
Abstract
Two geometrical structures have been extensively studied for a manifold of probability distributions. One is based on the Fisher information metric, which is invariant under reversible transformations of random variables, while the other is based on the Wasserstein distance of optimal transportation, which reflects the structure of the distance between underlying random variables. Here, we propose a new information-geometrical theory that provides a unified framework connecting the Wasserstein distance and Kullback–Leibler (KL) divergence. We primarily considered a discrete case consisting of n elements and studied the geometry of the probability simplex \(S_{n-1}\), which is the set of all probability distributions over n elements. The Wasserstein distance was introduced in \(S_{n-1}\) by the optimal transportation of commodities from distribution \({\varvec{p}}\) to distribution \({\varvec{q}}\), where \({\varvec{p}}\), \({\varvec{q}} \in S_{n-1}\). We relaxed the optimal transportation by using entropy, which was introduced by Cuturi. The optimal solution was called the entropy-relaxed stochastic transportation plan. The entropy-relaxed optimal cost \(C({\varvec{p}}, {\varvec{q}})\) was computationally much less demanding than the original Wasserstein distance but does not define a distance because it is not minimized at \({\varvec{p}}={\varvec{q}}\). To define a proper divergence while retaining the computational advantage, we first introduced a divergence function in the manifold \(S_{n-1} \times S_{n-1}\) composed of all optimal transportation plans. We fully explored the information geometry of the manifold of the optimal transportation plans and subsequently constructed a new one-parameter family of divergences in \(S_{n-1}\) that are related to both the Wasserstein distance and the KL-divergence.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Information geometry [1] studies the properties of a manifold of probability distributions and is useful for various applications in statistics, machine learning, signal processing, and optimization. Two geometrical structures have been introduced from two distinct backgrounds. One is based on the invariance principle, where the geometry is invariant under reversible transformations of random variables. The Fisher information matrix, for example, is a unique invariant Riemannian metric from the invariance principle [1,2,3]. Moreover, two dually coupled affine connections are used as invariant connections [1, 4], which are useful in various applications.
The other geometrical structure was introduced through the transportation problem, where one distribution of commodities is transported to another distribution. The minimum transportation cost defines a distance between the two distributions, which is called the Wasserstein, Kantorovich or earth-mover distance [5, 6]. This structure provides a tool to study the geometry of distributions by taking the metric of the supporting manifold into account.
Let \(\chi = \left\{ 1, \ldots , n \right\} \) be the support of a probability measure \({\varvec{p}}\). The invariant geometry provides a structure that is invariant under permutations of elements of \(\chi \) and results in an efficient estimator in statistical estimation. On the other hand, when we consider a picture over \(n^2\) pixels \(\chi = \left\{ (ij); i, j=1, \ldots , n \right\} \) and regard it as a distribution over \(\chi \), the pixels have a proper distance structure in \(\chi \). Spatially close pixels tend to take similar values. A permutation of \(\chi \) destroys such a neighboring structure, suggesting that the invariance might not play a useful role. The Wasserstein distance takes such a structure into account and is therefore useful for problems with metric structure in support \(\chi \) (see, e.g., [7,8,9]).
An interesting question is how these two geometrical structures are related. While both are important in their own respects, it would be intriguing to construct a unified framework that connects the two. With this purpose in mind, we examined the discrete case over n elements, such that a probability distribution is given by a probability vector \({\varvec{p}}=(p,\ldots , p_n)\) in the probability simplex
It is easy to naively extend our theory to distributions over \({\varvec{R}^n}\), ignoring mathematical difficulties of geometry of function spaces. See Ay et al. [4] for details. We consider Gaussian distributions over the one-dimensional real line X as an example of the continuous case.
Cuturi modified the transportation problem such that the cost is minimized under an entropy constraint [7]. This is called the entropy-relaxed optimal transportation problem and is computationally less demanding than the original transportation problem. In addition to the advantage in computational cost, Cuturi showed that the quasi-distance defined by the entropy-relaxed optimal solution yields superior results in many applications compared to the original Wasserstein distance and information-geometric divergences such as the KL divergence.
We followed the entropy-relaxed framework that Cuturi et al. proposed [7,8,9] and introduced a Lagrangian function, which is a linear combination of the transportation cost and entropy. Given a distribution \({\varvec{p}}\) of commodity on the senders side and \({\varvec{q}}\) on the receivers side, the constrained optimal transportation plan is the minimizer of the Lagrangian function. The minimum value \(C({\varvec{p}}, {\varvec{q}})\) is a function of \({\varvec{p}}\) and \({\varvec{q}}\), which we called the Cuturi function. However, this does not define the distance between \({\varvec{p}}\) and \({\varvec{q}}\) because it is non-zero at \({\varvec{p}} = {\varvec{q}}\) and is not minimized when \({\varvec{p}}\) = \({\varvec{q}}\).
To define a proper distance-like function in \(S_{n-1}\), we introduced a divergence between \({\varvec{p}}\) and \({\varvec{q}}\) derived from the optimal transportation plan. A divergence is a general metric concept that includes the square of a distance but is more flexible, allowing non-symmetricity between \({\varvec{p}}\) and \({\varvec{q}}\). A manifold equipped with a divergence yields a Riemannian metric with a pair of dual affine connections. Dually coupled geodesics are defined, which possess remarkable properties, generalizing the Riemannian geometry [1].
We studied the geometry of the entropy-relaxed optimal transportation plans within the framework of information geometry. They form an exponential family of probability distributions defined in the product manifold \(S_{n-1} \times S_{n-1}\). Therefore, a dually flat structure was introduced. The m-flat coordinates are the expectation parameters \(({\varvec{p}}, {\varvec{q}})\) and their dual, e-flat coordinates (canonical parameters) are \(({\varvec{\alpha }}, {\varvec{\beta }})\), which are assigned from the minimax duality of nonlinear optimization problems. We can naturally defined a canonical divergence, that is the KL divergence \(KL[({\varvec{p}}, {\varvec{q}}) : ({\varvec{p}'}, {\varvec{q}'})]\) between the two optimal transportation plans for \(({\varvec{p}}, {\varvec{q}})\) and \(({\varvec{p}'}, {\varvec{q}'})\), sending \({\varvec{p}}\) to \({\varvec{q}}\) and \({\varvec{p}'}\) to \({\varvec{q}'}\), respectively.
To define a divergence from \({\varvec{p}}\) to \({\varvec{q}}\) in \(S_{n-1}\), we used a reference distribution \(\varvec{r}\). Given \(\varvec{r}\), we defined a divergence between \({\varvec{p}}\) and \({\varvec{q}}\) by \(KL[({\varvec{r}}, {\varvec{p}}) : ({\varvec{r}}, {\varvec{q}})]\). There are a number of potential choices for \(\varvec{r}\): one is to use \({\varvec{r}} = {\varvec{p}}\) and another is to use the arithmetic or geometric mean of \({\varvec{p}}\) and \({\varvec{q}}\). These options yield one-parameter families of divergences connecting the Wasserstein distance and KL-divergence. Our work uncovers a novel direction for studying the geometry of a manifold of probability distributions by integrating the Wasserstein distance and KL divergence.
2 Entropy-constrained transportation problem
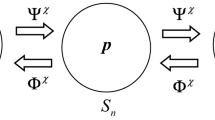
Let us consider n terminals \(\chi = \left( X_1, \ldots , X_n \right) \), some of which, say \(X_1, \ldots , X_s\), are sending terminals at which \(p_1, \ldots , p_s\) (\(p_i > 0\)) amounts of commodities are stocked. At the other terminals, \(X_{s+1}, \ldots , X_n\), no commodities are stocked (\(p_i=0\)). These are transported within \(\chi \) such that \(q_1, \ldots , q_r\) amounts are newly stored at the receiving terminals \(X_{j_1}, \ldots , X_{j_r}\). There may be overlap in the sending and receiving terminals, \(\chi _S = \left\{ X_1, \ldots , X_s \right\} \) and \(\chi _R = \left\{ X_{j_1}, \ldots , X_{j_r} \right\} \), including the case that \(\chi _R=\chi _S=\chi \) (Fig. 1). We normalized the total amount of commodities to be equal to 1 so that \({\varvec{p}}=\left( p_1, \ldots , p_s\right) \) and \({\varvec{q}}= \left( q_1, \ldots , q_r \right) \) can be regarded as probability distributions in the probability simplex \(S_{s-1}\) and \(S_{r-1}\), respectively,
Let \(S_{n-1}\) be the probability simplex over \(\chi \). Then \(S_{s-1} \subset \bar{S}_{n-1}\), \(S_{r-1} \subset \bar{S}_{n-1}\), where \(\bar{S}_{n-1}\) is the closure of \(S_{n-1}\),

Transportation from the sending terminals \(\chi _S\) to the receiving terminals \(\chi _R\)
It should be noted that if some components of \(\varvec{p}\) and \(\varvec{q}\) are allowed to be 0, we do not need to treat \(\chi _S\) and \(\chi _R\) separately, i.e., we can consider both \(\chi _S\) and \(\chi _R\) to be equal to \(\chi \). Under such a situation, we simply considered both \(\varvec{p}\) and \(\varvec{q}\) as elements of \(\bar{S}_{n-1}\).
We considered a transportation plan \({\mathbf{P}}=\left( P_{ij}\right) \) denoted by an \(s \times r\) matrix, where \(P_{ij} \ge 0\) is the amount of commodity transported from \(X_i \in \chi _S\) to \(X_j \in \chi _R\). The plan \(\mathbf{P}\) was regarded as a (probability) distribution of commodities flowing from \(X_i\) to \(X_j\), satisfying the sender and receivers conditions,
We denoted the set of \(\mathbf{P}\) satisfying Eq. (4) as \(U({\varvec{p}}, {\varvec{q}})\).
Let \(\mathbf{M}=\left( m_{ij}\right) \) be the cost matrix, where \(m_{ij} \ge 0\) denotes the cost of transporting one unit of commodity from \(X_i\) to \(X_j\). We can interpret \(m_{ij}\) as a generalized distance between \(X_i\) and \(X_j\). The transportation cost of plan \(\mathbf{P}\) is
The Wasserstein distance between \({\varvec{p}}\) and \({\varvec{q}}\) is the minimum cost of transporting commodities distributed by \({\varvec{p}}\) at the senders to \({\varvec{q}}\) at the receivers side,
where min is taken over all \(\mathbf{P}\) satisfying the constraints in Eq. (4) [5, 6].
We considered the joint entropy of \(\mathbf{P}\),
Given marginal distributions \({\varvec{p}}\) and \({\varvec{q}}\), the plan that maximizes the entropy is given by the direct product of \({\varvec{p}}\) and \({\varvec{q}}\),
This is because the entropy of \(\mathbf{P}_D\),
is the maximum among all possible \(\mathbf{P}\) belonging to \(U({\varvec{p}}, {\varvec{q}})\), i.e.,
where \(H(\mathbf{P})\), \(H({\varvec{p}})\) and \(H({\varvec{q}})\) are the entropies of the respective distributions.
We consider the constrained problem of searching for \(\mathbf{P}\) that minimizes \(\langle \mathbf{M}, \mathbf{P} \rangle \) under the constraint \(H(\mathbf{P}) \ge \text{ const }\). This is equivalent to imposing the condition that \(\mathbf{P}\) lies within a KL-divergence ball centered at \(\mathbf{P}_D\),
for constant d, because the KL-divergence from plan \(\mathbf{P}\) to \(\mathbf{P}_D\) is
The entropy of \(\mathbf{P}\) increases within the ball as d increases. Therefore, this is equivalent to the entropy constrained problem that minimizes a linear combination of the transportation cost \(\langle \mathbf{M}, \mathbf{P} \rangle \) and entropy \(H(\mathbf{P})\),
for constant \(\lambda \) [7]. Here, \(\lambda \) is regarded as a Lagrangian multiplier for the entropy constraint and \(\lambda \) becomes smaller as d becomes larger.
3 Solution to the entropy-constrained problem: Cuturi function
Let us fix \(\lambda \) as a parameter controlling the magnitude of the entropy or the size of the KL-ball. When \(\mathbf{P}\) satisfies the constraints in Eq. (4), minimization of Eq. (13) is formulated in the Lagrangian form by using Lagrangian multipliers \({\alpha }_i\), \({\beta }_j\),
where \(\lambda \) in (13) is slightly modified. By differentiating Eq. (14) with respect to \(P_{ij}\), we have
By setting the above derivatives equal to 0, we have the following solution,
Let us put
Then, the optimal solution is written as
where \(a_i\) and \(b_j\) are positive and correspond to the Lagrangian multipliers \(\alpha _i\) and \(\beta _j\) to be determined from the constraints [Eq. (4)]. c is the normalization constant. Since \(r+s\) constraints [Eq. (4)] are not independent because of the conditions that \(\sum p_i = 1\) and \(\sum q_{j}=1\), we can use \(b_r=1\). Further, we noted that \(\mu {\varvec{a}}\) and \({\varvec{b}}/\mu \) yield the same answer for any \(\mu >0\), where \({\varvec{a}}=\left( a_i \right) \) and \({\varvec{b}}= \left( b_j \right) \). Therefore, the degrees of freedom of \({\varvec{a}}\) and \({\varvec{b}}\) are \(s-1\) and \(r-1\), respectively. We can choose \({\varvec{a}}\) and \({\varvec{b}}\) such that they satisfy
Then, \(\varvec{a}\) and \(\varvec{b}\) are included in \(S_{s-1}\) and \(S_{r-1}\) respectively. We have the theorem below.
Theorem 1
The optimal transportation plan \({\varvec{P}}^{*}_{\lambda }\) is given by
where two vectors \({\varvec{a}}\) and \({\varvec{b}}\) are determined from \({\varvec{p}}\) and \({\varvec{q}}\) using Eq. (4).
We have a generalized cost function of transporting \({\varvec{p}}\) to \({\varvec{q}}\) based on the entropy-constrained optimal plan \({\mathbf{P}}^{*}_{\lambda }({\varvec{p}}, {\varvec{q}})\):
We called it the Cuturi function because extensive studies have been conducted by Cuturi and colleagues [7,8,9]. The function has been used in various applications as a measure of discrepancy between \({\varvec{p}}\) and \({\varvec{q}}\). The following theorem holds for the Cuturi function:
Theorem 2
The Cuturi function \(C_{\lambda } ({\varvec{p}}, {\varvec{q}})\) is a convex function of \(({\varvec{p}}, {\varvec{q}})\).
Proof
Let \(\mathbf{P}^{*}_1\) and \(\mathbf{P}^{*}_2\) be the optimal solutions of transportation problems \(\left( {\varvec{p}}_1, {\varvec{q}}_1 \right) \) and \(\left( {\varvec{p}}_2, {\varvec{q}}_2 \right) \), respectively. For scalar \( 0 \le \nu \le 1\), we use
We have
because \(H(\mathbf{P})\) is a concave function of \(\mathbf{P}\). We further have
since the minimum is taken for \(\mathbf{P}\) transporting commodities from \(\nu {\varvec{p}}_1 + (1-\nu ){\varvec{p}}_2\) to \(\nu {\varvec{q}}_1+ (1-\nu ){\varvec{q}}_2\). Hence, the convexity of \(C_{\lambda }\) is proven. \(\square \)
When \(\lambda \rightarrow 0\), it converges to the original Wasserstein distance \(C_W({\varvec{p}}, {\varvec{q}})\). However, it does not satisfy important requirements for “distance”. When \({\varvec{p}}={\varvec{q}}\), \(C_{\lambda }\) is not equal to 0 and does not take the minimum value, i.e., there are some \({\varvec{q}}\) (\(\ne {\varvec{p}}\)) that yield smaller \(C_{\lambda }\) than \({\varvec{q}} =\varvec{p}\):
4 Geometry of optimal transportation plans
We first showed that a set of optimal transportation plans forms an exponential family embedded within the manifold of all transportation plans. Then, we studied the invariant geometry induced within these plans. A transportation plan \(\mathbf{P}\) is a probability distribution over branches (i, j) connecting terminals of \(\chi _i \in \chi _S\) and \(\chi _j \in \chi _R\). Let x denote branches (i, j). We used the delta function \(\delta _{ij}(x)\), which is 1 when x is (i, j) and 0 otherwise. Then, \(\mathbf{P}\) is written as a probability distribution of the random variable x,
By introducing new parameters
it is rewritten in parameterized form as
This shows that the set of transportation plans is an exponential family, where \(\theta ^{ij}\) are the canonical parameters and \(\eta _{ij}=P_{ij}\) are the expectation parameters. They form an \(\left( sr-1\right) \)-dimensional manifold denoted by \(S_{TP}\), because \(\theta ^{sr}=0\).
The transportation problem is related to various problems in information theory such as the rate-distortion theory. We provide detailed studies on the transportation plans in the information-geometric framework in Sect. 7, but here we introduce the manifold of the optimal transportation plans, which are determined by the senders and receivers probability distributions \(\varvec{p}\) and \(\varvec{q}\).
The optimal transportation plan specified by \(({\varvec{\alpha }}, {\varvec{\beta }})\) in Eq. (16) is written as
The notation \(\psi \) is a normalization factor called the potential function which is defined by
where c is calculated by taking the summation over all of x,
This corresponds to the free energy in physics.
Using
we see that the set \(S_{OTP, {\lambda }}\) of the optimal transformation plans is a submanifold of \(S_{TP}\). Because Eq. (34) is linear in \({\varvec{\alpha }}\) and \({\varvec{\beta }}\), \(S_{OTP, {\lambda }}\) itself is an exponential family, where the canonical parameters are \(({\varvec{\alpha }}, {\varvec{\beta }})\) and the expectation parameters are \(({\varvec{p}}, {\varvec{q}}) \in S_{s-1} \times S_{r-1}\). This is confirmed by
where \(\mathrm{{E}}\) denotes the expectation. Because of \({\varvec{p}} \in S_{s-1}\) and \({\varvec{q}} \in S_{r-1}\), \(S_{OPT, {\lambda }}\) is a \((r+s-2)\)-dimensional dually flat manifold, We can use \(\alpha _s=\beta _r=0\) without loss of generality, which corresponds to using \(a_s=b_r=1\) instead of the normalization \(\sum a_i = \sum b_j = 1\) of \({\varvec{a}}\) and \({\varvec{b}}\).
In a dually flat manifold, the dual potential function \(\varphi _{\lambda }\) is given from the potential function \(\psi _{\lambda }\) as its Legendre dual, which is given by
When we use new notations \({\varvec{\eta }}= ({\varvec{p}}, {\varvec{q}})^T\), \({\varvec{\theta }}= ({\varvec{\alpha }}, {\varvec{\beta }})^T\), we have
which is the Legendre relationship between \({\varvec{\theta }}\) and \({\varvec{\eta }}\), and we have the following theorem:
Theorem 3
The dual potential \(\varphi _{\lambda }\) is equal to the Cuturi function \(C_{\lambda }\).
Proof
Direct calculation of Eq. (37) gives
\(\square \)
We summarize the Legendre relationship below.
Theorem 4
The dual potential function \(\varphi _{\lambda }\) (Cuturi function) and potential function (free energy, cumulant generating function) \(\psi _{\lambda }\) of the exponential family \(S_{OPT, {\lambda }}\) are both convex, connected by the Legendre transformation,
or
Since \(S_{OPT, {\lambda }}\) is dually flat, we can introduce a Riemannian metric and cubic tensor. The Riemannian metric \({\mathbf{G}}_{\lambda }\) is given to \(S_{s-1} \times S_{r-1}\) by
in the \({\varvec{\eta }}\)-coordinate system \(({\varvec{p}}, {\varvec{q}})\). Its inverse is
Calculating Eq. (44) carefully, we have the following theorem:
Theorem 5
The Fisher information matrix \(\mathbf{G}^{-1}_{\lambda }\) in the \({\varvec{\theta }}\)-coordinate system is given by
Remark 1
The \({\varvec{p}}\)-part and \({\varvec{q}}\)-part of \({\mathbf{G}}^{-1}_{\lambda }\) are equal to the corresponding Fisher information in \(S_{s-1}\) and \(S_{r-1}\) in the e-coordinate systems.
Remark 2
The \({\varvec{p}}\)-part and the \({\varvec{q}}\)-part of \({\mathbf{G}}_{\lambda }\) are not equal to the corresponding Fisher information in the m-coordinate system. This is because \(({\varvec{p}}, {\varvec{q}})\)-part of \(\mathbf{G}\) is not 0.
We can similarly calculate the cubic tensor,
but we have not shown the results here.
From the Legendre pair of convex functions \(\varphi _{\lambda }\) and \(\psi _{\lambda }\), we can also introduce the canonical divergence between two transportation problems \(({\varvec{p}}, {\varvec{q}})\) and \(({\varvec{p}}', {\varvec{q}}')\),
where \(({\varvec{\alpha }}, {\varvec{\beta }})\) corresponds to \(({\varvec{p}}, {\varvec{q}})\). This is the KL-divergence between the two optimal transportation plans,
5 \(\lambda \)-divergences in \(S_{n-1}\)
5.1 Derivation of \(\lambda \)-divergences
We define a divergence between \(\varvec{p} \in S_{n-1}\) and \(\varvec{q} \in S_{n-1}\) using the canonical divergence in the set \(S_{OTP, \lambda }\) of the optimal transportation plans [Eq. (48)]. For the sake of simplicity, we hereafter only study the case \(\chi _S = \chi _R = \chi \). We introduce a reference distribution \(\varvec{r} \in S_{n-1} \) and define the \(\varvec{r}\)-referenced divergence between \(\varvec{p}\) and \(\varvec{q}\) by
where \(\gamma _{\lambda }\) is a scaling factor, which we discuss later, and \(\mathbf{P}^{*}_{\lambda }({\varvec{r}}, {\varvec{p}})\) is the optimal transportation plan from \({\varvec{r}}\) to \({\varvec{p}}\). Note that its dual
is another candidate. There are other combinations but we study only Eq. (49) as the first step.
There are various ways of choosing a reference distribution \(\varvec{r}\). We first considered the simple choice of \(\varvec{r}=\varvec{p}\), yielding the following \(\lambda \)-divergence:
Theorem 6
\(D_{\lambda }[{\varvec{p}}: {\varvec{q}}]\) with the scaling factor \(\gamma _{\lambda }= \frac{\lambda }{1+\lambda }\) is given by
which is constructed from the Cuturi function.
Proof
The optimal transportation plans are rewritten by the \(\varvec{\theta }\) coordinates in the form
Then, we have
Since we showed that \(\varphi _{\lambda }=C_{\lambda }\) in Theorem 3, we obtain Eq. (52). \(\square \)
This is a divergence function satisfying \(D_{\lambda }[{\varvec{p}}:{\varvec{q}}] \ge 0\), with equality when and only when \({\varvec{p}}={\varvec{q}}\). However, it is not a canonical divergence of a dually flat manifold. The Bregman divergence derived from a convex function \(\tilde{\varphi }({\varvec{p}})\) is given by
This is different from Eq. (52), which is derived from \(\varphi _{\lambda }({\varvec{p}},{\varvec{q}})\). Thus, we call \(D_{\lambda }[{\varvec{p}}:{\varvec{q}}]\) Bregman-like divergence.
In the extremes of \(\lambda \), the proposed divergence \(D_{\lambda }[{\varvec{p}}:{\varvec{q}}]\) is related to the KL-divergence and Wasserstein distance in the following sense:
-
1.
When \(\lambda \rightarrow \infty \), \(D_{\lambda }\) converges to \(KL[{\varvec{p}}:{\varvec{q}}]\). This is because \(\mathbf{P}^*\) converges to \({\varvec{p}} \otimes {\varvec{q}}\) in the limit and we easily have
$$\begin{aligned} KL[ {\varvec{p}} \otimes {\varvec{p}}: {\varvec{p}} \otimes {\varvec{q}}] = KL[\varvec{p} : \varvec{q}]. \end{aligned}$$(57) -
2.
When \(\lambda \rightarrow 0\), \(D_{\lambda }\) with \(\gamma _{\lambda } = \lambda /(1+\lambda )\) converges to 0, because \(KL \left[ \mathbf{P}_{0}^*({\varvec{p}}, {\varvec{p}}): {\mathbf{P}}^*_{0}({\varvec{p}}, {\varvec{q}})\right] \) takes a finite value (see Example 1 in the next section). This suggests that it is preferable to use a scaling factor other than \(\gamma _{\lambda }= \lambda /(1+\lambda )\) when \(\lambda \) is small. When \(\lambda =0\), \(C_\lambda =\varphi _\lambda \) is not differentiable. Hence, we cannot construct the Bregman-like divergence from \(C_0\) [Eq. (52)] in a simple example given in Sect. 5.3.
5.2 Other choices of reference distribution r
We can consider other choices of the reference distribution \(\varvec{r}\). One option is choosing \(\varvec{r}\), which minimizes the KL-divergence.
However, obtaining the minimizer \(\varvec{r}\) is not computationally easy. Thus, we can simply replace the optimal \(\varvec{r}\) with the arithmetic mean or geometric mean of \(\varvec{p}\) and \(\varvec{q}\). The arithmetic mean is given by the m-mixture midpoint of \({\varvec{p}}\) and \({\varvec{q}}\),
The geometric mean is given by the e-midpoint of \({\varvec{p}}\) and \({\varvec{q}}\),
where c is the normalization constant.
5.3 Examples of \(\lambda \)-divergence
Below, we consider the case where \(\varvec{r}=\varvec{p}\). We show two simple examples, where \(D_{\lambda }({\varvec{p}}, {\varvec{q}})\) can be analytically computed.
Example 1
Let \(n=2\) and
We use \(a_2=b_2=1\) for normalization,
Note that \(\varepsilon \rightarrow 0\) as \(\lambda \rightarrow 0\).
When \(\lambda >0\), the receiver conditions require
where we use \(a=a_1\), \(b=b_1\) and
Solving the above equations, we have
where
We can show \(D_{\lambda }[{\varvec{p}}:{\varvec{q}}]\) explicitly by using the solution, although it is complicated.
When \(\lambda =0\), we easily have
where \({\varvec{p}}=(p, 1-p)\) and \({\varvec{q}}=(q, 1-q)\). \(C_0(p, q)\) is piecewise linear, and cannot be used to construct a Bregman-like divergence. However, we can calculate the limiting case of \(\lambda \rightarrow 0\) because the optimal transportation plans \(\mathbf{P}^*\) where \(\lambda \) is small are directly calculated by minimizing \(C_\lambda (\varvec{p},\varvec{q})\) as
where we set \(q>p\). The limit of KL divergence is given by
In the general case of \(n \ge 2\), the optimal transportation plan is \(\mathbf{P}^*_{0}(\varvec{p}, \varvec{p}) = (p_i \delta _{ij})\). The diagonal parts of the optimal \(\mathbf{P}^*_{0}(\varvec{p}, \varvec{q}) \) are \(\min \{p_i,q_i\}\) when \(m_{ii}=0, \ \ m_{ij}>0 \ \ (i \ne j)\). Thus, the KL divergence is given by
Remark that when \(\lambda \rightarrow \infty \),
Example 2
We take a family of Gaussian distributions \(N \left( \mu , \sigma ^2 \right) \),
on the real line \(\chi = \left\{ x \right\} \), extending the discrete case to the continuous case. We transport \(p \left( x \;;\; \mu _p, \sigma ^2_p \right) \) to \(q \left( x\;;\; \mu _q, {\sigma }^2_q \right) \), where the transportation cost is
Then, we have
where we use \(2 \lambda ^2\) instead of previous \(\lambda \) for the sake of convenience.
The optimal transportation plan is written as
where a and b are determined from
The solutions are given in the Gaussian framework, \(x \sim N \left( \tilde{\mu }, \tilde{\sigma }^2 \right) \), \(y \sim N \left( \tilde{\mu }', \tilde{\sigma }'^2 \right) \). As derived in Appendix A, the optimal cost and divergence are as follows:
Note that \(D_{\lambda }=KL \left[ \mathbf{P}^*_{\lambda }({\varvec{p}}, {\varvec{p}}): \mathbf{P}^*_{\lambda }({\varvec{p}}, {\varvec{q}})\right] \) diverges to infinity in the limit of \(\lambda \rightarrow 0\) because the support of the optimal transport \(\mathbf{{P}}^*_{\lambda }({\varvec{p}}, {\varvec{q}})\) reduces to a 1-dimensional subspace. To prevent \(D_{\lambda }\) from diverging and to make it finite, we set the scaling factor as \(\gamma _{\lambda } = \frac{\lambda }{1+\lambda }\). In this case, \(D_{\lambda }\) is equivalent to the Bregman-like divergence of the Cuturi function as shown in Theorem 6. With this scaling factor \(\gamma _{\lambda }\), \(D_{\lambda }\) in the limits of \(\lambda \rightarrow \infty \) and \(\lambda \rightarrow 0\) is given by
6 Applications of \(\lambda \)-divergence
6.1 Cluster center (barycenter)
Let \({\varvec{q}}_1, \ldots , {\varvec{q}}_k\) be k distributions in \(S_{n-1}\). Its \(\lambda \)-center is defined by \({\varvec{p}}^{*}\), which minimizes the average of \(\lambda \)-divergences from \({\varvec{q}}_i\) to \({\varvec{p}} \in S_{n-1}\),
The center is obtained from
which yields the equation to give \({\varvec{p}}^{*}\),
where
It is known [5] that the mean (center) of two Gaussian distributions \(N \left( \mu _1, \sigma ^2_1 \right) \) and \(N \left( \mu _2, \sigma ^2_2 \right) \) over the real line \(\chi =\mathbf{R}\) is Gaussian \(N \left( \frac{\mu _1+ \mu _2}{2}, \frac{\left( \sigma _1+ \sigma _2 \right) ^2}{4} \right) \), when we use the square of the Wasserstein distance \(W^2_2\) with the cost function \(|x_1-x_2|^2\). It would be interesting to see how the center changes depending on \(\lambda \) based on \(D_{\lambda }[{\varvec{p}}:{\varvec{q}}]\).
We consider the center of two Gaussian distributions \({\varvec{q}}_1\) and \({\varvec{q}}_2\), defined by
When \(\lambda \rightarrow 0\) and \(\lambda \rightarrow \infty \), we have
However, if we use \(C_{\lambda }\) instead of \(D_{\lambda }\) the centers are
which are not reasonable for large \(\lambda \).
6.2 Statistical estimation
Let us consider a statistical model M,
parameterized by \(\varvec{\xi }\). An interesting example is the set of distributions over \(\chi = (0, 1)^n\), where \({\varvec{x}}\) is a vector random variable defined on the n-cube \(\chi \).
The Boltzmann machine M is its submodel, consisting of probability distributions which do not include higher-order interaction terms of random variables \(x_i\),
where \({\varvec{\xi }= \left( b_i, w_{ij}\right) }\). The transportation cost is
which is the Hamming distance [10].
Let \(\hat{\varvec{q}}= \hat{\varvec{q}}({\varvec{x}})\) be an empirical distribution. Then, \(D_{\lambda }\)-estimator \({\varvec{p}}^{*}= {\varvec{p}}^{*}({\varvec{x}}, {\varvec{\xi }}^{*}) \in M\) is defined by
Differentiating \(D_{\lambda }\) with respect to \(\varvec{\xi }\), we obtain the following theorem:
Theorem 7
The \(\lambda \)-estimator \({\varvec{\xi }}^{*}\) satisfies
6.3 Pattern classifier
Let \({\varvec{p}}_1\) and \({\varvec{p}}_2\) be two prototype patterns of categories \(C_1\) and \(C_2\). A separating hyper-submanifold of the two categories is defined by the set of \({\varvec{q}}\) that satisfy
or
It would be interesting to study the geometrical properties of the \(\lambda \)-separating hypersubmanifold (Fig. 2).

\(\lambda \)-separating hyperplane
7 Information geometry of transportation plans
We provide a general framework of the transportation plans from the viewpoint of information geometry. The manifold of all transportation plans is a probability simplex \(M = S_{n^2-1}\) consisting of all the joint probability distributions \(\mathbf{P}\) over \(\chi \times \chi \). It is dually flat, where m-coordinates are \(\eta _{ij}= P_{ij}\), from which \(P_{nn}\) is determined.
The corresponding e-coordinates are \(\log P_{ij}\) divided by \(P_{nn}\) as
We considered three problems in \(M=S_{n^2-1}\), when the cost matrix \(\mathbf{M}= \left( m_{ij}\right) \) is given.
7.1 Free problem
Minimize the entropy-relaxed transportation cost \(\varphi _{\lambda }(\mathbf{P})\) without any constraints on \(\mathbf{P}\). The solution is
where c is a normalization constant. This clarifies the meaning of the matrix K [Eq. (17)], i.e., K is the optimal transportation plan for the free problem.
7.2 Rate-distortion problem

e-projection in the rate-distortion problem
We considered a communication channel in which \({\varvec{p}}\) is a probability distribution on the senders terminals. The channel is noisy and \(P_{ij}/p_i\) is the probability that \(x_j\) is received when \(x_i\) is sent. The costs \(m_{ij}\) are regarded as the distortion of \(x_i\) changing to \(x_j\). The rate distortion-problem in information theory searches for \(\mathbf{P}\), which minimizes the mutual information of the sender and receiver under the constraint of distortion \(\langle \mathbf{M}, {\mathbf{P}} \rangle \). The problem is formulated by maximizing \(\varphi _{\lambda }(\mathbf{P})\) under the senders constraint \({\varvec{p}}\), where \({\varvec{q}}\) is free (R. Belavkin, personal communication; see also [16]).
The optimal solution is given by
since \({\varvec{q}}\) is free and \({\varvec{\beta }}=0\) or \(b_j=1\). \(a_i\) are determined from \({\varvec{p}}\) such that the senders condition
is satisfied. Therefore, the dual parameters \(a_i\) are given explicitly as
Let \(M ({\varvec{p}}, \cdot )\) be the set of plans that satisfy the senders condition
Then, we will see that \(\mathbf{P}^{*}_{rd}\) is the e-projection of \(\mathbf{P}^{*}_\mathrm{{free}}\) to \(M({\varvec{p}}, \cdot )\). The e-projection is explicitly given by Eq. (107) (Fig. 3).
7.3 Transportation problem
A transportation plan satisfies the senders and receivers conditions. Let \(M(\cdot , {\varvec{q}})\) be the set of plans that satisfies the receivers conditions
Then, the transportation problem searches for the plan that minimizes the entropy-relaxed cost in the subset
Since the constraints Eqs. (108) and (109) are linear in the m-coordinates \(\mathbf{P}, M({\varvec{p}}, \cdot )\), \(M(\cdot , {\varvec{q}})\) and \(M({\varvec{p}}, {\varvec{q}})\) are m-flat submanifolds (Fig. 4).

m-flat submanifolds in the transportation problem
Since \(\varvec{p}\) and \(\varvec{q}\) are fixed, \(M({\varvec{p}}, {\varvec{q}})\) is of dimensions \((n-1)^2\), in which all the degrees of freedom represent mutual interactions between the sender and receiver. We define them by
They vanish for \(\mathbf{P}_D={\varvec{p}} \otimes {\varvec{q}}\), as is easily seen Eq. (111). Since \({\varTheta }_{ij}\) are linear in \(\log P_{ij}\), the submanifold \(E \left( {\varTheta }_{ij}\right) \), in which \({\varTheta }_{ij}\)’s take fixed values but \({\varvec{p}}\) and \({\varvec{q}}\) are free, is an \(2(n-1)\)-dimensional e-flat submanifold.
We introduce mixed coordinates
such that the first \(2(n-1)\) coordinates \(({\varvec{p}}, {\varvec{q}})\) are the marginal distributions in the m-coordinates and the last \((n-1)^2\) coordinates \(\varTheta \) are interactions in the e-coordinates given in Eq. (111). Since the two complementary coordinates are orthogonal, we have orthogonal foliations of \(S_{n^2-1}\) [1] (Fig. 5).

Orthogonal foliations of \(S_{n^2-1}\) with the mixed coordinates
Given two vectors \({\varvec{a}}= \left( a_i \right) \) and \({\varvec{b}}= \left( b_j \right) \), we considered the following transformation of \(\mathbf{P}\),
where c is a constant determined from the normalization condition,
\(\varXi \) is the mixed coordinates of \(\mathbf{P}\) and m-flat submanifold \(M({\varvec{p}}, {\varvec{q}})\), defined by fixing the first \(2(n-1)\) coordinates, is orthogonal to e-flat submanifold \(E\left( \varTheta \right) \), defined by making the last \((n-1)^2\) coordinates equal to \({\varTheta }_{ij}\). This is called the RAS transformation in the input-output analysis of economics.
Lemma
For any \({\varvec{a}}\), \({\varvec{b}}\), transformation \(T_{{\varvec{a}}{\varvec{b}}}\) does not change the interaction terms \({\varTheta }_{ij}\). Moreover, the e-geodesic connecting \({\mathbf{P}}\) and \(T_{\varvec{a b}}{} \mathbf{P}\) is orthogonal to \(M({\varvec{p, q}})\).
Proof
By calculating the mixed coordinates of \(T_{\varvec{a b}}{} \mathbf{P}\), we easily see that the \({\varTheta }\)-part does not change. Hence, the e-geodesic connecting \(\mathbf{P}\) and \(T_{\varvec{ab}}{} \mathbf{P}\) is given, in terms of the mixed coordinates, by keeping the last part fixed while changing the first part. This is included in \(E\left( {\varTheta }\right) \). Therefore, the geodesic is orthogonal to \(M(\varvec{p},\varvec{q})\). \(\square \)
Since the optimal solution is given by applying \(T_{\varvec{a b}}\) to \(\mathbf{K}\), even when \({\mathbf{{K}}}\) is not normalized, such that the terminal conditions [Eq. (4)] are satisfied, we have the following theorem:
Theorem 8
The optimal solution \(\mathbf{P}^{*}\) is given by e-projecting \(\mathbf{K}\) to \(M({\varvec{p}}, {\varvec{q}})\).
7.4 Iterative algorithm (Sinkhorn algorithm) for obtaining a and b
We need to calculate \(\varvec{a}\) and \(\varvec{b}\) when \(\varvec{p}\) and \(\varvec{q}\) are given for obtaining the optimal transportation plan. The Sinkhorn algorithm is well known for this purpose [5]. It is an iterative algorithm for obtaining the e-projection of \(\mathbf{K}\) to \(M({\varvec{p}}, {\varvec{q}})\).
Let \(T_{A \cdot }\) be the e-projection of \(\mathbf{P}\) to \(M({\varvec{p}}, \cdot )\) and let \(T_{\cdot B}\) be the e-projection to \(M(\cdot , {\varvec{q}})\). From the Pythagorean theorem, we have
where \(\mathbf{P}^{*}= T_{\varvec{ab}}{} \mathbf{P}\) is the optimal solution; that is, the e-projection of \(\mathbf{K}\) to \(M({\varvec{p}}, {\varvec{q}})\). Hence, we have
and the equality holds when and only when \(\mathbf{P} \in M({\varvec{p}}, \cdot )\). The e-projection of \(\mathbf{P}\) decreases the dual KL-divergence to \(\mathbf{P}^{*}\). The same property holds for the e-projection to \(M(\cdot , {\varvec{q}})\). The iterative e-projections of \(\mathbf{K}\) to \(M({\varvec{p}}, \cdot )\) and \(M(\cdot , {\varvec{q}})\) converges to the optimal solution \({\mathbf{P}}^{*}\).
It is difficult to have an explicit expression of the e-projection of \(\mathbf{P}\) to \(M({\varvec{p}}, {\varvec{q}})\), but those of e-projections to \(M({\varvec{p}}, \cdot )\) and \(M(\cdot , {\varvec{q}})\) are easily obtained. The e-projection of \(\mathbf{P}\) to \(M({\varvec{p}}, \cdot )\) is given by
where \({\varvec{a}}\) is given explicitly by
Similarly, the e-projection to \(M(\cdot , {\varvec{q}})\) is given by
with
Therefore, the iterative algorithm, which is known as the Sinkhorn Algorithm [7, 12] of e-projection from \(\mathbf{K}\) is formulated as follows:
Iterative e -projection algorithm
-
1.
Begin with \(\mathbf{P}_0=\mathbf{K}\).
-
2.
For \(t=0, 1, 2, \ldots \), e-project \(P_{2t}\) to \(M({\varvec{p}}, \cdot )\) to obtain
$$\begin{aligned} \mathbf{P}_{2t+1} = T_{A \cdot } \mathbf{P}_{2t}. \end{aligned}$$(121) -
3.
To obtain \(\mathbf{P}_{2t+2}\), e-project \({\mathbf{P}}_{2t+1}\) to \(M(\cdot , {\varvec{q}})\),
$$\begin{aligned} \mathbf{P}_{2t+2} = T_{\cdot B} \mathbf{P}_{2t+1}. \end{aligned}$$(122) -
4.
Repeat until convergence.

Sinkhorn algorithm as iterative e-projections
Figure 6 schematically illustrates the iterative e-projection algorithm for finding the optimal solution \(\mathbf{P}^{*}\).
8 Conclusions and additional remarks
We elucidated the geometry of optimal transportation plans and introduced a one-parameter family of divergences in the probability simplex which connects the Wasserstein distance and KL-divergence. A one-parameter family of Riemannian metrics and dually coupled affine connections were introduced in \(S_{n-1}\), although they are not dually flat in general. We uncovered a new way of studying the geometry of probability distributions. Future studies should examine the properties of the \(\lambda \)-divergence and apply these to various problems. We touch upon some related problems below.
-
1. Uniqueness of the optimal plan
The original Wasserstein distance is obtained by solving a linear programming problem. Hence, the solution is not unique in some cases and is not necessarily a continuous function of \({\mathbf{M}}\). However, the entropy-constrained solution is unique and continuous with respect to \(\mathbf{M}\) [7]. While \(\varphi _{\lambda }({\varvec{p}}, {\varvec{q}})\) converges to \(\varphi _0({\varvec{p}}, {\varvec{q}})\) as \(\lambda \rightarrow 0\), \(\varphi _0({\varvec{p}}, {\varvec{q}})\) is not necessarily differentiable with respect to \({\varvec{p}}\) and \({\varvec{q}}\).
-
2. Integrated information theory of consciousness
Given a joint probability distribution \(\mathbf{P}\), the amount of integrated information is measured by the amount of interactions of information among different terminals. We used a disconnected model in which no information is transferred through branches connecting different terminals. The geometric measure of integrated information theory is given by the KL-divergence from \(\mathbf{P}\) to the submanifold of disconnected models [13, 14]. However, the Wasserstein divergence can be considered as such a measure when the cost of transferring information through different terminals depends on the physical positions of the terminals [15]. We can use the entropy-constrained divergence \(D_{\lambda }\) to define the amount of information integration.
-
3. f -divergence
We used the KL-divergence in a dually flat manifold for defining \(D_{\lambda }\). It is possible to use any other divergences, for example, the f-divergence instead of KL-divergence. We would obtain similar results.
-
4. q -entropy
Muzellec et al. used the \(\alpha \)-entropy (Tsallis q-entropy) instead of the Shannon entropy for regularization [16]. This yields the q-entropy-relaxed framework.
-
5. Comparison of \(C_{\lambda }\) and \(D_{\lambda }\)
Although \(D_{\lambda }\) satisfies the criterion of a divergence, it might differ considerably from the original \(C_{\lambda }\). In particular, when \(C_\lambda ({\varvec{p}}, {\varvec{q}})\) includes a piecewise linear term such as \(\sum d_i|p_i - q_i|\) for constant \(d_i\), \(D_\lambda \) defined in Eq. (52) eliminates this term. When this term is important, we can use \(\{ C_\lambda ({\varvec{p}}, {\varvec{q}}) \}^2\) instead of \(C_\lambda ({\varvec{p}}, {\varvec{q}})\) for defining a new divergence \(D_\lambda \) in Eq. (52). In our accompanying paper [17], we define a new type of divergence that retains the properties of \(C_{\lambda }\) and is closer to \(C_{\lambda }\).
References
Amari, S.: Information Geometry and Its Applications. Springer, Japan (2016)
Chentsov, N.N.: Statistical Decision Rules and Optimal Inference. Nauka (1972) (translated in English, AMS (1982))
Rao, C.R.: Information and accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc. 37, 81–91 (1945)
Ay, N., Jost, J., Le, H.V., Schwachhöfer, L.: Information Geometry. Springer, Cham (2017)
Santambrogio, F.: Optimal Transport for Applied Mathematicians. Birkhauser, Basel (2015)
Villani, C.: Topics in Optimal Transportation. Graduate Studies in Math. AMS, Providence (2013)
Cuturi, M.: Sinkhorn distances: light speed computation of optimal transport. In: Advances in Neural Information Processing Systems, pp. 2292–2300 (2013)
Cuturi, M., Avis, D.: Ground metric learning. J. Mach. Learn. Res. 15, 533–564 (2014)
Cuturi, M., Peyré, G.: A smoothed dual formulation for variational Wasserstein problems. SIAM J. Imaging Sci. 9, 320–343 (2016)
Montavon, G., Muller K., Cuturi, M.: Wasserstein training for Boltzmann machines (2015). arXiv:1507.01972v1
Belavkin, R.V.: Optimal measures and Markov transition kernels. J. Glob. Optim. 55, 387–416 (2013)
Sinkhorn, R.: A relationship between arbitrary positive matrices and doubly stochastic matrices. Ann. Math. Stat. 35, 876–879 (1964)
Oizumi, M., Tsuchiya, N., Amari, S.: Unified framework for information integration based on information geometry. Proc. Natl. Acad. Sci. 113, 14817–14822 (2016)
Amari, S., Tsuchiya, N., Oizumi, M.: Geometry of information integration (2017). arXiv:1709.02050
Oizumi, M., Albantakis, L., Tononi, G.: From the phenomenology to the mechanisms of consciousness: integrated information theory 3.0. PLoS Comput. Biol. 10, e1003588 (2014)
Muzellec, B., Nock, R., Patrini, G., Nielsen, F.: Tsallis regularized optimal transport and ecological inference (2016). arXiv:1609.04495v1
Amari, S, Karakida, R. Oizumi, M., Cuturi, M.: New divergence derived from Cuturi function (in preparation)
Author information
Authors and Affiliations
Corresponding author
Appendix: The proof of Example 2
Appendix: The proof of Example 2
Let us assume that functions a(x) and b(y) are constrained into Gaussian distributions: \(a(x) = N \left( \tilde{\mu }, \tilde{\sigma }^2 \right) \), \(b(y) = N \left( \tilde{\mu }', \tilde{\sigma }'^2 \right) \). This means that the optimal plan \( P^{*}(x, y)\) is also given by a Gaussian distribution \(N ({\varvec{\mu }},\varSigma )\). The marginal distributions p and q require the mean value of the optimal plan to become
It is also necessary for the diagonal part of the covariance matrix to become
Because the entropy-relaxed optimal transport is given by Eq. (79), \(\varSigma \) is composed of \(\tilde{\sigma }^2\) and \(\tilde{\sigma }'^2\) as follows:
Solving Eqs. (A.4, A.5) under the conditions given in Eqs. (A.2, A.3), we have
Substituting the mean [Eq. (A.1)] and variances [Eqs. (A.6, A.7)] into the definition of the cost [Eq. (23)], after straightforward calculations, we get Eq. (82). In general, the \(\eta \) coordinates of the Gaussian distribution q are given by \((\eta _1, \eta _2) = (\mu _q, \mu _q^2+ \sigma _q^2)\). After differentiating \(C_{\lambda }(p,q)\) with the \(\eta \) coordinates and substituting them into Eq. (52), we get Eq. (83).
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Amari, Si., Karakida, R. & Oizumi, M. Information geometry connecting Wasserstein distance and Kullback–Leibler divergence via the entropy-relaxed transportation problem. Info. Geo. 1, 13–37 (2018). https://doi.org/10.1007/s41884-018-0002-8
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41884-018-0002-8