
Abstract
Hybrid quantum-classical classifiers promise to positively impact critical aspects of natural language processing tasks, particularly classification-related ones. Among the possibilities currently investigated, quantum transfer learning, i.e., using a quantum circuit for fine-tuning pre-trained classical models for a specific task, is attracting significant attention as a potential platform for proving quantum advantage. This work shows potential advantages, in terms of both performance and expressiveness, of quantum transfer learning algorithms trained on embedding vectors extracted from a large language model to perform classification on a classical linguistics task—acceptability judgements. Acceptability judgement is the ability to determine whether a sentence is considered natural and well-formed by a native speaker. The approach has been tested on sentences extracted from ItaCoLa, a corpus that collects Italian sentences labeled with their acceptability judgement. The evaluation phase shows results for the quantum transfer learning pipeline comparable to state-of-the-art classical transfer learning algorithms, proving current quantum computers’ capabilities to tackle NLP tasks for ready-to-use applications. Furthermore, a qualitative linguistic analysis, aided by explainable AI methods, reveals the capabilities of quantum transfer learning algorithms to correctly classify complex and more structured sentences, compared to their classical counterpart. This finding sets the ground for a quantifiable quantum advantage in NLP in the near future.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Deep learning models have fostered significant advances in natural language processing (NLP), especially in machine translation, text classification, and syntactic analysis. These improvements are primarily due to transformer models, such as BERT, which changed the previously adopted paradigm thanks to the introduction of context-aware mechanisms. However, training large and complex language models requires massive amounts of data and resources. Hence, when dealing with specific NLP tasks, it is customary to use pre-trained models and use them carefully adapted for solving the task. The adaptation is generally given by a new deep learning algorithm to be trained that uses the outputs of the pre-trained model as input features. Taking a model trained to do one task and then fine-tuning it to work on a related but different task is at the essence of what is called transfer learning. Transfer learning has been widely used in NLP to improve various tasks (Ruder et al. 2019), ranging from cross-lingual approaches to overcome limitations of low-resource languages (Guarasci et al. 2021; Schuster et al. 2019) or trying to infer linguistic knowledge between typologically different languages (Guarasci et al. 2022b; Kim et al. 2017) and domain adaptation (Ma et al. 2019) in machine-translation (Shah et al. 2018) or named-entity recognition-related tasks (Ruder et al. 2017).
Quantum machine learning (QML) is gaining attention as an alternative approach that exploits powerful aspects borrowed from quantum mechanics to overcome the computational limitations of current approaches. A strand derived from QML is the sub-field of quantum NLP (QNLP) (Coecke et al. 2010), which aims to solve natural language-related tasks using quantum properties, applying algorithms derived from quantum theory or testing new approaches using real quantum hardware.
However, quantum-based approaches currently suffer the limitations of available hardware, and there are open issues about scalability because the quantum circuit can be considered a linear or, at most, sub-linear model in the feature space (Schuld et al. 2021). There is an ongoing research effort concerning the encoding of classical data into quantum computers, which in principle allows the extraction of information and makes computations more efficient than classical computers, but with a strong backside when considering large datasets or data represented as large vectors in feature space. Nowadays, hardware has a limited amount of qubits, and when the number of qubits is sufficient for embedding data, the lack of fault tolerance, i.e., the quantum noise associated with the computation, hinders the performances and destroys the potential advantages of quantum computing. To overcome these limitations, novel hybrid approaches combining classic pre-trained models and quantum techniques have been proposed (Li et al. 2022; Li et al. 2023). This type of approach offers the advantage of implementing specific layers of models on a quantum device, while classical models for non-linear operations handle intermediate results. A successful example of such hybrid approaches is the so-called classical–quantum transfer learning (Mari et al. 2020a). It encodes input features in a multiqubit state, and then a quantum circuit transforms and measures such features. In this pipeline, output probabilities are projected to the task label space, and losses are backpropagated to update parameters.
Starting from the approach proposed by Li et al. (Li et al. 2023), this work proposes a hybrid transfer learning model for QNLP applied to a binary classification task. It uses two pre-trained models, namely BERT and ELECTRA, and fine-tunes them to perform the classification. This approach has been tested on current noisy intermediate-scale quantum (NISQ) machines (Torlai and Melko 2020). It exploits the advantage and robustness of classic pre-trained language features already well-known in the literature (Qiu et al. 2020) and integrates quantum encodings to turn classical data into quantum state and parametrized variational circuits (Li and Deng 2021) to perform classification. In this sense, the quantum model used for the classification task falls into the broad category of variational quantum classifiers (VQCs) (Chen et al. 2020a). Here, the VQC algorithms are designed to perform binary classification on acceptability judgements, a fundamental task in theoretical and computational linguistics (Lau et al. 2015; Linzen et al. 2016; Sprouse et al. 2013a) and computation, which has gained much popularity in recent years in the field of NLP (Linzen 2019; Warstadt et al. 2019). This particular task has been chosen because QNLP has proven particularly effective in binary classification (Correia et al. 2021; Guarasci et al. 2023; Meichanetzidis et al. 2020; Sordoni et al. 2013).
In NLP, acceptability judgements refer to assessing whether a given sentence is grammatically correct, semantically meaningful, or perceived as natural by native speakers. Many approaches in recent years have addressed this task, running into numerous critical issues (Linzen et al. 2016; Sprouse and Almeida 2013). Foremost is the scarcity of available resources. Obtaining annotated data on acceptability judgements is an onerous and time-consuming activity that requires expert native speakers (Sprouse et al. 2013a). This problem becomes even more acute when dealing with low-resource languages other than English.
For this work, which focuses on the Italian language, the dataset chosen has been ItaCoLa (Trotta et al. 2021). It is the largest existing resource for this task in Italian, collecting sentences labeled with their judgements by expert linguists. Here, it is demonstrated that the quantum transfer learning approach for these topics can give enhanced accuracy in classification without being time and resource consuming. The quantum advantage given by the quantum classifier is inferred by direct comparison with the state-of-the-art classical deep learning models used for the ItaCola Acceptability Judgements (namely LSTMs and ITABert).
The paper is organized as follows: in Section 2, the research works available in the literature related to what is presented are described. In Section 3, the dataset and applied methodologies are presented. Section 4 provides details about the experimental phase, such as the parameter in use and details about the computational pipelines. Then, in Section 5, the results obtained are exposed, relevant aspects are discussed, and finally, overall conclusions are drawn in Section 6.
2 Related work
2.1 Quantum machine learning
Numerous examples have received increasing interest in recent years concerning the adaptation of classical machine learning algorithms through the use of properties and techniques borrowed from quantum mechanics. One notable approach is quantum support vector machines (QSVMs), which aim to enhance the performance of traditional support vector machines (SVMs) by utilizing quantum algorithms. QSVMs have shown promising results in various text classification tasks, including sentiment analysis, topic classification, and document classification. Another area of research is quantum-inspired algorithms for text classification. Quantum-inspired algorithms, such as quantum-inspired genetic algorithm (QGA) and quantum-inspired particle swarm optimization (QPSO), draw inspiration from quantum mechanics and apply quantum-like principles to improve traditional optimization techniques. These algorithms have been explored in the context of feature selection and parameter optimization for text classification, demonstrating their potential to enhance classification accuracy and efficiency. Moreover, quantum embeddings have gained attention as a means to represent and analyze textual data. Quantum embeddings leverage the concepts of quantum superposition and entanglement to capture semantic relationships between words or documents. These embeddings aim to capture more nuanced and context-dependent information than traditional word embeddings. By utilizing quantum representations, classification models can benefit from enhanced semantic understanding, improving performance in various NLP tasks.
Furthermore, quantum machine learning algorithms, such as quantum neural networks (QNNs) and quantum Boltzmann machines (QBMs), have been explored in text classification. These quantum-inspired models leverage the unique computational capabilities of quantum systems to perform complex computations efficiently. Although still in its early stages, quantum machine learning holds the potential to address the computational challenges associated with large-scale language data and to provide more robust models for classification tasks.
Among the most immediate and promising applications of quantum machine learning algorithm, classical-to-quantum (CQ) (Mari et al. 2020a) transfer learning is attracting growing attention as it promises to show quantum advantage on specific tasks, using both the representation power of state-of-the-art pre-trained deep learning models and the expressivity of quantum circuit, which are constructed to tackle the problems to be solved.
2.2 Quantum transfer learning
Typically, transfer learning indicates a set of techniques in artificial intelligence where knowledge acquired from a specific task is transferred to solve a different problem. This idea has been successfully applied in various contexts, from image classification to sentiment analysis. Generally, a pre-trained network is used, trained on a particular dataset, from which the last layer is removed. The truncated pre-trained network is then interpreted as a feature extractor on the new dataset. The feature vectors are then used to train a dedicated neural network designed to address the task. Quantum transfer learning can be realized within two frameworks: quantum-transfer learning algorithms use feature vectors extracted from a trained quantum machine learning algorithm and then fed into a quantum neural network. Instead, a classical-quantum transfer learning algorithm uses the features extracted from a classical neural network, which are then encoded into a task-tailored quantum neural network. In this work, the latter approach is used, as it is convenient for elaborating the highly informative feature vectors extracted from large language models (BERT and ELECTRA) and then using a quantum classifier to infer the relation between vectors and the target classes.
2.3 Quantum natural language processing
The growing interest in exploring the potential of QML in language-related tasks has led to the birth of the QNLP. As a sub-field of QML, QNLP offers a new paradigm focused on processing and analyzing language data by leveraging the principles of quantum mechanics.
At the dawn of the QNLP, the first approaches proposed were only at the theoretical level. They proposed algorithms based on quantum theory that are potentially implementable on quantum hardware but not tested on actual data (Coecke et al. 2020; Zeng and Coecke 2016). These approaches covered different tasks of NLP, from generic aspects of sentence representations using distributional or compositional properties to specific tasks (Abbaszade et al. 2021; Correia et al. 2021).
More in theme with the purpose of this paper, however, are the approaches that were tested on real datasets using classical hardware (quantum-inspired approaches) or currently available quantum machines (quantum-computer approaches). Quantum-inspired approaches are typically structured in a specific manner. They start with the classic model and then integrate the advancements of quantum mechanics to enhance their performance, proving that a quantum approach can surpass the current state-of-the-art. Some of these studies have been evaluated against benchmark datasets found in the literature, while others have utilized custom-made samples for their assessments.
Finally, quantum-computer approaches proposed alternatives to simple NLP tasks that can be performed on quantum hardware (NISQ). Currently, experiments are limited to small-to-medium scale datasets due to the current limits of quantum hardware. Notice that several studies have investigated the application of quantum computing in classification tasks within NLP; a detailed review is described in (Guarasci et al. 2022a).
An alternative way proposed to push through the limitations inherent in the scalability of such experiments is represented by hybrid approaches. A hybrid classical-quantum scheme using a quantum self-attention neural network (QSANN) has been recently proposed (Li et al. 2022). Even if it introduces the possibility of non-linearity, significantly improving over other QNLP models (Lloyd et al. 2020), this approach is limited by the continuous switching between quantum and classical hardware at each self-attention layer needed to run the network.
Li et al. (Li et al. 2023) proposed a more viable approach to solve the low non-linearity issue for QNLP models using the classical-quantum transfer learning paradigm (Mari et al. 2020a). Using the classical-quantum transfer mechanism and pre-trained quantum encodings seems the most promising approach to develop scalable QNLP models, paving the way for the possibility of being implemented on real quantum hardware. Given this high potential and the increasing appeal of this approach, it was chosen for use in this work.
2.4 Acceptability judgement task
Understanding and accurately predicting acceptability judgements are crucial for various NLP applications, including grammar correction, machine translation, and automated dialogue systems. Therefore, there are some open issues. First, acceptability is often subjective and context-dependent, varying across different languages. Second, various linguistic phenomena affect such judgements. Therefore, models that have addressed this task so far have had to cope with these factors, capturing fine-grained linguistic features (Linzen and Oseki 2018) and generalizing across diverse linguistic contexts using cross-lingual approaches (Cherniavskii et al. 2022). Furthermore, labeled data for training such models is typically scarce and costly to obtain, as it requires expert annotation or crowd-sourcing efforts. This scarcity of labeled data necessitates using transfer learning and other techniques to leverage pre-trained language models and enhance the performance of acceptability judgement prediction models.
In recent years, significant progress has been made in developing neural network architectures, such as recurrent neural networks (RNNs), convolutional neural networks (CNNs), and transformer models, which have shown promising results in predicting and classifying acceptability judgements. These models leverage sentences’ syntactic structure and semantic content, capturing the contextual information necessary for accurate acceptability predictions.
Automatically assessing acceptability tasks gained great popularity since the release of the CoLa corpus (Warstadt et al. 2019), the first large-scale corpus of English acceptability, containing more than 10k sentences from linguistic literature.
The CoLA corpus has been presented with several experiments to assess the performance of neural networks on a novel binary acceptability task. Furthermore, it has been included in the GLUE dataset (Wang et al. 2018), a very popular multi-task benchmark for English natural language understanding, and an acceptability challenge has been launched on KaggleFootnote 1. For such reasons, the number of studies dealing with binary acceptability has remarkably increased. However, proposed approaches have often used different metrics for evaluation, so comparisons cannot always be made.
Starting with the same methodology introduced in COLA, similar resources have been released in recent years in various typologically different languages, ranging from Italian (Bonetti et al. 2022; Trotta et al. 2021)—which is the subject of this work—Norwegian (Jentoft and Samuel 2023), Swedish (Volodina et al. 2021) and Russian (Mikhailov et al. 2022), Japanese (Someya and Oseki 2023), and Chinese(Xiang et al. 2021).
Notice that other acceptability datasets already existed in the literature, but these were small resources that arose for purely theoretical purposes or within psycholinguistic experiments (Lau et al. 2014; Marvin and Linzen 2018; Sprouse and Almeida 2013). Regarding languages other than English, (Linzen and Oseki 2018) they evaluate informal acceptability judgements in Hebrew and Japanese. A similar study has been conducted in French (Feldhausen and Buchczyk 2020) and in Chinese (Chen et al. 2020b). A small dataset in the context of the Evalita 2020 evaluation campaign on complexity and acceptability for the Italian language (AcComplIt task) (Brunato et al. 2020) has been released.
3 Materials and methods
3.1 Neural language models
For this work, two neural language models (NLMs) have been considered, namely BERT and ELECTRA.
3.1.1 BERT
Among NLMs in literature, BERT (Devlin et al. 2019) is the most widely used due to its efficiency and high performance. Generally speaking, BERT is a multi-layer, bidirectional architecture based on the original Transformer encoder (Vaswani et al. 2017), pre-trained on large-scale unlabeled text via two training goals, i.e., masked language modeling and next-sentence prediction.
A pre-trained BERT model typically provides a powerful context-dependent sentence representation that can be successively adapted to a downstream NLP task through a fine-tuning procedure according to different needs. The finetuning procedure requires configuring several hyperparameters whose values directly influence the results that can be obtained.
The BERTbase model consists of 12 hidden layers, each one having 768 hidden dimensional states and 12 attention heads, with a total of 110 million parameters. The BERTbase model accepts input sequences of words, with a maximum length of 512. Each layer of the model encodes a distinct embedded representation of the input words, which can be leveraged for various NLP tasks, including the syntactic probe discussed in this paper.
Masked language modeling involves randomly masking a percentage of words in the training corpus. By doing so, the pre-trained model learns to encode information from both directions of the sentences and simultaneously predict the masked words. The input vocabulary can be either cased or uncased, resulting in two different pre-trained models. The flexibility offered by bidirectional analysis simultaneously allows, on the one hand, to maintain a large generating capacity through the inner layers of the deep constituent network and, on the other hand, to use the outer layers of the network to adapt to the specific task through the fine-tuning phase; it is what has allowed BERT to be the benchmark model in the literature in recent years.
BERT expects that each input sequence of words starts with a unique token [CLS], used to obtain in output a vector of size H, i.e., the size of the hidden layers, representing the entire input sequence. Moreover, the unique token [SEP] must be placed within the input sequence at the end of each sentence.
Given an input sequence of words t = (t1,t2,...,tm), the output of BERT is h = (h0,h1,h2,...,hm) where h0 ∈ RH is the final hidden state of the special token [CLS] and provides a pooled representation for the full input sequence, while h1,h2,...,hm are the final hidden states of other input tokens.
To fine-tune BERT for classifying input sequences of words into K different text categories, the final hidden state h0 can be used to feed a classification layer, with a subsequent softmax operation to turn the scores of each text category into likelihoods (Sun et al. 2019):
where W ∈ RK×H is the parameter matrix of the classification layer.
3.1.2 ELECTRA
The second NLM taken into account is ELECTRA (Clark et al. 2020) since it has shown a better ability to capture contextual word representations outperforming, in its downstream performance, other models, like BERT, given the same model size, data, and computation (Rogers et al. 2020).
Generally speaking, ELECTRA is a pre-training approach that trains two transformer models, namely the generator G and the discriminator D. The role of model G is to replace tokens in a sequence and is, therefore, usually trained as a masked language model. Model D, which is typically the ELECTRA model of interest, tries instead to identify which tokens were replaced by G in the sequence, and it may be a BERT-based model, virtually any model producing an output distribution over tokens.
In particular, for a given input sequence, where some tokens are randomly replaced with a special [MASK] token, G is trained to predict the original tokens for all masked ones, after which G generates a fake input sequence for D by replacing the [MASK] tokens with fakes. Finally, D is given the fake sequence as input and is trained to predict whether their tokens are original or fake. This approach, replaced by token detection (RTD), allows the use of a minor number of examples without losing performance.
More formally, given an input sentence s of raw text χ, composed of a sequence of tokens s = w1,w2,...,wn where wt (1 ≤ t ≤ n) represents the generic token, both G and D firstly encode s into a sequence of contextualized vector representations h(s) = h1,h2,...,hn. Then, for each position t for which wt = [MASK], the generator G predicts, through a softmax layer, the probability of generating a specific token wt:
where e(·): wt ∈ s → Rdim is the embedding function, and dim is the chosen embedding size.
The discriminator D predicts, via a sigmoid layer, if wt is original or “fake”:
During the pre-training, the following combined loss function is minimized:
where LGen and LDis are the loss functions of G and D, respectively.
At the end of the pre-training, G is discarded, and only D is effectively used for fine-tuning the specific task.
Masked language modeling pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then training a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, they generally require large amounts of computing to be effective. As an alternative, replaced token detection is a more sample-efficient pre-training task that corrupts the input by replacing some tokens with plausible alternatives sampled from a small generator network instead of masking the input. The main reason ELECTRA efficiency results improved concerning BERT-like NLMs is that predictions are calculated not only over masked tokens but also for the other tokens in the input sequence, and, thus, the discriminator loss can be calculated over all input tokens. It allows using a minor number of examples without losing in performance.
3.1.3 Pre-trained models in the Italian language
For the purpose of this work, since training an NLM demands considerable time and computational resources, two pre-trained versions of BERT and ELECTRA in the Italian language have been adopted.
As a pre-trained version of BERT, the cased and XXL version of the dbmdz Italian BERT modelFootnote 2 has been chosen. This model has been trained with cased vocabularies with an initial sequence length of 512 subwords for 2–3 million steps. The source data consists of an “XXL” corpus composed of a Wikipedia dump, various texts from the OPUSFootnote 3 corpora collection, and data from the Italian part of the OSCARFootnote 4 corpus. Thus, the final training corpus has a size of 81 GB and 13,138,379,147 tokens.
As the pre-trained version of ELECTRA, the cased and XXL version of the dbmdz Italian ELECTRA modelFootnote 5 (Fig. 1) has been chosen. This model has been trained on the “XXL” corpus for 1 million steps in total using a batch size of 128. The training procedure followed is the one used for BERTurkFootnote 6.

ELECTRA overview with replaced token detection
Notice that in recent years, other pre-trained versions of BERT and ELECTRA in the Italian language have been made available (Polignano et al. 2019). However, they are usually trained on social media and Twitter corpora, since they present an often non-standard linguistic variety at the syntactic and lexical levels. For this reason, the dbmdz models, which have been trained on a corpus formed by documents written in standard language, are the most appropriate choice in a task that aims to assess acceptability.
3.2 ItaCola dataset
The dataset used for this work is ItaCoLA, the Italian Corpus of Linguistic Acceptability (Trotta et al. 2021). This corpus was designed to represent a broad range of linguistic phenomena while distinguishing between sentences that are considered acceptable and those that are not. The process used to create the corpus was modeled as closely as possible on the methodology employed for the English CoLA dataset (Warstadt et al. 2019). ItaCoLA consists of approximately 9700 sentences drawn from various sources that cover numerous linguistic phenomena.
The acceptability annotation for these sentences is based on Boolean judgements formulated by experts who authored the different data sources. It ensures robustness and simplifies classification. The sentences are sourced from various linguistic publications spanning four decades, transcribed manually, and released in digital format. The sources include theoretical linguistics textbooks and scientific articles on phenomena such as idiomatic expressions, locative constructions, and verb classification. An example of how the data are structured in the corpus is shown in Table 1.
ItaCola is divided into training, validation, and test splits, including 7801, 946, and 975 examples. Notice that each split is balanced concerning sources composing the whole dataset, and the acceptability to not acceptability ratio is preserved.
4 Experimental phase
In this study, two quantum classification pipelines are employed. A schematic of each model is presented in Fig. 2. These quantum pipelines are compared with the corresponding classical equivalent. A detailed explanation is provided subsequently.

Schematic of the quantum transfer learning scheme adopted. Sentences from ItaCola dataset are tokenized and then embeddings from BERT and ELECTRA (both pre-trained) are obtained for each data point. The embeddings are then encoded in the parametrized quantum circuit via amplitude encoding. The results of the measurement on the quantum states are then fed into a multi-layer perceptron (MLP) through which the classification is performed
4.1 Quantum pipelines
This section outlines the methodology for incorporating Italian BERT and ELECTRA embeddings in the quantum natural language processing (QNLP) pipeline for the classification task of acceptability judgements. For convenience, the two transfer learning pipelines are called BERT-Quant and ELECTRA-Quant in the following sections. The proposed pipeline is articulated in the following steps:
4.1.1 Data preprocessing
Sentences extracted from ItaCola must be preprocessed and prepared for embedding generation.
4.1.2 Embedding generation
For this work, pre-trained BERT and ELECTRA embeddings have been used. Feature vectors extracted via both models considered have 768 real-valued entries. These values must be encoded in a quantum state to train a quantum classifier.
4.1.3 Quantum data encoding phase
In order to realize a BERT-Quant and an ELECTRA-Quant pipeline, embedding from pre-trained BERT and ELECTRA needs to be transformed in a quantum object, either a state vector or an operator to be used in the quantum computational pipeline. Several methods exist to encode classical data into quantum states; one possibility is to encode data into the complex amplitudes of a multi-qubit state. This approach requires that the N-dimensional feature vector is encoded in the superposition of n = log2N qubits. Additionally, the embeddings can be encoded as angular values of single-qubit rotational gates. In this case, the N-dimensional feature vector requires n = N qubits to be adequately encoded in a quantum state. The embeddings are generated by encoding the classical embeddings into quantum states, where the amplitudes represent the weights or probabilities associated with each word or document. Quantum circuits or operators perform transformations on the quantum state, enabling the manipulation and analysis of the quantum embeddings.
4.1.4 Quantum classification model
Once the quantum embeddings are constructed, they can be used as inputs to quantum classification models for various NLP tasks. This work constructs the variational quantum classifier with quantum-inspired neural networks (QNNs). These are generally composed of single- and two-qubit gates with free parameters trained in the learning phase. The structure of these circuits needs to be sufficiently complex to accommodate the possible solutions of the task and yet simple enough to prevent detrimental effects from quantum noise. There is currently an ongoing research effort aiming to find the optimal strategy for the construction of variational quantum circuits (Du et al. 2022): one of the critical elements to take into account is a certain level of entanglement, i.e., quantum correlation, between qubits so that information is shared among each element of the computation, and complex solutions are potentially explored during training. Here, a basic entanglement ansatz is used, where each qubit will be forced into a quantum-correlated state with another qubit pairwisely.
4.1.5 Model training and evaluation
The quantum classification model and the quantum embeddings are trained using a labeled dataset. This dataset consists of instances with their corresponding class labels. Model training involves optimizing the parameters of the quantum classification model to minimize a predefined loss function. The trained model is evaluated using appropriate evaluation metrics, such as accuracy, precision, recall, and F1 score, to assess its performance on unseen data.
4.1.6 Evaluation
To assess the effectiveness of quantum embeddings in QNLP tasks, comparing their performance against classical embedding-based models is beneficial. Classical models like traditional machine learning algorithms or neural networks can be trained and evaluated using the same dataset and evaluation metrics. The performance of the quantum embedding-based model can be compared to these classical models to determine the impact and benefits of quantum embeddings in QNLP tasks. It is worth noting that the specific implementation details of the methodology may vary depending on the chosen embedding technique, quantum embedding construction approach, and the specific quantum classification model employed. The above steps provide a general framework for integrating embeddings in quantum natural language processing.
4.1.7 Quantum amplitude encoding
Classical data must be encoded in a quantum state to be manipulated in a quantum computational pipeline. One prevalent approach for this purpose is quantum amplitude encoding, representing classical data as amplitudes within a quantum superposition. This encoding method facilitates parallel computation and harnesses quantum interference for data processing tasks. With quantum amplitude encoding, classical data are mapped onto quantum states by assigning complex amplitudes to specific computational basis states. More formally, consider here a classical dataset denoted by a feature vector x = (x1,x2,...,xN), where N represents the dimensionality of the feature vector. The quantum amplitude encoding scheme transforms this feature vector into a quantum superposition state |x⟩. To perform quantum amplitude encoding, a set of n = ⌈log2N⌉ qubits is utilized, with each qubit representing one element of the feature vector. The quantum state |x⟩ is given by:
where |i⟩ denotes the i-th computational basis state of the n qubits, and αi represents the complex amplitude associated with each basis state. The amplitudes αi are determined by the classical data values xi. Classical data are first normalized, i.e., the feature vector x is divided by the normalization factor C: this fact guarantees that the resulting quantum state is properly normalized, thus preserving the probabilistic interpretation of the wave function. Once the feature vector is normalized
where \({x}^{\prime }=\left({x}_1^{\prime },{x}_2^{\prime },\dots, {x}_N^{\prime}\right)\), the next step is the actual encoding phase. Here, the complex amplitudes αi for each computational basis state |i⟩ are given by:
ensuring that the quantum state |x⟩ is properly normalized, with the sum of squared amplitudes equal to 1. Quantum amplitude encoding offers a means to transform classical data into quantum states, facilitating the utilization of quantum algorithms for data processing and machine learning tasks.
4.1.8 Parametrized quantum circuit
The embeddings encoded in the quantum amplitudes of a state vector are processed by a parametrized quantum circuit. A parametrized quantum circuit is technically a chain of quantum gates with free parameters (Benedetti et al. 2019), which are iteratively updated to optimize an objective function. In this sense, a parametrized quantum circuit in a learning optimization algorithm is the quantum equivalent of a classical neural network. To exploit the computational and learning capabilities of parametrized quantum circuits, it is necessary to put the qubits involved in an entangled state; these can be obtained with different approaches and with varying topologies. There is no general procedure to infer which form of the entangling layers is more indicated for the specific task to be tackled; in this work, a basic entangling layer is provided by Pennylane (Bergholm et al. 2018). The basic entangling layer is composed of a single-parameter one-qubit gate, applied on every qubit, and a ring of CNOT gates, i.e., two-qubit gates connecting every qubit with the closest neighbor. The ring structure is given by the connection between the last qubit and the first one considered.
4.2 Explainability with SHAP values
To aid a qualitative analysis of the results discussed later in this work and extract a meaningful explanation about how a quantum transfer learning pipeline can be helpful in the acceptability judgement task, a SHAP value analysis is performed here. SHAP (SHapley Additive exPlanations) (Rodríguez-Pérez and Bajorath 2020) is a game-theoretical–inspired approach to explain the output of an agnostic parametrized function, such as many deep learning models, using the inputs provided. In essence, SHAP values measure the relative contribution of each feature vector (in the task now considered, a single-word embedding) on the model’s outcome. In this sense, SHAP values provide a quantitative mean for the local interpretability of an AI model. Hence, they are indirect quantifiers of the model’s inner structure and computational reasoning. While SHAP values are evaluated on single features, i.e., in the models considered here on single tokens, they can be clustered hierarchically in terms of the final score’s co-occurring importance, revealing the overall contribution to the classification score of entire sections of sentences. This fact is of pivotal relevance for performing a qualitative analysis of the results of the models, as it allows to understand better which linguistic features impact correct classification and recurring patterns related to specific syntactic phenomena present in acceptable or unacceptable sentences. The methodology mentioned above for a qualitative analysis of the experimental findings is illustrated in more detail in the following section.
5 Results and discussion
Two quantum transfer learning pipelines (BERT-Quant and ELECTRA-Quant) have been trained for the acceptability judgements on the Itacola dataset. Similarly, for comparing the results, two classical transfer learning pipelines are considered (BERT-Classic and ELECTRA-Classic). For each of them, the main properties, hyperparameters, and training strategies are listed in the following
5.1 BERT-Quant
The embedding extracted from BERT is encoded in a quantum state with the amplitude encoding strategy. To encode all the 768 dimensions of the BERT feature vectors, the minimum number of qubit required is n = ⌈log2(768)⌉ = 10, where the rest of the 1024 amplitudes are padded all with 0.01. The padding constant is non-informative, but its value needs to be selected in accordance with the chosen ansatz, as correlation phenomena between in-use qubit and not-useful qubits might emerge during the computation. A rather simple but substantial empirical study has been conducted, revealing that a small but non-zero value is more convenient for the learning process: this is due to the fact that some elements of the original feature vector need to be encoded in the portion of the Hilbert space spanned by the padding qubits (Gianani et al. 2022); hence, a zero probability of occurrence would simply erase some relevant information too. Specifically, the value of the padding constant has been chosen to be on the same scale as the other amplitudes (normalized), to reduce at minimum the chances of biasing the result. After the encoding phase, the state obtained is used as an input for six layers of parametrized BasicEntangledLayer. The outcome from the measurements, which consist in the expectation of Pauli-Z for each qubit, is then passed to a multi-layer perceptron with a Softmax activation function, and input-output dimension of 10 − 2, trained for the classification, together with the entire circuit pipeline. The training is performed with an Adam optimizer, with a learning rate of 10−5, a batch size of 32, and a categorical cross-entropy as an objective function. The whole training process lasts for seven epochs.
5.2 ELECTRA-Quant
The embedding extracted from ELECTRA was encoded in a quantum state with the amplitude encoding strategy. To encode all the 768 dimensions of the BERT feature vectors, the minimum number of qubit required is n = ⌈log2(768)⌉ = 10, where the rest of the 1024 amplitudes are padded all with 0.01. After the encoding phase, the state obtained is used as an input for eight layers of parametrized BasicEntangledLayer. The outcome from the measurements, which consist in the expectation of Pauli-Z for each qubit, is then passed to a multi-layer perceptron with a Softmax activation function, and input-output dimension of 10 − 2, trained for the classification, together with the entire circuit pipeline. The training is performed with an Adam optimizer, with a learning rate of 10−5, batch size of 32, and a categorical cross-entropy as the objective function. The whole training process lasts for seven epochs.
5.3 BERT-Classic and ELECTRA-Classic
Two classical transfer learning pipelines have been adopted for fine-tuning BERT and ELECTRA for sequence classification (Sun et al. 2019). The training is performed with an Adam optimizer, with a learning rate of 2·10−5 and eps of 10−8, and a batch size of 32 with 2 as the number of labels, 0 as the number of warm-up steps, 64 as the maximum length of the input sequences of words, and a categorical cross-entropy as the objective function. The whole training process lasts for five epochs.
Concerning the quantum pipelines, the optimal number of layers for each model has been found empirically, taking into account the need for a trade-off between the performances and the computational cost (Abbas et al. 2021). While generally more layers are helpful in the learning process, they are computationally expensive. This goes together with the possibility of increasing the quantum noise in the computation as the number of gates increases. In the experiments here exposed, given the nature of the quantum hardware and the size of the problem, six layers for the basic entangling layer give the optimal classification performances.
For the sake of completeness, also the performance achieved by a baseline using LSTM with FasText embeddings (Trotta et al. 2021) has been reported.
Evaluations were performed using two metrics: accuracy, the most used measure used to evaluate acceptability on the GLUE benchmark and Matthews correlation coefficient (MCC) (Peters et al. 2018), which is a correlation measure for Boolean variables mainly fitted when evaluating unbalanced binary classifiers.
The training phase of the two quantum transfer learning strategies is constructed, namely, BERT-Quant and ELECTRA-Quant, both with learning rates of 10−5, batch sizes of 16, and a categorical cross-entropy as the objective function. In both cases, the parametrized quantum circuit is made of six basic entangling layers. The training reveals that ELECTRAQuant is more effective for minimizing the loss, and thus learns better than BERT-Quant to classify the acceptability of the sentences.
5.4 Quantitative analysis
Concerning the quantum transfer learning pipelines, results of the various training are shown in Fig. 3. It is evident from the training phase that ELECTRAQuant converges faster and to a lower objective function value than BERTQuant, thus indicating the higher expressive value of the embedding extracted from the pre-trained ELECTRA model. This, in fact, is confirmed by the accuracy and the MCC on the test set, as shown in Table 2. Both the BERT-Quant and ELECTRA-Quant outperform the LSTM model from the leaderboard, but BERT-Quant falls narrowly behind BERT-Classic in terms of accuracy and MCC. On the contrary, ELECTRA-Quant outperforms all the leaderboard models, with a mean accuracy of 0.92 and a mean MCC of 0.676. Concerning accuracy scores, these values are comparable with those achieved by ELECTRA-Classic using the classical approach (0.923), while the BERT-Classic stops at 0.904.

Loss function for the training of BERT-Quant and ELECTRA-Quant
The result is even more significant considering the MCC as a metric, which is much better suited to this type of task (Peters et al. 2018). In such case, although the best result is still achieved using ELECTRA-Classic with the classical approach, the deviation with ELECTRA-Quant is minimal (0.698 vs 0.676), confirming the potential of quantum circuits to represent language data in complex high-dimensional vector spaces. This ability can fuel the most sophisticated NLP deep learning model with higher expressive capabilities, potentially impacting task performances beyond the binary classification hereby investigated.
5.5 Qualitative analysis
Furthermore, a qualitative analysis of a sample extracted from the ItaCola dataset has also been conducted. In particular, we have selected a set of 100 representative sentences showing different phenomena according to ItaCola expert annotations (Trotta et al. 2021).
Listed below are the phenomena chosen to be included in the sample and why they were chosen:
5.5.1 Simple
Sentences that have a single verb and only the mandatory arguments, e.g., “Il cane rosicchia un osso” (En. The dog gnaws a bone.). These are the most uncomplicated complexity sentences; they have a linear syntax and present no particular difficulty. The possible unacceptability of the sentence lies only in the violation of the order of the constituents.
5.5.2 Cleft constructions
Sentences where a constituent has been moved to put it in focus, e.g., “E Max che Maria ha invitato per cena” (En. It is Max who Maria invited for dinner.). This phenomenon is exciting because Italian language has an almost free word order (Bates et al. 1982), unlike both English and other Romance languages such as French, which instead respect the canonical subject-verb-object (SVO) order. This great syntactic flexibility leads to complex syntactic constructions with inversion of constituents concerning the verbal head (Guarasci et al. 2020).
5.5.3 Subject–verb agreement
Sentences characterized by the presence or lack of subject and verb agreement in gender or number, e.g., “Ho saputo che ieri la zia di Maria ti ha raccontato che Andrea ha incontrato Mauro” (En. [I] heard that yesterday Maria’s aunt told you that Andrea met with Mauro.). Given the morphological richness of Italian and its relative freedom in constructing phrasal structures (Tsarfaty et al. 2010), verbal inflection determines the agreement between constituents and not their positional proximity. Various studies have correlated these inflectional properties with syntactic ones and phenomena such as the omission of the subject pronoun (pro-drop) (Liu and Xu 2012). Acceptability violations of sentences of this kind are both in the suffix indicating gender and number agreement and in the potential nested subordinate propositions.
To study how different phenomena impact differently and better understand how and what parts of a given syntactic structure impact classification, the visual formalism of the dendrogram was used. The choice is due to several reasons. First, the dendrogram is SHAP-compliant, allowing visual output to be easily interpreted and compared. Second, this work does not focus on an exclusively syntactic task, since no accurate syntactic analysis was performed on the sentences via the canonical dependency parse tree (DPT). Without a proper DPT—a mandatory step in every NLP pipeline—it is impossible to have a hierarchical structure labeled via the syntactic relations of each sentence. The dendrogram, therefore, is the best compromise, having already been used in some studies as an approximation of syntactic relations instead of DPT in tasks involving syntactic features (Sagae and Gordon 2009), in particular for rich-inflected languages (Bohnet et al. 2013).
From the analysis performed on the sample under review, different behaviors are noted based on the phenomena that distinguish the sentences.
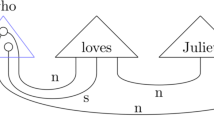
For instance, in the unacceptable sentence “Chi Leonardo ama?” (Who does Leonardo love?) shown in Fig. 4, arcs highlighted in orange represent the portions of the sentences (in this case the sentence as a whole) that contribute to the correct classification, i.e., classify the sentence as unacceptable.

Example of a dendrogram representation for a simple sentence in an interrogative form. Orange arcs represent the parts of the sentence that positively impact classification, classifying it as an unacceptable sentence
Moving to a more complex sentence, such as the one in Fig. 5 “E’ Tommaso che beve troppo vino” (It is Thomas who drinks too much wine), arcs in two different colors can be seen. As mentioned above, green arcs indicate the phrase that contributes to classifying the sentence correctly, and the orange ones have a negative effect. Analyzing this dendrogram in detail, it is possible to see that the portion of the sentence correctly influential for correct classification coincides de facto with the main clause “beve troppo vino” ([He] drinks too much wine). Notice that in this case, the main clause is placed after the dependent one “E’ Tommaso che” (It is Thomas that). This is because it is a cleft sentence whose peculiarity lies in having the order of constituents inverted, namely the dependent clause (usually a prepositional phrase) before the main clause.

Example of an acceptable sentence presenting a cleft structure. Orange arcs, representing correctly classified words, coincide with the main clause, which is also the most readable part, while the subordinate is the part that negatively impacts the correct classification of the sentence as acceptable (blue arcs)
The key to interpreting dendrograms can already be deduced from these two examples. In the first example, given a simple and unacceptable sentence, all the words that compose it impact the correct classification. In the second case, when dealing with an acceptable complex sentence, the portion that does not contribute to the correct identification is found in the less readable part of the sentence, namely, the prepositional dependent clause at the beginning. The criterion is, therefore, influenced not only by the judgement of acceptable/unacceptable but also by the readability of the sentence, expressed in terms of syntactic complexity.
5.6 Quantum vs classic dendrograms
From the analysis conducted on the sample, some differences in the behavior of classic and quantum models have been observed. In particular, the comparison has been focused on dendrograms produced by models that respectively achieved the best results, ELECTRA-Classic and Quantum. The behavior of the two different models concerning each of the phenomena included in the sample is briefly described below. As expected, both models find no difficulty handling simple sentences, showing similar classification behavior.
The behavior of the two models about cleft constructions is more erratic. For instance, specific moderately complex sentences such as the one depicted in Fig. 6, “è in giardino dal balcone che Alessandro ha lanciato il pallone” (It is from the balcony that Alessandro has thrown the ball into the garden), are accurately classified only by ELECTRA-Classic.

Example of a sentence containing cleft construction phenomenon correctly classified. The main clause is identified by green arcs, while the relative clause placed before is in red
Conversely, the same model misclassifies straightforward sentences like the one shown in Fig. 7 “è al garage che Lorenzo ha piantato fiori dal giardino” (It is in the garage that Lorenzo has planted flowers from the garden). In this case, the verb “piantare” (to plant) is erroneously split, and the portion of the sentence that affects the classification is identified within a meaningless sequence lacking a verbal head, namely “fiori dal giardino” (flowers from the garden).

Example of a cleft sentence wrongly classified. Constituents that impact classification are meaningless, and the verb is divided into two tokens
Nevertheless, a recurring pattern does not appear to emerge: in some instances, the behavior is reversed, with ELECTRA-Quantum demonstrating improved performance on complex sentences and poorer performance on simpler ones, or vice versa.
In contrast, the situation is more precise in the case of sentences containing subject-verb agreements. This phenomenon, directly influenced by the rich inflectional morphology of Italian, can result in syntactically very complex sentences with various levels of embedded clauses in which the constituents’ position makes readability difficult.
As shown in Fig. 8, an unacceptable sentence such as “Questa donna mi hanno colpito” (This woman they impressed me.) is handled identically by the models producing the same dendrograms, with the exact phrases concurring to impact positively or negatively in classifying.

Example of a sentence containing subject-verb agreement phenomenon
However, by increasing the complexity of the sentence, the behavior changes. Figure 9 sentence is much less readable than the previous one: “La donna che i vicini credono che i ragazzi dicono che accompagnava i bambini è Sofia” (The woman the neighbors believe the boys say was accompanying the children is Sofia). The sentence, while hostile even for a native speaker, is acceptable even though grammatically, it has a construction that pushes the dependent clauses nesting allowed by Italian to the maximum.

Example of a sentence containing subject-verb agreement phenomenon with a high level of nested dependent clauses
ELECTRA-Quantum tends to make fewer errors and classify better in sentences such as this one, which is highly represented in the dataset. As can be seen from the figure, the green arcs that contribute to the correct interpretation approximate the independent clause. In contrast, the red arcs correspond to the less readable part consisting of a series of nested dependent clauses cascading between them.
While ELECTRA-Quantum classifies better a certain class of structured sentences, it falls shortly behind the classical ELECTRA model on simpler and less structured ones. This phenomenon is captured by the overall accuracy of the model: a net outperformance on any element of the dataset of the quantum model would have led to higher accuracy or MCC in the classification, and this is clearly not the case. To understand the reason behind this, it is necessary to reason around the structure of the quantum circuit—the amplitude encoding in particular, here employed for writing BERT/ELECTRA vectors onto a quantum state, while convenient in terms of qubits, is not entirely lossless as an encoding protocol; it has been demonstrated in fact that a growing number of queries is necessary to fully determine the belonging class of a feature vector encoded in the amplitude of a quantum state (Wiebe 2020). It follows that the single-word embeddings lose partially their representation power. Hence, short sentences, where the weight of the single-word representation is concurrent in importance with the syntactic structure for the acceptability, suffer more for the limitations posed by the encoding. The acceptability of long and structured sentences, on the contrary, heavily depends on the correctness of the syntactic relationships, which are well captured by the parametrized ansatz; and thus, they are correctly interpreted by the ELECTRA-Quantum model.
This is a fascinating behavior since Classical NLMs indeed have already shown excellent results in the literature in handling syntactic phenomena such as this one (Guarasci et al. 2021; Guarasci et al. 2022b). The improved performance offered by quantum models opens up new possibilities for more effective management of problematic phenomena pervasive in languages such as Italian and often challenging syntactic parsers due to convoluted syntax and sentence length (Brunato et al. 2018).
6 Conclusion
In this work, a novel approach for transfer learning with quantum computing has been investigated, and focused on the acceptability judgement task on the Italian language using an annotated dataset.
Specifically, using BERT and ELECTRA embeddings, two quantum classifiers have been trained: BERT-Quant and ELECTRA-Quant. The training results demonstrate this approach’s potential: the metrics of BERT-Quant outperform the LSTM model while falling shortly behind BERT-Classic. ELECTRA-Quant, on the contrary, is comparable to all the models mentioned above, in terms of both accuracy and of MCC. A qualitative linguistic analysis of the training results, aided by the SHAP dendrograms, has shown differences in behavior based on the syntactic phenomena characterizing the sentence. It suggests new effective quantum-based management methods for complex linguistic structures, which have always been challenging to manage in NLP in inflectional languages such as Italian.
It is a promising result because it envisions not only the possibility of quantum transfer learning outperforming all of the significant standard transfer learning approaches, but also even beyond the NLP domain. The most intriguing features revealed by the experiments and the analysis lie in the ability of quantum computers to map the syntactic structures and the functional connection between constituents, composing the whole sentence more efficiently and with higher expressive power. This behavior is probably due to the structure of Hilbert space and to the intrinsic tensor operation performed by a quantum computer: the isomorphism between language, specifically the Lambek grammar, and the quantum operation was already demonstrated by Bob (Coecke et al. 2010). Future work will focus on the possibility of a more general isomorphism between syntactic properties and quantum computations beyond the specific task presented here and not limited to the Italian language. From a strictly linguistic point of view, the prediction and classification of acceptability judgements in NLP play a crucial role in improving the quality and fluency of various NLP applications, ranging from language models to language generation. By advancing the understanding and modeling of acceptability judgements, researchers aim to enhance the effectiveness and naturalness of human–computer interactions, making NLP systems more linguistically informed and aligned with human expectations.
It is worth mentioning that while quantum computing shows promise for NLP classification tasks, the field is still in its nascent stages, and many challenges need to be addressed. These challenges include the limited availability of quantum hardware, the development of quantum algorithms that effectively exploit the characteristics of language data, and the need for scalable and efficient quantum–classical hybrid systems to process large-scale language datasets. In summary, the exploration of quantum computing in NLP classification tasks offers a novel perspective on addressing language processing challenges. Quantum-inspired algorithms, quantum embeddings, and quantum machine learning models present exciting avenues for improving classification accuracy, semantic understanding, and computational efficiency. Further research and development in this interdisciplinary field have the potential to unlock new possibilities for quantum-assisted natural language processing.
Notes
References
Abbas A, Sutter D, Zoufal C, Lucchi A, Figalli A, Woerner S (2021) The power of quantum neural networks. Nat Comput Sci 1(6):403–409. https://doi.org/10.1038/s43588-021-00084-1
Abbaszade M, Salari V, Mousavi SS, Zomorodi M, Zhou X (2021) Application of quantum natural language processing for language translation. IEEE Access 9:130434–130448
Bates E, McNew S, MacWhinney B, Devescovi A, Smith S (1982) Functional constraints on sentence processing: A cross-linguistic study. Cognition 11(3):245–299. https://doi.org/10.1016/0010-0277(82)90017-8
Benedetti M, Lloyd E, Sack S, Fiorentini M (2019) Parameterized quantum circuits as machine learning models. Quantum Sci Technol 4(4):043001
Bergholm V, Izaac J, Schuld M, Gogolin C, Ahmed S, Ajith V, Sohaib Alam M, Alonso-Linaje G, AkashNarayanan B, Asadi A, Arrazola JM, Azad U, Banning S, Blank C, Bromley TR, Cordier BA, Ceroni J, Delgado A, Di Matteo O, Dusko A, Garg T, Guala D, Hayes A, Hill R, Ijaz A, Isacsson T, Ittah D, Jahangiri S, Jain P, Jiang E, Khandelwal A, Kottmann K, Lang RA, Lee C, Loke T, Lowe A, McKiernan K, Meyer JJ, Montañez-Barrera JA, Moyard R, Niu Z, O’Riordan LJ, Oud S, Panigrahi A, Park CY, Polatajko D, Quesada N, Roberts C, Sá N, Schoch I, Shi B, Shu S, Sim S, Singh A, Strandberg I, Soni J, Száva A, Thabet S, Vargas-Hernández RA, Vincent T, Vitucci N, Weber M, Wierichs D, Wiersema R, Willmann M, Wong V, Zhang S, Killoran N (2018) PennyLane: automatic differentiation of hybrid quantum-classical computations. arXiv e-prints arXiv:1811.04968. https://doi.org/10.48550/arXiv.1811.04968
Bohnet B, Nivre J, Boguslavsky I, Farkas R, Ginter F, Hajič J (2013) Joint morphological and syntactic analysis for richly inflected languages. Trans Assoc Comput Linguist 1:415–428
Bonetti F, Leonardelli E, Trotta D, Guarasci R, Tonelli S (2022) Work hard, play hard: collecting acceptability annotations through a 3d game. Proceedings of the thirteenth language resources and evaluation conference. European Language Resources Association, pp 1740–1750
Brunato D, Chesi C, Dell’Orletta F, Montemagni S, Venturi G, Zamparelli R (2020) Accompl-it @ EVALITA2020: overview of the acceptability & complexity evaluation task for Italian. In: Basile V, Croce D, Maro MD, Passaro LC (eds) Proceedings of the seventh evaluation campaign of natural language processing and speech tools for Italian. Final workshop (EVALITA 2020), Online event, December 17th, 2020, vol 2765. CEURWS.org, http://ceur-ws.org/Vol-2765/paper163.pdf. CEUR Workshop Proceedings
Brunato D, De Mattei L, Dell’Orletta F, Iavarone B, Venturi G (2018) Is this sentence difficult? Do you agree? In: Riloff E, Chiang D, Hockenmaier J, Hockenmaier J (eds) Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Brussels, Belgium, pp 2690–2699. https://doi.org/10.18653/v1/D18-1289
Chen SY-C, Huang C-M, Hsing C-W, Kao Y-J (2020a) Hybrid quantum-classical classifier based on tensor network and variational quantum circuit. arXiv preprint arXiv:2011.14651
Chen Z, Xu Y, Xie Z (2020b) Assessing introspective linguistic judgments quantitatively: the case of the syntax of Chinese. J East Asian Linguis 29(3):311–336
Cherniavskii D, Tulchinskii E, Mikhailov V, Proskurina I, Kushnareva L, Artemova E, Barannikov S, Piontkovski D, Burnaev E (2022) Acceptability judgements via examining the topology of attention maps. In: Goldberg Y, Kozareva Z, Zhang Y (eds) Findings of the association for computational linguistics: EMNLP 2022. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, pp 88–107. https://doi.org/10.18653/v1/2022.findings-emnlp.7
Clark K, Luong MT, Le QV, Manning CD (2020) ELECTRA: pre-training text encoders as discriminators rather than generators. In: ICLR. https://openreview.net/pdf?id=r1xMH1BtvB
Coecke B, de Felice G, Meichanetzidis K, Toumi A (2020) Foundations for near-term quantum natural language processing. arXiv preprint arXiv:2012.03755
Coecke B, Sadrzadeh M, Clark SJ (2010) Mathematical foundations for a compositional distributional model of meaning. Linguistic Analysis 36(1):345–384
Correia A, Moortgat M, Stoof H (2021) Grover’s algorithm for question answering. arXiv preprint arXiv:2106.05299
Devlin J, Chang MW, Lee K, Toutanova K (2019) BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, Volume 1 (Long and Short Papers). pp. 4171–4186. ACL, Minneapolis, Minnesota. https://doi.org/10.18653/v1/N19-1423, https://www.aclweb.org/anthology/N191423
Du Y, Huang T, You S, Hsieh MH, Tao D (2022) Quantum circuit architecture search for variational quantum algorithms. Npj Quantum Inf 8, 62(1). https://doi.org/10.1038/s41534-022-00570-y
Feldhausen I, Buchczyk S (2020) Testing the reliability of acceptability judgments for subjunctive obviation in French. In: Going romance 2020
Gianani I, Mastroserio I, Buffoni L, Bruno N, Donati L, Cimini V, Barbieri M, Cataliotti FS, Caruso F (2022) Experimental quantum embedding for machine learning. Adv Quantum Technol 5(8):2100140. https://doi.org/10.1002/qute.202100140
Guarasci R, Buonaiuto G, De Pietro G, Esposito M (2023) Applying variational quantum classifier on acceptability judgements: a qnlp experiment. Numerical Computations: Theory and Algorithms NUMTA 116
Guarasci R, Damiano E, Minutolo A, Esposito M, De Pietro G (2020) Lexicongrammar based open information extraction from natural language sentences in italian. Expert Syst Appl 143:112954
Guarasci R, De Pietro G, Esposito M (2022a) Quantum natural language processing: challenges and opportunities. Appl Sci 12(11):5651
Guarasci R, Silvestri S, De Pietro G, Fujita H, Esposito M (2021) Assessing BERT’s ability to learn Italian syntax: a study on null-subject and agreement phenomena. J Ambient Intell Humaniz Comput 14(1):289–303
Guarasci R, Silvestri S, De Pietro G, Fujita H, Esposito M (2022b) BERT syntactic transfer: a computational experiment on Italian, French and English languages. Comput Speech Lang 71:101261
Jentoft M, Samuel D (2023) NoCoLa: the Norwegian corpus of linguistic acceptability. In: Alumäe T, Fishel M (eds) Proceedings of the 24th Nordic conference on computational linguistics (NoDaLiDa). University of Tartu Library, Tórshavn, Faroe Islands, pp 610–617. https://aclanthology.org/2023.nodalida-1.60
Kim J-K, Kim Y-B, Sarikaya R, Fosler-Lussier E (2017) Cross-lingual transfer learning for {POS} tagging without cross-lingual resources. In: Palmer M, Hwa R, Riedel S (eds) Proceedings of the 2017 Conference on empirical methods in natural language processing. Copenhagen, Denmark, Association for Computational Linguistics, pp 2832–2838. https://doi.org/10.18653/v1/D17-1302
Lau JH, Clark A, Lappin S (2014) Measuring gradience in speakers’ grammaticality judgements. Proceedings of the annual meeting of the cognitive science society, vol 36, no 36. pp 99–105
Lau JH, Clark A, Lappin S (2015) Unsupervised prediction of acceptability judgements. In: Proceedings of the 53rd annual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing (Volume 1: Long Papers). 1618–1628. Association for Computational Linguistics, Beijing, China. https://doi.org/10.3115/v1/P151156, https://www.aclweb.org/anthology/P15-1156
Li G, Zhao X, Wang X (2022) Quantum self-attention neural networks for text classification. arXiv preprint arXiv:2205.05625
Li Q, Wang B, Zhu Y, Lioma C, Liu Q (2023) Adapting pre-trained language models for quantum natural language processing. arXiv preprint arXiv:2302.13812
Li W, Deng DL (2021) Recent advances for quantum classifiers. Sci China Phys Mech Astron 65(2):220301. https://doi.org/10.1007/s11433-021-1793-6
Linzen T (2019) What can linguistics and deep learning contribute to each other? Response to Pater. Language 95(1):e99–e108
Linzen T, Dupoux E, Goldberg Y (2016) Assessing the ability of lstms to learn syntaxsensitive dependencies. Trans Assoc Comput Linguist 4:521–535
Linzen T, Oseki Y (2018) The reliability of acceptability judgments across languages. Glossa: J Gen Linguist 3(1)
Liu H, Xu C (2012) Quantitative typological analysis of Romance languages. Poznań Studies in Contemporary Linguistics 48(4):597–625. https://doi.org/10.1515/psicl-2012-0027
Lloyd S, Schuld M, Ijaz A, Izaac J, Killoran N (2020) Quantum embeddings for machine learning. arXiv preprint arXiv:2001.03622
Ma X, Xu P, Wang Z, Nallapati R, Xiang B (2019) Domain Adaptation with {BERT}-based domain classification and data selection. In: Cherry C, Durrett G, Foster G, Haffari R, Khadivi S, Peng N, Ren X, Swayamdipta S (eds) Proceedings of the 2nd workshop on deep learning approaches for low-resource NLP (DeepLo 2019). Association for Computational Linguistics, Hong Kong, China, 76-83. https://doi.org/10.18653/v1/D19-6109
Mari A, Bromley TR, Izaac J, Schuld M, Killoran N (2020a) Transfer learning in hybrid classical-quantum neural networks. Quantum 4:340
Marvin R, Linzen T (2018) Targeted syntactic evaluation of language models. In: Riloff E, Chiang D, Hockenmaier J, Tsujii J (eds) Proceedings of the 2018 Conference on empirical methods in natural language processing. Association for Computational Linguistics, Brussels, Belgium, pp 1192–1202. https://doi.org/10.18653/v1/D18-1151
Meichanetzidis K, Toumi A, de Felice G, Coecke B (2020) Grammar-aware question-answering on quantum computers. arXiv preprint arXiv:2012.03756
Mikhailov V, Shamardina T, Ryabinin M, Pestova A, Smurov I, Artemova E (2022) RuCoLA: Russian corpus of linguistic acceptability. In: Goldberg Y, Kozareva Z, Zhang Y, (eds) Proceedings of the 2022 conference on empirical methods in natural language processing. Association for Computational Linguistics, pp 5207–5227. https://doi.org/10.18653/v1/2022.emnlp-main.348
Peters ME, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, Zettlemoyer L (2018) Deep contextualized word representations. In: Walker M, Ji H, Stent A (eds) Proceedings of the 2018 Conference of the North American Chapter of the association for computational linguistics: human language technologies, vol 1 (Long Papers). Association for Computational Linguistics, New Orleans, LO, pp 2227–2237. https://doi.org/10.18653/v1/N18-1202
Polignano M, Basile V, Basile P, de Gemmis M, Giovanni S (2019) AlBERTo: Italian BERT language understanding model for NLP challenging tasks based on Tweets. In: Proceedings of the Sixth Italian Conference on Computational Linguistics (CLiC-it 2019), vol 2481. CEUR
Qiu X, Sun T, Xu Y, Shao Y, Dai N, Huang X (2020) Pre-trained models for natural language processing: a survey. Sci China Technol Sci 63(10):1872–1897
Rodríguez-Pérez R, Bajorath J (2020) Interpretation of machine learning models using shapley values: application to compound potency and multi-target activity predictions. J Comput Aided Mol Des 34(10):1013–1026. https://doi.org/10.1007/s10822-020-00314-0
Rogers A, Kovaleva O, Rumshisky A (2020) A primer in bertology: what we know about how BERT works. Trans Assoc Comput Linguist 8:842–866
Ruder S, Ghaffari P, Breslin JG (2017) Knowledge adaptation: Teaching to adapt. arXiv preprint arXiv:1702.02052
Ruder S, Peters ME, Swayamdipta S, Wolf T (2019) Transfer learning in natural language processing. In: Sarkar A, Strube M (eds) Proceedings of the 2019 conference of the north American chapter of the association for computational linguistics: tutorials. Association for Computational Linguistics, Minneapolis, pp 15–18. https://doi.org/10.18653/v1/N19-5004
Sagae K, Gordon AS (2009) Clustering words by syntactic similarity improves dependency parsing of predicate-argument structures. In: Bunt, Harry, de la Clergerie EV. Proceedings of the 11th international conference on parsing technologies (IWPT '09). Association for Computational Linguistics, Paris, pp 192–201. https://aclanthology.org/W09-3829
Schuld M, Petruccione F, Schuld M, Petruccione F (2021) Quantum models as kernel methods. Machine learning with quantum computers. Springer International Publishing, Cham, pp 217–245
Schuster S, Gupta S, Shah R, Lewis M (2019) Cross-lingual transfer learning for multilingual task oriented dialog. In: Burstein J, Doran C, Solorio T (eds) Proceedings of the 2019 conference of the north American chapter of the association for computational linguistics: human language technologies, vol 1 (long and short papers). Association for Computational Linguistics, Minneapolis, pp 3795–3805. https://doi.org/10.18653/v1/N19-1380
Shah D, Lei T, Moschitti A, Romeo S, Nakov P (2018) Adversarial domain adaptation for duplicate question detection. In: Riloff E, Chiang D, Hockenmaier J, Tsujii J (eds) Proceedings of the 2018 conference on empirical methods in natural language processing. Association for Computational Linguistics, Brussels, pp 1056–1063. https://doi.org/10.18653/v1/D18-1131
Someya T, Oseki Y (2023) JBLiMP: Japanese benchmark of linguistic minimal pairs. In: Vlachos A, Augenstein I (eds) Findings of the association for computational linguistics: EACL 2023. Association for Computational Linguistics, Dubrovnik, pp 1581–1594. https://doi.org/10.18653/v1/2023.findings-eacl.117
Sordoni A, Nie J-Y, Bengio Y (2013) Modeling term dependencies with quantum language models for IR. In: Proceedings of the 36th international ACM SIGIR conference on research and development in information retrieval, pp 653–662
Sprouse J, Almeida D (2013) The empirical status of data in syntax: a reply to Gibson and Fedorenko. Lang Cogn Process 28(3):222–228
Sprouse J, Schütze C, Almeida D (2013a) Assessing the reliability of journal data in syntax: linguistic inquiry 2001–2010. Lingua 134:219–248
Sun C, Qiu X, Xu Y, Huang X (2019) How to fine-tune BERT for text classification? In: China national conference on Chinese computational linguistics. Springer, pp 194–206
Torlai G, Melko RG (2020) Machine-learning quantum states in the nisq era. Annu Rev Condens Matter Phys 11:325–344
Trotta D, Guarasci R, Leonardelli E, Tonelli S (2021) Monolingual and cross-lingual acceptability judgments with the Italian CoLA corpus. In: Moens M-F, Huang X, Specia L, Yih SW-t (eds) Findings of the association for computational linguistics: EMNLP 2021. Association for Computational Linguistics, Punta Cana, pp 2929–2940. https://doi.org/10.18653/v1/2021.findings-emnlp.250
Tsarfaty R, Seddah D, Goldberg Y, Kuebler S, Versley Y, Candito M, Foster J, Rehbein I, Tounsi L (2010) Statistical parsing of morphologically rich languages (SPMRL) what, how and whither. In: Seddah D, Koebler S, Tsarfaty R (eds) Proceedings of the NAACL HLT 2010 first workshop on statistical parsing of morphologically-rich languages. Association for Computational Linguistics, Los Angeles, pp 1–12. https://aclanthology.org/W10-1401
Vaswani A, No S, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems 30 (NIPS 2017)
Volodina E, Mohammed YA, Klezl J (2021) DaLAJ – a dataset for linguistic acceptability judgments for Swedish. In: Proceedings of the 10th workshop on NLP for computer assisted language learning. LiU Electronic Press, pp 28–37 https://aclanthology.org/2021.nlp4call-1.3
Wang A, Singh A, Michael J, Hill F, Levy O, Bowman S (2018) GLUE: a multi-task benchmark and analysis platform for natural language understanding. In: Linzen T, Chrupała G, Alishahi A (eds) Proceedings of the 2018 EMNLP workshop BlackboxNLP: analyzing and interpreting neural networks for NLP. Association for Computational Linguistics, Brussels, pp 353–355. https://doi.org/10.18653/v1/W18-5446
Warstadt A, Singh A, Bowman SR (2019) Neural network acceptability judgments. Trans Assoc Comput Linguist 7:625–641. https://doi.org/10.1162/tacl_a_00290https://www.aclweb.org/anthology/Q19-1040
Wiebe N (2020) Key questions for the quantum machine learner to ask themselves. New J Phys 22(9):091001. https://doi.org/10.1088/13672630/abac39
Xiang B, Yang C, Li Y, Warstadt A, Kann K (2021) CLiMP: a benchmark for Chinese language model evaluation. In: Proceedings of the 16th conference of the European chapter of the association for computational linguistics: main volume. Association for Computational Linguistics, pp 2784–2790. https://doi.org/10.18653/v1/2021.eacl-main.242
Zeng W, Coecke B (2016) Quantum algorithms for compositional natural language processing. Electron Proc Theor Comput Sci 221:67–75. https://doi.org/10.4204/eptcs.221.8
Funding
Open access funding provided by Consiglio Nazionale Delle Ricerche (CNR) within the CRUI-CARE Agreement. We acknowledge financial support from the project PNR MUR project PE0000013-FAIR.
Author information
Authors and Affiliations
Contributions
All the authors collaborated in writing the paper; in particular, G.B. was mainly concerned with the parts about the purely quantum domain, R.G.a the ones more focused on Natural Language Processing aspects, A.M. and M.E. those on machine and deep learning-based approaches. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Buonaiuto, G., Guarasci, R., Minutolo, A. et al. Quantum transfer learning for acceptability judgements. Quantum Mach. Intell. 6, 13 (2024). https://doi.org/10.1007/s42484-024-00141-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42484-024-00141-8