
Abstract
This research explores substitution of the fittest (SF), a technique designed to counteract the problem of disengagement in two-population competitive coevolutionary genetic algorithms. SF is domain independent and requires no calibration. We first perform a controlled comparative evaluation of SF’s ability to maintain engagement and discover optimal solutions in a minimal toy domain. Experimental results demonstrate that SF performs similarly to alternative techniques presented in the literature but has the advantage of requiring no parameter tuning. We then address the more complex real-world problem of evolving recommendations for health and well-being. We introduce a coevolutionary extension of EvoRecSys, a previously published evolutionary recommender system. We demonstrate that SF is able to maintain a better trade-off between engagement and performance than other techniques in the literature, and the resultant recommendations using SF are higher quality and more diverse than those produced by EvoRecSys.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
While attempting the problem of designing optimal sorting networks using a genetic algorithm (GA), Hillis decided that rather than use randomly generated input lists to evaluate sorting networks, he would instead co-evolve a population of input lists that are evaluated on their ability to not be sorted [1]. By coupling the evolution of input lists with the evolution of the networks to sort those lists, Hillis attempted to create an “arms race” dynamic such that input lists consistently challenge networks that are sorting them. As networks improve their ability to sort, so lists become more difficult to sort, etc. This coevolutionary approach significantly improved results and generated wide interest, offering a new ability to tackle domains where an evaluation function is unknown or difficult to operationally define; and offering the potential for open-ended evolutionary progress through self-learning.
However, it soon emerged that coevolution can suffer from pathologies that cause the system to behave in an unwanted manner and prevent continual progress towards some desired goal. For example, populations may continually cycle with no overall progress; populations may progress in an unintended and unwanted direction; populations may stop competing and settle into a mediocre stable state; and populations may disengage and stop progressing entirely. These pathologies have been studied in depth and a variety of techniques have been introduced as remedy (see [2]). Yet, there is still much to be understood, and no panacea has been discovered.
In previous work [3], the current authors proposed substitution of the fittest (SF), a novel domain-independent method designed to tackle the problem of disengagement in two-population competitive coevolutionary systems. In [3], SF was explored in the deliberately simple greater than domain, a toy problem originally introduced to elaborate the dynamics of coevolution [4]. In this paper, we extend [3] in two ways. First, we perform a more extensive comparative analysis of SF in the greater than domain; using mutation bias as a control to simulate the dynamics of more complex real-world application domains. Second, we test the applicability of the findings from the greater than game by addressing the more complex problem of recommender systems for health and well-being; and we show that a coevolutionary approach using SF outperforms the evolutionary approach published in [5]. We present this as evidence that SF is likely to be generally beneficial across a variety of real-world application domains where coevolutionary disengagement occurs.
The rest of this paper is organised as follows. Section “Background” presents a review of coevolutionary genetic algorithms, their pathologies, and techniques to counteract said pathologies. Much of this background is reproduced directly from [3]. In Section “Substitution of the Fittest”, we introduce substitution of the fittest. Section “Explorations in the “Greater Than” Game” presents a series of controlled experiments conducted in the deliberately minimal greater than domain and the performance of SF is compared against other techniques from the literature, reduced virulence (RV) [6] and autonomous virulence adaptation (AVA) [7]. In Section “Coevolving Well-Being Recommendations”, we present experiments conducted in the more complex real-world domain of recommender systems for health and well-being. This work introduces a coevolutionary extension of a previously published evolutionary recommender system (EvoRecSys) [5]. It is shown that SF is able to produce recommendations that are of higher quality and more diverse than the results obtained using RV and AVA, and also produces better overall recommendations than the standard evolutionary approach of EvoRecSys. Finally, Section “Conclusions” presents conclusions and avenues for future research investigation.
Background
Coevolutionary genetic algorithms with two distinct populations are often described using terminology that follows the biological literature. As such, and following Hillis’ original formulation, the populations are often named as “hosts” and “parasites” [1]. In such cases, the host population tends to denote the population of candidate “solutions” that we are interested in optimising (e.g., the sorting networks), while the parasite population tends to denote the population of test “problems” for the solution population to solve (e.g., the lists to sort); i.e., the hosts are the models and the parasites are the training set; or alternatively the hosts are the learners and the parasites are the teachers. Throughout this paper, we tend to use the host-parasite terminology to distinguish coevolving populations. However, while this terminology is meaningful in asymmetric systems where one population (the model) is of most interest, it should be noted that in symmetric systems, such as games of self-play where both coevolving populations are models with the same encoding scheme, the two populations become interchangeable and the names host and parasite have less meaning. In an ideal scenario, two-population competitive coevolution will result in an arms race such that both populations continually evolve beneficial adaptions capable of outperforming competitors.
As a result, there is continual system progress towards some desired optimum goal. However, this ideal scenario rarely materialises. In practice, coevolutionary systems tend to exhibit pathologies that restrict progress [4]. These include cycling, where populations evolve through repeated trajectories like players in an endless game of rock-paper-scissors; and while short-term evolution exhibits continual progress, there is no long-term global progress [8].
Alternatively, populations may start to overspecialise on sub-dimensions of the game, such that evolved solutions are brittle and do not generalise [9]. Furthermore, one population may begin to dominate the other to such an extent that populations disengage and evolutionary progress fails altogether, with populations left to drift aimlessly [6]. The likelihood of suffering from these pathologies can be exacerbated by the problem domain. Cycling is more likely when the problem exhibits intransitivity; overspecialisation is more likely in multi-objective problems; and disengagement is more likely if the problem has an asymmetric bias that favours one population [4].
Numerous techniques have been proposed for mitigating the pathologies that prevent continual coevolutionary progress (for detailed reviews, see [2, 10]). We can roughly group these approaches into three broad categories; although in practice many techniques straddle more than one category.
First, there are archive methods, which are designed to preserve potentially valuable adaptations from being “lost” during the evolutionary process. The first coevolutionary archiving technique is the Hall of Fame (HoF) [11]. Every generation, the elite member of each population is stored in the HoF archive. Then, individuals in the current population are evaluated against current competitors and also against members of the HoF. This ensures that later generations are evaluated on their capacity to beat earlier generations as well as their contemporaries. However, as the archive grows each generation, simple archiving methods like the HoF can become unwieldy over time. To counter this, more sophisticated and efficient archiving methods have been introduced to simultaneously minimise archive size while maximising archive “usefulness”. An efficient example is the Layered Pareto Coevolutionary Archive (LAPCA), which only stores individuals that are non-dominated and unique; while the archive itself is pruned over time to keep the size within manageable bounds [12].
More recent variations on Pareto archiving approaches include rIPCA, which has been applied to the problem of network security through the coevolution of adversarial network attack and defence dynamics [13]. Pareto dominance has also been employed for selection without the use of an archive, for example the Population-based Pareto Hill Climber [14]; and Pareto fronts have been incorporated into an “extended elitism” framework, where offspring are selected only if they Pareto dominate parents when evaluated against the same opponents [15].
A second popular class of approaches attempt to maintain a diverse set of evolutionary challenges through the use of spatial embedding and multiple populations. Spatially embedded algorithms—where populations exist on an n-dimensional plane and individuals only interact with other individuals in the local neighbourhood—have been shown to succeed where other non-spatial coevolutionary approaches fail. Explanations for how spatial models can help combat disengagement through challenge diversity have been explored in several works [16, 17]. Challenge diversity can also be maintained through the use of multiple genetically-distinct populations (i.e., with no interbreeding or migration). Examples include the friendly competitor, where two model populations (one “friendly” and one “hostile”) are coevolved against one test population [18]. Tests are rewarded if they are both easy to be defeated by a friendly model and hard to be beaten by a hostile model; thereby ensuring pressure on tests to evolve at a challenge-level consistent with the ability of models. Recently, a new method incorporating the periodic spawning of sub-populations, and then re-integration of individuals that perform well across multiple sub-populations back into the main population has been shown to encourage continual progress in predator–prey robot coevolution [19].
Finally, there are approaches that focus on adapting the mechanism for selection such that individuals are not selected in direct proportion to the number of competitions that they win; i.e., selection favours individuals that are not unbeatable. An early endeavour in this area is the phantom parasite, which marginally reduces the fitness of an unbeatable competitor, while all other fitness values remain unchanged [20]. Later, the \(\Phi\) function was introduced for the density classification task to coevolve cellular automata rules that classify the density of an initial condition [21]. The \(\Phi\) function translates all fitness values such that individuals are rewarded most highly for being equally difficult and easy to classify (i.e., by being classified correctly half of the time); while individuals that are always classified or always unclassified are punished with low fitness. However, while \(\Phi\) worked well, it was limited by being domain-specific.
More generally applicable is the reduced virulence (RV) technique [6, 22]. Inspired by the behaviour of biological host-parasite systems, where the virulence of pathogens evolves over time, reduced virulence is the first domain-independent technique with tunable parameters that can be configured. After generating a parasite score through competition, reduced virulence applies the following non-linear function to generate a fitness for selection:
where \(0 \le x_i \le 1\) is the relative (or subjective) fitness of individual i and \(0.5 \le \upsilon \le 1\) represents the virulence of the parasite population. When \(\upsilon =1\), Eq. 1) preserves the original ranking of parasites (i.e., the ranking of competitive score, x) and is equivalent to the canonical method of rewarding parasites for all victories over hosts. When \(\upsilon =0.5\), Eq. (1) rewards maximum fitness to parasites that win exactly half of all competitions. Therefore, in domains where there is a bias in favour of one population (the “parasites”), setting a value of \(\upsilon <1\) for the advantaged population reduces the bias differential to preserve coevolutionary engagement. Reduced virulence demonstrated improved performance, but is limited by requiring \(\upsilon\) to be determined in advance. In many domains, bias may be difficult to determine and may change over time. To tackle this problem, reduced virulence has been incorporated into a human-in-the-loop system enabling a human controller to steer coevolution during runtime by observing the system behaviour and altering the value of \(\upsilon\) in real time [23].
Later, autonomous virulence adaptation (AVA)—a machine learning approach that automatically updates virulence during coevolution—was proposed [7]. Each generation t, AVA updates \(\upsilon\) using:
where \(0 \le \alpha , \mu , \tau \le 1\) are learning rate, momentum, and target value, respectively; and \(\overline{X_t}\) is the normalised mean subjective score of the population.Footnote 1 Rigorous calibration of AVA settings demonstrated that values \(\alpha = 0.0125\), \(\mu = 0.3\), and \(\tau = 0.56\) can be applied successfully in a number of diverse domains. In particular, it was shown that AVA can coevolve high performing sorting networks and maze navigation agents with much greater computational efficiency than archive techniques such as LAPCA [7].
Substitution of the Fittest
First introduced in [3], substitution of the fittest (SF) is a domain-independent technique designed to keep coevolving populations engaged. In essence, one can consider that SF acts to keep populations evolving at the same pace by applying a brake on the population evolving more quickly and applying an accelerator on the population evolving more slowly.
In competitive coevolution, subjective fitness \(\psi _i\) of individual i is evaluated through competition such that \(0\le \psi _i\le 1\) is the proportion of victories gained by i. Let \(0\le \sigma _{A}\le 1\) and \(0\le \sigma _{B}\le 1\) represent the mean subjective fitness of individuals in populations A and B, respectively. Then we can calculate disengagement in a two-population coevolutionary system as \(\delta = |\sigma _{A} - \sigma _{B} |\), where \(0 \le \delta \le 1\). When \(\delta =1\) populations are fully disengaged, such that all n individuals in one population are victorious against all opponents in the other population. Each generation, \(\delta\) is calculated and if it has increased from the previous generation then SF is triggered.
The first step of SF is to calculate the number of individuals to be substituted as \(\kappa = \lceil n\delta ^{\frac{1}{\delta }} \rceil\). In the second step, we use the following rules for each population, depending on which has the lowest/highest mean relative fitness \(\sigma\):
- Population with lowest \(\sigma\)::
-
Rank all individuals by subjective fitness \(\psi _i\). Replace bottom \(\kappa\) individuals with the lowest \(\psi _i\) with top \(\kappa\) individuals with the highest \(\psi _i\). Finally, increase the subjective fitness of every individual by \(\psi _{i}'= \min (\psi _{i} + \delta ,1)\).
- Population with highest \(\sigma\)::
-
Rank all individuals by subjective fitness \(\psi _i\). Replace top \(\kappa\) individuals with the highest \(\psi _i\) with bottom \(\kappa\) individuals with the lowest \(\psi _i\). Finally, decrease the subjective fitness of every individual by \(\psi _{i}'= \max (\psi _{i} - \delta ,0)\).
For more details about the dynamics induced by SF, see [3].
Explorations in the “Greater Than” Game
The greater than game [4] was introduced as a minimal coevolutionary substrate capable of demonstrating the pathology of disengagement. Here, we use a variation of the greater than game to explore the performance and behaviour of SF against RV and AVA. We select this domain because it is analytically tractable and simple to configure, which allows us to understand coevolutionary dynamics. The solutions of the game are not of interest in themselves.
Individuals are encoded as bit-strings of length l. The scalar value of each individual is calculated as the sum of the number of bits equal to one. The aim of the game is to maximise this scalar value by discovering individuals with all bits equal to one (i.e., individuals with scalar value l). This problem is trivial in a evolutionary setting if scalar values of individuals can be directly measured. However, the greater than game assumes that the scalar values of individuals can only be accessed by comparing two values such that the subjective fitness of individual \(\alpha\) is derived from a comparison against individual \(\gamma\) as \(score(\alpha ,\gamma )=1\) if \(\alpha >\gamma\); 0.5 if \(\alpha =\gamma\); and 0 otherwise. Each individual is compared against a sample of S opponents drawn from the competing population, with subjective fitness calculated as the mean score in competition against these S opponents.
To control the likelihood of disengagement, we add a mutation bias parameter \(\beta\), where \(0\le \beta \le 1\). When a parent is selected to generate an offspring clone, each bit in the offspring has a probability m of mutating. When mutation occurs, the bit is assigned a new value at random, with probability \(\beta\) of assigning a value of 1 and probability \(1-\beta\) of assigning a value of 0. Consequently, when \(\beta =0.5\) mutation is unbiased there is an equal chance of assigning the bit to 1 or 0; when \(\beta =0\) mutation will always assign the bit to 0; and when \(\beta =1\) mutation will always assign the bit to 1. This bias parameter allows the simple game to emulate the intrinsic asymmetry exhibited by more complex domains, where it is often easier for one coevolving population to outperform the other—for instance, when coevolving list-sorting algorithms and input lists [1], it’s much easier to be an unsorted list than an algorithm that can sort a list. When populations disengage, selection pressures are removed and populations are left to drift through mutation alone. In the greater than game, we expect drifting populations to tend towards individuals with a proportion of ones equal to \(\beta\). Therefore, in the case that \(l=100\) and \(\beta =0.25\), a drifting population will tend towards scalar values of 25.
In our two-population competitive set up, we label the populations as hosts and parasites. Each population has an independent bias value \(\beta\). We use \(\beta _\mathrm{h}\) to label the bias value of the host population and \(\beta _\mathrm{p}\) to label the bias value of the parasite population. When bias differential is high, i.e., when the value of \(\beta _\mathrm{p}\) is much larger than the value of \(\beta _\mathrm{h}\) (or vice versa), disengagement becomes more likely as the game is much easier for the parasites (alternatively, the hosts) to succeed. By varying \(\beta _\mathrm{p}\) and \(\beta _\mathrm{h}\), we are able to control the asymmetry of domain.

Example coevolutionary dynamics. On the left, when there is an inherent advantage to parasites (\(\beta _\mathrm{p} = 0.75 > \beta _\mathrm{h} = 0.25\)), populations disengage and selection pressure is removed, leaving populations to drift. On the right, when there is no advantageous bias favouring one population (\(\beta _\mathrm{h} = \beta _\mathrm{p} = 0.5\)), populations maintain engaged and selection pressure drives the system towards solutions that are close to optimum value of 100
Figure 1 presents two examples of greater than coevolution to demonstrate the pathology of disengagement and the effects of bias. Scalar values of all individuals are plotted. On the left, the system has a differential bias favouring parasites, with \(\beta _\mathrm{p}=0.75\) and \(\beta _\mathrm{h}=0.25\). Initially, both populations remain engaged and selection drives evolutionary progress, with populations reaching scalar values of 50 by generation 150. However, the impact of differential bias leads to a disengagement event such that all parasites are greater than their competing hosts. This results in a subjective score of zero for all hosts and a subjective score of one for all parasites. At this point selection pressure is removed as all individuals have an equal (and therefore random) chance of selection, which leaves the populations to drift under mutation alone. Subsequently, the high bias differential between populations (\(\beta _\mathrm{p} - \beta _\mathrm{h} = 0.5\)) ensures that disengaged populations drift through different regions of genotype space and do not re-engage through chance alone. As expected, the parasite population drifts to the parasite mutation bias (dotted line) of 75 while hosts degrade to the host mutation bias of 25. In contrast, the figure on the right presents an example of unbiased coevolution, where populations have equal bias \(\beta _\mathrm{p}=\beta _\mathrm{h}=0.5\). Populations remain engaged throughout, providing a continual gradient of selection that results in the discovery of individuals with optimum scalar values equal to the maximum \(l=100\). This is far higher than the scalar value of 50 (dotted line) that both populations would be expected to reach when drifting under mutation alone, i.e., when selection pressure is removed.
Experimental Method
Our experimental set up is detailed as follows. We coevolve two isolated populations, each with 25 individuals (\(n=25\)). The length of the binary array (an individual) is 100 (\(l=100\)) and each bit is initialised to 0. To generate a subjective fitness, each individual is compared against a random sample of five (\(S=5\)) individuals chosen from the competing population. We use tournament selection with tournament size two. Populations are asexual (i.e., there is mutation but no recombination). The probability of mutation per bit is 0.005 (\(m=0.005\)). Finally, each evolutionary run lasts for 1000 generations.
We deliberately select asexual reproduction to keep the system as simple as possible so that analysis of system dynamics is more tractable. Sexual recombination introduces additional complexity of crossover, and the specific design of the crossover operator will affect the evolutionary trajectory of populations and therefore the rates of disengagement. Since the primary aim of this study is to strictly control the likelihood of disengagement by varying mutation bias, we reject the use of sexual recombination. However, sexual recombination is an interesting avenue of further investigation that we reserve for future work.
Due to the stochastic nature of the system, results of coevolution will vary each time. Therefore, to ensure statistical confidence in results, we perform \(N=100\) repeated trials for each experimental condition.
Comparing RV, AVA and SF
To measure the performance of SF, we perform a thorough comparison against RV and AVA in the greater than game. To understand how the three approaches are likely to perform in more complex domains, where populations are likely to exhibit asymmetries, we vary mutation bias across all possible levels \(\beta _\mathrm{p},\beta _\mathrm{h}\in [0.1, 1.0]\) s.t. \(\beta _\mathrm{p} \ge \beta _\mathrm{h}\). We have assumed that hosts are the population of interest and configured mutation bias in favour of parasites (except when \(\beta _\mathrm{p} = \beta _\mathrm{h}\)); however, this choice is arbitrary as biases in favour of hosts would yield symmetrically similar results. For each bias scenario, we performed 100 experimental trials.
To analyse performance of SF, AVA and RV we utilised three metrics: (i) the reliability of the technique to maintain population engagement; (ii) the capacity to discover optimal hosts containing all ones; and (iii) the mean number of ones that hosts reach before disengagement occurs. The following sections describe our insights.
Maintaining Engagement
The main objective of RV, AVA and SF is to maintain engagement regardless of asymmetrical bias, therefore we begin by studying the response of each technique under different bias scenarios. Figure 2 presents a heatmap showing the number of trials (out of a total of \(N=100\)) where RV, AVA and SF maintained population engagement during the full coevolutionary run of 1000 generations (regardless of whether or not an optimal host is found). Here, lighter shaded regions are better. Figure 3 summarises the same information, by presenting the total number of bias scenarios that produce at least x trials with no disengagement.

RV, AVA, and SF; showing number of trials with no disengagement

Number of bias scenarios where at least x trials had no disengagement
Overall, Fig. 3 shows that SF is able to maintain engagement more successfully than AVA and RV. For 35 of the 55 bias pairings, SF maintains engagement for the full coevolutionary run of 1000 generations across all 100 trials. For AVA, however, this number is only 22, whereas for RV this number is only 11. Moreover, SF maintains engagement for the full coevolutionary run in at least 90 out of 100 trials across 45 bias pairings, while for AVA this number is 42 and for RV is 29.
The heatmaps of Fig. 2 suggest that RV and AVA tend to struggle in scenarios (a) where the bias of both populations are either the same (symmetrical systems) or similar; and (b) where parasite bias is very high (e.g., \(\beta _\mathrm{p}=1.0\)) and there is a large bias differential between parasites and hosts. In comparison, although SF also fails in scenarios where parasites have very high bias, SF is capable of maintaining engagement where RV and AVA are not.
These results for AVA are different to those presented in the original AVA study [7]. We suspect two main reasons for this: (i) AVA was originally calibrated to handle bias levels across the smaller range \(\beta _\mathrm{h},\beta _\mathrm{p} \in [0.5, 1.0]\); and (ii) the original experiments in [7] had shorter trials that ended after 750 generations. The duration of experimental trials is a key factor inasmuch AVA, in a number of bias scenarios, tends to allow disengagement after optimal hosts are found. For instance, when \(\beta _\mathrm{h} = 0.5,\) \(\beta _\mathrm{p}=1.0\), populations tend to first reach the optimum, but then later, around generations 850-900, the populations disengage. This unexpected behaviour suggests that AVA parameters may require recalibration to maintain engagement over long time periods and over more extreme bias differentials. This demonstrates an advantage of SF, as there are no parameter settings to calibrate.
Reaching the Optimum
Another essential aspect to analyse is the capability to reach the optimal zone. Figure 4 presents the number of runs where hosts (more precisely, at least one host) reached the optimal, regardless of whether or not populations disengage after this point. Figure 5 summarises the same information, by presenting the total number of bias scenarios that discover optimal hosts in at least x trials.

RV, AVA, and SF; showing number of runs where hosts reached optimum value

Number of bias scenarios where at least x trials reached optimal state
Here, we see a similar pattern for RV, AVA and SF. From Fig. 5, we see that RV reached the optimal zone across all 100 trials under 18 bias pairings, AVA reached it under 16 bias pairings, and SF reached it under 17 bias pairings. Furthermore, RV, AVA and SF all reached the optimal zone at least 90 times under 19 bias pairings. Perhaps unsurprisingly, as shown in Fig. 4, no technique was capable of discovering optimal hosts when hosts have a very low mutation bias (\(\beta _\mathrm{h} < 0.5\)).
General Performance
Figure 6 shows the mean maximum number of ones of the best host across all bias configurations, regardless of whether or not populations disengage or hosts reach the optimum. Figure 7 summarises the same information, by presenting the total number of bias scenarios where the best host discovered has at least x number of ones.

Performance of RV, AVA, and SF; showing mean number of ones of best host

Number of bias scenarios where best host has at least x number of ones
From Fig. 7, it is clear that the performance of RV, AVA and SF show a very similar trend. RV reaches at least 90 ones under 34 bias scenarios, AVA reaches at least 90 ones in 36 scenarios, and SF reaches at least 90 ones under 35 scenarios. Furthermore, RV reaches 100 ones under 18 scenarios, AVA reaches 100 ones under 16 scenarios, and SF reaches 100 ones under 17 scenarios. These results suggest RV, AVA and SF tend to behave similarly across most bias levels. However, when there is a significant bias differential (e.g., \(\beta _\mathrm{h}=0.1,\) \(\beta _\mathrm{p}=0.9\)), AVA enables populations to reach a greater performance (closer to the optimum) than both RV and SF (see Fig. 6).
Summary
Overall, SF has demonstrated reliable capacity to overcome disengagement in the simple greater than game across a wide range of asymmetrical bias differentials. However, the performance of SF is not significantly better than AVA or RV. Yet, unlike RV and AVA, SF offers the advantage of having no tunable parameters and therefore requires no domain calibration. This suggests that SF may be more reliable in complex domains where asymmetry is a priori unknown and likely to vary over time. In the following section, we test this hypothesis by exploring the performance of the three techniques in a more complex domain with potential real-world application.
Coevolving Well-Being Recommendations
In this section we explore the performance of SF, RV and AVA in the domain of recommender systems for health and well-being. Furthermore, we introduce a coevolutionary adaptation of an evolutionary recommender system, first introduced in [5].
EvoRecSys: Evolutionary Recommender System
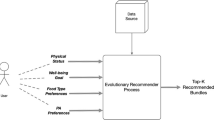
EvoRecSys (Evolutionary Recommender System) is a multi-objective health recommender system that uses a genetic algorithm to discover optimal recommendations. The constraints on recommendations are defined by user’s preferences, their well-being goal, and their physical condition. The output of EvoRecSys contains a list of bundles enclosing a meal plan (a set of ingredients) and an exercise activity (see Fig. 8 for a schematic of a bundle). Each food item contains: (i) name; (ii) type of food; (iii) suitability for vegetarians/vegans; (iv) nutritional information (in grams)—serving size, protein, carbohydrates, sugar, fibre, fat, saturated fat, sodium; and (v) kilocalories associated with the serving size. In addition, the exercise activity contains: (i) name; (ii) intensity; (iii) Metabolic Equivalent of Task (MET); and (iv) duration.

An individual contains three bundles, each consisting of one meal and one exercise
Under the evolutionary approach, individuals are represented by a list of three bundles. The fitness \(\phi _{i}\) of individual i is calculated as the error across four restrictions:
where \(hf_i\) (healthy food) evaluates the amount of nutrients contained in a food item, following the dietary recommendations published by Public Health England [24]; \(ea_i\) (exercise activity) evaluates the degree of matching between a recommended exercise time and the usual time that the user spends exercising; \(cd_i\) (consistency and diversity) evaluates the diversity and proportionality of meal items and exercise; and \(\Psi _i\) (user preferences) evaluates how likeable the recommended items are in comparison to the user’s preferences. The error is the mean of these restrictions, normalised to the range [0.0, 1.0].
Tournament selection (size two) is used to select individuals for reproduction, where the fittest individual is the one with the lowest error \(\phi _{i}\). In contrast to the simple greater than domain, where only asexual reproduction was used (see Section “Experimental Method”), here we introduce sexual recombination by introducing a crossover operator. Thus, a child offspring is first created as an exact clone of parent F. Then, the genetic operators act on the child as follows:
-
Crossover:
Occurs with probability \(P_\mathrm{c}\). A second parent M is selected at random from the population. Then, some elements from parent M are injected into the child following the method of [5, Algorithms 8–9]. Each bundle in the child has items injected from parent M with probability \(P_\mathrm{b}=0.9\). A single item of the bundle is injected into the child such that main food is injected with probability 0.2, side food is injected with probability 0.6, and exercise activity is injected with probability 0.2.
-
Mutation:
Occurs with probability \(P_\mathrm{m}\). Collaborative filtering is used to find the nearest neighbour N with most similar user preferences to parent F. One element in the child is then selected at random with uniform probability and is replaced by the equivalent element taken from the most similar neighbour N. This non-standard mutation operator is described in detail in [5, Algorithms 10–11].
These relatively complex genetic operators have been shown to improve performance of EvoRecSys [25]. Table 1 presents four illustrative examples of individual bundles that have evolved during one run of EvoRecSys. We see that a relatively small change in fitness error of a bundle can make a large qualitative difference in the output. The bottom row in the table has coherent output that meets user preferences with an acceptable level. Therefore, we consider 0.33 as a suitable fitness threshold (i.e., the highest acceptable error).
Coevolution: CoEvoRecSys
One potential use of health recommender systems consists of building weekly or monthly meal-activity plans. Since EvoRecSys has been designed to provide recommendations for a single day, there is a tendency towards a lack of diversity in recommendations over time. To address this issue, we introduce a coevolutionary adaptation, which we name CoEvoRecSys. The aim of CoEvoRecSys is to generate more diverse meal-activity plans that nevertheless still ensure user preferences and well-being goals are met.
To generate a coevolutionary implementation of EvoRecSys, we use two competing populations, hosts and parasites. Parasites are initialised using user’s physical data (to calculate the suggested number of intake calories according to well-being goal) and food and exercise preferences (e.g., if the user is vegetarian and cannot swim, a recommendation of a beefsteak meal followed by a session of swimming is unlikely to appear). This is the canonical initialisation method utilised in [5]. In contrast, hosts are initialised at random: neither user’s physical data nor user’s preferences are considered. We include this host population to introduce diversity. This initialisation routine ensures that parasites have an intrinsic fitness advantage over hosts as parasites are much more likely to meet user preferences and therefore have lower error \(\phi _{i}\) than randomly initialised parasites.
A subjective fitness score for individuals is calculated by comparing error values of individual i against a sample of S opponents from the other population. Comparative score of host i is defined as:
where \(\phi _{h_i}\) is the error of host i and \(\phi _{p_j}\) is the error of parasite j (see Eq. 4). Subjective fitness of host i is then calculated as the mean score against S parasite competitors drawn at random from the other population.
Experimental Configuration
Our experimental set-up consists of two coevolving populations. We use a sample size \(S=5\) to obtain the competitive fitness of individuals. Tournament selection is used with tournament size two, and mutation and crossover operators are implemented for both populations with probabilities \(P_\mathrm{c}=0.8\) and \(P_\mathrm{m}=0.1\), respectively. Each run lasts 500 generations. For user preferences and physical attributes, we re-use the anonymised data collected from participants during the original EvoRecSys experiments [5]. To ensure statistical confidence in results, we perform \(N=30\) repeated trials for each experimental condition.
Disengagement in CoEvoRecSys
Figure 9 presents results from two example runs of CoEvoRecSys. On the left, we see an example where host and parasite populations remain engaged throughout the run, with both populations obtaining acceptable solutions (i.e., populations reach the recommendation threshold). On the right, we see an example where hosts and parasites quickly disengage, leaving the populations to drift at random through genetic space. From the start, parasites easily outperform hosts due to their inherent advantage of incorporating user preferences during initialisation. The system falls into a mediocre stable state (e.g., see [18]) such that progress halts and acceptable recommendations are never discovered. Therefore, to ensure CoEvoRecSys is able to discover acceptable solutions, it is imperative to avoid disengagement.

CoEvoRecSys examples: When populations are engaged (left), selection pressure encourages the discovery of acceptable solutions that reach the maximum error threshold of 0.33. When populations disengage (right), parasites easily outperform hosts and the system tends to stabilise in a mediocre state with error well above the acceptable threshold
CoEvoRecSys: Comparison of RV, AVA and SF
In this section, we compare the ability of RV, AVA and SF to counteract disengagement in CoEvoRecSys. As a baseline, also compare the performance of CoEvoRecSys with no disengagement-mitigation technique applied. We trial each approach in simulations where we vary the size of each population \(n\in \{30,60,130,260,510\}\). Under all conditions, we perform 30 experimental trials. We configure RV and AVA using settings taken from their original publications. Hence, we set RV to have virulence \(v=0.75\) [6]; for AVA, we set learning rate \(\alpha = 0.0125\), momentum \(\mu = 0.3\), and target value \(\tau = 0.56\) [7].
To analyse performance of RV, AVA and SF, four metrics are used: (i) capacity to maintain engagement (Section “Ability to Maintain Engagement”); (ii) capacity to discover acceptable recommendations (Section “Ability to Find Acceptable Recommendations”); (iii) capacity to discover diverse recommendations (Section “Ability to Find Diverse Recommendations”); and (iv) capacity to discover both acceptable and diverse recommendations (Section “Ability to Find Acceptable and Diverse Recommendations”).

Mean number of disengaged generations during an experimental trial; CoEvoRecSys (top-left); CoEvoRecSys with RV (top-right), CoEvoRecSys with AVA (bottom-left) and CoEvoRecSys with SF (bottom-right) across all parameter configurations (30 trials)
Ability to Maintain Engagement
We begin by exploring the capacity of RV, AVA and SF to maintain engagement in CoEvoRecSys. Figure 10 presents heatmaps illustrating the mean number of disengaged generations that occur during each 500-generation trial, as population size is varied as \(n\in \{30,60,130,260,510\}\).
In general, as population size increases (top to bottom of each heatmap), we see that the number of disengaged generations falls. This is to be expected, as larger populations mean that there is a greater chance for populations to engage through random mutation of individuals. When population size is large (i.e., when \(n\in \{260,510\}\)), there is very little disengagement under any condition, including the baseline. However, for smaller population sizes (i.e., when \(n\in \{30,60\}\)), disengagement is common in the baseline CoEvoRecSys. The results for RV are similar to the baseline, indicating that RV may require recalibration. In contrast, AVA and SF are able to counter the effects of disengagement, resulting in many fewer disengaged generations when population sizes are small. While AVA and SF both perform well overall, results suggest that AVA is able to maintain engagement more reliably than SF.
Ability to Find Acceptable Recommendations
One of the most important metrics of performance is the ability to discover recommendations that have error below the acceptable threshold of 0.33. Figure 11 presents heatmaps showing the mean error reached by the best host during each coevolutionary run. As expected, under all four conditions, when the number of individuals is small the performance is poor; and performance improves as population sizes are increased.
We see that the baseline system just about manages to reach the acceptable threshold when population size is \(n=260\). At this population size, RV, AVA, and SF all discover solutions of better quality than the baseline. Indeed, SF is able to find acceptable solutions when population size is only \(n=130\). To determine whether differences in performance are statistically significant, we first confirm that results data are normally distributed (Shapiro-Wilk test; \(p>0.05\), so cannot reject the null). The result of one-way ANOVA shows that there are significant differences among the approaches (\(p<0.01\)). Finally, post-hoc tests (Tukey-HSD test; \(p<0.01\)) determine that there are significant differences in performance between all techniques. This generates the following ranking for recommendation performance: SF > AVA > RV > baseline.

Mean error of best host: CoEvoRecSys (top-left); CoEvoRecSys under RV (top-right); CoEvoRecSys under AVA (bottom-left); and CoEvoRecSys under SF (bottom-right)
Ability to Find Diverse Recommendations
In a practical scenario, CoEvoRecSys would likely be used to provide meal plans over a longer time period than a one day. Therefore, diversity in recommendations is important so that users are not expected to eat the same meals and perform the same exercise activities every day. Here, we generate recommendations for a 28 day period (i.e., 1 month) and evaluate their diversity. The evaluation function is an adaptation of \(cd_i\) (see Section “EvoRecSys: Evolutionary Recommender System”), such that diversity of item categories are considered in addition to items themselves; for example {carrots, asparagus, cauliflower} has a lower diversity than {beans, quinoa, broccoli} because all items in the former set are vegetables.

Mean diversity error of best host: CoEvoRecSys (top-left); CoEvoRecSys under RV (top-right), CoEvoRecSys under AVA (bottom-left); and CoEvoRecSys under SF (bottom-right)
To provide an acceptable diversity threshold, we used EvoRecSys to conduct 28 experimental trials (equivalent to one month of recommendations). EvoRecSys was configured using the same parameter settings presented in [5], apart from elitism was disabled and the length of each run was set to 500 generations. The mean diversity error was 0.2753, with standard deviation 0.022. We therefore consider 0.2753 as the maximum acceptable threshold of diversity error.
Results of running CoEvoRecSys are presented in Fig. 12. These heatmaps show the mean diversity error reached by the best host, where a lower value of diversity error indicates a more diverse set of recommendations. Once again, we observe the general trend that larger populations produce higher performance (i.e., greater diversity). While the heatmaps suggest that SF produces the most diversity (reaching the threshold when \(n=260\)) and AVA produces the least diversity (marginally failing to reach the threshold even when \(n=510\)), these differences are not statistically significant. We determine this by first confirming that the data is not normally distributed (Shapiro–Wilk test; \(p<0.05\), so reject the null); then, using the non-parametric Kruskal–Wallis test, we are unable to reject the null hypothesis that there are no significant differences between the four approaches (Kruskal–Wallis test; \(p>0.05\)).
Ability to Find Acceptable and Diverse Recommendations
Here, we consider configurations where solutions are both acceptable and diverse. Figure 13 presents heatmaps showing configurations where both thresholds are reached, indicated by the light-grey regions. Results shows that AVA is not capable of reaching both thresholds in any configuration: although AVA finds high quality recommendations, it marginally misses the required threshold of diversity. In comparison, RV and the baseline are able to reach both thresholds when population sizes are large (\(n=510\)). However, SF is capable of achieving both thresholds even with smaller population size \(n=260\). Therefore, we conclude that SF is the most efficient and robust approach for this CoEvoRecSys problem domain.

Parameter configurations (light shade) that reach both fitness threshold and diversity threshold; CoEvoRecSys (top-left); CoEvoRecSys with RV (top-right); CoEvoRecSys with AVA (bottom-left); and CoEvoRecSys with SF (bottom-right)
Evolution vs Coevolution
Here, we perform a comparison of EvoRecSys against CoEvoRecSys over 28 experimental trials (equivalent to one month of meal-exercise recommendations). Based on the results obtained in Section “CoEvoRecSys: Comparison of RV, AVA and SF”, we select SF as the best technique to use in CoEvoRecSys. To perform a comparison in a real-based environment, we use the set-up implemented for the web-based application introduced in [5]. Table 2 presents the values utilised for each parameter. We utilise a sample size of five opponents (\(S=5\)) to calculate competitive score. We use tournament selection with tournament size two (\(T=2\)) and elitism is not implemented.
Figure 14 presents violin plots showing comparative performance of EvoRecSys, CoEvoRecSys and CoEvoRecSys with SF. Each violin presents minimum, maximum, and median value, as well as a kernel density estimation of the frequency distribution of values across all 28 runs. On the left plot of general performance, we see that CoEvoRecSys with SF tends to reach recommendations that are significantly more suitable and coherent than both EvoRecSys and the CoEvoRecSys baseline (Shapiro–Wilk test: \(p>0.05\); one-way ANOVA test and Tukey-HSD test: \(p<0.01\)). On the right plot of diversity, we see CoEvoRecSys with SF also tends to reach significantly more diverse food items and exercise activities than both EvoRecSys and the CoEvoRecSys baseline (Shapiro–Wilk test: \(p<0.05\); Kruskal–Wallis test and Dunn’s test: \(p<0.01\)).
In general, results indicate that the coevolutionary approach with SF significantly outperforms the evolutionary approach of EvoRecSys in terms of suitable and diverse recommendations. When coevolution is used without SF, strong asymmetrical bias between host and parasite populations produces disengagement, which leads to detrimental performance. By mitigating against disengagement, SF enables the coevolutionary system to maintain engagement and discover solutions that are better than those discovered by single-population evolution alone.

Comparison of EvoRecSys and CoEvoRecSys across one month of recommendations. CoEvoRecSys with SF has best performance (left) and best diversity (right)
We can explain the benefit of coevolution over evolution in this domain by considering the differences in the initialisation process. Remember that the host population in CoEvoRecSys is initialised entirely at random, taking no account of user preferences or physical ability (see Section “Coevolution: CoEvoRecSys”). Therefore, the host population begins with much greater genetic diversity than the single population in EvoRecSys. As a result, CoEvoRecSys can explore a wider search space and is able to produce more diverse recommendations; whereas EvoRecSys tends to produce a meal-activity plan with more repetition across days. While EvoRecSys is able to discover meal-activity bundles that generally satisfy user preferences, one of the constituents of fitness score is cd (see Eq. 4; Section “EvoRecSys: Evolutionary Recommender System”), which measures the diversity and proportionality of meal items and exercise. Therefore, ceteris paribus, more diverse recommendations will produce higher fitness.
However, when SF is not used, the coevolving populations of CoEvoRecSys disengage and the host population drifts at random. While this produces a population with lots of genetic diversity, the resulting phenotypes (i.e., the meal bundles) are not necessarily diverse as they may consist entirely of similar food types such as lettuce and broccoli. The diversity metric we use (Eq. 4) punishes meals containing multiple elements belonging to the same food category. Therefore, in this domain, the genetic diversity maintained through random drift does not directly translate to phenotypic diversity of meals. As a result, CoEvoRecSys baseline produces the lowest diversity meal plan. In contrast, when SF is used, the system remains engaged. This maintains selection pressure and drives the continual discovery of meals with more phenotypic diversity. As a result, CoEvoRecSys-SF results in greater diversity than EvoRecSys; while CoEvoRecSys-baseline has the lowest diversity of all.
Conclusions
We have introduced and explored the capacity of substitution of the fittest (SF) to counteract disengagement, a pathology that hinders progress in two-population competitive coevolutionary GAs. First, using the deliberately simple greater than domain, SF was shown to overcome disengagement across a wide range of asymmetrical bias differentials (see Section “Explorations in the “Greater Than” Game”). When compared against RV and AVA, alternative techniques from the literature, SF does not have significantly better performance overall. However, unlike RV and AVA, SF offers the advantage of having no tunable parameters and therefore requires no domain calibration. This suggests that SF may be more reliable in complex domains where asymmetry is a priori unknown and likely to vary over time.
Subsequently, we attempted the more challenging real-world problem of coevolving recommendations for health and well-being (see Section “Coevolving Well-Being Recommendations”). We called this coevolutionary approach CoEvoRecSys as it extends a previously published evolutionary approach to recommender systems called EvoRecSys. Results showed that the baseline CoEvoRecSys suffers from disengagement, resulting in poorer solutions than those discovered by EvoRecSys. However, when SF is introduced into CoEvoRecSys, disengagement is successfully countered, leading to solutions that are significantly better than those discovered by EvoRecSys. We also show that SF outperforms both RV and AVA in CoEvoRecSys. However, for these experiments, we configure RV and AVA using parameter values taken from the literature and it is therefore possible that RV and AVA underperform because their parameter values require recalibration. In contrast, SF has no parameters to calibrate, making it a more robust domain-independent technique that can be used “out of the box”.
In future, we plan to extend CoEvoRecSys as a web-service or mobile application that enables users to interact with the system to provide real-time feedback on the subjective quality of recommendations. We will also further explore the performance of SF in coevolutionary domains with natural asymmetry between populations, such as maze-robot navigation or list-sorting networks (e.g., see [7]).
Data availability
Open-source code is available at https://github.com/oguh1-61803/coevorecsys.
Notes
To avoid immediate disengagement in cases of extreme bias differential, for the initial \(t<5\) generations Eq. (3) is replaced by \(\Delta _t = (0.5-\overline{X_t})/t\). This allows virulence to immediately adapt to high (\(\upsilon =1\)) or low (\(\upsilon =0.5\)) values.
References
Hillis WD. Co-evolving parasites improve simulated evolution as an optimization procedure. Phys D. 1990;42(1–3):228–34. https://doi.org/10.1016/0167-2789(90)90076-2.
Popovici E, Bucci A, Wiegand RP, De Jong ED. Coevolutionary principles. In: Handbook of Natural Computing, pp. 987–1033. Springer, Berlin, Heidelberg 2012. https://doi.org/10.1007/978-3-540-92910-9_31
Alcaraz-Herrera H, Cartlidge J. Substitution of the fittest: A novel approach for mitigating disengagement in coevolutionary genetic algorithms. In: Proceedings of the 13th International Joint Conference on Computational Intelligence. ECTA, 2021;59–67. https://doi.org/10.5220/0010661200003063
Watson RA, Pollack JB. Coevolutionary dynamics in a minimal substrate. In: Genetic and Evolutionary Computation Conference. GECCO, 2001;702–709. https://dl.acm.org/doi/10.5555/2955239.2955343
Alcaraz-Herrera H, Cartlidge J, Toumpakari Z, Western M, Palomares I. EvoRecSys: Evolutionary framework for health and well-being recommender systems. User Modeling and User-Adapted Interaction. 2022. https://doi.org/10.1007/s11257-021-09318-3.
Cartlidge J, Bullock S. Combating coevolutionary disengagement by reducing parasite virulence. Evolutionary Computation. 2004;12(2):193–222. https://doi.org/10.1162/106365604773955148.
Cartlidge J, Ait-Boudaoud D. Autonomous virulence adaptation improves coevolutionary optimization. IEEE Transactions on Evolutionary Computation. 2011;15(2):215–29. https://doi.org/10.1109/TEVC.2010.2073471.
Cartlidge J, Bullock S. Unpicking tartan CIAO plots: Understanding irregular coevolutionary cycling. Adaptive Behavior. 2004;12(2):69–92. https://doi.org/10.1177/105971230401200201.
Cartlidge J, Bullock S. Caring versus sharing: How to maintain engagement and diversity in coevolving populations. In: Banzhaf, W., Ziegler, J., Christaller, T., Dittrich, P., Kim, J.T. (eds.) Advances in Artificial Life, pp. 299–308. Springer, Berlin, Heidelberg. 2003 https://doi.org/10.1007/978-3-540-39432-7_32
Miguel Antonio L, Coello Coello CA. Coevolutionary multiobjective evolutionary algorithms: Survey of the state-of-the-art. IEEE Transactions on Evolutionary Computation. 2018;22(6):851–65. https://doi.org/10.1109/TEVC.2017.2767023.
Rosin CD, Belew RK. New methods for competitive coevolution. Evolutionary Computation. 1997;5(1):1–29. https://doi.org/10.1162/evco.1997.5.1.1.
de Jong ED. A monotonic archive for pareto-coevolution. Evolutionary Computation. 2007;15(1):61–93. https://doi.org/10.1162/evco.2007.15.1.61.
Garcia D, Lugo AE, Hemberg E, O’Reilly U-M. Investigating coevolutionary archive based genetic algorithms on cyber defense networks. In: Genetic and Evolutionary Computation Conference Companion. GECCO, 2017;1455–1462. https://doi.org/10.1145/3067695.3076081
Bari AG, Gaspar A, Wiegand RP, Bucci A. Selection methods to relax strict acceptance condition in test-based coevolution. In: Congress on Evolutionary Computation. CEC, 2018;1–8. https://doi.org/10.1109/CEC.2018.8477934
Akinola A, Wineberg M. Using implicit multi-objectives properties to mitigate against forgetfulness in coevolutionary algorithms. In: Genetic and Evolutionary Computation Conference. GECCO, 2020;769–777. https://doi.org/10.1145/3377930.3389825
Wiegand RP, Sarma J. Spatial embedding and loss of gradient in cooperative coevolutionary algorithms. In: Parallel Problem Solving from Nature. PPSN, 2004;912–921. https://doi.org/10.1007/978-3-540-30217-9_92
Williams N, Mitchell M. Investigating the success of spatial coevolution. In: Genetic and Evolutionary Computation Conference. GECCO, 2005;523–530. https://doi.org/10.1145/1068009.1068096
Ficici SG, Pollack JB. Challenges in coevolutionary learning: Arms-race dynamics, open-endedness, and mediocre stable states. In: International Conference on Artificial Life. ALIFE, 1998;238–247. https://dl.acm.org/doi/10.5555/286139.286166
Simione L, Nolfi S. Long-term progress and behavior complexification in competitive coevolution. Artificial Life. 2021;26(4):409–30. https://doi.org/10.1162/artl_a_00329.
Rosin CD. Coevolutionary search among adversaries. PhD thesis, Department of Computer Science, University of California, San Diego, California 1997.
Pagie L, Mitchel M. A comparison of evolutionary and coevolutionary search. International Journal of Computational Intelligence and Applications. 2002;2(1):53–9. https://doi.org/10.1142/S1469026802000427.
Cartlidge J, Bullock S. Learning lessons from the common cold: How reducing parasite virulence improves coevolutionary optimization. In: Congress on Evolutionary Computation. CEC, 2002;1420–14252. https://doi.org/10.1109/CEC.2002.1004451
Bullock S, Cartlidge J, Thompson M. Prospects for computational steering of evolutionary computation. In: Workshop Proceedings 8th Int. Conf. on Artificial Life. ALIFE, 2002;131–137. https://eprints.soton.ac.uk/261459/1/Prospects.pdf
Public Health England: Government Dietary Recommendations. PHE publications gateway number: 2016202, August 2016. Online [Available] 2016. https://www.gov.uk/government/publications/the-eatwell-guide
Alcaraz-Herrera H, Cartlidge J. Exploration of ontological representations for evolutionary computation. In: IEEE Congress on Evolutionary Computation. CEC, 2022;1–8. https://doi.org/10.1109/CEC55065.2022.9870376
Funding
Hugo Alcaraz-Herrera’s PhD is supported by The Mexican Council of Science and Technology (Consejo Nacional de Ciencia y Tecnología-CONACyT).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no conflicts of interest.
Ethics Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed Consent
Participants’ anonymous preference data used for building health and well-being recommendations in Sect. “Coevolving Well-Being Recommendations” was previously collected for the work on EvoRecSys, published in [5]. Informed consent was obtained from all individual participants included in the EvoRecSys study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Computational Intelligence” guest edited by Kurosh Madani, Kevin Warwick, Juan Julian Merelo, Thomas Bäck and Anna Kononova.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Alcaraz-Herrera, H., Cartlidge, J. Using Coevolution and Substitution of the Fittest for Health and Well-Being Recommender Systems. SN COMPUT. SCI. 4, 319 (2023). https://doi.org/10.1007/s42979-023-01749-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-023-01749-6