
Abstract
Short-term hydrological forecasting is crucial for suitable multipurpose water resource management involving water uses, hydrological security, and renewable production. In the Alpine Regions such as South Tyrol, characterized by several small watersheds, quick information is essential to feed the decision processes in critical cases such as flood events. Predicting water availability ahead is equally crucial for optimizing resource utilization, such as irrigation or snow-making. The increasing data availability and computational power led to data-driven models becoming a serious alternative to physically based hydrological models, especially in complex conditions such as the Alpine Region and for short predictive horizons. This paper proposes a data-driven pipeline to use the local ground station data to infer information in a Support Vector Regression model, which can forecast streamflow in the main closure points of the area at hourly resolution with 48 h of lead time. The main steps of the pipeline are analysed and discussed, with promising results that depend on available information, watershed complexity, and human interactions in the catchment. The presented pipeline, as it stands, offers an accessible tool for integrating these models into decision-making processes to guarantee real-time streamflow information at several points of the hydrological network. Discussion enhances the potentialities, open challenges, and prospects of short-term streamflow forecasting to accommodate broader studies.
Highlights
-
Data-driven approach offers viable alternatives to traditional hydrological models for short-term predictions.
-
Support Vector Regression model results suitable for hydrological modelling also in complex Alpine Region.
-
Data-driven pipeline can effectively bridge the gap between research and operational aspects of water management.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Hydrological modelling and forecasting are crucial for sustainable water management [36, 45], from resource availability to extreme disaster prevention. Indeed, the water management goal is to correctly use the resources available to satisfy actual and future demands.
As a result, two main needs arise: the prediction of future water demand along with the expected resource availability. For the latter reason, streamflow forecasting is considered a paramount focus in hydrological research, as emphasized in recent studies such as [61, 62].
The different temporal resolution and prediction lead time of streamflow forecasting depend on the kind of application, such as energy production [2], water supply systems [67] and floods [5]. In Alpine Regions, this task is complicated by the complexity due to the spatial heterogeneity of the area, which mainly influences the temperature and precipitation variability [9, 56]. This leads to a direct influence on the hydrological cycle, particularly the snowmelt processes [27] and the seasonal behaviour [68, 73]. Furthermore, the climate change scenarios reported how these areas are particularly affected by the climatic changes [10, 21, 40], that significative affect long-term streamflow scenarios and the frequency of extreme events. This must be considered in all the applications but is mainly crucial in flood forecasts, where it is important the prediction celerity to prevent disasters [6].
Physical-based hydrological models have played a pivotal role in comprehending various facets of the water cycle [14], with dedicated tools in mountain areas [17, 70]. The insights gained from both field observations and the application of these models are invaluable, forming the foundation upon which many water management tools have been developed [4]. These models describe the physical problem using equations that manage the non-linearity of the hydrological field approximating the real system [3, 58, 60]. As a consequential effect, these models need to be calibrated, regularly updated and coupled with data assimilation techniques to guarantee accurate simulations able to adapt to specific environments and conditions [55, 57].
On the other side, data-driven models are capable of handling the complexity of non-linear problems directly by exploiting the information of the past values of the target time series along with the relationship with exogenous variables [7, 16, 34]. The advances in computational power and data availability lead to an extensive use of data-driven techniques in water resource management such as for example in agriculture [25], energy production [13, 65], human and utilization [15, 68], flood prediction [28, 72]. Different data-driven methods have been investigated in the literature without a clear dominance of a specific model in all the applications [35, 42, 64]. Data-driven models for streamflow forecast have been mainly studied in the last decade [50], but only recently have been taken into account analysis in the mountain areas [33].
For streamflow forecasting, different data-driven models were applied in literature: Linear Regression (LR) [31], Autoregressive Integrated Moving Average (ARIMA) [63], Decision Tree (DT) [54], Support Vector Machine (SVM) [41], Neural Network (NN) [12], and Long Short-Term Memory (LSTM) [59]. Other data-driven techniques can be coupled with streamflow forecasting, such as Bayesian Models to deal with uncertainties [26, 49], Data Assimilation to integrate real time data into hydrological models [17] or Bias Analysis to post-process the outcomes [20]. The present research analyses the feasibility of the Support Vector Regression (SVR) as a data-driven model to be used in streamflow forecast at the hourly time step in the Alpine Region. This application is unique because there are no other attempts in literature with this high temporal resolution in such a complex area. Indeed, the good coverage in the case study of local ground stations with hourly data allows the training of data-driven models that are not usually common. The entire case study has been tested using historical data by [51] as a unique basin and independently using each sub-basin. To underline the possible practical outcomes of this work, two basins were tested using real forecasting data (i.e. DWD ICON-D2 by [23]) with 48 h of lead time.
The paper is composed of this Introduction in Sect. 1, and the data pre-processing and data-driven approach are explained in Sect. 2. In Sect. 3, the results are reported and then discussed in Sect. 4 with the possible future investigation. Finally, Sect. 5 contains the conclusion.
2 Materials and methods
2.1 Region of interest and data
The region of interest for this work is the South Tyrol/Südtirol Province (ST hereafter) in Italy. This area is a typical Alpine region characterized by high-elevation mountains divided by distinct valleys. The primary composition of this region is shaped by three main rivers: Adige, Isarco and Rienza. The Adige River is the second-longest river in Italy and the biggest basin in ST. It originates in the Italian Alps near the Reschen Pass and flows through the heart of the region in the western part. The Isarco River originates in the Brenner Pass area, flowing North to South, joining the Adige River in the town of Bolzano/Bozen. Finally, the Rienza River originates in the Braies Lake and flows through the Pusteria Valley before eventually joining the Isarco River near Bressanone/Brixen. The entire administrative area is \(7400~{km}^{2}\) with elevation spanning from 70 m a.m.s.l. of Salorno to 3950 m a.m.s.l. of Ortles. The Alpine climatology well describes the case study, with precipitation and temperature as the main hydrological drivers. Average annual precipitation over the entire ST region is 775 mm. In winter, the precipitation is partially retained as snowpack at the highest elevation where the temperature reaches \(-35~^{\circ}C\) on the mountain peaks. The snow usually melts in spring and summer when the temperature rises to \(37~^{\circ}C\) in Bolzano. On the other side, precipitation is concentrated mainly in summer and autumn with local and high-intensity storms. In these seasons, the combination of snow melting and higher precipitation event frequency leads to higher streamflow discharge in the rivers.
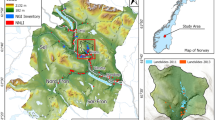
The hydrological work presented in this paper is based on the main hydrological closure points, defined by a geo-morphological analysis. The identified hydrological basins cover the ST area, mainly overlapping the administrative area. There are 19, and they are defined using selected gauging stations on the three main rivers of the area. Figure 1 shows the position of the area in Italy, the basins identified for the hydrological simulations and the meteorological and gauging stations of the area, also reported in the table in Appendix 1 5. Temperature, precipitation and streamflow ground station are the reference data in this work. The South Tyrol Province distributes this data [51], and the time series are validated for the past to exclude the sensor failures. In South Tyrol, 51 precipitation stations, 83 temperature stations, and 19 streamflow stations are available online. The spatial distribution of the data is, of course, affected by the topography of the area, with fewer points covering high elevation due to maintenance difficulties.

Morphological map of South Tyrol (ST), indicating the identified basins according to the presented ground stations along with the position of ground stations for temperature, precipitation and streamflow, with the basins identified
The data described above are the main data used in this work. However, weather predictions of a regional weather model are used to show the suitability of the proposed data-driven streamflow model as an operative hydrological forecasting tool, highlighting strengths and challenges. Indeed, the ICOsahedral Nonhydrostatic (ICON hereafter) regional numerical weather prediction model was used to understand the feasibility of their output as input in an operative streamflow forecasting pipeline. ICON [74] was recently developed, and it is operated by the German Weather Service (DWD) and the Max-Planck Institute for Meteorology (MPI-M) in Hamburg (Germany). ICON-D2 product has an hourly resolution, 2.2 km spatial resolution (after the resampling process) and a lead time up to 48 h with a release every 3 h. DWD offers weather and climate data free of charge on its Open Data server. The period considered in this demonstration is from December 2021 to September 2022.
2.2 Geo-morphological study
Section 2.1 gives a description of the proposed case study and the related gauging stations. In Fig. 1 also, the basins are shown, as a result of the geo-morphological study carried out exploiting the QGIS software [52] together with the Horton Machine Spatial ToolBox [1, 22]. This process has the goal to identify a representative basin for each of the gauging stations. Starting from the Digital Terrain Model (DTM) of the entire ST [19], which contains information regarding the elevation at the spatial resolution of 25 m, gradients and slopes were evaluated. These allow to identify the drainage directions defined as the directions that the generic water particle follows due to the morphological characteristics of the terrain [47]. Among the different approaches known in the literature to entangle this step, this study adopted a standard method that considers 8 possible flow directions as described by [46]. In order to overcome the limit imposed by the discrete nature of the DTM, a correction algorithm is applied to obtain more accurate drainage direction results [48]. Once these steps are completed, the total contributing areas (tca) are determined by accumulating the flows along the various possible paths. This allows the extraction of the river network, which must be validated by comparing it with the real network. A watershed is defined as a portion of land for which the water flowing through or under the surface converges to a specific point [30]. The closure points are defined in our application by the nearest point between the streamflow gauging stations and the watercourse identified with the geo-morphological process.
2.3 Data analysis and imputation
The ST Province weather service provides data that are initially distributed at a sub-hourly interval, but for the purposes of this study, they have been aggregated to an hourly time scale. The period considered in the analysis is from 1st October 1985 to 30th September 2022, with the hydrological year as a reference for the simulations [37].
The data-driven models need the input data to be as clean as possible, to avoid noise and to correctly interpret the correlations between predicted variables and predictors [69, 71]. The analysis and pre-processing of the meteorological and hydrological data are, for this reason, mandatory tasks that were applied in three steps: outliers identification, statistics on missing data and selection of the stations with a good temporal coverage, with imputation to close minor gaps.
Outliers are identified following [8, 38, 39] checking negative values for streamflow and precipitation, and in general hourly absolute extreme events compared with local highest maximum and ranges. Temporal consistency is also considered between consecutive steps. Figure 2 describes the steps of the outliers identification phase that is carried out on each of the ground stations in the area. This process is repeated step by step, and it substitutes the identified outliers with Not-a-Number (NaN hereafter).

Algorithmic process for detecting and replacing outliers in ground station data, specifically on temperature, precipitation, and streamflow variables
For precipitation, the criteria to be considered as an outlier are the one-hour high peaks that exceed hourly Italian record [18] or are isolated. Temperature checks involve the local climatology to catch the values out of range for the area. Then, the serial data is investigated, and on a moving window of three hours, the constant values and the abnormal spikes are considered outliers. Finally, streamflow not valid time series elements are identified for each station data where high and low values are inconsistent compared with their neighbours. Of course, negative values are considered as not valid both for precipitation and streamflow.
Once the outliers were identified and overwritten by NaN values, the missing data were analysed using the aggregation at the hydrological year. Using the percentage of hourly data available along each hydrological year, the years were marked as valid or not valid. The threshold for temperature and precipitation time series to be valid was defined as maximum 25% of missing data, a lower threshold of 10% was assumed instead for the streamflow. These different percentages of missing data were accepted based on the type of imputation that was then performed. To drop the not-valid years was the last step on temporal data, the schema in Fig. 3 describes the procedure applied at each basin independently to drop the not-valid stations: (a) missing streamflow years are dropped; (b) the temperature and the precipitation sensors with most of the data are considered mandatory, dropping the years where once is missing; (c) drop the sensors without valid data in all the years.

Process by which hydrological years and sensors were excluded due to an excessive amount of missing data, exemplifying the mode of removal in the dataset
The imputation was the last step of the data preprocessing to close the gaps in the valid time series [69]. In particular, univariate imputation was performed for each streamflow station, based on the k-nearest neighbors (KNN) algorithm [43] (Uni-KNN in Fig. 4) .
This approach considers only the past data of the single time series analysed without external inference. This is related to the fact that no significant links exist between different rivers belonging to different basins (i.e. each basin has its specific morphology and characteristics). Instead, the imputation was performed for both precipitation and temperature data using the multivariate approach (Multi-KNN in Fig. 4).
This means to consider as information both the past data and the nearest meteorological stations, even using other correlated variables. This is feasible due to the fact that climate is a characteristic correlated among regions.
The result of the data analysis and imputation is a basin-specific hourly dataset of temperature, precipitation and streamflow. Precipitation and temperature could be composed by more than one sensor. To apply the streamflow forecasting in our case study, the temporal mean of all the sensors in the same basin was calculated. Thus, in Phase 2 (see Fig. 4), the input comprises a dataset containing individual time series for temperature, precipitation, and streamflow.
2.4 Experimental pipeline
The simulations were conducted as lumped over all the basins identified, using a simple two-phase pipeline encompassing data pre-processing and model inference (e.g., [53]). Figure 4 represents the phases with two blocks and all the steps inside the blocks. In the pre-processing, the data analysis was carried out, both spatial data (see Sect. 2.2) and temporal data (see Sect. 2.3) were processed. The goal of the pre-processing phase was to extract the basins and, for each of them, the mandatory temporal data in the correct format (i.e., precipitation, temperature and streamflow time series). The second phase is composed by training and testing and it have been carried out based on the pre-processed data. The training task was based on a grid search to select the best SVR model for each basin. This means different lags and hyperparamenters were tested to reach the best possible performance in the training period. Testing task is intended as the application of the trained model on the same kind of data used in the training step on the testing period. This last task is necessary to understand if the model is able to forecast on a unknown period using the setup obtained in the training. Throughout the entire pipeline, historical ground station data were employed. Additionally, the SVR-trained models were also forced by another data type in demonstration as explained in Sect. 2.6.

Schematic machine learning pipeline: Phase 1 is the pre-processing of the data and Phase 2 execution of the training/testing and demonstration
2.5 Data-driven approach
Conventional Support vector machines (SVMs) are well-established classification methods focused on non-linear separable problems [11]. A SVM determines the optimal hyperplane that maximizes the distance between two groups and minimizes the margin error in order to reach this separation. To achieve this, the input data is projected onto a higher dimensional space, and the non-linearly separable data in the original space can be linearly separated using the SVM. From this idea, Support vector regression (SVR) is a method that applies such principles over regression problems. In this case, the aim is to find the best data regression hyperplane that fits the data points in a continuous space. Therefore, such methods have to build a mapping (\(\phi\)) of the data points using a kernel function. In order to model input data, the SVR method allows a specific margin \(\varepsilon\) of error to be accepted without compromising the prediction quality. In other words, the SVR model accepts that there might be some predicted points that lie outside the region formed by \(\pm \varepsilon\). So, given a generic input data \(x_i\) associated with an observed output data \(y_i\), the aim is to find a function as follows:
where w represents the weight vector and b is the bias term. \(\phi (x)\) is the mapping into a higher-dimensional space (i.e., feature space) of the input data x. The function computes the inner product of the weight vector w and the mapped input data \(\phi (x)\) and then adds the bias term b. The main idea is to find such a function that, at most, deviates \(\varepsilon\) from the observation data \(y_i\) while simultaneously keeping the model complexity minimum. In other words:
which is a convex optimisation problems and assumes that \(\hat{f}(x)\) exists for all observations and that has a precision of \(\varepsilon\). The margin of error, denoted by \(\varepsilon\), allows the SVR model to tolerate some level of error in its predictions without compromising the overall quality of the prediction. This is especially useful when dealing with noisy data or situations where a perfect fit might not be achievable or desirable. In fact, the solution to the problem might not exist. Hence, such method proposes the inclusion of slack variables to introduce a penalty whenever the model deviates more than \(\varepsilon\) from the actual observation. Hence, slack variables are defined as:
where \(\xi ^+\) and \(\xi ^-\) are the slack variables in case of predicted values that are higher or lower than \(\varepsilon\) compared to the observation, respectively. Finally, the objective of the optimisation problem can be read as:
where n is the size of the training observation dataset, and C is a parameter that acts as a trade-off between the tolerated error of the model and its complexity.
The C and the \(\varepsilon\) are the so-called hyperparameters for the SVR. The efficacy of the model hinges on selecting appropriate values for these parameters, a task typically accomplished using grid search. So, the algorithm starts with the identification of the training and testing data sets defined using a simple split point that divides the input period into two parts, maintaining a temporal consistency. The grid search was executed for each basin on the training data sets of temperature, precipitation and streamflow. These inputs as lags and the model hyperparameters were the domain of parameters used to minimize \(R^2\) for each basin and select the best model. The use of a series of past values (i.e., lags) is particularly important and the selection of which lags to use is crucial. Indeed, regression models like SVR require information from the past to build the forecasting model. In this case study, to infer past information, temperature, precipitation and streamflow lags were used. Five combinations of lags for each of the three input variables were identified as a list of past hours to infer into the models: A [1 to 12], B [1 to 24], C [1 to 48], D [1 to 6 and 12,24,36,48], and E [1 to 12 and 22,23,24,46,47,48]. All these lag combinations were used as inputs in the training process, in which the hyperparameters were tuned to identify the best SVR model.
The metrics used in the evaluation procedure are three: \(R^2\), MAE and MAPE as described by [44] and reported in 6, 7 and 8 respectively. The \(R^2\) is the one used in the training algorithm to evaluate the goodness of the selected hyperparameters at each epoch. Instead, all three are used as comparisons in testing and demonstration.
where n is the length of the time series, \(\hat{y}_i\) the predicted value, \({y}_i\) the reference value and \(\bar{y}\) the mean over the entire reference time series.
2.6 Demonstration with ICON-D2
Section 2.4 describes the data-driven pipeline, which takes as input meteorological and geo-morphological data to produce streamflow as output [41]. The historical ground station measurements are the meteorological input data to train the models for each basin. This leads to a data-driven re-forecast of the streamflow, composed by training and testing tasks, that are used to carry out the analysis in Sect. 3. Nevertheless, an effective real forecast is possible just using operative forecast meteorological input data, such as the ICON-D2. This is called demonstration and it allows for an understanding of how much the trained models can generalize the information. In demonstration, the SVR models trained in the training phase using historical data are applied on two different basins out of the 19 extracted. For each available day between 15th December 2021 and 15th December 2022 a simulation based on the ICON release of 6AM was carried out for a total days equal to 290. First of all, the ICON-D2, as described in Sect. 3.1, were downloaded from DWD OpenData [24]. This model output is distributed in grib2 format, so the data was cropped to the area of interest starting from the raw files. The data are available for both temperature and precipitation as 48 h ahead forecast, and in this paper, these data were used as future information to pass to the model. More specifically, to each simulation historical data was given to the model to cover the past data up to the starting date and time of the forecast, and historical temperature and precipitation were given to the model as a proxy of weather forecasting to include the future data. Due to the fact the SVR models in this paper take as input an individual time series for each variable, a spatial aggregation was carried out as the average of all the grid points inside each basin. The analysis of the results in this demonstration was based on the same metrics as training and testing but evaluated within 48 h of simulation prediction.
3 Results
3.1 Phase 1: pre-processing results
The spatial analysis results in the South Tyrol case study are graphically reported in Fig. 1 with 19 basins identified and the related ground stations based on each basin coverage area. Table 1 summarises the area of each basin, indicating the number of valid stations in each of them. Other information in Table 1 is related to the temporal analysis of the data described in Sect. 2. Namely, the quality check carried out on the raw sensors’ time series underlines the low number of outliers for all variables (i.e., temperature, precipitation, and streamflow), which were substituted as NaN. Then, the missing data analysis was carried out, and it was used to drop the not-valid hydrological years basin by basin. This analysis reports that the ground station data guarantees 10 years of hourly data on \(75\%\) of the points for the three variables considered. This percentage is determined as the number of sensors with a valid data record divided by the total number of sensors for that variable, multiplied by 100. Furthermore, when considering a timeframe of 5 years, the percentage of points with sufficient data increases to \(95\%\), with only one station that experienced data gaps.
Different is the percentage reported in Table 1, which indicates the percentage of imputed data considering only the valid data from the previous steps. Indeed, Table 1 reports the number of valid temperature and precipitation stations considered for each basin and, evaluated the streamflow data, the number of valid hydrological years for each basin.
The imputation algorithm as described in Sect. 2.3 produces fulfilled time series of data. As an example, Fig. 5 shows how the imputation is working in the case of temperature 5(a), precipitation 5(b) and streamflow 5(c).

Example of KNN imputation results for temperature, precipitation, and streamflow
3.2 Phase 2: data-driven model results
The results of grid-search on the different basins are the combination of lags and hyperparameters as reported in Table 2. For comprehensive insights, the table includes details on split points, training and testing periods, and corresponding lags for the three variables (i.e., temperature, precipitation and streamflow), specified using the letter as explained in the list of Sect. 2.5. Finally, in the last two columns of Table 2 the hyperparameters identified for each basin are reported.
The SVR models trained and tested on each basin separately lead to the results reported in Table 3 according to the metrics as described in Sect. 2.5. MAE allows a direct understanding of the performance specifically for every single basin, instead, MAPE and \(R^2\) ensure the comparison of the model performance in different basins by interpreting the simulation errors and behaviours, respectively. Table 3 underlines the direct comparison of the training and testing periods to emphasise the quality of the model training. If these are similar, it means the models are well trained without overfitting the training data sets [66]. Furthermore, due to the time dependent data, the training and the testing periods could be affected by discrepancies in the quality or representativeness [32].
In general, the SVR results are good, with some exceptions discussed in Sect. 4. Indeed, the \(R^2\) mean over the 19 basins is 0.91 in training and 0.83 in testing. The MAPE mean is 12.17 in training and 15.09 in testing, confirming the goodness of the SVR trained models.
Further investigations were carried out to understand how some physical aspects of the basins influence the data-driven pipeline results. Figure 6 compares the dimension of the basins against the \(R^2\) in the testing period, taking into consideration the nature of the watershed itself. Specifically, not-natural basins refer to watersheds significantly influenced by human activities, such as the presence of hydropower plants and irrigation withdrawals. In contrast, natural basins remain largely unaffected by human intervention, serving as the standard initial condition in hydrological models. In Fig. 6 natural and not-natural are divided to analyse particular trends among the different aspects. The two types of basins show two different clusters of performances: the natural-based watersheds have better performance than not-natural ones proving to be more readily modelled due to the absence of non-predictable interference caused by human water resource use. In addition, while the reduction of performances with the decrease of the watershed sizes in the not-natural basins is fairly significant, this trend is less evident for the natural basins that generally are also smaller.

Natural-Not Natural basin: trend analysis between the area and the \(R^2\) metric
Finally, Table 4 reports the results of the demonstration using ICON-D2 data as explained in Sect. 2.6. MAE and MAPE are evaluated independently for each day, and the average of the 290 simulations metrics are reported in the table. Both the basins analysed show good results, with a normal reduction in the performance compared with the testing, from 7.23 to 11.41 in the first and from 8.30 to 16.91 in the second.
4 Discussion
4.1 Data preprocessing
Data preprocessing was the first phase in the pipeline. It is, in general, a crucial task, and to handle it in this paper, each basin was considered independent. Due to the scarcity of reference papers for the kind of data analysed (i.e., time series data), the data preprocessing was not easy. Specifically, the most challenging variable to handle was the streamflow, primarily due to frequent sensor failures, the low accuracy due to the nature of this variable and the potential factors leading to invalidation. Indeed, in mountain areas, the low temperature could invalidate the measurements of streamflow due to the creation of ice on the sensors or in the river itself, mainly in low-discharge watercourses. In general, the difficulties in maintaining the sensors in isolated areas, mostly during the winter, result in data unavailability. Other issues due to the temperature and precipitation sensors could influence the results (i.e., undercatchment). The scientific community faced most of these issues, and some upgrades have been done, but in general, working with ground stations brings some uncertainties to the simulations. On the other side, these data are the most accurate measurements at the local scale, which is crucial in mountain areas like the analysed case study, where the maintenance of the station and the validation of the data are consistent.
Data-driven models need long, clean and complete input data to extrapolate the most, for this reason, the steps in the data preprocessing are mandatory to achieve this goal. The outliers identification introduced some gaps (i.e., NaN values) increasing the cleanness of the data sets. This reduces the availability of data, but it decreases the possible noise in the data forcing the SVR models. The same result is obtained by dropping the hydrological years, and sensors do not satisfy the thresholds defined because, with large gaps, the data-driven models cannot infer the input information to the output. Large gaps are not imputed well without introducing noise in the time series. In both outliers identification and dropping a trade off between losing data and reduce noise must be find. Noise could bring to lower performing hyperparameters and consequently to a worse representation of the output. On the other side, less data decreases the capacity of the SVR models to learn the correlation between input and output. Indeed, the decisions on how to drop the hydrological years and how to remove a sensor were considered an important part of the setup of the data-driven forecasting chain. In this work, fixed percentages of missing data were allowed, according to each variable, to consider the hydrological year valid. These percentages lead to keep the most consistent years and are defined for the specific goal of short-term hydrological forecasting. In this regard, different constraints can be fixed in other data-driven applications depending on the final aim. The missing data analysis revealed different situations in each basin, for this reason, it is difficult to implement an automatic tool to check the data and drop the sensors. For this reason, all the basins were analysed, and the dropping procedure was evaluated manually for each of them. Specific methodology for these tasks could upgrade the data preprocessing and the scalability of this pipeline approach to larger areas. Finally, to exploit the most from the remaining data, gap-filling was applied to create complete and long input data, crucial to enabling the SVR model to catch all information. The imputation methods used are proven on the short-term forecast by [69] testing different algorithms against three machine learning methods. Figure 5 reports the behaviour on the data used in this work that confirms the goodness of this algorithm, mostly using a multivariate approach (i.e., temperature and precipitation). The univariate approach employed for streamflow encounters challenges in maintaining precision when dealing with long data gaps. This limitation primarily arises from the inherent noise in the raw data attributed to the sensors’ precision. Specifically, the streamflow raw data exhibits consistent oscillations with a precision of \({0.1}\,\hbox {m}^{3}/\hbox {s}\). This precision discrepancy introduces noise into the KNN algorithm, resulting in a tendency to replicate this noise during the filling of extended data gaps. The combination of the steps in the data preprocessing allowed to obtain for the period analysed the longer, cleaner and the most complete input data of temperature, precipitation and streamflow.
4.2 Data-driven approach
The presented data-driven approach is the first proposed comprehensive pipeline to forecast streamflow in complex areas such as South Tyrol with an hourly temporal resolution. Due to its unique characteristics, there are no straightforward standards to compare the physically-based hydrological model outcomes proposed in previous works with our results. Indeed, the absence of models with the same set-up (i.e., prediction with specific lead steps of 48 h and moving data setup at each simulation towards operative forecasting tool) along with different data and basins, make metrics comparison difficult and of limited usefulness. Nevertheless, the correct calculation of the model’s performance is essential to make this work a benchmark for future works. For this reason, the results are discussed in general terms based on the common data-driven metrics definitions comparing among the analysed basins (see Sect. 2.5).
Table 3 summarizes the obtained results for each basin, showing promising outcomes using the proposed pipeline without a particular pattern. Indeed, \(R^2\) is always above 0.88, except for the basins 2, 10 and 18, which are significantly influenced by human activities (i.e., hydropower plant production). This human intervention introduces complex noise into the streamflow data due to the non-natural behaviour of the basin, which challenges the interpretability of Support Vector Regression (SVR) models. Consequently, the SVR models may struggle to fully comprehend and capture the intricate dynamics present in such basins, resulting in limitations in their predictive capabilities. In addition, working with time series means a strict relation of performance to the period analysed. Thus, sometimes the metrics demonstrate inverted model outcomes in the training and testing periods, such as basin 2.
The influence of human activities is summarised in the analysis of the SVR results, where the basins are divided into ‘natural’ or ‘not-natural’. To test the trend significance, a t-test was carried out separately on ‘natural’ and ‘not-natural’ basins evaluating the p-value [29], which indicates a significant relationship if the null hypothesis is true (i.e., \(P value< 0.05\)). The statistical significance tests were conducted on various factors, including the basin area, the percentage of sensors per area, the available hydrological years, and the amount of missing data: all yielded non-significant p-values. This lack of significance can be attributed to the methodology employed in the pipeline (i.e., lumped), which involves approaches that intentionally diminish correlations. For instance, the lumped approach aggregates multiple sensors into a single time series, a strategy particularly effective in smaller basins where it provides a representative overview. However, this approach tends to average out information in larger areas, potentially flattening peaks and diminishing the model’s training capacity. This analysis dividing the ‘natural’ and ‘not-natural’ basins underlines the influence of this aspect, as shown in Fig. 6 with the \(R^2\) metric against the basins area. Even if the previously explained analysis returns no significance, it is clear the performance reduction in the ‘not-natural’ basins. This confirms the comments above on the basins 2, 10 and 18.
The demonstration executed using the DWD ICON-D2 forecasting meteorological data confirms the capacity of the SVR to generalize. Indeed, in the two basins tested, the metrics obtained are worse than the historical testing, as expected, but the decreasing performance is not so important. The MAPE is the most affected by this performance reduction, and this means the demonstration outcomes are worse in periods when the streamflow is lower. The data used in this demonstration are affected by meteorological forecast uncertainties, which can cause a slight drop in performance due to the inclusion of the weather forecast error.
4.3 Challenges and prospects
Data preprocessing could be one of the main challenges in inferring the information into data-driven models. Exploring variables beyond temperature and precipitation represents a crucial step in advancing such approaches within the field of hydrology, particularly in mountainous regions. While this work acknowledges ground station data as the reference, the application is constrained to temperature and precipitation due to the limited availability of other types of data. Another limit is the lumped approach, considering a single metered point for each basin, that can be upgraded using distributed or semi-distributed methodologies to better emphasise the physical behaviour of the basins. Indeed, the relation between sub-basins is not taken into consideration in the lumped approach of this work that considers for each outlet a single basin. While these two tasks may appear straightforward, they involve different challenging steps. They encompass changing the data provider, assessing the feasibility of alternative data sets, adapting the model to incorporate different inputs, and selectively utilizing only the most correlated data to derive essential information without noise. Additional enhancements can be implemented on the model integrated into the pipeline, despite the promising results obtained with SVR in short-term streamflow forecasting. For example, it involves the utilization of multiple data-driven models (e.g., Long Short Term Memory (LSTM)) by introducing the concept of an ensemble. This strategy was explored in other applications in literature, and it encapsulates more information, allowing the pipeline to propagate uncertainties inherent in the individual models to the final outcomes, contributing to a more robust representation of the predicted values. The demonstration of the results on ICON-D2 reports the capability of the model to generalize. A generalization is not able to adapt completely to the different data due to forecasted temperature and precipitation uncertainties. To upgrade these results, the ICON-D2 data should be bias-corrected to align with the historical data, and the models should be updated to replicate better the single events. Indeed, the model is generally well structured to forecast the streamflow along the year, but the performance could be increased on an event-based time scale, specifically for extreme events. Another possible challenging task is the combination of different weather forecast models as forcing of the pipeline, which is similar to the model ensemble explained above, but in this case, it allows the propagation of meteorological uncertainties instead of the model uncertainties.
5 Conclusion
This work explores the potential of a data-driven pipeline for short-term hydrological forecasting in the complex Alpine area of South Tyrol. The developed pipeline allows the upgrade of each single phase separately from data managing to outcomes prediction, and so to enlarge the analysis and discussion in different directions. This work is one of the first to address hydrological prediction at the hourly time scale with a fully data-driven methodology by exploiting only information from temperature and precipitation in the past and future, as well as the streamflow in the past. The Support Vector Regression multi-output model is confirmed to be a feasible choice in the short-term forecast of the streamflow, even more considering its use on 48 h of lead time. Indeed, the methodology developed shows promising results along with its suitability to be applied operationally. This work proves how a data-driven pipeline can be effective in joining both research and operational aspects of water management. Finally, as this work is one of the first approaches to tackling the challenge of hydrology forecasting using Support Vector Regression at high frequency without a physical-based model, many aspects could be investigated in future studies, as described in Sect. 4.3.
Data availability
Data used in this work are free and available to be downloaded in the referenced web pages.
Code availability
Available on request to authors.
References
Abera W, Antonello A, Franceschi S, et al. The udig spatial toolbox for hydro-geomorphic analysis. Geomorphol Tech. 2014;2(4):19.
Avesani D, Zanfei A, Di Marco N, et al. Short-term hydropower optimization driven by innovative time-adapting econometric model. Appl Energy. 2022;310: 118510. https://doi.org/10.1016/j.apenergy.2021.118510.
Beven K. Rainfall-Runoff Modelling: The Primer. 2nd ed. Hoboken: John Wiley and Sons; 2012. p. 457. https://doi.org/10.1002/9781119951001.
Beven K, Feyen J. The future of distributed modelling. Hydrol Processes. 2002;16(2):169–72. https://doi.org/10.1002/hyp.325.
Blöschl G, Reszler C, Komma J. A spatially distributed flash flood forecasting model. Environ Model Softw. 2008;23(4):464–78. https://doi.org/10.1016/j.envsoft.2007.06.010.
Borga M, Stoffel M, Marchi L, et al. Hydrogeomorphic response to extreme rainfall in headwater systems: flash floods and debris flows. J Hydrol. 2014;518(PB):194–205. https://doi.org/10.1016/j.jhydrol.2014.05.022.
Ceppi A, Ravazzani G, Salandin A, et al. Effects of temperature on flood forecasting: analysis of an operative case study in Alpine basins. Nat Hazards Earth Syst Sci. 2013;13(4):1051–62. https://doi.org/10.5194/nhess-13-1051-2013.
Cerlini PB, Silvestri L, Saraceni M. Quality control and gap-filling methods applied to hourly temperature observations over Central Italy. Meteorol Appl. 2020;27(3): e1913. https://doi.org/10.1002/met.1913.
Collados-Lara AJ, Pardo-Igúzquiza E, Pulido-Velazquez D, et al. Precipitation fields in an alpine Mediterranean catchment: Inversion of precipitation gradient with elevation or undercatch of snowfall? Int J Climatol. 2018;38(9):3565–78. https://doi.org/10.1002/joc.5517.
Colombo N, Valt M, Romano E, et al. Long-term trend of snow water equivalent in the Italian Alps. J Hydrol. 2022. https://doi.org/10.1016/j.jhydrol.2022.128532.
Cortes C, Vapnik V. Support-vector networks. Mach learn. 1995;20:273–97.
Dawson CW, Wilby RL. Hydrological modelling using artificial neural networks. Prog Phys Geogr: Earth Environ. 2001;25(1):80–108. https://doi.org/10.1177/030913330102500104.
Deihimi A, Showkati H. Application of echo state networks in short-term electric load forecasting. Energy. 2012;39(1):327–40. https://doi.org/10.1016/j.energy.2012.01.007.
Devia GK, Ganasri BP, Dwarakish GS. A review on hydrological models. Aquat Proced. 2015;4:1001–7. https://doi.org/10.1016/j.aqpro.2015.02.126.
Dhawan P, Dalla Torre D, Zanfei A, et al. Assessment of ERA5-land data in medium-term drinking water demand modelling with deep learning. Water. 2023;15(8):1495. https://doi.org/10.3390/w15081495.
Di Lascio FML, Menapace A, Righetti M. Joint and conditional dependence modelling of peak district heating demand and outdoor temperature: a copula-based approach. Stat Methods Appl. 2019. https://doi.org/10.1007/s10260-019-00488-4.
Di Marco N, Avesani D, Righetti M, et al. Reducing hydrological modelling uncertainty by using MODIS snow cover data and a topography-based distribution function snowmelt model. J Hydrol. 2021;599: 126020. https://doi.org/10.1016/j.jhydrol.2021.126020.
EUMETSAT. Record-breaking rainfall in northern italy. 2021.https://www.eumetsat.int/record-breaking-rainfall-northern-italy, Accessed 15 Dec 2022
European Environment Agency. European digital elevation model (eu-dem). 2011.https://www.eea.europa.eu/en/datahub/datahubitem-view/d08852bc-7b5f-4835-a776-08362e2fbf4b, prod-ID: DAT-193-en, Published 20 Apr 2016, Last modified 30 Oct 2023, Accessed 15 Dec 2022.
Farmer WH, Over TM, Kiang JE. Bias correction of simulated historical daily streamflow at ungauged locations by using independently estimated flow duration curves. Hydrol Earth Syst Sci. 2018;22(11):5741–58. https://doi.org/10.5194/hess-22-5741-2018.
Feng D, Beck H, Lawson K, et al. The suitability of differentiable, physics-informed machine learning hydrologic models for ungauged regions and climate change impact assessment. Hydrol Earth Syst Sci. 2023;27(12):2357–73. https://doi.org/10.5194/hess-27-2357-2023.
Formetta G, Antonello A, Franceschi S, et al. Hydrological modelling with components: a gis-based open-source framework. Environ Model Softw. 2014;55:190–200. https://doi.org/10.1016/j.envsoft.2014.01.019.
German Meteorological Service (DWD). Deutscher wetterdienst website. 2023. https://www.dwd.de/, Accessed 15 Nov 2023.
German Meteorological Service (DWD). Open data server of the german meteorological service. 2023. https://opendata.dwd.de, Accessed 15 Nov 2023.
Gharbia S, Riaz K, Anton I, et al. Hybrid data-driven models for hydrological simulation and projection on the catchment scale. Sustainability. 2022;14(7):4037. https://doi.org/10.3390/su14074037.
Ghobadi F, Kang D. Multi-step ahead probabilistic forecasting of daily streamflow using bayesian deep learning: a multiple case study. Water. 2022;14(22):3672. https://doi.org/10.3390/w14223672.
Guidicelli M, Rebecca G, Gabella M, et al. Continuous spatio-temporal high-resolution estimates of swe across the swiss alps - a statistical two-step approach for high-mountain topography. Front Earth Sci. 2021;9: 664648. https://doi.org/10.3389/feart.2021.664648.
Guo Z, Moosavi V, Leitão JP. Data-driven rapid flood prediction mapping with catchment generalizability. J Hydrol. 2022;609: 127726. https://doi.org/10.1016/j.jhydrol.2022.127726.
Helsel DR, Hirsch RM, Ryberg KR, et al. Statistical methods in water resources. Tech. Rep. 4-A3, U.S. Geological Survey, 2020; https://doi.org/10.3133/tm4A3,
Hutapea S. Biophysical characteristics of deli river watershed to know potential flooding in Medan City Indonesia. J Rangel Sci. 2020;10(3):316–27
Irving K, Kuemmerlen M, Kiesel J, et al. Data descriptor: a high-resolution streamflow and hydrological metrics dataset for ecological modeling using a regression model background and summary. Sci Data. 2018. https://doi.org/10.1038/sdata.2018.224.
Kelleher J, Mac Namee B, D’Arcy A. Fundamentals of machine learning for predictive data analytics: algorithms, worked examples, and case studies. Cambridge: The MIT Press; 2015.
Korsic SAT, Notarnicola C, Quirno MU, et al. Assessing a data-driven approach for monthly runoff prediction in a mountain basin of the Central Andes of Argentina. Environ Chall. 2023;10: 100680. https://doi.org/10.1016/j.envc.2023.100680.
Kubáň M, Parajka J, Tong R, et al. The effects of satellite soil moisture data on the parametrization of topsoil and root zone soil moisture in a conceptual hydrological model. J Hydrol Hydromech. 2022;70:295–307. https://doi.org/10.2478/johh-2022-0021.
Lara-Benítez P, Carranza-García M, Riquelme JC. An experimental review on deep learning architectures for time series forecasting. Int J Neural Syst. 2021. https://doi.org/10.1142/S0129065721300011.
Latif SD, Ahmed AN. Streamflow prediction utilizing deep learning and machine learning algorithms for sustainable water supply management. Water Resour Manag. 2023;37(8):3227–41. https://doi.org/10.1007/s11269-023-03499-9.
Law Insider. Hydrological year. Website, 2023. https://www.lawinsider.com/dictionary/hydrological-year, Accessed 15 Oct 2023.
Lewis E, et al. Quality control of a global hourly rainfall dataset. Environ Modell Softw. 2021;144: 105169. https://doi.org/10.1016/j.envsoft.2021.105169.
Lott J. The quality control of the integrated surface hourly database. In: 14th Conference on Applied Climatology, American Meteorological Society, Seattle, Wash, 2004. https://www1.ncdc.noaa.gov/pub/data/inventories/ish-qc.pdf.
Majone B, Villa F, Deidda R, et al. Impact of climate change and water use policies on hydropower potential in the south-eastern Alpine region. Sci Total Environ. 2016;543:965–80. https://doi.org/10.1016/j.scitotenv.2015.05.009.
Menapace A, Dalla Torre D, Zanfei A, et al. Assessment of the Short-Term Streamflow Forecasting Using Machine Learning Fed by Deutscher Wetterdienst ICON Climate Forecasting Model. In: Proceedings of the 39th IAHR World Congress. International Association for Hydro-Environment Engineering and Research (IAHR), 2022; pp 4915–4921, https://doi.org/10.3850/IAHR-39WC2521711920221774.
Mohammadi B. A review on the applications of machine learning for runoff modeling. Sustain Water Resour Manag. 2021;7:98. https://doi.org/10.1007/s40899-021-00584-y.
Mucherino A, Papajorgji PJ, Pardalos PM. k-nearest neighbor classification. New York: Springer New York; 2009. p. 83–106. https://doi.org/10.1007/978-0-387-88615-2_4.
Murphy KP. Machine learning: a probabilistic perspective. Cambridge: MIT Press; 2012.
Wj Niu, Zk Feng. Evaluating the performances of several artificial intelligence methods in forecasting daily streamflow time series for sustainable water resources management. Sustain Cities Soc. 2021;64: 102562. https://doi.org/10.1016/j.scs.2020.102562.
O’Callaghan JF, Mark DM. The extraction of drainage networks from digital elevation data. Comput Vis, Gr Image Process. 1984;28(3):323–44. https://doi.org/10.1016/S0734-189X(84)80011-0.
Orlandini S, Moretti G. Determination of surface flow paths from gridded elevation data. Water Resour Res. 2009. https://doi.org/10.1029/2008WR007099.
Orlandini S, Moretti G, Franchini M, et al. Path-based methods for the determination of nondispersive drainage directions in grid-based digital elevation models. Water Resour Res. 2003. https://doi.org/10.1029/2002WR001639.
Ossandón A, Rajagopalan B, Lall U, et al. A bayesian hierarchical network model for daily streamflow ensemble forecasting. Water Resour Res. 2021;57(9):e2021WR029920. https://doi.org/10.1029/2021WR029920.
Papacharalampous G, Tyralis H. A review of machine learning concepts and methods for addressing challenges in probabilistic hydrological post-processing and forecasting. Front Water. 2022. https://doi.org/10.3389/frwa.2022.961954.
Provincia Autonoma di Bolzano. Meteo provincia bolzano. 2023. https://meteo.provincia.bz.it, Accessed 15 Nov 2023.
QGIS Development Team (2023) QGIS geographic information system. Open Source Geospatial Foundation Project, https://qgis.org
Quemy A. Two-stage optimization for machine learning workflow. Inf Syst. 2019. https://doi.org/10.48550/arXiv.1907.00678.
Ragettli S, Zhou J, Wang H, et al. Modeling flash floods in ungauged mountain catchments of China: A decision tree learning approach for parameter regionalization. J Hydrol. 2017. https://doi.org/10.1016/j.jhydrol.2017.10.031.
Rajat Athira P. Calibration of hydrological models considering process interdependence: a case study of SWAT model. Environ Modell Softw. 2021;144: 105131. https://doi.org/10.1016/j.envsoft.2021.105131.
Scherrer S. Temperature monitoring in mountain regions using reanalyses: lessons from the Alps. Environ Res Lett. 2020;15: 044005. https://doi.org/10.1088/1748-9326/ab702d.
Seibert J. Multi-criteria calibration of a conceptual runoff model using a genetic algorithm. Hydrol Earth Syst Sci. 2000;4(2):215–24. https://doi.org/10.5194/hess-4-215-2000.
Serafin F, David O, Carlson JR, et al. Bridging technology transfer boundaries: integrated cloud services deliver results of nonlinear process models as surrogate model ensembles. Environ Modell Softw. 2021;146: 105231. https://doi.org/10.1016/j.envsoft.2021.105231.
Sheikh Khozani Z, Barzegari F, Ehteram M, et al. Combining autoregressive integrated moving average with Long Short-Term Memory neural network and optimisation algorithms for predicting ground water level. J Clean Prod. 2022. https://doi.org/10.1016/j.jclepro.2022.131224.
Sirisena TAJG, Maskey S, Ranasinghe R. Hydrological model calibration with streamflow and remote sensing based evapotranspiration data in a data poor basin. Remote Sens. 2020;12(22):3768. https://doi.org/10.3390/rs12223768.
Sushanth K, Mishra A, Mukhopadhyay P, et al. Real-time streamflow forecasting in a reservoir-regulated river basin using explainable machine learning and conceptual reservoir module. Sci Total Environ. 2022;861: 160680. https://doi.org/10.1016/j.scitotenv.2022.160680.
Szczepanek R. Daily streamflow forecasting in mountainous catchment using XGBoost LightGBM and CatBoost. Hydrology. 2022;9(12):226. https://doi.org/10.3390/hydrology9120226.
Valipour M, Banihabib ME, Behbahani S. Parameters Estimate of Autoregressive Moving Average and Autoregressive Integrated Moving Average Models and Compare Their Ability for Inflow Forecasting. J Math Stat. 2012;8:330–8. https://doi.org/10.3844/jmssp.2012.330.338.
Wang X, Yang Y, Lv J, et al. Past, present and future of the applications of machine learning in soil science and hydrology. Soil Water Res. 2023;18(2):67–80. https://doi.org/10.17221/94/2022-SWR.
Wang Y, Liao W, Chang Y. Gated recurrent unit network-based short-term photovoltaic forecasting. Energies. 2018;11(8):2163. https://doi.org/10.3390/en11082163.
Webb GI. Overfitting. In: Sammut C, Webb GI, editors. Encyclopedia of machine learning. Boston: Springer; 2010. p. 744–744. https://doi.org/10.1007/978-0-387-30164-8_623.
Zanfei A, Brentan B, Menapace A, et al. Graph convolutional recurrent neural networks for water demand forecasting. Water Resour Res. 2022. https://doi.org/10.1029/2022WR032299.
Zanfei A, Brentan BM, Menapace A, et al. A short-term water demand forecasting model using multivariate long short-term memory with meteorological data. J Hydroinf. 2022;24(5):1053–65. https://doi.org/10.2166/hydro.2022.055.
Zanfei A, Menapace A, Brentan BM, et al. How does missing data imputation affect the forecasting of urban water demand? J Water Resour Plan Manag. 2022;148(11):04022060. https://doi.org/10.1061/(ASCE)WR.1943-5452.0001624.
Zaramella M, Borga M, Zoccatelli D, et al. TOPMELT 1.0: a topography-based distribution function approach to snowmelt simulation for hydrological modelling at basin scale. Geosci Model Dev. 2019;12(12):5251–65. https://doi.org/10.5194/gmd-12-5251-2019.
Zheng A, Casari A. Feature engineering for machine learning: principles and techniques for data scientists. Springfield: O’Reilly; 2018.
Zhou Q, Teng S, Situ Z, et al. A deep-learning-technique-based data-driven model for accurate and rapid flood predictions in temporal and spatial dimensions. Hydrol Earth Syst Sci. 2023;27(9):1791–808. https://doi.org/10.5194/hess-27-1791-2023.
Zolezzi G, Bellin A, Bruno MC, et al. Assessing hydrological alterations at multiple temporal scales: Adige River Italy. Water Resour Res. 2009. https://doi.org/10.1029/2008WR007266.
Zängl G, Reinert D, Rípodas P, et al. The icon (icosahedral non-hydrostatic) modelling framework of dwd and mpi-m: description of the non-hydrostatic dynamical core. Quart J Royal Meteorol Soc. 2015;141(687):563–79. https://doi.org/10.1002/qj.2378.
Funding
This study has been partially funded by the project “Extreme Events in Mountain Environments (EXTREME)” of the Free University of Bozen-Bolzano (Italy) [Grant TN202R, 2022–2025]. This work was supported by the Open Access Publishing Fund of the Free University of Bozen-Bolzano.
Author information
Authors and Affiliations
Contributions
Conceptualization, D.D.T., A.M. and A.Z.; methodology, D.D.T., A.L., A.M. and A.Z.; software, D.D.T., A.L. and A.Z.; validation, A.L., A.M. and A.Z.; formal analysis, D.D.T., A.L. and A.M.; resources, A.M. and M.R.; data curation, D.D.T. and A.L; writing—original draft preparation, D.D.T. and A.L.; writing—review and editing, D.D.T., A.L., A.M. and A.Z.; visualization, D.D.T. and A.L.; supervision, A.M. and M.R.; project administration, A.M. and M.R.; funding acquisition, A.M., A.Z. and M.R.. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and Consent to participate
Not applicable
Consent for publication
Not applicable
Competing interests
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix 1
Appendix 1
See Table 5
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dalla Torre, D., Lombardi, A., Menapace, A. et al. Exploring the feasibility of Support Vector Machine for short-term hydrological forecasting in South Tyrol: challenges and prospects. Discov Appl Sci 6, 154 (2024). https://doi.org/10.1007/s42452-024-05819-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-024-05819-z