
Abstract
The next Point of Interest (POI) recommendation is the core technology of smart city. Current state-of-the-art models attempt to improve the accuracy of the next POI recommendation by incorporating temporal and spatial intervals or by partitioning the POI coordinates into grids. However, they all overlook a detail that in real life, people always want to know where to go at an exact time point or after a specific time interval instead of aimlessly asking where to go next. Moreover, due to individual preferences, different users may visit different places at the same timestamp. Therefore, utilizing timestamp queries can enhance the personalized recommendation capability of the model and mitigate overfitting risks. These implies that using timestamp can achieve more precise recommendations. To the best of our knowledge, we are the first to use the next timestamp for next POI recommendation. In particular, we propose a Time-Stamp Cross Attention Network (TSCAN). TSCAN is a two-layer cross-attention network. The first layer, Time Stamp Cross Attention Block (TSCAB), uses cross-attention between the next timestamp and historical timestamps, and multiplies the attention scores on corresponding POI to predict the next POI that is most related to the history. The other layer, Cross Time Interval Aware Block (CTIAB), applies the time intervals between the next timestamp and historical timestamps to the POI obtained by TSCAB and historical POIs, allowing temporally adjacent POIs to have a greater similarity. Our model not only has a significant improvement in accuracy but also achieves the goal of personalized recommendation, effectively alleviating overfitting. We evaluate the proposed model with three real-world LBSN datasets, and show that TSCAN outperforms the state-of-the-art next POI recommendation models by 5~9%. TSCAN can not only recommend the next POI, but also recommend the possible POI to visit at any specific timestamp in the future.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
With the rapid development of mobile internet, people have become more inclined to share their experiences and opinions about Point-of-Interests (POIs) using mobile applications such as Facebook, Yelp, and WeChat. This trend has greatly contributed to the growth and popularity of Location-Based Services (LBS). One of the key components of LBS is the next POI recommendation system, which takes advantages of a historical check-in sequence of user to predict his/her next visit POI [1]. This task not only enhances the user experience but also enables merchants to target their advertising efforts more effectively.
Previously, the approach for sequence recommendation was used to serve next POI recommendation. Early research, such as FPMC [2], adopts a combination of Markov Chain (MC) and Matrix Factorization (MF) to model user preferences by combining transition matrix and matrix factorization. With the improvement in computation power and data quality, deep learning-based models, such as MLP, CNN, and RNN, dominate sequential recommendation. NEXT [3] uses DeepWalk [4] to obtain POI representation vectors, which are coupled with MLP to make suggestions for individuals. Caser [5] applies convolutional kernels to capture dependent relationships across POIs. GRU4Rec [6] uses a modified recurrent gate for context-aware processing. Further advancement in the field of natural language processing with self-attention mechanism [7] have benefited sequential recommendation. SASRec [8] introduces this method to sequential recommendation and has made significant progress. Lian et al. [9], Luo et al. [10], Wang et al. [11] attempt to incorporate spatiotemporal information which are state-of-the-art models for next POI recommendation.
Nevertheless, there are two main challenges not yet addressed among these methods. The first one is that these models fail to provide effective personalized recommendations. Lian et al. [9], Luo et al. [10], Guo and Qi [12] have tentatively embedded timestamps and user-id into sequence representations for personalized recommendation, yet there was no improvement in performance, likely due to the mismatch between historical sequences and candidate POI sets [9]. The second one is that these models fail to effectively capture temporal periodicity. Most advanced models capture temporal periodicity by incorporating time intervals. For example, Feng et al. [13], Yang et al. [14] have token time intervals into account, but these methods were weak in modeling spatiotemporal periodicity due to structural constraints. Luo et al. [10] and Wang et al. [11], utilizes self-attention combined with time intervals to capture temporal periodicity. Although the self-attention method has shown significant improvements compared to previous approaches, they fundamentally load historical information onto the last POI embedding and then search within the candidate pool to find the POI that is most similar to the last POI embedding. However, these approach makes it difficult to establish a connection with the next POI.
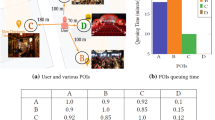
These models all ignored the crucial fact that individuals are likely to visit the same location around the same time on different days. For instance, as shown in Fig. 1, if a user visited a cinema at around 3pm on day1, it implies that the user’s preference for going to the cinema is around 3pm. Thus, if the user’s next visit time is also at 3pm, such as at 3pm on day3, the visiting location is very likely to be a cinema. This method of recommendation based on timestamps can effectively capture the periodicity of user visits to POIs and enhance the personalization capability of the model. Because at similar timestamp, different people may visit different places. As shown in Fig. 2, user1 and user2 have their own respective historical check-in sequences. When recommending places that they may visit at 3pm, using the spatiotemporal periodicity, we are more likely to recommend a school for user1 and a market for user2, respectively. By leveraging the timestamp, different users are recommended different POIs, achieving a personalized effect. Furthermore, incorporating the next timestamp allows us to establish a better connection with the next POI in our recommendation results.

The y-axis represents the dates of users’ check-in sequences while the x-axis represents the time of day, with \(\Delta\)t denotes the time interval and Ground Truth indicates the true POI that the user will visit on the third day at 3pm
Based on the above ideas, we have designed two modules. The first one is a timestamp cross attention block \(\left( {\textbf {TSCAB}}\right)\). Firstly, to enable the model to learn similar time representations not only within the same hour on different days (which could be the same week of different months, the same day of different weeks, or the same quarter of different hours), we convert timestamps to the date form of \(\left[ month, weekday, day, hour, quarter\right]\) and then embed them. Secondly, we calculate an attention matrix [7] between the next timestamp embedding and historical timestamp embedding. Lastly, we multiply the result by the location embedding at the corresponding position. This method perfectly applies the influence of timestamps on the check-in sequences, uncovering the periodic temporal patterns of users. The more similar timestamp is, the more similar poi is, which enables TSCAB to possess long-term memory capabilities. We will describe it in detail in Sect. 4.2. To better capture temporal periodicity, we designed a second module called cross-time interval aware block \(\left( {\textbf {CTIAB}}\right)\). Obtaining the time interval is equivalent to indirectly acquiring the timestamp. CTIAB incorporates cross time intervals, which are the intervals between the next timestamp and historical timestamps, into the cross attention matrix. This allows the model to leverage the time interval of the next visit to make corresponding recommendations. The closer in time, the more likely a POI is to be visited, which enables CTIAB to possess short-term memory capabilities. The details of CTIAB is in Sect. 4.3.
The contributions can be summarized as follows:
-
We propose a TimeStamp Cross Attention Block \(\left( {\textbf {TSCAB}}\right)\), which can recommend POI that may visit at the next timestamp by querying historical similar timestamps. This method uncovers the periodic temporal patterns of user visits.
-
We propose a Cross-Time Interval Aware Block\(\left( {\textbf {CTIAB}}\right)\), which adds time interval between past timestamp and next one to attention matrix. This method helps establish better connections between the next POI and temporally neighboring POIs.
-
We propose TimeStamp-aware sequential recommender based on Cross-Attention Network (TSCAN), which integrates TSCAB and CTIAB, for next POI recommendation, to capture long and short term sequential dependence and to make fully effective use of timestamp information.
-
We evaluate TSCAN with three real-world LSBN datasets. The results not only reflect the outstanding performance of TSCAN, but also demonstrate that our proposed method has good performance in terms of portability and preventing overfitting.
The rest of the paper is organized as follows. Section 2 reviews some related work. Section 3 gives several basic concept definitions. Section 4 elaborates the details of our proposed approaches. We analyze the experimental results in Sect. 5. Finally, we conclude the paper in Sect. 6.

Different check-in sequences for user1 and user2
2 Related Work
We first review relevant literatures, including sequence recommendation based on attention mechanism and state-of-the-art next POI recommendation, then discuss the similarities and differences between our work and previous studies.
2.1 Attention Mechanism in Recommendations
Attention mechanism has demonstrated effectiveness in various domains. Such as natural language processing [7] and computer vision [15]. The core idea of attention mechanism is to assign higher weights to inputs with greater relevance. This method is equally applicable to recommendation systems, as people often habitually purchase different items together. Based on a multi-layer neural network, DIN [16] design an attention activation unit, enabling the model to capture the correlation between user and item features. DINE [17] add an attention module to the structure of the GRU model, allowing the model to learn changes of user’s interest over time.
The model directly using full attention mechanism shows significantly better performance. BST [18] directly stacked self attention modules to enhance sequence modeling capability. SASRec [8] only uses layered self-attention modules, learning different item features and predicting user preferences in the candidate set. Bert4Rec [19] adopts the training method of Bert [20], further improving the performance of SASRec, but it is harder to train and converge. LightSAN [21] reduces the dimensionality of the attention score matrix in SASRec, improving its performance and accuracy.
To enhance the precision of recommendations for the subsequent locations that a user may potentially visit, we have adopt an attention-based approach. Diverging from conventional models that solely rely on self-attention, we have developed a cross-attention module that deliberately incorporates the next timestamp during the model training process.
2.2 Next POI Recommendation
Traditional approaches for sequence recommendation often use Hidden Markov Models to obtain user-item interaction features [22, 23]. The basic idea is to estimate the transition matrix from the previous state to the current state. A typical representative of such methods is the Factorized Personalized Markov Chain FPMC [1], which estimates a personalized transition matrix and analyzes the contextual connections of user through matrix decomposition techniques. Currently, most next POI recommendation models are based on RNN architectures. STRNN [24] adds transformation matrices specific to time and space in each layer of the original RNN network to model local spatiotemporal contexts. DeepMoves [13] incorporates an attention mechanism in GRU to focus on users’ unique movement patterns. STGN [25] adds a spatiotemporal gating mechanism in LSTM to capture spatiotemporal information, which effectively reduces the number of parameters and improves performance. Flashback [14] proposes an innovative Flashback mechanism, in which the time intervals between check-in sequence of individuals is assumed to follow a Harvey sine distribution, while the location intervals follow a power-law distribution. Based on this assumption, a spatiotemporal weight matrix is designed to capture visiting patterns of users, thus alleviating the issue of RNNs struggling to model sparse data.
Previous methods have attempted to enhance the ability of RNNs for next POI recommendation tasks as much as possible. However, the design structure of RNNs itself may result in problems such as gradient vanishing and explosion when modeling long sequence, which have not been resolved. Therefore, models based on self-attention have gradually shown outstanding performance in this field. GeoSAN [9] and SANST [12] encode POIs with geographic location and use self-attention to learn their relative positions. STAN [10] expands the time intervals of TiSASRe [26] which designs a two-layer self-attention network and adds a linear spatiotemporal matrix as a relative position encoding to learn the continuous and non-continuous dependency relationships between POIs. Building upon geosan, STiSAN [11] designs absolute positional encoding and relative spatiotemporal encoding, which strengthens the spatiotemporal proximity relationship between POIs and achieve sota performance with fewer parameters.
Inspired by GeoSAN and STiSAN, we also adopt the method of grid encoding to embed POIs, but utilize distinct time interval awareness from [10, 11, 26]. Cross-Time Interval Aware Block\(\left( {\textbf {CTIAB}}\right)\) abandoned self-attention time interval awareness in favor of cross-attention time interval awareness which can better capture the neighboring relationship between the next POI and historical POIs.
3 Preliminaries
3.1 Basic Definition
Let \(U=\{u_1,u_2,\cdots ,u_{|U|}\}\) and \(L=\{\ell _1,\ell _2,\cdots ,\ell _{|L|}\}\) be the sets of users and locations, respectively. \(T=\{t_1,t_2,\cdots ,t_{|T|}\}\) is the set of timestamps. The location is a tuple that contains two variables \(\left( lat_i,lon_i\right)\) which represents coordinate of POIs. The check-in trajectory of user \(u_i\) is a sequence of triplets denote as \(h_k = (u_i,\ell _k,t_k)\) which indicates that user \(u_i\) visited POI \(\ell _k\) at time \(t_k\). Each user may have various length trajectory \(tra(u_i) = \{h_1,h_2,\cdots ,h_m\}\). Therefore, when they are feed into the model, we transform them into a fixed length n. if \(m>n\), we extract subsequences from it with a length of n each time until none of them are left. if \(m<n\), we pad zeros to the right until the sequence length is n.
3.2 The Next POI Recommendation
Given the historical check-in records of user \(tar(u_i)=\{h_1,h_2,\cdots ,h_n\}\), the next POI recommendation refers to select the most likely place the user will visit at the next timestamp from the candidate set. It can be described as the following formula,
\(TopK^{u_i}\) refers to the top K POIs that user \(u_i\) is most likely to visit at the next timestamp, sorted by their probabilities. The abstract notation \(Rec(\cdot )\) is used to refer to this type of POI recommendation system. Because we explicitly utilize the next timestamp \(t_f\), the formula is rewritten as follows,

The architecture of the proposed TSCAN model, the details of CTIAB and TSCAB are revealed in dashed boxes
4 Methodology
Figure 3 illustrates the architecture of the proposed Time Stamp Cross Attention Network (TSCAN) for next POI recommendation. TSCAN consists of two decoder structures. Timestamp Cross Attention Block (TSCAB), with the future timestamp \(T_f\) as a prompt, generates the next POI embedding A for Cross Time Interval Block (CTIAB). The temporal matrix R calculated from the current timestamp \(T_p\) and the next timestamp \(T_f\) serves as the relative positional encoding for CTIAB to generates the recommended POI embedding B.
During the training process, TSCAN takes a trajectory of user \(tra(u_i)\), which excludes the last check-in \(h_1 \rightarrow h_2 \rightarrow \cdots \rightarrow h_n\) (where the last one is unvisited POI previously) as the input sequence. Additionally, timestamps \(T_p = \{ t_1,t_2,\cdots ,t_{n} \}\) and \(T_f = \{ t_2,t_3,\cdots ,t_{n+1} \}\) are also included in the training. The output sequence of TSCAN is the trajectory of the user visiting POIs, excluding the first one \(h_2 \rightarrow h_3 \cdots \rightarrow h_{n+1}\). Each part of TSCAN will be elaborated in the following sections.
4.1 Embedding Layer
We have perform different types of embedding for user, location, and timestamp. The user embedding is encoded in a d-dimensional continuous vector space using one-hot embedding,Footnote 1\(\mathbf {E_{u_i}} \in \mathbb {R}^{n \times d}\). Following GeoSAN, we performed one-hot embedding and geo-encoderFootnote 2 transformation on POIs and GPS coordinates, respectively, and concatenated them together, that is, \(\mathbf {E_{\ell }} = \{ \mathbf {E_p}:\mathbf {E_g}\} \in \mathbb {R}^{n \times 2d}\)
To capture more semantic information, we convert timestamps into dates and represents them in the format of \([m_m,w_w,d_d,h_h,q_q]\), which, respectively, represents the nth month of each year, the m-th day of each week, the d-th day of each year, the h-th hour of each day, and the q-th quarter of each hour. We then apply linear transformation to obtain the embedding of each timestamp, as shown in the following formula,
\(d_i\) represents the date representation of the ith timestamp, \(\mathbf {W_t} \in \mathbb {R}^{5 \times d}\) is the weight of the linear transformation. \(\mathbf {E_{t_p}} \in \mathbb {R}^{n \times d}\) represents the embedding of historical timestamps, \(\mathbf {E_{t_f}} \in \mathbb {R}^{n \times d}\) represents the embedding of the next timestamp. \([\cdot ]\) denotes the Hadamard product.
4.2 Timestamp Cross Attention Block (TSCAB)
Human activity trajectories often exhibit temporal periodicity. To capture this pattern, We utilize a temporal querying approach to search for locations visited by the user at timestamps similar to the next timestamp in their history records, which can help predict the potential next destination. This is the core idea of TimeStamp Cross Attention Block which is shown in Fig. 4. When we want to predict the nth POI that may visit, we need to calculate the similarity between the timestamp embedding \(e_{t_n}\) and the historical timestamp embedding \(e_{t_i}\) (i < n). The more similar the timestamp is, the more likely the user will visit the same place. Therefore, we multiply the similarity score \(\alpha _{n,i}\) we calculated with the corresponding location embedding \(e_{\ell _i}\), to obtain the nth POI. The calculation can be done as follows,
We will provide a detailed description of each component of the TSCAB below.
4.2.1 Timestamp Cross Attention Layer
First, we will introduce the generation strategies for Query(Q), Key(K), and Value(V) that differ from traditional cross-attention, as formulated in (5),
Where \(\mathbf {Q_{tf}},\mathbf {K_{tp}} \in \mathbb {R}^{n \times d}\),\(\mathbf {V_{\ell }} \in \mathbb {R}^{n \times 2d}\) and \(\mathbf {W_{tf}^Q},\mathbf {W_{tp}^K} \in \mathbb {R}^{d \times d}\),\(\mathbf {W_{\ell }^V} \in \mathbb {R}^{2d \times 2d}\). Then we combine them to compute the attention matrix as formulated in (6),
Where \(\frac{\mathbf {Q_{tf}} \cdot \mathbf {K_{tp}}^T}{\sqrt{d}} \in \mathbb {R}^{n \times n}\) is attention matrix. \({\textbf{A}} \in \mathbb {R}^{n \times 2d}\) is the new location embedding obtained by attention computation. \(\textbf{Mask}\) is an upper triangular matrix with \(-\infty\) to prevent information leakage [7].
Here, we explicitly use the next timestamp to query similar timestamps from historical, and multiply the correlation weights on corresponding location embeddings. This causes the model to focus on the locations that are most likely to be visited at the next time, allowing model to acquire the property of long term interest modeling.
4.2.2 Normlayer
We used layernorm as follow to accelerate model convergence,
Where \(\odot\) indicates element-wise product, \(\mu\) and \(\sigma\) represent the mean and standard deviation of the input x, and \(\alpha\), \(\beta\), and \(\epsilon\) are the scaling, bias and offset parameters that are learned during training.

\(e_t\) represents the timestamp embedding, \(e_{\ell }\) represents the location embedding, \(\alpha\) represents the attention score, \(\times\) represents matrix multiplication, \(\textbf{Mask}\) is the mask matrix. the shaded area represents the occluded portions, and the orange histogram represents the scores \(\alpha _{n,i}\) of correlation between \(e_{\ell _n}\) and \(e_{\ell _i}\)
4.3 Cross Time Interval Aware Block (CTIAB)
Due to the linear relationship between human activity trajectories and time, such as the pattern of taking a walk after a meal, we combined relative positional encoding and cross-attention. Unlike previous approaches [10, 11] that used self-attention with relative positional encoding, the cross-attention positional encoding enables more intelligent recommendations based on the next time interval, rather than simply increasing the similarity between two POIs. As Fig. 5 shows, taking the recommendation of the nth POI as an example, we calculate the similarity score \(\beta _{n,i}\) by taking the dot product between the next location embedding \(e_{\ell f_n}\) obtained from TSCAB and the historical location embedding \(e_{\ell _i}\) \((i<n)\). To emphasize the correlation of POIs closer to n, we subtract the previous time \(t_i\) from the time \(t_n\) and calculate \(\Delta _{n,i}\) using the formulation (9) and (11), where smaller \(n-i\) results in larger \(\Delta _{n,i}\). We then add \(\Delta _{n,i}\) to \(\beta _{n,i}\) to obtain a new attention score, which, when multiplied by \(e_{\ell f_n}\), gives us the embedding bn of the nth POI that we want to recommend. We will provide a detailed description of each component of the CTIAB below.
4.3.1 Cross Time Interval Aware Layer
We introduce the cross temporal interval matrix \(\textbf{R} \in \mathbb {R}^{n \times n}\), which will be used in the subsequent attention calculation.
The elements in each row of the matrix \(\textbf{R}\) are computed by subtracting the historical timestamp from the next timestamp. We consider precise time intervals beyond a certain limit to be useless [11], and we use the threshold \(k_t\) to perform pruning, as formulated in (9),
To achieve temporal relevance, we added matrix \(\textbf{R}\) onto the attention matrix to capture the time interval for the POI. Similar to equations (5) and (6), we introduced a new cross attention block called CTIAB, as formulated in (10),
Where \(\mathbf {Q_{\ell f}}, \mathbf {K_{\ell p}}, \mathbf {V_{\ell p}} \in \mathbb {R}^{n \times 2d}\), \(\mathbf {W_{\ell f}^Q}, \mathbf {W_{\ell p}^K}, \mathbf {W_{\ell p}^V} \in \mathbb {R}^{2d \times 2d}\), \(\textbf{A}\) is the output of TSCAB, \(\textbf{B}\in \mathbb {R}^{n\times 2d}\) is the next POI vector predicted through time-awareness. But adding original time intervals to the attention matrix does not reflect the fact that POIs visited closer in time have stronger correlations. This is because as the time interval between POIs becomes closer, the corresponding values of \(R_{i,j}\) becomes smaller, leading to a smaller contribution to the attention score matrix. Therefore, before calculating attention, we use the following formula to modify R again,
\(\max _{i,j}{\left( \textbf{R}_{i,j}\right) }\) is a function to retrieve the maximum value of the matrix \(\textbf{R}\). Revised \(\textbf{R}\) assigns greater weight to temporal adjacent POIs, allowing CTIAB to acquire the property of temporal proximity perception.
The major advantage of CTIA compared to previous time interval awareness methods lies in its utilization of cross-attention and the next timestamp, enhancing the relevance with the next POI rather than just improving the relevance with adjacent temporal POIs.
4.3.2 Feed Forward Layer
To enhance the generalization ability of the model, we combine linear layers and residual connections to form a feed forward layer follow [7], then add the output A from TSCAB and the output B from CTIA and fed it into the feed forward layer (FF), which is formulated in (12),
Where \(\mathbf {B'}\in \mathbb {R}^{2d\times 2d}\) is an intermediate variable, \(\textbf{X} \in \mathbb {R}^{n\times 2d}\) is the input of function \(\text {FF}\), \(\mathbf {W_1}\in \mathbb {R}^{2d\times 2d_h}\), \(\mathbf {W_2}\in \mathbb {R}^{2d_h\times 2d}\). \(s.t.d_h \ge d\) and \(b_1,b_2\in \mathbb {R}^{1\times 2d}\) are the learned bias terms.

t represents the timestamp, \(e_{\ell f}\) is the location embedding obtained from TSCAB, \(\Delta\) is the time interval, \(\beta\) is the attention score, and \(b_n\) is the nth location embedding we predict
4.4 Matching and Ranking
Using inner product similarity scores as recommendation scores is the most commonly employed approach in recommendation systems. Recall that preference vector of user at step i is \(\textbf{B}_i \in \mathbb {R}^{1 \times 2d}\). To calculate the preference score \(y_{i,j}\) of the candidate POI j at step i, we use the following function,
Where \(\textbf{B}_i \in \mathbb {R}^{1 \times 2d}\) is the outcome of a linear transformation and a layernorm operation, with the additional incorporation of a residual connection. \(\textbf{C}_j \in \mathbb {R}^{1 \times 2d}\) is the representation vector of POI j. \(f(\cdot )\) is inner production.
4.5 Model Training
The binary cross-entropy loss function is commonly used in sequence recommendation. However, the regular binary cross-entropy loss only involves one negative sampling. In order to improve the training of the model, we adopt the approach proposed by GeoSAN. For each target POI \(p_i\), we retrieve the L nearest POIs around it as negative samples, and introduce the following weighted binary cross-entropy loss function,
where tra is the set of all training sequences and \(w_{\ell } =\frac{exp\left( y_{i,\ell } / T \right) }{\sum _{\ell =1}^L exp \left( y_{i,\ell } /T \right) }\) is defined as the weight for negative POI \(\ell\), T represents the temperature parameter which controls the distribution of negative samples and L is the total number of possible negative POIs.
5 Experiments and discussion
5.1 Datasets
We selected three publicly-available datasets to evaluate the performance of our model: Gowalla,Footnote 3 Brightkite,Footnote 4 and Weeplaces.Footnote 5 We remove the users who visit less than 20 POIs and the POIs that are interacted with fewer than 10 times. During the data partitioning, as for the evaluation set, for each user check-in sequence, we select the most recent \(n+1\) POIs for evaluation, where the last previously unvisited POI is the target, and the first n are inputs. As for the training set, all of the sequences before the target POI are used for training. The input sequence length n of the model is set to 100. The details about datasets are shown in Table 1.
5.2 Baselines
For evaluating TSCAN effectiveness, we adopt the following baselines:
-
FPMC-LR [1] incorporates geographic location constraints based on Markov method to recommend the next POI.
-
ST-RNN [24] is a RNN-based model which incorporates a specific transition matrices for modeling spatial temporal information.
-
STGN [25] proposes a new spatio-temporal gate network to capture sequential correlations between successive POIs.
-
TiSASRec [26] first introduces the concept of personalized time intervals. In contrast, we propose a novel cross-attention time interval that leads to improved model performance.
-
GeoSAN [9] encodes POIs with quadkey tree and gets relative spatial positions with self-attention mechanism.
-
STAN [10] adopts a two-layer spatio-temporal self-attention model, achieving significant improvements in POI recommendation.
-
STiSAN [11] is a state-of-the-art POI recommender that explicitly incorporates spatiotemporal distance matrices into the attention score matrix, allowing spatiotemporal neighboring POIs to have greater relational weight.
5.3 Metrics
We choose two widely-used metrics, Hit Rate (HR), and Normalized Discounted Cumulative Grin (NDCG) to evaluate the recommendation performance of the model. HR@k is formulated in (15),
where Eval, \(Top_k\) represents the evaluation set and recommendation list, trg stands for true label, HR@k indicates the rate of the target label hits in the top-k probability samples. NDCG@k is formulated in (16),
\(Top_{k_i}\) means the top i-th ranked sample of candidates and D is a normalization constant. NDCG@k measures the ranking quality of the top-k recommendations, emphasizing the importance of the positions in the recommendation list.
Unlike the STiSAN evaluation method that selects 100 POIs that have never been visited near the target POI of users as the negative candidate set, we do not know the user’s target POI in real-world scenarios, and users are likely to revisit places they have been to before. Therefore, we randomly select 100 POIs near the current POI as the negative candidate set.
5.4 Experimental Settings
Our model is implemented on Pytorch 1.7.0 and conducts all experiments on a server named virtaicloudFootnote 6 with 24GB RAM, 8-core CPU, and 24GB VRAM GPU. The code is available at Github.Footnote 7
As GeoSAN and STiSAN show poor performance in our experiments, we select the best results during the training process for presentation. To ensure the fairness of the experiments, we set the hyperparameter \(k_t\) to 10, the grid hierarchy in the geo-encoder to 17, and the temperature parameter T in the loss function is set to 1.0, consistent with GeoSAN and STiSAN. Other parameters are set as follows.
To standardize the dimensions, we set the dimension of all embeddings to 50. We use the Adam optimizer with a learning rate of 0.001 and a dropout rate of 0.5 for training the model. For each training epoch on each dataset, we set it to be 15 and use only one layer of TSCAB and CTIAB. For the loss computation, we randomly select 15 points from a pool of 2000 points near the target POI for negative sampling.
5.5 Recommendation Performance
The experimental results are presented in Table 2. The traditional machine learning method FPMC-LR exhibit weaker performance than other baseline approaches due to its lack of sequence modeling capability. Among the RNN-based models, STRNN and STGN effectively improve the accuracy of RNN networks for the next POI recommendations by incorporating temporal and spatial intervals using different methods. However, inherent flaws in RNNs when processing long sequences prevent the RNN-based models from achieving further improvements in performance.
Unlike previous models, the attention-based GeoSAN model encode POIs grid with quadkey tree and establish strong relationships among POIs using self-attention mechanism. Building upon this approach, STiSAN explicitly incorporate temporal and spatial intervals to further enhance the strength of this relationship.
It can be observed that our TSCAN model outperform state-of-the-art models on all three datasets, with an average improvement of \(5.6\%\) in HR@5, \(8.7\%\) in NDCG@5, \(8.9\%\) in HR@10, and \(3.7\%\) in NDCG@10. We analyze the reasons for the effective enhancement of TSCAN. On the one hand, we actually capture spatiotemporal periodicity. Compared to the position encoding method (STiSAN), timestamp cross-attention can better capture temporal periodicity, rather than relying solely on the visit sequence for predicting the next POI. This approach aligns better with the patterns of human activities. On the other hand, we implement personalized recommendations. Even though we do not explicitly add user embedding, the characteristic of visiting similar locations at similar times holds true for all users. We leverage this characteristic to make different recommendations for different users at the same timestamp, thus indirectly achieving the effect of personalized recommendations. Our experiments confirmed the importance of personalized recommendation for predicting the next POI.
To demonstrate that TSCAN can be easily integrated into any attention-based model, we integrate TSCAN with GeoSAN and STiSAN, and conduct comparisons among them. Since GeoSAN and STiSAN are both self-attention structures, they can be directly incorporated as location embeddings in TSCAN, as illustrated in Fig. 6. In Table 2, we can observe that the performance of the combined model is at least as good as the original performance or even better, which demonstrates the effectiveness and transferability of our model. Additionally, it can be noted that GeoSAN+TSCAN outperforms STiSAN+TSCAN most of the time, but still falls short of TSCAN. We hypothesize that this could be attributed to the self-attention mechanism which makes unrelated location embeddings more similar, leading to TSCAN’s inability to accurately identify POIs relevant to the next timestamp. The spatiotemporal matrix of STiSAN further exacerbates this problem.

The architecture of GeoSAN/STiSAN + TSCAN
5.6 Ablation Study
To demonstrate the effectiveness of the proposed method, we deconstruct TSCAN and conduct extensive experiments on the Gowalla dataset, followed by rigorous analysis. The details of the experiment and analysis are presented below.
-
Remove TS(Timestamp). We no longer use timestamps and instead use the POI sequence. In this case, TSCAN degenerates to a GeoSAN with only two layers. Modify the formula (5) as formula (17), and then modify the formula (10) as formula (18),
$$\begin{aligned} \begin{aligned}&\mathbf {Q_{\ell }} = \mathbf {E_{\ell }} \cdot \mathbf {W_{\ell }^Q}, \mathbf {K_{\ell }} = \mathbf {E_{\ell }} \cdot \mathbf {W_{\ell }^K}, \mathbf {V_{\ell }} = \mathbf {E_{\ell }} \cdot \mathbf {W_{\ell }^V} \\ \end{aligned} \end{aligned}$$(17)$$\begin{aligned} \begin{aligned}&\textbf{B} = \text {softmax} \left( \frac{\mathbf {Q_{\ell f}} \cdot \mathbf {K_{\ell p}^T}}{\sqrt{d}} + \textbf{Mask} \right) \cdot \mathbf {V_{\ell p}} \end{aligned} \end{aligned}$$(18)Where \(\mathbf {Q_{\ell }},\mathbf {K_{\ell }}, \mathbf {V_{\ell }} \in \mathbb {R}^{n \times 2d}\), \(\mathbf {W_{\ell }^Q},\mathbf {W_{\ell }^K}, \mathbf {W_{\ell }^V} \in \mathbb {R}^{2d \times 2d}\).
-
Remove NTS(Next Timestamp). We do not use the next timestamp in TSCAN, and instead replace it with present timestamp. Modify the \(\mathbf {Q_{tf}}\) in formula (5) as formula (19) and modify the matrix (8) as matrix (20),
$$\begin{aligned} \begin{aligned} \mathbf {Q_{tf}} = \mathbf {E_{tp}} \cdot \mathbf {W_{tf}^Q} \end{aligned} \end{aligned}$$(19)$$\begin{aligned} \begin{aligned}&\textbf{R} = \begin{bmatrix} t_1-t_1&{}0&{}\ldots &{}0 \\ t_2-t_1&{}t_2-t_2&{}\ldots &{}0 \\ \vdots &{}\vdots &{}\ddots &{}\vdots \\ t_{n}-t_1&{}t_{n}-t_2&{}\ldots &{}t_{n}-t_n\\ \end{bmatrix} \end{aligned} \end{aligned}$$(20) -
Remove CTIA(Cross Time Interval Awareness. We removed CTIA as formula (18), in order to compare the effect of Remove TS and assess the impact of TSCA.
-
Remove TSCA(TimeStamp Cross Attention). We removed TSCA as formula (17), in order to compare the effect of Remove TS and assess the impact of CTIA.
-
Remove CTIA &TSCA-NTS. We removed CTIA and the next timestamp of TSCA, only reserve TSCA with present timestamp, as fromula (18) and formula (19), in order to compare the effect of Remove TSCA and assess the impact of next timestamp for CTIA.
-
Remove TSCA &CTIA-NTS. We removed TSCA and the next timestamp of CTIA, only reserve CTIA with present timestamp, as fromula (17) and formula (20), in order to compare the effect of Remove CTIA and assess the impact of next timestamp for TSCA.
-
Add UE(User Embedding): We add the user embedding to the next timestamp embedding in TSCAB. Just like the \(\textbf{Q}\) in the revised formula (5) as follows,
$$\begin{aligned} \begin{aligned} \mathbf {Q_{tf}} =\left( \mathbf {E_{tf}}+\mathbf {E_{u_i}}\right) \cdot \mathbf {W_{tf}^Q} \end{aligned} \end{aligned}$$(21)
The results are shown in Table 3, from which we draw the following conclusions.
-
Finding 1: From -TS we found that the method without timestamps performed worse than any other methods, which precisely confirms the validity of incorporating timestamps to improve recommendation accuracy.
-
Finding 2: By comparing -NTS and -TS, it can be observed that adding timestamps effectively improves the accuracy of recommending the next POI.
-
Finding 3: By comparing -TS and -CTIA, we can observe that TSCA significantly improves the model performance. Furthermore, by comparing -CTIA and -CTIA &TSCA-NTS, we find that combining TSCA with the next timestamp enhances the model performance, the next timestamp is effective for TSCA.
-
Finding 4: By comparing -TS and -TSCA, we observe that CTIA can improve the TSCAN’s recommendation performance, but not significantly compared to TSCA. Furthermore, comparing -TSCA and -TSCA &CTIA-NTS, we find that the next timestamp can enhance the CTIA effect, although the improvement is not significant. This might be due to the fact that without TSCA, the POI embedding A generated by TSCAB cannot establish a better connection with the next POI. Therefore, even when CTIA is combined with the next timestamp, it does not have a significant impact.
-
Finding 5: We also attempt to incorporate user embedding to improve the performance, however, the results demonstrate that the noisy impact from introducing additional factors undermines the effectiveness of the model, given that it already possesses personalized capability by itself.
5.7 Time Complexity Analysis
To demonstrate the performance of the TSCAN model, we conducted a comparative analysis of the complexities of the TSCAN and STiSAN. Table 4 clearly shows that TSCAN has \(2.7\%\) fewer parameters compared to STiSAN. STiSAN uses a four-layer self-attention structure, with each layer containing a linear transformation layer. Assuming the sequence length is L and the embedding dimension is d, the time complexity of STiSAN is \(O(4*L^2*d + 4*L*d^2)\). In contrast, TSCAN only uses two layers of cross attention and one layer of linear transformation, resulting in a time complexity of \(O(2*L^2*d + L*d^2)\). The inference and backpropagation processes are much faster compared to STiSAN.
5.8 Parameter Sensitivity Analysis
We conduct sensitivity analysis on the dimension of timestamp embedding. We vary the dimension used in the timestamp embedding from 20 to 60 with a step of 10. The experimental results on Gowalla, Brightkite and Weeplaces are reported in Fig. 7.
We can observe that with different datasets, the embedding dimension of timestamps has a negligible impact on model accuracy, with variations of around \(1\%\). This indicates that TSCAN exhibits good stability and, at the same time, reflects its ability to resist overfitting.

The impact of timestamp embedding dimension for model performances
5.9 Future POI Recommendation
To demonstrate that TSCAN is capable of recommending POI with arbitrary future timestamps, we conduct the following experiments. Since it is no longer about recommending neighboring POI, we remove the time interval-aware matrix as shown in equation (18). In terms of model training, we train the model using the first \(n-8\) data in the user check-in sequence and select the parameters that yield the best model performance for the following tests. The input for evaluation consists of check-in data from \([n-108:n-8]\) to predict the POI at timestamps \(n-6\), \(n-3\), and n.
Obviously, previous methods for next POI recommendation lack the ability to predict the \(n_{th}\) POI in the future. We only conduct experiments on TSCAN. The experimental results are shown in Table 5. It can be observed that TSCAN still performs well for the task of recommending the nth future POI. We believe that the reason why TSCAN has a lower performance in predicting the \(n_{th}\) POI than other POI is not due to the large time span, but rather because the \(n_{th}\) POI has not been accessed before, which greatly increases the difficulty of recommendation.
5.10 Performance Analysis
Our model not only greatly improves accuracy of next POI recommendation, but also achieves fast convergence and prevents overfitting. We illustrate its convergence process in these datasets separately in Fig. 8.
It is evident that TSCAN typically converges at around 5 epochs on these three datasets and gradually becomes stable. To highlight the convergence speed and overfitting prevention ability of our model, we compared the convergence process of STiSAN and TSCAN on the Brightkite dataset. Specifically, we extended the number of epochs in TSCAN to the same 35 as in STiSAN, which is shown in Fig. 9.

Performance on different datasets

Performance between TSCAN and STiSAN
Obviously, TSCAN reaches a good peak at around 5 epochs, while STiSAN needs 15 epochs, and the accuracy of STiSAN continuously decreases with the increase of epochs. This is because STiSAN only learns the general rules in the dataset and fails to achieve personal recommendation, resulting in overfitting. We also discuss in “Appendix A.1” why the previous personalized methods that simply add or concatenate user embedding with location embedding fail to produce desirable results.
The experiment also demonstrates that, rather than simply pursuing the goal of enhancing performance by incorporating spatiotemporal information into sequence recommendation models, it is more important to carefully consider how to improve the ability of models to perform personalized modeling.
6 Conclusions
In this paper, we fully utilize the timestamp information to propose a novel network model, the TimeStamp Cross Attention Network (TSCAN). This model consists of two modules: TimeStamp Cross Attention Block (TSCAB) and Cross Time Interval Aware Block (CTIAB). TSCAB explores the spatiotemporal periodicity by utilizing the similarity of timestamps for long-term sequence modeling. CTIAB employs cross time interval awareness to enhance the relevance between the next timestamp’s potentially visit POI and the historical neighboring POIs, for short-term sequence modeling. In comparative experiments, we demonstrate that TSCAN outperforms state-of-the-art models by an average of 5~9%, and exhibits transferability. Through ablation experiments, we show the necessity of each module of TSCAN. In the time complexity analysis and parameter sensitivity analysis, we have demonstrate the model’s low time complexity and high stability. In future POI recommendation and model performance analysis, we verify that TSCAN is capable of recommending POIs that may be visited at any future timestamp and achieves high accuracy with fewer epochs of training. Additionally, it exhibits remarkable performance in preventing overfitting, affirming the personalized recommendation ability of our model.
In the future, we will investigate the use of graph embedding to incorporate more features into location embedding to improve TSCAN performance, and explore ways to further enhance the personalized modeling ability of the model. Furthermore, we will continue to investigate whether TSCAN can be effective in other sequence recommendation tasks.
Notes
We use torch.nn.embedding() to perform one-hot embedding.
Following by https://github.com/libertyeagle/GeoSAN.
References
Cheng C, Yang H, Lyu MR, King I (2013) Where you like to go next: successive point-of-interest recommendation. In: Proceedings of the twenty-third international joint conference on artificial intelligence. IJCAI ’13, pp 2605–2611. AAAI Press, Beijing
Rendle S, Freudenthaler C, Schmidt-Thieme L (2010) Factorizing personalized markov chains for next-basket recommendation. In: Proceedings of the 19th international conference on world wide web. WWW ’10, pp 811–820. Association for Computing Machinery, New York. https://doi.org/10.1145/1772690.1772773
Zhang Z, Li C, Wu Z, Sun A, Ye D, Luo X (2020) Next: a neural network framework for next poi recommendation. Front Comput Sci 14(2):314–333. https://doi.org/10.1007/s11704-018-8011-2
Perozzi B, Al-Rfou R, Skiena S (2014) Deepwalk: online learning of social representations. In: Proceedings of the 20th ACM SIGKDD international conference on knowledge discovery and data mining, pp 701–710. https://doi.org/10.1145/2623330.2623732
Tang J, Wang K (2018) Personalized Top-N sequential recommendation via convolutional sequence embedding
Hidasi B, Karatzoglou A, Baltrunas L, Tikk D (2016) Session-based recommendations with recurrent neural networks
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need
Kang W-C, McAuley J (2018) Self-attentive sequential recommendation. In: 2018 IEEE international conference on data mining (ICDM), pp 197–206. IEEE, Singapore. https://doi.org/10.1109/ICDM.2018.00035
Lian D, Wu Y, Ge Y, Xie X, Chen E (2020) Geography-aware sequential location recommendation. In: Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pp 2009–2019. ACM, Virtual Event. https://doi.org/10.1145/3394486.3403252
Luo Y, Liu Q, Liu Z (2021) Stan: Spatio-temporal attention network for next location recommendation. In: Proceedings of the web conference 2021, pp 2177–2185. https://doi.org/10.1145/3442381.3449998
Wang E, Jiang Y, Xu Y, Wang L, Yang Y (2022) Spatial-temporal interval aware sequential poi recommendation. In: 2022 IEEE 38th international conference on data engineering (ICDE), pp 2086–2098. IEEE, Kuala Lumpur. https://doi.org/10.1109/ICDE53745.2022.00202
Guo Q, Qi J (2020) SANST: a self-attentive network for next point-of-interest recommendation
Feng J, Li Y, Zhang C, Sun F, Meng F, Guo A, Jin D (2018) Deepmove: predicting human mobility with attentional recurrent networks. In: Proceedings of the 2018 world wide web conference on world wide web - WWW ’18, pp 1459–1468. ACM Press, Lyon, France. https://doi.org/10.1145/3178876.3186058
Yang D, Fankhauser B, Rosso P, Cudre-Mauroux P (2020) Location prediction over sparse user mobility traces using RNNS: flashback in hidden states! In: Proceedings of the twenty-ninth international joint conference on artificial intelligence, pp 2184–2190. International joint conferences on artificial intelligence organization, Yokohama, Japan. https://doi.org/10.24963/ijcai.2020/302
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J, Houlsby N (2021) An image is worth 16x16 words: transformers for image recognition at scale
Zhou G, Song C, Zhu X, Fan Y, Zhu H, Ma X, Yan Y, Jin J, Li H, Gai K (2018) Deep interest network for click-through rate prediction
Zhou G, Mou N, Fan Y, Pi Q, Bian W, Zhou C, Zhu X, Gai K (2018) Deep interest evolution network for click-through rate prediction
Chen Q, Zhao H, Li W, Huang P, Ou W (2019) Behavior sequence transformer for E-commerce recommendation in Alibaba
Sun F, Liu J, Wu J, Pei C, Lin X, Ou W, Jiang P (2019) Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. In: Proceedings of the 28th ACM international conference on information and knowledge management, pp 1441–1450. ACM, Beijing China. https://doi.org/10.1145/3357384.3357895
Devlin J, Chang M-W, Lee K, Toutanova K (2019) BERT: pre-training of deep bidirectional transformers for language understanding
Fan X, Liu Z, Lian J, Zhao WX, Xie X, Wen J-R (2021) Lighter and better: low-rank decomposed self-attention networks for next-item recommendation. In: Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, pp 1733–1737. ACM, Virtual Event Canada. https://doi.org/10.1145/3404835.3462978
Cho K, van Merrienboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using RNN encoder-decoder for statistical machine translation
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Liu Q, Wu S, Wang L, Tan T (2016) Predicting the next location: a recurrent model with spatial and temporal contexts. In: Proceedings of the AAAI conference on artificial intelligence. https://doi.org/10.1609/aaai.v30i1.9971
Zhao P, Zhu H, Liu Y, Xu J, Li Z, Sheng VS, Zhou, X (2019) Where to go next: a spatio-temporal gated network for next poi recommendation. In: AAAI
Li J, Wang Y, McAuley J (2020) Time interval aware self-attention for sequential recommendation. In: Proceedings of the 13th international conference on web search and data mining, pp 322–330. ACM, Houston. https://doi.org/10.1145/3336191.3371786
Acknowledgements
This work is supported in part by the National Natural Science Foundation of China (61772249), Scientific Research Project of Liaoning Provincial Department of Education (LJ2019QL017, LJKZ0355).
Funding
This work was supported by the National Science Foundation of China (No. 61772249).
Author information
Authors and Affiliations
Contributions
Not applicable.
Corresponding author
Ethics declarations
Conflict of interest
Not applicable.
Appendix A
Appendix A
1.1 A.1 The Reason Why not Personality
In this section, We discuss why personalized methods that relied on concatenating or adding user embedding with location embedding in previous attention-based models [9, 11] were ineffective. concatenating user embedding
Formula (22) provides an abstract representation of the dot product in attention mechanisms, where \(\textbf{u}\) and \(\textbf{p}\) represents embedding of the user and POI. Obviously, since \(\textbf{u}\) in the input sequence is the same in self-attention models, the first term inside the parentheses on the right-hand side of the equation is meaningless, and cannot draw the user’s attention to the corresponding POI. Therefore, regardless of the check-in sequence of any user as input, \(\alpha _{i,j}\) cannot reflect the relationship between \(\mathbf {u_i}\) and \(\mathbf {p_i}\) \((\mathbf {p_j})\).
adding user embedding
Similar to the interpretation of formula (22), in the Eq. (23), the computation of the first term on the right-hand side is meaningless. Moreover, the second and third terms represent the attention levels of \(\mathbf {u_i}\) on \(\mathbf {p_i}\) and \(\mathbf {p_j}\), respectively, while last term represents the correlation between \(\mathbf {p_i}\) and \(\mathbf {p_j}\), and the two are not match. Consequently, the first three terms do not serve to personalize the model and only add noise. This also means that \(\alpha _{i,j}\) lacks the ability to represent the relationship between \(\mathbf {u_i}\) and \(\mathbf {p_i}\) \((\mathbf {p_j})\).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Duan, J., Meng, X. & Liu, G. Where To Go at the Next Timestamp. Data Sci. Eng. 9, 88–101 (2024). https://doi.org/10.1007/s41019-023-00240-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41019-023-00240-9