
Abstract
Structural health monitoring (SHM) provides an economic approach which aims to enhance understanding the behavior of structures by continuously collecting data through multiple networked sensors attached to the structure. These data are then utilized to gain insight into the health of a structure and make timely and economic decisions about its maintenance. The generated SHM sensing data are non-stationary and exist in a correlated multi-way form which makes the batch/off-line learning and standard two-way matrix analysis unable to capture all of these correlations and relationships. In this sense, the online tensor data analysis has become an essential tool for capturing underlying structures in higher-order datasets stored in a tensor \({\mathcal {X}} \in {\mathbb {R}} ^{I_1 \times \cdots \times I_N} \). The CANDECOMP/PARAFAC (CP) decomposition has been extensively studied and applied to approximate X by N loading matrices \(A(1),\ldots ,A(N)\) where N represents the order of the tensor. We propose a novel algorithm, FP-CPD, to parallelize the CANDECOMP/PARAFAC (CP) decomposition of a tensor \({\mathcal {X}} \in {\mathbb {R}} ^{I_1 \times \cdots \times I_N} \). Our approach is based on stochastic gradient descent (SGD) algorithm which allows us to parallelize the learning process, and it is very useful in online setting since it updates \({\mathcal {X}}^{t+1}\) in one single step. Our SGD algorithm is augmented with Nesterov’s accelerated gradient and perturbation methods to accelerate and guarantee convergence. The experimental results using laboratory-based and real-life structural datasets indicate fast convergence and good scalability.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
There has been an exponential growth of data which is generated by the accelerated use of modern computing paradigms. A prominent example of such paradigms is the Internet of Things (IoTs) in which everything is envisioned to be connected to the Internet. One of the most promising technology transformations of IoT is a smart city. In such cities, enormous number of connected sensors and devices continuously collect massive amount of data about things such as city infrastructure to analyze and gain insights on how to manage the city efficiently in terms of resources and services.
The adoption of smart city paradigm will result in massive increase of data volume (data collected from a large number of sensors) as well as a number of data features which increase data dimensionality. To make prices and in-depth insights from such data, advanced and efficient techniques including multi-way data analysis were recently adopted by research communities.
The concept of multi-way data analysis was introduced by Tucker in 1964 as an extension of standard two-way data analysis to analyze multidimensional data known as tensor [22]. It is often used when traditional two-way data analysis methods such as Non-negative Matrix Factorization (NMF), Principal Component Analysis (PCA) and Singular Value Decomposition (SVD) are not capable of capturing the underlying structures inherited in multi-way data [9]. In the realm of multi-way data, tensor decomposition methods such as Tucker and CANDECOMP/PARAFAC (CP) [22, 30] have been extensively studied and applied in various fields including signal processing [11], civil engineer [20], recommender systems [30], and time series analysis [10]. The CP decomposition has gained much popularity for analyzing multi-way data due to its ease of interpretation. For example, given a tensor \({\mathcal {X}} \in {\mathbb {R}} ^{I_1 \times \cdots \times I_N} \), CP method decomposes \({\mathcal {X}}\) by N loading matrices \(A^{(1)}, \ldots , A^{(N)}\) each represents one mode explicitly, where N is the tensor order and each matrix A represents one mode explicitly. In contrast to Tucker method, the three modes can interact with each other making it difficult to interpret the resultant matrices.
The CP decomposition approach often uses the Alternating Least Squares (ALS) method to find the solution for a given tensor. The ALS method follows the batch mode training process which iteratively solves each component matrix by fixing all the other components; then, it repeats the procedure until it converges [19]. However, ALS can lead to sensitive solutions [4, 12]. Moreover, in the domain of big data and IoTs such as smart cities, the ALS method raises many challenges in dealing with data that is continuously measured at high velocity from different sources/locations and dynamically changing over time. For instance, a structural health monitoring (SHM) data can be represented in a three-way form as \(location \times feature \times time\) which represents a large number of vibration responses measured over time by many sensors attached to a structure at different locations. This type of data can be found in many other application domains including [1, 5, 23, 37]. The iterative nature of employed CP decomposition methods involves intensive computational processing in each iteration. A significant challenge arises in such algorithms (including ALS and its variations) when the input tensor is sparse and has N dimension. This means as the dimensionality of the tensor increases, the calculations involved in the algorithm become computationally more expensive, and thus incremental, parallel and distributed algorithms for CP decomposition become essential to achieving a more reasonable performance. This is especially the case in large applications and computing paradigms such as smart cites.
The efficient processing of CP decomposition problem has been investigated with different hardware architecture and techniques including MapReduce structure [17] and shared and distributed memory structures [18, 36]. Such approaches present algorithms that require alternating hardware architectures to enable parallel and fast execution of CP decomposition methods. The MapReduce and distributed computing approaches could also incur additional performance from network data communication and transfer. Our goal is to devise a parallel and efficient CP decomposition execution method with minimal hardware changes to the operating environment and without incurring additional performance resulting from new hardware architectures. Thus, to address the aforementioned problems, we propose an efficient solver method called FP-CPD (Fast Parallel-CP Decomposition) for analyzing large-scale high-order data in parallel based on stochastic gradient descent. The scope of this paper is smart cities and, in particular, SHM of infrastructure such as bridges. The novelty of our proposed method is summarized in the following contributions:
-
1.
Parallel CP Decomposition. Our FP-CPD method is capable of efficiently learning large-scale tensors in parallel and updating \({\mathcal {X}}^{(t+1)}\) in one step.
-
2.
Empirical analysis on structural datasets. We conduct experimental analysis using laboratory-based and real-life datasets in the field of SHM. The experimental analysis shows that our method can achieve more stable and fast tensor decomposition compared to other known existing online and offline methods.
The remainder of this paper is organized as follows. Section 2 introduces background knowledge and review of the related work. Section 3 describes our novel FP-CPD algorithm for parallel CP decomposition based on SGD algorithm augmented with the NAG method and perturbation approach. Section 4 presents the motivation of this work. Section 5 shows the performance of D-CPD on structural datasets and presents our experimental results on both laboratory-based and real-life datasets. The conclusion and discussion of future research work are presented in Sect. 6.
2 Background and related work
2.1 CP decomposition
Given a three-way tensor \({\mathcal {X}} \in \Re ^{I \times J \times K} \), CP decomposes \({\mathcal {X}}\) into three matrices \(A \in \Re ^{I \times R}\), \(B \in \Re ^{J \times R} \)and \( C \in \Re ^{K \times R}\), where R is the latent factors. It can be written as follows:
where “\(\circ \)” is a vector outer product. R is the latent element; \(A_{ir}, B_{jr} \) and \(C_{kr}\) are r-th columns of component matrices \(A \in \Re ^{I \times R}\), \(B \in \Re ^{J \times R} \)and \( C \in \Re ^{K \times R}\). The main goal of CP decomposition is to decrease the sum square error between the model and a given tensor \({\mathcal {X}}\). Equation 2 shows our loss function L needs to be optimized.
where \(\Vert {\mathcal {X}}\Vert ^2_f\) is the sum squares of \({\mathcal {X}}\) and the subscript f is the Frobenius norm. The loss function L presented in Eq. 2 is a non-convex problem with many local minima since it aims to optimize the sum squares of three matrices. Several algorithms have been proposed to solve CP decomposition [25, 31, 38]. Among these algorithms, ALS has been heavily employed which repeatedly solves each component matrix by locking all other components until it converges [29]. The rational idea of the least square algorithm is to set the partial derivative of the loss function to zero with respect to the parameter we need to minimize. Algorithm 1 presents the detailed steps of ALS.

Zhou et al. [42] suggests that ALS can be easily parallelized for matrix factorization methods, but it is not scalable for large-scale data especially when it deals with multi-way tensor data. Later Zhou et al. [41] proposed another method called onlineCP to address the problem of online CP decomposition using ALS algorithm. The method was able to incrementally update the temporal mode in multi-way data but failed for non-temporal modes [19] and not parallelized.
2.2 Stochastic gradient descent
A stochastic gradient descent algorithm is a key tool for optimization problems. Here, the aim is to optimize a loss function L(x, w), where x is a data point drawn from a distribution \({\mathcal {D}}\) and w is a variable. The stochastic optimization problem can be defined as follows:
The stochastic gradient descent method solves the above problem defined in Eq. 3 by repeatedly updates w to minimize L(x, w). It starts with some initial value of \(w^{(t)}\) and then repeatedly performs the update as follows:
where \(\eta \) is the learning rate and \(x^{(t)}\) is a random sample drawn from the given distribution \({\mathcal {D}}\). This method guarantees the convergence of the loss function L to the global minimum when it is convex. However, it can be susceptible to many local minima and saddle points when the loss function exists in a non-convex setting. Thus it becomes an NP-hard problem. Note, the main bottleneck here is due to the existence of many saddle points and not to the local minima [13]. This is because the rational idea of gradient algorithm depends only on the gradient information which may have \(\frac{\partial L}{\partial u } = 0\) even though it is not at a minimum.
Previous studies have used SGD for parallel matrix factorization. Gemulla [14] proposed a new parallel method for matrix factorization using SGD. The authors indicate the method was able to handle large-scale data with fast convergence efficiently. Similarly, Chin et al. [8] proposed a fast parallel SGD method for matrix factorization in recommender systems. The method also applies SGD in shared memory systems but with a careful consideration to the load balance of threads. Naiyang et al. [16] applies Nesterov’s optimal gradient method to SGD for non-negative matrix factorization. This method accelerates the NMF process with less computational time. Similarly, Shuxin et al. [40] used an SGD algorithm for matrix factorization using Taylor expansion and Hessian information. They proposed a new asynchronous SGD algorithm to compensate for the delay resultant from a Hessian computation.
Recently, SGD has attracted several researchers working on tensor decomposition. For instance, Ge et al. [13] proposed a perturbed SGD (PSGD) algorithm for orthogonal tensor optimization. They presented several theoretical analysis that ensures convergence; however, the method is not applicable to non-orthogonal tensor. They also did not address the problem of slow convergence. Similarly, Maehara et al. [26] propose a new algorithm for CP decomposition based on a combination of SGD and ALS methods (SALS). The authors claimed the algorithm works well in terms of accuracy. Nevertheless, its theoretical properties have not been completely proven and the saddle point problem was not addressed. Rendle and Thieme [32] propose a pairwise interaction tensor factorization method based on Bayesian personalized rank. The algorithm was designed to work only on three-way tensor data. To the best of our knowledge, the first work applies a parallel SGD algorithm augmented with Nesterov’s optimal gradient and perturbation methods for fast parallel CP decomposition of multi-way tensor data.
3 Fast parallel CP decomposition (FP-CPD)
Given an \(N^{th}\)-order tensor \({\mathcal {X}} \in {\mathbb {R}}^{I_1 \times \dots \times I_N}\), we solve the CP decomposition by splitting the problem into a convex N sub-problems since its loss function L defined in Eq. 1 is non-convex problem which may have many local minima. In case of distributing this solution, another challenge is raised where the value of the \(w^{(t)}\) must be globally updated before computing \(w^{(t+1)}\) where w represents A, B and C. However, the structure and the process of tensor decomposition allows us to exploit this challenge. For illustration purposes, we present our FP-CPD method based on three-way tensor data. The same logic can be naturally extended to handle a higher-order tensor, though.
Definition 1
Two training points \(x_1 = (i_1,j_1,k_1) \in {\mathcal {X}}\) and \(x_2 = (i_2,j_2,k_2) \in {\mathcal {X}}\) are interchangeable with respect to the loss function L defined in Eq. 1 if they are not sharing any dimensions, i.e., \(i_1\ne i_2, j_1 \ne j_2\) and \(k_1 \ne k_2\).
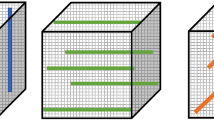
Based on Definition 1, we develop a new algorithm, called FP-CPD, to carry the tensor decomposition process in parallel. The core idea of FP-CPD algorithm is to find and run the CPD in parallel by considering all the defined interchangeable training points in one single step without affecting the final outcome of w. Our FP-CPD algorithm partitions the training tensor \({\mathcal {X}} \in \Re ^{I \times J \times K} \) into set of potentially independent blocks \({\mathcal {X}}_1,\dots , {\mathcal {X}}_b\). Each block consists of t interchangeable training points which are identified by finding all the possible combinations of each dimension of a given tensor \({\mathcal {X}}\). To illustrate this process, we consider a three-order tensor \({\mathcal {X}} \in {\mathbb {R}}^{3 \times 3 \times 3}\) as shown in Fig. 1. This tensor is partitioned into d independent blocks which cover the entire given training data \({\mathcal {D}}_{b=1}^{d} {\mathcal {X}}_b\). The value of \(d = \frac{i \times j \times k}{\min (i,j,k)}\). Each \({\mathcal {X}}_b\) contains a parallelism parameter p which deduces the possible number of tasks that can be run in parallel. In our three-way tensor example \(p =3\) interchangeable training points.

Independent blocks for \({\mathcal {X}} \in \Re ^{3 \times 3 \times 3} \)
3.1 The FP-CPD algorithm
Given the set of independent blocks \({\mathcal {D}}_{b=1}^{d} {\mathcal {X}}_b\), we can decompose \({\mathcal {X}} \in \Re ^{I \times J \times K} \) in parallel into three matrices \(A \in \Re ^{I \times R}\), \(B \in \Re ^{J \times R} \) and \( C \in \Re ^{K \times R}\), where R is the latent factors. In this context, we reconstitute our loss function defined in Eq. 2 to be the sum of losses per block:\( L (A, B, C) = \sum _{b=1}^{d} L_b ( A, B, C) \). This new loss function provides the rational of our parallel CP decomposition which will allow SGD algorithm to learn all the possible interchangeable data points within each block in parallel. Therefore, SGD computes the partial derivative of the loss function \(L_b (A, B, C) = \sum _{(i,j,k) \in {\mathcal {D}}_{b} } L_{i,j,k}(A, B, C)\) with respect to the three modes A, B and C alternatively as follows:
where \(X^{(i)}\) is an unfolding matrix of tensor \({\mathcal {X}}\) in mode i. The gradient update step for A, B and C is as follows:
3.1.1 Convergence
Regardless if we are applying parallel SGD or just SGD, the partial derivative of SGD in non-convex setting may encounter data points with \(\frac{\partial L}{\partial w } = 0\) even though it is not at a global minimum. These data points are known as saddle points which may detente the optimization process to reach the desired local minimum if not escaped [13]. These saddle points can be identified by studying the second-order derivative (aka Hessian) \(\frac{\partial L}{\partial w }^2\). Theoretically, when the \(\frac{\partial L}{\partial w }^2(x;w)\succ 0\), x must be a local minimum; if \(\frac{\partial L}{\partial w }^2(x;w) \prec 0\), then we are at a local maximum; if \(\frac{\partial L}{\partial w }^2(x;w)\) has both positive and negative eigenvalues, the point is a saddle point. The second-order methods guarantee convergence, but the computing of Hessian matrix \(H^{(t)}\) is high, which makes the method infeasible for high-dimensional data and online learning. Ge et al. [13] show that saddle points are very unstable and can be escaped if we slightly perturb them with some noise. Based on this, we use the perturbation approach which adds Gaussian noise to the gradient. This reinforces the next update step to start moving away from that saddle point toward the correct direction. After a random perturbation, it is highly unlikely that the point remains in the same band and hence it can be efficiently escaped (i.e., no longer a saddle point). We further incorporate Nesterov’s method into the perturbed-SGD algorithm to accelerate the convergence rate. Recently, Nesterov’s accelerated gradient (NAG) [27] has received much attention for solving convex optimization problems [15, 16, 28]. It introduces a smart variation of momentum that works slightly better than standard momentum. This technique modifies the traditional SGD by introducing velocity \(\nu \) and friction \(\gamma \), which tries to control the velocity and prevents overshooting the valley while allowing faster descent. Our idea behind Nesterov’s is to calculate the gradient at a position that we know our momentum is about to take us instead of calculating the gradient at the current position. In practice, it performs a simple step of gradient descent to go from \(w^{(t)} \) to \(w^{(t+1)}\), and then it shifts slightly further than \(w^{(t+1)}\) in the direction given by \(\nu ^{(t-1)}\). In this setting, we model the gradient update step with NAG as follows:
where
where \(\epsilon \) is a Gaussian noise, \(\eta ^{(t)}\) is the step size, and \(||A||_{L_{1,b}}\) is the regularization and penalization parameter into the \(L_1\) norms to achieve smooth representations of the outcome and thus bypassing the perturbation surrounding the local minimum problem. The updates for \((B^{(t+1)}, \nu ^{(B, t)})\) and \((C^{(t+1)},\nu ^{(C, t)} )\) are similar to the aforementioned ones. With NAG, our method achieves a global convergence rate of \(O(\frac{1}{T^2})\) comparing to \(O(\frac{1}{T})\) for traditional gradient descent. Based on the above models, we present our FP-CPD algorithm 2.

4 Motivation
Numerous types of data are naturally structured as multi-way data. For instance, structural health monitoring (SHM) data can be represented in a three-way form as \(location \times feature \times time\). Arranging and analyzing the SHM data in a multidimensional form would allow us to capture the correlation between sensors at different locations and at the same time which was not possible using the standard two-way matrix \(time\times feature\). Furthermore, in SHM only positive data instances, i.e., healthy state, are available. Thus, the problem becomes an anomaly detection problem in higher-order datasets. Rytter [33] affirms that damage identification also requires also damage localization and severity assessment which are considered much more complex than damage detection since they require a supervised learning approach [39].
Given a positive three-way SHM data \({\mathcal {X}} \in {\mathbb {R}}^{feature \times location \times time}\), FP-CPD decomposes \({\mathcal {X}}\) into three matrices A, B and C. The C matrix represents the temporal mode where each row contains information about the vibration responses related to an event at time t. The analysis of this component matrix can help to detect the damage of the monitored structure. Therefore, we use the C matrix to build a one-class anomaly detection model using only the positive training events. For each new incoming \({\mathcal {X}}_{new}\), we update the three matrices A, B and C incrementally as described in Algorithm 2. Then the constructed model estimates the agreement between the new event \(C_{new}\) and the trained data.
For damage localization, we analyze the data in the location matrix B, where each row captures meaningful information for each sensor location. When the matrix B is updated due to the arrival of a new event \({\mathcal {X}}_{new}\), we study the variation of the values in each row of matrix B by computing the average distance from B’s row to k-nearest neighboring locations as an anomaly score for damage localization. For severity assessment in damage identification, we study the decision values returned from the one-class model. This is because a structure with more severe damage will behave much differently from a normal one.
5 Evaluation
In this section we present the details of the experimental settings and the comparative analysis between our proposed FP-CPD algorithm and the alike parallel tensor decomposition algorithms: PSGD and SALS. We first analyze the effectiveness and speed of the training process of the three algorithms based on four real-world datasets from SHM. We, then, evaluate the performance of our approach, along with other baselines using the SHM datasets, in terms of damage detection, assessment and localization.
5.1 Experiment setup and datasets
We conducted all our experiments using a dual Intel Xeon processors with 32 GB memory and 12 physical cores. We use R development environment to implement our FP-CPD algorithm and PSGD and SALS algorithms with the help of the two packages rTensor and e1071 for tensor tools and one-class model.
We run our experiments on four real-world datasets, all of which inherently entails multi-way data structure. The datasets are collected from sensors that measure the health of building, bridge or road structures. Specifically, these datasets comprise of:
-
1.
bridge structure measurement data collected from sensors attached to a cable-stayed bridge in Western Sydney, Australia (BRIDGE) [5].
-
2.
building structure measurement data collected from sensors attached to a specimen building structure obtained from Los Alamos National Laboratory (LANL) [24] (BUILDING).
-
3.
measurements data collected from loop detectors in Victoria, Australia (ROAD) [34].
-
4.
road measurements collected from sensors attached to two buses travelling through routes in the southern region of New South Wales, Australia (BUS) [3].
All the datasets are stored in a three-way tensor represented by \(sensor \times frequency \times time\). Further details about these datasets are summarized in Table 1. Using these datasets, we run a number of experiment sets to evaluate our proposed FP-CPD method as detailed in the following sections.
5.2 Evaluating performance of FP-CPD
The goal of first experiment set is to evaluate the performance of our FP-CPD method in terms of training time error rate. To achieve this, we compare the performance of our proposed FP-CPD and PSGD and SALS algorithms. To make a fair and objective comparison, we implemented the three algorithms under the same experimental settings as described in Sect. 5.1. We evaluated the performance of each method by plotting the time needed to complete the training process versus the root-mean-square error (RMSE). We run the same experiment on the four datasets (BRIDGE, BUILDING, ROAD and BUS). Figure 2 shows the RMSE and the training time of the three algorithms resulted from our experiments. As illustrated in the figure, our FP-CPD algorithm significantly outperformed the PSGD and SALS algorithms in terms of convergence and training speed. The SALS algorithm was the slowest among the three algorithms due to the fact that CP decomposition is a non-convex problem which can be better handled using scholastic methods. Furthermore, another important factor that contributed to the significant performance improvements in our FP-CPD method is the utilization of the Nesterov method along with the perturbation approach in our FP-CPD method. From the first experiment set, it can be concluded that our FP-CPD method is more effective in terms of RMSE and can carry on training faster compared to similar parallel tensor decomposition methods.

Comparison of training time and RSME of FP-CPD, SALS and PSGD on the four datasets
5.3 Evaluating effectiveness of FP-CPD

Damage estimation applied on Bridge data using decision values obtained by one-class SVM

Damage localization for the Bridge data: FP-CPD successfully localized damage locations

Damage estimation applied on Building data using decision values obtained by one-class SVM

Damage localization for the Building data: FP-CPD successfully localized damage locations
Our FP-CPD method demonstrated better speed and RSME in comparison to PSGD and SALS methods. However, it is still crucial to ensure that the proposed method is also capable of achieving accurate results in practical tensor decomposition problems. Therefore, the second experiment set aims to demonstrate the accuracy of our model in practice, specifically building structures in smart cities. To achieve this, we evaluate the performance of our FP-CPD in terms of its accuracy to detect damage in build and bridge structures, assessing the severity of detected damage and the localization of the detected damage. We carry on the evaluation on the BRIDGE and BUILDING datasets which are explained in the following sections. For comparative analysis, we choose SALS method as a baseline competitor to our FP-CPD. This is because PSGD has similar convergence as FP-CPD but the later takes less time to train as illustrated in Sect. 5.2.
5.3.1 The cable-stayed bridge dataset
In this dataset, 24 uni-axial accelerometers and 28 strain gauges were attached at different locations of the cable-stayed bridge to measure the vibration and strain responses of the bridge. Figure 7 illustrates the positioning of the 24 sensors on the bridge deck. The data of interest in our study are the accelerations data which were collected from sensors Ai with \(i\in [1;24]\). The bridge is in healthy condition. In order to evaluate the performance of damage detection methods, two different stationary vehicles (a car and a bus) with different masses were placed on the bridge to emulate two different levels of damage severity [7, 21]. The three different categories of data were collected in that study are: “Healthy-Data” when the bridge is free of vehicles; “Car-Damage” when a light car vehicle is placed on the bridge close to location A10; and “Bus-Damage” when a heavy bus vehicle is located on the bridge at location A14. This experiment generates 262 samples (i.e., events) separated into three categories: “Healthy-Data” (125 samples), “Car-Damage” data (107 samples) and “Bus-Damage” data(30 samples). Each event consists of acceleration data for a period of 2 s sampled at a rate of 600 Hz. The resultant event’s feature vector composed of 1200 frequency values. Figure 7 illustrates the setup of the sensors on the bridge under evaluation.

The locations on the bridge’s deck of the 24 Ai accelerometers used in the BRIDGE dataset. The cross-girder j of the bridge is displayed as CGj [5]
5.3.2 The LANL building dataset
These data are based on experiments conducted by LANL [24] using a specimen for a three-story building structure as shown in Fig. 8. Each joint in the building was instrumented by two accelerometers. The excitation data were generated using a shaker placed at corner D. Similarly, for the sake of damage detection evaluation, the damage was simulated by detaching or loosening the bolts at the joints to induce the aluminum floor plate moving freely relative to the Unistrut column. Three different categories of data were collected in this experiment: “Healthy-Data” when all the bolts were firmly tightened; “Damage-3C” data when the bolt at location 3C was loosened; and “Damage-1A3C” data when the bolts at locations 1A and 3C were loosened simultaneously. This experiment generates 240 samples (i.e., events) which also were separated into three categories: Healthy-Data (150 samples), “Damage-3C” data (60 samples) and “Damage-1A3C” data(30 samples). The acceleration data were sampled at 1600 Hz. Each event was measured for a period of 5.12 s resulting in a vector of 8192 frequency values.

Three-story building and floor layout [24]
5.3.3 Feature extraction
The raw signals of the sensing data collected in the aforementioned experiments exist in the time domain. In practice, time domain-based features may not capture the physical meaning of the physical structure. Thus, it is important to convert the generated data to a frequency domain. For all the datasets, we initially normalized the time-domain features to have zero mean and one standard deviation. Then we used the fast Fourier transform method to convert them into the frequency domain. The resultant three-way data collected from the cable-stayed bridge now have a structure of 600 features \(\times \) 24 sensors \(\times \) 262 events. For the LANAL BUILDING dataset, we computed the difference between signals of two adjacent sensors which resulted in 12 different joints in the three stories as in [24]. Then we selected the first 150 frequencies as a feature vector which resulted in a three-way data with a structure of 768 features \(\times \) 12 locations \(\times \) 240 events.
5.3.4 Experiments
For both BUILDING and BRIDGE datasets, we applied the following procedures:
-
Using the bootstrap technique, we selected 80% of the healthy samples randomly for training and the remaining 20% for testing in addition to the damage samples. We computed the accuracy of our FP-CPD model based on the average results over ten trials of the bootstrap experiment.
-
We used the core consistency diagnostic (CORCONDIA) technique described in [6] to determine the number of rank-one tensors \({\mathcal {X}}\) in the FP-CPD.
-
We used the one-class support vector machine (OSVM) [35] as a model for anomaly detection. The Gaussian kernel parameter \(\sigma \) in OCSVM is tuned using the Edged Support Vector (ESV) algorithm [2], and the rate of anomalies \(\nu \) was set to 0.05.
-
We used the \(\textit{F-score}\) measure to compute the accuracy of data values resulted from our model for damage detection. It is defined as \(\text {\textit{F-score}} = 2 \cdot \dfrac{\text {Precision} \times \text {Recall} }{\text {Precision} + \text {Recall}}\) where \(\text {Precision} = \dfrac{\text {TP} }{\text {TP} + \text {FP}}\) and \(\text {Recall} = \dfrac{\text {TP} }{\text {TP} + \text {FN}}\) (the number of true positive, false positive and false negative is abbreviated by TP, FP and FN, respectively).
-
We compared the results of the competitive method SALS proposed in [26] against the ones resulted from our FP-CPD method.
5.3.5 Results and discussion
5.3.6 The cable-stayed bridge dataset
Our FP-CPD method with one-class SVM was initially validated using the vibration data collected from the cable-stayed bridge (described in Sect. 5.3.1). The healthy training three-way tensor data (i.e., training set) was in the form of \( {\mathcal {X}} \in \Re ^{24 \times 600 \times 100}\). The 137 examples related to the two damage cases were added to the remaining 20% of the healthy data to form a testing set, which was later used for model evaluation. We conducted the experiments as followed the steps described in Section. As a result, this experiment generates a damage detection accuracy \(\textit{F-score}\) of \(1 \pm 0.00\) on the testing data. On the other hand, the \(\textit{F-score}\) accuracy of one-class SVM using SALS is recorded at \(0.98 \pm 0.02\).
As demonstrated from the results of this experiment, the tensor analysis with our proposed FP-CPD is capable to capture the underlying structure in multi-way data with better convergence. This is further illustrated by plotting the decision values returned from one-class SVM-based FP-CPD (as shown in Fig. 3). We can clearly separate the two damage cases (“Car-Damage” and “Bus-Damage”) in this dataset where the decision values are further decreased for the samples related to the more severe damage cases (i.e., “Bus-Damage”). These results suggest using the decision values obtained by our FP-CPD and one-class SVM as structural health scores to identify the damage severity in a one-class aspect. In contrast, the resultant decision values of one-class SVM based on SALS are also able to track the progress of the damage severity in the structure but with a slight decreasing trend in decision values for “Bus-Damage” as shown in Fig. 3.
The last step in this experiment is to analyze the location matrix B obtained from FP-CPD to locate the detected damage. Each row in this matrix captures meaningful information for each sensor location. Therefore, we calculate the average distance from each row in the matrix \(B_{new}\) to k-nearest neighboring rows. Figure 4 shows the obtained k-nn score for each sensor. The first 25 events (depicted on the x-axis) represent healthy data, followed by 107 events related to “Car-Damage” and 30 events to “Bus-Damage.” It can be clearly observed that FP-CPD method can localize the damage in the structure accurately, whereas sensors A10 and A14 related to the “Car-Damage” and “Bus-Damage,” respectively, behave significantly different from all the other sensors apart from the position of the introduced damage. In addition, we observed that the adjacent sensors to the damage location (e.g., A9, A11, A13 and A15) react differently due to the arrival pattern of the damage events. The SALS method, however, is not able to accurately locate the damage since it fails to update the location matrix B incrementally.
5.3.7 The building dataset
Following the experimental procedure described in section, our second experiment was conducted using the acceleration data acquired from 24 sensors instrumented on the three-story building as described in Sect. 5.3.2. The healthy three-way data (i.e., training set) are in the form of \( X \in \Re ^{12 \times 768 \times 120}\). The remaining 20% of the healthy data and the data obtained from the two damage cases were used for testing (i.e., testing set). The experiments we conducted using FP-CPD with one-class SVM have achieved an \(\textit{F-score}\) of \(95 \pm 0.01\) on the testing data compared to \(0.91 \pm 0.00\) obtained from one-class SVM and SALS experiments.
Similar to the BRIDGE dataset, we further analyzed the resultant decision values which were also able to characterize damage severity. Figure 5 demonstrates that the more severe damage to the 1A and 3C location test data, the more deviation from the training data with lower decision values.
Similar to the BRIDGE dataset, the last experiment is to compute the k-nn score for each sensor based on the k-nearest neighboring of the average distance between each row of the matrix \(B_{new}\). Figure 6 shows the resultant k-nn score for each sensor. The first 30 events (depicted on the x-axis) represent the healthy data, followed by 60 events describing when the damage was introduced in location 3C. The last 30 events represent the damage occurred in both locations 1A and 3C. It can be clearly observed that the FP-CPD method is capable to accurately localize the structure’s damage where sensors 1A and 3C behave significantly different from all the other sensors apart from the position of the introduced damage. However, the SALS method is not able to locate that damage since it fails to update the location matrix B incrementally (Figs. 7, 8).
In summary, the above experiments on the four real datasets demonstrate the effectiveness of our proposed FP-CPD method in terms of time needed to carry out training during tensor decomposition. Specifically, our FP-CPD significantly improves speed of model training and error rate compared to similar parallel tensor decomposition methods, PSGD and SALS. Furthermore, the other experiment sets on the BRIDGE and BUILDING datasets showed empirical evidence of the ability of our model to accurately carry on tensor decomposition on practical case studies. In particular, the experimental results demonstrated that our FP-CPD is able to detect damage in the build and bridge structures, assess the severity of detected damage and localize of the detected damage more accurately than SALS method. Therefore, it can be concluded that our FP-CPD tensor decomposition method is able to achieve faster tensor model training with minimal error rate while carrying on accurate tensor decomposition in practical cases. Such performance and accuracy gains can be beneficial for many parallel tensor decomposition cases in practice especially in real-time detection and identification problems. We demonstrated such benefits with real use cases in structural health monitoring, namely building and bridge structures.
6 Conclusion
This paper investigated the CP decomposition with a stochastic gradient descent algorithm for multi-way data analysis. This leads to a new method named Fast Parallel-CP Decomposition (FP-CPD) for tensor decomposition. The proposed method guarantees the convergence for a given non-convex problem by modeling the second-order derivative of the loss function and incorporating little noise to the gradient update. Furthermore, FP-CPD employs Nesterov’s method to compensate for the optimization process’s delays and accelerate the convergence rate. Based on laboratory and real datasets from the area of SHM, our FP-CPD, with a one-class SVM model for anomaly detection, achieves accurate results in damage detection, localization and assessment in online and one-class settings. Among the key future work is how to parallelize the tensor decomposition with FP-CPD. Also, it would be useful to apply FP-CPD with datasets from different domains.
Our future work mainly includes the following aspects. First, the proposed model in this research was to detect, localize and assessing the severity of damage in buildings and bridge structures. Does the model have the same prediction performance when we apply it on other domain such as recommender system? Future work should include building a personalized recommender systems but not only based on 2D latent factor models such as users and items. Such personalization requires considering other important information such as user age or gender, and item detail. For example, some books could be more preferred by users of certain age groups. Similarly, movies of specific genre could be a preference for certain age group compared to others. Future work also should consider implementing this system in a federated learning settings which can be also useful when data are distributed among different clients/sources and not feasible to be centralized in a single location/server.
References
Acar, E., Yener, B.: Unsupervised multiway data analysis: A literature survey. IEEE Trans. Knowl. Data Eng. 21(1), 6–20 (2009)
Anaissi, A., Braytee, A., Naji, M.: Gaussian kernel parameter optimization in one-class support vector machines. In: 2018 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. IEEE (2018)
Anaissi, A., Khoa, N.L.D., Rakotoarivelo, T., Alamdari, M.M., Wang, Y.: Smart pothole detection system using vehicle-mounted sensors and machine learning. J. Civ. Struct. Heal. Monit. 9(1), 91–102 (2019)
Anaissi, A., Lee, Y., Naji, M.: Regularized tensor learning with adaptive one-class support vector machines. In: International Conference on Neural Information Processing, pp. 612–624. Springer, Berlin (2018)
Anaissi, A., Makki Alamdari, M., Rakotoarivelo, T., Khoa, N.: A tensor-based structural damage identification and severity assessment. Sensors 18(1), 111 (2018)
Bro, R., Kiers, H.A.L.: A new efficient method for determining the number of components in parafac models. J. Chemom. 17(5), 274–286 (2003)
Cerda, F., Garrett, J., Bielak, J., Rizzo, P., Barrera, J.A., Zhang, Z., Chen, S., McCann, M.T., Kovacevic, J.: Indirect structural health monitoring in bridges: scale experiments. In: Proceedings of International Conference on Bridge Maintenance, Safety and Management, Lago di Como, pp. 346–353 (2012)
Chin, W.-S., Zhuang, Y., Juan, Y.-C., Lin, C.-J.: A fast parallel stochastic gradient method for matrix factorization in shared memory systems. ACM Trans. Intell. Syst. Technol. (TIST) 6(1), 1–24 (2015)
Cichocki, A., Mandic, D., De Lathauwer, L., Zhou, G., Zhao, Q., Caiafa, C., PHAN, H.A.: Tensor decompositions for signal processing applications: From two-way to multiway component analysis. IEEE Signal Process. Mag. 32(2), 145–163 (2015)
Cong, F., Lin, Q.-H., Kuang, L.-D., Gong, X.-F., Astikainen, P., Ristaniemi, T.: Tensor decomposition of EEG signals: a brief review. J. Neurosci. Methods 248, 59–69 (2015)
De Lathauwer, L., De Moor, B.: From matrix to tensor: multilinear algebra and signal processing, pp. 1–11 (1996)
Eldén, L.: Perturbation theory for the least squares problem with linear equality constraints. SIAM J. Numer. Anal. 17(3), 338–350 (1980)
Ge, R., Huang, F., Jin, C., Yuan, Y.: Escaping from saddle points-online stochastic gradient for tensor decomposition. In: Conference on Learning Theory, pp. 797–842 (2015)
Gemulla, R., Nijkamp, E., Haas, P.J., Sismanis, Y.: Large-scale matrix factorization with distributed stochastic gradient descent. In: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 69–77 (2011)
Ghadimi, S., Lan, G.: Accelerated gradient methods for nonconvex nonlinear and stochastic programming. Math. Program. 156(1–2), 59–99 (2016)
Guan, N., Tao, D., Luo, Z., Yuan, B.: NeNMF: an optimal gradient method for nonnegative matrix factorization. IEEE Trans. Signal Process. 60(6), 2882–2898 (2012)
Kang, U., Papalexakis, E., Harpale, A., Faloutsos, C.: Gigatensor: Scaling tensor analysis up by 100 times-algorithms and discoveries. In: Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’12, pp. 316–324, New York, NY, USA. Association for Computing Machinery (2012)
Kaya, O., Uçar, B.: Scalable sparse tensor decompositions in distributed memory systems. In: SC ’15: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–11 (2015)
Khoa, N.L.D., Anaissi, A., Wang, Y.: Smart infrastructure maintenance using incremental tensor analysis. In: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pp. 959–967. ACM (2017)
Khoa, N.L.D., Anaissi, A., Wang, Y.: Smart infrastructure maintenance using incremental tensor analysis: extended abstract. In: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, CIKM ’17, pp. 959–967, New York, NY, USA. Association for Computing Machinery (2017)
Kody, A., Li, X., Moaveni, B.: Identification of physically simulated damage on a footbridge based on ambient vibration data. In: Structures Congress 2013: Bridging Your Passion with Your Profession, pp. 352–362 (2013)
Kolda, T.G., Bader, B.W.: Tensor decompositions and applications. SIAM Rev. 51(3), 455–500 (2009)
Kolda, T.G., Sun, J.: Scalable tensor decompositions for multi-aspect data mining. In: 2008 Eighth IEEE International Conference on Data Mining. IEEE, pp. 363–372 (2008)
Larson, A.C., Von Dreele, R.B.: Los alamos national laboratory report no. Technical report, LA-UR-86-748 (1987)
Lebedev, V., Ganin, Y., Rakhuba, M., Oseledets, I., Lempitsky, V.: Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv preprint arXiv:1412.6553 (2014)
Maehara, T., Hayashi, K., Kawarabayashi, K.: Expected tensor decomposition with stochastic gradient descent. In: Thirtieth AAAI Conference on Artificial Intelligence (2016)
Nesterov, Y.: Introductory Lectures on Convex Optimization: A Basic Course, vol. 87. Springer, Berlin (2013)
Nitanda, A.: Stochastic proximal gradient descent with acceleration techniques. In: Advances in Neural Information Processing Systems, pp. 1574–1582 (2014)
Papalexakis, E.E., Faloutsos, C., Sidiropoulos, N.D.: Tensors for data mining and data fusion: models, applications, and scalable algorithms. ACM Trans. Intell. Syst. Technol. (TIST) 8(2), 16 (2017)
Rendle, S., Marinho, L.B., Nanopoulos, A., Schmidt-Thieme, L.: Learning optimal ranking with tensor factorization for tag recommendation. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’09, pp. 727–736, New York, NY, USA. Association for Computing Machinery (2009)
Rendle, S., Marinho, L.B., Nanopoulos, A., Schmidt-Thieme, L.: Learning optimal ranking with tensor factorization for tag recommendation. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 727–736. ACM (2009)
Rendle, S., Schmidt-Thieme, L.: Pairwise interaction tensor factorization for personalized tag recommendation. In: Proceedings of the Third ACM International Conference on Web Search and Data Mining, pp. 81–90. ACM (2010)
Rytter, A.: Vibrational Based Inspection of Civil Engineering Structures. Ph.D. thesis, Dept. of Building Technology and Structural Engineering, Aalborg University (1993)
Schimbinschi, F., Nguyen, X.V., Bailey, J., Leckie, C., Vu, H., Kotagiri, R.: Traffic forecasting in complex urban networks: Leveraging big data and machine learning. In: 2015 IEEE International Conference on Big Data (Big Data), pp. 1019–1024. IEEE (2015)
Schölkopf, B., Williamson, R.C., Smola, A.J., Shawe-Taylor, J., Platt, J.C.: Support vector method for novelty detection. In: Advances in Neural Information Processing Systems, pp. 582–588 (2000)
Smith, S., Ravindran, N., Sidiropoulos, N. D., Karypis, G.: Splatt: Efficient and parallel sparse tensor-matrix multiplication. In: 2015 IEEE International Parallel and Distributed Processing Symposium, pp. 61–70 (2015)
Sun, J., Tao, D., Papadimitriou, S., Philip S, Yu., Faloutsos, C.: Incremental tensor analysis: theory and applications. ACM Trans. Knowl. Discov. Data (TKDD) 2(3), 11 (2008)
Symeonidis, P., Nanopoulos, A., Manolopoulos, Y.: Tag recommendations based on tensor dimensionality reduction. In: Proceedings of the 2008 ACM Conference on Recommender Systems, pp. 43–50. ACM (2008)
Worden, K., Manson, G.: The application of machine learning to structural health monitoring. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 365(1851), 515–537 (2006)
Zheng, S., Meng, Q., Wang, T., Chen, W., Yu, N., Ma, Z.-M., Liu, T.-Y.: Asynchronous stochastic gradient descent with delay compensation. In: Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 4120–4129. JMLR. org (2017)
Zhou, S., Vinh, N.X., Bailey, J., Jia, Y., Davidson, I.: Accelerating online cp decompositions for higher order tensors. In: Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1375–1384. ACM (2016)
Zhou, Y., Wilkinson, D., Schreiber, R., Pan, R.: Large-scale parallel collaborative filtering for the netflix prize. In: International Conference on Algorithmic Applications in Management, pp. 337–348. Springer, Berlin (2008)
Acknowledgements
The authors wish to thank the Roads and Maritime Services (RMS) in New South Wales, New South Wales Government in Australia and Data61 (CSIRO) for provision of the support and testing facilities for this research work. Thanks are also extended to Western Sydney University for facilitating the experiments on the cable-stayed bridge.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Anaissi, A., Suleiman, B., Alyassine, W. et al. A fast parallel tensor decomposition with optimal stochastic gradient descent: an application in structural damage identification. Int J Data Sci Anal 17, 359–371 (2024). https://doi.org/10.1007/s41060-023-00402-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41060-023-00402-y