
Abstract
Visual systems are receiving increasing attention in underwater applications. While the photogrammetric and computer vision literature so far has largely targeted shallow water applications, recently also deep sea mapping research has come into focus. The majority of the seafloor, and of Earth’s surface, is located in the deep ocean below 200 m depth, and is still largely uncharted. Here, on top of general image quality degradation caused by water absorption and scattering, additional artificial illumination of the survey areas is mandatory that otherwise reside in permanent darkness as no sunlight reaches so deep. This creates unintended non-uniform lighting patterns in the images and non-isotropic scattering effects close to the camera. If not compensated properly, such effects dominate seafloor mosaics and can obscure the actual seafloor structures. Moreover, cameras must be protected from the high water pressure, e.g. by housings with thick glass ports, which can lead to refractive distortions in images. Additionally, no satellite navigation is available to support localization. All these issues render deep sea visual mapping a challenging task and most of the developed methods and strategies cannot be directly transferred to the seafloor in several kilometers depth. In this survey we provide a state of the art review of deep ocean mapping, starting from existing systems and challenges, discussing shallow and deep water models and corresponding solutions. Finally, we identify open issues for future lines of research.
Zusammenfassung
Optische Bildgebungs- und Bildwiederherstellungstechniken für die Tiefseekartierung: Eine umfassende Übersicht. Visuelle Systeme erhalten in Unterwasser-Anwendungen zunehmend Aufmerksamkeit. Während in der Photogrammetrie- und Computer Vision Literatur bisher weitgehend auf Flachwasseranwendungen abgezielt wurde, ist in letzter Zeit auch die Forschung zur Kartierung in der Tiefsee in den Fokus gerückt. Der Großteil des Meeresbodens und auch der Erdoberfläche insgesamt befindet sich mehr als 200m unter Wasser und ist noch weitgehend unkartiert. Da kein Sonnenlicht in die Tiefsee gelangt, ist in so einer Umgebung permanenter Dunkelheit künstliche Beleuchtung notwendig, durch die die aufgrund von Lichtabsorption und -streuung bereits schwierigen Unterwassersichtbedingungen in der Regel noch verschlechtert werden. Das zusätzliche mitgeführte Licht erzeugt ungewollte und ungleichmäßige Beleuchtungsmuster in den Bildern sowie nicht-isotrope Streueffekte in der Nähe der Kamera. Wenn all diese Effekte nicht richtig kompensiert werden, dominieren sie aus vielen Bildern zusammengesetzte Meeresbodenmosaike und können die tatsächlichen Meeresbodenstrukturen überlagern oder sogar verdecken. Außerdem müssen Tiefseekameras vor dem hohen Wasserdruck geschützt werden, z.B. durch Gehäuse mit dicken Glasfenstern, die aber zu Lichtbrechung führen können. Zudem ist keine Satellitennavigation zur Unterstützung der Lokalisierung verfügbar. All diese Probleme machen die visuelle Tiefseekartierung zu einer herausfordernden Aufgabe, und die meisten der entwickelten Methoden und Strategien für Luft, Land oder Flachwasser können nicht direkt auf den Meeresboden in mehreren Kilometern Tiefe übertragen werden. In diesem Beitrag bieten wir einen aktuellen Überblick über die visuelle Kartierung der Tiefsee, ausgehend von bestehenden Systemen und Herausforderungen, einer Diskussion von Flach- und Tiefwassermodellen und entsprechenden Lösungen. Schließlich identifizieren wir offene Fragen für zukünftige Forschungsrichtungen.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
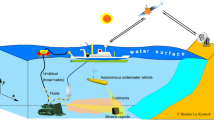
More than half of Earth’s surface is situated in the deep ocean, covered by several hundred or several thousand meters of water above it. However, only very little of this largest surface portion of Earth has been explored, because accessing the deep sea is challenging. Among the different sensing and exploration technologies, optical images are attractive because of their resolution, and because they are well-suited for human interpretation and do not require physical contact for data collection. On land and in space, the rapid growth of optical imaging techniques enables excellent quality photogrammetric surveys. Nowadays hundreds of satellites and airborne imaging platforms are frequently updating high resolution imagery which is playing a fundamental role in the modern society. Image-based mapping of the surface even is an important step in planetary explorations and even the Moon and Mars surface have been visually charted. Unfortunately, all these matured solutions cannot be directly transferred to deep ocean mapping. Optical imaging in the deep ocean not only requires the camera to deal with the extremely high water pressure as well as navigation in a satellite-denied environment, but also adequate artificial lighting to illuminate the scene in the permanent darkness (see Fig. 1). Besides special technical necessities, deep sea mosaicing needs effective image restoration algorithms to remove strong water attenuation, scattering and lighting patterns for producing high-quality data products.

GEOMAR AUV ANTON (Girona 500) performing subsea visual mapping tasks in the darkness with its own lighting offshore Norway. The co-moving light source creates a light cone in water, illuminates the seafloor non-homogeneously and forms up an artificial pattern in image
1.1 Deep Sea Exploration Platforms
To carry out imaging in the deep ocean, imaging systems have to be brought to location and navigated to scan a survey area. In this article we focus on dynamic platforms and omit stationary observatories. Dynamic platforms for deep sea operations can roughly be categorized into four basic types of vehicles: Remotely Operated Vehicles (ROVs), Autonomous Underwater Vehicles (AUVs), Human Occupied Vehicles (HOVs), and towsleds (see Fig. 2). They can be classified into two major groups according to their power supply: Cabeled and uncabeled platforms. Cabeled platforms are connected to operating ships or surface stations, such as ROVs (Drap et al. 2015; Johnson-Roberson et al. 2010). They are tethered underwater platforms electrically connected to the ship, all control commands and signals are transmitted between platforms and the operators via these cables. Additionally, more passive, towsleds are also often used for deep ocean imaging: they can either be remotely powered and transmit signals directly to the support vessel via cables (Barker et al. 1999; Lembke et al. 2017; Purser et al. 2018), or operate independently of the ship (Fornari and Group 2003; Jones et al. 2009). Uncabeled platforms refer to untethered underwater vehicles (UVs), including AUVs (Iscar et al. 2018; Kunz et al. 2008; Singh et al. 2004; Yoerger et al. 2007) and HOVs. AUVs are unoccupied underwater robots which are fully controlled by their onboard computers. HOVs are crewed craft that bring a few passengers directly underwater for limited periods of time. Uncabeled platforms survey the ocean depths without any attached cables thus they are battery powered. They have limited deployment endurance that mainly depends on the platforms’ energy budget (or living supplies for HOVs).
Because of the poor underwater visibility conditions, all these platforms have to be operated close to the seafloor, leading to small footprints and mapping speeds in the order of a hectare per hour or less (Kwasnitschka et al. 2016). Also diving up and down to great depths takes several hours and so large scale benthic visual maps require very long missions. ROVs, HOVs and towsleds all demand labor intensive operation, and, whenever cables are in the water, very careful coordination is mandatory to avoid the surface vessel’s propellers. Often, safety guidelines forbid using more than one cabled device in the water at the same time, making parallelization difficult. In contrast, in the case of AUVs, multiple fully automatic vehicles can work together or in parallel for vast deep ocean mapping tasks.

Examples of four different types of platforms which been employed for deep sea mapping. From left to right: ROV (GEOMAR KIEL 6000), AUV (GEOMAR ABYSS Tiffy), HOV (GEOMAR JAGO) and towsled (OFOS frame)
1.2 Overview of Deep Sea Visual Mapping
Deep sea imaging has a long history since the second world war. Pioneering work in deep sea photography was performed by Harvey (1939), using a pressure chamber enduring two miles of water depth. At that time, the basic composition of a deep sea imaging system was already defined: camera, pressure housing and artificial illumination. Early examples implemented deep sea photo mosaicing for visualizing the sunken submarine Thresher (Ballard 1975) and the famous sunken ship Titanic (Ballard et al. 1987). At that time, digital image processing was not available, researchers manually pieced photos together to create larger mosaics. Nowadays, quantitative underwater visual mapping has been deployed for wide applications in the deep sea scenario: (1) geological mapping; (Escartín et al. 2008; Yoerger et al. 2000) created mosaics for hydrothermal vents and spreading ridges, assessments of ferromanganese-nodule distribution (Peukert et al. 2018) (2) biological surveys; (Corrigan et al. 2018; Lirman et al. 2007; Ludvigsen et al. 2007; Simon-Lledó et al. 2019; Singh et al. 2004) used them to map benthic ecosystems and species. (3) in archaeology; (Ballard et al. 2002; Bingham et al. 2010; Foley et al. 2009; Johnson-Roberson et al. 2017) documented ancient shipwrecks via mosiacs. (Gracias and Santos-Victor 2000; Gracias et al. 2003) applied charted mosaics for later (4) navigation purposes. (5) underwater structure inspection; (Shukla and Karki 2016) produced mosaics to inspect underwater industry infrastructure.
Early works mainly demonstrate 2D subsea mosaicing in relatively small areas, directly compiled from image stitching (Eustice et al. 2002; Marks et al. 1995; Pizarro and Singh 2003; Vincent et al. 2003). At that time, lighting issues have already been considered, compensation methods have also been demonstrated later in some large area mapping tasks (Prados et al. 2012; Singh et al. 2004). Moreover, recently 3D photogrammetric reconstruction (Drap et al. 2015; Johnson-Roberson et al. 2010, 2017; Jordt et al. 2016) by using structure from motion (SfM) (Hartley and Zisserman 2004; Maybank and Faugeras 1992) or simultaneous localization and mapping (SLAM) (Durrant-Whyte and Bailey 2006) are providing more advanced 3D mosaics.
Traditionally, vision systems are designed for inspection or exploration purposes. A visual mapping system requires the camera not only to “see” the subsea, but also to capture images according to a well understood photogrammetry model that allows measuring with high accuracy. For early systems, and even for some systems of today, photogrammetric mapping was however not a key design goal, leading to the problem that cameras often suffer from refractive distortions at the housings. In case the overall system cannot be considered central anymore (pinhole model), calibration is additionally complicated by the bulky hardware. Desirable geometric properties and hardware design considerations for a deep sea imaging system for accurate mapping, will be discussed in Sect. 2. On top of the refraction issues, captured images usually suffer from several water and lighting effects: (1) loss of contrast and sharpness due to scattering, (2) distorted color by attenuation and (3) uneven illumination generated by co-moving artificial light sources, all of which are unsuitable for creating mosaics directly. In the subsequent Sect. 3, image restoration methods are surveyed which can be utilized to generate a high quality subsea mosaics with uniform and correct color texture. At the end, in Sect. 4, missing pieces for deep sea mapping are identified and open issues are discussed.
2 Deep Sea Imaging System Design
A deep sea imaging system usually consists of a camera, a water proof housing with a window and an artificial illumination system. Many commercial cameras on the market are able to acquire high definition images, but they might still be difficult to use for visual mapping, as is discussed in this section.
2.1 Camera Housings and Optical Interfaces
As water pressure increases by about 1 atmosphere for every 10 meters of depth, deep sea camera systems are typically protected by a housing with a thick transparent window (e.g. glass or sapphire) against the salt water and high pressures. The two most common interfaces for underwater imaging systems are flat ports and dome ports. However, also other constructions, including upcoming pressure-proof deep ocean lenses employed directly in the water or cylindrical windows exist, but have not been used extensively for deep seafloor mapping so far. Flat ports are being widely employed in underwater photography due to a relatively cheap and easy manufacturing process. Flat refractive geometry has been intensively studied in both photogrammetry (Kotowski 1988; Maas 1995; Telem and Filin 2010) and computer vision (Agrawal et al. 2012; Treibitz et al. 2011), many methods have been proposed to calibrate the flat port underwater camera systems (Jordt-Sedlazeck and Koch 2012; Lavest et al. 2000; Shortis 2015) and to consider refraction correction during the visual 3D reconstruction pipeline (Jordt et al. 2016; Chadebecq et al. 2017; Song et al. 2019). However, underwater reconstructions solutions for flat port images are either closed source or do not consider refraction correction in all parts of the reconstruction steps. The community still does not have a complete and mature solution that considers refractive geometry in each step during the entire dense 3D reconstruction pipeline. Several scholars (Kunz and Singh 2008; Menna et al. 2016; Nocerino et al. 2016; She et al. 2019, 2022) point out that dome ports have several advantages over flat ports, they are better suited for visual mapping. She et al. (2022) gives an in-depth overview on refractive geometry with domes and camera decentering calibration.

Left: when the entrance pupil of the camera is precisely positioned at the center of the dome, the principal rays are not refracted because they all pass through the air-glass-water interface orthogonally (She et al. 2019). The complete system can be considered as a normal pinhole camera. Right: An ROV equipped with a deep sea camera rig with multiple dome ports
In underwater photography, light rays change direction when they pass interfaces between media with different optical densities according to Snell’s law. For flat ports only the ray perpendicular to the interface is not refracted, and the refraction drastically reduces the field of view of the camera underwater. In dome ports, the situation is different: incoming principal rays will not be refracted if the camera’s optical center is positioned exactly in the center of the dome (see Fig. 3). The remaining intrinsic characteristics, such as lens distortions, can be obtained from standard camera calibration procedures. Therefore dome ports are able to preserve the FOV and focal length of the camera, which is particularly vital for subsea mapping. Compared to a flat port system, a camera behind a dome port produces a larger footprint on the seafloor and requires less photos to cover the same area on the same flying attitude. Additionally, images taken by a large FOV lens tend to perform better in pose estimation than narrow ones (Streckel and Koch 2005), which is even more important in the satellite-denied deep sea environment with challenging external localization. Moreover, dome ports bear less chromatic aberration and can achieve a sharper image (Menna et al. 2017).
Besides optical properties, deep sea devices need to be mechanically stable for operating in high water pressure environments. The thickness requirements of flat port glass for deep sea imaging do not scale well with its diameter and the water depth, allowing only tiny flat ports in the deep ocean, or extremely thick glass. Spherical ports (dome ports) are geometrically more stable as the spherical shape withstands water pressure from different directions symmetrically and equally. Therefore it requires much thinner glass as compared to the flat port for the same pressure. During the mechanical design of the system, one more critical issue is that the camera has to be fixed directly to the port in order to achieve stable optical properties (Harvey and Shortis 1998).
We sample some of the currently available high definition (HD) subsea cameras on the market and list their technical features relevant to deep sea mapping in Table 1. Many of the systems use a dome port nowadays that can avoid refraction when properly centered. Here, e.g. (She et al. 2019) introduced a practical solution to precisely center the camera inside a dome port housing, which enables us to simply assemble a refraction free dome port imaging system (She et al. 2021). Avoiding refraction largely simplifies subsequent processing steps, as existing software can be used that cannot consider refraction. Upcoming lens systems as announced by (ZEISS 2022) even use a lens directly computed for use in water that does not suffer from refraction.
2.2 Lighting System
Light is absorbed when it travels through the water body, and sunlight from the water surface only penetrates the first few hundred meters into the ocean. To illuminate the scene in the absolute darkness of the deep sea, UVs need to bring additional artificial light sources to provide adequate illumination. The co-moving light sources project illumination patterns onto the seafloor and the light cones generate scattering effects that are much less homogeneous than in sunlight: the appearance of deep sea images strongly depends on the geometric relationships between the camera, light source and the object (see Fig. 4).

The appearance of the captured deep sea images is significantly influenced by its particular lighting configuration. Left: two spotlights are on the left and right sides from the camera in the South Pacific Ocean. Right: a light rig with 24 LED arrays are placed 1.9 m on top of the camera in the South Pacific Ocean (Kwasnitschka et al. 2016)
These geometric relationships also strongly influence the captured image quality. Close object distances and large separation of lights and camera are beneficial to limit the water effects, especially the backscatter in images (Jaffe et al. 2001; Patterson 1975; Sheinin and Schechner 2016; Singh et al. 2004). However, image footprints become very small with low altitudes, so efficient subsea mapping requires underwater vehicles to fly at higher altitudes in order to cover larger areas. This brings more water volume in front of the camera and leads to stronger light attenuation in the images, as the signal is attenuated exponentially with distance. Flying higher therefore demands more powerful light sources to compensate for this. On the other hand, deep sea robotic platforms have to have a very compact design for being deployable and operable, and the illumination layout usually is strictly limited by the vehicle size and payload. Therefore, at higher altitudes, the limited distance of camera and light forms smaller angles with the seafloor, which introduces heavier backscatter into the image. Recent advances in light emitting diode (LED) technology allow more lightweight and flexible illumination configurations with many small light sources (see Fig. 5), but this creates the question of how to choose a good lighting setup. Multi-LED illumination optimization approaches were suggested (Jaffe 1990; Song et al. 2021b) to tackle this question.

LED has the advantage of lightweight, flexible installation and less energy consumption over traditional Xenon strobes. It is being increasingly employed in modern underwater system design. Left: GEOMAR manned submersible JAGO with multiple LEDs. Right: A newly designed AUV underwater imaging camera system equips with 8 LEDs on a ring shaped frame
In traditional underwater photography, scuba divers often use thin color filters (mostly warm colors in ocean water) in front of the lens or flashes to capture aesthetic images (Edge 2012). By suppressing green and blue light such filters relatively amplify the warm parts of the signal, but typically at the expense of requiring much longer exposure times or ISO settings, effectively loosing a lot of the available energy. However, large scale robotic visual mapping must consider energy limitations for scene illumination, in particular uncabled vehicles. (Jordt 2014) illustrates that only 10% of the red light intensity is left after 6.6 m in pure water, so the amount of warm light one is willing to invest into a mission has to be carefully weighed. Details and discussions about using LEDs of different light spectra underwater can be found in Sticklus et al. (2018a, 2018b).
2.3 Localization Systems
Georeferencing of deep-sea data is a difficult challenge, as water blocks electromagnetic signals from navigation satellites, such that UVs cannot be localized using global navigation satellite systems (GNSS) underwater. The deep sea is also inaccessible to divers and it is very challenging and time-consuming to setup external instruments in several kilometers water depth, making good localization a major challenge in the deep sea even nowadays. UVs in shallow water can frequently surface to receive GNSS signal for a position fix, but this is not applicable in deep diving missions. The live GPS reference can be transferred from the support vessels to deep UVs via cables (Salgado-Jimenez et al. 2010; Vincent et al. 2003). The most frequently applied way to achieve absolute positioning is based on runtime differences of acoustic signals through beacons, such as ultra-short-baseline localization (USBL) and long baseline localization (LBL). However, acoustic sensors have a local range underwater and can not be installed like a worldwide GNSS. Rather they are temporarily deployed (LBL) or operated from vessels (USBL). Due to refraction at water layers, multi-path propagation, background noise and other effects, absolute localization errors of tens of meters are not uncommon in practice, which is an order of magnitude higher than robotic visibility in the deep sea. Deep diving UVs usually integrate multiple sensors, such as Doppler velocity loggers (DVL) and inertial navigation systems (INS), and combine them with surface absolute position information to georeference the underwater vehicles (Zhang et al. 2020). Visual SLAM techniques, which have been widely utilized on land, are also being gradually adapted to ocean applications, but are still facing many challenges (Köser and Frese 2020). These dead reckoning (DR) sensors provide differential measurements such that the error accumulates without bound as the vehicle stays underwater. The other sensors which provide partly absolute positioning information, such as pressure sensors (altimeter), compass, inclinometer, and attitude-heading reference systems (AHRS). Their measurements are often integrated and fused (e.g. by Kalman filters) to improve the localization. More details about UV localization techniques are summarized in (Leonard and Bahr 2016; Paull et al. 2013).
Ultimately, all sensors including camera-lighting systems need to be synchronized within a unique time reference and each image must be georeferenced (position and orientation) by fusing global positioning data with measurements of the DR sensors. Since image matching can provide accurate relative pose estimation, utilizing image matching techniques for post-processing can refine the coarse UV localization information (Elibol et al. 2011; Eustice et al. 2008; Negahdaripour and Xu 2002; Woock and Frey 2010). Furthermore, additional constraints such as loop detection and geophysical maps-based correction (Gracias et al. 2013) can also be applied during post processing to further improve the localization data. Examples of deep sea mapping deployments with their imaging and navigation configurations are summarized in Table 2.
3 Underwater Image Restoration
Captured subsea images suffer from water and artificial lighting effects that require complex post-processing before creating mosaics (see Fig. 6). Such underwater image processing either utilizes a physical based image formation model or targets at qualitative criteria. The corresponding approaches are named restoration or enhancement, respectively. According to a strict definition, restoration should refer to real world distances and optical properties in order to recover the “true” color as it is seen in air. Dozens of literature surveys and reviews were published with regard to underwater image enhancement or restoration over the past decade (Anwar and Li 2020; Vlachos and Skarlatos 2021; Yang et al. 2019). Ideally, subsea mapping should deliver correct spectral information of the seafloor that enables later scientific usage (e.g. inferring material properties, identification of fauna etc.), which demands a “real” restoration during the image processing and not only an image that looks plausible. Unfortunately, the extra information that is required to achieve this is often not available, in particular in single image restoration methods. These methods thus often utilize prior knowledge or assumptions (e.g. gray world) to infer depth variations and combine the depth proxy with a physical model to restore images. While image enhancement is a very useful technique for many applications, it is very difficult to quantitatively evaluate, and often the suggested way for qualitative evaluation is how much humans like the enhanced image (Mangeruga et al. 2018), i.e. human visual inspection. Therefore, this section does not focus on image enhancement but primarily surveys image restoration techniques.

Around 20m\(\times\)20m area of orthomosaic constructed from 106 images taken by an AUV with artificial illumination in Kiel Fjord, Germany. Left: directly generated from raw images (During capturing, the camera red channel gain was set to a higher number in order to acquire more contrast). Right: generated from restored images (Köser et al. 2021). Image processing is vital for producing high quality subsea mosaics as it restores the correct spectrum information, improves the contrast and removes the uneven lighting, which will benefit the later biological, geochemical, geological and mapping applications
3.1 Underwater Image Formation and Approximations
The low level physics of light transport in water are well understood (Mobley 1994; Preisendorfer 1964) when looking at infinitesimally small volumes. Essentially, when light travels through such a small volume, a fraction of the light is absorbed. Another fraction changes direction due to interaction with the water, i.e. by scattering. The direction of the scattering is encoded in a physically- or empirically-motivated phase function, which is a water parameter. Using statistical or physical models, the amount of light leaving a small volume into a particular direction can be predicted from the water parameters and the distribution of the incoming light over all directions. Considering the interactions of all the (infinitesimally) small volumes of an underwater scene at the same time in order to obtain a closed-form solution for image restoration is a challenging, if not impossible, endeavour. Consequently, several approximations to the low-level physical model have been proposed in the literature, including assuming a macroscopic atmosphere-like fog model for shallow water, a single scatter-model for artificial light sources and numerical/discretized simulation of the full problem using Monte-Carlo-based methods. In the following we outline approaches based on these assumptions.
Early works modeled underwater effects (mainly scattering) using a point spread function (PSF) (Mertens and Replogle 1977). Based on the PSF, a group of methods (Barros et al. 2018; Chen et al. 2019; Han et al. 2017; Hou et al. 2007; Liu et al. 2001) synthesize underwater images by generating in-air images of scenes, convolving them by the imaging system’s response at the particular distance and applying the water effects of attenuation and backscatter. The underwater light transmission can then be simplified as a linear system and the restoration is basically a denoised deconvolution on images.
The most commonly adopted underwater image formation approximation for shallow water is derived from the atmospheric scattering model (Cozman and Krotkov 1997), which describes the underwater image I(x) as a linear combination of the attenuated signal and the backscatter:
where J(x) represents the object color without any perturbation at pixel location x and \(B_{\infty }\) denotes the “pure” water color. The transmission map T is often expressed by \(T(x) = e^{-\eta d(x)}\), which comprises the water attenuation effect. Here \(\eta\) is the attenuation coefficient and d is the scene distance. Many variations have been developed starting from this formulation for underwater applications. The atmospheric model was initially designed for in-air dehazing applications and it assumes that the scene is seen under the homogenous illumination, ignoring particular water properties. For non-homogeneous illumination cases, T(x) often multiplies with an extra illumination term which approximates the light propagation by Koschmieder’s model (Koschmieder 1924). The basic atmospheric model applies the same coefficient in the transmission and the backscatter term which does not represent the underwater conditions well (Akkaynak and Treibitz 2018; Song et al. 2021a). According to the definition from (Mobley 1994), the attenuation in the transmission is composed of absorption and total scattering. (Blasinski et al. 2014) simplified the backscatter term and extended the total attenuation by the summation of pure water and three other particle absorption coefficients. (Akkaynak and Treibitz 2018) revised the model by applying different attenuation coefficients associated with the direct signal and the backscatter.
Another well known underwater image formation approximation, mostly used for settings with artificial light (e.g. deep ocean) is the Jaffe–McGlamery (J–M) model (Jaffe 1990; McGlamery 1980). It composes the underwater image by direct signal, forward scattering and backscatter components. It describes the entire underwater light transportation from light sources to the object and finally to the camera. Therefore it better suits the settings in which the scene is illuminated by artificial light sources and utilizes the knowledge of relative geometry between the camera, the underwater scene and the light sources. Several modifications have been proposed to improve the model to adapt to multiple and non-isotropic spotlights (Bryson et al. 2016; Sedlazeck and Koch 2011; Song et al. 2021a).
In the J–M model, the scattering components are complicated as scattered light does not only cumulate along the distance, but also varies with respect to the direction into which the ray is scattered. Most work considers only single scattering that is assumed symmetric around the incident light ray, which is formulated by a scattered angle dependent volume scattering function (VSF) or its corresponding phase function. In early oceanography optics, (Petzold 1972) built an instrument and carefully measured the VSFs for three types of oceanic water (very clear, productive coastal and turbid water) over almost the whole range of scattering angles. Later, several approaches (Lee and Lewis 2003; Narasimhan et al. 2006; Sullivan and Twardowski 2009; Tan et al. 2013) have been developed to measure the VSFs for different types of water. Besides the direct oceanographic measurement of VSF, many analytic formulas of phase functions have been proposed to describe the angular scattering distribution of the photons interacting with different sizes and properties of particles. The Mie phase function (Mie 1976) and the Rayleigh phase function (Lord 1871) formulate the scattering of light when interacting with small spherical particles, which have been intensively utilized in atmospheric research. However, (Mobley 1994) stresses the issue that a sphere might not be a good representative for the shape of aquatic particles. (Chandrasekhar 2013) introduced a low-order polynomial phase function relating to planetary illumination, due to its simplicity, it has been used in several photometric stereo methods for estimating the water scattering phase function. Another popular analytic model is the Henyey-Greenstein (HG) phase function which was initially proposed for simulating the scattering by interstellar dust clouds and has later been widely adopted in many fields, one reason being its simplicity and tractability. (Mobley 1994) pointed out that obvious discrepancies exist between the HG phase functions and real oceanic measurements. One property of HG is that depending on the value of its free “g”-parameter it can only represent forward or backward scattering. A linear combination of two HG phase functions, which is also called two-term HG (TTHG) phase function, was proposed to address this drawback (Haltrin 1999, 2002). Alternatively, a more realistic Fournier-Forand (FF) phase function (Fournier and Forand 1994) and its later form (Fournier and Jonasz 1999) have been proposed which yield increasing attention in oceanography.
After this short overview of different concepts, we start looking in depth into the “fog model” based methods, before we come to the other approaches.
3.2 Atmospheric Fog Approximation based Methods
These methods assume the scene is illuminated by sunlight. But rather than explicitly modeling the sun, it is assumed that the object is illuminated uniformly and that the intensity received at the camera is a blend of attenuated object color and backscatter. The backscatter is often represented by a uniform background color and the attenuation between object and camera is induced by a transmittance map that depends on the distance to each scene point. Most of these methods are proposed for single image restoration which is ill-posed: They require additional distance measurements (e.g. a depth map) or have to guess a proxy depth map derived from priors for the restoration. Generally, these methods can be concluded to three basic steps: scene distance (or equivalent representations) estimation, backscatter removal and transmission map estimation.
3.2.1 Scene Distance Estimation
Scene distance (depth maps) is essential in physical model based restoration approaches. It is the prerequisite to estimate the transmission image, to correct the attenuation and leverage the backscatter removal according to the image formation model. Depth information can be directly acquired using external devices e.g. a Lidar (He and Seet 2004) or acoustic sensors (Kaeli et al. 2011), estimated from images pairs via stereo matching (Akkaynak and Treibitz 2019; Geiger et al. 2010; Shortis et al. 2009) or images with structured light (Bodenmann et al. 2017; Narasimhan and Nayar 2005; Narasimhan et al. 2005; Sarafraz and Haus 2016) or images captured by light-field cameras (Tao et al. 2013; Wang et al. 2015). Depth information can also be estimated from multiple measurements: A group of methods (Hu et al. 2018; Schechner et al. 2001; Schechner and Karpel 2004; Treibitz and Schechner 2008) use polarization filters and acquire multiple images with varying polarizer orientations to infer depth information from estimated backscatter. Nayar and Narasimhan (1999) estimates the structure of a static scene from multiple images with different illumination conditions. Structure-from-motion (SfM) has also been applied to estimate the depth map (Sedlazeck et al. 2009) but it requires scale information, e.g. from a stereo system, from reference targets in the scene with known sizes or from navigation data. Deducing depth from multiple images requires the images to have sufficient overlap and baseline, which is not applicable for single image settings. However, it is suitable for visual mapping as this is also the prerequisite to stitch images.
In case depth information is not available directly, it can be inferred or approximated as often done in single underwater image restoration approaches. A popular idea is related to using the dark channel prior (DCP) (He et al. 2010), which was applied succesfully for single image dehazing in white or bright grey fog or smoke. It assumes that in a haze-free image most of the local patches should contain at least one color channel with a very low intensity, but in a real image in fog, the more fog is in between the observer and the scene, the more the “dark” channels appear brighter. DCP inspired the development of single image dehazing methods and later this scene-depth derivation method has also been intensively applied in single underwater image enhancement (Chao and Wang 2010; Chiang and Chen 2011; Li et al. 2016a, b; Mathias and Samiappan 2019; Yang et al. 2011; Zhao et al. 2015). Nevertheless, due to the severe attenuation of red light in underwater images, the standard DCP result does not fit for underwater scenarios and requires some modifications: (Carlevaris-Bianco et al. 2010) computes the intensity difference between the red channel and the maximum of the green and blue channels per-patch which terms maximum intensity prior (MIP). (Drews et al. 2013) proposes Underwater DCP (UDCP) which omits the red channel and apply DCP only in the green and blue channels. Later (Galdran et al. 2015) extends the UDCP with the inverted red channel, namely the Red Channel Prior (RCP). Lu et al. (2015) discovered that ω in a turbid underwater images is not always the red channel but is occasionally the blue channel, it uses these two channels through a median operator to define the underwater median DCP (UMDCP). (Łuczyński and Birk 2017) inverts red and green channel to calculate the DCP by shifting the RGB coordinate system of underwater images from blue to white. Peng et al. (2018) suggests a generalized DCP (GDCP) based on the depth-dependent color change, via calculating the difference between the ambient light and the raw intensity.
Besides DCP and its derivatives, some other priors are also proposed as a proxy to indicate depth variation in the image. (Peng et al. 2015) leverages the image blurriness which is increasing with distance and suggests the blurriness prior, later (Peng and Cosman 2017) combines it with the MIP and proposes the image blurring and light absorption (IBLA) prior. (Fattal 2014) discovers that pixels in a small image patch distribute along a straight line in RGB color space, known as the Color-Lines Prior (CLP). The Color Attenuation Prior (CAP) (Zhu et al. 2015) creates a linear model for depth estimation according to the brightness and the saturation of the image. (Berman et al. 2016) introduces a non-local prior, the Haze-Lines Prior (HLP), which suggests that pixels in a image can be clustered into few clusters. Pixels which belong to the same cluster in a hazy image are distributing along a line in RGB color space and all these lines pass through the background light. Bui and Kim (2017) proposes the Color Ellipsoid Prior (CEP) based on the observation that the vectors in the RGB color space of a small patch from hazy images are clustering in a ellipsoid. In the underwater scenario, image degradation is influenced not only by the object distance but also by the wavelength dependent attenuation, which the standard HLP does not consider. Wang et al. (2017b) claims that the pixels in the same color cluster will no longer form a straight line but a power function curve in RGB space, which is named Attenuation-Curve Prior (ACP). Afterwards, (Wang et al. 2017a) improves the ACP to the adaptive ACP (AACP), which is more general for different kinds of imaging environments.
Finally, learning based depth estimation approaches also been intensively studied on land (Eigen et al. 2014; Godard et al. 2019; Li and Snavely 2018; Pillai et al. 2019) and have later been transferred to the underwater field (Gupta and Mitra 2019; Zhou et al. 2021). However, similar to other prior based methods, learning based approaches are able to provide plausible relative object relations, but the derived depth information is not in physical units and depends on the training data.
3.2.2 Backscatter Removal
As an additive effect, backscatter introduces a loss of contrast or a foggy appearance that increases with distance. The total backscatter that the camera sees is a cumulative effect which sums up all the scattered light along a viewing direction through the medium between the camera and the object. Since it is superimposed onto the image, subtracting the backscatter component (if known) can effectively improve the image contrast. This backscatter removal issue has been studied in image de-hazing for a long time and current underwater methods mostly are based on them. Physical model based de-hazing mechanisms require the knowledge of the scene depth, therefore de-hazing is highly correlated to the depth estimation and, vice versa, scene depth can be achieved as a by-product once de-hazing is solved.
This paper classifies image de-hazing solutions into four main categories: Hardware-based, multiple-image based, prior-based approaches and learning-based.
-
1.
Hardware-based approaches use additional devices for image acquisition, for instance, directly blocking the backscattered signal through range gated imaging (Li et al. 2009; Tan et al. 2005, 2006), taking at least two static scene images with different orientations of a polarization filter in front of the camera (Schechner et al. 2001, 2003; Schechner and Karpel 2004, 2005; Schechner and Averbuch 2007; Shwartz and Schechner 2006) or the light source (Dubreuil et al. 2013; Hu et al. 2018; Huang et al. 2016; Treibitz and Schechner 2006, 2008), capture images by a light field camera system (Skinner and Johnson-Roberson 2017) or a stereo imaging system (Roser et al. 2014).
-
2.
Multiple-image approaches have first been proposed for in-air applications which take multiple images under varying visibility conditions and scene depth, and backscatter is estimated simultaneously during the optimization (Liu et al. 2018; Narasimhan and Nayar 2002, 2003a; Tarel and Hautiere 2009), similar underwater approaches have been introduced in Sect. 3.4. These methods are developed for webcam like stationary settings. They not only require a static camera, but also demand significant changes between different conditions. When illumination configurations are relatively fixed, the non object image contains the complete backscatter information. (Fujimura et al. 2018; Tsiotsios et al. 2014) assume that images share the same backscatter component and subtract the non-object image from the underwater images to remove the backscatter. In shallow water, this solution is difficult to apply since the amount of scatter observed depends on the camera orientation relative to the sun as well as the water depth through which the sunlight has passed. However, in deep sea mapping scenarios most of UVs carry a fixed artificial lighting system and often fly on a fixed, relative high altitude, therefore the backscatter pattern is stable over images. Additionally, it takes hours for UVs to dive down to the seafloor, during this period of time, large amount of pure water images with only backscatterred lighting patterns are acquired, which is ideal for backscatter removal (Bodenmann et al. 2017; Köser et al. 2021).
-
3.
Prior-based approaches are mostly single image approaches in shallow water with sunlight. When the scene geometry and distance is exactly known (Hautière et al. 2007; Kopf et al. 2008; Narasimhan and Nayar 2003b), backscatter can be directly fitted by an analytical model, or separated from a raw image by Independent Component Analysis (ICA) (Fattal 2008). If the scene geometry is not measured, prior knowledge can be used to obtain an approximate depth map. According to the most commonly used atmospheric model in Eqt. 1, the backscatter component of the image is expressed as \(B_{\infty } \cdot (1 - T(x))\). Consequently, the background light (BL) \(B_{\infty }\), which is also named background color, veiling light, ambient light or water color in the literature, is needed for computing the backscatter component. Usually, pixel that do not see an object (with maximum depth) will be picked as the BL (Kratz and Nishino 2009). Most of the priors were initially proposed for in-air de-hazing, such as DCP, CLP and HLP (see Sect. 3.2.1), they often take the uniform BL assumption over the entire field of view. DCP based in-air de-hazing approaches select the brightest pixel (in the image or dark channel) from a far scene as the BL (He et al. 2010; Tan 2008). Here, bright objects in the scene can lead to erroneous results. Several adaptations were developed for more accurate BL selection, such as using hierarchical quadtree ranking (Emberton et al. 2015; Kim et al. 2013; Park et al. 2014a; Peng and Cosman 2017; Wu et al. 2017), patch-based selection (Chiang and Chen 2011; Serikawa and Lu 2014), estimated from different priors or using extended models (Akkaynak and Treibitz 2019; Carlevaris-Bianco et al. 2010; Henke et al. 2013) and additional selection according to some other rules (Ancuti et al. 2010; Li et al. 2017; Wang et al. 2014; Zhao et al. 2015). Besides that, the BL can also be detected from the smoothest spot on the background for in-air de-hazing (Berman et al. 2016; Fattal 2014) and underwater backscatter removal (Berman et al. 2017, 2020; Li and Cavallaro 2018; Lu et al. 2015; Peng et al. 2015; Peng and Cosman 2017; Wang et al. 2017a). Moreover, using an unique value to represent backscatter assumes that the illumination is uniform, which is an approximation from outdoor hazy scenes. For the deep sea scenario the backscatter depends on the lighting configurations (Song et al. 2021a) and significantly varies with image position. Using a local estimator to provide a more accurate backscatter map is desired for precise artificial lighting backscatter removal (Ancuti et al. 2016; Li and Cavallaro 2018; Tarel and Hautiere 2009; Treibitz and Schechner 2008; Yang et al. 2019).
-
4.
Learning-based image dehazing has become very popular in recent years (Cai et al. 2016; Fu et al. 2017; Liu et al. 2018, 2019; Ren et al. 2018; Zhang et al. 2017a). But these methods generally have the problem that the processing quality strongly depends on the training data, it is difficult to predict how well it generalizes to other scenes.
Backscatter is actually a macroscopic effect that results from the volume scattering function, or the phase function, of the medium (Mobley 1994). These functions characterize in which directions an incoming photon is scattered when it interacts with the medium. In ocean water, this function has a peak in backwards direction, therefore backscatter is an important effect. But photons are also redirected into other directions. In particular also small optical density variations (due to temperature, pressure or salinity fluctuations) of the medium lead to tiny direction changes of photons. On a macroscopic level, all these effects are summarized as forward scattering, leading to distance-dependent unsharpness of the image, since photons silghtly deviate slightly from the direct line of sight. In simulation, forward scattering is often modeled by analytical filtering (Fujimura et al. 2018; Negahdaripour et al. 2002; Murez et al. 2015), that incorporates the underwater optical properties and convolves the image with the appropriate blur kernel. When removing forward scattering, PSF (or its frequency domain form MTF) is often estimated (Barros et al. 2018; Chen et al. 2015, 2019; Han et al. 2017; Hou et al. 2007; Liu et al. 2001), and one tries to reverse the effects by deconvolution. Other filters such as joint trilateral filter (JTF) (Serikawa and Lu 2014; Xiao and Gan 2012), self-tuning filter (Trucco and Olmos-Antillon 2006), trigonometric bilateral filter (Lu et al. 2013) and Wiener filter (Wang et al. 2011) also been used to describe the forward scattering effect. However, these methods are essentially spatially varying image sharpening operators that can introduce artifacts. Hence, many image restoration methods simply ignore forward scattering.
3.2.3 Transmission Estimation
From Eq. 1, after removing the additive backscatter in the image, the transmission map is estimated to restore the scene radiance from the direct signal. Similar to the Retinex model for artificial lighting compensation introduced in Sect. 3.3, the direct signal in underwater image formation is represented by the multiplication of the transmission and the object reflectance. Transmission is reciprocal to the attenuation (Mobley 1994; Preisendorfer 1964), which has to be integrated along the line of sight, leading to an exponential expression based on the Beer-Lambert law and depends to the scene depth and water attenuation coefficient. Therefore, transmission is also strongly correlated to scene distance. Once the attenuation coefficient is obtained, the transmission can be computed for recovering the scene radiance (Akkaynak and Treibitz 2019; Schechner and Karpel 2004).
The attenuation coefficients can either be directly measured by optical instruments like transmissiometers (Bongiorno et al. 2013), or be estimated from the image (Akkaynak and Treibitz 2019; Schechner and Karpel 2004). Jerlov classified global ocean waters into eight types (Jerlov 1968) and measured their attenuation, following his work, the attenuation parameters then can be directly obtained according to the water types (Akkaynak et al. 2017; Solonenko and Mobley 2015). However, once taken transmissiometer or spectrometer measurements might not perfectly apply to all captured images, even the same type of water may have varying attenuation in different season and depth, and coefficients vary with wavelength. Additionally, the image color depends on the spectral sensitivity of the camera, which is usually not known. In this case, attenuation coefficients can be derived from in-situ images by photographing a reference target with known spectrum at different known distances (Blasinski et al. 2014; Winters et al. 2009).
If neither scene distances, nor the reference target are available, an approximate scene layout can be derived from priors to estimate the transmission. For example transmission estimation make use of DCP (Chao and Wang 2010; Chiang and Chen 2011; Serikawa and Lu 2014; Yang et al. 2011; Zhao et al. 2015), MIP (Carlevaris-Bianco et al. 2010; Li et al. 2016b), UDCP (Drews et al. 2013; Emberton et al. 2015; Lu et al. 2015), RCP (Wen et al. 2013), CLP (Zhou et al. 2018), HLP (Berman et al. 2017, 2020) and ACP (Wang et al. 2017a, b). The Red channel is the most degraded channel in an underwater image, thus it is also used to estimate the transmission map (Li et al. 2016b).
Per-pixel transmittance estimation is sensitive to the image noise. In order to achieve a dense and accurate transmittance map, post refinement is often needed to improve the transmittance estimation quality. A popular refinement technique is guided image filtering (He et al. 2012), this edge-preserving smoothing operator has been widely applied in transmission map refinement (Berman et al. 2020; Drews et al. 2015; Li et al. 2016b; Wen et al. 2013; Zhou et al. 2021). Other refinement techniques are e.g. median filter (Tarel and Hautiere 2009), fuzzy segmentation (Bui and Kim 2017), Markov random field (Fattal 2008, 2014; Tan 2008), weighted least squares (WLS) filter (Emberton et al. 2015) and image matting (Drews et al. 2013; Chiang and Chen 2011).
3.2.4 Exemplary Systems
This section gives a detailed survey on the representative underwater image restoration pipelines. Their corresponding approaches for estimating depth, backscatter (including BL) and transmission (with refinement) are introduced and summarized in Table 3.
Schechner and Karpel (2004) images the scene through a polarizer at different orientations, the backscatter component is derived from the extreme intensity measurements. Global parameter BL is estimated by measuring pixels corresponding to non object regions, which is later used to derive the transmission map. It is the pioneer work which utilizes the atmospheric model for underwater image restoration.
Trucco and Olmos-Antillon (2006) assumes uniform illumination and low-backscatter conditions, and considers only the forward scattering component. They present a self-tuning restoration filter based on a simplified J–M model. The Tenengrad criterion (average squared gradient magnitude) is measured as the optimization target to determine the filter parameters by a Nelder-Mead simplex search. Image restoration is performed by inverting the filter in frequency domain on the raw image.
Hou et al. (2007) models image formation as the original signal convolved by the imaging system’s response and extends the PSF by incorporating underwater effects. The actual image restoration is then implemented by a denoised deconvolution.
Sedlazeck et al. (2009) first utilizes SfM and dense image matching to generate depth maps for color correction. The BL is defined from the background patch in the image. Based on the atmospheric model, the backscatter and transmission (one attenuation coefficient) are estimated from a set of known white objects seen from different distances.
Chao and Wang (2010) first introduces DCP from He et al. (2010) to underwater image de-scattering. The pixels with highest intensity among the the brightest pixels in the dark channel is picked as the BL. The dark channel of the normalized image is used to estimate the transmission. It removes the scattering effect in the image but the absorption issue still remains unsolved.
Inspired by DCP, (Drews et al. 2013) proposed UDCP which considers the blue and green channels are underwater informative and ignores red channel. It provides a rough initial estimate of the medium transmission which later been refined by image matting. Similar to DCP, the BL is estimated by finding the brightest pixel in the underwater dark channel.
Galdran et al. (2015) inverts the red channel and proposes the RCP for BL and transmission estimation. The BL is picked from the brightest 10% of pixels the one that has lowest red intensity. The transmission map is later refined by using the guided filter.
Emberton et al. (2015) adopts a hierarchical rank-based estimator for backscatter removal. The method exams over three features in the image, UDCP, the standard deviation of each color channel and magnitude of the gradient, to estimate the BL. The transmission map is generated from the UDCP and refined with the WLS filter (Farbman et al. 2008).
Ancuti et al. (2016) uses the DCP over both small and large patches to locally estimate the backscatter, later fuse them together with the Laplacian of the original image to improve the underwater image visibility. These three derived inputs are seamlessly blended via a multi-scale fusion approach, using saliency, contrast, and saturation metrics to weight each input.
Peng and Cosman (2017) computes the blurriness prior according to their previous work (Peng et al. 2015). The BL is also determined from the candidates estimated from blurry regions. Afterwards, the scene depth is estimated based on light absorption and image blurriness and refined by image matting or guided filter. The transmission map then is calculated for scene radiance recovery.
Wang et al. (2017a) omits the depth estimation and acquires relative transmission based on ACP. It first filters the smooth patches with the low total variation (TV), then the homogeneous BL is located where the pixel has considerable differences in R-G and R-B channel; Pixels are classified into attenuation-curves in RGB space and turned into the lines using logarithm, transmission of the red channel is estimated from each line, and refined by WLS filter similar to Berman et al. (2016). The attenuation factor is then estimated to compute B,G transmissions.
Inspired by the illumination estimation method from Rahman et al. (2004), Yang et al. (2019) decomposed the dark channel and extracted the transmission based on the Retinex model. The backscatter light is obtained locally by using Gaussian lowpass filtering of the observed image. Afterwards, a statistical colorless slant correction and contrast stretch is adopted to correct the color.
Akkaynak and Treibitz (2019) applies a revised image formation model (Akkaynak and Treibitz 2018) which formalizes the direct signal and the backscatter components with distinct attenuation coefficients. It first generates the scene depth using SfM. Estimation of the backscatter (BL and backscatter attenuation coefficient) is inspired by DCP, but is based on the darkest RGB triplet and utilizes a known range map. The transmission (direct signal attenuation coefficient) is estimated using an illumination map obtained using local space average color as input.
Bekerman et al. (2020) provides a method for robustly estimating attenuation ratios and BL directly from the image. The initial BL is searched in a textureless background area and is later fine-tuned through an iterative curve fitting minimization. In each iteration the attenuation ratios are calculated accordingly. In the end, the transmission is estimated based on the HLP from Berman et al. (2016) and regularized by a constrained WLS for scene radiance restoration.
3.3 Artificial Lighting Pattern Compensation
Artificial light patterns have a strong effect on the global homogeneity of the mosaic, therefore their compensation is of high importance for the performance and result of subsequent mosaicing processing. Small brightness differences (for very narrow field of view cameras with almost uniform illumination) can be treated similar to image vignetting in air, simply by multi-band-blending strategies (e.g. Brown and Lowe (2007)) during image stitching that make the patterns less obvious. For wide-angle lenses, as often used for deep sea mapping, uniform illumination becomes more difficult or impossible. Unfortunately, above mentioned restoration methods barely consider the artificial lighting effects. Since the exact illumination conditions are often unknown, in the previous literature, this problem is mostly addressed by subjective approaches according to qualitative criteria. We individually survey this issue here, as we want to raise awareness of considering lighting compensation in deep sea visual mapping.
A group of methods that tackle the lighting dispersion depends on histogram information, another group is based on the Retinex theory (Land and McCann 1971; Land 1977) which assumes the image to be a product of an illumination and a reflectance signal, the illumination signal is modeled and exploited to recover the reflectance image. It has been widely adopted to estimate the local illuminant (Beigpour et al. 2013; Bleier et al. 2011; Finlayson et al. 1995; Kimmel et al. 2003) in image processing and later also been utilized in underwater cases (Fu et al. 2014; Zhang et al. 2017b). Garcia et al. (2002) gives a nice overview on this issue and categorizes the solutions by four strategies. Here, we adopt their definitions and summarize the related work into following three categories: (1) Exploitation of the illumination-reflectance model, it considers the image as a product of the illumination and reflectance, the illumination-reflectance model is estimated by a smooth function. The uneven lighting effect is then eliminated by removing the illumination pattern. Several methods have been proposed: (Pizarro and Singh 2003) averages frames to estimate an illumination image in log space. Arnaubec et al. (2015) employs a mean or median filter to extract the illumination pattern and describes this spot pattern as a third order polynomial. Köser et al. (2021) robustly estimates all multiplicative effects including the light pattern, also using a sliding window median. Bodenmann et al. (2017) also approximates the lighting and water effects as an multiplicative factor. It is estimated empirically from a series of images taken at different distances on known seafloor objects. Borgetto et al. (2003) uses natural halo images to model the lighting pattern. Johnson-Roberson et al. (2010) assumes a single unimodal Gaussian distribution to correct illumination variations and later (Johnson-Roberson et al. 2017) proposes a two-level clustering process to improve the performance. Rzhanov et al. (2000) de-trends the illumination field through a polynomial spline adjustment. (2) Histogram equalization adjusts the image intensity histogram to a desired shape. This technique increases the image contrast by flattening its histogram, but does not perform well in non-uniformly illuminated cases such as deep sea images. Adaptive histogram equalization (AHE) (Pizer et al. 1987) is applied in (Eustice et al. 2000), to enhance the mosaicing images by equalizing the histogram in the local window through the entire image. Eustice et al. (2002) utilizes a variant of AHE, called contrast limited adaptive histogram equalization (CLAHE) (Zuiderveld 1994), which executes histogram equalization in each block of the image and interpolates the neighboring blocks to eliminate the boundary artifacts. (Lu et al. 2013, 2015) expand the histogram in different color spaces based on pixel intensity redistribution. (3) Homomorphic filtering: since illumination effects are multiplicative, they become additive in log-space. Here, the illumination component can be modelled through low-pass filtering or parametric surface fitting, since the illumination-reflectance model is linear (Bazeille et al. 2006; Guillemaud 1998; Singh et al. 1998, 2007).
Besides above mentioned approaches particularly deal with artificial lighting compensation, this issue is also considered in several underwater image enhancement approaches (Chiang and Chen 2011; Peng and Cosman 2017) during the depth or transmission estimation, or fused with several processing steps (e.g. Gamma correction (Cao et al. 2014), white balancing) to enhance the image contrast (Ancuti et al. 2012, 2016, 2017a, b; Bazeille et al. 2006).
Early researches in this section only deal with monochromatic images, where underwater image processing methods at that time were still aimed to improve and image contrast (remove scattering) and to compensate light pattern for mosaicing. The loss of attenuation variations in different channels make the early lighting pattern compensation approaches non-physically based, they are mostly utilized in the image enhancement applications. Overall, the quantitative properties ignore the differences in image position and are strongly correlated with the image content, such that any relative geometry changes between camera, light sources and scene can create abrupt patterns in the mosaic.
3.4 J–M Approximation Based Methods
The J–M model considers light propagation of artificial light sources, therefore it better suits deep sea scenarios. It assumes single scattering and approximates the forward scattering and backscatter using PSF and VSF respectively. Based on the J–M model, if any of the properties of scene depth, water parameters and lighting configuration is known, the remaining unknown properties can be derived from the appearance variations between image correspondences of multiple images. In most of the cases, the water properties are part of the unknown parameters to be estimated. The water properties in the complete J–M model consist of two groups of parameters: attenuation and VSF parameters, and the number of the VSF parameters depend on the phase function model used. Some researchers assume the proportion of scattered light has a uniform directional distribution, such that the corresponding VSF becomes constant (Bryson et al. 2016) and might be negligible during the restoration. Only some works actually attempt to estimate the VSF parameters from images: (Narasimhan and Nayar 2005; Narasimhan et al. 2005; Tsiotsios et al. 2014) use the phase function from Chandrasekhar (2013), (Murez et al. 2015; Nakath et al. 2021; Narasimhan et al. 2006; Spier et al. 2017; Tian et al. 2017) utilize the HG phase function and (Pegoraro et al. 2010) models a general phase function model by using Legendre polynomial basis or Taylor series.
Similar to the depth cue estimation in haze images, this group of methods requires multiple correspondences with variations to solve the final optimization. When capturing multiple images under different known lighting configurations, this becomes a typical underwater photometric stereo problem (Fujimura et al. 2018; Murez et al. 2015; Narasimhan and Nayar 2005; Negahdaripour et al. 2002; Queiroz-Neto et al. 2004; Tian et al. 2017; Tsiotsios et al. 2014). (Spier et al. 2017) shows that the water properties can be derived even from empty scene backscatter images with a controlled light source movement. If the scene depth information is given, it becomes a light source calibration problem using a known lambertian surface (Park et al. 2014b; Weber and Cipolla 2001) where, however, additional water effects have to be considered.
Estimation of the unknown parameters requires the observations to be in a good configuration (e.g. significant differences). As directly solving the equations can be very complex or intractable, often iterative methods are employed that minimize some error function in a gradient descent manner. Those schemes need to start from good initial values, otherwise parameter estimation can be trapped in local minima or degenerate cases. Additional constraints with respect to the lighting configurations together with scene depth information can further strengthen the robustness of water parameters estimation (Bryson et al. 2016).
3.5 Monte Carlo Based Methods
The J–M approximation only considers single scattering in the model, which is still a simplification of underwater radiative transfer. Mobley (1994) introduced Monte Carlo techniques for solving the underwater Radiative Transfer Equation (RTE) and discussed ray-tracing techniques for simulating light ray propagation underwater. Powered by advances in GPU technology and physics-based simulation, nowadays graphic engines are able to synthesize complex underwater effects using ray-tracing efficiently (Zwilgmeyer et al. 2021). Latest approaches even employ Monte Carlo-based differentiable ray-tracing to replace an explicit image formation model for image restoration, by simply characterizing the water by differential properties and then optimizing (Nakath et al. 2021). Such an approach can implicitly handle multi-scattering, shadows as well as different phase functions.
3.6 Learning Based Methods
Many learning based underwater image restoration methods emerged over the last decade, e.g. (Fabbri et al. 2018; Lu et al. 2021; Torres-Méndez and Dudek 2005; Yu et al. 2018). However, Akkaynak and Treibitz (2019); Bekerman et al. (2020) have addressed the shortcomings of these methods, such as strong dependence on the training data, and there is still large uncertainty in what scenarios they can reliably be applied e.g. when a robot is diving to a previously unseen ocean region and for other open applications. Simply, there is a massive shortage of underwater image datasets with ground truth (in terms of in air appearance) available for training. In particular, it is very difficult to know how a particular seafloor spot in the deep sea would really look without water, which is however what would be naturally needed for training. Current learning based methods either use synthetic images or restoration results from other methods as the training data, which make their training problematic. Meanwhile, deep sea images’ appearances strongly depend on the camera-lighting-scene configurations and water properties, which is even more challenging for learning methods to restore such images with general training sets. Therefore, we did not list this group of methods in this survey as they currently are not applicable for deep ocean mapping.
4 Discussion
Hardware for Deep Sea Imaging Three key issues of deep sea imaging systems for mapping are discussed in Sect. 2: (1) Several technical barriers for building a refraction-free deep sea imaging system have been overcome. Dome port housing with wide angle cameras are gradually replacing the traditional flat port camera systems on the market. Latest system design even drops the camera housing window and embeds the front lens of the camera in direct contact with water. The development of subsea cameras is transferring from simple inspection to professional measuring and mapping purposes. (2) Advances in LED technology allow deep sea imaging systems to carry more flexible illumination configurations with multiple light sources. Optimization of multi-LED illumination for different configurations and tasks, is increasingly considered in UV designs, the development can be supported by simulation techniques. (3) Deep sea localization still remains challenging nowadays, fused localization data are much less precise than on land and can only be used to initialize the georeferencing process for each image: visual geo-localization, place recognition and loop detection could be future tools to improve the situation.
Image Restoration In Sect. 3, we surveyed the image restoration techniques for deep sea mapping. It requires the algorithms to recover the degradation from scattering, attenuation effects and artificial light cones. We notice that there were few missing pieces and gaps between the real ocean visual mapping and current image processing approaches: (1) Most of the underwater image restorations apply the atmospheric scattering model or its derivatives, but these are only suitable in shallow water cases where the scene is illuminated by sunlight. Single image restoration is the most popular researched topic, but it is an ill-posed problem and requires extra observations and does not consider consistency for mapping: practical applications need more reliable approaches. Assumptions like the DCP allow to restore single images without additional measurements which has been widely adopted. Similar to the enhancement approaches, most of these single view restoration approaches do not use true distance, may have consistency problem when processing over the image sequences. Moreover, the presence of artificial lighting could easily influence the prior estimation. (2) Removing artificial illumination patterns (light cones) has the most significant impact on underwater mosaicing, but so far it did not draw much attention within the underwater image restoration community. Current lighting compensation methods either analyze quantitative properties in single images, which may perform inconsistently over image sequences, especially when the scene contents change significantly, and are not able to handle complex lighting conditions; or subtract some sort of “mean” pattern of an image sequence, which has strict assumptions on flatness and uniformity of the scene and the relative poses between the camera, the light sources and the scene have to be stable. (3) The J–M approximation based approaches consider point light source propagation which is desirable for dealing with the deep sea image restoration problem with artificial illumination. Since the scene depth estimation and image restoration is a chicken-egg dilemma, current methods all require multiple observations of the same 3D point to estimate the water properties and the scene depth. Most of these work are only demonstrated in turbid media in a well controlled lab environment. At the same time, the J–M methods model each light source individually, which becomes tricky for complex lighting conditions. Recent imaging platforms tend to utilize many LEDs in complex configurations, such that it becomes more difficult and impractical to execute calibration for each light source separately. (4) The J–M approximation only considers single scattering, which is a simplification for the complex underwater radiative transfer. The upcoming GPU-enabled Monte Carlo based ray tracing simulates the light propagation in the micro scale physics, and is able to solve more challenging restoration problems with multi-scattering and shadows. However, it still has a similar problem as the J–M based approaches that restoration and reconstruction depend on one another, and multi light sources increase the computational complexity. (5) Learning based approaches have the consistency problem. The difficulties of acquiring ground truth for underwater (and more so: deep sea) images becomes the bottle neck of developing training based restoration approaches. (6) In situ calibration in the deep sea is still a missing part. To our best knowledge, there is no real implementation yet for calibrating radiometric, light pattern and water properties in the deep ocean.
Besides the aforementioned issues, underwater images could also be degraded because of several other additional real-world effects such as smoke from the black smokers, plankton or marine snow (see Fig. 7) which makes restoration an even more challenging task. Such images require additional procedures to filter the effects and more robust solutions for depth estimation and restoration.

Underwater images can also be heavily degraded by floating particles which requires additional efforts during the image restoration. Left: Dense “smoke” blown from hydrothermal vents in SE Pacific Ocean. Right: Heavy floating particles (e.g. marine snow) in the Baltic Sea
5 Conclusions
In this paper we have first discussed the key components of imaging systems for deep ocean visual mapping. We discussed the advantages of using non-refractive systems, pointed out the tendency of using optimized multi-LED lighting system and addressed the current status of deep sea vehicle localization. Afterwards, we comprehensively surveyed the image processing techniques for underwater image restoration, particularly the images under artificial illumination in the deep sea scenario. Methods were grouped according to the image formation approximations they are based on, and only a small fraction applies to deep sea data. After the survey, we discussed several missing pieces and gaps between the real ocean visual mapping applications and current approaches, and outlined the open problems in the last section.
References
Agrawal A, Ramalingam S, Taguchi Y, Chari V (2012) A theory of multi-layer flat refractive geometry. In: 2012 IEEE conference on computer vision and pattern recognition, IEEE, pp 3346–3353
Akkaynak D, Treibitz T (2018) A revised underwater image formation model. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6723–6732
Akkaynak D, Treibitz T (2019) Sea-thru: a method for removing water from underwater images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1682–1691
Akkaynak D, Treibitz T, Shlesinger T, Loya Y, Tamir R, Iluz D (2017) What is the space of attenuation coefficients in underwater computer vision? In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), IEEE, pp 568–577
Ancuti C, Ancuti CO, Haber T, Bekaert P (2012) Enhancing underwater images and videos by fusion. In: 2012 IEEE conference on computer vision and pattern recognition, IEEE, pp 81–88
Ancuti C, Ancuti CO, De Vleeschouwer C, Garcia R, Bovik AC (2016) Multi-scale underwater descattering. In: 2016 23rd international conference on pattern recognition (ICPR), IEEE, pp 4202–4207
Ancuti CO, Ancuti C, Hermans C, Bekaert P (2010) A fast semi-inverse approach to detect and remove the haze from a single image. In: Asian conference on computer vision. Springer, Berlin, pp 501–514
Ancuti CO, Ancuti C, De Vleeschouwer C, Bekaert P (2017) Color balance and fusion for underwater image enhancement. IEEE Trans Image Process 27(1):379–393
Ancuti CO, Ancuti C, De Vleeschouwer C, Neumann L, Garcia R (2017b) Color transfer for underwater dehazing and depth estimation. In: 2017 IEEE international conference on image processing (ICIP), IEEE, pp 695–699
Anwar S, Li C (2020) Diving deeper into underwater image enhancement: a survey. Signal Process Image Commun 89:115978
Arnaubec A, Opderbecke J, Allais AG, Brignone L (2015) Optical mapping with the ariane hrov at ifremer: the matisse processing tool. In: OCEANS 2015-Genova, IEEE, pp 1–6
Ballard RD (1975) Photography from a submersible during project famous. Oceanus 18(3):40–43
Ballard RD, Archbold R, Atcher R, Lord W (1987) The discovery of the Titanic. Warner Books, New York
Ballard RD, Stager LE, Master D, Yoerger D, Mindell D, Whitcomb LL, Singh H, Piechota D (2002) Iron age shipwrecks in deep water off ashkelon, Israel. Am J Archaeol 2002:151–168
Barker BA, Helmond I, Bax NJ, Williams A, Davenport S, Wadley VA (1999) A vessel-towed camera platform for surveying seafloor habitats of the continental shelf. Cont Shelf Res 19(9):1161–1170. https://doi.org/10.1016/S0278-4343(99)00017-5
Barros W, Nascimento ER, Barbosa WV, Campos MF (2018) Single-shot underwater image restoration: a visual quality-aware method based on light propagation model. J Vis Commun Image Represent 55:363–373
Bazeille S, Quidu I, Jaulin L, Malkasse JP (2006) Automatic underwater image pre-processing. In: CMM’06, p 2
Beigpour S, Riess C, Van De Weijer J, Angelopoulou E (2013) Multi-illuminant estimation with conditional random fields. IEEE Trans Image Process 23(1):83–96
Bekerman Y, Avidan S, Treibitz T (2020) Unveiling optical properties in underwater images. In: 2020 IEEE international conference on computational photography (ICCP), IEEE, pp 1–12
Berman D, Avidan S, et al. (2016) Non-local image dehazing. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1674–1682
Berman D, Treibitz T, Avidan S (2017) Diving into haze-lines: color restoration of underwater images. In: Proc. British Machine Vision Conference (BMVC), BMVA Press
Berman D, Levy D, Avidan S, Treibitz T (2020) Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans Pattern Anal Mach Intell 2020:55
Bingham B, Foley B, Singh H, Camilli R, Delaporta K, Eustice R, Mallios A, Mindell D, Roman C, Sakellariou D (2010) Robotic tools for deep water archaeology: surveying an ancient shipwreck with an autonomous underwater vehicle. J Field Robot 27(6):702–717. https://doi.org/10.1002/rob.20350
Blasinski H, Breneman J, Farrell J (2014) A model for estimating spectral properties of water from rgb images. In: 2014 IEEE international conference on image processing (ICIP), IEEE, pp 610–614
Bleier M, Riess C, Beigpour S, Eibenberger E, Angelopoulou E, Tröger T, Kaup A (2011) Color constancy and non-uniform illumination: Can existing algorithms work? In: 2011 IEEE international conference on computer vision workshops (ICCV Workshops), IEEE, pp 774–781
Bodenmann A, Thornton B, Ura T (2017) Generation of high-resolution three-dimensional reconstructions of the seafloor in color using a single camera and structured light. J Field Robot 34(5):833–851
Bongiorno DL, Bryson M, Williams SB (2013) Dynamic spectral-based underwater colour correction. In: 2013 MTS/IEEE OCEANS-Bergen, IEEE, pp 1–9
Borgetto M, Rigaud V, Lots JF (2003) Lighting correction for underwater mosaicking enhancement. In: Proceedings of the 16th international conference on vision interface
Brown M, Lowe DG (2007) Automatic panoramic image stitching using invariant features. Int J Comput Vis 74(1):59–73
Bryson M, Johnson-Roberson M, Pizarro O, Williams SB (2016) True color correction of autonomous underwater vehicle imagery. J Field Robot 33(6):853–874
Bui TM, Kim W (2017) Single image dehazing using color ellipsoid prior. IEEE Trans Image Process 27(2):999–1009
Cai B, Xu X, Jia K, Qing C, Tao D (2016) Dehazenet: an end-to-end system for single image haze removal. IEEE Trans Image Process 25(11):5187–5198
Cao G, Zhao Y, Ni R, Li X (2014) Contrast enhancement-based forensics in digital images. IEEE Trans Inf Forensics Secur 9(3):515–525
Carlevaris-Bianco N, Mohan A, Eustice RM (2010) Initial results in underwater single image dehazing. In: Oceans 2010 Mts/IEEE Seattle, IEEE, pp 1–8
Cathx Ocean (2020) Fast fly video. https://cathxocean.com/scout/#hardware. Accessed 28 Mar 2020
Chadebecq F, Vasconcelos F, Dwyer G, Lacher R, Ourselin S, Vercauteren T, Stoyanov D (2017) Refractive structure-from-motion through a flat refractive interface. In: Proceedings of the ieee international conference on computer vision, pp 5315–5323
Chandrasekhar S (2013) Radiative transfer. Courier Corporation
Chao L, Wang M (2010) Removal of water scattering. In: 2010 2nd international conference on computer engineering and technology, IEEE, vol 2, pp V2–35
Chen Y, Zeng Z, Pan Y (2019) A new degradation model for imaging in natural water and validation through image recovery. IEEE Access 7:123244–123254
Cheng CY, Sung CC, Chang HH (2015) Underwater image restoration by red-dark channel prior and point spread function deconvolution. In: 2015 IEEE international conference on signal and image processing applications (ICSIPA), IEEE, pp 110–115
Chiang JY, Chen YC (2011) Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans Image Process 21(4):1756–1769
Corrigan D, Sooknanan K, Doyle J, Lordan C, Kokaram A (2018) A low-complexity mosaicing algorithm for stock assessment of seabed-burrowing species. IEEE J Oceanic Eng 44(2):386–400
Cozman F, Krotkov E (1997) Depth from scattering. In: Proceedings of IEEE computer society conference on computer vision and pattern recognition, IEEE, pp 801–806
CTeledyne Marine (2021) Surveyor-wahd. http://www.teledynemarine.com/surveyor-wahd. Accessed 28 Mar 2022
DeepSea Power & Light (2022a) Seacam, hd zoom. https://www.deepsea.com/hd-zoom-seacam/. Accessed 28 Mar 2022
DeepSea Power & Light (2022b) Seacam, ip apex. https://www.deepsea.com/ip-apex-seacam/. Accessed 28 Mar 2022
DeepSea Power & Light (2022c) Seacam, mxd. https://www.deepsea.com/mxd/. Accessed 28 Mar 2022
DeepSea Power & Light (2022d) Seacam, optim. https://www.deepsea.com/optim-seacam/. Accessed 28 Mar 2022
DeepSea Power & Light (2022e) Seacam, super wide-i. https://www.deepsea.com/super-widei-seacam/. Accessed 28 Mar 2022
DeepSea Power & Light (2022f) Seacam, vertex. https://www.deepsea.com/vertex-seacam/. Accessed 28 Mar 2022
DeepSea Power & Light (2022g) Seacam, wide-i. https://www.deepsea.com/widei-seacam/. Accessed 28 Mar 2022
Drap P, Seinturier J, Hijazi B, Merad D, Boi JM, Chemisky B, Seguin E, Long L (2015) The rov 3d project: deep-sea underwater survey using photogrammetry: applications for underwater archaeology. J Comput Cult Heritage (JOCCH) 8(4):1–24
Drews P, Nascimento E, Moraes F, Botelho S, Campos M (2013) Transmission estimation in underwater single images. In: Proceedings of the IEEE international conference on computer vision workshops, pp 825–830
Drews P, Nascimento ER, Campos MF, Elfes A (2015) Automatic restoration of underwater monocular sequences of images. In: 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, pp 1058–1064
Dubreuil M, Delrot P, Leonard I, Alfalou A, Brosseau C, Dogariu A (2013) Exploring underwater target detection by imaging polarimetry and correlation techniques. Appl Opt 52(5):997–1005
Durrant-Whyte H, Bailey T (2006) Simultaneous localization and mapping: part i. IEEE Robot Autom Mag 13(2):99–110
Edge M (2012) The underwater photographer. Routledge, Cambridge
Eigen D, Puhrsch C, Fergus R (2014) Depth map prediction from a single image using a multi-scale deep network. arXiv:14062283
Elibol A, Garcia R, Gracias N (2011) A new global alignment approach for underwater optical mapping. Ocean Eng 38(10):1207–1219
Emberton S, Chittka L, Cavallaro A (2015) Hierarchical rank-based veiling light estimation for underwater dehazing. In: Proceedings of the British Machine Vision Conference (BMVC) 2015, pp 125.1–125.12
Escartín J, Garcia R, Delaunoy O, Ferrer J, Gracias N, Elibol A, Cufi X, Neumann L, Fornari D, Humphris S et al (2008) Globally aligned photomosaic of the lucky strike hydrothermal vent field (mid-atlantic ridge, 37 18.5 n): release of georeferenced data, mosaic construction, and viewing software. Geochem Geophys Geosyst 9:12
Eustice R, Singh H, Howland J (2000) Image registration underwater for fluid flow measurements and mosaicking. In: OCEANS 2000 MTS/IEEE Conference and Exhibition. Conference Proceedings (Cat. No. 00CH37158), IEEE, vol 3, pp 1529–1534
Eustice R, Pizarro O, Singh H, Howland J (2002) Uwit: Underwater image toolbox for optical image processing and mosaicking in matlab. In: Proceedings of the 2002 Interntional Symposium on Underwater Technology (Cat. No. 02EX556), IEEE, pp 141–145
Eustice RM, Pizarro O, Singh H (2008) Visually augmented navigation for autonomous underwater vehicles. IEEE J Oceanic Eng 33(2):103–122
Fabbri C, Islam MJ, Sattar J (2018) Enhancing underwater imagery using generative adversarial networks. In: 2018 IEEE international conference on robotics and automation (ICRA), IEEE, pp 7159–7165
Fabri MC, Vinha B, Allais AG, Bouhier ME, Dugornay O, Gaillot A, Arnaubec A (2019) Evaluating the ecological status of cold-water coral habitats using non-invasive methods: an example from cassidaigne canyon, northwestern mediterranean sea. Prog Oceanogr 178:102172. https://doi.org/10.1016/j.pocean.2019.102172
Farbman Z, Fattal R, Lischinski D, Szeliski R (2008) Edge-preserving decompositions for multi-scale tone and detail manipulation. ACM Trans Graph (TOG) 27(3):1–10
Fattal R (2008) Single image dehazing. ACM Trans Graph (TOG) 27(3):1–9
Fattal R (2014) Dehazing using color-lines. ACM Trans Graph (TOG) 34(1):1–14
Finlayson GD, Funt BV, Barnard K (1995) Color constancy under varying illumination. In: Proceedings of IEEE international conference on computer vision, IEEE, pp 720–725
Foley BP, Dellaporta K, Sakellariou D, Bingham BS, Camilli R, Eustice RM, Evagelistis D, Ferrini VL, Katsaros K, Kourkoumelis D, et al. (2009) The 2005 chios ancient shipwreck survey: new methods for underwater archaeology. Hesperia, pp 269–305
Fornari DJ, Group WT (2003) A new deep-sea towed digital camera and multi-rock coring system. EOS Trans Am Geophys Union 84(8):69–73. https://doi.org/10.1029/2003EO080001
Fournier GR, Forand JL (1994) Analytic phase function for ocean water. Ocean Opti XII Int Soc Opt Photon 2258:194–201
Fournier GR, Jonasz M (1999) Computer-based underwater imaging analysis. Airborne In-Water Underwater Imag Int Soc Opt Photon 3761:62–70
Fu X, Zhuang P, Huang Y, Liao Y, Zhang XP, Ding X (2014) A retinex-based enhancing approach for single underwater image. In: 2014 IEEE international conference on image processing (ICIP), IEEE, pp 4572–4576
Fu X, Huang J, Ding X, Liao Y, Paisley J (2017) Clearing the skies: a deep network architecture for single-image rain removal. IEEE Trans Image Process 26(6):2944–2956
Fujimura Y, Iiyama M, Hashimoto A, Minoh M (2018) Photometric stereo in participating media using an analytical solution for shape-dependent forward scatter. IEEE Trans Pattern Anal Mach Intell 42(3):708–719
Galdran A, Pardo D, Picón A, Alvarez-Gila A (2015) Automatic red-channel underwater image restoration. J Vis Commun Image Represent 26:132–145
Garcia R, Nicosevici T, Cufí X (2002) On the way to solve lighting problems in underwater imaging. In: OCEANS’02 MTS/IEEE, IEEE, vol 2, pp 1018–1024
Geiger A, Roser M, Urtasun R (2010) Efficient large-scale stereo matching. In: Asian conference on computer vision, Springer, pp 25–38
Godard C, Mac Aodha O, Firman M, Brostow GJ (2019) Digging into self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 3828–3838
Gracias N, Santos-Victor J (2000) Underwater video mosaics as visual navigation maps. Comput Vis Image Underst 79(1):66–91
Gracias N, Ridao P, Garcia R, Escartín J, l’Hour M, Cibecchini F, Campos R, Carreras M, Ribas D, Palomeras N, et al. (2013) Mapping the moon: Using a lightweight auv to survey the site of the 17th century ship ‘la lune’. In: 2013 MTS/IEEE OCEANS-Bergen, IEEE, pp 1–8
Gracias NR, Van Der Zwaan S, Bernardino A, Santos-Victor J (2003) Mosaic-based navigation for autonomous underwater vehicles. IEEE J Ocean Eng 28(4):609–624
Guillemaud R (1998) Uniformity correction with homomorphic filtering on region of interest. In: Proceedings 1998 international conference on image processing. ICIP98 (Cat. No. 98CB36269), IEEE, vol 2, pp 872–875
Gupta H, Mitra K (2019) Unsupervised single image underwater depth estimation. In: 2019 IEEE international conference on image processing (ICIP), IEEE, pp 624–628
Haltrin VI (1999) Two-term henyey-greenstein light scattering phase function for seawater. In: IEEE 1999 international geoscience and remote sensing symposium. IGARSS’99 (Cat. No. 99CH36293), IEEE, vol 2, pp 1423–1425
Haltrin VI (2002) One-parameter two-term henyey-greenstein phase function for light scattering in seawater. Appl Opt 41(6):1022–1028
Han P, Liu F, Yang K, Ma J, Li J, Shao X (2017) Active underwater descattering and image recovery. Appl Opt 56(23):6631–6638
Hartley R, Zisserman A (2004) Multiple View Geometry in Computer Vision, 2nd edn. Cambridge University Press. https://doi.org/10.1017/CBO9780511811685
Harvey EN (1939) Deep sea photography. Science 90(2330):187
Harvey ES, Shortis MR (1998) Calibration stability of an underwater stereo-video system: implications for measurement accuracy and precision. Mar Technol Soc J 32(2):3–17
Hautière N, Tarel JP, Aubert D (2007) Towards fog-free in-vehicle vision systems through contrast restoration. In: 2007 IEEE conference on computer vision and pattern recognition, IEEE, pp 1–8
He DM, Seet GG (2004) Divergent-beam lidar imaging in turbid water. Opt Lasers Eng 41(1):217–231
He K, Sun J, Tang X (2010) Single image haze removal using dark channel prior. IEEE Trans Pattern Anal Mach Intell 33(12):2341–2353
He K, Sun J, Tang X (2012) Guided image filtering. IEEE Trans Pattern Anal Mach Intell 35(6):1397–1409
Henke B, Vahl M, Zhou Z (2013) Removing color cast of underwater images through non-constant color constancy hypothesis. In: 2013 8th international symposium on image and signal processing and analysis (ISPA), IEEE, pp 20–24
Hou W, Gray DJ, Weidemann AD, Fournier GR, Forand J (2007) Automated underwater image restoration and retrieval of related optical properties. In: 2007 IEEE international geoscience and remote sensing symposium, IEEE, pp 1889–1892
Hu H, Zhao L, Li X, Wang H, Liu T (2018) Underwater image recovery under the nonuniform optical field based on polarimetric imaging. IEEE Photon J 10(1):1–9
Huang B, Liu T, Hu H, Han J, Yu M (2016) Underwater image recovery considering polarization effects of objects. Opt Express 24(9):9826–9838
Imenco (2022a) Bramble shark hd - wide-angle hd camera. https://imenco.no/product/bramble-shark. Accessed 28 Mar 2022
Imenco (2022b) Oe14-504 high definition wide angle colour zoom camera. https://imenco.no/product/oe14-504-high-definition-wide-angle-colour-zoom-camera. Accessed 28 Mar 2022
Imenco (2022c) Spinner ii shark - high end hd zoom camera. https://imenco.no/product/spinner-ii-shark. Accessed 28 Mar 2022
Iscar E, Barbalata C, Goumas N, Johnson-Roberson M (2018) Towards low cost, deep water auv optical mapping. In: OCEANS 2018 MTS/IEEE Charleston, IEEE, pp 1–6
Jaffe JS (1990) Computer modeling and the design of optimal underwater imaging systems. IEEE J Oceanic Eng 15(2):101–111
Jaffe JS, Moore KD, McLean J, Strand MP (2001) Underwater optical imaging: status and prospects. Oceanography 14(3):66–76. https://doi.org/10.5670/oceanog.2001.24
Jerlov N (1968) Irradiance optical classification. Optical Oceanogr 1968:118–120
Johnson-Roberson M, Pizarro O, Williams SB, Mahon I (2010) Generation and visualization of large-scale three-dimensional reconstructions from underwater robotic surveys. J Field Robot 27(1):21–51. https://doi.org/10.1002/rob.20324
Johnson-Roberson M, Bryson M, Friedman A, Pizarro O, Troni G, Ozog P, Henderson JC (2017) High-resolution underwater robotic vision-based mapping and three-dimensional reconstruction for archaeology. J Field Robot 34(4):625–643. https://doi.org/10.1002/rob.21658
Jones DO, Bett BJ, Wynn RB, Masson DG (2009) The use of towed camera platforms in deep-water science. Underw Technol 28(2):41–50. https://doi.org/10.3723/ut.28.041
Jordt A (2014) Underwater 3d reconstruction based on physical models for refraction and underwater light propagation. PhD thesis, Self-Publishing of Department of Computer Science, Kiel
Jordt A, Köser K, Koch R (2016) Refractive 3d reconstruction on underwater images. Methods Oceanogr 15–16:90–113
Jordt-Sedlazeck A, Koch R (2012) Refractive calibration of underwater cameras. In: European conference on computer vision, Springer, pp 846–859
Kaeli JW, Singh H, Murphy C, Kunz C (2011) Improving color correction for underwater image surveys. In: OCEANS’11 MTS/IEEE KONA, IEEE, pp 1–6. https://doi.org/10.23919/OCEANS.2011.6107143
Kim JH, Jang WD, Sim JY, Kim CS (2013) Optimized contrast enhancement for real-time image and video dehazing. J Vis Commun Image Represent 24(3):410–425
Kimmel R, Elad M, Shaked D, Keshet R, Sobel I (2003) A variational framework for retinex. Int J Comput Vis 52(1):7–23
Kopf J, Neubert B, Chen B, Cohen M, Cohen-Or D, Deussen O, Uyttendaele M, Lischinski D (2008) Deep photo: model-based photograph enhancement and viewing. ACM Trans Graph (TOG) 27(5):1–10
Koschmieder H (1924) Theorie der horizontalen sichtweite. Beitrage zur Physik der freien Atmosphare, pp 33–53
Köser K, Frese U (2020) Challenges in underwater visual navigation and slam. In: AI Technology for Underwater Robots, Springer, pp 125–135. https://doi.org/10.1007/978-3-030-30683-0_11
Köser K, Song Y, Petersen L, Wenzlaff E, Woelk F (2021) Robustly removing deep sea lighting effects for visual mapping of abyssal plains
Kotowski R (1988) Phototriangulation in multi-media photogrammetry. Int Arch Photogram Remote Sens 27(B5):324–334
Kratz L, Nishino K (2009) Factorizing scene albedo and depth from a single foggy image. In: 2009 IEEE 12th international conference on computer vision, IEEE, pp 1701–1708
Kunz C, Singh H (2008) Hemispherical refraction and camera calibration in underwater vision. In: OCEANS 2008, IEEE, pp 1–7
Kunz C, Murphy C, Camilli R, Singh H, Bailey J, Eustice R, Jakuba M, Nakamura Ki, Roman C, Sato T, et al. (2008) Deep sea underwater robotic exploration in the ice-covered arctic ocean with auvs. In: 2008 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 3654–3660
Kwasnitschka T, Köser K, Sticklus J, Rothenbeck M, Weiß T, Wenzlaff E, Schoening T, Triebe L, Steinführer A, Devey C et al (2016) Deepsurveycam-a deep ocean optical mapping system. Sensors 16(2):164. https://doi.org/10.3390/s16020164
Land EH (1977) The retinex theory of color vision. Sci Am 237(6):108–129
Land EH, McCann JJ (1971) Lightness and retinex theory. Josa 61(1):1–11
Lavest JM, Rives G, Lapresté JT (2000) Underwater camera calibration. In: European conference on computer vision, Springer, pp 654–668
Lee ME, Lewis MR (2003) A new method for the measurement of the optical volume scattering function in the upper ocean. J Atmos Oceanic Tech 20(4):563–571
Lembke C, Grasty S, Silverman A, Broadbent H, Butcher S, Murawski S (2017) The camera-based assessment survey system (c-bass): A towed camera platform for reef fish abundance surveys and benthic habitat characterization in the gulf of mexico. Cont Shelf Res 151:62–71. https://doi.org/10.1016/j.csr.2017.10.010
Leonard JJ, Bahr A (2016) Autonomous underwater vehicle navigation. Springer Handbook of Ocean Engineering pp 341–358, https://doi.org/10.1007/978-3-319-16649-0_14
Li C, Quo J, Pang Y, Chen S, Wang J (2016a) Single underwater image restoration by blue-green channels dehazing and red channel correction. 2016 IEEE international conference on acoustics. speech and signal processing (ICASSP), IEEE, pp 1731–1735
Li CY, Guo JC, Cong RM, Pang YW, Wang B (2016b) Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans Image Process 25(12):5664–5677
Li C, Guo J, Guo C, Cong R, Gong J (2017) A hybrid method for underwater image correction. Pattern Recogn Lett 94:62–67
Li CY, Cavallaro A (2018) Background light estimation for depth-dependent underwater image restoration. In: 2018 25th IEEE international conference on image processing (ICIP), IEEE, pp 1528–1532
Li H, Wang X, Bai T, Jin W, Huang Y, Ding K (2009) Speckle noise suppression of range gated underwater imaging system. In: Applications of Digital Image Processing XXXII, international society for optics and photonics, vol 7443, p 74432A
Li Z, Snavely N (2018) Megadepth: Learning single-view depth prediction from internet photos. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2041–2050
Lirman D, Gracias NR, Gintert BE, Gleason ACR, Reid RP, Negahdaripour S, Kramer P (2007) Development and application of a video-mosaic survey technology to document the status of coral reef communities. Environ Monit Assess 125(1):59–73
Liu Q, Gao X, He L, Lu W (2018) Single image dehazing with depth-aware non-local total variation regularization. IEEE Trans Image Process 27(10):5178–5191
Liu R, Ma L, Wang Y, Zhang L (2018) Learning converged propagations with deep prior ensemble for image enhancement. IEEE Trans Image Process 28(3):1528–1543
Liu R, Hou M, Liu J, Fan X, Luo Z (2019) Compounded layer-prior unrolling: a unified transmission-based image enhancement framework. In: 2019 IEEE international conference on multimedia and expo (ICME), IEEE, pp 538–543
Liu Z, Yu Y, Zhang K, Huang H (2001) Underwater image transmission and blurred image restoration. Opt Eng 40(6):1125–1131
Lord R (1871) On the light from the sky, its polarization and colour. Phil Mag 41:274
Lu H, Li Y, Serikawa S (2013) Underwater image enhancement using guided trigonometric bilateral filter and fast automatic color correction. In: 2013 IEEE international conference on image processing, IEEE, pp 3412–3416
Lu H, Li Y, Zhang L, Serikawa S (2015) Contrast enhancement for images in turbid water. JOSA A 32(5):886–893
Lu J, Yuan F, Yang W, Cheng E (2021) An imaging information estimation network for underwater image color restoration. IEEE J Ocean Eng 2021:5
Łuczyński T, Birk A (2017) Underwater image haze removal with an underwater-ready dark channel prior. In: OCEANS 2017-Anchorage, IEEE, pp 1–6
Ludvigsen M, Sortland B, Johnsen G, Singh H (2007) Applications of geo-referenced underwater photo mosaics in marine biology and archaeology. Oceanography 20(4):140–149
Maas HG (1995) New developments in multimedia photogrammetry. Optical 3D measurement techniques III
Maki T, Sato Y, Matsuda T, Shiroku RT, Sakamaki T (2014) Auv tri-ton 2: an intelligent platform for detailed survey of hydrothermal vent fields. In: 2014 IEEE/OES autonomous underwater vehicles (AUV), IEEE, pp 1–5
Mangeruga M, Cozza M, Bruno F (2018) Evaluation of underwater image enhancement algorithms under different environmental conditions. J Mar Sci Eng 6(1):10
Marks RL, Rock SM, Lee MJ (1995) Real-time video mosaicking of the ocean floor. IEEE J Ocean Eng 20(3):229–241
Mathias A, Samiappan D (2019) Underwater image restoration based on diffraction bounded optimization algorithm with dark channel prior. Optik 192:162925
Maybank SJ, Faugeras OD (1992) A theory of self-calibration of a moving camera. Int J Comput Vis 8(2):123–151
McGlamery B (1980) A computer model for underwater camera systems. Ocean Opt VI Int Soc Opt Photon 208:221–231
Menna F, Nocerino E, Fassi F, Remondino F (2016) Geometric and optic characterization of a hemispherical dome port for underwater photogrammetry. Sensors 16:1. https://doi.org/10.3390/s16010048
Menna F, Nocerino E, Remondino F (2017) Optical aberrations in underwater photogrammetry with flat and hemispherical dome ports. In: Videometrics, range imaging, and applications XIV, international society for optics and photonics, vol 10332, p 1033205
Mertens LE, Replogle FS (1977) Use of point spread and beam spread functions for analysis of imaging systems in water. JOSA 67(8):1105–1117
Mie G (1976) Contributions to the optics of turbid media, particularly of colloidal metal solutions. Contrib Opt Turbid Media 25(3):377–445
Mobley CD (1994) Light and water: radiative transfer in natural waters. Academic Press, Cambridge
Morris KJ, Bett BJ, Durden JM, Huvenne VA, Milligan R, Jones DO, McPhail S, Robert K, Bailey DM, Ruhl HA (2014) A new method for ecological surveying of the abyss using autonomous underwater vehicle photography. Limnol Oceanogr Methods 12(11):795–809
Murez Z, Treibitz T, Ramamoorthi R, Kriegman D (2015) Photometric stereo in a scattering medium. In: Proceedings of the IEEE international conference on computer vision, pp 3415–3423
Nakath D, She M, Song Y, Köser K (2021) In-situ joint light and medium estimation for underwater color restoration. In: Proceedings of the IEEE/cvf international conference on computer vision workshops, IEEE, pp 0–0
Narasimhan SG, Nayar SK (2002) Vision and the atmosphere. Int J Comput Vis 48(3):233–254
Narasimhan SG, Nayar SK (2003) Contrast restoration of weather degraded images. IEEE Trans Pattern Anal Mach Intell 25(6):713–724
Narasimhan SG, Nayar SK (2003b) Interactive (de) weathering of an image using physical models. In: ICCV workshop on color and photometric methods in computer vision (CPMCV), France
Narasimhan SG, Nayar SK (2005) Structured light methods for underwater imaging: light stripe scanning and photometric stereo. In: Proceedings of OCEANS 2005 MTS/IEEE, IEEE, pp 2610–2617
Narasimhan SG, Nayar SK, Sun B, Koppal SJ (2005) Structured light in scattering media. In: Tenth IEEE international conference on computer vision (ICCV’05) Volume 1, IEEE, vol 1, pp 420–427
Narasimhan SG, Gupta M, Donner C, Ramamoorthi R, Nayar SK, Jensen HW (2006) Acquiring scattering properties of participating media by dilution. ACM Trans Graph 25(3):1003–1012
Nayar SK, Narasimhan SG (1999) Vision in bad weather. Proceedings of the Seventh IEEE international conference on computer vision, IEEE 2:820–827
Negahdaripour S, Xu X (2002) Mosaic-based positioning and improved motion-estimation methods for automatic navigation of submersible vehicles. IEEE J Oceanic Eng 27(1):79–99
Negahdaripour S, Zhang H, Han X (2002) Investigation of photometric stereo method for 3-d shape recovery from underwater imagery. In: OCEANS’02 MTS/IEEE, IEEE, vol 2, pp 1010–1017
Nocerino E, Menna F, Fassi F, Remondino F (2016) Underwater Calibration of Dome Port Pressure Housings. ISPRS - International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences pp 127–134. https://doi.org/10.5194/isprs-archives-XL-3-W4-127-2016
Okamoto A, Seta T, Sasano M, Inoue S, Ura T (2019) Visual and autonomous survey of hydrothermal vents using a hovering-type auv: Launching hobalin into the western offshore of kumejima island. Geochem Geophys Geosyst 20(12):6234–6243
Park D, Park H, Han DK, Ko H (2014a) Single image dehazing with image entropy and information fidelity. In: 2014 IEEE international conference on image processing (ICIP), IEEE, pp 4037–4041
Park J, Sinha SN, Matsushita Y, Tai YW, So Kweon I (2014b) Calibrating a non-isotropic near point light source using a plane. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2259–2266
Patterson R (1975) Backscatter reduction for artificially illuminated in-water camera systems. Opt Eng 14(4):144357
Paull L, Saeedi S, Seto M, Li H (2013) Auv navigation and localization: areview. IEEE J Ocean Eng 39(1):131–149
Pegoraro V, Schott M, Parker SG (2010) A closed-form solution to single scattering for general phase functions and light distributions. In: Proceedings of the 21st Eurographics Conference on Rendering, Wiley Online Library, Eurographics Association, pp 1365–1374
Peng YT, Cosman PC (2017) Underwater image restoration based on image blurriness and light absorption. IEEE Trans Image Process 26(4):1579–1594
Peng YT, Zhao X, Cosman PC (2015) Single underwater image enhancement using depth estimation based on blurriness. In: 2015 IEEE international conference on image processing (ICIP), IEEE, pp 4952–4956
Peng YT, Cao K, Cosman PC (2018) Generalization of the dark channel prior for single image restoration. IEEE Trans Image Process 27(6):2856–2868
Petzold TJ (1972) Volume scattering functions for selected ocean waters. Tech. rep, Scripps Institution of Oceanography La Jolla Ca Visibility Lab
Peukert A, Schoening T, Alevizos E, Köser K, Kwasnitschka T, Greinert J (2018) Understanding mn-nodule distribution and evaluation of related deep-sea mining impacts using auv-based hydroacoustic and optical data. Biogeosciences 15(8):2525–2549
Pillai S, Ambruş R, Gaidon A (2019) Superdepth: self-supervised, super-resolved monocular depth estimation. In: 2019 international conference on robotics and automation (ICRA), IEEE, pp 9250–9256
Pizarro O, Singh H (2003) Toward large-area mosaicing for underwater scientific applications. IEEE J Oceanic Eng 28(4):651–672
Pizer SM, Amburn EP, Austin JD, Cromartie R, Geselowitz A, Greer T, ter Haar Romeny B, Zimmerman JB, Zuiderveld K (1987) Adaptive histogram equalization and its variations. Comput Vis Graph Image Process 39(3):355–368
Prados R, Garcia R, Gracias N, Escartin J, Neumann L (2012) A novel blending technique for underwater gigamosaicing. IEEE J Oceanic Eng 37(4):626–644
Preisendorfer R (1964) Physical aspect of light in the sea. Univ Hawai Press Honolulu Hawaii 51:60
Purser A, Marcon Y, Dreutter S, Hoge U, Sablotny B, Hehemann L, Lemburg J, Dorschel B, Biebow H, Boetius A (2018) Ocean floor observation and bathymetry system (ofobs): a new towed camera/sonar system for deep-sea habitat surveys. IEEE J Ocean Eng 44(1):87–99. https://doi.org/10.1109/JOE.2018.2794095
Purser A, Hoge U, Hagemann J, Lehmenhecker S, Dauer E, Korfman N, Boehringer L, Merten V, Priest T, Dreutter S, et al. (2021) Arctic seafloor integrity cruise no. msm95–(gpf 19-2_05)
Queiroz-Neto JP, Carceroni R, Barros W, Campos M (2004) Underwater stereo. In: Proceedings. 17th Brazilian symposium on computer graphics and image processing, IEEE, pp 170–177
Rahman Zu, Jobson DJ, Woodell GA (2004) Retinex processing for automatic image enhancement. J Electron Imaging 13(1):100–110
RCU Underwater Systems (2021) Inspecam, dw. https://www.rcu-underwater.com/wp-content/uploads/2021/10/InspecamDWHD.pdf. Accessed 28 Mar 2022
RCU Underwater Systems (2022) Inspecam, hd-ip. https://www.rcu-underwater.com/wp-content/uploads/2022/01/InspecamHD-IP2.pdf. Accessed 28 Mar 2022
Remote Ocean Systems (ROS) (2021a) C460. https://www.rosys.com/all-products/products/subsea_oceanographic/cameras-ocean/c460-ultra-low-light-camera/. Accessed 28 Mar 2022
Remote Ocean Systems (ROS) (2021b) C600. https://www.rosys.com/all-products/products/subsea_oceanographic/cameras-ocean/c600-hd-color-zoom/. Accessed 28 Mar 2022
Remote Ocean Systems (ROS) (2021c) Spectator. https://www.rosys.com/all-products/products/subsea_oceanographic/cameras-ocean/spectator-sd-color-zoom-camera/. Accessed 28 Mar 2022
Ren W, Ma L, Zhang J, Pan J, Cao X, Liu W, Yang MH (2018) Gated fusion network for single image dehazing. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3253–3261
Robert K, Huvenne VA, Georgiopoulou A, Jones DO, Marsh L, Carter GD, Chaumillon L (2017) New approaches to high-resolution mapping of marine vertical structures. Sci Rep 7(1):1–14
Roser M, Dunbabin M, Geiger A (2014) Simultaneous underwater visibility assessment, enhancement and improved stereo. In: 2014 IEEE international conference on robotics and automation (ICRA), IEEE, pp 3840–3847
Rzhanov Y, Linnett LM, Forbes R (2000) Underwater video mosaicing for seabed mapping. In: Proceedings 2000 International conference on image processing (Cat. No. 00CH37101), IEEE, vol 1, pp 224–227
Salgado-Jimenez T, Gonzalez-Lopez J, Martinez-Soto L, Olguin-Lopez E, Resendiz-Gonzalez P, Bandala-Sanchez M (2010) Deep water rov design for the mexican oil industry. In: OCEANS’10 IEEE SYDNEY, IEEE, pp 1–6
Sarafraz A, Haus BK (2016) A structured light method for underwater surface reconstruction. ISPRS J Photogramm Remote Sens 114:40–52
Schechner YY, Averbuch Y (2007) Regularized image recovery in scattering media. IEEE Trans Pattern Anal Mach Intell 29(9):1655–1660
Schechner YY, Karpel N (2004) Clear underwater vision. In: Proceedings of the 2004 IEEE computer society conference on computer vision and pattern recognition, 2004. CVPR 2004., IEEE, vol 1, pp I–I
Schechner YY, Karpel N (2005) Recovery of underwater visibility and structure by polarization analysis. IEEE J Ocean Eng 30(3):570–587
Schechner YY, Narasimhan SG, Nayar SK (2001) Instant dehazing of images using polarization. In: Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001, IEEE, vol 1, pp I–I
Schechner YY, Narasimhan SG, Nayar SK (2003) Polarization-based vision through haze. Appl Opt 42(3):511–525
Sedlazeck A, Koch R (2011) Simulating deep sea underwater images using physical models for light attenuation, scattering, and refraction. In: VMV 2011, The Eurographics Association
Sedlazeck A, Köser K, Koch R (2009) 3d reconstruction based on underwater video from rov kiel 6000 considering underwater imaging conditions. In: OCEANS 2009-EUROPE, IEEE, pp 1–10
Serikawa S, Lu H (2014) Underwater image dehazing using joint trilateral filter. Comput Electr Eng 40(1):41–50
She M, Song Y, Mohrmann J, Köser K (2019) Adjustment and calibration of dome port camera systems for underwater vision. In: German conference on pattern recognition, Springer, pp 79–92. https://doi.org/10.1007/978-3-030-33676-9_6
She M, Song Y, Weiß T, Greinert J, Köser K (2021) Deep sea bubble stream characterization using wide-baseline stereo photogrammetry. arXiv:211207414
She M, Nakath D, Song Y, Köser K (2022) Refractive geometry for underwater domes. ISPRS J Photogramm Remote Sens 183:525–540
Sheinin M, Schechner YY (2016) The next best underwater view. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3764–3773
Shortis M (2015) Calibration techniques for accurate measurements by underwater camera systems. Sensors 15(12):30810–30826
Shortis MR, Harvey ES, Abdo DA (2009) A review of underwater stereo-image measurement for marine biology and ecology applications. Oceanogr Mar Biol Annu Rev 47:269–304
Shukla A, Karki H (2016) Application of robotics in offshore oil and gas industry-a review part ii. Robot Auton Syst 75:508–524
Shwartz S, Schechner Y (2006) Blind haze separation. In: 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), IEEE, vol 2, pp 1984–1991
Simon-Lledó E, Bett BJ, Huvenne VA, Köser K, Schoening T, Greinert J, Jones DO (2019) Biological effects 26 years after simulated deep-sea mining. Sci Rep 9(1):1–13
Singh H, Howland J, Yoerger D, Whitcomb L (1998) Quantitative photomosaicking of underwater imagery. In: IEEE Oceanic Engineering Society. OCEANS’98. Conference Proceedings (Cat. No. 98CH36259), IEEE, vol 1, pp 263–266
Singh H, Armstrong R, Gilbes F, Eustice R, Roman C, Pizarro O, Torres J (2004) Imaging coral i: imaging coral habitats with the seabed auv. Subsurf Sens Technol Appl 5(1):25–42
Singh H, Can A, Eustice R, Lerner S, McPhee N, Roman C (2004) Seabed auv offers new platform for high-resolution imaging. EOS Trans Am Geophys Union 85(31):289–296
Singh H, Howland J, Pizarro O (2004) Advances in large-area photomosaicking underwater. IEEE J Oceanic Eng 29(3):872–886. https://doi.org/10.1109/JOE.2004.831619
Singh H, Roman C, Pizarro O, Eustice R, Can A (2007) Towards high-resolution imaging from underwater vehicles. Int J Robot Res 26(1):55–74
Skinner KA, Johnson-Roberson M (2017) Underwater image dehazing with a light field camera. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp 62–69
Solonenko MG, Mobley CD (2015) Inherent optical properties of jerlov water types. Appl Opt 54(17):5392–5401
Song Y, Köser K, Kwasnitschka T, Koch R (2019) Iterative refinement for underwater 3d reconstruction: Application to disposed underwater munitions in the baltic sea. ISPRS - international archives of the photogrammetry, remote sensing and spatial information sciences XLII-2/W10:181–187
Song Y, Nakath D, She M, Elibol F, Köser K (2021a) Deep sea roboting simulator. In: Pattern Recognition. ICPR international workshops and challenges, Springer International Publishing, Cham, pp 375–389. https://doi.org/10.1007/978-3-030-68790-8_29
Song Y, Sticklus J, Nakath D, Wenzlaff E, Koch R, Köser K (2021b) Optimization of multi-led setups for underwater robotic vision systems. In: Pattern Recognition. ICPR international workshops and challenges. Springer International Publishing, Cham, pp 390–397. https://doi.org/10.1007/978-3-030-68790-8_30
Spier O, Treibitz T, Gilboa G (2017) In situ target-less calibration of turbid media. In: 2017 IEEE international conference on computational photography (ICCP), IEEE, pp 1–9
Sticklus J, Hieronymi M, Hoeher PA (2018) Effects and constraints of optical filtering on ambient light suppression in led-based underwater communications. Sensors 18(11):3710
Sticklus J, Hoeher PA, Röttgers R (2018) Optical underwater communication: the potential of using converted green leds in coastal waters. IEEE J Oceanic Eng 44(2):535–547
Streckel B, Koch R (2005) Lens model selection for visual tracking. In: Joint Pattern Recognition Symposium, Springer, pp 41–48
SubC Imaging (2020) 1cam mk6. https://www.subcimaging.com/1cam-mk6. Accessed 28 Mar 2022
SubC Imaging (2021) Rayfin benthic 6000m. https://www.subcimaging.com/rayfin-benthic-6000m. Accessed 28 Mar 2022
SULIS (2021) C600. https://www.sulissubsea.com/sulis-line. Accessed 28 Mar 2022
Sullivan JM, Twardowski MS (2009) Angular shape of the oceanic particulate volume scattering function in the backward direction. Appl Opt 48(35):6811–6819
Tan C, Seet G, Sluzek A, He D (2005) A novel application of range-gated underwater laser imaging system (ulis) in near-target turbid medium. Opt Lasers Eng 43(9):995–1009
Tan C, Sluzek A, GL GS, Jiang T (2006) Range gated imaging system for underwater robotic vehicle. In: OCEANS 2006-Asia Pacific, IEEE, pp 1–6
Tan H, Doerffer R, Oishi T, Tanaka A (2013) A new approach to measure the volume scattering function. Opt Express 21(16):18697–18711
Tan RT (2008) Visibility in bad weather from a single image. In: 2008 IEEE conference on computer vision and pattern recognition, IEEE, pp 1–8
Tao MW, Hadap S, Malik J, Ramamoorthi R (2013) Depth from combining defocus and correspondence using light-field cameras. In: Proceedings of the IEEE International Conference on Computer Vision, pp 673–680
Tarel JP, Hautiere N (2009) Fast visibility restoration from a single color or gray level image. In: 2009 IEEE 12th international conference on computer vision, IEEE, pp 2201–2208
Teledyne Marine (2021) Explorer-pro. http://www.teledynemarine.com/explorer-pro/?BrandID=5. Accessed 28 Mar 2022
Teledyne Marine (2022) Bowtech l3c-hd. http://www.teledynemarine.com/l3c-hd/?BrandID=5. Accessed 28 Mar 2022
Telem G, Filin S (2010) Photogrammetric modeling of underwater environments. ISPRS J Photogramm Remote Sens 65(5):433–444
Tian J, Murez Z, Cui T, Zhang Z, Kriegman D, Ramamoorthi R (2017) Depth and image restoration from light field in a scattering medium. In: Proceedings of the IEEE international conference on computer vision, pp 2401–2410
Torres-Méndez LA, Dudek G (2005) Color correction of underwater images for aquatic robot inspection. In: International workshop on energy minimization methods in computer vision and pattern recognition, Springer, pp 60–73
Treibitz T, Schechner YY (2006) Instant 3descatter. In: 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), IEEE, vol 2, pp 1861–1868
Treibitz T, Schechner YY (2008) Active polarization descattering. IEEE Trans Pattern Anal Mach Intell 31(3):385–399
Treibitz T, Schechner Y, Kunz C, Singh H (2011) Flat refractive geometry. IEEE Trans Pattern Anal Mach Intell 34(1):51–65
Trucco E, Olmos-Antillon AT (2006) Self-tuning underwater image restoration. IEEE J Ocean Eng 31(2):511–519
Tsiotsios C, Angelopoulou ME, Kim TK, Davison AJ (2014) Backscatter compensated photometric stereo with 3 sources. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2251–2258
Vincent A, Pessel N, Borgetto M, Jouffroy J, Opderbecke J, Rigaud V (2003) Real-time geo-referenced video mosaicking with the matisse system. In: Oceans 2003. Celebrating the Past ... Teaming Toward the Future (IEEE Cat. No.03CH37492), vol 4, pp 2319–2324 Vol.4. https://doi.org/10.1109/OCEANS.2003.178271
Vlachos M, Skarlatos D (2021) An extensive literature review on underwater image colour correction. Sensors 21(17):5690
Voyis (2022) Observer pro. https://voyis.com/observer-nova-pro/. Accessed 28 Mar 2022
Wang B, Song Y, Du Z, Li C, Zhang J, Yang H, Luan Z, Zhang X, Lian C, Yan J (2019) A submarine imaging and laser profiling system and its application to cold seep site investigation off southwestern taiwan (in chinese). Mar Geol Front 35(11):60–65
Wang G, Zheng B, Sun FF (2011) Estimation-based approach for underwater image restoration. Opt Lett 36(13):2384–2386
Wang K, Dunn E, Tighe J, Frahm JM (2014) Combining semantic scene priors and haze removal for single image depth estimation. In: IEEE winter conference on applications of computer vision, IEEE, pp 800–807
Wang TC, Efros AA, Ramamoorthi R (2015) Occlusion-aware depth estimation using light-field cameras. In: Proceedings of the IEEE international conference on computer vision, pp 3487–3495
Wang Y, Liu H, Chau LP (2017a) Single underwater image restoration using adaptive attenuation-curve prior. IEEE Trans Circuits Syst I Regul Pap 65(3):992–1002
Wang Y, Liu H, Chau LP (2017b) Single underwater image restoration using attenuation-curve prior. In: 2017 IEEE international symposium on circuits and systems (ISCAS), IEEE, pp 1–4
Weber M, Cipolla R (2001) A practical method for estimation of point light-sources. In: BMVC, British Machine Vision Association, pp 471–480
Wen H, Tian Y, Huang T, Gao W (2013) Single underwater image enhancement with a new optical model. In: 2013 IEEE international symposium on circuits and systems (ISCAS), IEEE, pp 753–756
Williams SB, Pizarro O, Foley B (2016) Return to antikythera: Multi-session slam based auv mapping of a first century bc wreck site. In: Field and Service Robotics, Springer, pp 45–59
Winters G, Holzman R, Blekhman A, Beer S, Loya Y (2009) Photographic assessment of coral chlorophyll contents: implications for ecophysiological studies and coral monitoring. J Exp Mar Biol Ecol 380(1–2):25–35
Woock P, Frey C (2010) Deep-sea auv navigation using side-scan sonar images and slam. In: OCEANS’10 IEEE SYDNEY, IEEE, pp 1–8
Wu M, Luo K, Dang J, Li D (2017) Underwater image restoration using color correction and non-local prior. In: OCEANS 2017-Aberdeen, IEEE, pp 1–5
Xiao C, Gan J (2012) Fast image dehazing using guided joint bilateral filter. Vis Comput 28(6):713–721
Yang HY, Chen PY, Huang CC, Zhuang YZ, Shiau YH (2011) Low complexity underwater image enhancement based on dark channel prior. In: 2011 Second international conference on innovations in bio-inspired computing and applications, IEEE, pp 17–20
Yang M, Hu J, Li C, Rohde G, Du Y, Hu K (2019) An in-depth survey of underwater image enhancement and restoration. IEEE Access 7:123638–123657
Yang M, Sowmya A, Wei Z, Zheng B (2019) Offshore underwater image restoration using reflection-decomposition-based transmission map estimation. IEEE J Ocean Eng 45(2):521–533
Yoerger DR, Kelley DS, Delaney JR (2000) Fine-scale three-dimensional mapping of a deep-sea hydrothermal vent site using the jason rov system. Int J Robot Res 19(11):1000–1014
Yoerger DR, Jakuba M, Bradley AM, Bingham B (2007) Techniques for deep sea near bottom survey using an autonomous underwater vehicle. Int J Robot Res 26(1):41–54
Yu X, Qu Y, Hong M (2018) Underwater-gan: Underwater image restoration via conditional generative adversarial network. In: International conference on pattern recognition, Springer, pp 66–75
ZEISS (2022) Duw distagon. https://www.zeiss.de/oem-solutions/home/duw-distagon.html. Accessed 28 Mar 2022
Zhang K, Zuo W, Gu S, Zhang L (2017a) Learning deep cnn denoiser prior for image restoration. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3929–3938
Zhang S, Wang T, Dong J, Yu H (2017) Underwater image enhancement via extended multi-scale retinex. Neurocomputing 245:1–9
Zhang T, Han G, Lin C, Guizani N, Li H, Shu L (2020) Integration of communication, positioning, navigation and timing for deep-sea vehicles. IEEE Netw 34(2):121–127
Zhao X, Jin T, Qu S (2015) Deriving inherent optical properties from background color and underwater image enhancement. Ocean Eng 94:163–172
Zhou J, Liu Z, Zhang W, Zhang D, Zhang W (2021) Underwater image restoration based on secondary guided transmission map. Multimedia Tools Appl 80(5):7771–7788
Zhou J, Yang T, Ren W, Zhang D, Zhang W (2021) Underwater image restoration via depth map and illumination estimation based on a single image. Opt Express 29(19):29864–29886
Zhou Y, Wu Q, Yan K, Feng L, Xiang W (2018) Underwater image restoration using color-line model. IEEE Trans Circ Syst Video Technol 29(3):907–911
Zhu Q, Mai J, Shao L (2015) A fast single image haze removal algorithm using color attenuation prior. IEEE Trans Image Process 24(11):3522–3533
Zuiderveld K (1994) Contrast limited adaptive histogram equalization. In: Graphics gems IV. Academic Press Professional Inc, USA, pp 474–485
Zwilgmeyer PGO, Yip M, Teigen AL, Mester R, Stahl A (2021) The varos synthetic underwater data set: Towards realistic multi-sensor underwater data with ground truth. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 3722–3730
Acknowledgements
This publication has been funded by the German Research Foundation (Deutsche Forschungsgemeinschaft, DFG) Projektnummer 396311425, through the Emmy Noether Programme. The authors would also like to thank CSSF, Schmidt Ocean Institute, GEOMAR AUV and JAGO Team for providing the underwater image materials.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Song, Y., Nakath, D., She, M. et al. Optical Imaging and Image Restoration Techniques for Deep Ocean Mapping: A Comprehensive Survey. PFG 90, 243–267 (2022). https://doi.org/10.1007/s41064-022-00206-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41064-022-00206-y