
Abstract
This case study refutes some controversial findings about a minor connection between the vaccination coverage and the spread of COVID-19. We try to eliminate some methodological shortcomings and risks, which are included in such previously published studies. Firstly, our selection comprises all regional units in one country. Secondly, the quality of data is basically identical in all examined regions within the country. Thirdly, all Slovak regions had an equal starting position. They were at the same stages of the COVID-19 wave, and the measures taken were analogous in all regions. Slovakia with a significantly different vaccination rates among regions is a very suitable study case. We used the empirical data at the level of its LAU 1 regions for the two latest COVID-19 waves at that time (Delta, Omicron). The methods of regression analysis and geostatistical methods were applied in the study. Indubitably, there is an obvious link between the vaccination coverage and the spread of COVID-19. We have shown that the incidence-trajectories among regions vary based on the vaccination rates. The positivity and incidence in the most vaccinated regional populations were significantly lower than in the least vaccinated regions in a whole analyzed period. Their values in the best vaccinated regions were lower by roughly 20–25 % during the delta and omicron wave-peaks. Using the spatial autocorrelation, we also managed to clearly identify a close relationship between vaccination on the one hand and standardized incidence and positivity on the other hand, although some regions deviated from this general finding.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction and Background
As expected, the number of studies addressing various aspects of the COVID-19 proliferation has been growing very fast (Ye et al. 2021). These studies may be divided into the two fundamental groups. The first group has a medical, microbiological, and virological character, with several works clearly confirming that vaccination reduces the risk of Delta variant infection (Singanayagam et al. 2022; Levine-Tiefenbrun et al. 2021). In many cases, these studies are based on the measurement of viral load in samples and, subsequently, on proposals for an appropriate methodology to detect the relationships between viral load and transmission (Hay et al. 2021). Eyre et al. (2022) using a retrospective observational cohort conclude that vaccination is associated with a smaller reduction in the transmission of the Delta variant than the Alpha variant, and the effects of vaccination decrease over time, but the impact on reduction has remained.
The second type of studies utilizes mathematical, geostatistical, demographic, and geographical procedures. Recently, a multitude of such studies have been produced dealing with various attributes of COVID-19. However, only a smaller part of them are directly dedicated to measuring the effects of vaccination and to revealing the relationships between vaccination and the virus spread. The studies using mathematical approaches form one group. For instance, Yang et al. (2022) developed a sophisticated mathematical model concluding that, together with vaccination, reducing the contact rate of persons and increasing the isolation rate of infected individuals would substantially decrease the number of infections and shorten the time of the COVID-19 spread. This study belongs among those emphasizing the impact of vaccination if it is supported by other measures, especially epidemiological ones. As there were applied basically the same epidemiological measures in the entire territory of Slovakia, it was possible to measure the net effect of vaccination. Some other studies also devote themselves to mathematical modelling the COVID-19 spread, but not all of them are directly focused on the influence of vaccination on it (Kifle & Obsu 2022). Or, they are specially dedicated to the impacts of lockdowns and intervention strategies (Bugalia et al. 2020) and were developed at the time when vaccines were not available yet.
There is also a small group of studies that use geospatial modeling and geostatistics, in some cases related to demographic and population characteristics. Maza and Hierro (2021) analyze the transmission factors shaping the spatial distribution of COVID-19 infections during the distinct phases of the pandemic’s first wave in Madrid. They use a spatial regression model reflecting neighborhood effects among the municipalities. They focus on some geographical and demographic factors such as population, mobility, and some others. A study by Pizzuti et al. (2020) was produced already before the administration of vaccines; it modeled the spread of the virus using network-based prediction. Temerev et al. (2022) is an example of another study that uses the vaccination coverage for geospatial modeling.
Some complicated models try to capture the complex reality and background of the virus proliferation. However, such models may not well estimate the (isolated) effect of vaccination on the virus spread over space and time. Nevertheless, studies of this kind do exist, but their results are disputable. Our study reacts precisely to these works. Subramanian and Kumar (2021) completely doubt the impact of vaccination on the virus spread. For that reason, their study met with negative responses (e.g., Coleman et al. 2021; Gianicolo et al. 2021). It really used only trivial statistical procedures, but surprisingly — with such a methodological apparatus — was published in a prestigious epidemiological journal. Most likely, this work would not stand up in geographic or demographic journals.
But our study goes beyond brief, albeit true, critiques. It tries to show one of the possible ways of how such a case study could be performed. Its major contribution resides in original demonstration that the black-and-white vision does not exist in times of the COVID-19 pandemic either. The elimination of some methodological shortcomings and risks, which — in our opinion — are contained in simplified works, could be another asset of the study. Firstly, our selection includes all regional units in Slovakia. Secondly, the quality of data is basically the same in all examined regions of the country. Thirdly, all regions had an identical starting position within a general national framework, i.e., they were at the same stages of the COVID-19 wave, and the adopted measures were very similar in all Slovak regions, while countries of the world have been substantially differentiated from this aspect.
We would like to underline that even using all regional units, comparing only two 7-day averages as in case of US counties in the study by Subramanian and Kumar from 2021 is simply not enough. It is necessary to analyze a longer period, ideally from the beginning of the wave to its end. Our study deliberately deals with the spread of COVID-19 exclusively in regional populations. It does not address hospitalizations, numbers of patients on pulmonary ventilation, lethality, or mortality. These all are related phenomena, but their research requires a number of further methodological approaches. And the relationship between the virus proliferation and vaccination is very difficult to be clearly proven empirically. Finally, there is a large group of studies focused on the social and economic background and consequences of COVID-19 (Bidisha et al. 2021; Bukari et al. 2022).
Data and Methods
Slovakia has recently been a suitable “laboratory” for research on the spread of the virus, also thanks to the strong regional disparities in the vaccination coverage. Its percentage values in several (LAU 1) districts exceeded 70%, whereas in some others were below 40%. Moreover, an increase in the vaccination coverage was negligible despite the culminating Omicron wave (roughly mid-February 2022). The LAU 1 regions also seem rather appropriate for analyses. In most cases, they approximately or partially coincide with the functional regions, i.e., the daily urban systems with the most intensive mobility and interactions of persons inside the units. In total, Slovakia consists of 79 LAU 1 units. Their use is a proper compromise between the efficient number of units, population size, and data availability. LAU 1 (formerly NUTS 4) is hierarchically higher statistical units joining LAU 2 (communes) together. The numbers of communes, the Slovak LAU 1 districts consist of, vary from 12 to more than 100, plus special urban units in the cities of Bratislava and Košice. What is also important, the LAU 1 borders were closed during the strict lockdowns. This means, the intra-regional vaccination rates matter more than inter-regional mobility and dispersion of the virus from one region to another.
Slovakia was affected considerably in both waves. The overall number of deaths is reported to exceed 20 thousand (April 2023). The total number of laboratory tests performed currently approaches 7.5 million, of which 1.7 million were positive. Mainly, the mRNAs (those from Pfizer and Moderna) were applied, and 97% out of all doses were these two types. Thus, the type of vaccine probably does not play a role in interregional differences.
Then, all data come from the National Health Information Centre (NCZI). All primary data are available also on the website korona.gov.sk. Firstly, we used correlation and regression analysis procedures, in which the vaccination of population (those fully vaccinated) in percent is the independent variable. The 7-day incidence from PCR tests (per 100,000 inhabitants) and the positivity of tests (in per cent) were used as the dependent variables. Here, the 7-day rolling averages were applied. In principle, given the availability of primary data from the PCR testing, there is nothing better for making analyses. However, we added also the rate of standardized incidence, which considers different levels and fluctuations in the volume of PCR tests carried out in the individual regions. The calculation works on the principle of weighting the regional share of PCR tests, using the proportion of inhabitants of the respective region in the total. It means that in those regions where the extent of testing was above average, the number of identified positive cases was lower. On the contrary, in those regions where the extent of testing was below average, the number of positive cases practically increased. The corresponding mathematical expression is as follows:
where
stIi — standardized incidence in the region i
stTipos— standardized number of positive PCR tests in the region i
Tipos— number of positive PCR tests in the region i
stTiall— overall number of PCR tests carried out in the region i
Pi — number of inhabitants in the region i
The standardization was done separately for each respective date.
Secondly, we separately analyzed two time series corresponding to the third (Delta) and fourth (Omicron) waves. September 1, 2021 can be identified as the beginning of the third COVID-19 wave in Slovakia. Already, the end of August of that year showed signs of a modest growth in the number of patients, but the September values may be considered more significant. While the Delta wave reached the peak during December 1–16, 2021, its end came approximately in mid-January 2022. The Omicron wave began soon — the starting date in the analysis is January 16, 2022, its peak was roughly in mid-February. Instead of analyzing the set of 79 units like in the first approach, we classified the LAU 1 units into the three categories, namely tertiles, for a better interpretation. The classification was based on the share of vaccinated persons in the total population on the respective dates. It reduced possible distortions associated with the different pace of vaccination in the regions from September 2021 to January 2022. If the vaccination level matters, the most telling value may likely be found at the beginning of the wave. We also tried a classification based on the values from the peak of the wave, but the results were essentially unaffected. In terms of vaccination, the position of the units within one wave was relatively stable.
The districts were also categorized alternatively as follows: the least vaccinated districts (30–40% of vaccinated persons), those with 40–50% of such persons, those with 50–60%, and the most vaccinated districts (60–70% of vaccinated persons). For the Omicron wave, the intervals were increased by 5% (35–45%, 45–55%, 55–65%, 65% and more, respectively), and the districts were re-grouped. However, the problem with this classification resided in the fact that the numbers of districts in each category were too different. The number of the most vaccinated districts with at least 60% of vaccinated persons was simply too low compared to the number of districts with less than 40% of those vaccinated. Although the differences between the most and least vaccinated regional populations were sizeable, we did not include these results due to statistical significance.
The third method we used is the hot-spot analysis — a local version of spatial autocorrelation (Getis & Ord 1992). This procedure, when applied to incidence, positivity and standardized incidence, allows identifying the extreme positions related to the virus spread at various rates of significance — that is, those regions where the situation was the worst or the best. At the same time, we used the hot-spot analysis also for the identification of regions where the largest deviations from the values of the regression model were achieved. This too served to describe the spatial variability of the COVID-19 spread. Likewise, we used the hot-spot analysis since one of its basic properties is the ability to identify only those high or low values that may be found — besides the region concerned — also in neighboring regions. This is the essence of the spatial autocorrelation procedure (Bleha & Ďurček 2019). The analysis of residuals was carried out as well.
The results in the form of residuals (more in the “Results and Discussion” section) allowed the application of the last method, namely geographically weighted regression (GWR). The main reason for using the GWR model is the fact that the basic ordinary least squares (OLS) model is unable to capture the existence of spatial differences for two or more variables. That means that through the GWR method, we are able to measure these spatial differences, especially in the clusters of residuals. GWR is a local form of linear regression calculated for each unit and the nearest neighbors. Thus, the model can be written as:
where
y i is the dependent variable.
X ji is the jth independent variable.
βj (ui,v i ) is the jth coefficient at location (ui,vi).
ε i is the random error term.
Unlike OLS, the parameters are allowed to vary by location (ui,vi).
Defining the neighborhood represents the most challenging point in the whole GWR analysis. The two basic possibilities of defining are the so-called fixed kernel and the adaptive kernel (Sachdeva & Fotheringham 2020). After testing several variants of defining the neighborhood (more also in Brunsdon et al. 1996; Haining 2003; Smith et al. 2018; Horák 2019; Horák et al. 2020), we chose the fixed kernel — here, we included 20 nearest neighbors for each unit. We used software ArcGis, namely the tool “Geographically Weighted Regression,” to calculate GWR. The global value of R2 or adjR2 was calculated as the average of local results in the individual regional units. The AICc indicator was used to compare the models that have a different dependent variable. The model with a lower AICc value provided a better fit to the observed data.
Results and Discussion
Table 1 demonstrates the basic results of the statistical analysis in the selected time sections. The trend of indicators is evident. With the rising Delta wave during October and November 2021, there was a growing indirect dependence between the share of vaccinated persons and positivity, and also between the share of vaccinated persons and standardized incidence.
The coefficient of determination indicates that more and more variability of indicators over time may be explained through the vaccination rate when the wave was rising. This is largely true for more suitable indicators such as positivity and standardized incidence. To increase the objectivity of the analysis, we also present the adjusted coefficient of determination, which reflects the number of statistical units. However, its values do not differ much from an unadjusted version. Intercept b0 shows the values of indicators in a hypothetical case, if each Slovak region achieved a zero level of vaccination (no vaccines were available). The slope b1 indicator demonstrates a theoretical change in the values, if the vaccination rate increased by 1 percentage point against the current value. Thus, a higher vaccination coverage would significantly reduce both positivity and incidence values in the model. As regards the Delta wave, the model predicts that in case of 65% vaccination, the current values of positivity would be roughly 20% instead of more than 30%. Moreover, 65% is still a value considerably below the values in the most vaccinated countries. With respect to the Delta wave, if the half of less vaccinated regional populations had been virtually “removed” from the total Slovak population, the country would have been in the better half in the European ranking of the virus spread instead of being in the worst quartile. Within the Omicron wave, the values of correlation and determination are only slightly lower. Despite the quicker and easier spread of the Omicron variant in populations, vaccination seems to be an effective “preventer.”
n count, x mean, s standard deviation, r Pearson’s correlation coefficient, r2 coefficient of determination (R square), adjr2 adjusted coefficient of determination, F significance level of correlation coefficient, b0 intercept, Pb0 significance level of coefficient b0, Lowb0 lower bound of the 95% confidence interval of coefficient b0, Upb0 upper bound of the 95% confidence interval of coefficient b0, b1 slope, Pb1 significance level of coefficient b0, Lowb1 lower bound of the 95% confidence interval of coefficient b1, Upb1 upper bound of the 95% confidence interval of coefficient b1
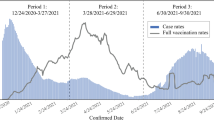
Figure 1 depicts the development of the three dependent variables over time, with the LAU 1 regions arranged into three tertiles according to the rate of vaccination in the Delta wave. All three indicators show a gradual “scissors opening” between the groups of more and less vaccinated regional populations. The greatest divergence is manifested in positive PCR tests. The only exception is formed by non-standardized incidence, the latest values of which do not differ much. This indicator is gradually losing its explanatory power and ability to demonstrate the variability. Concerning rate of positivity and standardized incidence, there is an evident gap between the group of the most vaccinated regional populations and the other groups. The difference is most pronounced at the peak of the wave.

Delta wave characteristics in the groups of districts by rate of vaccination. 1st tertile is least vaccinated group of districts; 3rd tertile is most vaccinated group of districts
Figure 2 depicts the development of the three dependent variables over time, with the LAU 1 regions arranged into three tertiles according to the rate of vaccination in the Omicron wave. A comparison of the curves in Figs. 1 and 2 suggests that vaccination in the Omicron wave had slightly a lesser effect on inter-regional differences. But even here, the impact is not negligible, particularly as regards a gap between one-third of the most vaccinated units and the other units.

Omicron wave characteristics in the groups of districts by rate of vaccination. 1st tertile is least vaccinated group of districts; 3rd tertile is most vaccinated group of districts
Opponents of the effect of vaccination on the virus spread and on inter-regional differences in positivity and incidence might not be convinced by the values in Table 1 as well as Fig. 1 and 2. However, especially in the Delta wave, the values of statistical indicators are relatively high, surely not negligible. Nevertheless, there is certainly not a high correlation. Therefore, we went further and applied other two procedures (Figs. 3 and 4), which may reveal regional clusters where vaccination works more and less.

The spatial distribution of observed indicators and the spatial autocorrelation of residuals from the OLS model in the set of LAU 1 regions (Omicron wave)

Main results of the GWR method in the set of LAU 1 regions (Omicron wave)
Figure 3 is a series of maps where the hot-spot spatial autocorrelation method was applied to a set of regions in Slovakia as of February 14, 2022 (i.e., at the crude peak of the Omicron wave). An interesting finding is documented by three maps on the right showing the residual values of the regression model. The maps offer an interpretation — the identification of districts that match our model within the 90% confidence interval (Std. Dev. V-1.65 to 1.65). They form a major part out of the 79 country’s districts, especially in the second and third maps on the right. In this majority group, we managed to clearly identify a close relationship between vaccination on the one hand and standardized incidence and positivity on the other hand.
There are several possible explanations of why some regions face a better/worse situation than the model-predicted values. Among others, the impact of the previous waves on regional populations could play an important role. There is still no robust dataset on the presence of antibodies from laboratories that would meet the criteria for a significant geostatistical analysis. Some factors may be classified as “behavioral” ones. From the sociological, economic, and demographic viewpoints, though being a small population unit, Slovakia is a very heterogeneous country with distinct regional disparities. An elementary, very crude, division comprises the two macro-regions, namely the “poor South-East” and the “rich North-West” (Korec 2014). This basically reflects the vaccination coverage, but it could also encompass aspects such as reluctance towards the measures and COVID-19 rules. The political parties with a strong anti-vax and anti-rules agenda have a stronger support in poorer regions with lower education levels as well as higher unemployment rates (Plešivčák et al. 2018). This could be manifested in a more difficult tracking of contacts and some other aspects resulting in an easier proliferation of the virus in respective regions. Below, we also discuss the possible impact of different declines in regional mobility.
The global values of R2 oscillate around 0.7 (Fig. 4). The adjusted values are slightly lower, but still significantly higher than those for normal regression (OLS) given in Table 1. The model best fits for the indicator of positivity, as evidenced by the lowest AICc value. The better GWR score compared to OLS unambiguously confirms that the relationship between vaccination and rates of the COVID-19 spread is generally strong, but varies considerably among the regions. A strong negative correlation (R2 > 0.5; b1 < 0) may be found in the western part of the country. The central part of Slovakia normally has a weak negative correlation (R2 < 0.3; b1 < 0). An interpretation of the figures could be that vaccination here helps prevent the spread of the virus less — and it seems that vaccination has no effect on incidence and positivity in the easternmost part of the country (R2 > 0.3; b1 > 0). This can be explained also by the fact that there was only a small decline in mobility in this area compared to the beginning of September 2021. This hypothesis is also supported by Community Mobility Reports data from Google. Indeed, the decline in mobility in eastern Slovakia was on average lower than in western Slovakia. On the other hand, the regional data on mobility comprise also several discrepancies, and its explanatory power is thus limited.
There is a great difference between the big cities and rural or underdeveloped areas with generally lower mobility, primarily the intensity of commuting. This means that high mobility is likely to negate the benefits of vaccination in slowing down the spread of the virus. However, other factors too need to be taken into account, particularly those that may cause a weakening of the link between vaccination and the COVID-19 proliferation in regional units. Among others, let us mention socio-demographic characteristics — for instance, the different shares of segregated Roma communities occurring mainly in the south of central Slovakia and in its east (Šprocha & Bleha 2018). In these areas, the low level of vaccination is associated with low labor mobility; on the other hand, the virus is easier to spread here due to high population density.
There are several possible explanatory schemes and factors. We have included some of them into Table 2, where at least a moderate degree of dependence is expressed by the Pearson coefficient. In general, the higher vaccinated regions are those with better social-economic status (wages, educational structure), and this is why the positivity was lower in such regions, but the values of Pearson’s coefficient were moderate, and dependency was significant but not very strong. Furthermore, some dependencies are stable over time, but some are fluctuating.
Conclusions
The results of our statistical and geostatistical analysis for the LAU 1 regions in Slovakia quite clearly indicate that the vaccination rates matter. The statistical dependence of indicators in the set of 79 units (i.e., country’s administrative districts) was undeniably increasing, the scissors between the most and least vaccinated regions in the values of incidence and positivity were opening, and this trend was lasting for two and a half months in the Delta wave. In terms of the Omicron wave, the results are roughly the same, depending on a concrete indicator. This is true despite facts such as a lower decrease in mobility, less strict measures, and weaker adherence to them. Because of their massive numbers, the tracing of contacts of infected persons was also a problem. In spite of that, even in the case of the Omicron wave, a significant effect was demonstrated using more elementary methods. It turns out that simpler methods too can have a telling value, if properly used and if data are consistent as well as robust enough. However, it is beneficial to add geostatistical approaches helping reveal the causes of lower correlation achieved by conventional statistics. This is especially true if there are not enough suitable indicators for a factor analysis, as in the case of this study.
The key message of the results is that a black-and-white vision of the vaccination effect on the virus spread in the population barely exists. Spatial methods disclose the real strength of the link between the vaccination coverage and positivity or incidence. Casting doubt on the impact of vaccination stands on shaky grounds. On the other side, presenting the results of maps with an almost perfect correlation between incidence and vaccination, for example in a set of European countries, is inappropriate too. Certainly, this link existed for hospitalizations and deaths to a substantial extent during the Delta wave; however, the different timing of the wave in various countries makes such comparisons inadequate. In regional populations, further attention should be paid to socio-demographic and geographical predictors increasing/decreasing the vaccination effect. By this, we mean not only age, but also the level of education, mobility, willingness to respect anti-pandemic rules, and several other factors.
References
Bidisha SH, Mahmood T, Hossain MB (2021) Assessing food poverty, vulnerability and food consumption inequality in the context of COVID-19L a case of Bangladesh. Soc Indic Res 155:187–210
Bleha B, Ďurček P (2019) An interpretation of the changes in demographic behaviour at a sub-national level using spatial measures in post-socialist countries: a case study of the Czech Republic and Slovakia. Paper Reg Sci 98(1):331–351. https://doi.org/10.1111/pirs.12318
Brunsdon C, Fotheringham AS, Charlton M (1996) Geographically weighted regression: a method for exploring spatial nonstationarity. Geograph Anal 28(4):281–298. https://doi.org/10.1111/j.1538-4632.1996.tb00936.x
Bugalia S, Bajiya VP, Tripathi JP, Li MT, Sun GQ (2020) Mathematical modeling of COVID-19 transmission: the roles of intervention strategies and lockdown. Math Biosci Eng 17(5):5961–5986. https://doi.org/10.3934/mbe.2020318
Bukari C, Aning-Agyei MA, Kyerermen C, Essilfie G, Amuquandoh KF, Owusus AA, Otoo IC, Bukari KI (2022) Effect of COVID-19 on household food insecurity and poverty: evidence from Ghana. Soc Indic Res 159:991–1015
Coleman T, Sarian A, Grad S (2021) Re: Subramanian and Kumar. Vaccination rates and COVID-19 cases. Eu J Epidemiol 36:1245–1246. https://doi.org/10.1007/s10654-021-00821-w
de Vaus D (2014) Surveys in social research. Routledge, London
Eyre WD, Phil D, Taylor D (2022) Effect of Covid-19 vaccination on transmission of alpha and delta variant. New England J Med 386:744–756. https://doi.org/10.1056/NEJMoa2116597
Getis A, Ord JK (1992) The analysis of spatial association by use of distance statistics. Geograph Anal 24(3):189–206
Gianicolo E, Wollschläger D, Blettner M (2021) Re: Subramanian and Kumar. Vaccination rates and COVID-19 cases. Eu J Epidemiol 36:1241–1242. https://doi.org/10.1007/s10654-021-00816-7
Haining R (2003) Spatial data analysis theory and practice. Cambridge University Press, Cambridge
Horák J (2019) Prostorové analýzy dat. VŠB-TU, Ostrava
Korec P (2014) Lagging regions of Slovakia in the context of their competitiveness. In: The social and economic growth vs. The emergence of economic growth and stagnation areas. Bugucki Wydawnictvo Naukove, Poznan, pp 107–128
Levine-Tiefenbrun M, Yelin I, Katz R et al (2021) Initial report of decreased SARS-CoV-2 viral load after inoculation with the BNT162b2 vaccine. Nat Med 27:790–792. https://doi.org/10.1038/s41591-021-01316-7
Singanayagam A, Hakki S, Dunning J, Madon KJ, Crone MA, Koycheva A, Derqui-Fernandez N, Barnett JL, Whitfield MG, Varro R, Charlett A (2022) Community transmission and viral load kinetics of the SARS-CoV-2 delta (B.1.617.2) variant in vaccinated and unvaccinated individuals in the UK: a prospective, longitudinal, cohort study. Lancet Infect Dis 22(2):183–195. https://doi.org/10.1016/S1473-3099(21)00648-4
Šprocha B, Bleha B (2018) Does socio-spatial segregation matter? ‘Islands’ of high Romany fertility in Slovakia. Tijdschrift voor Economische en Sociale Geografie 109(2):239–255. https://doi.org/10.1111/tesg.12270
Subramanian SV, Kumar A (2021) Increases in COVID-19 are unrelated to levels of vaccination across 68 countries and 2947 counties in the United States. Eu J Epidemiol 36:1237–1240. https://doi.org/10.1007/s10654-021-00808-7
Hay JA, Kennedy-Shaffer L, Kanjilal S, Lennon NJ, Gabriel SB, Lipsitch M, Mina MJ (2021) Estimating epidemiologic dynamics from cross-sectional viral load distributions. Science 373(6552). https://doi.org/10.1126/science.abh0635
Horák, J., Orlíková, L., Arjona, J., & Svoboda, R. (2020). Prostorové regresní modelování s příklady. Prostorová data pro Smart City a Smart Region. Ostrava, Conference, January18-20, 2020.
Kifle ZS, Obsu LL (2022) Mathematical modeling for COVID-19 transmission dynamics: a case study in Ethiopia. Results Phys 34(105191). https://doi.org/10.1016/j.rinp.2022.105191
Maza A, Hierro M (2021) Modelling changing patterns in the COVID-19 geographical distribution: Madrid’s case. Geograph Res. https://doi.org/10.1111/1745-5871.12521
Pizzuti C, Socievole A, Prasse B et al (2020) Network-based prediction of COVID-19 epidemic spreading in Italy. Appl Net Science 5(91). https://doi.org/10.1007/s41109-020-00333-8
Plešivčák, M., Przybyla, V., & Buček, J. (2018). Electoral geography of a small country: determining factors, threat of radical right, and comments on referenda held in Slovakia. In Wood, T. (ed). Slovakia: Culture, History and People. New York: Nova Science Publishers, 1-40. ISBN: 978-1-53614-134-4 (eBook)
Sachdeva, M., & Fotheringham, A. S. (2020). The geographically weighted regression framework. The Geographic Information Science & Technology Body of Knowledge (4th Quarter 2020 Edition).
Smith, M. J., Goodchild, M. F., & Longley, P. A. (2018). Geospatial analysis. Retrieved January 7, 2022, from http://www.spatialanalysisonline.com
Temerev A, Rozanova L, Keiser O, Estill J (2022) Geospatial model of COVID-19 spreading and vaccination with event Gillespie algorithm. Nonlin Dyn. https://doi.org/10.1007/s11071-021-07186-5
Yang B, Yu Z, Cai Y (2022) The impact of vaccination on the spread of COVID-19: studying by a mathematical model. Physica A Stat Mech Appl 590. https://doi.org/10.1016/j.physa.2021.126717
Ye X, Du J, Na S, Weimin L, Kudva S (2021) Geospatial and semantic mapping platform for massive COVID-19 scientific publication search. J Geovisual Sp Anal 5. https://doi.org/10.1007/s41651-021-00073-y
Funding
Open access funding provided by The Ministry of Education, Science, Research and Sport of the Slovak Republic in cooperation with Centre for Scientific and Technical Information of the Slovak Republic This study was supported by the Operation Program of Integrated Infrastructure for the project, UpScale of Comenius University Capacities and Competence in Research, Development and Innovation, ITMS2014+: 313021BUZ3, co-financed by the European Regional Development Fund.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical Approval
This article does not contain any study conducted by any of the authors that would require ethical approval.
Informed Consent
On behalf of all authors, the corresponding author states that no human participants are involved in the research and, therefore, informed consent is not required by them. On behalf of all authors, the corresponding author consent to the submission of this manuscript.
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bleha, B., Ďurček, P. Unambiguous Linkage Between the Vaccination Coverage and the Spread of COVID-19: Geostatistical Evidence from the Slovak LAU 1 Regions. J geovis spat anal 7, 14 (2023). https://doi.org/10.1007/s41651-023-00144-2
Accepted:
Published:
DOI: https://doi.org/10.1007/s41651-023-00144-2