
Abstract
This paper introduces a first-order integer-valued autoregressive process with a new innovation distribution, shortly INARPQX(1) process. A new innovation distribution is obtained by mixing Poisson distribution with quasi-xgamma distribution. The statistical properties and estimation procedure of a new distribution are studied in detail. The parameter estimation of INARPQX(1) process is discussed with two estimation methods: conditional maximum likelihood and Yule-Walker. The proposed INARPQX(1) process is applied to time series of the monthly counts of earthquakes. The empirical results show that INARPQX(1) process is an important process to model over-dispersed time series of counts and can be used to predict the number of earthquakes with a magnitude greater than four.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Destructive earthquakes are one of the biggest problems of all humanity. Earthquakes are not only natural disasters that threaten the people’s lives, but also affect the economies of the countries negatively. Therefore, statistical modeling of the counts of earthquakes and taking measures according to the model results are of great importance. Many different statistical models have been used in the literature to model earthquake events. Turkan and Ozel [26] used the linear regression, beta regression, and semi-parametric additive regression to model the casualty rate of earthquakes and related covariates. The relation between the magnitude of an earthquake and the number of deaths was investigated in several piece of researches such as Samardjieva and Badal [22], Gutiérrez et al. [10], Wyss [30], Koshimura et al. [15], Zhao et al. [31], and Wu et al. [29]. Besides these regression models, stochastic models are also powerful tools to model earthquakes. Stochastic point process models for earthquakes were discussed by Brillinger [7], Vere-Jones [27], Ogata [19, 20] and Zhuang et al. [32, 33]. Gospodinov and Rotondi [9] and Aktas et al. [1] used the compound Poisson process to model the cumulative energy release of mainshocks and the expected value of the earthquake, respectively. Ozel [21] introduced a bivariate compound Poisson model to predict the number of foreshocks and aftershocks.
The first-order integer-valued autoregressive process, shortly INAR(1), is an alternative model to predict the number of the time of series of counts such as monthly deaths from corona-virus, monthly counts of passengers for a specific airline company or monthly counts of destructive earthquakes for a specific region or a country. The INAR(1) process with Poisson innovations, known as INARP(1), was developed by McKenzie [17, 18] and Al-Osh and Alzaid [2] and increased its popularity in the last decade. The time series of counts generally display over-dispersion. The INARP(1) process can be used to model equi-dispersed time series of counts which means that the ratio of sample variance to sample mean should be one. The over-dispersion occurs when the sample variance is greater than the sample mean, the opposite indicates the under-dispersion. After the important researches of McKenzie [17, 18] and Al-Osh and Alzaid [2], the researches have focussed on the distribution of an innovation process of INAR(1) to develop new models for over-dispersed or under-dispersed time series of counts. In what follows, we list some recent contributions on overdispersed INAR(1) processes: INAR(1) process with geometric innovations (INARG(1)) by Jazi et al. [13], INAR(1) with Poisson–Lindley innovations (INARPL(1)) by Lívio et al. [16], compound Poisson INAR(1) by Schweer and Weiß [23], processes INAR(1) process with Katz family innovations by Kim and Lee [14], INAR(1) process with generalized Poisson and double Poisson innovations by Bourguignon et al. [6] , INAR(1) process with geometric marginals by Borges et al. [5] and INAR(1) process with Skellam innovations by Andersson and Karlis [4], INAR(1) process with a new Poisson-weighted exponential innovations by Altun [3].
In this study, we first introduce a new two-parameter discrete distribution as an alternative distribution for the case of over-dispersion. The proposed distribution is obtained by mixing the Poisson distribution with a quasi-xgamma distribution of Sen and Chandra [24]. The resulting distribution is called as Poisson-quasi-xgamma (PQX) distribution. The statistical properties of the PQX distribution are studied in detail as well as its parameter estimation with different methods of estimations. Then, we introduce a new INAR(1) model by using the PQX distribution as an innovation process and called this process as a INARPQX(1). The goal of the presented study is to open a new opportunity to model over-dispersed time series of counts with a more flexible innovation distribution than existing ones. To demonstrate the effectiveness of the proposed process, we use the earthquake data set (magnitude 4 and above) of Turkey. The earthquake data set is regularized as a monthly basis to predict the monthly counts of the earthquakes with magnitude 4 and above occurred in Turkey. We model the monthly counts of earthquakes by INAR(1) processes with several innovation distributions as well as PQX distribution.
The ongoing sections of the study are organized as follows. In Sect. 2, the PQX distribution is presented with its statistical properties. In Sect. 3, we discuss the parameter estimation procedure of the PQX distribution with maximum likelihood and method of moments estimation methods. In Sect. 4, Expectation–Maximization (EM) algorithm for the PQX distribution is given. Section 5 deals with the simulation study to compare the finite sample performance of the estimation methods. In Sect. 6, we introduce a new INAR(1) process with PQX innovations. Section 7 contains an application to the earthquake data of Turkey. We summarize the findings of the study in Sect. 8.
2 Poisson-quasi-xgamma distribution
Let the random variable (rv) X follows a Poisson distribution. The probability mass function (pmf) of X is
where \(\lambda >0\). The Poisson distribution is an attractive distribution and is widely used in many fields because of its tractable properties and software support. However, many count data sets exhibit over-dispersion or under-dispersion in which case the Poisson distribution does not work well. When the empirical variance is greater than the empirical mean, the over-dispersion occurs, and opposite case represents the under-dispersion. The negative-binomial (NB) distribution is a common choice for over-dispersed count data sets. However, in the last decade, researchers have introduced more sophisticated discrete probability distributions to open a new opportunity to model fat-tailed over-dispersed count data sets. Here, we introduce an alternative distribution to model over-dispersed time series of counts. To do this, the quasi-xgamma distribution, introduced by Sen and Chandra [24], is used as a mixing distribution for Poisson parameter \(\lambda \). The probability density function (pdf) of quasi-xgamma distribution is
where \(\alpha >0\) and \(\theta >0\). The quasi-xgamma distribution is a special mixture of exponential and gamma densities and contains \(\text {Gamma}\left( \theta ,3\right) \) (for \(\alpha =0\)) and \(\text {xgamma}\left( \theta \right) \) (for \(\alpha =\theta \)), introduced by Sen et al. [25], distributions as its submodels. Now, we introduce a new two-parameter discrete distribution by mixing Poisson distribution with quasi-xgamma distribution.
Proposition 1
Assume that the parameter \(\lambda \) of the Poisson distribution follows a quasi-xgamma distribution. Then, the resulting distribution is
where \(\alpha >0\) and \(\theta >0\). Hereafter, we refer to (3) as \(\text {PQX}\left( \alpha ,\theta \right) \).
Proof
The proof is straightforward. \(\square \)
Remark 1
The PQX distribution contains the below distributions as its sub-models or limiting case.
-
1.
The PQX distribution reduces to Poisson-xgamma distribution for \(\alpha =\theta \),
-
2.
The PQX distribution reduces to \(\text {NB}\left( 3,\theta / (\theta +1)\right) \) for \(\alpha =0\),
-
3.
The PQX distribution reduces to \(\text {Geometric}\left( \theta / (\theta +1)\right) \) for \(\alpha \rightarrow \infty \).
The corresponding cumulative distribution function (cdf) to (3) is
The rest of the section is devoted to the inference of the statistical properties of PQX distribution and its parameter estimation.
2.1 Statistical properties
Proposition 2
Let the rv X follow a PQX distribution. The factorial moments of X are given by
Proof
The factorial moments of X can be obtained by using mixing formula, as follows
The proof is completed. \(\square \)
Using (5), the mean and variance of PQX distribution are given, respectively, by
The dispersion index (Var(X)/E(X)) of PQX is given by
As seen from (8), since the parameter \(\alpha \) and \(\theta \) are greater than zero, the dispersion index of PQX distribution is always greater than 1 which ensures that the PQX distribution is over-dispersed.
Proposition 3
The probability generating function (pgf) of PQX distribution is given by
Proof
The pgf of X can be written in the form
Using (10), the pgf of X can be obtained as follows
\(\square \)
The moment generating function of PQX distribution can be easily obtained by substituting s with \(\exp \left( t\right) \) in (9). Then, we have
The quasi-xgamma distribution is a special mixture of \(\text {exponential}\left( \theta \right) \) and \(\text {gamma}\left( 3,\theta \right) \) distributions with mixing proportion, \(p=\alpha /\left( \alpha +1\right) \). This property of the quasi-xgamma distribution can be used to generate rvs from PQX distribution. The below algorithm is given based on the mixture property of the quasi-xgamma.

The skewness and kurtosis measures of PQX distribution can be easily obtained based on the first four raw moments by using
The skewness and kurtosis plots of the PQX distribution against the mean and dispersion values are displayed in Fig. 1. The parameter \(\alpha \) is taken 1 and parameter \(\theta \) is increased in the interval (0.5, 15). From these figures, we conclude that the skewness and kurtosis decrease when the mean and dispersion increase.

The skewness and kurtosis plots of the PQX distribution against the mean and dispersion values
The pmf of the NB distribution is
where \(\theta >0\), \(p \in (0,1)\). The mean, variance, skewness, and kurtosis values of the NB distribution are given, respectively, by

The skewness and kurtosis plots of the NB distribution against the mean and dispersion values
The skewness and kurtosis plots of the NB distribution against the mean and dispersion values are displayed in Fig. 2. The parameter \(\theta \) is taken 0.5, and parameter p is increased in the interval (0.1, 0.9). From these figures, we conclude that the skewness and kurtosis decrease when the mean and dispersion increase. So, the NB and PQX distributions have the similar behaviors. However, to understand the differences between these distributions, we compare the mean-parametrized versions of both distributions. Substituting \(p=\mu / (\mu +\theta )\) in (14), the mean-parametrized NB distribution is given by
where \(\theta >0\), \(\mu >0\) and \(E\left( Y\right) =\mu \). Substituting \(\alpha = {{\left( {3 - \theta \mu } \right) } / {\left( {\theta \mu - 1} \right) }}\) in (3), we have the pmf of the mean-parametrized PQX, given by
where \(\theta >0\), \(\mu >0\), \(1<\theta \mu <3\) and \(E\left( X\right) =\mu \). Figure 3 displays the skewness and kurtosis values of the mean-parametrized NB and PQX distributions against their dispersion values. The mean parameter is determined as 1 for both distributions. The parameter \(\theta \) and \(\alpha \) are increased in the interval (1.5, 2.5) since we have condition on the parameter space of the mean-parametrized PQX distributions, such as \(1<\theta \mu <3\). As seen from these figures, when the dispersion increases, the skewness and kurtosis increase for both distributions. However, under these re-parametrization, the PQX distribution is able to model wider range of skewness and kurtosis than the NB distribution.

The skewness and kurtosis comparison of the mean-parametrized NB and PQX distributions
We also compare the right-tail probabilities of the mean-parametrized NB and PQX distributions. Table 1 lists the tail probabilities of the NB and PQX distributions for some values of the mean parameter \(\mu \) and \(\theta \). The results given in Table 1 indicate that the PQX has fatter right-tail than the NB distribution.
2.2 Shape of PQX\((\alpha ,\theta )\) distribution
Using (3), the ratio of successive probabilities \(P(X=x+1)/P(X=x)\) for PQX\((\alpha ,\theta )\) is given as
Further, the ratio \(\frac{P(X=x+1)}{P(X=x)} < (>)1\) implies that the pmf is decreasing (increasing). Hence, solving the equation \(\frac{P(X=x+1)}{P(X=x)}=1\) for non-integer x (say), the roots are given as
Hence, it can be easily verified as that
-
i.
If \(\left( 0<\theta<\frac{2}{3} \cap \alpha> \frac{(2+\theta )^2}{8(1+\theta )^2}\right) \cup \left( \frac{2}{3}\le \theta <2 \cap \alpha> \frac{\theta (2-\theta )}{(1+\theta )^2}\right) \cup (\theta \ge 2 \cap \alpha >0 )\), the ratio is less than 1; hence, the PQX\((\alpha ,\theta )\) is unimodal with mode at 0.
-
ii.
If \(\frac{2}{3}\le \theta <2 \cap \alpha = \frac{\theta (2-\theta )}{(1+\theta )^2}\), then mode of PQX\((\alpha ,\theta )\) is at 1.
-
iii.
If \(0<\theta<2 \cap 0<\alpha <\frac{\theta (2-\theta )}{(1+\theta )^2}\), then the PQX\((\alpha ,\theta )\) is unimodal and the mode is at \(\lceil x_0^{**} \rceil \), where \(\lceil . \rceil \) denote the ceiling function.
-
iv.
If \(\left( 0<\theta<\frac{2}{3} \cap \frac{\theta (2-\theta )}{(1+\theta )^2} <\alpha \le \frac{(2+\theta )^2}{8(1+\theta )^2}\right) \), PQX\((\alpha ,\theta )\) is bimodal with the mode at 0 and \(\lceil x_0^{**} \rceil \).
The results given above are graphically summarized in Fig. 4 which displays the modality regions of the PQX distribution with respect to the values of the parameters \(\alpha \) and \(\theta \).

The modality of the PQX distribution
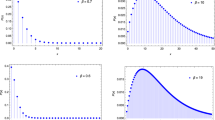
In Fig. 5, we depict different shapes of PQX\((\alpha ,\theta )\) distribution for different parameters values. As seen from these figures, PQX distribution has bimodal and unimodal shapes with right skewness and symmetric. Moreover, for large value for \(\alpha \) and \(\theta \) the PQX distribution can be used to zero inflated count data sets.

Probability mass function of \({PQX}(\alpha ,\theta )\) distribution for different combinations of the parameter values
3 Estimation
3.1 Maximum likelihood
Let \(x_{1},x_{2},\dots ,x_{n}\) be a random observations from the \(\text {PQX}\) distribution. The log-likelihood function is
The partial derivatives of (19) with respect to \(\alpha \) and \(\theta \), the following score vectors are obtained.
The simultaneous solution of (20) and (21) gives the maximum likelihood estimates (MLEs) of \(\alpha \) and \(\theta \). However, since the likelihood equations contain nonlinear functions, there is no explicit form for the MLEs of the parameters of PQX distribution. Therefore, the log-likelihood function in (19) should be maximized by using statistical software such as R, S-PLUS, Mathematica or MATLAB. Here, nlm function of R software is used to minimize the minus of log-likelihood function which is equivalent to maximization of log-likelihood. The inverse of observed information matrix evaluated at MLEs of the parameters is used to obtain corresponding standard errors. To do this, fdHess function of R software is used. The asymptotic confidence intervals of the parameters are obtained by
where \(z_{p/2}\) is the upper p/2 quantile of the standard normal distribution.
3.2 Method of moments
The method of moments estimators of the parameters \(\alpha \) and \(\theta \) can be obtained by equating theoretical moments of PQX distribution to sample moments, given as follows
where \(m_1\) and \(m_2\) are the first and second sample moments, respectively. Simultaneous solution of (22) and (23) yields to following results
Proposition 4
For fixed \(\alpha \), the MM estimator \(\hat{\theta }\) of \(\theta \) is positively biased.
Proof
Let \({\hat{\theta } _{MM}}=g(\bar{x})\) where \(g\left( t \right) = {{\left( {\alpha + 3} \right) } / {\left( {t\left( {1 + \alpha } \right) } \right) }}\) for \(t>0\). Taking the second partial derivative of g(t), we have
which ensures that the g(t) is strictly convex. Using the Jensen’s inequality,
So, since \( g\left( {E\left( {\bar{X}} \right) }\right) =g(\mu )=g\left[ {{{2\left( {\alpha + 3} \right) } / {\left( {\theta \left( {2\alpha + 2} \right) } \right) }}} \right] =\theta \), we obtain \(E\left( \hat{\theta }_{MM}\right) >\theta \). \(\square \)
Proposition 5
For fixed \(\alpha \), the MM estimator \(\hat{\theta }\) of \(\theta \) is consistent and asymptotically normal

where
Proof
Since \(g'\left( \mu \right) \) exists and is nonzero valued, by the delta method, we have

where \(g\left( {\bar{x}} \right) =\hat{\theta }\), \(g\left( {\mu } \right) =\theta \) and
The proof is completed. \(\square \)
4 EM algorithm for PQX\((\alpha ,\theta )\) distribution
In this section, we deals in the estimation of parameter \(\theta \) and \(\alpha \) of PQX distribution by another estimation method known as Expectation–Maximization (EM) (see Dempster et al., [8]). The EM algorithm consists of two steps: the E-step and the M-step. E-Step computes the expectation of the unobservable part given the current values of the parameters and M-step maximizes the complete data likelihood and updates the parameters using the conditional expectations obtained in E-step. This procedure can be useful when there are no closed-form expressions for estimating the parameters and the derivatives of the likelihood are complicated.
To start with, a hypothetical complete-data distribution is defined with joint probability function
It is straightforward to verify that the E-step of an EM cycle requires the computation of the conditional expectations of \(\left( \frac{\lambda ^2}{2\alpha +\lambda ^2\theta ^2} |x_i;\theta ^{(h)},\alpha ^{(h)}\right) \), \(\left( \frac{1}{2\alpha +\lambda ^2\theta ^2} |x_i;\theta ^{(h)},\alpha ^{(h)}\right) \) and \(\left( \lambda |x_i;\theta ^{(h)},\alpha ^{(h)} \right) \), say \(t_i^{(h)}\), \(s_i^{(h)}\) and \(u_i^{(h)}\), respectively, where \(\left( \theta ^{(h)},\alpha ^{(h)} \right) \) is the current value of \((\theta , \alpha )\). Using,
The EM cycle completes with the M-step, involving complete data maximum likelihood over \((\theta , \alpha )\), with the missing \(\lambda \)’s replaced by their conditional expectations
5 Simulation
The finite sample performance of MM and MLE methods is compared via simulation study. The below simulation procedure is implemented for this purpose.
-
1.
Determine the sample size n and the parameter values of PQX distribution, \(\varvec{\Theta }=\left( \alpha ,\theta \right) \),
-
2.
Generate random observations from PQX distribution for given n and parameter vector,
-
3.
Using the random sample in step 2, estimate \(\varvec{\Theta }\) with MLE and MM methods,
-
4.
Repeat the steps 2 and 3 based on the replication number, N,
-
5.
Using the estimated parameter vector, \(\hat{\varvec{\Theta }}\), and true parameter vector, \(\varvec{\Theta }\), calculate the biases, mean relative estimates (MREs) and mean square errors (MSEs) by using,
$$\begin{aligned} \mathrm{{Bias}}= & {} \sum \limits _{j = 1}^N {\frac{{{{ {\hat{\varvec{\theta }} }_{i,j}}} - { \varvec{\Theta }_i}}}{N}},\,\,\,\,\mathrm{{MRE}} = \sum \limits _{j = 1}^N {\frac{{{{{{{{\hat{\varvec{\Theta }} }}}_{i,j}}} / {{{\varvec{\Theta }_i }}}}}}{N}}, \nonumber \\ \mathrm{{MSE}}= & {} \sum \limits _{j = 1}^N {\frac{{{{\left( {{{{\hat{\varvec{\Theta }} }}_{i,j}} - {{\varvec{\Theta }_i }}} \right) }^2}}}{N}{\mathrm{}}},\,\,\,\ i=1,2. \end{aligned}$$(33)
The simulation is carried out with statistical software R. We generate \(n=50,55,60,\ldots ,300\) sample of size from PQX distribution. The simulation replication number is \(N=1000\). The true parameter vector is \(\varvec{\Theta }=\left( \alpha =0.5,\theta =1.5\right) \). Figure 6 displays the simulation results. We expect that the estimated biases and MSEs should be near the zero for large n values. The results verify the expectation. The biases and MSEs approach the their nominal value, zero, for \(n \rightarrow \infty \). Additionally, the MREs are near the one. The MLE and MM methods behave very similar for the parameter \(\alpha \). However, the MLE method approaches the nominal values of biases, MSEs, and MREs more faster than MM method for the parameter \(\theta \). Therefore, we suggest practitioners to use MLE method for estimating the parameters of PQX distribution.

Estimated biases, MSEs, and MREs of the parameters of PQX distribution based on the MLE and MM estimation methods
6 INAR(1) model with PQX innovations
Let the innovations \(\left( \varepsilon _t\right) _{\mathbb {N}}\) be an independent and identically distributed (iid) process with \({\mathrm{E}}\left( {{\varepsilon _t}} \right) = {\mu _\varepsilon }\) and \({\mathrm{Var}}\left( {{\varepsilon _t}} \right) = \sigma _\varepsilon ^2\). The process, \(\left( X_t\right) _{\mathbb {N}}\), is called as INAR(1) if it follows a recursion
where \(0\le p <1\). The symbol, \(\circ \), represents a binomial thinning operator and is defined as
where \(\left\{ Z _j \right\} _{j \ge 1}\) is referred to as a counting series and be a sequence of iid Bernoulli rvs with \(\Pr \left( {{Z_j} = 1} \right) = p\). The INAR(1) process is stationary for \(0\le p <1\). The process is non-stationary for the case \(p=1\). The INAR(1) process is a homogeneous Markov chain with the one-step transition probabilities given by McKenzie [17], Al-Osh and Alzaid [2])
The mean, variance, and dispersion index of INAR(1) process are given, respectively, by Weiß [28]
where \(\mu _\varepsilon \), \(\sigma _\varepsilon ^2\) and \(DI_{\varepsilon }\) are the mean, variance, and dispersion index of innovation distribution, respectively. In real-life problems, the empirical dispersion is greater than one (over-dispersion) in general. For instance, monthly counts of passengers, yearly number of destructive earthquakes, yearly number of goals of a and among others. To model these kind of datasets, the innovation distribution of INAR(1) process should be able to model over-dispersion. Here, we propose a new INAR(1) process with PQX innovations to model such data sets. Let \({\left\{ {{\varepsilon _t}} \right\} _{\mathbb {N}}}\) follows a PQX distribution given in (3). The one-step transition probability of INARPQX(1) model is given by
Frow now on, this process is called as INARPQX(1) process. Using the properties of INAR(1) process, the mean, variance, and dispersion index of INARPQX(1) process are given, respectively, by
According to the results given in Al-Osh and Alzaid [2], the conditional expectation and variance of INARPQX(1) process are given, respectively, by
6.1 Estimation
The estimation procedure of INAR(1) process is discussed with three estimation methods. These are conditional maximum likelihood (CML), Yule–Walker (YL), and conditional least squares (CLS). The finite sample performance of these estimation methods is compared via extensive simulation study. The rest of this section is devoted to theoretical background of the used estimation methods.
6.1.1 Conditional maximum likelihood
Let \(X_1,X_2,...,X_T\) be a random sample from the stationary process, INARPQX(1). The conditional log-likelihood function of INARPQX(1) is
The CML estimators of \(\left( p,\alpha ,\theta \right) \) can be obtained by direct maximization of log-likelihood function given in (46). The nlm function of R software is used to minimize the minus of log-likelihood function. The inverse of observed information matrix is used to obtain corresponding standard errors of the CML estimation of the INARPQX(1) process. The observed information matrix is obtained by fdHess function of R software.
6.1.2 Yule–Walker
The YW estimators of INARPQX(1) process are obtained by equating the sample moments to the theoretical moments of the process. Since the autocorrelation function (ACF) of INAR(1) process at lag h is \({\rho _x}\left( h \right) = {p^h}\), the YW estimator of p is given by
The YW estimators of \(\alpha \) and \(\theta \) are obtained by equating the sample mean and sample dispersion to theoretical mean and theoretical dispersion of the process. The YW estimator of \(\theta \) is given by
where \(\bar{X} = {{\sum \nolimits _{t = 1}^T {{X_t}} } / N}\). Substituting \(\theta \) with (48) in (43) and equating (43) to sample dispersion, \({\widehat{DI}}_X\), we have
6.2 Model accuracy
The standardized Pearson residual is used to check the fitted model accuracy. The standardized Pearson residuals are given by
where \({\mathrm{E}}\left( {\left. {{X_t}} \right| {x_{t - 1}}} \right) \) and \({\mathrm{Var}}\left( {\left. {{X_t}} \right| {x_{t - 1}}} \right) \) are given in (44) anf (45), respectively. When the model is adequate for fitted data set, the standardized Pearson residuals should be uncorrelated with zero mean and unit variance. If the variance of standardized Pearson residuals is higher/lower than one, it shows that there is more or less dispersion considered by fitted model (see, Harvey and Fernandes, [11]).
6.3 Simulation
We compare the finite sample performance of CML and YW estimators of the parameters of INARPQX(1) process with a brief simulation study. We generate \(n=100, 300\) and 500 sample of sizes from INAR(1) process with PQX innovations. The simulation replication number is \(N=1,000\). The two parameter vectors are used: \(\left( p=0.3,\alpha =0.5,\theta =0.5\right) \), \(\left( p=0.3,\alpha =0.5,\theta =2\right) \). The simulation is carried out with R software. The results are interpreted based on the estimated biases, MSEs and MREs. The required formulas of these measures are given in Sect. 4. We expect to see that the estimated biases and MSEs approach to zero for large values of n. Beside this, the estimated MREs should be near the one. The simulation results are given in Table 2. Based on the results given in this table, it is clear that the estimated biases and MSEs are very near the their desired value, zero. Moreover, all estimated MREs are near the one. However, the CML estimators approach to the nominal values of MSEs and MREs more faster than those of YW estimators. Therefore, we suggest practitioners to use CML estimation method to obtain the unknown parameters of INARPQX(1) process. Actually, the both estimation methods work well for large sample sizes. So, if the number of time series of counts are large enough, YW estimation method is also preferable.
7 Empirical study
In this section, we illustrate the importance of the INARPQX(1) by an application on the earthquake data of Turkey. Firstly, we describe the created earthquake catalog and its properties. In the second step, INAR(1) processes defined under different innovation distributions are used to model the monthly counts of the earthquake.
7.1 Study area and data
The earthquake data of the Turkey is obtained from the Disaster & Emergency Management Authority Presidential of Earthquake Department, Turkey. The data are available from https://deprem.afad.gov.tr/?lang=en. The used data contain the earthquakes with magnitude 4 and above occurred in Turkey between the dates 6 January 2012 and 14 October 2018. Firstly, the earthquake catalog of the Turkey is created by using the ETAS package of the R software. The detail on this package can be found in Jalilian [12]. The earthquake catalog is displayed in Fig. 7. The top-left figure shows the spatial distribution of the earthquakes under the study area. The three figures in the right part of Fig. 7 show the changes of the latitude, longitude, and magnitude of the earthquakes over the time. The two figures in the bottom-right part of Fig. 7 show the completeness and time stationary of the earthquake catalog. Here, \(N_m\) represents the number of earthquakes with magnitude \(\ge m\). If the plot of \(\log (N_m)\) versus m shows linear trend, it represents the completeness of the earthquake catalog. Besides, the stationary of the earthquake catalog is evaluated based on the plot of \(N_t\) versus t. Here, \(N_t\) represents the number of earthquakes up to time t. If the plotted points of \(N_t\) versus t have a functional form such as \(N_t=\lambda _0 t\) where \(\lambda >0\), it is an evidence that the time series of the earthquake is stationary. Therefore, we conclude that the used earthquake catalog is stationary and complete.

The plots of the earthquake catalog of Turkey
7.2 Modeling of the number of earthquakes
The importance of INARPQX(1) model is demonstrated with an application to the monthly counts of earthquakes in Turkey. The proposed model, INARPQX(1), is compared with well-known INAR processes, INARP(1), INARPL(1), INARG(1), and INAR(1) with NB innovations shortly INARNB(1). The one-step translation probabilities of the used models are given, respectively, by
To analyze the reported data set in the previous section, the earthquakes are grouped monthly to predict the monthly number of the earthquakes with magnitude \(\ge 4\). We use the \(-\ell \), Akaike Information Criteria (AIC), and Bayesian Information Criteria (BIC) statistics to select the most appropriate model for the used data set. The lowest values of these criteria show the best fitted model. The used data sets consist of 82 monthly counts of earthquakes with magnitude greater than 4 between the date of January 2012 and March 2018. Firstly, the possible over-dispersion in the data set should be explored. For this aim, we use the hypothesis test for over-dispersion proposed by Schweer and Weiß [23]. The test statistic value of the over-dispersion hypothesis is 24.187, and its corresponding p value is \(<0.001\) which indicates that the used data set displays over-dispersion. Therefore, the innovation distribution of the INAR(1) process should be able to capture the over-dispersion in the data set.

The plots of time series, autocorrelation, and partial autocorrelation functions for the monthly counts of earthquakes in Turkey
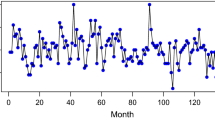
The some useful plots of the used data set displayed in Fig. 8. As seen from autocorrelation function (ACF) and partial ACF (PACF) plots, there is a clear cut of at first lag which ensures that the AR(1) process can be used to model this data set.
The estimated parameters of the fitted INAR(1) processes and corresponding AIC, BIC values are listed in Table 3. As seen from the results reported in Table 3, the proposed INARPQX(1) process has the lowest values of AIC and BIC values which indicates the proposed model performs better than INARP(1), INARG(1), INARPL(1), and IARNB(1) models. Moreover, we analyze the departure from error distribution by means of residual analysis. For this aim, we use the Pearson residuals. The Pearson residuals can be calculated by using
where \(E\left( {\left. {{X_t}} \right| {X_{t - 1}}} \right) \) and \(\text {Var}\left( {\left. {{X_t}} \right| {X_{t - 1}}} \right) \) are given in (44) and (45), respectively. When the fitted model is correct, the mean and variance of the Pearson residuals should be near the zero and one, respectively. Also, there should be no autocorrelation problem for the estimated Pearson residuals. The mean and variance of the Pearson residuals are calculated 0.0009 and 0.9754, respectively, which are very near the desired values. Additionally, the ACF plot of the Pearson residuals is displayed in right side of Fig. 9 which indicates that there is no autocorrelation problem for the Pearson residuals. The fitted INARPQX(1) model is given by
where \({\varepsilon _t} \sim \text {PQX}\!\left( 94.964,0.238\right) \). The predicted values of the number of earthquakes can be obtained by using (56).
The predicted values of monthly counts of earthquakes are displayed in the left side of Fig. 9.

The predicted values of the monthly counts of earthquakes in Turkey
8 Conclusion and future work
This study introduces a new two-parameter discrete distribution, shortly PQX, for modeling the over-dispersed counts. The statistical properties of the PQX distribution are derived and estimation of the unknown parameters of the proposed distribution is discussed in detail. INARPQX(1) processes are introduced based on the PQX distribution to predict the monthly counts of the earthquakes with magnitude 4 and above in Turkey. Empirical results show that the INARPQX(1) processes perform better than INARP(1), INARP(1), INARG(1), and INARNB(1) processes for the data used. As a future work of this study, we will try to extend the INARPQX(1) to multivariate case for joint modeling of the more than one region in predicting the monthly counts of earthquakes. We believe that the PQX distribution will increase its popularity find a wider application area in different sciences such medical, finance, and actuarial.
Change history
01 March 2021
A Correction to this paper has been published: https://doi.org/10.1007/s42452-021-04401-1
References
Aktas S, Konsuk H, Yigiter A (2009) Estimation of change point and compound Poisson process parameters for the earthquake data in Turkey. Environmetrics 20(4):416–427
Al-Osh MA, Alzaid AA (1987) First-order integer-valued autoregressive (INAR (1)) process. J Time Ser Anal 8(3):261–275
Altun E (2020) A new generalization of geometric distribution with properties and applications. Commun Stat Simul Comput 49(3):793–807
Andersson J, Karlis D (2014) A parametric time series model with covariates for integers in \(\mathbb{Z}\). Stat Model 14(2):135–156
Borges P, Bourguignon M, Molinares FF (2017) A generalised NGINAR (1) process with inflated-parameter geometric counting series. Aust N Z J Stat 59:137–150
Bourguignon M, Rodrigues J, Santos-Neto M (2019) Extended Poisson INAR (1) processes with equidispersion, underdispersion and overdispersion. J Appl Stat 46:101–118
Brillinger DR (1993) Earthquake risk and insurance. Environmetrics 4(1):1–21
Dempster AP, Laird NM, Rubin DB (1977) Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc Ser B (Methodol) 39(1):1–22
Gospodinov D, Rotondi R (2001) Exploratory analysis of marked Poisson processes applied to Balkan earthquake sequences. J Balkan Geophys Soc 4(3):61–68
Gutiérrez E, Taucer F, De Groeve T, Al-Khudhairy DHA, Zaldivar JM (2005) Analysis of worldwide earthquake mortality using multivariate demographic and seismic data. Am J Epidemiol 161(12):1151–1158
Harvey AC, Fernandes C (1989) Time series models for count or qualitative observations. J Bus Econ Stat 7(4):407–417
Jalilian A (2019) ETAS: an R package for fitting the space-time ETAS model to earthquake data. J Stat Softw 88(1):1–39
Jazi MA, Jones G, Lai CD (2012) Integer valued AR (1) with geometric innovations. J Iran Stat Soc 11(2):173–190
Kim H, Lee S (2017) On first-order integer-valued autoregressive process with Katz family innovations. J Stat Comput Simul 87:546–562
Koshimura S, Katada T, Mofjeld HO, Kawata Y (2006) A method for estimating casualties due to the tsunami inundation flow. Nat Hazards 39(2):265–274
Lívio T, Mamode Khan N, Bourguignon M, Bakouch H (2018) An INAR (1) model with Poisson–Lindley innovations. Econ Bull 38:1505–1513
McKenzie E (1985) Some simple models for discrete variate time series 1. JAWRA J Am Water Resour Assoc 21:645–650
McKenzie E (1986) Autoregressive moving-average processes with negative binomial and geometric marginal distrbutions. Adv Appl Probab 18:679–705
Ogata Y (1988) Statistical models for earthquake occurrences and residual analysis for point processes. J Am Stat Assoc 83(401):9–27
Ogata Y (1998) Space-time point-process models for earthquake occurrences. Ann Inst Stat Math 50(2):379–402
Ozel G (2011) A bivariate compound Poisson model for the occurrence of foreshock and aftershock sequences in Turkey. Environmetrics 22(7):847–856
Samardjieva E, Badal J (2002) Estimation of the expected number of casualties caused by strong earthquakes. Bull Seismol Soc Am 92(6):2310–2322
Schweer S, Weiß CH (2014) Compound Poisson INAR (1) processes: stochastic properties and testing for overdispersion. Comput Stat Data Anal 77:267–284
Sen S, Chandra N (2017) The quasi xgamma distribution with application in bladder cancer data. J Data Sci 15:61–76
Sen S, Maiti SS, Chandra N (2016) The xgamma distribution: statistical properties and application. J Mod Appl Stat Methods 15(1):38
Turkan S, Ozel G (2014) Modeling destructive earthquake casualties based on a comparative study for Turkey. Nat Hazards 72(2):1093–1110
Vere-Jones D (1995) Forecasting earthquakes and earthquake risk. Int J Forecast 11(4):503–538
Weißs CH (2018) An introduction to discrete-valued time series. Wiley, New York
Wu XY, Gu JH, Wu HY (2009) A modified exponential model for reported casualties during earthquakes. Acta Seismol Sin 31(4):457–463
Wyss M (2005) Human losses expected in Himalayan earthquakes. Nat Hazards 34(3):305–314
Zhao YZ, Wu ZL, Li YT (2008) Casualty in earthquake and tsunami disasters: internet-based monitoring and early estimation of the final death toll. In: Proceedings of the 14th world conference on earthquake engineering, Beijing
Zhuang J, Ogata Y, Vere-Jones D (2002) Stochastic declustering of space-time earthquake occurrences. J Am Stat Assoc 97(458):369–380
Zhuang J, Ogata Y, Vere-Jones D (2004) Analyzing earthquake clustering features by using stochastic reconstruction. J Geophys Res 109(B5):B05301. https://doi.org/10.1029/2003JB002879
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original version of this article has been revised: Three errors in the last paragraphs of section 7.2 have been corrected.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Altun, E., Bhati, D. & Khan, N.M. A new approach to model the counts of earthquakes: INARPQX(1) process. SN Appl. Sci. 3, 274 (2021). https://doi.org/10.1007/s42452-020-04109-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-020-04109-8