
Abstract
In this paper, we provide a generalization of the concept of cohesion as introduced recently by Berenhaut et al. (Proc Natl Acad Sci 119:2003634119, 2022). The formulation presented builds on the technique of partitioned local depth by distilling two key probabilistic concepts: local relevance and support division. Earlier results are extended within the new context, and examples of applications to revealing communities in data with uncertainty are included. The work sheds light on the foundations of partitioned local depth, and extends the original ideas to enable probabilistic consideration of uncertain, variable and potentially conflicting information.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Uncovering structural communities and clusters within complex data can be of interest across disciplines. In [1], the authors harness the richness of a social perspective to derive community network structure in the presence of heterogeneity. Therein, a key concept of locality to a pair of data points is provided, leading to informative measures of (local) depth and cohesion. In this paper, we provide a generalization of this approach, by distilling two key probabilistic concepts: local relevance and support division. The approach sheds light on the foundations of partitioned local depth, and removes reliance on static distance comparisons, to enable probabilistic consideration of uncertain, variable and potentially conflicting information.
The notion of local (community) depth introduced in [1] builds on existing approaches to data depth (see for instance [2, 3]). Partitioning the probabilities defining local depth leads to a quantity referred to as cohesion, which can be understood as a measure of locally perceived closeness. The resulting framework also gives rise to a natural threshold for distinguishing strongly and weakly cohesive pairs and provides an alternative perspective for the concept of near neighbors. Topological features of the data can be considered via networks of pairwise cohesion, and meaningful structure can be identified without additional inputs (e.g., number of clusters or neighborhood size), optimization criteria, iterative procedures or distributional assumptions. For a review of the general method, referred to as partitioned local depth (PaLD), see Sect. 2; for further details see [1], and the references therein.
It is crucial to note the importance of accounting for varying local density, particularly in applications involving complex evolutionary processes (see, for instance, [4,5,6,7], and examples in [1]). In [1], relative positioning is considered through distance comparisons within triples of points, which may be of value in non-metric and high-dimensional settings.
Now, consider a given finite set of interest, S. If, for \(x,y,z\in S\), we have definitive answers to questions such as “Is z more similar to x than to y?”, then PaLD community analysis can proceed directly [1, 8]. Still, these may not be the most informative answers to such queries. For example, answers might instead have inherent variability, e.g., 80% of information available suggests that z is more similar to x than to y. It may, on the other hand, be the case that there is some true, definitive answer but this answer is subject to inherent uncertainty.
As an example application of PaLD, as introduced in [1], Fig. 1 displays community structure for cultural distance information obtained in [9] from two recent waves of the World Values Survey (2005 to 2009 and 2010 to 2014) [10]. Distances are computed using the cultural fixation index (CFST), which is a measure built on the framework of fixation indices from population biology [11, 12]. Note that PaLD employs within-triplet comparisons and allows for the employment of such application-dependent, non-Euclidean measures of dissimilarity. In Fig. 1A colored edges correspond to strong mutual cohesion as results from partitioning local depths. For a review of the derivation of such networks, see Sect. 2. Histograms for within-group cohesion and distance are provided in Fig. 1B; colored bars for (mutual) cohesion indicate values above the threshold of 0.0217 (see 14 below). Note that community structure can be identified without additional inputs (e.g., number of clusters or neighborhood size), optimization criteria, iterative procedures or distributional assumptions.
The data reflect that while, culturally speaking, regions within the USA are far more similar to each other than regions within India, the latter displays similar levels of strong internal cohesion.

Cultural communities from survey data; adapted from [1] with permission. In A, we display the community structure obtained from the cultural fixation index values from [9] for regions within the USA, China, India and the European Union. In B, we display the distribution of within-group cohesions and distances; colored bars for (mutual) cohesion indicate values above the threshold of 0.0217 (see 14). Note that distances are brought to comparable levels of cohesion
The remainder of the paper proceeds as follows. In Sect. 2, we provide some preliminaries and notation, including a review of the development of PaLD as introduced in [1] which highlights its formulation in terms of static dissimilarity comparisons. Section 3 provides an introduction to the abstracted concepts of local relevance and support division, and the given generalization of PaLD, to incorporate uncertainty, and Sect. 4 follows with theoretical results on properties of cohesion mirroring those in [1], for the new scenario. Section 5 includes mention of potential applications to multiple dissimilarity measures, event-based data and data uncertainty.
We now turn to some preliminaries and notation.
2 Preliminaries and Notation
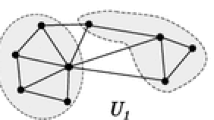
Suppose \(S=\{a_1,a_2,\dots , a_n\}\) is a finite set with a corresponding notion of pairwise dissimilarity or distance \(d: S \times S \rightarrow \mathbb {R}\). For any pair \((x,y)\in S\times S\), the set of relevant local data (or local focus), \(U_{x,y}\), is defined to be the set of elements \(z\in S\) which are as close to x as y is to x, or as close to y as x is to y, i.e.,
From a social perspective, the set, \(U_{x,y}\), local to the pair of individuals (x, y), consists of individuals with alignment-based impetus for involvement in a “conflict" between x and y (see Social Framework in [1] for a discussion of the underlying social latent space and related references). In the case of a symmetric distance, \(U_{x,y}\) is comprised of those z as close to x or y as they are to each other. The sense of local could be altered depending on applications.
The local depth of x, \(\ell _S(x)\), is a measure of local support, which leverages the concept of local that is implicit in the definition of \(\{ U_{x,y} \}\):
where Y is selected uniformly at random from the set \(S\setminus \{x\}\) and Z is selected uniformly at random from the local set \(U_{x,Y}\) (see Fig. 2). For convenience, the term resolving ties in distance (via coin flip), in (2), will be suppressed in what follows. The important concept of cohesion can then be obtained through partitioning of the probabilities defining \(\ell \). In particular, we have that \(C_{x,w}\), the cohesion of w to x, is given by

The local focus for a fixed point x and a random point Y, in two-dimensional Euclidean space. The points in red are outside the focus. Those in green (and Z in blue) are in the focus and closer to x, while those in gray are closer to Y
The cohesion network is the weighted, directed graph with node set S and edge weights \(\{C_{x,w}\}\); typically, an undirected version is displayed by considering the minimum of the bi-directional cohesions for each edge pair, with thicker edges depicting larger weights. Unless stated otherwise, we will employ the Fruchterman–Reingold algorithm [13] to display cohesion networks. Through cohesion, the dissimilarity measure, \(d\), is locally adapted, to reflect relative locally-based support (see, for example, Fig. 1). For additional discussion and applications of PaLD, in the context of considerations of data depth, embedding, clustering and near-neighbors, see [1].
As mentioned, though PaLD is formulated in terms of \(d\), the above definitions in (1), (2) and (3) depend only on relative closeness comparisons—e.g., whether z is closer to x than it is to y. Thus, as observed in [1, 8], an oracle for triplet comparisons is sufficient to determine the directed cohesion network. Note that previous work has suggested that one can often more reliably provide distance comparisons than exact numerical evaluations [2, 14].
As we will see in the remainder of the paper, due to its probabilistic formulation, PaLD is quite readily adapted to allow for uncertainty in dissimilarities.
3 Generalized PaLD
Whereas membership of a given z in the local focus \(U_{x,y}\) is assumed to be captured by an indicator in \(\{0, 1\}\) in (1), we will generalize the notion of “locality” to a pair (x, y), probabilistically. In a similar manner, support from Z can be formulated stochastically, to give generalized concepts of local depth as in (2) and cohesion as in (3).
Example 1
Before proceeding with formal definitions, for context, consider the simplistic generative process for triplet comparisons depicted in Fig. 3. Here, we assume that x, y and z are fixed, but distance comparisons are based on observed \(X^*\), \(Y^*\) and \(Z^*\) random in neighborhoods about x, y and z, respectively. We could be interested in uncertain events such as \(d(Z^*,X^*)<d(Y^*,X^*)\), say (see Fig. 3). Note that static comparisons such as \(d(z,x)<d(y,x)\) may not be fully informative, here.

Conceptual generative process for random triplet comparisons
We now introduce the abstracted concepts of local relevance and support division.
3.1 Local Relevance and Support Division
We are interested in generalized definitions of local focus, local depth and cohesion, which reflect uncertainty in dissimilarities.
For fixed \(x,y\in S\), membership in the local focus \(U_{x,y}\) can be generalized as follows. For each \(x,y,z\in S\), define the local relevance of z to the pair (x, y), \(R_{x,y,z}\), as the probability that z is local to the pair (x, y), or more formally
where \(\mathcal {N}{\mathop {=}\limits ^{\textrm{def}}}\{N(x,y):(x,y)\in S\times S\}\) is a random (pairwise) neighborhood structure on the set of pairs \(S\times S\). Note that we consider the elements in S here as fixed, with no required underlying sense of distance or position; stochasticity is provided through \(\mathcal {N}\) (akin to neighborhoods in random graphs). When convenient, we may also consider the full \(n \times n \times n\) array of probabilities, \(\varvec{R}{\mathop {=}\limits ^{\textrm{def}}}[R_{x,y,z}]\).
To obtain constructions for local depth and cohesion, here, we require a mechanism to sample an element, \(Z\in S\), local to (x, y). For this, we consider the process of selecting uniformly at random an element \({\tilde{Z}}\in S\), and with acceptance probability \(R_{x,y,{\tilde{Z}}}\) taking this as the value of Z, repeating the process until a Z is accepted. It is not difficult to see that, for \(z\in S\),
For fixed \(x,y,z\in S\), we may also consider the probability
where \(\mathcal {C}_z\) is a random choice function, defined on the set of two-element subsets of S, i.e., \(\mathcal {C}_z(A)\in A\). Here, \(Q_{x,y,z}\) reflects the support division for z with respect to the pair (x, y). Note that the choice mechanism defined through \(\{\mathcal {C}_z:z\in S\}\) need not be related, per se, to the neighborhood system \(\mathcal {N}\), emphasizing further that the points in S are not required to have fixed position in some underlying, say Euclidean, space. For convenience, we set \(\varvec{Q}{\mathop {=}\limits ^{\textrm{def}}}[Q_{x,y,z}]\). For general discussion of random choice, see, for instance, [15].
The local depth of x can then be given by
where Y is selected uniformly from \(S\setminus \{x\}\), and Z is selected with relative weight as in (5). Likewise, the cohesion of w to x, \(C_{x,w}\), generalizes directly as in (3):
Note that the quantity \(C_{x,w}\) can be defined independently of \(\ell (x)\). We include (7), as the work here also generalizes the concept of local depth as defined in [1] (see 2).
For examples of computing the arrays \(\varvec{R}\) and \(\varvec{Q}\), see Sect. 5.
We will assume, throughout, the following basic structural properties on the arrays \(\varvec{R}\) and \(\varvec{Q}\). Suppose \(x,y,z\in S\),
-
(a)
\(0 \le R_{x,y,z},Q_{x,y,z} \le 1\), (b) \(R_{x,y,z}=R_{y,x,z}\),
-
(c)
\(Q_{x,y,z}=1-Q_{y,x,z}\), (d) \(R_{x,y,x}=R_{x,y,y}=1\).
In (a), we are expressing the fact that the entries in \(\varvec{R}\) and \(\varvec{Q}\) represent probabilities; in (b), we have that local relevance does not depend on the ordering of x and y, (c) reflects the fact that Z supports either x or y (and there is no loss in probability) and (d) states that any individual is locally relevant to any pair in which it is an entry.
An algorithmic formalization of PaLD, generalized for uncertainty, then follows as in Algorithm 1. The implementation takes the specification of local relevance and support division (through \(\varvec{R}\) and \(\varvec{Q}\), respectively) as input, to output cohesion. Local depths can be obtained from the row sums of the output matrix, C.

Generalized partitioned local depth
Note that for a given distance function \(d:S\times S\rightarrow \mathbb {R}\), and \(U_{x,y}\) as in (1), setting
and
the computation of cohesion in [1] is recovered.
Before turning to some applications, we summarize some theoretical results, which generalize and shed light on those given in [1].
4 Results
In this section, we provide results regarding properties of cohesion, mirroring those in [1], including (a) dissipation of cohesion under separation, (b) irrelevance of density under separation and (c) dissipation of cohesion for concentrated sets of increasing size, in the context of uncertainty; proofs can be found in Appendix A. Throughout, unless stated otherwise, we will assume that the arrays \(\varvec{R}\) and \(\varvec{Q}\) are fixed, and satisfy the basic assumptions (a)–(d), listed in Sect. 3.1. In addition, \(x\in S\) is fixed, Y is selected uniformly at random from \(S\setminus \{x\}\) and Z is selected as in Eq. (5).
We begin with three definitions regarding structural properties of the set S with respect to the arrays \(\varvec{R}\) and \(\varvec{Q}\). The first provides conditions under which two disjoint subsets, A and B, of S are sufficiently separated. In essence, for \(c,c^*\in A\) and \(d \in B\), \(c^*\) is local to the pair (c, d) and fully supports c in that context, while d is not local to the pair \((c,c^*)\).
Definition
(Sufficiently Separated) Suppose \(A,B\subseteq S\). The set A is said to be sufficiently separated from B (with respect to \(\varvec{R}\) and \(\varvec{Q}\)) if \(A\cap B =\emptyset \), and for all \(c,c^*\in A\) and \(d\in B\), the following hold:
(a) \(R_{c,d,c^*}=1\), (b) \(R_{c,c^*,d}=0\), (c) \(Q_{c,d,c^*}=1\).
The sets A and B are said to be (mutually) sufficiently separated if A is sufficiently separated from B, and B is sufficiently separated A.
The second definition is crucial to stating Theorem 2, and addresses equivalence of ordinal structure for two subsets of S of equal cardinality.
Definition
(Equivalence of Ordinal Structure) Suppose two sets A, B satisfy \(A=\{a_1,a_2,\dots ,a_m\}\), and \(B=\{b_1,b_2,\dots ,b_m\}\), then A and B are said to have equivalent ordinal structure, if they are \((\varvec{R},\varvec{Q})\)-equivalent, i.e., for \(i,j,k\in \{1,2,\dots ,m\}\),
Finally, the following definition suggests a point-like property of one subset, \(B \subseteq S\), with respect to another, A. In particular if locality to any given pair of elements of A is constant over the set B, and all elements of B fully support other elements of B in comparisons with elements of A, then B is concentrated with respect to A.
Definition
(Concentrated) Suppose \(A,B\subseteq S\), then B is said to be concentrated with respect to A (for given \(\varvec{R}\) and \(\varvec{Q}\)), if there exists a function \(f: A \times A \rightarrow [0,1]\), such that
for \(a,a^* \in A\) and \(b,b^* \in B\).
We have the following results regarding properties of cohesion. Proofs are provided in Appendix A.
Theorem 1
(Dissipation of cohesion under separation) Suppose \(\varvec{R}\) and \(\varvec{Q}\) are fixed, S is a disjoint union of A and B, and A and B are sufficiently separated with respect to \(\varvec{R}\) and \(\varvec{Q}\), then the between-set cohesion values are zero, i.e., \(C_{a,b}\) = \(C_{b,a}=0\) for \(a \in A\) and \(b \in B\).
Theorem 2
(Irrelevance of density under separation) Suppose \(A=\{a_1,a_2,\dots ,a_m\}\) and \(A'=\{a'_1,a'_2,\dots ,a'_m\}\) have equivalent ordinal structure and \(S=A\cup B\) (resp. \(S'=A'\cup B\)), for some set B, where A and B (resp \(A'\) and B) are sufficiently separated. Then for any \(1 \le i,j \le m\), \(C_{a_i,a_j} = C_{a'_i,a'_j}\), i.e., the corresponding (within-set) pairwise cohesion values are equal.
Theorem 3
(Dissipation of cohesion for concentrated sets of increasing size) Suppose S is a disjoint union of A and B, and B is sufficiently separated from, and concentrated with respect to A. Then, for \(a \in A\) and \(b \in B\), the cohesion of b to a is bounded above by \((|A|/ |B|) (1/n)\).
The next result follows from the probabilistic definition of local depth along with the assumptions (c) and (d), from Sect. 3.1, namely
Here, the first assumption provides conservation of probability and the second guarantees proper selection of Z.
Theorem 4
(Conservation of Cohesion) We have
Finally, in [1], a threshold distinguishing strong from weak cohesion is provided. In particular, define
where X, Y, Z and W are selected uniformly at random from S, \(S\setminus \{x\}\), \(U_{X,Y}\) and \(U_{X,Y}\), respectively. For the generalization provided here, the analogue of the final equality in (14) no longer necessarily holds, but we do have the following.
Theorem 5
Set \(T{\mathop {=}\limits ^{\textrm{def}}}T_{S,\varvec{R},\varvec{Q}}=P(Z=W, \mathcal {C}_Z(\{X,Y\})=X)\). Then,
Key to the proof of Theorem 5 is the fact that here, in place of \(P(Z=W)= P(Z=X)\) as available in [1], we only have \(P(Z=W)\le P(Z=X)\) due to selection being dependent on the local relevance array, \(\varvec{R}\). One would have equality in the case of a \((0,1)-\varvec{R}\) array, even in the presence of flexibility allowed for support division.
We now turn to discussion of some potential applications.
5 Applications
In this section, we consider applications of the concepts of local relevance and support division in revealing community structure in complex data. Results follow upon determination of the arrays \(\varvec{R}\) and \(\varvec{Q}\). Importantly, the foundational framework from [1] carries over (see the results in Sect. 4). Note at the outset that the perspective on community structure developed in [1] (and extended here) is quite distinct from clustering. See Discussion and Conclusions in [1] for further details on implications of the underlying PaLD perspective in this context.
5.1 Combining Multiple Dissimilarity Measures
Our ability to reason directly from local relevance and support division allows for flexibility to combine multiple, possibly conflicting, dissimilarity measures. Instead of linearly combining such measures to form one, say, we can proceed probabilistically.
Example 2
Recall the cultural values data considered earlier in Fig. 1. Distances for politically-related questions are provided at [16] for the dimensions of Politics, Democracy, Egalitarianism, Conservatism, Neoliberalism, Authoritarianism, Libertarianism, Change, and Social. We will focus, here, on the subset of 25 European countries (out of 27) for which there is complete data for these dimensions. Define the respective resulting distance matrices as \(\varvec{D}_1,\varvec{D}_2,\dots ,\varvec{D}_9\).
Consider two potential methods for combining the pairwise distance information for the countries, to obtain cohesion networks. In one, we could obtain a single distance matrix, via simple linear weighting, i.e., for a nonnegative weight vector, \(\varvec{w}=(w_1,w_2,\dots ,w_9)\), satisfying \(\sum _i w_i=1\)
and proceed with PaLD, as in [1]. Alternatively, we could obtain respective arrays \(\varvec{R}_1,\varvec{R}_2,\dots ,\varvec{R}_9\) and \(\varvec{Q}_1,\varvec{Q}_2,\dots ,\varvec{Q}_9\), (as in (9) and (10)), and weight these to give
and
Note that the (i, j, k)-entry in the array \(\varvec{R}^*_{\varvec{w}}\) can be viewed as
expressing the fact that \((\varvec{R}_{\varvec{w}}^*)_{i,j,k}\), the (i, j, k)-entry in the array \(\varvec{R}^*_{\varvec{w}}\), is the probability that when a dimension, \(\delta \), is selected according to the distribution \(\varvec{w}\), we have \(a_k \in N(a_i,a_j)\) under that respective distance. Since relations are considered solely under individual distance matrices, this allows dimensions of differing scales and data types to be readily considered.
For illustration, Fig. 4 contains a display of the cohesion networks resulting from weight vectors where the relative weight on \(\varvec{D}_9\) (for the Social dimension, with equal weights for others), increases through the values 0, 0.5, 1.0, 2.0, 10, 100.

Cohesion networks based on \(\varvec{D}^*_{\varvec{w}}\) as the relative weight on the Social dimension increases through the values 0, 0.5, 1.0, 2.0, 10, 100. Ties above the threshold in (14) are displayed. The layout for each plot is that based on the Social dimension in isolation
Figure 5 contains a display of the cohesion networks resulting from weight vectors where the relative weights on \(\varvec{R}_9\) and \(\varvec{Q}_9\) increase through the same values 0, 0.5, 1.0, 2.0, 10, 100. Note some potential added stability in the cohesion network, as the weight on the Social dimension increases.

Cohesion networks based on \(\varvec{R}^*_{\varvec{w}}\) and \(\varvec{Q}^*_{\varvec{w}}\) as the relative weight on the Social dimension increases through the values 0, 0.5, 1.0, 2.0, 10, 100. Ties above the threshold in (15) are displayed. The layout for each plot is that based on the Social dimension in isolation
Typically one may choose to use uninformative uniform weights \(\{w_i\}\), in obtaining \(\varvec{R}^*\) and \(\varvec{Q}^*\). Further considerations of combining measures, and weight selections is work in progress. For discussion of combining dissimilarity measures from mixed-type data in the context of clustering, see, for instance, [17], and the references therein. Note as mentioned the probabilistic framework here maintains the properties of PaLD, and avoids need to consider standardization choices within dimensions.
5.2 Event-Based Data
Another potential application of the concepts of local relevance and support division is to similarity determined by multiple events. For instance, consider a set S of individuals, where for each pair \((x,y)\in S\times S\), we have a set of dissimilarities \(A_{x,y}\), each with nonzero cardinality \(n_{x,y}{\mathop {=}\limits ^{\textrm{def}}}|A_{x,y}|\). Note that it is not necessary that \(n_{x,y}\) be constant over pairs (x, y). There are several ways in which such similarities might arise. Consider the following example.
Example 3
Suppose we have competing entities for which multiple events determine pairwise distance, e.g. firms in different markets or competitors in an athletic context. For fixed \(x,y,z\in S\), values for \(Q_{x,y,z}\) and \(R_{x,y,z}\) can be determined as probabilities through random (potentially weighted) selections from \(A_{x,y}\), \(A_{y,z}\) and \(A_{x,z}\). For concreteness, in Fig. 6, we consider a cohesion network based on pairwise similarities determined by competitiveness in games played between teams during the 2021–2022 season of the National Basketball Association (NBA). Here, dissimilarity in a particular event (game) was determined as the proportion of (absolute) point differential to overall game point total. For instance, a score of 110-90 would result in a non-competitiveness score of \(|110-90|/(110+90)=0.10\). Note that, in this case, the values of \(\{n_{x,y}\}\) vary between 2 and 4. The edges corresponding to strong pairwise cohesions above the threshold bound in (15) are displayed, in Fig. 6. Note that the figure shows a general gradient from weaker teams at the top right to stronger teams at the bottom left. The largest cohesion is between the Dallas Mavericks and Brooklyn Nets, while the lowest is between the Phoenix Suns and the Charlotte Hornets. Some weaker teams display relative competitiveness with stronger teams head-to-head, such as the Detroit Pistons with the Denver Nuggets (two games with proportional point differentials of 6/(117 + 111) and 5/(105 + 110)).

The cohesion network for the 2021–2022 NBA basketball season based on proportional point differentials. Shading of nodes is according to mean proportional point differential; the highest is for the Phoenix Suns (0.034122; red) and lowest is for the Portland Trail Blazers (− 0.04019; yellow). Edge width is proportional to mutual cohesion. Note that team names have been abbreviated for display
Further applications could include any instances where event results determine distances. Similar ideas could also be used, when the events are drawn from sampling pairs of entities (and measuring dissimilarities) over time.
The final application included here is a line of potential further work, with applicability in the context of addressing discrete jumps in cohesion, adapting to cases where there is known levels of data precision and considerations of structural persistence.
5.3 Data Uncertainty
If we have information regarding data uncertainty, then, for fixed \(x,y,z\in S\), it is possible to adjust \(R_{x,y,z}\) and \(Q_{x,y,z}\) from indicators, as in (9) and (10), directly to probabilities. That is, \(R_{x,y,z}\) could reflect the probability of membership of z in the local focus of (x, y) and \(Q_{x,y,z}\), the probability of z being closer to x than to y. More generally, adjustment for various sources of uncertainty becomes possible and has the potential advantage of making cohesion continuous in the data.
Example 4
If we assume a sufficiently simple model, exact calculations of \(\varvec{R}\) and \(\varvec{Q}\) are relatively straightforward. Suppose that \(\epsilon >0\) is fixed and each \(a\in S\subseteq \mathbb {R}\) has random associated value \(A^*\in S^*\subseteq \mathbb {R}\), uniformly distributed in an \(\epsilon \)-ball centered at a. Here, \(S^*\) is the set of associated values. We can then compute the arrays \(\varvec{R}\) and \(\varvec{Q}\), in terms of corresponding entries in the set \(S^*\). If \(\epsilon \) (under uniformity) accurately reflects measurement uncertainty, then cohesion can be more faithfully modeled.
In this scenario, cohesion can be seen to be stable with respect to small changes in the data. Rather than having discrete jumps, due to discontinuities in (9) and (10), a positive \(\epsilon \) (e.g., reflecting the precision used to store the data) makes cohesion a continuous function of S. For instance, for \(x,y,z\in S\), with \(x<y<z\), if z is sufficiently close to y (relative to \(\epsilon \)), then z is in the local focus with probability one, i.e., \(R_{x,y,z}=1\). However, if z is gradually increased (moving farther from y), \(R_{x,y,z}\) transitions to the value zero.
Finally, we can consider how cohesion varies as \(\epsilon \) increases, in a manner similar to persistent homology [18]. It is currently work in progress to consider higher-dimensional scenarios and more complex settings. For consideration of clustering in the context of uncertain data, see, for instance [19, 20].
6 Conclusion
The generalization of partitioned local depth, developed here, enhances PaLD’s theoretical underpinnings and broadens the potential application of cohesion to complex data for which there may be uncertain, variable or conflicting information.
Two key probabilistic concepts, local relevance and support division, are introduced leading to an extended probabilistic framework for revealing communities in data.
Base properties of the resulting cohesion values have been proven and initial potential applications in the contexts of multiple dissimilarity measures, event-based data and data uncertainty are discussed. Several questions remain, as suggested throughout the manuscript. We have provided examples of applications in Sect. 5, but general determination of arrays \(\varvec{R}\) and \(\varvec{Q}\) (and their impact for representative community structure) is important for future work. It is hoped that the present work may lead to further consideration of communities in data.
References
Berenhaut KS, Moore KE, Melvin RL (2022) A social perspective on perceived distances reveals deep community structures. Proc Natl Acad Sci 119(4):2003634119. https://doi.org/10.1073/pnas.2003634119
Kleindessner M, Von Luxburg U (2017) Lens depth function and \(k\)-relative neighborhood graph: versatile tools for ordinal data analysis. J Mach Learn Res 18(1):1889–1940
Zuo Y, Serfling R (2000) General notions of statistical depth function. Ann Stat 28:461–482
Campello RJ, Kröger P, Sander J, Zimek A (2020) Density-based clustering. Wiley Interdiscip Rev Data Min Knowl Discov 10(2):1343
Breunig MM, Kriegel H-P, Ng RT, Sander J (2000) LOF: identifying density-based local outliers. In: Proceedings of the 2000 ACM SIGMOD international conference on management of data, pp 93–104
Domingues R, Filippone M, Michiardi P, Zouaoui J (2018) A comparative evaluation of outlier detection algorithms: experiments and analyses. Pattern Recogn 74:406–421
Everitt BS (1979) Unresolved problems in cluster analysis. Biometrics 35:169–181
Baron JD, Darling RWR, Davis JL, Pettit R (2021) Partitioned k-nearest neighbor local depth for scalable comparison-based learning. Available at: arXiv:2108.08864
Muthukrishna M, Bell AV, Henrich J, Curtin CM, Gedranovich A, McInerney J, Thue B (2020) Beyond western, educated, industrial, rich, and democratic (weird) psychology: measuring and mapping scales of cultural and psychological distance. Psychol Sci 31:678–701
Inglehart R, Haerpfer C, Moreno A, Welzel C, Kizilova K, Diez-Medrano J, Lagos M, Norris P, Ponarin E, Puranen B (2014) World values survey: all rounds-country-pooled datafile 1981–2014. JD Systems Institute, Madrid
Bell AV, Richerson PJ, McElreath R (2009) Culture rather than genes provides greater scope for the evolution of large-scale human prosociality. Proc Natl Acad Sci 106(42):17671–17674
Cavalli-Sforza LL, Menozzi P, Piazza A (1994) The history and geography of human genes. Princeton University Press, Princeton
Fruchterman TM, Reingold EM (1991) Graph drawing by force-directed placement. Softw Pract Exp 21(11):1129–1164
Ukkonen A (2017) Crowdsourced correlation clustering with relative distance comparisons. In: 2017 IEEE international conference on data mining (ICDM). IEEE, pp 1117–1122
Rubinstein A, Salant Y (2006) A model of choice from lists. Theor Econ 1(1):3–17
Cultural distance. http://culturaldistance.com. Accessed 17 Mar 2023
Costa E, Papatsouma I, Markos A (2022) Benchmarking distance-based partitioning methods for mixed-type data. Adv Data Anal Classif 1–24
Wasserman L (2018) Topological data analysis. Annu Rev Stat Appl 5:501–532
Schubert E, Koos A, Emrich T, Züfle A, Schmid KA, Zimek A (2015) A framework for clustering uncertain data. Proc VLDB Endow 8(12):1976–1979
Gullo F, Ponti G, Tagarelli A (2008) Clustering uncertain data via k-medoids. In: International conference on scalable uncertainty management. Springer, pp 229–242
Acknowledgements
The authors thank Katherine Moore, Richard Darling, several individuals at Metron, Inc., and others for stimulating discussions on communities in data.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the special issue “AISC 2022” guest edited by Abhyuday Mandal, Javid Shabbir, Tahani Coolen-Maturi, and Qian Xiao.
Appendix A Proofs of Results
Appendix A Proofs of Results
Proof of Theorem 1
Suppose \(a \in A\) and \(b \in B\), Y is selected uniformly at random, and for \(s \in S\),
Then partitioning according to the location of Y, and employing the definition in (8),
In the case that \(Y \in A\), since A is sufficiently separated from B, \(R_{a,Y,b}=0\). If \(Y\in B\), since B is sufficiently separated from A, \(Q_{a,Y,b}=0\), and hence \(C_{a,b}=0\). Similarly, \(C_{b,a}=0\). \(\square \)
Proof of Theorem 2
Suppose that \(1 \le i, j \le m\) are fixed and set \(x=a_i\) and \(w=a_j\) \(\big (\mathrm{resp.}\;x^{\prime }=a_i^{\prime }\;\textrm{and}\; w^{\prime }=a_j^{\prime }\big )\). As in (A2),
In the case \(Y \in A\) (resp. \(Y' \in A'\)), since A and \(A'\) are separated from B, \(R_{x,Y,b}=R_{x',Y',b}=0\) for all \(b \in B\), and hence, since A and \(A'\) have equivalent ordinal structure,
On the other hand, if \(Y \in B\), then since A is sufficiently separated from B, \(R_{x,Y,w}=1\) and \(Q_{x,Y,w}=1\), and since B is sufficiently separated from A, for \(b \in B\), \(R_{x,Y,b}=1\) and \(Q_{x,Y,b}=0\). Therefore,
Since \(P(Y \in A)=P\left( Y \in A^{\prime }\right) \), the result now follows. \(\square \)
Proof of Theorem 3
Suppose \(a \in A\) and \(b \in B\). Since B is sufficiently separated from A, \(Q_{a,y,b}=0\) for all \(y \in B\), and hence,
For \(y \in A\), since B is concentrated with respect to A,
and hence
and the results follows. \(\square \)
Proof of Theorem 5
The proof follows as in [1], except, whereas therein \(P(Z=W)=P(Z=X)\), here by the assumption (d) in Sect. 3.1, \(R_{X,Y,W}\le R_{X,Y,X}\), and hence
The result follows by employing the definition of \(C_{x, x}\), the assumption (b) in Sect. 3.1 and leveraging the symmetry in the selection of X and Y. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Berenhaut, K.S., Foley, J.D. & Lyu, L. Generalized Partitioned Local Depth. J Stat Theory Pract 18, 10 (2024). https://doi.org/10.1007/s42519-023-00356-1
Accepted:
Published:
DOI: https://doi.org/10.1007/s42519-023-00356-1