
Abstract
Metacontingencies describe a functional relationship between interlocking behavioral contingencies that produce an aggregate product and a selecting environment. Various metacontingency procedures employ operant contingencies and metacontingencies concurrently to investigate participant’s choices to engage in a behavior as a function of either the magnitude or frequency of consequences. However, little research attention has been given to evaluate macrocontingencies to metacontingencies in the context of between-group competition. The present study compared the results of three experimental groups. In experimental group 1, participants responded to the task together and were allowed to use vocal communication. In experimental group 2, participants responded to the task individually. In experimental group 3, participants responded to the task together but were not allowed to use vocal communication. The results showed that some participants in group 2 reached a high percentage of correct responses, but the sum of their performance (macrocontingency) was not significantly better than chance. The performance of participants who cooperated (groups 1 and 3) was significantly better than chance. We discuss the role of between-group selection, within-group variability and social contingencies in the adaptive value of cooperation.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
The behavior analytic conceptual framework and experimental efforts are grounded in an understanding of the ways in which an organism’s behavior can be predicted by examining its interactions with environmental events. In natural selection, traits within a species population vary, are retained, and are transmitted. During the selection of an organism’s behavior, classes of responses vary and are retained (Glenn, 2004). Within groups of social organisms, classes of behavior vary among a population, are selected as cultural practices, and are transmitted through such mechanisms as imitation, instructions, and direct shaping (Baum, 2017). When behaving in groups, individuals share the labor and product of their joint efforts. Through cooperation, joint responses may enable effects on the environment with a higher frequency/magnitude than would be possible for organisms that behave independently. Shared practices may benefit each member of a group, but consequences can be contingent on the practicing group rather than on each organism’s behavior.
In parallel to operant behavior, in which studies investigate the effects of environmental changes (independent variable) on response classes (dependent variable), one may consider the effects of environmental changes (independent variable) on the dynamics of a practicing group (dependent variable). When employing consequences to study groups and their dynamics, it is challenging to differentiate the variables that shape the behavior of organisms from variables that select their interaction (i.e., cooperation). Glenn (1986, 1988) attempted to resolve this issue by proposing the concepts of macrocontingency and metacontingency. A macrocontingency describes a relationship between behaviors that are maintained by operant contingencies and a cumulative effect of social significance that consist of an aggregate sum of consequences of those individual behaviors (namely macrobehaviors; see Glenn, 2004, Glenn et al., 2016). A metacontingency describes the functional relationship between interlocking behavioral contingencies (IBCs), their aggregate product (AP), and a selecting environment. Interlocking behavioral contingencies and corresponding APs can be considered a unit of analysis, defined as culturant (Glenn et al., 2016).
Laboratory micro-culture experiments have been used to examine fundamental processes of cultural evolution for more than 50 years (e.g., Baum et al., 2004; Jacobs & Campbell, 1961). Within the metacontingency literature, the first laboratory experiment was designed by Vichi et al. (2009). The metacontingency procedure of Vichi et al. (2009) employed a reversal design with two groups of four participants who bet tokens individually before collectively choosing a row on a matrix. Each cell in the matrix contained a plus or minus sign. The experimenter announced whether the participants won or lost points for that trial. The trial ended after the participants distributed their earnings. The distribution pattern of points that were earned in the previous trial determined whether the group would earn points in the subsequent trial. Under some conditions, the programmed consequences were contingent on an equal distribution of earnings. Under other conditions, the programmed consequences were contingent on an unequal distribution. Thus, their metacontingency was defined as the dependent relationship between the participants’ discussion (IBCs), a given distribution pattern (AP), and the consequence that was delivered by the experimenter. Their results showed that programmed consequences differentially selected the distribution of earnings (equal or unequal), and the findings were reversible. Following the tradition of Vichi et al. (2009), multiple experimental procedures that were based on a behavioral analytical framework have studied effects of metacontingencies on the selection of culturants (Cihon et al., 2020). For example, Vasconcelos and Todorov (2015) and de Carvalho et al. (2017) investigated effects of programmed consequenceson the variability of culturants.
Several procedures have been used to investigate effects of operant contingencies and metacontingencies when they are available concurrently. Baia et al. (2015) found that participants engaged in operants or culturants depending on the magnitude of consequences for each. These choices were also transmitted across new generations of participants. Borba et al. (2017) demonstrated that the immediacy, delay, and magnitude of consequences affected the occurrence of operants or culturants. Their results suggested that delayed cultural consequences that benefit the group as a whole favored the emission of culturants (i.e., an ethically self-controlled response), although more immediate and larger magnitude operant contingencies were concurrently available (i.e., an impulsive response). Most recently, Guimarães et al. (2019) extended this line of research by exploring effects of negative punishment on impulsive culturants (two or three participants that produce more individually, but lose cultural consequences) and self-controlled culturants (two or three participants that produce less individually, but earn cultural consequences). Their results suggested that negative punishment, when applied to culturants, produced similar results to studies of negative punishment that were conducted at the operant level. Specifically, negative punishment effectively reduced the percentage of impulsive culturants and increased the percentage of self-controlled culturants.
In summary, most laboratory studies employ procedures that explore effects of consequences on the selection of different features of culturants (e.g., frequency and variability of IBCs and APs) and participants’ engagement in operants and culturants when they are concurrently available. However, little research attention has been given to comparisons of macrocontingencies and metacontingencies as cultural practices under conditions of between-group competition.
In the present study, we evaluated macrocontingencies and metacontingencies across three groups by comparing the performance of participants who responded to a task together or individually to performance by chance. In experimental group 1, six groups of four participants agreed (through vocal and/or nonvocal communication) to select one of four alternatives in 65 trials. Consequences for the agreed-upon choice were delivered as common feedback throughout four experimental phases (A-B-C-B-C reversal design). In experimental group 2, nine participants responded to the same task individually. In experimental group 3, another six groups (five quartets and one triad) responded to the same task together, but they were not permitted to communicate vocally. To evaluate the performance of groups 1-3, we compared the agreed upon choices in groups 1 and 3 (i.e., culturants) and the sum of individual choices in experimental group 2 (i.e., macrobehavior) to performance by chance.
Method
Participants
Fifty-six participants between the ages of 18 and 50 were recruited in Oslo, Norway. Each participant was assigned to one of three experimental groups. Group 1 consisted of 24 participants, divided into six quartets. They responded to the experimental task together and were allowed to use vocal communication during the sessions. Hereafter, group 1 is referred to as the vocal group (VG). In group 2, nine participants responded alone and independently to the same task. Hereafter, group 2 is referred to as the individual group (IG). Group 3 consisted of 23 participants, divided into five quartets and one triad. Participants in group 3 were not allowed to communicate vocally during sessions. Hereafter, group 3 is referred to as the nonvocal group (NVG). The participants had no previous knowledge of behavior analysis and did not know each other before the experimental sessions. No compensation was offered for participation.
Setting and Material
Experimental sessions were conducted in a conference room (8 m × 7 m) at the Institute of Behavioral Science, Oslo Metropolitan University, Oslo, Norway. The conference room contained a large table with up to four chairs for participants (one for IG and four for VG and NVG) along one side and two chairs for experimenters on the other side (see Fig. 1). Three HP EliteBook 840 laptop computers were used to conduct the experimental task. One computer was connected to the projector screen that was placed to the left of the participants. The presentation slides that were used in each trial were created using Microsoft PowerPoint. The slides were displayed on the screen, connected to a projector. The second and third computers were connected via Google slides and showed participants a shared screen. The first computer also included a feedback screen (scoreboard and signals of correct/incorrect) that was visible to the participants on a 24-inch Samsung monitor that was connected to the second computer. The numbered cards were used by the participants to show their choices in each trial. Figure 1 depicts the experimental room and apparatus that was used during the experimental sessions.

Top view of the experimental room. (1) Two experimenters. The first computer (2) controlled a central screen (3) where task slides were displayed to the four participants (4). The second and third computers (5 and 6) controlled feedback and points that were displayed on a monitor (7) that faced the participants. Each participant had access to four answer cards, numbered 1 to 4 (8)
Procedure
Instructions
At the onset of each experimental session, the participants were seated along one side of the conference table, and the two experimenters sat on the opposite side of the table. The participants then signed an informed consent form and read instructions that were displayed on the projector screen. The instructions were the following:
Hello, Thank you for your participation! Now, you are going to work on an activity together. You will have access to slides. You are to choose the alternative that best represents the slide. There will be four cards with the numbers 1 to 4 on the table and for each slide there will be four alternatives. You must agree on the answer that represents your impression of the picture and hold up the number that corresponds with the chosen alternative. The experimenter will check your answer and give you a community point if it is in accordance to the answers given by groups that went through the same experiment previously.
Guidelines:
-
1)
You should choose the alternative that you think best represents the slide.
-
2)
Do not think too much when choosing. Make it as fast as possible.
-
3)
You are allowed to talk to each other at any time.
-
4)
Avoid talking to the experimenter.
-
5)
You must all agree on one alternative. All participants must choose the same.
-
6)
The answers must be the same, but each participant should show his/her own answer card.
-
7)
The answers will be checked after the trial time is over, and if they are compatible to the previous groups’ answers you will receive community points.
-
8)
Try to score as many points as possible.
After reading the instructions, the experimenters clarified the participant's question but did not provide any additional information beyond what was specified in the instructions. Note that the instructions above were given to the VG. The information that was displayed was adapted for the IG and NVG.
Experimental Task
Upon beginning the experimental sessions, the participants were presented with the first of 65 slides. Each slide displayed a picture of a person in an everyday situation alongside four text alternatives (Fig. 2). The text alternatives included four descriptions of the picture, numbered 1–4 and displayed on the projector screen. The text alternatives were divided into two arbitrary categories, defined for scoring purposes as “person” or “environment.” For the “person” category, the alternatives described the physical characteristics or behavior that was expressed in the picture (e.g., “cute baby” and “playing with water”). For the “environment” category, the alternatives described the environmental surroundings (e.g., “pleasant park” and “pink sticks”). The same set of 65 slides was used for all experimental sessions, but the pictures and order of alternatives were randomized across sessions.

Example of slide, with the picture on the left and text alternatives that described the picture on the right. Two text alternatives described the person (1 and 2), and two described the environment (3 and 4)
The participants were instructed to choose the alternative they “considered to best represent the slide.” Participants in the IG responded to the task individually and only in the presence of both researchers. Participants in VG and NVG had to agree on the same alternative (IBCs) and subsequently show their own laminated numbered card at the same time (AP). As participants showed their choice concomitantly, no order was recorded—only the alternative that was picked by the group was recorded. Participants in the VG could talk freely amongst themselves at all times. Participants in the NVG had to use nonvocal gestures to agree on their choices. The slide was displayed a maximum of 60 seconds. If the participants did not make a choice within 60 seconds, then the picture was replaced by the text “Your time is up,” in which case the participants were requested to make an immediate decision. In the instructions, the participants were told, “The experimenter will check your answer and give you a community point if it is in accordance with the answers given by groups that went through the same experiment previously.” However, points were actually delivered according to a criterion that was set by the experiments for each phase (i.e., alternative that described “person” behavior or “environment”).
The 65 slides were divided into a baseline (A) that consisted of five trials and four intervention phases with 15 slides each (A-B1-C1-B2-C2). During baseline trials, participants’ choices were recorded, Feedback B (Figure 3; “You did not score any points in this phase. Please wait for the next.”) was delivered, and no points were added to the scoreboard. By the end of the baseline, experimenters evaluated participants’ preference for one of the two categories. Next, the experimenters set the criterion to earn points in phase B1 as the opposite of the preferred category. For example, if participants chose the “person” category three or more times during baseline, then the reinforced choice in B1 was set as “environment.” Next, the reinforced choices would be “environment” in C1, “person” in B2, and “environment” in C2. During the four intervention phases, responses within the targeted category resulted in Feedback A (“You scored 10 points,” alongside a smiley face), and 10 points were added to the scorecard. Responses in the nontargeted category resulted in Feedback B (“You did not score any points. Please wait for the next”), with no points added to the scoreboard.

Feedback A and B. Feedback A was given following correct answers in accordance with the contingency. Afterward, 10 points were added to a cumulative point counter on the right side of the screen. Feedback B was given following incorrect answers in accordance with the condition criteria. Following incorrect answers, no points were added to the cumulative point counter
Experimental Design
The three experimental groups (VG, IG, and NVG) were designed to emulate two strategies to perform the same experimental task. Participants in the VG discussed the alternatives using vocal and nonvocal communication (IBCs) and agreed on a choice (AP). Participants in the NVG used only nonvocal communication to discuss the alternatives (IBCs) and agree on a choice (AP). Feedback messages and points were delivered contingent on VG and NVG agreed upon choices. Participants in the IG performed the same task alone and received feedback messages and points contingent on their individual choices. The VG and NVG emulated a population in which individual interaction (IBCs) operates in the environment (i.e., metacontingency). The IG emulated a population in which the behavior of multiple individuals, occurring independently and according to similar operant contingencies, operates in the environment. Thus, a macrocontingency was emulated by summing the performance of IG participants. An A-B-C-B-C design was used to evaluate the performance of groups to chance within groups.
Data Analysis
The intervention phases consisted of 15 trials with a shift in the criterion (environment/person) in an A-B-C-B-C reversal design. As choices in each trial were made between four alternatives that belonged to two categories, a random choice would be correct at a 50% level of chance (cf. Iversen, 2016). To evaluate whether correct responses were significantly better than chance, we divided each intervention phase into three blocks of trials. The first block consisted of trials 1 to 5. The second block consisted of trials 6 to 10. The third block consisted of trials 11 to 15. We then used a single-sample t-test to compare the sum of agreed choices for the VG and NVG and individual choices for the IG in each block of trials to chance. Comparisons of choices and chance were performed by testing the discrimination of categories in blocks of trials with a hypothetical trial block with means set at 50%, with sample size standard deviation values kept equal to the block that was compared. Comparing means to chance allows the evaluation of significance levels in discrimination tasks without the need for baseline conditions or control groups (Iversen, 2016). This data analysis was adequate for the present experimental design, which consisted of four intervention phases.
Results
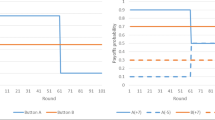
Figure 4 shows the aggregate responses of the VG, IG, and NVG. Data were grouped per trial in each phase, cumulating 15 data points for each group. In the VG, the first data point, for example, represents the mean of the first trial in Phase 1 (B1) for the agreed choice of the six groups. The mean percentage of correct responses in the VG systematically improved across trials. Average responses reached above the level of chance at around 60% correct choices in trial 3. However, only from trial 7 did standard deviation bars go above the level of chance, stabilizing in the third block of trials. Average responses in the NVG were also above the level of chance from trial 3, with two of five standard deviation bars from the second block of trials below the level of chance and all standard deviation bars of the third trials above it. Although average responses in the IG improved over the sets of trials (i.e., staying above the level of chance from trial 7), standard deviation bars were close to or below the level of chance in three of the five trials in the second and third blocks of trials. This indicates that the choice behavior of only some participants in this experiment came under control of the phase’s criteria.

The datapoints represent the mean cumulative points scored for each phase (B1-C1-B2-C2) for the VG, IG, and NVG. The first data point, for example, represents the mean of VG trial 1 (first phase; B1), trial 6 (second phase; C1), trial 31 (third phase; B2), and trial 45 (fourth phase; C2) of each of the six groups). Trials 1–5 and 11–15 are represented by empty markers, and trials 11–15 are represented by filled markers. The horizontal line crossing the graph represents the 50% level of chance
The percentage of correct responses during each block of trials in the IG, VG, and NVG are shown in Table 1. Of nine participants in the IG, only four (2, 4, 7, and 8) scored above 60% in trials 6-10, and five (2, 4, 6, 7, and 8) scored above 60% in trials 11–15. Three of the six groups in the VG (1, 2, and 3) and four of the six groups in the NVG (1, 3, 5, and 6) scored higher than 60% in trials 6–10. In trials 11–15, five of the six groups in the VG (1, 2 3, 5, and 6) and NVG (1, 3, 4, 5, and 6) scored higher than 60%.
To evaluate whether correct responses were significantly better than chance, we performed a t-test to compare average responses in each block of trials for each group in each of the four phases to a hypothetical group with average correct responses of 50%, with a sample size and standard deviation kept at the same values of a comparison block of data (Fig. 5). The average response scores for the three blocks of trials (1–5, 6–10, and 11–15) in each phase are presented in Fig. 4. The horizontal line displays a 50% level of chance. The data showed that the percentage of correct responses from the first block to the second and third blocks of trials gradually improved for all groups. However, only the results of the VG (third block) and NVG (second and third blocks) were significant (a = 0.05) compared with the level of chance.

Average response scores (±SD) for the first, second, and third blocks of five trials. For example, the first block for the VG represents average responses of all groups and phases in trials 1–5 (first block of trials), trials 6 to 16 to 20 (second phase), trials 31–35 (third phase), and trials 46–50 (fourth phase). That is, 4 phases × 5 trials × 6 (n) = 120 trials; 100%. The horizontal line represents the mean of the hypothetical group (with a 50% level of chance). *p ≤ .05, **p ≤ .01
Table 2 shows the results of the t-test comparisons of each block of trials to the level of chance (i.e., hypothetical blocks with a mean of 50% correct), with all other parameters held equal. Means and standard deviations were calculated for the VG (n = 6), IG (n = 9), and NVG (n = 6) for each of the three blocks of trials. Values of p represent the level of significance relative to the hypothetical datasets, including t values. Table 2 shows that in the first block of trials (1–5) none of the groups’ means were significantly above chance (α = 0.05). This result was expected because those were the first five trials of each phase, after changing the criterion for a correct choice. The average correct choices in the second block of trials were considerably higher in all of the groups. However, the results were only statistically significant for the NVG (M = 0.76, SD = 0.20; t4 = 2.22, p = 0.05). Data from the third block of trials for both the VG (M = 0.80, SD = 0.15) and NVG (M = 0.80, SD = 0.183) were significantly different from chance (t4 = 3.53, p = 0.005, and t4 = 2.225, p = 0.01, respectively). Although the IG presented a gradual decline in p values across blocks of trials, the mean values were not significantly different from chance in any of the three blocks of trials.
Discussion
The present study compared the performance of participants who responded to a task individually and cooperatively, as an analog of populations (i.e., experimental groups) under similar selective pressure constraints (experimental task). The IG was an analog of a population under a macrocontingency (i.e., participants made choices individually, and their fitness was evaluated by comparing the sum of responses to chance). IG group mimicked real-life situations in which the sum of consequences of many individual choices (e.g., throw garbage in a trashcan or on the environment) produce cumulative effects of social significance (cf. Hayashi et al., 2019; Glenn, 2004). The VG and NVG were analogs of populations under a metacontingency (i.e., participants cooperated [IBCs] to produce choices [APs], and their overall fitness was evaluated by comparing the sum of APs to chance). Although several participants in the IG (2, 3, 6, 7, 8) reached high percentages of correct choices in the last block of trials, the sum of their responses was never better than chance. Conversely, correct choices in the VG reached significant levels in the third block, and the NVG reached significant levels in the second and third blocks of trials. Results from the NVG suggest that performing at levels better than chance did not depend on vocal communication.
Studies of metacontingency commonly follow a paradigm that is similar to operant contingencies. Research on operant behavior focuses on effects of consequences (independent variable) on features of behavior (dependent variable), whereas metacontingency studies often manipulate consequences (independent variable) and measure effects on features of culturants (IBCs+APs). The present study addressed a fundamental facet of behavior analytic investigations of cultural practices, namely the competitive advantage of metacontingencies vs. macrocontingencies when the selective pressure (task) is the same. This experimental design is an analog of a situation that involves between-group competition, in which cultural practices may be diverse in a social organization (e.g., metacontingencies and macrocontingencies) and across populations. Further studies are needed to understand how macrocontingencies and metacontingencies differ as cultural practices, including the ways they influence operant behavior.
Within-group variability may be a feature that differentiates metacontingencies and macrocontingencies. In operant conditioning, response classes are selected within the organism’s range of behavioral variation, influencing their overall fitness. In a macrocontingency, the cumulative effect of two or more organisms’ behaviors will affect the population’s overall fitness (i.e., the IG). When cooperating (i.e., the VG and NVG), group members bring different behavioral variants. These variants compete, and the member's behaviors that provides a higher fitness to the group are selected from this within group variability. The participants in the VG and NVG had to agree on the alternative to choose, and diverse choice strategies could be tested and selected from each participant’s repertoire. Future studies should investigate the extent to which the within-group diversity of strategies affects a group’s performance.
The present experiment extends previous findings on the role of verbal behavior in sustaining cooperation within IBCs. For example, Costa et al. (2012), Hosoya and Tourinho (2016), Sampaio et al. (2013, 2020), Soareset al. (2018), and Ardila-Sánchez et al. (2020) investigated effects of verbal behaviors in metacontingency and found that verbal (and vocal) groups outperformed non-verbal groups (see also Fonseco et al., 2022). The fact that our VG and NVG performed at high levels at the end of each condition does not contradict these results. In all those previous research, the non-verbal groups could not engage in any type of verbal interactions, while our NVG could use gestures to decide on which option to choose. Thus, given the current conditions, our results point to the fact that vocal communication are not a necessary condition for maintaining cooperation in metacontingencies, as non-human experimental and observational research has consistently demonstrated (e.g., Tan & Hackenberg, 2016; Pitman & Durban, 2011).
In addition to programmed contingencies, members of the VG and NVG were under the control of each other’s behavior, possibly providing antecedent and consequent stimuli for choice strategies. Social contingencies may enable participants to learn from each other over time through imitation, rule-following, and direct shaping. Thus, the best choice strategy could be selected from group members’ behavioral variability. Baum et al. (2004) showed that group strategies were produced from shifts in members’ choices, both toward and also sometimes away from optimal responses. Future studies should evaluate the role of social contingencies on macrobehavior by allowing participants to respond to the task individually while observing each other. Such a procedure would allow participants to learn from each other through observational learning but would not require interaction (i.e., shaping and rule governance).
Within-group variability may have also favored the VG and NVG if additional tasks (selective pressure) were added to the procedure. In the present task, only five of the nine IG participants obtained high scores in the last block of trials. Evaluating participants’ performance across tasks would require each participant to have the repertoire that matches programmed contingencies for different procedures, thus decreasing overall fitness of the IG. Ten of the 12 groups in the VG and NVG obtained high scores in the last block of trials. When responding to a new task, a member from the VG and NVG the poll of behavioral repertoire to match the contingencies of new procedures would increase their overall fitness. Thus, comparing macrobehavior and culturants in procedures in which two or more tasks are required will further test the role of within-group variability and innovators in cooperation.
Couto and Sandaker (2016) described two distinct selection processes when explaining cultural phenomena: the selection of cultures and cultural selection. In the selection of cultures, population practices are shaped by cultural consequences, becoming frequent over time. In cultural selection, group practices become a social environment in which members’ behaviors are shaped and maintained. Differentiating between the selection of cultures and cultural selection becomes important when identifying sources of consequences for both group practices (selection of cultures) and the cultural selection of members’ behavior. The present study evaluated the selection of cultures (i.e., the performance of participants in a task when using macrobehavior or culturant as a strategy). Future studies may extend this analysis by evaluating cultural selection processes that enable the selection of best practices (e.g., within-group variability, observation learning, rule governance, social reinforcement, and punishment).
Data Availability
The authors confirm that the data supporting the findings of this study are available within the article supplementary materials.
References
Ardila-Sánchez, J. G., Houmanfar, R. A., & Fleming, W. (2020). Interindividual performance in metacontingencies. Revista Mexicana de Análisis de la Conducta, 46, 162–201. https://doi.org/10.5514/rmac.v46.i2.77878
Baia, F. H., & Vasconcelos, L. A. (2015). Efeitos de consequências culturais concorrentes na seleção de culturantes. [Effects of concurrent cultural upon culturants]. Brazilian Journal of Behavior Analysis, 11, 125–136. https://doi.org/10.18542/rebac.v11i2.3781
Baia, F. H., Azevedo, F. F., Segantini, S. M., Macedo, R. P., & Vasconcelos, L. A. (2015). Efeitos de diferentes magnitudes de consequências individuais e culturais sobre culturantes [Effects of different magnitudes of individual consequences and cultural consequences on culturants ́ selection]. Acta Comportamentalia, 23(3), 257–272. https://www.revistas.unam.mx/index.php/acom/article/view/52057
Baum, W. M. (2017). Selection by consequences, behavioral evolution, and the price equation. Journal of the Experimental Analysis of Behavior, 107(3), 321–342. https://doi.org/10.1002/jeab.256
Baum, W. M., Richerson, P. J., Efferson, C. M., & Paciotti, B. M. (2004). Cultural evolution in laboratory microsocieties including traditions of rule giving and rule following. Evolution and Human Behavior, 25, 305–326. https://doi.org/10.1016/j.evolhumbehav.2004.05.003
Borba, A., Tourinho, E. Z., & Glenn, S. S. (2017). Effects of cultural consequences on the interlocking behavioral contingencies of ethical self-control. The Psychological Record, 67(3), 399–411. https://doi.org/10.1007/s40732-017-0231-6
Cihon, T. M., Borba, A., Lopez, C. R., Kazaoka, K., & de Carvalho, L. C. (2020). Experimental analysis in culturo-behavior science: The search for basic processes. In T. M. Cihon & M. A. Mattaini (Eds.), Behavior analysis: Theory, research, and practice. Springer. https://doi.org/10.1007/978-3-030-45421-0_6
Costa, D., Nogueira, C. P. V., & Vasconcelos, L. A. (2012). Effects of communication and cultural consequences on choices combinations in INPDG with four participants. Revista Latinoamericana de Psicología, 44(1), 121–131.
Couto, K. C., & Sandaker, I. (2016). Natural, behavioral and cultural selection-analysis: An integrative approach. Behavior and Social Issues, 25, 54–60. https://doi.org/10.5210/bsi.v25i0.6891
de Carvalho, L. C., Couto, K. C., Gois, N. D. S., Sandaker, I., & Todorov, J. C. (2017). Evaluating effects of cultural consequences on the variability of interlocking behavioral contingencies and their aggregate products. European Journal of Behavior Analysis, 18(1), 84–98. https://doi.org/10.1080/15021149.2016.1231003
Fonseca, S. A., Costa, D. C., & AAS, S. (2022). O estudo experimental das relações entre cultura e comportamento verbal: uma revisão de escopo. [The experimental study of relations between culture and verbal behavior: A scoping review]. Perspectivas em Análise do Comportamento, 13(2), 031–053. https://doi.org/10.18761/PAC000764.nov22
Glenn, S. S. (1986). Metacontingencies in Walden Two. Behavior Analysis and Social Action, 5, 2–8. https://doi.org/10.1007/BF03406059
Glenn, S. S. (1988). Contingencies and metacontingencies: Toward a synthesis of behavior analysis and cultural materialism. The Behavior Analyst, 11(2), 161–179. https://doi.org/10.1007/BF03392470
Glenn, S. S. (2004). Individual behavior, culture, and social change. The Behavior Analyst, 27(2), 133–151. https://doi.org/10.1007/BF03393175
Glenn, S., Malott, M. E., Andery, M. A. P. A., Benvenuti, M., Houmanfar, R., Sandaker, I., Todorov, J. C., Tourinho, E. Z., & Vasconcelos, L. (2016). Toward consistent terminology in a behaviorist approach to cultural analysis. Behavior and Social Issues, 25, 11–27. https://doi.org/10.5210/bsi.v25i0.6634
Guimarães, T. M. M., Leite, F. L., de Carvalho Neto, M. B., Tourinho, E. Z., & Tonneau, F. (2019). The effects of punishment in laboratory microcultures. Behavior and Social Issues, 28(1), 160–173. https://doi.org/10.1007/s42822-019-00004-z
Hosoya, N., & Tourinho, E. (2016). Efeitos de interações verbais na seleção e manutenção de contingências comportamentais entrelaçadas [Effects of verbal interactions in the selection and maintenance of interlocking behavioral contingencies]. Acta Comportamentalia, 24(3), 331–345 https://www.redalyc.org/pdf/2745/274546929006.pdf
Iversen, I. H. (2016). Problems with “percent correct” in conditional discrimination tasks. European Journal of Behavior Analysis, 17(1), 69–80. https://doi.org/10.1080/15021149.2016.1139368
Jacobs, R. C., & Campbell, D. T. (1961). The perpetuation of an arbitrary tradition through several generations of a laboratory microculture. Journal of Abnormal and Social Psychology, 52(3), 649–658. https://doi.org/10.1037/h0044182
Pitman, R. L., & Durban, J. W. (2011). Cooperative hunting behavior, prey selectivity and prey handling by pack ice killer whales (Orcinus orca), type B. Antarctic peninsula waters. Marine Mammal Science, 28(1), 16–36. https://doi.org/10.1111/j.1748-7692.2010.00453.x
Sampaio, A. A. S. (2020). Verbal interaction promotes cooperation in an iterated prisoner’s dilemma game: a multiple baseline metacontingency experiment. Revista Mexicana de Análisis de la Conducta, 46, 259–292. https://doi.org/10.5514/rmac.v46.i2.77883
Sampaio, A. A. S., Araújo, L. A. S., Gonçalo, M. E., Ferraz, J. C., Alves Filho, A. P., Brito, I. S., Barros, I., & Calado, J. I. F. (2013). Exploring the role of verbal behavior in a new experimental task for the study of metacontingencies. Behavior and Social Issues, 22, 87–102. https://doi.org/10.5210/bsi.v22i0.4180
Soares, P., Rocha, A., Guimaraes, T., Leite, F., Andery, M., & Tourinho, E. (2018). Effects of verbal and non-verbal cultural consequences on culturants. Behavior and Social Issues, 27, 31–46. https://doi.org/10.5210/bsi.v27i0.8252
Tan, L., & Hackenberg, T. D. (2016). Functional analysis of mutual behavior in laboratory rats (Rattus norvegicus). Journal of Comparative Psychology, 130(1), 13–23. https://doi.org/10.1037/com0000015
Vasconcelos, I. G., & Todorov, J. C. (2015). Experimental analysis of the behavior of persons in groups: Selection of an aggregate product in a metacontingency. Behavior and Social Issues, 24, 111–125. https://doi.org/10.5210/bsi.v24i0.5424
Vichi, C., Andery, M. A. P. A., & Glenn, S. S. (2009). A metacontingency experiment: The effects of contingent consequences on patterns of interlocing contingencies of reinforcement. Behavior and Social Issues, 18, 41–57. https://doi.org/10.5210/bsi.v18i1.2292
Funding
Open access funding provided by OsloMet - Oslo Metropolitan University
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no conflict of interest associated with this study.
Additional information
The authors would like to thank Espen Sjøberg, Gunnar Ree and Samantha Kelly Berge for their valuable comments on previous versions of this manuscript.
Supplementary Information
ESM 1
(XLSX 131 kb)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Couto, K.C., Bahari, M., Stokken, AL. et al. Experimental Analysis of Macrocontingencies and Metacontingencies Between Group Competition. Behav. Soc. Iss. 32, 360–375 (2023). https://doi.org/10.1007/s42822-023-00135-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42822-023-00135-4