) assumption in all generalisations of the secretary problem, but in this paper such assumption is given explicitly for the sake of applications—see Sect. 4.
In the rest of this paper we will assume random arrival order. The proposed algorithm is similar to the algorithm known as Secretary Problem.
Algorithm 1
At each step the observer knows the weight of the chosen element e and performs the actions below:
-
1.
Fix the closed family of test sets \(\mathbf {T}\) or \(\sigma (\mathbf {T})\).
-
2.
Reject all elements \(e_t\) for subsequent t while \(A_t\subset \sigma (\mathbf {T})\) (\(A_t\ne \sigma (\mathbf {T})\)) for some T. If only \(\left| \mathbf {T}\right|\) is known then reject all first \(e_t\) elements.
-
3.
For the next t reject it if \(w(e_t)<w(A_{t-1})\) or \(e_t\in \sigma (A_{t-1})\).
-
4.
If \(w(e_t)>w(A_{t-1})\) and \(e_t\notin \sigma (A_{t-1})\) accept \(e_t\) and stop the process.
We can take as the criterion the subspaces of the appropriately chosen rank, say rank \(k_0\). Therefore, we unconditionally reject the elements \(e_t\) until \(\rho (A_t)=k_0\). For the next t we reject the element \(e_t\) if \(w(e_t)<w(A_{t-1})\) or \(e_t\in \sigma (A_{t-1})\). If \(w(e_t)>w({A_{t-1}})\) and \(e_t\notin \sigma (A_{t-1})\) we accept \(e_t\) and stop the process. To solve this problem we need to determine the distribution of the random variable \(\rho (A_t)\).
The presented model in the matroid case is different from the known so far Matroid Secretary Problem introduced in [1] (see also [2]). Their model is a generalisation of the multiple choice secretary problem by an additional condition that the chosen set has to be independent. In such a model the accepted elements do not have to be independent of the previously rejected elements. The paper [21] (see also [22]) gives an exhaustive review of known results and presents some new ones.
3 Special Cases
3.1 Uniform Matroid
Uniform matroid \(U_{k,n}=(E,\mathcal {I})\), where independent sets are all subsets of \(E=\left[ n\right]\) with the number of elements not greater than k:
Obviously there must be \(k>v\). Assume \(w(i)=i\). Then the best choice is with probability:
as in Theorem 1. The maximum is achieved for \(v\approx k/e\) and the optimal probability is (k/n)/e. If \(k=n\) we obtain the classical case with the solution given by Theorem 1.
3.2 Binary Trees
Definition 1
A binary tree with n vertices is an empty tree \(T=\emptyset\) if \(n=0\) or a triple \(T=(L,r,R)\) where r is the root of the tree, L (left subtree) is a binary tree with l vertices and R (right subtree) is a binary tree with p vertices, where \(n=l+p+1\). For nonempty T, the root of L is called a left child of r and the root of R is called a right child of r. If \(T=(\emptyset ,v,\emptyset )\), then v is a leaf.
Definition 2
A complete binary tree is a binary tree in which all nodes other than the leaves have two children. If moreover all leaves have the same height, the binary tree is complete and full.
The number l of leaves in a complete and full binary tree with n vertices is \(l=(n+1)/2=2^h\). Thus, \(n=2^{h+1}-1\) is the number of vertices of such a tree. The sequence \(v_1,\dots ,v_k\) is linear if \(h(v_{i+1})=h(v_i)+1\).
Note that for any vertex v of the complete and full binary tree T, \(\sigma (\left\{ v\right\} )\) is a binary tree with v as the root and has \(2^{h-h(v)+1}-1\) vertices. Therefore, the set A is an independent set only if A is the sum of disjoint trees.
Similarly to Example 1 we will consider two different cases. First, let us consider the case \(w(v)=h-h(v)+1\). Therefore, the root r has the maximal weight \(w(r)=h+1\) and leaves u have the minimal weights \(w(u)=1\).
In the second case we assume that
-
1.
the set of weights has exactly \(h+1\) values,
-
2.
exactly \(j+1\) vertices have the value w(j),
-
3.
\(w(0)>w(1)>\dots >w(h)\),
-
4.
values are equally likely distributed on all \(n=2^{h+1}-1\) vertices.
Similar to our Case 1 there is the known model which was considered by [19] (see also [9]). Instead of closure \(\sigma (A)\) used in Algorithm 1 the procedure used in this model checks whether
-
\(w(e_k)>\max \left\{ w(v_1),\dots ,w(v_{k-1})\right\}\) and
-
\(\left\{ v_1,\dots ,v_{k-1}\right\}\) not linear or it is linear and \(k>h/2\).
The element \(e_k\) is accepted if both of the above conditions are fulfilled.
Theorem 3
[19]] Algorithm 1 gives an optimal strategy for the choice of the element r, i.e. \(\Pr (v_k=r)\) is the maximal possible. If \(h\rightarrow \infty\) then the Algorithm 1 gives an optimal choice with probability tending to 1.
3.3 Graphical Matroids
3.3.1 Graphical Model of Secretary Problem
Let \(G=(V,E)\) be an undirected graph where V is the set of vertices and E is the set of edges. An independent set is any set of edges which does not contain any cycles, i.e. the independent set forms a forest. In this section only the case \(G=K_n\), where \(K_n\) is an n-vertices complete graph, is considered.
The random graph introduced by [7] is constructed by connecting nodes randomly. Since that time many monographs and textbooks have been devoted to the theory of random graphs. Among others we refer the reader to the following books: [3, 13] and [23].
In this paper we will consider the so called “random graph process” (see [13], p. 4). Let n, a number of vertices be fixed. Let \(G_{n,t}\) be any fixed graph with n vertices and t edges. The random graph process is a stochastic process which begins with no edges at time \(t=0\) and adds new edges, one at time; each new edge is selected at random, uniformly among all edges not presented until now. At the moment t, \(0\le t\le m=\left( {\begin{array}{c}n\\ 2\end{array}}\right)\), the random graph \(G_n(t)\) has t edges and
Let us consider the asymptotic case where \(n\rightarrow \infty\) and \(t=t(n)\). To simplify the notation, use the abbreviation a.a.s (asymptotic almost surely) instead of the term “with the probability tending to 1 when \(n\rightarrow \infty\)”. If \(k>2\) and \(t\ll n\) but \(t=n^{1-o(1)}\) then a.a.s, \(G_n(t)\) has no cycles, i.e. the set of edges forms an independent set (see [13], p. 104). This means that the beginning of such the process is similar to the beginning of the process without dependence restrictions. Nevertheless, the number \(t=n^{1-o(1)}\) of tested elements is too small to obtain a reasonable decision.
In order to change to the proper range of numbers of edges which give a sufficient information to obtain an optimal decision, we have to consider such a case, where the number t of tested edges is big enough and furthermore the number of edges which are not dependent tested as well as the number of rejected edges are also big enough. Such a situation is given by the following fundamental result, proved by Erdős and Rényi in their famous paper [7] (see [13] and [23]).
Theorem 4
If
where \(\lambda >0\), then the random graph a.a.s. has one giant component and N isolated vertices. The random variable N has Poisson distribution with mean \(\lambda\).
For the big \(\lambda\) we can obtain a better balance between a number of tested elements (given by Eq. (14)) and a number of edges possible to choose, i.e. edges which do not belong to the giant component. From Theorem 4, the giant component has a.a.s. \(n(\ln n+\ln \lambda )\) elements (edges) and the rank \(n-N\). Because every new edge a.a.s. joins an isolated vertex with the giant component, then we can choose an optimal k elements set from \(N(n-N)\) elements.
From \(3\sigma\) rule we have approximately \(\Pr (N-\lambda >3\sqrt{\lambda })\le 0.005\). To obtain \(\rho (T)=n-\lambda\) we should a.a.s. test at least
elements plus perhaps an additional next \(3\sqrt{\lambda }/2\) elements.
Example 2
In Table 2 are shown the values of the necessary number \(t_0\) of testing steps to achieve the set T of rank given before. Let \(\rho (T)=\lambda\).
Note, that after rejecting approximately next \(\lambda\) edges after the moment \(t_0\), \(\rho (R)\sim n\), the process will be finished. If all values \(w(e_j)\) are different for \(j=1,2,\dots ,\left( {\begin{array}{c}n\\ 2\end{array}}\right)\), then it is clear that the probability of choosing the optimal solution (the edge of maximal weight or the set of k edges with maximal sum of weights) rapidly tends to zero.
3.3.2 Linearly Decreasing Number of Linearly Ordered Weights
Let us assume that there exist only \(n-1\) values of weights of edges in the n-vertices graph. In this section we restrict ourselves to the case \(k=1\), i.e. to the choice of only one, the best element. Without the loss of generality one can assume that \(w(e)\in \left\{ 1,2,\dots ,n-1\right\}\) for all edges of the graph \(K_n\). Similarly to Example 1 we consider the three completely different cases.
-
1.
Let \(V=\left\{ 1,2,\dots ,n\right\}\) be the set of vertices and \(e_{ij}=\left\{ i,j\right\}\). For \(i=1,2,\dots ,n-1\) and \(k=i+1,\dots ,n\) let \(w(e_{i,k})=k\).
-
2.
Let \(V=\left\{ 1,2,\dots ,n\right\}\) be the set of vertices and \(e_{ij}=\left\{ i,j\right\}\). For \(i=1,2,\dots ,n-1\) and \(k=i+1,\dots ,n\) let \(w(e_{i,k})=n-k\).
-
3.
Every value appears approximately n/2 times, and these values are distributed equally likely.
At first, let us consider Case 1. In this case we have only one best element, but \(n-1\) the worst element. If the maximal element belongs to the giant component, then the optimal solution does not exist. In Case 2 we have \(n-1\) the best elements, but only one worst element. If the maximal element belongs to the giant component, then the optimal solution does not exist.
4 Applications: Cloud Computing
It is obvious that the simplest model closely related with the name Secretary Problem is very far from real applications. In this section we describe the simplified, but more realistic model of cloud computing, which can used as an example of an application to the computer networks. Below we shortly describe the model.
Cloud computing is definitely one of the fastest developing technologies in IT sector. Year by year this kind of solutions become more popular. This idea actually has its implementations in many different models. Regardless of the fact which of them is used the general idea is still the same: most of the duties related to IT infrastructure maintenance is moved from the user (customer) to the service provider. In other words we can say that the same classical element (i.e. server or software running on it) becomes just a service, available for the user by the computer network. The user, who has a task to be performed, just orders the resources needed for this particular time. This solution is very comfortable for the user as more efficient resources usage guarantees also economic benefits. Since in typical cloud computing service many different users share with each other limited hardware and software resources, optimisation of their utilisation is the key problem.
Let us consider the situation, where the user has same the computing task to be performed in the shortest possible time. To do this job, a virtual machine with required hardware resources (computing cores, RAM memory etc.) must be rented. Then there is a need to deliver a significant amount of data required for computing. This operation is strictly related to the transfer time. Some parameters of the virtual machine are simple to compare (results of popular benchmarks, user estimation based on declared hardware parameters). In the real environment also some other parameters, often difficult for forecasting, should also be considered. One of them is an actually available throughput of the computer network between the client host and the computing node. While the bandwidth can be considered constant, the throughput is directly connected with the current utilisation of the network. Due to the above, time of transfer can be approximated no sooner than after sending a few TCP datagrams and receiving acknowledgements. At the moment when the transmission speed would classified as unsatisfactory, it can be interrupted and the next localisation can be considered. However, what is very important at the time of the resignation of the given service provider, the resources can be assigned to other tasks, and they are not available anymore. What is more, there can be some relationship between individual service providers. Their hardware resources can be located in the same network segments. Therefore, the rejection of one or more of the service providers in the network should also result in the elimination of other nodes located in the same network location and depended of rejected nodes. Many remarks in a scope of our research one can find in [5].
To justify an application of our model of the optimal choice in above presented problem in cloud computing, let us consider the conditions 1–7 from Sect. 2.5. Condition 1 is obvious, because the logical structure of the cloud is determined by its technical structure. However, from the users point of view, the knowledge of this structure usually is unimportant.
The requirement that elements arrive sequentially (Condition 2) is obvious and necessary in the most particular cases. We consider the case, when the sequence of the tasks is a permutation that is related to business model, i.e. the optimal scheduling due to the penalty for starting or completing tasks too late. At any moment t we know which element arrives and we know its weight (cost, capacity etc.). Knowledge of closure of \(A_{t-1}\) may be, however, questionable. Therefore, Condition 3 needs more attention.
Condition 5 should be fulfilled as result of natural structure of network: if some (local) system must not work then its subsystem does not work. Condition 7 is the end of procedure but of course in a real network, the procedure has to start again.
Based on the observations, the load state of the network, computing nodes, databases etc. over a finite period of time can be approximately considered constant. Assuming a certain statistical model, the length of this period can be estimated and it will be typical for a specific environment. Of course, in the long term, this assumption is obviously wrong because, firstly, the situation in the entire environment may change due to independent factors, and secondly, as a result of the presented algorithm (which seems to be obvious). Therefore, after a certain period of time mentioned above, the algorithm should be restarted without any previous calculation history. This approach seems to be right, in particular in distributed systems, where specific resources are available in many locations, and the critical criterion is the response time (task completion)—e.g. web applications using a large number of database queries, etc. Therefore, one can assume that Condition 8 fulfilled.
Models presented in Sections 2.4.2 and 2.4.3 can be suitable tools to describe some specified kinds of clouds.
Let us consider as an example the tree from Fig. 1. In this case nodes are represented as vertices \(v\ne r\). Our aim is to allocate our resources in the best possible server. Assume that our test set is any set \(T\in \mathbf {T}\) such that \(\left| T\right| =2\). Therefore, we have to skip two first servers. If, for example, we chose at first the servers a and f we have to wait until we can choose server b or c because there exist only two servers \(b,c\notin \sigma (\left\{ a,f\right\} )\). Assume that the chosen server is b. If \(w(b)>w(\left\{ a,f\right\} )\) then we stop the algorithm. If not, we have to wait until the server c will be chosen. Then if \(w(c)<w(\left\{ a,b,f\right\} )\) we must stop the procedure without a choice of the optimal solution.
Similar but a bit more complicated case is presented in Section 2.4.3, Fig. 2. In this case servers are represented as arcs and there exist multiple subordinations. Nevertheless, the procedure of finding the best solutions is the same.
A more serious problem can arise if dependence structure is not regular enough, i.e. for example, if greedoid (matroid, antimatroid) cannot be presented as graphs. Such situation can be arise, for example, in wireless networks with dynamical changing structure.
Note finally that greedy algorithms are extensively study in the theory of cloud computing, but in the different (however, similar) context—see, for example, [4] and reference therein.
5 Conclusion
We presented a model of optimal choice among objects which are connected by different dependencies. Our aim is to choose an object or a set object but in a such way so that the chosen objects were independent in some sense. The independence in the model is described in the term of greedoids and as special cases—matroids, antimatroids and more special cases, for example, rooted trees and random graphs.
Data Availability
Not applicable.
Code Availability
Not applicable.
Notes
Any similarity to actual events is purely coincidental.
See footnote 1
References
Babaioff M, Immorlica N, Kempe D, Kleinberg R (2008) Online auctions and generalized secretary problems. SIGecom Exch 7 (2): 7:1–7:11. ISSN 1551-9031. 10.1145/1399589.1399596. https://doi.org/10.1145/1399589.1399596
Babaioff M, Immorlica N, Kleinberg R (2018) Matroid secretary problems. J ACM 65 (6): 35:1–35:26
Bollobás B (2001) Random Graphs. Academic Press, London
Dai H, Yang Y, Yin JS, Jiang H, Li C (2019) Improved greedy strategy for cloud computing resources scheduling. ICIC Express Lett 13(6):499–504. http://www.icicel.org/ell/contents/2019/6/el-13-06-09.pdf
Dai Y-S Yang B, Dongarra J, Zhang G (2009) Cloud service reliability: Modeling and analysis. In 15th IEEE Pacific Rim Intern Symp Depend Comput. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.214.143&rep=rep1&type=pdf
Dynkin EB (1963) The optimum choice of the instant for stopping a Markov process. Soviet Math Dokl 4: 627–6290
Erdős P, Rényi A (1960) On the evolution of random graphs. Publications of the Math Inst Hungarian Acad Sci 5: 17–61
Ferguson TS (1989) Who solved the secretary problem? Stat Sci 4 (3): 282–289
Garrod B, Morris R (2013) The secretary problem on an unknown poset. RANSA 43 (4): 429–451
Girdhar Y, Dudek G (2009) Optimal online data sampling or how to hire the best secretaries. In Canadian Conf Comp Robot Vision 292–298
Goecke O, Korte B, Lovás L (1989) Examples and algorithmic properties of greedoids. In B. Simeone, editor, Combinatorial optimization, volume 1403 of Lecture Notes in Mathematics, pages 113–161. Springer
Hajiaghayi MT, Kleinberg R, Parkes DC (2004) Adaptive limited-supply online auctions. In EC’04:Proceedings of the 5th ACM Conference on Electronic Commerce, pages 71–80, New York, ACM Press
Janson S, Łuczak T, Ruciński A (2000) Random Graphs. Wiley, New York
Kleinberg R (2005) A multiple-choice secretary algorithm with applications to online auctions. In Proceedings of the sixteenth annual ACM-SIAM symposium on Discrete algorithms, SODA ’05, pages 630–631, Philadelphia, PA, USA. Soc Industrial Appl Math. ISBN 0-89871-585-7. http://dl.acm.org/citation.cfm?id=1070432.1070519
Klimesch W (1994) The Structure of Long-term Memory: A Connectivity Model of Semantic Processing. Lawrence Erlbaum Associates Inc, Publishers
Korte B, Lovás L (1983) Structural properties of greedoids. Combinatorica 3–4 (3): 359–374
Korte B, Vygen J (2012) Combinatorial Optimization, volume 21 of Algorithms and Combinatorics. Springer-Verlag, Berlin Heidelberg, 5 edition
Korte B, Lovász L, Schrader R (1991) Greedoids, volume 4 of Algorithms and Combinatorics. Springer-Verlag, Berlin Heidelberg
Morayne M (1998) Partial order analogue of the secretary problem: the binary tree case. Discrete Math 184: 165–181
Oxley JG (2011) Matroid Theory. Oxford University Press, Oxford, 2 edition
Soto JA (2013) Matroid secretary problem in the random-assignment model. SIAM J Comput 42 (1): 178–211
Soto JA, Turkieltaub A, Verdugo V (2018) Algorithms for the ordinal matroid secretary problem. In SODA ’18 Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 715–734, Philadelphia, USA. Soc Industrial Appl Math
van der Hofstad R (2016) Random Graphs and Complex Networks: Volume 1. Cambridge University Press, USA, 1st edition. ISBN 110717287X
Welsh DJA (1976) Matroid Theory. Academic Press, London
Wilson RJ (2010) Introduction to Graph Theory. Prentice Hall, 5 edition
Acknowledgements
The author thanks Piotr Nadybski who helped to formulate the problem of operations in a cloud.
Funding
No funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The author declares that he has no conflicts or competing of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kordecki, W. Secretary Problem: Graphs, Matroids and Greedoids. Oper. Res. Forum 2, 63 (2021). https://doi.org/10.1007/s43069-021-00092-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43069-021-00092-x