
Abstract
Gaussian process models (GPMs) are widely regarded as a prominent tool for learning statistical data models that enable interpolation, regression, and classification. These models are typically instantiated by a Gaussian Process with a zero-mean function and a radial basis covariance function. While these default instantiations yield acceptable analytical quality in terms of model accuracy, GPM inference algorithms automatically search for an application-specific model fitting a particular dataset. State-of-the-art methods for automated inference of GPMs are searching the space of possible models in a rather intricate way and thus result in super-quadratic computation time complexity for model selection and evaluation. Since these properties only enable processing small datasets with low statistical versatility, various methods and algorithms using global as well as local approximations have been proposed for efficient inference of large-scale GPMs. While the latter approximation relies on representing data via local sub-models, global approaches capture data’s inherent characteristics by means of an educated sample. In this paper, we investigate the current state-of-the-art in automated model inference for Gaussian processes and outline strengths and shortcomings of the respective approaches. A performance analysis backs our theoretical findings and provides further empirical evidence. It indicates that approximated inference algorithms, especially locally approximating ones, deliver superior runtime performance, while maintaining the quality level of those using non-approximative Gaussian processes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Applying Gaussian Process Models (GPMs) for interpolation [26, 38], regression [14, 45], and classification [19, 26] necessitates to instantiate the underlying Gaussian Process by a covariance function and a mean function. While the latter is typically instantiated by a constant, zero-mean function, the covariance function is modelled either by (i) a general-purpose kernel [50], (ii) a domain-specific kernel that is individually tailored to a specific application by a domain expert [1, 36, 50], or (iii) a composite kernel that is computed automatically by means of a GPM inference process [14, 28] in order to decompose the statistical characteristics underlying the data into multiple sub-models. Although the first option (i) produces GPMs of sufficiently high model accuracy, both (ii) and (iii) encapsulate data’s peculiarities and versatilities in a more detailed manner due to their data-informed approaches. Making use of domain-specific kernels requires laborious fine-tuning and extensive expert knowledge. Employing an automated, domain-agnostic GPM inference process, on the other hand, produces expressive composite kernels for diverse data analytical tasks without requiring any human interference.
Exhaustive automated GPM inference algorithms apply an open-ended greedy search in the space of all feasible composite covariance functions in order to determine an optimal instantiation of the underlying Gaussian Process [14, 25, 28, 43]. The resulting inextricable GPM needs to account for all different kinds of statistical peculiarities of the underlying data and thus potentially lacks expressiveness with regards to local phenomena. Additionally, evaluating a GPM by usual measures such as the likelihood [31] function entails calculations of cubic computation time complexity, which limits the application of GPM inference algorithms to small-to-moderate data collections [25]. Therefore, locally approximated algorithms [6, 8, 9] concurrently initiate multiple local inference procedures on dynamically partitioned data, which enable efficient inference of GPMs for dataset on the scale of millions of records.
In this paper, we provide an overview of the current state of the art of automated Gaussian Process Model inference [6,7,8,9, 14, 25, 28, 43] presenting both an empirical perspective as well as the theoretical background information. First, we present related work and background information on Gaussian Processes in “Background and related work”. Secondly, we provide an overview of current state-of-the-art algorithms for Automated GPM Inference in Sect. "Automated model inference for Gaussian processes". Thirdly, their individual performance with regards to several uni- and multidimensional benchmark datasets (i) indicating the performance of state-of-the-art GPM inference algorithms and (ii) highlighting their individual strengths and shortcomings is presented in "Evaluation". Finally, we conclude our paper in "Conclusion".
Background and Related Work
Gaussian Process
Gaussian Processes are non-parametric probabilistic kernel machines [36] that offer a statistically tractable and interpretable data representation [19, 28]. They have a wide range of possible applications in data analysis, including regression for uni- and multivariate data [42, 45], nearest neighbour analysis [13], interpolation [26], classification [42] and clustering [24]. They are also used for information retrieval in biology [49] and image processing [29]. In recent works, Gaussian Processes have been used for forecasting the spread of COVID-19 [4]. They are applied in 3D-animation [44] to model the influence of emotions on movements, and in traffic simulations [2] to predict human behavior. Overall, they are considered a prominent method in the field of probabilistic machine learning [15].
Gaussian Processes [36] are categorized as stochastic processes over random variables \(\{f(x) \, | \, x \in \mathcal {X}\}\), indexed by a set \(\mathcal {X}\), where every subset of random variables follows a multivariate normal distribution. The distribution of a Gaussian Process is the joint distribution of all of these random variables and it is thus a probability distribution over the space of functions \(\{f\, | \,f:\mathcal {X} \rightarrow \mathbb {R} \}\). A Gaussian Process is formalized as follows:
where the mean function \(m: \mathcal {X} \rightarrow \mathbb {R}\) and the covariance function \(k : \mathcal {X} \times \mathcal {X} \rightarrow \mathbb {R}\) are defined \(\forall x \in \mathcal {X}\) as follows:
Given a finite dataset \(D=\{X, y\}\) with \(X=\{x_i \, | \, x_i \in \mathcal {X} \wedge 1 \le i \le n\}\) representing the underlying input data (such as timestamps) and \(y \in \mathbb {R}^{n}\) representing the target data values, such as sensor values or other complex measurements, hyperparameters \(\theta\) of the mean and covariance functions are optimized by maximizing the log marginal likelihood [36] of the Gaussian Process, which is defined as follows:
As can be seen in Eq. (4), the log marginal likelihood of a Gaussian Process for a given dataset D of n records relies on mean vector \(\mu \in \mathbb {R}^{n}\), and covariance matrix \(\varSigma \in \mathbb {R}^{n \times n}\) which are defined as \(\mu [i] = m(x_i)\), and \(\varSigma [i,j] = k(x_i,x_j)\) for \(1\le i,j\le n\), respectively. We use the short-hand notation \(GP_\theta\) to denote a GPM whose underlying mean function m and covariance function k are parameterized via hyperparameters \(\theta\) (cf. [10, 12]). Commonly, the covariance function is structured via multiple compositional covariance functions in order to obtain the resulting compositional kernel-based covariance function [8].
Since computation time complexity of evaluating and applying an exact Gaussian process lies in \(\mathcal {O}(n^3)\) [19], different approximation techniques have been developed [41]. In the following two subsections, we outline the two major categories of Gaussian process approximations, i.e. local and global approximation, and present prominent representatives for each category.
Global Approximations
One prominent type of approximation used to speed up Gaussian Process evaluation and application is the group of global approximations [27, 41]. Instead of considering every single data record of a dataset of interest, these approximations focus on a (ideally representative) sample [27]. The family of Subset-of-Data (SoD) approaches [17] only use \(m \ll n\) data points for training, reducing complexity to \(\mathcal {O}(m^3)\). While these SoD approaches leave the general framework of a Gaussian Process unchanged and thus offer an easy solution to the problem of runtime complexity, they often suffer from an “overconfident prediction variance” [27] in comparison to other global approaches such as sparse approximations [16]. Although the latter still utilize a set of inducing points considerable smaller than the training set, they are better suited to make predictions with regards to the whole training set [27].
These approximations include the Nyström-approximation [36], a low-rank approximation of the covariance matrix (\(\mathcal {O}(n m^2)\)), which became quite prominent in an optimized form either called Sparse Pseudo-input Gaussian Process (SPGP) [40] or Fully Independent Training Conditional (FITC) [5]. Furthermore, Titsias [45] introduced Variational Free Energy (VFE), which also improves on the basic Nyström-approximation via a regularization term for the likelihood. Orthogonal to these improvements, Wilson and Nickisch [51] introduce the Structured Kernel Interpolation (SKI) method to further speed up these kinds of matrix approximations by linearly interpolating the full covariance matrix based on a small set of inducing data points m.
In general, these global approximations are able to capture global patterns, but lack capabilities to capture local ones due to their sampling nature [25, 27]. Thus, globally approximated Gaussian Processes focus on the expressive capacity of their respective sample rather than the full dataset.
Local Approximations
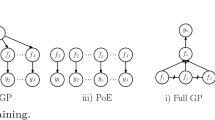
Local approximations are the other major group of Gaussian Process approximations and utilize local experts, i.e. distinct Gaussian Process sub-models for data segments. They are organized in three categories. While mixture-of-experts (MoE) [32, 53] and product-of-experts (PoE) approaches [20] try to smooth out the transition between segments and experts, only strict, thus non-smoothing approaches (also called Naïve Local Experts (NLE) [27]) can fully exploit the algorithmic advantages of local approximations [37, 41]. Therefore, current state-of-the-art GPM inference algorithms focus on the latter kind, which are simply called local approximations throughout this paper for the sake of simplicity.
Liu et al. [27] as well as Rivera and Burnaev [37] highlight these approximations as a key possibility to reduce complexity of common GPM evaluations based on likelihood measures. Instead of inferring an approximate GPM based on a data subset (cf. global approximations), they construct a holistic GPM from locally-specialized models trained on non-overlapping partitions of the data. Thus, the covariance matrix of the holistic GPM is composed of the respective matrices of its local sub-models [27]. This divide- &-conquer approach accelerates calculation of log marginal likelihood, since the resulting covariance matrix is a block diagonal matrix [37], whose inverse and determinant can be computed efficiently [34]. Rivera and Burnaev [37] emphasize that local approximations allow to “model rapidly-varying functions with small correlations” in contrast to low-rank matrix approximations.
Embedding the concept of local approximations into GPM inference algorithms requires a globally partitioning covariance function K. We use an indicator functions (also called Heaviside step function [22]) to concatenate independent sub-models into one coherent, partitioned GPM. This leads us to the definition of a partitioning covariance function K. We employ a predefined set of disjoint partitions \(\mathcal {P} = \{X_i, y_i\}_{i=1}^a\) to partition K into a independent sub-models \(k_i\):
The parameter \(a \in \mathbb {N}\) defines the number of sub-models \(k_i: \mathcal {X} \times \mathcal {X} \rightarrow \mathbb {R}\), where each sub-model \(k_i\) can be thought of as a local covariance function modeling the restricted domain \(X_i \subseteq \mathcal {X}\). The usage of indicator functions (thus having disjoint data segments) produces a block diagonal covariance matrix [30], which facilitates independently and thus efficiently searching the most likely local covariance function (i.e. sub-model) per data segment.
To mathematically show the implication of aforementioned independence, we have to investigate the internal structure of the corresponding log marginal likelihood function \(\mathcal {L}(m, k, \theta \, | \,D)\). To this end, we assume the covariance matrix \(\varSigma \in \mathbb {R}^{n\times n}\) (cf. Eq. 4) to be a block diagonal matrix. That is, it holds that \(\varSigma = diag(\varSigma _1, ..., \varSigma _m)\), where each matrix \(\varSigma _i \in \mathbb {R}^{n_i\times n_i}\) for \(1 \le i \le m\) is of individual arbitrary size \(n_i \in \mathbb {N}\) such that \(\sum _i{n_i} = n\). Furthermore, let \((\mathcal {I}_1, ..., \mathcal {I}_m)\) denote the partitioning of index set \(\{1, ..., n\} \subseteq \mathbb {N}\) according to the given blocks, i.e. for a submatrix of \(\varSigma\) over index set \(\mathcal {I}_i\) the following holds: \(\varSigma _{\mathcal {I}_i, \mathcal {I}_i} = \varSigma _i \forall i \in [1,m]\). Given this notation, one can show (i) that the quadratic form \((y-\mu )^T \varSigma ^{-1} (y-\mu )\) of the log marginal likelihood function \(\mathcal {L}(m, k, \theta \, | \,D)\) is equivalent to \(\sum _{i=1}^{a}{(\tilde{y}_i-\tilde{\mu }_i)^T \varSigma _i^{-1} (\tilde{y}_i-\tilde{\mu }_i)}\), where \(\tilde{y}_i = (y_i)_{I\in \mathcal {I}_i} \in \mathbb {R}^{n_i}\) and \(\tilde{\mu }_i = (\mu _i)_{I\in \mathcal {I}_i} \in \mathbb {R}^{n_i}\) are defined according to the block diagonal structure and (ii) that the logarithmic determinant can be decomposed as follows: \(\log \det (\varSigma ) =\log \prod _{i=1}^{a}{\det (\varSigma _i)} = \sum _{i=1}^{a}{\log \det (\varSigma _i)}\). By making use of the aforementioned algebraic simplifications, we can simplify the calculation of the log marginal likelihood function as shown below:
As shown above, the equivalence \(\mathcal {L}(m, k, \theta \, | \,D) = \sum _{i=1}^{a}{\mathcal {L}(m, k_i, \theta \, | \,\mathcal {P})}\) affects the computation of a GPM by means of K for a given data set D and its non-overlapping partitions \(\mathcal {P}\). Instead of jointly optimizing a holistic statistical model fitting the entire data set D, we are able to independently optimize individual sub-models \(k_i\). This will not only increase the expressiveness of the overall GPM, but also reduce the computation time required for calculating such a model.
Automated Model Inference for Gaussian Processes
In general, inference is regarded as a process that addresses the uncertainty involved in choosing an apt instantiation of a variable facing certain observations. While Gaussian Process inference focuses mainly on hyperparameter optimization [19] (and if applicable finding optimal inducing points and inputs [39]) for a predefined model comprising specific covariance and mean function, inference of Gaussian Process models also takes the uncertainty of the latter constituents and their structure into account to infer the whole model. For this purpose, the mean function of the Gaussian Process is commonly instantiated by a constant zero function [14, 36], so as to correspond to an additional data normalization step. The second constituent, i.e. covariance function k, is algorithmically composed via operators implementing addition and multiplication among different (composed) base kernels \(b \in \mathcal {B}\). Prominent base kernels include the linear kernel, Radial Basis Function (RBF) kernel, and periodic kernel, which are able to capture for instance smooth, jagged, and periodic behavior [14].
In general, we define automatic GPM inference as follows (cf. [6]):
Definition 1
(Automatic GPM inference) Automatic GPM inference means to search a search space of GPMs \(\mathcal {G}\) for an optimal GPM \(GP_\theta ^* \in \mathcal {G}\), which is not outperformed by any other GPM \(GP_\theta \in \mathcal {G}\) in terms of a predefined quality measure, here exemplarily instantiated by the likelihood \(\mathcal {L}(m, k, \theta \, | \, D)\):
In this section, we outline state-of-the-art, automatic GPM inference algorithms organized into the categories of exhaustive (cf. "Exhaustive model inference") and partitioned (cf. "Partitioned model inference") inference algorithms. While the latter consists of those employing local approximations and is thus suited for big data, the first encompasses approaches producing one universal, inextricable GPM for the whole dataset.
Exhaustive Model Inference
Exhaustive inference algorithms, such as Compositional Kernel Search (CKS) [14], Automatic Bayesian Covariance Discovery (ABCD) [28, 43], and Scalable Kernel Composition (SKC) [25], apply an open-ended, greedy search in the space of all feasible kernel combinations to progressively compute a GPM fitting the entire dataset D, respectively \(y \in D\). The CKS algorithm [14] follows a simple iterative procedure, which aims to improve the best covariance function k inferred in one iteration over the course of the next one. Therefore, this strategy produces a set of candidate covariance functions \(\mathcal {C}_k\) based on the previous best covariance function k. In doing so, a new candidate is created by extending any subexpression of k by means of a further base kernel \(b \in \mathcal {B}\) [14]. We express this candidate generation via the following term, abstracted for the sake of comprehensibility:
ABCD extends that candidate set with regards to a sigmoid change point operator \(\mathbf ]\![\) [43], to locally restrict the effect of covariance functions [28]:
Algorithm 1 summarizes steps taken by exhaustive inference algorithms, where candidate GPMs of increasing complexity are evaluated in an iterative procedure until either further complexity is not improving model quality or a complexity bound \(c(k_{best}) < c_{max}\) is met. Usually, complexity bound \(c(\cdot )\) represents an upper bound for the amount of base kernels constituting covariance function \(k_{best}\). CKS and ABCD only differ in their candidate set \(\mathcal {C}_k\) (cf. Eqs. 7 and 8). Starting with a set of base kernels \(\mathcal {B}\), the candidates of every following iteration are generated via expanding upon the best candidate of the previous iteration. Moreover, a new candidate is also generated for every replacement of a base kernel b with another one \(b'\).

The performance of those given automated GPM inference algorithms is impeded by two major bottlenecks. Evaluating every candidate conceived by expanding on any subexpression of the current best covariance function \(k_{best}\) poses one of these bottlenecks. Thus, reducing the set of candidates per iteration to cover just the most promising candidates improves on the performance of the respective algorithms, presumably without affecting model quality. Moreover, assessing model quality in terms of log marginal likelihood epitomizes another bottleneck of current algorithms, which is intrinsic to the framework of Gaussian Processes itself [19]. The cubic runtime complexity of that basic measure inhibits analysis of large-scale datasets (cf. [25]). Kim and Teh [25] present SKC as a way to overcome at least the latter one of those bottlenecks. The algorithm improves the efficiency of the kernel search process by accelerating CKS using VFE [45] for hyperparameter optimization and a custom upper bound on \(\mathcal {L}\) for determining \(k_{best}\) [25]. These approximations enable SKC to infer GPMs for datasets of up to 100,000 records in a reasonable amount of time according to Kim and Teh [25]. Furthermore, SKC uses a candidate generation strategy, which produces fewer candidates. In particular, this strategy only considers candidates generated by expanding the full \(k_{best}\) by further added base kernels \(b \in \mathcal {B}\) instead of expanding every subexpression [25].Footnote 1
To summarize, state-of-the-art exhaustive, automated GPM inference algorithms are well applicable to small datasets but are not suited for the analysis of large-scale datasets beyond 100,000 records due to their cubic computation time complexity as well as due to their large candidate sets, which need to be evaluated during the search procedure [25].
Partitioned Model Inference
In this section, we outline partitioned GPM inference algorithms making use of the efficiency improvement of locally approximated covariance function K (cf. Eq. 5) and a more rigid candidate selection. Although differing in their algorithmic design, all partitioned inference approaches use the same formalization of candidate set \(\mathcal {C}_k\) for inferring local sub-models later concatenated by K [6,7,8,9]. They restrict the candidate set to those covariance functions complying with the sum-of-products form and subsequently reduce redundancy in the candidate set [8]:
The Large-Scale Automatic Retrieval of GPMs (LARGe)Footnote 2 algorithm [6, 7] initiates multiple local kernel searches on dynamically partitioned data. Subsequently, LARGe concatenates the resulting sub-models, i.e. each independent composite kernel-based covariance function \(k_i\), into a joint large-scale GPM by means of K (cf. Eq. 5) and a zero-mean function. Prior to the computation of these independent sub-models, a global partitioning needs to be determined in advance. We use clustering algorithms [52] for multi-dimensional data and change point detection mechanisms [3, 46] for uni-dimensional input data. Besides \(\mathcal {P}\), the given dataset \(D=\{X,y\}\) (cf. "Gaussian process") and complexity parameter \(c_{\rm max}\), restricting sub-model size, are given as parameters [6].
Algorithm 2 illustrates the LARGe algorithm. Without loss of generality we initiate the sub-models \(k_i \in K\) for every data partition \(\mathcal {P}\) via a white noise kernel \(k_{WN}\). The set \(\mathcal {I}\) encompasses the indices of all non-final sub-models \(k_i \in K\). The following while-loop is executed until this set of indices is empty. During every iteration the segment \(S_i\) with the lowest model quality by means of log marginal likelihood \(\mathcal {L}\) is selected, candidate covariance functions \(\mathcal {C}_{S_i}\) for that segment are found using the predefined candidate generation strategy and the best performing covariance function \(k^{\star }\) is determined. This mechanism enables to return a preliminary GPM early on in the process [6].Footnote 3 If that covariance function \(k^{\star }\) reaches maximum complexity \(c_{max}\) in terms of number of involved base kernels or delivers equal quality w.r.t. the previous best expression \(S_i\), it is considered final and thus removed from \(\mathcal {I}\). Finally, a GPM utilizing a K-based (cf. Eq. 5) concatenation of sub-models \(k_i \in K\) and zero-mean is returned [6, 7].

The Concatenated Composite Covariance Search (3CS) [9] algorithm follows similar steps for finding a locally approximated GPM for a given dataset D given a complexity constraint \(c_{max}\)Footnote 4, but is based on a sequential procedure and a Gaussian-process-based change point detection mechanism [9]. The latter uses the partitioning covariance function K and two partitions resulting from a single change point \(\tau\) separating two white noise kernels \(k_{WN}\) to find an optimal change point \(\tau ^*\) in the current data partition of interest. 3CS uses a sliding window \(D_i\) to describe this data partition of size w, searches for an apt change point and employs exhaustive search with the adjusted candidate set defined in Equation 9 to find an optimal local model \(k^\star\) [8, 9].

Finally, Algorithm 4 illustrates Lineage GPM Inference (LGI) [8], which aims to overcome one of the major issues of local approximations, i.e. very large partitions. Since every local model of a locally approximated GPM is virtually an exact GPM on its own, large partitions cause the same runtime issues faced by non-approximative Gaussian Processes [8]. Thus, LGI was proposed to overcome that problem by employing local and global approximations and alternating between both over the course of its recursive procedure. At first, the recursive search is started with regards to the whole dataset D, complexity constraint \(c_{max}\), and a white-noise kernel as initial model. Utilizing a global approximation \(\varOmega\) an improved model \(k^\star\) for the current data partition of interest \(\hat{D}\) is found. If an improvement with regards to the previous model \(\hat{k}\) is not possible, the previous model is returned. Otherwise, \(\hat{D}\) is partitioned and recursive search is started again for all resulting partitions. Eventually, LGI is designed to find “increasingly particularized sub-models for partitions of further shrinking size” [8].

In this section, we have outlined the state-of-the-art, automated GPM inference algorithms, both using exact Gaussian Processes as well as approximative ones. Their respective commonalities and differences with regards to utilized approximations, ability to analyze multi-dimensional data, and largest dataset size processable in a reasonable amount of time according to the literature are summarized by Table 1. Their individual merits and weaknesses are further empirically analyzed in the following section.
Evaluation
In this section, we investigate the performance of the outlined GPM inference algorithms in terms of runtime efficiency and accuracy. In order to ensure comparability with existing and prospective algorithms, we base our experiments on publicly available datasets, which were used in the majority of other papers proposing GPM inference algorithms [6,7,8,9, 14, 25, 28] (cf. Table 2). Kim and Teh [25] note that datasets larger than a few thousand points are “far beyond the scope of [...] GP optimisation in CKS” and consequently beyond the scope of ABCD as well. Therefore, datasets 1–6 are rather small. Especially for scalability analysis, we include five larger datasets (datasets 7–11 in Table 2). Besides covering datasets of different sizes, the given collection of datasets also includes different application domains and dimensionalities.
All experiments are executed on a multi-core machine with 3.9 GHz CPU and 128 GB main memory. The latter capability accommodates for the high storage complexity, i.e. \(\mathcal {O}(n^2)\), cf. [19], of non-approximate Gaussian Process Inference by means of CKS and ABCD. All algorithms were implemented using Python 3.9 and Tensorflow 2.7 (no GPU acceleration enabled). Since commonly likelihood \(\mathcal {L}\) is just used for optimizing models and Root Mean Squared Error (RMSE) for assessing model quality [6, 14], we will adopt that procedure as well. 90% of the respective data is used for training, while the remaining 10% are kept aside for determining test accuracy. To produce reliable results every single run of an algorithm is repeated with five different train-test-splits. Thus, Tables 4 and 3 report on the median metric across these five runs. To thoroughly evaluate every candidate GPM, their hyperparameter optimization is repeated ten times with different hyperparameter initializations (i.e. random restarts [25]).
Since the given six algorithms vary largely with regards to their parallelization capacities, we do not use multi-processing to ensure comparability. Still, we enable Tensorflow to internally parallelize mathematical operations (e.g. matrix inversion and matrix multiplication) using up to eight threads. We use complexity constraint \(c_{max}= 4\) for all algorithms, Bottom-Up Segmentation for partitioning uni-dimensional data and k-Means for partitioning multi-dimensional data. Furthermore, LGI uses a SoD approach as global approximation \(\varOmega\) (cf. [6,7,8,9, 14, 25, 28]).

Distribution of relative runtime for different automatic GPM inference algorithms
Figure 1Footnote 5 summarizes GPM inference runtime for all six algorithms. It becomes apparent that non-approximative methods, i.e. CKS and ABCD, as well as the solely globally approximating method, i.e. SKC, are less efficient in terms of runtime than the remaining locally approximating ones. Therefore, the execution of these less efficient algorithms was omitted for larger datasets (datasets 9–11). Furthermore, LGI is the most runtime-efficient algorithm among the partitioned model inference procedures, while the other two approaches are apparently less efficient. Table 3 further details the efficiency of all six algorithms by stating their runtime with regards to the different considered datasets. Since ABCD and 3CS solely rely on change points for partitioning data, they are only evaluated for uni-dimensional input data.

Distribution of model error in terms of RMSE per model resulting from different automatic GPM inference algorithms
To put the findings with regards to runtime efficiency into perspective, Fig. 2Footnote 6 illustrates the distribution of model accuracy per model inference approach. Despite substantial advantages in runtime efficiency, the models produced by partitioned automatic GPM inference algorithms are able to maintain the level of quality of those models produced by non-approximative algorithms. LGI’s gains in runtime performance come at the cost of a slight reduction in model quality when compared to other partitioned algorithms. Table 4 further details these findings.
To conclude, we have evaluated the performance of six state-of-the-art GPM inference algorithms on various uni-dimensional and multi-dimensional benchmark databases. Our performance study indicates that partitioned approaches for GPM inference provide higher performance on average in terms of runtime efficiency, while maintaining the level of quality delivered by non-approximative algorithms.
Conclusion
In this paper, we have investigated automated GPM inference algorithms. In doing so, we first exposed the mathematical and statistical background of Gaussian Processes and current approaches to apply them in an approximate manner. Based on that theoretical background, we outlined state-of-the-art inference algorithms and highlighted the respective differences and commonalities.
Furthermore, we evaluated these algorithms from a practical perspective. Our performance evaluation has revealed that GPMs resulting from partitioned inference algorithms, i.e. 3CS, LARGe, and LGI, deliver similar model quality in comparison to those models produced by non-partitioned algorithms. In addition, runtime of the inference process is reduced considerably especially for larger time series, where partitioned approaches achieve a speed-up factor of up to 50 with regards to non-partitioned methodsFootnote 7, i.e. CKS, ABCD and SKC.
Availability of data and materials
The data, that has been used for the evaluation conducted for this paper, is available via the sources cited in Table 2.
Code availability
The code, that has been used for the evaluation conducted for this paper, is available via our own GitHub repository(cf. https://github.com/Bernsai/GaussianProcessModelRetrieval) dedicated to model inference algorithms for Gaussian Processes. It encompasses an implementation for all the evaluated algorithms.
Notes
In contrast to CKS and ABCD, SKC also includes a so-called kernel buffer. To increase comparability with CKS and ABCD, we abstract from that kernel buffer by using buffer size 1, which is often used by Kim and Teh [25] themselves.
Focusing on uni-dimensional input data, such as time series, LARGe has also been called Timeseries Automatic GPM Retrieval (TAGR) in an earlier publication [7].
A mechanism to return a preliminary GPM is not included in other automatic GPM inference algorithms. To increase comparability, this mechanism is omitted in our evaluations of LARGe as well. In doing so, line 5 of Algorithm 2 is changed to \(i = min(\mathcal {I})\) corresponding to the sequential traversal strategy presented in [6].
To increase comparability, we use the same complexity constraint for 3CS as for the other algorithms. Originally, 3CS was proposed accompanied by a slightly different constraint [9].
In Fig. 1, we use the measure of relative runtime. It is defined as the original measure divided by the average one for the respective dataset across all algorithms. In doing so, it abstract from the peculiarities of a dataset, such as dataset size and its complexity.
Fastest non-partitioned approach on the largest dataset, where execution was not aborted, is SKC on uni-dimensional Power Plant. SKC needed about 20,305 seconds (i.e. 05:38:25), while LGI terminated after 360 seconds (i.e. 00:06:00): \(\frac{20,305}{360} \approx 56.\)
References
Abrahamsen P. A review of gaussian random fields and correlation functions. In: Technical report. 1997, p 917. https://doi.org/10.13140/RG.2.2.23937.20325. https://www.nr.no/directdownload/917_Rapport.pdf
Alsaleh R, Sayed T. Microscopic modeling of cyclists interactions with pedestrians in shared spaces: a gaussian process inverse reinforcement learning approach. Transportmetrica A Transport Sci. 2021. https://doi.org/10.1080/23249935.2021.1898487.
Aminikhanghahi S, Cook DJ. A survey of methods for time series change point detection. Knowl Inf Syst. 2017;51(2):339–67.
Arias Velásquez RM, Mejía Lara JV. Forecast and evaluation of covid-19 spreading in USA with reduced-space gaussian process regression. Chaos Solit Fractals. 2020;136:109924. https://doi.org/10.1016/j.chaos.2020.109924. https://www.sciencedirect.com/science/article/pii/S0960077920303234.
Bauer M, van der Wilk M, Rasmussen CE. Understanding probabilistic sparse gaussian process approximations. In: NIPS. 2016;1525–1533.
Berns F, Beecks C. Automatic gaussian process model retrieval for big data. In: CIKM. ACM 2020;1965–1968.
Berns F, Beecks C. Large-scale retrieval of Bayesian machine learning models for time series data via gaussian processes. In: KDIR. SciTePress 2020;71–80.
Berns F, Beecks C. Complexity-adaptive gaussian process model inference for large-scale data. In: SDM. SIAM 2021.
Berns F, Schmidt K, Bracht I, Beecks C. 3CS algorithm for efficient gaussian process model retrieval. In: 25th international conference on pattern recognition (ICPR). 2020.
Cheng C, Boots B. Variational inference for gaussian process models with linear complexity. In: NIPS. 2017;5184–5194.
Chollet F. Deep learning with Python. Shelter Island: Manning Publications Co; 2018.
Csató L, Opper M. Sparse representation for gaussian process models. In: NIPS. MIT Press 2000;444–450.
Datta A, Banerjee S, Finley AO, Gelfand AE. Hierarchical nearest-neighbor gaussian process models for large geostatistical datasets. J Am Stat Assoc. 2016;111(514):800–12.
Duvenaud D, Lloyd JR, Grosse RB, Tenenbaum JB, Ghahramani Z. Structure discovery in nonparametric regression through compositional kernel search. In: ICML (3), JMLR workshop and conference proceedings, vol. 28. JMLR.org 2013;1166–1174.
Ghahramani Z. Probabilistic machine learning and artificial intelligence. Nature. 2015;521(7553):452–9.
Gittens A, Mahoney MW. Revisiting the Nystrom method for improved large-scale machine learning. J Mach Learn Res. 2016;17:117:1-117:65.
Hayashi K, Imaizumi M, Yoshida Y. On random subsampling of gaussian process regression: a graphon-based analysis. In: AISTATS, Proceedings of machine learning research, vol 108, p. PMLR 2020;2055–2065.
Hebrail G, Berard A. Individual household electric power consumption data set. https://archive.ics.uci.edu/ml/datasets/individual+household+electric+power+consumption. 2012. Accessed: 09 Jan 2020.
Hensman J, Fusi N, Lawrence ND. Gaussian processes for big data. In: UAI. AUAI Press; 2013.
Hinton GE. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002;14(8):1771–800.
Hong T, Pinson P, Fan S. Global energy forecasting competition 2012. Int J Forecast. 2014;30(2):357–63. https://doi.org/10.1016/j.ijforecast.2013.07.001.
Iliev AI, Kyurkchiev N, Markov S. On the approximation of the step function by some sigmoid functions. Math Comput Simul. 2017;133:223–34.
Kibler DF, Aha DW, Albert MK. Instance-based prediction of real-valued attributes. Comput Intell. 1989;5:51–7.
Kim H, Lee J. Clustering based on gaussian processes. Neural Comput. 2007;19(11):3088–107. https://doi.org/10.1162/neco.2007.19.11.3088.
Kim H, Teh YW. Scaling up the automatic statistician: scalable structure discovery using gaussian processes. In: AISTATS, Proceedings of machine learning research, vol. 84. PMLR 2018;575–584.
Li SC, Marlin BM. A scalable end-to-end gaussian process adapter for irregularly sampled time series classification. In: NIPS, 2016;1804–1812.
Liu H, Ong Y, Shen X, Cai J. When gaussian process meets big data: a review of scalable gps. IEEE Trans Neural Netw Learn Syst. 2020;31(11):4405–23.
Lloyd JR, Duvenaud D, Grosse RB, Tenenbaum JB, Ghahramani Z. Automatic construction and natural-language description of nonparametric regression models. In: AAAI. AAAI Press 2014;1242–1250.
Loh YP, Liang X, Chan CS. Low-light image enhancement using gaussian process for features retrieval. Signal Process Image Commun. 2019;74:175–90. https://doi.org/10.1016/j.image.2019.02.001.
Low KH, Yu J, Chen J, Jaillet P. Parallel gaussian process regression for big data: Low-rank representation meets Markov approximation. In: AAAI. AAAI Press 2015;2821–2827.
Malkomes G, Schaff C, Garnett R. Bayesian optimization for automated model selection. In: NIPS. 2016;2892–2900.
Masoudnia S, Ebrahimpour R. Mixture of experts: a literature survey. Artif Intell Rev. 2014;42(2):275–93.
Max Planck Institute for Biogeochemistry: Weather Station Beutenberg/Weather Station Saaleaue: Jena Weather Data Analysis. https://www.bgc-jena.mpg.de/wetter/. 2019. Accessed: 09 Jan 2020.
Park C, Apley DW. Patchwork kriging for large-scale gaussian process regression. J Mach Learn Res. 2018;19:7:1-7:43.
Quinlan JR. Combining instance-based and model-based learning. In: ICML. Morgan Kaufmann 1993;236–243.
Rasmussen CE, Williams CKI. Gaussian processes for machine learning. Adaptive computation and machine learning. New York: MIT Press; 2006.
Rivera R, Burnaev E. Forecasting of commercial sales with large scale gaussian processes. In: ICDM workshops, IEEE Computer Society 2017;625–634.
Roberts S, Osborne M, Ebden M, Reece S, Gibson N, Aigrain S. Gaussian processes for time-series modelling. Philos Trans Ser A Math Phys Eng Sci. 2013;371(1984):20110550. https://doi.org/10.1098/rsta.2011.0550.
Rossi S, Heinonen M, Bonilla EV, Shen Z, Filippone M. Sparse gaussian processes revisited: Bayesian approaches to inducing-variable approximations. In: AISTATS, Proceedings of machine learning research, vol. 130, p. PMLR 2021;1837–1845.
Snelson E, Ghahramani Z. Sparse gaussian processes using pseudo-inputs. In: NIPS. 2005;1257–1264.
Snelson E, Ghahramani Z. Local and global sparse gaussian process approximations. In: AISTATS, JMLR Proceedings, vol. 2. JMLR.org 2007;524–531.
Stanton S, Maddox W, Delbridge IA, Wilson AG. Kernel interpolation for scalable online gaussian processes. In: Banerjee A, Fukumizu K (eds) The 24th international conference on artificial intelligence and statistics, AISTATS 2021, April 13–15, 2021, Virtual event, Proceedings of machine learning research, vol. 130, PMLR 2021;3133–3141. http://proceedings.mlr.press/v130/stanton21a.html.
Steinruecken C, Smith E, Janz D, Lloyd JR, Ghahramani Z. The automatic statistician. In: Automated machine learning, The Springer series on challenges in machine learning. New York: Springer; 2019. p. 161–73.
Taubert N, Christensen A, Endres D, Giese MA. Online simulation of emotional interactive behaviors with hierarchical gaussian process dynamical models. In: Proceedings of the ACM symposium on applied perception, SAP ’12, pp. 25–32. Association for Computing Machinery, New York. 2012. https://doi.org/10.1145/2338676.2338682.
Titsias MK. Variational learning of inducing variables in sparse gaussian processes. In: AISTATS, JMLR proceedings, vol. 5, pp. 567–574. JMLR.org 2009.
Truong C, Oudre L, Vayatis N. Selective review of offline change point detection methods. Signal Process. 2020;167
Tsanas A, Xifara A. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools. Energy Build. 2012;49:560–7.
Tüfekci P. Prediction of full load electrical power output of a base load operated combined cycle power plant using machine learning methods. Int J Electric Power Energy Syst. 2014;60:126–40. https://doi.org/10.1016/j.ijepes.2014.02.027.
Verrelst J, Alonso L, Camps-Valls G, Delegido J, Moreno JF. Retrieval of vegetation biophysical parameters using gaussian process techniques. IEEE Trans Geosci Remote Sens. 2012;50(5–2):1832–43. https://doi.org/10.1109/TGRS.2011.2168962.
Wilson AG, Adams RP. Gaussian process kernels for pattern discovery and extrapolation. In: ICML (3), JMLR workshop and conference proceedings, vol. 28, pp. 1067–1075. JMLR.org. 2013.
Wilson AG, Nickisch H. Kernel interpolation for scalable structured gaussian processes (KISS-GP). In: ICML, JMLR workshop and conference proceedings, vol. 37, pp. 1775–1784. JMLR.org. 2015.
Xu D, Tian Y. A comprehensive survey of clustering algorithms. Ann Data Sci. 2015;2(2).
Yüksel SE, Wilson JN, Gader PD. Twenty years of mixture of experts. IEEE Trans Neural Netw Learn Syst. 2012;23(8):1177–93.
Zamora-Martínez F, Romeu P, Botella-Rocamora P, Pardo J. On-line learning of indoor temperature forecasting models towards energy efficiency. Energy Build. 2014;83:162–72. https://doi.org/10.1016/j.enbuild.2014.04.034.
Funding
Open Access funding enabled and organized by Projekt DEAL. The project underlying this paper has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 957331 (knowlEdge). This paper reflects only the authors’ views and the commission is not responsible for any use that may be made of the information it contains. Furthermore, this research was supported by the research training group “Dataninja” (Trustworthy AI for Seamless Problem Solving: Next Generation Intelligence Joins Robust Data Analysis) funded by the German federal state of North Rhine-Westphalia.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This paper is an extended version of a previous paper by Berns and Beecks [7].
This article is part of the topical collection “Knowledge Discovery, Knowledge Engineering and Knowledge Management” guest edited by Joaquim Filipe, Ana Fred, Jan Dietz, Ana Salgado and Jorge Bernardino.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Berns, F., Hüwel, J. & Beecks, C. Automated Model Inference for Gaussian Processes: An Overview of State-of-the-Art Methods and Algorithms. SN COMPUT. SCI. 3, 300 (2022). https://doi.org/10.1007/s42979-022-01186-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-022-01186-x