
Abstract
Groundwater governance uses modeling to support decision making. Therefore, data science techniques are essential. Specific difficulties arise because variables must be used that cannot be directly measured, such as aquifer recharge and groundwater flow. However, such techniques involve dealing with (often not very explicitly stated) ethical questions. To support groundwater governance, these ethical questions cannot be solved straightforward. In this study, we propose an approach called “open-minded roadmap” to guide data analytics and modeling for groundwater governance decision making. To frame the ethical questions, we use the concept of geoethical thinking, a method to combine geoscience-expertise and societal responsibility of the geoscientist. We present a case study in groundwater monitoring modeling experiment using data analytics methods in southeast Brazil. A model based on fuzzy logic (with high expert intervention) and three data-driven models (with low expert intervention) are tested and evaluated for aquifer recharge in watersheds. The roadmap approach consists of three issues: (a) data acquisition, (b) modeling and (c) the open-minded (geo)ethical attitude. The level of expert intervention in the modeling stage and model validation are discussed. A search for gaps in the model use is made, anticipating issues through the development of application scenarios, to reach a final decision. When the model is validated in one watershed and then extrapolated to neighboring watersheds, we found large asymmetries in the recharge estimatives. Hence, we can show that more information (data, expertise etc.) is needed to improve the models’ predictability-skill. In the resulting iterative approach, new questions will arise (as new information comes available), and therefore, steady recourse to the open-minded roadmap is recommended.
Graphic abstract

Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Groundwater governance is the commitment to provide water security in terms of quality and quantity for all citizens, making it necessary to ensure that everyone receives water (equity) with transportation methods that avoid losses (efficiency), maintain quality (responsibility) with forms of monitoring and control that equalize the freedom (autonomy), and power (representativeness) of all agents involved [1,2,3,4,5,6]. To achieve this dynamic balance required by governance, historical data from the past, monitoring data in the present, and modeling about the future are needed.
Groundwater governance is an interdisciplinary field, dealing frequently with ethical issues in both decision making and resources planning. Researchers in the field of Hydrogeology are breaking traditional boundaries of disciplines to embrace comprehensive and multidisciplinary studies, as pointed out 10 years ago by Liu et al. [7]. In general, it demands data modeling and recently data science [8,9,10], presenting various degrees of ethical issues that must be considered.
Relevant topics on data ethics are the need for recourse and accountability, and fighting against feedback loops, bias, and disinformation [11]. Examples of issues to be raised are: Should we even be doing this? What bias is in the data? Can the code and data be audited? What are the error rates for different subgroups? What is the accuracy of a simple rule-based alternative? What processes are in place to handle appeals or mistakes? [11]. A benchmarking analysis of 84 documents containing ethical guidelines for the use of artificial intelligence (considering data preparation and processing, modeling, and evaluation of results, applied to many uses such as data analytics and decision making [11,12,13]) in public and private companies identified a global convergence around five ethical principles: (1) transparency, (2) justice, (3) non-maleficence, (4) responsibility, and (5) privacy. They also identified a substantive divergence in how these principles are interpreted, how and why they are considered important and how they should be implemented [12]. In another benchmarking analysis, Fjeld et al. [13] consider that 32 documents converged on eight ethical principles: (1) accountability, (2) equity and non-discrimination, (3) human control of technology, (4) privacy, (5) professional responsibility, (6) promotion of human values, (7) security, and (8) transparency and the ability to be explained.
Geoethics deals with ethics related to the social, economic, environmental, and cultural consequences of geological research and practice, providing a point of intersection between geosciences, sociology, and philosophy [14, 15]. Geoethics was originated from assumptions that support its principles and main concerns [16, 17]. This can be organized into four major groups: (1) environmental and social effects; (2) communication; (3) predicting and remedying potential dangers; and (4) consideration with future generations. Thus, geoethics is an emerging concept in the scientific scenario that congregates human sciences, geosciences, and engineering based on environmental sustainability. Identifying and addressing ethical issues should be a crucial part of the design of data science and modeling project [1, 2]. The issues raised within data ethics are often complex and interdisciplinary. But nowadays and further, water ethics will also need to include ethics in the use of geospatial data, so how then to deal with it? In this perception, Crampton [18] proposed 26 years ago a four-stage sequence of ethical practices for the use of geographic information systems (GIS):
-
1.
ignoring ethics (or rather being unaware of ethical issues);
-
2.
considering ethics from an internal perspective only;
-
3.
considering ethics from both an internal and an external perspective; and
-
4.
establishing a dialectical relationship, which modifies both internal and external perspectives.
Merging these two concepts, the geoethics of geospatial analysis is constructed by a series of principles that guide the researcher to continuously improve his/her scientific conduct as suggested in the Crampton’s fourth stage. So, groundwater governance must combine the ethical use of groundwater and the ethical use of geospatial data [19, 20]. When interdisciplinary fields such as groundwater governance use AI applications, it is necessary to associate data ethics (from AI) with the inherent ethical issues of the field (from groundwater governance). It makes the ethical issues even more complex. Therefore, a comprehensive framework is needed to deal with these ethical issues in the dual context of the professional expertise of technical decision makers and the social relevance of the actions to be taken.
We propose to use the concept of geoethics to guide us in the search for ethical solutions for the use of geospatial data in groundwater governance. To deal with this sort of ethical issue, it is necessary to take a critical but also open-minded view. Open-mindedness is defined as a mode of thinking based on the openness to new experiences [21], tolerance for ambiguity, receptivity toward and curiosity about unconventional ideas or 'intellectual non-conformity' [22]. Thus, an open-minded roadmap should be an ethical attitude with explicit principles and open to the issues that will arise, but which were not necessarily fully anticipated and covered by the rigid and non-dialectical moral code.
The present research aims to present an open-minded roadmap for a geoethical analysis of data analytics and modeling for groundwater governance decision making. The concepts are illustrated by a case study with geospatial data from groundwater monitoring and modeling. We applied models based on fuzzy logic (with high expert intervention) and data-driven methods (with low expert intervention) to discuss the outputs confronting it with applied groundwater ethical issues.
2 Geoethical framework and its philosophical background
Western classical ethics, which involves philosophical writings by authors such as Plato (428–348), Aristotle (384–428), and Immanuel Kant (1724–1804), centralize the human being always at the same time as an end, never merely as means and lays a foundation for relationships between human beings. With the technological advance initiated by the Industrial Revolution and accentuated in the Post-World War II, Ethics rethought its bases to also include the “knowledge” and “doing” created by the human being. The traditional pre-World War II technique was considered ethically neutral, both in relation to the object (the technology produced) and the subject of the action (the scientist and the user of this technology). Hans Jonas (1903–1993) raised this issue in 1979, when he published Das Prinzip Verantwortung (“The Imperative of Responsibility: In Search of an Ethics for the Technological Age”).
Jonas [23] considers traditional ethics incapable of facing the challenges of the current environmental crisis, because classical ethics is confined to spatial and temporal horizons limited to "human being as an end in itself". Also, places responsibility as the center of ethics, to underline not only man's duties to himself but also to posterity and the maintenance of earthly life. For Jonas [23], the dominant model of economic development is inseparable from technological progress, this simultaneity constituting perhaps one of its greatest dangers. The danger of current technology does not arise merely from technological devices themselves, but on the impact that its use has on human beings, in which all beings transform themselves into quantifiable and manipulable objects, including the human being himself, showing that technology cannot be considered only as a passive instrument. Moreover, this is a relatively recent danger [23]. Contemporary technology has moved towards seemingly more and more grandiose achievements, the success of which is measured by the ability to control the environment. Thus, Jonas considers that, given the nature and magnitude of our interventions in the Earth System, the distance between everyday and extreme issues is becoming increasingly smaller. Before extreme events were occasional, and more and more become routine.
Jonas [23] proposes “The Heuristics of Fear,” an attitude that gives priority to the most pessimistic future scenarios despite the most optimistic scenarios, thus creating a barrier to what he considers to be the uncontrollable technological power. This is not a position contrary to technological progress, but rather the creation of a safeguarding attitude, so that the course triggered by technological advances does not become contrary and counterproductive to the maintenance of life on Earth. In this context, the need to expand ethical thinking to fields beyond the relationship between humans, but also their relationship with the environment and with technology has generated new disciplines within ethics, such as bioethics, environmental ethics and geoethics. In this context, the “resurrection of ethics” occurs as the expansion of classical ethics, including in its scope not only relationships between humans, but also the relationship between humans and animals (Bioethics) [24,25,26], ecological complexes (Environmental Ethics) [27, 28] or with the underground environment (Geoethics) [29]. These are examples of new open debates in this discipline of philosophy.
In the list of fundamental values set out in the Cape Town Statement on Geoethics [29], it is clear that the concept of geoethics is not about a new discipline, but a practical approach for promote new ethical basis for scientific studies in geosciences. These values include honesty, integrity, transparency, and reliability of the geoscientist, including strict adherence to scientific methods. According to Peppoloni et al. [30], geoscientists have grounded the concept of geoethics based on (1) concern with the individual responsibility of the self and profession in conducting actions in geosciences and (2) analyzing the context and making decisions in the social sphere on issues inherent to geoscience. The theoretical frameworks of geoethics have been analyzed in many scientific publications [31,32,33,34,35,36,37,38]. The most comprehensive definition of geoethics is provided by Di Capua, Peppoloni, and Bobrowsky [29]:
(Geoethics) Consists of research and reflection on the values which underpin appropriate behaviors and practices, wherever human activities interact with the Earth system. Deals with the ethical, social, and cultural implications of geoscience knowledge, research, practice, education, and communication, and with the social role and responsibility of geoscientists in conducting their activities. Encourages geoscientists and wider society to become fully aware of the humankind’s role as an active geological force on the planet and the ethical responsibility that this implies. Is considered a point of intersection for Geosciences, Sociology, Philosophy and Economy.
This definition clearly shows the strong link between ethics, geosciences, and human activities. Mogk and Bruckner [39] demarcate two moments of ethical thinking: (1) the Self-level geoethics (microethics) and (2) the global level geoethics (macroethics). The microethical and macroethical consequences are correlated and constitute a feedback system. Microethical decisions interfere in the universe of macroethics, which performs an ethical-conceptual rearrangement in its own conceptual framework that, through feedback, returns the same or different ethical consequences for the context of microethics and vice-versa. Thus, regarding groundwater governance, Silva et al. [1] considers that the self (microethics) and societal (macroethics) responsibility, and geoethical implication is distributed to all the components in the geoethical decision making process in (ground)water governance. The ethical dimension of practices associated with groundwater governance requires assessing how individual reception (microethics) will impact society's response (macroethics) to water management in a dialectical way.
At Fig. 1, we relate the varied ethics fields with groundwater governance. We looked deeper into Hans Jonas' Imperative of Responsibility and Heuristics of Fear [23] because it is a philosophical foundation that can link the four fields of Ethics by expanding moral decisions beyond human relationships. This expansion makes it possible to also evaluate the ethical relationship with machines, for example, such as AI Ethics [11,12,13]. We highlight the geoethics because it is a powerful tool to deal with the challenges of groundwater governance.

Interactions between groundwater governance and ethics fields and its philosophical basis
Highlighting and exploring ethical dilemmas are essential to prevent and mitigate ethical issues [39]. We consider that making ethical assumptions explicit is necessary because it makes explicit its tacit dimension [40]. It involves a crucial functional relation, such that one knows the first term only by relying on one’s awareness of it for attending to the second. Moral behavior can often be characterized by being tacit, difficult to express verbally. That is why an effort is made here to present some elements of Contemporary Philosophy that can help us explain the knowledge that underlies (geo)ethics.
3 Case study
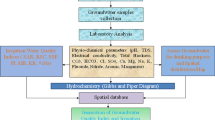
We propose an open-minded (geo)ethical roadmap for data analytics applications for groundwater governance (Fig. 2) directed towards the use of artificial intelligence methods. The ideas presented and discussed so far are confronted with real data analysis results and finally discussed in the scope of geoethics. The double-sense arrows indicate that the issues can generate feedback between them.

Open-minded (geo)ethical roadmap for data analytics applications for groundwater governance
Each of these stages contained in Fig. 2 deserves more detail, as we present below.
-
a.
Data acquisition
-
Measure: Defining the research problem and what data is needed is the basis of any modeling project. The need for obtaining primary data in-situ or using secondary data is assessed at this stage. Preliminary or preceding studies help the researcher to define which data are relevant to the research problem.
-
Organize: In this step the need for data transformations (such as normalization and standardization), filling in missing data (such as interpolations) or data selection (such as applying filters and Principal Component Analysis) is evaluated. Pyle [41] considers that data preparation is the most time-consuming step within a project and is the foundation for success. Exploring the available data as a way of understanding how a research problem can be solved is essential. In the real world, data may be incomplete (absence of attributes of interest for research, contain noise (existence of errors or outliers) and be inconsistent (be out of date or the result of errors).
-
-
b.
Modeling
-
Expert intervention: Characterizing the level of intervention that the expert can perform is essential to diagnose the types of potential conflicts: there may be conflicts of human being versus machine, human being versus data, human being versus Big Data and even machine versus machine [42,43,44].
-
Implement: Implementation is the phase of developing the model using a particular programming language, for example coding a Machine Learning model with Python language packages. This implementation is performed using the acquired and organized data. Pyle [41] considers that the specification of the modeling strategy occupies 1% of the time but represents 51% of the importance for the success of the project.
-
Evaluate: After performing the modeling, it is necessary to apply evaluation metrics for its effectiveness in prediction. This stage is directly linked to the validation process.
-
-
c.
Open-minded (geo)ethical attitude
-
Validate: Model validation is the process by which model outputs are compared to independent real-world observations to judge the quantitative and qualitative correspondence with reality [45]. It is based on the evaluation metrics, which will be confronted with the expert's knowledge, who will evaluate the uncertainties and risks in the use of this model.
-
Search for gaps: The validation of the model should show us in which situations the model fails and in which situations it gets it right, and thus it is possible to determine the conditions where its use is safe and the conditions where it cannot be used. This search for gaps can indicate where data acquisition and/or implementation has been unsuccessful.
-
Anticipate issues: the inquiries raised by Jonas go beyond compliance with moral codes, bringing to light the need of anticipating ethical issues that have not yet emerged as fact. Unger [46] presents the concept of "imagination" as "the work of crisis without crisis, making it possible for us to experience change without undergoing ruin". To be able to be imaginative, in the manner presented by Unger [46], is one of the necessary skills to act ethically in the dialectic relations.
-
Create scenarios: Brainstorming moments are the opportunity to turn the application more effective by taking into account possible solutions before they are needed.
-
Decision making: After investigating and discussing all the steps of the open-minded (geo)ethical roadmap, there are subsidies for decision making. The risks and uncertainties in the use of the model were surveyed to diagnose the conditions necessary for its safe use or its uselessness for the particular situation studied.
-
3.1 Data acquisition
3.1.1 Study area
The Santa Bárbara Ecological Station (EEcSB) is a conservation area located inside the Santa Bárbara State Forest, in Águas de Santa Bárbara, central-western São Paulo State, Brazil. The land use is varied, including native vegetation, and reforestation with pine and eucalyptus trees [47, 48]. Figure 3 shows the study area and its location with respect to the main ecological and hydrogeological features. The geological configuration is predominantly composed of sandstones from the Adamantina and Marilia Formations (of the Bauru Group) in the top, and extrusive igneous rocks and basalts of the Serra Geral Formation (of the São Bento Group) in the bottom [47]. The Bauru aquifer system is crucial for the water supply in São Paulo State because of its expansive territorial distribution (106,996 km2), stable flow rates with little oscillation, and easy access [49,50,51].

Location of study area with the main ecological and hydrogeological features
Several studies in EEcSB have investigated the behavior of groundwater resources in response to climatic anomalies that occurred in the State of São Paulo between 2013 and 2016, based on different approaches, like time-series analysis [52, 53], geostatistical approaches [54, 55], geostatistical approaches combined with time-series analysis [47, 56, 57], and remotely sensed-based analysis of groundwater recharge and water table depths retrieved by water balance approach [58, 59]. These researches emphasized the need to monitor and predict groundwater levels accurately and consistently for decision making.
3.1.2 Groundwater level monitoring data and field observations
From 2013 to 2016, São Paulo State (SP), Brazil, passed through two marked periods of climatic anomalies, facing one of the worst droughts ever recorded [47, 60] and later the effects of El Niño South Oscillation (ENSO) phenomena, both of which had a direct impact on water resources. During this period, a monitoring network of groundwater table depths with 55 wells were distributed in the Guarantã (14 wells), Bugre (13 wells), Santana (12 wells), Boi (9 wells), and Passarinho (5 wells) watersheds. Figure 4 shows the monitoring network on these five watersheds.

Water table monitoring network along four watersheds
The groundwater level has been measured since September 5th, 2014, and this study investigated a hydrological year (until September 30, 2015). From these data was calculated the groundwater recharge for 2015 using water table fluctuation (WTF) method as described by Healy [61] and the amplitude (ΔH) of groundwater level. Also, an agrometeorological station was installed inside EEcSB to monitor reference evapotranspiration on a reference surface where the albedo is 0.23 and the LAI is 2.88. These data were used to retrieve actual evapotranspiration. Hydraulic conductivity, slope, evapotranspiration, and soil resistance to penetration data were observed and/or calculated nearby each monitoring well [62] to create an inference model for groundwater recharge.
3.2 Modeling methodology
3.2.1 Expert intervention
We applied two approaches: a fuzzy logic approach and data-driven models’ approach (using three algorithms: artificial neural networks, J48, and Random Forest). Table 1 shows the benchmarking between the two approaches. The two approaches start from different ways of applying the modeling but generated outputs and metrics of the same type, allowing for comparative analysis. In the fuzzy logic approach, the protagonist is the rules developed by the expert, while in data-driven models the protagonist is the data which will guide the machine, so there is no expert intervention like in the fuzzy logic approach.
In both approaches, the predicted class is categorical, in this specific case, the aquifer recharge classes presented in Table 2 with their corresponding recharge ranges according to the groundwater recharge for 2015 calculated using WTF method [63].
The models studied here led to two types of relationships and decisions. Fuzzy models have high expert intervention and focus on the human versus machine relationship. Data-driven models internalize relationships and generate machine versus machine relationships, where the machine observes patterns, organizes them, and creates models [64,65,66]. Neural networks are considered "black box" models, which allow only interventions on their hyperparameters, but the internal organization is completely independent of expert intervention [67, 68].
3.2.2 Fuzzy approach
In recent years, the fuzzy set theory, introduced by Zadeh [69], has been used to classify and quantify several environment diffuse effects and behaviors. The goal of the fuzzy sets is a conceptual framework suitable for the treatment of problems possessing intrinsic subjectivity [70]. Fuzzy sets and logic made possible an alternative (in terms of the standard classical sets) and formal treatment for a data class whose truth condition is defined over a numerical range corresponding to different degrees of truth [2]. The Mamdani's Fuzzy Inference System (MFIS) is the most commonly fuzzy methodology [71] and was applied to EEcSB dataset using the module Fuzzy Logic Toolbox of Matlab R2018a [72]. Figure 5 shows the fuzzy sets that have been classified linguistically. “Appendix” shows the membership rules.

Input variables and output with membership functions of triangular shape
3.2.3 Data-driven approach
3.2.3.1 Artificial neural network
Deep learning approach is highly developed in different tasks such as numerical classification of variables with complex interaction and pattern identification to predict responses to input variables [67, 68]. Artificial neural networks are commonly designed by using various interconnected nodes (so-called neurons). In an artificial neural network (ANN), there are at least three layers involving the input layer as well as the hidden and output layer. Input data needs to be divided into three databases: a training dataset to build the ANN, the validation dataset to be applied in the trained ANN and a third dataset to perform an independent test. The neural network of multilayer perceptron (MLP) is a widely utilized ANNs that identifies itself by using three layers. These layers are commonly defined using layers namely input, hidden, and output and including various computational modules named nodes or neurons. In this study, we used five numeric input variables from EEcSB dataset as shown in Fig. 6.

Artificial neural network architecture
A perceptron creates a single output according to several observed value inputs by generating a linear combination using its input weights as \(y=\vartheta \sum_{i=1}^{n}{w}_{i}{x}_{i}+b=\vartheta \left({w}^{\mathrm{T}}x+b\right)\), where \({w}_{i}\) is vector of weights, \({x}_{i}\) is vector of inputs, \(b\) is the bias, and \(\vartheta\) is the non-linear activation function. We applied an ANN with 5 neurons, 2 hidden layers, each one with 6 neurons and the ReLU activation function. The validation was performed with 25% of the database. Weights were adjusted using Adam optimization algorithm. For error adjustment, the calculations were performed in subsets of 10 registers (batch_size = 10) for 50 epochs. ANN predicted numerical data which were converted into categorical data following Table 2. ANNs were implemented with Tensorflow and Keras in Python environment.
3.2.3.2 J48 Algorithm
The J48 algorithm is known as a suitable classifier which creates C4.5 Decision Trees [73]. The trees generated by C4.5 algorithm usually are small and exact. These appropriate characteristics of C4.5 approach make decision trees a popular tool in the case of categorical classification tasks [74]. We used the J48 function available in WEKA 3.8.4 applying numerical values as input data for categorical predicting.
3.2.3.3 Random Forest
The Random Forest approach [75] is obtained by developing the classification and regression trees-CART [76]. Random Forest is an ensemble learning method which produces various trees according to random bootstrapped of the training database patterns. This method performs random binary trees which produce a training subset above bootstrapping approach. In addition, a random choice of the training information is employed and accomplished to create the model from the initial database; however, out-of-the bag (OOB) is known as the data that is not involved [77]. A Random Forest is defined as a predictor consisting of a collection of randomized base regression trees \(\{{r}_{n}\left(x,{\theta }_{n},{D}_{n}\right),m\ge 1\}\). These random trees are integrated to create the aggregated regression estimate as \(\stackrel{-}{{r}_{n}}\left(X,{D}_{n}\right)={E}_{\theta }\left[{r}_{n}\left(x,\theta ,{D}_{n}\right)\right]\), where \({E}_{\theta }\) defines expectation regarding random parameters, conditionally on \(X\) and dataset \({D}_{n}\). We used the Random Forest function available in WEKA 3.8.4 applying numerical values as input data for categorical predicting.
3.3 Final evaluation
In order to evaluate the results using an open-minded (geo)ethical attitude, we perform a validation using global accuracy measurements and confusion matrices. We do not consider only the global accuracy measurements as they are not sufficient for validation since they can generate interpretation biases. Rarer classes (with few occurrences), even if poorly predicted, have little relevance in the global accuracy calculation [78,79,80]. We used confusion matrices to locate and quantify the correctly and incorrectly predicted classes, thus making it possible to locate local failures of the models.
From these evaluation tools, gaps were searched, issues anticipated, scenarios created and finally decision making discussed from both perspectives, traditional and (geo)ethical.
4 Results and discussion
The membership functions established for the MFIS used in this study were previous used by Manzione and Matulovic [2] in order to verify the applicability of these functions to EEcSB dataset and respective watersheds. The recharge calculated by these functions at Boi watershed present 99% correlation with the WTF method recharge calculations [2]. Taking this great performance of MFIS to estimate recharge at this spot of EEcSB, in this study we extrapolate these results to all watershed and obtained the global accuracy of 29.54%. Even in a small and controlled area as EEcSB, the small variations in land cover and use, soil properties and management influence heavily in the recharge estimative (Table 3).
Here we have our first ethical issue: adopt this MFIS to the whole are since it works in some spots or return to the field and get more data and/or try a new (better) modeling of these data.
Accepting the first choice the analyst can revel (or not) the total performance of the model and convince the audience that it is the best model possible with this dataset and with the budget they had to perform the study. Since it works somehow in some areas, it is appealing that the data can be wrong, and we assume the risks of the model approval. So, geoethical thinking shall be applied when deciding how to communicate the outputs of a modeling study, check the level of the audience in terms of mathematical and hydrogeological background to understand it, aiming to adjust the language, being as honest as possible.
Now, taking the second way, and blaming the model for the weak overall performance we check the same dataset with state-of-art classification methods based on AI. All three methods using artificial neural network, J48 and Random forest algorithms performed worst than the established MFIS. Even with all model requirements, there was no progress estimating groundwater recharge since the confusion matrix show much more inconsistencies for data-driven approach than in the fuzzy approach (Tables 4, 5, 6, 7). The classification confusion matrix reading is performed by crossing the actual class (in a row) with the class predicted by the model (in a column) properly indicated. Each confusion matrix displays how many data were predicted correctly (diagonal of the matrix, where the predicted class is equal to the actual class) and how many were predicted incorrectly (off-diagonal of the matrix, where the predicted class is different from the actual class).
By analyzing the confusion matrixes further, we can find dangerous prediction failures for groundwater governance. The fuzzy logic and Random Forest models predicted three and two "Bad" recharge occurrences as “Good,” respectively. The ANN model predicted one "Excellent" occurrence as "Very Bad", while the J48 model predicted one "Very Bad" occurrence as "Excellent".
5 Discussion
From these results, we can return to the open-minded (geo)ethical roadmap for data analytics applications for groundwater governance and discuss its main highlighted points.
5.1 Validation
Validation is the moment to analyze the uncertainties quantifiable by the evaluation metrics. In our case study, the low accuracy makes the generalized use of the models for groundwater management in the studied watersheds ethically impossible. It was demonstrated through the confusion matrices that areas with excellent recharge can be confused by the models with areas with very bad recharge. These failures prevent effective groundwater governance.
Sometimes validation is possible, when auxiliary dataset is available, or the dataset is large enough to separate part of the data for validation purposes. But sometimes is not possible to validate a model. Knowing the differences between an empirical model and a validated model can increase the chances of success and the trust on modeling practices in further studies. Silva et al. [59] pointed out that aquifer recharge is a variable that cannot be measured directly, but only by residual methods, such as estimation by water balance or the WTD method. In this case study, the uncertainty of the WTF model does not make the low accuracy of the models negligible.
Established methods may be in use without the necessary re-validation. For example, Silva and Manzione [81] analyzed a flow regionalization method developed in 1988 (which estimates river flows in watersheds without data) and found that it underestimates flows from 1990 on, because the dataset on which it was based did not consider the effects of climate change. These underestimated flows can generate more restrictive decision making (negatively impacting agriculture and industry) and be a poor parameter for civil constructions, such as bridges, where predictability of flooding is essential. Anticipating and preventing this sort of problem is essential to make the use of models in (ground)water governance effective. This example shows how the identification of a validation problem exposes a gap and with this perception we anticipate another possible issue.
5.2 The search for gaps
Is it the best model? Are we comparing comparable things? Is the dataset large enough? Did I really understand model outputs? As already pointed out by Manzione and Matulovic [2], the fuzzy logic approach allows greater intervention by the expert. For the current dataset, it is the most desirable option, since the scarcity of data means that the satisfactory application of data-driven models is impractical. Data-driven models need large datasets to find patterns and reproduce them correctly [41] and for their effective application in databases it is mandatory to increase the dataset. Data mining strategies can make the dataset less skewed and biased, but in our case, we first need to obtain a larger amount of data. In the mind of a professional educated under geoethical principles, many other questions may arise and conduct the investigation processes.
5.3 Anticipating issues
According to the modeler experience, it is possible to anticipate certain issues and avoid undesirable results, such as designing the sampling spatially [82]. We have already pointed out that the validation anticipated issues related to the errors that the model would generate when erroneously classifying the recharge. This would generate problems such as releasing more groundwater extraction from locations with "Bad" recharge because the model classifies it as "Good".
5.4 Scenarios and dilemmas
How to communicate bad results? Forcing data and model is trick and complicated, but possible. So, it is important to create a strong ethical and moral code between professionals to strength geoethical behavior. It starts in the universities when these professionals receive their formal education, but also lies on syndicates and personal behavior. With the large number of works already carried out in these watersheds, efforts can be directed to increase the database and expand the studies with remotely sensed data, as already done in recent studies [58, 59], which come from periodic and consistent data.
5.5 Decision making
Finally, when applying the output of a modeling experiment the model used should know model uncertainty and consider it during all decision making processes. These knowledges can make the difference between a successful experience and a failure. In this case study it is clear that the models should be performed again with more data to find representative patterns (data-driven models) or make it possible to create more credible rules for each the watersheds we have studied.
Walker et al. [83] suggest that environmental and water governance decision makers need to consider the social responses as well as the economic and environmental impacts of our decisions. These goals can be reached by including members of society (or at least their behavior) in the policymaking process or making the policy adaptive and include monitoring and learning. In other words, policymaking must be able to be adapted in the complex reality that we are living. These complex approaches include the use of (1) agent-based models to simulate the behavior of individual or collective entities, (2) stakeholders who represent the social component interacting with computer models of the water systems within a decision support framework or within the framework, or (3) dynamic adaptive policies, including monitoring and adapting rather than implementing a determined policy.
Another challenge for policymakers is the understandability and accessibility of scientific research outcomes. Open data and new modeling methods would help groundwater governance for addressing challenges that are not tractable in the past. AI is quite different from a simple hype or trendy expression. AI has shown itself to be increasingly mature for advanced, high-impact positive applications in social reality. There is a whole new generation of professionals, not only from geosciences, but that are also more and more immersed in the world of AI and it is necessary to propose holistic ways of accessing this world that is constantly advancing and improving. It is not new for modeling experts to face questions about model acceptability and validation as we expose here, but they were trained in a different context and environment when comparing with the currently era of data scientists exposed to AI. Efforts are being made to promote greater transparency in algorithms with low levels of expert intervention [84,85,86,87,88]. Miller [89] names these efforts as "explainable artificial intelligence research" and considers that there will be an increasing need to integrate AI with other fields of knowledge, such as philosophy, cognitive psychology/science, and social psychology. So, it is important to develop this open-minded (geo)ethical attitude from the universities to empower the new professionals to take assertive and pertinent decisions, based on scientific evidence and proper methodologies.
5.6 How does the feedback between the stages of the open-minded roadmap support the decision making process?
Accumulated experience in decision making based on different model applications provides feedback for other stages of the roadmap. For example, we can consider requiring a minimal dataset in the data acquisition stage that past experience suggests are especially important to monitor. In practice this minimal data will not always be relevant for all model applications. It can be better understood by looking more closely at the models with greater or less expert intervention.
Models with greater intervention usually have greater acceptance in the regulatory environment than data-driven models because its rules are previously and rigidly defined. In Brazil, environmental indicators monitored by São Paulo State Environmental Agency (CETESB, in its acronym in Portuguese) are define by deterministic equations and reference values that established the environmental quality classes for water, air, and soil pollution. This is an example of models with greater expert intervention which can have its rules redesigned by using fuzzy logic. Pessoa et al. [90] developed a fuzzy water quality index for lotic environments based on the CETESB deterministic water quality index. It was identified that the fuzzy application avoided the attenuation that variables classified in “critical conditions” suffer under the influence of other variables classified in “good conditions.” Similar results were obtained analyzing fuzzy application in Water Quality Index [91] and Soil Quality Index [92].
In the other hand, for the case of data-driven models, often theoretically important variables may not have relevant variance and therefore do not add valuable input to the modeling. This is detected at the data organization stage by the application of variable selection methods, such as principal components analysis (PCA) [93]. PCA is a multivariate statistical procedure designed to classify variables based on their correlations with each other. The goal of PCA, and other factor analysis procedures, is to consolidate a large number of observed variables into a smaller number of factors that can be more readily interpreted [94]. For each factor, the total variance of the dataset explained by this group of variables is quantified. Then, one can identify variables that have low variance and consequently lower impact on model prediction [93, 95, 96].
Mathes and Rasmussen [97] analyzed theoretically relevant variables to delineate potential groundwater contamination zones as total dissolved solids (TDS), pH, aluminum (Al), calcium (Ca), chloride (Cl), iron (Fe), potassium (K), magnesium (Mg), sodium (Na), silica (Si) and sulfate (SO4), and two additional variables, tritium and tetrachloroethylene (PCE). When applying PCA, it was identified that Cl and PCE were best correlated with the factor with the lowest variance explaining capacity. In practical terms for the use of data-driven models, it is possible to reduce the input data for the variables grouped in the first three factors. Although Cl and PCE are especially important data to monitor, they are not necessarily relevant for this specific case of modeling contamination in a given study area (Savannah River Site, South Carolina, USA) and in a given period (From 1993 to 1995). Thus, it is relevant data to be monitored but in certain modeling applications they are not relevant. But their relevance can be determined only if there is a dataset for assessing it. Here we see how the decision making stage can redesign the data acquisition stage.
Decision makers may define theoretically relevant minimal data that should be monitored, but in the case of data-driven models it may not be relevant for certain model applications. The open-minded roadmap can be applied on a case-by-case basis because there are situations where discarding a variable that explains little variance can improve the accuracy and precision of the model.
In a wider context, to make “groundwater ethics” effective, it must be incorporated into decision making. The conscious application of ethics in the decision making can improve the “rules of the game.” Groundwater governance research is still very incipient and underdeveloped compared with the physical science aspects of hydrogeology [4, 5, 8, 9], and there is a lack of systematic, nonanecdotal data on groundwater governance research [10].
6 Conclusions and outlook
This study applied current advances in data analysis in a groundwater management problem questing the elements for a discussion about where artificial intelligence can really lead geoscientists. The case study focused on extrapolating a validated aquifer recharge classes prediction model in only one watershed to its neighboring watersheds. We found that this extrapolation fails to predict recharge in the neighboring watersheds, and thus it is not safe to base decision making in groundwater governance on this model. Further data collection is needed to create models with greater predictive ability. Therefore, it is unethical to extrapolate this model to neighboring watersheds.
Ethical responsibility in the use of data analysis and artificial intelligence tools must be global and distributed since each agent or organization makes decisions according to the values intrinsic to each of them. There will be as many new questions as new data is available, and for this reason, we consider that an open-minded roadmap is needed, as presented in this study. We emphasize that in the modeling stage it is necessary to explicit the level of expert intervention. Also, in the last stage, an open-minded (geo)ethical attitude during model validation, search for gaps in the model use and issues anticipation to reach a final decision should be an interactive process where these actions can feedback each other.
References
Silva COF, Matulovic M, Manzione RL (2021) The geoethics of using geospatial Big Data in water governance. In: Abrunhosa M, Chambel A, Peppoloni S, Chaminé HI (eds) Advances in geoethics and groundwater management: theory and practice for a sustainable development. Proceedings of the 1st Congress on Geoethics and Groundwater Management (GEOETH&GWM'20), Porto, Portugal 2020. Springer International Publishing, New York, pp 51–54. https://doi.org/10.1007/978-3-030-59320-9_12
Manzione RL, Matulovic M (2021) Decision-making in groundwater management: where artificial intelligence can really lead geoscientists?. In: Abrunhosa M, Chambel A, Peppoloni S, Chaminé HI (eds) Advances in geoethics and groundwater management: theory and practice for a sustainable development. Proceedings of the 1st Congress on Geoethics and Groundwater Management (GEOETH&GWM'20), Porto, Portugal 2020. Springer International Publishing, New York, pp 441–445. https://doi.org/10.1007/978-3-030-59320-9_93
Mukherji A, Shah T (2005) Groundwater socio-ecology and governance: a review of institutions and policies in selected countries. Hydrogeol J 13:328–345. https://doi.org/10.1007/s10040-005-0434-9
Llamas MR, Mukherji A, Shah T (2006) Social and economic aspects of groundwater governance. Hydrogeol J 14(3):269–274. https://doi.org/10.1007/s10040-006-0025-4
Moench M, Kulkarni H, Burke J (2012) Trends in local groundwater management institutions. Thematic Paper 7. In: Groundwater governance: a global framework for country action. GEF ID 3726, Groundwater Governance. http://www.zaragoza.es/contenidos/medioambiente/onu/968-eng-v7.pdf. Accessed 28 Apr 2021
Jennings B, Paul H, Kathryn K (2009) Principles of water ethics. Minding Nat 2(2):25–28
Liu J, Zhang M, Zheng C (2010) Role of ethics in groundwater management. Ground Water 48(1):1–1. https://doi.org/10.1111/j.1745-6584.2009.00611.x
Foster S, van der Gunn J (2016) Groundwater governance: key challenges in applying the global framework for action. Hydrogeol J 24:749–752. https://doi.org/10.1007/s10040-016-1376-0
Seward P, Xu Y (2019) The case for making more use of the Ostrom design principles in groundwater governance research: a South African perspective. Hydrogeol J 27:1017–1030. https://doi.org/10.1007/s10040-018-1899-7
Faysse N, Petit O (2012) Convergent readings of groundwater governance? Engaging exchanges between different research perspectives. Irrig Drain 61:106–114. https://doi.org/10.1002/ird.1654
Howard J, Gugger S (2020) Deep learning for coders with Fastai and PyTorch: AI applications without a PhD. O’Reilly Media, Sevastopol
Jobin A, Ienca M, Vayena E (2019) The global landscape of AI ethics guidelines. Nat Mach Intell 1:389–399. https://doi.org/10.1038/s42256-019-0088-2
Fjeld J, Nele A, Hannah H, Adam N, Madhulika S (2020) Principled artificial intelligence: mapping consensus in ethical and rights-based approaches to principles for AI. http://nrs.harvard.edu/urn-3:HUL.InstRepos:42160420. Accessed 12 Jan 2021
Peppoloni S, Di Capua G (2012) Geoethics and geological culture: awareness, responsibility and challenges. Ann Geophys Italy 55(3):335–341. https://doi.org/10.4401/ag-6099
Peppoloni S (2012) Ethical and cultural value of the Earth sciences. Interview with Prof. Giulio Giorello. Ann Geophys Italy 55(3):343–346. https://doi.org/10.4401/ag-5755
Nikitina NK (2016) Geoethics: theory, principles, problems. Geoinformmark, Moscow
Peppoloni S, Di Capua G (2016) Geoethics: ethical, social, and cultural values in geosciences research, practice, and education. In: Wessel G, Greenberg J (eds) Geoscience for the public good and global development: toward a sustainable future (Special Paper 520). Geological Society of America, McLean, pp 17–21. https://doi.org/10.1130/2016.2520(03)
Crampton J (1995) The ethics of GIS. Cartogr Geogr Inform 22(1):84–89. https://doi.org/10.1559/152304095782540546
Modi N (2020) Why nature needs to cover politics now more than ever. Nature 586(7828):169–170. https://doi.org/10.1038/d41586-020-02797-1
DiBiase D, Francis H, Christopher G, Dawn W (2012) The GIS professional ethics project: practical ethics for GIS professionals. In: Teaching geographic information science and technology in higher education. Wiley, Chichester, pp 199–209
Lambier J (2014) How to be critically open-minded: a psychological and historical analysis. Palgrave Macmillan, New York
Kruglanski AW, Boyatzi LM (2012) The psychology of closed and open mindedness, rationality, and democracy. Crit Rev 24(2):217–232. https://doi.org/10.1080/08913811.2012.711023
Jonas H (1979) The imperative of responsibility: in search of ethics for the technological age . University of Chicago Press, Chicago
Beecher HK (1966) Ethics and clinical research. N Engl J Med 274(24):1354–1360. https://doi.org/10.1056/NEJM196606162742405
Callahan D (1971) Values, facts, and decision-making. Stud Hastings Cent 1(1):1
Callahan D (1973) Bioethics as a discipline. Stud Hastings Cent 1(1):66–73
Leopold A (1949) A sand county almanac and sketches here and there. Oxford University Press, New York
Callicott JB (1980) Animal liberation: a triangular affair. Environ Ethics 2:311–338
Di Capua G, Peppoloni S, Bobrowsky P (2017) The Cape town statement on geoethics. Ann Geophys Italy 60(7):7553. https://doi.org/10.4401/ag-7553
Peppoloni S, Bilham N, Di Capua G (2019) Contemporary geoethics within the geosciences. In: Bohle M (ed) Exploring geoethics: ethical implications, societal contexts, and professional obligations of the geosciences. Palgrave Pivot, Cham
Bohle M (ed) (2019) Exploring geoethics: ethical implications, societal contexts, and professional obligations of the geosciences. Palgrave Pivot, Cham
Peppoloni S, Di Capua G (eds) (2015) Geoethics: the role and responsibility of geoscientists. Geological Society, London
Peppoloni S, Di Capua G (2017) Geoethics: ethical, social and cultural implications in geosciences. In: Peppoloni S, Di Capua G, Bobrowsky PT, Cronin VS (eds) Geoethics: at the heart of all geosciences. Ann Geophys 60(7):7473. https://doi.org/10.4401/ag-7473
Peppoloni S, Di Capua G (2018) Ethics. In: Bobrowsky PT, Marker B (eds) Earth sciences series. Encyclopedia of engineering geology. Springer International Publishing, Cham. https://doi.org/10.1007/978-3-319-12127-7_115-1
Peppoloni S, Bobrowsky P, Di Capua G (2015) Geoethics: a challenge for research integrity in geosciences. In: Steneck N, Anderson M, Kleinert S, Mayer T (eds) Integrity in the Global Research Arena. World Scientific, New York, pp 287–294. https://doi.org/10.1142/9789814632393_0035
Bobrowsky P, Cronin V, Di Capua G, Kieffer S, Peppoloni S (2018) The emerging field of geoethics. In: Gundersen LC (ed) Scientific integrity and ethics: with applications to the geosciences (Special Publications 73). American Geophysical Union, Wiley, Washington
Gundersen LC (ed) (2018) Scientific integrity and ethics in the geosciences. American Geophysical Union, Wiley
Wyss M, Peppoloni S (eds) (2015) Geoethics: ethical challenges and case studies in earth sciences. Elsevier, Massachusetts
Mogk DW, Bruckner MZ (2020) Geoethics training in the Earth and environmental sciences. Nat Rev Earth Environ 1:81–83. https://doi.org/10.1038/s43017-020-0024-3
Polanyi M (1983) The Tacit Dimension (Reprint 1966). Peter Smith, Glouchester
Pyle D (1999) Data preparation for data mining. Morgan Kaufmann Publishers, San Francisco
Klein M (1992) Detecting and resolving conflicts among cooperating human and machine-based design agents. Artif Intell Eng 7(2):93–104. https://doi.org/10.1016/0954-1810(92)90008-P
Dwivedi YK, Hughes L, Ismagilova E, Aarts G, Coombs C, Crick T, Williams MD (2019) Artificial Intelligence (AI): multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. Int J Inform Manag 8(2):101994. https://doi.org/10.1016/j.ijinfomgt.2019.08.002
Coombs C, Stacey P, Kawalek P, Simeonova B, Becker J, Bergener K, Carvalho JA, Fantinato M, Garmann-Johnsen NF, Grimme C, Stein A, Trautmann H (2021) What is it about humanity that we can’t give away to intelligent machines? A European perspective. Int J Inform Manag 58:102311. https://doi.org/10.1016/j.ijinfomgt.2021.102311
Jager T (2016) Dynamic modeling for uptake and effects of chemicals. In: Blasco J, Chapman PM, Campana O, Hampel M (eds) Marine ecotoxicology: current knowledge and future issues. Academic Press, Waltham, pp 71–98. https://doi.org/10.1016/B978-0-12-803371-5.00003-5
Unger RM (2007) The self awakened: Pragmatism unbound. Harvard University Press, Cambridge
Takafuji EHM, Rocha MM, Manzione RL (2019) Groundwater level prediction/forecasting and assessment of uncertainty using SGS and ARIMA models: a case study in the Bauru Aquifer System (Brazil). Nat Resour Res 28:487–503. https://doi.org/10.1007/s11053-018-9403-6
Melo ACG, Durigan G (2011) Plano de manejo da Estação Ecológica de Santa Bárbara, Secretaria do Meio Ambiente do Governo do Estado de São Paulo (Instituto Florestal). http://iflorestal.sp.gov.br/institutoflorestal/files/2013/03/Plano_de_Manejo_EEc_Santa_Barbara.pdf. Accessed 31 Jan 2021 (in Portuguese)
DAEE (2013) Águas subterrâneas no Estado de São Paulo. Diretrizes de Utilização e Proteção, Departamento de Águas e Energia Elétrica do Estado de São Paulo. http://201.55.6.68/acervoepesquisa/Atlas%20-%20%C3%81guas%20Subterr%C3%A2neas%20(DAEE-LEBAC).pdf. Accessed 28 Apr 2021 (in Portuguese)
CETESB (2015) Qualidade das águas subterrâneas do estado de São Paulo 2013–2015, Companhia Ambiental do Estado de São Paulo. https://cetesb.sp.gov.br/aguas-subterraneas/wp-content/uploads/sites/13/2013/11/Cetesb_QualidadeAguasSubterraneas2015_Web_20-07.pdf. Accessed 28 Apr 2021 (in Portuguese)
Santos T, Bonotto D (2014) 222Rn, 226Ra and hydrochemistry in the Bauru Aquifer System, São José do Rio Preto (SP), Brazil. Appl Radiat Isotopes 86:109–117. https://doi.org/10.1016/j.apradiso.2013.12.003
Nava A, Manzione RL (2015) Resposta de niveis freáticos do sistema Aquifero Bauru (formação adamantina) em função da precipitação e evapotranspiração sob diferentes usos da terra. Ag Sub 29(2):191–205. https://doi.org/10.14295/ras.v29i2.28402 (in Portuguese with English abstract)
Manzione RL, Soldera BC, Wendland EC (2016) Groundwater system response at sites with different agricultural land uses: case of the Guarani Aquifer outcrop area, Brotas/SP-Brazil. Hydrolog Sci J 62:28–35. https://doi.org/10.1080/02626667.2016.1154148
Manzione RL, Takafuji EHM, De Iaco S, Cappello C, Rocha MM (2019) Spatio-temporal kriging to predict water table depths in a conservation area at São Paulo State, Brazil. Geoinfor Geostat Overv 7(1):1000205. https://doi.org/10.4172/2327-4581.1000205
Manzione RL, Castrignanò A (2019) A geostatistical approach for multi-source data fusion to predict water table depth. Sci Total Environ 696(15):133763. https://doi.org/10.1016/j.scitotenv.2019.133763
Manzione RL (2018) Water table depths trends identification from climatological anomalies occurred between 2014 and 2016 in a Cerrado conservation area in the Médio Paranapanema Hydrographic Region/SP-Brazil. Bol Goia Geogr 38(1):68–85. https://doi.org/10.5216/bgg.v38i1.52815
Manzione RL, Nava A, Sartori MMP (2020) Modelo híbrido de oscilação de níveis freáticos a partir de diferentes variáveis ambientais. Rev Bras Geog Fis 13(3):1231–1247. https://doi.org/10.26848/rbgf.v13.3.p1231-1247 (in Portuguese with English abstract)
Silva COF, Manzione RL, Albuquerque Filho JL (2018) Large-scale spatial modeling of crop coefficient and biomass production in agroecosystems in southeast Brazil. Horticulturae 4(4):44–64. https://doi.org/10.3390/horticulturae4040044
Silva COF, Manzione RL, Albuquerque Filho JL (2019) Combining remotely sensed actual evapotranspiration and GIS analysis for groundwater level modeling. Environ Earth Sci 78(15):462. https://doi.org/10.1007/s12665-019-8467-x
Coelho CAS, Cardoso DHF, Firpo MAF (2016) Precipitation diagnostics of an exceptionally dry event in São Paulo, Brazil. Theor Appl Climatol 125(3–4):769–784. https://doi.org/10.1007/s00704-015-1540-9
Healy RW (2010) Estimating groundwater recharge. Cambridge University Press, Cambridge
Santarosa LV, Manzione RL (2018) Soil variables as auxiliary information in spatial prediction of shallow water table levels for estimating recovered water volume. RBRH 23:e24. https://doi.org/10.1590/2318-0331.231820170115
Gonçalves VFM, Manzione RL (2019) Estimativa da recarga das águas subterrâneas no Sistema Aquífero Bauru (SAB). GeoUERJ 35:e37063. https://doi.org/10.12957/geouerj.2019.37063 (in Portuguese with English abstract)
Verberne FMF, Ham J, Midden CJH (2012) Trust in smart systems. Hum Factors 54(5):799–899. https://doi.org/10.1177/0018720812443825
Beller J, Heesen M, Vollrath M (2013) Improving the driver-automation interaction. Hum Factors 55(6):1130–1140. https://doi.org/10.1177/0018720813482327
Lasota PA, Fong T, Shah JA (2017) A survey of methods for safe human–robot interaction. Found Trends Rob 5(4):261–349. https://doi.org/10.1561/2300000052
Adadi A, Berrada M (2018) Peeking inside the black-box: a survey on explainable artificial intelligence (XAI). IEEE Access 6:52138–55216. https://doi.org/10.1109/ACCESS.2018.2870052
Guidotti R, Monreale A, Ruggieri S, Turini F, Pedreschi D, Giannotti F (2018) A survey of methods for explaining Black Box models. http://arxiv.org/abs/1802.01933
Zadeh LA (1965) Fuzzy sets. Inf. Control 8(3):338–353. https://doi.org/10.1016/S0019-9958(65)90241-X
Pradhan B (2011) Manifestation of an advanced fuzzy logic model coupled with Geo-information techniques to landslide susceptibility mapping and their comparison with logistic regression modelling. Environ Ecol Stat 18:471–493. https://doi.org/10.1007/s10651-010-0147-7
Mamdani EH, Assilian S (1975) An experiment in linguistic synthesis with a fuzzy logic controller. Int J Man-Mach Stud 7:1–13. https://doi.org/10.1016/S0020-7373(75)80002-2
MathWorks (2018) Fuzzy Logic Toolbox™ User’s Guide. ©Copyright 1995–2018 by The MathWorks Inc.
Quinlan JR (1993) The Morgan Kaufmann series in machine learning, San Mateo
Kotsiantis SB (2007) Supervised machine learning: a review of classification techniques. Informatica 31:249–268
Breiman L (2001) Random forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
Breiman L (1984) Classification and regression trees. Chapman & Hall/CRC, Boca Raton
Catani F, Lagomarsino D, Segoni S, Tofani V (2013) Landslide susceptibility estimation by random forests technique: sensitivity and scaling issues. Nat Hazards Earth Syst Sci 13:2815–2831. https://doi.org/10.5194/nhess-13-2815-2013
Fielding AH, Bell JF (1997) A review of methods for the assessment of prediction errors in conservation presence/absence models. Environ Conserv 24:38–49. https://doi.org/10.1017/S0376892997000088
Congalton RG, Green K (2009) Assessing the accuracy of remotely sensed data: principles and practices, 2nd edn. Lewis, Boca Raton
Pontius RG, Millones M (2011) Death to Kappa: birth of quantity disagreement and allocation disagreement for accuracy assessment. Int J Remote Sens 32(15):4407–4429. https://doi.org/10.1080/01431161.2011.552923
Silva COF, Manzione RL (2020) Revisitando a regionalização de vazões na região do Médio Paranapanema no Estado de São Paulo: utilização de curvas de permanência em microbacias hidrográficas. Rev Inst Geo 41(2):1–13. https://doi.org/10.33958/revig.v41i2.678 (in Portuguese with English abstract)
de Gruijter JJ, Brus DJ, Bierkens MFP, Knotters M (2006) Sampling for natural resource monitoring. Springer, Berlin
Walker WE, Loucks DP, Carr G (2015) Social responses to water management decisions. Environ Proc 2:485–509. https://doi.org/10.1007/s40710-015-0083-5
Iadarola G, Martinelli F, Mercaldo F, Santone A (2021) Towards an interpretable deep learning model for mobile malware detection and family identification. Comput Secur 105:102198. https://doi.org/10.1016/j.cose.2021.102198
Langer M, Oster D, Speith T, Hermanns H, Kästner L, Schmidt E, Sesing A, Baum K (2021) What do we want from Explainable Artificial Intelligence (XAI)?—A stakeholder perspective on XAI and a conceptual model guiding interdisciplinary XAI research. Artif Intell 296:103473. https://doi.org/10.1016/j.artint.2021.103473
Confalonieri R, Weyde T, Besold TR, Martin FMP (2021) Using ontologies to enhance human understandability of global post-hoc explanations of black-box models. Artif Intell 296:103471. https://doi.org/10.1016/j.artint.2021.103471
Ariffin KAZ, Ahmad FH (2021) Indicators for maturity and readiness for digital forensic investigation in era of industrial revolution 4.0. Comput Secur 105:102237. https://doi.org/10.1016/j.cose.2021.102237
Kliegr T, Bahník S, Fürnkranz J (2021) A review of possible effects of cognitive biases on interpretation of rule-based machine learning models. Artif Intell 295:103458. https://doi.org/10.1016/j.artint.2021.103458
Miller T (2019) Explanation in artificial intelligence: insights from the social sciences. Artif Intell 267:1–38
Pessoa MAR, Souza FJ, Domingos P, Azevedo JPS (2020) Índice fuzzy de qualidade de água para ambiente lótico—IQAFAL. Eng Sanit Ambient 25(1):21–30. https://doi.org/10.1590/s1413-41522020147587 (in Portugues with English abstract)
Roveda SRMM, Bondança APM, Silva JGS, Roveda JAF, Rosa AH (2010) Development of a water quality index using a fuzzy logic: a case study for the Sorocaba river. In: 2010 IEEE international conference on fuzzy systems (FUZZ). IEEE, pp 1–5.https://doi.org/10.1109/FUZZY.2010.5584172
de Souza JC, Sales JCA, do Nascimento Lopes ER, Roveda ERJAF, Roveda SRMM, Lourenço RW (2019) Valuation methodology of laminar erosion potential using fuzzy inference systems in a Brazilian savanna. Environ Monit Assess 191:624. https://doi.org/10.1007/s10661-019-7789-1
Zakhem BA, Al-Charideh A, Kattaa B (2017) Using principal component analysis in the investigation of groundwater hydrochemistry of Upper Jezireh Basin. Syria Hydrol Sci J 62:2266–2279. https://doi.org/10.1080/02626667.2017.1364845
Abdi H, Williams LJ (2010) Principal component analysis. Wiley Interdiscip Rev Comput Stat 2:433–459. https://doi.org/10.1002/wics.101
Tiouiouine A, Yameogo S, Valles V, Barbiero L, Dassonville F, Moulin M, Bouramtane T, Bahaj T, Morarech M, Kacimi I (2020) Dimension reduction and analysis of a 10-year physicochemical and biological water database applied to water resources intended for human consumption in the Provence-Alpes-Côte d’Azur Region, France. Water 12(2):525. https://doi.org/10.3390/w12020525
Sanchez-Martoz F, Jimenez ER, Pulido BA (2001) Mapping groundwater quality variables using PCA and geostatistics: a case study of BajoAndarax, southeastern Spain. Hydrol Sci J 46(2):227–242. https://doi.org/10.1080/02626660109492818
Mathes SE, Rasmussen TC (2006) Combining multivariate statistical analysis with geographic information systems mapping: a tool for delineating groundwater contamination. Hydrogeol J 14:1493–1507. https://doi.org/10.1007/s10040-006-0041-4
Funding
This work was supported by São Paulo State Foundation for Scientific Research (FAPESP—Grants Nos. 2014/04524-7 and 2016/09737-4) and Brazilian National Council for Scientific and Technological Development—(CNPq—Grant No. 421782/2016-1).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Explicit tables of fuzzy logic rules
Appendix: Explicit tables of fuzzy logic rules
For our purposes, the explicit tables with the data taken from the experiments guided the base of rules construction.
-
R1: If (Slope is Bad) and (Evapotranspiration is Good) and (Hydraulic conductivity is Fast) and (Soil resistance to penetration is Average) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Excellent);
-
R2: If (Slope is Good) and (Evapotranspiration is Good) and (Hydraulic conductivity is Fast) and (Soil resistance to penetration is Average) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Very Good);
-
R3: If (Slope is Average) and (Evapotranspiration is Average) and (Hydraulic conductivity is Very Fast) and (Soil resistance to penetration is Average) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Average);
-
R4: If (Slope is Good) and (Evapotranspiration is Average) and (Hydraulic conductivity is Very Fast) and (Soil resistance to penetration is Bad) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Bad);
-
R5: If (Slope is Good) and (Evapotranspiration is Average) and (Hydraulic conductivity is Fast) and (Soil resistance to penetration is Average) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Good);
-
R6: If (Slope is Average) and (Evapotranspiration is Average) and (Hydraulic conductivity is Fast) and (Soil resistance to penetration is Average) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Average);
-
R7: If (Slope is Average) and (Evapotranspiration is Good) and (Hydraulic conductivity is Fast) and (Soil resistance to penetration is Bad) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Very Bad);
-
R8: If (Slope is Average) and (Evapotranspiration is Good) and (Hydraulic conductivity is Very Fast) and (Soil resistance to penetration is Good) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Average);
-
R9: If (Slope is Bad) and (Evapotranspiration is Average) and (Hydraulic conductivity is Fast) and (Soil resistance to penetration is Good) and (Amplitude of groundwater level is Bad) then (Aquifer recharge is Average)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
de Oliveira Ferreira Silva, C., Matulovic, M. & Lilla Manzione, R. New dilemmas, old problems: advances in data analysis and its geoethical implications in groundwater management. SN Appl. Sci. 3, 607 (2021). https://doi.org/10.1007/s42452-021-04600-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-021-04600-w