
Abstract
Previous video object segmentation approaches mainly focus on simplex solutions linking appearance and motion, limiting effective feature collaboration between these two cues. In this work, we study a novel and efficient full-duplex strategy network (FSNet) to address this issue, by considering a better mutual restraint scheme linking motion and appearance allowing exploitation of cross-modal features from the fusion and decoding stage. Specifically, we introduce a relational cross-attention module (RCAM) to achieve bidirectional message propagation across embedding sub-spaces. To improve the model’s robustness and update inconsistent features from the spatiotemporal embeddings, we adopt a bidirectional purification module after the RCAM. Extensive experiments on five popular benchmarks show that our FSNet is robust to various challenging scenarios (e.g., motion blur and occlusion), and compares well to leading methods both for video object segmentation and video salient object detection. The project is publicly available at https://github.com/GewelsJI/FSNet.

Article PDF
Similar content being viewed by others
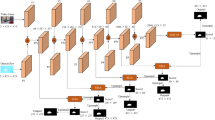

Avoid common mistakes on your manuscript.
References
Wang, Y. Q.; Xu, Z. L.; Wang, X. L.; Shen, C. H.; Cheng, B. S.; Shen, H.; Xia, H. End-to-end video instance segmentation with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8737–8746, 2021.
Chen, X.; Li, Z. X.; Yuan, Y.; Yu, G.; Shen, J. X.; Qi, D. L. State-aware tracker for real-time video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9381–9390, 2020.
Abramov, A.; Pauwels, K.; Papon, J.; Wörgötter, F.; Dellen, B. Depth-supported real-time video segmentation with the Kinect. In: Proceedings of the IEEE Workshop on the Applications of Computer Vision, 457–464, 2012.
Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford RobotCar dataset. The International Journal of Robotics Research Vol. 36, No. 1, 3–15, 2017.
Jain, S.; Grauman, K. Click carving: Segmenting objects in video with point clicks. Proceedings of the AAAI Conference on Human Computation and Crowdsourcing Vol. 4, No. 1, 89–98, 2016.
Wang, H.; Deng, C.; Ma, F.; Yang, Y. Context modulated dynamic networks for actor and action video segmentation with language queries. Proceedings of the AAAI Conference on Artificial Intelligence Vol. 34, No. 7, 12152–12159, 2020.
Ding, M. Y.; Wang, Z.; Zhou, B. L.; Shi, J. P.; Lu, Z. W.; Luo, P. Every frame counts: Joint learning of video segmentation and optical flow. Proceedings of the AAAI Conference on Artificial Intelligence Vol. 34, No. 7, 10713–10720, 2020.
Ji, G. P.; Chou, Y. C.; Fan, D. P.; Chen, G.; Fu, H.; Jha, D.; Shao, L. Progressively normalized self-attention network for video polyp segmentation. In: Medical Image Computing and Computer Assisted Intervention — MICCAI 2021. Lecture Notes in Computer Science, Vol. 12901. Springer Cham, 142–152, 2021.
Chen, B.; Ling, H.; Zeng, X.; Gao, J.; Xu, Z.; Fidler, S. ScribbleBox: Interactive annotation framework for video object segmentation. In: Computer Vision — ECCV 2020. Lecture Notes in Computer Science, Vol. 12358. Vedaldi, A.; Bischof, H.; Brox, T.; Frahm, J. M. Eds. Springer Cham, 293–310, 2020.
Seo, S.; Lee, J. Y.; Han, B. URVOS: Unified referring video object segmentation network with a large-scale benchmark. In: Computer Vision — ECCV 2020. Lecture Notes in Computer Science, Vol. 12360. Vedaldi, A.; Bischof, H.; Brox, T.; Frahm, J. M. Eds. Springer Cham, 208–223, 2020.
Pan, Y. W.; Yao, T.; Li, H. Q.; Mei, T. Video captioning with transferred semantic attributes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 984–992, 2017.
Lee, S. H.; Jang, W. D.; Kim, C. S. Contour-constrained superpixels for image and video processing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 5863–5871, 2017.
Reso, M.; Jachalsky, J.; Rosenhahn, B.; Ostermann, J. Temporally consistent superpixels. In: Proceedings of the IEEE International Conference on Computer Vision, 385–392, 2013.
Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of optical flow estimation with deep networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1647–1655, 2017.
Teed, Z.; Deng, J. RAFT: Recurrent all-pairs field transforms for optical flow. In: Computer Vision — ECCV 2020. Lecture Notes in Computer Science, Vol. 12347. Vedaldi, A.; Bischof, H.; Brox, T.; Frahm, J. M. Eds. Springer Cham, 402–419, 2020.
Hu, P.; Wang, G.; Kong, X.; Kuen, J.; Tan, Y. Motion-guided cascaded refinement network for video object segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 42, No. 8, 1957–1967, 2020.
Tokmakov, P.; Alahari, K.; Schmid, C. Learning video object segmentation with visual memory. In: Proceedings of the IEEE International Conference on Computer Vision, 4491–4500, 2017.
Fan, D. P.; Wang, W. G.; Cheng, M. M.; Shen, J. B. Shifting more attention to video salient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8546–8556, 2019.
Chen, Z. X.; Guo, C. C.; Lai, J. H.; Xie, X. H. Motion-appearance interactive encoding for object segmentation in unconstrained videos. IEEE Transactions on Circuits and Systems for Video Technology Vol. 30, No. 6, 1613–1624, 2020.
Yang, Z.; Wang, Q.; Bertinetto, L.; Bai, S.; Hu, W.; Torr, P. Anchor diffusion for unsupervised video object segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 931–940, 2019.
Jain, S. D.; Xiong, B.; Grauman, K. FusionSeg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2117–2126, 2017.
Khoreva, A.; Benenson, R.; Ilg, E.; Brox, T.; Schiele, B. Lucid data dreaming for object tracking. In: Proceedings of the 2017 DAVIS Challenge on Video Object Segmentation — CVPR 2017 Workshops, 2017.
Cheng, J.; Tsai, Y.-H.; Wang, S.; Yang, M.-H. SegFlow: Joint learning for video object segmentation and optical flow. In: Proceedings of the IEEE International Conference on Computer Vision, 686–695, 2017.
Xiao, H. X.; Kang, B. Y.; Liu, Y.; Zhang, M. J.; Feng, J. S. Online meta adaptation for fast video object segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 42, No. 5, 1205–1217, 2020.
Zhou, T. F.; Wang, S. Z.; Zhou, Y.; Yao, Y. Z.; Li, J. W.; Shao, L. Motion-attentive transition for zero-shot video object segmentation. Proceedings of the AAAI Conference on Artificial Intelligence Vol. 34, No. 7, 13066–13073, 2020.
Tsai, Y.-H.; Yang, M.-H.; Black, M. J. Video segmentation via object flow. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3899–3908, 2016.
Lin, F. Q.; Chou, Y.; Martinez, T. Flow adaptive video object segmentation. Image and Vision Computing Vol. 94, 103864, 2020.
Nilsson, D.; Sminchisescu, C. Semantic video segmentation by gated recurrent flow propagation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6819–6828, 2018.
Li, H.; Chen, G.; Li, G.; Yu, Y. Motion guided attention for video salient object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 7273–7282, 2019.
Peng, Q. M.; Cheung, Y. M. Automatic video object segmentation based on visual and motion saliency. IEEE Transactions on Multimedia Vol. 21, No. 12, 3083–3094, 2019.
Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. Human Neurobiology Vol. 4, No. 4, 219–227, 1985.
Wolfe, J. M.; Cave, K. R.; Franzel, S. L. Guided search: An alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human Perception and Performance Vol. 15, No. 3, 419–433, 1989.
Wang, W. G.; Shen, J. B.; Lu, X. K.; Hoi, S. C. H.; Ling, H. B. Paying attention to video object pattern understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 43, No. 7, 2413–2428, 2021.
Bharadia, D.; McMilin, E.; Katti, S. Full duplex radios. ACM SIGCOMM Computer Communication Review Vol. 43, No. 4, 375–386, 2013.
Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 724–732, 2016.
Ji, G. P.; Fu, K. R.; Wu, Z.; Fan, D. P.; Shen, J. B.; Shao, L. Full-duplex strategy for video object segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 4902–4913, 2021.
Seong, H.; Hyun, J.; Kim, E. Kernelized memory network for video object segmentation. In: Computer Vision — ECCV 2020. Lecture Notes in Computer Science, Vol. 12367. Vedaldi, A.; Bischof, H.; Brox, T.; Frahm, J. M. Eds. Springer Cham, 629–645, 2020.
Bhat, G.; Lawin, F. J.; Danelljan, M.; Robinson, A.; Felsberg, M.; van Gool, L.; Timofte, R. Learning what to learn for video object segmentation. In: Proceedings of the Computer Vision — ECCV 2020: 16th European Conference, 777–794, 2020.
Hu, L.; Zhang, P.; Zhang, B.; Pan, P.; Xu, Y. H.; Jin, R. Learning position and target consistency for memory-based video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4142–4152, 2021.
Duke, B.; Ahmed, A.; Wolf, C.; Aarabi, P.; Taylor, G. W. SSTVOS: Sparse spatiotemporal transformers for video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5908–5917, 2021.
Zhou, T.; Li, J.; Wang, S.; Tao, R.; Shen, J. MATNet: Motion-attentive transition network for zero-shot video object segmentation. IEEE Transactions on Image Processing Vol. 29, 8326–8338, 2020.
Ochs, P.; Brox, T. Higher order motion models and spectral clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 614–621, 2012.
Fragkiadaki, K.; Zhang, G.; Shi, J. B. Video segmentation by tracing discontinuities in a trajectory embedding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1846–1853, 2012.
Li, F.; Kim, T.; Humayun, A.; Tsai, D.; Rehg, J. M. Video segmentation by tracking many figure-ground segments. In: Proceedings of the IEEE International Conference on Computer Vision, 2192–2199, 2013.
Perazzi, F.; Wang, O.; Gross, M.; Sorkine-Hornung, A. Fully connected object proposals for video segmentation. In: Proceedings of the IEEE International Conference on Computer Vision, 3227–3234, 2015.
Wang, W. G.; Shen, J. B.; Porikli, F. Saliency-aware geodesic video object segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3395–3402, 2015.
Wang, W. G.; Shen, J. B.; Li, X. L.; Porikli, F. Robust video object cosegmentation. IEEE Transactions on Image Processing Vol. 24, No. 10, 3137–3148, 2015.
Galasso, F.; Cipolla, R.; Schiele, B. Video segmentation with superpixels. In: Computer Vision — ACCV 2012. Lecture Notes in Computer Science, Vol. 7724. Lee, K. M.; Matsushita, Y.; Rehg, J. M.; Hu, Z. Eds. Springer Berlin Heidelberg, 760–774, 2013.
Xu, C.; Xiong, C.; Corso, J. J. Streaming hierarchical video segmentation. In: Computer Vision — ECCV 2012. Lecture Notes in Computer Science, Vol. 7577. Fitzgibbon, A.; Lazebnik, S.; Perona, P.; Sato, Y.; Schmid, C. Eds. Springer Berlin Heidelberg, 626–639, 2012.
Song, H.; Wang, W.; Zhao, S.; Shen, J.; Lam, K. M. Pyramid dilated deeper ConvLSTM for video salient object detection. In: Computer Vision — ECCV 2018. Lecture Notes in Computer Science, Vol. 11215. Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. Eds. Springer Cham, 744–760, 2018.
Wang, W. G.; Song, H. M.; Zhao, S. Y.; Shen, J. B.; Zhao, S. Y.; Hoi, S. C. H.; Ling, H. Learning unsupervised video object segmentation through visual attention. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3059–3069, 2019.
Zheng, J.; Luo, W. X.; Piao, Z. X. Cascaded ConvLSTMs using semantically-coherent data synthesis for video object segmentation. IEEE Access Vol. 7, 132120–132129, 2019.
Tokmakov, P.; Alahari, K.; Schmid, C. Learning motion patterns in videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 531–539, 2017.
Siam, M.; Jiang, C.; Lu, S.; Petrich, L.; Gamal, M.; Elhoseiny, M.; Jagersand, M. Video object segmentation using teacher-student adaptation in a human robot interaction (HRI) setting. In: Proceedings of the International Conference on Robotics and Automation, 50–56, 2019.
Li, S.; Seybold, B.; Vorobyov, A.; Lei, X.; Kuo, C. C. J. Unsupervised video object segmentation with motion-based bilateral networks. In: Computer Vision — ECCV 2018. Lecture Notes in Computer Science, Vol. 11207. Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. Eds. Springer Cham, 215–231, 2018.
Wang, W.; Shen, J.; Yang, R.; Porikli, F. Saliency-aware video object segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 40, No. 1, 20–33, 2018.
Zhou, X. F.; Liu, Z.; Gong, C.; Liu, W. Improving video saliency detection via localized estimation and spatiotemporal refinement. IEEE Transactions on Multimedia Vol. 20, No. 11, 2993–3007, 2018.
Xu, M. Z.; Liu, B.; Fu, P.; Li, J. B.; Hu, Y. H.; Feng, S. Video salient object detection via robust seeds extraction and multi-graphs manifold propagation. IEEE Transactions on Circuits and Systems for Video Technology Vol. 30, No. 7, 2191–2206, 2020.
Hu, Y. T.; Huang, J. B.; Schwing, A. G. Unsupervised video object segmentation using motion saliency-guided spatio-temporal propagation. In: Computer Vision — ECCV 2018. Lecture Notes in Computer Science, Vol. 11205. Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. Eds. Springer Cham, 813–830, 2018.
Wang, W. G.; Shen, J. B.; Shao, L. Video salient object detection via fully convolutional networks. IEEE Transactions on Image Processing Vol. 27, No. 1, 38–49, 2018.
Le, T. N.; Sugimoto, A. Deeply supervised 3D recurrent FCN for salient object detection in videos. In: Proceedings of the British Machine Vision Conference, 38.1-38.13, 2017.
Min, K.; Corso, J. TASED-net: Temporally-aggregating spatial encoder-decoder network for video saliency detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2394–2403, 2019.
Li, G. B.; Xie, Y.; Wei, T. H.; Wang, K. Z.; Lin, L. Flow guided recurrent neural encoder for video salient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3243–3252, 2018.
Le, T. N.; Sugimoto, A. Video salient object detection using spatiotemporal deep features. IEEE Transactions on Image Processing Vol. 27, No. 10, 5002–5015, 2018.
Li, Y. X.; Li, S.; Chen, C.; Hao, A. M.; Qin, H. Accurate and robust video saliency detection via self-paced diffusion. IEEE Transactions on Multimedia Vol. 22, No. 5, 1153–1167, 2020.
Borji, A.; Cheng, M. M.; Hou, Q. B.; Jiang, H. Z.; Li, J. Salient object detection: A survey. Computational Visual Media Vol. 5, No. 2, 117–150, 2019.
Zhou, T.; Fan, D. P.; Cheng, M. M.; Shen, J. B.; Shao, L. RGB-D salient object detection: A survey. Computational Visual Media Vol. 7, No. 1, 37–69, 2021.
Chen, C.; Wang, G. T.; Peng, C.; Zhang, X. W.; Qin, H. Improved robust video saliency detection based on long-term spatial-temporal information. IEEE Transactions on Image Processing Vol. 29, 1090–1100, 2020.
Yan, P. X.; Li, G. B.; Xie, Y.; Li, Z.; Wang, C.; Chen, T. S.; Lin, L. Semi-supervised video salient object detection using pseudo-labels. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 7283–7292, 2019.
Tang, Y.; Zou, W. B.; Jin, Z.; Chen, Y. H.; Hua, Y.; Li, X. Weakly supervised salient object detection with spatiotemporal cascade neural networks. IEEE Transactions on Circuits and Systems for Video Technology Vol. 29, No. 7, 1973–1984, 2019.
Wang, Z.; Yan, X. Y.; Han, Y. H.; Sun, M. J. Ranking video salient object detection. In: Proceedings of the 27th ACM International Conference on Multimedia, 873–881, 2019.
Zhao, W. B.; Zhang, J.; Li, L.; Barnes, N.; Liu, N.; Han, J. W. Weakly supervised video salient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16821–16830, 2021.
He, K. M.; Zhang, X. Y.; Ren, S. Q.; Sun, J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778, 2016.
Wei, J.; Wang, S. H.; Huang, Q. M. F3Net: Fusion, feedback and focus for salient object detection. Proceedings of the AAAI Conference on Artificial Intelligence Vol. 34, No. 7, 12321–12328, 2020.
Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. ExFuse: Enhancing feature fusion for semantic segmentation. In: Computer Vision — ECCV 2018. Lecture Notes in Computer Science, Vol. 11214. Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. Eds. Springer Cham, 273–288, 2018.
Sevilla-Lara, L.; Liao, Y.; Guüney, F.; Jampani, V.; Geiger, A.; Black, M. J. On the integration of optical flow and action recognition. In: Pattern Recognition. Lecture Notes in Computer Science, Vol. 11269. Brox, T.; Bruhn, A.; Fritz, M. Eds. Springer Cham, 281–297, 2019.
Wu, Z.; Su, L.; Huang, Q. Stacked cross refinement network for edge-aware salient object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 7263–7272, 2019.
Lin, T. Y.; Dollár, P.; Girshick, R.; He, K. M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 936–944, 2017.
Zhao, H. S.; Shi, J. P.; Qi, X. J.; Wang, X. G.; Jia, J. Y. Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 6230–6239, 2017.
Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention — MICCAI 2015. Lecture Notes in Computer Science, Vol. 9351. Navab, N.; Hornegger, J.; Wells, W.; Frangi, A. Eds. Springer Cham, 234–241, 2015.
Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. et al. PyTorch: An imperative style, high-performance deep learning library. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems, 8026–8037, 2019.
He, K. M.; Zhang, X. Y.; Ren, S. Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 37, No. 9, 1904–1916, 2015.
Lu, X. K.; Wang, W. G.; Ma, C.; Shen, J. B.; Shao, L.; Porikli, F. See more, know more: Unsupervised video object segmentation with co-attention Siamese networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3618–3627, 2019.
Krähenbühl, P.; Koltun, V. Efficient inference in fully connected CRFs with Gaussian edge potentials. In: Proceedings of the 24th International Conference on Neural Information Processing Systems, 109–117, 2011.
Kim, H.; Kim, Y.; Sim, J. Y.; Kim, C. S. Spatiotemporal saliency detection for video sequences based on random walk with restart. IEEE Transactions on Image Processing Vol. 24, No. 8, 2552–2564, 2015.
Ochs, P.; Malik, J.; Brox, T. Segmentation of moving objects by long term video analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 36, No. 6, 1187–1200, 2014.
Wang, L. J.; Lu, H. C.; Wang, Y. F.; Feng, M. Y.; Wang, D.; Yin, B. C.; Ruan, X. Learning to detect salient objects with image-level supervision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3796–3805, 2017.
Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1597–1604, 2009.
Cheng, M. M.; Mitra, N. J.; Huang, X. L.; Torr, P. H. S.; Hu, S. M. Global contrast based salient region detection. IEEE Transactions on Pattern Analysis and Machine Intelligence Vol. 37, No. 3, 569–582, 2015.
Borji, A.; Cheng, M. M.; Jiang, H. Z.; Li, J. Salient object detection: A benchmark. IEEE Transactions on Image Processing Vol. 24, No. 12, 5706–5722, 2015.
Fan, D. P.; Cheng, M. M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In: Proceedings of the IEEE International Conference on Computer Vision, 4558–4567, 2017.
Wang, W. G.; Lu, X. K.; Shen, J. B.; Crandall, D.; Shao, L. Zero-shot video object segmentation via attentive graph neural networks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 9235–9244, 2019.
Faisal, M.; Akhter, I.; Ali, M.; Hartley, R. EpO-net: Exploiting geometric constraints on dense trajectories for motion saliency. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision, 1873–1882, 2020.
Tokmakov, P.; Schmid, C.; Alahari, K. Learning to segment moving objects. International Journal of Computer Vision volume Vol. 127, No. 3, 282–301, 2019.
Koh, Y. J.; Kim, C. S. Primary object segmentation in videos based on region augmentation and reduction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7417–7425, 2017.
Lao, D.; Sundaramoorthi, G. Extending layered models to 3D motion. In: Computer Vision — ECCV 2018. Lecture Notes in Computer Science, Vol. 11214. Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. Eds. Springer Cham, 441–457, 2018.
Papazoglou, A.; Ferrari, V. Fast object segmentation in unconstrained video. In: Proceedings of the IEEE International Conference on Computer Vision, 1777–1784, 2013.
Yang, Z.; Wei, Y.; Yang, Y. Collaborative video object segmentation by foreground-background integration. In: Computer Vision — ECCV 2020. Lecture Notes in Computer Science, Vol. 12350. Vedaldi, A.; Bischof, H.; Brox, T.; Frahm, J. M. Eds. Springer Cham, 332–348, 2020.
Johnander, J.; Danelljan, M.; Brissman, E.; Khan, F. S.; Felsberg, M. A generative appearance model for end-to-end video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8945–8954, 2019.
Oh, S. W.; Lee, J. Y.; Sunkavalli, K.; Kim, S. J. Fast video object segmentation by reference-guided mask propagation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7376–7385, 2018.
Voigtlaender, P.; Chai, Y. N.; Schroff, F.; Adam, H.; Leibe, B.; Chen, L. C. FEELVOS: Fast end-to-end embedding learning for video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9473–9482, 2019.
Cheng, J. C.; Tsai, Y. H.; Hung, W. C.; Wang, S. J.; Yang, M. H. Fast and accurate online video object segmentation via tracking parts. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7415–7424, 2018.
Caelles, S.; Maninis, K. K.; Pont-Tuset, J.; Leal-Taixé, L.; Cremers, D.; van Gool, L. One-shot video object segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 5320–5329, 2017.
Perazzi, F.; Khoreva, A.; Benenson, R.; Schiele, B.; Sorkine-Hornung, A. Learning video object segmentation from static images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3491–3500, 2017.
Chen, Y. H.; Zou, W. B.; Tang, Y.; Li, X.; Xu, C.; Komodakis, N. SCOM: Spatiotemporal constrained optimization for salient object detection. IEEE Transactions on Image Processing Vol. 27, No. 7, 3345–3357, 2018.
Cong, R. M.; Lei, J. J.; Fu, H. Z.; Porikli, F.; Huang, Q. M.; Hou, C. P. Video saliency detection via sparsity-based reconstruction and propagation. IEEE Transactions on Image Processing Vol. 28, No. 10, 4819–4831, 2019.
Xu, M. Z.; Liu, B.; Fu, P.; Li, J. B.; Hu, Y. H. Video saliency detection via graph clustering with motion energy and spatiotemporal objectness. IEEE Transactions on Multimedia Vol. 21, No. 11, 2790–2805, 2019.
Gu, Y. C.; Wang, L. J.; Wang, Z. Q.; Liu, Y.; Cheng, M. M.; Lu, S. P. Pyramid constrained self-attention network for fast video salient object detection. Proceedings of the AAAI Conference on Artificial Intelligence Vol. 34, No. 7, 10869–10876, 2020.
Fan, D.-P.; Ji, G.-P.; Qin, X.; Cheng, M.-M. Cognitive vision inspired object segmentation metric and loss function. SCIENTIA SINICA Informationis Vol. 51, No. 9, 1475–1489, 2021. (in Chinese)
Mahadevan, S.; Athar, A.; Ošep, A.; Hennen, S.; Leal-Taixé, L.; Leibe, B. Making a case for 3D convolutions for object segmentation in videos. In: Proceedings of the 31st British Machine Vision Conference, 2020.
Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. L. Microsoft COCO: Common objects in context. In: Computer-Vision — ECCV 2014. Lecture Notes in Computer-Science, Vol. 8693. Fleet, D.; Pajdla, T.; Schiele, B.; Tuytelaars, T. Eds. Springer Cham, 740–755, 2014.
Xu, N.; Yang, L.; Fan, Y.; Yang, J.; Yue, D.; Liang, Y.; Price, B.; Cohen, S.; Huang, T. YouTube-VOS: Sequence-to-sequence video object segmentation. In: Computer Vision — ECCV 2018. Lecture Notes in Computer Science, Vol. 11209. Ferrari, V.; Hebert, M.; Sminchisescu, C.; Weiss, Y. Eds. Springer Cham, 603–619, 2018.
Wang, W. H.; Xie, E. Z.; Li, X.; Fan, D. P.; Song, K. T.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 548–558, 2021.
Zhuge, M. C.; Gao, D. H.; Fan, D. P.; Jin, L. B.; Chen, B.; Zhou, H. M.; Qiu, M.; Shao, L. Kaleido-BERT: Vision-language pre-training on fashion domain. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12642–12652, 2021.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (62176169, 61703077, and 62102207).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Ge-Peng Ji received his master degree in communication and information systems from the School of Computer Science, Wuhan University, in 2021. He is currently a research intern at the Inception Institute of Artificial Intelligence (IIAI), Abu Dhabi, United Arab Emirates. His research interests lie in designing deep neural networks and applying deep learning to various fields of computer vision, such as camouflaged and salient object detection, video salient object detection, and medical image segmentation.
Deng-Ping Fan received his Ph.D. degree from Nankai University in 2019. He joined the Inception Institute of Artificial Intelligence (IIAI) in 2019. He has published about 30 top journal and conference papers in outlets such as IEEE TPAMI, IEEE TMI, IJCV, CVPR, ICCV, ECCV, etc. His research interests include computer vision, deep learning, and saliency detection. He served as a senior program committee member for IJCAI 2021.
Keren Fu received dual Ph.D. degrees from Shanghai Jiao Tong University, Shanghai, China, and Chalmers University of Technology, Gothenburg, Sweden, under the joint supervision of Prof. Jie Yang and Prof. Irene Yu-Hua Gu. He is currently a research associate professor with the College of Computer Science, Sichuan University, China. His current research interests include visual computing, saliency analysis, and machine learning.
Zhe Wu received his Ph.D. degree in computer science from the School of Computer and Control Engineering, University of the Chinese Academy of Sciences, Beijing, in 2020. He is a post-doctoral researcher in the Peng Cheng Laboratory, Shenzhen, China. His current research interests include visual attention, computer vision, and traffic prediction.
Jianbing Shen is a full professor in the School of Computer Science, Beijing Institute of Technology. He has published about 100 journal and conference papers in outlets such as IEEE TPAMI, CVPR, and ICCV. He has received many honors, including a Fok Ying Tung Education Foundation from the Ministry of Education, and awards from the Program for Beijing Excellent Youth Talents from Beijing Municipal Education Commission, and the Program for New Century Excellent Talents from the Ministry of Education. His research interests include computer vision and deep learning. He is an Associate Editor of IEEE TNNLS and IEEE TIP.
Ling Shao is the CEO and Chief Scientist of the Inception Institute of Artificial Intelligence (IIAI). He was the initiator and the Founding Provost and Executive Vice President of the Mohamed bin Zayed University of Artificial Intelligence (the world’s first AI University), United Arab Emirates. His research interests include computer vision, machine learning, and medical imaging. He is a fellow of the IEEE, the IAPR, the IET, and the BCS.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Other papers from this open access journal are available free of charge from http://www.springer.com/journal/41095. To submit a manuscript, please go to https://www.editorialmanager.com/cvmj.
About this article

Cite this article
Ji, GP., Fan, DP., Fu, K. et al. Full-duplex strategy for video object segmentation. Comp. Visual Media 9, 155–175 (2023). https://doi.org/10.1007/s41095-021-0262-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41095-021-0262-4