
Abstract
Hierarchical Text Classification (HTC) is a formidable task which involves classifying textual descriptions into a taxonomic hierarchy. Existing methods, however, have difficulty in adequately modeling the hierarchical label structures, because they tend to focus on employing graph embedding methods to encode the hierarchical structure while disregarding the fact that the HTC labels are rooted in a tree structure. This is significant because, unlike a graph, the tree structure inherently has a directive that ordains information flow from one node to another—a critical factor when applying graph embedding to the HTC task. But in the graph structure, message-passing is undirected, which will lead to the imbalance of message transmission between nodes when applied to HTC. To this end, we propose a unidirectional message-passing multi-label generation model for HTC, referred to as UMP-MG. Instead of viewing HTC as a classification problem as previous methods have done, this novel approach conceptualizes it as a sequence generation task, introducing prior hierarchical information during the decoding process. This further enables the blocking of information flow in one direction to ensure that the graph embedding method is better suited for the HTC task and thus resulted in the enhanced tree structure representation. Results obtained through experimentation on both the public WOS dataset and an E-commerce user intent classification dataset demonstrate that our proposed model can achieve superlative results.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction

An example of the E-commerce user intent classification dataset. In the HTC task, the user query corresponds to some nodes in the hierarchical prior tree. The blue nodes indicate the manually labeled results of the questions asked by the user in the HTC task
Hierarchical text classification (HTC) is a particular multi-label text classification task, where the classification results correspond to some nodes of a taxonomic hierarchy. It plays an important role in many real-world applications, such as webpage topic classification, product categorization, and user feedback classification. Figure 1 is an example of the E-commerce user intent classification dataset; the goal of HTC is to use the structural relationship of labels to find the correct classification answers. The prior probability tree of HTC is constructed based on the labels that have been manually labeled, and the manually labeled labels have hierarchical structure information between them so that the constructed prior probability tree can use the structural information of the labels between different levels. In the example of the E-commerce user intent classification dataset in Fig. 1, level 1, level 2, and level 3 represent the three-level structure of all labels, respectively. The role of the root node is to construct the labels in the level 1 layer into a complete tree structure, so it is called level 0 and has no meaning at level 0. In the HTC task, the user query corresponds to some nodes in the hierarchical prior tree. The blue nodes in each layer indicate the multi-label classification results of the user utterance, and the HTC task is dedicated to improving the accuracy of multi-label classification in the hierarchy. All nodes in the E-commerce user intent classification dataset are not fully listed in Fig. 1, and there are many more labels in the actual dataset.
Two kinds of methods are widely used for HTC, which are the local methods and the global methods. The local methods [1,2,3,4] focus on constructing multiple cascaded classifiers, and the number of classifiers depends on the number of label layers. Multiple classifiers built by local-based methods can learn features from different layers and then obtain multi-label classification results. The advantage of the local methods is that it can utilize more fine-grained hierarchical information. But those methods are easily affected by the parent classifiers. Each classifier’s loss can easily affect the final model’s performance. And the computational cost is very high.
In order to integrate the multiple cascaded classifiers’ loss, researchers try to use global methods. The global methods [5, 6] focus on building a whole classifier, which can utilize structural information of hierarchical prior tree. The global approach is rapidly gaining a lot of attention due to its low computational cost and high classification accuracy. So in this paper, we mainly focus on improving the accuracy of the global approach. The hierarchical prior tree is constructed from manually labeled labels in order to extract the structural relationship between labels. Recent global methods employ the graph convolutional neural network (GCN) [5] to utilize the structural features. GCN is a graph structure feature extractor, which can extract features from graph structure data to obtain an embedded representation of the graph. As the tree structure is a special form of graph structure, the method based on graph structure can also be used to extract tree structure features. It is not the first time used GCN to model tree structure problems; Zhang et al. [7] employ GCN to fit the dependency tree in dependency parsing.
In this paper, we argue that it is inappropriate to use undirected graph structure approach to model directed tree structure data in the HTC task, and there are some fundamental differences between tree and graph structures. In graph embedding methods, node features are shared for the whole graph. The update direction and order of graph nodes are random. But in the HTC tree structure, the nodes should be updated from the root node instead of randomly selected nodes. Updating the features of the second layer nodes at first will not help much in decoding the first layer labels in the HTC task. And the information update direction is also very important, all nodes should be updated in the same direction as the prior tree, which is more suitable for the HTC task.
We also regard the hierarchical classification task as a sequence-to-sequence task, different from the previous work used the Seq2Seq to generate text, but we use it to generate labels. Each label in the different decoding time step t is the multi-label classification result, so the decoding results set is the final results after t time decoding process. Sequence-to-sequence (Seq2Seq) learning [8] is widely used in machine translation tasks and text generation tasks. The Seq2Seq method proposes an encoder and decoder architecture, which has a large degree of freedom in its inputs and outputs, so it can be adapted to many tasks. Some researchers [9] use the Seq2Seq method for multi-label classification before, but they focus on using external knowledge rather than hierarchical structure information. The Seq2Seq method can dynamically fuse other models into a holistic model without incurring hierarchical loss propagation. Based on the learning of the global method, we believe that the encoder and decoder structure is more suitable to integrate GCN in the decoding process. The model can not only learn the semantic representation of the sentence, but also utilize the hierarchical structure information to help the model improve the multi-label classification accuracy.
To deal with the directional characteristic, we regard hierarchical label extraction as a sequence generation task. We first construct a prior tree of the whole hierarchical structure tree and use it as the hierarchical information to guide the final multi-label classification. Unlike the previous multi-label classification task, the decoder is formed as an auto-regressive structure, in which each time step can decode a corresponding label, and after time t, the decoding results of each time step form the final multi-label classification results together. Using the encoder and decoder structure, the features of the parent layer labels can be effectively used to decode the current layer. Based on the framework of the encoder-decoder, we employ a GCN to model the characteristics of a hierarchical tree. Then, aiming at the hierarchy of message transmission between tree nodes, we propose a method to suppress one-directional data flow to ensure a complete hierarchical tree structure and get the enhanced representation of hierarchical tree structure. We designed two unidirectional node update patterns, which are Top-Down and Down-Top. And we believe that using unidirectional node update patterns can enhance the representation of the tree structure in the HTC task.
The contributions of this paper are summarized as follows:
-
We use auto-regressive decoder for the HTC task and propose the UMP-MG model, which introduces GCN to get the representation of hierarchical structure, and the decoder can use hierarchical structure information effectively.
-
In the process of modeling the hierarchical structure tree, we propose two unidirectional message-passing methods in GCN, which are Top-Down and Down-Top to enhance the representation of tree structure.
-
We compare UMP-MG with several baselines, and our model UMP-MG has achieved the best results on E-commerce user intent classification dataset Intent dataset and WOS public dataset.
2 Related Work
HTC is a particular multi-label text classification (MLC) problem, and the classification of MLC tasks results in multiple category labels. The labels of the HTC task have a hierarchical tree structure with the relationship between each level of labels, and the final classification results of the HTC task correspond to some nodes of the hierarchical tree. Existing methods for HTC could be categorized into two groups: the local method and the global method.
The local approach tends to construct multi-classifiers according to the different structural layers. Researchers tend to construct different forms of multi-classifiers to fit the features in different level. Cesa-Bianchi et al. [10] propose a classification method using hierarchical SVM. Using this method is as efficient as training independent SVM-light classifiers for each node. Recently, Huang et al. [1] build a hierarchical attention-based recurrent layer; each recurrent layer can be considered as a local classifier. They classify the documents into the most relevant categories level by level via integrating texts and the hierarchical category structure. Kazuya et al. [2] use text-cnn to extract parent labels’ features, and then, they use fine-tuning method to fit the children level labels’ features. Banerjee et al. [4] propose a transfer learning method to train parent classifiers and child classifier. Wehrmann et al. [3] propose simultaneously optimizing local and global loss functions for discovering local hierarchical class relationships. Mirończuk et al. [11] propose a multi-view framework for text classification that is composed of two levels of information fusion. Lin et al. [12] extract an interpretable sentence embedding by introducing self-attention.
The global approach regards HTC as a flat MLC problem on the basis of making full use of structural information as much as possible. Early efforts for the HTC task focused on building a flat-based global classifier, and researchers often used Decision Tree and Naive Bayes [13] methods. These methods ignore the hierarchical structure information. There are many applications in the industry nowadays and with the emergence of pre-trained language models, which have also achieved good results in the HTC task. However, these methods ignore the structural information between the hierarchical labels, which means that the structural information is not utilized at all in the actual classification process. Moreover, the inference speed is slow in the actual classification process due to a large number of parameters. A Neural Network called the MHC-CNN model is presented by Borges et al. [14] to predict all categories in the hierarchical structure. Harika et al. [15] present the first semi-supervised work for the multi-label classification. Cerri et al.[16] present a new hierarchical multi-label classification method based on multiple neural networks for the task of protein function prediction. In recent years, with the emergence of some new methods in deep learning, some researchers try to use meta-learning [6] to solve HTC problems. Mao et al. [17] use a reinforcement learning approach called HiLAP to transform the HTC task as a Markov decision process. Peng et al. [18] propose a novel hierarchical taxonomy-aware and attentional graph capsule recurrent CNNs framework for large-scale multi-label text classification. Chen et al. [19] propose to model the word and label hierarchies by embedding them jointly in the hyperbolic space. Zhang et al. [20] designed to hierarchically extract important information from the text based on the labels from different hierarchy levels. Deng et al. [21] propose HTCInfoMax to address these issues by introducing information maximization which includes text-label mutual information maximization and label prior matching. Wang et al. [22] imitate the cognitive structure learning process into the HMLTC learning and propose a unified framework. Chen et al. [23] recognize human intentions from electroencephalographic (EEG) signals and explore correlations between specific segments of an EEG signal and an associated intention.
The use of graph neural networks to solve HTC problems has been studied by many researchers. Zhou et al. [5] get the idea from the graph embedding method and use GCN to extract the structural features of the hierarchical tree, as a tree structure is a special graph structure. Du et al. [24] collect multi-view data from different information sources or with distinct feature extraction approaches via clustering algorithm. It is not the first time to use GCN to model tree structure. Zhang et al. [7] employ GCN to fit the dependency tree in dependency parsing. Tree LSTM [25] can also model tree structure. However, tree LSTM has a large number of parameters and is inferior to GCN in performance and training time. Sequence-to-Sequence learning [8] is widely used in machine translation and text generation. Sequence-to-Sequence learning proposes an encoder and decoder architecture, which has great flexibility for the input and output. Rojas et al. [9] employ an encoder and decoder structure to fit the HTC task, as the architecture can fuse external knowledge. Chen et al. [26] propose a explainable framework that interprets the path-reasoning process with first-order logic, which provides a knowledge-enhanced interpretable prediction framework. Ning et al. [27] combine the subjective pivotal information from the explicit dependency tree with sentence implicit semantic information. Graph neural networks have also emerged in newer variants after the GCN, with P Veličković et al. [28] weighting the edges on top of the GCN, called GAT. Zhao et al. [29] believe ontology information is the key for building knowledge-driven decision-making processes. Describing complex systems in nature is very important, Zhao et al. [30] propose a novel deep attributed network representation learning model framework to preserve the highly nonlinear coupling and interactive network topological structure and attribute information.
In this paper, we believe that the difference between the two structures should be considered when using the undirected graph embedding method to solve the tree structure problem, so we control the message-passing direction to make the graph embedding method more suitable for the tree structure.
3 Our Model - UMP-MG

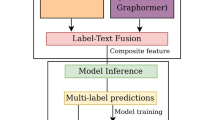
The overall structure of our model. Different colors represent different states of the network
In this section, we illustrate our model in detail, whose architecture is depicted in Fig. 2. The complete UMP-MG model consists of three parts: a user utterance information extraction Encoder, a hierarchical structure Extractor, and a label Decoder. Different colors represent different states of the network, the yellow states represent the word embeddings of user utterances in the Encoder area, and the green states represent the hidden vectors of the UMP-MG model. The outputs of the UMP-MG model are the three levels of hierarchical labels. Since a generative model is used, we set a \(<BOS>\) tag at the beginning of the decoder and a \(<EOS>\) tag at the end of the decoder, which is not included in the hierarchical labels.
The transformer structure consists of an encoder and a decoder. After this, there are many pre-trained models based on encoders or encoders and decoders trained on large-scale corpora, respectively. The advantage of the encoder- and decoder-based architecture is that it can handle data of unequal length and can fully understand the semantic information of the sentences. Moreover, on top of this structure, other model architectures can be easily fused, and the approach proposed in this paper is a graph structure approach fused on top of the encoder and decoder.
3.1 Encoder
Our encoder is composed of transformer blocks [31]. Considering the length of sentences, this encoder can capture long-distance semantic dependency features. The transformer is a high-performance feature extractor, which consists of multi-head attention mechanism modules to extract features of sentences from different perspectives, and the attention mechanism is calculated as follows:
where Q, K, and V represent the query vectors, keys, and values. The attention mechanism can calculate the similarity scores between query and keys, and the final vector is obtained by multiplying the calculated weights by values. Multi-head attention focuses on feature information from different perspectives, it randomly initializes some identical attention mechanisms, and the multi-head attention is calculated as follows:
where i represents the i th Attention mechanism. The \(Q_i\), \(K_i\), \(V_i\) represent the matrix in the i th Attention mechanism, respectively. To keep the latitude of the model constant after computing multiple attention mechanisms, a linear network is used to fuse the multi-headed attention information.
where \(W_l\) represents linear weights, and the H represents the final sentence representation.
Given the input \(\varvec{X} = \left( x_1, x_2,..., x_n\right)\), where \(x_i\) represents the word in the user utterance sentence. The encoder calculation formula is as follows, where H represents the sentence representation.
In the transformer encoder block, the attention mechanism uses a self-attention mechanism in which the values of query, key, and values are equal, representing Q, K, and V in the formula, respectively. We use the transformer block to encode the user’s utterance into a fixed dimension.
3.2 Hierarchical Structure Construction
In this section, we will introduce the details of building a hierarchical classification tree structure. The E-commerce dataset is collected from the historical conversation information of users on E-commerce websites, and we looked for professionals to mark three levels. The nodes in child layers have inheritance relationships from their parent layers. Take the E-Commerce dataset as an example, because the E-Commerce dataset has more layers and more complex nodes, the hierarchical structure tree constructed is also larger. Each input sentence has its corresponding three-level label as shown in Fig. 1. Given the input \(sentenc{e_i}\), the corresponding labels are \({l_i}^1\), \({l_i}^2\), \({l_i}^3\). The hierarchical labels obtained from each input sentence have an inheritance relationship. We collect the hierarchical labels of all sentences in dataset to build a complete global tree structure, that is why our model is a global method for hierarchical label classification. In the next, we combine all sentences labels into a whole tree, \(Hierarchical \ labels = sentenc{e_1} \cup sentenc{e_2} \cup sentenc{e_i}\), i represents the size of E-commerce dataset.
3.3 Hierarchical Structure Extractor
Graph convolutional neural networks are widely used as structure extractors for aggregating node information in natural language processing. Graph neural networks are very effective for modeling structured information like knowledge graphs, and they can find the relationship between different nodes or infer the character of nodes after n hops. However, the HTC is a typical tree structure, which is different from the undirected graph structure. We believe that GCN should fully learn the tree structure and balance the message transmission between tree nodes, so as to make GCN more suitable for HTC tasks. In this paper, we believe that controlling the GCN node message-passing direction can improve the final effect of the model, so we design two hierarchical message-passing patterns for the labeled prior tree, from down to top and from top to down, respectively.
In order to ensure the balance between the root node of our hierarchical probability tree, we control the message-passing direction in GCN, so as to model the hierarchical tree structure as a unidirectional tree and update the node information directly and hierarchically. As shown in Fig. 3 structure extractor, we propose two unidirectional tree patterns, which are GCN(Down) and GCN(Top). We first construct a directed graph following the method of constructing graphs from previous work on GCN and then assign different weights to each edge. So, take the GCN(Top) an example, there is no edge from down to top. And the direction of the node update information will be updated cyclically from the top to the bottom level. What’s more, as we fuse the GCN module into the decoder stage, so in decoder stage, each decoder stage can learn the representation of all nodes from GCN module. And we use attention mechanisms to focus on different levels of representation in the process of decoding the corresponding labels.
In the GCN module, each node represents the corresponding label and each edge indicates an inheritance relationship between two nodes. The initialization of nodes in GCN is random, because we believe that the learning of tree structure should not include the semantic information of node (label), but should focus on the tree structure itself as much as possible. Therefore, each node has only specific position information in the GCN module, instead of the multi-labels’ semantic information.

Two unidirectional message-passing patterns in the HTC task
We follow the previous method in the HTC task [1, 5] to build a hierarchical tree, each node in it represents a manually labeled label. We use the GCN method to extract the relationships between labels; the initialization of each node is random same as the original GCN. The role of the root node is to construct the first-level labels into a complete tree structure and the root node has no actual meaning.
Given the hierarchical node set \(Node = \{ {n_1},{n_2},...,{n_i}\}\), where \(n_i\) represents the \(node_i\) in the hierarchical prior tree. The structure extractor is jointly trained with the whole model. The message-passing paradigm between nodes is calculated as:
where \(N_{\left( i \right) }\) is the set of neighbors of \(Node_i\), \(c_j{_i}\) is the product of the square root of node degrees, \({b^{\left( l \right) }}\) is bias, and \(\sigma\) is an activation function. We use the node vector features in the last layer of GCN, which have fused the structural information, as shown in Fig. 2 blue nodes.
3.4 Decoder
In the decoder stage, we use the hierarchical prior structure features while decoding the HTC labels in each time step t. The hierarchical structure features used for decoding are the steady-state node vectors from the last layer of the GCN. Our model is jointly trained so that it can improve the accuracy of HTC labels and the representation of the tree structure.
The target response sequence is \(\varvec{Y}\mathrm{{ = }}\left( {{y_1},{y_2},...,{y_n}} \right)\), for each word \(y_t\) in Y, we employ the mask operation during the training process to avoid the model seeing the correct answer in advance. For each word \(y_t\), we mask \(\left\{ {{y_{t + 1}},...,{y_n}} \right\}\) and the model can only see \(\left\{ {{y_1},...,{y_{t}}} \right\}\) while decoding the hierarchical label in the time step t.
The formula for the decoder in the time step t can be written in the following equation:
where \(Output_t\) is the label distribution at time t. Starting from the first output, we perform the attention operation on the \(Output_t\) and the node features obtained by GCN. The obtained structure awareness representation is sent to the decoder in the next time step t. Every time we decode the current layer label, our model has inherited the information of the previous time step, which is the parent information of the current layer label. The structure awareness (\(h_t^{SA}\)) attention equation is as follows:
where \(h^{\left( {L} \right) }\) is the representation of the last layer of GCN. The last layer of the GCN indicates that the information transfer between nodes in the tree structure tends to a steady state. Using the attention mechanism can calculate the similarity between the output of this layer and the nodes of the hierarchical prior tree at different levels, so that correspondence relations can be established in order to improve the model’s utilization of structural information.

In the decoding process, the overall probability of the label sequence generated by the model is calculated by the most likelihood estimation. The most likelihood of the response sequence can be calculated as follows:
where \(h_t^{SA}\) is the attention fusion vector of label and hierarchical prior tree node features obtained by decoding at each time step t. The \(output_{t}\) decoded by unidirectional message-passing GCN network finally use softmax to obtain the corresponding multiple labels.
3.5 UMP-MG Model Process
In order to summarize the encoder and decoder processes of the UMP-MG model more completely, we summarize Algorithm 1 to describe the model in detail. The UMP-MG model contains three parts, sentence encoder, structure extractor and multi-label decoder, where the encoder uses the transformer block to encode the user’s utterance and uses an attention mechanism to fuse the relationship between the labels captured by the unidirectional GCN during decoding. Since the decoder is an auto-regressive structure, each time step can decode a corresponding label, and after time t, the decoding results of each time step form the final multi-label classification results together. We use \(Labels = labels \cup labe{l_t}\) in Algorithm 1 to represent the merging of each label result.
4 Experiment
In this section, we will introduce our experiment details of our UMP-MG model, which includes the dataset details, baselines, the variations of our UMP-MG model and the implementation and experiment design.
4.1 Datasets
We used E-commerce user intent classification dataset and WOS dataset [5] for experiments. This E-commerce user intent classification dataset is collected from an intelligent service robot designed for creating an innovative online shopping experience in an E-commerce website. We collected the historical conversation information of users on E-commerce websites and looked for professionals to mark three levels. Due to the protection of user privacy and trade secrets, we cannot disclose this data set. Each parent level and its child level have a certain degree of dependency. And the WOS dataset collected abstracts of published papers from Web of Science, which includes the abstract and specific topics. So in the WOS dataset, there is a two-level classification structure, the first level data are collected from different domains. These areas include Computer Science, Electrical Engineering, Psychology, Mechanical Engineering, Civil Engineering, Medical Science, and biochemistry. The classes in second level are the specific topics of each abstract, so that the WOS dataset is a fair hierarchical classification data set.
Different classes in each level are shown in Table 1. From the table, we can see the E-commerce user intent classification dataset is more complex than WOS in quantity, as there is no third level in WOS dataset and our E-commerce dataset in each level has more classes than the WOS dataset.
4.2 Evaluation Metrics
In this paper, we followed the previous work and used the same evaluation metrics, which are Micro-F1 and Macro-F1 metrics. We use standard evaluation metrics [32], including Micro-F1 and Macro-F1. Micro-F1 takes the overall precision and recall of all the instances into account, while Macro-F1 equals the average F1-score of labels. So Micro-F1 gives more weight to frequent labels, while Macro-F1 equally weights all labels.
4.3 Baselines
We select several common baselines to test our UMP-MG model, such as TextCNN, BERT(Global), Seq2Seq(Att), HiAGM [5], HARNN [1]. The HiAGM and HARNN both are the most advanced HTC models in recent years. The HiAGM is a strong baseline model using the global method in hierarchical text classification, and the HARNN is a representative model of using local methods in hierarchical text classification.
4.3.1 TextCNN(Global)
Text classification model based on Convolutional Neural Network [33]. TextCNN is widely used in industrial applications, as its small number of parameters and quick response. And it is still a classical model in hierarchical text classification model.
4.3.2 BERT(Global)
BERT(Global) is widely used in some actual applications, using BERT encoder to encode a sentence and directly get the global classification [34] results. We use BERT(Global) to evaluate global classification performance at the pre-trained level.
4.3.3 Seq2Seq(Att)
Seq2Seq model with attention mechanism [8]. It is a classical encoder and decoder model, and many models use it as a baseline model. We use it to evaluate the effectiveness of generative method in the HTC task.
4.3.4 HARNN
Using attention-based Recurrent Network Approach to model taxonomic hierarchy [1]. HARNN is a representative model of using local methods in hierarchical text classification. It is the latest local method in the HTC task and considers the each layer as a recurrent structure.
4.3.5 HiAGM
Using Graph embedding method to model the hierarchy structure and it’s the global method in the HTC task [5], which has achieved best results without external knowledge. The HiAGM is a strong baseline model using the global method in hierarchical text classification
4.4 Variations of Our UMP-MG Model
Table 2 gives details about the different combinations of individual encoder, decoder and GCN for several variants of UMP-MG. In UMP-MG(BERT) model’s encoder is composed of pre-trained levels of BERT, and the pre-trained BERT model uses the base version. The decoder is the normal transformer block with attention mechanism. The Undirected GCN is the normal GCN, which don’t use the method proposed in this paper. We concatenate the node features in both Down-Top and Top-Down in Bi-direction structure extractor. We propose several UMP-MG variants of the model to verify that our proposed unidirectional messaging passing method is valid.
4.5 Implementation and Experiment Design
To keep the fairness across baseline models in the experiment, we used the same parameters on all groups of experimental models. The hidden layer size is set to 256, and the batch size is set to 64. We use 8 heads of attention, 6 layers of the encoder and the model parameters’ optimizer is Adam. The learning rate is 0.001. We use Pytorch to run all models on four Tesla P40 GPU. The experiments will be designed to compare on several latitudes, the first set of experiments is to compare with the commonly used models, the second set of experiments is to compare with the recent state-of-the-art models, and the third set of experiments is to compare some variants of our proposed UMP-MG model.
The first set of experiments contains some basic models commonly used in industry. BERT pre-trained model is often used in industry as its ability to understand natural language, so we design experiments to compare our UMP-MG model with pre-trained models. TextCNN is a classical classification model that is also widely used in practical applications, and the Seq2Seq model is a classical encoder and decoder generation model. In addition, in the Seq2Seq model, we use the attention mechanism, and using the attention mechanism can significantly increase the performance of the Seq2Seq model. The first set of experiments was designed to verify the effectiveness of the model from different perspectives.
The second set of experiments used the most recent baseline models, where HARNN is a hierarchical label classification model based on a local approach and HiAGM model is a hierarchical label classification model based on a global approach. The second set of experiments is designed to compare the effect of the model proposed in this paper with the strong baseline model.
In the third set of experiments, we focus on which module in the UMP-MG model has the greatest impact on the UMP-MG model. First, we design UMP-MG(Normal) and UMP-MG(BERT) to improve the performance of the encoder and decoder structure. The purpose is to verify the effectiveness of the approach using generative encoder and decoder structure in multi-label classification. Then, we design a normal GCN model without using the methods in this paper, with the purpose of verifying that unidirectional propagation performs better than undirected propagation in GCN. Finally, we designed two models, called UMP-MG(GCNDown) and UMP-MG(GCNTop), based on the two different directional message-passing patterns proposed in this paper. The purpose is to verify the effect of different directional messaging patterns on the UMP-MG model. UMP-MG(GCNCat) is used to verify whether fusing two different directions of information will be more effective than unidirectional message-passing.
5 Experiment Results and Analysis
5.1 Experiment Results
The experiment results are shown in Table 3. From Table 3, our UMP-MG(GCNTop) achieves the best results in every evaluation metric. F1 value can clearly show the effectiveness of our proposed model. The F1 value shows that the proposed global hierarchical classification model achieves the best results compared with the previous strong baseline model. In comparison with Seq2Seq, our proposed model of integrating hierarchical label structure is better than the simple use of generative model, which shows that it is very effective to learn the structural information between labels. When performing global classification directly in the HTC task, the performance of using encoder–decoder architecture(Seq2Seq(Att)) is almost same as using BERT(base) global classification directly. Our model is also compared with the BERT global classification based on the pre-training model. The results show that the effect of our small parameter model is better than that of the pre-training model, which shows that the generated structure we use is better than the pre-training model in the hierarchical label classification task.
5.2 Ablation Study
The ablation results are shown in Table 4. UMP-MG(Normal) is a common transformer structure, and it performs better than Seq2Seq. The attention mechanism-based transformer module is much better than the RNN-based Seq2Seq model. Most importantly, the performance of UMP-MG(Normal) using the generative method to fit the HTC task is better than that of BERT(Global) method based on pre-training. As the Seq2Seq(Att) and UMP-MG(Normal) are based on encoder and decoder architecture, the results of this set of experiments show that the encoder and decoder-based architecture is more suitable for the HTC task.
In terms of the utilization of hierarchical information, the effect of UMP-MG(GCN) is significantly better than UMP-MG(Normal). And the UMP-MG(GCN) uses the undirected message-passing method. This suggests that it is effective to focus on structural information in the encoder–decoder architecture through the unspecified design of the GCN. In terms of solving the HTC problem, the decoder in UMP-MG(GCN) uses the attention mechanism to consider the relationship between the current layer node and other layers in the hierarchy tree when we decode the label of the current layer. Using attention mechanism can effectively integrate the hierarchical structure information with the decoder.
UMP-MG(GCNTop) and UMP-MG(GCNDown) use unidirectional information flow, and the results are significantly better than UMP-MG(GCN) embedded in the graph structure. The relationship features between layers are obtained by constraining the unidirectional information flow in GCN. This shows that the method of unidirectional message-passing has more advantages than the traditional undirected UMP-MG(GCN). It also shows that it is unwise to employ the undirected graph methods to fit the task based on directed tree structure. And it’s very effective to use the unidirectional message-passing method to enhance the representation of tree structure. Moreover, the effect of using UMP-MG(GCNTop) is better than that of UMP-MG(GCNDown), and it also improves the model’s performance compared with the recent models such as HiAGM [5] and HARNN [1]. This is also in line with the cognition of Top-Down decoding in the encoder–decoder architecture, and the HTC is also decoded one by one from Top-Down.
In UMP-MG(BERT), we try to replace the encoder with the BERT [34] pre-trained encoder and compared with our best UMP-MG(GCNTop). The UMP-MG(GCNTop) model achieves the best performance in terms of the performance and the number of parameters. In this set of experiments, it is well illustrated that using a GCN generative model with an enhanced tree structure representation achieves comparable results on the HTC task to a pre-trained model, which would have a large number of parameters and would be very time-consuming if applied to real-life situations.
We also try to integrate the bidirectional features in UMP-MG(GCNCat), we concatenate bidirectional node features, the results aren’t as good as UMP-MG(GCNTop), but it is still better than UMP-MG(GCN). We believe that compared with undirected message-passing method, unidirectional information transmission proves its effectiveness again. And the performance of UMP-MG(GCNCat) is better than UMP-MG(GCNDown), which shows that in the process of concatenating Bi-directional information, UMP-MG(GCNDown) absorbs valuable information from UMP-MG(GCNTop), so UMP-MG(GCNTop) pattern is more suitable for the HTC task.
On both the two datasets, the values of Macro-F1 are generally lower than those of Micro-F1, because Macro-F1 focuses more on the accuracy of the classification of each sample in the test set, while Micro-F1 focuses on the weighted distribution of the number of samples in the test set. In general, any unidirectional UMP-MG model is better than the undirected UMP-MG model. The use of generative method is helpful for hierarchical HTC tasks, and the decoder can skillfully integrate structural information.
6 Conclusion
In this paper, we argued that using undirected graph structure to model the directed tree structure feature is not appropriate in the HTC task. We proposed a Top-Down hierarchical aware generative method for realizing the hierarchical text classification by controlling the direction of message-passing in a graph embedding method and used generative method to fuse the relational features between tags during decoding. The experiments showed the superiority of our model. In future, we will explore the application of more GCN variations in the HTC task, using pre-trained embeddings of each nodes in the graph and how to extract structural features more effectively.
Data Availability
All data in the experiment are authoritative and available.
References
Huang W, Chen E, Liu Q, Chen Y, Huang Z, Liu Y, Zhao Z, Zhang D, Wang S (2019)Hierarchical multi-label text classification: an attention-based recurrent network approach. In: Proceedings of the 28th ACM international conference on information and knowledge management pp 1051–1060
Shimura K, Li J, Fukumoto F (2018) Hft-cnn: Learning hierarchical category structure for multi-label short text categorization. In: Proceedings of the 2018 conference on empirical methods in natural language processing. pp 811–816
Wehrmann J, Cerri R, Barros R (2018) Hierarchical multi-label classification networks. In: International conference on machine learning , PMLR, pp 5075–5084
Banerjee S, Akkaya C, Perez-Sorrosal F, Tsioutsiouliklis K (2019) Hierarchical transfer learning for multi-label text classification. In: Proceedings of the 57th annual meeting of the association for computational linguistics. pp 6295–6300
Zhou J, Ma C, Long D, Xu G, Ding N, Zhang H, Xie P, Liu G (2020) Hierarchy-aware global model for hierarchical text classification. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp 1106–1117
Wu J, Xiong W, Wang WY (2019) Learning to learn and predict: a meta-learning approach for multi-label classification. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP)
Zhang Y, Qi P, Manning CD (2018) Graph convolution over pruned dependency trees improves relation extraction. In: Proceedings of the 2018 conference on empirical methods in natural language processing. pp 2205–2215
Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. Adv Neural Inform Process Syst 27
Rojas KR, Bustamante G, Oncevay A, Cabezudo MAS (2020) Efficient strategies for hierarchical text classification: external knowledge and auxiliary tasks. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp 2252–2257
Cesa-Bianchi N, Gentile C, Tironi A, Zaniboni L (2004) Incremental algorithms for hierarchical classification. Adv Neural Inform Process Syst 17
Mirończuk MM, Protasiewicz J, Pedrycz W (2019) Empirical evaluation of feature projection algorithms for multi-view text classification. Expert Syst Appl 130:97–112
Lin Z, Feng M, Santos CND, Yu M, Xiang B, Zhou B, Bengio Y (2017) A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130
Fall CJ, Törcsvári A, Benzineb K, Karetka G (2003) Automated categorization in the international patent classification. In: Acm Sigir Forum. vol. 37, pp 10–25. ACM New York, NY, USA
Borges HB, Nievola JC (2012) Multi-label hierarchical classification using a competitive neural network for protein function prediction. In: The 2012 international joint conference on neural networks (IJCNN). IEEE, pp 1–8
Abburi H, Parikh P, Chhaya N, Varma V (2021) Fine-grained multi-label sexism classification using a semi-supervised multi-level neural approach. Data Sci Eng 6(4):359–379
Cerri R, Barros RC, de Carvalho PLF, André C, Jin Y (2016) Reduction strategies for hierarchical multi-label classification in protein function prediction. BMC Bioinform 17(1):1–24
Mao Y, Tian J, Han J, Ren X (2020) Hierarchical text classification with reinforced label assignment. In: 2019 conference on empirical methods in natural language processing and 9th international joint conference on natural language processing. EMNLP-IJCNLP 2019, Association for Computational Linguistics, pp 445–455
Peng H, Li J, Wang S, Wang L, Gong Q, Yang R, Li B, Philip SY, He L (2019) Hierarchical taxonomy-aware and attentional graph capsule rcnns for large-scale multi-label text classification. IEEE Trans Knowl Data Eng 33(6):2505–2519
Chen B, Huang X, Xiao L, Cai Z, Jing L (2020) Hyperbolic interaction model for hierarchical multi-label classification. In: Proceedings of the AAAI conference on artificial intelligence. vol. 34, pp 7496–7503
Zhang X, Xu J, Soh C, Chen L (2022) La-hcn: label-based attention for hierarchical multi-label text classification neural network. Expert Syst Appl 187:115922
Deng Z, Peng H, He D, Li J, Philip SY (2021) HTCinfomax: A global model for hierarchical text classification via information maximization pp 3259–3265
Wang B, Hu X, Li P, Philip SY (2021) Cognitive structure learning model for hierarchical multi-label text classification. Knowl-Based Syst 218:106876
Chen W, Yue L, Li B, Wang C, Sheng QZ (2019) Damtrnn: a delta attention-based multi-task RNN for intention recognition. In: International conference on advanced data mining and applications. Springer, pp 373–388
Du G, Zhou L, Yang Y, Lü K, Wang L (2021) Deep multiple auto-encoder-based multi-view clustering. Data Sci Eng 6(3):323–338
Tai KS, Socher R, Manning CD (2015) Improved semantic representations from tree-structured long short-term memory networks. In: Proceedings of the 53rd annual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing. pp 1556–1566
Chen Z, Wang X, Wang C, Li J (2022) Explainable link prediction in knowledge hypergraphs. In: Proceedings of the 31st ACM international conference on information & knowledge management. pp 262–271
Ning B, Zhao D, Liu X, Li G (2022) Eags: An extracting auxiliary knowledge graph model in multi-turn dialogue generation. World Wide Web. 1–22
Veličković P, Cucurull G, Casanova A, Romero A, Lio P, Bengio Y (2017) Graph attention networks. arXiv preprint arXiv:1710.10903
Li Z, Liu X, Wang X, Liu P, Shen Y (2022) Transo: a knowledge-driven representation learning method with ontology information constraints. World Wide Web. 1–23
Li Z, Wang X, Li J, Zhang Q (2021) Deep attributed network representation learning of complex coupling and interaction. Knowl-Based Syst 212:106618
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A.N, Kaiser, Ł, Polosukhin I (2017) Attention is all you need. Adv Neural Inform Process Syst 30
Gopal S, Yang Y (2013) Recursive regularization for large-scale classification with hierarchical and graphical dependencies. In: Proceedings of the 19th ACM SIGKDD international conference on knowledge discovery and data mining. pp 257–265
Kim Y (2014) In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), Association for Computational Linguistics, Doha, Qatar , pp 1746–1751 https://doi.org/10.3115/v1/D14-1181. https://aclanthology.org/D14-1181
Devlin J, Chang M.-W, Lee K, Toutanova K (2018) Bert: Pre-training of deep bidirectional transformers for language understanding
Acknowledgements
The work was supported by the National Natural Science Foundation of China (NSFC, No. 61976032) and the Scientific Research Foundation of Liaoning Provincial Department of Education (No. LJKZ0063). The authors are grateful to the anonymous reviewers for their constructive comments, which have helped improved this work significantly.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Consent for publication
All authors have read and agreed to the published version of the manuscript.
Ethical approval and Consent to participate
This article does not contain any studies involving human participants and/or animals by any of the authors.
Human and animal participants
Not applicable.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ning, B., Zhao, D., Zhang, X. et al. UMP-MG: A Uni-directed Message-Passing Multi-label Generation Model for Hierarchical Text Classification. Data Sci. Eng. 8, 112–123 (2023). https://doi.org/10.1007/s41019-023-00210-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41019-023-00210-1