
Abstract
Full Adder (FA) circuits are integral components in the design of Arithmetic Logic Units (ALUs) of modern computing systems. Recently, there have been massive research interests in this area due to the growing need for low-power and high-performance computing systems. Researchers have proposed a variety of FA cells with diverse design techniques, each having its pros and cons. As a result, a systematic method for performance comparison of FA cells using a common simulation platform has become necessary. In this work, we present an extensive study of FA cells. We have compared the performance of thirty-three (33) existing 1-bit FA cells. The drive powers of these FA cells have been compared by applying a variety of load conditions. In addition, the 1-bit FA cells have been extended to 32-bit structures to test their scalability and to investigate their performance in wide-word structures. We have determined that twenty-one (21) of the thirty-three (33) FA cells cannot operate in a 32-bit structure, even though some of them exhibit excellent performance as a 1-bit cell. The main finding of this research is that the single-bit performance parameters of FA cells should not be considered as the main basis for performance comparison. Any FA cell should be analyzed in a multi-bit structure to determine its practical effectiveness.
Article Highlights
-
Hybrid full adders offer better performance than single logic full adders
-
Many existing full adder cells are not scalable
-
Conventional Mirror CMOS full adder offers better performance than many recent full adders in wide adder structure
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Due to the massive use of battery-powered, portable electronic gadgets, the use of VLSI circuits, that require high speed and consume less power, has become crucial [1,2,3]. Full Adders (FAs) form a vital component in the VLSI system design of advanced microchips. FAs are essential for the implementation of certain mathematical operations such as magnitude comparison [4], multiplication [5, 6], subtraction [7], etc. In most cases, adder falls within the critical path of these operations which govern the comprehensive performance of the overall system [8]. Moreover, the implementation of a wide adder tree requires full adder cells [9,10,11]. Due to the towering utilization and crucial role in various operations, a multitude of FA cells have been implemented, each having its advantages and disadvantages.
Since numerous FA topologies have been proposed, especially in recent times, it is necessary to evaluate their performance metrics using a common platform to enable VLSI designers to pick the right FA topology that best suits their system requirements [12]. In many recent works, comparative analyses of FA designs have been discussed. For example, Prasad et al. [13] and Wariya et al. [14] compared XOR-XNOR-based FA circuits. A comparative study of FAs conducted in by Singh et al. [15] and Harish et al. [16] explored FAs that are implemented using various logics. However, the investigation was only conducted for four FAs in [15] and five FAs in [16]. FA comparison in [17] compared 7 cells. The study conducted in [18] provided the impact of voltage variation on FA cells. Research conducted in [19] analyzed the performance of FA in tree-structured arithmetic units. In [20], only 4 FA cells have been analyzed and compared. However, these studies are not up-to-date as they do not have the FA designs developed in the past 10 years. In [21], an extensive investigation among various FA cells has been conducted for 180 nm CMOS process node, which is rarely applied to modern-day circuits. FA comparison in [22] contains simulation results for only 14 FA cells, which may not be enough for a comprehensive study.
To have a complete overview of FA cells, recent contributions need to be considered and performance comparison should not be limited to 1-bit cell. Therefore, FAs should be analyzed in multiple-bit structures. Moreover, the drive power of VLSI circuits is an important parameter. However, comparative analysis of FA drive power is missing in the existing literature.
In this work, we report an extensive analysis of 33 existing FA cell designs utilizing Cadence tools. The benefits and drawbacks of each FA design have been thoroughly discussed and summarized to allow VLSI designers to select the desired FA for circuit implementation.
The organization of the remaining portion of this research is as follows. In Sect. 2, a comprehensive review of FA cells has been provided. Section 3 provides information on circuit simulation parameters, transistor sizing, and simulation testbench. In Sect. 4, a comprehensive comparison of FA cells has been conducted based on the simulated results. Section 5 provides the major findings of this research. At last, concluding statements are provided in Sect. 6.
2 Literature review of existing full adder cells
Various FA designs using different techniques have been realized with the aim to enhance performance parameters. Although the FA cells perform exactly the same operation, design patterns for generating internal nodes, logic design techniques and the number of transistors utilized are completely different. Variations in logic designs increase some performance parameters while degrading others. Some cells utilize only one logic design technique for the implementation of the entire FA cell. This sort of FA cell is known as single logic FA. FA cells employing more than one logic style is known as hybrid logic FA [23].
2.1 Single logic full adders
The early age of CMOS VLSI design highly relied on Complementary Pass Logic (CPL) where n-channel CMOS (NMOS) transistors were utilized for logic interpretation [24]. This logic technique is proficient in terms of logic swing. However, due to the utilization of only NMOS transistors, the design technique can only provide strong logic 0. In the case of providing logic 1, the output voltage becomes Vdd—Vt (here, Vdd = supply voltage, Vt = threshold voltage of NMOS). Therefore, CPL is unable to provide strong logic 1. FA employing CPL utilizes 32 NMOS for logic interpretation [25]. In addition to providing weak logic 1, high transistor count (TC) of CPL FA causes high power dissipation which is responsible for creating hot spots in IC [26]. Another FA employing CPL logic presented in [27] requires only 12 transistors (addressed as 12-T FA in this article). Although low TC reduces power dissipation and area requirements in IC, voltage degradation remains the key concern. Due to voltage degradation, CPL has been supplemented by Complementary CMOS (CCMOS) logic which is widely used in modern ICs [28]. In addition to providing strong logic 0 and 1, the CCMOS logic family is highly robust against voltage scaling [29]. Moreover, due to having ample drive power, CCMOS logic is highly suitable for high-fan out conditions [28]. FA employing CCMOS logic presented in [30] requires 28 transistors (14 NMOS and 14 PMOS). FAs in [25, 27, 30] fall under the realm of single logic devices.
2.2 Hybrid logic full adders
Hybrid logic-based FA circuits have become popular because they leverage the benefits of various logic designs within the same circuit [31]. Transmission gate (TG) based logic implementation solves the issue of voltage degradation of CPL logic by adding swing restoring PMOS transistors [32]. Transmission Gate FA (TGA) in [33] and Transmission Function FA (TFA) in [34] employ TGs for FA logic interpretation. Although the issue of voltage degradation is solved, poor drive power is the major issue associated with these FA designs [33, 34].
FAs employing 10 transistors (10-T) [35], 16 transistors (16-T) [36], 14 transistors (14-T and New 14-T) [37], 18 transistors (18-T) [38], and 26 transistors in [39] utilize hybrid logic style designs, unlike TGA and TFA FAs. 24-T FA employs a 3-input XOR gate to compute Sum. Carry-out bit calculation is the same as CCMOS based FA in [30]. In 14-T FA [36], a hybrid XOR gate works as the soul of the design since the output from the XOR gate is used for computing both sum and carry-out signals.
Two more hybrid FA cells named Hybrid Pass Static CMOS (HPSC) and Novel HPSC (NHPSC) are presented in [40, 41]. HPSC uses Pass Transistor (PT) for XOR-XNOR function generation which works as internal nodes. The output side employs CCMOS logic to provide the circuit with ample drive power required in high-fan out cases.
Low-Power High-Speed (LPHS) FA design in [43] employs only 15 CMOS transistors for FA function implementation. However, threshold voltage drop remains the major issue associated with this design. Double Pass Logic (DPL) FA and Swing-Restored CPL (SRCPL) FA design in [44] utilize 3 logic techniques: PTL, CCMOS logic, and TG logic. More hybrid FA cells are available in [45,46,47,48,49,50,51,52,53,54] (referred to as HBD 1 – HBD 12 in the latter part of this article).
Nowadays, the Gate Diffusion Input (GDI) method of implementing logic functions has become quite popular for implementing low power circuits [55,56,57,58]. GDI method was first introduced in [59] which later became a popular method for VLSI circuit design [60]. Logic implementation using the GDI technique can be realized from [61], where basic logic gates using the GDI technique, have been presented. The major issue regarding GDI method-based circuit is its voltage degradation which reduces drive capability significantly [62]. Several FAs employing the GDI technique have been developed for low-power applications which require less surface area due to low TC [63]. GDI FA in [64] suffers from low drive power due to threshold voltage drop in GDI logic gates. However, low TC and low-power dissipation make them suitable for low-power applications. To provide full swing output in GDI gates, modified GDI gate-based FA designs have been implemented in [65, 66].
3 Circuit simulation in cadence
To evaluate the performance metrics of various designs of FA cells, circuits are required to be simulated in a common simulation environment to ensure a fair comparison. Therefore, circuit simulation parameters need to be fixed and a proper transistor sizing technique needs to be applied for all FA cells. These are discussed in the following sub-sections.
3.1 Circuit simulation parameters
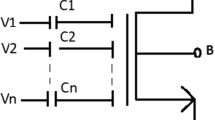
To simulate FA circuits to investigate their performance, a 45 nm CMOS process has been utilized. Supply voltage has been set to 1.0 V. Average power, propagation delay, and Power Delay Product (PDP) are the performance metrics that are used to compare the effectiveness of various FA cells. The input waveform for power and delay calculation is presented using Fig. 1, where it can be visualized that all possible input combinations from 000 to 111 are present in the waveform. In VLSI circuits, power and delay vary for different input combinations since pull-up and pull-down transistor paths for different input combinations are different. Therefore, to determine the average power dissipation of a FA cell, all possible input combinations are applied to the testbench and total power consumption due to each input combination is calculated. Later, an average value of total power, due to all input patterns, was taken as the average power. In the case of propagation delay calculation, 50% of input–output signal swing for the critical path (worst case delay path) has been chosen. For delay, all input–output combinations from 000 to 111 are generated separately and delay occurred due to all possible input combinations were calculated individually. Then, only the maximum delay has been considered as propagation delay of the circuit. PDP is simply the product of average power and propagation delay.

Input waveform for power and delay calculation
3.2 Transistor sizing
In the case of VLSI design, optimal implementation of circuits plays a crucial role [67, 68]. In general, transistor sizing refers to increasing or decreasing the width of transistors to optimize the performance parameters of circuits. Due to its effectiveness in optimizing the performance of VLSI circuits, transistor sizing should be handled in a proper manner [69]. Transistor sizing for circuits comprising of a small number of transistors can be done manually. However, modern-day ICs are comprised of millions of transistors for which it becomes impossible to optimize transistor sizes manually. Therefore, bringing automation in design optimization becomes inevitable to cope up with the high integration density and complexity of modern IC designs.
The transistor sizing method in [70] presents a linear method of performing a trade-off between CMOS circuit parameters: power, delay, and area. However, modern-day VLSI circuits behave in a non-linear manner for which this algorithm is unable to yield optimal performance. Transistor sizing methods in [19, 33, 71] present a simple but effective way of determining transistor sizes for delay optimization. However, only the critical path is considered in these two methods, for which power consumptions of circuits are not optimized. Nowadays, Power-Delay Product (PDP), which is simply the product of power consumption and delay of a circuit, has become the vital parameter and transistors have been sized for obtaining minimum PDP [35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54, 64,65,66]. Particle Swarm Optimization (PSO) has become a popular method for optimization of VLSI design [72, 73]. PSO-based inverter circuit optimization is presented in [74]. However, the algorithm is not tested for circuits having a large number of transistors and hybrid logic styles. Another PSO-based transistor sizing method is presented in [75]. But the algorithm is only tested for CCMOS logic-based designs. Simple Exact Algorithm (SEA) based transistor sizing presented in [76] has been specially designed for arithmetic circuits, taking into account various hybrid logic design methodologies. The authors have tested the algorithm for various FA cells such as: CPL [25], CCMOS [30], TGA [33], TFA [34], 14-T [37], NHPSC [41]. Due to the ability to optimize hybrid logic cells, the SEA transistor sizing method in [76] has been used in this paper for optimizing FA cells.
3.3 Simulation testbench
To inspect the performance parameters of FA cells, a feasible structure is required to perform simulations. Various simulation testbench, reported by researchers for FA simulation, have been illustrated in Fig. 2. In the case of testbench in Fig. 2a, three stages of FAs are connected having buffers in the input and output terminals. Delay for this testbench is measured from input terminals of the 1st FA stage to the last signals in the 3rd FA. Hence, it does not represent the delay of a single FA block. Moreover, inputs are only applied to the 1st FA stage. Therefore, the 2nd and 3rd FA stages are not tested properly. As a result, the power consumed by various FA stages is different. In addition, the fan-out of Sum is 1 whereas the fan-out of Cout is 2. Therefore, the FA blocks are not similarly loaded. FA test benches in Fig. 2b and c are similar except for the last parts. Both of the test benches are free from the limitations of the testbench in Fig. 2a. Since the SEA transistor sizing method, described in sub-Sect. 3.2 used the simulation test bench in Fig. 2c, we have also used this test bench for FA simulation in this work.

The testbench in Fig. 2c, which is used in this research contains a set of buffers attached to the input terminals. In fabricated processors or ICs, the signals pass through several non-ideal circuit components which make the signals distorted. Therefore, while generating input signals for simulation, it is necessary to replicate the real-time scenario by introducing signal distortion. For this reason, the buffers are attached to input terminals to bring distortions in the input signals. On the other hand, the output of a circuit is always connected to other components in an IC which work as a load to the circuit. Therefore, in the case of simulation, it becomes necessary to attach a load circuit with an output terminal to work as load. The testbench demonstrated in Fig. 2c comprises buffers in the output terminals as load circuits to the output terminals.
4 Simulation results and performance comparison
For comparative investigations of performance parameters, simulations have been conducted considering various aspects and operating conditions. Obtained simulation results for FA cells are presented in the following sub-sections.
4.1 Performance of FAs as single cells
Obtained simulation results using simulation testbench in Fig. 2c has been presented in Table 1 and Fig. 3. It can be observed from Fig. 3a that HBD 6 FA design in ref. [49] obtained superior performance in terms of average power consumption. This FA design provides full swing operation utilizing only 16 transistors. The circuit has no threshold voltage drop issue in the internal nodes. Due to having a low transistor count with no threshold voltage drop issue, the circuit could provide low power operation. CPL FA in [25] is considered to be the highest power-consuming FA as per simulation results. As per Table 1, CPL FA has the highest transistor count among FA cells. Moreover, since only the NMOSs are used in CPL FA, the pull-up circuit is subjected to the threshold voltage drop issue. Due to these reasons, CPL FA has very high average power. Although 12-T [27], 10-T [35] and 14-T [37], LPHS [43], and GDI 1 [64] FA cells have low transistor count, yet their corresponding average power is high due to loss in threshold voltage. Among single logic FAs, CCMOS [30] has the least power consumption. Moreover, it can be noticed that CCMOS has better performance in power compared to some of the recent hybrid FA designs. Among GDI cells, GDI 3 design in [66] obtained superior performance in power dissipation.

Performance comparison of Full Adders a Average Power, b Propagation Delay, c Power Delay Product (PDP)
In the case of speed (propagation delay), HBD 7 FA in [50] obtained predominant performance. HBD 7 FA cell used input signal Cin as the gate control of transistors in the outermost terminals. As a result, the portion of the outermost terminal got switched on before the time it takes to generate signals in the internal nodes. Once the internal signals are generated, they instantly appear in the output terminals since the output terminal has been turned on beforehand. By this scheme, the circuit could ensure better speed. HBD 3 [46], GDI 2 [65], and GDI 3 [66] are close contesters of HBD 7 [50] in speed. Speed of CPL [25] and CCMOS [30] FAs are quite satisfactory in spite of being some of the oldest FA topologies. 12-T [27], 10-T [35], 14-T [37], NHPSC [41], and HBD 6 [48] FA cells have a very high level of propagation delay which limits their application in high-speed systems. 12-T [27], 10-T [35], 14-T [37] and NHPSC [41] FAs have threshold voltage drop issues in the internal nodes for which the internal nodes are subjected to voltage degradation. When this degraded voltage is used as the gate control of a transistor, it takes more time for the transistor to turn on. For this reason, 12-T [27], 10-T [35], 14-T [37] and NHPSC [41] FAs have severe speed issues. In HBD 6 FA design [48], at first, input terms A and B are used in an XNOR circuit. Then, an inverter is used to invert the XNOR signal into XOR. Later, these XOR-XNOR signals are used in sum and carry-out circuits to generate the final outputs. Since, the XOR signal faces one inverter stage delay than the XNOR signal, the sum and the carry-out circuits become slower. This is the main reason behind the speed issues of HBD 6 FA [48].
In terms of PDP, HBD 7 [50] acquired the highest performance. HBD 7 obtained the best performance in speed while maintaining quite satisfactory performance in power consumption. For this reason, HBD 7 could attain the best performance in PDP. In spite of excellent performance in speed, CPL [25] has very high PDP due to its high average power. 16-T [36], HBD 1 [45], HBD 2 [45], HBD 3 [46], HBD 4 [47], GDI 1 [64], GDI 2 [65], GDI 3 [66], GDI 4 [66] and GDI 5 [66] have considerably low PDP compared to other FAs.
4.2 Performance of FAs in various load conditions
Drive power of VLSI circuits is an important parameter that is highly required for high-fan out conditions. High-performance circuits (high speed and low power circuits), with low drive power, might fail to operate in an IC. Therefore, the drive power of VLSI circuits is a critical parameter that needs to be optimized. To analyze the drive power of FA cells, unit size inverter cells have been utilized as load. Load conditions, ranging from Fan-Out of 4-unit size inverters (FO-4) to FO-64, have been applied to each FA cell and propagation delays corresponding to the different load conditions have been calculated. Results are recorded in Table 2.
After extensive investigation of the data presented in Table 2, FA cells are categorized in three major groups: low drive power FA (marked by bold italic texts in the Drive Power column of Table 2), moderate drive power FA (marked by italic texts in the Drive Power column of Table 2) and high drive power FA (marked by bold texts in the Drive Power column of Table 2). Simulation data of each group (low drive power, moderate drive power and high drive power FA) are displayed in Fig. 4a, b and c, respectively. CPL [25], 12-T [27], 10-T [35], 14-T [37], LPHS [43], HBD 4 [47], and GDI 1 [64] FAs fall in low drive power group. TGA [33], TFA [34], 16-T [36], 18-T [38], DPL [44], SR-CPL [44], HBD 1 [45], HBD 2 [45], HBD 3 [46], HBD 5 [48], HBD 6 [49], HBD 7 [50], HBD 10 [53], HBD 11 [54], HBD 12 [54], GDI 3 [66], GDI 4 [66], and GDI 5 [66] are medium drive power FAs. As last, CCMOS [30], HPSC [40], NHPSC [41], ULPFA [42], HBD 8 [51], HBD [52], and GDI 2 [65] consist of high drive power group.

Performance of Full Adders in various load conditions a low drive power Full Adders, b moderate drive power Full Adders, c high drive power full adders, d comparison among low, moderate and high drive power Full Adder graphs
To compare among the groups, three FA cells from each group have been selected as representatives. The representatives from each group are: (1) FA that achieved best drive power, (2) FA that has least drive power and, (3) FA having middle-most drive power data between type (1) and type (2) FAs. The associated propagation delays for each type are shown in Fig. 4d. In Fig. 4d, CPL [25], 14-T [37], and GDI1 [64] FAs are the representatives from low drive power FA group. TFA [34], HBD 7 [50], and HBD 10 [53] represent moderate drive power FA group whereas ULPHA [42], HBD 8 [51], and GDI 2 [55] represent high drive power FA. It can be seen that, with increasing fan-outs, propagation delays for moderate drive power FAs rise at a higher pace compared to the graphs representing high drive power FAs. In the case of low drive power FAs, the propagation delay increased quite rapidly compared to the other groups. Output terminals of FAs that have voltage degradation issues mainly fall in the low drive power group.
4.3 Performacne of FAs in wide adder structure
Modern ALUs require wide adder structures (16-bit, 32-bit, etc.) to perform computation [77]. Therefore, it is important to compare the performance of FAs operating in wide adder architecture. To do so, the FA cells have been extended up to 32-bits using the Ripple-Carry Adder style [78]. Simulation results on performance parameters have been recorded in Table 3. No voltage level restoring buffers have been added while extending the FA cells to a wide adder structure.
It has been observed that 21 out of 33 FA cells (marked with ‘F’ in Table 3) could not operate when they were extended to 32-bits. This occurred due to the degradation of signal strength while propagating through a series of logic circuits. To eliminate this issue, level restoration buffers are required to be installed, which costs additional circuitry. As a result, delay and power consumption will increase. Therefore, circuits that can be incorporated directly in a system without the need of additional hardware are preferred by industrial circuit designers and academic researchers. Figure 5 presents a comparison of carry-output graph between a scalable and a non-scalable FA cell extended using RCA style. CCMOS FA [30] represents scalable FA while HBD 1 [45] represents non-scalable FA in Fig. 5. For CCMOS FA in Fig. 5a, no voltage degradation in carry signals could be seen. On the other hand, carry signals C4 and C8 of HBD 1 in Fig. 5b seem to have voltage degradation issues. Due to this voltage degradation issue, the carry signal gets below threshold voltage at a point while propagating through series of FA cells. As a result, the signal becomes unable to drive the next stage and the circuit fails to operate. Due to this reason, carry signals C16 and C32 of HBD 1 FA are not available in Fig. 5b. Unlike HBD 1 FA, the condition is applicable for the circuits that could not operate in multiple-bit structures.

Example of carry output signals of a scalable FA b non-scalable FA
Among the remaining 12 FAs, output terminals of CCMOS [30], 24-T [39], HPSC [40], NHPSC [41], ULPFA [42], HBD 8 [51], HBD 9 [52] and GDI 2 [65] FA cells are comprised of CCMOS logic circuits. The pull-up network of the CCMOS logic circuit is connected to Vdd and the pull-down network to Ground. As a result, while extended to wide adder architecture, output signal voltage gets replenished after every FA stage. For the remaining 4 FA cells, which could be extended to 32-bits, the same output-carry signal does not propagate throughout the entire 32-bit stages. Hence, voltage strengths of signals do not decline [50]. As a result, the FA cells could operate successfully in wide adder architecture without using voltage restoring buffers.
5 Major finding and discussion
As modern microprocessors are not limited to only a 1-bit addition operation, FA cells need to have the ability to be scaled up to wide word-length adders. Therefore, scalability is a major factor that needs to be investigated while analyzing FA cells. In this research, the scalability test conducted in Sect. 4.3 reveals that only one-third (11 out of 33) of the FA designs could be scaled up to multiple bits in the simple RCA style. The remaining 22 FA cells failed to operate while scaled up to 32-bits. After extensive analysis of Table 1, Fig. 3, and Table 3, it was found that some FAs, having high-performance parameters as single cells were unable to operate in 16-bit or 32-bit structure. For instance, performance of 16-T [36], 18-T [38], HBD 1–4 [45,46,47], HBD 6 [49], HBD 10–11 [53, 54], GDI 1 [64] and GDI 3 [66] FAs are quite satisfactory as per simulation data presented in Table 1 and Fig. 2. However, they could not operate while extended to 16-bits and 32-bits. Based on this analogy, it can be said that the performance comparison of adders based on only a 1-bit operation should not be the main parameter for analyzing FAs. Rather, it should be analyzed if the 1-bit adder cells are scalable or not.
Moreover, based on data presented in Table 3, it is essential to mention that the classic CCMOS FA cell obtained better performance than many FA cells in case of operating in a wide word-length structure. This is the main reason for which CCMOS logic remains as the prominent circuit design methodology despite of being one of the oldest VLSI circuit design methods.
In recent research activities, the concept of fast parallel prefix adder has evolved which aims to generate carry terms in parallel to reduce carry propagation delay [79]. Most of the parallel prefix adders require carry-propagate and carry-generate to perform addition [80]. Carry propagate is the XOR function between the input bits that are required to be added. On the other hand, carry generate is the AND function between the input bits. Therefore, for fast parallel adders, FA cells incorporating XOR and AND functions will be highly suitable. Among FAs analyzed in this research, DPL [44], SR-CPL [44], HBD 7 [7], and GDI 4 [66] FAs have AND and XOR functions for which they will be able to create carry generate and carry propagate signals without any extra hardware. As a result, these FAs will be more suitable for modern fast adder architectures.
The multiplier is another potential application of FA. In multiplier, carry output of on stage do not need to propagate through several stages for which scalability is not the major concern [81, 82]. For this reason, FA cells having good performance parameters while operating as 1-bit are quite suitable for utilization in multipliers. As per performance analysis of 1-bit cells, 16-T [36], HBD 1 [45], HBD 2 [45], HBD 3 [46], HBD 4 [47], HBD 7 [50], GDI 1 [64], GDI 2 [65], GDI 3 [66], GDI 4 [66] and GDI 5 [66] FAs have good performance due to which they will be good candidates for utilization in multipliers.
If transistors are scaled to lower technology nodes, then parasitics associated with the transistors will decrease for which any circuit operating in lower technology nodes will exhibit better performance than operating in higher technology nodes. However, if FAs are simulated in lower technology node than the 45 nm CMOS process, then the performance difference among FA cells will likely remain the same since parasitics will decrease in the same manner for all FA cells. But in the case of lower technology nodes, interconnect parasitics does not decrease in the same manner as transistor parasitics do [83]. For this reason, interconnect widths are required to be optimized in lower technology nodes to maintain the performance levels of FA cells [83].
6 Conclusion
A comprehensive literature review and performance comparison of various FA designs have been conducted in this research. The performance of FA cells, operating both as single bit and wide-adder structures, has been investigated. The simulation results include average power, propagation delay, and PDP (Power-Delay-Product) that covers most of the main performance metrics. To determine the effectiveness of FAs in high fan-out cases, and to have a comparative analysis of their drive powers, the FA designs have also been simulated using various load conditions. According to this study, only a few of the existing FA cells are capable of performing well when they are scaled up to multiple-bit structures. Hence, although it is popular to compare FA cells by comparing their performance parameters in the 1-bit structure, this research recommends that the practical effectiveness of FA cells be compared using their wide-word structures.
References
Warnock J et al (2014) Circuit and physical design of the zenterprise ec12 microprocessor chips and multi-chip module. IEEE J Solid State Circuits 49(1):9–18
Naseri H, Timarchi S (2018) Low-power and fast full adder exploring new XOR and XNOR gates. IEEE Trans Very Larg Scale Integr (VLSI) Syst 26(8):1481–1493
Sorwarv A, Sojib EA, Dipto MAZ, Rangon MMT, Chowdhury MSA, Siddique AH (2020) Design of a high-performance 2-bit magnitude comparator using hybrid logic style. In: 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–5
Chaudhary V, Mehra R (2013) 2-bit comparator design using different logic style of full adder. Int J Soft Comput Eng 3(2):277–279
Imana JL (2018) Fast bit-parallel binary multiplier based on type-1 pentanomials. IEEE Trans Comput 67(6):898–904
Navi K, Moaiyeri MH, Mirzaee RF, Hashemipour O, Nezhad BM (2009) Two new low-power full adder based on majority-not gates. Microelectron J 40(1):126–130
Kouretas I, Basetas C, Paliouras V (2013) Low-power logarithmic number system addition/subtraction and their impact on their digital filters. IEEE Trans Comput 62(11):2196–2209
Pal A (2015) Low-power VLSI Circuits and Systems. Springer, India
Ramkumar B, Kittur HM (2012) Low-power and area-efficient carry select adder. IEEE Trans Very Larg Scale Integr (VLSI) Syst 20(2):371–375
Mohanty BK (2019) Efficient fixed-width adder-tree design. IEEE Trans Circuits Syst II Express Briefs 66(2):292–296
Zlatanovici R, Kao S, Nikolic B (2009) Energy-delay optimization of 64-bit carry-lookahead adders with a 240 ps 90 nm CMOS design example. IEEE J Solid State Circuits 44(2):569–583
Lorenz JK, Bar E, Clees T, Evanschitzky P, Jancke R, Kampen C, Paschen U, Salzig CPJ, Sleberherr S (2011) Hierarchical simulation of process variation and their impact on circuits and systems: results. IEEE Trans Electron Devices 58(8):2227–2234
Prasad BY, Babu HN, Reddy RKV, Dhanabal R (2014) Comparative performance analysis of XOR-XNOR based high-speed CMOS full adder circuits. In: 2014 International Conference on Reliability Optimization and Information Technology (ICROIT)
Wariya S, Nagaria RK, Reddy RKV, Dhanabal R (2012) Comparative performance analysis of XOR-XNOR function based high-speed CMOS full adder circuits for low voltage VLSI design. Int J VLSI Des Commun Syst 3(2):221–242
Singh NK, Sharma PK (2014) Power and delay comparison of 1-bit full adder designs at 180nm and 90nm technology. In: 2014 International Conference on Control, instrumentation, Communication and Computational technologies (ICCCICCT)
Harish B, Sivani K, Rukmini MSS (2017) Performance comparison of various CMOS full adders. In: 2017 International Conference on Energy, Communication, Data Analytics and Soft Computing (ICECDS)
Alito M, Palumbo G (2002) Analysis and comparison on full adder block in submicron technology. IEEE Trans Very Larg Scale Integr (VLSI) Syst 10(6):806–823
Alito M, Palumbo G (2006) Impact of supply voltage variations on full adder delay: analysis and comparison. IEEE Trans Very Larg Scale Integr (VLSI) Syst 14(12):1322–1335
Chang CH, Gu J, Zhang M (2005) A review on 0.18-/spl/mu/m full adder performances for tree structured arithmetic circuits. IEEE Trans Very Larg Scale Integr (VLSI) Syst 13(6):686–695
Sharma T, Sharma KG, Singh BP (2010) High performance full adder cells: a comparative analysis. Presented at the 2010 IEEE Students Technology Symposium (TechSymp)
Wariya S, Nagaria RK, Tiwari S (2011) Performance analysis of high speed hybrid CMOS full adder circuits for low voltage. VLSI Des. https://doi.org/10.1155/2012/173079
Hasan M, Hossein MJ, Saha UK, Tarif MS (2018) Overview and comparative performance analysis of full adder cells in 90 nm technology. In: 2018 4th International Conference on Computing, Communication and Automation (ICCCA)
Basireddy H, Challa K, Nikoubin T (2019) Hybrid logical effort for hybrid logic style full adders in multistage structures. IEEE Trans Very Larg Scale Integr (VLSI) Syst 27(5):1138–1147
Oklobdzija VG, Duchene B (1997) Synthesis of high-speed pass-transistor logic. IEEE Transact Circuits Systems II Anal Digit Signal Process 44(11):974–976
Zimmerman R, Fichtner W (1997) Low-power logic styles: CMOS versus pass-transistor logic. IEEE J Solid State Circuits 32(7):1079–1090
Perpina X, Altet J, Jorda X, Vellvehi M, Millan J, Mestres N (2008) Hot-spot detection in integrated circuits by substrate heat-flux sensing. IEEE Trans Electron Device Lett 29(10):1142–1144
Giang Y, Al-Sheraidah A, Wang Y, Sha E, Chung J (2004) A novel multiplexer-based low-power full adder. IEEE Trans Circuits Syst II Express Briefs 51(70):345–348
Jiang Y, Sapatnekar SS, Bamji C (2001) Technology mapping for high performance CMOS and pass transistor logic designs. IEEE Trans Very Larg Scale Integr (VLSI) Syst 9(5):577–589
Pacha C, Schmal A, Schulz T, Gottsche R, Steinhogl W (2003) Evaluation of circuit performance of ultra-thin-body SOI CMOS. Solid-State Electron 47(7):1205–1211
Weste NHE, Harris DM (2010) CMOS VLSI design: a circuits and systems perspective. Addison-Wesley, Boston, MA
Wariya S, Nagaria RK, Tiwari S (2011) New design methodologies for high-speed low-voltage 1 bit CMOS full adder circuits. Int J VLSI Des Commun Syst 2(2):190–198
Jiang Y, Klumperink E, Gao X, Ru Z, Zee RVD, Nauta B (2013) Flip-flops for accurate multiphase clocking: transmission gate versus current mode logic. IEEE Trans Circuits Syst II Express Briefs 60(7):422–426
Shams AM, Darwish IK, Bayoumi MA (2002) Performance analysis of low-power full adder cells. IEEE Trans Very Larg Scale Integr (VLSI) Syst 10(1):20–29
Alioto M, Cataldo GD, Palumbo G (2007) Mixed full adder topologies for high-performance low-power arithmetic circuits. Microelectron J 38(1):130–139
Dokania V, Verma R, Guduri M, Islam A (2018) Design of 10T full adder cell for ultralow-power applications. Ain Shams Eng J 9(4):2363–2372
Shams AM, Bayoumi MA (2000) A novel high-performance CMOS 1-bit full-adder cell. IEEE Transact Circuits Syst II Anal Dig Signal Process 47(5):478–481
Vesterbacka M (1999) A 14-transistor CMOS full adder with full voltage swing nodes. In: 1999 IEEE workshop on signal processing systems
Amini-Valashani M, Ayat M, Mirzakuchaki S (2018) Design and analysis of a novel low-power energy-efficient 18T hybrid full adder. Microelectron J 74:49–59
Tung CK, Hung YC, Huang GS (2007) A low-power high-speed hybrid CMOS full adder for embedded system. In: 2007 IEEE design and diagnostics of electronics circuits and systems
Zhang M, Gu J, Chang CH (2003) A novel hybrid pass logic with static CMOS output drive full-adder cell. In: proceedings of the 2003 international symposium of circuits and systems
Goel S, Kumar A, Bayoumi MA (2006) Design of a robust, energy-efficient full adders for deep sub-micrometer design using hybrid-CMOS logic style. IEEE Trans Very Larg Scale Integr (VLSI) Syst 14(12):1309–1321
Hassoune I, Flandre D, O’Connor I, Legat J (2010) ULPFA: a new energy efficient design of a power-aware full adder. IEEE Trans Circuits Syst I Regul Pap 57(8):2066–2074
Tung CK, Sheih SH, Cheng CH (2013) A low-power high-speed full adder for portable electronic devices. Electron Lett 49(17):1063–1064
Aguirre-Hernandez M, Linares-Aranda M (2011) CMOS full-adders for energy-efficient arithmetic applications. IEEE Trans Very Larg Scale Integr (VLSI) Syst 19(4):718–721
Kumar P, Sharma RK (2017) An energy efficient logic approach to implement CMOS full adder. J Circuits Syst Comput 26(1):1750084
Kumar P, Sharma RK (2016) Low voltage high performance hybrid full adder, engineering science and technology. Int J 19(1):559–565
Parameshwara MC, Srinivasaiah HC (2017) Low-power hybrid 1-bit full adder circuit for energy efficient arithmetic applications. J Circuits Syst Comput 26(1):1–15
Mirzaee RF, Moaiyeri MH, Khorsand H, Navi K (2011) A new robust and hybrid high-performance full adder cell. J Circuits, Syst Comput 20(4):641–655
Bhattacharyya P, Kundu B, Ghosh S, Kumar V, Dandapat A (2015) Performance of a low-power high-speed hybrid 1-bit full adder circuit. IEEE Trans Very Larg Scale Integr ntegr (VLSI) Sntegr (VLSI) S Syst 23(10):2001–2008
Hasan M, Hossein MJ, Hossain M, Zaman HU, Islam S (2020) Design of a scalable low-power 1-bit hybrid full adder for fast computation. IEEE Trans Circuits Syst II Express Briefs 67(8):1464–1468
Ghadiry MH, A’Ain AK, Nadi MS (2011) Design and analysis of a novel low PDP full adder cell. J Circuits Syst Comput 20(3):439–445
Navi K, Kavehei O (2008) Low-power and high-performance 1-bit CMOS full-adder cell. J Comput 3(2):48–54
Foroutan V, Taheri MR, Navi K, Mazreah AA (2014) Design of two low-power full adder cells using GDI structure and hybrid CMOS logic style. Integration 47(1):48–61
Tirumalasetty VR, Machupalli MR (2018) Design and analysis of low power high-speed 1-bit full adder cells for VLSI applications. Int J Electron 106(4):521–536
Radhakrishnan S, Nirmalraj T, Karn RK (2019) An enhanced gate diffusion input technique for low power applications. Microelectron J 93:104621
Shoba M, Nakkeeran R (2017) Energy and area efficient hierarchy multiplier architecture based on vedic mathematics and GDI logic. Eng Sci Technol Intern J 20(1):321–331
Morgenshtein A, Yuzhaninov V, Kovshilovsky A, Fish A (2014) Full swing gate diffusion input logic- case-study of low-power CLA adder design. Integration 47(1):62–70
Morgenshtein A, Moreinis M, Ginosar R (2014) Asynchronous gate-diffusion-input (GDI) circuits. IEEE Trans Very Larg Scale Integr (VLSI) Syst 12(8):847–856
Morgenshtein A, Fish A, Wagner IA (2002) Gate diffusion input (GDI): a power-efficient method for digital combinatorial circuits. IEEE Trans Very Larg Scale Integr (VLSI) Syst 10(5):566–581
Kandasamy N, Ahmad F, Reddy S, Babu R, Telagam N, Ultapalli S (2018) Performance evaluation of 4-bit MAC using hybrid GDI and transmission gate based adder multiplier circuits in 180 and 90 nm technology. Microprocess Microsyst 59:15–28
Gard A, Joshi G (2018) Gate diffusion input based 4-bit vedic multiplier design. IET Circuits Devices Syst 12(6):764–770
Hasan M, Zaman HU, Hossain M, Biswas P, Islam S (2020) Gate diffusion input technique based full swing and scalable 1-bit hybrid full adder for high performance applications. Eng Sci Technol Intern J 23(6):1364–1373
Sheel P, Mehra R (2016) Comparative analysis of gate diffusion input based full adder. IOSR J VLSI Signal Process 6(3):24–30
Sanapala K, Sakthivel R (2019) Ultra-low-voltage GDI-based hybrid full adder design for area and energy-efficient computing systems. IET Circuits Devices Syst 13(4):465–470
Hasan M, Saha UK, Sorwar A, Dipto MAZ, Hossain MS, Zaman HU (2019) A novel hybrid full adder based on gate diffusion input technique, transmission gate and static CMOS logic. In: IEEE 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT)
Shoba M, Nakkeeran R (2016) GDI based adders for energy efficient arithmetic applications. Eng Sci Technol Intern J 19(1):485–496
Rogenmoser R, Kaeslin H (1997) The impact of transistor sizing on power efficiency in submicron CMOS circuits. IEEE J Solid-State Circuits 32(7):1142–1145
Kasamsetty K, Ketkar M, Sapatnekar SS (2000) A new class of convex functions for delay modeling and its applications to the transistor sizing problem [CMOS gates]. IEEE Trans Comput Aided Des Integr Circuits Syst 19(7):779–788
Sapatnekar S, Chuang W (2000) Power-delay optimizations in gate sizing. ACM Trans Design Autom Electron Syst 5(1):98–114
Berkelaar MRCM, Jess JA (1994) Computing the entire active area/power consumption versus delay trade-off curve for gate sizing with a piecewise linear simulator. In: IEEE/ACM international conference on computer-aided design
Karandikar SK, Sapatnekar SS (2005) Fast comparisons of circuit implementations. IEEE Trans Very Larg Scale Integr (VLSI) Syst 12(13):1329–1339
Zhang Y, Wang S, Ji G (2015) A comprehensive survey on particle swarm optimization algorithm and its applications. Math Probl Eng. https://doi.org/10.1155/2015/931256
Kumar SBV, Rao PV, Sharath HA, Sachin BM, Ravi US, Momica BV (2018) Review on VLSI design using optimization and self-adaptive particle swarm optimization. J King Saud Univ Comput Inf Sci 32(10):1095–1107
Vural RA, Der O, Yildirim T (2010) Particle swarm optimization based inverter design considering transient performance. Dig Signal Process 20(4):1215–1220
White L, While L, Deeks B, Boussaid F (2015) Transistor sizing using particle swarm optimization. In: 2015 IEEE symposium series on computational intelligence
Nikoubin T, Bahrebar P, Pouri S, Navi K, Iravani V (2010) Simple exact algorithm for transistor sizing of low-power high-speed arithmetic circuits. VLSI Des. https://doi.org/10.1155/2010/264390
Perri S, Corsonello P, Cocorullo G (2003) A high-speed energy-efficient 64-bit reconfigurable binary adder. IEEE Trans Very Larg Scale Integr (VLSI) Syst 11(5):939–943
Papachatzopoulos K, Paliouras V (2019) Static delay variation models for ripple-carry and borrow-save adders. IEEE Trans Circuits Syst I Regul Pap 66(7):2546–2559
Roy S, Choudhury M, Puri R, Pan DZ (2014) Towards optimal performance-area trade-off in adders by synthesis of parallel prefix structures. IEEE Trans Comput Aided Des Integr Circuits Syst 33(10):1517–1530
Akbari O, Kamal M, Afzali-Kusha A, Pedram M (2018) RAP-CLA: a reconfigurable approximate carry look-ahead adder. IEEE Trans Circuits Syst II Express Briefs 65(8):1089–1093
Yan W, Ercegovac MD, Chen H (2016) An energy-efficient multiplier with fully overlapped partial products reduction and final addition. IEEE Trans Circuits Syst I Regul Pap 63(11):1954–1963
Waters RS, Swartzlander EE (2010) A reduced complexity wallace multiplier reduction. IEEE Trans Comput 59(8):1134–1137
Pan C, Naeemi A (2015) A paradigm shift in local interconnect technology design in the era of nanoscale multigate and gate-all-around devices. IEEE Electron Device Lett 36(3):274–276
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Availability of data and material
The manuscript has no associated data/ materials obtained from external sources.
Code availability
No code is available for this research.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hasan, M., Siddique, A.H., Mondol, A.H. et al. Comprehensive study of 1-Bit full adder cells: review, performance comparison and scalability analysis. SN Appl. Sci. 3, 644 (2021). https://doi.org/10.1007/s42452-021-04640-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-021-04640-2