
Abstract
The variational quantum eigensolver (VQE) is a leading strategy that exploits noisy intermediate-scale quantum (NISQ) machines to tackle chemical problems. It is expected to demonstrate quantum advantage when handling a large number of qubits, where the density matrix cannot be processed efficiently on classical computers. To gain such computational advantages on large-scale problems, a feasible solution is the QUantum DIstributed Optimization (QUDIO) scheme, which partitions the original problem into \(\varvec{K}\) subproblems and allocates them to \(\varvec{K}\) quantum machines followed by the parallel optimization. Despite the provable acceleration ratio, the efficiency of QUDIO may heavily degrade by the synchronization operation. To conquer this issue, here we propose Shuffle-QUDIO to involve shuffle operations into local Hamiltonians during the quantum distributed optimization. Compared with QUDIO, Shuffle-QUDIO significantly reduces the communication frequency among quantum processors and simultaneously achieves better trainability. Particularly, we prove that Shuffle-QUDIO enables a faster convergence rate over QUDIO. Extensive numerical experiments are conducted to verify that Shuffle-QUDIO allows both a wall-clock time speedup and low approximation error in the tasks of estimating the ground state energy of a molecule. We empirically demonstrate that our proposal can be seamlessly integrated with other acceleration techniques, such as operator grouping, to further improve the efficacy of VQE.
Similar content being viewed by others
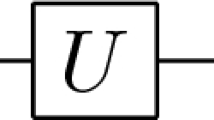
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Quantum computing is expected to demonstrate advantages over classical computers in dealing with certain tasks, such as boson sampling (Spring et al. 2013; Wang et al. 2017; Bulmer et al. 2021) and integer factorization (Jiang et al. 2018; Peng et al. 2019). With the advent of noisy intermediate-scale quantum (NISQ) era (Preskill 2018; Bharti et al. 2022), Google has experimentally verified that when sampling the output of a pseudo-random quantum circuit, current NISQ devices can run faster than the state-of-the-art classical computers (Arute et al. 2019). Recently, the University of Science and Technology of China (USTC) has achieved more difficult sampling tasks on Zuchongzhi 2.1 to further push the frontier of quantum computational advantages (Zhu et al. 2022). However, the unavoidable system noise and the restricted coherence time prevent the execution of complicated quantum algorithms on NISQ devices. To accommodate the limitations of NISQ machines, variational quantum algorithms (VQAs) (McClean et al. 2016; Cerezo et al. 2021; Marco et al. 2020; Qian et al. 2022; Tian et al. 2023) which employ a classical optimizer to train a parametrized quantum circuit, have emerged. Concisely, VQAs alternately interact between quantum circuits and classical optimizers, while the former evolves the quantum state and outputs classical information by measurements, and the latter is responsible for seeking the best parameters of quantum circuit to minimize the discrepancy between the predictions and the targets. Pioneer studies have verified the power of VQAs in quantum finance (Roman et al. 2019; Pistoia et al. 2021), quantum chemistry (Grimsley et al. 2019; Arute et al. 2020; Kandala et al. 2017; Robert et al. 2021; Kais 2014; Wecker et al. 2015; Cai et al. 2020; Wang et al. 2019; Romero et al. 2018; Cervera-Lierta et al. 2021; Parrish et al. 2019), many-body physics (Huang et al. 2022; Lee et al. 2021; Endo et al. 2020), machine learning (Huang et al. 2021, 2022; Du and Tao 2021; Caro et al. 2022; Gili et al. 2022), and combinational optimization (Farhi et al. 2014; Zhou et al. 2020; Harrigan et al. 2021; Lacroix et al. 2020; Hadfield et al. 2019; Zhou et al. 2023) from both theoretical and experimental aspects.
Although VQAs promise the practical applications of NISQ machines, they are challenged by the scalability issue. The required number of measurements for VQAs scales with \(O(poly(n, 1/\epsilon ))\) with n being the problem size and \(\epsilon \) being the tolerable error, which implies an expensive runtime for large-scale problems. One canonical instance is the variational quantum eigensolver (VQE) (Peruzzo et al. 2014), which is developed to estimate the low-lying energies and corresponding eigenstates of molecular systems. VQE contains two key steps. First, the electronic Hamiltonian is reformulated to the qubit Hamiltonian \(H=\sum _{i=1}^M\alpha _iH_i\) through Jordan-Wigner, Bravyi-Kitaev, or parity transformations (Seeley et al. 2012; Bravyi and Kitaev 2002; Jordan and Wigner 1993), where \(H_i\in \{\sigma _X, \sigma _Y, \sigma _Z, \sigma _I\}^{\otimes n}\) and \(\alpha _i\in \mathbb {R}\) for \(\forall i \in [M]\), and M is the number of Pauli operators. The property of H is then estimated by a variational quantum circuit whose parameters are updated by a classical optimizer. Principally, it requires \(O(poly(M, 1/\epsilon ))\) queries to the quantum circuit in each iteration to collect the updating information (Gonthier et al. 2020). With this regard, VQEs towards large-scale molecules request an intractable time expense on the measurements. This scalability issue impedes the journey of VQEs to the quantum advantages.
Approaches for reducing the computational overhead of quantum measurements in VQE can be roughly classified into five categories, including operator grouping (Ralli et al. 2021; Verteletskyi et al. 2020; Zhao et al. 2020; Gokhale et al. 2019), ansatz adjustment (Tkachenko et al. 2021; Zhang et al. 2022), shot allocation (Arrasmith et al. 2020; van Straaten and Koczor 2021; Gu et al. 2021; Kübler et al. 2020; Menickelly et al. 2022), classical shadows (Huang et al. 2020; Hadfield et al. 2022), and distributed optimization (Pablo and Chris 2019; Barratt et al. 2021; Yuxuan 2022; Mineh and Montanaro 2022). Specifically, the operator grouping strategy focuses on finding the commutativity between local Hamiltonian terms \(\{H_i\}\) in H. The commutable Hamiltonians can be evaluated by the same measurements, which enable the measurement reduction (Kandala et al. 2017; Ralli et al. 2021; Verteletskyi et al. 2020; Zhao et al. 2020; Gokhale et al. 2019). Ansatz adjustment targets to tailor the layout of ansatz to reduce the circuit depth (Tkachenko et al. 2021; Tang et al. 2021; Grimsley et al. 2019) or the number of qubits (Zhang et al. 2022). For example, Ref. Tkachenko et al. (2021) attempts to assign two qubits with stronger mutual information to the adjacent locations with direct connectivity on the physical quantum chips, leading to shallower circuits over the original VQEs to reach a desired accuracy. Shot allocation aims to assign the number of shots among \(\{H_i\}\) in a more intelligent way. A typical solution is to allocate more shots to the terms with a larger coefficient \(|\alpha _i|\) and a larger variance of \(\langle {H_i}\rangle \) (Arrasmith et al. 2020). Another measurement reduction method, classical shadows, constructs an approximate classical representation of a quantum state based on few measurements of the state (Huang et al. 2020). With this representation, \(O(\log (M))\) measurements are enough to estimate the expectation value of whole observable with high precision.
On par with reducing computational complexity of the quantum part, we can reduce the computational time of the optimization of VQE by using multiple quantum processors (workers), inspired by the success of distributed optimization in deep learning and the growing number of available quantum chips. There are generally two types of distributed VQAs. The first paradigm is decomposing the primal quantum systems into multiple smaller circuits and running them in parallel (Barratt et al. 2021; DiAdamo et al. 2021). The second paradigm is utilizing the quantum cloud server in which the problem Hamiltonian can be pre-divided into several partitions and distributed into Q local quantum workers respectively. Each worker estimates the expectation value of partial local Hamiltonians with no more than O(poly(M/Q)) queries and delivers the result to the rest of the workers after a single iteration. Noticeably, such a methodology inevitably encounters the communication bottleneck, quantum circuit noise, and the risk of privacy leakage. As such, Ref. Yuxuan (2022) devises the QUantum DIstributed Optimization (QUDIO), a novel distributed-VQA scheme in a lazy communication manner, to address this issue. It is important to note that QUDIO utilizes local stochastic gradient descent (SGD) to optimize parameters based on a pre-divided subset of the entire samples, assuming that all samples are independent and identically distributed (i.i.d). However, the local Hamiltonians allocated to different quantum processors are not i.i.d. Therefore, the naive allocation method is not suitable for VQEs. Besides, the coefficients \(\{\alpha _i\}\) of the local Hamiltonian terms \(\{H_i\}\) are varied, leading to unbalanced contributions to the overall variance of Hamiltonian estimation. Such an estimation error can be exacerbated by the increased communication interval, which renders the trade-off between the acceleration ratio and the approximation error of VQEs.
To maximally suppress the negative effects of large communication interval on the convergence rate, here we propose a new quantum distributed optimization framework, called Shuffle-QUDIO. Different from QUDIO, for every local worker, the local Hamiltonian terms are randomly shuffled and sampled without replacement according to the worker’s rank before each iteration. From a statistical view, this operation alleviates the issue such that every local worker may only observe incomplete local Hamiltonians during the optimization. Moreover, the dynamic allocation of Hamiltonian terms alleviates the accumulated deviation with respect to the target Hamiltonian H after a large number of local updates. In this way, Shuffle-QUDIO achieves faster convergence while keeping low communication cost, leading to a high speedup with respect to time-to-accuracy. Consequently, it is particularly well-suited for addressing large-scale quantum chemistry problems. Another advantage of our proposal is its compatibility across various quantum hardware architectures, which makes it possible to unify existing quantum devices to accelerate the training of VQEs.
To theoretically exhibit the advance of our proposal, we prove that Shuffle-QUDIO allows a faster convergence rate than that of QUDIO. By leveraging the non-convex optimization theory, we exhibit that the dominant factors affecting the convergence rate are the number of distributed quantum machines K, the local updates (communication interval) W, and the global iterations T, i.e., O(poly(W, K, 1/T)). To benchmark the performance of Shuffle-QUDIO, we conduct systematic numerical experiments on VQEs under both fault-tolerant and noisy scenarios. The achieved results confirm that Shuffle-QUDIO achieves smaller approximation error over QUDIO, as well as lower communication overhead among clients and server, and sub-linear speedup ratio. In addition, we demonstrate that the performance of Shuffle-QUDIO under the noisy setting can be further boosted by combining the advanced operator grouping strategy. To further facilitate the development of a community of quantum acceleration algorithms, we provide an open-source code repository: https://github.com/QQQYang/Shuffle-QUDIO.
The remaining parts of this paper are organized as follows. Section 2 briefly introduces the preliminary knowledge about the optimization of variational quantum circuits. Section 3 presents the pipeline of the proposed algorithm and presents the convergence analysis. Section 4 exhibits numerical simulation results. Section 5 gives a summary and discusses the outlook.
2 Preliminary
The essence of VQE is tuning an n-qubit parameterized quantum state \(\rho ({\varvec{\theta }})=| \psi (\varvec{\theta }) \rangle \langle \psi (\varvec{\theta }) |\) with \(\varvec{\theta }\in \mathbb {R}^P\) to minimize the energy of a problem Hamiltonian
where \(H_i\) refers to the i-th local Hamiltonian term with the weight \(\alpha _i\). The energy minimization is formulated by the loss function
With a slight abuse of notation, we denote \(H_i\) as \(\alpha _iH_i\) and simplify the above loss function as
The parameterized quantum state is prepared by an ansatz with \(| \psi (\varvec{\theta }) \rangle =U(\varvec{\theta })| \phi \rangle \) and \(| \phi \rangle \) being an initial quantum state. A generic form of \(U(\varvec{\theta })\) is
where \(O_i\) is a Hermitian matrix and \(U_{e}\) denotes a fixed unitary composed of multi-qubit gates. By iteratively updating the circuit parameters \(\varvec{\theta }\) to minimize the loss, the quantum state \(\rho ({\varvec{\theta }})\) is expected to approach the eigenstate of H with the minimum eigenvalue.
2.1 Optimization of VQE
Gradient descent (GD) based optimizers are widely used in previous literatures of VQE. The parameters \(\varvec{\theta }^{t+1}\) at the \((t+1)\)-th iteration is updated alongside the steepest descent direction with learning rate \(\eta \), i.e.,
Unlike classical neural networks that utilize gradient back-propagation to update parameters (LeCun et al. 1988), VQE adopts the parameter-shift rule (Banchi and Crooks 2021; Wierichs et al. 2022) to obtain the unbiased estimation of the gradient. The gradient with respect to the i-th parameter is
where \(\varvec{e}_i\) denotes the indicator vector for the i-th element of parameter vector \(\varvec{\theta }\). When the number of trainable parameters is P, the required number of measurements to complete the gradient computation scales with O(poly(PM)) without applying any measurement reduction strategies.

The scheme of Shuffle-QUDIO. The Shuffle-QUDIO consists of three subroutines, including initialization, local updates and global synchronization. During the phase of initialization, multiple copies of the original ansatz and the corresponding problem Hamiltonian H are dispatched into each local processor. Note that each processor shares the same seed of the random number generator. For each iteration in the local updates, the set of observables \(\{H_i\}_{i=1}^M\) is randomly shuffled and the i-th local processor picks the subset of whole observables according to the assigned random number. In this way, the observables of each processor do not overlap with each other and the union of their observables exactly constitutes the problem Hamiltonian H. After W local updates, the parameters of each local ansatz are aggregated and then reassigned to all local processors, which is called global synchronization. When the maximal number T of iterations is reached, Shuffle-QUDIO executes the final synchronization and outputs the trained parameters
2.2 Optimization of the distributed VQE
To accelerate the training of VQA, Ref. Yuxuan (2022) proposed the QUantum DIstributed Optimization (QUDIO) scheme. The key idea of QUDIO is to partition the problem Hamiltonian H in Eq. (1) into several groups and distribute them into multiple quantum processors to be manipulated in parallel. Mathematically, suppose that there are K available quantum processors \(\{\mathcal {Q}_i\}_{i=1}^K\), the Hamiltonian terms \(\{H_i\}_{i=1}^M\) are divided into K subgroups \(\{\mathcal {S}_i\}_{i=1}^K\), where \(\mathcal {S}_i=\cup _{j\in S_i} \{H_j\}\), so that \(\sum _{i=1}^K |S_i| =M\) and \(S_i\cap S_j=\emptyset \) when \(i\ne j\).
In the initialization process, the i-th subgroup \(\mathcal {S}_i\) is allocated to the i-th quantum processor \(\mathcal {Q}_i\) for \(\forall i \in [K]\). All local processors share the same initial parameters \(\varvec{\theta }^0\) with \(\varvec{\theta }_i^{(0,0)}=\varvec{\theta }^0\) for \(\forall i\in [K]\). The subsequent training process alternately switches between the local updates and the global synchronization. During the phase of local updates, each quantum processor follows the gradient descent rule to update the parameters to minimize the local loss function \(L(\varvec{\theta }_i,H_{S_i})=\sum _{j\in S_i}{{\,\textrm{Tr}\,}}(\rho ({\varvec{\theta }_i})H_j)\), i.e., the parameters of the i-th processor at the (t, w)-th step is updated as Eq. (3). After fulfilling W local updates, all parameters from distributed quantum processors are synchronized by averaging the collected parameters \(\varvec{\theta }^{t+1}=\frac{1}{K}\sum _{i=1}^K\varvec{\theta }_i^{(t,W)}\). Repeating the above two phases until the termination conditions (e.g., the maximum number of iterations) are met, the synchronized parameters are returned as the final parameters.
Ignoring the communication overhead among quantum processors, QUDIO with \(W=1\) is expected to linearly accelerate the optimization of VQE. However, the communication bottleneck could degrade the acceleration efficiency. An optional solution is to increase W to reduce the communication frequency. As indicated in Yuxuan (2022), the performance of VQA witnesses a rapid drop with the increased W.
3 Shuffle-QUDIO for VQE
The performance of QUDIO suffers from a high sensitivity of the communication interval. Intuitively, this issue originates from the fact that each quantum processor in QUDIO only perceives a static subset of the whole observable set during the entire training process. The i-th processor updates its local parameters based on the partial observations before communicating with other processors. Meantime, the coefficients \(\{\alpha _i\}\) and the variance of Pauli operators \(\{H_i\}\) differ from each other, leading to different contributions to the expectation estimation of H. As a result, the local processor fails to characterize the full property of the problem Hamiltonian H. With multiple local updates, the accumulation of bias further degrades the performance of QUDIO. To tackle this issue, here we devise a novel quantum distributed optimization scheme, called Shuffle-QUDIO, to avoid the performance drop when synchronizing in a low frequency.

The pseudocode of Shuffle-QUDIO
3.1 Algorithm descriptions
The paradigm of Shuffle-QUDIO is depicted in Fig. 1, which consists of three steps.
-
1.
Initialization. The variational quantum circuit \(U(\varvec{\theta })\) in Eq. (2) of each quantum processor is initialized with the same parameters \(\varvec{\theta }_i^{(0,0)}=\varvec{\theta }^0\) for \(i=\{1,...,K\}\) and all local Hamiltonian terms \(\{H_i\}\) are distributed to each processor.
-
2.
Local updates. Each processor independently updates the parameters \(\varvec{\theta }^{(t,w)}_i\) following the gradient descent principle. First, Shuffle-QUDIO randomly shuffles the sequence of local Hamiltonian terms. Note that the random number of each processor is generated from the same random seed. Assuming the permutation vector is denoted by \(\pi ^{(t,w)}\), the visible Hamiltonians for the i-th processor at the t-th iteration are \(\mathcal {H}^{(t,w)}_i=\{H_{\pi ^{(t,w)}(j)}\}_{j=\frac{M}{K}(i-1)+1}^{\frac{M}{K}i}\) (suppose M is exactly divided by K). Then each processor estimates the gradient \(\varvec{g}_i^{(t,w)}\) by the parameter-shift rule. Note that \(\varvec{g}\) denotes the estimated gradient on the quantum device due to the finite number of measurements, while \(\nabla L\) refers to the corresponding accurate gradient. The parameters are updated as
$$\begin{aligned} \varvec{\theta }^{(t,w+1)}_i=\varvec{\theta }^{(t,w)}_i-\eta \varvec{g}_i^{(t,w)}, \end{aligned}$$(5)where \(\eta \) is the learning rate. Repeat the above local updates for W local steps.
-
3.
Global synchronization. Once the local updates are completed, the central server synchronizes parameters among all quantum processors in an averaged manner, i.e.,
$$\begin{aligned} \varvec{\theta }^{t+1}=\frac{1}{K}\sum _{i=1}^K \varvec{\theta }^{(t,W)}_i. \end{aligned}$$(6)If the number of the global iterations reaches T, the parameters \(\varvec{\theta }^T\) are returned as the output; otherwise, return back to step 2.
The pseudocode of Shuffle-QUDIO is summarized in Fig. 2. Compared with conventional VQE which sequentially measures the expectation value of every single observable, the strategy of distributed parallel optimization accelerates the estimation of the complete observables by K times. Furthermore, the shuffling operation alleviates the deviation of the optimization direction during the local updates and thus warrants more stable performance after increasing communication interval. This is because in a statistical view, each processor can leverage the information of all local Hamiltonian terms to update local parameters in the training process.
Lemma 1
Let \(\{H_1,...,H_M\}\) be M Hermitian matrices in \(\mathbb {C}^{2^n\times 2^n}\), \(H=\sum _{i=1}^MH_i\). Let \(\rho (\varvec{\theta })\) be an n-qubit quantum state parameterized by \(\varvec{\theta }\). For any \(k\in \{1,...,M\}\), let \(H_{\pi (1)},...,H_{\pi (k)}\) be uniformly sampled without replacement from \(\{H_1,...,H_M\}\). Let \(L={{\,\textrm{Tr}\,}}(\rho (\varvec{\theta })H)\) and \(L_m={{\,\textrm{Tr}\,}}(\rho (\varvec{\theta })\sum _{i=1}^mH_{\pi (i)})\). Then we have
Refer to Appendix B for proof details. Lemma 1 implies that the direction of the expected gradient of each local quantum processor in Shuffle-QUDIO is unbiased. This guarantees that the local quantum circuits are individually optimized forward along the right direction when they do not communicate frequently with each other, which narrows the performance gap between a single processor and the synchronized model. By contrast, during the local updates of QUDIO, there always exists a bias between the locally estimated gradient and the global gradient. Specifically, Shuffle-QUDIO achieves smaller gradient deviation than vanilla QUDIO, as indicated by the following lemma, whose proof is provided in Appendix C.
Lemma 2
Assume the norm of local gradient \(\varvec{g}_k(\varvec{\theta }, H_k)\) is bounded by \(\left\| \varvec{g}_k\right\| ^2\le G^2\) where G is a positive constant, and \(K>1\). Compared with QUDIO, the discrepancy between the local gradient \(\varvec{g}_k(\varvec{\theta }, H_k)\) and the global gradient \(\left\| \nabla L(\varvec{\theta },H)\right\| \) in Shuffle-QUDIO is reduced from \(2(K^2+1)G^2\) to \((K-1)^2G^2\).
3.2 Convergence analysis
We next show the convergence guarantee of Shuffle-QUDIO. When running VQE on NISQ devices, the system imperfection introduces noise into the optimization. To this end, we consider the worst scenario in the convergence analysis, where the system noise is modeled by the depolarizing channel. It introduces an equal probability of bit-flip, phase-flip, and both bit- and phase-flip in a depolarizing channel and will finally drive the quantum system into maximally mixed state. Mathematically, the depolarizing channel \(\mathcal {N}_p\) transforms the quantum state \(\rho \in \mathbb {C}^{2^n\times 2^n}\) to \(\mathcal {N}_p(\rho )=(1-p)\rho +p\mathbb {I}/2^n\), and with increasing the noise strength p, the quantum state finally evolves to the maximally mixed state. As proved in Yuxuan et al. (2021), the depolarizing channel applied on each circuit depth can be merged at the end of the quantum circuit. Therefore, without loss of generality, the estimated gradient with respect to the i-th parameter is
The convergence rate of Shuffle-QUDIO is summarized by the following theorem whose proof is provided in Appendix D.
Theorem 1
Let the gradient of loss function L be F-Lipschitz continuous, G be the upper bound of the gradient norm, \(\eta \) be the learning rate of optimizer, p be the strength of depolarizing noise, T be the total number of global iterations, K and W be the number of distributed quantum processor and local iterations respectively, the convergence of Shuffle-QUDIO in the noisy scenario is summarized as
Theorem 1 reveals that an increased quantum noise rate p leads to poor convergence of Shuffle-QUDIO, which emphasizes the significance of error mitigation (Endo et al. 2018, 2021; Strikis et al. 2021; Yuxuan et al. 2022) in quantum optimization. Meantime, the shorter communication interval W among distributed quantum processors guarantees a better performance of Shuffle-QUDIO. Note that although a large W still hinders the distributed optimization, Shuffle-QUDIO achieves faster convergence than QUDIO for equivalent W values. Refer to Appendix D for a detailed discussion.
This divergence in performance between QUDIO and Shuffle-QUDIO stems from their distinct constraints on Hamiltonians. Shuffle-QUDIO is specifically designed for quantum chemistry and quantum many-body physics problems, while QUDIO is more suitable for machine learning tasks, such as data classification and regression. The different targets of the two algorithms result in different achievements. Therefore, we consider QUDIO and Shuffle-QUDIO as complementary to each other. Regarding the performance, we would like to emphasize that QUDIO is inferior to Shuffle-QUDIO in learning quantum chemistry problems due to the difference in the distribution of local Hamiltonians. QUDIO is designed for i.i.d examples, whereas the local Hamiltonians allocated to different quantum processors are not i.i.d. As such, QUDIO suffers from an obvious performance drop when increasing the communication interval among quantum chips. By contrast, the proposed Shuffle-QUDIO allows smaller approximation error as well as lower communication overhead among clients and server, and lower runtime cost, which provides bigger potential to achieve higher speedup with more quantum resource available and faster communication.
From the technical view, although the proof of Theorem 1 is derived from the classical results on local SGD (Haddadpour et al. 2019), there are some key differences between them. First, in classical local SGD, each worker independently samples a mini-batch from the whole dataset without other limitations. By contrast, the distributed quantum processors randomly sample the local Hamiltonian terms without replacement in each local iteration, which means that the Hamiltonian terms of each processor do not overlap and the union exactly constitutes the complete molecule Hamiltonians. This special sampling method guarantees the integrity of the problem Hamiltonian, but poses a challenge for theoretical analysis. Second, our analysis does not rely on the strong assumptions, such as convexity or Polyak-Lojasiewicz (PL) condition (Sweke et al. 2020). Furthermore, the quantum noise in NISQ devices inevitably shifts the quantum state and biases the estimated gradients, which differentiates VQE from classical machine learning.
4 Numerical results
To verify the effectiveness of Shuffle-QUDIO, we apply it to estimate the ground state of several molecules with the lowest energy. Jordan-Wigner transformation (Jordan and Wigner 1993) is employed to transform these electronic Hamiltonians into the qubit Hamiltonians represented by Pauli operators. For example, the LiH system is totally described by 12 qubits and 631 local Pauli terms \(\{\sigma _I,\sigma _X,\sigma _Y,\sigma _Z\}^{\otimes 12}\). The ansatz is designed in a hardware-efficient style inspired by Kandala et al. (2017), whose layout is shown in Fig. 3. We conduct numerical experiments on classical device with Intel(R) Xeon(R) Gold 6267C CPU @ 2.60GHz and 128 GB memory. For each setting, the experiment is repeated for 5 times with different random seeds to mitigate the effect of randomness. Stochastic gradient descent is used to update trainable parameters, where the learning rate is set as \(\eta = 0.4\).

Layout of hardware-efficient ansatz. The gate “Rot” represents the concatenation of rotation gate \(R_z\), \(R_y\), \(R_z\), and \(\theta \) represents the rotation angle

Comparison of speedup of QUDIO and Shuffle-QUDIO for VQE to solve the ground state of LiH. The label “\(W=a\)” refers that the number of local iterations is a. The label “linear speedup” represents the reference line of the linear speedup
4.1 Acceleration ratio
We consider the speedup w.r.t time-to-accuracy as the performance indicator of Shuffle-QUDIO and compare it with QUDIO. Specifically, denote \(T_{acc}(K,W)\) as the time spent on training the model to reach a specific accuracy under the setting of K quantum processors and W local iterations. Mathematically, \(T_{acc}(K,W)\) can be modeled as
where \(C_{acc}\) is the number of iterations required for training a model to reach a specific accuracy, \(T_{iter}(*)\) is the wall-clock time of every optimization iteration, \(T_{comm}(*)\) denotes the wall-clock time spent in one communication, and \(\tilde{T}_{comm}(K,W)=\frac{T_{comm}(K)}{W}\) can be regarded as the average communication time allocated evenly into every iteration. The speedup with respect to time-to-accuracy, denoted as \(s^{K,W}\), is defined as \(s^{K,W}=T_{acc}(K,W)/T_{acc}(1,1)\). Intuitively, the positive effects on communication time reduction (small \(\tilde{T}_{comm}(K,W)\)) and negative effects on convergence drop (large \(C_{acc}\) or \(T_{acc}(K,W)\)) caused by increasing W lead to a trade-off between achieving shorter running time and faster convergence when adjusting W.
Figure 4 shows the results of solving the ground state of LiH. The right panel illustrates that increasing K from 1 to 4 nearly achieves a linear speedup for \(W=1,2,4,8,16\), and there is no significant difference of performance between different W. However, the speedup of \(W=1\) decreases when the number of local nodes (K) reaches 8 due to the communication bottleneck for larger K and small W. To alleviate this, we can increase W to reduce communication frequency. When \(W=8\), the highest speedup among all settings is achieved. It is worth noting that larger \(W=16\) achieves lower speedup than \(W=8\) at point \(K=8\) due to the poor convergence brought by the large W. When K continues to grow, such as \(K=16\), the performance of all settings begins to decline because the increase in communication cost resulting from a large number of communication nodes outweighs the decrease in computational cost for estimating the expectation of the Hamiltonian. Therefore, a larger W does not guarantee higher speedup w.r.t time-to-accuracy than smaller W. Please refer to Appendix F for more detailed explanations.
Furthermore, comparing the left panel with the right panel of Fig. 4, we observe that Shuffle-QUDIO allows for larger K (\(K=8\)) and W (\(W=8\)) than QUDIO (\(K=4\) and \(W=4\)) and achieves a higher speedup ratio.

Training process of VQE optimized by QUDIO and Shuffle-QUDIO respectively. Each data point is collected after the synchronization. The dashed black line denotes the exact ground state energy (GSE) at the same setting. The first row: the loss curve with respect to iterations in QUDIO. With exponentially increasing W, the convergence of training is severely degraded, as depicted in subplot at first row, sixth column. The second row: the loss curve with respect to the iterations in Shuffle-QUDIO. The speed of loss decrease sees a relatively slow decay with W growing. When \(W=32\) (second row, sixth column), the loss still converges to the same level of \(W=1\) within 200 iterations

Energy potential surface of molecule LiH. The black line with label “ExactEigensolver” represents the exact energy potential surface of the molecule LiH

Mean value \(\overline{Err}\) and standard deviation \(\delta (Err)\) of the approximation error. Each data point is collected over various bond distances and random seeds. Shuffle-QUDIO outperforms QUDIO in achieving smaller approximation error and lower sensitivity to communication frequency W
4.2 Sensitivity to communication frequency
We compare QUDIO with Shuffle-QUDIO to show how the increased number of local iterations W effects their performance under the ideal scenario. The molecules LiH with varied inter-atomic length, i.e., 0.3Å to 1.9Å with step size 0.2Å, are explored. For QUDIO, the entire set of Pauli terms constituting the problem Hamiltonian is uniformly partitioned into 32 subsets and distributed into 32 local quantum processors. The accessible Hamiltonian terms for each local processor remain fixed during the whole training process. The number of local iterations W varies in \(\{1,2,4,8,16,32\}\).
The simulation results of VQE for the molecule LiH with 0.5Å are illustrated in Fig. 5. Because the number of local iterations W varies among different settings, we uniformly collect data point after every 32 iterations (i.e., the least common multiple of all W) to guarantee the loss is obtained exactly after synchronization. The first row of Fig. 5 records the loss curves of QUDIO with respect to the training steps under different local iterations W. QUDIO experiences a severe drop of performance, and an evident gap between the estimated and the exact results appears when \(W\ge 8\). By contrast, as shown in the bottom row of Fig. 5, Shuffle-QUDIO well estimates the exact ground energy even when \(W=32\). Comparing the subplots of the same column, Shuffle-QUDIO shows a distinct advantage in improving the convergence of the distributed VQE when requiring a lower communication overhead. For example, Shuffle-QUDIO achieves \(-6.8Ha\) at the 96-th iteration with \(W=8\), while QUDIO only reaches \(-4.1Ha\).
The potential energy surface of LiH solved by the conventional VQE is shown in Fig. 6, where the left panel describes the results of QUDIO with the varied number of local iterations W and the right panel records the results of Shuffle-QUDIO. There exists a distinct boundary among the potential energy surfaces estimated by the different level of W in QUDIO. More precisely, the estimated potential energy surface is gradually away from the exact potential energy surface (black line) with the increased W, which reveals the vulnerability of QUDIO when reducing the communication frequency among distributed workers. By contrast, Shuffle-QUDIO exhibits a fairly stable performance even when increasing W from 1 to 32, drawn from the nearly coincident curves of potential energy surface at each setting of W. Note that the slight gap between the exact potential energy surface and the optimal estimated results originates from the restricted expressive power of the employed ansatz, which does not guarantee the prepared state definitely covers the ground state of LiH.
To further quantify the stability of Shuffle-QUDIO, we statistically compute the mean and standard deviation of the approximation error \(Err=\left| E^{VQE}-E^{ideal}\right| \) over various bond distances and random seeds. As illustrated in Fig. 7(a), the average approximation error \(\overline{Err}\) of QUDIO exponentially scales with increased W. When \(W\ge 8\), the approximation error estimated by QUDIO exceeds 2Ha, which fails to capture the ground state of LiH. Instead, Shuffle-QUDIO achieves an imperceptible increment (0.093) of the approximation error when W grows from 1 to 32, making it possible to largely reduce the communication overhead with a little performance drop. Figure 7(b) depicts the standard deviation of the approximation error derived by both methods, showing that Shuffle-QUDIO enjoys a smaller variance and a stronger stability than those of QUDIO. These observations provide the convincing empirical evidence that Shuffle-QUDIO efficiently reduces the susceptibility to W in the quantum distributed optimization.

Speedup of operator grouping to VQE for \(\mathrm{H_2}\). The label “base” refers to the case that no operator grouping is applied. The label “linear speedup” represents the reference line of linear speedup
4.3 Sensitivity to quantum noise
To better characterize the ability of Shuffle-QUDIO run on NISQ devices, we benchmark its performance under the depolarizing noise and the realistic quantum noise modeled by PennyLane (Bergholm et al. 2018). The noise strength of the global depolarizing channel p ranges from 0 to 0.3 with step size 0.1. The realistic noise model is extracted from the 5-qubit IBM ibmq_quito device. Note that the measurement error introduced by a finite number of shots is also considered.
We first benchmark the performance of Shuffle-QUDIO with the operator grouping when the shot noise is considered. In practice, the process begins by distributing the entire Hamiltonians across local quantum processors. Subsequently, we implement operator grouping on these local Hamiltonians. For each processor, the operators within its local Hamiltonian are organized into several groups. Operators within the same group are selected for their ability to commute qubit-wise, a feature that facilitates the simultaneous measurement of multiple operators by measuring their common eigenbases. Rotation gates may be applied as needed to align the quantum state with the appropriate basis for measurement.
The results are shown in Fig. 8. After applying operator grouping to the molecule Hamiltonian, the trainable quantum state fast converges to the ground state of the molecule than that of the original measurement strategy. In the light of the speedup provided by the operator grouping, we can integrate this technique into the framework of Shuffle-QUDIO to gain better performance. On the other hand, with growing number of quantum processors, the acceleration rate with the operator grouping strategy gradually decays. This phenomenon partially results from the fact that a small number of Hamiltonian terms leads to a small proportion of operators that can be grouped together.

Performance comparison in NISQ era. ideal represents the fault-tolerant case without noise, \(p=a\) represents the case where there exists a depolarizing channel with strength a in the circuit, NISQ represents the case of running on a real NISQ device
We next apply QUDIO, QUDIO with the operator grouping, Shuffle-QUDIO, and Shuffle-QUDIO with the operator grouping to estimate the ground energy of the \(\mathrm{H_2}\) molecule under both the system and shot noise. For each method, the hyper-parameters are set as \(K=4\), \(W=32\), and the number of measurements is 100. Each setting is conducted for 5 times to capture the effect of stochastic noise on the performance. The simulation results are shown in Fig. 9. When the depolarizing noise is not big enough (\(p<=0.2\)), Shuffle-QUDIO achieves much smaller approximation error than QUDIO. When \(p=0.3\), it appears that the overwhelming noise disables both Shuffle-QUDIO and QUDIO. Under the realistic noise setting, Shuffle-QUDIO still works well with a tolerable approximation error 0.063. By contrast, QUDIO is incapable of estimating the accurate ground state energy. Note that although parameter random initialization leads to nonnegligible fluctuations in the final approximation error, the advantage of Shuffle-QUDIO over QUDIO remains significant and cannot be ignored. Moreover, the operator grouping can further widen the performance gap between QUDIO and Shuffle-QUDIO, by inhibiting the negative effect of quantum noise on Shuffle-QUDIO.

Performance comparison of various model aggregation algorithms. The closer the curve is to the upper left, the more accurate the estimated ground state energy is
4.4 Aggregation strategy
Shuffle-QUDIO narrows the discrepancy among distributed processors by randomly changing the observables of each processor in every local iteration, which partially guarantee the rationality of taking average of all models for synchronization. To further explore the effect of various aggregation strategy on the performance of Shuffle-QUDIO, we devise three additional model aggregation algorithms, named as random aggregation, median aggregation and weighted aggregation.
-
Random aggregation: randomly select a local processor and distribute its parameters of quantum circuit to other processors.
-
Median aggregation: rank all local processors by their loss value and select the median as the synchronized quantum circuit.
-
Weighted aggregation: combine all quantum circuits of local processors by loss-induced weighted summation. The smaller the value of the loss function for a local processor, the bigger contributions the processor makes to the synchronized quantum model.

Training process of VQE for hydrogen molecule optimized by shot-based distributed VQE and Hamiltonian-based distributed VQE (Shuffle-QUDIO) respectively. The label “\(K=a\)” refers that the number of nodes is a. Each setting is run with \(W=1\). The dashed black line denotes the exact ground state energy (GSE) at the same setting
Refer to Appendix G for more details.
We implement four quantum model aggregation methods in the framework of Shuffle-QUDIO to solve the ground state energy of molecule \(\mathrm{H_2}\) and \(\textrm{LiH}\). The hyper-parameters are set as \(W\in \{1,2,4,8,16,32\}\), \(K\in \{1,2,4,8,16\}\). Figure 10 demonstrates the cumulative distribution function (CDF) of the approximation error to ground state energy. It appears no large cleavage of the approximation error among four aggregation strategies, indicating the strong robustness of Shuffle-QUDIO to quantum model aggregation. This stability may give credit to the introduction of the shuffle operation during distributed quantum computation, which diminishes the bias among different local quantum models. On the other hand, it is worth noting that average aggregation always achieves smaller approximation error with higher probability than random aggregation in the statistical sense. This difference of CDF implies that a superior aggregation algorithm for the quantum distributed optimization could further enhance the efficiency of Shuffle-QUDIO. We leave the design of an optimal aggregation method as the future work.
4.5 Comparison with shot-based method
In addition to Shuffle-QUDIO/QUDIO, which partitions the whole Hamiltonian terms into multiple small sets and distributes them to multiple quantum processors, another intuitive method to accelerate VQE is to allocate the total budget of shot number into multiple quantum nodes. We refer to these two strategies as the Hamiltonian-based method and the shot-based method, respectively, in our work. Let \(S^{total}\) denote the total shot budget in shot-based distributed VQE. Let K be the number of quantum processors. let M denote the number of Hamiltonian terms of a molecule. Let \(S^{single}\) denote the number of shot for each quantum processor in QUDIO/Shuffle-QUDIO. If \(S^{total}=S^{single}*K\), the running time of shot-based distributed VQE is equal to that of QUDIO/Shuffle-QUDIO with \(W=1\). However, the shot noise of shot-based distributed VQE differs from that of QUDIO/Shuffle-QUDIO. With the budget of shot number \(S^{total}\), the allocated number of shot for each Hamiltonian term in shot-based distributed VQE and QUDIO/Shuffle-QUDIO is \(\frac{S^{total}}{KM}\) and \(\frac{S^{total}}{M}\) respectively. Therefore, QUDIO/Shuffle-QUDIO introduces smaller shot noise than shot-based distributed VQE.
To investigate the difference between proposed Shuffle-QUDIO and the shot-based method, we conduct numerical experiments to demonstrate the performance of these two methods to solve the ground state of hydrogen molecule. In this study, we set \(M=15\) and \(S^{total}=15,000\). As shown in the top row of Fig. 11, the training process of Hamiltonian-based distributed VQE (Shuffle-QUDIO) with \(K=15\) is equivalent to that of other 4 settings (\(K=\{1,2,4,8\}\)). The bottom row of Fig. 11 depicts the training process of shot-based distributed VQE with varying values of K. When K increases from 1 to 15, the number of shot allocated to each Hamiltonian term gradually decreases, leading to greater disturbance and poorer convergence in the estimation of the energy.
5 Discussion
In this paper, we propose Shuffle-QUDIO, as a novel distributed optimization scheme for VQE with faster convergence and strong noise robustness. By introducing the shuffle operation into each iteration, the Hamiltonian terms received by each local processor are not fixed during the optimization. From the statistical view, the shuffle operation warrants that the gradients manipulated by all local processors are unbiased. In this way, Shuffle-QUDIO allows an improved convergence and a lower sensitivity to communication frequency as well as quantum noise. Meanwhile, the operator group strategy can be seamlessly embedded into Shuffle-QUDIO to reduce the number of measurements in each iteration. Theoretical analysis and extensive numerical experiments on VQE further verify the effectiveness and advantages in accelerating VQE and guaranteeing small approximation errors in both ideal and noisy scenarios.
Although the random shuffle operation performs well on the \(\mathrm H_2\) and LiH molecules, the performance can be further improved by developing more advanced shuffling strategies. First, instead of random shuffle, we can design a problem-specific and hardware-oriented Hamiltonian allocation tactic, which can eliminate the deviation of the optimization path of local models and better adapt to the limited quantum resources of various local processors. Second, due to the existence of barren plateau (McClean et al. 2018; Marrero et al. 2021; Wang et al. 2021; Cerezo et al. 2021; Arrasmith et al. 2021) in the optimization of ansatz, the training of local quantum models may get stuck. Inspired by the study that local observables enjoy a polynomially vanishing gradient (Cerezo et al. 2021), a promising direction is to group Hamiltonian terms with similar locality in QUDIO to avoid the barren plateau of some processors. Finally, a more fine-grained partition of the quantum circuit structure besides observables can be employed to reduce the number of parameters to be optimized for each local processor, as implemented in Zhang et al. (2022).
Another feasible attempt to enhance the performance of distributed VQE in practice is to unify Shuffle-QUDIO with other measurement reduction techniques. One successful example is operator grouping, as discussed in Section 4.3. Specifically, when optimizing the circuit run on each distributed quantum processor, we can utilize the operator grouping strategy to reduce the required number of measurements of the allocated Hamiltonian. In this way, the measurement noise in the framework of Shuffle-QUDIO is eliminated under finite budget of shot number. Other two methods, like shot allocation and classical shadows, can be also integrated into Shuffle-QUDIO in the similar manner.
Besides the potential improvements in convergence and speedup for Shuffle-QUDIO, the data privacy leakage during transmitting gradient information among local nodes should be avoided. One the one hand, the shuffle operation in Shuffle-QUDIO naturally adds randomness to the system, hindering the recovery of intact data. On the other hand, previous studies proposed differential privacy (Du et al. 2022, 2021) and blind quantum computing (Li et al. 2021) to protect data security. When combining these techniques and Shuffle-QUDIO, it remains open to explore the consequent influence on the convergence of optimization.
Apart from utilizing the quantum-specific properties to enhance Shuffle-QUDIO, we can also leverage the experience from classical distributed optimization, such as Elastic Averaging SGD (Zhang et al. 2015), decentralized SGD (Koloskova et al. 2020). It is worth noting that the flexibility of Shuffle-QUDIO makes it easy to replace some components with advanced classical techniques, as discussed in Section 4.4. Taken together, it is expected to utilize Shuffle-QUDIO and its variants to speed up the computation of variational quantum circuits and tackle real-world problems with NISQ devices.
In summary, we believe that the significant speedup w.r.t time-to-accuracy, and the scalability of our proposed algorithm make a valuable contribution to the field of quantum chemistry and quantum computing in general. With increasing number of quantum chips in the future, Shuffle-QUDIO provides a more practical way in applying VQE on large-scale molecules, and it has the potential to significantly impact the field of quantum chemistry and beyond.
The appendix is organized as follows. Appendix A introduces basic notations and properties of the loss function. Appendices B, C, and D present the proofs of Lemma 1, Lemma 2, and Theorem 1, respectively. Appendix G explains the aggregation methods discussed in Section 4.4. Appendix H demonstrates the additional experiment results and analysis about Shuffle-QUDIO.
Code availability
The source code of Shuffle-QUDIO open-source is available at https://github.com/QQQYang/Shuffle-QUDIO.
References
Arrasmith A, Cerezo M, Czarnik P, Cincio L, Coles PJ (2021) Effect of barren plateaus on gradient-free optimization. Quantum 5:558
Arrasmith A, Cincio L, Somma RD, Coles PJ (2020) Operator sampling for shot-frugal optimization in variational algorithms. Preprint arXiv:2004.06252
Arute F, Arya K, Babbush R, Bacon D, Bardin JC, Barends R, Biswas R, Boixo S, Brandao FGSL, Buell DA et al (2019) Quantum supremacy using a programmable superconducting processor. Nature 574(7779):505–510
Arute F, Arya K, Babbush R, Bacon D, Bardin JC, Barends R, Boixo S, Broughton M, Buckley BB, Buell DA et al (2020) Hartree-fock on a superconducting qubit quantum computer. Science 369(6507):1084–1089
Banchi L, Crooks GE (2021) Measuring analytic gradients of general quantum evolution with the stochastic parameter shift rule. Quantum 5:386
Barratt F, Dborin J, Bal M, Stojevic V, Pollmann F, Green AG (2021) Parallel quantum simulation of large systems on small nisq computers. NPJ Quantum Inf 7(1):1–7
Barratt F, Dborin J, Bal M, Stojevic V, Pollmann F, Green AG (2003) Parallel quantum simulation of large systems on small quantum computers (2020). Preprint arXiv:2003.12087
Bergholm V, Izaac J, Schuld M, Gogolin C, Alam MS, Ahmed S, Arrazola JM, Blank C, Delgado A, Jahangiri S et al (2018) Pennylane: Automatic differentiation of hybrid quantum-classical computations. Preprint arXiv:1811.04968
Bharti K, Cervera-Lierta A, Kyaw TH, Haug T, Alperin-Lea S, Anand A, Degroote M, Heimonen H, Kottmann JS, Menke T et al (2022) Noisy intermediate-scale quantum algorithms. Rev Mod Phys 94(1):015004
Bravyi SB, Kitaev AY (2002) Fermionic quantum computation. Ann Phys 298(1):210–226
Bulmer JFF, Bell BA, Chadwick RS, Jones AE, Moise D, Rigazzi A, Thorbecke J, Haus U-U, Van Vaerenbergh T, Patel RB et al (2021) The boundary for quantum advantage in gaussian boson sampling. Sci Adv 8(4):eabl9236
Cai X, Fang W-H, Fan H, Li Z (2020) Quantum computation of molecular response properties. Phys Rev Res 2(3):033324
Caro MC, Huang H-Y, Sharma K, Sornborger A, Cincio L, Coles PJ (2022) Generalization in quantum machine learning from few training data. Nat Commun 13(1):1–11
Cerezo M, Arrasmith A, Babbush R, Benjamin SC, Endo S, Fujii K, McClean JR, Mitarai K, Yuan X, Cincio L et al (2021) Variational quantum algorithms. Nat Rev Phys 3(9):625–644
Cerezo M, Sone A, Volkoff T, Cincio L, Coles PJ (2021) Cost function dependent barren plateaus in shallow parametrized quantum circuits. Nat Commun 12(1):1–12
Cervera-Lierta A, Kottmann JS, Aspuru-Guzik A (2021) Meta-variational quantum eigensolver: Learning energy profiles of parameterized hamiltonians for quantum simulation. PRX Quantum 2:020329
DiAdamo S, Ghibaudi M, Cruise J (2021) Distributed quantum computing and network control for accelerated vqe. IEEE Trans Quantum Eng 2:1–21
Du Y, Hsieh M-H, Liu T, Tao D, Liu N (2021) Quantum noise protects quantum classifiers against adversaries. Phys Rev Res 3(2):023153
Du Y, Hsieh M-H, Liu T, You S, Tao D (2022) Quantum differentially private sparse regression learning. IEEE Trans Inf Theory
Du Y, Tao D (2021) On exploring practical potentials of quantum auto-encoder with advantages. Preprint arXiv:2106.15432
Endo S, Benjamin SC, Li Y (2018) Practical quantum error mitigation for near-future applications. Phys Rev X 8(3):031027
Endo S, Sun J, Li Y, Benjamin SC, Yuan X (2020) Variational quantum simulation of general processes. Phys Rev Lett 125(1):010501
Endo S, Cai Z, Benjamin SC, Yuan X (2021) Hybrid quantum-classical algorithms and quantum error mitigation. J Phys Soc Jpn 90(3):032001
Farhi E, Goldstone J, Gutmann S (2014) A quantum approximate optimization algorithm. Preprint arXiv:1411.4028
Gili K, Hibat-Allah M, Mauri M, Ballance C, Perdomo-Ortiz A (2022) Do quantum circuit born machines generalize? Preprint arXiv:2207.13645
Gokhale P, Angiuli O, Ding Y, Gui K, Tomesh T, Suchara M, Martonosi M, Chong FT (2019) Minimizing State Preparations in Variational Quantum Eigensolver by Partitioning into Commuting Families. arXiv:1907.13623 [quant-ph]
Gonthier JF, Radin MD, Buda C, Doskocil EJ, Abuan CM, Romero J (2020) Identifying challenges towards practical quantum advantage through resource estimation: the measurement roadblock in the variational quantum eigensolver. Preprint arXiv:2012.04001
Grimsley HR, Economou SE, Barnes E, Mayhall NJ (2019) An adaptive variational algorithm for exact molecular simulations on a quantum computer. Nat Commun 10(1):1–9
Gu A, Lowe A, Dub PA, Coles PJ, Arrasmith A (2021) Adaptive shot allocation for fast convergence in variational quantum algorithms. Preprint arXiv:2108.10434
Haddadpour F, Kamani MM, Mahdavi M, Cadambe V (2019) Local sgd with periodic averaging: Tighter analysis and adaptive synchronization. Advances in Neural Information Processing Systems, 32
Hadfield S, Wang Z, O’Gorman B, Rieffel EG, Venturelli D, Biswas R (2019) From the quantum approximate optimization algorithm to a quantum alternating operator ansatz. Algorithms 12(2):34
Hadfield C, Bravyi S, Raymond R, Mezzacapo A (2022) Measurements of quantum hamiltonians with locally-biased classical shadows. Commun Math Phys 391(3):951–967
Harrigan MP, Sung KJ, Neeley M, Satzinger KJ, Arute F, Arya K, Atalaya J, Bardin JC, Barends R, Boixo S et al (2021) Quantum approximate optimization of non-planar graph problems on a planar superconducting processor. Nat Phys 17(3):332–336
Huang H-Y, Kueng R, Preskill J (2020) Predicting many properties of a quantum system from very few measurements. Nat Phys 16(10):1050–1057
Huang H-Y, Broughton M, Mohseni M, Babbush R, Boixo S, Neven H, McClean JR (2021) Power of data in quantum machine learning. Nat Commun 12(1):1–9
Huang H-Y, Kueng R, Torlai G, Albert VV, Preskill J (2022) Provably efficient machine learning for quantum many-body problems. Science 377(6613):eabk3333
Huang H-Y, Broughton M, Cotler J, Chen S, Li J, Mohseni M, Neven H, Babbush R, Kueng R, Preskill J et al (2022) Quantum advantage in learning from experiments. Science 376(6598):1182–1186
Jiang S, Britt KA, McCaskey AJ, Humble TS, Kais S (2018) Quantum annealing for prime factorization. Sci Rep 8(1):1–9
Jordan P, Wigner EP (1993) über das paulische äquivalenzverbot. In: The Collected Works of Eugene Paul Wigner, pp 109–129. Springer
Kais S (2014) Introduction to quantum information and computation for chemistry. Quantum information and computation for chemistry, pp 1–38
Kandala A, Mezzacapo A, Temme K, Takita M, Brink M, Chow JM, Gambetta JM (2017) Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature 549(7671):242–246
Koloskova A, Loizou N, Boreiri S, Jaggi M, Stich S (2020) A unified theory of decentralized sgd with changing topology and local updates. In: International conference on machine learning, pp 5381–5393. PMLR
Kübler JM, Arrasmith A, Cincio L, Coles PJ (2020) An adaptive optimizer for measurement-frugal variational algorithms. Quantum 4:263
Lacroix N, Hellings C, Andersen CK, Di Paolo A, Remm A, Lazar S, Krinner S, Norris GJ, Gabureac M, Heinsoo J et al (2020) Improving the performance of deep quantum optimization algorithms with continuous gate sets. PRX Quantum 1(2):110304
LeCun Y, Touresky D, Hinton G, Sejnowski T (1988) A theoretical framework for back-propagation. In: Proceedings of the 1988 connectionist models summer school, vol 1, pp 21–28
Lee CK, Patil P, Zhang S, Hsieh CY (2021) Neural-network variational quantum algorithm for simulating many-body dynamics. Phys Rev Res 3(2):023095
Li W, Lu S, Deng D-L (2021) Quantum private distributed learning through blind quantum computing. Preprint arXiv:2103.08403
Marco C, Alexander P, Lukasz C, Coles PJ (2020) Variational quantum fidelity estimation. Quantum 4:248
Marrero CO, Kieferová M, Wiebe N (2021) Entanglement-induced barren plateaus. PRX. Quantum 2(4):040316
McClean JR, Romero J, Babbush R, Aspuru-Guzik A (2016) The theory of variational hybrid quantum-classical algorithms. New J Phys 18(2):023023
McClean JR, Boixo S, Smelyanskiy VN, Babbush R, Neven H (2018) Barren plateaus in quantum neural network training landscapes. Nat Commun 9(1):1–6
Menickelly M, Ha Y, Otten M (2022) Latency considerations for stochastic optimizers in variational quantum algorithms. Preprint arXiv:2201.13438
Mineh L, Montanaro A (2022) Accelerating the variational quantum eigensolver using parallelism. Preprint arXiv:2209.03796
Pablo A-M, Chris H (2019) Automated distribution of quantum circuits via hypergraph partitioning. Phys Rev A 100(3):032308
Parrish RM, Hohenstein EG, McMahon PL, Martínez TJ (2019) Quantum computation of electronic transitions using a variational quantum eigensolver. Phys Rev Lett 122(23):230401
Peng WC, Wang BN, Feng H, Wang YJ, Fang XJ, Chen XY, Wang C (2019) Factoring larger integers with fewer qubits via quantum annealing with optimized parameters. Sci China Phys Mech Astron 62(6):1–8
Peruzzo A, McClean J, Shadbolt P, Yung M-H, Zhou X-Q, Love PJ, Aspuru-Guzik A, O’brien JL (2014) A variational eigenvalue solver on a photonic quantum processor. Nat Commun 5:4213
Pistoia M, Ahmad SF, Ajagekar A, Buts A, Chakrabarti S, Herman D, Hu S, Jena A, Minssen P, Niroula P et al (2021) Quantum machine learning for finance iccad special session paper. In: 2021 IEEE/ACM international conference on computer aided design (ICCAD), pp 1–9. IEEE
Preskill J (2018) Quantum computing in the nisq era and beyond. Quantum 2:79
Qian Y, Wang X, Du Y, Wu X, Tao D (2022) The dilemma of quantum neural networks. IEEE Trans Neural Netw Learn Syst
Ralli A, Love PJ, Tranter A, Coveney PV (2021) Implementation of measurement reduction for the variational quantum eigensolver. Phys Rev Res 3(3):033195
Robert A, Barkoutsos PKl, Woerner S, Tavernelli I (2021) Resource-efficient quantum algorithm for protein folding. NPJ Quantum Inf 7(1):1–5
Roman O, Samuel M, Enrique L (2019) Quantum computing for finance: Overview and prospects. Rev Phys 4:100028
Romero J, Babbush R, McClean JR, Hempel C, Love PJ, Aspuru-Guzik A (2018) Strategies for quantum computing molecular energies using the unitary coupled cluster ansatz. Quantum Sci Technol 4(1):014008
Seeley JT, Richard MJ, Love PJ (2012) The bravyi-kitaev transformation for quantum computation of electronic structure. J Chem Phys 137(22):224109
Spring JB, Metcalf BJ, Humphreys PC, Kolthammer WS, Jin X-M, Barbieri M, Datta A, Thomas-Peter N, Langford NK, Kundys D et al (2013) Boson sampling on a photonic chip. Science 339(6121):798–801
Strikis A, Qin D, Chen Y, Benjamin SC, Li Y (2021) Learning-based quantum error mitigation. PRX Quantum 2(4):040330
Sweke R, Wilde F, Meyer J, Schuld M, Fährmann PK, Meynard-Piganeau B, Eisert J (2020) Stochastic gradient descent for hybrid quantum-classical optimization. Quantum 4:314
Tang HL, Shkolnikov VO, Barron GS, Grimsley HR, Mayhall NJ, Barnes E, Economou SE (2021) qubit-adapt-vqe: An adaptive algorithm for constructing hardware-efficient ansätze on a quantum processor. PRX Quantum 2(2):020310
Tian J, Sun X, Du Y, Zhao S, Liu Q, Zhang K, Yi W, Huang W, Wang C, Wu X et al (2023) Recent advances for quantum neural networks in generative learning. IEEE Trans Pattern Anal Mach Intell
Tkachenko NV, Sud J, Zhang Y, Tretiak S, Anisimov PM, Arrasmith AT, Coles PJ, Cincio L, Dub PA (2021) Correlation-informed permutation of qubits for reducing ansatz depth in the variational quantum eigensolver. PRX Quantum 2(2):020337
van Straaten B, Koczor B (2021) Measurement cost of metric-aware variational quantum algorithms. PRX Quantum 2(3):030324
Verteletskyi V, Yen T-C, Izmaylov AF (2020) Measurement Optimization in the Variational Quantum Eigensolver Using a Minimum Clique Cover. J Chem Phys 152(12):124114
Wang H, He Y, Li Y-H, Su Z-E, Li B, Huang H-L, Ding X, Chen M-C, Liu C, Qin J et al (2017) High-efficiency multiphoton boson sampling. Nat Photonics 11(6):361–365
Wang D, Higgott O, Brierley S (2019) Accelerated variational quantum eigensolver. Phys Rev Lett 122(14):140504
Wang S, Fontana E, Cerezo M, Sharma K, Sone A, Cincio L, Coles PJ (2021) Noise-induced barren plateaus in variational quantum algorithms. Nat Commun 12(1):1–11
Wecker D, Hastings MB, Wiebe N, Clark BK, Nayak C, Troyer M (2015) Solving strongly correlated electron models on a quantum computer. Phys Rev A 92(6):062318
Wierichs D, Izaac J, Wang C, Lin CY-Y (2022) General parameter-shift rules for quantum gradients. Quantum 6:677
Yuxuan D, Hsieh M-H, Liu T, You S, Tao D (2021) Learnability of quantum neural networks. PRX Quantum 2(4):040337
Yuxuan D, Qian Y, Xingyao W, Tao D (2022) A distributed learning scheme for variational quantum algorithms. IEEE Trans Quantum Eng 3:1–16
Yuxuan D, Huang T, You S, Hsieh M-H, Tao D (2022) Quantum circuit architecture search for variational quantum algorithms. NPJ Quantum Inf 8(1):1–8
Zhang Y, Cincio L, Negre CFA, Czarnik P, Coles PJ, Anisimov PM, Mniszewski SM, Tretiak S, Dub PA (2022) Variational quantum eigensolver with reduced circuit complexity. NPJ Quantum Inf 8(1):1–10
Zhang S, Choromanska AE, LeCun Y (2015) Deep learning with elastic averaging sgd. Advances in neural information processing systems, 28
Zhao A, Tranter A, Kirby WM, Ung SF, Miyake A, Love PJ (2020) Measurement reduction in variational quantum algorithms. Phys Rev A 101(6):062322
Zhou L, Wang S-T, Choi S, Pichler H, Lukin MD (2020) Quantum approximate optimization algorithm: Performance, mechanism, and implementation on near-term devices. Phys Rev X 10(2):021067
Zhou Z, Yuxuan D, Tian X, Tao D (2023) Qaoa-in-qaoa: solving large-scale maxcut problems on small quantum machines. Phys Rev Appl 19(2):024027
Zhu Q, Cao S, Chen F, Chen M-C, Chen X, Chung T-H, Deng H, Yajie D, Fan D, Gong M et al (2022) Quantum computational advantage via 60-qubit 24-cycle random circuit sampling. Sci Bull 67(3):240–245
Acknowledgements
The authors would like to thank Xinbiao Wang and Liu Liu for fruitful discussions. This work is partially funded by the Faculty of Engineering Research Scholarship funded by the Faculty of Engineering at the University of Sydney.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions.
Author information
Authors and Affiliations
Contributions
Yang Qian and Yuxuan Du wrote the manuscript. Yang Qian designed and implemented the proposed framework, and conducted the experiments. Yang Qian and Yuxuan Du analyzed the results. Yuxuan Du and Dacheng Tao supervised the whole project. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Notations and properties of the loss function
1.1 A.1 Notations
The notations are unified as follows. We denote W as the number of local iterations between the global synchronization, K as the number of quantum processors, and T as the number of total iterations. During the optimization, we denote \(\varvec{\theta }\) as the collection of trainable parameters, \(\varvec{\theta }_k^t\) as the parameters of the k-th processor at the t iteration, \(\eta \) as the learning rate, L as the loss function, and \(\varvec{g}_k^t\) (\(\overline{\varvec{g}}_k^t\)) as the exact (estimated) gradient for the k-th quantum processor at the t-th iteration. We denote the operation \(\langle {\varvec{a},\varvec{b}}\rangle \) as the inner product of \(\varvec{a}\) and \(\varvec{b}\).
1.2 A.2 Some properties of the loss function
As explained in the main text, the loss function to be minimized in VQE is
where H is the problem Hamiltonian and \(\varvec{\rho }(\varvec{\theta })\) is the density matrix of the prepared quantum system parameterized by \(\varvec{\theta }\). Without loss of generality, the problem Hamiltonian H is expressed as a weighted summation of Pauli operators \(H=\sum _{i=1}^M\alpha _iH_i\in \mathbb {C}^{2^n\times 2^n}\), where \(H_i\in \{\sigma _X, \sigma _Y, \sigma _Z, \sigma _I\}^{\otimes n}\). The properties of the loss function L are summarized in following four lemmas, which quantify the bounded gradient and Lipschitz continuity and will be employed in the subsequent context.
Lemma 3
(Bounded gradient norm of the loss function) The norm of the gradient of loss function L with respect to parameter \(\varvec{\theta }\) is bounded by a constant \(\left\| \frac{\partial L(\varvec{\theta })}{\partial \varvec{\theta }} \right\| \le G\), where \(G=P\sum _{i=1}^M|\alpha _i|\), and P is the dimension of the parameters \(\varvec{\theta }\).
Proof of Lemma 3
For the i-th parameter \(\varvec{\theta }_i\), we can obtain the exact gradient by the parameter-shift rule
where \(\varvec{e}_i\) is an indicator vector for the i-th element. Recall that
where the inequality holds because \(|{{\,\textrm{Tr}\,}}(\rho (\varvec{\theta })H_i)|\le 1\) when \(H_i\in \{\sigma _X, \sigma _Y, \sigma _Z, \sigma _I\}^{\otimes n}\). The relation \(\left\| \frac{\partial L(\varvec{\theta })}{\partial \varvec{\theta }} \right\| \le G\) with \(G=P\sum _{i=1}^M|\alpha _i|\) can be achieved by substituting Eq. (13) into Eq. (12). \(\square \)
Lemma 4
(\(F_1\)-Lipschitz continuity of the loss function (Sweke et al. 2020)) The loss function \(L(\varvec{\theta })={{\,\textrm{Tr}\,}}(\rho (\varvec{\theta })H)\) is \(F_1\)-Lipschitz continuous \(\left| L(\varvec{\theta })-L(\varvec{\beta })\right| \le F_1\left\| \varvec{\theta }-\varvec{\beta }\right\| \) with \(F_1=G\).
Proof of Lemma 4
Recall the mean value theorem, for a differentiable loss function L, \(\exists \varvec{\gamma }\in (\varvec{\theta }, \varvec{\beta })\) such that
Furthermore, using \(\langle {x,y}\rangle \le \left\| x\right\| \left\| y\right\| \), we have
where the second inequality holds based on Lemma 3. This lead to \(F_1=G\). \(\square \)
Lemma 5
(\(F_2\)-Lipschitz continuity of gradient) Define a map \(g:[0,2\pi )^P\rightarrow \mathbb {R}^P\) formulated as \(g(\varvec{\theta })=\frac{\partial L(\varvec{\theta })}{\partial \varvec{\theta }}\). Then \(g(\varvec{\theta })\) is \(F_2\)-Lipschitz continuous \(\left\| g(\varvec{\theta })-g(\varvec{\beta })\right\| \le F_2\left\| \varvec{\theta }-\varvec{\beta }\right\| \) with \(F_2=PG\).
Proof of Lemma 5
Combining Eq. (12) and Lemma 4, we have
where the first inequality follows the triangle inequality \(|x+y|\le |x|+|y|\) and the second inequality is directly derived from Lemma 4. Therefore, for a quantum state controlled by P parameters, we have \(\left\| g(\varvec{\theta })-g(\varvec{\beta })\right\| \le F_2\left\| \varvec{\theta }-\varvec{\beta }\right\| \) with \(F_2=PF_1\). \(\square \)
Lemma 6
(Gradient of the noisy loss function) Let \(\mathcal {N}_p\) be the global depolarizing channel with the strength p. For a quantum state \(\rho (\varvec{\theta })\) parameterized by \(\varvec{\theta }\), the gradient after applying the depolarizing channel is
Proof of Lemma 6
Recalling the depolarizing channel \(\mathcal {N}_p(\rho )=(1-p)\rho +p\mathbb {I}/2^n\), we have the noisy loss function
Following the parameter-shift rule in Eq. (12), the estimated gradient under the depolarizing noise is
\(\square \)
Appendix B: Proof of Lemma 1
For each iteration, \(L_m\) is estimated by the randomly sampled m terms without replacement. Therefore, we have
According to the parameter-shift rule, the exact gradient of \(L_m\) with respect to the i-th parameter \(\varvec{\theta }_i\) is expressed as
where \(\varvec{e}_i\) is an indicator vector for the i-th element. Without loss of generality, each trainable parameter is assumed to be mutually independent. The expectation of gradient vector is expressed as
Appendix C: Proof of Lemma 2
With the condition that the norm of local gradient of each processor is bounded by \(||\varvec{g}_k(\varvec{\theta }, H_k)||^2\le G^2\), we have \(||\nabla L(\varvec{\theta },H)||^2=||\sum _{k=1}^K\varvec{g}_k(\varvec{\theta }, H_k)||^2\le K^2G^2\).
For QUDIO, the discrepancy between local gradient and global gradient is bounded by
where the first inequality follows \((a-b)^2\le 2(a^2+b^2)\).
For Shuffle-QUDIO, the discrepancy \(\mathbb {E}_{H_k|\varvec{\theta }_k^t}\left[ \left\| \nabla L(\varvec{\theta }^t_k,H)-\varvec{g}^t_k(\varvec{\theta }_k^t, H_k)\right\| ^2\right] \) is quantified by taking expectation over the randomly shuffling Hamitonians \(H_k\) given parameters \(\varvec{\theta }_k^t\), i.e.,
where the second equality is derived by utilizing Lemma 1, the first inequality comes from the bound of gradient norm in Lemma 3, and the last inequality uses the induced bound of \(\left\| \nabla L(\varvec{\theta },H)\right\| ^2\) and holds when \(K\ge 2\) required by the condition \(1-\frac{2}{K}\ge 0\).
Appendix D: Proof of Theorem 1
Introduce the ancillary variables
According to the F-Lipschitz continuity of loss function in Lemma 4, we have
where \(\nabla L(\varvec{\theta }^t)=\nabla L(\varvec{\theta }^t, H)=\sum _{k=1}^K\varvec{g}^t_k(\varvec{\theta }^t, H_k^t)\) and \(\varvec{g}^t_k=\varvec{g}^t_k(\varvec{\theta }^t_k, H_k^t)\). Note that \(H=\sum _{k=1}^MH_k\) is a constant all the time, which is the reason why the superscript t is discarded. The first equality is derived by utilizing \(\langle {\varvec{a},\varvec{b}}\rangle =\frac{1}{2}(||\varvec{a}||^2+||\varvec{b}||^2-||\varvec{a}-\varvec{b}||^2)\). The second equality holds by merging the second term and the fourth term in the first equality.
Next, the term T1 in Eq. (25) yields
where the first inequality follows the Jensen’s inequality \(\left\| \frac{1}{n}\sum _{i=1}^n\varvec{a}_i\right\| ^2\le \frac{1}{n}\sum _{i=1}^n\left\| \varvec{a}_i\right\| ^2\), the second inequality holds because of the triangle inequality \(\left\| \varvec{a}+\varvec{b}\right\| \le \left\| \varvec{a}\right\| +\left\| \varvec{b}\right\| \), the last inequality is derived by F-Lipschitz continuity condition of gradient function in Lemma 5.
We first calculate the upper bound of \(\left\| \varvec{\theta }^t-\varvec{\theta }^t_k\right\| ^2\). Assume the latest model synchronization happens at the iteration \(t_c\) with \(t-t_c<W\), then \(\varvec{\theta }_k^{t_c+1}=\varvec{\theta }^{t_c}\). According to the gradient descent rule, the parameter \(\varvec{\theta }_k^t\) is derived as
where the subscript of parameters \(\varvec{\theta }^{t_c+1}\) in the second equality is discarded without ambiguity because \(\varvec{\theta }^{t_c+1}_k=\varvec{\theta }^{t_c+1}_l,\forall k,l\in \{1,...,K\}\). Then
Therefore, the deviation between local quantum model \(\varvec{\theta }^t_l\) (note that we use notation \(\varvec{\theta }^t_l\) instead of \(\varvec{\theta }^t_k\) to avoid the confusion between a specified quantum worker l and the general representation of the k-th worker in the following derivation) and the average model \(\varvec{\theta }^t\) is measured as
where the first and second inequalities follows \(\left\| \sum _{i=1}^Na_i\right\| ^2\) \(\le N\sum _{i=1}^N||a_i||^2\), and the last inequality is deduced based on the bound of gradient.
We now derive the upper bound of the second term T2 in the last inequality. Recall Lemma 3 such that the norm of the gradient of each worker is bounded by \(||\varvec{g}_k(\varvec{\theta }, H_k)||^2\le G^2\). We have \(||\nabla L(\varvec{\theta },H)||^2=\left\| \sum _{k=1}^K\varvec{g}_k(\varvec{\theta }, H_k)\right\| ^2\le K^2G^2\) and \(||\overline{\varvec{g}}_k(\varvec{\theta }, H_k)||^2\le (1-p)^2G^2\).
Convergence of QUDIO. For the case of QUDIO where each quantum processor is assigned fixed partial Hamiltonian terms at the beginning, T2 is bounded by
Combining Eqs. (26), (30), and (29), we can quantify the progress of one global iteration under the fixed Hamiltonian partition strategy as
where the last term in the last inequality follows \(\left\| \sum _{i=1}^n\varvec{a}_i\right\| ^2\) \(\le n\sum _{i=1}^n||\varvec{a}_i||^2\).
Rearranging the inequality above and summing over t, we achieve
Convergence of Shuffle-QUDIO. For the case of Shuffle-QUDIO where the whole Hamiltonian terms are shuffled and reassigned to local processors during each iteration, we can obtain a tighter bound for T2 by taking expectation over the random local Hamiltonians \(H_k\) given parameters \(\varvec{\theta }_k^t\)
where the first inequality is based on Lemma 1 and property of bounded gradients of each worker, and the second inequality is derived by applying the induced bound of \(\left\| \nabla L(\varvec{\theta }^t_k,H)\right\| ^2\). Note that we introduce the implicit constraint \(K>2(1-p)\) to assure the coefficient of \(\left\| \nabla L(\varvec{\theta }^t_k,H)\right\| ^2\) in the first inequality is non-negative.
On the other hand, when shuffling the Hamiltonian terms in every iteration, the loss reduction is bounded by
Then the convergence of gradient is quantified by
Comparing Eqs. (32) and (35), especially for the terms highlighted by the bold face, it is obvious that Shuffle-QUDIO achieves faster convergence than original QUDIO.
Appendix E: Survey of accelerating variational quantum algorithms

Survey of accelerating variational quantum algorithms
Current literature on accelerating quantum computation can be broadly categorized into two main approaches: computational complexity reduction and computational time reduction, as summarized in Fig. 12. In terms of computational complexity reduction, one strategy is to slim the circuit, including circuit depth (Tkachenko et al. 2021; Tang et al. 2021; Grimsley et al. 2019) and the number of qubits (Zhang et al. 2022), as well as reducing the required number of measurements (Ralli et al. 2021; Verteletskyi et al. 2020; Zhao et al. 2020; Gokhale et al. 2019; Arrasmith et al. 2020; van Straaten and Koczor 2021; Gu et al. 2021; Kübler et al. 2020; Menickelly et al. 2022; Huang et al. 2020; Hadfield et al. 2022). For instance, Ref. Tkachenko et al. (2021) proposes assigning qubits with stronger mutual information to adjacent locations with direct connectivity on physical quantum chips, resulting in shallower circuits compared to original VQE while maintaining the desired accuracy. Additionally, techniques such as operator grouping (Ralli et al. 2021; Verteletskyi et al. 2020; Zhao et al. 2020; Gokhale et al. 2019) and classical shadows (Huang et al. 2020; Hadfield et al. 2022) aim to optimize the measurement process by utilizing as few measurements as possible to efficiently estimate observables.
On the other hand, computational time reduction techniques involve the utilization of multiple quantum processors for parallel quantum computation (Pablo and Chris 2019; Barratt et al. 2021; Yuxuan 2022; Mineh and Montanaro 2022). Generally, there are two paradigms for computational time reduction. The first paradigm involves decomposing the primary quantum system into multiple smaller circuits and executing them in parallel (Barratt et al. 2021; DiAdamo et al. 2021). The second paradigm, which Shuffle-QUDIO specifically focuses on, involves partitioning the problem Hamiltonian and simultaneously measuring these partitions using multiple quantum processors. This approach effectively balances the trade-off between communication overhead and convergence speed by leveraging distributed optimization and introducing a synchronization interval. By achieving simultaneous measurements of partitioned Hamiltonians, Shuffle-QUDIO achieves a high wall-clock time speedup while maintaining low approximation error in the estimation of ground state energy. Consequently, it is particularly well-suited for addressing large-scale quantum chemistry problems.
Appendix F: Role of W in speedup w.r.t time-to-accuracy

Running time of a distributed optimization algorithm
The running time of a distributed optimization algorithm depends on the optimization cost and communication overhead, as shown in Fig. 13. Mathematically, the total running time can be simplified as
where C is the number of iterations in the whole training process, K is the number of local workers, M is the overall number of Hamiltonian terms with \(H=\sum _{i=1}^M H_i\), \(T_{iter}(*)\) is the wall-clock time of every optimization iteration, \(T_{comm}(*)\) denotes the wall-clock time spent in one communication, and \(\tilde{T}_{comm}(K,W)=\frac{T_{comm}(K)}{W}\) can be regarded as the average communication time allocated evenly into every iteration. In general, smaller \(\frac{M}{K}\) means fewer Hamiltonian terms allocated to each processor, leading to smaller \(T_{iter}\). As for communication time, fewer number of processors or equivalently smaller K leads to smaller \(T_{comm}\).
Similarly, denote \(T_{acc}(K,W)\) as the time spent to reach a specific accuracy. Mathematically, \(T_{acc}(K,W)\) can be modeled as
where \(C_{acc}\) is the number of iterations required for training a model to reach a specific accuracy. Note that \(C_{acc}\le C\) reflects the convergence speed of a training process and depends on the settings of K and W. Then the speedup w.r.t time-to-accuracy is measured by \(s^{K,W} = \frac{T_{acc}(1,1)}{T_{acc}(K,W)}\).

Trade-off between communication overhead and convergence with respect to W. The number of local nodes is set as \(K=8\), and the specific accuracy achieved by \(C_{acc}\) iterations is set as \(-6.9Ha\) (the ground state energy is \(-7.05Ha\)). Labels \(\tilde{T}_{comm}\), \(C_{acc}\) and \(s_2\) are defined in Eq. (37)
In terms of metric \(s^{K,W}\), we need consider both the positive effects on communication time reduction (small \(\tilde{T}_{comm}(K,W)\)) and negative effects on convergence drop (large \(C_{acc}\) or \(T_{acc}(K,W)\)) caused by increasing W. It becomes a trade-off between achieving shorter running time and faster convergence when adjusting W. To be more specific, there exists a threshold \(W_{ideal}\), where growing W(\(W < W_{ideal}\)) improves s until performance begins to drop when \(W > W_{ideal}\), explained as follows.
-
1.
The synchronization interval W determines the average communication time for every iteration \(\tilde{T}_{comm}\). The bigger the W, the smaller the \(\tilde{T}_{comm}\) in Eq. (36). In addition, the effect of \(\tilde{T}_{comm}\) on \(T_{acc}\) depends the relative magnitude of \(T_{iter}\) and \(\tilde{T}_{comm}\). Namely, when the time spent in a single communication \(T_{comm}\) is much higher than optimization time \(T_{iter}\), increasing W will significantly reduce the \(T_{acc}\). In contrast, when \(T_{comm}\) is lower than \(T_{iter}\), the overall time consumption \(T_{acc}\) is less sensitive to the change of W.
-
2.
The synchronization interval W also determines the convergence of distributed optimization of VQE or \(C_{acc}\). Recall that the convergence of our proposal proved in Theorem 1 of our manuscript is \( \frac{1}{T}\sum _{t=1}^T\left\| \nabla L(\varvec{\theta }^t)\right\| \le O(\textit{poly}(W^2,T^{-1}))\), indicating that a large W severely degrades the convergence, leading to a large \(C_{acc}\). There are other factors that also affect the optimization of distributed VQE, such as the partition of whole Hamiltonian terms, which may be beyond the scope of our manuscript.
The phenomenon about the trade-off between \(C_{acc}\) and \(\tilde{T}_{comm}\) with respect to W is vividly illustrated in Fig. 14. As W increases, the average communication time \(\tilde{T}_{comm}\) gradually decreases, indicating reduced communication overhead. However, this reduction in communication time comes at the cost of increased \(C_{acc}\), as more iterations are required to achieve the desired accuracy.
Based on the contradict role of W plays in the running time and convergence, large W leads to the reduced time consumption but poor convergence. Accordingly, in the measure of \(s^{K,W}\), there exists an optimal \(W_{ideal}\) that achieves the highest speedup. Our work, Shuffle-QUDIO, is committed to mitigating the negative effects of W on the convergence, thus allowing for larger \(W_{ideal}\) than QUDIO such that it can further improve the speedup ratio.
Appendix G: Aggregation methods for quantum distributed optimization
The framework of QUDIO can be roughly deconstructed into two alternating operations, including local updates and global synchronization. While the former operation is upgraded by introducing the shuffle operation, the latter can be also modified by more advanced techniques. In the original Shuffle-QUDIO in Algorithm 2, the average aggregation method is simply employed to merge the information from distributed nodes, which may be sub-optimal without considering the differences among these nodes. In this section, we give detailed descriptions about another three novel aggregation algorithms.
Random aggregation
For each distributed quantum model with parameter \(\varvec{\theta }_{i}^{(t,W)}\) after completing local updates, the synchronized parameter \(\varvec{\theta }^{t+1}=\varvec{\theta }_{j}^{(t,W)}\), where \(j\in [K]\) is randomly generated.
Median aggregation
Different from average aggregation and random aggregation, median aggregation utilizes the loss value of every local quantum model as reference to determine the synchronized quantum model. To be concrete, assuming the loss of the i-th quantum processor at the t-th synchronization is denoted by \(L^{(t)}_i\), the quantum model run on processor j whose loss value \(L^{(t)}_j\) is the median of \(\{L^{(t)}_i\}_{i=1}^K\) is selected as the synchronized model \(\varvec{\theta }^{t+1}=\varvec{\theta }_{j}^{(t,W)}\).
Weighted aggregation
Instead of simply utilizing a single local quantum model with median loss as the aggregated model, weighted aggregation merges all local quantum models in a weighted summation fashion. The direct motivation is that a local quantum model achieving lower loss should contribute more to the synchronized model. Similar to median aggregation method, we first collect the loss value of every local quantum model \(\{L^{(t)}_i\}_{i=1}^K\) to compute the weights. Specifically, a monotone decreasing function is first applied to the loss and then a softmax function is adopted to obtained a normalized weight vector. The mathematical process is formulated as
Based on the loss-induced weights, the synchronized quantum model is obtained as \(\varvec{\theta }^{(t + 1)} = \sum _{i=1}^K w^{(t)}_i\varvec{\theta }^{(t,W)}_i\).
Appendix H: Optimization trajectory visualization of Shuffle-QUDIO

Convergence of local quantum models to the global synchronized model. The longitudinal axis represents the sequence number of distributed workers. The color of each grid represents the distance to the synchronized model
To investigate the potential changes brought by the shuffle operation that leads to faster convergence of Shuffle-QUDIO, we analyze the parameter trajectory of each worker during the whole training process. To be more concrete, the parameters \(\varvec{\theta }_k^t\) of the quantum circuits run on each local processor are collected before every global synchronization. Then we measure the distance between the local parameters and synchronized parameters after the average aggregation \(\left\| \varvec{\theta }_k^t-\frac{1}{K}\sum _{k=1}^K\varvec{\theta }_k^t\right\| \).
As shown in Fig. 15, there are significant differences about parameter trajectory between vanilla QUDIO and Shuffle-QUDIO. In the early stage of optimization (the number of iterations is less than 128), almost every local quantum model in Shuffle-QUDIO witnesses a large distance to the synchronized model. This phenomenon reveals the diversity of local models, indicating that each local model can effectively capture the nature of different aspects of the whole system. As the training goes on, the distance gradually decreases and each local model converges to the same point. By contrast, the local models in vanilla QUDIO suffer from severe bias and insufficient training. It appears that the synchronized model is always dominated by some local models, resulting in that other local models do not get trained sufficiently and the final synchronized model fails to work well for the complete system.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Qian, Y., Du, Y. & Tao, D. Shuffle-QUDIO: accelerate distributed VQE with trainability enhancement and measurement reduction. Quantum Mach. Intell. 6, 32 (2024). https://doi.org/10.1007/s42484-024-00167-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42484-024-00167-y