
Abstract
Predicting results in electronic sports (e-sports) matches is not an easy task. Different methods can be used for this purpose. A well-known video game in the field of Multiplayer Online Battle Arena (MOBA) is the game League of Legends (LoL), which has a relevant professional scene. An important part of professional gaming is analyzing past matches overall and an individual player’s performance to prepare for future matches. In this paper, we follow a design-oriented research methodology (analysis, design, and evaluation) and propose performance metrics that use data from past matches to evaluate a player’s performance. We analyze the necessary data which we acquire by selecting a player, analyzing the player’s latest games, and repeating the process recursively with the players found in his latest games. The data is utilized within a Machine Learning (ML) Model that computes an overall score from individual player variables. From this, we designed a heuristic approach and evaluated it by applying it to the challenge of winning predictions in e-sports. The difference in the influence of the individual player roles on the outcome of the game was also investigated. It was found that this difference is negligible and that the heuristic performance metric can predict the outcome of a game with an accuracy of 86%. Furthermore, the concept of a match calculator is explored, which calculates the outcome of a match using the ML model and different player stats.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
As the popularity of video games increased, so did the number of players in e-sports competitions, where the game League of Legends (LoL) is one of the most played Multiplayer Online Battle Arena (MOBA) games. As the number of players (called summoners) increased, so did the number of professional players and the methods used to prepare for games. These methods include analyzing past games to create player profiles or using analysis and profiling tools to predict winnings. These tools are used by professional players and coaches to prepare more efficiently for future matches. Amateur players can also use such tools to gain quantifiable insights into their personal skills.
Regarding LoL, summoners choose a champion at the beginning of a match, which they control during the match. Each summoner is assigned a role and a position. In the game LoL there are five different roles, namely ADC (attack damage carry, main physical damage dealer), support (healing and utility provision), jungler (exploring the terrain and concentrating attacks), tank (front line fighter), and mid lane (pressing enemies in the middle of the map, often also called APC attack power carry, main magic damage dealer). Each summoner also has an assigned position on which he mainly acts, but which he can also change during the match, unlike his champion and his role.
This paper follows a design-oriented research methodology after Österle et al. [1] and makes the following contributions:
-
We explore a proposition for two performance metrics for the modeling of a player’s overall performance using an ML approach and a derived heuristic performance metric using one variable of the ML model.
-
We analyze the importance of the different roles to the outcome of a match to see if there are roles that have a bigger impact on the result of the match than others.
-
We present a winning prediction based on our heuristic performance models.
-
We conceptualize a player score calculator, where the match result can be recalculated using the ML model by changing individual player stats.
The goal of this paper is to create new insights into the game, both for professional players as well as amateur players through the exploration of role importance and the calculation of transparent player scores.
Our work is based on a paper by Bahrololloomi et al. [2] and extends it: We elaborated on the study and discuss the use of the Searching for Uncorrelated List of Variables (SULOV) algorithm in more detail and we enhanced the proposed algorithm for generating the base data for this work. We conducted an extended related works research to the current state of the art and included the possibility of using the proposed model to analyze the influence of changes in individual performance values on the predicted outcome of the game within our approach.
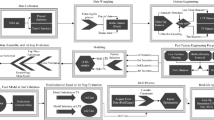
The paper is organized as follows. First, this paper takes a look at the current state of research. In the next section, the process of how the data, that is used for this paper was obtained, is described. The subsequent section explains how the ML model was implemented and evaluated followed by which the heuristic player performance metrics and the player role impact as well as the derived winning prediction and a match calculator are proposed. Figure 1 shows what is studied in detail in each section and how the sections are connected. Finally, a summary of the paper is given and possible future research directions are listed.

Diagram depicting the application flow, divided into the four sub-areas of Data Acquisition, Data Preparation, Model Engineering, and Application
Related Works
LoL is one of the most played games both in the field of MOBA games and in gaming in general. Research on LoL has already been conducted on the topic of winning prediction. In this section, relevant research results are presented and discussed.
Using Recurrent Neural Networks, a Winning Prediction was conducted in the paper Continuous Outcome Prediction of LoL Competitive Matches Using Recurrent Neural Networks by Silva et al. [3] It is described that minute-by-minute game data is collected from different matches. Afterward, the accuracy of the winning prediction is measured concerning the time from which the match data are taken. So it is compared whether or not with early match data (e.g., from the 10th minute of a match) already a similarly accurate winning prediction as with data from the 20th minute of the match is possible. As a result, they hold that using Deep Learning methods, an accuracy of up to 83.54% when using data from the 20th to 25th minute of the game can be achieved. This accuracy of their winning prediction decreases the further the time window is shifted forward. In contrast to the present work, the work of Silva et al. [3] is based on Deep Learning methods instead of Machine Learning methods. Likewise, the dataset from the present work does not consist of minute-by-minute data, but data from the end of the game. It does not examine the performance of individual players and evaluate their impact on the outcome of the game, but looks at the individual minutes of the game. Furthermore, the different roles of the players are not observed separately in Silva et al.
In the article Predicting Wins in League of Legends, Angulo [4] explores predicting the outcome of a match using data from various tournaments and leagues. These include:
-
Campeonato Brasileiro de League of Legends (CBLoL).
-
League of Legends Champions Korea (LCK)
-
Campeonato Brasileiro de League of Legends (CBLoL)
-
League of Legends Championship Series (LCS)
-
League of Legends European Championship (LEC)
-
League of Legends Master Series (LMS)
-
Mid-Season Invitational 2019 (MSI)
Thus, in contrast to the present work, the dataset consists of professional matches rather than solo Q matches. Furthermore, the management of the individual players was not considered, but only the two teams were compared. For example, the difference between Dragons and Baron Nashors (both large monsters that when killed reward the team with a buff to their champions strength) killed by team 1 and team 2. An interesting approach of this work is to examine to what extent the side of the card affects the outcome of the match. Thus, it was investigated whether the red side (the upper side) or the blue side (the lower side) gives the advantage to win the match. As a result of this investigation, it is noted that the team on the blue side has a higher probability of winning the match. Since in this work the performance of the team was considered and not the performance of the individual players, no statements were made here regarding the relevance of the different roles of the players.
Harikumar et al. [5] also investigate the possibilities of winning prediction in LoL. They use Pre-match Features and Within-match Features for the prediction. Thus, in contrast to the present work, features such as Champion, Bans, Summoner, and Spells are also included. Furthermore, their dataset also consists of matches from professional players only. Using a random forest model, an accuracy of 95.52% is achieved with the pre-matches features, and an accuracy of 98.18% is achieved with the within-match features. Combined, this results in an accuracy of 99.75%. Wang et al. [6] investigate whether taking into account the experience of players with their chosen champions, can lead to an accurate winning prediction. In contrast to the present work, Wang et al. consider the mastery points. These indicate the experience a player has with the particular champion.
Work by Hodge et al. [7] examines Dota 2 matches (a game similar to LoL). They conduct real-time match evaluations in the professional gaming world. For spectators, it could be interesting to get a better picture of which team is winning. This is a known practice in other sports like chess. Real-time evaluations of chess engines like Stockfish are often shown here during online live broadcasts of professional games so that viewers can better assess the progress of the game.
In their work Khromov et al. [8] focus on predicting a player’s biometric skill for e-sports (e.g., dynamics of key pressings) rather than predicting a match’s outcome. Biometric-based features, for example, in Counter-Strike: Global Offensive are used to train an ML model. The model is able to predict a player’s skill with an accuracy of 90%. As their work is based on biometric-based features, in-game features like shot-accuracy, average damage per round, headshot percentage, etc., are not included in their model.
Our literature analysis has shown that, apart from winning prediction, there also exists recent work about data visualization and analytics considering eSports [9,10,11,12,13]. A well-established project that is commonly utilized by LoL players is op.gg [14]. Here, too, the individual match data can be viewed in a processed form. However, no information is given on how many kills were achieved in comparison to other players, for example. Similar to the current work, performance scores are also calculated here. However, this score (here called OP score) is not explained or only very vaguely (‘OP Score is an evaluation system that estimates your in-game performance. Points are awarded from 0 to 10 depending on your in-game performance.’ [14]). Therefore, the exact composition of the score is unknown. It is also not possible to do winning predictions for different players or to change the data in your own game and check how these changes might have influenced the outcome of the game.
Another example called Mobalytics also comes with a score that is supposed to reflect the performance of the players. This score is between 0 and 100 and is awarded for individual aspects of the game. However, these do not consist of in-game features, but specially created metrics such as Fighting, Farming, and Survivability. However, the composition of these metrics is not explained here. In this application, it is also possible to activate an In-Game Overlay. This is an application that runs parallel to the game and displays data about the game and information about the opponent on its own screen while the game is still in progress. Mobalytics assigns custom attributes to players, such as Early Eyes (“This player averages over 6.66 wards placed by 15 min. They are used to carrying the load for their team in terms of vision control during the early game)”. With the help of this information about the opponent, initial assessments can be made about the playing style of the opponents and teammates. Based on this information, better decisions can be made that might lead to victory.
Finally, our literature research shows that various work on player performances and winning prediction in the field of LoL exists. However, the mentioned work does not take into account the aspect of player roles in their approaches. Furthermore, existing products for player analysis do not make their performance metrics publicly available, so that it is unclear if these consider player roles or positions at all.
Data Acquisition
The following pseudocode illustrates our proposed algorithm used to acquire the data for our work: The algorithm begins by defining a procedure called Recursion which takes in a single input called summoner. It then declares a list called lastMatches and assigns the last matches of the given summoner to the list. For each match in the list is then checked if the match was already checked. To avoid duplicates the match will be skipped if it is already known. Each match consists of 10 summoners which are then saved into a list. Afterwards, the procedure is recursively called for each summoner in the list.

To be able to examine possible differences in the playing styles of the different ranks and regions, separate data sets are to be generated for each of them. To obtain a dataset for a specific rank, a player is first sought who is representative of this rank. This player is then used as the starting value for the recursive algorithm. First, the account of this player is determined via his summoner name. In the following, the last X games are queried from this account. There are different game modes in LoL. However, only 5v5 ranked solo games in the standard map Summoner’s Rift are considered here. Since only 5v5 games are considered, each game has 10 players. These consist of 5 opponents, 4 fellow players, and the starting player himself. These 9 other players are now used as starting points for the same procedure. Before that, however, the players found are checked for duplicates, as it can happen that the same player has been found in several games. The last X games of these players are also determined. The games that have already been found are removed. This is usually at least 1 game per round. This is the game that the starting player and the subsequently found player played together.
This process can be repeated as often as desired. Depending on the number of iterations and the number of last players queried, this algorithm very quickly produces a large number of games. In this project, the last 20 games were queried and 2 iterations were used.
This algorithm is based on the assumption that the first player selected is representative of his rank. When selecting this player, care should, therefore, be taken that this player has been in this rank for a longer time and does not have a very high win rate. Otherwise, the player might be a smurf. A smurf is a player who actually plays in a higher rank. LoL allows players to create multiple accounts. It is, therefore, possible that a player who has already reached a higher rank (for example, challenger) creates a new account and starts again in the lower ranks (for example, platinum), as all new accounts are classified in a lower rank after the first few games. If this player now plays in a significantly lower rank on his new account than on his old account, this is called a smurf. This player will usually be significantly better in his games than his fellow players and opponents and as a result, will win most of his games. Therefore, smurf accounts are usually characterized by a high win rate, among other things. The matchmaking system of LoL recognizes this and will put him in a match with better players from a higher rank or with other smurfs after some time. The latter is also referred to as the smurf-queue. So it is possible that a smurf who currently has the rank Gold I will be matched into a game with players who are Diamond I. Since the algorithm would then be applied to his teammates and opponents, this would not result in a dataset that is representative of Gold I. As a rule, however, the LoL matchmaking system usually only compiles matches that consist of players of the same rank. This ensures that the algorithm mainly finds matches of the same rank, as long as the starting player is not a smurf.
LoL has individual servers for each region to avoid delays for players who would otherwise have a greater distance to the server if the server would be in the USA, for example. So there is no need to manually filter the games by region, as players from different regions cannot play with each other as they play on different servers. All players found by the algorithm, therefore, come from the same region. The process was repeated for each region. The resulting data sets were not merged in order to analyze regional differences.
ML Model Engineering and ML Winning Prediction
In Section “Data Acquisition” it was explained that the dataset contains a large number of match data, each containing features, i.e. the statistical values of a summoner from a match. Through experiments, we determined which features are influenced by all other features and correlate with each other. We could point out that xpPerMin is a suitable target feature for model development. xpPerMin is used to determine the average experience points (xp) gained by a player over a given time period. The average xp per minute can be calculated by summing the xp gained in each time interval xpPerTimeInterval and dividing the result by the total number of time intervals. A higher average xp per minute indicates that a player is gaining xp at a faster rate. The behavior of each player is represented by xpPerMin. The value is determined as follows:
As a result, we obtain an average score. The accumulated experience points arise from the different sources in the game, making them less dependent on the different roles or the positions of the summoners. During the calculation of the score, only the players with the same position and roles are compared, thus this value becomes very useful as a target feature and can be used as a good measure to check the quality of a played match. Moreover, besides this single feature, it is possible to create a combination of the score, which includes all roles and positions. For our approach, such a procedure was not considered.
The suitable feature to train the models was identified using a supervised model approach to predict the target features [15]. The identified target features consist of float values. By being continuous values, the underlying problem is treated as a regression problem rather than a classification problem [16].
A total of eight regression models and two ensemble approaches were examined in this paper. The models used in this paper are Random Forest Regressor (RF), eXtreme Gradient Boosting Regressor (XGB), MultiLayer Perceptron Regression (MLPR), Gradient Boosting Regressor (GradB), K-Nearest Neighbors Regressor (KNNR), epsilon Support Vector Regressor (SVR), Categorical Gradient Boosting Regressor (CatB), Ridge Regression (Ridge). The ensemble approaches are a Bagging Regressor (BagR) and a Voting Regressor (VotR).
The best models are selected only after they have been trained and their hyperparameters optimized using Gridsearch [17]. Using hyperparameter optimization, the models are optimized again to improve the goodness of fit. This serves to measure the model quality, for this, it is necessary to evaluate the trained models with the help of metrics. To do this, the \(R^2\) Score, the accuracy, the Median Absolute Deviation (MAD), the Mean Absolute Error (MAE) and the Root Mean Squared Deviation (RMSD) were used as metrics. With the help of the tool SHapley Additive exPlanations (SHAP) [18, 19] we determined the best model through Gridsearch and its evaluation, to decide on the features which have the largest influence on the model.
All the mentioned concepts were realized in this project. The data needed for training the models were collected using the official API of Riot Games and with the help of the tool Featurewiz [20], a feature reduction was performed concerning a target variable. For the original dataset, data was collected from 2901 games. A correlation analysis was used to determine the ratio 0.81 for Featurewiz as the best threshold. In the first step, the dataset was reduced from 109 features by not considering the target feature to 91 features. This reduction was achieved by eliminating features on the dataset that consisted of either IDs only, empty entries, or those that contained no information content. We used the SULOV method, which is a modification form of the Minimum Redundancy Maximum Relevance approach [21]. Figure 2 shows the graph of the SULOV analysis and the correlation of the feature pairs. The larger dots represent a higher Mutual Information Score (MIS) of the features to the target feature and the thicker bars represent a higher correlation between the feature pairs to each other.

Reduction of features based on SULOV
From this, 10 features were identified that had a correlation threshold greater than 0.81. These were removed from the dataset for further feature optimization. The remaining 81 features were passed to an XGB. The recursive analysis of the XGB model generated a dataset consisting of the top 15 features. In Fig. 3, the correlation matrix containing these 15 features is listed after going through all the Featurewiz steps.

Correlation matrix of the 15 features after applying Featurewiz
After a training dataset consisting of the 15 best features was generated, these data were passed to the 11 regression models explained in the previous chapter with their base parameters. After that, hyperparameter optimization was performed for all ML models. In the next step, the model quality is determined using the metrics \(R^2\)-score, accuracy, MAD, MAE, and RMSD. To get a better estimation of the stability of the ML models in relation to the model’s goodness and to better assess it, the evaluation of each model is repeated 100 times. In addition, the mean and standard deviation are determined for each metric. This is a modified form of cross-validation and is performed on a data basis. After each iteration, the data are shuffled from the dataset, taking care to use the same ratio to split the data. By optimizing the models through training, the best model could be selected after analyzing the evaluation. SHAP analysis was then used to identify the influence of the features on the model result. This serves to measure the influence of the features on the training model as well as on the prediction model.
The \(R^2\) score is a scale-free metric for which it does not matter whether the values passed to it are too large or too small. This distinguishes this metric from the mean absolute percent deviation (MAPD) score which is needed to calculate the accuracy. The second advantage of this metric compared to the MAPD score is the linear dependence between the ground truth and the predicted value. If the \(R^2\) score is at a value of one, this means that these values have a perfect linear dependence on each other and if the \(R^2\) score is zero, there is no linear dependence between the values.
The \(R^2\) score has a problem in detecting the overfitting of the models. While the \(R^2\) score is a good metric that can be used to evaluate model’s goodness of fit, it is not able to identify if a model has overfitted, causing models to develop poor generalizability and only perform well on data that resembles the training data. To better address the problem of poor generalizability and to better assess model performance, the MAE, RMSD, and MAD values are used as regression metrics in addition to the accuracy and \(R^2\) scores.
Using the second regression metric, it is possible to perform a better analysis of the model’s goodness. To calculate the accuracy of the models, the difference between the MAPD and the number 100 is calculated, which allows the percent error value to be determined. The value obtained after calculating the normal MAPD metric must be close to zero in the best case. The accuracy is calculated as follows:
Multiplying the number 100 to it, the MAPD value calculates the percentage value of this metric. Here, accuracy is considered better when the metric approaches 100. One problem with this metric is that it does not work well with data that has taken on the value of zero or an extreme value. The problem just mentioned would also occur with accuracy, since it includes the MAPD value as a necessary condition in the form of a variable.
In addition to its drawbacks, the MAPD metric also offers many advantages. It is much more robust to the outliers from the dataset. Nevertheless, the metric has a major problem in that it has a vulnerability to the division operator. If the result approaches zero, it is not possible to compute a result because dividing by zero is not possible. This creates an undefined area for the MAPD metric. It is possible to obtain a too-large score for very small values. To better assess the model quality, it is necessary to use other metrics in addition to the accuracy to better understand the model quality.
The next metric is the MAD score, it has a robustness against outliers and is also like the MAPD metric, the MAE and the RMSD score only accurate if there is not a too high number of them in the dataset. As with robustness, the range of values for the MAD score is the same as for the MAE or RMSD score and therefore also lies between zero and \(\infty\).
The next metric is the MAE score, which has a range of values between zero and \(\infty\). Here, a value that is close to zero is better. The next metric that is used in addition to the accuracy, the \(R^2\) score, and the MAE score to determine the model quality is the RMSD score.
This last metric is used in Table 1 to compensate for problems that the other metrics have. To get a better understanding of the metric, the RMSD is also set in relation to the MAD score. As with the MAE score, the range of values for the RMSD score is also between zero and \(\infty\), although a value close to zero also indicates better model quality for this metric. A key difference between these two metrics in relation to the accuracy or the \(R^2\) score is that the direction of the error plays no role in determining the model’s goodness. The main difference between the RMSD score and the MAE score is in the calculation of the error. In the RMSD score, in contrast to the MAE score, the error is squared before it is averaged, which means that larger errors are included in the metric with a higher weighting during the calculation of the metric.
In order to better compare the metric results and thus determine the best ML model for the further steps, all results were summarized in Table 1. Here, all metric results were rounded to four decimal places, with the best model highlighted in bold. From the metric analysis, it can be seen that among all ML models, the GradB model performs best.
For the final stage of model evaluation, the stability of the six models was tested in terms of their accuracy and performance. This test is used to estimate the probability of whether an ML model produces a good result by chance or this corresponds to the rule case. For this purpose, the average and standard deviation of 100 different runs of each metric are calculated.
For better comparability of the ML models, the results from all models were rounded up to four decimal places, with the best result highlighted in bold and all calculated results are listed in Table 2.
These analyses showed that GradB gave the best result in almost all metrics during repeated testing of the ML models.

Bar plot of SHAP analysis of GradB during prediction after hyperparameter optimization

Comparison of SHAP analysis of GradB after training (top) and after prediction (bottom) [2]
Now that a selection of the best ML models has been made by different evaluation techniques, the best model is interpreted using the SHAP analysis tool. Here, 15 features and their associated influences on model performance are considered. The features being champLevel, the level of the champion played by the summoner, totalMinionsKilled, the total amount of minions killed including the neutral minions in the jungle, lane, the assigned position of the summoner, totalDamageDealt, damage done to enemy champions, minions and other objectives, deaths, the amount of deaths of the summoner during the match, kills, the amount of killed enemy champions by the summoner, wardsPlaced, the amount of wards (items that provide vision) placed during the match, neutralMinionsKilled, monsters in the jungle count as neutral minions, role, the assigned role of the summoner, perk3, the chosen primary rune path of the summoner, assists, the amount of assists on kills of enemy champions, firstInhibitorAssist, Boolean value which shows whether the summoner assisted destroying the first inhibitor of the game, physicalDamageDealt, the amount of physical damage dealt to champions, minions and other objectives, perkSubStyle, the chosen secondary rune path of the summoner and win, a Boolean value which shows whether the summoner was in the winning team or not.
Figure 4 shows the average SHAP values for each feature during training. This means that a model can only be trained from the features champLevel and totalMinionsKilled, since they affect the target feature the most.
These findings are further confirmed by the values from Fig. 5. In Fig. 5, two summary graphs are shown, which were generated after training (top) and after prediction (bottom). The summary graph displays the relationship between feature importance and feature effects, with each point representing a value for a feature and an instance. The position on the y-axis is determined by the feature and on the x-axis by the value, and the color indicates the value of the feature. The overlapping points are displayed in the y-axis direction to show the distribution of values per feature. The features are ordered by importance. The summary graph provides an initial understanding of the relationship between a feature’s value and its impact on the prediction. In both graphs, the relevance of the features champLevel and totalMinionsKilled can be observed in both the training and prediction phases. Both features had a very strong impact on the model result in relation to xpPerMin.
All features were sorted in descending order with respect to their impact size and the Calculated Sum of SHAP values from the entire sample. Here, all features that had the greatest impact were listed at the top of the graph and all features that had the least impact were listed at the bottom of the graph. This means that if the values in the characteristics champLevel, totalMinionsKilled is large, this also has the largest influence on the prediction. During SHAP analysis, the first step is to remove a feature and compare the subsequent model result with the previous model results. This allows the effect of this feature on all others to be calculated. Each feature is represented by a color-coded point. The resulting distribution is calculated for all features, for which the whole dataset is used. Using this analysis, it was found that the feature win had the smallest changes relative to the target feature xpPerMin [22].
In conclusion, these analyses showed that GradB was able to produce the best model results of all six ML models. This was also reflected during the stability analysis in Table 2, where GradB outperformed all other ML models in all metrics and achieved an accuracy of 92.7%. Thus, it can be concluded that GradB is able to find a very accurate player score using the values given to it as described in the previous section, which is even slightly more accurate than the scores discussed in the literature as they are based on other data or games (e.g. [8] with Counterstrike: Global Offensive and the biometric-based features).
Performance Metric, Player Role Impact, and Winning Prediction
In addition to the ML performance metric, we also create a facile heuristic performance metric, which is explained in more detail in this section. We investigate whether the respective roles have a different influence on the outcome of the game and finally, the last performances of the players were used to create a winning prediction for future matches.
Heuristic Player Performance Score
The playing style of players differs vastly based on their role and position. As the name suggests a player of a carry role will try to carry the team’s damage while a player of the support role will support his team with vision and crowd control. Thus a player of a carry role will usually have a higher amount of kills than a support player. In order to accurately classify the performance of the carry player it is necessary to compare his performance scores not with those of support players but with players of the same role and position. The permutation of the five roles and positions results in a total of 25 different categories. Each player is assigned to a category and his values from the performance metric are only compared with players of the same category in order to prevent the different playing styles to be reflected in the player scores.
The player score consists of the percentile rank of a player’s performance. A performance score of 90 indicates that the player has achieved a better performance than 90% of the players with the same role and position in a certain category. This representation was used to more intuitively indicate a player’s performance compared to the numerical values.
To calculate the player score the match data was split up into player data and divided to account for the 25 different permutations of roles and positions. Each category is then sorted in ascending order. The given value of for example kills of the player is compared to the respective category. The index of a dataset with the same kill count divided by the length of the data structure of the category acts as the percentile rank that indicates what percentage of players achieved a worse kill count than the given player.
Importance of Roles and Winning Prediction
To calculate the importance of the different roles our dataset of 2901 matches was used. For each of these matches, the player scores of all players were calculated and weighted with their role. For each match, the teams are represented as the sum of their weighted player scores. The team scores for the two teams (\({t_{i}}\)) are illustrated in the following formulas:
\({p_{i}}\) represents the calculated player score for each player within the corresponding team and \({w_{i}}\) represents the weights based on the importance of the roles. The team with the higher player score sum is predicted to be the winner. Linear optimization was used to compute the weights of the roles in order to satisfy the higher sum of the winning team in as many equations as possible.
For the proposed calculation the player scores of the given target feature (xpPerMin) are added up within the team to build the team score. For each of the 2901 matches, the team score of the losing team is subtracted from the team score of the winning team to calculate the difference between the team scores. These values are then used as input for the optimization function. The following weights are the result of the optimization: [0.1996, 0.1995, 0.1995, 0.2005, 0.2006]
As there are five roles a weight of 0.2 is to be expected under the assumption that each role is equally important. The result shows a difference between the individual factors of Eqs. 3 and 4 of only 0.1%. Considering this result we argue that each role in LoL is equally important. The differences in the impact of single roles regarding the outcome of the match are negligible.
Since our calculation of the importance of the different roles showed that the differences are negligible, the weights of the different roles are not used for our winning prediction. The winning prediction is instead based on the player scores. To predict the outcome of a match the player scores of the last games for each player are calculated. Afterward, the average of the calculated player score is determined. The acquired averages are then added up for the two teams. The team with the higher sum of player scores is predicted to have a higher chance of winning the match. To test whether the winning team historically had the higher sum of player scores, we used our dataset of games and determined the number of matches that fulfilled this assumption. In 86% of the matches the winning team had a higher sum of player scores. This shows that even though this assumption is correct in most games, in some games the team with the lower sum of player scores will win and that our ML-based winning prediction is more accurate.
Changing Match Parameters
Furthermore, it is possible to use our LoL model to analyze changes in the course of the game. If player X from team 1 had done one action differently the result of the match might be different. To do this, it is possible in our application to change the individual parameters and then calculate the assumed outcome of the match again. This also makes it possible to analyze the different influences of the individual parameters on the outcome of the match. A limiting factor here, however, is that changes to individual scores do not automatically change the other scores that are influenced by them. For example, if player X from team 1 gets one additional kill, the death score of a player from team 2 would also have to be changed. Thus, scores that are connected to each other are not automatically changed. Furthermore, it is not possible to make a statement about how the course of the game would have changed as a result of the changed action. If player X from team 1 for example, one kill is added, it could be that he would have gained an advantage over the whole game and could have extended this advantage to generate even more kills.
Conclusion and Future Work
This paper presented two different performance metrics for the game LoL, which evaluate the overall performance of a player as well as the performance of the player in individual subcategories. A base of 29010 player stats from 2901 matches was utilized for our analysis. Due to the different playing styles of different roles and positions, only players who played the same role and position were compared.
Our GradB ML model was able to determine a player score with a precision of 92.7% and a heuristic approach, where we broke down a player score into specific aspects resulting in a winning prediction accuracy of 86%. Furthermore, the effect of the different roles and positions on the outcome of a match was examined and it was found that the different roles and positions only have a difference of 0.1% on the outcome of the match.
In future work, it is of interest to create several more transparent metrics to cover more application possibilities as well as to then combine these metrics in interactive tools like Mobalytics or op.gg. Amateur players in particular would benefit from such tools, as they tend to lack the resources to perform effective pre- or post-match analysis of individual matches. The ML-based approach appears to be the most promising based on the findings in this paper and should be pursued in future work.
The approaches and metrics presented here are not only interesting for LoL, but can also be applied to other team sports with different positions or roles. These can be other e-sports games as well as sports like basketball, football, or soccer.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Österle H, Becker J, Frank U, Hess T, Karagiannis D, Krcmar H, Loos P, Mertens P, Oberweis A, Sinz EJ. Memorandum on design-oriented information systems research. Eur J Inf Syst. 2011;20(1):7–10.
Bahrololloomi F, Sauer S, Klonowski F, Horst R, Dörner R. A machine learning based analysis of e-sports player performances in league of legends for winning prediction based on player roles and performances. In: Proceedings of the 17th International Joint Conference on computer vision, imaging and computer graphics theory and applications—volume 2: HUCAPP. 2022; p. 68–76. SciTePress, Setúbal . https://doi.org/10.5220/0010895900003124. INSTICC.
Silva ALC, Pappa GL, Chaimowicz L. Continuous outcome prediction of league of legends competitive matches using recurrent neural networks. In: SBC-Proceedings of SBCGames. 2018; p. 2179–2259.
Quintana DA. Predicting wins in League of Legends. 2019. https://rpubs.com/diegolas/LogisticLoL. Accessed 13 Sep 2021.
Ani R, Harikumar V, Devan AK, Deepa OS. Victory prediction in league of legends using feature selection and ensemble methods. In: 2019 International Conference on intelligent computing and control systems (ICCS). 2019; p. 74–7. https://doi.org/10.1109/ICCS45141.2019.9065758
Do TD, Wang SI, Yu DS, McMillian MG, McMahan RP. Using machine learning to predict game outcomes based on player-champion experience in league of legends. In: The 16th International Conference on the Foundations of Digital Games, 2021. p. 1–5
Hodge V, Devlin S, Sephton N, Block F, Cowling P, Drachen A. Win prediction in multi-player esports: live professional match prediction. IEEE Trans Games. 2019. https://doi.org/10.1109/TG.2019.2948469.
Khromov N, Korotin A, Lange A, Stepanov A, Burnaev E, Somov A. Esports athletes and players: a comparative study. IEEE Pervasive Comput. 2019;18(3):31–9.
Eaton JA, Sangster M-DD, Renaud M, Mendonca DJ, Gray WD. Carrying the team: the importance of one player’s survival for team success in league of legends. In: Proceedings of the Human Factors and Ergonomics Society Annual Meeting. 2017; vol. 61, pp. 272–276. SAGE Publications Sage CA: Los Angeles, CA.
Horst R, Lanvers M, Kacsoh Lv, Dörner R. Moba coach: exploring and analyzing multiplayer online battle arena data. In: International Symposium on visual computing, 2021; p. 197–209. Springer.
Novak AR, Bennett KJ, Pluss MA, Fransen J. Performance analysis in esports: modelling performance at the 2018 league of legends world championship. Int J Sports Sci Coach. 2020;15(5–6):809–17.
Maymin PZ. Smart kills and worthless deaths: esports analytics for league of legends. J Quant Anal Sports. 2020;1:11–27 (ahead-of-print).
Afonso AP, Carmo MB, Moucho T. Comparison of visualization tools for matches analysis of a moba game. In: 2019 23rd International Conference information visualisation (IV). 2019; p. 118–126. IEEE.
OPGG: OP.GG. 2021. https://euw.op.gg/. Accessed 13 Sep 2021.
Soni D. Supervised vs. unsupervised learning. 2020. https://towardsdatascience.com/supervised-vs-unsupervised-learning-14f68e32ea8d. Accessed 30 Aug 2021.
Tiwari R. Regression vs classification in machine learning: What is the difference? 2020. https://in.springboard.com/blog/regression-vs-classification-in-machine-learning/. Accessed 30 Aug 2021.
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–30.
Lundberg SM, Lee S-I. A unified approach to interpreting model predictions. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R. editors. Advances in neural information processing systems, vol 30. Curran Associates, Inc.; 2017, pp. 4765–4774. http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf. Accessed 1 Sep 2021.
Lundberg SM, Erion G, Chen H, DeGrave A, Prutkin JM, Nair B, Katz R, Himmelfarb J, Bansal N, Lee S-I. From local explanations to global understanding with explainable ai for trees. Nat Mach Intell. 2020;2(1):2522–5839.
AutoViML: Autoviml/featurewiz: use advanced feature engineering strategies and select the best features from your data set fast with a single line of code. 2020. https://github.com/AutoViML/featurewiz. Accessed 30 Aug 2021.
Peng H, Long F, Ding C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell. 2005;27(8):1226–38.
Radečić D. Shap: how to interpret machine learning models with python. 2020. https://towardsdatascience.com/shap-how-to-interpret-machine-learning-models-with-python-2323f5af4be9. Accessed 14 Sep 2021.
Acknowledgements
This publication was produced as part of the REQUAS qualification programme, which was funded by the German Federal Ministry of Education and Research in the context of the federal-state program ‘FH-Personal’ under the grant number 03FHP147A. The responsibility for the content of this publication lies with the authors.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Advances on Computer Vision, Imaging and Computer Graphics Theory and Applications” guest edited by Kadi Bouatouch, Augusto Sousa, Mounia Ziat and Helen Purchase.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bahrololloomi, F., Klonowski, F., Sauer, S. et al. E-Sports Player Performance Metrics for Predicting the Outcome of League of Legends Matches Considering Player Roles. SN COMPUT. SCI. 4, 238 (2023). https://doi.org/10.1007/s42979-022-01660-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-022-01660-6