
Abstract
Deep neural networks (DNN) are highly effective in a number of tasks related to machine learning across different domains. It is quite challenging to apply the information gained to textual data because of its graph representation structure. This article applies innovative graph structures and protection techniques to secure wireless systems and mobile computing applications. We develop an Intrusion Detection System (IDS) with DNN and Support Vector Machine (SVM) to identify adversarial inversion attacks in the network system. It employs both normal and abnormal adversaries. It constantly generates signatures, creates attack signatures, and refreshes the IDS signature repository. In conclusion, the assessment indicators, including latency rates and throughput, are used to evaluate the effectiveness and efficiency of the recommended framework with Random Forest. The results of the proposed model (SVM with DNN) based on adversarial inversion attacks were better and more efficient than traditional models, with a detection rate of 93.67% and 95.34% concerning latency rate and throughput. This article also compares the proposed model (SVM with DNN) accuracy with other classifiers and the accuracy comparison for feature datasets of 90.3% and 90%, respectively.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the modern era, there has been an increased concentration on researching how resilient Natural Language Processing (NLP) [1, 2] models are too adversarial attacks, including novel techniques for producing these attacks and improved strategies for fending them off. The sophistication of cyberattacks [3, 4] has increased recently, particularly those targeting systems that store or handle sensitive data. Due to the reliance on their systems for vital information or services, critical national infrastructures are the primary targets of cyberattacks [5, 6]. As a result, both businesses and governments are concerned about how to safeguard them. Attacks on these vital systems can involve network intrusions and installing malicious tools or applications that can leak confidential information or change how certain physical devices behave. Researchers and industry experts are working to build unique systems [7, 8] and defense mechanisms [9, 10] to combat this developing tendency. IDSs [11] are used as a second line of defense with other preventative security measures like adversarial attacks, access restriction and identification. IDSs [12, 13] may identify legitimate and malicious conduct based on certain rules or indicators of the system's typical behavior. Millions of autonomous systems worldwide link billions of people to the Internet. The exponential increase in Internet traffic has been widely observed for many decades. This enormous increase in network traffic includes information from various sources. Significantly, this data may contain various oddities that might damage network infrastructure. In order to prevent these problems, a huge spectrum of mechanisms, including user authentication, data encryption methods, and firewalls, are used. Analysis alone is insufficient for these technologies, though. Several adversarial attacks [14, 15] network systems are employed to more thoroughly examine network packets than standard mechanisms for intrusion detection and intrusion tolerant systems to overcome these techniques' limitations. Such technologies are made for homogenous environments and are unable to identify abnormalities from diverse sources. Additionally, due to the enormous aspects and quantities of data, there are considerable obstacles, such as the complexity of these systems and the increased storage and computing requirements; the difficulties posed by redundant and unnecessary data; the difficulty in detecting zero-day attacks; and the low monitoring and high false alert rate. The data fusion approach offers a potentially effective way to address these intrusion problems. The procedure for finding adversarial attacks is called IDS [16, 17]. In a computer system, an adversarial attack is logically defined as any activity that violates the system's security policy. Over the past 30 years, intrusion detection has been researched. It is predicated on the notions that an unauthorized user’s behavior will differ dramatically from that of a legal user and that many unlawful activities will be obvious. As an additional layer of security to safeguard information systems, IDS [18, 19] are typically used with other preventative security measures like access restriction and authentication.
1.1 Risks associated with wireless networks
Wireless network environments are inherently more vulnerable to an attacker’s adversarial attack [11]. Initially, the network is adversarial to attacks varying from passive attacks to active interference due to the utilization of wireless connectivity. The disclosure of sensitive information, message tampering, and node impersonation are examples of damages. Secondly, mobility nodes are separate, autonomous entities with travelling capabilities. This indicates that nodes with insufficient physical security are vulnerable to capture, infiltration, and hijacking. Thirdly, in a wireless network environment, decision-making can occasionally be distributed, and certain wireless communication methods depend on the collaboration of all nodes and the architecture. Owing to the deficiency of central control, the challengers might take benefit of this flaw to takeoff novel varieties of attacks directed at abolishing the collaborative mechanisms.
1.2 An overview of adversarial attacks
Using algorithms, AI-based models are trained to automatically discover the underlying correlations and patterns in data. Once trained, an AI-based model may be used to anticipate the trends in new data. The trained model must be accurate to perform well, also called a generalization. However, the trained model might be misled by introducing noise to the data, such as through targeted and non-targeted adversarial AI attacks. To deceive the AI-based models, adversarial AI attacks are created by introducing a perturbation to a valid data point or an adversarial example. Adversarial AI threats come in various forms, including evasion, data poisoning, and model inversion attacks. System administrators can use adversarial attack detection systems to address the ever-changing data security challenge. These devices can monitor various possibly dangerous circumstances and warn the security team using a number of the recently covered ways. A combination of software and hardware elements known as IDS is used to identify unusual or suspicious activity on a target, network, or host. IDS, Host Intrusion Detection System (H-IDS), Network Intrusion Detection System (NIDS), Hybrid IDS, and Intrusion Prevention System (IPS) are all members of this family of technologies. IDS provides two key benefits. It can first identify new attacks, even ones that appear isolated. Second, it is easily customizable for any purpose.
1.3 Adversarial attack types
Evasion attacks (model testing), data poisoning attacks (model training), and model inversion attacks are the three types in which adversarial attacks might occur. Figure 1 shows the adversarial attack types. It relies on the attacker’s ability to introduce hostile interference: Evasion attack assumes that the trained model's attributes remain constant. The attacker tries to create the trained model's adversarial samples. Evasion attacks only affect the testing data; therefore, the model does not need to be retrained. Data poisoning attack: including hostile samples in the training dataset, the poisoning attack seeks to influence how well the model performs. Most current efforts use poisoning attacks and transudative learning to complete node classification jobs. In this instance, the model is retrained after the attacker modifies the data. Model inversion seeks to produce new data points close to the original data points to uncover the sensitive information included in the particular data points.

Types of adversarial attacks
1.4 Adversarial attack detection’s necessity
Wireless networks can utilize adversarial attack prevention techniques like encryption and verification to lessen attacks but not completely prevent them. Identification and encryption, for instance, are powerless against hacked wireless network nodes, which frequently hold secret keys. As with secure routing, integrity verification utilizing unnecessary features depends on other nodes' reliability, which might potentially be a weak point for clever attacks. The wireless network infrastructure contains innate weaknesses that are difficult to avoid. Adversarial attack detection and response techniques must be used to protect wireless computing deployments. More research is required to adapt these methods from their original usage in static wireless networks to the new surroundings.
1.5 Issues with existing IDS methods
Research is ongoing to develop new solutions for automatically detecting abnormal system usage. Subsequently, researchers have created and used several methods to systematize the network ID procedure. The “IoT” and big data revolutions are expected to result in more than 26 billion connected gadgets in 2020. The diversity and amount of cyber security encounters are estimated to increase, as well as this tendency. Response time, false detection rates, and low detection rates are some of these issues, as imbalanced datasets and many more, which are as follows:
-
Ensuring successful arrangement: If an organization wishes to attain a high level of risk exposure, it must ensure that adversarial attack recognition devices are correctly placed and optimized. Because of cost and maintenance constraints, deploying NIDS and HIDS detectors throughout an IT infrastructure may be impossible.
-
Taking care of the numerous alarms: The massive number of alerts that threat identification produces may burden group members. Dangerous conduct usually goes undiscovered because numerous system warnings are false positives, and businesses rarely have the time or money to evaluate all indications properly.
-
Investigating and comprehending notifications: It can take a significant amount of money and time to investigate IDS alarms. Occasionally, extra information from many other platforms is needed to help determine how serious an alert is. Specific expertise is needed to assess network outcomes, but many firms lack dedicated security professionals who can do this crucial duty.
-
Understanding how to deal with threats: For enterprises adopting IDS, a typical problem is a lack of adequate emergency preparedness capabilities. Identifying the problem is part of the battle won; the other involves knowing how and where to solve it and having the resources to accomplish it.
1.6 How to handle your IDS issues?
Enterprises should consider conducting an independent risk evaluation before adopting an Intrusion Detection System to comprehend their domain better, especially the critical assets that need to be protected. With this knowledge, you can ensure an ID is suitably sized to provide the most worth and benefits. Considering the challenges of continuing structure upkeep, checking, and apprehension analysis, many enterprises may want to consider employing a successful provision to do all the work. When using a managed IDS service, hiring specialized security staff is unnecessary. If appropriate, the service may also contain all essential technology, avoiding the requirement for initial capital investment.
1.7 Motivations
This study aims to suggest and evaluate a system safety that operates proactively and automatically creates attack signatures for new adversarial attacks with the least amount of human involvement. Identifying innovative adversarial attacks with high accuracy and detection rates is essential to create attack signatures. After over three decades, the current Internet architecture is a very complicated system. As a result, the legacy internet lacks the flexibility to adapt to modern applications' constantly shifting needs and dynamic nature. Developing an adversarial attack detection system with a 100% success rate is challenging or nearly impossible. Many security issues exist in the majority of systems nowadays. Not all incursions are known to exist. Therefore, reducing network security concerns will be made possible by the development of an effective and precise adversarial attack detection system. One of the most critical technologies is an IDS tool for network security. The anomaly-based IDS finds facts that differ from a reference model. Several methods have been put forth for anomaly-based IDS, including Artificial Neural Networks (ANN), SVM, and Bayesian networks. Moreover, these approaches' false alarm rates and accompanying computing costs are considerable. Deep Learning (DL) is a novel strategy that offers greater accuracy than conventional Machine Learning methods. Since DL can handle raw facts and pick up high-level characteristics independently, it makes a compelling argument for flexibility in networks with limited resources.
1.8 Contributions
According to the present research course, Deep Neural Networks may provide a more effective method for implementing IDS for wireless networks. In conclusion, the main contributions of our paper are as follows:
-
Creating a sizable dataset includes numerous adversarial inversion attacks in wireless network components from the suggested network testbed. Additionally, the effect of the created attacks on the various wireless network components is examined. The experts may use this to detect possible gaps and suggest several responses depending on these needs.
-
To increase a model’s resilience, this article uses NSL-KDD dataset for adversarial inversion attack training from the literature for our standardized model. The proposed system employs for both normal and abnormal adversaries. It constantly generates signatures, creates attack signatures, and refreshes the IDS signature repository.
-
A novel model inversion technique that works better with DNNs is suggested. Reconstruction of the training visuals is a key performance indicator for model inversion techniques. We are evaluating and contrasting wireless network's adversarial inversion attacks from earlier efforts using standardized models and datasets. We examine the IDSs datasets' drawbacks, reviewing and categorizing attacks on various wireless network levels. We also assess how well our proposed model strategy performs. The test results demonstrate the enormous potential of our technique in real-time detection rate of 93.67% and 95.34% concerning latency rate and throughput. This article also compares the proposed model (SVM with DNN) accuracy with other classifiers and the accuracy comparison for feature datasets of 90.3% and 90%, respectively.
The rest of the paper is organized as shadows: The previous research in adversarial inversion attack detection and signature development is covered in Sect. 2. TheIDSs are provided in Sect. 3. Section 4 offers information on the proposed architecture for IDS by using deep learning techniques. The implementation, experimental setup and performance of the proposed model using deep learning techniques are explained in Sect. 5. Lastly, in Sect. 6, conclusions and recommendations for the future are given.
2 Related work
Several types of research suggest various methods for detecting intrusions in wireless networks: To increase the gradient-based perturbations on graphs, [20] suggest a unique exploratory adversarial approach (dubbed EpoAtk). EpoAtk’s exploratory technique consists of three phases: generation, assessment, and recombination, to avoid any potential deception that the greatest gradient can present.To create adversarial samples and assess the IoT network intrusion detection effectiveness [21], create an adversarial samples generating method. Then, using feature grouping and multi-model fusion, the authors provide a novel framework called FGMD (Feature Grouping and Multi-Model Fusion Detector) that may thwart adversarial assaults. In order to successfully attack the black-box intrusion detection system and maintain network traffic functioning [22], offer attackGAN, an enhanced adversarial attack model based on a Generated Adversarial Network. They also built a new loss function for this assault..
In [23], the researchers suggested a NIDS and obtained a low proportion of false alarms utilizing even one Support Vector Machine for their study. The structure was accomplished on a hostile network dataset compared to previous research. The researchers of [24, 25] suggest a multi-layer perceptron and gravitational algorithm examine-based and flow-based anomaly recognition structure. The system has a high accuracy rate for classifying innocuous and harmful traffic. IDS were subjected to the SVM approach by Horng et al. [26]. Although classic Machine Learning techniques are quite successful in detecting intrusions, they are nevertheless constrained by the necessity to create sample characteristics artificially. Its quality affects how well it performs. Authors have developed deep learning algorithms to address this issue.
By merging several Machine Learning approaches, such as Support Vector Machines, Bayesian classification, and Decision Trees, Chung et al. [27] created a collection of physical Intrusion Detection Systems. Braga et al. [16] describe a simple method employing a Self-Organizing Map (SOM) to identify DDoS attacks in the SDN. Based on six traffic flow parameters, this method provides good detection precision. Trung et al. [28] integrate rigorous identification parameters with the fuzzy inference method to assess the possibility of DDoS attacks based on real-world performance parameters across normal and malicious phases. These three characteristics, diffusion of inter-arrival duration, dispersion of packet amount per flow, and flow size to a server were chosen to help detect the attack. Additional studies employ a variety of feature collection methods to increase recognition correctness. For identifying DDoS attacks in the SDN, the researchers of [29] suggest a deep learning-based technique utilizing a stacked autoencoder (SAE). They attained rather great results and a low FAR based on their dataset.
The researchers of [30] implement the inception random walk with credit-based rate limitation, rate limiting, maximum entropy, and NETAD as four traffic anomaly detection methods in the SDN. By altering the settings, Shin et al. [31] utilized the bogeyman method to determine how similar the data were. In an attempt to boost the scalability of native OpenFlow, a unique solution mixing OpenFlow and sFlow has been detailed in [32] for an efficient and adaptable anomaly recognition and reduction technique in an SDN setting. Deep trust networks were used by Gao et al. [33] to improve intrusion detection over other conventional Machine Learning techniques. The LSSVM model for network intrusion detection was introduced by Fuqun [34]. SVM is employed to identify DDoS attacks quite effectively in [35] and [36].
These methods discussed above have overfitting issues because they don't employ the data fusion methodology and only evaluate models on one dataset. Additionally, there is no discussion of the Accuracy (ACC) or False-Positive Rate (FPR). This paper's major contribution is combining data from many sources for more accurate and illuminating results. The three layers the data fusion may be deployed are the decision, feature, and data layers. The ultimate conclusion is produced by the decision layer fusion, which merges the decisions of several processing units. The feature-level fusion aids in the reduction of preprocessed data's features. By deleting pointless features from the high-dimensional dataset, feature selection plays a crucial role in improving the model's performance. The raw data from many sources is integrated for greater comprehension via data layer fusion. Another name for it is low-level fusion. Applying fused data to a Machine Learning algorithm (e.g., DNN with SVM) as a basis classifier for the bagging approach) will allow you to evaluate the performance of the algorithm after fusion. Table 1 compares different aspects (e.g., technique, data fusion, and evaluation metrics).
3 Intrusion detection systems (IDSs) approaches
An IDS safeguards a structure’s privacy, security, and accessibility. Signature-based (SIDS) or Anomaly-based Intrusion Detection Systems (IDS) are two kinds of IDS that are made to identify certain problems (AIDS). IDS might be hardware or software. IDS normally uses one of the following approaches shown in Fig. 2.

Overview of intrusion detection systems (IDSs) approaches
3.1 Statistical model for IDS
The traffic flow activity is recorded, and a picture of its unpredictable behavior is constructed using statistically based approaches. This picture is created on traffic size, packet size for each protocol, connection capacity, amount of unique IP addresses, etc. The actual picture is established when network events occur, and the normal detection score is calculated by comparing the two actions. The Intrusion Detection System will report normal behavior when the score exceeds a predetermined threshold since the score typically represents the level of abnormality for a particular event. An IDS that relies on statistics generates a distributed system for the distinctive action patterns before identifying low-probability happenings as suspected attacks. In most cases, the statistical IDS service is one of the representations below.
-
Univariate: This approach is utilized whenever a normal statistical pattern is established for only one indicator of behaviors in computer schemes. Univariate IDS checks for anomalies in every particular parameter. “Uni” denotes “one”; thus, it indicates the data contains only one parameter.
-
Multivariate: To comprehend the links between variables, it focuses on connections between two or more measurements. This approach might be useful if experimental results demonstrate that combining associated measurements yields better categorization than analyzing them independently. The researchers investigate a multivariate worth control strategy for detecting adversarial inversion attacks by constructing a long-term summary of routine activities. Predicting probabilities for the subject to excessive is the core challenge with advanced regression IDs.
-
Time series model: A time sequence is a pool of measurements performed across a specific period. A new finding is anomalous if its probability of happening at that instant is also small. Many studies handled intrusion recognition aware aggregated by time series and suggested a technique for identifying network irregularities by learning the sudden fluctuation in time series data. Simulation tests were used to verify the method's practicality.
3.2 Normal VS abnormal detection for IDS
The capacity to discriminate between normal, abnormal activity and that which is deviant or deliberately destructive is at the basis of intrusion detection. There are two methods to this problem, with IDS employments using some mix of these; firstly, adversarial inversion attack recognition tries to simulate normal activities. Any occurrences deviating from this paradigm are considered suspicious. A typically quiet public web server may indicate a larva infestation, e.g., trying to open influences to many statements. Secondly, misappropriation recognition tries to simulate anomalous actions: Any happening that designates system abuse. E.g., HTTP requests denoting the cmd.exe file may specify violence. Although there are several anomaly IDS methods, they all follow the following fundamental modules or steps.
-
1.
Parameterization: At this point, a predetermined form is used to describe the detected instances of the target network.
-
2.
Training Step: A model is created following the system's normal or abnormal behavior. Depending on the type of A-NIDS being evaluated, this can be done in various methods, both automatically and manually.
-
3.
Detection step: The (parameterized) recorded data is matched with the system model when it becomes accessible. An alert will sound if the deviation discovered exceeds (or falls short of, in the case of abnormality models) a predetermined threshold.
-
4.
Classifier analysis: This non-parametric approach uses vector representations to describe event flows, categorizing samples into class behaviors. Clusters show comparable user behaviors or activities, allowing normal and abnormal behavior to be differentiated.
3.3 Protocols for IDS
An Intrusion Detection System that monitors and analyses the protocol used by the computer system is known as a protocol-based Intrusion Detection System. These systems are usually implemented on web servers. A protocol will frequently consist of a program or sensor that resides at the front end of a server, detecting and analyzing the connection between an associated scheme and the structure it maintains. It will monitor the dynamic behavior and position of the protocol. Numerous attack strategies depend on using strange or improperly formatted protocol (e.g., TCP, UDP, RP) fields handled improperly by solicitation schemes. Protocol authentication tools carefully examine protocol parks and behavior compared to heuristic predictions or established norms. Data that deviates from the pertinent parameters is marked as suspicious. This method, employed in several commercial applications, can identify many typical attacks, although it comes from many protocols' inadequate standards compliance. Furthermore, applying this approach to proprietary or poorly defined procedures may be challenging or result in false positives.
4 Proposed architecture
In order to prevent a breach of data privacy, the suggested intrusion detection system detects adversarial inversion attacks using a deep neural network algorithm and anomaly detection technique without accessing data in the packet payload. This system is established in the following phases as shown in Fig. 3. There are four steps to it. Stage 1 deals with preparing the dataset, while Stage 2 involves the preprocessing setting. The normalization procedure and text mapping are the two key components of the preprocessing in this paradigm. Deep neural networks, which include numerous hidden layers with nodes and ways to link them, are one of the most significant computational networks at stage 3. Three key phases may be used to sum up the deep learning process that creates the model in this study. The model's topology, which details the number of layers, neurons in each layer, and connections between them, comes first. Second: the forward propagation, which is employed by the artificial neurons' perceptron classifier and activation function. The backpropagation with a loss function and an optimizer come in third. The classification of normal and abnormal traffic with the assessment step, which guarantees the correctness of our technique for anomaly detection, will make up the last stage.

The block diagram for adversarial inversion using Deep Neural Network involves four stages. First is the model's topology, which describes the number of layers, the number of neurons in each layer, and the connections between the neurons. Second, the artificial neurons' perceptron classifier and activation function use forward propagation. The third place goes to the backpropagation with a loss function and an optimizer. The final phase will be categorising regular and abnormal traffic with the assessment step, which ensures the accuracy of our approach to detect anomalies
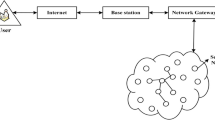
The quick development of the Internet not only makes it possible to share resources and information and presents new difficulties for the intrusion detection community. Conventional IDSs, created for different hosts and small-scale networking technologies, cannot be readily deployed to large-scale systems because of their sophistication and the volume of audit data they generate. Wireless network-based IDSs have several benefits. First, Wireless-Network-based IDSs can benefit from the established design of network protocols like TCP/IP. This is a useful method for avoiding misunderstandings arising from wireless systems variability. Second, Wireless-Network-based IDSs often operate on a separate (dedicated) computer, freeing up resources on the PCs they protect. To meet the requirements of wireless networks, adversarial inversion attack recognition and reply schemes should be dispersed and supportive. Every node in the wireless network takes part in adversarial inversion attack detection and action in our proposed solution, as shown in Fig. 4. Every node is in charge of locally and independently identifying indicators of infiltration, and nearby nodes can work together to investigate in the broader area. Separate IDS agents are installed on every node in the systems aspect. Every IDS agent works autonomously and monitors neighbourhood activity (including user and systems activities). It starts a reaction when it notices an incursion from nearby traces. If an abnormality is found in the native data or the indication is ambiguous, and a more thorough investigation is necessary, surrounding systems can be used to compare and find previous incursions. For instance, a signature rule for the “guessing password attack” may be “there are more than four unsuccessful login attempts in less than 2 min.”

Proposed architecture for an adversarial attack using Deep Neural Network: Each node is responsible for locally and independently recognizing infiltration signs, and neighbouring nodes can cooperate in conducting wide-ranging investigations. On each node in the systems aspect, a unique IDS agent is deployed. Each IDS agent operates independently while monitoring nearby activity (both user and system activities)
The primary benefit of abuse exposure is its ability to identify instances of recognized attacks precisely and effectively. With a wireless network model, an adversarial inversion text attack seeks to construct attacks that alter input sequences in a way that both achieves the attack's objectives and complies with predetermined linguistic rules. Attacking a wireless network model may be conceptualized as a computational search problem. The attacker must look through all possible transformations to identify a set of adaptations that provide a successful adversarial inversion example. Four elements can be combined to create a single attack: (1) goal function, (2) constraints, (3) transformation and (4) search method. The goal function is task-specific and assesses the effectiveness of the assault regarding the model outcomes. The group of restrictions used to assess the validity of a perturbation concerning the source. The transformation produces several possible deviations from a single input. The search strategy repeatedly probes the model and identifies potential disturbances from various alterations. Existing IDSs, created for individual hosts and small-scale internet connections, cannot be readily deployed to large-scale systems because of their complexity and the volume of audit data they produce. The proposed model uses the structural links between the instances that make up an intrusion signature; they suggested an abstract hierarchy for categorizing intrusion signatures. High-level events in such a hierarchy can instantiate the abstract hierarchy into concrete by being specified in low-level audit trail events. This categorization approach has the advantage of making the complexity of identifying signatures at each level of the hierarchy clear. It also specifies the conditions that patterns in all categorization categories must satisfy to reflect the range of frequently occurring invasions fully. This article guarantees that the fluctuations are undetectable by maintaining crucial data properties. Imperceptible perturbations, such as new edges and altered node properties, are the main strategies for the recently presented attack techniques. In order to ensure theoretical resilience against adversarial inversion assault, we propose novel neighbourhood aggregation schemas for the defense models in place of the previously-used adversarial training methodologies.
4.1 Deep neural network approach for adversarial inversion attack detection
DNN approach has recently been engaged to identify adversarial inversion network attacks. In general, the DL class is a subclass of ML that uses feature representation through consecutive layers of information processing. Deep learning has become more popular since processing power is readily available, computer gear is reasonably priced, and significant advances in ML research have been made. The substance of ML methods is forming an explicit or implicit architecture that permits the analysis of forms to be classified. These structures are exclusive in that they involve labelled data to train the behavioral model, which is a time and resource-intensive method. The use of Machine Learning concepts frequently overlaps with statistical procedures, even though the former focuses on creating a model that enhances performance based on past outcomes. Deep Belief Networks (DBN), DNN, Recurrent Neural Networks (RNN), Long-Short Term Memory (LSTM), and Convolutional Neural Networks (CNN) are the several deep learning methods that are now accessible. The suggested D-Sign system uses multilayer LSTM, a Deep Recurrent Neural Network, to identify new threats in the data stream. To create supple and operational IDS to identify and categorize unpredicted and unexpected cyber threats, a DNN, a form of DL system, is investigated in this paper. The fast growth of attacks and the ongoing change in network behavior need the evaluation of multiple datasets produced over time using static and dynamic methods. This research makes choosing the optimal algorithm for reliably identifying upcoming cyber-attacks easier. A thorough analysis of DNN and other traditional Machine Learning classifier studies is presented on several benchmark ransomware datasets that are freely accessible. The proposed architecture mainly consists of three components (e.g., dataset and preprocessing, feature extraction and training, and classification).
4.2 Data set and preprocessing
Our study employs a DNN to find adversaries. To identify attacks, 12 fundamental features are selected in Table 2 with descriptions and types: duration, protocol_type, service, flag, src_bytes, dst_bytes, num_failed_mtps, logged_in, same_src_rate, diff_src_rate, dst_host_serror_rate, dst_host_srv_serror_rate, dst_host_rerror_rate, dst_host_srv_rerror_rate, class. Before learning more about the distributions, we first draw the univariate histograms of the feature data, as shown in Fig. 5. Since we apply simple preprocessing and feature extraction from the perspective of wireless networking, this is the primary distinction between our work and previous works. We use a dataset from Kaggle, which includes 15 characteristics and 3 symbolic features that make up this object. For these attributes, the dataset must be processed independently (e.g., numerical characterization of symbolic features and normalization of numerical features). The distribution of numeric features is shown in Fig. 5. Before learning more about the distributions, we first draw the univariate histograms of the feature data. Certain characteristics act as if they are constant features based on the findings of distributions mentioned above. To further grasp the characteristics, we'll demonstrate two measurements: According to value count, the percentage of each feature's value with the highest count. The variation of each aspect is seen from a value standpoint. Data were separated into three protocols during the communication protocol stage (e.g., TCP, RP and DHCP). The benchmarking dataset for many cutting-edge wireless network adversarial inversion attack techniques, the NSL-KDD dataset, is utilized for training and evaluating the suggested methods. The dataset is subjected to many sophisticated preprocessing procedures to retrieve the data in its optimal form, producing results superior to those of other systems. A multi-class classification exercise is carried out by determining whether an attack is there and categorizing the kind of behavior (Normal, Abnormal), achieving an accuracy of 93.67% using just five of the 12 fundamental properties of NSL-KDD.

Distribution of numeric features
4.3 Feature extraction and training
We use DNN for feature extraction and data training. While implementing a detection model requires careful consideration of feature selection and extraction. Based on the justification, we train-test splitting into the data to stop a particular kind of data leakage called train-test poisoning. That is, we divided a hold-out dataset into final testing data first. KFold cross-validation will also be used for the training dataset to test the model’s generalizability. To be more precise, given that we employ classifiers as detectors, we must choose or create features from the appraisal statistics which have a significant evidence increase. These characteristics include data on traffic flow (e.g., the number of packets and bytes in both forward and backward directions).
We employ certain feature data for labelling processing, such as Source IP and Destination IP. To account for various behavior's, we built a sizable feature set. Running all experiments with all of these characteristics is not efficient. The required feature set varies depending on the routing protocol and the circumstance. To build “knowledge,” feature selection, a typical data preparation method, is combined with a Deep Neural Network model. Most of the time, applying all domain properties may appear impractical or computationally infeasible. Table 2 provides some illustrations of particular system features. Features are retrieved and weighted following their rank regarding their contribution to the system information. Remember that depending on the Machine Learning phase's context of interpretation, features may hold varying amounts of information. A distinct loss function will replace the usual mean square error in Eq. (1).
where yi is the anticipated value, xi is the ground truth value, and N is the number of subcarriers. When training the neural network receiver, we use this instead of the mean square error in the loss function.
4.4 Classification
We useSVM classifier to classify (a detection model that distinguishes between abnormal and normal using the deviation scores) and get the classification results. The SVM classifier is combined with principal component analysis rules and utilized in an intrusion detection application. The model is trained and optimized for identifying anomalous patterns using this method's dataset (from Kaggle). Normal data educate SVM to forecast what would typically happen after n occurrences. An anomaly occurs in checking when the real occurrence differs from what the classifier anticipated. Features with a significant statistics achievement (or reduction in selective measures) are required for building a classifier. In other words, feature assessment checks are necessary for a classifier to divide the unique (varied and high entropy) dataset into pure (and low entropy) subsections, each preferably containing one (right) class of data. We apply the following method for adversarial inversion attack identification using this framework: The steps are as follows:
-
(I)
Choose the review statistics so that the normal dataset has little entropy.
-
(II)
Transform the data appropriately based on the selective measures (for example, generate novel structures with extraordinary statistics achievement).
-
(III)
The classification model is calculated utilizing training examples.
-
(IV)
Employ the classification to test data.
-
(V)
We are producing attack summaries after processing the alerts. The complete procedure for adversarial inversion attack and defense using Deep Neural Networks is explained in Algo. 1.
The perturbations are only applied to the network coordinates, X = (K, L +), in the setting of atomistic simulations. An adversarial inversion assault is made against the collective variables (CVs) that better explain the method, s = s(L), by using X = (K,s1(s +)) as well as D and G, our data models corresponding to E inputs. By suitably selecting the largest p-norm, the set may be defined. Nonetheless, it is frequently interesting to characterize these restrictions regarding the energy of the states that will be sampled and the sampling temperature in atomistic simulations. To that purpose, the ground truth data X may be used to create a normalization constant A of the system at a specific temperature T. Due to the absence of information on all the states the system might exist in, even if the partition function of the system inspires the shape of A, it does not accurately reflect the partition function. The necessary extensive sampling, reserved for the production simulation following AL, includes accessing as many of them as feasible..however, we can calculate the proportionality of the probability p that a state Eδ,i with anticipated energy F(Eδ,i) will be sampled. Figure 6 shows the flow diagram, which isolated the statistics admittance figure of the suggested method. The defenders are exposed to the key exchanged among the training and test stages and the training data. We consider the attacker to have access to just the practice data. The protector can mix the information and the top secret in various conducts, such as by inserting secret key-based arbitrary sound, reflecting the input against arbitrary basis routes made from the secret key, using key-driven arbitrary gathering or asymmetric manipulations, etc. The suggested approach based on Kerckhoffs's cryptographic principle implies that the attacker is aware of the classifier's design and the defense technique in use, has access to the training data set, is unaware of a secret key, and cannot access the system’s internal states. Key-based randomization that has been particularly devised gives the system its resilience. Using the secret key provides the defence with an informational edge over the attacker. As we have already discussed, the attacker only has access to the shared training data set, whereas the defense has access to the secret shared between the training and test stages and the training data. The defiance has a probe Xadv and the secret key during the test stage, whereas the attacker has the training set. An attacker can generate an adversarial (xadv) and watch the system c's decision output for acceptance or rejection. The only option is to increase the number of adversarial tests to be carried out following the observable output, as the attacker lacks direct access to the defender’s perturbation, defined by a significant amount of entropy. Due to this, adversarial inversion attacks on this system are more complicated and less effective.

Flow diagram of the suggested model

Pseudocode for the adversarial training of Deep Neural Network
5 Experimental setup and performance evaluation
All experiments were run on a Lenovo machine with an Intel Pentium Gold G6400 processor running at 3.00 GHz and 16 GB of RAM. The model in this case study was trained using the Kaggle dataset. The dataset categorizes network intrusion using two categories (Normal and Abnormal). Every feature serves as a representation of each behavior. We use 39,023 samples for training and 35,098 samples for testing. This case study’s distinctive quality is that it uses a deep learning neural network to gradually simplify the eigenvalues while still adhering to various communication protocols for data categorization. The procedures were divided into data selection and preprocessing, feature extraction and training, and SVM classification test validation. Accuracy (ACC) is used in this experiment as a model impact metric. Figure 7a and b displays the evaluation parameters for the four assaults derived from the confusion matrices. The ACC formula is in Eq. (2) as follows:

Confusion matrix on NSL-KDD and KDD Cup 99
Regarding these, AP is the quantity of attack behavior patterns that are accurately categorized; AN is the quantity of normal behavior sample sets that have been appropriately categorized; EN represents the number of samples of misclassified attack behaviors, whereas EP represents the number of samples of misclassified normal behaviors. The 15% dataset utilized in this case study for Accuracy (ACC) as a validation metric. The sinking element's duration, breadth, and walking speed are all set to 2, and the pooling layer uses max. The Deep Neural Network with length and width set to 2 and step length set to 1. The accumulating method uses the Deep Neural Network technique to optimize the error rate by downsampling. By adjusting the neural network number of epochs, we can track changes in accuracy. Figure 8 shows that accuracy increases as the number of epochs continuously increases. The dataset has three categorical features, including protocols, services and flags.

Pie chart of protocol type
5.1 Protocol analysis module
In our scenario, we use three types of protocols (TCP, UDP, RP) shown in Fig. 8. The Data Linker Layer, Network Layer, Transport Layer, and Application Layer protocols are all used through the protocol examination unit to examine the facts that have been collected. The data buffer module will save the study results for later presentation and analysis. Wireless observing is frequently employed in cooperating with wireless LAN and wireless LAN system safety studies. Additionally, wireless protocol monitoring uses a wireless observing system. Wireless protocol information is crucial for the IEEE 802.11 wireless LAN's security and surveillance. Because of vulnerabilities in the MAC protocol and fundamental characteristics of wireless networks, such as open standard and agility, the IEEE 802.11 WLAN is considered security vulnerable. We must continuously monitor information from wireless networks to detect such security issues properly. Thus, security monitoring and surveillance are crucial for efficient network protection, like real-time wireless information.

Pie chart of services
5.2 Services analysis module
Rather than utilizing the seven-layer OSI reference architecture, this system's protocol stack is based on the TCP/IP protocol stack, which has a four-layer (application layer, transport layer, network layer and link layer) structure. Each layer uses network services, as shown in Fig. 9, offered by the subsequent layer to suit its demands. Simple Mail Transfer Protocol (SMTP), File Transfer Protocol (FTP), Network Remote Access Protocol (Telnet), and many other are examples of applications that fall within the application layer, which is a layer for inter-application communication. Transmission Control Protocol (TCP) and User Datagram Protocol (UDP) are two instances of the data transmission protocols provided by the transport layer. Its primary job is to format data and offer a means of data transport. The network layer, such as Internet Protocol (IP), performs the fundamental data packet transmission operation and ensures that packets access their destinations. The link layer controls the real network media, defines how to transport data over the Internet, and gets and transmits network layer datagrams across transmission lines. The proposed system uses a protocol to encapsulate the transferred data. The first step is to utilize an application layer protocol, such as HTTP, to encapsulate data. TCP is the foundation of the HTTP protocol. It is contained inside the TCP and HTTP data section of the TCP protocol. Based on the IP protocol, the TCP protocol was created. Therefore, the TCP segment may be considered the load, and an IP datagram may be created by adding an IP header. Due to the Ethernet-based nature of the IP datagram, it is this time enclosed within an Ethernet frame before the structure transfers the data using Ethernet frames. The system will break apart data packets after obtaining network data. On the other hand, decompose and encapsulate the process (see Fig. 9).

Pie chart of flags
5.3 Figures flag analysis module
While some TCP segments include data, others are only acknowledgments of previously transmitted packets. The well-known 3-way interaction uses the SYNs and ACKs provided by TCP to finish the connection before data is delivered. We hypothesise that each TCP segment has a specific function established with the TCP flag choices. This lets the sender or receiver designate which flags should be used so the other end treats the segment appropriately. We admit the “SYN,” “ACK,” and “FIN” flags as shown in Fig. 10 , which are used to create connections, signal successful segment transfers, and, finally, terminate associations, are the most often used flags. Even though the other flags are less well-known, they can often be just as significant because of their function. We will start our investigation by looking at all six flags, beginning with the Urgent Pointer. A flag called the Urgent Pointer flag is used to mark receiving data as “urgent.” These arriving segments are transmitted straight and processed immediately rather than waiting until the receiving end digests the prior segments. The successful receipt of packets is acknowledged by setting the ACKnowledgement flag. The reset flag is utilized whenever a chunk is not meant for the present connection. The SYN flag is initially sent when establishing the traditional three-way host interaction. The FIN flag, which stands for the term “FINished,” is the last one that is accessible. The FIN flag normally occurs when the final packets are sent among a connection since it terminates the virtual links established with the preceding flag (SYN).

Dataset distribution of normal and abnormal labels
5.4 Figures distribution of normal and abnormal behavior
Several ML and DL models in this article have been employed to categorize adversarial inversion attacks like poisoning, evasion, inversion, DDoS, worms, backdoors, and numerous others from regular network traffic and network adversarial inversion attack detection. Adversarial inversion attack detection may be characterized as a binary classification issue, which is how we address it using a Machine Learning methodology. In other words, the objective is to ascertain whether or not the network traffic represents an abnormal behavior, as shown in Fig. 11 Network devices are now employed in various applications, including smart homes, drones, fire systems, and healthcare. If someone with malicious intent gains access to such networks, you can only picture the catastrophe. NIDS analyses all traffic, identifies a negative activity, and helps the organization identify potential security threats.

Evaluation of throughput
6 Results and discussions
This section discussed the metrics for assessing adversarial inversion attacks and defensive performance. We classify and obtain the classification results using the SVM classifier, a detection model that distinguishes between abnormal and normal using the deviation scores. An intrusion detection application uses The SVM classifier with principal component analysis rules. Using the dataset for this method (from Kaggle), the model is trained and refined for detecting abnormal patterns. SVM learns from normal data to predict what would occur following n occurrences. A checking anomaly occurs when the event departs from the classifier’s prediction. We first give a quick overview of the generic evaluation metrics and observe how they are explicitly used in adversarial performance evaluation. Then, we thoroughly introduce specific assessment criteria created for attacks and defences.
6.1 Evaluation of throughput
The average response time of the proposed system for each of the three testing scenarios is shown in Fig. 12. As we can see, the overhead on the proposed system is brought on both the Bagging and the Random Forest. Because the proposed model is less complex than the Bagging and the Random Forest, it performs marginally better than the Bagging and the Random Forest. The Random Forest, however, achieves well than the Bagging in positions of detection accuracy. The Random Forest and the Bagging are both foreseeable and inevitable. When the number of epochs in the network is increased from 200 to 1000, the throughput somewhat declines. When there are less than 1000 epochs in the network, performance suffers by around 2.5%. The throughput may be roughly decreased when the number of epochs is increased over the network. We follow the latency rate formula in Eq. (3) where TH denote average outcome for a resource for a given specific time, I resource and T how long time is required to develop the resource.
6.2 Evaluation of latency rate
As seen in Fig. 13, the latency rate is the same as the network size expands. The burden on the system also increases due to expanding the network, which is not overhead. The highest overhead does not affect the proposed system. In Fig. 13, the overall decline is around 11%. Overall, the proposed model overhead is relatively minimal compared to the Bagging and the Random Forest. As a result, our suggested technique offers a lot of promise for real-time adversarial inversion attack recognition in wireless systems. This choice between performance and safety is one that all network managers must manage from the standpoint of the network. We follow the latency rate formula in Eq. (4) where LR denote latency rate PD processing delay, QD queuing delay, TD transmission delay and PRD propagation delay.

Evaluation of latency rate
Table 3 shows a classifier comparison with other proposed approaches. Accuracy (AC) is used in this experiment as a model effect evaluation metric. We follow AC formula in Eq. (1). Among them, TP represents the proportion of samples of attack behaviors that are correctly classified; TN represents the proportion of samples of normal behaviors that are correctly classified; FP represents the proportion of samples of normal behaviors that are incorrectly classified; and FN represents the proportion of samples of incorrectly classified attack behaviors.
6.3 Evaluation of link precision
The outcomes of link precision employing adversarial inversion attacks are shown in Fig. 14.It is clear that for link precision adversarial inversion attacks, our technique is better than KNN and DT. The experiment results further demonstrate that when the adversarial inversion attack percentages rise, the link precision equivalent to DNN rapidly decreases, demonstrating the superiority of our method over existing link precision classifiers. Furthermore, the adaptability of our adversarial inversion attack approach for link precision is amply illustrated by contrasting the prediction outcomes of KNN, DT and the other classifiers.

Evaluation of link precision with other classifiers
6.4 Comparison of DNN with other models
Figure 15 contrasts the accuracy of the model’s recognition impact with that of the KNN, DT, and DNN algorithms. The upgraded DNN model has a greater detection impact than other techniques. As a result, the suggested model works. Table 4 shows the evaluation measures comparison with other proposed approaches.

Comparison of DNN with other models
6.5 Accuracy comparisons of different algorithms
In this section, our findings were contrasted with several other machine-learning techniques. Over the past few years, machine learning has become frequently utilized in wireless networks to recognize different network adversaries, enabling administrators to take the necessary precautions to stop network invasions. Still, most conventional machine learning approaches are inadequate learning methods, including Linear Regression, Logistic Regression, Decision Tree, Naive Bayes, KNN, Random Forest K-means, and many others. Traditional learning techniques have some issues, such as a strong reliance on feature engineering and feature selection, a poor capacity to identify undiscovered network assaults and high false alarm rates. Additionally, they cannot successfully categorise massive amounts of invasion data in the complicated network application environment.
To construct better detection models, SVM with DNN learning techniques may automatically extract superior high-level abstract characteristics from the data. Other authors train and test several algorithms using a complete training and testing set of thirteen characteristics. The results of these tests allow the authors to assess how well these algorithms work on their dataset. Table 5 shows that, with an accuracy of 93.63%, our DNN technique is relatively subpar compared to other algorithms. The Random Forest, with a precision of 82.02%, is the most accurate Machine Learning algorithm. The NB tree technique can generalize the normal and abnormal traffic characteristics extremely well since this accuracy was attained using the entire feature training set. Table 5 shows the accuracy compared with other algorithms.
6.6 Accuracy comparisons for feature dataset
In this section, we employ the feature set for training and testing for further assessment. The suggested DNN method from this paper was contrasted with the Machine Learning algorithms in the following experiment. Table 5 summarizes how each Machine Learning technique was performed using a sub-feature dataset. We get the best results from any method using the suggested DNN algorithm. With only six attributes, the other Machine Learning algorithms cannot adequately generalize the characteristics of training samples, leading to their low performance. Table 5 shows the accuracy comparison for the feature dataset.
Finally, we compared different model accuracies with our proposed model to different evaluation matrices with existing techniques and feature datasets. The upgraded DNN model has a greater detection impact than other techniques. As predicted, the Deep Neural Network algorithm with SVM performs better than others. Our DNN method produces a greater accuracy rate with a lower false positive rate than previous algorithms. With the help of the information shown above, we could show how the suggested DNN technique generalises and abstracts the properties of both regular and abnormal traffic with a minimal amount of features and with a promising level of accuracy.
7 Conclusions
Computer network security must include adversarial inversion attack detection. By enabling the analysis of access patterns to identify users engaging in unusual behaviour and acting as a disincentive to users’ attempts to circumvent system privileges or security measures, adversarial inversion attack detection enhances the security of wireless network systems. Due to the datasets and numerous Machine Learning algorithms presented over the past two decades, which employ just a restricted set of characteristics for improved anomaly detection and more effective network security, adversarial inversion attack detection systems in wireless networks based on Machine Learning techniques have garnered much interest. An open-source system for evaluating the dependability of wireless network models, adversarial text attack, is introduced. This is the first technique to carry out an arbitrarily targeted inversion attack on tasks related to general wireless networks. Our findings demonstrated that our attacks could have high success rates without deceiving people. The DNN technique with SVM is used in this research to offer abnormal-based IDS for the wireless network environment. We utilized a dataset from Kaggle for training and testing in this work. Techniques for feature regularization, feature selection, and data preparation are used to enhance and elevate the algorithm's performance for precise calculation and to make training as easy and efficient as possible. We demonstrate that, with an accuracy of 93.67%, the DNN with SVM surpasses other cutting-edge algorithms. Based on the results of the experiment, the accuracy of the DNN with SVM in the detection and classification of adversarial inversion attacks is 93.67% and 95.34% concerning latency rate and throughput.
As a consequence, it can be seen that the provided strategies were successful in locating and classifying adversarial inversion attacks in wireless networks. Compared to other cutting-edge methods, our system employs the fewest characteristics possible. This increases the computational efficiency of the model for real-time recognition. As a result, it may be implemented practically in the context of the wireless network. Future iterations of our model will be improved, and introducing more characteristics will increase the accuracy. Additionally, to lessen the burden on the controller, we will endeavor to disperse the implementation of our strategy. Soon, we'll also attempt to use this methodology in a real SDN system with actual network traffic to assess the entire network's bandwidth and response time performance.
References
Mimura M, Ito R (2022) Applying NLP techniques to malware detection in a practical environment. Int J Inf Secur 21(2):279–291
Ahmad A, Saad M, Al Ghamdi M, Nyang D, Mohaisen DJISJ (2021) Blocktrail: A service for secure and transparent blockchain-driven audit trails. IEEE Syst J 16(1):1367–1378
Lin H-C, Wang P, Chao K-M, Lin W-H, Chen J-H (2022) Using deep learning networks to identify cyber attacks on intrusion detection for in-vehicle networks. Electronics 11(14):2180
Darwish MA, Yafi E, Al Ghamdi MA, Almasri A (2020) Decentralizing privacy implementation at cloud storage using blockchain-based hybrid algorithm. Arab J Sci Eng 45:3369–3378
Javed SH, Ahmad MB, Asif M, Muhammad SH, Almotiri K. Masood et al (2022) An intelligent system to detect advanced persistent threats in industrial internet of things (I-IoT). Electronics 11(5):742
Almotiri S., and Al Ghamdi M. (2022) Network quality assessment in heterogeneous wireless settings: an optimization approach. Computers, Materials & Continua 71:439
Ishtiaq M, Almotiri S, Amin R, Al Ghamdi M et al (2020) Deep learning based intelligent surveillance system. International Journal of Advanced Computer Science and Applications, 5:35. https://doi.org/10.14569/IJACSA.2020.0110479
Al Ghamdi M (2023) A fine-grained system driven of attacks over several new representation techniques using machine learning. IEEE Access 11:96615
Sohail M, Ali G, Rashid J, Ahmad I, Almotiri SH et al (2021) Racial identity-aware facial expression recognition using deep convolutional neural networks. Appl Sci 12(1):88
Kes A, Almazrooie M, Samsudin A, Al-Somani TF (2021) A compact quantum reversible circuit for simplified-DES and applying Grover attack. In: Arai Kohei (ed) Advances in information and communication: Proceedings of the 2021 future of information and communication conference (FICC), vol 1. Springer, Cham, pp 849–864
Ullah S, Khan MA, Ahmad J, Jamal SS, Huma Z et al (2022) HDL-IDS: a hybrid deep learning architecture for intrusion detection in the internet of vehicles. Sensors 22(4):1340
Sengan S, Khalaf OI, Sharma DK, Hamad AA (2022) Secured and privacy-based IDS for healthcare systems on e-medical data using machine learning approach. Int J Reliab Qual e-Healthcare 11(3):1–11
Almotiri SHJIA (2021) Integrated fuzzy based computational mechanism for the selection of effective malicious traffic detection approach. IEEE Access 9:10751–10764
Aqdus A, Amin R, Ramzan S, Alshamrani SS, Alshehri A et al (2023) Detection collision flows in SDN based 5G using machine learning algorithms. CMC-Comput Mater Continua 74(1):1413–1435
LoAi AT, Somani TF (2016) More secure Internet of Things using robust encryption algorithms against side channel attacks. 2016 IEEE/ACS 13th international conference of computer systems and applications (AICCSA). IEEE, NewYork, pp 1–6
Liu G, Zhao H, Fan F, Liu G, Xu Q et al (2022) An enhanced intrusion detection model based on improved KNN in WSNs. Sensors 22(4):1407
Sajid Asher, Sonbul Omar S, Rashid Muhammad, Zia Muhammad Yousuf Irfan (2023) A hybrid approach for efficient and secure point multiplication on binary edwards curves. Appl Sci 13(9):5799
Jakka G, Alsmadi IM (2022) Ensemble models for intrusion detection system classification. Int J Smart Sens Adhoc Netw 3(2):8
Rashid M, Hazzazi MM, Khan SZ, Alharbi AR, Sajid A, Aljaedi AJE (2021) A novel low-area point multiplication architecture for elliptic-curve cryptography. Electronics 10(21):2698
Lin X et al (2023) Exploratory adversarial attacks on graph neural networks for semi-supervised node classification. Pattern Recognit 133:109042
Jiang H, Lin J, Kang HJFGCS (2022) FGMD: A robust detector against adversarial attacks in the IoT network. Future Gener Comput Syst 132:194–210
Zhao S, Li J, Wang J, Zhang Z, Zhu L, Zhang YJPCS (2021) Attackgan: adversarial attack against black-box ids using generative adversarial networks. Procedia Comput Sci 187:128–133
Winter P, Hermann E, Zeilinger M (2011) Inductive intrusion detection in flow-based network data using one-class support vector machines. In: 2011 4th IFIP international conference on new technologies, mobility and security, 2011, Paris, France. IEEE, pp 1–5
Jadidi Z, Muthukkumarasamy V, Sithirasenan E, Sheikhan M (2013) Flow-based anomaly detection using neural network optimized with GSA algorithm. In: 2013 IEEE 33rd international conference on distributed computing systems workshops, 2013, Philadelphia, PA, USA. IEEE, pp. 76–81
Alsuwat E, Solaiman S, Alsuwat HJC (2023) Concept drift analysis and malware attack detection system using secure adaptive windowing. Comput Mater Continua 75(2):3743
Horng S-J, Su M-Y, Chen Y-H, Kao T-W, Chen R-J, Lai J-L et al (2011) A novel intrusion detection system based on hierarchical clustering and support vector machines. Expert Syst Appl 38(1):306–313
Praanna K, Sruthi S, Kalyani K, Tejaswi AS (2020) A CNN-LSTM model for intrusion detection system from high dimensional data. J inf comput sci 10(3):1362–1370
Van Trung P, Huong TT, Van TD, Duc DM, N. H. Thanh NH et al (2015) A multi-criteria-based DDoS-attack prevention solution using software defined networking. In: 2015 international conference on advanced technologies for communications (ATC), Ho Chi Minh City, Vietnam, 2015. IEEE, pp 308–313
Niyaz Q, Sun W, Javaid A (2016) A deep learning based DDoS detection system in software-defined networking (SDN). ArXiv preprint arXiv:.07400
Mehdi SA, Khalid J, Khayam SA (2011) Revisiting traffic anomaly detection using software defined networking. In: Recent advances in intrusion detection: 14th international symposium, RAID 2011, Menlo Park, CA, USA, September 20–21, 2011. Proceedings 14, 2011. Springer, pp 161–180
Shin DH, An KK, Choi SC, Choi H-K (2016) Malicious traffic detection using k-means. J Korean Inst Commun Inform Sci 41(2):277–284
Giotis K, Argyropoulos C, Androulidakis G, Kalogeras D, Maglaris V (2014) Combining openflow and sflow for an effective and scalable anomaly detection and mitigation mechanism on SDN environments. Comput Netw 62:122–136
N. Gao, L. Gao, Q. Gao and H. Wang (2014) An intrusion detection model based on deep belief networks. In: 2014 Second international conference on advanced cloud and big data, Huangshan, China. IEEE, pp. 247–252
Fuqun Z (2015) Detection method of LSSVM network intrusion based on hybrid kernel function. Mod Electron Tech 21:027
R. Kokila, S. T. Selvi and K. Govindarajan (2014) DDoS detection and analysis in SDN-based environment using support vector machine classifier. In: 2014 sixth international conference on advanced computing (ICoAC), Chennai, India. IEEE, pp 205–210
Phan TV, Van Toan T, Van Tuyen D, Huong TT, Thanh NH (2016) OpenFlowSIA: An optimized protection scheme for software-defined networks from flooding attacks. 2016 IEEE sixth international conference on communications and electronics (ICCE). IEEE, Ha-Long, pp 13–18
Braga R, Mota E, Passito A (2010) Lightweight DDoS flooding attack detection using NOX/OpenFlow. In: Priya R (ed) IEEE local computer network conference. IEEE, Denver, pp 408–415
Khalid Alkahtani H et al (2023) optimal graph convolutional neural network-based ransomware detection for cybersecurity in IoT environment. Appl Sci 13(8):5167
Shieh C-S, Nguyen T-T, Lin W-W, Lai WK, Horng M-F, Miu DJE (2022) Detection of adversarial ddos attacks using symmetric defense generative adversarial networks. Electronics 11(13):1977
Owezarski P (2023) Investigating adversarial attacks against Random Forest-based network attack detection systems. NOMS 2023–2023 IEEE/IFIP network operations and management symposium. IEEE, New York, pp 1–6
Kumar VS, Alemran A, Karras DA, Gupta SK, Dixit CK, Haralayya B (2022) Natural language processing using graph neural network for text classification. 2022 international conference on knowledge engineering and communication systems (ICKES). IEEE, New York, pp 1–5
Funding
The author extends his appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia, for funding this research work through the project number IFP22UQU4250002DSR228.
Author information
Authors and Affiliations
Contributions
The author (Mohammed Al Ghamdi) confirms that the manuscript is an original work on its own merit, that it has not been previously published in whole or in part, and that it is not being considered for publication elsewhere. The author also confirms that, he works on this work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Conflict of interest
The author declares that he has no conflicts of interest to report regarding the present study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Al Ghamdi, M.A. Analyze textual data: deep neural network for adversarial inversion attack in wireless networks. SN Appl. Sci. 5, 386 (2023). https://doi.org/10.1007/s42452-023-05565-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-023-05565-8