
Abstract
We investigate quantum circuits for graph representation learning, and propose equivariant quantum graph circuits (EQGCs), as a class of parameterized quantum circuits with strong relational inductive bias for learning over graph-structured data. Conceptually, EQGCs serve as a unifying framework for quantum graph representation learning, allowing us to define several interesting subclasses subsuming existing proposals. In terms of the representation power, we prove that the subclasses of interest are universal approximators for functions over the bounded graph domain. This theoretical perspective on quantum graph machine learning methods opens many directions for further work, and could lead to models with capabilities beyond those of classical approaches. We also provide experimental evidence, and observe that the performance of EQGCs scales well with the depth of the model.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In recent years, the field of quantum computing has made significant steps towards practical usefulness, which has sparked increasing interest in many areas, including machine learning (Perdomo-Ortiz et al. 2018; Benedetti et al. 2019). The growing field of quantum machine learning has since led to proposals for quantum analogs of many types of classical models, such as convolutional neural networks (Cong et al. 2019) and graph neural networks (Verdon et al. 2019).
Many existing quantum machine learning approaches rely on the assumption that the exponentially large Hilbert space spanned by possible quantum states will lead to an advantage compared to classical methods. This, however, is far from being clear: encoding useful quantum states efficiently and measuring them accurately are challenges that make straightforward speed-ups difficult (Aaronson 2015). Furthermore, since existing quantum devices are very limited, empirical benchmarks are often impossible at the scales where quantum methods might lead to a real advantage. Due to these difficulties, theoretical analysis plays a fundamental role, and recent works focusing on characterizing the capabilities and limitations of potential quantum models have shown significant results (Schuld et al. 2021; Liu et al. 2021; Kübler et al. 2021; Goto et al. 2021).
The goal of this paper is to establish a framework for learning functions over graphs using quantum methods and to study its theoretical properties. Graphs play a key role in modern machine learning, and are used to encode various forms of relational data, such as knowledge graphs (Bordes et al. 2011), social networks (Zhang and Chen 2018), and importantly also molecules (Wu et al. 2018), which are a particularly promising application domain of quantum computing due to their inherent quantum properties.
Graph neural networks (GNNs) (Kipf and Welling 2017; Veličković et al. 2018) are prominent models for classical relational learning, as they encode desirable properties such as permutation invariance (resp., equivariance) relative to graph nodes, enabling a strong relational inductive bias (Battaglia et al. 2018). While broadly applied, the expressive power of prominent GNN architectures, such as message-passing neural networks (MPNNs) (Gilmer et al. 2017), is shown to be upper bounded by the 1-dimensional Weisfeiler-Lehman graph isomorphism test (Xu et al. 2019; Morris et al. 2019). This limitation motivated a large body of work aiming at more expressive models, including higher- order models (Morris et al. 2019; Maron et al. 2019a), as well as extensions of MPNNs with unique node identifiers (Loukas 2020), or with random node features (Sato et al. 2021; Abboud et al. 2021).
In this paper, we investigate quantum analogs of GNNs and make the following contributions:
-
We define criteria for quantum circuits to respect the invariances of the graph domain, leading to equivariant quantum graph circuits (EQGCs) (Section 4).
-
We define equivariant hamiltonian quantum graph circuits (EH-QGCs) and equivariantly diagonalizable unitary quantum graph circuits (EDU-QGCs) as special subclasses, and relate these classes to existing proposals, providing a unifying perspective for quantum graph representation learning (Section 4.2).
-
We characterize the expressive power of EH-QGCs and EDU-QGCs, proving that they are universal approximators functions defined over arbitrarily large bounded graph domains. This result is achieved by showing a correspondence between EDU-QGCs and MPNNs enhanced with random node initialization which are universal approximators over bounded graphs (Abboud et al. 2021). Differently, our model does not require any extraneous randomization, and the result follows from the model properties (Section 5).
-
We experimentally show that even simple EDU-QGCs go beyond the capabilities of popular GNNs, by empirically verifying that they can discern graph pairs, which are indiscernible by standard MPNNs (Section 6).
This paper is based on work done for the MSc dissertation of the first author at the University of Oxford, first published in ICML 2022. This version includes extended details of all proofs and constructions.
The rest of this paper is organized as follows. We first discuss related work in the field of quantum machine learning in Section 2, then give an overview of important methods and results in graph representation learning that we build on in Section 3. After these preliminaries, we present our proposed framework and discuss important subclasses in Section 4, show our theoretical results on model expressivity in Section 5 and provide empirical evaluation in Section 6. We finish with a discussion of our results and possible further directions in Section 7.
2 Related work
The field of quantum machine learning includes a wide range of approaches. Early work had partial successes in speeding up important linear algebra subroutines (Harrow et al. 2009), but these methods usually came with caveats (e.g., requirements of the input being easy to prepare or being sparse, or approximate knowledge of the final state being sufficient) that made them hard to apply to large problem classes in practice (Aaronson 2015). Recent approaches tend to use quantum circuits to mimic or replace larger parts of classical techniques: quantum kernels use a quantum computer to implement a fixed kernel function in a classical learning algorithm (Schuld and Killoran 2019; Liu et al. 2021), while parameterized quantum circuits (PQCs) use tunable quantum circuits as machine learning models in a manner similar to neural networks (Perdomo-Ortiz et al. 2018; Benedetti et al. 2019). Lacking the possibility of standard backpropagation, there are alternative ways of calculating gradients (Schuld et al. 2019), and gradient-free optimization methods are also used (Ostaszewski et al. 2021). In this paper, we focus on PQCs.
There is also a growing body of work on the capabilities and limitations of such models. Ciliberto et al. (2018) and Kübler et al. (2021) give rigorous results about when we can and cannot expect the inductive bias quantum of kernels to give them an advantage over classical methods; Servedio and Gortler (2004) and Liu et al. (2021) demonstrate carefully chosen function classes that quantum kernels can provably learn more efficiently than any classical learner. PQCs have been harder to reason about due to their non-convex nature, but there have been important steps in showing conditions under which certain PQCs are universal function approximators over vector spaces (Schuld et al. 2021; Goto et al. 2021), similarly to multi-layer perceptrons in the classical world (Hornik et al. 1989). There has been also rigorous work on the PAC-learnability of the output distributions of local quantum circuits (Hinsche et al. 2021).
For learning functions over graphs, the literature is sparse: there are some proposals supported by small-scale experiments, but there is generally a lack of formal justification for the particular model choices. In particular, we are not aware of any theoretical work on the capabilities of these models. We propose a framework unifying PQC models that build a circuit for each example graph in a structurally appropriate way when running inference, such as Verdon et al. (2019), Zheng et al. (2021), and Henry et al. (2021). Such PQCs are also used as a building block by Ai et al. (2022), who apply them to subgraphs, thereby requiring fewer qubits and enabling scaling to larger graphs. We discuss considerations for these, and investigate their expressive power.
There are also other approaches that we do not cover, such as using edges primarily in classical pre- or post-processing steps of a PQC (Chen et al. 2021), or running a PQC for each node independently and using the connectivity only to formulate the error terms calculated from the measurements (Beer et al. 2021).
3 Graph neural networks
GNNs can be dated back to earlier works of Scarselli et al. and Gori et al. and are designed to have a graph-based inductive bias: the functions they learn should be invariant to the ordering of the nodes or edges of the graph, since the ordering is just a matter of representation and not a property of the graph. This includes invariant functions that output a single value that should be unchanged on permuting nodes, and equivariant functions that output a representation for each node, and this output is reordered consistently as the input is shuffled (Hamilton 2020).
Formally, a function f is invariant over graphs if, for isomorphic graphs \(\mathcal {G},{\mathscr{H}}\) it holds that \(f(\mathcal {G}) {=} f({\mathscr{H}})\); a function f mapping a graph \(\mathcal {G}\) with vertices \(V(\mathcal {G})\) to vectors \({\boldsymbol x\in \mathbb {R}^{a V(\mathcal {G})a}}\) is equivariant if, for every permutation π of \(V(\mathcal {G})\), it holds that \({f(\mathcal {G}^{\pi })=f(\mathcal {G})^{\pi }}\).
Message-passing neural networks (MPNNs) (Gilmer et al. 2017) are a popular and highly effective class of GNNs that iteratively update the representations of each node based on their local neighborhoods. In an MPNN, each node v is assigned some initial state vector \({\boldsymbol {h}}_{v}^{(0)}\) based on its features. This is iteratively updated based on the current state of its neighbors \(\mathcal N(v)\) and its own state, as follows:
where { {⋅} } denotes a multiset, and aggk(⋅) and upd(k)(⋅) are differentiable functions.
The choice for the aggregate and update functions varies across approaches (Kipf and Welling 2017; Veličković et al. 2018; Xu et al. 2019; Li et al. 2016). After several such layers have been applied, the final node embeddings are pooled to form a graph embedding vector to predict properties of entire graphs. The pooling often takes the form of simple averaging, summing or elementwise maximum.
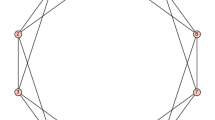
The expressive power of MPNNs is upper bounded by the 1-dimensional Weisfeiler-Lehman algorithm (1-WL) for graph isomorphism testing (Xu et al. 2019; Morris et al. 2019). Considering a pair of 1-WL indistinguishable graphs, such as those shown in Fig. 1, any MPNN will learn the exact same representations for these graphs, yielding the same prediction for both, irrespectively of the target function to be learned. In particular, this means that MPNNs cannot learn functions such as counting cycles, or detecting triangles.

Two graphs indistinguishable by 1-WL: \({\mathcal {G}}_{1}\) consisting of two triangles (left), and \({\mathcal {G}}_{2}\) being a single 6-cycle (right)
The limitations in the expressive power of GNNs motivated a large body of work. Xu et al. (2019) proposed the graph isomorphism networks (GINs), as maximally expressive MPNNs, and showed this model is as powerful as 1-WL, owing to its potential of learning injective aggregate-update functions. To break the expressiveness barrier, some approaches considered unique node identifiers (Loukas 2020), or random pre-set color features (Dasoulas et al. 2020), and alike, so as to make graphs discernible by construction (since 1-WL can distinguish graphs with unique node identifiers), but these approaches suffer in generalization. Other approaches are based on higher-order message passing (Morris et al. 2019), or higher-order tensors (Maron et al. 2019b; Maron et al. 2019a), and typically have a prohibitive computational complexity, making them less viable in practice.
Rather recently, MPNNs enhanced with random node initialization (Sato et al. 2021; Abboud et al. 2021) are shown to increase the expressivity without incurring a large computational overhead, and while preserving invariance properties in expectation. Sato et al. showed that such randomized MPNNs can detect any fixed substructure (e.g., a triangle) with high probability, and Abboud et al. proved that randomized MPNNs are universal approximators for functions over bounded graphs, building on an earlier logical characterization of MPNNs (Barceló et al. 2020). Intuitively, random node initialization assigns unique identifiers to different nodes with high probability and the model becomes robust via more sampling, leading to strong generalization. However, it is harder to train these models, since they need to see many different random labelings to eventually become robust to this variation. The extent of this effect can be mitigated by using fewer randomized dimensions (Abboud et al. 2021).
4 Equivariant quantum graph circuits
In this section, we give and describe the class of models we are considering and formalize the requirement of respecting the graph structure in our definition of equivariant quantum graph circuits. We then discuss two subclasses and their relation to each other.
4.1 Model setup
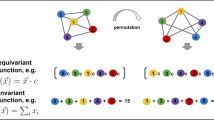
Let \({\mathbb {G}}^{n}\) be the set of graphs up to size n. Consider a graph \({\mathcal {G}} \in {\mathbb {G}}^{n}\), with adjacency matrix \({\boldsymbol {A}} \in \mathbb B^{n \times n}\) and a node feature vector xi for each node \(i \in \{1 {\dots } n\}\). We consider a broad class of models with the following simple structure, as shown in Fig. 2:
-
1.
For each node with features xi, a quantum state \(|{v_{i}}\rangle = |{\rho ({\boldsymbol {x}}_{i})}\rangle \in \mathbb {C}^{s}\) is prepared via some fixed feature map ρ(⋅). The dimensionality of this state is s = 2q when using q qubits per node.
-
2.
The node states are composed with the tensor product to form the product state \(|{{\boldsymbol {v}}}\rangle = \bigotimes _{i=1}^{n} |{v_{i}}\rangle \in \mathbb {C}^{s^{n}}\).
-
3.
We apply some circuit encoding a unitary matrix \({\boldsymbol {C}}_{{\boldsymbol {\theta }}}({\boldsymbol {A}}) \in \mathbb {C}^{s^{n} \times s^{n}}\), dependent on the adjacency matrix A and tunable parameters 𝜃, to the initial state of the system.
-
4.
Each node state is measured in the computational basis, leading to a one-hot binary vector \(|{y_{i}}\rangle \in \mathbb B^{s}\) for each node. Over the entire system, we measure any \(|{{\boldsymbol {y}}}\rangle = \bigotimes _{i=1}^{n} |{y_{i}}\rangle \in \mathbb B^{s^{n}}\) with probability P(y) = |〈y|C𝜃(A)|v〉|2 as dictated by the Born rule. This means the probability of any specific measurement is given by the magnitude of a single element in the final state vector \({\boldsymbol {C}}_{{\boldsymbol {\theta }}}({\boldsymbol {A}}) |{{\boldsymbol {v}}}\rangle \in \mathbb {C}^{n^{s}}\).
-
5.
These are aggregated by some permutation-invariant parameterized classical function \(g_{{\boldsymbol {\theta }}^{\prime }}\) to provide a prediction \(g_{{\boldsymbol {\theta }}^{\prime }}({\boldsymbol {y}})\).

Overview of our model setup. (a) A product state is prepared based on individual nodes, (b) a parameterized circuit C is applied based on the adjacency matrix A, (c) the nodes states are measured and (d) aggregated by some classical function g
While this setup rules out certain possibilities such as using mixed-state quantum computing with mid-circuit measurements, or somehow aggregating the node states inside the quantum circuit, it still leaves a broad and powerful framework that subsumes existing methods (as we will discuss in Section 4.2). We do not consider details of how to design the classical aggregator \(g_{{\boldsymbol {\theta }}^{\prime }}\) — for questions of expressivity, we will simply assume that it is a universal approximator over multisets, which is known to be achievable by combining multi-layer perceptrons with sum aggregation (Zaheer et al. 2017; Xu et al. 2019). The choice of the feature map ρ does have to be made upfront, but our proofs all use simple constructions encoding the data in the computational basis.
Our focus is instead on the circuit C𝜃(A), and how it should behave in order to interact well with the graph. As in the case of classical GNNs, we want to make sure the ordering of nodes and edges does not matter. In our case, this means that for any input, reordering the nodes and edges should reorder the probabilities of all measurements appropriately.
Example 1
With n = 3 nodes represented by a single qubit each (s = 2), the probability of observing some output 〈y1y2y3| is p = 〈y1y2y3|C𝜃(A)|v1v2v3〉. If we cycle the nodes around to form the input state |v2v3v1〉, and also use an appropriately reordered adjacency matrix \({\boldsymbol {A}}^{\prime }\), we should find the probability of the reordered observation \(\langle {y_{2}y_{3}y_{1}}|{\boldsymbol {C}}_{{\boldsymbol {\theta }}}({\boldsymbol {A}}^{\prime })|{v_{2}v_{3}v_{1}}\rangle \) to be p as well.
This brings us to the definition of equivariant quantum graph circuits (EQGCs):
Definition 1
Let \({\boldsymbol {A}} \in {\mathbb {B}}^{n \times n}\) be an adjacency matrix, \({{\boldsymbol {P}} \in {\mathbb {B}}^{n \times n}}\) a permutation matrix representing a permutation p over n elements, and \(\tilde {{\boldsymbol {P}}} \in {\mathbb {B}}^{s^{n} \times s^{n}}\) a larger matrix that reorders the tensor product, mapping any \(|{v_{1}}\rangle |{v_{2}}\rangle \dots |{v_{n}}\rangle \) with \(|{v_{i}}\rangle \in \mathbb {C}^{s}\) to \(|{v_{p(1)}}\rangle |{v_{p(2)}}\rangle \dots |{v_{p(n)}}\rangle \).
An EQGC is an arbitrary parameterized function C𝜃(⋅) mapping an adjacency matrix \({\boldsymbol {A}} \in {\mathbb {B}}^{n \times n}\) to a unitary \({\boldsymbol {C}}_{{\boldsymbol {\theta }}}({\boldsymbol {A}}) \in \mathbb {C}^{s^{n} \times s^{n}}\) that behaves equivariantly for all 𝜃:
In the following sections, we will generally leave the parameter 𝜃, and sometimes also A, as implicit when they are clear from context.
In accordance to our model setup, an EQGC C𝜃(⋅) represents a probabilistic model over graphs only when combined with a fixed feature map ρ(⋅) to prepare each node state, as well as measurement and classical aggregation \(g_{{\boldsymbol {\theta }}^{\prime }}\) at the end of the circuit. Putting these together, we can formally speak of the capacity of EQGCs in representing functions.
Definition 2
We say that a (Boolean or real) function f defined on \({\mathbb {G}}^{n}\) can be represented by an EQGC C𝜃 with error probability 𝜖 if there is some feature map ρ and invariant classical aggregation function g𝜃, such that for any input graph \({\mathcal {G}} \in {\mathbb {G}}^{n}\) the model’s output is \(f({\mathcal {G}})\) with probability 1 − 𝜖. In the special case, where 𝜖 = 0, we simply say that the function f can be represented by an EQGC C𝜃.
Remark 1 (A note on directedness)
Unlike many works on GNNs, our definition of EQGCs allows us to consider directed graphs naturally, and this will also be true for the subclasses we consider later. Of course, we can still easily operate on undirected data by either adding edges in both directions, or placing extra restrictions on our models. For the purposes of expressivity, we will still focus on classifying graphs in the undirected case, as this is better explored in previous works on classical methods.
4.2 Subclasses of EQGCs
Note that we cannot and should not aim to use all possible EQGCs as a model class. If we did, the prediction of our models on any graph would not restrict their behavior on other, non-isomorphic graphs in any way. This would not only make such a class impossible to characterize with a finite set of parameters 𝜃, but the models would also have no way to generalize to unseen inputs. Therefore, EQGCs should be seen as a broad framework, and we investigate more restricted subclasses that do not have such problems.
We are particularly interested in subclasses that scale well with the number of nodes in a graph, so in the following sections we discuss approaches based on uniform single-node operations and two-node interactions at edgesFootnote 1. All of the following models are parameterized by identical operations being applied for each node or for each edge, ensuring that a single model can efficiently learn about graphs of various sizes. It is also a useful starting point for ensuring equivariance, although as we will see, we also have to make sure that the ordering of these operations does not affect our results.
Note however that for the sake of making our analysis feasible, our model classes are not closely tied to realizations in quantum gates. We consider arbitrary Hamiltonian and unitary operators which can be approximated with a universal gate set to any required accuracy, but this might require very deep circuits. Due to this as well as the number of qubits required that we derive in Theorem 2, we do not expect our specific constructions to be practically realized in near-term hardware — rather, their primary value is in characterizing the capabilities of a broad class of models, and we leave more practical parameterizations for future work.
4.2.1 Parameterization by Hamiltonians
Operations on the quantum states of nodes or pairs of nodes can be easily represented as unitaries, but these are tricky to parameterize directly: e.g., a linear combination of unitaries is not unitary generally. One alternative is to use the fact that any unitary U can be expressed using its Hamiltonian H, a Hermitian matrix of the same size such that \({\boldsymbol {U}} = \exp (-i{\boldsymbol {H}})\). We can let the Hamiltonian depend linearly on the adjacency matrix, with Hermitian operators applied based on the structure of the graph:
Definition 3
An equivariant hamiltonian quantum graph circuit (EH-QGC) is an EQGC given by a composition of finitely many layers \({\boldsymbol {C}}_{{\boldsymbol {\theta }}}({\boldsymbol {A}}) = {\boldsymbol {L}}_{{\boldsymbol {\theta }}_{1}}({\boldsymbol {A}}) \circ {\dots } \circ {\boldsymbol {L}}_{{\boldsymbol {\theta }}_{k}}({\boldsymbol {A}})\), with each \({\boldsymbol {L}}_{{\boldsymbol {\theta }}_{j}}\) for 1 ≤ j ≤ k given as:
where the parameter set 𝜃 = (H(edge), H(node)) is comprised of two Hermitian matricesFootnote 2 over one- and two-node state, and the indexing \({\boldsymbol {H}}^{\text {(edge)}}_{j,k}, {\boldsymbol {H}}^{\text {(node)}}_{v}\) refers to the same operators applied at the specified node(s) — i.e., one EH-QGC layer is fully specified by a single one-node Hamiltonian and a single two-node Hamiltonian.
This means that if the graph is permuted, the operators will be applied at changed positions appropriately. There is also no sequential ordering of operations in a summation, so the model is equivariant. For example, \({\boldsymbol {H}}^{\text {(node)}}_{3} = {\boldsymbol {I}} \otimes {\boldsymbol {I}} \otimes \hat {\boldsymbol {H}}^{\text {(node)}} \otimes {\boldsymbol {I}}\) in the case of n = 4 nodes.
EH-QGCs is closely related to the approach taken by Verdon et al. (2019) for their quantum graph convolutional neural network (QGCNN) model as well as the parameterized quantum evolution kernel of Henry et al. (2021). They both define operations in terms of Hamiltonians based on the graph structure. The difference is that for any given learning tasks, they consider a restricted class of models with hand-picked Hermitians, and leave only scalar weights multiplying these as learnable parameters. This helps for efficiently compiling small circuits, and allows better scaling to a larger number of qubits per node (which should be possible on future hardware). If we consider the full set of possible choices for these QGCNNs models, we get exactly our set of EH-QGCs as defined above. For our purposes, working with the broader class of arbitrary Hamiltonians lends itself better to theoretical analysis, and we leave it to future work to investigate circuit classes with better scaling in the number of qubits.
4.2.2 Parameterization by commuting unitaries
A similar, but more direct approach would be to consider two-node unitaries instead of Hamiltonians and apply a single learned unitary for each edge of the graph. As before, this ensures the number of operations scales linearly with the number of edges in a graph. This is also the approach taken by Zheng et al. (2021), but we need to add extra conditions that they do not consider to ensure equivariance.
Specifically, we need to enforce that the order we apply these unitaries in does not matter. This gives us the following commutativity condition for a two-node unitary U:

If the graphs are undirected, we should ensure the following to make sure the direction of the edge representation does not affect our predictions:

In the case of directed graphs, Eq. 4 need not apply, but Eq. 3 is also not sufficient in itself, since we need to consider cases where the unitary might be applied in different directions. Specifically, we need to ensure the following extra conditions:



Equation 5 ensures commutativity of directed edges to the same target, Eq. 6 of edges from the same source, and Eq. 7 of 2 cycles between two nodes.
Of course, such a directed unitary can also be used for directed graphs by applying it in both directions: in fact, if Eq. 7 is satisfied, this composition itself satisfies the undirected Eq. 4:



It is not clear whether we can parameterize the space of all such commuting unitaries, but we can focus on a subclass.
Definition 4
An equivariantly diagonalizable unitary (EDU) is a unitary that can be expressed in the form U = (V‡⊗V‡)D(V ⊗V) for a unitary \({\boldsymbol {V}}\in \mathbb {C}^{s \times s}\) and diagonal unitary \({\boldsymbol {D}} \in \mathbb {C}^{s^{2} \times s^{2}}\).
Note that all unitaries can be diagonalized in the form U = P‡DP for some other unitary P and diagonal unitary D. The above is simply the case when P decomposes as V ⊗V for one single-node unitary V. All EDUs satisfy the given commutativity conditions. Using the facts that I ⊗D is still a diagonal matrix and that diagonal matrices commute, we can see that equivariantly diagonalizable unitaries satisfy Eq. 3:

The directed versions (Eqs. 5, 6 and 7) are similar, since V ⊗V and V‡⊗V‡ commute with the swap, and then analogous derivations apply.
Furthermore, a square matrix is unitary if and only if all of its eigenvalues (the diagonal elements of D) have absolute value 1. We can therefore parameterize these unitaries by combining arbitrary single-node unitaries V with diagonal matrices D of unit modulus numbersFootnote 3.
This allows us to parameterize the following class of EQGCs:
Definition 5
An equivariantly diagonalizable unitary quantum graph circuit (EDU-QGC) is an EQGC expressed as a composition of node layersLnode and edge layersLedge given as follows on a graph with node and edge sets \((\mathcal V, \mathcal E)\):
In short, we either apply the same single-node unitary to all nodes, or we apply the same EDU appropriately for each edge. Since both types of layers are equivariant by construction, so is their composition, hence EDU-QGCs are a valid EQGC class.
It can be shown that EDU-QGCs are a subclass of the Hamiltonian-based EH-QGCs discussed in Section 4.2.1. This is particularly useful for investigating questions of expressivity: we also get a result about the expressivity of EH-QGCs by showing the existence of EDU-QGC constructions representing some function.
Theorem 1
Any EDU-QGC can be expressed as an EH-QGC.
To show this result, we consider node layers and edge layers separately and show that both can be represented by one or more EH-QGC layers. We first prove the case for node layers, then diagonal edge layers; finally, we build on these two to prove the case for all edge layers, completing the proof. The details are provided in Appendix A.
5 Expressivity results
In this section, we analyze the expressivity of the EQGCs discussed in Section 4.2: Hamiltonian-based EH-QGCs and EDU-QGCs defined using commuting unitaries.
Quantum circuits operate differently from MPNNs and other popular GNN architectures, so one might hope that they are more expressive. Since current classical methods with high expressivity are either computationally expensive (like higher-order GNNs) or require a large number of training samples to converge (like GNNs with random node initialization), this could in principle lead to a form of quantum advantage with sufficiently large-scale quantum computers.
We first show that EDU-QGCs subsume MPNNs: a class of MPNNs, including maximally expressive architectures, can be “simulated” by a suitable EDU-QGC configuration. We then prove that they are in fact universal models for arbitrary functions on bounded-size graphs, building on prior results regarding randomized MPNNs. Since we have proven EDU-QGCs to be a subclass of EH-QGCs in Theorem 1, the results immediately follow for EH-QGCs as well.
5.1 Simulating MPNNs
Recall that MPNNs are defined via aggregate and combine functions in Eq. 3. In this section, we focus on MPNNs where the aggregation is of the form \(\textsc {agg}^{(k)}(\{\!\!\{{\boldsymbol {h}}_{i}\}\!\!\}) = {\sum }_{i} {\boldsymbol {h}}_{i}\), which includes many common architectures.
Remark 2
We consider MPNNs node states with real numbers represented in fixed-point arithmetic. Although GNNs tend to be defined with uncountable real vector state spaces, these can be approximated with a finite set if the data is from a bounded set.
We show that EDU-QGCs can simulate MPNNs with sum aggregation in the following sense:
Theorem 2
Any (Boolean or real) function over graphs that can be represented by an MPNN with sum aggregation, can also be represented by an EDU-QGC.
We prove this result by giving an explicit construction to simulate an arbitrary MPNN with sum aggregation, detailed in Appendix B.1. In particular, our construction for Theorem 2 implies that for an MPNN with k layers with an embedding dimensionality of w, with a fixed-point real representation of b bits per real number, this EDU-QGC needs (2k + 1)wb qubits per node.
Since MPNNs with sum aggregation (e.g., GINs) can represent any function learnable by any MPNN (Xu et al. 2019), we obtain the following corollary to Theorem 2:
Corollary 2.1
Any (Boolean or real) function that can be represented by any MPNN can also be represented by some EDU-QGC.
5.2 Universal approximation
We build on results about randomization in classical MPNNs, discussed in Section 3 (Sato et al. 2021; Abboud et al. 2021), to show that our quantum models are universal.
We simulate classical models that randomize some part of the node state by putting some qubits into the uniform superposition over all bitstrings, then operating in the computational basis. Unlike in the classical case, where this randomization had to be explicitly added to extend model capacity, we can do this without modifying our model definition — our results apply to EDU-QGCs and their superclasses. Analogously to the universality of MPNNs with random features, this allows us to prove the following theorem:
Theorem 3
For any real function f defined over \({\mathbb {G}}^{n}\), and any 𝜖 > 0, an EDU-QGC can represent f with an error probability 𝜖.
We cannot directly rely on the results of either Abboud et al. (2021) or Sato et al. (2021): although our theorem is analogous to that of Abboud et al., they used MPNNs extended with readouts at each layer, which our quantum models cannot simulate. Sato et al. used MPNNs without readouts, but did not quite prove such a claim of universality. Therefore, we give a novel MPNN construction that is partially inspired by Sato et al., but relies solely on the results of Xu et al. (2019), and use it to show Theorem 3.
Briefly, we use the fact that for bounded-size graphs individualized by random node features, a GIN can in principle assign final node states that injectively depend on the isomorphism class of each node’s connected component. These node embeddings can be pooled to give a unique graph embedding for each isomorphism class of bounded graphs, which an MLP can map to any desired results. All of this can be simulated on an EDU-QGC, hence they are universal models. The details are given in Appendix B.2.
6 Empirical evaluation
While our primary focus is theoretical, and it is challenging to execute experiments large enough to give interesting results, we performed two small experiments as well. We first look at a very restricted EDU-QGC model and observe that it can the graphs \({\mathcal {G}}_{1}\) and \({\mathcal {G}}_{2}\) with nontrivial probability (which is beyond the capabilities of MPNNs), and also reason about this simple case analytically. After this, we construct a small classification dataset of cycle graphs in a way that MPNNs could achieve no more than 50% accuracy, and we successfully train deeper EDU-QGCs to high performance.
6.1 Testing expressivity beyond 1-WL
We performed a simple experiment to verify that EDU-QGC models can give different outputs for graphs that are indistinguishable by deterministic classical MPNNs. As our inputs, we used the two graphs \({\mathcal {G}}_{1}\) and \({\mathcal {G}}_{2}\) shown in Fig. 1 without node features (i.e., fixed initial node states in our quantum circuit), the simplest example where MPNNs fail. Our models should identify which graph is input. Using a single qubit per node, we expect our accuracy to be better than 50%, but far from perfect.
Experimental setup
To keep the experiment as simple as possible, we used a very simple subset of EDU-QGCs parameterized by a single variable α, similar to instantaneous quantum polynomial circuits (Bremner et al. 2016):
-
Each node state |vi〉 is initialized as the \(|{+}\rangle =H|{0}\rangle =\frac {1}{\sqrt 2}(|{0}\rangle +|{1}\rangle )\) state on one-node qubit (q = 1). By \(H = \frac {1}{\sqrt 2}\left (\begin {array}{cc} 1 & 1 \\ 1 & -1 \end {array}\right )\) we denote the Hadamard gate.
-
We apply an edge layer as given by Eq. 11, with a \(CZ(\alpha ) = \text {diag}(1,1,1,\exp (-i\alpha ))\) gate as the applied unitary acting on two neighboring node-qubits.
-
We apply a node layer with an H gate at each node.
-
After a single measurement, we measure k nodes as a |1〉 state and 6 − k as |0〉. For each value of k, the aggregator gα(⋅) can map this to a different prediction.
Using ZX-diagram notation (Coecke and Kissinger 2018), Fig. 3 (top) shows the circuits we get for our choice of C in the case of \({\mathcal {G}}_{1}\) and \({\mathcal {G}}_{2}\). The probabilities of observing k |1〉s for each graph and all possible values of k as a function of our single parameter α are also shown in Fig. 3 (bottom).

The two circuits in the experiment in top-to-bottom ZX-diagram notation, with the α-box between white spiders representing a CZ(α) gate (a standard ZX-calculus shorthand (Coecke and Kissinger 2018)), followed by probabilities of observing given number of |1〉s as a function of α ∈ [−π,π] for each circuit. The two distributions differ most visibly when α is near ± π
We find that as α gets near ± π, the distributions of the number of |1〉s measured do differ, and an accuracy of 0.625 is achievable with a single measurement shot (and an arbitrarily low error rate can be achieved with a sufficiently high number of measurements). This would naturally get better as we increase the number of qubits used, but this already shows an expressivity exceeding that of deterministic MPNNs.
6.1.1 Theoretical analysis of the experiment
In an effort to better understand the power of such circuits, we focused on analyzing the most well-behaved special case of the above EDU-QGC, with CZ(π) rotations and were able to analytically derive the observed measurement probabilities of this simple IQP circuit for any graph consisting of cycles.
Using the ZX-calculus, we show that applying it to any n-cycle graph results in a uniform distribution over certain measurement outcomes, give a simple algorithm to check for a given n-length bitstring whether it is one of these possible outcomes, and prove that the number of measured |1〉s always has the same parity as the size n of the graph.
With α = π, the α-boxes representing the CZ-gates in Fig. 3 turn into simple Hadamard. So for any specific bitstring \(|{b_{1}{\dots } b_{n}}\rangle \), we can get the probability of measuring it by simplifying the following scalar:

where the numerical term comes from normalizing each CZ-gate with a factor of \(\sqrt {2}\).
We can substitute the appropriate white and gray spiders for the |+〉,|0〉 and |1〉 states to apply ZX-calculus techniques (Coecke and Kissinger 2018): a white spider with phase 0 for the |+〉 state, and gray spiders with 0 and π phases respectively for |0〉 and |1〉. All of these need to be normalized with a factor of \(\frac {1}{\sqrt 2}\). Due to the Hadamard gates, these all turn into white spiders that can be fused together, so this is equal to a simple trace calculation:

where αi = 0 ifbi = 0 andπ ifbi = 1.
This can be simplified step by step. Firstly, as long as there are any spiders with αi = 0 and two distinct neighbors (i.e., there are at least 3 nodes in total), we can remove them and fuse their neighbors:

After repeating this, we get one of two outcomes. Firstly, we might end up with one of 3 possible circuits with that still have some αi = 0 but less than 3 nodes, which we can evaluate by direct calculation of their matrices:

Or all the remaining spiders have αi = π, we can repeatedly eliminate them in groups of 4:

On repeating this, we end up with 0 to 3 nodes with αi = π, which we can evaluate directly:

Observe that during the simplifications, we only introduced phases with an absolute value of 1, which do not affect measurement probabilities. Furthermore, we always decreased the number of nodes involved by 2 or 4, hence the parity is unchanged. This means for odd n, we will always end up with one of the odd-cycle base cases with a trace of 0 or \(\pm \sqrt 2\), while for even n, we get to the even-cycle base cases with traces of 0 or 2.
Combining with the initial coefficient of \(\big (\frac {1}{\sqrt 2}\big )^{n}\) and taking squared norms, we get that for odd n, each bitstring is observed with probability 0 or \(\frac {1}{2^{n-1}}\) (so half of all possible bitstrings are observed), while with even n, each bitstring is observed with probability 0 or \(\frac {1}{2^{n-2}}\) (so we see only a quarter of all bitstrings).
Furthermore, to check which bitstrings are observed, we can summarize the ZX-diagram simplification as a simple algorithm acting on cyclic bitstrings (where the first and last bits are considered adjacent):
-
As long as there is a 0 in the bitstring and the length of the bitstring is more than 2, remove the zero along with its two neighbors, and replace them with the XOR of the neighbors.
-
If you end up with just |00〉, the state has a positive probability to be observed. If you end up with |0〉 or |01〉, it has 0 probability.
-
When there are only |1〉s remaining, if the number of these is 2 mod 4, the input has 0 probability to be observed, otherwise positive.
This shows us why the observed number of |1〉s always has the same parity as n: at each step, both the parity of |1〉s and the parity of the bitstring’s length is unchanged. The only even-length base case with an odd number of ones is |01〉, which corresponds to states with 0 probability; and similarly the only odd-length base case with an even number of ones is |0〉, which has the same outcome.
We can also derive the specific probabilities observed in the experiment. It’s easy to see from this that in the case of a triangle, the observable states are |001〉,|010〉,|100〉,|111〉. This allows us to calculate the probabilities observed for the case of two triangles. For the 6-cycle, the observable states are |000000〉, six rotations of |000101〉, six rotations of |001111〉, and three rotations of |101101〉, giving the expected probabilities as well.
6.2 Synthetic dataset of cycle graphs
We created a synthetic dataset of 6- to 10-node graphs consisting of either a single cycle, or two cycles. The single-cycle graphs were oversampled to create two equally sized classes for a binary classification task. Eight-cycle graphs were reserved for evaluation, while all others were used for training.
We trained EDU-QGC models of various depths with a single qubit per node on this dataset. Each node state was initialized as \(|{+}\rangle =\frac {1}{\sqrt 2}(|{0}\rangle +|{1}\rangle )\), then an equal number \(k\in \{1, \dots , 14\}\) general node and edge layers were applied alternatingly. After measurement, the fraction of observed |1〉s was used to predict the input’s class through a learnable nonlinearity. Exact probabilities of possible outcomes were calculated, and the Adam optimizer was used to minimize the expected binary cross-entropy loss for 100 epochs, with an initial learning rate of 0.01 and an exponential learning rate decay with coefficient of 0.99 applied at each epoch.
Results are shown in Fig. 4. We report the one-sample accuracy (the average probability of a correct prediction across the dataset), and the highest achievable many-sample accuracy (the fraction of the dataset where a model was right with at least 50% probability). Importantly, we observe a consistent benefit from increasing depth, in contrast with the oversmoothing problems of GNNs (Li et al. 2018). We also did not experience any issues with the near-zero gradients or “barren plateaus” that make it challenging to optimize many PQC models (McClean et al. 2018), although we have not investigated whether this would hold with the noisy gradients one would get in a real quantum experiment as opposed to our exact classical simulation.

Accuracies of EDU-QGC models on the synthetic cycles dataset. The many-sample accuracy bound is calculated as the fraction of examples in the dataset where the model was correct with more than 50% accuracy. Results are based on an average of 10 runs, with the shaded region representing standard deviation
Interestingly, the model performs better on the evaluation set than the training set. This is due to the fact that it is hard for the model to reliably correctly classify 9- and 10-node graphs containing two cycles when these contain subgraphs that are in the one-cycle class. For example, the model associates a high number of measured |1〉s with single-cycle graphs, then a 6-cycle will lead to many |1〉s. Since a disjoint union of a 6-cycle and a 3-cycle contains this subgraph, it will also have a relatively high fraction of |1〉s, leading to an incorrect prediction. Clearly, this would not be an issue if more qubits per node could be used (which may be feasible in future): the size of a cycle could be encoded exactly in the larger set of possible observations, and this could be easily aggregated invariantly to count the number of cycles. Note also that one of 10 runs with was dropped as an outlier in the case of 4 layers. Through some unlucky initialization, the model failed to learn anything and stayed at 50% accuracy in this single run.
6.2.1 Effective parameter count
The model was able to fit this dataset with a very small number of parameters: after accounting for redundancy, the model contains only 6 real-valued degrees of freedom for each pair of node and edge layers:
-
The node layer is given by an arbitrary single-qubit unitary, which can be given by 3 Euler-angle rotations of the Bloch sphere.
-
The edge layer can involve an arbitrary equivariantly diagonalizable unitary (V ⊗V)D(V‡⊗V‡) as given in Definition 4. However, the V is redundant when surrounded by two-node layers applying single-node unitaries U1, U2 everywhere: modifying these to be V ×U1 and \({\boldsymbol {U}}_{2} \times {\boldsymbol {V}}^{\dagger }\) respectively would have the same effect. Hence it suffices to consider the diagonal unitary D, which applies some phase in each of the |00〉,|01〉,|10〉 and |11〉 cases. To satisfy the undirected graph constraint of Eq. 4, the phases for |01〉 and |10〉 need to be the same. This leaves us with 3 real parameters for each of the phases.
Note that in order to have an efficient implementation, we implemented edge layers as just diagonal unitaries over two nodes. This is justified by the above argument regarding their redundancy for all layers except the last, which is not surrounded by node layers — in this case it could slightly affect the performance of the model in principle.
7 Conclusions, discussions, and outlook
In this paper, we proposed equivariant quantum graph circuits, a general framework of quantum machine learning methods for graph-based machine learning, and explored possible architectures within that framework. Two subclasses, EH-QGCs and EDU-QGCs, were proven to have desirable theoretical properties: they are universal for functions defined up to a fixed graph size, just like randomized MPNNs. Our experiments were small-scale due to the computational difficulties of simulating quantum computers classically, but they did confirm that the distinguishing power of our quantum methods exceeds that of deterministic MPNNs.
By defining the framework of EQGCs and their subclasses, many questions can be raised that we did not explore in this paper. EDU-QGCs and EH-QGCs have important limitations: using arbitrary node-level Hamiltonians or unitaries allowed us to show expressivity results, but they are not feasible to scale to a large number of qubits per node, since the space of parameters grows exponentially. Perhaps a small number of qubits will already turn out to be useful, but EQGC classes with better scalability to large node states should also be investigated.
There are also design choices beyond the EQGC framework that might be interesting. For example, rather than measuring only at the end of the circuit, mid-circuit measurements and quantum-classical computation might offer possibilities that we have not analyzed.
Ultimately, the biggest questions in the field of quantum computing are about quantum advantage: what useful tasks can we expect quantum computers to speed up, and what kind of hardware do these applications require? Recent work on the theoretical capabilities of quantum machine learning architectures is already contributing to this: it has been shown that we can carefully engineer artificial problems that provably favor quantum methods (Kübler et al. 2021; Arute et al. 2019; Liu et al. 2021), but this is yet to be seen for practically significant problem classes. At the same time, there are convincing arguments that quantum computers will be useful for computational chemistry tasks such as simulating molecular dynamics, where EQGCs could be useful, which is a direction worth exploring.
Notes
We also considered the case, where C𝜃(⋅) depends only on the graph size rather than the adjacency matrix, and we report these findings in Appendix C as they are not central to our main results.
Technically 𝜃 should be considered to cover the upper triangular half of each matrix, since the second half follows from the Hermitian property.
To add the inductive bias of undirected graphs, we can set D|e1e2〉 = D|e2e1〉 for any computational basis vectors |e1〉,|e2〉, approximately halving the number of free parameters.
References
Aaronson S (2015) Read the fine print. Nat Phys 11(4):291–293
Abboud R, Ceylan İİ, Grohe M et al (2021) The surprising power of graph neural networks with random node initialization. In: IJCAI
Ai X, Zhang Z, Sun L et al (2022) Decompositional quantum graph neural network. arXiv:220105158
Arute F, Arya K, Babbush R et al (2019) Quantum supremacy using a programmable superconducting processor. Nature 574(7779):505–510
Barceló P, Kostylev EV, Monet M et al (2020) The logical expressiveness of graph neural networks. In: ICLR
Battaglia PW, Hamrick JB, Bapst V et al (2018) Relational inductive biases, deep learning, and graph networks. arXiv:180601261
Beer K, Khosla M, Köhler J et al (2021) Quantum machine learning of graph-structured data. arXiv:210310837
Benedetti M, Lloyd E, Sack S, et al. (2019) Parameterized quantum circuits as machine learning models. Quant Sci Technol 4(4):043,001
Bordes A, Weston J, Collobert R et al (2011) Learning structured embeddings of knowledge bases. In: AAAI
Bremner MJ, Montanaro A, Shepherd DJ (2016) Average-case complexity versus approximate simulation of commuting quantum computations. Phys Rev Lett 117(8):080,501
Chen SYC, Wei TC, Zhang C et al (2021) Hybrid quantum-classical graph convolutional network. arXiv:210106189
Ciliberto C, Herbster M, Ialongo AD, et al. (2018) Quantum machine learning: a classical perspective. Proc R Soc A: Math Phys Eng Sci 474(2209):20170,551
Coecke B, Kissinger A (2018) Picturing quantum processes. In: International conference on theory and application of diagrams. Springer, pp 28–31
Cong I, Choi S, Lukin M D (2019) Quantum convolutional neural networks. Nat Phys 15 (12):1273–1278
Dasoulas G, Santos LD, Scaman K et al (2020) Coloring graph neural networks for node disambiguation. In: IJCAI
Gilmer J, Schoenholz SS, Riley PF et al (2017) Neural message passing for quantum chemistry. In: ICML. PMLR, pp 1263–1272
Gori M, Monfardini G, Scarselli F (2005) A new model for learning in graph domains. In: IJCNN
Goto T, Tran QH, Nakajima K (2021) Universal approximation property of quantum machine learning models in quantum-enhanced feature spaces. Phys Rev Lett 127(9):090,506
Hamilton WL (2020) Graph representation learning. Synth Lect Artif Intell Mach Learn 14 (3):1–159
Harrow AW, Hassidim A, Lloyd S (2009) Quantum algorithm for linear systems of equations. Phys Lett 103(15):150,502
Henry LP, Thabet S, Dalyac C et al (2021) Quantum evolution kernel: Machine learning on graphs with programmable arrays of qubits. Phys Rev A 104(3):032,416
Hinsche M, Ioannou M, Nietner A et al (2021) Learnability of the output distributions of local quantum circuits. arXiv:2110.05517
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Netw 2(5):359–366
Kipf TN, Welling M (2017) Semi-supervised classification with graph convolutional networks. In: ICLR
Kübler JM, Buchholz S, Schölkopf B (2021) The inductive bias of quantum kernels. arXiv:210603747
Li Q, Han Z, Wu XM (2018) Deeper insights into graph convolutional networks for semi-supervised learning. In: AAAI. AAAI Press
Li Y, Tarlow D, Brockschmidt M et al (2016) Gated graph sequence neural networks. In: ICLR
Liu Y, Arunachalam S, Temme K (2021) A rigorous and robust quantum speed-up in supervised machine learning. Nat Phys 17(9):1013–1017
Loukas A (2020) What graph neural networks cannot learn: depth vs width. In: ICLR
Maron H, Ben-Hamu H, Serviansky H et al (2019a) Provably powerful graph networks. In: NeurIPS
Maron H, Ben-Hamu H, Shamir N et al (2019b) Invariant and equivariant graph networks. In: ICLR
McClean JR, Boixo S, Smelyanskiy VN et al (2018) Barren plateaus in quantum neural network training landscapes. Nat Commun 9(1):1–6
Morris C, Ritzert M, Fey M et al (2019) Weisfeiler and leman go neural: Higher-order graph neural networks. In: AAAI
Ostaszewski M, Grant E, Benedetti M (2021) Structure optimization for parameterized quantum circuits. Quantum 5:391
Perdomo-Ortiz A, Benedetti M, Realpe-Gómez J et al (2018) Opportunities and challenges for quantum-assisted machine learning in near-term quantum computers. Quant Sci Technol 3(3):030,502
Sato R, Yamada M, Kashima H (2021) Random features strengthen graph neural networks. In: SDM, SIAM, pp 333–341
Scarselli F, Gori M, Tsoi AC et al (2009) The graph neural network model. Trans Neur Netw 20(1):61–80
Schuld M, Killoran N (2019) Quantum machine learning in feature Hilbert spaces. Phys Rev Lett 122(4):040,504
Schuld M, Bergholm V, Gogolin C et al (2019) Evaluating analytic gradients on quantum hardware. Phys Rev A 99(3):032,331
Schuld M, Sweke R, Meyer JJ (2021) Effect of data encoding on the expressive power of variational quantum-machine-learning models. Phys Rev A 103(3):032430
Servedio RA, Gortler SJ (2004) Equivalences and separations between quantum and classical learnability. SIAM J Comput 33(5):1067–1092
Veličković P, Cucurull G, Casanova A et al (2018) Graph attention networks. In: ICLR
Verdon G, McCourt T, Luzhnica E et al (2019) Quantum graph neural networks. arXiv:190912264
Wu Z, Ramsundar B, Feinberg E et al (2018) Moleculenet: a benchmark for molecular machine learning. Chem Sci 9(2):513–530
Xu K, Hu W, Leskovec J et al (2019) How powerful are graph neural networks?. In: ICLR
Zaheer M, Kottur S, Ravanbakhsh S et al (2017) Deep sets. In: NIPS
Zhang M, Chen Y (2018) Link prediction based on graph neural networks. In: NIPS, pp 5165–5175
Zheng J, Gao Q, Lv Y (2021) Quantum graph convolutional neural networks. arXiv:210703257
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
This work was performed as part of an MSc research project, with no funding involved. The authors have no financial or non-financial competing interests.
Additional information
Code availability
For the implementation of the two experiments, see the following repository: https://github.com/pmernyei/eqgc-experiments.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A. Proof of Theorem 1
To prove that EDU-QGCs are a subclass of EH-QGCs, we initially consider EDU-QGC node layers and EDU-QGC edge layers separately and show that both can be represented by (one or more) EH-QGC layers, and afterwards combine these layers to show EH-QGCs can represent any EDU-QGC.
The proof is structured as follows: we first prove the case for node layers (Lemma 3.1), then diagonal edge layers (Lemma 3.2); and, finally, we build on these two to prove the case for all edge layers (Lemma 3.3), completing the proof of Theorem 1.
Lemma 3.1
Any node layer \({\boldsymbol {L}}_{\text {node}} = {\boldsymbol {V}}^{\otimes a\mathcal Va}\) (as defined in Eq. 10) can be expressed as an EH-QGC layer.
Proof
Let \(a\mathcal Va=n\) and let R be the Hamiltonian for V. Then, \({\boldsymbol {H}} = {\boldsymbol {R}}^{\otimes n} = {\sum }_{v \in \mathcal V}{\boldsymbol {R}}_{v}\) is an appropriate EH-QGC Hamiltonian (of the form defined in Eq. 2). We can easily show H is then the Hamiltonian for the EDU-QGC layer V⊗n:
□
Lemma 3.2
Any diagonal edge layer \({\boldsymbol {L}}_{\text {diag}} = {\prod }_{(j,k)\in \mathcal E}\) Djk, with a diagonal unitary applied for each edge, can be expressed as an EH-QGC layer.
Proof
A diagonal unitary D has a diagonal Hamiltonian R, where \({\boldsymbol {D}}_{jj}=\exp (-i{\boldsymbol {R}}_{jj})\). Using the fact that \(\exp ({\boldsymbol {A}})\exp ({\boldsymbol {B}})=\exp ({\boldsymbol {A}}+{\boldsymbol {B}})\) for commuting matrices A and B, and that all diagonal matrices commute, we will derive that applying the Hamiltonian R for each edge at the same time has the effect of applying the unitary D for each.
Consider two edges {(v1, u1), (v2, u2)}. The overall unitary we apply, with implicit identities on all other nodes, is
This generalizes easily to n nodes: the Hamiltonian of the overall unitary is \({\sum }_{(j,k)\in \mathcal E} {\boldsymbol {R}}_{jk}\) as required. □
Lemma 3.3
Any edge layer \({\boldsymbol {L}}_{\text {edge}} = {\prod }_{(j,k)\in \mathcal E}{\boldsymbol {U}}_{jk}\) (as defined in Eq. 11), with any equivariantly diagonizable unitary U, can be expressed as an EH-QGC layer.
Proof
This relies on Lemmas 3.1 and 3.2. We can show that a layer of equivariantly diagonalizable unitaries can be expressed as a layer of diagonal unitaries sandwiched between two layers of single-node unitaries. Each of these can be represented as an EH-QGC layer by the previous lemmas, therefore giving us a 3-layer EH-QGC construction for this statement.
Consider an equivariantly diagonalizable unitary U = (V‡⊗V‡)D(V ⊗V) applied for each edge in a layer \({\prod }_{(j,k)\in \mathcal E}{\boldsymbol {U}}_{jk}\). From the perspective of each node involved in edges, this decomposes as follows:
-
a single-node unitary V
-
some number of two-node diagonal matrices separated by V‡×V = I, which can be ignored
-
a single-node unitary V‡
For nodes that are not part of any edge, we have the identity matrix that can be written as V‡×V. So we can rewrite the layer:
This is of the 3-layer form we discussed, proving the lemma. □
Given these, we can prove the result:
Proof of Theorem 1
Putting together Lemmas 3.1 and 3.3 completes the proof: both types of EDU-QGC layers given by Eqs. 10 and 11 can be represented by one or more EH-QGC layers, so a sequence of EH-QGC layers can represent any EDU-QGC. □
Appendix B. Proofs of expressivity results
1.1 B.1. Proof of Theorem 2: Simulating MPNNs
We give an explicit construction to simulate an arbitrary MPNN with sum aggregation, i.e., an arbitrary MPNN where the aggregation is of the form:
The node states will be conceptually split into registers representing fixed-point real numbers in two’s complement in the computational basis. We first need to establish that we can perform addition on these registers using unitary transformations.
Lemma 3.4
Consider two-node states with two registers each, storing unsigned integers: |a1, a2〉⊗|b1, b2〉, with \(a_{i},b_{i} \in \{0, \dots , 2^{b}-1\}\) for some b. Let U map |a1, b1〉⊗|a2, b2〉 to |a1, b1 + a2〉⊗|a2, b2 + a1〉, with standard overflowing addition. Then, U is an equivariantly diagonalizable unitary and satisfies the undirected symmetry condition in Eq. 4.
Proof
Let Sa be a single-node unitary that increments integers encoded in the computational basis by a. Note that \({\boldsymbol {S}}_{a} = {{\boldsymbol {S}}_{1}^{a}}\). Diagonalize S1 as V‡DV, then \({\boldsymbol {S}}_{a} = ({\boldsymbol {V}}^{\dagger }{\boldsymbol {D}}{\boldsymbol {V}})^{a} = {\boldsymbol {V}}^{\dagger }{\boldsymbol {D}}^{a}{\boldsymbol {V}}\).
Now U can be represented by applying V to the second register of each node, conditionally applying D to the second register of each node some number of times depending on the value of the first register, and finally applying V‡ to the second registers. The controlled application of a diagonal matrix is still diagonal, so this decomposition diagonalizes U equivariantly with (I ⊗V)⊗2.
The undirected symmetry Eq. 4 can be seen easily from the definition of U: swapping a1 with a2 and b1 with b2 results in swapping the values in the output. □
Lemma 3.5
Consider two-node states with two registers each, storing fixed-point unitaries in two’s complement: |a1, a2〉⊗|b1, b2〉, with \(a_{i},b_{i} \in \{(-2^{b-1}+1)\times 2^{-k}, \dots , 2^{b-1}\times 2^{-k}\}\) for some b,k. Let U map |a1, b1〉⊗|a2, b2〉 to |a1, b1 + a2〉⊗|a2, b2 + a1〉, with standard overflowing addition. Then, U is an equivariantly diagonalizable unitary.
Proof
As far as the bit-level operations are concerned, this is exactly the same as Lemma 3.4: with two’s complement, standard overflowing addition of unsigned integers can represent addition of signed integers, and fixed-point reals are essentially integers interpreted with a multiplication of 2−k. □
Having established Lemma 3.5, we are ready to prove the result:
Proof of Theorem 2
Let M be an MPNN with k layers and width w, where the initial states are \({\boldsymbol {h}}_{1} {\dots } {\boldsymbol {h}}_{n}\). We define an EDU-QGC C which computes the same final node embeddings as M, based on M’s iterated message-passing and node update procedure.
In the following, we conceptually divide the qubits for each node v into (k + 1) × w registers \({\boldsymbol {h}}_{v}^{(0,0)}, \dots , {\boldsymbol {h}}_{v}^{(k,w-1)}\) of b qubits each, and k × w registers \({\boldsymbol {a}}_{v}^{(1,0)}, \dots , {\boldsymbol {a}}_{v}^{(k,w-1)}\) of b qubits each. This is a total of (k + 1)w × b + kw × b = (2k + 1)wb qubits as expected. The \({\boldsymbol {s}}_{v}^{(0)}\) registers are initialized to the initial MPNN node states hv, and all other qubits are set to |0〉.
Then, for each MPNN layer, we first simulate its message-passing phase with two-node unitaries for all edges, and afterwards, we simulate the update functions with single-node unitaries. Specifically, for the k-th message-passing layer of M, we apply a unitary U(k) for each edge (v,u) that should have the effect of adding the value of \({\boldsymbol {h}}_{v}^{(k-1,i)}\) to \({\boldsymbol {a}}_{u}^{(k,i)}\) and vice versa for each \(i \in \{0 {\dots } w-1\}\). This results in the \({\boldsymbol {a}}_{v}^{(k, \cdot )}\) registers eventually storing the sum of their neighbors’ states from the previous layer, which simulates the sum aggregation. This is an equivariantly diagonalizable unitary acting well on undirected graphs by Lemma 3.5, so applying it for each edge is a valid EDU-QGC layer.
For the k-th update layer, a unitary is applied to each node that XORs the result of the MPNN’s update function, \(\textsc {update}^{(k)}({\boldsymbol {h}}_{v}^{(k-1,\cdot )}, {\boldsymbol {a}}_{v}^{(k)})\) onto the set of registers \({\boldsymbol {h}}_{v}^{(k,\cdot )}\), which are until this point still initialized to all zeros. This is a permutation and therefore a unitary, so applying it for each node is a valid EDU-QGC layer.
At the end of the circuit, we measure all qubits, which will include the final node states \({\boldsymbol {h}}_{v}^{(k,\cdot )}\). We can classically aggregate in the same way the MPNN pools its results to give our prediction. This will match the MPNN’s output for all inputs with 0 error probability. □
1.2 B.2. Proof of Theorem 3: universality result
We show that EDU-QGCs are universal approximators for (real and Boolean) functions over bounded graph domains, by showing EDU-QGCs can simulate MPNNs extended with random node initialization.
1.2.1 B.2.1. From Boolean to real-valued functions
We will prove Theorem 3 by first looking at the case of Boolean-valued functions over graphs, and show that the case for real functions follows by the same argument as Abboud et al. (2021).
Lemma 3.6
For any Boolean function f defined over \({\mathbb {G}}^{n}\), and any 𝜖 > 0, there is an EDU-QGC that calculates \(f({\mathcal {G}})\) with probability (1 − 𝜖) for any graph \({\mathcal {G}}\).
Let us start by showing how Theorem 3 follows from Lemma 3.6:
Proof of Theorem 3 given Lemma 3.6
Consider the outputs of any real-valued function f over graphs of size n expressed in binary decimal form, in the form of zeros and ones assigned to different positions. Since there is a finite number of such graphs, there is a finite number k of different decimal places where the result differs for any two graphs. For each of these, a binary classifier can be represented by EDU-QGCs by Lemma 3.6 that gives the correct prediction with probability \(1-\frac {\epsilon }{k}\).
Say the i-th binary classifier predicts an output Fi(G) ∈{0, 1} for any bounded-size graph G that represents the bit at position \(k_{i} \in {\mathbb {Z}}\) of the desired real-number output. Running these “next to each other” is also a valid EDU-QGC, and their results can then be combined by an MLP to calculate the real output:
By the union bound, the total probability of any classifier making a mistake is 𝜖, so with probability (1 − 𝜖) our prediction can be as accurate as allowed by our representation of real numbers. □
1.2.2 B.2.2. Individualizing graphs
Abboud et al. (2021) prove their results about the power of MPNNs as follows: say a graph is individualized if all nodes are extended with unique features. They construct MPNNs that accurately model any function from a large class assuming the input graph is individualized. And for any graph of n nodes and arbitrarily small desired error rate 𝜖, if we randomize some node features appropriately, the result will be individualized with probability at least (1 − 𝜖).
In the case of EDU-QGCs, if we assume some part of all node states is initialized to all |0〉s, we can have the first EDU-QGC layer apply a unitary on all nodes consisting of Hadamard gates on the appropriate qubits. This maps them to the uniform superposition over all bitstrings. If we then use the construction from Theorem 2 that acts classically on the computational basis, and then measure the results, we get the same result as running the MPNN with a randomized initial state. The following lemma bounds the number of qubits required for this:
Lemma 3.7
Putting n sets of \(b \geq 2\log (n)+\log (1/\epsilon )\) qubits each in the uniform superposition and measuring them leads to n unique bitstrings with probability at least (1 − 𝜖).
Proof
We are effectively just randomizing b classical bits uniformly. If we randomize b individual bits of node state uniformly at random, each pair of nodes would get the same label with just 2−b probability. This applies for each of the n(n − 1)/2 < n2 pairs of nodes, so by the union bound, the total probability of any match is at most 2−bn2. This is less than 𝜖 if \(b \geq 2\log (n)+\log (1/\epsilon )\) bits are randomized. □
1.2.3 B.2.3. Achieving universality
As noted in Section 5.2, we cannot directly rely on the results of either Abboud et al. (2021) or Sato et al. (2021), and instead give a novel MPNN construction that is partially inspired by Sato et al., but rely solely on the results of Xu et al. (2019) about their graph isomorphism networks.
We essentially rely on the following about graph isomorphism networks which follows directly from Corollary 6 of Xu et al.:
Lemma 3.8
Let \(\mathcal X\) be a countable set of vectors, and let \(\mathcal P_{k}(\mathcal X)\) be the set of multisets of elements of \(\mathcal X\) with size at most k. The aggregate-update function of GINs applied to inputs from \((\mathcal X \times \mathcal P_{k}(\mathcal X))\) (representing a node’s previous state and the multiset of its neighbors’ previous states) can learn injective functions over such an input space.
From this result, we build up to MPNNs that can injectively encode the connected subgraph of each node into their final states if the initial features are unique. To formalize this, we need the following auxiliary definition:
Definition 6
For a graph G with initial node features hv for each node v, a node u in G and \(k \in {\mathbb {Z}}^{+}\), define
where \(\mathcal N(u)\) represents the set of neighbors of a node u.
Following Sato et al., we call this a level-k tree, and it represents total information propagated to a node in k message-passing steps.
We show that GINs with k layers can injectively encode the level-k tree of a node:
Lemma 3.9
Let GIN𝜃(G)v represent the final node features of node v in a graph G after applying a graph isomorphism network with parameters 𝜃. There is some configuration 𝜃∗ of a k-layer GIN such that for any nodes v1, v2 in degree-bounded graphs G1, G2 respectively, with initial node features chosen from a countable space, if T(G1, v1, k)≠T(G2, v2, k) then \(GIN_{\boldsymbol {\theta }^{*}}(G_{1})_{v_{1}} \not = GIN_{\boldsymbol {\theta }^{*}}(G_{2})_{v_{2}}\).
Proof
By induction. The base case k = 1 follows directly from Lemma 3.8. The inductive step follows from the same claim, since the outputs of a GIN layer applied to a countable input space still form a countable space: the set of bounded-size multisets from a countable space is still countable, and so is any image of this set under some function. □
Furthermore, we show that the level-n tree of a node in a graph of n nodes identifies the isomorphism class of the node’s connected component:
Lemma 3.10
Let G1, G2 be two non-isomorphic graphs with node sets V1, V2 of size n with node feature vectors hv unique within each graph, and take any v1 ∈ V1, v2 ∈ V2. Then, the following statements hold:
-
If the graphs G1 and G2 are connected, then T(G1, v1, n)≠T(G2, v2, n)
-
If the graphs G1 and G2 are not connected, then \(T(G_{1}^{\prime }, v_{1}, n)\not =T(G_{2}^{\prime },v_{2},n)\), where \(G_{1}^{\prime }\) and \(G_{2}^{\prime }\) are the induced connected components of v1 and v2 in G1 and G2, respectively, representing the isomorphism classes.
Proof
We first prove the case where the graphs are connected. Let \(\{{\boldsymbol {v}}_{1}, \dots , {\boldsymbol {v}}_{n}\}\) be the unique node feature vectors in G1. Note that all of these will appear in T(G1, v1, n), because the features of any nodes at distance d from v1 will appear in T(G1, v1, d) by induction, and a connected graph of n nodes has a diameter at most (n − 1). Therefore, if G2 contains a different set of unique node features, we get T(G1, v1, n)≠T(G2, v2, n) immediately.
Otherwise for each i, we can denote \(v_{i}^{(1)}\) as the node in G1 with feature vector vi, and \(v_{i}^{(2)}\) as the node in G2 with the same vector. These are unique by the uniqueness of feature vectors. From T(G1, v1, n), we can extract the sets \(\mathcal N_{1}({\boldsymbol {v}}_{i}) = \{{\boldsymbol {h}}_{u}~a~ u \in \mathcal N(v_{i}^{(1)})\}\), i.e., the features of nodes adjacent to the node with the feature vector vi. This also follows by induction: T(G1, v1, k) recursively includes a tuple \(({\boldsymbol {h}}_{u}, \{\!\!\{T(G_{1},w,k-d-1)~a~w \in \mathcal N(u)\}\!\!\})\) for any u at d ≤ k − 1 steps from v1, and T(G1, w,k − d − 1) gives us hw for any k,d. Similarly, from T(G2, v2, n), we can extract \(\mathcal N_{2}({\boldsymbol {v}}_{i}) = \{{\boldsymbol {h}}_{u}~a~ u \in \mathcal N(v_{i}^{(2)})\}\). If T(G1, v1, n) = T(G1, v2, n), then \(\mathcal N_{1}({\boldsymbol {v}}_{i}) = \mathcal N_{2}({\boldsymbol {v}}_{i})\) for all i, which gives an isomorphism between G1 and G2: the nodes \(v_{i}^{(1)}\) and \(v_{i}^{(2)}\) are in correspondence.
This can be extended to the case for disconnected graphs because T(G,v,n) = T(C,v,n) for a any graph G with a node v in a connected component C, and then the same derivation applies. □
These results finally allow us to prove Lemma 3.6 and thereby also complete the proof of Theorem 3:
Proof of Lemma 3.6
We start by initializing a sufficient number of qubits of each node to |+〉 such that with probability (1 − 𝜖), observing all n initial node states leads to n unique measurements. By Lemma 3.7, \(\lceil 2 \log (n) + \log (1/\epsilon )\) quits suffice. We apply an n-layer GIN to this input, which our EDU-QGC can simulate by Theorem 2. By combining Lemmas 3.9 and 3.10, with appropriate parameterization the GIN, the final node states will be an injective function of the node’s connected component.
Since there is a finite number of such graphs, the set of the GIN’s outputs is bounded, so an MLP applied to the node state can turn this into a vector of indicator variables for each isomorphism class within some required accuracy: let an indicator \(I_{C}^{(v)}\), part of the node state for node v, be between \(1-\frac {1}{3n}\) and 1 if the v’s component is isomorphic to a graph C (without regard for the random features) and between 0 and \(\frac {1}{3n}\) otherwise. Since the update function in the GIN architecture is an MLP, this computation can be built into its final layer, which our EDU-QGC can simulate.
We can then pool the node states by summing them into graph-level indicators: for each isomorphism class C of at most n-node graphs, the pooled embedding will contain a summed value NC encoding the number of nodes whose connected component is in that isomorphism class. For each IC, the total error is at most \(\frac {1}{3}\), so graphs with a different multiset of connected components will be mapped to different vectors. Since the set of graphs of size n is finite, the space of these vectors is bounded, and we can apply an MLP to these values to learn any Boolean function over bounded graphs. If we construct an MLP with accuracy of 0.4, the output is always more than 0.6 if the correct answer is 1 and always less than 0.4 if the correct answer is 0. This can be mapped to discrete values in {0, 1} with perfect accuracy via a continuous function easily representable by further MLP layers. Therefore, the output of the model will be exactly correct as long as observing the |+〉 states leads to a unique initial state for each node, which has probability at least (1 − 𝜖) as required. □
Appendix C. Characterising equivariant unitaries
While investigating the behavior of EQGCs, we have considered what happens if we restrict C𝜃(⋅) to only depend on the graph size rather than the adjacency matrix. In this case, for each n it must apply a unitary that treats each node the same. These unitaries are of interest because they could be considered PQCs with an inductive bias for learning functions over sets rather than graphs, and they are also the unitaries that any EQGC must assign if given a graph that is either empty or complete.
Definition 7
Let \({\textsf {\upshape EU}_{s}^{n}}\) be the subset of \(\mathbb {C}^{s^{n} \times s^{n}}\) corresponding to equivariant unitaries over n nodes of dimensionality s, i.e., unitaries that satisfy Eq. 1 in place of C𝜃(⋅).
These are the matrices that could serve as the value of C𝜃(n) in an EQGC that did not depend on the adjacency matrix A. In this appendix, we prove upper and lower bounds on the dimensionality of this set, and show some necessary and some sufficient conditions for an sn × sn matrix to be in \({\textsf {\upshape EU}_{s}^{n}}\). We show that the dimensionality of \({\textsf {\upshape EU}_{s}^{n}}\) grows without a bound in n. This implies that contrary to the closely related invariant and equivariant networks studied by Maron et al. (2019b), even for our restricted EQGCs, no finite parameterization could achieve all allowed unitaries for arbitrarily high n.
We focus on the case s = 2, but also discuss how one would generalize our results to larger node states.
1.1 C.1. An upper bound: equivariant linear layers
The unitarity constraint is tricky to analyze, so in this section we will focus on a superset of \({\textsf {\upshape EU}_{s}^{n}}\) with simpler structure:
Definition 8
Let \(\textsf {\upshape EU}_{s}^{n,+}\) be the subset of \(\mathbb {C}^{s^{n} \times s^{n}}\) corresponding to arbitrary complex matrices that satisfy Eq. 1 in place of C𝜃(⋅).
First let us consider the case when s = 2, so each node is assigned a single qubit which is in a superposition of |0〉 and |1〉, and the action of any matrix L in \(\textsf {\upshape EU}_{2}^{n,+}\) can be represented as mapping bitstrings of length n (i.e., computational basis vectors in \(\mathbb {C}^{2^{n}}\)) to linear combinations of such bitstrings. The general case for s > 2 is conceptually analogous, but this is easier to state and prove clearly.
Theorem 4
A matrix \({\boldsymbol {L}} \in \mathbb {C}^{2^{n} \times 2^{n}}\) is in \(\textsf {\upshape EU}_{2}^{n,+}\) if and only if it can be expressed by weights \(w_{ijk} \in \mathbb {C}\) for 0 ≤ i ≤ n, 0 ≤ j ≤ i and 0 ≤ k ≤ n − i as follows: for computational basis states |ψ〉,|𝜃〉, 〈𝜃|L|ψ〉 = wijk if the bitstring representing |ψ〉 contains |1〉s in i different positions, the bitstring representing |𝜃〉 contains j |1〉s at positions where |ψ〉 had |1〉s and k |1〉s at positions where |ψ〉 had |0〉s.
Example 2
For n = 3,
This shows that 〈001|L|100〉 = 〈010|L|100〉 = w101 since 〈001| and 〈010| both contain one 〈1| in a position where |100〉 has a |0〉, and no 〈1| where |100〉 has a |1〉; and 〈101|L|100〉 = 〈110|L|100〉 = w111, because they both contain one 〈1| for the |0〉s in |100〉 and one 〈1| for the single |1〉 in |100〉. The other inner products involving |100〉 all differ in how many 〈1|s meet |1〉s and |0〉s, so they can be chosen independently of each other. (Note however that they are not independent of other values of the matrix L such as those in the vectors L|001〉 and L|010〉, as we will see in the proof.)
For further clarity, consider representing the following EQSCs with such weights:
Example 3 (C Z(α)-gates between all pairs of nodes)
Consider a circuit L consisting of controlled Z-rotations with a parameter α applied between each pair of qubits. For computational basis states |e1〉,|e2〉, this only applies phases, therefore we have a diagonal matrix and 〈e1|L|e2〉 = 0 if |e1〉≠|e2〉. The phase applied is e−iα for each pair of qubits that are both set to one, so if the input contains i ones then we get a phase of e−i(i− 1)α/2 in total. Therefore L is represented by wijk = e−i(i− 1)α/2 if j = i,k = 0 and 0 otherwise.
Example 4 (Arbitrary single-qubit unitaries applied everywhere)
Let \({\boldsymbol {U}} = \big (\begin {array}{cc} u_{0,0} & u_{0,1}\\ u_{1,0} & u_{1,1} \end {array}\big )\). Then, for x,y ∈{0, 1}, we have 〈x|U|y〉 = ux,y. Suppose we apply this unitary to all n qubits. Then, for two computational basis states |e1〉,|e2〉, \(\langle {e_{1}}|{\boldsymbol {U}}^{\otimes n}|{e_{2}}\rangle \) is of the form \(u_{0,0}^{a}\times u_{0,1}^{b}\times u_{1,0}^{c}\times u_{1,1}^{d}\), where a and d are the number of overlapping |0〉s and |1〉s respectively in the bitstring representation of |e1〉,|e2〉, b is the number of positions where |e1〉 contains a |0〉 and |e2〉 contains a |1〉, and c is the same in the other direction.
This lets us express the wijk parameters representing U⊗n from inner products of computational basis states 〈e1|U|e2〉 and expressing a,b,c,d as above:
-
d, the number of overlapping ones, is just j.
-
c, the number of ones in 〈e1| meeting zeros in |e2〉, is just k.
-
We can get b, the number of zeros in 〈e1| meeting ones in |e2〉 as i − j, subtracting the overlapping ones from the number of ones in the input.
-
We can get a, the number of overlapping zeros as (n − i) − k, getting the number of zeros in |e2〉 as (n − i) and then subtracting the k positions where 〈e1| has a one.
So we get that U⊗n is represented by \(w_{ijk} = u_{0,0}^{n-i-k}\times u_{0,1}^{i-j}\times u_{1,0}^{k}\times u_{1,1}^{j}\).
We will prove this theorem through two simple lemmas.
Lemma 4.1
Any matrix \({\boldsymbol {L}} \in \textsf {\upshape EU}_{2}^{n,+}\) is entirely characterized by its output on \(|{s_{0}}\rangle = |{00\dots 00}\rangle , |{s_{1}}\rangle = |{00{\dots } 01}\rangle , \dots , |{s_{n-1}}\rangle =|{01{\dots } 11}\rangle , |{s_{n}}\rangle = |{11\dots 11}\rangle \).
Proof
Consider any the computational basis vector \(|{e}\rangle \in \mathbb {C}^{2^{n}}\). This corresponds to some string of zeros and ones. Then, for the |si〉 containing the same number of zeros and ones, there is some permutation of indices \(\tilde {\boldsymbol {P}} \in \mathbb {C}^{2^{n} \times 2^{n}}\) such that \(|{e}\rangle = \tilde {\boldsymbol {P}}|{s_{i}}\rangle \) and therefore \({\boldsymbol {L}}|{e}\rangle = {\boldsymbol {L}}\tilde {\boldsymbol {P}}|{s_{i}}\rangle \). Multiplying by \(\tilde {\boldsymbol {P}}^{T}\) gives \(\tilde {\boldsymbol {P}}^{T}{\boldsymbol {L}}|{e}\rangle = \tilde {\boldsymbol {P}}^{T} {\boldsymbol {L}}\tilde {\boldsymbol {P}}|{s_{i}}\rangle = {\boldsymbol {L}}|{s_{i}}\rangle \) by equivariance, so \({\boldsymbol {L}}|{e}\rangle = \tilde {\boldsymbol {P}}{\boldsymbol {L}}|{s_{i}}\rangle \). So knowing L|si〉 for each |si〉 determines L|e〉 for all computational basis vector, hence determining it entirely. □
Lemma 4.2
We must have 〈e1|L|si〉 = 〈e2|L|si〉 for computational basis vectors |e1〉,|e2〉 which can be transformed to each other by permuting over indices that have the same value (0 or 1) in |si〉.
Proof
Consider the permutation of indices \(\tilde {\boldsymbol {P}}\) that turns |e1〉 to |e2〉. Note that \(\tilde {\boldsymbol {P}}|{s_{i}}\rangle = |{s_{i}}\rangle \) by the given premise, so by equivariance we have \(\langle {e_{1}}|{\boldsymbol {L}}|{s_{i}}\rangle = \langle {e_{1}}|\tilde {\boldsymbol {P}}^{T}{\boldsymbol {L}}\tilde {\boldsymbol {P}}|{s_{i}}\rangle = \langle {e_{1}}|\tilde {\boldsymbol {P}}^{T}{\boldsymbol {L}}|{s_{i}}\rangle = \langle {e_{2}}|{\boldsymbol {L}}|{s_{i}}\rangle \). □
Proof of Theorem 4
Lemma 4.2 showed that L|si〉 expressed in the computational basis will have the same weight for any basis vector with j ones where |si〉 had ones, and k ones where |si〉 had zeros. Denote this weight wijk. By Lemma 4.1, these parameters uniquely characterize the equivariant linear layer.
This proves the theorem in the forward direction: any matrix in \(\textsf {\upshape EU}_{2}^{n,+}\) can be characterized by weights wijk. Now we show the other direction, that any linear transformation characterized by an arbitrary choice of wijk satisfies Eq. 1 and therefore is in \(\textsf {\upshape EU}_{2}^{n,+}\). Consider an arbitrary \({\boldsymbol {L}} \in \mathbb {C}^{2^{n} \times 2^{n}}\) given in this form. It suffices to show that it behaves correctly with respect to swap permutations and input states in the computational basis: more complex permutations can be built by composing swaps, and more complex states by linear combinations of basis states. For any bitstring input |e〉, we can have two kinds of swaps:
-
In the first case, we swap two indices with the same digit in the bitstring (both |0〉 or |1〉). The input to L is unchanged, and equivariance is respected because the same coefficients from wijk are multiplying pairs of output vectors that should be swapped.
-
In the second case, the digits at the two indices differ. The inputs passed to L on the two sides of the equation are different, and equivariance is ensured by the number of overlapping |1〉s changing in a way that the wijk coefficients get swapped consistently.
□
As a consequence, we can easily see that the dimensionality of the set \(\textsf {\upshape EU}_{2}^{n,+}\) is unbounded in terms of n, as opposed to the equivariant layers studied by Maron et al. (2019b), so we cannot hope to uniformly parameterize the entire space for unbounded n.
Corollary 4.1
The dimensionality of the set \(\textsf {\upshape EU}_{2}^{n,+}\) with a single qubit per node over n nodes is:
Proof
The left-hand side follows from the above by considering the number of (i,j,k) triples with 0 ≤ i ≤ n, 0 ≤ j ≤ i, 0 ≤ k ≤ n − i. We get the closed form on the right using the formula for pyramid numbers and simplifying. □
1.1.1 C.1.1. Generalizing to larger node states
An analogous result holds for \(\textsf {\upshape EU}_{s}^{n,+}\) with s > 2. Say we have s possible node basis states \(\{|{0}\rangle , \dots , |{s-1}\rangle \}\). In this case, a single matrix element 〈𝜃|L|ψ〉 for computational basis states |ψ〉,|𝜃〉 is depends on the entire set of how many |i〉 appear in |ψ〉 in positions where |𝜃〉 contains a |j〉, for all \(i,j\in \{0{\dots } s-1\}\).
To prove this, similarly to Lemma 4.1, we can show that it suffices to specify L|ψ〉 for each distribution of input node states; and similarly to Lemma 4.2, we can show that 〈𝜃|L|ψ〉 is invariant to changing 〈𝜃| in a way that does not change the number of any 〈i| to |j〉 “matches” as described above.
1.1.2 C.1.2. Implications for \({\textsf {\upshape EU}_{s}^{n}}\)
Corollary C.1 has implications for our original set of equivariant unitaries \({\textsf {\upshape EU}_{s}^{n}}\) — it gives an upper bound for the dimensionality of the set.
1.2 C.2. A lower bound: diagonal equivariant unitaries
To see whether the size of the space of EQSCs grows with the size of the set, we can investigate a more restricted space as a lower bound: diagonal unitaries satisfying the equivariance condition in Eq. 1.
A general diagonal unitary can apply an arbitrary phase to each computational basis state independently. The equivariance condition restricts us to applying the same phase for inputs that could be transformed to each other by permuting the indices, i.e., inputs that contain the same distribution of node states (the same number of |0〉s and |1〉s when using one qubit per node). This gives a lower bound of n + 1 on the dimensionality of equivariant unitaries over sets of size n using a single qubit per node, which is still unbounded in n. More generally, for n nodes with s possible states each, the lower bound is the number of unique s-tuples of nonnegative integers that sum to n, which is given by \({n+s-1 \choose s-1}\). This is also a lower bound on the dimensionality of \({\textsf {\upshape EU}_{s}^{n}}\).
1.3 C.3. Comparison with classical invariant/equivariant graph networks
In their paper on invariant and equivariant graph networks, Maron et al. (2019b) ask similar questions to characterize and implement classical equivariant/invariant models operating on tensors representing relational data. While the questions we investigate were partly inspired by them, and our data can also be seen as high-order tensors, there are significant differences in our setting.
Most importantly, the order of k the tensors they dealt with was fixed and independent of the size n of the input graph, while the size of the tensors along each of those k dimensions depended n. For example, their input included the adjacency matrix, a tensor in \(\mathbb {R}^{n^{2}}\). For EQGCs, this is the other way around. Adding more nodes means working with a larger tensor product, but each dimension is of a fixed size s. For example, with a single qubit per node, our state is in \(\mathbb {C}^{2^{n}}\). This matters for the notion of equivariance/invariance: applying a permutation p brings the element at an index \((i_{1}, i_{2}, \dots , i_{n})\) to \((i_{p(1)}, i_{p(2)}, \dots , i_{p(n)})\) for us, instead of \((p(i_{1}), p(i_{2}), \dots , p(i_{n}))\) as in the previous work.
Finally, there are a few more obvious differences: due to the quantum context, we are working with complex numbers rather than reals, and we are interested in the extra condition of unitarity rather than arbitrary linear layers.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mernyei, P., Meichanetzidis, K. & Ceylan, İ.İ. Equivariant quantum graph circuits: constructions for universal approximation over graphs. Quantum Mach. Intell. 5, 6 (2023). https://doi.org/10.1007/s42484-022-00086-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42484-022-00086-w