
Abstract
The digital elevation model (DEM) is crucial in many global and regional scientific studies in civilian and military applications. The aim of this research is to develop and test a new DEM approach for correcting the various errors in the Shuttle Radar Topography Mission (SRTM) digital elevation model. Firstly, the DEMs with the feature attributes from Sentinel-2 multispectral imagery are generated. Secondly, SRTM DEM with one band and attributes of a sentinel-2 image with eight bands are used as input data in supervised max-like hood, an artificial neural network (ANN), and support vector machine (SVM) classification models. Thirdly, ANN, supervised max-like hood, and SVM classification models, which have various properties, are fused by fuzzy majority voting (probability fusion). Finally, the fused probability is assigned for each pixel of the image, which has 12 fixed ground control points (GCPs), which is considered new input data for the inverse probability weighted interpolation (IPWI) approach to create the corrected SRTM elevations. The results were contrasted with a reference DEM (RD) created by image matching with Worldview-1 stereo satellite images, which had a 1-m vertical accuracy. The results of this study demonstrated that the RMSE of the original SRTM DEM was 5.95. On the other hand, the RMSE of the estimated elevations by the IPWI approach has been improved to 1.98 compared with that of the MLR method (3.01). The study shows a series of significant improvements in the SRTM when assessed with the reference DEM, with an RMSE reduction of (66.72%) when compared to the widely utilized multiple linear regression (MLR) method. It can be concluded that the elevation error of the original SRTM DEM is clearly reduced by the suggested approach.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
A digital elevation model, or DEM, is a representation of a terrain surface in three dimensions. DEMs have tremendous potential in a variety of fields, including geographical studies, hydrological modeling, ecological research, navigational systems, forest management, and many others [1]. Data collected by remote sensing technologies, such as synthetic aperture radar (SAR) and airborne light detection and ranging (LiDAR), as well as digital topographic maps and field survey results, are used to create 3D models of terrain, are the main sources of demographic data used in this study [2]. The primary functions of digital elevation models (DEMs) are to help generate topographic maps and to produce terrain visualization [3]. Other sources of data included in the study include synthetic aperture radar (SAR) and field survey data. Instead of carrying out field surveys, the standard method for surveying communities these days is to generate digital elevation models (DEMs) by making use of data that has been collected remotely includes systems like the Radar Topography Mission (SRTM) of the Space Shuttle, which has a resolution of 30 m for areas with vegetation. The 2-ASTER-ASTERl Digital Elevation Model had a resolution of 90 m globally; however, the resolution in the USA (mountainous areas) was only 30 m. 3-Global ALOS World 3D from JAXA is a digital surface model (DSM) taken by Japan with a resolution of 30 m globally. A short while ago, this DSM was made available to the general public. 4-Light Detection and Ranging (LiDAR) with a resolution of 1 m, and 5-Infrared Synthetic Aperture Radar (Sentinel 1A/1B-Sentinel 2A) with a resolution of 10 m. 7-MOLA, which has a resolution of 30 m, is compatible with 6 Tan Dem-X, which has resolutions of 90 m, 30 m, and 12 m. Despite the fact that it has a few errors, the Shuttle Radar Topography Mission (SRTM) digital elevation model (DEM), which makes use of radar technology and shadowing techniques, is usually considered to be the most frequently used worldwide Digital Elevation Model (DEM) due to its remarkable quality and enormous global reach [4]. The Shuttle Radar Topography Mission (SRTM) has made it possible to access a virtually worldwide high-resolution digital elevation model (DEM) for the very first time. This DEM comes with the advantages of having a consistent quality and being openly available. The processing of data and the uses of SRTM DEM have both improved rapidly during the past decade years or more. Alongside the National Geospatial-Intelligence Agency (NGA) as well as the German and Italian Space Agencies, the National Aeronautics and Space Administration (NASA) took part in the Shuttle Radar Topography Mission (SRTM), which was conducted on the Space Shuttle Endeavour between February 11 and February 22, 2000. SRTM was part of the Shuttle Radar Topography Mission (SRTM)[5]. The purpose of the Shuttle Radar Topography Mission was to gather a digital elevation model of all land between latitudes 60 N and 56 S, which accounts for approximately 80% of the land surface of the Earth. Because of its consistent resolution and accuracy over the majority of the Earth’s surface, SRTM DEM has been put to use in a variety of study domains, and a great deal of progress has been made in the scientific community as a result [6]. The SRTM elevations have been corrected based on the findings of a great number of earlier research that have been carried out.
Wendi et al. [7] suggested, with the aid of an artificial neural network, increasing the accuracy of SRTM as a source of publicly available DEM by integrating publicly available multispectral images with training data from areas with high-quality, dependable Dems. The suggested method has been put to the test in Singapore’s forested areas.
Salah. [4] A proposed approach involved the utilization of inverse probability weighted interpolation and artificial neural networks (ANNs) in conjunction with Sentinel-2 imagery to enhance the precision of the SRTM elevations. The study creates a set of posterior probabilities by utilizing ANN’s strength in pattern recognition. The posterior probabilities were then combined using an IPWI-based method to calculate more precise SRTM elevations.
Bhang et al. [8] used the Geoscience Laser Altimeter System (GLAS) on board the Ice, Cloud, and Land Elevation Satellite (ICE Sat) to analyze the SRTM DEM over vegetated areas. They found that the SRTM elevation was located in the middle of the gap between the actual land surface and the canopy top.
In order to evaluate the effectiveness of the SRTM DEM, Su et al. [9] made use of nine airborne LiDAR flights that covered the entirety of the USA. They discovered that the SRTM DEM was regularly 10–20 m higher than the actual ground in mountainous regions that were covered in vegetation. During our analysis of the SRTM DEM’s performance, we came upon this observation. They went one step further and used accurate aerial LiDAR-derived vegetation products to make corrections to the SRTM DEM. They discovered that by utilising a regression model between the SRTM DEM error and vegetation products (such as tree height and leaf area index), the accuracy of the SRTM DEM may be significantly improved. This was discovered as a result of their investigation. Because of this, they were able to substantially improve the resolution of the SRTM DEM.
Kulp et al. [10] utilized the ANN to provide more accurate SRTM data in coastal regions. The ANN model made advantage of the information that was provided by ICESat (which stands for Ice, Cloud, and Land Elevation Satellite), as well as slope, canopy height, vegetation density, and population density. The RMSE of the SRTM DEM that was produced as a result rose by almost half. It is impossible to use this strategy in highly crowded urban regions since it is only successful in rural and wilderness settings.
Kim et al. [11] used Sentinel-2 multispectral imagery and SRTM data as inputs for ANN to increase the original SRTM DEM’s accuracy the target data utilized to train the ANN was high-quality DEM. Then, with the help of the trained ANN, a superior DEM with a 38% RMSE improvement was successfully created.
Nguyen et al. [12] employed a multi-channel CNN model with a U-Net structure to raise the quality of the SRTM DEM in the densely populated city of Nice, which is located in Singapore. This was done in order to improve the accuracy of the DEM. As inputs into the model were utilized the multispectral Sentinel-2 data as well as the data from Google Earth, and the objective of the model was to produce a reference DEM of high quality. The root-mean-square error (RMSE) of the model that was applied in the MATLAB deep learning toolbox revealed a value of 4.8 m, which is a value that is much lower than the RMSE of the initial DEM, which was 9.2 m.
The study by Carabajal et al. [13] When compared to the accuracy of the SRTM DEM in plain regions, the SRTM 90 m DEM demonstrates positive variations in vegetation areas for the ATL08 product when using ICESat-2 data in the Australia region for areas with tree cover and vegetation heights. These results may be seen in areas with tree cover and vegetation heights.
Bagheri et al. [14] found that Tan DEM-X and Cartosat-1 data were fused using ANN to enhance both datasets quality. The results demonstrated a 50% improvement in the relative accuracy of the produced Dems. Because fuzzy majority voting (FMV) is one of the most prominent ways of probability fusion to enhance the accuracy of altitudes for SRTM by using (IPWI), this research suggested a novel approach to improve the accuracy of SRTM elevations by fusing three classifiers with different formulas using fuzzy majority voting (FMV). This was done in order to improve the accuracy of SRTM elevations. The method that has been recommended will be abbreviated as IPWI/FMV from now on. This is an abbreviation for the inverse probability weighted interpolation that the SRTM calculates using the output probabilities that are produced from the SVM algorithm. The first section of the paper is named “Study Area and Data Sources,” and it contains a description of the study areas as well as the sources of the data. Part 2 of the “Methodology” section provides a description of the suggested technique, and Part 3 of the “Results” section provides a presentation of the findings as well as a discussion of the findings. In addition, the “Conclusions” section included in Part 4 brings the entire article to a close.
Materials and methods
Study area and data sources
Study area
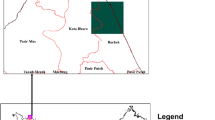
The study location was in Cairo City, Egypt, in the north-east, as depicted in Fig. 1. The property has a mix of open spaces, highways, and urban structures. Approximately 80% of the test area is covered by structures, with an average height of 25 m. The heights range between 12 and 300 m above the ellipsoid. We selected this area to apply our method to correct the SRTM elevations in dense urban areas.

The location of the study area
Data sources
SRTM DEM
According to Fig. 2a, the SRTM data were downloaded in Geo-TIFF format with a 30 m resolution from http://earthexplorer.usgs.gov. The UTMWGS84/Zone 36 projection was used to change over to the geographical longitude as well as latitude are used to calculate the horizontal coordinates, as shown in Table 1. The Earth’s Gravity Models-1996 (EGM96), also known simply as the model is utilized as the vertical datum for the SRTM data, and Table 2 provided an overview of its features. The vertical accuracy is quantified in terms of a linear error. (LE90), while commonly, the measurement of horizontally precision is depicted as a circular mistake (CE90) at a confidence level of 90%.

a Downloaded SRTM data. b Sentinel-2 multispectral imagery. c The final SRTM data
Sentinel-2 multispectral imagery
The sentinel-2 image has been collected on July 10, 2022, as shown in Fig. 2b from Copernicus Open Access Hub (copernicus.eu), Table 3 presents an illustration of the properties of the Sentinel-2 multispectral image. The Sentinel-2 imagery is composed of a total of 13 bands, as illustrated in Table 4, in the visible, near-infrared, and short-wave infrared parts of the spectrum, systematic global coverage of land surfaces from 56° S to 84° N, coastal waters, and all the Mediterranean Sea, spatial resolution of 10 m, 20 m, and 60 m, and a swath width of 290 km. In this study, the four bands that have been used are B2, B3, B4, and B5. Because of their reflectance in urban areas, the bands were resampled to 10 m and then projected to 30 m. With an RMSE of 0.9 pixels, the image from Sentinel-2 has been mapped into UTM/WGS-84 zone 36N.
Final SRTM with attributes
The new approach to SRTM DEM correction started in this step, where the SRTM DEM with one band and the extracted attributes from the sentinel-2 image are collected to reach a final SRTM DEM with nine bands where the SRTM data were downloaded in Geo-TIFF format with a 30 m resolution and the bands for sentinel-2 image were resampled to 10 m and then projected to 30 m to match resolutions. The UTMWGS84/Zone 36 projection was used to change over to the geographical longitude as well as latitude are used to calculate the horizontal coordinates, as shown in Fig. 2c. This final image is the input of the second step (the classification step).
Reference DEM
It is necessary for the precision of the reference data to be superior by at least one magnitude compared to the accuracy of the data that is being examined in order for an evaluation of the results to be possible. The reference DEM that was utilized in this inquiry was generated through the use of semi-global matching (SGM). It has a vertical precision of around 1 m, and its horizontal resolution is also approximately 1 m. (Hirschmuller 2007) and was derived from a November 2013 GeoEye-1 stereo pair that had a spatial resolution of 0.5 m. In the research conducted by Salah (2020), fuzzy c-means clustering (FCM) was applied in order to filter remote sensing point clouds while making use of the same reference DEM. Even so, the reference digital elevation model (DEM), more precisely the Universal Transverse Mercator (UTM) projection on the World Geodetic System 1984 (WGS84) ellipsoid, is related with the data from the Shuttle Radar Topography Mission (SRTM). The orthometric heights that are represented by these SRTM data have been aligned with the geoid defined by the Earth Gravitational Model 1996 (EGM96). The reference digital elevation model is shown in Fig. 3. The ellipsoidal height, when calculating the elliptical height, the geoid undulation is taken into account and removed, it ends up giving us the orthometric height H for the DEM height, h, that we used for reference being derived (H = h-N). The F477 program, which NGA/NASA makes available at https://earth-info.nga.mil/, was utilized in order to compute the N values. This was accomplished by using the F477 program. After that, a raster image with a spatial resolution of 10 m was created by interpolating the gridded N values with a bilinear interpolation approach.

Reference DEM
Generated attributes
A total of 24 texture properties may be derived using the Sentinel-2 images band in the grey-level co-occurrence matrix (GLCM) that represents the spectrum of gray levels, which are predicted to lower the classification errors, this guideline does not constitute a complete texture analysis but may allow confident use of GLCM texture attributes to enhance the efficiency of the image classification and the accuracy of the image features obtaining is improved. In order to implement the new approach in the study. The attributes generally derived from band 1 of the Sentinel-2 picture are extracted. (Contrast, dissimilarity, entropy, homogeneity, mean, correlation, variance, and second moment) [15] as shown in Fig. 4. The spatial resolutions of the utilized data range from 30 m (SRTM data), 10 m (Sentinel-2 picture), and 1 m (Reference DEM). To obtain a similar resolution, these data were resampled to 30 m resolution, and then we merged the SRTM data with one band and the attributes of the Sentinel-2 image with eight bands to obtain SRTM DEM data with nine bands.

The selected attributes from band 1 of sentinel-2 image
Ground control point
As can be seen in Fig. 5, the twelve ground control points (GCPs) around the research site have been used. These points were chosen due to their even distribution and clear definition. These points go over the majority of the LULC topics that will be on the test. Table 5 presents an illustration of the features of the spots that were selected. Utilizing two Trimble-R8 receivers, a field survey was carried out in order to ascertain the precise locations of the ground control points (GCPs). In the survey, each measurement was separated by a delay of 5 s, and the mask angle was set at 13 degrees. The following analysis was taken from an observation session that lasted for ten minutes and was carried out in RTK mode. This session produced an approximate horizontal accuracy of five to ten centimeters and a vertical accuracy of one to two centimeters. The data was processed with the help of the Trimble Business Centre (TBC) software, and the coordinates were referenced using the UTMWG-S84/zone 36N system.

The distribution of the ground control points
Methodology
The revised strategy for SRTM DEM rectification operations is depicted in Fig. 6. First, data prepressing: SRTM DEM with nine bands. Second, the classification step: there are three methods for classification in this research: ANN (artificial neural network). 2: supervised classification (maximum likelihood) 3: SVM (support vector machine). Third, use probability fusion (fuzzy majority voting) to reach the final probabilities. Forth, by using GPS GCPs with height conversion and the FMV probabilities, the initial improved SRTM DEM extracted, low-pass filtering, and then the final improved SRTM DEM. Finally, accuracy assessment, error statistics, correlation coefficient, and scatter plot. The software for statistical and graphical analysis that has been used is MATLAB.

The flowchart of the new approach to SRTM DEM correction
Artificial neural network classification
There are several advantages to be gained from utilizing neural networks for binary classification. Taking into consideration that they are able to manage complex data sets that contain a large number of components and nonlinear interactions, the backpropagation (BP) technique, which is represented in Fig. 7 and expressed in Eq. (1), is a learning procedure that is commonly used for artificial neural networks. The BP neural network is the one that takes up the most space in a network model. The input layer, the hidden layer, and the output layer are the three components that make up a BP neural network, which is a kind of three-tier or three-tier on top of the neural network. Network settings were used. Input layer raw domain input goes to the input layer. This layer computes nothing. Nodes here just send features to the buried layer. As the name implies, this layer’s nodes are hidden. They are abstract neural networks. The hidden layer computes all input layer features and sends them to the output layer. (Output Layer) The network’s final layer receives the hidden layer’s data and returns the final value. Although the neurons in the layers before and after are not coupled to one another, the connections between them are still present overall. In the field of machine learning, the artificial neural network (ANN) that is utilized the most frequently is the conventional multilayer perceptron, also known as the MLP. Hidden neurons should be between input and output layer sizes. The hidden neurons should be 2/3 of the input and output layers combined. The number of hidden neurons should be less than twice the size of the input layer. The number of nodes in a hidden layer is not limited. How we decide is up to us. A neural network’s parameter set grows in proportion to the number of nodes in its hidden layer. It makes use of a backpropagation strategy, which is represented by the Eq. (1), with the goal to learn the algorithm and mapping the input information into an accumulation of clustered outputs [16].
where w indicates the synapse weights, v represents the input vectors of the neuron, b represents the bias, u represents the activation function, and v represents the output of the neuron. The function known as activation maps the relationship between the inputs and outputs using the activation function, which is also used to set an output’s maximum amplitude. It has been demonstrated that the activation function of the sigmoid, written as 1/(1 + e − v), successfully maps nonlinear relationships (Cybenko, 1989). In this study, the benefits of ANN in pattern recognition and classification were used to estimate outputs that were similar to probabilities, which were then applied as input to the following step to select the more correct probabilities. Twelve image pixels that were associated with SRTM as well as GPS altitudes were utilized as training data for the algorithm. Consequently, each pixel is given a probability that is calculated using a combination of 12 clusters and 12 picture pixels whose heights are determined by GPS. The twelve clusters have been selected for classification due to the availability of this number of ground points that are used in the classification process. There is no specific number of points, but it depends on the number of points available in the study area. There is not a maximum distance for using ground control points because it depends on the density of the points and not on the distance between the points and each other. The values of the probabilities range anywhere from 0 to 1, with one signifying the complete identification regarding a specific pixel to a certain elevation that serves as a reference and zero signifying the utmost improbability. The output of the ANN probability is shown in Fig. 8.

Backpropagation (BP) algorithm

The output of ANN probabilities
Supervised classification (Max like hood)
A user or image analyst “supervises” the pixel categorization process in supervised classification. The user specifies the various pixel values, or spectral signatures, that should be associated with each class. To do this, representative sample training sites or areas with a given cover type are chosen, as shown in Fig. 9. Assuming that the statistics for each class in each band are normally distributed, we use the maximum likelihood technique to calculate the likelihood that a given pixel belongs to a specific class. Maximum likelihood classifiers assign each pixel to the group to which it belongs with the highest probability. Assume this is the norm. For Max-like hood to work, an explicit model of character alteration must be developed, including probabilities for each potential transition between states. Maximum likelihood classification determines the chance that a particular pixel belongs to a specific class based on the assumption that the statistics for each class in each band are normally distributed. All pixels are labelled unless a probability threshold is set. Maximum likelihood is used to determine which category each pixel belongs to. For this purpose, we used 12 picture pixels as training samples whose SRTM and GPS elevations were known. The likelihood for each pixel is calculated by adding the known GPS heights of 12 picture pixels to the possibility of 12 clusters.

The maximum-likelihood expectation–maximization algorithm
Support vector machine (SVM)
Support vector machine (SVM) is a supervised classification technique that, when applied to complicated and noisy data, frequently produces accurate classification results. It is derived from statistical learning theory. With a decision surface that optimizes the margin between the classes, it separates the classes. The closest data points to the hyperplane are referred to as support vectors, and the surface is frequently referred to as the ideal hyperplane. There is data normalization prior to SVM classification. The normalizing of numerical inputs is necessary for SVM. For mapping the data into a more advantageous plane that is more convenient for calculation, normalization is yet another kernel method. An intricate normalization technique will have a significant impact on the amount of time required for processing due to the vast amount of data that is being processed. A method that is both quick and efficient is desirable.
There have been a few different approaches to normalization proposed, including the zero-mean normalization, the sigmoidal normalization, the soft max normalization, the decimal scaling, the max normalization, and the min–max normalization. By putting all the attribute’s numerical values on the same scale, normalization prevents the solution from being skewed or dominated by attributes with a larger original scale. Support vector machines, or SVM Separate training and test samples from the dataset using the training set and train the model. A test utilizing training data and sample performance metrics. An SVM model is just a hyperplane in multi-dimensional space that represents several classes. SVM will iteratively create the hyperplane to provide the least amount of error. Divide the datasets into classes using SVM in order to identify a maximum marginal hyperplane (MMH), as shown in Fig. 10.

Important concepts in SVM
Probability fusion
The process of assigning two or more probabilities to pieces of evidence that support the same theories is known as “fusion.” The probability assignments are typically diverse and come from various lines of evidence. It is generally known that a set of consistent boundaries must be met for evidence to be fused given a set of probability assignments.
Fuzzy majority voting
Combining classifiers is essential for feature extraction and mapping applications. The most popular fuzzy set technique is FMV because it is simple to implement and can handle imperfect data [17]. FMV is applied to combine the weighted probabilities from the three classifiers (ANN, SVM, and Max-like hood) and form the final decision. The probability based on FMV \(\left( {P_{{{\text{FMV}}}} } \right)\) can be calculated as expressed in Eq. (2):
where with k is the number of classes and \(W_{{{\text{PP}}}}\) is the weights based on the linguistic quantifier as expressed in Eq. (3):
According to the \(i{\text{th}}\) classifier’s results, \(Q_{{{\text{PP}}_{i} }}\) is the membership functions of relative quantifiers for the pixel. \(j_{i}\) is the position of the ith classifier after all classifiers have ranked the pixel’s \(Q_{{{\text{PP}}_{i} }}\) values in descending order. The number of classifiers is N. The \(i{\text{th}}\) classifier’s output of the membership function of relative quantifiers for a particular pixel is as expressed in Eq. (4):
The class membership of the pixel is represented by the parameters a, b, [0, 1], and, as determined for the classifier. The number of classifiers in our case is N, and by using Eq. (3), the relevant weighting vector for the specified pixel,
where \(W_{{{\text{ANN}}}}\) is the weights based on artificial neural network, \(W_{{{\text{SVM}}}}\) is the weights based on support vector machine and \(W_{{{\text{MLH}}}}\) is the weights based on max like hood classification. Figure 11 illustrates the possibilities of 12 clusters for the study area.

The possibilities of 12 clusters for the study area
In spite of the fact that there are numerous shapes of fuzzy membership functions, such as Gaussian, trapezoidal, and triangular, among others, the optimal choice of membership function for the model is determined by the mean square error (MSE) in relation to the outputs of the working database [18].
By creating a fuzzy membership function, FMV has proven to be an effective technique for handling uncertainties and imprecision in remotely sensed data. An explanation of how a certain point in the input space will be represented as a membership value in the output space is provided by a membership function. The idea of the system is to combine probabilities from multiple algorithms with various properties in order to make up for the weaknesses of each method with the advantages of the others.
Improved SRTM elevations estimated using (IPWI)
The IPWI is founded on the premise that all study participants have access to individual information that can predict their probability of inclusion (non-missingness). Studies have demonstrated that the vertical and horizontal errors of the SRTM DEM are fewer than 20 m and 16 m, respectively, with 90% confidence which is regarded a relatively reliable DEM data source [6]. Through the application of machine learning, fuzzy majority voting, and weighted interpolation techniques, we were able to establish a straightforward approach to rectify the elevation error that was present in the SRTM DEM. The study’s proposed IPWI approach modifies the well-known inverse distance-weighted interpolation method. Any unknown pixel’s estimated SRTM elevation z can be determined as a function of the probabilities acquired (the likelihood that the unknown pixel is one of the 12 picture pixels with known GPS heights). The predicted SRTM elevations must be more similar to reference elevations with greater probabilities than those with lower probabilities, as we mentioned. The predicted SRTM elevations is influenced by a point’s higher likelihood. The equation used for estimating the improved SRTM elevation is in Eq. (5).
The variables \(P_{{{\text{FMV}}}}\) represent the probabilities of the unknown pixel’s FMV (Feature Matching and Verification) belonging to each of the k GPS elevations. Here, i denotes the order of the GPS elevations, while k represents the total number of GPS elevations or classes. Ze refers to the estimated SRTM (Shuttle Radar Topography Mission) elevation for the pixel. On the other hand, \(z_{{{\text{GPS}}_{i} }}\) represents the GPS elevation at the ith point in the grid, and \(z_{{{\text{SRTM}}_{i} }}\) represents the estimated SRTM elevation for the unknown pixel.
Accuracy assessment
All accuracy evaluations begin with a comparison of the estimated results to the actual results, followed by a measurement of the difference between the two. Consider the impact that the adjustment has had. The accuracy assessment for the proven SRTM DEM has been applied in this research by comparing the elevations of the DEM with the reference DEM. The proposed method has been put into practice by utilizing statistics such as the minimum (Min.), maximum (Max.), mean (Mean), standard deviation (SD), root-meansquare error (RMSE), correlation coefficient (R), and scatter plots as shown in Eqs. (6–8). R is a coefficient that indicates how well the values fit in comparison to the values that were originally used. A percentage can be calculated using the value from 0 to 1, which ranges from that range. If the value is higher, then the model is of higher quality. When the root-mean-square error (RMSE) is smaller, a model can “fit” a dataset more successfully. A standard deviation that is low implies that the data are concentrated close to the mean, whereas a standard deviation that is high shows that the data are more dispersed. As may be shown from Eqs. (6–8).
where n represents the total amount of pixels, Zr stands for a reference elevation, Ze stands for the expected elevation, and Ze represents the mean of all the estimated values, and Zr is the mean of all reference values and represents the total number of pixels. The SRTM DEM augmentation method was used with the help of a collection of codes. MATLAB was the environment in which the author’s development took place. (Version R2018b, Math Works Inc., Natick, Massachusetts).
Results and discussion
A merge operation between the generated attributes of the Sentinel-2 image and SRTM DEM has been performed in order to obtain an SRTM DEM with nine bands, which helps in the improvement process. This merge operation was performed in order to ensure the significance of the contribution of the Sentinel-2 multispectral image and its generated attributes in the process of elevation correction. After utilizing this picture as the source of the data for the calculation, which is explained in the section titled “Technique,” the three probabilities have been determined. Probability fusion was used to determine the ultimate probabilities associated with them as well. The outcome of this method and the elevations obtained from the GPS were then used as input data for the IPWI model, which was used to estimate the heights of the corrected SRTM.
We have used 88% of the gathered data deemed as an input to the proposed algorithm (sample point) for constructing a high-resolution DEM, while the remaining 12% is taken as checkpoints to analyze the performance of the estimated surface.
This new approach was validated using the reference DEM that was used in Salah’s work (2020). Comparing the results with previous studies, the validity of the results used in the process of improving elevation accuracy was confirmed. Therefore, this model can be applied to any study area where some ground control points are available without comparison with another reference DEM. Which requires time and a high cost. Achieving computational efficiency involves a combination of algorithmic improvements, code optimizations, and hardware considerations. Continuous monitoring, profiling, and iterative refinement are key to ensuring that your code remains optimized for performance. The systems used in the programming process are DESKTOP-UVVKBA9, Windows 10 Pro 64-bit, and HP ZBook 15 G3. The process of processing and analyzing the results takes a few minutes and gives the results with very high accuracy. Note that the proposed manuscript can be done on other devices with different capabilities and less than the ones used, and it also gives results in a short time and with high accuracy as well. A variety of statistics, including correlation coefficients, standard deviations, root mean square errors, and scatter plots, were used to support the evaluation. A scatter plot is a typical method that is used to evaluate the performance of the interpolation approach in order to select the most suitable model. This is accomplished by determining the difference between the reference elevation and the predicted height at each point. For the purpose of defining the trend and autocorrelation models, it is utilized to assign the effect of elevation error on estimation reliability through the use of the test dataset. We have tested and benchmarked our code to make sure that it works correctly and meets the performance requirements. Benchmark our code to measure its performance and identify potential performance improvements.
Accuracy assessment of the original SRTM DEM
To begin, a comparison between the reference DEM and the initial SRTM DEM was carried out. Table 6 displays the statistical information regarding the elevational differences that can be found between the reference DEM and the original SRTM. The original SRTM DEM is very different from the reference DEM, which has a standard deviation of 3.08 m and a root mean square error of 5.95 m. One item that has been brought to people’s attention is the wide range of variances; the minimum, maximum, and mean were, respectively, 4.27, 15.72, and 11.57. A scatter plot is used to compare the reference elevations to the original ones in the frequency distribution of elevation variations between the reference DEM and the original SRTM, which is illustrated in Fig. 12a and b.

a Histogram showing the elevation differences between the-reference DEM and the original SRTM DEM b scatter plot comparing the reference DEM to the original SRTM DEM
It is observed that the original and reference elevations have a maximum correlation coefficient R of 0.8044. The red line, a first-order polynomial, which reflects the fitted linear model between the estimated and reference altitudes, is a term in this expression. (y = 1.002x + 5.199), where y is equivalent to the original SRTM height and x is equivalent to the reference height. According to a sample T-test, the correlation is quite significant (p < 0.0001). The fitted line between the original and reference elevations is shown in red.
Comparison with the MLR approach
According to what is said in the “Methods employed in comparison” section, the MLR technique that is now in use has been evaluated alongside the technique that has been suggested. The MLR approach was utilized in order to calculate the corrected SRTM elevations with a precision of 10 m, making use of the same 12 GPS GCPs that are displayed in Fig. 13. Table 7 displays the statistical information regarding the differences in elevation that can be found between the reference DEM and the MLR. The original SRTM DEM is quite different from the reference DEM, with a standard deviation and root mean square error of 1.45 and 3.01 m, respectively. The RMSE of the upgraded SRTM DEM improved by 49.4%, going from 5.95 m to 3.01 m after being updated. The standard deviation of the improved SRTM DEM fell from 3.08 m to 1.45 m, representing an improvement of 52.92%. A scatter plot is used to compare the reference elevations to the original heights in the frequency distribution of elevation variations between the reference DEM and the original SRTM, which is illustrated in Fig. 14a and b. It has come to our attention that the greatest correlation coefficient R between the original heights and the reference elevations is 0.8196.

The improved SRTM DEM obtained for MLR approach

a Histogram showing the elevation differences between the reference DEM and the MLR. b Scatter plot comparing the reference DEM to MLR
The red line, which depicts the fitted linear model between the estimated and reference altitudes, is a first-order polynomial and has the form (y = 0.9728x + 0.6818), where y is equivalent to the original SRTM height and x is equivalent to the reference height. The model was created by fitting the estimated altitudes to the reference height. The first step in developing this model was to match the predicted elevation up with the reference elevation. The findings of a sample T-test reveal that the association is extremely significant (p is less than 0.0001), which is a very high level of statistical significance. The line in red represents the line that was drawn to suit the data between the original height and the reference elevation.
On the other hand, the data show that there is a large range of variation, with a mean of 7.81 m and a range that goes all the way up to 15.58 m. Which frequently shares characteristics with the Reference DEM.
In this particular instance, the reflectance values from the final SRTM DEM with nine bands are included in the input layer. Furthermore, as training data, twelve picture pixels whose GPS heights were known were utilized, as can be seen in Fig. 15. It has been determined that the FMV model was executed with an input layer. Table 8 displays the statistical information pertaining to the elevational differences that can be found between the reference DEM and the MLR. Significant deviations can be seen between the original SRTM DEM and the reference DEM in both the standard deviation (SD) and root mean square error (RMSE), which come in at 1.03 m and 1.98 m, respectively. The RMSE of the upgraded SRTM DEM has decreased from 5.95 to 1.98 m, representing an improvement of 66.72%. The standard deviation of the modified SRTM DEM has decreased from 3.08 to 1.03 m, representing an improvement of 66.56%. A scatter plot is used to compare the reference elevations to the original heights in the frequency distribution of elevation variations between the reference DEM and the original SRTM, which is illustrated in Fig. 16a and b. It has come to our attention that the maximum correlation coefficient R between the original heights and the reference elevations is 0.9210. A first-order polynomial can be seen as the red line, which depicts the linear model that best fits the relationship between the estimated and reference altitudes.

The improved SRTM DEM obtained for FMV approach

a Histogram showing the elevation differences between the reference DEM and the FMV. b Scatter plot comparing the reference DEM to FMV
The results, on the other hand, show a wide range of fluctuations, which vary from − 2.07 to 7.1 m, with a mean of − 21 m. The standard deviation is also shown to be − 2.07 m. It is anticipated that using the texture attributes in the classification steps will result in a reduction in the degree to which the spectral responses of the various features in the Sentinel-2 image are comparable to one another. In this case, you can say that it has the highest accuracy in the results in comparison with the original DEM and MLR approaches. This underscores the importance of using probability fusion in the elevation correction process.
Finally, the results have been compared for the original DEM, MLR system, and IPWI/FMV system, as illustrated in Table 9. The decreased RMS and SD in the case of IPWI/FMV, as shown in Fig. 17, proved that the proposed method is better than other systems and is able to correct the linear and nonlinear errors when the MLR approach fails. The lower the RMSE and SD, the better a given model is able to “fit” a dataset.

The RMSE and SD for the results of the three systems
Conclusion
In this research, an approach has been suggested to improve SRTM elevations in a study area in Cairo, Egypt. The novel approach used the SRTM DEM, and the texture attributes obtained from sentinel-2 multispectral imagery to get the final SRTM DEM with nine bands. As training data, twelve picture pixels with known GPS heights were used. For each pixel, 12 probability values have been computed in this regard by three different systems (an artificial neural network, a support vector machine, and a supervised max-like hood), and then the output probabilities were fused by fuzzy majority voting. The suggested IPWI model was then used to estimate improved SRTM elevations using the obtained probabilities as input. The result showed that using this approach has improved the elevations with a RMSE reduction of 3.97m (66.72% improvement) and a SD reduction of 2.05m (66.56% improvement). Finally, significant improvements in SRTM are visibly noted with RMSE and SD reduction. In conclusion, the proposed methodology is proven to be able to improve SRTM DEM significantly in the selected study area. In our future study, we will explore some attribute features using deep learning to enhance the interpolation approach in order to accurately correct the elevation error of the SRTM DEM and continue the search for alternatives and modern methods to increase the accuracy of SRTM elevations.
References
Ma X, Li H, Chen Z (2023) Feature-enhanced deep learning network for digital elevation model super resolution. IEEE J Sel Top Appl Earth Obs Remote Sens. https://doi.org/10.1109/JSTARS.2023.3288296
Hh M, Al-Janabi I, Odaa SA (2020) Land cover reflectance of Iraqi marshlands based on visible spectral multiband of satellite imagery. Results Eng 8:100167. https://doi.org/10.1016/j.rineng.2020.100167
Li Z, Zhu X, Yao S et al (2023) A large scale digital elevation model super-resolution transformer. Int J Appl Earth Obs Geoinf 124:103496. https://doi.org/10.1016/j.jag.2023.103496
Salah M (2021) SRTM DEM correction over dense urban areas using inverse probability weighted interpolation and Sentinel-2 multispectral imagery. Arab J Geosci 14:801. https://doi.org/10.1007/s12517-021-07148-6
Jiang L, Hu Y, Xia X et al (2020) A multi-scale mapping approach based on a deep learning cnn model for reconstructing high-resolution urban dems. Water 12:1369. https://doi.org/10.3390/w12051369
Li Y, Fu H, Zhu J et al (2022) A method for SRTM DEM elevation error correction in forested areas using ICESat-2 data and vegetation classification data. Remote Sens 14:3380. https://doi.org/10.3390/w12030816
Wendi D, Liong S, Sun Y, Doan CD (2016) An innovative approach to improve SRTM DEM using multispectral imagery and artificial neural network. J Adv Model Earth Syst 8:691–702. https://doi.org/10.1002/2015MS000536
Bhang KJ, Schwartz FW, Braun A (2006) Verification of the vertical error in C-band SRTM DEM using ICESat and landsat-7, otter tail county, MN. IEEE Trans Geosci Remote Sens 45:36–44. https://doi.org/10.1109/TGRS.2006.885401
Su Y, Guo Q (2014) A practical method for SRTM DEM correction over vegetated mountain areas. ISPRS J Photogramm Remote Sens 87:216–228. https://doi.org/10.1016/j.isprsjprs.2013.11.009
Kulp SA, Strauss BH (2018) CoastalDEM: a global coastal digital elevation model improved from SRTM using a neural network. Remote Sens Environ 206:231–239. https://doi.org/10.1016/j.rse.2017.12.026
Kim DE, Liong S-Y, Gourbesville P et al (2020) Simple-yet-effective SRTM DEM improvement scheme for dense urban cities using ANN and remote sensing data: application to flood modeling. Water 12:816. https://doi.org/10.3390/w12030816
Nguyen NS, Kim DE, Jia Y et al (2022) Application of multi-channel convolutional neural network to improve DEM data in urban cities. Technologies 10:61. https://doi.org/10.3390/technologies10030061
Carabajal CC, Harding DJ (2005) ICESat validation of SRTM C-band digital elevation models. Geophys Res Lett. https://doi.org/10.1029/2005GL023957
Bagheri H, Schmitt M, Zhu XX (2018) Fusion of TanDEM-X and Cartosat-1 elevation data supported by neural network-predicted weight maps. ISPRS J Photogramm Remote Sens 144:285–297. https://doi.org/10.1016/j.isprsjprs.2018.07.007
Basyouni H, Salah M, Zarzoura F, El-Mewafi PDM (2023) Smart monitoring of road pavement deformations from UAV images by using machine learning. Innov Infrastruct Solut 9:1–18. https://doi.org/10.1007/s41062-023-01315-2
Seiffert U (2001) Multiple layer perceptron training using genetic algorithms. In: ESANN. Citeseer, pp 159–164. https://doi.org/10.3390/math11143080
Ponti Junior MP (2011) Combining classifiers: from the creation of ensembles to the decision fusion. In: 24th SIBGRAPI conference on graphics, patterns, and images tutorials. https://doi.org/10.1109/SIBGRAPI-T.2011.9
Prajapati S, Fernandez E (2020) Performance evaluation of membership function on fuzzy logic model for solar PV array. In: 2020 IEEE international conference on computing, power and communication technologies (GUCON). pp 609–613. https://doi.org/10.1109/GUCON48875.2020.9231202
Acknowledgements
The Department of Surveying at the Engineering College Shoubra, Benha University in Egypt, provided the datasets for this work, for which the author is grateful.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
The first author analyzed and wrote the introduction, methodology, and results, while the second author steered the preparation of the document and validation. The third author implemented the software with the first author and the fourth author. The creator of the basic concept oversaw all elements and authored conclusions and recommendations and pursue with corresponding authors to ensure the completeness and verification procedure.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflict of interest to declare that are relevant to this article.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
For this type of study, formal consent is not required.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kandil, W.M., Zarzoura, F.H., Salah, M. et al. New approach for satellite DEM accuracy enhancement by combing machine learning, fuzzy majority voting, and weighted interpolation techniques. Innov. Infrastruct. Solut. 9, 103 (2024). https://doi.org/10.1007/s41062-024-01401-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41062-024-01401-z