
Abstract
Analyses of spatial and temporal patterns of land use and land cover through multi-resolution remote sensing data provide valuable insights into landscape dynamics. Land use changes leading to land degradation and deforestation have been a prime mover for changes in the climate. This necessitates accurately assessing land use dynamics using a machine-learning algorithm’s temporal remote sensing data. The current study investigates land use using the temporal Landsat data from 1973 to 2021 in Chikamagaluru district, Karnataka. The land cover analysis showed 2.77% decrease in vegetation cover. The performance of three supervised learning techniques, namely Random Forest (RF), Support Vector Machine (SVM), and Maximum Likelihood classifier (MLC) were assessed, and results reveal that RF has performed better with an overall accuracy of 90.22% and a kappa value of 0.85. Land use classification has been performed with supervised machine learning classifier Random Forest (RF), which showed a decrease in the forest cover (48.91%) with an increase of agriculture (6.13%), horticulture (43.14%) and built-up cover (2.10%). Forests have been shrinking due to anthropogenic forces, especially forest encroachment for agriculture and industrial development, resulting in forest fragmentation and habitat loss. The fragmentation analysis provided the structural change in the forest cover, where interior forest cover was lost by 27.67% from 1973 to 2021, which highlights intense anthropogenic pressure even in the core Western Ghats regions with dense forests. Temporal details of the extent and condition of land use form an information base for decision-makers.
Article Highlights
-
Landscape dynamics were assessed in the Chikamagaluru district of Karnataka state over five decades
-
Vegetation decreased by 209.58 sq. km from 65.5% in 1973 to 62.7% in 2021
-
The forest cover has decreased by 48.91% (3527.73 sq. km) with increase in horticulture from 4.35 to 25.05%.
-
Random Forest performed better among machine learning algorithms
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Landscape comprises heterogeneous elements with diverse ecological, biological, geological, hydrological, social, economic, and environmental characteristics. Local ecosystems with land cover are the primary elements of the landscape [1]. The structure of a landscape decides the functional capabilities which are reflected through bio-geo-socio-economic variables and the resources associated with them [2]. Landscape dynamics refers to the changes in the landscape structure due to natural and anthropogenic reasons, which is assessed through temporal land use (LU) and land cover (LC) analyses.
LC represents the biophysical cover of the land surface, like vegetation and non-vegetation. In contrast, land use denotes the anthropogenic use of land like built-up, agriculture, horticulture, mining, etc. A quantitative analysis of LULC determines the extent and changes in spatial distributions [3], which indicate human interaction with their local environment and its associated changes.
Rapid LU changes are dynamic and unsustainable, necessitating the analysis of the spatial patterns of quantitative changes [4] for planned interventions with minimal impacts of changes in forest cover, agricultural lands, etc. Land use changes leading to degradation and deforestation have been a prime influencer of changes in ecosystems with alterations in climate patterns, bio-geochemical cycles, etc., affecting the livelihood of people [5,6,7,8]. Forest ecosystems provide services supporting economic development and maintain ecology in balance [1, 9, 10]. However, after globalization in the nineties, unplanned developmental activities witnessed large-scale forest land transitions [11,12,13].
LU changes have altered the structure of the landscape, fragmenting contiguous forests into smaller patches which is detrimental to the sustenance of biodiversity, carbon sequestration potential, and other ecological services at local and global scales [14,15,16,17,18,19]. Fragmentation of forests creates disturbances in ecological and socio-economic processes [20] with habitat loss, distribution of habitats into patches, a decrease in habit patch size, loss of species diversity, etc., leading to disruptions in wildlife habitats and aggravating human-wildlife conflicts [21,22,23,24,25]. Hence, it necessitates analyzing and monitoring the forest ecosystem to restrict deforestation and degradation of forests.
The forest fragmentation analysis quantifies the area under five categories, namely interior, perforated, transitional, patch, and edge forest [26, 27], which aids in monitoring and quantifying spatial and temporal patterns of forest ecosystem transitions [28]. Forest fragmentation analysis in biodiversity-enriched regions would help in formulating conservation strategies for the prudent management of ecologically fragile habitats of endemic taxa [9, 18]. Hence, dynamics of LULC aids in planning, managing, and prioritizing the area for sustainable development, conserving biodiversity, and maintaining bio-geo-climatic processes to sustain socio-economic activities [29, 30] by mitigating the degradation and destruction of natural resources. [3, 31,32,33,34,35].
Depleting vegetation cover in forest areas has led to the decline of carbon sequestration potential and the ability to moderate micro-climate, evident from increased land surface temperature [36]. The spatial patterns of the landscape structure and composition are ascertained through spatial matrices.
Multiresolution (spatial, spectral and temporal) geospatial data provide information about ecosystem structure which help in resource management, resource monitoring, mapping, and change detection [34]. The availability of long-term, temporal multispectral remote sensing data helps to identify and quantify LU dynamics [33] and understand the effects of unplanned anthropogenic interventions on the natural LC [3]. Integrating LU information with collateral data through a Geographic Information System (GIS) aid in comprehending land use information with agents of change, including policy interventions.
Different spectral indices such as the Normalised Difference Vegetation Index (NDVI), Normalised Difference Water Index (NDWI), Normalised Difference Built-up Index (NDBI), Bare Soil Index (BSI), Thermal Index (TI) have been used to identify landscape structure, patterns of land use changes, changes in vegetation cover, and the impact of urbanisation and development, which help in the regional planning for sustainable management [3, 10, 37,38,39]. NDVI is the primary spatial index commonly used for classifying LC as vegetation and non-vegetation [15, 40,41,42].
Land uses (LU) in a region are discerned through the classification of spatial data based on supervised and unsupervised algorithms. The unsupervised classification is based on clusters of pixels without prior knowledge of common spectral signatures and characteristics. Commonly used techniques include K-Means Clustering [43, 44], ISODATA, and Principal Component Analysis. In contrast to these, supervised classifiers depend on prior knowledge through training datasets and techniques, including Random Forest (RF) [45,46,47], Support Vector Machine (SVM) [48], Classification and Regression Trees (CART) [49], Gaussian Maximum Likelihood (MLC) [17, 18, 40], Artificial Neural Network (ANN) [50, 51], Minimum Distance-to-means Classifier [6], and Mahalanobis Distance Classifier [14]. Recent advancements in the classification of big data (spatial) through machine learning algorithms based on learning aid in making an informed optimal decision due to the availability of accurate land use information in less time. Deriving LU information from spatial data depends on spatial and spectral characteristics of data, classification algorithm, and training or ground truth data [14]. Adopting appropriate classification algorithm aid in accurately assessing spatiotemporal changes in land use.
Random Forest classifier [7, 39, 43, 46, 47, 52,53,54,55,56,57,58,59] is the most widely used ML algorithm based on ensemble methods like bagging and boosting [60]. It provides accurate classification in a heterogeneous landscape through a set of decision trees from a randomly selected subset of the training set and aggregates decisions for deciding the final class. The accuracy of the classifier is assessed through samples (not used for training), which provide unbiased error estimates. RF randomly selects variables from training samples at each node to determine the best split to construct a tree based on the Gini index measure that gives a measure of impurity within a node.
Support Vector Machine classifier [50, 55, 57,58,59, 61,62,63,64] constructs a hyperplane or set of hyperplanes based on the number of features in a high or infinite dimensional space for classifying spatial data with a small amount of training data [60].
Gaussian Maximum Likelihood Classifier (GMLC) uses mean and covariance values with probability density functions for deriving LU information and is a parametric supervised classification technique [4, 6,7,8, 11, 32, 34, 50, 55, 59, 65].
1.1 Objectives
Objectives of the current study are:
-
1.
Assessing LULC dynamics in Chikamagaluru district, Karnataka State, India using temporal remote sensing data.
-
2.
Understanding spatial patterns of forest structure through assessment of fragmentation of forests.
-
3.
Evaluation of the performance of classification algorithms.
2 Materials and method
2.1 Study area
Chikamagaluru district, which covers an area of 7101 sq. km (3.8% of Karnataka), is in the southwestern part of Karnataka between 12 °54′ 42″ and 13° 53′ 53″ N and 75° 04′ 46″ and 76° 21′ 50″ E. The district stretches 138.4 km from east to west and 88.5 km from north to south, and is divided into seven taluks—Chikamagaluru, Kadur, Koppa, Mudigere, Narashimharajapura, Sringeri, and Tarikere (Ajjampura and Tarikere taluks as per the 2021 statistical report). According to the 2011 Census, the district has a total population of 1,137,961, which accounts for 1.9% of the population of the state [66] and ranks 25th in Karnataka. The district has a population density of 158 per sq km, which is the 3rd least dense district in Karnataka. The literacy rate is 79.25%, and the Scheduled Caste and Scheduled Tribe populations make up 22.3% and 4% of the total population, respectively. About 81% of the population lives in rural areas, while 19% live in urban areas. The district is well-connected by road to Hassan, Mysore, Bangalore, Shivamogga, Udupi, and Mangaluru, and the nearest airports are Mysore and Mangalore. There are two railway junctions at Kadur and Birur. The district is divided into three agro-climatic zones (Fig. 1): the hilly zone (Chikamagaluru, Koppa, Mudigere, Narashimharajpura, and Sringeri), central dry zone (Kadur), and southern transition zone (Tarikere). The economy of the district is primarily based on rural agriculture and is supplemented by income from tourism. Chikamagaluru has a higher per capita income of 68,956 Rs (2008–09) than other districts in Karnataka, and the GDP of the district was 5222 cr. in the year 2012–13. The per capita annual income of the district was 66,366 Rs (2012–13) [67,68,69].

Study area (Chikmagalur district, Karnataka) with Agro-climatic zones
The district of Chikamagaluru is divided into two distinct regions, the western part being a forested hilly area known as the 'Malnad' area, while the eastern part is dominated by a plain region or ‘Maidan’ area. The forest cover in the district is managed by five divisions, including Chikamagaluru, Koppa, Bhadravathi, Kudremukh National Park, and Bhadra Wildlife Sanctuary. The vegetation in the district can be broadly categorized into four types: dry deciduous hill type, moist deciduous type, evergreen type, and Sholas and Grassland type. Mullayanagiri, the highest peak in the district, rises 1926 m above MSL. The major rivers in the district are Tunga and Bhadra, while other perennial rivers include Hemavati, Netravati, and Vedavathi [70].
The district has rocks formed during the Archaean age, with gneiss formations in the southwestern, northern, and eastern parts, and schist formations in the central and western parts. The district's soil is rich in iron, magnetite, and granite deposits, with black soil found around Baba Budan Giri hills, enriching the coffee plantation, and red and gravel soils found in the southern part of the district. Due to the presence of extensive hilly areas, the climate in the district is cooler, with April being the hottest month, with a mean daily maximum temperature of 36 °C and a mean daily minimum temperature of 19 °C. The average annual rainfall in the Chikamagaluru district is 1925 mm, ranging from 595 to 2379 mm. Sringeri taluk receives the highest rainfall in the district, amounting to 3773.2 mm, while Kadur taluk receives the lowest rainfall of 620.3 mm.
The major crops grown in the region include ragi, paddy, sunflower, jowar, Bengal gram, groundnut, and maize. The district has 5727 ha of canal-based irrigation facilities. The major horticulture crops grown in the district are areca nut, coconut, black pepper, banana, mango, cardamom, ginger, and vegetables. Coffee is primarily grown in the valleys of Baba Budan Giri hills.
2.2 Data
Temporal LULC analyses of the Chikamagaluru district were done using Landsat series data from 1973 to 2021 and the collateral data, which included a vegetation map of 1:250,000 of South India developed by the French Institute (1986) and Bhuvan LULC maps of 1:50,000 from 2005 to 2016. The vegetation map of South India (1986) was useful in identifying various forest cover types. Table 1 lists the data used for assessing LULC dynamics. Landsat ETM + data of 2005 were corrected for the SLC error by image enhancement and restoration techniques using the nearest neighbour interpolation.
2.3 Method
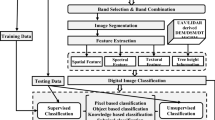
The analysis was performed in a series of steps as depicted in Fig. 2. Spatial data acquired through space-borne sensors corresponding to the study region were downloaded from the public domain and carried out pre-processing through geometric and radiometric rectification followed by the land cover and land use analyses [71].

Method followed for assessing the extent and condition of land cover and land uses
Land cover analysis was done to delineate the regions under vegetation and non-vegetation through computation of the Normalized Difference Vegetation Index (NDVI) as per Eq. 1. NDVI ranges from − 1 to 1, and lower values indicate regions under non-vegetation, while positive values indicate vegetation cover.
Land use analyses are done through supervised machine learning algorithms using Google Earth Engine at an open-source cloud-based platform. The land use analyses using spatial data involved (i) identification of heterogeneous areas in the study region through false color composite (FCC) of spatial data acquired at NIR, Red, and Green wavelength. (ii) Polygons corresponding to heterogeneous patches in FCC and uniformly distributed throughout the region were digitised from FCC and supplemented by digitising polygons in virtual data (Google Earth). Digitised polygons are representative of heterogeneous patches (or likely land uses), uniformly distributed throughout the study region, and cover at least 15% of the spatial extent of the study region. (iii) Land use analysis was done through supervised non-parametric and parametric classifiers (1) Random Forest (Classifier.smileRandomForest), (2) Support Vector Machine or SVM (Classifier.libsvm) and (3) Maximum Likelihood classifier. Random Forest and Support Vector Machine classifiers were implemented in the Google Earth Engine platform and the Maximum Likelihood classifier was used in GRASS (Geographic Resources Analysis Support System) GIS. The performances of these classifiers (algorithms) have been evaluated through accuracy assessment and Kappa statistics.
2.3.1 Random forest
(RF) uses bagging or Bootstrap aggregation, which chooses a random sample from the data set (Fig. 3). So, each model is generated from the samples (bootstrap samples) provided by the original data with a replacement. The algorithm considers the prediction from each tree, and the final output is predicted based on the majority votes of predictions [52, 72, 73]. RF considers decision trees based on average values of data subsets that improve predictive accuracy. The final output depends on majority voting after aggregating the results of all models.

Random forest classifier
2.3.2 Support vector machine (SVM)
Is used for classification as well as regression analysis [61]. The SVM algorithm generates the best line or decision boundary (or hyperplane) that segregates n-dimensional space into classes so that the new data can easily be put in the correct category in the future. SVM chooses the extreme points or support vectors that help in creating the hyperplane (Fig. 4).

Support vector machine
The distance between the vectors and the hyperplane is called a margin. The goal of SVM is to maximize the margin between classes. The hyperplane with the maximum margin is called the optimal hyperplane. Linear SVM is a parametric model, but a radial-based kernel SVM is non-parametric.
2.3.3 Maximum likelihood classifier (MLC)
Qualitatively evaluates the variance and covariance of spectral reflectance for each class as per Eq. 2.
where
n = spectral resolution
L = likelihood of X belonging to class k
μk = mean vector of class k
Σk = variance–covariance matrix of class k
In the current study, the best classifier (the Random Forest classifier) was prioritized by assessing the relative performance of three chosen classification algorithms.
Spatial data were classified into 12 LU classes i.e., evergreen forest, moist deciduous forest, dry deciduous forest, shola forest, scrubland, waterbody, cropland, fallow land, open space, rocky area and built-up area. These classes were combined broadly into the forest, shola forest, scrubland, waterbody, agriculture, built-up and open space to understand the spatial extent of land uses.
Accuracy assessment of LU classification is done through computation of confusion matrix and Kappa statistics by comparing computed LU information with the training data. Overall accuracy represents the total classification accuracy (Eq. 3), which is calculated as the percentage of the ratio of the total number of correctly classified pixels and the total number of reference pixels. Producer and user accuracy are computed as per Eqs. 4 and 5.
The Kappa Statistic or Cohen's Kappa is a statistical measure of the reliability of categorical variables as per Eq. 6.
where
r = the number of rows in the error matrix
xii = the number of observations in row i and column i
xi+ = total of observations in row i
x+i = total of observations in column i
N = total number of observations included in the matrix.
LU change is computed considering temporal land uses based on the base year (1973) and current year (2021) data as per Eq. 7.
2.3.4 Forest fragmentation
Fragmentation of forests is assessed through fragmentation metrics, namely patch, transitional, edge, perforated, and interior forests [27] through computation of Pf and Pff considering 3 × 3 kernel with moving window approach Pf determines the proportion of forest pixels in the window (Eq. 8) and Pff determines the proportion of all adjacent or cardinal pixel pairs that include at least one forest pixel, for which both pixels are forested (Eq. 9).
Figure 5 illustrates forest fragmentation classification into six fragmentation categories based on Pf and Pff.

Forest fragmentation metrics Pf and Pff in a fixed area window
In this study, forest class included evergreen, moist deciduous, dry deciduous, scrubland, and shola forest, whereas the non-forest category included agriculture, horticulture, built-up and open spaces.
3 Results and discussion
3.1 Land cover analyses
LC assessed through NDVI using temporal remote sensing data, given in Table 2 shows a decline in vegetation cover from 65.5% (1973) to 62.73% (2021) due to anthropogenic activities (Fig. 6). The area under non-vegetation areas increased from 34.5 to 37.27% due to agricultural and urban expansion. Unplanned developmental activities coupled with enhanced agriculture (crop lands and horticulture) activities were prime reasons for the irreversible loss of forest cover.

Land cover based on NDVI of Chikamagaluru district from 1973 to 2021
3.2 Land use analyses
Temporal (1973 to 2021) LU were computed through a supervised classifier based on the Random Forest algorithm (Fig. 7), revealing a decline in forest cover of 32.77% and an increase in agricultural area by 6.31% and horticulture by 43.14%.

Change of land uses in Chikamagaluru district from 1973 to 2021
Temporal LU listed category-wise in Table 3 reveal a reduction in forest cover from 46.38 to 30.65% from 1973 to 2021. In the forest, evergreen forest covered 1293.59 sq km (1973), 1175.42 sq. km (1991), 1155.5 sq. km (1998), 1107.73 sq. km (2005), 1060.33 sq. km (2013) and 706.38 sq. km (2021). The main reason behind the decline of forest cover is the transition of forested areas into agricultural and horticultural categories. Cumulatively the forest cover has decreased from 46.38 to 30.65% during five decades. The Bhadra wildlife sanctuary and Kudremukh National Park mainly consist of the reserve forest.
Agricultural land has been increasing in this district from 1973 (29.71% or 2143.03 sq. km) to 2021 (32.65% or 2355.10 sq. km). There is a constant increase in agricultural land use of 6.13% from 1973 to 2021 (Fig. 8).

Category-wise LU changes of Chikamagaluru from 1973 to 2021
The change in the horticultural area increased from 4.45% or 313.43 sq km in 1973 to 25.05% or 1807.16% in 2021, showing an increase of 43.14%. Many parts of the district, forests, and agricultural lands transition into horticultural land.
The open space in the area covered around 187.04 sq km or 1.92% area in 1973 and 103.27 sq km or 1.43% area in 2021. The conversion of open spaces was seen in agricultural fields and built-up areas. The spatial extent of built-up also increased by 2.10% from 32.84 sq km (0.61%) in 1973 to 105.48 sq km (1.46% of the area) in 2021 (Fig. 9).

LU analysis of Chikamagaluru district from 1973 to 2021
LU Classifiers were evaluated based on the accuracy assessment (Table 4, Fig. 10). The comparative evaluation reveals that the supervised classifier Random Forest has performed better, evident from the kappa value of 0.8567 compared to SVM (0.6177) and MLC (0.8264) and higher overall accuracy of 90.22% in RF, compared to 66.32% (in SVM) and 85.18% (in MLC). The category-wise evaluation shows that commission error in RF ranged from 43.8 to 0.1 (highest in shola forest by 43.8) and omission error ranged from 65.5 to 8.9 (highest in built-up by 65.5). Built-up has been misclassified into open spaces. SVM shows a range of commission errors from 53.6 to 0.5 (highest in 53.6 in shola) and 59.1 to 0.5 omission errors (highest in 59.1 in shola). MLC provided a range of commission errors from 25.3 to 5.1 (25.3 as highest in scrub) and omission errors from 34.8 to 1.3 (34.8 as highest in dry deciduous). Table 5 provides category-wise LU statistics based on supervised classification algorithms (RF, SVM, MLC).

Land use classification by RF, SVM and MLC
The comparison shows that RF gave the highest Kappa coefficient and overall accuracy than SVM and MLC. Random Forest classifier outperformed the other classifiers based on kappa, and overall accuracy and results conform with the earlier studies [43, 49,50,51, 58, 74,75,76,77,78,79,80]. Classification parameters are further tuned in RF classifier by maintaining multi-class variance was maintained as the spectral bands are correlated and overlap spectral regions.
3.2.1 Forest fragmentation
Fragmentation analyses of forests in Chikmagaluru district reveal of decline in the contiguous forest from 55.72% or 4018.89 sq. km in 1973 to 28.05% or 2023.07 sq. km in 2021 (Table 6) with an increase in patch forests to 0.01% or 0.79 sq. km in 2021 (Fig. 11). Transitional forest increased from 0.45% or 32.37 sq. km in 1973 to 1.80% or 129.76 sq. km in 2021. Edge forest and perforated forest also increased from 1973 to 2021 from 3.61% or 260.04 sq. km to 5.11% or 368.33 sq. km and 1.38% or 99.37 sq. km to 2.71% or 2023.07 sq. km, respectively. The trend of fragmentation of forests in Chikmagaluru district is depicted in Fig. 12.

Forest fragmentation analysis of Chikamagaluru from 1973 to 2021

trend of forest fragmentation in Chikamagaluru from 1973 to 2021
3.3 Discussion
The spatial extent of non-vegetation has increased from 65.5% (1973) to 62.73% (2021) due to urban expansions, etc. Land use analysis showed a sharp decline in native forest cover and an increase in agriculture and horticultural activities expanded into the forest areas. Also, the area under unpaved surfaces increased because of the increasing population and industrialization in the district. Assessment of forest fragmentation showed a decrease in interior or contiguous forest cover, emphasizing the need to maintain forest ecosystem integrity to sustain ecosystem services.
The evaluation of performance of Random Forest (RF), Support Vector Machine (SVM) and Maximum Likelihood (MLC) classifiers for LU classification in a heterogenous landscape like Chikamagaluru district showed that Random Forest provided the most accurate results evident from the higher accuracy and kappa coefficient.
4 Conclusion
Landscape dynamics in hilly terrain (Chikamagaluru district, Karnataka State) during five decades were assessed using temporal remote sensing data in the cloud platform using machine learning algorithms, namely Random Forest (RF) and Support Vector Machines (SVM) and compared with the parametric maximum likelihood classifier. The land cover analysis showed a decreasing trend of vegetation (209.58 sq. km) land cover in the study area from 65.5% in 1973 to 62.7% in 2021. The land use analysis showed a drastic decline in forest cover and an increase in agriculture and horticultural practice in five decades. Forest cover has decreased by 48.91% (3527.73 sq. km) due to the conversion of forest areas into horticulture, agricultural lands, and urban areas. Horticulture practice has increased from 4.35 to 25.05%, which showed a 3111.94 sq. km increase in land use. The built-up area has been expanded by 2.1% (151.34 sq. km) in the study area in five decades. Spatiotemporal analysis of the forest structure in Chikamagaluru district was analysed using fragmentation analysis. The result showed a decrease in the interior forest by 27.67% (1995.82 sq. km) within the five decades and an increase in non-forest by 23.5% (1694.68 sq. km).
The evaluation of performances of machine learning algorithms (Random Forest, Support Vector Machine) and parametric classifier Maximum Likelihood classifier, reveals that the supervised classifier based on the Random Forest algorithm has performed better, evident from higher overall accuracy and Kappa value.
Data availability
Data used in the analyses are compiled from the field. Data is anlysed and organized in the form of table, which are presented in the manuscript. Also, synthesized data are archived at http://wgbis.ces.iisc.ernet.in/energy/water/paper/researchpaper2.html#ce, http://wgbis.ces.iisc.ernet.in/biodiversity/
References
Forman RT (1995) Some general principles of landscape and regional ecology. Landscape Ecol 10(3):133–142. https://doi.org/10.1007/BF00133027
Anandhi A, Douglas-Mankin KR, Srivastava P, Aiken RM, Senay G, Leung LR, Chaubey I (2020) DPSIR-ESA vulnerability assessment (DEVA) framework: synthesis, foundational overview, and expert case studies. Trans ASABE 63(3):741–752. https://doi.org/10.13031/trans.13516
Ramachandra TV, Bharath HA (2012) Spatio-temporal pattern of landscape dynamics in Shimoga, Tier II City, Karnataka State, India. Int J Emerg Technol Adv Eng 2(9):563–576
Vivekananda GN, Swathi R, Sujith AVLN (2021) Multi-temporal image analysis for LULC classification and change detection. Eur J Remote Sens 54(sup2):189–199. https://doi.org/10.1080/22797254.2020.1771215
Houet T, Verburg PH, Loveland TR (2010) Monitoring and modelling landscape dynamics. Landscape Ecol 25(2):163–167. https://doi.org/10.1007/s10980-009-9417-x
Ganasri BP, Dwarakish GS (2015) Study of land use/land cover dynamics through classification algorithms for Harangi catchment area, Karnataka State, India. Aquatic Procedia 4:1413–1420. https://doi.org/10.1016/j.aqpro.2015.02.183
Wondie M, Schneider W, Melesse AM, Teketay D (2011) Spatial and temporal land cover changes in the Simen Mountains National Park, a world heritage site in Northwestern Ethiopia. Remote Sens 3(4):752–766. https://doi.org/10.3390/rs3040752
Ramachandra TV, Bharath S (2018) Geoinformatics based valuation of forest landscape dynamics in central Western Ghats India. J Remote Sens GIS 7(227):2. https://doi.org/10.4172/2469-4134.1000227
Ramachandra T, Setturu B, Chandran S (2016) Geospatial analysis of forest fragmentation in Uttara Kannada District, India. Forest Ecosyst 3(1):1–15. https://doi.org/10.1186/s40663-016-0069-4
Bera B, Saha S, Bhattacharjee S (2020) Estimation of forest canopy cover and forest fragmentation mapping using landsat satellite data of Silabati River Basin (India). KN-J Cartogr Geogr Inform 70(4):181–197. https://doi.org/10.1007/s42489-020-00060-1
Torahi AA, Rai SC (2011) Land cover classification and forest change analysis, using satellite imagery-a case study in Dehdez area of Zagros mountain in Iran. J Geographic Inform Syst 3(1):1.
Amin A, Fazal S (2017) Assessment of forest fragmentation in district of Shopian using multitemporal land cover (A GIS Approach). J Geosci Geomatics 5(1):12–23. https://doi.org/10.12691/jgg-5-1-2
Gupta SK, Pandey AC (2018) Research article forest canopy density and fragmentation analysis for evaluating spatio-temporal status of forest in the Hazaribagh Wild Life Sanctuary, Jharkhand (India), https://doi.org/10.3923/rjes.2018.198.212
Lele N, Joshi PK, Agrawal SP (2008) Assessing forest fragmentation in northeastern region (NER) of India using landscape matrices. Ecol Ind 8(5):657–663. https://doi.org/10.1016/j.ecolind.2007.10.002
Ramachandra TV, Kumar U (2011) Characterisation of landscape with forest fragmentation dynamics. J Geogr Inf Syst 3(03):242. https://doi.org/10.4236/jgis.2011.33021
Riitters KH, Coulston JW, Wickham JD (2012) Fragmentation of forest communities in the eastern United States. For Ecol Manage 263:85–93. https://doi.org/10.1016/j.foreco.2011.09.022
Kulkarni G, Bhat SP, Rao GR, Balachandran C, Mukri V, Naik S, Settur B, Chandran MS, Ramachandra TV (2014) Land use dynamics and floral diversity of Southern montane wet temperate forests in chikmagalur, central Western Ghats, India., Sahyadri E-News Issue XLVII. https://wgbis.ces.iisc.ac.in/biodiversity/sahyadri_enews/newsletter/issue47/index.htm
Batar AK, Watanabe T, Kumar A (2017) Assessment of land-use/land-cover change and forest fragmentation in the Garhwal Himalayan Region of India. Environments 4(2):34. https://doi.org/10.3390/environments4020034
Liu J, Coomes DA, Gibson L, Hu G, Liu J, Luo Y, Wu C, Yu M (2019) Forest fragmentation in China and its effect on biodiversity. Biol Rev 94(5):1636–1657. https://doi.org/10.1111/brv.12519
Wu JJ (2012) Jianguo (Jingle) Wu. Ecological systems selected entries from the encyclopedia of sustainability. Sci Technol. https://doi.org/10.1007/978-1-4419-0851-3
Phua MH, Minowa M (2005) A GIS-based multi-criteria decision-making approach to forest conservation planning at a landscape scale: a case study in the Kinabalu Area, Sabah. Malaysia Landsc Urban plann 71(2–4):207–222. https://doi.org/10.1016/j.landurbplan.2004.03.004
Echeverría C, Coomes D, Salas J, Rey-Benayas JM, Lara A, Newton A (2006) Rapid deforestation and fragmentation of Chilean temperate forests. Biol Cons 130(4):481–494. https://doi.org/10.1016/j.biocon.2006.01.017
Roy PS, Murthy MSR, Roy A, Kushwaha SPS, Singh S, Jha CS, Joshi PK, Jagannathan C, Karnatak HC, Saran S, Gupta S (2013) Forest fragmentation in India. Curr Sci. https://doi.org/10.1016/j.jag.2015.03.003
Sharma M, Chakraborty A, Garg JK, Joshi PK (2017) Assessing forest fragmentation in north-western Himalaya: a case study from Ranikhet forest range, Uttarakhand India. J Forestry Res 28(2):319–327. https://doi.org/10.1007/s11676-016-0311-5
Nguyen LH, Joshi DR, Clay DE, Henebry GM (2020) Characterizing land cover/land use from multiple years of Landsat and MODIS time series: a novel approach using land surface phenology modeling and random forest classifier. Remote Sens Environ 238:111017. https://doi.org/10.1016/j.rse.2018.12.016
Holdt BM, Civco DL, Hurd JD (2004) Forest fragmentation due to land parcelization and subdivision: remote sensing and GIS analysis. In ASPRS Annual conference proceedings, pp. 1–8
Ritters K, Wickham J, O’Neill R, Jones B, Smith E (2000) Global-scale patterns of forest fragmentation. Conserv Ecol. https://doi.org/10.5751/es-00299-040203
Moreno-Sanchez R, Torres-Rojo JM, Moreno-Sanchez F, Hawkins S, Little J, McPartland S (2012) National assessment of the fragmentation, accessibility and anthropogenic pressure on the forests in Mexico. J Forestry Res 23(4):529–541. https://doi.org/10.1007/s11676-012-0293-x
Gamanya R, De Maeyer P, De Dapper M (2009) Object-oriented change detection for the city of Harare, Zimbabwe. Expert Syst Appl 36(1):571–588. https://doi.org/10.1016/j.eswa.2007.09.067
Attri P, Chaudhry S, Sharma S (2015) Remote sensing & GIS based approaches for LULC change detection–a review. Int J Curr Eng Technol 5:3126–3137
Ramachandra TV, Kumar U (2004) Geographic resources decision support system for land use, land cover dynamics analysis. In: Proceedings of the FOSS/GRASS users conference, Vol. 15
Rawat JS, Kumar M (2015) Monitoring land use/cover change using remote sensing and GIS techniques: a case study of Hawalbagh block, district Almora, Uttarakhand, India. Egypt J Remote Sens Space Sci 18(1):77–84. https://doi.org/10.1016/j.ejrs.2015.02.002
Thyagharajan KK, Vignesh T (2019) Soft computing techniques for land use and land cover monitoring with multispectral remote sensing images: a review. Arch Comput Meth Eng 26(2):275–301. https://doi.org/10.1007/s11831-018-9266-1
Manjunatha MC, Basavarajappa HT (2020) Mapping of land units and its change detection analysis in Chitradurga taluk of Karnataka State, India using geospatial technology. Int Adv Res J Sci, Eng Technol 7(7):61–68. https://doi.org/10.17148/IARJSET.2020.7711
Chughtai AH, Abbasi H, Karas IR (2021) A review on change detection method and accuracy assessment for land use land cover. Remote Sens Appl: Soci Environ 22:100482. https://doi.org/10.1016/j.rsase.2021.100482
Bharath S, Rajan KS, Ramachandra TV (2013) Land surface temperature responses to land use land cover dynamics. Geoinfor Geostat: An Overview 54:50–78
Gašparović M, Zrinjski M, Gudelj M (2019) Automatic cost-effective method for land cover classification (ALCC). Comput Environ Urban Syst 76:1–10. https://doi.org/10.1016/j.compenvurbsys.2019.01.003
Balew A, Korme T (2020) Monitoring land surface temperature in Bahir Dar city and its surrounding using Landsat images. Egypt J Remote Sens Space Sci 23(3):371–386. https://doi.org/10.1016/j.ejrs.2020.01.005
Tassi A, Gigante D, Modica G, Di Martino L, Vizzari M (2021) Pixel-vs Object-based landsat 8 data classification in google earth engine using random forest: the case study of maiella national park. Remote Sens 13(12):2299. https://doi.org/10.3390/rs13122299
Xiao H, Weng Q (2007) The impact of land use and land cover changes on land surface temperature in a karst area of China. J Environ Manage 85(1):245–257. https://doi.org/10.1016/j.jenvman.2006.09.026
Cakir HI, Khorram S, Nelson SA (2006) Correspondence analysis for detecting land cover change. Remote Sens Environ 102(3–4):306–317. https://doi.org/10.1016/j.rse.2006.01.017
Ramachandra TV, Bhat SP, Kulkarni G, Aithal BH (2019) Assessment of forest dynamics in Chikkamagalur District, Central Western Ghats using temporal remote sensing data and spatial metrics. Indian Forester 145(8):757–766
Ali U, Esau TJ, Farooque AA, Zaman QU, Abbas F, Bilodeau MF (2022) Limiting the collection of ground truth data for land use and land cover maps with machine learning algorithms. ISPRS Int J Geo Inf 11(6):333. https://doi.org/10.3390/ijgi11060333
Hudait M, Patel PP (2022) Crop-type mapping and acreage estimation in smallholding plots using Sentinel-2 images and machine learning algorithms: some comparisons. Egypt J Remote Sens Space Sci 25(1):147–156. https://doi.org/10.1016/j.ejrs.2021.09.009
Rahman A, Abdullah HM, Tanzir MT, Hossain MJ, Khan BM, Miah MG, Islam I (2020) Performance of different machine learning algorithms on satellite image classification in rural and urban setup. Remote Sens Appl: Soci Environ 20:100410. https://doi.org/10.1016/j.rsase.2020.100410
Amini S, Saber M, Rabiei-Dastjerdi H, Homayouni S (2022) Urban land use and land cover change analysis using random forest classification of landsat time series. Remote Sens 14(11):2654. https://doi.org/10.3390/rs14112654
Nasiri V, Deljouei A, Moradi F, Sadeghi SMM, Borz SA (2022) Land use and land cover mapping using sentinel-2, landsat-8 satellite images, and google earth engine: a comparison of two composition methods. Remote Sens 14(9):1977. https://doi.org/10.3390/rs14091977
Baig MF, Mustafa MRU, Baig I, Takaijudin HB, Zeshan MT (2022) Assessment of land use land cover changes and future predictions using CA-ANN simulation for selangor. Malaysia Water 14(3):402. https://doi.org/10.3390/w14030402
Pan X, Wang Z, Gao Y, Dang X, Han Y (2021) Detailed and automated classification of land use/land cover using machine learning algorithms in Google Earth Engine. Geocarto Int. https://doi.org/10.1080/10106049.2021.1917005
Srivastava PK, Han D, Rico-Ramirez MA, Bray M, Islam T (2012) Selection of classification techniques for land use/land cover change investigation. Adv Space Res 50(9):1250–1265. https://doi.org/10.1016/j.asr.2012.06.013
Zhang S, Yang P, Xia J, Wang W, Cai W, Chen N et al (2022) Land use/land cover prediction and analysis of the middle reaches of the Yangtze River under different scenarios. Sci Total Environ 833:155238. https://doi.org/10.1016/j.scitotenv.2022.155238
Breiman L (1996) Bagging predictors. Mach Learn 24(2):123–140. https://doi.org/10.1023/A:1018054314350
Ghosh A, Sharma R, Joshi PK (2014) Random forest classification of urban landscape using Landsat archive and ancillary data: combining seasonal maps with decision level fusion. Appl Geogr 48:31–41. https://doi.org/10.1016/j.apgeog.2014.01.002
Nguyen HTT, Doan TM, Radeloff V (2018) Applying random forest classification to map land use/land cover using Landsat 8 OLI. Int Arch Photogramm Remote Sens Spat Inf Sci 42(3):W4. https://doi.org/10.5194/isprs-archives-XLII-3-W4-363-2018
Erdanaev E, Kappas M, Wyss D (2022) The identification of irrigated crop types using support vector machine, random forest and maximum likelihood classification methods with Sentinel-2 Data in 2018: Tashkent Province Uzbekistan. Int J Geoinform. https://doi.org/10.52939/ijg.v18i2.2151
Ismayilova I, Timpf S (2022) Classifying Urban Green Spaces using a combined Sentinel-2 and Random Forest approach. AGILE: GIScience Series, 3:1–6. https://doi.org/10.5194/agile-giss-3-38-2022
Kang CS, Kanniah KD (2022) Land use and land cover change and its impact on river morphology in Johor River Basin. Malaysia J Hydrol: Reg Stud 41:101072. https://doi.org/10.1016/j.ejrs.2021.01.007
Ouma Y, Nkwae B, Moalafhi D, Odirile P, Parida B, Anderson G, Qi J (2022) Comparison of machine learning classifiers for multitemporal and multisensor mapping of urban LULC features. Int Arch Photogramm, Remote Sens Spat Inform Sci 43:681–689. https://doi.org/10.5194/isprs-archives-XLIII-B3-2022-681-2022
Theres BL, Selvakumar R (2022) Comparison of landuse/landcover classifier for monitoring urban dynamics using spatially enhanced landsat dataset. Environ Earth Sci 81(5):1–8. https://doi.org/10.1007/s12665-022-10242-x
Shetty S (2019) Analysis of machine learning classifiers for LULC classification on Google Earth engine. Dissertation, University of Twente
Vapnik V (1999) The nature of statistical learning theory. Springer, Berlin
Ma L, Fu T, Blaschke T, Li M, Tiede D, Zhou Z et al (2017) Evaluation of feature selection methods for object-based land cover mapping of unmanned aerial vehicle imagery using random forest and support vector machine classifiers. ISPRS Int J Geo-Inform 6(2):51. https://doi.org/10.3390/ijgi6020051
Thanh Noi P, Kappas M (2017) Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 18(1):18. https://doi.org/10.3390/s18010018
Dinata A, Dhiniati F, Diansari LE (2022) Identification of land use and land cover using the image Landsat 8 in upstream Lematang sub-watershed by support vector machine and random trees methods. IOP Conf Series: Earth Environ Sci 1041(1):012048. https://doi.org/10.1088/1755-1315/1041/1/012048
Lillesand TM, Kiefer RW (2015) Remote sensing and image interpretation, 7th edn. Wiley, Hoboken
Directorate of Census Operations, Karnataka (2011) Census district handbook. Karnataka, district Chikmagalur
District Disaster Management Plan (DDMP) for Chikkamagaluru District Accessed 2019–20 https://ksdma.karnataka.gov.in/storage/pdf-files/Chikkamagaluru%20DDMP%202019-20.pdf. Accessed 14 March 2023
The State Gazetteer Advisory Committee (1983) Karnataka State Gazetteer. Government of Karnataka Publication, Part II
National Informatics Centre, Ministry of Electronics & Information Technology, Government of India https://chikkamagaluru.nic.in/en/about-district/ Accessed 14 March 2023
Nagaraja BC, Hemanjali AM, Somashekar RK, Pramod K (2014) Assessment of forest encroachment in Chikamagaluru district of western ghats using RS and GIS. Int J Remote Sens Geosci (IJRSG) 3(6):1–5
Phiri D, Morgenroth J, Xu C, Hermosilla T (2018) Effects of pre-processing methods on Landsat OLI-8 land cover classification using OBIA and random forests classifier. Int J Appl Earth Obs Geoinf 73:170–178. https://doi.org/10.1016/j.jag.2018.06.008
Breiman L (2001) Random forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Breiman L, Friedman JH, Olshen RA, Stone CJ (2017) Classification and regression trees. Routledge, Cambridge
Pal M (2005) Random forest classifier for remote sensing classification. Int J Remote Sens 26(1):217–222. https://doi.org/10.1080/01431160412331269698
Rodriguez-Galiano VF, Ghimire B, Rogan J, Chica-Olmo M, Rigol-Sanchez JP (2012) An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J Photogramm Remote Sens 67:93–104. https://doi.org/10.1016/j.isprsjprs.2011.11.002
Shiraishi T, Motohka T, Thapa RB, Watanabe M, Shimada M (2014) Comparative assessment of supervised classifiers for land use–land cover classification in a tropical region using time-series PALSAR mosaic data. IEEE J Select Top Appl Earth Observ Remote Sens 7(4):1186–1199. https://doi.org/10.1109/JSTARS.2014.2313572
Adam E, Mutanga O, Odindi J, Abdel-Rahman EM (2014) Land-use/cover classification in a heterogeneous coastal landscape using RapidEye imagery: evaluating the performance of random forest and support vector machines classifiers. Int J Remote Sens 35(10):3440–3458. https://doi.org/10.1080/01431161.2014.905498
Mao W, Lu D, Hou L, Liu X, Yue W (2020) Comparison of machine-learning methods for urban land-use mapping in Hangzhou city, China. Remote Sens 12(17):2817. https://doi.org/10.3390/rs12172817
Talukdar S, Singha P, Mahato S, Pal S, Liou YA, Rahman A (2020) Land-use land-cover classification by machine learning classifiers for satellite observations—a review. Remote Sens 12(7):1135. https://doi.org/10.3390/rs12071135
Adugna T, Xu W, Fan J (2022) Comparison of random forest and support vector machine classifiers for regional land cover mapping using coarse resolution FY-3C images. Remote Sens 14(3):574. https://doi.org/10.3390/rs14030574
Acknowledgements
We acknowledge the support of (i) the ENVIS Division (internship for students), The Ministry of Environment, Forests and Climate Change (MoEFCC), the Government of India, and (ii) the Indian Institute of Science for the financial and infrastructure support, (ii) the Karnataka Forest Department for permitting to undertake ecological research.
Funding
This research was supported the grant (student internships) from the ENVIS division, the Ministry of Environment, Forests and Climate Change, Government of India.
Author information
Authors and Affiliations
Contributions
RTV Concept Design, field data collection, data analysis and interpretation of data; revising the article critically for important intellectual content; final editing. TM field data collection, data analysis and interpretation of data, manuscript writing. BS Design of the experiment, review of data analysis and manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest, either financial or non-financial.
Consent for publication
The publication is based on the original research and has not been submitted elsewhere for publication or web hosting.
Human and animal rights
The research does not involve either humans, animals or tissues.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ramachandra, T.V., Mondal, T. & Setturu, B. Relative performance evaluation of machine learning algorithms for land use classification using multispectral moderate resolution data. SN Appl. Sci. 5, 274 (2023). https://doi.org/10.1007/s42452-023-05496-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-023-05496-4