
Abstract
Monitoring aquatic vegetation, including both floating and emergent types, plays a crucial role in understanding the dynamics of freshwater ecosystems. Our research focused on the Lower Dniester Basin in Southern Ukraine, covering approximately 1800 square kilometers of steppe plains and wetlands. We applied traditional machine learning algorithms, specifically random forest and boosting trees, to analyze Sentinel-2 satellite imagery for segmenting aquatic vegetation into emergent and floating types. Our methodology was validated against detailed in-situ field measurements collected annually over a 5-year study period. The machine learning classifiers achieved an F1-score of 0.88 ± 0.03 in classifying floating vegetation, outperforming our previously suggested histogram-based thresholding methodology for the same task. While emergent vegetation and open water were easily identifiable from satellite imagery, the robustness and temporal transferability of our methodology included accurately delineating floating vegetation as well. Additionally, we explored the significance of various features through the Minimum Redundancy - Maximum Relevance algorithm. This study highlights advancements in aquatic vegetation mapping and demonstrates a valuable tool for ecological monitoring and future research endeavors.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Freshwater ecosystems constitute a vital resource, delivering ecosystem services that infulence the well-being of local communities and regional economies. These services encompass critical functions such as the production of drinking water, support for tourism, aquaculture, and the generation of hydropower [1]. Nevertheless, these precious ecosystems face a growing vulnerability to anthropogenic influences.
The primary driver of ecological concerns in numerous transboundary river catchments, including the Dniester, stems from the excessive anthropogenic load of nutrients. This load results from a spectrum of human activities, including agriculture, industrial processes characterized by wastewater discharges and gas emission redeposition, domestic sewage discharges, and other anthropogenic actions [2,3,4]. These activities have led to a pronounced escalation in eutrophication within river deltas, their associated lakes, and adjacent estuaries [5].
Furthermore, the changing climate is introducing alterations in temperature and precipitation patterns, while the construction of hydro power facilities disrupts fluvial water flow. These combined factors frequently exacerbate and intensify the negative impacts on biodiversity, biological resources, and the provision of ecosystem services [6]. Concomitant with the issue of algal blooms is the challenge posed by the overgrowth of aquatic vegetation, which is a common occurrence in vulnerable deltaic regions.
Aquatic plants, whether emergent, floating, or submerged, are intrinsic components of most aquatic ecosystems and are pivotal to their functioning. However, when these plants become overgrown or experience excessive blooms, they can trigger adverse consequences for water quality, biodiversity, ecosystem functioning, and the delivery of ecosystem services. These consequences manifest through a range of mechanisms, including [7,8,9]:
-
Reduction of dissolved oxygen levels.
-
Alteration of pH levels.
-
Diminished light penetration, leading to decreased water clarity and increased water temperature.
-
Elevated siltation rates, particularly in slow-moving streams.
-
Serving as mechanical substrates for the proliferation of filamentous algae.
-
Obstruction or hindrance of navigation channels and areas utilized for fishing and tourism.
-
Diminished recreational and touristic appeal of water bodies
Given these challenges, there is a pressing need for the development of near-real-time (semi-) automatic monitoring techniques for aquatic vegetation cover, coupled with the capability to identify different types and species. Such capabilities hold significant value for governing authorities and the administrations of natural and national parks [10].
There are different ways to estimate features in Earth observation using satellite images. Some researchers have used histograms and satellite imagery to do this [11]. Other researchers, like Chen et al. [12], used decision trees to figure out underwater plant life. Espel et al. [13] compared two algorithms, Random Forest and Support Vector Regression, to estimate underwater plant cover using very high resolution (VHR, 50 cm) satellite images from Pléiades and both demonstrated promising accuracy metrics. Some studies focused on identifying floating vegetation in different water bodies using Sentinel-2 images. They found that accuracy depended on how densely packed the vegetation was [14, 15] and the specific types of plants [16].
Deep learning (DL), particularly convolutional neural networks and the vision transformers [17], has revolutionized the field of remote sensing by enabling the extraction of complex patterns and features from satellite imagery that were previously unattainable with traditional ML methods. DL’s ability to automatically learn hierarchical feature representations makes it exceptionally suited for classifying and segmenting high-dimensional remote sensing data [18]. The integration of self-supervised learning approaches and foundation models exemplifies DL’s capacity to achieve significant accuracy even in few-shot learning scenarios, where annotated data are scarce. In specific, recent advances in self-supervised foundation models [19, 29] have been incorporated successfully in mapping underwater vegetation with very limited annotated data [20].
Building upon our prior work presented on the 9th International Conference on Geographical Information Systems Theory, Applications and Management - GISTAM 2023 [10], we’ve developed a method for automatically monitoring aquatic plants in freshwater ecosystems. This approach involves hierarchically thresholding various bands and indices, with thresholds determined from histograms, enabling us to distinguish and map three key aquatic vegetation categories: floating plants, emergent plants, and open water areas devoid of plants. Several indicators, which are derived by algebraic combinations of the satellite bands, are exploited within a multicriteria hierarchical analysis approach on top of a verified unsupervised thresholding approach [11, 21].The methodology has undergone rigorous testing and validation within the WQeMS H2020 project, utilizing data from the Dniester River in Ukraine collected over five consecutive years within the a series of the studies: research activities funded by the Ministry of Education and Science of Ukraine, GEF-UNEP funded project Towards INMS and ENI CBC BSB PONTOS (BSB 889) project.
In this ongoing study, we continue to validate our approach in the same Ukrainian region over a five-year period, utilizing Sentinel-2 satellite imagery. However, we have incorporated traditional machine learning techniques to enhance aquatic vegetation segmentation accuracy when compared to our previous hierarchical histogram thresholding method. Additionally, we explore the effectiveness of classical texture features for mapping aquatic vegetation and conduct a feature importance analysis using the Maximum Relevance and Minimum Redundancy (MRMR) algorithm [22] to further improve the accuracy and robustness of our approach.
Materials and Methods
Study Area
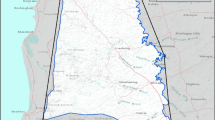
Our research focus lies within the Lower Dniester Basin, encompassing the Dniester Delta and the adjoining Dniester Estuary in Southern Ukraine, covering an approximate total area of 1800 square kilometers (as depicted in Fig. 1). This region includes the expanse of the Lower Dniester National Nature Park (LDNNP). Notably, the Dniester River, which flows into the Black Sea, holds the distinction of being the largest transboundary river in Western Ukraine and Moldova. Situated within the Black Sea lowland, this area primarily comprises steppe plains. The landscape is characterized by gently undulating plains, which have played a pivotal role in the formation of expansive wetland areas along the river’s floodplain. These wetlands are intricately dissected by branches and ancient riverbeds, often subject to flooding, as documented by OSCE in 2005 [23].

The study area encompasses the Dniester Delta (outlined in red) and includes the region occupied by the Lower Dniester National Nature Park (shown as a dashed area), superimposed on a snapshot from Google Earth imagery. Image sourced from [10]
The pilot area experiences a temperate continental climate. Over the period from 2000 to 2014, the average annual mean air temperature stood at 10.5\(^\circ \hbox {C}\), with fluctuations ranging from \(8.4^\circ \hbox {C}\) to \(12.5^\circ \hbox {C}\) [2]. During this same time frame, the long-term average annual precipitation amounted to 464 mm. However, there have been significant variations in recent years, with precipitation levels ranging from 420 mm in 2020 to 771 mm in 2021. The rate of atmospheric total nitrogen (TN) deposition is of a moderate nature, approximately 11.4 kg N per hectare per year [3], with organic constituents contributing to approximately \(67\%\) of this total. A similar substantial organic contribution is also observed in the open waters of the northwestern part of the Black Sea [24, 25].
Satellite Imagery
Sentinel-2 (Level 2A) datasets have been retrieved from the Copernicus European Space Agency (ESA) repository for the following dates: 11/08/2017, 11/08/2018, 17/07/2019, 05/08/2020, and 10/08/2021. These data acquisitions pertain to the specific geographical tile identified as T35TQM.
Validation data
Field measurements of aquatic vegetation boundaries were carried out in the northern part of the Dniester Estuary by Odesa National I.I. Mechnikov University (ONU) as part of annual surveys conducted in July from 2010 to 2021. These surveys were conducted within national projects focused on studying Dniester ecosystems and were financially supported by the Ministry of Education and Science of Ukraine [9, 26]. The methodology involved several key steps:
Tracking the boundaries of emergent and floating vegetation using a boat-mounted GPS device, specifically the Eagle SeaCharter 640CDF GPS, with a horizontal accuracy of 3–5 ms. In cases where it was challenging to distinguish between floating and densely semi-submerged vegetation, the sum of both types was recorded as floating vegetation.
Visual assessment of emergent and floating vegetation, including identification of vegetation types and estimation of their coverage. This information was documented through a photo report.
Post-expeditionary processing of geolocation data, which involved downloading and converting GPS data into a coordinate system compatible with Geographical Information Systems (GIS) software.
In GIS software, the position of aquatic vegetation boundaries was reviewed and manually adjusted, as needed. This process was aided by available satellite images (such as LandSat 5, 7, 8, and Sentinel-2), particularly in areas where navigating the boat through aquatic vegetation polygons was challenging due to dense vegetation cover or other obstacles.
Spatial analysis of aquatic vegetation polygons was conducted using GIS software. This analysis included corrections for boat indentation from the vegetation boundaries, generation of digital maps depicting emergent and floating vegetation cover, and examination of spatiotemporal variations in emergent and floating aquatic vegetation within specific sectors of the Dniester Delta (as depicted in Fig. 2). The study area was divided into five sectors based on geohydromorphological characteristics: (i) Sector A: the northern part of the Dniester estuary with extensive wetland areas on the right bank of the river (76.3 km²); (ii) Sector B: the area between two branches (Deep Turunchuk and Dniester) of the Dniester river (81.2 km²); (iii) Sector D: the area around the mouth of the Dniester branch and its adjacent region (20.3 km²); (iv) Sector E: the area encompassing the left bank of the Dniester branch and Karaholsky bay (26.9 km²); (v) Sector F: the open water central part of the Dniester Estuary (51.6 km²).

Geographical representation of sectors employed for spatiotemporal analysis of emergent and floating vegetation cover within the deltaic part of the Lower Dniester. Image sourced from [10]
Ground reference data collected on 01/08/2017, 22/07/2018, 17/07/2019, 05/08/2020, and 26/07/2021 were employed for validation purposes as follows:
Data from 01/08/2017 were used to validate predictions made for 11/08/2017. Data from 22/07/2018 were used to validate predictions made on 11/08/2018. Data from 17/07/2019 were used to validate predictions made for 17/07/2019. Data from 05/08/2020 were used to validate predictions for 05/08/2020. Data from 26/07/2021 were used to validate predictions for 10/08/2021. It’s worth noting that due to varying cloud conditions, some ground and satellite data acquisition dates differed by zero (0) to twenty (20) days. While this effect is considered negligible in terms of the development of plant communities during this period, it is still visible in the results and is discussed accordingly.
Methodology
Histogram-Based Thresholding Approach
A number of machine learning techniques based on band combinations and texture features were compared with the methodology from our prior work (Manakos et al. [10]), which approach involves an unsupervised thresholding methodology to segment the study area into three key aquatic vegetation categories (open water, emergent vegetation, and floating vegetation). This approach comprises three stages:
Stage 1: Initial Classification: Employing Sentinel-2 bands B04 (red), B08(near infrared; NIR), and B11(shortwave infrared; SWIR), the region was categorized as land, open water, or emergent vegetation. This was in line with the thresholding approach proposed by Kordelas et al., 2018 [11] (Refer to Fig. 3). Pixels with SWIR values less than the first deep valley (as indicated in Fig. 3, left red dashed line presenting the applied mean value across the dates) were labeled as open water. Emergent vegetation was discerned by:
-
1.
SWIR band pixel values lying between the first and second deep valleys (Fig. 3, between left and right dashed line, presenting the applied mean value across the dates),
-
2.
\(NDVI = \frac{B08+B04}{B08-B04}\) values beyond the first valley that is greater than 0.3 (Fig. 3, dashed line presenting the applied mean value across the dates).
-
3.
Remaining regions were designated as ’unclassified’ due to their peripheral relevance to aquatic vegetation mapping.
Stage 2: Floating Vegetation Identification: Additional Sentinel-2 bands, B05 (red edge; RE) and B12 (shortwave infrared; SWIR2) were harnessed. The floating vegetation detection was based on three specific criteria developed from histogram analyses and insights on spectral responses of water and vegetation. Specifically:
-
1.
\(\frac{B05}{B11}\) ratio positioned between 0.6 and 1.5,
-
2.
\(NDWI = \frac{B08-B11}{B08+B11}\) values between 0.2 and 0.45,
-
3.
B12 band values ranged from 100 to 900.
Stage 3: Integration of Results: Findings pertaining to floating vegetation from Stage 2 were layered atop Stage 1 outcomes. Areas confirmed as floating vegetation superseded any prior classifications. The concluding output was a comprehensive map showcasing all three vegetation types.

Sentinel-2 bands and indices thresholds in histograms as suggested by Manakos et al. [10], for identifying floating vegetation, emergent vegetation and open water classed in different dates. The y axis represents actual number of pixels
Machine Learning Approach
The machine learning approach for classifying floating, emergent, and open water classes using Sentinel-2 imagery is assessed using a leave-one-date-out strategy. This entails evaluating various ML models on a single date after they have been trained on all other dates, and this process is iteratively carried out for each date. Besides the 12 bands of the Sentinel-2 L2A products for each pixel, additional features have been introduced based on the domain knowledge acquired from our previous work and from texture features.
Specifically, features such as the Normalized Difference Vegetation Index (NDVI), Normalized Difference Water Index (NDWI), and the ratio ’B05/B11’ are calculated as supplementary features. Our earlier study [10] showed significant discriminative potential in these features after histogram thresholding. In addition, texture features for each band are derived using the Local Binary Pattern (LBP) method. The LBP method is renowned for its ability to highlight textures in an image, making it useful for distinguishing various land cover types [27]. This multiresolution and rotation invariant texture analysis adds another layer of feature richness, enabling to better interpret the classification results. LBP examines the points around a central point and determines whether these surrounding points are higher or lower than the central point, yielding a binary outcome. The radius of the circle for LBP features is set to 2 units, while the number of circularly symmetric neighbor set points is set to 16.
In order to conduct a comprehensive analysis that remains unbiased by the distinctive strengths of any one classifier, we selected classifiers from two primary categories. Additionally, we employed diverse sets of hyperparameters for each classifier. This approach mitigates the potential influence of hyperparameter selection, allowing us to concentrate exclusively on the efficacy of each feature set.
Random Forest (RF): This ensemble method constructs multiple decision trees and combines their outputs to enhance multiclass classification accuracy. RF utilizes a bagging technique, building several decision trees in parallel, with the final decision derived from a majority vote. The minimum number of samples required to split an internal node is set to 2, [50–150] is the number of estimators and the Gini impurity metric is used for the decision of a tree split.
XGBoost [28]: XGBoost employs a boosting approach where decision trees are built sequentially. Each subsequent tree aims to correct the errors made by the one before it. The final output is an aggregate result from all the trees. This classifier is powered by the XGBoost library, which is built upon the gradient boosting framework. This framework uses decision trees as its foundational learners and incorporates regularization and various optimizations to enhance speed and performance. The ranges of hyperparameters used are: [0.3\(-\)0.5] for learning rate, [8–12] for maximum depth of a tree, 1 for L2 regularization term on weights and [50–150] number of estimators.
The assessment of accuracy was conducted using three metrics: F1-score, producer’s accuracy (PA), often termed recall, and user’s accuracy (UA), frequently referred to as precision. The F1-score is a measure that harmoniously integrates UA and PA, yielding a single score that accounts for both false positives and false negatives. PA, or recall, is calculated by taking the ratio of correctly classified pixels for a particular class to the total number of reference pixels for that class, highlighting instances of false negatives. In contrast, UA, or precision, focuses on false positives. It’s derived by dividing the number of correctly predicted pixels for a class by the total pixels classified as that class. This metric illustrates how well a classified pixel aligns with its true class on the ground.
Feature Importance Analysis
Feature importance in machine learning is useful in understanding which features predominantly influence the prediction outcomes of the model. For this study, the Max-Relevance Min-Redundancy (MRMR) algorithm was employed to quantify and rank the significance of features.
The MRMR algorithm operates on two primary criteria: maximizing the relevance of features with the target class while simultaneously minimizing the redundancy among the features themselves [27]. The idea is to identify a subset of features that not only has high discriminative power but also retains low inter-feature correlation, ensuring the diversity of the selected features.
To evaluate the classification performance based on the MRMR-determined feature ordering, we carried out experiments using subsets of features. These subsets were formed incrementally, starting with the top-ranked feature and gradually adding the next important feature according to the MRMR ranking. For instance, the first experiment used only the most important feature, the second experiment used the top two features, and so on. This allowed us to observe how classification performance evolved as more features were included.
Results
The classification maps for the three classes-floating vegetation, emergent vegetation, and open water-are depicted in Fig. 7. Within this figure, each row corresponds to a specific date over the 5-year study period, and each column represents a distinct classification algorithm. The first column showcases the ground-truth reference data, as elaborated in Section “Validation data”. The second column reproduces results from our previous study by Manakos et al. [10] using the histogram thresholding method described in Section “Methodology”. In the last two columns, the outcomes from various ML algorithms and hyperparameters are presented. Specifically, the third column relies solely on the 12 bands of Sentinel-2 for its input features. In contrast, the fourth column incorporates, along with the 12 bands, the indices [’NDVI’, ’NDWI’, ’B05/B11’] as advised by [10].
The barplots in Figs. 4, 5, and 6 illustrate a quantitative analysis of the classification performance for each of the three classes. This is gauged in terms of F1-score, user’s accuracy (UA or precision), and producer’s accuracy (PA or recall). These figures compare the performance of different feature sets fed into ML algorithms against the baseline results from our prior study by Manakos et al. [10]. The exhaustive testing of ML algorithms and hyperparameter selections are represented as 95th-percentile confidence intervals.

Comparison of F1-scores using different input features and algorithms. Assessing different ML algorithms and hyperparameters selection is represented as 95th-percentile confidence intervals

Comparison of user’s accuracy (precision) using different input features and algorithms. Assessing different ML algorithms and hyperparameters selection is represented as 95th-percentile confidence intervals

Comparison of producer’s accuracy (recall) using different input features and algorithms. Assessing different ML algorithms and hyperparameters selection is represented as 95th-percentile confidence intervals

Classification maps for floating vegetation, emergent vegetation, and open water. The dark blue class represents land or unclassified pixels in the case of [10]
In the figures, blue represents metrics for the results reproduced using the histogram thresholding method from [10]. As this thresholding approach, detailed in Sect. 2.4, deterministically computes a series of if-then scenarios for each date, no confidence intervals are depicted. Orange color assesses the group of ML methods (XGBoost classifier and random forest, with various hyperparameters) using only the 12 Sentinel-2 bands. Green introduces the indices [’NDVI’, ’NDWI’, ’B05/B11’] to the feature vector, complementing the Sentinel-2 bands. Purple evaluates classifiers using only the five indices [’NDVI’, ’NDWI’, ’B05/B11’, ’B11’, ’B12’] as used solely in [10]. Lastly, red incorporates 12 texture features computed by the local binary pattern (LBP) for each of the 12 bands, resulting in a total of 27 features for each pixel.
Table 1 summarizes the classification performance metrics, specifically tailored for the floating vegetation class. The last row revisits findings from Manakos et al. [10] using the histogram thresholding method. Subsequent entries detail results from ML algorithms with diverse feature sets. This table facilitates a direct comparison, highlighting the efficacy of each method in classifying challenging vegetation segments.
The last segment of our analysis focuses on feature importance and selection. Table 2 showcases the rankings of the top 20 features as determined by the MRMR algorithm. This ranking was obtained from multi-class classification, consolidating data across all dates. Building upon this, Fig. 8 illustrates the classification performance of the most challenging floating vegetation class for each individual date, relying on varying subsets of features as dictated by the MRMR order. Notably, the F1-scores presented for the floating vegetation class are derived from different ML algorithms and hyperparameters.

Classification performance of the floating vegetation class based on subsets of features derived from the MRMR ordering: 1.B11, 2.B12, 3.B09, 4.NDVI, 5.B08, 6.B07, 7.B06, 8.B01, 9.B05, 10.B05/B11, 11.B8A, 12.B02, 13.NDWI, 14.B03, 15.B04, 16.\(LBP_{B08}\), 17.\(LBP_{B07}\), 18.\(LBP_{B04}\), 19.\(LBP_{B06}\), 20.\(LBP_{B02}\). The F1-scores for the floating vegetation class are computed using a combination of ML algorithms and hyperparameters
Discussion
From the classification maps in Fig. 7, we generally observe a good classification in agreement with the reference maps in the first column. A notable discrepancy is evident in the 2017 map that uses only Sentinel-2 bands (third column, last row), where false positives appear for the floating vegetation class within the open water region. This issue is rectified when incorporating the indices recommended by [10] as input features, increasing the robustness of the ML algorithms. This observation is further supported quantitatively in Figs. 4, 5 and 6 for the floating vegetation class.
In the examination of the performance metrics related to various input feature sets, several observations can be noted from the summarized Table 1. Specifically, the feature set that combines bands and indices yields the top F1 score of 0.88, comparable to the combination of indices with texture. In contrast, solely using the bands yields a slightly reduced F1 score of 0.864±0.055 but maintains commendable classification performance. Limiting the feature set to just indices drops the performance further to 0.852±0.031. These results indicate that adding the three indices (NDVI, NDWI, and the ratio B05/B11) increase the methodology’s robustness, as evident from a single date evaluation. However, no discernible enhancement is observed from integrating texture features of local binary patterns for each band. Finally, the employed ML models for classifying the challenging floating vegetation class, outperforming the reproduced results of the histogram-based thresholding method from Manakos et al. [10] with F1 score of 0.697±0.041.
In line with findings from our earlier study [10], the ’Open Water’ class consistently registered the highest F1-scores, precision (UA), and recall (PA) across the five validation dates. Conversely, the ’Floating Vegetation’ class consistently underperformed, particularly in terms of PA (recall). This highlights the inherent difficulties in discerning this class from its surrounding environment. Such trends are evident in Figs. 4, 5, and 6, where the ’Open Water’ class is almost impeccably classified across all methods. Regions of emergent vegetation, on the other hand, exhibited diminished recall when classified using the histogram-based thresholding approach from [10]. In this context, low recall signifies a higher count of False Negatives. These discrepancies are effectively rectified when deploying simple ML methodologies. The preference for these simple ML solutions over newer or more experimental approaches, such as deep learning, is grounded in their robustness, interpretability, and proven success in similar applications.
Several factors contribute to the challenges in correctly identifying water lilies and chestnuts, which represent the floating vegetation in our study area. Notably, the classification accuracy seems to be influenced by the species of the floating vegetation and its density. According to [14], testing across various wetlands in the lake revealed that high-density floating vegetation resulted in elevated producer’s accuracy (PA), whereas user’s accuracy (UA) was higher in areas with low-density floating vegetation. This observation is consistent with the findings from a study on Lake Luupuvesi in Finland by [15], which also reported a higher PA for dense floating vegetation and a superior UA for sparser vegetation. Additionally, potential discrepancies between reference and classification dates, (1 to 20 days, as described in Section “Validation data”), can introduce label errors. Such variances could stem from genuine shifts in floating vegetation distribution, wind-induced changes in vegetation polygon density or geometry, or even wave- or water-level-induced effects causing plant leaves to become moistened or partially submerged in the estuary during these periods.
Utilizing the leave-one-date-out validation technique offers a robust evaluation for the ML algorithms. Given that the five dates under examination span a 5-year period, we can confidently assert that a classifier trained on this limited dataset is temporally transferable, i.e., training a model with only a few dates can be used in other dates of similar seasonality. One possible limitation of the study is the inclusion of imagery solely during summer time for training and validation. However, the model’s transferability in time enables aquatic vegetation mapping of this region back to 2016, coinciding with the beginning of the Sentinel-2 mission’s imagery provision. Beyond the evident cost benefits of foregoing yearly mapping missions for emergent and floating vegetation, such an approach holds practical utility and could greatly enhance related ecological studies.
Moreover, the feature importance analysis, informed by the MRMR algorithm, elucidates two significant dimensions of our study:
Firstly, upon analyzing the first 10 features from our comprehensive feature vector, a saturation point becomes evident, as illustrated in Fig. 8. This point denotes a threshold beyond which the inclusion of additional features doesn’t substantively improve the classification outcomes. Moreover, the incorporation of further features doesn’t diminish the classification’s efficiency either. Identifying such a saturation point aids in evading overfitting and simultaneously upholds model simplicity without sacrificing precision.
Secondly, our resultant feature ranking harmonizes with the conclusions drawn in our preceding study [10]. It emphasizes the distinctively influential roles of bands B11, B12, B09, and the NDVI index in the delineation of aquatic vegetation. Moreover, the addition of index B05/B11, together with NDVI and NDWI as input features has shown to increas the robustness of the classifier. It’s worth noting, however, that certain features, despite receiving a lower rank from the MRMR algorithm due to inherent redundancy, may still hold intrinsic value. Their contribution, in specific contexts, could be substantial to the overall classification task.
Conclusion
This study presented a comprehensive exploration into the classification of aquatic (emergent and floating) vegetation using various feature sets from Sentinel-2 images and deploying traditional machine learning algorithms, building upon our prior study [10] that suggested a histogram-based thresholding methodology. Our research has benefited from and underscored the value of field measurements and meticulous validation methodologies. The employed ML algorithms, namely random forest and boosting trees, consistently showcased commendable performance, distinctly surpassing the histogram-based thresholding technique.
While the 12 bands from Sentinel-2 L2A imagery already provided a robust feature set, the inclusion of select indices (NDVI, NDWI, and the ratio B05/B11) further refined the methodology, especially evident during a singularly challenging date. Moreover, the feature importance analysis conducted using the MRMR algorithm revealed a saturation point for robustly classifying aquatic vegetation with just 10 distinct features. Beyond the Sentinel-2 bands (mainly B11, B12, B09), this includes the NDVI and B05/B11 indices. These results verify the ones from our previous work [10]. In addition, worth to mention is that the introduction of texture features yielded no additional enhancement to the already superior accuracy; yet, resulted to no diminishing effect either.
Our results suggest an accurate alignment between the ML based classification maps from spaceborne images and the reference in situ data over a 5-year study period. Using the leave-one-date-out validation scheme, the temporal transferability of our classifier is thus demonstrated. This method allows for aquatic vegetation mapping back to 2016, aligned with the start of the Sentinel-2 mission. This approach not only saves costs but also offers valuable insights for ecological studies.
Data Availibility Statement
The data presented in this study are available on request from the corresponding authors. The data are not publicly available due to their use for ongoing research and intended publications on the topic by the authorship working teams.
References
Sutton MA, Howard CM, Erisman JW, Billen G, Bleeker A, Grennfelt P, Van Grinsven H, Grizzetti B. The European Nitrogen Assessment: Sources. Cambridge: Effects and Policy Perspectives. Cambridge University Press; 2011.
Medinets S, Gasche R, Skiba U, Medinets V, Butterbach-Bahl K. The impact of management and climate on soil nitric oxide fluxes from arable land in the southern ukraine. Atmos Environ. 2016;137:113–26.
Medinets S, Kovalova N, Medinets V, Mileva A, Gruzova I, Soltys I, Cherkez E, Kozlova T, Morozov V, Trombitsky I. Assessment of riverine loads of nitrogen and phosphorus to the dniester estuary and the black sea over 2010–2019. In: XIV International Scientific Conference “Monitoring of Geological Processes and Ecological Condition of the Environment”, 2020;vol. 2020, pp. 1–5 . European Association of Geoscientists & Engineers
Medinets S, Mileva A, Kotogura S, Gruzova I, Kovalova N, Konareva O, Cherkez E, Kozlova T, Medinets V, Derevencha V. Rates of atmospheric nitrogen deposition to agricultural and natural lands within the lower dniester catchment. In: XIV International Scientific Conference “Monitoring of Geological Processes and Ecological Condition of the Environment”, 2020;vol. 2020, pp. 1–5 . European Association of Geoscientists & Engineers
Kovalova N, Medinets V, Medinets SV. Peculiarities of long-term changes in bacterioplankton numbers in the dniester liman. Hydrobiological Journal. 2021;57:(1)
Rouholahnejad E, Abbaspour KC, Srinivasan R, Bacu V, Lehmann A. Water resources of the black sea basin at high spatial and temporal resolution. Water Resour Res. 2014;50(7):5866–85.
Greenfield BK, Siemering GS, Andrews JC, Rajan M, Andrews SP, Spencer DF. Mechanical shredding of water hyacinth (eichhornia crassipes): Effects on water quality in the sacramento-san joaquin river delta, california. Estuaries Coasts. 2007;30:627–40.
Hussner A, Stiers I, Verhofstad M, Bakker E, Grutters B, Haury J, Van Valkenburg J, Brundu G, Newman J, Clayton J. Management and control methods of invasive alien freshwater aquatic plants: a review. Aquat Bot. 2017;136:112–37.
Medinets S, Gazyetov Y, Ridka Y, Pavlik T, Yakuba I, Medinets V, Pauzer O, Snihirov S, Kovalova N. Accumulation of nitrogen, phosphorus, potash, and dynamic patterns of cover growth in emergent and floating aquatic vegetation of the dniester delta region. Monitoring of Geological Processes and Ecological Condition of the Environment .2023;
Manakos I, Katsikis E, Medinets S, Gazyetov Y, Alagialoglou L, Medinets V. Identification of Emergent and Floating Aquatic Vegetation Using an Unsupervised Thresholding Approach: A Case Study of the Dniester Delta in Ukraine. GISTAM, ??? 2023;
Kordelas GA, Manakos I, Aragonés D, Díaz-Delgado R, Bustamante J. Fast and automatic data-driven thresholding for inundation mapping with sentinel-2 data. Remote Sensing. 2018;10(6):910.
Chen Q, Yu R, Hao Y, Wu L, Zhang W, Zhang Q, Bu X. A new method for mapping aquatic vegetation especially underwater vegetation in lake ulansuhai using gf-1 satellite data. Remote Sensing. 2018;10(8):1279.
Espel D, Courty S, Auda Y, Sheeren D, Elger A. Submerged macrophyte assessment in rivers: An automatic mapping method using pléiades imagery. Water Res. 2020;186: 116353.
Midwood JD, Chow-Fraser P. Mapping floating and emergent aquatic vegetation in coastal wetlands of eastern georgian bay, lake huron, canada. Wetlands. 2010;30:1141–52.
Valta-Hulkkonen K, Kanninen A, Pellikka P. Remote sensing and gis for detecting changes in the aquatic vegetation of a rehabilitated lake. Int J Remote Sens. 2004;25(24):5745–58.
Ade C, Khanna S, Lay M, Ustin SL, Hestir EL. Genus-level mapping of invasive floating aquatic vegetation using sentinel-2 satellite remote sensing. Remote Sensing. 2022;14(13):3013.
Han K, Wang Y, Chen H, Chen X, Guo J, Liu Z, Tang Y, Xiao A, Xu C, Xu Y. A survey on vision transformer. IEEE Trans Pattern Anal Mach Intell. 2022;45(1):87–110.
Zhu XX, Tuia D, Mou L, Xia G-S, Zhang L, Xu F, Fraundorfer F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE geoscience and remote sensing magazine. 2017;5(4):8–36.
Kirillov A, Mintun E, Ravi N, Mao H, Rolland C, Gustafson L, Xiao T, Whitehead S, Berg AC, Lo W-Y, et al. Segment anything. 2023; arXiv preprint arXiv:2304.02643
Alagialoglou L, Manakos I, Papadopoulou S, Chadoulis R-T, Kita A. Mapping underwater aquatic vegetation using foundation models with air-and space-borne images: The case of polyphytos lake. Remote Sensing. 2023;15(16):4001.
Manakos I, Kordelas GA, Marini K. Fusion of sentinel-1 data with sentinel-2 products to overcome non-favourable atmospheric conditions for the delineation of inundation maps. European Journal of Remote Sensing. 2020;53(sup2):53–66.
Zhao Z, Anand R, Wang M. Maximum relevance and minimum redundancy feature selection methods for a marketing machine learning platform. In: 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA).2019; pp. 442–452 IEEE
OSCE: Transboundary diagnostic study for the dniester river basin. Project Report. 2005; 94
Medinets S, Medinets V. Investigations of atmospheric wet and dry nutrient deposition to marine surface in western part of the black sea. Turk J Fish Aquat Sci. 2012;12(5):497–505.
Medinets S. The black sea nitrogen budget revision in accordance with recent atmospheric deposition study. Turk J Fish Aquat Sci. 2014;14(5):981–92.
Rudka Y, Medinets S, Yakuba I, Gazyetov Y, Medinets V, Nazarchuk Y, Pauzer O. Heavy metal accumulation in aquatic plants growing in water bodies of the lower dniester catchment (ukraine). In: 16th International Conference Monitoring of Geological Processes and Ecological Condition of the Environment.2022; vol. 2022, pp. 1–5 European Association of Geoscientists & Engineers
Ojala T, Pietikainen M, Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans Pattern Anal Mach Intell. 2002;24(7):971–87.
Chen T, Guestrin C. XGBoost: A scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD ’16, pp. 785–794. ACM, New York, NY, USA. 2016; https://doi.org/10.1145/2939672.2939785 . http://doi.acm.org/10.1145/2939672.2939785
Jakubik, J., Roy, S., Phillips, C.E., Fraccaro, P., Godwin, D., Zadrozny, B., Szwarcman, D., Gomes, C., Nyirjesy, G., Edwards, B. and Kimura, D., 2023. Foundation models for generalist geospatial artificial intelligence. arXiv preprint arXiv:2310.18660.
Acknowledgements
This study has been financially supported by the European Union’s Horizon 2020 Research and Innovation Action program, granted under Agreement Number 101004157 - WQeMS. Additionally, it received partial backing from the ’Towards INMS’ project, funded by GEF-UNEP (www.inms.international). Ground reference data were obtained through research and activities, funded by the Ministry of Education and Science of Ukraine (2017–2022), and ENI CBC BSB PONTOS, under Grant Agreement BSB 889.
Funding
This study has been financially supported by the European Union’s Horizon 2020 Research and Innovation Action program, granted under Agreement Number 101004157 - WQeMS.
Author information
Authors and Affiliations
Contributions
Conceptualization and methodology development: All the authors; Software and data analysis: L.A., I.M., E.K.; Data acquisition and Validation: L.A., E.K., S.M., Y.G., V.M.; Writing and reviewing: L.A., I.M., E.K., S.M., A.D.; Supervision and funding acquisition: L.A., I.M., A.D.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no Conflict of interest.
Informed Consent
Not applicable.
Research Involving Human and /or Animals
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Advances on Geographical Information Systems Theory, Applications and Management” guest edited by Lemonia Ragia, Cédric Grueau and Armanda Rodrigues.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alagialoglou, L., Manakos, I., Katsikis, E. et al. Machine Learning for Identifying Emergent and Floating Aquatic Vegetation from Space: A Case Study in the Dniester Delta, Ukraine. SN COMPUT. SCI. 5, 597 (2024). https://doi.org/10.1007/s42979-024-02873-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-024-02873-7