
Abstract
Recently, many deep learning-based models have been successfully applied to click-through rate prediction. However, most previous models focus only on feature-level interactions between a single user behavior and the target item or only treat the user’s historical behavior as a sequence to uncover the hidden interests behind it when mining user interests. This can lead to user interest that evolves over time dynamically being ignored or the interest shown by a single user’s behavior not being exploited. Based on the above problems, we propose evolving interest with feature co-action network (EIFCN). Specifically, we first design user dynamic interest network to treat the user’s historical behavior as a sequence of information, and tap into the user’s hidden interests over time. In this part, we use a multi-head self-attention mechanism to initially process the data and then pass it into the deep learning network. Then a feature co-action network is designed to mine the user’s single behavior and the displayed feature-level interactions of the target item. Experimental results show that the EIFCN model performs better than other models.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Click-through rate prediction is used to predict how likely a user is to click on a target item, and it plays a vital role in many areas, such as recommending items or advertising placement. For significant Internet companies, there are various ways to charge, among which cost per click (CPC) is one of the most common ways. Advertisers pay after each user clicks on an ad. In this way of charging, the accuracy of the click-through rate prediction plays a decisive role, and if the prediction result is not good enough, it will greatly reduce the company’s revenue and the user’s experience.
In the early days of industry recommendation algorithms, LR was the most extensive one to make CTR prediction. Later developed, a lot of models no longer only focus on individual features but explore the relationship between different features and give various combinations of features diverse weights, such as POLY2. However, with high dimension and high sparsity characteristics, POLY2 performs poorly. Factorization Machines (FM) [1] introduces the concept of hidden vectors to learn the weights of crossover features. By adding the concept of “field”, Field-aware Factorization Machines (FFM) [2] was further enhanced on the foundation of FM and attained better outcomes. With the continuous improvement of hardware devices, DNNs are rapidly evolving and have achieved success in many areas, such as image processing [3], computer vision [4, 5], natural language processing [6], social influence modeling [7], and crowdfunding project recommendation [8]. Then it was quickly applied to the field of click-through rate prediction. For instance, WDL [9] was the first one to combine two sub-networks while accounting for both low-order and high-order features. Similar models are Deep Factorization Machines (DeepFM) [10], etc. Although the above models succeeded in this field, they require the manual design of feature interactions. To solve the above problems, explicit feature interaction networks are proposed. such as Deep & Cross Network (DCN) [11], Compressed Interaction Network (xDeepFM) [12] and Automatic Feature Interaction Learning (AutoInt) [13]. These methods can be good at mining the relationship between different features, and applied in the field of click-through rate prediction can mine the interest relationship between the user’s behavior and the target item, but can only stay on a single behavior, without taking multiple user behaviors over time as a sequence to mine the hidden information behind.
Many models focus on tapping into the evolutionary interests of users over time, several state-of-the-art CTR prediction models [14,15,16] have been proposed to capture user interests by extracting behavioral features based on historical user behaviors. Deep Interest Network (DIN) [14] is the first approach to apply the attention mechanism to this domain, to tap the diversity of interests in users’ historical behaviors and to mine the relationship between users’ historical behaviors and target items through the attention mechanism. Deep Interest Evolution Network (DIEN) [15] improves on Deep Interest Network (DIN) by further tapping into users’ interests over time. Deep Session Interest Network (DSIN) [16] finds the behavior in a session is highly homogeneous. These methods treat the user’s behavior over time as a sequence, which can be good for mining the potential interest behind the user’s behavior sequence, but ignore the possible relationship between the user’s single behavior and the target items.
Motivated by the above observations, we propose Evolving Interest with Feature Co-action Network(EIFCN) to model a user’s sequential behaviors with explicit pairwise feature interactions in the CTR prediction task. There are two main components: User Dynamic Interest Network (UDIN), and Feature Co-action Network(FCN). User Dynamic Interest Network treats the user’s historical behavior as a sequence to uncover the hidden potential interest behind it. Feature Co-action Network is used to tap the interest exhibited between a single user behavior and the target item.
The main contributions of this paper are as follows:
-
1.
We propose using Evolving Interest with Feature Co-action Network(EIFCN) to mine the relationship between users’ historical behaviors and target items. We pass user historical behaviors and target items into a two-tower style structure to explore the interest relationship between user historical single behaviors and target items, and the hidden potential interest behind the sequence of user historical behaviors, respectively. It solves the problem of inadequate information mining caused by focusing on a single interest or only treating historical behaviors as sequences to uncover the hidden interests behind the behaviors in most previous models.
-
2.
In User Dynamic Interest Network(UDIN), we use a multi-head self-attention mechanism to purify the data before passing it into the deep learning network after embedding, which is more useful for the subsequent neural networks to function and better explore the hidden interests behind the user behavior sequences. At the same time, we use the data after multi-head self-attention to interact with the target items and pass the results of the interaction into the GRU sequence network. Through the above work, user interest preferences can be mined from two perspectives: the individual user behavior itself and the dependency relationships in the behavior sequence, respectively.
-
3.
In Feature Co-action Network(FCN), we use a novel feature interaction approach to mine the interest relationship that exists between each individual behavior and the target items in the user’s historical behavior, and introduce fewer parameters than the traditional Cartesian product.
-
4.
We evaluate our proposed model on real-world datasets in terms of click-through rate prediction. The results show that Evolving Interest with Feature Co-action Network(EIFCN) outperforms the state-of-the-art solution.
2 Related Work
In this section, we focus on some models that already exist in the field of click-through rate prediction. They focus partly on feature interactions and mining the information hidden behind the user’s historical behavior.
2.1 Feature Interaction
With the rapid development of deep neural networks, the ability to represent and combine features has been greatly enhanced. Most deep learning models follow the structure of embedding and multi-layer perception (MLP). In many papers, a lot of raw data represented as the one-hot vector is high-dimension sparse, such as user IDs and item IDs. Furthermore, most of the processing methods transform these data into fixed-length low-scale dense vectors after embedding. In the end, these vectors are concatenated and entered into the MLP. From this way of thinking, more and more approaches focus on the interaction between features.
Factorization Machines(FM) [1] have been a usual method for a long time. The method adds second-order (or higher-order) feature interactions to the ordinary linear model while using the idea of Matrix Factorization to map the n*n weight matrix into the n*k space. FFM [2] introduces the concept of field-aware based on FM to achieve better results. Product-based Neural Network(PNN) [17] introduces a product layer to capture feature interactions between inter-field categories. The Operation-aware Neural Network (ONN) [18] learns feature interaction through different operations. AFN [19] proposes a Logarithmic Transformation Layer that automatically captures which features should interact and what order of interaction should be performed. AutoFIS [20] is able to automatically identify feature interactions that are important in the factorization model. Fi-GNN [21] model complex interactions between features in a more flexible and explicit way in the graph structure. CAN [22] using a new method to mine explicit feature interactions. Unlike the previously used Cartesian product, it uses the concept of MLP to mine the relationship between different features. It also has an advantage over previous models in terms of time complexity. All of these approaches have been successful in feature-level interactions that can mine the relationships between different features, but lack the ability to mine the hidden interests behind a user’s historical behavior sequence.
2.2 User Evolving Interest
In many other directions of deep learning, user-item interactions over time are recorded. Recently, it was discovered that such data might significantly contribute to the development of more richer user behavior and identify more behavioral patterns. In recommendation systems, DMN+ [23] uses attention based GRU(AGRU), by which the attention mechanism can be made more sensitive to both the order and the position of the input data. DIN is the first approach to introducing attention mechanism into the field to mine the diversity of interests in users’ historical behaviors through attention mechanism. DIEN can be considered as an improved version of DIN. It uses GRU with attention update gate to model the evolution of user interest. MIND [24] mines the complicated patterns between users and items using a massive number of vectors. To explore the relationship between products and users’ long-term interests, MIMN [25] presents a memory-based architecture. DHAN [26] introduces a multidimensional hierarchy to focus on the first attention layer of a single item, which is used to explore the hierarchical relationships that exist in user interests. DMIN [27] uses two layers of multi-head self-attention to model multiple potential primary interests of users. The recently proposed DUMN [28] abandons the relationship between items and items, which has been the focus of most previous papers, and pioneers mining the relationship between users and users. DRINK [29] proposes a method to dynamically capture the characteristics of goods to solve the problem of possible sparse historical user behavior. All these algorithms presented above focus on mining the deep information behind the user’s historical behavior but ignore some apparent relationships between different features, which might hurt the performance.
Most of the aforementioned papers, when mining interest preferences by user behavior, do not sufficiently take into account both explicit and implicit user interest perspectives. Besides, most of the previous works do not process the raw data adequately and do not consider the possible noise effects when mining user behavior sequences using RNN sequences. To solve the above problems, we received inspiration from [15, 22] and designed EIFCN.

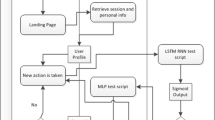
The architecture of the proposed EIFCN
3 The Proposed Method
In this section, we introduce the Evolving Interest with Feature Co-action Network (EIFCN) in detail. The overall architecture is illustrated by Fig. 1. We use a two-tower style structure to mine information from two perspectives: feature-level interactions between individual user history behaviors and target items, and hidden interests behind user history behavior sequences, respectively.
3.1 Embedding Layer
In this paper, we use four main groups of features: User Profile, User Historical Behavior, Context, and Target Item. Each category of feature has several fields. The fields of User Profile are user id, age, sex, and so on. User Historical Behavior is a list of user visited commodity id. Context is a group of features including but not limited to time, trigger id, and so on. Target Item refers to the candidate item with corresponding features such as item id, category id, and so on. Each feature can be encoded into a high-dimension one-hot vector. The usual method is embedding to turn large-scale sparse features into low-dimensional dense features. For example, the item id can be represented by a matrix \(\textrm{E} \in \mathbb {R}^{\textrm{k} \times \textrm{d}_{\textrm{e}}}\), where K is the total number of items and \(d_{e}\) is the embedding size with \(d_{e} \ll K\). With the embedding layer, User Profile, User Historical Behavior, Context, and Target Item can be represented as \(x_{p},x_{b},x_{c}\) and \(x_{i}\), respectively. User History Behavior, in particular, and user’s behavior is represented by the product, which consists of multiple items and is therefore represented as \(x_{b}=\left\{ e_{1}, e_{2}, \ldots , e_{T}\right\} \in \mathbb {R}^{T \times d_{\text{ model } }}\), where T is the number of user’s history behaviors and \(d_{\text{ model } }\) is the dimension of item embedding. It is worth noting that the User History Behavior and the Target Item share the same embedding matrices.

The architecture of micro-MLP in FCN
3.2 Feature Co-Action Network (FCN)
Feature Co-action Network (FCN) corresponds to the left half of Fig. 1. In this section, we use a feature interaction approach, that uses micro-MLP to mine feature co-action. The structure of micro-MLP can be seen in Fig. 2. This method mines the relationship between two features by applying an MLP to each feature pair. In the field of CTR prediction, it is important that the hidden information between the user’s historical behavior and the target items. By interacting the user’s historical behavior and target items, we can mine the user’s interest preferences, so in this paper, we focus on exploring the hidden information between these two features. First, we interact each user behavior with the target item separately, so for each micro-MLP, we take one behavior from the behavior sequence \(x_{b}\) as \(U_\textrm{input}\). While the target item \(x_{i}\) is chosen as \(M_\textrm{sum}\). For a specific user behavior \(u_{o^{\prime }} \in U_{\text{ input }}\), we use parameter lookup to obtain \(\quad P_{\text{ input }} \in \mathbb {R}^{D^{\prime }}\), while item feature \(m_{o} \in M_\textrm{sum}\) to obtain \(\quad P_{\text{ sum }} \in \mathbb {R}^{D}\). In fact, \(P_\textrm{input}\) and \(P_\textrm{sum}\) are interchangeable. However, in the dataset used in this paper, the candidate items are only a small fraction of the total number of items, and the number of candidate items is less than the number of items previously clicked by the user compared to the user’s historical behavior. So we choose the target item as \(P_\textrm{sum}\).
For the traditional MLP equation \(s \otimes x + b\), s and b are the training parameters, and the optimal s and b are obtained by continuous optimization of the loss function, while in the micro-MLP of this paper, s and b are divided by \(P_\textrm{sum}\), and the main purpose is to interact with \(P_\textrm{input}\). In the process of feature interaction, we should introduce as much interaction information as possible to obtain better prediction results, and we can see from equation \(s \otimes x + b\) that b does not interact with the incoming parameter \(P_\textrm{input}\), which causes the lack of information. Therefore, \(P_\textrm{sum}\) is reshaped and splited into the weight matrix for the micro-MLP,
where \(s_{i}\) is the weight of ith layer of micro-MLP, \(|.|\) gets the size of the variables, L indicates the total number of layers in the micro-MLP. After the weights and biases of micro-MLP are determined, \(P_\textrm{input}\) is passed into:
where F represents the interaction between target items and user behavior, and H represents the interaction by passing \(P_\textrm{input}\) and \(P_\textrm{sum}\) into micro-MLP. Since the \(P_\textrm{input}\) is a sequence feature in this paper, so after using micro-MLP to mine the information, we use a sum-pooling to better process the sequence information:
For the above introduction, the Feature Co-action Network, we performed them all on first-order features. However, one-dimensional feature interactions end without good results. Although the method proposed in this paper can also learn higher-order feature interactions, it will extend the training time to some extent and may not be practical due to the sparse data. Therefore, we introduce multi-order information artificially to help feature interaction networks get higher-order features:
where C is the number of orders. Numerical problems are most likely to arise when dealing with higher-order terms. Therefore, when interacting with \(P_\textrm{sum}\) and \(P_\textrm{input}\), we use a Tanh activation function to process the result after each matrix multiplication, which can effectively alleviate the numerical problem and bring better model training results. Using this approach, the model can be improved to capture the nonlinear relationship between features.
3.3 User Dynamic Interest Network (UDIN)
In this paper, we design a User Dynamic Interest Network (UDIN) that uses attention mechanisms and RNN sequences to mine hidden interest preferences in user behavior sequences. This approach seems to have been used in previous work. For example, DIEN [15] uses attention mechanism and GRUs to mine users’ interest preferences. However, there are several obvious problems in the previous work, firstly, the direct use of RNN to mine user behavior sequences does not take into account that not all behaviors in the behavior sequences have dependencies on each other, and secondly, there are some accidental behaviors in the behavior sequences which are also known as noise, and the direct use of RNN sequences will make the subsequent behaviors suffer from the negative effects produced by the previous noisy behaviors.
Based on the above analysis, we designed UDIN to solve these problems. We first purify the raw data using multi-head self-attention. By this step, we can capture both dependent and non-dependent behaviors in the user behavior sequence, and increase the weight of important behaviors and decrease the weight of accidental behaviors in the behavior sequence. The one-step processing of the raw data is of great benefit to the subsequent learning of the neural network [28,29,30]. The one-step processing of the raw data is of great benefit to the subsequent learning of the neural network. Then we use the processed data to interact with the target items using the attention mechanism, which will further explore the weight of important behaviors in the user behavior sequence and further reduce the adverse effect of noise on the experimental results. Finally, we use an RNN sequence to mine the hidden interest preference information in the user behavior sequence. After the previous two steps, the behavior sequence is a more focused sequence of important behaviors, at this time, each behavior of the user is positively influenced by the previous behavior is beneficial, and will not be affected by the noise or even reduce the importance of its own behavior.
We designed UDIN to better mine the dependency and non-dependency relationships between behaviors in user behavior sequences, and after our processing of the data, we can make the RNN sequences focus more on the relationships between important behaviors in the behavior sequences and reduce the noise pollution caused by chance behaviors, so as to get better prediction results.
3.3.1 Behavior Purify Layer
As we can see from the right half of Fig. 1, the user history behavior sequence enters a multi-head self-attention structure again after the embedding process. Next we describe how to use multi-head self-attention [31] to purify the matrix of historical user behavior sequences after embedding.
Multi-head self-attention has achieved good results in many fields. For example, it has shown superiority in both machine translation, sentence embedding [32], and capturing graph embedding node similarity [33]. The input of the self-attentive mechanism consists of three parts in total: query, key, and value. Multi-head self-attention is an improvement of self-attention that combines multiple self-attention and can learn the relationship in different representation subspaces. To be specific, the output of the \(\text{ head }{ }_{\textrm{h}}\) is calculated as follows:
where \(W_{h}^{Q}, W_{h}^{K}, W_{h}^{V} \in R^{d_{\text{ model } } \times d_{h}}\) are projection matrices of the h-th head for query, key and value separately. Thus the item representation of the h-th subspace is expressed by \(\text{ head }{ }_{\textrm{h}}\).
The results obtained from different heads are connected to get a brand new representation of the item:
where \(\text{ H }{ }_{\textrm{N}}\) is the number of heads, \(W^{O} \in \mathbb {R}^{d_{\text{ model } } \times d_{\text{ model } }}\) is a linear matrix. In addition to get better experimental results, we use residual connection [34], dropout [35], and layer normalization [36] in the model.
In the previous studies, we found that the auxiliary loss used in DIEN [15] can be applied to item representation learning to get better results. It uses the original item embedding of the (t+1)th to supervise the learned tth learnt item representation, which is the tth row vector of Z. This auxiliary loss requires the use of both positive examples and negative examples, where the positive example is the next action in the sequence of user actions, and the negative example is a random selection of items from the entire set of items that the user has not clicked on. Mathematically, the auxiliary loss is formulated as,
where \(\sigma (.)\) is the sigmoid activation function, \(\langle \),\(\rangle \) is the inner product, \(\quad \hat{e}_{t+1}^{i}\) is the original embedding of the negative sample, N represents the number of training samples.
3.3.2 Interest Evolving Layer
In our previous observations, we found that users’ interests are not static and are influenced by their surroundings, as well as that interests change over time. For example, users may like clothes for a while, but they may be interested in food after a while. Although interests may affect each other, each commodity will have its own evolutionary path. Therefore, in this paper, we only focus on the evolutionary process related to the target item to more accurately predict whether the user will click on the target item or not. To mine the weight of the correlation between user behavior and target items, we use an attention function. The attention function can be formulated as:
where \(x_{i}\) is the concat of embedding vectors from fields in category ad, \(W \in \mathbb {R}^{d_{\text{ model } } \times d_{\text{ model } }}\). The magnitude of the attention score obtained indicates the magnitude of the correlation between \(z_{t}\) and \(x_{i}\).
Next, we pass the \(z_{t}\) and \(a_{t}\) into GRU with attention update gate(AUGRU):
where \(\sigma \) is the sigmoid activation function, \(\circ \) is the element-wise product, \(W^{u}, W^{r}, W^{h} \in R^{n_{H} \times d_{\text{ model }}}\), \(U^{u}, U^{r}, U^{h} \in R^{n_{H} \times n_{H}}\), \(n_{H}\) is hidden size, and \(d_{\text{ model }}\) is the dimension of item embedding. \(i_{t}\) is the input of AUGRU, \(i_{t}\) = \(z_{t}\) represents the t-th behavior that the user taken, \(h_{t}\) is the t-th hidden states. This strategy enables the user’s changing interest to be effectively captured over time.
3.4 MLP & Loss Function
The results obtained from Feature Co-action Network(FCN) and User Dynamic Interest Network (UDIN), as well as information such as user profiles, are connected and then passed into the MLP with the activation function such as RELU for the final prediction. Finally, a soft-max activation function is used to predict the likelihood that a user will click on the target item.
Negative log-likelihood function is a loss function widely used in deep CTR models, which is usually defined as:
where \(x=\left[ x_{\textrm{p}}, x_{\textrm{b}}, x_{\textrm{c}}, x_{\textrm{i}}\right] \in \mathcal {D}\), \(\mathcal {D}\) is the training set of size N. \(\textrm{y} \in \{0,1\}\) represents whether the user will click the target item. The output of our network is p(x), which shows the predicted possibility that a user would click the target item.
In addition, in the Behavior Purify Layer we use auxiliary loss, so that the global negative function is:
where \(\eta \) is the hyper-parameter which balances the interest representation and CTR prediction.
3.5 Time Complexity
In this paper, there are three main modules, and we analyze the time complexity of each module separately. Firstly, for Feature Co-Action Layer, suppose user history behavior and target item with both n IDs, if the Cartesian product is used, then the time complexity will be O\(\left( \textrm{n}^2 \times \textrm{D}\right) \). In this paper, D denotes the commodity embedding dimension \(d_{model}\). And by using use micro-MLP, the time complexity will be reduced to O\(\left( \textrm{n} \times \left( \textrm{D}+\textrm{D}^{\prime }\right) \right) \), where \(D^{'}\) is the dimension of the \(P_{sum}\). After that, for the Behavior Purify Layer, hidden_size(d) = num_attention_heads(m) \(\times \) attention_head_size(a), the time complexity is O\(\left( \textrm{n}^2 \times \textrm{a} \times \textrm{m}\right) \) = O\(\left( \textrm{n}^2 \times \textrm{d}\right) \). Finally, Interest Evolving Network is a RNN-structure, so the overall time complexity can be expressed in terms of O\(\left( \textrm{n} \times \textrm{D}^2\right) \). In summary, the overall time complexity of EIFCN is O\(\left( \textrm{n} \times \left( \textrm{D}+\textrm{D}^{\prime }\right) + \textrm{n}^2 \times \textrm{d} + \textrm{n} \times \textrm{D}^2\right) \).
4 Experiments
In this section, we conduct experiments on two real-world datasets to answer the following question:
-
1.
(RQ1)How does our model EIFCN compare to other state-of-the-art methods in CTR prediction?
-
2.
(RQ2)How do some model hyper-parameters affect the EIFCN?
-
3.
(RQ3)How do the main structures proposed above affect the experimental results?
4.1 Experimental Setup
4.1.1 Datasets
We use the Amazon Dataset,Footnote 1 which contains product reviews and metadata from Amazon. There are 24 categories in this dataset, and we chose Electronics, Kindle_store, Movies_and_TV, Office_Products and Sports_and_Outdoors as the datasets in our experiments. Assuming there are H behaviors in a user behavior sequence, our task is to predict whether the user will perform the H-th comment based on the user’s first H-1 behaviors.
We create training, validation, and test sets with a split rate of 80%, 10%, 10%. This process is repeated five times on each dataset, and we take the average of the five experimental results as the final experimental result. The statistics for this are summarized in Table 1.
4.1.2 Evaluation Metrics
AUC: The Area Under ROC (Receiver Operating Characteristic) Curve evaluation indicators are widely used in classification problems. Its actual definition is the probability that the positive example score is ranked before the negative example when the model is scored.
4.1.3 Compared Models
We compare EIFCN with some mainstream CTR prediction methods:
-
1.
BaseModel uses the same embedding and MLP settings as EIFCN, and uses sum pooling operation to integrate behavior embeddings.
-
2.
WDL [9] is a widely used approach in industry that mixes a wide model relying on manual feature engineering with a deep learning model similar to BaseModel. It opens up the idea of joint training of the two parts, which is of great importance.
-
3.
PNN [17] based on the basemodel, it uses a product layer to capture interactive patterns between interfield category. The structure of PNN is characterized by emphasizing that the intersection between feature Embedding vectors is diverse.
-
4.
DIN [14] is a network that uses attention mechanisms to model user behavior sequence data. By introducing Attention to capture the user’s interest points, which are used to represent the user’s interest in the historical behavior of an item, the user’s Embedding vector changes with the change of the candidate item, which effectively improves the expressiveness of the model.
-
5.
DIEN [15] can be considered as an improved version of DIN, it uses GRU with attention update gate to model the evolution user interest.
-
6.
DHAN [26] introduces a multidimensional hierarchy to focus on the first attention layer of a single item, which is used to explore the hierarchical relationships that exist in user interests.
-
7.
DMIN [27] assumes that users have multiple interests at the same time, and that these potential interests will eventually manifest themselves through user behavior, so it uses two layers of multi-head self-attention to model multiple potential primary interests of users.
-
8.
DUMN [28] adds the behavior sequence on the item side to the modeling, and expresses the similarity between target user and target item by calculating the user-to-user similarity.
-
9.
CAN [22] uses the MLP structure to mine the relationship between users’ historical behaviors and target items as a way to mine users’ interest preferences. Compared with the Cartesian product commonly used in the past, CAN can get better results while introducing fewer parameters.
4.1.4 Implementation Details
In this experiment, we realized that all the models with Tensorflow in our experiments using Adam to optimize the training procedure. The dimension of \(d_\textrm{model}\) is set as 36, the dimension of user profile embedding is 18. We set the maximum value of user history behavior length to 20. All compared models have the same settings, their batch_size is set to 128 and their learning rate is 0.001. In the end, a three-layer MLP with layers \(200\times 80\times 2\) is used for final CTR prediction. In addition, there are many other hyper-parameters that will not be introduced here one by one.
4.2 Performance Comparison (RQ1)
In this section, we will compare the proposed EIFCN model with the models in baseline methods and show the result in Table 2. In the table, we label the best results on each dataset using bold, and the next best results we underline. To better demonstrate the validity of the model proposed in this thesis, we use a method similar to k-fold cross-validation. Each data set is divided into five times equally, and one of them is selected as the test and validation set each time, and the remaining four are used as the training set. Thus, on each data set, the experiment is performed five times, and we take the average of the five results as the final result. For convenience, we denote the datasets Electronics as Ele, Kindle_store as Kindle, Movies_and_TV as Movies, Office_Products as Office and Sports_and_Outdoors as Sports.
After five experiments to take the average, from the experimental results, EIFCN has achieved the best performance compared to the state-of-the-art methods. On Ele, Movies and Office, DUMN is the best method except for EIFCN. In these datasets, EIFCN outperforms DUMN by 1.67%, 6.71% and 1.20% in terms of AUC. In addition, DMIN achieved the best results other than EIFCN on the Kindle dataset, while our proposed EIFCN improves the AUC by 1.12% over DMIN. EIFCN improved the AUC by 1.64% in Sports dataset. We can easily see that WDL relies on manual feature engineering and does not perform very well. The PNN can automatically learn the interaction between features, and the result is better than WDL. DIN represents the user’s interest in the target product, and its results are mostly better than those of WDL and PNN. Based on DIN, DIEN further uses GRU to capture the dynamically evolving interest of users and obtains a better representation of user interest than DIN. DHAN uses multiple Attention Units to capture the user’s hierarchical interest, but the results are not ideal if not combined with DIEN, which also shows the importance of capturing the evolutionary interest of users. DMIN manifests the efficacy of modeling and tracking user’s latent multiple interests. DUMN adds the behavioral sequences on the item side to the model as well, and expresses the similarity between the target user and the target item by calculating the similarity between the user and the user. CAN mine the information between user and item through multiple MLPs. Each of the three models introduced above has different advantages, and thus their performance on different datasets will vary. And our proposed EIFCN gets better results than the above mentioned models on all datasets.
4.3 Hyper-parameter Tuning (RQ2)
We explore the effect of different orders on the experimental results of the Electronics data set. From Fig. 3, we can see that the performance decreases when the number of micro-MLP Layers increases for 1st and 2nd order terms. The 3rd order term leads to better results and better fit as the number of micro-MLP layers increases. Then, for the 4th order term, where the performance decreases and plateaus again as the number of micro-MLP Layers increases. Therefore, we can conclude the following: For 1st and 2nd order terms, increasing the micro-MLP Layer does not attain better results, we speculate that it may be because the overly complex network structure could produce overfitting when the feature interaction is at low order. For the 4th order term, the results are not satisfactory as the layer increases, probably because the amount of data is not enough and therefore the complex network structure cannot be trained well. Therefore, to get good experimental results, it is not feasible to constantly introduce multi-order information explicitly and apply sophisticated networks but to choose the correct high-order term as well as the proper network structure.

The performance of different numbers of layer
From Fig. 4, we can find that the AUC shows a trend of first increasing and then decreasing with the increase of the order term. It follows that the constant introduction of Multi-order does not always have a good effect on the results, and it is more beneficial to choose the right Multi-order.

The influence of the introduce multi-order
In addition, the proposed behavior purify layer in this paper uses a multi-head self-attention mechanism to integrate the information better in the original user data, so we reasonably guessed that the number of heads is also an important parameter, and we conducted experiments to verify this conjecture. From Fig. 5, we can see that when the number of heads keeps increasing, the AUC does not show a trend of increasing or decreasing all the time, but shows a trend of increasing and then decreasing or decreasing and then increasing, so increasing the head does not necessarily lead to the best results. This phenomenon occurs when we speculate that this is because of the different sparsity of the original data in each dataset, which leads to different sensitivity to the heads. Therefore, to get good experimental results, selecting the number of multiple self-attention heads is also a crucial part.

The impact of the number of head
After exploring the parameters in the model that may have an effect on the experiment, we next explore the factors that may have an effect during the experiment. First, we believe that the size of batch_size during the learning process has an impact on the training results, so we only adjust the size of batch_size to observe the impact on the experimental results in an environment where the remaining variables are guaranteed to be identical. We conducted experiments on all five data sets and set the batch_size size to 16, 32, 64, and 128 respectively. From Fig. 6 we can see that the AUC shows a decreasing trend on all data sets as the batch_size gradually increases from 16 to 128, and then tends to flatten out as the batch_size increases unevenly. The slope is greatest on the Movies dataset, and we speculate that it is because this dataset contains less information and therefore produces a greater impact.

The impact of the batch_size
We know that the learning rate, as an important hyper-parameter in deep learning, controls the learning progress of the network model and determines whether the global optimal solution can be found and the time to find the global optimal solution. If the learning rate is set too large, it may cause the learning network to fail to converge and keep hovering around the optimal solution. And if the learning rate is set too small, it may lead to a long learning time to the optimal solution and may even be confined in the local optimal solution and unable to break free, which eventually leads to not learning the real optimal solution of the network. We therefore conduct experiments on each of the five data sets to investigate whether the learning rate has an effect on the results in the learning network of this paper. We set the learning rates to 0.01, 0.001, and 0.0001, respectively. From Fig. 7, we can see that there is a general trend of increasing and then decreasing with increasing learning rates on the five data sets. On the Movie dataset, however, the results appear different from other datasets. We speculate that it may be because the amount of data in this dataset is too small, and therefore the three learning rates designed in this paper have not yet achieved the best convergence in the training process on this dataset.

The impact of the learning rate
4.4 Ablation Experiment (RQ3)
In this section, we experimentally demonstrate the usefulness of the three main structures proposed in this paper. We experimented on each of the five data sets mentioned above. Firstly, removing Feature Co-action Network and naming it no micro-MLP. As we can see from Fig. 8, after removing the Feature Co-action Network, the AUC decreases on all the five datasets, especially on Office_Products and Sports_and_Outdoors. Therefore, we believe that the interest shown between a user’s historical single behavior and the target item is indispensable in click-through rate prediction. Secondly, we removed the Behavior Purify Layer. Accordingly, from Fig. 8 we can see the AUC decreases to different degrees on various datasets, especially on Kindile_store and Electronics. This can prove that after the data is processed by embedding and then purified by the multi-head self-attention mechanism, it is beneficial for the subsequent deep learning network to perform better. Finally we remove the Interest Evolving Layer and name the remaining part of EIFCN as no evolving. AUC was significantly reduced on all five data sets especially in Kindile_store and Electronics. It can be seen that it is necessary to tap the hidden interests behind the user’s historical behavior sequence.

The impact of the main structure
5 Conclusion
In this paper, we propose the novel model EIFCN, which focuses on both feature-level interactions between users’ historical individual behaviors and target items and on the hidden interests behind users’ time-varying behavioral sequences. We use two networks to mine users’ interests separately. First, we use the Feature Co-action Network (FCN) to mine the relationship between a user’s historical single behavior and the target product to determine the user’s direct interest. A User Dynamic Interest Network (UDIN) is also used to treat the user’s historical behavior as a sequence, first purifying the raw data using multi-head self-attention, and then using AUGRU to uncover the hidden interests behind the behavior. From the experimental results, the model has better results in CTR prediction compared with the previous mainstream models. This shows that it is necessary to consider both of these aspects when exploring users’ interests. However, this paper only focuses on two types of information, namely user history behavior and target items. In addition, there is a lot of information that users can use, so in the future we will try to introduce more user information and use more personalized interest networks to get better prediction results.
Data Availability
Enquiries about data and materials availability should be directed to the authors.
References
Rendle S (2010) Factorization machines. In: Webb, G.I., Liu, B., Zhang, C., Gunopulos, D., Wu, X. (eds.) ICDM 2010, The 10th IEEE International Conference on Data Mining, Sydney, Australia, 14-17 December 2010, pp 995–1000. https://doi.org/10.1109/ICDM.2010.127
Juan Y, Zhuang Y, Chin W, Lin C (2016) Field-aware factorization machines for CTR prediction. In: Sen S, Geyer W, Freyne J, Castells P (eds.) Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, September 15-19, 2016, pp 43–50. https://doi.org/10.1145/2959100.2959134
Sb A, Pkrm A, Qvp B, Trg A, Srks A, Clc A, Ma C, Mjp D (2020) Deep learning and medical image processing for coronavirus (covid-19) pandemic: a survey. Sustain Cities Soc 65:102589
Esteva A, Chou K, Yeung S, Naik N, Socher R (2021) Deep learning-enabled medical computer vision. NPJ Digital Med 4(1):5
Xu S, Wang J, Shou W, Ngo T, Wang X (2020) Computer vision techniques in construction: a critical review. Arch Comput Methods Eng 28:3383–97
Galassi A, Lippi M, Torroni P (2021) Attention in natural language processing. IEEE Trans Neural Netw Learn Syst 32(10):4291–4308
Liu J, Xiao Y, Zheng W, Hsu C-H (2022) Siga: social influence modeling integrating graph autoencoder for rating prediction. Appl Intell 1–16
Xiao Y, Liu C, Zheng W, Wang H, Hsu C-H (2021) A feature interaction learning approach for crowdfunding project recommendation. Appl Soft Comput 112:107777
Cheng H, Koc L, Harmsen J, Shaked T, Chandra T, Aradhye H, Anderson G, Corrado G, Chai W, Ispir M, Anil R, Haque Z, Hong L, Jain V, Liu X, Shah H (2016) Wide & deep learning for recommender systems. In: Karatzoglou A, Hidasi B, Tikk D, Shalom OS, Roitman H, Shapira B, Rokach L (eds.) Proceedings of the 1st workshop on deep learning for recommender systems, DLRS@RecSys 2016, Boston, MA, USA, September 15, 2016, pp 7–10. https://doi.org/10.1145/2988450.2988454
Guo H, Tang R, Ye Y, Li Z, He X (2017) Deepfm: a factorization-machine based neural network for CTR prediction. In: Sierra, C. (ed.) Proceedings of the twenty-sixth international joint conference on artificial intelligence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017, pp 1725–1731. https://doi.org/10.24963/ijcai.2017/239
Wang R, Fu B, Fu G, Wang M (2017) Deep & cross network for ad click predictions. In: Proceedings of the ADKDD’17, Halifax, NS, Canada, August 13 - 17, 2017, pp 12–1127. https://doi.org/10.1145/3124749.3124754
Lian J, Zhou X, Zhang F, Chen Z, Xie X, Sun G (2018) xdeepfm: combining explicit and implicit feature interactions for recommender systems. In: Guo Y, Farooq F (eds.) Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, KDD 2018, London, UK, August 19-23, 2018, pp 1754–1763. https://doi.org/10.1145/3219819.3220023
Song W, Shi C, Xiao Z, Duan Z, Xu Y, Zhang M, Tang J (2019) Autoint: automatic feature interaction learning via self-attentive neural networks. In: Zhu W, Tao D, Cheng X, Cui P, Rundensteiner EA, Carmel D, He Q, Yu JX (eds.) Proceedings of the 28th ACM international conference on information and knowledge management, CIKM 2019, Beijing, China, November 3-7, 2019, pp 1161–1170. https://doi.org/10.1145/3357384.3357925
Zhou G, Zhu X, Song C, Fan Y, Zhu H, Ma X, Yan Y, Jin J, Li H, Gai K (2018) Deep interest network for click-through rate prediction. In: Guo, Y., Farooq, F. (eds.) Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, KDD 2018, London, UK, August 19-23, 2018, pp 1059–1068. https://doi.org/10.1145/3219819.3219823
Zhou G, Mou N, Fan Y, Pi Q, Bian W, Zhou C, Zhu X, Gai K (2019) Deep interest evolution network for click-through rate prediction. In: the thirty-third AAAI conference on artificial intelligence, AAAI 2019, the thirty-first innovative applications of artificial intelligence conference, iaai 2019, the ninth aaai symposium on educational advances in artificial intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019, pp 5941–5948. https://doi.org/10.1609/aaai.v33i01.33015941
Feng Y, Lv F, Shen W, Wang M, Sun F, Zhu Y, Yang K (2019) Deep session interest network for click-through rate prediction. In: Kraus, S. (ed.) proceedings of the twenty-eighth international joint conference on artificial intelligence, IJCAI 2019, Macao, China, August 10-16, 2019, pp 2301–2307. https://doi.org/10.24963/ijcai.2019/319
Qu Y, Cai H, Ren K, Zhang W, Yu Y, Wen Y, Wang J (2016) Product-based neural networks for user response prediction. In: Bonchi, F., Domingo-Ferrer, J., Baeza-Yates, R., Zhou, Z., Wu, X. (eds.) IEEE 16th international conference on data mining, ICDM 2016, December 12–15, 2016, Barcelona, Spain, pp 1149–1154. https://doi.org/10.1109/ICDM.2016.0151
Yang Y, Xu B, Shen S, Shen F, Zhao J (2020) Operation-aware neural networks for user response prediction. Neural Netw 121:161–168
Cheng W, Shen Y, Huang L (2020) Adaptive factorization network: learning adaptive-order feature interactions. In: the thirty-fourth AAAI conference on artificial intelligence, AAAI 2020, the thirty-second innovative applications of artificial intelligence conference, IAAI 2020, the tenth AAAI symposium on educational advances in artificial intelligence, EAAI 2020, New York, NY, USA, February 7–12, 2020, pp 3609–3616. https://ojs.aaai.org/index.php/AAAI/article/view/5768
Liu B, Zhu C, Li G, Zhang W, Lai J, Tang R, He X, Li Z, Yu Y (2020) Autofis: automatic feature interaction selection in factorization models for click-through rate prediction. In: Gupta R, Liu Y, Tang J, Prakash BA (eds.) KDD ’20: the 26th ACM SIGKDD conference on knowledge discovery and data mining, virtual event, CA, USA, August 23–27, 2020, pp 2636–2645. https://doi.org/10.1145/3394486.3403314
Li Z, Cui Z, Wu S, Zhang X, Wang L (2019) Fi-gnn: modeling feature interactions via graph neural networks for CTR prediction. In: Zhu, W., Tao, D., Cheng, X., Cui, P., Rundensteiner, E.A., Carmel, D., He, Q., Yu, J.X. (eds.) proceedings of the 28th ACM international conference on information and knowledge management, CIKM 2019, Beijing, China, November 3–7, 2019, pp 539–548. https://doi.org/10.1145/3357384.3357951
Bian W, Wu K, Ren L, Pi Q, Zhang Y, Xiao C, Sheng X, Zhu Y, Chan Z, Mou N, Luo X, Xiang S, Zhou G, Zhu X, Deng H (2022) CAN: feature co-action network for click-through rate prediction. In: Candan, K.S., Liu, H., Akoglu, L., Dong, X.L., Tang, J. (eds.) WSDM ’22: the fifteenth ACM international conference on web search and data mining, virtual event/tempe, AZ, USA, February 21–25, 2022, pp 57–65. https://doi.org/10.1145/3488560.3498435
Xiong C, Merity S, Socher R (2016) Dynamic memory networks for visual and textual question answering. In: Balcan, M., Weinberger, K.Q. (eds.) proceedings of the 33nd international conference on machine learning, ICML 2016, New York City, NY, USA, June 19–24, 2016. JMLR Workshop and Conference Proceedings, vol. 48, pp. 2397–2406. http://proceedings.mlr.press/v48/xiong16.html
Li C, Liu Z, Wu M, Xu Y, Zhao H, Huang P, Kang G, Chen Q, Li W, Lee DL (2019) Multi-interest network with dynamic routing for recommendation at tmall. In: Zhu W, Tao D, Cheng X, Cui P, Rundensteiner EA, Carmel D, He Q, Yu JX (eds.) proceedings of the 28th ACM international conference on information and knowledge management, CIKM 2019, Beijing, China, November 3–7, 2019, pp 2615–2623. https://doi.org/10.1145/3357384.3357814
Pi Q, Bian W, Zhou G, Zhu X, Gai K (2019) Practice on long sequential user behavior modeling for click-through rate prediction. In: Teredesai A, Kumar V, Li Y, Rosales R, Terzi E, Karypis G (eds.) Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, KDD 2019, Anchorage, AK, USA, August 4–8, 2019, pp 2671–2679. https://doi.org/10.1145/3292500.3330666
Xu W, He H, Tan M, Li Y, Lang J, Guo D (2020) Deep interest with hierarchical attention network for click-through rate prediction. In: Huang, J.X., Chang, Y., Cheng, X., Kamps, J., Murdock, V., Wen, J., Liu, Y. (eds.) proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval, SIGIR 2020, Virtual Event, China, July 25–30, 2020, pp 1905–1908. https://doi.org/10.1145/3397271.3401310
Xiao Z, Yang L, Jiang W, Wei Y, Hu Y, Wang H (2020) Deep multi-interest network for click-through rate prediction. In: d’Aquin, M., Dietze, S., Hauff, C., Curry, E., Cudré-Mauroux, P. (eds.) CIKM ’20: The 29th ACM international conference on information and knowledge management, virtual event, Ireland, October 19–23, 2020, pp 2265–2268. https://doi.org/10.1145/3340531.3412092
Huang Z, Tao M, Zhang B (2021) Deep user match network for click-through rate prediction. In: Diaz F, Shah C, Suel T, Castells P, Jones R, Sakai T (eds.) SIGIR ’21: The 44th international ACM SIGIR conference on research and development in information retrieval, virtual event, Canada, July 11–15, 2021, pp 1890–1894. https://doi.org/10.1145/3404835.3463078
Zhang J, Lin F, Yang C, Wang W (2022) Deep multi-representational item network for CTR prediction. In: Amigó E, Castells P, Gonzalo J, Carterette B, Culpepper JS, Kazai G (eds.) SIGIR ’22: The 45th international ACM SIGIR conference on research and development in information retrieval, Madrid, Spain, July 11–15, 2022, pp 2277–2281. https://doi.org/10.1145/3477495.3531845
Huang T, Zhang Z, Zhang J (2019) Fibinet: combining feature importance and bilinear feature interaction for click-through rate prediction. In: proceedings of the 13th ACM conference on recommender systems, RecSys 2019, Copenhagen, Denmark, September 16–20, 2019, pp 169–177
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. In: Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R. (eds.) Advances in neural information processing systems 30: annual conference on neural information processing systems 2017, December 4–9, 2017, Long Beach, CA, USA, pp 5998–6008
Lin Z, Feng M, dos Santos CN, Yu M, Xiang B, Zhou B, Bengio Y (2017) A structured self-attentive sentence embedding. In: 5th international conference on learning representations, ICLR 2017, Toulon, France, April 24–26, 2017, conference track proceedings (2017)
Velickovic P, Cucurull G, Casanova A, Romero A, Liò P, Bengio Y (2017) Graph attention networks. CoRR arxiv:https://arxiv.org/abs/1710.10903
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition, CVPR 2016, Las Vegas, NV, USA, June 27–30, 2016, pp 770–778 (2016). https://doi.org/10.1109/CVPR.2016.90
Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R (2012) Improving neural networks by preventing co-adaptation of feature detectors. CoRR arxiv:abs/1207.0580
Ba LJ, Kiros JR, Hinton GE (2016) Layer normalization. CoRR arXiv:abs/1607.06450
Acknowledgements
We also acknowledge the editorial committee’s support and all anonymous reviewers for their insightful comments and suggestions, which improved the content and presentation of this manuscript.
Funding
This work is supported by Tianjin ”Project + Team” Key Training Project under Grant No. XC202022.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by ZY, Peilin Yang and QH. The first draft of the manuscript was written by ZY, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
All authors declare that there is no conflict of interest regarding the publication of this article.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yuan, Z., Zheng, W., Yang, P. et al. Evolving Interest with Feature Co-action Network for CTR Prediction. Data Sci. Eng. 8, 344–356 (2023). https://doi.org/10.1007/s41019-023-00217-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41019-023-00217-8