
Abstract
This study predicts future values of energy consumption demand from a novel dataset that includes the energy consumption during COVID-19 lockdown, using up-to-date deep learning algorithms to reduce peer-to-peer energy system losses and congestion. Three learning algorithms, namely Random Forest (RF), Bi-LSTM, and GRU, were used to predict the future values of a building’s energy consumption. The results were compared using the RMSE and MAE evaluation metrics. The results show that predicting the future energy demand with accurate results is achievable, and that Bi-LSTM and GRU perform better, especially when trained as univariate models with only the energy consumption values and no other features included.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Distributed energy resources (DER) have witnessed a considerable increase worldwide in the last decade [2] [13] [27]. They have changed how energy is produced and distributed in the energy pipeline, allowing consumers and prosumers (users that produce and consume electricity) to share energy without the need for an intermediate distributor. Peer-to-peer (P2P) energy resources enable the trading of excess energy from prosumers to other nodes in the network, including consumers and prosumers. Figure 1 illustrates a distributed P2P connection between consumers, prosumers, and agents responsible for three goals: (i) fairly distributing profits to prosumers, (ii) coordinating with prosumers to deploy contracts, and (iii) optimally bidding in energy trading [22].
Peer-to-Peer (P2P) electricity trading fulfills the needs of both prosumers and consumers and decreases the amount of line loss. However, variability in energy demand and supply may lead to instability and affect the reliability of the P2P market. The “energy trilemma” reflects the core issues confronting the energy sector, including conflicting goals such as environmental sustainability, energy equity, and energy security.

p2p energy trading
Distributed energy resources (DERs) offer localized energy solutions that diverge from conventional unidirectional power systems, in which electricity is produced in power plants, transmitted using transmission networks, and distributed to consumers. Energy is traded in a peer-to-peer network using DERs, in which end-users are categorized into consumers and prosumers and both can share energy with each other, a process known as energy trading [43].
Trading is coordinated by a smart agent that can also be responsible for price and load demand prediction, household energy management, optimal DER scheduling, and optimal automated bidding in the network [37]. Coordination can be achieved using secure and immutable transactions between agents in the network. For example, Pradhan et al. [32] introduced a framework for the energy trading market that uses a scalable Directed Acyclic Graph (DAG) generated from bidding transactions, and the formed ledger is scalable and has low fees per transaction. The confirmation latency (the number of transactions submitted and confirmed on the ledger) is reduced compared to the confirmation latency of Ethereum and Fabric networks. Another coordination approach is to use Energy Management Systems (EMS) that applies scheduling algorithms to allocate energy and balance loads. These algorithms can be further optimized to enhance their performance using optimization algorithms such as the Whale Optimization algorithm [14] and reinforcement learning [7] [20].
In a hybrid model [21], Kumari et al. proposed a reinforcement learning model to minimize energy consumption during peak hours while storing energy management transactions using Ethereum’s smart contracts. They evaluated the performance of the proposed model using different metrics, including consumer participation, energy consumption reduction, total cost comparison, transaction efficiency, and data storage cost.
1.1 Motivation
Nowadays, due to the consequences of climate change and global warming, there is a growing need for renewable energy resources and distributed generation of energy to reduce the use of fossil fuels [35]. P2P energy trading is opening the way for prosumers to actively participate in the energy market and reduce energy peak demand and line congestion [36]. Energy demand forecasting eases the scheduling and management of trading platforms and helps allocate resources more efficiently.
The remainder of this paper is organized as follows: Sect. 2 reviews previous works in the field of energy forecasting, Sect. 3 details the methodology of this study and describes the dataset used, Sect. 4 presents the results obtained, and Sect. 5 concludes the paper.
2 Review
Forecasting power demand and supply can increase the operational costs and management of power system equipment. Using time series-based machine learning algorithms to predict unit price and energy demand in a smart grid architecture is challenging and time-consuming. The datasets are very large as they are generated within seconds; therefore, the prediction curves may overfit [34]. Regression machine learning algorithms, as well as artificial neural networks, have been widely used for prediction. For example, Sahoo et al. [34] combined the flower pollination algorithm with machine learning algorithms to predict future unit prices. They used three models: feature selection, principal component analysis, and a hybrid model for optimization and regression with three different sigma values (0.8, 0.9, and 0.94) and different Gaussian surfaces (i.e., Squared Exponential, Matern 5/2 GPR, Exponential GPR). They concluded that the flower pollination algorithm increases the accuracy of optimization by 21% compared to PSO or GA.
Lorenti et al. [23] compared the stochastic gradient method with a global optimizer in the neural network training phase to predict renewable energy production. The results revealed that both methods achieved the same outcome, but the gradient-based algorithm was faster in convergence with a lower value of reliability. Varghese et al. [38] presented a Multi-Objective Grasshopper Optimization Algorithm (MOGOA) with a Deep Extreme Learning Machine (DELM)-based short-term forecasting algorithm, referred to as MOGOA-DELM. The algorithm consists of four stages: (i) data cleaning, (ii) feature selection, (iii) forecasting load requirements, and (iv) hyper-parameter optimization. It achieves an accuracy of 85.80% on the UK Smart Meter dataset [29].
Furthermore, Kumari et al. [18] proposed a scheme called \(\rho \)Reveal, which utilizes a combination of neural networks that use Bidirectional Long Short-Term Memory and digital encryption to address security concerns for predicting energy prices and demand. The scheme also incorporates a load reduction algorithm that identifies the most effective strategy for reducing loads based on the predicted energy prices and the preferences and constraints of the user. They [19] also proposed a secure data analytics framework called Redills, short for Reduce bills, to analyze and prioritize appliance usage time-slots. Their work depends on predicting energy demand and is beneficial to both consumers and prosumers. The prediction is done using an LSTM model and evaluated using the RMSE metric, with a value of 0.0111 for household appliance loads only.
Recently, Zharova and Scherz [42] developed a three-step robust model for 24-hourly appliance load forecasting, including fridge, dryer, washing machine, dishwasher, and television electricity load, based on four datasets from four different regions (PecanSD [30] from the US, REFIT [12] from the UK, GREEND [28] from Austria, and AMPds2 [25] from Canada) with an equal set of appliances. Their work depends on weighted permutation entropy (wPE) [10]. wPE, presented in Eq. 3, uses sudden amplitude changes from Equation 1 to evaluate the predictability of the signal, with m and \(\tau \) as the embedding dimension and time delay, respectively, and wPE values above 0.5 reflect high randomness in the time series X.
Moreover, Zharova and Scherz [42] used the Standardscaler function from sklearn [11] to standardize all features and the mean absolute scaled error (MASE) to report the effectiveness of the forecasting algorithm. Experimental results show that cyclical encoding of time features and weather indicators with a long-short-term memory (LSTM) model provides the best performance.
Habbak et al. [16] compared the advantages and disadvantages of various energy forecasting techniques. They found that traditional models such as seasonal and non-seasonal time series models are simple to implement but may not be as accurate as more advanced models. Clustering-based and meta-heuristic based techniques may achieve high accuracy, but require a large amount of data and computational resources. Meta-heuristic algorithms may also require a good initialization solution to find global optimal or near-optimal solutions. On the other hand, time-series techniques require less data but may not be as accurate as more advanced methods. AI-based techniques have the advantage of being able to handle missing data, extreme events, and randomness, but may not be generalizable to other datasets. Overall, the choice of energy forecasting technique will depend on the specific requirements and constraints of the problem, including the amount of available data, computational resources, and desired level of accuracy.
In summary, managing and scheduling the energy flow in DERs can lower the system cost [1] and reduce losses and congestion in power lines [15]. Predicting short-term loads improves the reliability of DER systems [41]. In this study, a three-year energy consumption dataset was used to test the effectiveness of different machine learning algorithms in predicting the future values of energy demand and identify the features that improve the prediction performance. The algorithms used were random forest (RF), bidirectional long-short-term memory (Bi-LSTM), and gated recurrent unit (GRU). Choi et al. [5] used the same dataset to predict the number of occupants in an occupant-centric control (OCC) study using LSTM and GRU models and reported that the GRU outperformed the LSTM model and other RNN models.
3 Methodology
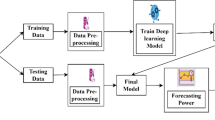
The purpose of this study is to forecast the energy consumption demand of a building that can be part of a trading group in a p2p energy trading network. The following steps summarize the methodology of this study before explaining each step in detail:
-
1.
Prepare the dataset as a data frame using Python’s Pandas library [26].
-
2.
Interpolate the missing readings.
-
3.
Check the predictability of the data as a time series using permutation entropy.
-
4.
Measure the correlation between the features.
-
5.
Add cyclic encoding as a feature.
-
6.
Choose the predicting learning algorithms.
-
7.
Compare the predictions results of each algorithm.
3.1 Dataset
The dataset used in this study includes the three-year energy consumption of a medium-sized office building located inside the Lawrence Berkeley National Laboratory (Berkeley Lab) campus in Berkeley, California, which was constructed in 2015 [24]. The dataset is public, free to use for research, reflects different consumption trends, and has not been studied before for energy demand prediction. It covers readings from 2018 to 2020, including the COVID-19 pandemic period [9].The novelty of our study lies in the fact that we analyzed a dataset that has not been explored before in the field of energy demand prediction. The dataset includes end-use energy consumption for different loads, as shown in Table 1, where mels_S and lig_S are the electric loads for the South Wing and North Wing, respectively, mels_N is the Lighting load for the South Wing, and HVAC_N and HVAC_S are Heating Ventilation and Air Conditioning (HVAC) loads for the North Wing and the South Wing, respectively. Figure 2 presents the dataset’s energy changes over time and in a boxplot that shows a scatter of the energy values, while Fig. 3 shows their degree of randomness using permutation entropy [31]. The values greater than 0.5 reflect high randomness, and the recommended embedding dimension dx for the data segment is between 3 and 7, as suggested by other researchers [40]. Figure 4 shows resampled weekly energy consumption, temperature, heating, and cooling temperature set points from the features in the dataset.

boxplot for the energy consumption in the building

PE values for the energy consumption in the building

weekly energy consumption, temperature, and heating and cooling temperature’s set point
3.2 Features
Moreover, the dataset includes temperature readings (air temperature and air dew temperature) from exterior wall-mounted sensors, air relative humidity, solar radiation, and 16 additional sensors in the interior zones to measure CO2 concentration, cooling and heating temperatures of the interior zones, HVAC system operating conditions, and occupant counts. Over three years, more than 300 sensors and meters on two office floors were used to build the dataset. However, some readings were missing, which could affect the training process. Therefore, features such as Wi-Fi connection counts and CO2 concentration were excluded, and features such as heating set point values were interpolated. The correlation of all remaining features with the building’s energy consumption is shown in the heat map in Fig. 5.

heat map of the features in the dataset
From the heat map, it can be seen that temperature (Temp) correlates with the building’s electricity demand. In addition, energy consumption has an hourly effect as it has more correlation with hours than days and months. The Spearman’s correlation between energy and hours, days, and months changes were 0.119, 0.016, and 0.058, respectively. Thus, the days and months columns were dropped in the training process. The hour’s column was further replaced with cyclic encoding using sine-cosine encoding. The values of the encodings are shown in Fig. 6. The Roof Top Unit in the HVAC supply air temperature set point in zones 2 and 3 has negatively correlated features and is also multi-collinear, so they were excluded. In addition, set point values of the cooling and heating temperature are negatively correlated, and either of them can replace the other for the prediction. Therefore, the cooling set point was dropped as a feature, as well as humidity and water pump temperature for their negative correlation. Furthermore, to stabilize the training process, the StandardScaler, MinMaxScaler, and RobustScaler [11] were used and compared to identify the output range before training and reduce the effect of larger numbers. Scaling brings all the features to the same range of values. Without scaling, high-valued features can have more weight in the ’best fit’ calculation that minimizes the distance between the fit line and the observed data.

cyclic encoding for the training data
The data were split into training and testing sets with ratios of 80% and 20%, respectively. The algorithms used for the predictions were Random Forest (RF), Bidirectional Long-Short-Term Memory (Bi-LSTM), and Gated Recurrent Unit (GRU). RF is capable of handling non-linear relationships better than other machine learning algorithms as it performs dynamic local investigations rather than global optimization and provides more accurate predictions [8]. The Grid Search algorithm was used to tune the parameters as it can search through a discrete grid from a combination of parameters and selects those that minimize the loss function. A cross-validation K-Fold CV=3 was used to ensure that the RF algorithm was trained with all segments of the dataset and to avoid having the training segment chosen randomly. Machine learning models typically require less data, training time, and memory space compared to deep learning models; however they can still achieve good performance.
Long-Short-Term Memory (LSTM) is a deep learning model that is different from feed-forward networks in that it remembers values over time. It consists of an input, an output, and a forget gate. The input gate determines which information to keep, the forget gate decides which information to discard, and the output gate controls the output to the current state of this cell in the network. All gates together allow the LSTM network to maintain meaningful, long-term information to make reliable predictions. Bi-directional LSTMs (Bi-LSTM) learn the input sequence forward and backward and merge both readings. Our code is implemented by wrapping the first hidden layer withthe bidirectional wrapper from Python’s Tensorflow and Keras [3]. Gated Recurrent Unit (GRU) is a type of Recurrent Neural Network (RNN) [6] that uses less memory than LSTM but does not provide readings as accurate as LSTM when predicting datasets with longer sequences.
4 Results
4.1 Evaluation metrics
The Root Mean Square Error (RMSE) and Mean Absolute Error (MAE) were used to evaluate the effectiveness of the algorithms. RMSE calculates the square root of the mean of the difference between the square of actual readings from the dataset and their corresponding predictions, as calculated by Equation 3 where N is the number of rows in the dataset. Lower values of RMSE and MAE reflect better performance of the algorithm. On the other hand, MAE measures the absolute value of the mean of the errors (difference between actual readings and the predictions), as calculated by Equation 4. Both metrics are widely used as evaluation metrics, and RMSE is shown to be a biased estimator rather than MAE and, therefore, more robust [4]. and the results of this study are shown in Table 2. Table 3 illustrates the evaluation metrics values for similar studies in the field of time-series forecasting.

Random forest’s prediction versus test data

GRU’s prediction in the univariate model versus test data

Bi-STM prediction in the univariate model versus test data
Table 2 shows the results and the specifications of the models used. The results show that the Random Forest algorithm performs better when used with more features, and all scalers produce almost the same results. Figure 7 shows the values of the predictions compared to the test data for the Random Forest algorithm when trained with all the correlated features.
The rather high values of RMSE and MAE can be explained by the non-fitting segments of the prediction and test data that happened to be in the year of the pandemic with rather randomly increasing and decreasing consumption. Furthermore, Bi-LSTM and GRU performed better when trained as univariate models with no features included, and the MinMaxScaler was the best scaler used. The models were trained with a look-back of 24 h and an early stop (patience) with 10 epochs if there are no further improvements applicable to the model. Unlike RF, adding more features worsened the performance of Bi-LSTM and GRU. Figures 8 and 9 show the prediction results of the GRU and Bi-LSTM models, respectively, compared to the test data when trained as univariate models. The training data was scaled using the MinMaxScaler. The figures show that the models fit the test data accurately despite its randomness. Meanwhile, Figs. 10 and 11 show the training and validation losses during the training process epochs and indicate that the models fit the new data well and rapidly.

Train loss and validation loss during training epochs for the GRU model

Train loss and validation loss during training epochs for the Bi-LSTM model
5 Conclusion
The use of Peer-to-Peer (P2P) energy trading is becoming increasingly popular as consumers and prosumers (those who both consume and produce energy) seek to buy and sell energy directly without the need for intermediaries. However, to ensure that this trading process is efficient and cost-effective, a managing agent is required to schedule the trading and reduce losses and congestion in the system. One important factor that can help improve the scheduling and trading process is accurate prediction of energy loads using machine learning models like Bi-LSTM and GRU. By training these models on historical energy consumption data, they can accurately predict future energy demand, which can help the managing agent make better decisions about the scheduling and trading process.The results of this study demonstrate that predicting energy demand in the future is achievable with accurate results. Moreover, the study found that Bi-LSTM and GRU models have the best performance, especially when trained as univariate models with only the energy consumption values and no additional features included. Overall, the use of machine learning models to predict energy demand can have significant benefits for P2P energy trading, including lower system costs, reduced losses, and improved reliability of the network.
Data Availability
Data sharing not applicable to this article as no datasets were generated and the dataset analysed can be found here [9].
References
Amir V, Jadid S, Ehsan M (2019) Operation of networked multi-carrier microgrid considering demand response. COMPEL- Int J Comput Math Electr Electron Eng
Bishnoi D, Chaturvedi H (2021) Emerging trends in smart grid energy management systems. Int J Renew Energy Res (IJRER) 11(3):952–966
Bisong E et al (2019) Building machine learning and deep learning models on Google cloud platform. Springer, Cham
Brassington G (2017) Mean absolute error and root mean square error: which is the better metric for assessing model performance? In: EGU general assembly conference abstracts, p 3574
Choi Y, Park B, Jiyeon H et al (2022) Development of occupancy prediction model and performance comparison according to recurrent neural network model. Proc Architect Inst Korea 38(10):231–240
Collins J, Sohl-Dickstein J, Sussillo D (2016) Capacity and trainability in recurrent neural networks. arXiv preprint arXiv:1611.09913
Deng D, Li J, Jhaveri RH, et al (2022) Reinforcement learning based optimization on energy efficiency in UAV networks for IoT. IEEE Internet Things J
Deng H, Fannon D, Eckelman MJ (2018) Predictive modeling for us commercial building energy use: a comparison of existing statistical and machine learning algorithms using CBECS microdata. Energy Build 163:34–43
Dryad (2022) A three-year building operational performance dataset for informing energy efficiency. https://doi.org/10.7941/D1N33Q
Fadlallah B, Chen B, Keil A et al (2013) Weighted-permutation entropy: a complexity measure for time series incorporating amplitude information. Phys Rev E 87(2):022911
Feurer M, Eggensperger K, Falkner S et al (2020) Auto-sklearn 2.0: Hands-free automl via meta-learning. J Mach Learn Res 23(261):1–61
Firth S, Kane T, Dimitriou V, et al (2017) Refit smart home dataset
Ghiasi M, Niknam T, Wang Z et al (2023) A comprehensive review of cyber-attacks and defense mechanisms for improving security in smart grid energy systems: past, present and future. Electr Power Syst Res 215(108):975
Goyal S, Bhushan S, Kumar Y et al (2021) An optimized framework for energy-resource allocation in a cloud environment based on the whale optimization algorithm. Sensors 21(5):1583
Guerrero J, Sok B, Chapman AC et al (2021) Electrical-distance driven peer-to-peer energy trading in a low-voltage network. Appl Energy 287(116):598
Habbak H, Mahmoud M, Metwally K et al (2023) Load forecasting techniques and their applications in smart grids. Energies 16(3):1480
Jamii J, Mansouri M, Trabelsi M, et al (2022) Effective artificial neural network-based wind power generation and load demand forecasting for optimum energy management. Front Energy Res 10
Kumari A, Tanwar S (2021) \(\rho \)reveal: an ai-based big data analytics scheme for energy price prediction and load reduction. In: 2021 11th international conference on cloud computing, data science & engineering (Confluence), IEEE, pp 321–326
Kumari A, Vekaria D, Gupta R, et al (2020) Redills: deep learning-based secure data analytic framework for smart grid systems. In: 2020 IEEE international conference on communications workshops (ICC Workshops), IEEE, pp 1–6
Kumari A, Gupta R, Tanwar S (2021) Prs-p2p: a prosumer recommender system for secure p2p energy trading using q-learning towards 6g. In: 2021 IEEE international conference on communications workshops (ICC Workshops), IEEE, pp 1–6
Kumari A, Kakkar R, Gupta R et al (2023) Blockchain-driven real-time incentive approach for energy management system. Mathematics 11(4):928
Liu Y, Wu L, Li J (2019) Peer-to-peer (p2p) electricity trading in distribution systems of the future. Electr J 32(4):2–6
Lorenti G, Mariuzzo I, Moraglio F et al (2022) Heuristic optimization applied to ANN training for predicting renewable energy sources production. COMPEL Int J Comput Math Electr Electron Eng 41(6):2010–2021
Luo N, Wang Z, Blum D et al (2022) A three-year dataset supporting research on building energy management and occupancy analytics. Sci Data 9(1):156
Makonin S, Ellert B, Bajić IV et al (2016) Electricity, water, and natural gas consumption of a residential house in Canada from 2012 to 2014. Sci Data 3(1):1–12
McKinney W et al (2011) Pandas: a foundational python library for data analysis and statistics. Python High Perform Sci Comput 14(9):1–9
Moafi M, Ardeshiri RR, Mudiyanselage MW et al (2023) Optimal coalition formation and maximum profit allocation for distributed energy resources in smart grids based on cooperative game theory. Int J Electr Power Energy Syst 144(108):492
Monacchi A, Egarter D, Elmenreich W, et al (2014) Greend: an energy consumption dataset of households in Italy and Austria. In: 2014 IEEE international conference on smart grid communications (SmartGridComm), IEEE, pp 511–516
Murray D, Stankovic L, Stankovic V (2017) An electrical load measurements dataset of United Kingdom households from a two-year longitudinal study. Sci Data 4(1):1–12
Parson O, Fisher G, Hersey A, et al (2015) Dataport and nilmtk: a building data set designed for non-intrusive load monitoring. In: 2015 IEEE global conference on signal and information processing (globalsip), IEEE, pp 210–214
Pessa AA, Ribeiro HV (2021) ordpy: a python package for data analysis with permutation entropy and ordinal network methods<? a3b2 show [editpick]?>. Chaos Interdiscip J Nonlinear Sci 31(6):063110
Pradhan NR, Singh AP, Verma S et al (2022) A blockchain based lightweight peer-to-peer energy trading framework for secured high throughput micro-transactions. Sci Rep 12(1):14523
Rao SNVB, Yellapragada VPK, Padma K et al (2022) Day-ahead load demand forecasting in urban community cluster microgrids using machine learning methods. Energies 15(17):6124
Sahoo S, Swain S, Dash R et al (2021) Novel gaussian flower pollination algorithm with IoT for unit price prediction in peer-to-peer energy trading market. Energy Rep 7:8265–8276
Sayed ET, Olabi AG, Alami AH et al (2023) Renewable energy and energy storage systems. Energies 16(3):1415
Soto EA, Bosman LB, Wollega E et al (2021) Peer-to-peer energy trading: a review of the literature. Appl Energy 283(116):268
Suthar S, Cherukuri SHC, Pindoriya NM (2023) Peer-to-peer energy trading in smart grid: frameworks, implementation methodologies, and demonstration projects. Electr Power Syst Res 214(108):907
Varghese LJ, Dhayalini K, Jacob SS et al (2022) Optimal load forecasting model for peer-to-peer energy trading in smart grids. CMC Comput Mater Contin 70(1):1053–1067
Wang C, Li X, Li H (2022) Role of input features in developing data-driven models for building thermal demand forecast. Energy Build pp. 112593
Zanin M, Zunino L, Rosso OA et al (2012) Permutation entropy and its main biomedical and econophysics applications: a review. Entropy 14(8):1553–1577
Zhang A, Zhang P, Feng Y (2019) Short-term load forecasting for microgrids based on DA-SVM. COMPEL Int J Comput Math Electr Electron Eng 38(1):68–80
Zharova A, Scherz A (2022) Multistep multiappliance load prediction. arXiv preprint arXiv:2212.09426
Zhou Y, Wu J, Long C et al (2020) State-of-the-art analysis and perspectives for peer-to-peer energy trading. Engineering 6(7):739–753
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study’s conception and design. Material preparation and data collection were performed by HG, The manuscript was written by her, and edited by AA and IE, all authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest associated with this study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hassan, H.G., Shahin, A.A. & Ziedan, I.E. Energy consumption forecast in peer to peer energy trading. SN Appl. Sci. 5, 211 (2023). https://doi.org/10.1007/s42452-023-05424-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-023-05424-6