
Abstract
To date, most studies of fire severity, which is the ecological damage produced by a fire across all vegetation layers in an ecosystem, using remote sensing have focused on wildfires and forests, with less attention given to prescribed burns and treeless vegetation. Our research analyses a multi-decadal satellite record of fire severity in wildfires and prescribed burns, across forested and treeless vegetation, in western Tasmania, a wet region of frequent clouds. We used Landsat satellite images, fire history mapping and environmental predictor variables to understand what drives fire severity. Remotely-sensed fire severity was estimated by the Delta Normalised Burn Ratio (ΔNBR) for 57 wildfires and 70 prescribed burns spanning 25 years. Then, we used Random Forests to identify important predictors of fire severity, followed by generalised additive mixed models to test the statistical association between the predictors and fire severity. In the Random Forests analyses, mean summer precipitation, mean minimum monthly soil moisture and time since previous fire were important predictors in both forested and treeless vegetation, whereas mean annual precipitation was important in forests and temperature seasonality was important in treeless vegetation. Modelled ΔNBR (predicted ΔNBRs from the best-performing generalised additive mixed model) of wildfire forests was higher than modelled ΔNBR of prescribed burns. This study confirms that western Tasmania is a valuable pyrogeographical model for studying fire severity of wet ecosystems under climate change, and provides a framework to better understand the interactions between climate, fire severity and prescribed burning.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Fire severity represents the magnitude of the ecological changes produced by a fire across all vegetation layers in an ecosystem, as opposed to fire intensity, which measures the energy released by a fire (sensu [73]). Conventionally, fire severity has been estimated from direct observations on the burnt ground by assessing canopy and stem scorch, plant mortality and soil loss [75]. However, in the last few decades, there has been increased access to remotely-sensed data (multispectral satellite images) suitable for assessing fire severity [38, 144, 166]. Multispectral images show changes in the reflectance of burnt areas, and these can be used to understand environmental drivers that influence fire severity [90, 164].
Fire severity is influenced by local and regional environmental drivers that interact at various spatio-temporal scales. For example, rainforests produce abundant aboveground biomass but, because they mostly remain wet, they only undergo high-severity fires after protracted drought [11, 27]. In contrast, ecosystems such as dry forests and savannas have enough aboveground biomass and recurrent dry periods to burn at varying fire severities [17, 117]. In addition, weather influences fire severity from a seasonal to an hourly scale through changes in humidity, precipitation, temperature and wind [18, 83]. For instance, in south-east Australia, vegetation begins to dry throughout late spring and early summer, while hot days with strong, north-westerly gusts are frequent, which, in the presence of ignitions, can lead to high-severity fires that spread rapidly [28]. Furthermore, fire severity is affected by environmental drivers that are temporally stable, such as topography [45].
Most studies of drivers of fire severity that have used satellite images have been limited in scale and centred on a single fire [82, 154, 164], a small set of fires occurring over a short timespan [6, 106, 155] or a fixed vegetation type, usually forests [35, 155]. The few studies that have focused on multiple fires have tended to consider the influence of a small number of environmental drivers on fire severity, commonly climate, topography, vegetation and weather [100, 106, 111, 114]. Moreover, few studies have investigated the drivers of fire severity in prescribed burns across forested and non-forested vegetation [6, 30, 154, 162].
The temperate Australian island of Tasmania, and especially western Tasmania, is an important study system for the response of vegetation to fire (Fig. 1a–c) [68, 171]. Fire is the only significant source of disturbance across western Tasmania and creates landscapes consisting of complex, small-scale mosaics of fire-adapted and fire-sensitive plant communities [49, 97]. Such spatial variation of post-fire landscapes, also influenced by different lengths of fire intervals, is known as pyrodiversity [99]. In western Tasmania, this pyrodiversity is partly driven by lightning fires, which have become the primary source of ignitions since the 2000s [142]. Although it is uncertain whether lightning has increased in western Tasmania in the last few decades, there remains evidence that lightning-ignited fires and total area burnt are increasing [16, 142]. Another feature of the pyrodiversity of western Tasmania is anthropogenic fires, including accidental ignitions and prescribed burning, which creates barriers to or reduces the spread and severity of wildfires [51, 78]. Indeed, Tasmania is a unique ecological system for pyrogeographical studies because of its multi-dimensional fire regimes and complex landscapes with various vegetation types.

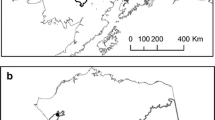
The study area in western Tasmania. (a) All 127 fires classified by aggregated vegetation (forested or treeless) in the Tarkine and the Tasmanian Wilderness World Heritage Area (TWWHA). The two fires shown in panels (d) and (e) are highlighted. (b) Major vegetation types. (c) Mean annual precipitation (mm) and elevation (m above mean sea level). (d, e) Examples of ΔNBR computed using Landsat images (left), and the redigitised fire boundaries by aggregated vegetation (right). (d) Mount Castor wildfire and (e) Dempster Plains North prescribed burn
This study aimed at identifying the main environmental drivers (predictor variables) of fire severity of wildfires and prescribed burns, in forested and treeless vegetation, in western Tasmania. We used multispectral Landsat (Land Satellite, United States Earth Observation program; [85]) images to estimate, through a spectral index (Delta Normalised Burn Ratio; [75]), the severity of a 25-year sample of fires. We then used these data to answer the questions: (1) what are the most important environmental drivers that affect fire severity?, and (2) can we validate with remote sensing that forest wildfires are generally more severe than prescribed burns? To date, it has been challenging to answer these questions in western Tasmania using satellite images because of the high frequency of clouds [138]. Our study is novel in that we determined the relative importance of a range of potential environmental drivers of fire severity across forested and treeless vegetation, for a sample containing wildfires and prescribed burns, in a region where clear satellite images are scarce.
2 Methods
2.1 Environmental Context of the Study Area, and Predictor Variables
The study area includes the Tasmanian Wilderness World Heritage Area in western Tasmania, plus the adjacent Tarkine region in north-west Tasmania (Fig. 1a) [8, 9]. This area contains one of the largest undeveloped temperate landscapes in the Southern Hemisphere [172] and is predominantly reserved, although it also contains significant areas of commercial forestry [7]. The region is mountainous and has a cool and wet climate, with approximately 80% more precipitation in winter (June–August) than in summer (December–February) [12, 13]. The contemporary climate of the region is strongly shaped by the interaction of westerly cyclonic winds and the rugged terrain of the island [49], leading to pronounced climate gradients, with mean annual precipitation ranging from slightly over 1000 mm in north-west Tasmania to over 3500 mm in montane areas of the central west (Fig. 1c; Figure S1) [13]. Short heatwaves during the summer and dry lightning can create conditions favourable for fire [50].
The combination of varied climate, geology and topography, and the practice of prescribed burning, is reflected in a complex mosaic of plant communities, including fire-adapted eucalypt forests and sedgelands, and pyrophobic cool-temperate rainforests and wetlands (Fig. 1b) [128]. Another important feature of western Tasmania is the abundance of organic soils, epitomised by moorlands dominated by tussock-forming sedges, especially the highly pyrogenic Gymnoschoenus sphaerocephalus, or buttongrass [69]. Sphagnum bogs are present but uncommon [165]. Buttongrass moorlands remain a priority in prescribed burning in western Tasmania due to their high flammability and rapid growth after rain [98]. Fire management is a prominent issue in the region, especially since the 2016 fire season, where lightning fires propagated quickly and damaged permanently fire-sensitive plant communities and Aboriginal heritage sites [124].
Considering the environmental characteristics and pyrodiversity of western Tasmania, and our knowledge of fire ecology, we identified a priori 42 ecologically relevant predictor variables that could influence fire severity in the study area. Our predictor variables were classified into four groups: six fire-related attribute variables, 19 bioclimatic variables, six fire-weather variables and 11 environmental and topographic variables (Table 1; Table S2).
The bioclimatic raster variables, from the WorldClim Global Climate dataset, are the variable averages for 1970–2000 [47], while the fire-weather raster variables, from the Bureau of Meteorology Atmospheric high-resolution Regional Reanalysis for Australia [143], are for the years 1990–2019. For the fire-weather variables, for each month from 1990 to 2016 and each pixel, we calculated the mean, mean maximum and mean minimum Forest Fire Danger Index (FFDI) and soil moisture [95]. Most rasters from all groups of variables had a small number of pixels with missing data, either inherited from the original raster data sources, or created during the rasterisation of vector layers to help increase processing speed later in the sampling process. Hence, we applied a three-by-three neighbourhood focal to all rasters to impute missing values using the focal function (mean) from the raster R package (version 3.3.13; [64]).
2.2 Fire History and Fire Selection
We used the Tasmanian fire history dataset [37] to select the boundaries of all prescribed burns and wildfires (ignition cause different than prescribed) in the study area. This dataset was limited because it did not provide fire end dates and did not contain fire isochrones (lines that show the growth of the fires throughout time). Fire perimeters in the fire history dataset were collected by a variety of means, including aerial photographic interpretation, and active aerial and on-ground surveys, and may be of varying accuracy, so efforts were made to refine these perimeters to actual burnt area as detected by satellite (see below). The study area is remote, with few roads, so suppression effort is low and most boundaries represent natural meteorological and topographical boundaries, rather than firefighting control lines. In the Tasmanian Wilderness World Heritage Area, we selected fires ≥ 100 ha from 2000 to 2016 because, due to the unavailability of more frequent overpasses afforded by Landsat 7, the quality of available satellite images before the 2000s was poor, with frequent clouds, cloud shadows and haze. Conversely, for the Tarkine, due to the larger number of fires, we selected fires ≥ 1000 ha from 1990 to 2016. We excluded fires in the Tarkine from before the 1990s due to the scarcity of Landsat images before this time.
Next, we used the EarthExplorer online database (EROS 2017–2020) to search and download multispectral Landsat images (30-m pixel resolution) of the selected fires. For each fire, we endeavoured to find the best available pre- and post-fire image, as close as possible in time to the ignition date, but ensuring that, at the time when the post-fire image was taken, the fire had finished burning (fire scar in the image matched or partially matched the fire boundary). It was important to select post-fire images soon after the fire to capture the fire scar with the maximum accuracy before vegetation regrowth or recovery begins (initial assessment sensu [75]), although it was often only possible to select post-fire images after or during the next growing season (extended assessment sensu [75]). Besides, to minimise seasonal (e.g. albedo) and phenological (e.g. tree flowering, leaf shedding) effects, pre- and post-fire images from the same time of year (e.g. summer) were preferred, although not necessarily from the same time of year as the fire ignition date (Table S1) [25]. This meant that, sometimes, we selected a pre- or post-fire image further back or later in time, respectively, from the fire ignition date, so both images were cloud-free and from the same season. Also, we verified that no other fires occurred within the fire boundary between the fire ignition date and the post-fire image date.
After excluding fires with unsuitable Landsat images (e.g. images with clouds, haze and detector failures; [158]), the sample consisted of 127 fires, comprising 112 different Landsat images from four Landsat scenes (path-row: 91–89, 91–90, 92–88 and 92–89) [2] and spanning three Landsat satellite missions: Landsat 5 Thematic Mapper (1984–2013), Landsat 7 Enhanced Thematic Mapper Plus (1999–ongoing), and Landsat 8 Operational Land Imager and Thermal Infrared Sensor (2013–ongoing) [159]. These 127 fires covered a burnt area of approximately 474,000 ha (Fig. 1a; Table S1). Most of the vegetation burnt was treeless (308,000 ha), followed by forests (150,000 ha) and other minor vegetation types (16,000 ha), such as agricultural, highland and saltmarsh. Overall, 45% of the fires were wildfires (392,000 ha) and 55% were prescribed burns (82,000 ha) (Fig. 1d; Table S1). About 54% of the fires occurred in the dry season (October–March), while 46% occurred in the cool season (April–September). Of the fires in the dry season, 45% were wildfires. In contrast, of the fires in the cool season, 97% were prescribed burns (Table S1).
The mean times between the pre-fire images and fire ignitions dates, pre- and post-fire images dates and fire ignitions and post-fire images dates were, respectively, 19.5 months ± 15.6 months (standard deviation), 27.9 months ± 17.4 months, and 8.4 months ± 5.4 months. About 20% and 80% of the post-fire images occurred, respectively, within 3 and 12 months of the fire (Figure S2), and about 40% and 60% of the fires were, respectively, initial and extended assessments. The extended assessment is approximate because the post-fire images could be from either any time during the next growing season (early, middle or late) or past the next growing season, so it is not possible to know with certainty whether initial recovery and delayed mortality was already present in the case of early or middle growing season (see discussion in [75]).
All Landsat images downloaded from EarthExplorer had been corrected geometrically (pixel coordinates matched the correct place on Earth according to the specific projection) and radiometrically (brightness intensity calibrated across the scene) [174]. The two types of radiometric correction applied to the Landsat images were Terrain Precision Correction, and Systematic Terrain Correction (only one image) [157]. To minimise residual bias in the images, we applied a topographic correction via the topocorr function from the landsat R package (version 1.1.0; [58]). The topographic arguments of this function (aspect and slope) were calculated from a 25-m Digital Elevation Model of Tasmania [149] using the terrain function from the raster R package (version 3.3.13), and the radiometric arguments (sun azimuth and sun elevation) were in the metadata file of each Landsat image. Due to the lack of local wind or progressive fire isochrons for our fires, we could not discriminate down-slope and up-slope spread based on the direction of fire spread; rather, slope was treated as a general topographic control variable.
After correcting all images topographically, we assessed the quality of pixels using the quality assessment raster band provided with each Landsat image [160]. First, we applied a filter in each quality assessment band to select pixels with a quality > 0, that is, pixels of lower quality as a result of clouds, cloud shadows, haze and stripes of missing data (only in Landsat 7 images due to a failure of the Scan Line Corrector; [158]). Second, we applied a five-by-five neighbourhood focal to the lower-quality pixels, using the focal function (mean) from the raster R package (version 3.3.13), to aggregate the pixels within the specified neighbourhood. Last, we polygonised the aggregated lower-quality pixels and created a layer of polygons for each quality assessment raster band.
2.3 Delta Normalised Burn Ratio
For each fire, we computed fire severity using a dimensionless spectral index known as the Delta Normalised Burn Ratio (ΔNBR), which is the difference between the pre- and post-fire Normalised Burn Ratio (NBR) [53]. NBR is calculated using the near-infrared (NIR: 760–900 nm) and shortwave-infrared 2 (SWIR2: 2000–2400 nm) bands of the electromagnetic spectrum, applying the following raster operation: NBR = (NIR − SWIR2) / (NRI + SWIR2) [67]. Commonly, ΔNBR is preferred to NBR because it provides greater contrast between burnt and unburnt vegetation [38, 75]. Other advantages of ΔNBR, compared with other spectral indices of fire severity (e.g. Delta Normalised Difference Vegetation Index), are its stronger correlation with fire severity measured in the field [39, 67], and its higher discriminatory power to differentiate between burnt and unburnt areas [41, 57], although this discriminatory power is normally greater in forests than in treeless vegetation [4, 163, 178]. Other studies have estimated remotely-sensed fire severity using a relativised form of ΔNBR, which estimates the amount of vegetation killed by the fire in relation to the total pre-fire vegetation [105, 115]. In contrast to this relativised ΔNBR, ΔNBR measures the absolute change in green, healthy vegetation caused by the fire, which we think is a better indicator of the ecological damage, across all vegetation layers, produced by a fire [67, 73].
2.4 New Fire Boundaries, and Random Sampling Points
We manually corrected the boundary of each fire in QGIS (version 3.10.6; [125]) using the post-fire images because it was mostly possible to visually distinguish burnt from unburnt vegetation in these images, although this was more evident in treeless than in forested vegetation. Forested vegetation where fire severity might have been extremely low (e.g. burnt patches on the ground layer) was unlikely to have been observed in the post-fire images; thus, we would have considered it unburnt and, therefore, excluded it from the corrected fire boundaries. Also, we removed areas from the fire boundaries that corresponded with waterbodies and watercourses, according to the Tasmanian hydrographic area dataset [152], because they may have a spectral signature similar to that of burnt areas [109]. Finally, we removed from the fire boundaries the polygons created from the quality assessment raster bands, and clipped all fire boundaries to the Tasmanian coastline [55]. This refinement of the fire boundaries reduced the total burnt area by 10% (Table S1).
Next, we used random sampling to evaluate ΔNBR within the corrected fire boundaries. First, to minimise the effects of spatial autocorrelation, the number of sampling points to sample per fire was calculated as: number of sampling points (rounded up to the nearest integer) = area of corrected fire boundary (m2) / pixel area (900 m2). Then, using the st_sample function (type = “random”) from the sf R package (version 0.9.5; [119]), we randomly generated this number of sampling points per fire and extracted the corresponding ΔNBRs of the sampling points via the extract function from the raster R package (version 3.3.13). We produced two variograms per fire, one with an exponential family and another with a spherical family [101], using the variogram function from the gstat R package (version 2.0.6; [118]). For each variogram, we calculated the range (the distance at which the variogram levels off) and the residual sum of squares. Last, for each fire, we chose the range of the variogram with the lowest residual sum of squares, as recommended by Burrough (1995) [22].
To further curtail the effects of spatial autocorrelation, and both over- and under-sampling, the process of randomly generating sampling points within each corrected fire boundary, extracting their ΔNBRs, producing two variograms per fire (exponential and spherical families) and choosing, for each fire, the range of the variogram with the lowest residual sum of squares, was repeated 100 times, resulting in 100 ranges per fire. Finally, we averaged the 100 ranges of each fire and recalculated the new number of sampling points to sample per fire as: new number of sampling points (rounded up to the nearest integer) = area of corrected fire boundary (m2) / square of the averaged range (m2). This produced 42,092 sampling points to sample within the 127 corrected fire boundaries.
2.5 Sampling of Predictor Variables and ΔNBR
We randomly generated the number of sampling points per fire within the corrected fire boundaries and extracted the corresponding values of ΔNBR and the 42 predictor variables. However, fire type, fire type of previous fire, and time since previous fire were obtained directly from the fire history dataset [37]. In addition, as the fire history dataset did not have fire isochrones showing the progression of the fires across space and time, each sampling point was assigned the mean, mean maximum and mean minimum FFDI and soil moisture of the month of the year of the fire ignition date, reflecting prevailing conditions of the month of the year when the fire began, rather than hour-to-hour weather of fire progression [111]. Regarding land tenure, because the boundary of the Tasmanian Wilderness World Heritage Area was extended in June 2013, sampling points from fires with an ignition date prior to the boundary extension were assigned the land tenure from the latest tenure dataset available before the extension, whereas sampling points after June 2013 received the land tenure from the 2015 dataset [151, 153]. In all, this sampling process produced a dataset with 42,092 records and 44 columns (fire id, ΔNBR and the 42 predictors).
To account for variability in our data, and following the process described in the previous paragraph, we generated 100 datasets with 42,092 records and 44 columns each. In all datasets, we only kept records with the following five vegetation types: buttongrass, wetland and peatland; dry eucalypt forest; rainforest; scrub, heathland and coastal; and wet eucalypt forest [152]. We eliminated records with soil types of vertosol or unknown because we could not reclassify them into one of the four major groups of soil types, namely dermosol, kandosol, organosol and tenosol (Table 1) [148]. The elimination of these records that did not meet our vegetation and soil type criteria accounted for, approximately, 3.5% of records per dataset. Due to the limited length of the fire history dataset, there were records without a fire type of previous fire and time since previous fire. For these records, the fire type of previous fire was set to unknown, and the date of previous fire to 1900-01-01.
2.6 Selecting Predictor Variables Through Random Forests
Given the large number of predictor variables selected a priori, we undertook a two-step process to identify a smaller subset of predictors. First, we randomly chose four datasets and produced correlation matrices between predictors. In each of the four datasets, we calculated the Pearson’s correlation coefficient between all pairs of quantitative, continuous predictors via the rcorr function from the Hmisc R package (version 4.4.1; [62]) (Table S4). Similarly, we calculated the Cramér’s V coefficient for all pairs of categorical predictors via the cramersV function from the lsr R package (version 0.5; [110]) (Table S5). Correlation matrices across the four datasets showed similar correlation coefficients between pairs of predictors. Hence, we selected 22 predictors for the first round of Random Forests (Fig. 2), supported by our knowledge of the ecological significance of these predictors in fire ecology, as follows: six fire-related attribute variables, six bioclimatic variables, four fire-weather variables, and six environmental and topographic variables (Table 1).

Variable selection through three successive rounds of Random Forests (RF). In each round, the RF models were constructed using the number of predictor variables indicated inside the arrows (asterisk), and the most important predictors were selected (number sign). Predictors were ranked according to aggregated vegetation (F for forested and T for treeless), and two measures of variable importance: impurity corrected (IC) and permutation (P). Prediction accuracy of the RF ensembles was assessed in each round based on the root mean square error and mean absolute error, averaged across 50 pairs of testing and training datasets. The four highest-ranked predictors from the third round of RF were used to conduct the generalised additive mixed models (GAMMs)
The second step to reduce the number of predictor variables was to use Random Forests, a machine-learning classifier [19, 32]. Random Forests is a strong classifier because it minimises overfitting, accepts quantitative and categorical predictors and allows for non-linear relationships between the predictors and the response variable [20]. In the Random Forests ensembles, consisting of many regression trees, it is possible to rank predictors by importance, reflecting their contribution to predicting the response variable. We used two measures of variable importance to rank the predictors: impurity corrected and permutation. Higher values of both measures indicate a higher contribution of the predictor to predicting the response variable [14]. In all regression trees, the number of predictors to split at each node was kept at the default value (square root of the number of predictors rounded down) because this value typically provides optimal performance [34]. The number of trees to grow per ensemble was 2000 because larger ensembles yielded negligible changes in the out of bag error and R2. Regression trees were constructed with sampling without replacement and through recursive partitioning [135]. All Random Forests analyses were undertaken with the ranger R package (version 0.12.1; [173]).
To better understand the relationships between the 22 predictor variables and the response variable (ΔNBR), we produced, for three of the datasets, one-way and two-way partial dependence plots of Random Forests models containing these 22 predictors, using the partial function from the pdp R package (version 0.7.0; [60]). One-way partial dependence plots indicated overfitting of a few predictors, such as distance to roads, distance to rivers/lakes, and mean FFDI. To curtail overfitting in subsequent Random Forests analyses, the two numerical predictors, distance to roads and distance to rivers/lakes, were converted into two categorical predictors: distances < 1 km were classified as near, while distances ≥ 1 km were classified as distant (Table 1). In the two-way partial dependence plots, there was no evidence of interactions between the bioclimatic and fire-weather predictors. Finally, we partitioned each dataset into two aggregated vegetation types (forested and treeless) because ΔNBR typically performs better in forests [163, 178]. Forested vegetation included dry and wet eucalypt forests and rainforests, whereas treeless vegetation comprised buttongrass, wetland and peatland, and scrub, heathland and coastal [152].
From an average of 40,601 records per dataset (± 32 standard deviation), 25% were forested and 75% treeless (Table S3). For forested records, 49% were wet eucalypt forest, 33% were dry eucalypt forest, and 18% were rainforest. For treeless records, 79% were buttongrass, wetland and peatland, and 21% were scrub, heathland and coastal. Considering the type of fire, 93% of forested records were wildfires and 7% were prescribed burns, while 65% of treeless records were wildfires and 35% were prescribed burns. In all five vegetation types, across wildfires and prescribed burns, except prescribed burns in rainforests, the protected tenure contained the most records, followed by forestry and non-protected. When considering tenure by aggregated vegetation, 59% and 78% of records were protected, respectively, in forested and treeless vegetation; 39% (forested) and 19% (treeless) were forestry; and 2% (forested) and 3% (treeless) were non-protected (Table S3).
The Random Forests analyses consisted of three successive rounds of Random Forests (Fig. 2) [34]. In each round, we input the 100 datasets, with each dataset partitioned by aggregated vegetation, but with fewer predictor variables than in the preceding round, except for the first round, which contained all 22 predictors. In each round and for each dataset, we ranked the predictors according to the two measures of variable importance. We then averaged the importance values of each predictor across the 100 datasets. In the first round of Random Forests, we chose the 11 most important predictors out of the 22 and used them as the predictors in the second round. In the second round of Random Forests, we chose the six most important predictors, which were the predictors in the third round. Finally, we selected the four highest-ranked predictors from the third round of Random Forests for the statistical analysis (Fig. 2). Residuals of the Random Forests models, containing these four predictors, computed via the predict function of the ranger R package (version 0.12.1), were normally distributed, showing no indication of spatial clustering (Figure S3).
To appraise the most suitable number of predictor variables of ΔNBR, we implemented cross-validation [20, 29]. The 100 datasets were randomly split into 50 pairs of training and testing datasets (Fig. 2). Within each pair, we used one of the datasets (training dataset), split by aggregated vegetation, to fit Random Forests models (impurity corrected and permutation) containing the 22, 11, six, four and three most important predictors. We used the second dataset (testing dataset) within each pair to test the Random Forests models fitted with the training dataset. In each pair, the prediction accuracy of the Random Forests models fitted with the training dataset and tested with the testing dataset was evaluated by the root mean square error (RMSE) and the mean absolute error (MAE). RMSE and MAE measure the agreement between paired observations consisted of the predicted and observed values, and are expressed in the units of the response variable [24, 167]. Last, we averaged the values of RMSE and MAE across the 50 pairs according to the number of predictors (22, 11, six, four and three), the two measures of variable importance (impurity corrected and permutation), and aggregated vegetation (forested and treeless). We selected four predictors for the statistical analysis because there were small changes in RMSE and MAE when using Random Forests with 22, 11, six and four predictors, but a larger loss in prediction accuracy when using three predictors (Table S6).
2.7 Statistical Analysis Using Generalised Additive Mixed Models
We used generalised additive mixed models (GAMMs) to statistically test the relationship between ΔNBR and the four highest-ranked predictor variables from the third round of Random Forests (Fig. 2). The benefit of generalised additive models over generalised linear models is that generalised additive models can model non-linear relationships between a response variable and a set of predictors [63, 175]. We used GAMMs rather than standard generalised additive models to account for the effect of individual fires [120]. We applied a thin-plate regression spline as the wiggliness penalty function for the smoothing terms [121]. The basis dimension of each smoothing term was 100, except for time since previous fire, which was 10, because increasing the basis dimensions beyond these values yielded small changes in the effective degrees of freedom, indicating little effect on the shape of the smooth [170]. All models were fitted using the bam function from the mgcv R package (version 1.8.31; [169]).
We used model selection to find the best-performing model, in each dataset, in a five-model candidate set. We preserved all datasets partitioned by aggregated vegetation, so the statistical analysis was consistent with the Random Forests analyses. The null model was the intercept-only model, while the base model contained a smoothing term for each of the four highest-ranked predictor variables from the third round of Random Forests, and both models had “fire id” as a random smoothing term [120]. Other models included extra predictors: spatial contained a smoothing term for spatial variation (easting and northing coordinates of the sampling point to further control for spatial autocorrelation), and categorical included three categorical predictors, as follows: fire type (wildfire or prescribed burn), land tenure (forestry, non-protected or protected) and the non-aggregated vegetation. The global model was the base + spatial + categorical + topography, with topography consisting of three predictors: northness and slope as linear regressions, and topographic position index as a thin-plate regression spline.
In each dataset, the five models were ranked by the Akaike’s Information Criterion (AIC), calculated with the AIC function from the stats R package (version 4.0.2; [126]). The best-performing model in the candidate set was the model with the lowest AIC. We calculated the delta AIC (ΔAIC), which represents the difference in AIC between the model and the best-performing model (accorded ΔAIC = 0). As the results of model selection were similar across all datasets, we averaged the AICs, explained deviances and ΔAICs of each model across the 100 candidate sets. Following Burnham and Anderson (2002) [21], we considered models with an averaged ΔAIC < 2 as statistically supported.
We produced partial dependency plots, by aggregated vegetation, for each of the predictor variables of the global model. First, we fitted the global model in each dataset, using the ggpredict function from the ggeffects R package (version 0.15.1; [96]), to generate ΔNBR predictions (modelled ΔNBR hereafter) for each of the predictors included in the model. Next, for each quantitative, continuous predictor, we averaged the modelled ΔNBRs across the predictions of the 100 global models and applied a cubic smoothing spline to the averaged modelled ΔNBRs via the smooth.spline function from the stats R package (version 4.0.2). For categorical predictors, we computed the mean of the modelled ΔNBRs for each category of the predictor across the predictions of the 100 global models. Here, we tested for statistical differences (P-value < 0.05) among the categories of the predictor via the non-parametric Kruskal–Wallis test by ranks (kruskal.test function from the stats R package; version 4.0.2), followed by post hoc means comparisons through the Bonferroni method (pairw.kw function from the asbio R package; version 1.6–7; [3]). For all predictors, we calculated the 95% confidence intervals from the global model predictions, and averaged the lower and upper limits of the 95% confidence intervals across the 100 models.
3 Results
3.1 Selecting Predictor Variables Through Random Forests
In both forested and treeless vegetation, precipitation of the driest quarter, mean minimum monthly soil moisture, and time since previous fire were among the four most important predictor variables selected in the third round of Random Forests (Fig. 2; Table 1). Mean annual precipitation was an important predictor in forests, whereas temperature seasonality (standard deviation) was important in treeless vegetation. Cross-validation indicated little loss of prediction accuracy of the Random Forests models containing the four most important predictors (forested: 0.155 RMSE and 0.113 MAE; treeless: 0.119 RMSE and 0.085 MAE), compared to models with the 22 predictors (forested: 0.147 RMSE and 0.110 MAE; treeless: 0.117 RMSE and 0.085 MAE) (Table S6).
3.2 Statistical Analysis Using Generalised Additive Mixed Models
The global model had the best support across all datasets in treeless vegetation (mean ΔAIC = 0), and in all but four of the 100 candidate sets of GAMMs in forested vegetation (mean ΔAIC = 0.8, range: 0–37) (Table 2). In each of the four exceptions, the base + spatial + categorical model was the best-fitting model, but the improved fit over the global model was small (mean ΔAIC < 2). Therefore, we selected the global model as the best-performing model for both forested and treeless vegetation.
Overall, we achieved a good sampling coverage of the four most important predictor variables of the global GAMM (Figure S4b–f; Figure S5a–h) across the 100 datasets, with time since previous fire presenting the highest difference in interquartile ranges between forested and treeless vegetation (Figure S4f) due to lack of ΔNBR values between 40 and 90 years (Figure S5g–h). Modelled ΔNBR (predicted ΔNBRs from the global GAMM) was negatively associated with mean annual precipitation in forested vegetation, with modelled ΔNBR < 0.44 above 2000 mm per annum, and > 1.1 below 1000 mm (Fig. 3a). Modelled ΔNBR increased with precipitation of the driest quarter in forested and treeless vegetation up to approximately 400 mm (Fig. 3c–d). There was a slight upward trend in modelled ΔNBR as time since previous fire increased up to 35 years (Fig. 3g–h). Modelled ΔNBR showed flat trends in temperature seasonality in treeless vegetation (Fig. 3b), and mean minimum monthly soil moisture in both forested and treeless vegetation (Fig. 3e–f). These predictors (temperature seasonality and mean minimum monthly soil moisture) were important in the Random Forests analyses because they explained a proportion of the variance not captured by other predictors, so removing them reduced model fit. Low sampling coverage affected the predictions for some regions of most predictors, notably for high values of precipitation-related variables (Fig. 3a, c–d; Figure S5a, c–d).

Partial dependence plots for important predictor variables of modelled ΔNBR in forested and treeless vegetation, based on the global GAMM. The solid black lines in plots (a–h) represent cubic smoothing splines on the mean of the ΔNBR predictions, while the grey-shaded areas show mean 95% confidence intervals. Plots (i–k) show mean modelled ΔNBR with 95% confidence intervals. Plots on the left (a, c, e, g) correspond to forests, while plots on the right (b, d, f, h) are for treeless vegetation. Plots (i–k) refer to both forests (black circles) and treeless vegetation (open squares). Different letters on the top right of the error bars (i–k) indicate significant differences between groups (P-value < 0.05) using a post hoc Bonferroni method applied after the Kruskal–Wallis test by ranks. See Figure S4 in the supplementary material for the partial dependence plots of the three topographic variables. Acronyms: DEF is dry eucalypt forest; WEF is wet eucalypt forest; R is rainforest; BWP is buttongrass, wetland and peatland; and SHC is scrub, heathland and coastal
Sampled values of the topographic predictor variables across the 100 datasets showed a large range of variability (large interquartile range) in northness for forested and treeless vegetation, while the topographic position index had a low range of variability, and slope had some more variability, but was left-skewed (Figure S4g–i; Figure S5i–n). Regarding modelled ΔNBR, northness had a flat trend in forested and treeless vegetation (Figure S6a–b). However, modelled ΔNBR was predicted to slightly decrease as slope increased in forested vegetation, and to increase as slope increased in treeless vegetation (Figure S6 c–d). Topographic position index influenced modelled ΔNBR in flat areas (0 m) in forested and treeless vegetation, but the response was unstable for topographic position indices < −5 m or > 5 m (Figure S6e–f).
For non-aggregated vegetation, sampled ΔNBRs across the 100 datasets showed similar ranges of variability, with dry eucalypt forests having the smallest interquartile range of all five vegetation types (Figure S4j). Dry and wet eucalypt forests presented the highest modelled ΔNBRs (0.61 ± 0.14 standard error of the mean and 0.58 ± 0.14, respectively) of all five vegetation types, and there was no statistical difference between these two vegetation types (Fig. 3k). In contrast, modelled ΔNBR of rainforests (0.53 ± 0.14) was statistically different from the other two forest types. In treeless vegetation, modelled ΔNBR of scrub, heathland and coastal (0.56 ± 0.08) was not statistically different to modelled ΔNBR of buttongrass, wetland and peatland (0.53 ± 0.08). Furthermore, there were no statistical differences in modelled ΔNBR between wet eucalypt forests and scrub, heathland and coastal, and among rainforest and the two treeless vegetation types (Fig. 3k).
In fire type, sampled ΔNBRs had similar interquartile ranges in forested and treeless vegetation across the 100 datasets regardless of the type of fire, although there was higher variability in treeless prescribed burns than in the other three groups (Figure S4k). For wildfires, modelled ΔNBR and prediction uncertainty (95% confidence interval) was higher in forests (0.61 ± 0.14) than in treeless vegetation (0.53 ± 0.08), with this difference being statistically different (Fig. 3i). In contrast, prescribed burns in treeless vegetation had higher modelled ΔNBR, but lower uncertainty (0.45 ± 0.09), than prescribed burns in forests (0.42 ± 0.15), and this difference was statistically different. Modelled ΔNBR was statistically different between wildfires and prescribed burns in forests, but not between wildfires and prescribed burns in treeless vegetation (Fig. 3i).
Land tenure was the categorical predictor variable that showed, across all its groups, the largest variability in the interquartile ranges of sampled ΔNBRs for all 100 datasets. This variability was small for forestry in both forested and treeless vegetation, and in non-protected forests, but larger in the other three groups (non-protected treeless, protected forested and protected treeless) (Figure S4l). Within both forested and treeless vegetation, modelled ΔNBR was statistically different between the forestry (forested: 0.61 ± 0.14; treeless: 0.53 ± 0.08) and protected (forested: 0.66 ± 0.14; treeless: 0.57 ± 0.07) tenures, but not between the forestry and non-protected (forested: 0.62 ± 0.14; treeless: 0.56 ± 0.07) tenures, and the non-protected and protected tenures.
4 Discussion
In this study, we have developed a methodological approach to rigorously select, and statistically test, predictor variables with ecological meaning in predicting fire severity estimated from remotely-sensed data. This approach provides predictions in a complex pyrogeographical system, covering 25 years of fire records, across forested and treeless landscapes.
4.1 Methodological Approach
Our methodological approach was developed to account for several of the major challenges of using remotely-sensed fire severity data, including spatial autocorrelation and multi-dimensional environmental drivers that interact at various spatio-temporal scales [29, 30]. We implemented Random Forests to select a smaller set of predictor variables, and fitted these models 100 times in each round of Random Forests to account for spatial autocorrelation and control the complex interactions between predictors (Fig. 2) [81]. Our Random Forests models appear to have been effective, given that variable importance rankings were similar across the 100 datasets, and the small loss of prediction accuracy when downsizing the number of predictors from 22 to four (Table S6).
To allow for the loss of a few important predictor variables in the Random Forests analyses (Fig. 2), we created a base GAMM using the four highest-ranked predictors from the third round of Random Forests, and added other likely predictors. The substantial fit improvement of the global GAMM validates this approach (Table 2). In particular, the strong effects of incorporating “fire id” as a random effect to control for inter-fire differences and local-scale effects supports the value of GAMMs over Random Forests [120]. Nonetheless, our GAMM models have not been designed for prediction in other ecosystems because it may not be possible to provide a comparable random effect for individual fires. In this study, we were interested in the ecological conclusions of the statistical analysis using GAMMs, rather than generating predictive models to apply across all ecosystems, because each ecosystem has specific ecological features that need to be considered when implementing and interpreting statistical models.
The strengths of our methodological approach are twofold. First, by using Random Forests, it is possible to obtain insights into the relative importance of interacting predictor variables [29], instead of selecting a priori a set of predictors for statistical analysis or implementing stepwise selection. Second, by using GAMMs and model selection, we can test the statistical relationships among predictors and improve model fit [81]. In addition, as the approach is semi-automatic, we can use existing knowledge of fire ecology to ensure that the outputs at each step of the approach are ecologically meaningful [127], and repeat any steps by modifying input variables in the Random Forests analyses and/or increasing model complexity in the candidate sets of GAMMs (Fig. 2; Table 2).
Future studies in fire severity that may follow our methodological approach would benefit from field validation. Here, we did not undertake field validation because of the sample size (127 fires), the remoteness of the study region, and the long time elapsed since most fires happened. Given this lack of field data, we chose a spectral index highly correlated with fire severity in the field and with a greater discriminatory power between burnt and unburnt vegetation than other spectral indices [39, 57]. Importantly, by partitioning our datasets into forested and treeless vegetation, we increased the accuracy of our analyses, since ΔNBR normally performs better in forested than in treeless vegetation [178]. Nevertheless, future studies could select a few distinguished fires (e.g. recent large wildfires and prescribed burns) to assess fire severity in the field (e.g. through the Composite Burn Index; [75]), and then calibrate the field fire severities with the remotely-sensed fire severity [111]. The benefits of determining ΔNBR ranges that correlate to field severity classes are that the results could be relevant to ecosystems with similar pyrogeographical features to western Tasmania.
4.2 Climate Variables and Time Since Previous Fire
The stronger relationships among predictor variables in treeless vegetation (deviance explained = 0.68) than in forests (0.54) in the global GAMM contrasts with previous studies that reported lower performance of ΔNBR in non-forested vegetation (Table 2) [4, 137, 140]. To ensure maximum accuracy of ΔNBR, especially in treeless areas, we searched multispectral pre- and post-fire satellite images as close as possible in time to the fire event and spanning the same season of the year [25]. These considerations are important when studying treeless communities, such as the Tasmanian buttongrass moorlands, where regrowth happens rapidly after fire if there is a wet period shortly thereafter [69].
Our results showed that precipitation-related variables were important drivers of fire severity in forested and treeless vegetation (Fig. 3a, c–d). In forests, higher levels of mean annual precipitation had a negative effect on modelled ΔNBR (Fig. 3a), which may be related to the role of annual precipitation in controlling ecosystem productivity [117]. Therefore, biomass connectivity and density may have been important in driving fire severity in our study area [134, 136]. Although previous research found that increases in annual precipitation led to high-severity surface and canopy fires through higher rates of horizontal and vertical biomass build-up [28, 84], annual precipitation may also have a negative relationship with fire danger indices in regions that lack regular dry periods that permit fire [122]. Another reason for the negative relationship between mean annual precipitation and modelled ΔNBR may be the positive association between annual precipitation and soil moisture, since wetter areas require more extreme weather conditions for fire ignition [5, 17]. For instance, Dimitrakopoulos et al. (2011) [36] showed that a year with normal annual precipitation in Mediterranean coniferous forests had > 48% low fire-danger days and < 88% extreme fire-danger days than a dry year (< 70% precipitation). The 25-year fire record in this study might have had few catastrophic fire days that could have originated fires of high intensity and severity [16, 71].
The negative relationship between modelled ΔNBR and mean annual precipitation in forests of western Tasmania (Fig. 3a) may reflect a dichotomy between the region’s mild and wet climate, but relatively frequent extreme weather conditions, such as dry lightning and short heatwaves [142]. Increased mean annual precipitation in the study region could be associated possibly with a trend towards denser, closed-canopy forests that require rare and extreme weather or severe drought to achieve fire intensities that would result in high-severity fires [131]. Future climate scenarios predict an increase in extreme weather conditions in Tasmania [50], so there will be a higher risk of large-scale and severe fires that may compromise the survival of fire-sensitive communities. For example, the palaeoendemic, slow-growing conifer Athrotaxis cupressoides, which persists in cool and wet refugia in western Tasmania, underwent a severe interval squeeze (68% adult mortality) as a result of fires from dry lightning in 2016 [15]. Other global climate modelling for the twenty-first century has shown that fluctuations in total annual precipitation in ecosystems of intermediate productivity, such as those found in western Tasmania, will be the main driver of ecosystem flammability and fire regimes [10, 116, 141].
The positive relationship between precipitation of the driest quarter, representing mean summer precipitation in this system, and modelled ΔNBR in both forested and treeless vegetation (Fig. 3c–d) may reflect greater plant productivity due to wet summers. Wetter summers can lead to horizontal and vertical biomass build-up, which may burn in hot days later in the summer [59, 88]. However, areas with high-average summer precipitation may still undergo episodic drought with high-severity fires [123, 156], a true case for western Tasmania [49, 171]. It is possible that, in ecosystems of intermediate productivity, a preceding wet summer may translate into higher fire risk in successive summers due to biomass build-up [56, 161]. Other studies worldwide have reported that such ecosystems are more affected by precipitation variability during the dry season than during the cool season [108, 113, 177] because cool seasons are not normally water-limited, contrarily to dry seasons, where precipitation increases lead to higher plant productivity and, therefore, more biomass available for burning [59, 89, 139].
A potential interaction between precipitation and temperature may explain why temperature seasonality was important in treeless vegetation (Fig. 3b). Treeless communities in our study region were mostly located in near-coastal areas (Fig. 1a–b), which are less affected by temperature fluctuation due to the modulating effect of the ocean. Consequently, lower fluctuations between minimum and maximum temperatures throughout the year may render plants longer growing periods, in opposition to areas with less thermally equable climates, where the lower temperatures of the cool season inhibit bud break and plant growth [80, 168].
Time since previous fire influenced fire severity in forested and treeless vegetation, with modelled ΔNBR continuing to increase to approximately 35 years after fire (Fig. 3g–h). This increase may be linked to the accumulation of finer biomass during fire-free periods, which becomes available for burning under adverse weather conditions, such as drought, high temperature, lightning, low humidity and wind [17]. These results align with previous studies that suggested that time since previous fire could be more important in the first years after a fire, while biomass is thinner and the understorey is regenerating [65, 92, 146]. Similar findings that highlighted the positive relationship between time since previous fire and fire severity have been reported in chaparral-dominated shrublands, fynbos, Australian heathlands, and Mediterranean forests of maritime pines [42, 74, 86, 176].
4.3 Relevance to Fire Management and Climate Change
Our research demonstrates that a multi-decadal satellite record can be successfully used to study fire severity in complex landscapes with a rich fire history. However, a caveat of this study was the coarse temporal resolution of the FFDI and soil moisture variables. Because we did not have fire isochrones, we did not know the day and time that each sampling point within the fire burnt, so we assigned to all sampling points within a fire the averaged FFDI and soil moisture of the month of the year of the fire ignition date. These averaged values of FFDI and soil moisture reflected the prevailing weather conditions of the month of the year when the fire began, rather than the specific weather conditions of the time of the day when the sampling point burnt. Specific weather conditions are important because most fires have outbursts that burn most of the area [31, 70, 91]. Given the importance of fire isochrones to better match fire severity to the local conditions when the fire burnt [45, 111], fire agencies would need to digitise fire isochrones to allow for better predictive modelling of fire severity. Furthermore, records on firefighting activities, including the timing and location of control lines and aerial waterbombing drops, are useful in fire severity analyses because the burnt area, fire intensity and fire severity may have been influenced by the firefighting efforts [43, 164].
The lower modelled ΔNBR in prescribed burns than in forest wildfires (Fig. 3i) was expected because prescribed burning uses low-intensity burns, which are attained by avoiding dry and hot weather conditions, to reduce biomass build-up, hence reducing fire hazards [46]. Nevertheless, the higher modelled ΔNBR of prescribed burns in treeless vegetation than in forests may be an artefact of the limited capacity of satellite images to capture reflectance changes of the understorey layer in forests. This layer is typically the part of the forest that burns during prescribed burning, but it is hindered by the tree canopies [93, 107]. In addition, the similar modelled ΔNBR of wildfires and prescribed burns in treeless vegetation may relate to the fewer layers available for burning in treeless communities, thus limiting fire severity [88, 117].
Modelled ΔNBR was higher in protected forests than in commercial forests, but not statistically different from modelled ΔNBR in non-protected forests (Fig. 3j), reflecting the greater continuity and density of aboveground biomass in forests [117]. By contrast, the similar modelled ΔNBR of protected and non-protected treeless areas was anticipated (Fig. 3j), because treeless vegetation burns more homogeneously due to biomass connectivity [72, 103]. Prescribed burning of treeless areas within protected forests can be an efficient management tool to reduce the occurrence and spread of future high-severity fires [77, 104, 162]. As an example, strict fire suppression policies led to large-scale, destructive wildfires in the Yellowstone National Park in 1988 [133]. This recommendation of burning treeless areas within forests to create mosaics of fuel structures is supported by previous experimental research [51, 66, 132] and simulation modelling [52, 77, 78]. Specifically, King et al. (2013) [79] underlined the effectiveness of prescribed burning in reducing unplanned fires and area burnt by large fires in south-west Tasmania, given the role of prescribed burns in fragmenting biomass connectivity.
Climate modelling for the twenty-first century projects a decrease in summer precipitation and an increase in winter precipitation in south-east Australia [33, 44], coupled with changes in frontal cyclones [129]. This modelling suggests a 69% increase in the number of days of dangerous fire weather in western Tasmania by the end of the twenty-first century [48, 50], possibly leading to more large-scale, high-severity wildfires [1, 94, 112]. Furthermore, climate modelling shows that the canonical driver of precipitation variability in Australia, El Niño–Southern Oscillation [112, 130], is predicted to become more severe than other climate systems, such as the Indian Ocean Dipole and the Southern Annular Mode, with extreme dry events associated with El Niño followed by greater favourable conditions for extreme wet weather associated with La Niña [23, 61, 76]. The increase in drought and fire days means that the weather window to apply prescribed burning will shorten in the future [26, 87]. Consequently, fire severity data collected during prescribed burning operations is important because it can help identify areas where prescribed burning would be more efficient.
5 Conclusions
Western Tasmania represents an interesting pyrogeographical model for studies in fire ecology due to its pyrodiversity and the potential impacts of climate change on wet ecosystems. The methodological approach developed here can be reproduced in other ecosystems to understand the drivers of fire severity. Our results showed that precipitation-related variables were the main drivers of fire severity in forested and treeless vegetation in western Tasmania. Importantly, our findings confirm previous base knowledge of the drivers of fire severity [28, 54, 102, 145]. However, additional studies would benefit from field validation, fine-scale fire weather, and fire progression data. Prescribed burns had lower remotely-sensed fire severity than forest wildfires, which supports that prescribed burning is suitable for reducing the connectivity and density of available biomass. In this study, we establish links between fire severity and both climate and weather, across a topographically and ecologically diverse ecosystem, over an extended time series of fires, and provide a framework to better understand the interactions between fire severity and prescribed burning under climate change.
Data Availability
Due to their large size, the data generated in this study are available from the corresponding author on request.
References
Abram NJ, Henley BJ, Sen Gupta A, Lippmann TJR, Clarke H, Dowdy AJ, Sharples JJ, Nolan RH, Zhang TR, Wooster MJ, Wurtzel JB, Meissner KJ, Pitman AJ, Ukkola AM, Murphy BP, Tapper NJ, Boer MM (2021) Connections of climate change and variability to large and extreme forest fires in southeast Australia. Commun Earth Environ 2:1–17. https://doi.org/10.1038/s43247-020-00065-8
ACRES (Australian Centre for Remote Sensing) (2000) Landsat path and row map of Australia. Accessed 31 March 2022: https://data.gov.au/dataset/ds-ga-a6e3ffda-9b=8b-747c-e044-00144fdd4fa6/details?q=
Aho K (2020) Package asbio: a collection of statistical tools for biologists. R package. Accessed 31 March 2022: https://CRAN.R-project.org/package=asbio
Allen JL, Sorbel B (2008) Assessing the differenced Normalized Burn Ratio’s ability to map burn severity in the boreal forest and tundra ecosystems of Alaska’s national parks. Int J Wildland Fire 17:463–475. https://doi.org/10.1071/wf08034
Archibald SA, Roy DP, van Wilgen BW, Scholes RJ (2009) What limits fire? An examination of drivers of burnt area in Southern Africa. Glob Change Bio 15:613–630. https://doi.org/10.1111/j.1365-2486.2008.01754.x
Arkle RS, Pilliod DS, Welty JL (2012) Pattern and process of prescribed fires influence effectiveness at reducing wildfire severity in dry coniferous forests. For Ecol Manag 276:174–184. https://doi.org/10.1016/j.foreco.2012.04.002
Australian Government (2013) Conservation agreement for the protection and conservation of areas of State Forest separating the Tasmanian Wilderness World Heritage Area from adjoining wood production coupes. Accessed 31 March 2022: https://www.stategrowth.tas.gov.au/__data/assets/pdf_file/0020/93332/Conservation-Agreement-SF-adjacent-to-TWWHA-signed-August-131.pdf
Australian Heritage Commission (1981) Nomination of Western Tasmanian Wilderness National Parks by the Commonwealth of Australia for inclusion on the World Heritage. Accessed 31 March 2022: https://www.environment.gov.au/system/files/pages/f99dbb51-03c2-4eb2-a66e-87c4044117b4/files/1981-nomination.pdf
Barton R (2017) “Our Tarkine, our future”: the Australian Workers Union use of narratives around place and community in West and North West Tasmania, Australia. Antipode 50:41–60. https://doi.org/10.1111/anti.12353
Batllori E, Parisien MA, Krawchuk MA, Moritz MA (2013) Climate change-induced shifts in fire for Mediterranean ecosystems. Glob Ecol Biogeogr 22:1118–1129. https://doi.org/10.1111/geb.12065
Berry LE, Driscoll DA, Stein JA, Blanchard W, Banks SC, Bradstock RA, Lindenmayer DB (2015) Identifying the location of fire refuges in wet forest ecosystems. Ecol Appl 25:2337–2348. https://doi.org/10.1890/14-1699.1
BoM (Bureau of Meteorology) (2009) Mean monthly and mean annual maximum, minimum and mean temperature data for the period 1961–1990 (base climatological data sets). Australian Government. Accessed 31 March 2022: http://www.bom.gov.au/climate/averages/climatology/gridded-data-info/metadata/average_temperature_metadata.pdf
BoM (Bureau of Meteorology) (2020) High resolution mean monthly and mean annual rainfall data for the period 1981–2010 (base climatological data sets). Australian Government. Accessed 31 March 2022: http://www.bom.gov.au/climate/averages/climatology/average-rainfall-metadata.shtml
Boulesteix AL, Janitza S, Kruppa J, Konig IR (2012) Overview of Random Forest methodology and practical guidance with emphasis on computational biology and bioinformatics. Wiley Interdiscip Rev Data Min Knowl Discov 2:493–507. https://doi.org/10.1002/widm.1072
Bowman DMJS, Bliss A, Bowman CJW, Prior LD (2019) Fire caused demographic attrition of the Tasmanian palaeoendemic conifer Athrotaxis cupressoides. Austral Ecol 44:1322–1339. https://doi.org/10.1111/aec.12789
Bowman DMJS, Rodriguez-Cubillo D, Prior LD (2021) The 2016 Tasmanian Wilderness fires: fire regime shifts and climate change in a Gondwanan biogeographic refugium. In: Canadell JG, Jackson RB (eds) Ecosystem collapse and climate change. Springer, Cham, pp 133–153. https://doi.org/10.1007/978-3-030-71330-0_6
Bradstock RA (2010) A biogeographic model of fire regimes in Australia: current and future implications. Glob Ecol Biogeogr 19:145–158. https://doi.org/10.1111/j.1466-8238.2009.00512.x
Bradstock RA, Hammill KA, Collins L, Price O (2010) Effects of weather, fuel and terrain on fire severity in topographically diverse landscapes of south-eastern Australia. Landsc Ecol 25:607–619. https://doi.org/10.1007/s10980-009-9443-8
Breiman L (2001) Random Forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
Brosofske KD, Froese RE, Falkowski MJ, Banskota A (2014) A review of methods for mapping and prediction of inventory attributes for operational forest management. For Sci 60:733–756. https://doi.org/10.5849/forsci.12-134
Burnham KP, Anderson DR (2002) Model selection and multi-model inference (second edition). Springer-Verlag New York. https://doi.org/10.1007/b97636
Burrough PA (1995) Spatial aspects of ecological data. In: Ter Braak CJF, van Tongeren OFR, Jongman RHG (eds) Data analysis in community and landscape ecology. Cambridge University Press, pp 213–251. https://doi.org/10.1017/CBO9780511525575
Cai WJ, Wang GJ, Santoso A, McPhaden MJ, Wu LX, Jin FF, Timmermann A, Collins M, Vecchi G, Lengaigne M, England MH, Dommenget D, Takahashi K, Guilyardi E (2015) Increased frequency of extreme La Niña events under greenhouse warming. Nat Clim Change 5:132–137. https://doi.org/10.1038/Nclimate2492
Chai T, Draxler RR (2014) Root mean square error (RMSE) or mean absolute error (MAE)? - arguments against avoiding RMSE in the literature. Geosci Model Dev 7:1247–1250. https://doi.org/10.5194/gmd-7-1247-2014
Chen D, Loboda TV, Hall JV (2020) A systematic evaluation of influence of image selection process on remote sensing-based burn severity indices in North American boreal forest and tundra ecosystems. ISPRS J Photogramm Remote Sens 159:63–77. https://doi.org/10.1016/j.isprsjprs.2019.11.011
Clarke H, Trau B, Boer MM, Price O, Kenny B, Bradstock RA (2019) Climate change effects on the frequency, seasonality and interannual variability of suitable prescribed burning weather conditions in south-eastern Australia. Agric For Meteorol 271:148–157. https://doi.org/10.1016/j.agrformet.2019.03.005
Cochrane MA, Schulze MD (1999) Fire as a recurrent event in tropical forests of the eastern Amazon: effects on forest structure, biomass, and species composition. Biotropica 31:2–16. https://doi.org/10.1111/j.1744-7429.1999.tb00112.x
Collins L, Bradstock RA, Penman TD (2014) Can precipitation influence landscape controls on wildfire severity? A case study within temperate eucalypt forests of south-eastern Australia. Int J Wildland Fire 23:9–20. https://doi.org/10.1071/wf12184
Collins L, Griffioen P, Newell G, Mellor A (2018) The utility of Random Forests for wildfire severity mapping. Remote Sens Environ 216:374–384. https://doi.org/10.1016/j.rse.2018.07.005
Collins L, McCarthy G, Mellor A, Newell G, Smith L (2020) Training data requirements for fire severity mapping using Landsat imagery and Random Forest. Remote Sens Environ 245:111839. https://doi.org/10.1016/j.rse.2020.111839
Cruz MG, Sullivan AL, Gould JS, Sims NC, Bannister AJ, Hollis JJ, Hurley RJ (2012) Anatomy of a catastrophic wildfire: the Black Saturday Kilmore East fire in Victoria, Australia. For Ecol Manag 284:269–285. https://doi.org/10.1016/j.foreco.2012.02.035
Cutler DR, Edwards TC Jr, Beard KH, Cutler A, Hess KT, Gibson J, Lawler JJ (2007) Random Forests for classification in ecology. Ecology 88:2783–2792. https://doi.org/10.1890/07-0539.1
Di Virgilio G, Evans JP, Clarke H, Sharples JJ, Hirsch AL, Hart MA (2020) Climate change significantly alters future wildfire mitigation opportunities in southeastern Australia. Geophys Res Lett 47:e2020GL088893. https://doi.org/10.1029/2020gl088893
Díaz-Uriarte R, Alvarez de Andrés S (2006) Gene selection and classification of microarray data using Random Forest. BMC Bioinform 7:1–13. https://doi.org/10.1186/1471-2105-7-3
Dillon GK, Holden ZA, Morgan P, Crimmins MA, Heyerdahl EK, Luce CH (2011) Both topography and climate affected forest and woodland burn severity in two regions of the western US, 1984 to 2006. Ecosphere 2:1–33. https://doi.org/10.1890/es11-00271.1
Dimitrakopoulos AP, Bemmerzouk AM, Mitsopoulos ID (2011) Evaluation of the Canadian fire weather index system in an eastern Mediterranean environment. Meteorol Appl 18:83–93. https://doi.org/10.1002/met.214
DPIPWE (Department of Primary Industries, Water and Environment) (2017) Tasmania fire history (1967–2016). Tasmanian Government. Available upon request: geodata.clientservices@dpipwe.tas.gov.au
Eidenshink J, Schwind B, Brewer K, Zhu ZL, Quayle B, Howard S (2007) A project for monitoring trends in burn severity. Fire Ecol 3:3–21. https://doi.org/10.4996/fireecology.0301003
Epting J, Verbyla DL, Sorbel B (2005) Evaluation of remotely sensed indices for assessing burn severity in interior Alaska using Landsat TM and ETM+. Remote Sens Environ 96:328–339. https://doi.org/10.1016/j.rse.2005.03.002
EROS (Earth Resources Observation and Science) (2017–2020) EarthExplorer online database. United States Geological Survey. Accessed 31 March 2022: https://earthexplorer.usgs.gov
Escuin S, Navarro R, Fernández P (2008) Fire severity assessment by using NBR (Normalized Burn Ratio) and NDVI (Normalized Difference Vegetation Index) derived from LANDSAT TM/ETM images. Int J Remote Sens 29:1053–1073. https://doi.org/10.1080/01431160701281072
Espinosa J, Palheiro P, Loureiro C, Ascoli D, Esposito A, Fernandes PM (2019) Fire-severity mitigation by prescribed burning assessed from fire-treatment encounters in maritime pine stands. Can J For Res 49:205–211. https://doi.org/10.1139/cjfr-2018-0263
Estes BL, Knapp EE, Skinner CN, Miller JD, Preisler HK (2017) Factors influencing fire severity under moderate burning conditions in the Klamath Mountains, northern California, USA. Ecosphere 8:1–20. https://doi.org/10.1002/ecs2.1794
Evans JP, Di Virgilio G, Hirsch AL, Hoffmann P, Remedio AR, Ji F, Rockel B, Coppola E (2021) The CORDEX-Australasia ensemble: evaluation and future projections. Clim Dyn 57:1385–1401. https://doi.org/10.1007/s00382-020-05459-0
Fang L, Yang J, White M, Liu Z (2018) Predicting potential fire severity using vegetation, topography and surface moisture availability in a Eurasian boreal forest landscape. Forests 9:1–26. https://doi.org/10.3390/f9030130
Fernandes PM, Botelho HS (2003) A review of prescribed burning effectiveness in fire hazard reduction. Int J Wildland Fire 12:117–128. https://doi.org/10.1071/Wf02042
Fick SE, Hijmans RJ (2017) WorldClim version 2: new 1-km spatial resolution climate surfaces for global land areas. Int J Climatol 37:4302–4315. https://doi.org/10.1002/joc.5086
Flannigan MD, Cantin AS, de Groot WJ, Wotton M, Newbery A, Gowman LM (2013) Global wildland fire season severity in the 21st century. For Ecol Manag 294:54–61. https://doi.org/10.1016/j.foreco.2012.10.022
Fletcher MS, Wolfe BB, Whitlock C, Pompeani DP, Heijnis H, Haberle SG, Gadd PS, Bowman DMJS (2014) The legacy of mid-Holocene fire on a Tasmanian montane landscape. J Biogeogr 41:476–488. https://doi.org/10.1111/jbi.12229
Fox-Hughes P, Harris R, Lee G, Grose M, Bindoff N (2014) Future fire danger climatology for Tasmania, Australia, using a dynamically downscaled regional climate model. Int J Wildland Fire 23:309–321. https://doi.org/10.1071/Wf13126
French BJ, Prior LD, Williamson GJ, Bowman DMJS (2016) Cause and effects of a megafire in sedge-heathland in the Tasmanian temperate wilderness. Aust J Bot 64:513–525. https://doi.org/10.1071/bt16087
Furlaud JM, Williamson GJ, Bowman DMJS (2018) Simulating the effectiveness of prescribed burning at altering wildfire behaviour in Tasmania, Australia. Int J Wildland Fire 27:15–28. https://doi.org/10.1071/WF17061
García MJL, Caselles V (1991) Mapping burns and natural reforestation using thematic Mapper data. Geocarto Int 6:31–37. https://doi.org/10.1080/10106049109354290
García-Llamas P, Suárez-Seoane S, Taboada A, Fernández-Manso A, Quintano C, Fernández-García V, Fernández-Guisuraga JM, Macos E, Calvo L (2019) Environmental drivers of fire severity in extreme fire events that affect Mediterranean pine forest ecosystems. For Ecol Manag 433:24–32. https://doi.org/10.1016/j.foreco.2018.10.051
Geoscape Australia (2014) Administrative boundaries of Australia. Accessed 31 March 2022: https://geoscape.com.au/data/administrative-boundaries
Gerten D, Luo Y, Le Maire G, Parton WJ, Keough C, Weng E, Beier C, Ciais P, Cramer W, Dukes JS, Hanson PJ, Knapp AAK, Linder S, Nepstad DAN, Rustad L, Sowerby A (2008) Modelled effects of precipitation on ecosystem carbon and water dynamics in different climatic zones. Glob Chang Biol 14:2365–2379. https://doi.org/10.1111/j.1365-2486.2008.01651.x
Gibson R, Danaher T, Hehir W, Collins L (2020) A remote sensing approach to mapping fire severity in south-eastern Australia using Sentinel 2 and Random Forest. Remote Sens Environ 240:111702. https://doi.org/10.1016/j.rse.2020.111702
Goslee S (2019) Package landsat: radiometric and topographic correction of satellite imagery. R package. Accessed 31 March 2022: https://CRAN.R-project.org/package=landsat
Gouveia CM, Bastos A, Trigo RM, DaCamara CC (2012) Drought impacts on vegetation in the pre- and post-fire events over Iberian Peninsula. Nat Hazards Earth Syst Sci 12:3123–3137. https://doi.org/10.5194/nhess-12-3123-2012
Greenwell BM (2017) pdp: an R package for constructing partial dependence plots. R J 9:421–436. Accessed 31 March 2022: https://CRAN.R-project.org/package=pdp
Grose MR, Narsey S, Delage FP, Dowdy AJ, Bador M, Boschat G, Chung C, Kajtar JB, Rauniyar S, Freund MB, Lyu K, Rashid H, Zhang X, Wales S, Trenham C, Holbrook NJ, Cowan T, Alexander L, Arblaster JM, Power S (2020) Insights from CMIP6 for Australia’s future climate. Earth’s Future 8:e2019EF001469. https://doi.org/10.1029/2019EF001469
Harrell FE, Dupont C (2006) Package Hmisc. R package. Accessed 31 March 2022: https://CRAN.R-project.org/package=Hmisc
Hastie T, Tibshirani R (1986) Generalized additive models. Stat Sci 1:297–318. https://doi.org/10.2307/2289439
Hijmans RJ, Van Etten J (2015) Package raster: geographic data analysis and modeling. R package. Accessed 31 March 2022: https://CRAN.R-project.org/package=raster
Hoffmann WA, Geiger EL, Gotsch SG, Rossatto DR, Silva LC, Lau OL, Haridasan M, Franco AC (2012) Ecological thresholds at the savanna-forest boundary: how plant traits, resources and fire govern the distribution of tropical biomes. Ecol Lett 15:759–768. https://doi.org/10.1111/j.1461-0248.2012.01789.x
Holz A, Wood SW, Veblen TT, Bowman DMJS (2015) Effects of high-severity fire drove the population collapse of the subalpine Tasmanian endemic conifer Athrotaxis cupressoides. Glob Change Biol 21:445–458. https://doi.org/10.1111/gcb.12674
Hudak AT, Morgan P, Bobbitt MJ, Smith AMS, Lewis SA, Lentile LB, Robichaud PR, Clark JT, McKinley RA (2007) The relationship of multispectral satellite imagery to immediate fire effects. Fire Ecol 3:64–90. https://doi.org/10.4996/fireecology.0301064
Jackson WD (1968) Fire, air, water and earth - an elemental ecology of Tasmania. Proc Ecol Soc Austral 3:9–16
Jarman SJ, Kantvilas G, Brown MJ (1988) Buttongrass moorland in Tasmania. Research Report No 2. Tasmanian Forest Research Council. Hobart, Tasmania, Australia
Jones BM, Kolden CA, Jandt R, Abatzoglou JT, Urban F, Arp CD (2009) Fire behavior, weather, and burn severity of the 2007 Anaktuvuk River Tundra Fire, North Slope, Alaska. Arct Antarct Alp Res 41:309–316. https://doi.org/10.1657/1938-4246-41.3.309
Jordan GJ, Harrison PA, Worth JRP, Williamson GJ, Kirkpatrick JB (2016) Palaeoendemic plants provide evidence for persistence of open, well-watered vegetation since the Cretaceous. Glob Ecol Biogeogr 25:127–140. https://doi.org/10.1111/geb.12389
Kahiu MN, Hanan NP (2018) Fire in sub-Saharan Africa: the fuel, cure and connectivity hypothesis. Glob Ecol Biogeogr 27:946–957. https://doi.org/10.1111/geb.12753
Keeley JE (2009) Fire intensity, fire severity and burn severity: a brief review and suggested usage. Int J Wildland Fire 18:116–126. https://doi.org/10.1071/WF07049
Keith DA, McCaw WL, Whelan RJ (2002) Fire regimes in Australian heathlands and their effects on plants and animals. In: Bradstock RA, Williams JE, Gill AM (eds) Flammable Australia: the fire regimes and biodiversity of a continent. Cambridge University Press, pp 199–237
Key CH, Benson NC (2005) Landscape assessment: ground measure of severity, the Composite Burn Index; and remote sensing of severity, the Normalized Burn Ratio. FIREMON: fire effects monitoring and inventory system. United States Department of Agriculture. https://doi.org/10.2737/RMRS-GTR-164
King AD, Klingaman NP, Alexander LV, Donat MG, Jourdain NC, Maher P (2014) Extreme rainfall variability in Australia: patterns, drivers, and predictability. J Clim 27:6035–6050. https://doi.org/10.1175/Jcli-D-13-00715.1
King KJ, Bradstock RA, Cary GJ, Chapman J, Marsden-Smedley JB (2008) The relative importance of fine-scale fuel mosaics on reducing fire risk in south-west Tasmania, Australia. Int J Wildland Fire 17:421–430. https://doi.org/10.1071/Wf07052
King KJ, Cary GJ, Bradstock RA, Chapman J, Pyrke A, Marsden-Smedley JB (2006) Simulation of prescribed burning strategies in south-west Tasmania, Australia: effects on unplanned fires, fire regimes, and ecological management values. Int J Wildland Fire 15:527–540. https://doi.org/10.1071/WF05076
King KJ, Cary GJ, Bradstock RA, Marsden-Smedley JB (2013) Contrasting fire responses to climate and management: insights from two Australian ecosystems. Glob Chang Biol 19:1223–1235. https://doi.org/10.1111/gcb.12115
Körner C, Basler D, Hoch G, Kollas C, Lenz A, Randin CF, Vitasse Y, Zimmermann NE (2016) Where, why and how? Explaining the low-temperature range limits of temperate tree species. J Ecol 104:1076–1088. https://doi.org/10.1111/1365-2745.12574
Kosicki JZ (2020) Generalised additive models and Random Forest approach as effective methods for predictive species density and functional species richness. Environ Ecol Stat 27:273–292. https://doi.org/10.1007/s10651-020-00445-5
Kraaij T, Baard JA, Arndt J, Vhengani L, van Wilgen BW (2018) An assessment of climate, weather, and fuel factors influencing a large, destructive wildfire in the Knysna region, South Africa. Fire Ecol 14:1–12. https://doi.org/10.1186/s42408-018-0001-0
Kraaij T, Cowling RM, van Wilgen BW (2013) Lightning and fire weather in eastern coastal fynbos shrublands: seasonality and long-term trends. Int J Wildland Fire 22:288–295. https://doi.org/10.1071/wf11167
Kraaij T, van Wilgen BW (2014) Drivers, ecology, and management of fire in fynbos. In: Allsopp N, Colville JF, Verboom GA, Cowling RM (eds) Fynbos: ecology, evolution, and conservation of a megadiverse region. Oxford University Press, pp 47–72. https://doi.org/10.1093/acprof:oso/9780199679584.001.0001
Kramer HJ (2002) Observation of the Earth and its environment: survey of missions and sensors (fourth edition). Springer-Verlag Berlin Heidelberg. https://doi.org/10.1007/978-3-642-56294-5
Kruger FJ, Bigalke RC (1984) Fire in fynbos. In: Booysen PV, Tainton NM (eds) Ecological effects of fire in South African ecosystems. Springer-Verlag Berlin Heidelberg, pp 67–114. https://doi.org/10.1007/978-3-642-69805-7
Kupfer JA, Terando AJ, Gao P, Teske C, Hiers JK (2020) Climate change projected to reduce prescribed burning opportunities in the south-eastern United States. Int Wildland Fire 29:764–778. https://doi.org/10.1071/WF19198
Lehmann CE, Archibald SA, Hoffmann WA, Bond WJ (2011) Deciphering the distribution of the savanna biome. New Phytol 191:197–209. https://doi.org/10.1111/j.1469-8137.2011.03689.x
Lenihan JM, Drapek R, Bachelet D, Neilson RP (2003) Climate change effects on vegetation distribution, carbon, and fire in California. Ecol Appl 13:1667–1681. https://doi.org/10.1890/025295
Lentile LB, Holden ZA, Smith AMS, Falkowski MJ, Hudak AT, Morgan P, Lewis SA, Gessler PE, Benson NC (2006) Remote sensing techniques to assess active fire characteristics and post-fire effects. Int J Wildland Fire 15:319–345. https://doi.org/10.1071/Wf05097
Leonard SWJ, Bennett AF, Clarke MF (2014) Determinants of the occurrence of unburnt forest patches: potential biotic refuges within a large, intense wildfire in south-eastern Australia. For Ecol Manag 314:85–93. https://doi.org/10.1016/j.foreco.2013.11.036
Lindenmayer DB, Hobbs RJ, Likens GE, Krebs CJ, Banks SC (2011) Newly discovered landscape traps produce regime shifts in wet forests. Proc Natl Acad Sci USA 108:15887–15891. https://doi.org/10.1073/pnas.1110245108
Loschiavo J, Cirulis B, Zuo Y, Hradsky BA, Di Stefano J (2017) Mapping prescribed fire severity in south-east Australian eucalypt forests using modelling and satellite imagery: a case study. Int J Wildland Fire 26:491–497. https://doi.org/10.1071/wf16167
Love P, Remenyi T, Harris RMB, Bindoff NL (2019) Tasmanian Wilderness World Heritage Area Climate Change and Bushfire Research Initiative, Technical Report. Antarctic Climate and Ecosystems Cooperative Research Centre, Hobart, Tasmania, Australia. Accessed 31 March 2022: https://swift.rc.nectar.org.au/v1/AUTH_4a33cd0edb47438ca9029479f143496b/rd-rocftr/TWWHA%20Climate%20Change%20and%20Bushfire%20Research%20Initiative.pdf
Lucas C (2010) On developing a historical fire weather data-set for Australia. Aust Meteorol Oceanogr J 60:1–13. https://doi.org/10.22499/2.6001.001
Lüdecke D (2018) ggeffects: tidy data frames of marginal effects from regression models. J Open Source Softw 3:1–5. https://doi.org/10.21105/joss.00772
Marsden-Smedley JB (1998) Changes in Southwestern Tasmanian fire regimes since the early 1800s. Pap Proc R Soc Tasmania 132:15–29. https://doi.org/10.26749/rstpp.132.15
Marsden-Smedley JB, Rudman T, Pyrke A, Catchpole WR (1999) Buttongrass moorland fire-behaviour prediction and management. Tasforests 11:87–99
Martin RE, Sapsis DB (1992) Fires as agents of biodiversity: pyrodiversity promotes biodiversity. Proceedings of Symposium on Biodiversity of Northwestern California, October 28–30, 1991, Santa Rosa, California, pp 150–157. Accessed 31 March 2022: https://www.sierraforestlegacy.org/Resources/Conservation/FireForestEcology/FireScienceResearch/FireEcology/FireEcology-Martin91.pdf
Matin MA, Chitale VS, Murthy MSR, Uddin K, Bajracharya B, Pradhan S (2017) Understanding forest fire patterns and risk in Nepal using remote sensing, geographic information system and historical fire data. Int J Wildland Fire 26:276–286. https://doi.org/10.1071/Wf16056
McBratney AB, Webster R (1986) Choosing functions for semi-variograms of soil properties and fitting them to sampling estimates. J Soil Sci 37:617–639. https://doi.org/10.1111/j.1365-2389.1986.tb00392.x
McCaw LW, Gould JS, Cheney PN, Ellis PFM, Anderson WR (2012) Changes in behaviour of fire in dry eucalypt forest as fuel increases with age. For Ecol Manag 271:170–181. https://doi.org/10.1016/j.foreco.2012.02.003
McColl-Gausden SC, Penman TD (2019) Pathways of change: predicting the effects of fire on flammability. J Environ Manage 232:243–253. https://doi.org/10.1016/j.jenvman.2018.11.063
Miller JD, Collins BM, Lutz JA, Stephens SL, van Wagtendonk JW, Yasuda DA (2012) Differences in wildfires among ecoregions and land management agencies in the Sierra Nevada region, California, USA. Ecosphere 3:1–20. https://doi.org/10.1890/Es12-00158.1
Miller JD, Thode AE (2007) Quantifying burn severity in a heterogeneous landscape with a relative version of the delta Normalized Burn Ratio (dNBR). Remote Sens Environ 109:66–80. https://doi.org/10.1016/j.rse.2006.12.006
Mitsopoulos I, Chrysafi I, Bountis D, Mallinis G (2019) Assessment of factors driving high fire severity potential and classification in a Mediterranean pine ecosystem. J Environ Manage 235:266–275. https://doi.org/10.1016/j.jenvman.2019.01.056
Murphy KA, Reynolds JH, Koltun JM (2008) Evaluating the ability of the differenced Normalized Burn Ratio (dNBR) to predict ecologically significant burn severity in Alaskan boreal forests. Int J Wildland Fire 17:490–499. https://doi.org/10.1071/Wf08050
Murray-Tortarolo G, Jaramillo VJ, Maass M, Friedlingstein P, Sitch S (2017) The decreasing range between dry- and wet- season precipitation over land and its effect on vegetation primary productivity. PLoS ONE 12:e0190304. https://doi.org/10.1371/journal.pone.0190304
Myint SW, Gober P, Brazel A, Grossman-Clarke S, Weng QH (2011) Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens Environ 115:1145–1161. https://doi.org/10.1016/j.rse.2010.12.017
Navarro D (2015) Package lsr: companion to “Learning Statistics with R”. R package. Accessed 31 March 2022: https://CRAN.R-project.org/package=lsr
Ndalila M, Williamson GJ, Bowman DMJS (2018) Geographic patterns of fire severity following an extreme Eucalyptus forest fire in southern Australia: 2013 Forcett-Dunalley Fire. Fire 1:40. https://doi.org/10.3390/fire1030040
Nicholls N, Lucas C (2007) Interannual variations of area burnt in Tasmanian bushfires: relationships with climate and predictability. Int J Wildland Fire 16:540–546. https://doi.org/10.1071/WF06125
O’Donnell AJ, Renton M, Allen KJ, Grierson PF (2021) Tree growth responses to temporal variation in rainfall differ across a continental-scale climatic gradient. PLoS ONE 16:e0249959. https://doi.org/10.1371/journal.pone.0249959
Parks SA, Abatzoglou JT (2020) Warmer and drier fire seasons contribute to increases in area burned at high severity in Western US forests from 1985 to 2017. Geophys Res Lett 47:22. https://doi.org/10.1029/2020GL089858
Parks SA, Dillon GK, Miller C (2014) A new metric for quantifying burn severity: the relativized burn ratio. Remote Sens 6:1827–1844. https://doi.org/10.3390/rs6031827
Parks SA, Holsinger LM, Miller C, Parisien MA (2018) Analog-based fire regime and vegetation shifts in mountainous regions of the western US. Ecography 4:910–921. https://doi.org/10.1111/ecog.03378
Pausas JG, Bradstock RA (2007) Fire persistence traits of plants along a productivity and disturbance gradient in Mediterranean shrublands of south-east Australia. Glob Ecol Biogeogr 16:330–340. https://doi.org/10.1111/j.1466-8238.2006.00283.x
Pebesma EJ (2004) Multivariable geostatistics in S: the gstat package. Comput Geosci 30:683–691. https://doi.org/10.1016/j.cageo.2004.03.012
Pebesma EJ (2018) Simple features for R: standardized support for spatial vector data. R J 10:439–446. R package. Accessed 31 March 2022: https://CRAN.R-project.org/package=sf
Pedersen EJ, Miller DL, Simpson GL, Ross N (2019) Hierarchical generalized additive models in ecology: an introduction with mgcv. PeerJ 7:1–42. https://doi.org/10.7717/peerj.6876
Perperoglou A, Sauerbrei W, Abrahamowicz M, Schmid M (2019) A review of spline function procedures in R. BMC Med Res Methodol 19:19–46. https://doi.org/10.1186/s12874-019-0666-3
Perry JJ, Cook GD, Graham E, Meyer CP, Murphy HT, VanDerWal J (2020) Regional seasonality of fire size and fire weather conditions across Australia’s northern savanna. Int J Wildland Fire 29:1–10. https://doi.org/10.1071/Wf19031
Prasad VK, Anuradha E, Badarinath KV (2005) Climatic controls of vegetation vigor in four contrasting forest types of India - evaluation from National Oceanic and Atmospheric Administration’s Advanced Very High Resolution Radiometer datasets (1990–2000). Int J Biometeorol 50:6–16. https://doi.org/10.1007/s00484-005-0268-0
Press AJ (2016) Tasmanian Wilderness World Heritage Area bushfire and climate change research project. Tasmanian Government, Hobart, Tasmania, Australia. Accessed 31 March 2022: http://www.dpac.tas.gov.au/divisions/climatechange/Climate_Change_Priorities/climate_risks_and_opportunities/bushfire_research_project
QGIS Development Team (2020) QGIS version 3.10.6-A Coruna. Open Source Geospatial Foundation Project. Accessed 31 March 2022: https://gisenglish.geojamal.com/2019/11/download-qgis-310-coruna-nov-2019.html
R Core Team (2020) The R Project for Statistical Computing. Accessed 31 March 2022: https://www.r-project.org
Reichstein M, Camps-Valls G, Stevens B, Jung M, Denzler J, Carvalhais N, Prabhat, (2019) Deep learning and process understanding for data-driven Earth system science. Nature 566:195–204. https://doi.org/10.1038/s41586-019-0912-1
Reid JB, Hill RS, Brown MJ, Hovenden MJ (2005) Vegetation of Tasmania (reprint 1999). Australian Biological Resources Study.
Risbey JS, Pook MJ, McIntosh PC (2013) Spatial trends in synoptic rainfall in southern Australia. Geophys Res Lett 40:3781–3785. https://doi.org/10.1002/grl.50739
Risbey JS, Pook MJ, McIntosh PC, Wheeler MC, Hendon HH (2009) On the remote drivers of rainfall variability in Australia. Mon Weather Rev 137:3233–3253. https://doi.org/10.1175/2009mwr2861.1
Rodriguez-Cubillo D, Prior LD, Bowman DMJS (2020) Variation in Eucalyptus delegatensis post-fire recovery strategies: the Tasmanian subspecies is a resprouter whereas the mainland Australian subspecies is an obligate seeder. For Ecol Manag 473:118292. https://doi.org/10.1016/j.foreco.2020.118292
Romanin LM, Hopf F, Haberle SG, Bowman DMJS (2016) Fire regime and vegetation change in the transition from Aboriginal to European land management in a Tasmanian eucalypt savanna. Aust J Bot 64:427–440. https://doi.org/10.1071/BT16032
Romme WH, Boyce MS, Gresswell R, Merrill EH, Minshall GW, Whitlock C, Turner MG (2011) Twenty years after the 1988 Yellowstone fires: lessons about disturbance and ecosystems. Ecosystems 14:1196–1215. https://doi.org/10.1007/s10021-011-9470-6
Sá ACL, Turkman MAA, Pereira JMC (2018) Exploring fire incidence in Portugal using generalized additive models for location, scale and shape (GAMLSS). Model Earth Syst Environ 4:199–220. https://doi.org/10.1007/s40808-017-0409-6
Sandri M, Zuccolotto P (2008) A bias correction algorithm for the Gini variable importance measure in classification trees. J Comput Graph Stat 17:611–628. https://doi.org/10.1198/106186008x344522
Sankaran M, Hanan NP, Scholes RJ, Ratnam J, Augustine DJ, Cade BS, Gignoux J, Higgins SI, Le Roux X, Ludwig F, Ardo J, Banyikwa F, Bronn A, Bucini G, Caylor KK, Coughenour MB, Diouf A, Ekaya W, Feral CJ, February EC, Frost PG, Hiernaux P, Hrabar H, Metzger KL, Prins HH, Ringrose S, Sea W, Tews J, Worden J, Zambatis N (2005) Determinants of woody cover in African savannas. Nature 438:846–849. https://doi.org/10.1038/nature04070
Schepers L, Haest B, Veraverbeke S, Spanhove T, Vanden Borre J, Goossens R (2014) Burned area detection and burn severity assessment of a heathland fire in Belgium using airborne imaging spectroscopy (APEX). Remote Sens 6:1803–1826. https://doi.org/10.3390/rs6031803
Sharples JJ, Mills GA, Mcrae RHD, Weber RO (2010) Foehn-like winds and elevated fire danger conditions in southeastern Australia. J Appl Meteorol Climatol 49:1067–1095. https://doi.org/10.1175/2010jamc2219.1
Silva PS, Bastos A, Libonati R, Rodrigues JA, DaCamara CC (2019) Impacts of the 1.5 °C global warming target on future burned area in the Brazilian cerrado. For Ecol Manag 446:193–203. https://doi.org/10.1016/j.foreco.2019.05.047
Smith AMS, Wooster MJ, Drake NA, Dipotso FM, Falkowski MJ, Hudak AT (2005) Testing the potential of multi-spectral remote sensing for retrospectively estimating fire severity in African savannahs. Remote Sens Environ 97:92–115. https://doi.org/10.1016/j.rse.2005.04.014
Strydom S, Savage MJ (2017) Potential impacts of climate change on wildfire dynamics in the midlands of KwaZulu-Natal, South Africa. Clim Change 143:385–397. https://doi.org/10.1007/s10584-017-2019-8
Styger J, Marsden-Smedley JB, Kirkpatrick JB (2018) Changes in lightning fire incidence in the Tasmanian Wilderness World Heritage Area, 1980–2016. Fire 1:38. https://doi.org/10.3390/fire1030038
Su CH, Eizenberg N, Steinle P, Jakob D, Fox-Hughes P, White CJ, Rennie S, Franklin C, Dharssi I, Zhu HY (2019) BARRA v1.0: the Bureau of Meteorology Atmospheric high-resolution Regional Reanalysis for Australia. Geosci Model Dev 12:2049–2068. https://doi.org/10.5194/gmd-12-2049-2019
Szpakowski DM, Jensen JLR (2019) A review of the applications of remote sensing in fire ecology. Remote Sens 11:1–31. https://doi.org/10.3390/rs11222638
Taylor AH, Harris LB, Drury SA (2021) Drivers of fire severity shift as landscapes transition to an active fire regime, Klamath Mountains, USA. Ecosphere 12:9. https://doi.org/10.1002/ecs2.3734
Taylor C, McCarthy MA, Lindenmayer DB (2014) Nonlinear effects of stand age on fire severity. Conserv Lett 7:355–370. https://doi.org/10.1111/conl.12122
The LIST (Land Information System Tasmania) (2003) Tasmanian hydrographic area dataset. Tasmanian Government. Accessed 31 March 2022: https://data.thelist.tas.gov.au/datagn/srv/eng/main.home?uuid=1df4ff66-4bad-4a5b-97b6-dd26a85eab03
The LIST (Land Information System Tasmania) (2005) 1:500,000 dominant soil orders of Tasmania using Land System boundaries. Tasmanian Government. Accessed 31 March 2022: https://data.thelist.tas.gov.au/datagn/srv/eng/main.home?uuid=87e87ea0-ad62-4c59-b09d-6ffa14c9740b
The LIST (Land Information System Tasmania) (2010) Tasmania 25-m Digital Elevation Model. Tasmanian Government. Accessed 31 March 2022: https://data.thelist.tas.gov.au/datagn/srv/eng/main.home?uuid=47b71113-a99d-4a9c-82c0-ba92c8313e79
The LIST (Land Information System Tasmania) (2011) Tasmania transport segments dataset. Tasmanian Government Accessed 31 March 2022: https://data.thelist.tas.gov.au/datagn/srv/eng/main.home?uuid=1ab7e34f-811c-4521-a549-212f295acc97
The LIST (Land Information System Tasmania) (2012) Tasmania land tenure archived dataset. Tasmanian Government. Available upon request: geodata.clientservices@dpipwe.tas.gov.au
The LIST (Land Information System Tasmania) (2013) TASVEG, version 3.0. Tasmanian Vegetation Monitoring and Mapping Program, Resource Management and Conservation Division. Tasmanian Government. Accessed 31 March 2022: https://data.thelist.tas.gov.au/datagn/srv/eng/main.home?uuid=6e3d672d-cdc1-40f3-8ee4-b45c5de68b68
The LIST (Land Information System Tasmania) (2015) Tasmania land tenure dataset. Tasmanian Government. Accessed 31 March 2022: https://data.thelist.tas.gov.au/datagn/srv/eng/main.home?uuid=9b8bf099-d668-433d-981b-a0f8f964f827
Tolhurst KG, McCarthy G (2016) Effect of prescribed burning on wildfire severity: a landscape-scale case study from the 2003 fires in Victoria. Aus For 79:1–14. https://doi.org/10.1080/00049158.2015.1127197
Tran BN, Tanase MA, Bennett LT, Aponte C (2018) Evaluation of spectral indices for assessing fire severity in Australian temperate forests. Remote Sens 10:1680. https://doi.org/10.3390/rs10111680
Trauernicht C (2019) Vegetation-rainfall interactions reveal how climate variability and climate change alter spatial patterns of wildland fire probability on Big Island. Hawaii Sci Total 650:459–469. https://doi.org/10.1016/j.scitotenv.2018.08.347
USGS (United States Geological Survey) (2019) Landsat collection 1 level 1 product definition (version 2.0). Accessed 31 March 2022: https://www.usgs.gov/media/files/landsat-collection-1-level-1-product-definition
USGS (United States Geological Survey) (2021a) Landsat known issues. Accessed 31 March 2022: https://www.usgs.gov/core-science-systems/nli/landsat/landsat-known-issues
USGS (United States Geological Survey) (2021b) Landsat missions. Accessed 31 March 2022: https://www.usgs.gov/core-science-systems/nli/landsat
USGS (United States Geological Survey) (2021c) Landsat collection 1 level-1 quality assessment band. Accessed 31 March 2022: https://www.usgs.gov/core-science-systems/nli/landsat/landsat-collection-1-level-1-quality-assessment-band?qt-science_support_page_related_con=0#qt-science_support_page_related_con
Van der Werf GR, Randerson JT, Giglio L, Gobron N, Dolman AJ (2008) Climate controls on the variability of fires in the tropics and subtropics. Glob Biogeochem Cycles 22:GB3028. https://doi.org/10.1029/2007gb003122
Van Wagtendonk JW, Lutz JA (2007) Fire regime attributes of wildland fires in Yosemite National Park, USA. Fire Ecol 3:34–52. https://doi.org/10.4996/fireecology.0302034
Veraverbeke S, Lhermitte S, Verstraeten WW, Goossens R (2011) Evaluation of pre/post-fire differenced spectral indices for assessing burn severity in a Mediterranean environment with Landsat Thematic Mapper. Int J Remote Sens 32:3521–3537. https://doi.org/10.1080/01431161003752430
Viedma O, Chico F, Fernandez JJ, Madrigal C, Safford HD, Moreno JM (2020) Disentangling the role of prefire vegetation vs. burning conditions on fire severity in a large forest fire in SE Spain. Remote Sens Environ 247:111891. https://doi.org/10.1016/j.rse.2020.111891
Whinam J, Hope GS, Clarkson BR, Buxton RP, Alspach PA, Adam P (2003) Sphagnum in peatlands of Australasia: their distribution, utilisation and management. Wetl Ecol Manag 11:37–49. https://doi.org/10.1023/A:1022005504855
White JD, Ryan KC, Key CC, Running SW (1996) Remote sensing of forest fire severity and vegetation recovery. Int J Wildland Fire 6:125–136. https://doi.org/10.1071/Wf9960125
Willmott CJ, Matsuura K (2005) Advantages of the Mean Absolute Error (MAE) over the Root Mean Square Error (RMSE) in assessing average model performance. Clim Res 30:79–82. https://doi.org/10.3354/cr030079
Wood LK, Hays S, Zinnert JC (2020) Decreased temperature variance associated with biotic composition enhances coastal shrub encroachment. Sci Rep 10:8210. https://doi.org/10.1038/s41598-020-65161-3
Wood SN (2015) Package mgcv: mixed GAM computation vehicle with automatic smoothness estimation. R package. Accessed 31 March 2022: https://CRAN.R-project.org/package=mgcv
Wood SN (2017) Generalized additive models: an introduction with R (second edition). Chapman and Hall/CRC. https://doi.org/10.1201/9781315370279
Wood SW, Bowman DMJS (2012) Alternative stable states and the role of fire-vegetation-soil feedbacks in the temperate wilderness of southwest Tasmania. Landsc Ecol 27:13–28. https://doi.org/10.1007/s10980-011-9677-0
World Heritage Committee (2016) Decision: 40 COM 7B.66 Tasmanian Wilderness (Australia). 40th session of the World Heritage Committee (Istanbul/UNESCO). Accessed 31 March 2022: https://whc.unesco.org/en/decisions/6731
Wright MN, Ziegler A (2017) ranger: a fast implementation of Random Forests for high dimensional data in C++ and R. J Stat Softw 77:1–17. https://doi.org/10.18637/jss.v077.i01
Wulder MA, Loveland TR, Roy DP, Crawford CJ, Masek JG, Woodcock CE, Allen RG, Anderson MC, Belward AS, Cohen WB, Dwyer J, Erb A, Gao F, Griffiths P, Helder D, Hermosillo T, Hipple JD, Hostert P, Hughes MJ, Huntington J, Johnson DM, Kennedy R, Kilic A, Li Z, Lymburner L, McCorkel J, Pahlevan N, Scambos TA, Schaaf C, Schott JR, Sheng YW, Storey J, Vermote E, Vogelmann J, White JC, Wynne RH, Zhu Z (2019) Current status of Landsat program, science, and applications. Remote Sens Environ 225:127–147. https://doi.org/10.1016/j.rse.2019.02.015
Yee TW, Mitchell ND (1991) Generalized additive models in plant ecology. J Veg Sci 2:587–602. https://doi.org/10.2307/3236170
Zedler PH, Gautier CR, McMaster GS (1983) Vegetation change in response to extreme events: the effect of a short interval between fires in California chaparral and coastal scrub. Ecology 64:809–818. https://doi.org/10.2307/1937204
Zeppel MJB, Wilks JV, Lewis JD (2014) Impacts of extreme precipitation and seasonal changes in precipitation on plants. Biogeosciences 11:3083–3093. https://doi.org/10.5194/bg-11-3083-2014
Zhu Z, Key CH, Ohlen D, Benson NC (2006) Evaluate sensitivities of burn-severity mapping algorithms for different ecosystems and fire histories in the United States. United States Department of Agriculture. Accessed 31 March 2022: https://www.researchgate.net/profile/Nate-Benson/publication/241687869_Evaluate_Sensitivities_of_Burn-Severity_Mapping_Algorithms_for_Different_Ecosystems_and_Fire_Histories_in_the_United_States/links/5641440208aec448fa607286/Evaluate-Sensitivities-of-Burn-Severity-Mapping-Algorithms-for-Different-Ecosystems-and-Fire-Histories-in-the-United-States.pdf
Acknowledgements
David Bowman initiated this project in 2017 and helped with the design. Mingxin Liu provided comments in the first version of the manuscript. We are thankful to the Tasmania Fire Service for providing end-user support, and the Department of Primary Industries, Parks, Water and Environment for access to the fire history dataset. We thank two anonymous reviewers for their comments, helping us improve earlier drafts of the manuscript.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. DRC was supported by funds from the University of Tasmania and the Bushfires and Natural Hazards Cooperative Research Centre (Melbourne, Australia). GJW is supported by the NSW Bushfire Risk Management Research Hub.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rodriguez-Cubillo, D., Jordan, G.J. & Williamson, G.J. Using Multi-decadal Satellite Records to Identify Environmental Drivers of Fire Severity Across Vegetation Types. Remote Sens Earth Syst Sci 5, 165–184 (2022). https://doi.org/10.1007/s41976-022-00070-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41976-022-00070-9