
Abstract
In recent years, Coronavirus disease 2019 (COVID-19) has become a global epidemic, and some efforts have been devoted to tracking and controlling its spread. Extracting structured knowledge from involved epidemic case reports can inform the surveillance system, which is important for controlling the spread of outbreaks. Therefore, in this paper, we focus on the task of Chinese epidemic event extraction (EE), which is defined as the detection of epidemic-related events and corresponding arguments in the texts of epidemic case reports. To facilitate the research of this task, we first define the epidemic-related event types and argument roles. Then we manually annotate a Chinese COVID-19 epidemic dataset, named COVID-19 Case Report (CCR). We also propose a novel hierarchical EE architecture, named multi-model fusion-based hierarchical event extraction (MFHEE). In MFHEE, we introduce a multi-model fusion strategy to tackle the issue of recognition bias of previous EE models. The experimental results on CCR dataset show that our method can effectively extract epidemic events and outperforms other baselines on this dataset. The comparative experiments results on other generic datasets show that our method has good scalability and portability. The ablation studies also show that the proposed hierarchical structure and multi-model fusion strategy contribute to the precision of our model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
At present, COVID-19 become a serious epidemic globally, and as of March 2022, there have been over 600 million confirmed COVID-19 cases, resulting in more than 6 million deaths [2]. Some surveillance efforts are devoted to using informative epidemic case reports to track and control the spread of COVID-19. However, conventional epidemic data processing methods require labor-intensive manpower input to effectively learn from past epidemic outbreaks. Therefore, how to build an efficient machine model to process epidemic data remains a challenging problem for healthcare workers and researchers.

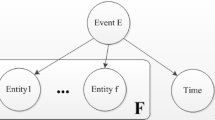
Example of EE
Recently, there has been extensive research on automatic epidemic EE. Epidemic event extraction (EE) aims to get structured epidemic event information, i.e., epidemic event trigger (with event type) as well as its corresponding arguments (with argument roles). It can be divided into two subtasks, i.e., event type identification (ETI) and event argument extraction (EAE). Figure 1 shows an example of epidemic EE. We input a piece of epidemic text into the model, and the output is the event type and the corresponding argument roles. Guo et al. [8] designed a three-stage pipeline method to extract epidemic events, achieving canto-level extraction. Mutuvi et al. [30] also propose a strong baseline and present a token-level dataset for multilingual epidemic EE.

Extraction results of different EAE models
However, the previous models face the issue of recognition bias. Differing from the inductive bias in machine learning [6], we define recognition bias as the uneven recognition performance of different event types. Figure 2 shows the EAE results of the same sentence by different EAE models. It can be seen that the BiLSTM model [43] correctly identifies three arguments “June 14 afternoon”, “by taxi” and “department store”, but incorrectly identifies the Number “61” as Time. The IDCNN model [17] can correctly identify the two arguments “June 14 afternoon” and “by taxi”, but fails to recognize “department store”. There are several reasons for the phenomenon of error by BiLSTM and IDCNN: (1) The quality of the dataset is not high enough, and there are noise and conflicting data. (2) The parameter setting is not optimized enough, which leads to the defects of the model itself. (3) Different neural networks may do well in learning different perspectives from the events during the optimization process. Therefore, to solve this problem, we introduce a multi-model fusion strategy to solve this problem effectively. We retain the correct part of each model and filter out the wrong part, which will greatly improve the recognition accuracy.
In summary, existing epidemic-oriented methods have two problems: (1) There is no open-source dataset of manually annotated Chinese epidemic case reports. (2) The previous models have the problem of recognition bias, which leads to low recognition accuracy for specific event types. To facilitate the research on epidemic EE, we urgently need a large-scale, manually annotated dataset, and an efficient method to serve the domain of epidemic EE.
In this paper, we present COVID-19 Case Report (CCR), a large-scale manually annotated epidemic case report dataset that contains 25,870 events and 109,350 argument roles. We also propose a multi-model fusion-based hierarchical event extraction (MFHEE) method for Chinese epidemic EE. MFHEE combines multiple advanced EE methods and retains the advantages of each model. MFHEE is a stronger epidemic EE method, which may further benefit other tasks related to COVID-19. We conduct thorough experiments on CCR under various settings and comprehensively evaluate the MFHEE method on different datasets, providing a promising research method for the study of epidemic EE.
This paper is organized as follows: after introduction in Sects. 1, 2 provide an overview of the work related to epidemic EE. In Sect. 3, we describe the dataset, and the architecture of the proposed method is elaborated in Sect. 4. In Sect. 5, we conduct ablation studies for hierarchical extraction and multi-model fusion, and compare our model with previous mainstream models in the field of epidemic EE. Finally in Sect. 6, we summarize some potential future work with our model.
2 Related Works
Identifying and extracting text elements is one of the research hotspots in the domain of information extraction. In the past practice, most of the EE methods are based on dictionary [12], rule [13], or statistical machine learning [33]. However, these methods rely too much on human engineering, which limits their generalization. In recent years, with the maturity of deep learning research, deep neural network-based EE method has also become an important supporting technology for text element recognition [41]. Compared with traditional machine learning methods, the deep learning methods have the advantages of deeper network layers and more complex learning features. Besides, these methods have no further need manually construct features. The EE task is divided into ETI and EAE subtasks. ETI [8] classifies a piece of text into a target event type. EAE [35] aims to identify event arguments and classify their roles in the event.
There are two mainstreams of deep learning-based EE approaches: (1) Pipeline-based approach [3, 10, 21, 22, 24, 28, 39, 45] that first performs ETI and then identifies arguments base on the results of ETI. (2) Joint-based approach [16, 25, 29, 31, 44, 47, 49] that treats EE as a structure extraction task, and predicts event type and corresponding arguments at the same time. Although pipeline-based approaches are simpler and more flexible than joint-based approaches, they suffer from the problem of error propagation. Our multi-model fusion strategy can reduce the error at each stage, so we adopt the pipeline-based approach.
Many recent NLP systems use pre-trained language models as backbones, such as BERT [5] and ERNIE [36]. A variety of strategies for incorporating the language models output are used in EE systems. Some studies use the contextualized word embedding sequence as the input to a conditional random field entity extraction layer, while others add an entity-aware attention mechanism and pooled output states to a fully transformer-based model [27]. Here, we employ Google’s BERT language model [5] and Baidu’s ERNIE language model [36] to conduct experiments.
Recently, some research efforts are paid to explore the EE of COVID-19. Some long short-term memory networks-based methods [38] approach the task of epidemic EE from the perspective of classification of documents. Considering that COVID-19 case reports are usually presented in paragraphs and sentences, [8] realized the document-level epidemic EE. However, the majority of previous EE studies are usually based on generic datasets, and there are also limited COVID-19 datasets. These limitations affect the performance of epidemic EE models. Therefore, we introduce the CCR dataset to expand the corpus for the epidemic EE domain. To further improve the accuracy of epidemic EE, we also propose a Chinese EE method named MFHEE.
3 CCR Dataset
In this section, we describe the process of constructing CCR in detail. The whole procedure can be divided into three steps: (1) We crawl a large number of unannotated Chinese epidemic case reports from websites, and define epidemic event types and argument roles according to the text characteristics. (2) We create a large candidate set via regularization matching and knowledge base alignment. (3) Human annotators filter out the wrong-labeled sentences and annotate the unlabeled events to finally obtain a clean CCR dataset.
3.1 Event Definition
Event definition refers to the definition of event types and argument roles. According to the characteristics of epidemic case reports, we define five epidemic event types, including outbreak, case information, activity, confirmed, and affected. Taking activity as an example, its related arguments include time, place, type, and group. The definitions of all five event types are listed in Table 1.
-
Outbreak Event An outbreak event is a specific occurrence related to the epidemic outbreak involving key elements. Its corresponding arguments include time, city, new cases number, new suspected cases number, cumulative cases number, and recovered cases number.
-
Case Information Event A case information event is a specific occurrence related to the case information involving key elements. Its corresponding arguments include place (location of cases), name, gender, age, origo (native place of the case), occupation, address, case (other cases this case contact with), and relation (relationship between case and contacts).
-
Activity Event An activity event is a specific occurrence related to the case activity involving key elements. Its corresponding arguments include time, place, type (mode of transportation of case), and group (companion of the case).
-
Confirmed Event A confirmed event is a specific occurrence related to the cases of confirmed involving key elements. Its corresponding arguments include time and hospital (where the case was treated).
-
Affected Event An affected event is a specific occurrence related to the epidemic spread involving key elements. Its corresponding arguments include time, place, type (type of vehicle involved in infection), and plate number.
3.2 Candidate Set Construction
In the first step, we annotate the epidemic case reports preliminarily by regularization matching. For example, we annotate a piece of epidemic text as the “confirmed event” if it contains the word “confirm”. In addition, we annotate some structured event arguments via regularization matching, such as time, date, gender, and age.
Second, we harness Wikipedia as the external knowledge base (KB) to assist the entity annotations. Wikipedia is a large-scale KB, where a large proportion of entities are already linked to Wikipedia articles [46]. Besides, we employ the entity linking technique [42] to extract more entities in texts. Specifically, we adopt the named entity recognition HanLP [26] to find possible entity mentions, then match each mention with the name of an entity in KBs. All matched entities are annotated as event arguments. Finally, we obtain a candidate set containing 26,324 events and 32,422 event arguments.
3.3 Human Annotation
Next, we invite well-educated annotators to filter candidate set data on the Label Studio platform which is a data annotation platform. The platform presents each annotator with one instance each time, by showing a piece of text and the preliminary annotations in the sentence. The annotators first judge whether the event type of the preliminary annotation is correct. Then determine if the argument roles are correct. If the annotation is incomplete, the annotator annotates all argument roles. Besides, the annotators mark an instance as negative if the sentence is incomplete.
Events are randomly assigned to an annotator, and each annotator consecutively annotates 20 instances of the same event type before switching to the next event type. To ensure annotation quality, each instance is annotated by at least two annotators. If two annotators have disagreements in this instance, it will be assigned to a third annotator. As a result, each instance has at least two same annotations, which will be the final decision [9]. After the annotation, we obtain the epidemic case report dataset CCR including well-annotated 25,870 epidemic event instances and 109,350 event arguments. Of these, 18,000 instances were used for training, 5870 for validation, and 2000 for testing.
3.4 Data Analysis
In this section, we analyze various aspects of CCR to provide a deeper understanding of the dataset and the task of epidemic EE.
Data Size Table 2 shows statistics of CCR, including event types and event argument roles. We find that CCR is a large dataset in many aspects, including the number of sentences, event instances and arguments, especially in aspects of argument types. The CCR dataset contains 25,870 event instances, 109,350 event argument roles, and each event instance contains an average of 4.23 argument roles. We hope the large-scale CCR dataset could drive the development of the epidemic EE domain.
Event Type As shown in Table 2, CCR includes five event types in the epidemic field. A notable property of our dataset is that the events types cover a broad range of categories, including outbreak (24.5%), case information (14.0%), activity (34.7%), confirmed (13.8%), and affected (13.2%), which means that almost every epidemic event can be matched.
Event Argument As shown in Table 2, CCR covers a variety of event arguments, including time (29.7%), place (36.5%), name (15.0%), type (4.8%), etc. It also annotates different argument roles for each event type, enhancing the accuracy of event expression. Each event type has an average of 4.23 argument annotations.
4 Method
In this section, we introduce a novel extraction method for epidemic events named MFHEE. MFHEE consists of three main parts: ETI, EAE, and Multi-Model Fusion.
-
(1)
ETI: we utilize three text classification models to detect epidemic event types. We select RNN-Attention, BERT-RCNN, and ERNIE-DPCNN as baselines of ETI.
-
(2)
EAE: we utilize three named entity recognition models to get the argument roles of the event. We select BERT-BiLSTM-CRF, IDCNN, and BERT-GlobalPointer as baselines of EAE.
-
(3)
Multi-model fusion: we utilize gradient-boosted decision tree (GBDT) [20] for multi-model fusion, which tackles the issue of recognition bias and improves the accuracy of the model.
The overall architecture of the MFHEE is illustrated in Fig. 3. Given a piece of epidemic text, ETI recognizes its event type. GBDT combines the results of the three models in ETI to obtain enhanced results. Then, EAE extracts the corresponding event argument roles according to the text event type. GBDT combines the results of the three models in EAE to obtain enhanced results.

Overall architecture of MFHEE
4.1 Baselines of ETI
RNN-Attention RNN-Attention first utilizes bidirectional LSTM to obtain long-distance advanced features. Then, the attention model is introduced to capture the internal dependence of sentences and calculate the contribution of different words to the text [23, 50]. Finally, the model outputs prediction results via softmax.
BERT-RCNN BERT is a transformer-based pre-trained language model which is widely applied to various NLP tasks [32]. RCNN [37] is a combination of recurrent and convolutional architectures. Two layers of LSTM [14] are employed in the architecture. One learns the context of words from left to right while the other learns contextually from right to left. The combination of BERT and RCNN can achieve better results.
ERNIE-DPCNN ERNIE utilizes multi-source data and prior knowledge for pre-training, which can capture the potential information in the training corpus more comprehensively [19]. DPCNN obtains more accurate local features of text through deep convolution, which can reduce the calculation and overcome the problem of difficulty in extracting long-distance text sequence dependencies [15].

Results of ETI baselines
Figure 4 shows the accuracy of three baselines in extracting the types of different epidemic events. It can be seen that different models have uneven recognition performance in different event types. For example, RNN-Attention performs best on the confirmed event, but is weak in identifying the affected event. BERT-RCNN performs best on the activity event, but is weak in identifying the case information event. ERNIE-DPCNN performs best on the outbreak event, but is weak in identifying the confirmed event. We hope that the strengths and weaknesses of these baselines can complement each other. In Sect. 4.3, we adopt the method of multi-model fusion strategy to filter out the errors and get the correct results.
4.2 Baselines of EAE
BERT-BiLSTM-CRF BERT-BiLSTM-CRF [7] utilizes the BERT to obtain the word vector corresponding to each input character in the corpus. Then the word vector sequence is input into a BiLSTM layer for semantic encoding, and finally, the output result is decoded through a CRF layer [43].
IDCNN IDCNN [40] improves the CNN structure by using holes. This method captures long-distance information of long text, which has better contextual and structured prediction capabilities than traditional CNNs.
BERT-GlobalPointer In pointer network designed for named entity recognition, we usually utilize two modules to identify the head and tail of the entity respectively, which leads to inconsistent training and prediction. GlobalPointer [21] treats both ends as a whole to deal with such inconsistencies. Therefore, GlobalPointer has a more global view.

Results of EAE baselines
Figure 5 shows the accuracy of three baselines in extracting argument roles of activity event. It can be seen that different models have uneven recognition performance in different event argument roles. For example, BERT-BiLSTM-CRF performs best on the type argument but is weak in extracting group argument. IDCNN performs best on place argument but is weak in extracting time argument. BERT-GlobalPointer performs best on group argument but is weak in extracting time argument. Similar to ETI, we also adopt multi-model fusion strategy to solve the problem of recognition bias.
4.3 Multi-model Fusion
We utilize GBDT algorithm to realize the multi-model fusion strategy. We harness the prediction results of baselines as the input to GBDT and GBDT outputs the final results via integrated learning. GBDT integrates the recognition advantages of baselines and solves the problem of recognition bias.
4.3.1 GBDT Algorithm
GBDT [20] is a machine learning algorithm using multiple decision trees (DTs) as base learners. A new DT increases the emphasis on the misclassified samples obtained from the previous DTs, and takes the residuals of the former DTs as the input of the next DT. Then, we harness the added DT to reduce the residuals so that the loss decreases following the negative gradient direction in each iteration. Finally, we determine the prediction result based on the sum of the results of all DTs. The result of the multi-model fusion is represented by y, and the result of each baseline is represented by x, where N is the number of samples of the training dataset. The goal of the decision tree is to solve the following formula:
where \(L\left( y_{i}, \gamma \right)\) is a loss function that reflects the accuracy of the training sample. \(\gamma\) is the initial constant value and the DT model harness the addition function to predict the output:
where \(\phi \in \left\{ f(x)=w_{q(x)}\right\}\) is the space of classification regression tree, equivalent to the independent tree structure q and leaf weight w corresponding to each \(f_k\).
Gradient propulsion method is adopted for parameter estimation to reduce residual error of the model:
The learning objective is defined as
where \(\Omega \left( f_{k}\right) =\gamma J+\lambda w^{2} / 2\) is a classified regression tree function, and GBDT model is obtained through M iterations:
This loop is performed until the specified iterations times or the convergence conditions are met.
4.3.2 GBDT Validity Verification
To verify the validity of GBDT, we introduce a simple example. Table 3 shows the recognition results of four epidemic event instances by three ETI baselines. We construct a simple DT by taking the minimum squared error attribute value [1] as the splitting node, as shown in Fig. 6. It can be seen that the accuracy of results after the identification by GBDT is higher than that of all baselines, reaching 100%. In the actual process of constructing DT, we will construct multiple DTs and take the residual of the former DTs as the input of the next DT to achieve the minimum loss.

Example of DT structure. The set in parentheses is the candidate instance
5 Experiment
To verify the effectiveness of MFHEE, we conduct ablation studies and comparative experiments to evaluate the MFHEE method on CCR dataset and generic datasets.
5.1 Experiment Settings
Model Hyper-parameters The model configuration was selected using threefold cross-validation on the training set. Table 4 summarizes the selected configuration. Training loss was calculated by summing the cross entropy across all span and argument role classifiers. Models were implemented using the Python PyTorch module [27].
Evaluation Metrics We conduct the experimental study based on two sets of evaluation metrics. The first set of metrics includes precision ratio (P), recall ratio (R), and F1-score (F1), which measures the performance of models. The other set of metrics includes false acceptance ratio (\(\mathrm{FAR}\)), false rejection ratio (\(\mathrm{FRR}\)), and detection cost function (\(\mathrm{DCF}\)), which measures the cost of recognizing errors in models [11].
where \(\mathrm{TA}\) is the number of correct acceptances, \(\mathrm{TR}\) is the number of correct rejections, FA is the number of false acceptances, and \(\mathrm{FR}\) is the number of false rejections. \(P_{\text{ miss }}\) is the loss rate, and \(P_{\mathrm{fa}}\) is the false positive rate. \(C_{\text {miss}}\) is the cost of a loss, and \(C_{\mathrm{fa}}\) is the cost of a false positive, both of which are set to 1 in our experimental settings. \(P_{\text{ target }}\) is the proportion of the error rejection rate and the error acceptance rate of prior knowledge. It is usually set as a constant value according to the specific application, which is set as 0.5.
5.2 Ablation Studies
To verify the effectiveness of each module of MFHEE, we conduct two ablation studies. We mainly study the contribution of hierarchical extraction and multi-model fusion strategy to the model. Table 5 shows the two ablation models.
-
(1)
MFHEE model is the full implementation of our model, which integrates hierarchical extraction and multi-model fusion strategy.
-
(2)
To verify the contribution of hierarchical extraction to our model, the multi-model fusion-based event extraction (MFEE) model removes the hierarchical extraction structure, which utilizes the baselines of EAE to extract event argument roles directly.
-
(3)
In order to verify the contribution of the multi-model fusion strategy, the hierarchical event extraction (HEE) model removes the part of multi-model fusion, and utilizes the highest F1-scores for ETI and EAE among all baselines for evaluation.
Table 6 summarizes the results of ablation studies, where the values in bold refer to the best results for the indicators F1-Score and DCF on ETI and EAE tasks. In ETI and EAE tasks, the F1-Score of MFHEE is significantly higher than that of ablation models, and the error detection cost is significantly lower than that of ablation models. It can be seen from the experiments that both hierarchical extraction and multi-model fusion contribute greatly to the improvement in model accuracy. In addition, the two parts are interrelated, and removing either of them has a negative impact on the model.
5.3 Comparative Experiments
To verify the advancement and scalability of MFHEE, we conduct comparative experiments to evaluate the MFHEE method on CCR dataset and generic datasets.
Datasets We select the following datasets for comparative experiments: (1) CCR is the epidemic EE domain dataset, which contains a wide variety of epidemic event types and argument roles; (2) DuEE1.0 [18] is the largest Chinese EE generic dataset; (3) CEC [48] is specially designed for Chinese EE. It is a small dataset, covering only five emergency event types.
Contrasted Models To verify the advancement and scalability of MFHEE, we set up the following models for comparison: (1) the three-stage pipeline EE method [8] realized the epidemic EE at the document-level; (2) DBRNN [34] extracts event triggers and arguments by dependency-bridge RNN; (3) BERT-DGCNN [4] is a BERT-based pipeline Chinese EE model.
Overall Results Table 7 shows the overall comparative experimental results on different datasets, where the values in bold refer to the best results for the indicators F1-Score and DCF on ETI and EAE tasks. Figure 7 shows the comparative experimental results of the MFHEE method on CCR dataset. In both the ETI task and ERE task, MFHEE has achieved the best results compared methods. However, the DCF of MFHEE method is slightly higher than three-stage method in the ETI task. The reason is that the three-stage method identifies event types at the document-level while MFHEE identifies event types at the sentence-level. Sentence has fewer features than document, making it harder to identify event types.

Radar diagram of comparative experiments results on CCR dataset (%)
On the generic dataset DuEE 1.0, the MFHEE method achieves similar performance to the advanced models. On the small-scale dataset CEC, the MFHEE method is better than all compared models. It illustrates that our method can obtain better prediction results through the multi-model fusion strategy and hierarchical extraction. Moreover, our method has good scalability and portability in other domains.
6 Conclusion
In this paper, we propose a new large and high-quality dataset CCR. This dataset provides a new point of view for the epidemic EE task. We also propose the MFHEE method to improve the accuracy of the epidemic EE model. This method solves the issue of recognition bias of previous EE models. The ablation studies suggest that both hierarchical extraction and multi-model fusion contribute greatly to our model. The comparative experiments suggest that the MFHEE method performs better than other EE baselines on CCR dataset and performs comparably to other advanced EE baselines on general datasets. Thus, we can use MFHEE as a stronger baseline for epidemic EE.
This paper leads to a variety of interesting future work, we are studying the effects of sentence segmentation on model accuracy. Besides, we are considering using transfer learning methods to simplify our model.
Availability of data and materials
We make CCR and the code for our baselines publicly available at https://github.com/liaozenghua/CCR-MFHEE.
Abbreviations
- EE:
-
Event extraction
- CCR:
-
COVID-19 case report
- MFHEE:
-
Multi-model fusion-based hierarchical event extraction
- ETI:
-
Event type identification
- EAE:
-
Event argument extraction
- ML:
-
Machine learning
- LSTMs:
-
Long short-term memory networks
- KB:
-
Knowledge base
- AM:
-
Attention model
- DTs:
-
Decision trees
- MFEE:
-
Multi-model fusion-based event extraction
- HEE:
-
Hierarchical event extraction
- GBDT:
-
Gradient-boosted decision tree
- COVID-19:
-
Coronavirus disease 2019
References
Cadzow JA (1990) Signal processing via least squares error modeling. IEEE ASSP Mag 7(4):12–31
Cascella M, Rajnik M, Aleem A et al (2022) Features, evaluation, and treatment of coronavirus (COVID-19). Statpearls [internet]
Chen Y, Xu L, Liu K et al (2015) Event extraction via dynamic multi-pooling convolutional neural networks. In: Proceedings of the 53rd annual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing (volume 1: long papers), pp 167–176
Chen A, Ye Y, Wang C et al (2021) Research on Chinese event extraction method based on BERT-DGCNN. Comput Sci Appl 11:1572
Devlin J, Chang MW, Lee K et al (2018) Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
Dietterich TG, Kong EB (1995) Machine learning bias, statistical bias, and statistical variance of decision tree algorithms. Tech. rep, Citeseer
Gao W, Zheng X, Zhao S (2021) Named entity recognition method of Chinese EMR based on BERT-BILSTM-CRF. In: Journal of physics: conference series. IOP Publishing, p 012083
Guo X, Gao C, Chen Q et al (2022) A three-stage chapter level event extraction method for COVID-19 news. Comput Eng Appl
Han X, Zhu H, Yu P et al (2018) FewRel: a large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. arXiv preprint arXiv:1810.10147
Huang R, Riloff E (2012) Modeling textual cohesion for event extraction. In: Proceedings of the AAAI conference on artificial intelligence, pp 1664–1670
Kim JK, Kim YB (2018) Joint learning of domain classification and out-of-domain detection with dynamic class weighting for satisficing false acceptance rates. arXiv preprint arXiv:1807.00072
Krstev C, Obradović I, Utvić M et al (2014) A system for named entity recognition based on local grammars. J Log Comput 24(2):473–489
Küçük D, Yazıcı A (2012) A hybrid named entity recognizer for Turkish. Expert Syst Appl 39(3):2733–2742
Lai S, Xu L, Liu K et al (2015) Recurrent convolutional neural networks for text classification. In: Twenty-ninth AAAI conference on artificial intelligence
Li J, Cao H (2022) Research on dual channel news headline classification based on ERNIE pre-training model. arXiv preprint arXiv:2202.06600
Li Q, Ji H, Huang L (2013) Joint event extraction via structured prediction with global features. In: Proceedings of the 51st annual meeting of the association for computational linguistics (volume 1: long papers), pp 73–82
Li N, Guan H, Yang P et al (2020a) Chinese named entity recognition method based on BERT-IDCNN-CRF. J Shandong Univ 55(1):102–109
Li X, Li F, Pan L et al (2020b) DuEE: a large-scale dataset for Chinese event extraction in real-world scenarios. In: CCF International conference on natural language processing and chinese computing. Springer, Berlin, pp 534–545
Li J, Zhang D, Wulamu A (2021) Chinese text classification based on ERNIE-RNN. In: 2021 2nd International conference on electronics, communications and information technology (CECIT). IEEE, pp 368–372
Liang W, Luo S, Zhao G et al (2020) Predicting hard rock pillar stability using GBDT, XGBoost, and LightGBM algorithms. Mathematics 8(5):765
Liang J, He Q, Zhang D et al (2022) Extraction of joint entity and relationships with soft pruning and GlobalPointer. Appl Sci 12(13):6361
Liao S, Grishman R (2010) Using document level cross-event inference to improve event extraction. In: Proceedings of the 48th annual meeting of the association for computational linguistics, pp 789–797
Liao Y, Peng Y, Liu D et al (2021) Intelligent classification of breast cancer based on deep learning. In: Journal of physics: conference series. IOP Publishing, p 012171
Lin H, Lu Y, Han X et al (2018) Nugget proposal networks for Chinese event detection. arXiv preprint arXiv:1805.00249
Liu X, Luo Z, Huang H (2018) Jointly multiple events extraction via attention-based graph information aggregation. arXiv preprint arXiv:1809.09078
Liu X, Zhu Z, Fu T et al (2021) Corpus annotation system based on HanLP Chinese word segmentation. In: The 2nd International conference on computing and data science, pp 1–17
Lybarger K, Ostendorf M, Thompson M et al (2021) Extracting COVID-19 diagnoses and symptoms from clinical text: a new annotated corpus and neural event extraction framework. J Biomed Inform 117(103):761
Ma J, Wang S, Anubhai R et al (2020) Resource-enhanced neural model for event argument extraction. arXiv preprint arXiv:2010.03022
McClosky D, Surdeanu M, Manning CD (2011) Event extraction as dependency parsing. In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pp 1626–1635
Mutuvi S, Boros E, Doucet A et al (2021) Token-level multilingual epidemic dataset for event extraction. In: International conference on theory and practice of digital libraries. Springer, Berlin, pp 55–59
Nguyen TH, Cho K, Grishman R (2016) Joint event extraction via recurrent neural networks. In: Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, pp 300–309
Nguyen QT, Nguyen TL, Luong NH et al (2020) Fine-tuning BERT for sentiment analysis of vietnamese reviews. In: 2020 7th NAFOSTED conference on information and computer science (NICS). IEEE, pp 302–307
Seker GA, Eryigit G (2017) Extending a CRF-based named entity recognition model for Turkish well formed text and user generated content. Semantic Web 8(5):625–642
Sha L, Qian F, Chang B et al (2018) Jointly extracting event triggers and arguments by dependency-bridge RNN and tensor-based argument interaction. In: Proceedings of the AAAI conference on artificial intelligence
Shen S, Qi G, Li Z et al (2020) Hierarchical Chinese legal event extraction via pedal attention mechanism. In: Proceedings of the 28th international conference on computational linguistics, pp 100–113
Sun Y, Wang S, Li Y et al (2020) Ernie 2.0: a continual pre-training framework for language understanding. In: Proceedings of the AAAI conference on artificial intelligence, pp 8968–8975
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. Adv Neural Inf Process Syst 30
Wang CK, Singh O, Tang ZL et al (2017) Using a recurrent neural network model for classification of tweets conveyed influenza-related information. In: Proceedings of the international workshop on digital disease detection using social media 2017 (DDDSM-2017), pp 33–38
Wang X, Wang Z, Han X et al (2019) Hmeae: hierarchical modular event argument extraction. In: Proceedings of the 2019 Conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pp 5777–5783
Wang Z, Wu Y, Lei P et al (2020) Named entity recognition method of Brazilian legal text based on pre-training model. In: Journal of physics: conference series. IOP Publishing, p 032149
Wichmann P, Brintrup A, Baker S et al (2020) Extracting supply chain maps from news articles using deep neural networks. Int J Prod Res 58(17):5320–5336
Wu G, He Y, Hu X (2018) Entity linking: an issue to extract corresponding entity with knowledge base. IEEE Access 6:6220–6231
Xie T, Yang J, Liu H (2020) Chinese entity recognition based on BERT-BILSTM-CRF model. Comput Syst Appl 29(7):48–55
Yang B, Mitchell T (2016) Joint extraction of events and entities within a document context. arXiv preprint arXiv:1609.03632
Yang S, Feng D, Qiao L et al (2019) Exploring pre-trained language models for event extraction and generation. In: Proceedings of the 57th annual meeting of the association for computational linguistics, pp 5284–5294
Zhang F, Yuan NJ, Lian D et al (2016) Collaborative knowledge base embedding for recommender systems. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 353–362
Zhang J, Qin Y, Zhang Y et al (2019) Extracting entities and events as a single task using a transition-based neural model. In: IJCAI, pp 5422–5428
Zhang C, Song N, Lin G et al (2021) Few-shot incremental learning with continually evolved classifiers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12455–12464
Zheng S, Cao W, Xu W et al (2019) Doc2edag: an end-to-end document-level framework for Chinese financial event extraction. arXiv preprint arXiv:1904.07535
Zheng Z, Lu XZ, Chen KY et al (2022) Pretrained domain-specific language model for natural language processing tasks in the AEC domain. Comput Ind 142(103):733
Acknowledgements
We also acknowledge the editorial committee’s support and all anonymous reviewers for their insightful comments and suggestions, which improved the content and presentation of this manuscript.
Funding
This work was partially supported by NSFC under grants Nos. 61872446, 62272469, and The Science and Technology Innovation Program of Hunan Province under grant No. 2020RC4046.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by (Zenghua Liao), (Zongqiang Yang) and (Ning Pang). The first draft of the manuscript was written by (Peixin Huang), (Zenghua Liao) and all authors commented on previous versions of the manuscript. The review and editing were done by (Xiang Zhao). All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liao, Z., Yang, Z., Huang, P. et al. Multi-Model Fusion-Based Hierarchical Extraction for Chinese Epidemic Event. Data Sci. Eng. 8, 73–83 (2023). https://doi.org/10.1007/s41019-022-00203-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41019-022-00203-6