
Abstract
Power quality is one of the most important research eras for the energy sector. Suddenly dropped voltages or suddenly rising voltages and harmonics in energy should be identified. All of these distortions are called power quality disturbances (PQDs). Deep learning based convolutional artificial neural networks with an attention model approach has been carried out. The main idea is to develop a new approach to convolutional neural network (CNN) based which classifies a particular power signal into its respective power quality condition. The attention model approach is based on the idea that the best solution will be taken from the newly produced data pool obtained by rescaling the available data according to the total number of pixels before the average data pool is created and then deep CNN processes will continue. In the attention model approach, all data is multiplied by the number of elements by the number of epoch time sixty-six tensors. The dataset used here contains signals which belong to one of the 9 classes. This means that each signal is characterized by 622 data points and 5600 data parameters. All signals provided are in time domain. Power quality (PQ) is directly depending on power disturbances’ absence or scarcity. The accuracy and error values of the developed model were obtained according to both the number of epochs and the number of iterations.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Countries are constantly investing to meet the increasing consumer energy demand. However, sudden increases in this demand and some malfunctions in energy systems cause various deteriorations in power systems. In the literature, many methods have been researched and applied to describe and classify these distortions [1]. Voltage sag, voltage swell, fluctuations of voltages, harmonics, interruption, transient and others deteriorate the energy quality [2]. It is necessary to analyse and identify these deteriorations and to do this very quickly. The main reason to do this is to provide high quality and sustainable energy.
Non-linear loads, generation of energy faults or transmission faults and dynamic transient effects deteriorate the energy quality [3, 4]. At the same time, the necessity of keeping energy quality deteriorations within a certain standard is another detail that should be remembered today. These standards set the limits of energy quality.
1.1 Motivation
The basic motivation is to develop a fast and efficient new method for classifying disturbances affecting power quality. In the literature, it is stated which standards should be obeyed by the deteriorations affecting the power quality. It is to realize a new approach that uses this standard information mainly in deteriorations identification. Well known PQDs, their standards and ratio values can be shown in Table 1.
IEEE1159 defines power quality disturbances, values, and their limits [5]. IEC61009 defines over currents applications in power systems and IEEE519 defines harmonics in power systems [6]. IEEE1100 defines power faults in power systems [7]. The limit values used in the developed new approach are within the limits of these standards.
1.2 Literature Review
PQDs are classified using one versus one (OVO) based support vector machine (SVM). This method classifies each image parameter information by correlating it with an error-free known reference [8]. In another study, independent component analysis with the SVM classification method was investigated. Each data compared with an independent part of the relevant incorrect image to be classified [9]. Matlab Simulink model and analysis of power quality deteriorations were performed [10]. The power quality disturbances were produced experimentally in the laboratory environment [11]. The parameter optimization technique was investigated by using random forest method to classify PQDs [12]. Another study end to end automatic classification developed with a weighted convolutional neural network (CNN) [13]. The pattern recognition technique is used for classification of PQDs [14]. An experimental testing methodology was developed to obtain disturbances dataset [15]. S-transform and kernel SVM is used for the classification of PQDs [16].
A decision tree-based algorithm is used to classify PQDs [17]. In many reviews, the types and classification methods of PQDs have been explained in detail [18]. Temporal spectral Images and CNN-LSTM based classification methods used newly for determination of PQDs [19]. Gated recurrent unit and probabilistic neural network methods are also used for classification of PQDs [20].
All the research described above produce good results in classification in the last two decades. But since power systems must deal with these faults in a very short time. Methods and algorithms with faster responses will always be attractive to researchers.
1.3 Contribution
For the classification of power quality disturbances, a rapid classification approach in line with international standards has been carried out in this study. For the sample application, a model of the power system was created in Matlab Simulink. 5600 data were collected from 622 signal points for 9 disturbances classes. The developed approach first runs the image processing model and pre-processing in data. The attention model provides creates a new data pool by multiplying image pixels. Data processing and classification are carried out over the data pool that is generally available in the literature. On the contrary, in this approach, a new pool is created each time by retraining the image pixel data in the data pool. This process continues until the error rate reaches the desired level in the network.
2 Methodology
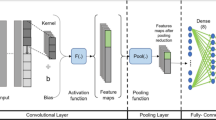
In classical CNN method, input image data passes through convolution, relu and pooling process. After these processes, the data trained in the classification is classified by a classifier. Unlike other classification methods in the literature, in this study, PQDs data passes through pre-processing stages. Then the attention model comes into play and unlike the classical CNN structure, the image data is multiplied by the pixel values and trained in a new data pool. A new value is calculated in each kernel based on the weight function in all layers. This process takes through 5 hidden layers. If the error rate is not at an acceptable value, attention model networks do not produce output. Image data input shape is 256 × 256 × 3. The image processing model creates 66 tensor data to train from input image. Actual values obtained from Matlab Simulink model. As a result, the model produces results when an acceptable error rate is reached in the attention model. The optimizer evaluates these error results, and a classification is performed. In this developed approach, 99.92% accuracy was obtained.
2.1 PQDs Simulations
PQDs simulations have been carried out with matlab Simulink. It can be seen in Fig. 1. Three phase power line for fault measurement consists of two fault blocks. One is the generation side the other one is load side. Total power line distance is 500 km. total power is 1500 MW and low voltage side is 13.8 kV and high voltage side is 380 kV. Also, the system has two series compensation units. To produce interruption and ground fault system has two circuit breakers.

Three-phase power line Matlab-Simulink model for fault measurement
Table 2 presents synthetic PQDs signals mathematical model which produced by matlab Simulink environment. Each deterioration mathematical model and their limits suitable with IEEE and IEC standards. This mathematical model expression refers to only one disturbance. The mathematical models of different distortion combinations are not included so that they do not affect the readability of the work. The limits chosen for some distortions are in line with international standards but are chosen randomly. In addition, the study was carried out with the assumption that the data obtained here are not affected by the measurement machine noise and environmental factor effects. The aim here is to ensure that real and erroneous data can be produced for the networks to be used in our deep learning-based classification method. Also, an s-transform is not required.
Obtained input data from matlab simulink simulation can be seen in Fig. 2. These data signals consist of time-domain pure sinusoidal wave, harmonics, sag disturbance, swell disturbance, interruption, transient, swell + harmonics and sag + harmonics. The decay signal periods are selected in a single interval so that they are shown in the same sampling.

PQDs matlab Simulink view a pure sinusoidal wave, b harmonics, c Sag disturbance, d Swell disturbance, e Interruption, f Transient, g Swell + harmonics, h Sag + harmonics
2.2 PQDs Dataset
PQDs dataset obtained from matlab Simulink model. The dataset used here contains signals which belong to one of the 9 classes. This means that each signal is characterized by 622 data points and 5600 data parameters. The data lengths are the period of the data obtained because of the simulation. It is not a structure that comes one after another, or in other words, one end to the other. Each parameter data was obtained in the time domain during the period. All PQDs image data was obtained from Matlab Simulink model. This image file data is not affected by the noise and environmental factor effects.
3 Deep Learning Model
Equations In this study, the deep learning model was used in the attention model, which includes the TensorFlow infrastructure and the weight approach. The PQDs image data forms a 256 × 256 matrix. It multiplies it with 3 × 3 feature detectors to make it smaller. In this way, the speed of the process is increased. 256 × 256-pixel input image file multiplied by it feature detector. At this stage, using the linear activation function may obtain the best features from input file in the model. At this time, the image data is subjected to max-pooling and sample boxes are placed on the left and right corners. This process is carried out in two stages. First, the data is reduced to 64 × 64 matrix shape, then 32 × 32 matrix shape data. There are five hidden layers in the model. With the latest 128 feature detectors produced the new training and validation dataset. Then they were sent to the attention model. The attention model part will also be explained in detail. It can be seen in Fig. 3 deep learning general algorithm view for purposed approach.

Deep learning model general algorithm view for purposed approach
In the deep learning model, GPU support provided by TensorFlow infrastructure is used. In order to reach the classification result, a deep learning model was created from two parallel arms. In the first branch, reading the input image data and starting the process with the basic classification process and continuing with its training and transferring it to the attention model, in the same algorithm, the trained model data in the second parallel arm is transferred to the attention model in a labelled form. The main difference from other deep learning models in the literature is due to this parallel processing. Evaluation of results data carried out by using a confusion matrix. Before this process error values were calculated, and Adam optimizer applied the result data for classification optimization. As a result, PQDs are classified and separated according to their respective classes.
The resulting instantaneous power sampling starts with separating the parts of the images that contain no colour or parts that are completely black. In case of need, the pictures are rotated and positioned to be compatible with the reference. It is resized or cropped if necessary. The aim here is to obtain easily trainable image data free from external factors.
3.1 Attention Model Approach
Attention model approach can be seen in Fig. 4. Consideration components are proposed to advance the execution of code analysis demonstrations for deep learning interpretation. The concept behind the consideration tool is to allow most used code parser important part of the input grouping adaptively through a weighted combination of all encoded input vectors, a very important vector being considered the most notable weight. The attention mechanism was introduced by Bahdanau et al. [21], to address the bottleneck created using fixed-length encoded vectors, where the decoder has limited access to the information provided by the input. The final classification is made after the neural network generated error is minimized, which is fed with double-sided processed data [22]. The Attention model can also be used in this way in PQDs.

Attention model with CNN general view for purposed approach
The pseudocode of the designed new approach is shown in Fig. 5. Each subprocess is not provided in pseudo code. This code is expected to describe the essence of the work done in a logical framework and close to the daily spoken language. It can be seen in pseudocode, which is clearly explained without using a special programming language. The Attention model approach also is in pseudocode. After using dense function in the classic neural networks, which is generally recommended to reach the result with an optimization algorithm, the training data is shared with the attention model and the classification result is obtained by applying the latest data from there to the optimization process with the dense function in Fig. 4.

Pseudocode of purposed method
All weights in neural network in attention model are computed every iteration in model. If model error limitation is satisfactory, then weight calculation in every layer will stop and global average pooling function will produce a new image data pool. It can be seen in Fig. 5.
3.2 Model Mathematical Architecture
In order to explain the mathematical model of the proposed method, it is necessary to know the classical artificial neural network method well. Equations 1, 2 and 3 describe the function and processing structure of classical neural networks.
x is input image data, g is number of hidden layers, f_i is ith activation function and F(x) is the output of network in Eq. 1, x, y, z is location of pixels, jk is convolution filter, Wk is weight of kth kernel and r, s, t are height, width and depth respectively in Eq. 2. h(x) is ReLU function of maximum pooling in Eq. 3.
Weight function can be expressed by Eq. 4. Newly produced image data map can be expressed in Eq. 5. In Eq. 5G is global average pool and GAPnew is increased new global average pool. λ is multiplication factor which produced total old image data value and the newly produced image data value in Eq. 6.
In attention model power quality class and target values are expressed by Eq. 7. For the era of the mimicked dataset, a Simulink demonstration of the lattice has been utilized. With this show it has been conceivable to create a few PQDs unsettling influences and organize them in a cell array. The unsettling influences that were executed within the Simulink demonstrate are the voltage droop, the voltage rise, the consonant twisting, the transient, the score and the interference. After the Simulink simulation is completed, a dataset is created. Consequently, the information is assembled with a script which generates a structured cell cluster. Once the method is completed, each blame is labelled with a target number as appeared in Eq. 7. To prepare the neural network arrangement, the information for the classes and target are rearranged together in arrange to get a generalized arrangement for the organize.
4 Results and Discussion
Training and validation data accuracy value versus epoch number and versus iteration number can be seen in Fig. 6a and b, respectively. Attention models provide quick classification with trained data. After the 12th epoch, the accuracy value reaches 99.92%. Purposed method needs approximately 1000 iterations in each loop.

Accuracy value of purposed method a versus epoch number, b versus iterations
Factors such as the fact that the data obtained from the sampling studies are in the time domain, that they can be classified without the need for an external process, and that the labelling process of PQDs is certain, have improved the accuracy value. After all the intermediate operations are done, there is almost no noise or environmental factor error in the training data. This high accuracy value can be obtained in the model without these factors. Even if a very small noise factor affects the classification process, the accuracy of the results is greatly reduced. For this reason, pre-processing should inevitably be used in these cases. The proposed method has been tested in different features with the metrics defined for its overall performance. The loss value of purposed method can be seen Fig. 7a and b, respectively.

Loss value of purposed method a versus epoch number, b) versus iterations
Table 3 show that attention model and other method of comparison. Previously used methods and their classifier with the number of PQDs parameters and dataset parameters number and their accuracy value. DCNN, FAWT, S-transform, CNN, Wavelet transform, and Hilbert transform were used previously. The classification value ratios of all methods are over 90%. Improvements in methods can now be made in the decimal places. It can be observed that the proposed method produces better accuracy than previous studies.
4.1 Evaluation Metrics
P is precision value of purposed method output, R is recall value, ACC is accuracy value, F1 shows the harmonic mean of Precision and Recall values. TP is true positives of confusion matrix, TN is true negatives of confusion matrix, FP is false positives and FN is false negatives of confusion matrix, respectively in Eq. 8.
Confusion matrix value of predicted and classified data accuracy value and PQDs parameters can be seen in Fig. 8. PQDs parameters equals 9e + 02. This means 900 for all parameters. If this value is divided by PQDs parameters number 9, we could get accuracy value of each parameter. Almost accuracy value for all PQDs parameters in classification process output is 1. This means that 100% accuracy value. Since the F1 value was obtained with data that is far from environmental factors and without noise, it was possible to obtain high in the proposed method. If our deep learning method was to classify by processing the raw data, the results would not be so good. However, since the input image data is extracted and labelled with pre-processing, the results are close to the most accurate. Evaluation metrics of purposed method are presented in Table 4.

Confusion matrix of purposed method
Beta loss shows that purposed method of its effectiveness. While the beta loss value was large when the first training data obtained. The beta loss value decreased as the number of epochs increased. The low loss obtained is an indication of the effective working of the proposed method. It can be seen from Fig. 9 beta loss value versus epoch number.

Purposed method beta loss value versus epoch number
The normalization process can also be used as an evaluation criterion in data classification. Normalization values of the proposed method are expected to be at or close to the exact value of 1.0 when the process is finished. As can be seen in the Fig. 10, the normalization values approached 1.0 as the epoch number increased. After the data obtained from the latest attention model, which is optimized with the adam method, it can be seen that the output data obtained is 100% correct classification for almost every PQDs class. The software code used to understand the effectiveness of the method developed in the classification process was recalculated and graphed after each epoch. When the graphs obtained are examined, it is clearly seen that both the normalization data and the error rate in this process decreased after the 13th epoch. This is a measure of the effectiveness of the used method. When we subject it to the dense function and after minor errors are excluded, this value means accuracy value is 99.92%. It can be seen in Fig. 11.

Purposed method normalization values of data versus epoch number

Purposed method data dense process values versus epoch number
4.2 Hardware
Nvidia Tesla K80 CUDA Cores Graphic Cards (GPU) and i7-9800 × 3.80 GHz microprocessor used for this study. This hardware provides us for calculation and implementation of all process 4992 CUDA cores and 2 × GK120 GPUs.
4.3 Memory
GPU has 24 GB memory and test platform has approximately 100 GB free memory for the implementation of the study. Total hard drive memory is 2 TB.
4.4 Time
The total training processing time was 1520 s. This equates to approximately 16.88 min. When training is finished classification time is under 40 s.
5 Conclusion
In this study, a new approach has been developed because of the attention model for the classification of disturbances in power quality. For the test of the developed model, a sample application was carried out with the PQDs dataset obtained in the Matlab Simulink environment. The evaluation parameters of the developed method and the results of these parameters are presented in the study. The mathematical infrastructure of the developed model was examined, and the algorithm was clearly explained in the study. The main idea is to develop a new approach to convolutional neural network (CNN) based which classifies a particular power signal into its respective power quality condition. This aim was successfully achieved in the study. In future studies, it can be predicted from the obtained results that the processing time can be shortened even more with more advanced processors and memory hardware. The accuracy value 99.92% obtained in this study is also compatible and superior in parallel with the studies in the literature.
References
Shin Y, Powers EJ, Grady M, Arapostathis A (2006) Power quality indices for transient disturbances. IEEE Trans Power Delivery 21(1):253–261
Marques CAG, Ferreira DD, Freitas LR, Duque CA, Ribeiro MV (2011) Improved disturbance detection technique for power-quality analysis. IEEE Trans Power Delivery 26(2):1286–1287
Zhao F, Yang R (2007) Power-quality disturbance recognition using s-transform. IEEE Trans Power Delivery 22(2):944–950
Herath HMSC, Gosbell VJ, Perera S (2005) Power quality (PQ) survey reporting: discrete disturbance limits. IEEE Trans Power Delivery 20(2):851–858
IEEE 1159 Standard, IEEE Recommended Practice for Monitoring Electric Power Quality, Recognized as an American National Standard (ANSI) 1998
IEC 61009 Standard, Resıdual Current Operated Cırcuıt-Breakers with Integral Overcurrent Protection For Household and Similar Uses, 2013
IEEE 1100, Recommended Practice for Powering and Grounding Electronic Equipment, 2005
Lin, M. W, et al., Classification of Multiple Power Quality Disturbances Using Support Vector Machine and One-versus-One Approach, International Conference on Power System Technology, pp, 1–8, 2006
Ignatova V, Granjon P, Bacha S (2009) Space vector method for voltage dips and swells analysis. IEEE Trans Power Delivery 24(4):2054–2061
Dhote PV, Deshmukh BT, Kushare BE “Generation of power quality disturbances using MATLAB-Simulink,” 2015 International Conference on Computation of Power, Energy, Information and Communication (ICCPEIC), Melmaruvathur, India, 2015, pp. 0301–0305
Li Z, Liu H, Zhao J, Bi T, Yang Q (2022) A power system disturbance classification method robust to PMU data quality issues. IEEE Trans Industr Inf 18(1):130–142
Eikeland OF, Holmstrand IS, Bakkejord S, Chiesa M, Bianchi FM (2021) Detecting and interpreting faults in vulnerable power grids with machine learning. IEEE Access 9:150686–150699
Xiao X, Li K (2021) Multi-label classification for power quality disturbances by integrated deep learning. IEEE Access 9:152250–152260
Pavlovski M, Alqudah M, Dokic T, Hai AA, Kezunovic M, Obradovic Z (2021) Hierarchical convolutional neural networks for event classification on PMU measurements. IEEE Trans Instrum Meas 70:1–13
Nandi K, Das AK, Ghosh R, Dalai S, Chatterjee B, "Hyperbolic Window S-Transform Aided Deep Neural Network Model-Based Power Quality Monitoring Framework in Electrical Power System," in IEEE Sensors Journal, vol. 21, no. 12, pp. 13695–13703, 15 June15, 2021
Alam MR, Bai F, Yan R, Saha TK (2021) Classification and visualization of power quality disturbance-events using space vector ellipse in complex plane. IEEE Trans Power Deliv 36(3):1380–1389
Kaushik R, Mahela OP, Bhatt PK, Khan B, Padmanaban S, Blaabjerg F (2020) A hybrid algorithm for recognition of power quality disturbances. IEEE Access 8:229184–229200
Chawda GS et al (2020) Comprehensive review on detection and classification of power quality disturbances in utility grid with renewable energy penetration. IEEE Access 8:146807–146830
Tang Q, Qiu W, Zhou Y (2020) Classification of complex power quality disturbances using optimized S-transform and Kernel SVM. IEEE Trans Ind Electron 67(11):9715–9723
Qiu W, Tang Q, Liu J, Yao W (2020) An automatic identification framework for complex power quality disturbances based on multifusion convolutional neural network. IEEE Trans Industr Inf 16(5):3233–3241
Bahdanau D, Chorowski J, Serdyuk D, Brakel P, Bengio Y "End-to-end attention-based large vocabulary speech recognition,". In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 2016, pp. 4945–4949
Topaloglu I. Deep Learning Based Convolutional Neural Network Structured New Image Classification Approach for Eye Disease Identification. Scientia Iranica. (2022). https://doi.org/10.24200/sci.2022.58049.5537
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Topaloglu, I. Deep Learning Based a New Approach for Power Quality Disturbances Classification in Power Transmission System. J. Electr. Eng. Technol. 18, 77–88 (2023). https://doi.org/10.1007/s42835-022-01177-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42835-022-01177-1