
Abstract
Thanks to the rapid advances in artificial intelligence, a brand new venue for database performance optimization is through deep neural networks and the reinforcement learning paradigm. Alongside the long literature in this regime, an iconic and crucial problem is the index structure building. For this problem, the prior works have largely adopted a pure learning-based solution replacing the traditional methods such as a B-tree and Hashing. While this line of research has drawn much attention in the field, they ubiquitously abandon the semantic guarantees and also suffer from performance loss in certain scenarios. In this work, we propose the Neural Index Search (NIS) framework. The core to this framework is to train a search policy to find a near optimal combination plan over the existing index structures, together with the required configuration parameters associated with each index structure in the plan. We argue that compared against the pure learning approaches, NIS enjoys the advantages brought by the chosen conventional index structures and further robustly enhances the performance from any singular index structure. Extensive empirical results demonstrate that our framework achieves state-of-the-art performances on several benchmarks.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A variety of index structures have been proposed in the literature. Some of them are included in the commercial DBMS (Database Management System), such as B-tree, R-tree and Hash index, while most others are invented to support specific types of applications [1,2,3]. Indeed, it is a challenging task to design a new index structure for every particular application. In this paper, we propose NIS, a Neural Index Search approach, to automatically assemble an index from existing index structures for a given dataset and query workload. The only assumption NIS bases on is that the users can provide a function to sort or partition the data, which is very much valid for most applications. Generally, the NIS framework first categorizes a variety of index structures into two abstract index building blocks—ordered block and unordered block. The ordered block, where keys are sorted in ascending order, can be implemented as B\(^+\)-Tree node. On the other hand, an unordered block, where keys are partitioned using customized functions, can be implemented as hash bucket. Both abstract blocks follow the format of \([key, value]^+\), where key denotes the indexed key, and value refers to the pointer to the next index block or the memory/disk address for the data values.
We apply the policy gradient algorithm [4] to train a reinforcement learning policy model employing a RNN (Recurrent Neural Network) as backbones, which can
-
Construct a tree-like index in a layer-by-layer way, where each layer is a sequence of abstract index blocks partitioning the search space with a pre-defined function.
-
Search the optimal configuration for each index block, including block type, block size, minimal and maximal number of keys in a block and etc.
In this paper, we focus on the in-memory version of NIS, where all index data are maintained in memory. Compared to the disk version, in-memory NIS is more challenging because (1) the in-memory index can have multiple layers, while the disk-based one is limited to 2–3 layers; (2) since fragmentation does not apply to memory-optimized indexes, each index block can have a customized size; and (3) in-memory index is more sensitive to the access patterns. In our experiments, NIS outperforms many existing state-of-the-art in-memory indexes on various workloads. Moreover, we also provide an incremental learning mechanism for NIS. So it can handle the case where query/data distribution changes gradually over time. Our experiments show that if newly inserted data follow the same distribution, indexes generated by NIS can provide a good performance without any adjustment. If only a few portion (e.g., 10%) of new data show a different distribution, NIS employs an economic incremental learning model to adjust the index configurations. Experiments show that it still provides a better performance than others.
The closest work to ours is the Learned Index Structures proposed by Google [5]. It tries to learn an ordered neural mapping function for each key and stack those functions as a tree index. While being conceptually promising, replacing the conventional index structures with learned indexes neglects the semantic guarantees and requires a significant amount of engineering efforts. By contrast, NIS adopts a different strategy by searching for the solution of how to combine existing index blocks and tune their parameters for specific applications. NIS does not suffer from the slow prediction of neural models, since once the index has been materialized, they work independently.
In summary, we make the following contributions in NIS.
-
We propose a full-fledged index structure solution to search and tune the generated indexes for a given dataset and query workload accordingly, based on a reinforcement learning paradigm.
-
We showcase a valid policy network construction by employing a conditional RNN as the backbone, where it generates multi-layer tree-like indexes, where each layer is a list of index blocks and the construction of a layer depends on all existing layers.
-
On top of the policy network deployment, we develop an incremental learning process to support and adapt to the gradually updated query patterns.
-
Experiments with state-of-the-art indexes show that the NIS-generated index outperforms the current state-of-the-art results published by prior work.
2 Background and Overview
2.1 Problem Formulations
Given a column C and workload W, how can we generate a proper tree-like hierarchical index structure \(\mathcal {I}\) for C, which is tuned to minimize the total processing latency of W with a storage budget B, computed as:
\(f(q_i)\) returns the latency of processing \(q_i\) with the existence of \(\mathcal {I}\). \(w(q_i)\) represents the weight of \(q_i\), which is set as the frequency of \(q_i\) in W currently. The total storage cost of the index should be less than B.
In [5], the index block is formalized as a function:
where p is the position of the value referred by the key and N is the total number of keys. The intuition is to learn a cumulative distribution function (CDF). So we can locate the key based on the estimation of the CDF. As mentioned before, we adopt a different strategy from [5]. Instead of learning the CDF, our model tries to predict how data can be partitioned using basic index blocks. In NIS, two abstract index blocks are supported, the ordered index block and unordered index block. We do not intent to invent new index structures. Instead, our plan is to reuse existing index structures and fine-tune them for our target workloads. Therefore, we introduce two abstract index blocks that can be materialized as popular existing index structures.
Definition 1
The ordered index block is described as \(I_{o}=\{S, F, [L, U), pt\}\), where S denotes a sorted list of keys, F is the mapping function, [L, U) denotes the key range of the block and pt points to the next sibling block. For \(I_o\), we have the properties:
-
\(\forall S[i]\in S, L\le S[i]<U\).
-
\(S[i]\le S[j]\), if \(i<j\).
-
\(F(S[i])\le F(S[j])\), if \(i<j\)
In the ordered index block, the mapping function F is maintained as a list of sorted key-value pairs \([(k_i, v_i)^*]\), where \(k_i<k_j\) for \(i<j\) and \(v_i\) refers to the position of the index block in the next layer or the real data values.
Definition 2
The unordered index block is denoted as \(I_u=\{S, H, [L, U), pt\}\), where S is a set of keys, H is a hash function(currently, we use the standard SHA-1 hash function), [L, U) denotes the key range of the block and pt points to the next sibling block. For \(I_u\), we have \(\forall S[i]\in S, L\le S[i]<U\). The hash function H maps S[i] into the corresponding bucket which points to the index block of the next layer.
Each index block can hold up to m keys. m can be calculated by the key size and the cache line size(for memory index) or block size(for disk index). However, the initial number of keys inside each block(denoted as x) is a tunable parameter, which is learned by the NIS through training. In unordered index block, the whole block is maintained as a hash table, where we have maximal m buckets and the buckets maintain pointers to index blocks in next layer.
Table 1 lists the parameters learned by the NIS.

General Idea of NIS
2.2 Overview of NIS
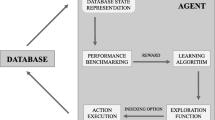
The design of NIS follows the same philosophy of the NAS. Figure 1 shows the general architecture. Given a database D and query workload W, NIS employs a controller to generate the architectural parameters of an index, which includes all the parameters listed in Table 1 and decides how the abstract index blocks can be assembled as an index. In this paper, the controller is a reinforcement-learning model, implemented as stacked RNNs, which applies the policy gradient [4] to update its policy. After the controller generates an index architecture, the index builder materializes the corresponding index and deploys it on the database by loading the data. We execute the query workload W using the index to get the latency and space utilization as our rewards, which are used as feedbacks for the controller to update its policy. In the next iteration, the controller will generate a new index architecture with its updated policy. The process loops, until the controller policy converges. Finally, the controller will return an optimal index structure for a given database D and workload W.
One challenging of applying NIS to predict the index structure is the scalability. Suppose we have 10 million keys and each block can hold up to 200 keys. We need at least 50,000 blocks to maintain those keys. In other words, the NIS needs to generate parameters for a large number of blocks sequentially. However, existing neural models are difficult to predict such a long sequence. To reduce the prediction cost of NIS, we classify the blocks into groups.
Definition 3
An index block group G is a set of index blocks responsible for consecutive key ranges and sharing the same parameters.
We use a simple example to intuitively describe the role of group. Suppose the initial number of keys in an index block is set as 200. We try to predict the parameters(\(Block\ Type\), x, \(\alpha\), \(\beta\)) for its 200 child blocks in the next layer. By adopting the group strategy, we can effectively reduce the prediction overhead. Suppose the 200 child blocks are grouped into two groups, consisting of 50 and 150 child blocks, respectively. We only need to predict parameters for two groups, as blocks of the same group adopt the same parameter configurations.
Given a set of keys in [min, max), to generate a new index, the controller first creates a layer with one index block and predicts its parameters. Suppose the block type is set as ordered and the initial number of keys is set as x by the controller. Namely, the block partitions the key range into x small ranges \(R_0=[k_0, k_1)\), \(R_1=[k_1, k_2)\),..., \(R_{x-1}=[k_{x-1}, k_{x})\). By default, we partition the key range evenly. The controller starts building the second layer of index for each range by adaptively generating an index block group. The parameters of a group are learned by the controller. Besides the single block parameters (\(Block\ Type\), x, \(\alpha\) and \(\beta\)), we need to predict parameter y (the number of blocks in the group). In this way, y index blocks are created for each group and the corresponding key range is partitioned into y non-overlapped consecutive ranges, one for each block.
Inside each group, to facilitate the query, each index block can create skip links up to \(\log {y}\) blocks inside the same group. In particular, suppose current group G has y index blocks: \(\{B_0,B_1...,B_{y-1}\}\). For block \(B_a\), it will create a skip link to \(B_b\) with a probability \(p_i\), if \(b=a+2^i (1 \le i \le \log {y})\) and \(b<y\). The probability \(p_i\) is estimated by the controller, so we have a parameter \(\gamma =\{p_1, p_2,...,p_{\log {y}}\}\), a probability vector for creating skip links inside a group.
The above index construction process continues for each index block, until no key range has more than \(\beta m\) keys. In this way, we may generate an imbalanced index search tree with skip links inside each block group.

An Example Index Generated by NIS

The Neural Model of NIS
The controller outputs its final decision as a sequence of operations, which are read by the index builder for construction. The index builder adopts a streaming approach to materialize the index. In particular, it first creates an abstract index by stacking the index blocks predicted by the controller. Then, it reads in the data and applies the data stream to materialize the index. During materialization, block separation and merging may occur. If block \(b_i\) is split into \(b_{i}\) and \(b_{i}'\), the new generated block \(b_{i}'\) will share the same parameters of \(b_i\). However, if the controller generates a good prediction, we do not need to split data blocks frequently. To speed up the index construction, the index builder employs multiple threads to assemble the index. Finally, the index is deployed on the database and tested against the given workload to get the corresponding latency and space utilization.
As an example, Fig. 2 shows an index generated by NIS. The blue and yellow nodes represent the ordered and unordered index blocks, respectively. The green part is a detailed description of the skip links inside a group. For simplicity, we only show the segmentation details of the first index block in each group. To process a query, we start from the root block as searching a B\(^+\)-tree. When reaching a group, we pick the skip links to simulate the search process as the skip-list.
By learning different parameters, NIS can simulate different types of conventional indexes, such as:
-
B\(^+\)-tree All the index blocks are ordered blocks with the same configuration of m and \(\alpha\) and \(\beta\) are set to 1 and 0.5, respectively. y is set as 1 for all groups.
-
Hash All the index blocks are unordered blocks and the index only has one layer.
-
Skip-list Each layer only has one index group and the upper layer group has fewer blocks (a smaller y).
It can be seen that the large search space of NIS allows us to explore more new index structures by combining different existing index structures for specific workloads and datasets.
3 Implementation of Controller
In this section, we show how the controller learns to predict the parameters for the index. We first discuss the architecture of our neural model and then elaborate on how the training process works.
3.1 The Architecture of Controller
Analogous to NAS [6], we consider the prediction of parameters as a task of sequence prediction since the list of the block configurations of each layer can be viewed as a parameter sequence, a variable-length string. The controller predicts one parameter at a time which is conditioned on previous predictions. Therefore, the backbone of our controller is a RNN network powered by the LSTM [7], which works well for prediction of long sequences. Figure 3 illustrates the basic architecture of the controller. The controller consists of multiple layers of LSTMs to predict a tree-like index architecture, which can be expressed as multiple parameter sequences. The index architecture is constructed in a top-down manner. The new layer will use the hidden states of previous layers as the context during its prediction.
Our model consists of a basic building block as shown in the bottom left part of Fig. 3. The neural block predicts the six parameters (Block Type, x, y, \(\alpha\), \(\beta\) and \(\gamma\)) for an index block group as a sequence via the RNN model. The whole block consists of three neural layers, an embedding layer, a LSTM layer and a softmax layer.
The bottom layer is an embedding layer, formalizing the input as a binary vector representation. For the first time step of the RNN, the min/max values of the keys, the number of unique keys and a coarse histogram are transformed into binary vectors and concatenated together as the input. For the following time steps, the generated vector from the softmax layer for previous state is used as the input, because the parameter prediction of the current time step are conditioned on previous prediction.
The middle layer applies the LSTM to learn the correlations between different time steps. Selections of previous parameters affect the choices for the following ones.
The top layer is a softmax layer for prediction. We transform our task into a classification problem by creating a set of pre-defined values for each parameter and only allowing the neural model to pick one of the pre-defined values. Table 2 lists our current pre-defined values. The parameter \(\gamma\) has no default values, since it depends on the value of y. Specifically, we will generate a probability vector \(\{p_1,p_2,...,p_{\log {y}}\}\) indicating whether to create skip links to the neighboring \(\log {y}\) blocks in the same group. The skip link between index block \(B_a\) and \(B_{a+2^i}\) will be established with a probability \(p_i\).
The basic neural blocks are chained together to predict the parameters for index block groups. After successfully generating the prediction for one layer of index, the controller can start up a new layer, if some index blocks need to be further partitioned. Then, the hidden states of current layer are used as the context during the prediction for the next layer.
Figure 3 illustrates the idea. The outputs from the softmax layer of a neural block are concatenated together and used as input to the neural blocks in the next layer. The neural block predicts the initial number of keys as x and the number of blocks in a group as y, indicating that all y blocks in the current group will be divided into x sub-ranges, resulting into a total of \(x \times y\) sub-ranges. If we continue to divide and build the next layer, we will use both the hidden outputs and softmax outputs of current neural block as the contexts for neural blocks in the following layer. In this way, we can progressively generate the parameters for a multi-level index, which, in fact, can simulate most existing index structures.
3.2 Training the Controller
The parameter sequences generated by the controller can be considered as a series of operators \(a_{1:t}\) (operators from the start to time t) which are used to construct a new index for a given workload W and database D. At convergence, the new index is integrated into D and we test it against the workload W. The total processing time \(c_t\) and the index space utilization cost \(c_s\) (the percentage of the index that has been used for maintaining keys) are our main concerns. So the evaluation metric is defined as follows, which is called reward:
\(c_b\) is the baseline processing time without any index and \(\rho\) is a tunable parameter to balance the importance of the two terms. We have conducted experiments to show the effect of \(\rho\).
We have more than 1000 parameter combinations for just one index block group. For datasets containing more than 100 million keys, we have thousands of block groups, resulting in millions of parameters for search. When the number of blocks increases, the exploration space becomes very large. Besides, the metric that our method needs to optimize is non-differentiable. So, we use the Reinforcement Learning which can learn directly from the reward signal. Since we cannot get a single-step rewardFootnote 1, we can only learn the policy of actor, not critic, so we choose the policy-based reinforcement learning method.
To find the optimal index, we ask the controller to maximize its expected reward, represented as \(J(\theta )\). We use \(\theta\) to denote all parameters of the controller model. We have:
The reward R is achieved by monitoring the performance of database D and, hence, is not differentiable. We apply the policy gradient strategy as in [4]:
T is the total number of parameters for predicting and b is a baseline function to reduce the variance of the reward. In fact, b is the exponential moving weighted average of reward. Let \(\mu\) be the aging factor. \(b^{(n)}\) in nth training sample is recursively defined as
As a result, \(b^{(n)}\) can be estimated as:
Equation 1 shows how the parameters \(\theta\) of the controller network are updated based on the reward R gradually, which is represented as
where \(\sigma\) is the learning rate.
In practice, we use the exhaustive weighted summation form to replace the expected value in Eq. 1. If we have enough training samples, we can estimate the \(\nabla J(\theta )\) as (N is the batch size of the controller):
In our experiments, we find that a small N is good enough for the model to converge to a satisfied result.
The intuition of policy gradient is to increase the probability of \(P(a_t \mid a_{t-1})\), if \(R-b\) is positive. Otherwise, we decrease the probability. However, during the training process, we find that if \(P(a_t \mid a_{t-1})\) is large enough, \(R-b\) will be always positive (because the model gives up on exploring new results and sticks to current sub-optimal one), causing \(P(a_t \mid a_{t-1})\) to converge to 1. On the contrary, if \(P(a_t \mid a_{t-1})\) is very small, \(R-b\) will be negative in most estimations, and hence, \(P(a_t \mid a_{t-1})\) will converge to 0. In both cases, we obtain a local optimal results. To avoid such problems, we clip the sample data and only update the probabilities within \([\epsilon , 1-\epsilon ]\), where \(0<\epsilon<<1\).
Similar to other policy gradient approaches, the training process lasts for days, since we need to build each predicted index and performs benchmarking to gather corresponding rewards. To speed up the training process, we apply two optimization techniques.
We generate a set of probabilities after the softmax layer of the controller. They are used to select the parameters. For example, we obtain the probabilities \([p_1,p_2,p_3,p_4]\) for parameter y, indicating that we may set y as 32, 64, 128, 256 with probabilities \(p_1\), \(p_2\), \(p_3\) and \(p_4\), respectively. In value-based learning approach, it was shown that random exploration can speed up the convergence. We adopt this approach for our policy-based approach. In particular, we ask the controller to ignore the generated probabilities and randomly pick a value for a parameter with a pre-defined probability \(\lambda\). But we only use it in the first few epochs of training. Initially, \(\lambda =1\) to allow a fast random exploration and quickly, we decrease \(\lambda\) to 0.
The training of vanilla policy gradient approach is extremely slow due to a large exploration space and the long interaction time of building the index and getting the reward. A new approach, PPO(Proximal Policy Optimization) [8], can be used to facilitate the parameter updates. In policy gradient, we update model parameters, only when we obtain new training samples. This strategy is called “on-policy” strategy. Instead, in PPO, we create a new controller model \(\theta '\), which is employed with the environment(in our case, the index builder and database) to get training samples. The training samples obtained from \(\theta '\) are repeatedly used by the real model \(\theta\), so that parameters of \(\theta\) get multiple updates for one sample, which significantly reduce the time overhead of interacting with the environment. This is called “off-policy” strategy.
Using PPO, Eq. 1 is rewritten as:
However, if the distribution of \(\theta '\) and \(\theta\) differs a lot, the approach may not work. So, PPO introduces the KL-divergence to balance the difference between two distributions. The equation is further revised as:
where \(\phi\) is a hyper-parameter that controls the penalty of KL divergence.
3.3 Incremental Updating
As mentioned before, most applications have a stable data and query distribution. So we can learn an index to achieve a good performance. However, data and query will slowly evolve. Hence, we design an incremental updating model, which is a by-product of the controller. In other words, we reuse training samples from controller to build the incremental updating model.

A Tree-LSTM for Incremental Updating
The intuition of incremental updating model is to learn a performance prediction function G. Given a data distribution \(\mathcal {D}\), query distribution \(\mathcal {Q}\) and specific index \(\mathcal {I}\), \(G(\mathcal {D}, \mathcal {Q}, \mathcal {I})\) returns the estimated processing latency of \(\mathcal {Q}\). We use equi-width histograms to maintain data distribution and query distribution. We generate a vector representation for each index block by encoding its configuration parameters. Finally, G is learned through a tree structured LSTM model [9]. Figure 4 shows the architecture of our model.
We train a neural block for each index block group and connect them as a tree structure, where parent node accepts hidden states from its child nodes as context for prediction. All neural blocks actually share the same network parameters trained with samples from controller. During the training of a controller, we obtain an index structure under a specific data distribution \(\mathcal {D}\) and query distribution \(\mathcal {Q}\). We collect the statistics of the processing latency for each index block. If a block is a leaf block, its latency is its total cost of processing queries. If the block is an internal block, its latency includes both its own cost and the accumulative costs of all its descendants. Then, we train a performance prediction network G to predict the cost of each index block. The network accepts \(\mathcal {D}\), \(\mathcal {Q}\), index configuration \(\mathcal {I}\) of the block and hidden states from child nodes as input. It outputs a hidden state which is further applied to generate predictions for internal nodes. Since we do not need a very precise estimation of latency, we transform the prediction into a classification problem, where we create 100 different performance classes and pick the class with maximal probability.
We consider queries in \(\mathcal {Q}\) as a training batch and also propose a batch loss function. The loss function is based on the KL-divergence:
where i is a performance class, P(i) and Q(i) indicate how many queries are assigned to class i in the prediction and real statistics.
The tree-LSTM is trained together with the controller. Then, it is applied to help us identify performance outliers. During the query processing, we collect the statistics of our index and use it to make a prediction for the performance periodically. Let \(x_0\) be the initial performance of an index block after the last update. We use \(x_t\) and \(x_t'\) to denote its predicted performance and real performance at the tth epoch. An index block is marked as an outlier if \(x_t-x_0>\omega x_0\). \(\omega\) can be tuned to balance the index tuning cost and processing cost.
To reduce the tuning cost, we identify the outliers in a bottom-up way. If an index block is outlier, we continue to check its parent. If all child blocks are not outliers, we stop the check for this block.

Materialization of the Index
4 Processing of the Index
In this section, we introduce how the predicted index can be materialized as a physical index, and how the index can be applied to process queries and updates.
4.1 Index Materialization
The index construction is performed in two steps. In the first step, the index builder loads the parameter predictions from the controller, which are indexed in a key-value store, to build a logical index. The logic index establishes the general structure of the index, but cannot support queries. In the second step, index builder scans data and feeds them into the logical index in a streaming way. The logical index fills in detailed key ranges and builds necessary pointers, which are finally materialized as a physical index.
4.1.1 Logical Index
To create the logical index, we first set up the parent-child relationships between index groups. The left index in Fig. 5 shows a logical index (to simplify the diagram, the skip links are not shown). During the construction of the logical index, we create the parent-child pointers, the key ranges of each index blocks and the skip links inside each index block group. Algorithm 1 shows the workflow of how the logical index is established. If parent node is an ordered block, we split its key range evenly and assign to each child block group. Otherwise, child block groups will share the same key range with their parent block, because the hash function will project keys into random block groups. Algorithm 2 illustrates how an index block group is set up. First, it partitions the key range evenly and generates a fixed number of index blocks based on the predicted parameters. Then, it creates multiple skip links with the probabilities specified in the parameters.


If all index blocks are ordered blocks, the generated index structure is similar to the B\(^+\)-tree. However, if unordered index blocks are adopted, the index structure becomes a hybrid one. For the left index in Fig. 5, suppose x is 2 for the root index block group. The first index block group and second index block group at level 2 are responsible for the key range [0, 99] and [100, 199], respectively. The first group is ordered blocks and suppose its y is set as 3. We create three ordered index blocks inside the group and partition the key range evenly as [0, 33], [34, 66] and [67, 99]. The second index block group in level 2 is unordered index group. If \(y=4\), we will create four unordered blocks by partitioning the key range [100, 199] uniformly. Because unordered block applies hash functions to map keys to its child block groups, the child block groups share the same key range with their parent. For example, group 4 and group 5 all have the key range [100, 124]. However, group 4 creates 3 blocks and group 5 creates 2 blocks. Note that in our index, two index block groups may have overlapped key ranges, but for the index blocks in the same group, they always maintain sorted non-intersected ranges.
4.1.2 Physical Index
The logical index cannot be applied to process queries, since it does not set up the pointers to data. In the second phase, the index builder loads data from the disk and feeds them to the logical index to materialize the index. The right index in Fig. 5 shows the corresponding physical index for the left logic index. The materialization process mainly handles three tasks:
-
1.
Update key ranges of index blocks. The key range of each block in logical index is just a rough estimation. During the materialization process, we maintain a set of [Min, Max] values for each block, indicating the actual minimal and maximal keys in each key range. After all data have been processed, we shrink the key ranges of an index block by the values. This helps us reduce the search cost by filtering the blocks as early as possible.
-
2.
Set up hash tables for unordered blocks. As shown in Fig. 5, when data are streamed over an unordered block, we will set up the corresponding hash table. Suppose there are x child index block groups and the next key is k. k will be routed to the ith group, where \(i=hash(k)\% x\). To help the search, we also create a bloom filter for each unordered block to check whether a key exists or not.
-
3.
Create pointers to disk data. When a key is routed to the bottom level of the index, we will create a pointer from the key to the disk offset of the corresponding record. For secondary index, one key may refer to multiple records. Then, we will merge them as a sorted list for disk offsets.

Algorithm 3 summarizes the whole materialization process. For a new tuple T and its disk offset O, we first retrieve the block whose key range overlaps with T.k. If current group is at the bottom level, we just insert the key and its offset. Otherwise, we forward the tuple to the corresponding child group. The same process repeats for the unordered block group. The only difference is that we apply the hash function to map the tuple to a specific child group.
The right index in Fig. 5 is the materialized index for the left one. We can find that the key ranges of index blocks are shrunk. E.g., the ranges of group 1 change from [0, 199], [200, 399], [400, 599], [600, 799] to [0,198], [212, 352],[429, 579], [654, 760]. The hash tables have been set up (we show the hash table of the third block in group 3). Note that we do not need to maintain the hash tables explicitly. We only need to know which hash function is being applied. Finally, we create the links from the keys to their disk offsets in the bottom level. Note that in Fig. 5, the gray nodes indicate that the nodes are empty, since their key ranges do not contain any keys. During the materialization, an index block at bottom layer may be overloaded during the materialization process, triggering the block splitting operation. We will discuss this issue in our index update section.

Processing of Lookup Queries
4.2 Search Via Index
After the index has been materialized, we can apply it to process queries. In this paper, we focus on the lookup and range queries. As a hybrid index, our search process is a combination of B\(^+\)-tree, Hash and skip-list. We use two examples in Figs. 6 and 7 to demonstrate the lookup and range queries, respectively.
Suppose a lookup query retrieves the key “167”. The search process works as follows. We first check the root block group(Group 1). Because the second key range of the first block contains 167, we route the query to the second child index group of the first block(Group 3). In group 3, the key ranges of the first block do not contain the key. So we route the queries based on the skip link to the third block. Then, we apply the hash function to retrieve the next index group(Group 7). Before forwarding the query to group 7, we also test it against the bloom filter of the block. If bloom filter returns a positive result, we continue the query in group 7. Since no skip link is set up in group 7, we scan the blocks one by one until reaching the third one, where the key is located.

Processing of Range Queries

Algorithm 4 gives the pseudo-code for the lookup. The function SkipListSearch simulates the search of skip list, where we follow the skip link which points to the block satisfying: either its key range contains the key or its maximal key is the largest maximal key smaller than the search key. For the range query [118, 124] in Fig. 7, we start the same process as the lookup query. The main difference is how the query is processed when reaching an unordered block group(Group 3). The query overlaps with the first block. But a hash function may distribute the keys to all the child block groups (Group 4 and Group 5). So the range query should be forwarded to both groups. Inside each group, we follow the skip link to locate the smallest key and then scan the remaining blocks until reaching the largest key. We discard the details of range search algorithm.
4.3 Update of the Index
During the index materialization, blocks at the bottom level may be overflowed, if more than \(\alpha m\) keys are inserted. This will trigger a node splitting operation. If the controller generates a good estimation for the data distribution, this problem can be partially avoided by generating an index tailored for the data distribution.
One key design philosophy of the NIS is that the index does not need to be balanced. It may create more levels of blocks for high-density data partition to facilitate the search. The unbalanced assumption reduces the complexity of node splitting and merging, since we can limit node splitting and merging to the groups at bottom level and do not propagate to the upper level.
When a bottom index block has more than \(\alpha m\) keys, we split the block evenly into two new blocks. The new blocks share the same parameters as they reside in the same group. The splitting does not affect the parent block, since the key range of the index group does not change. However, we need to update the skip links, since new blocks are inserted into the group.
The merge process follows the same strategy as the split one. Two consecutive blocks are merged together when both blocks have less than \(\beta m\) keys. And we update the skip links of the new block. During the insertion and deletion, we also need to handle the changes of key ranges. As shown in Fig. 5, the initial key ranges are setup during the materialization process. When a new key “150” is inserted, no existing index blocks can hold the key. So we need to find the nearest block to expand it key range. We called the process, expanding. The nearest block is defined as block B in the group with the minimal \(\min {(|B.L-k|, |B.U-k|)}\), where [B.L, B.U] is B’s key range.
In Fig. 5, the insertion process invokes the expanding function for group 3, who finds the closest block to key “150” is the third one and expands its range from [151, 174] to [150, 174]. Since this is an unordered block, it applies the hash function to decide which child index group should handle the insertion. Suppose it is group 6, who has one empty block and one block for [164, 172]. The empty block has the highest priority during the expanding process. So key “150” will be stored at the empty block, which updates its range as [150, 150]. The deletion process follows the same strategy by introducing a range shrinking processing. We will not elaborate the details.

Training of the Controller

Storage Overhead

Performance of Lookup-Only Workload

Performance of Mixed Workload
5 Experiments
We train the NIS using two servers sharing the same hardware configurations (Xeon CPU 32 cores, 64GB DDR3 RAM, 2MB L2 and 20MB L3 and NVIDIA GTX TITAN X). One server is dedicated to the training process of controller and the other one is used for index materialization and evaluations. We employ four datasets for evaluations: a synthesis uniform dataset (uniform64) and three real datasets (amzn, facebook, osmc). All datasets have 200 million keys. Detailed descriptions of the datasets can be found in [10].
For comparison purpose, we use the open-sourced implementations of B\(^+\)-Tree, SkipList, ART [11], FAST [12], Bw-Tree [13], Learned Index [5] (denoted as RMI) and PGM [14] as our baselinesFootnote 2. All indexes are in-memory indexes and no disk I/Os are involved.
5.1 Training the NIS
We first show the training performance of the controller for the osmc64 dataset with 1 million read-only workloads. During our training, the batch size of the controller is set as 16. Namely, it will generate 16 different index structures in one batch. To obtain proper rewards, those indexes are materialized by the index builder and deployed to be evaluated against the pre-defined workloads. The training process for one batch is considered as an epoch for the learning model. The training time is mainly composed of three parts: controller prediction, index materialization, and workload execution.
We tested different data size from 1 million to 100 million. Figure 8a illustrates that the controller can converge to a quite good value in only a few epochs (less than 5). Figure 8b shows the training time for different data volumes. After the index structure has been predicted, we need to construct the index on the database system. Figure 8c shows the cost of index materialization. The materialization cost reduces during the training, since the index structure has been cached and is only partially updated in the following epochs.
The reward function used in the controller is a combination of the processing latency and index space utilization cost. We use parameter \(\rho\) to tune the weights of the two terms. Figure 8d shows the effect of different reward functions. When \(\rho =0\), we only consider the space utilization and hence the generated index is almost full. On the other hand, if \(\rho =1\), the latency is the only concern. We observe that by tuning parameter \(\rho\), we can achieve a trade-off between the latency and space utilization. In the following experiments, \(\rho\) is set as 1 to minimize the search latency.
In addition, the system storage overhead consists of the storage cost of the policy network and the constructed index. In our experiments, we set the hidden size of LSTM to 256 and the layer to 4. For different datasets with 200 million keys, our network parameters are about 10M. However, the learning model is only employed to predict the index structure. During running time, the learning model is not involved in the query processing. In fact, the size of index is not determined by neural architecture but the dataset. So we only consider the storage cost of the constructed index when comparing with other indexes. Figure 9 reveals that on uniform64, NIS and RMI require 19MB and 11MB, respectively, while on osmc64, NIS(21M) incurs less overhead than RMI(40M). This is because the complex CDF of osmc64 requires more network parameters for RMI, while NIS is less influenced by the complexity of distribution. Figure 9 reveals that the complex CDF of osmc64 requires more network parameters for RMI, while NIS is much less influenced by the complexity of distribution.
5.2 Performance of Lookup-Only Workload
In this experiment, we compare the NIS with other baseline approaches. We generate 10 million single key lookup queries following the same distribution with the corresponding dataset. Namely, we have more queries for high-density data ranges.
Figure 10 shows the performances of different approaches on different datasets. The y-axis denotes the average processing cost of queries in nano-seconds.
uniform64 is a synthetic dataset with uniform distribution and is easier to simulate with neural models. Hence, RMI performs best on the uniform64, followed by our NIS. The reason is that NIS still maintains the structures of conventional indexes, incurs additional overhead, while RMI is more flexible by adopting a new index design. osmc, amzn and facebook are three different real datasets. Due to complex distributions, it is challenging for the RMI to precisely model the data, especially for the most complex dataset osmc64. So the performance of RMI may not be as good as some baseline indexes. On the contrary, NIS is able to learn the optimal index architecture for a given dataset and workload distribution.
5.3 Performance of Mixed Workload
In this experiment, we focus on two datasets, osmc and uniform, and generate four different workloads. W1 denotes the workload that we used in previous experiment (10 million lookup queries). W2 contains 1 million range queries with a selectivity 0.1%. W3 mixes 5 millions lookups and 5 millions insertions. W4 mixes 2 millions lookups, 2 millions insertions and 1 million range queries (selectivity = 0.1%). We show the average query processing cost in nano-seconds. Figure 11 shows the results. RMI is only shown in W1 and W2, because current open-sourced RMI implementation does not support updates.
We observe that for range workload and mixed workload, NIS shows a superior performance than the other indexes both on uniform dataset and real dataset.

Robustness and Incremental Learning
5.4 Performance of Incremental Learning
NIS assumes that data and query distributions of an application only change slowly and we propose an incremental learning technique to periodically update our index structure. In this experiment, we evaluate the robustness of our index with different distribution scenarios. There are four scenarios: (a) both dataset and workload distribution remains unchanged; (b) dataset distribution changes while the workload distribution remains unchanged; (c) both dataset and workload distribution changes; and (d) dataset distribution remains unchanged while the workload distribution changes.
All experiments are conducted on the uniform dataset with 200 million keys initially. Each experiment is run for 6 episodes, and different workloads are submitted for processing during each episode. Each workload contains 5 million lookups and 5 million insertions. So the size of dataset increases from 200 millions to 230 millions with 30 millions newly inserted data which may change the distribution. Specifically, the first workload is used to train the NIS model to get the initial index architecture. In the next 5 episodes, we apply the incremental learning approach to maintain the index. We compare three approaches. The orig approach will process the rest 5 workloads with the initial index without tuning. The inc approach applies the incremental training in next 5 episodes to update part of the index architecture and then process the workload. The retrain approach represents the ideal case, where we retrain a new model from scratch to get a new index architecture at each episode for all existing data and queries.

Performance of Incremental Learning
Figure 12 shows the results for scenario (a) to (d). We observe that when the distribution changes significantly, the index performance is also affected. Compared to the data distribution, the change on workload distribution has a more serious impact on performance, while incremental learning can partially address the problem.
We show the progress of incremental learning with a dramatic changing workload in Figure 13. We use a dataset with 50 million keys randomly sampled from osmc64 and 9 different workloads, each of which contains 10 million lookups and 10 million insertions, and follows a log-normal distribution with a different center. Due to a large number of insertions, the data size grows dramatically and so does the distribution. Every 10 seconds, the incremental learning is invoked to update the index. And we can see that the new index structure can provide a better performance until the next workload starts.
6 Related Work
In the database tuning area, the CMU group designs the OtterTuneFootnote 3, an autonomous database system [15,16,17]. The OtterTune collects the data for the running status of the database and builds a series of machine learning models to find the optimal configuration knobs. Following their approach, CBDTune [18] proposes to use the reinforcement learning model to perform the configuration tuning for the cloud database. By contrast, Li et. al. propose a query-aware automatic tuning approach, QTune[19]. QTune vectorizes a set of SQL queries by extracting the semantic features of the SQL queries.
Krishnan et. al. propose applying the deep learning techniques for join query optimization[20]. Their reinforcement learning model is integrated with Postgres and SparkSQL and is shown to be able to generate plans with optimization costs and query execution times competitive with the native query optimizer. Li et al. [21] propose using reinforcement learning with Tree-LSTM to select a proper join order and achieve good performances. SkinnerDB [22] further improves the prediction of join queries by splitting queries into many small time slices. Neo [23], on the other hand, tries to rewrite the database optimizer in a learning language. Instead of replacing the whole database optimizer, some work also try to improve the cost estimation using the deep learning model. In [24,25,26,27], deep learning models are applied to estimate the query selectivities or data cardinalities.
The deep learning approach can be adopted to search for new data structures for the DBMS [28]. The closest work to ours is the learned index from Google [5]. They formalize the index as a key mapping function and apply the neural models to learn the index in an ad hoc way. To make the approach support update and multi-dimensional data, a series of optimization techniques have been proposed [14, 29,30,31,32]. RadixSpline [32] improves the construction efficiency of existing learned index through a single-pass approach, while delivering comparable query performance. The key idea behind PGM [14] is to learn (k, rank(k)) for any key k through a piecewise geometric model. On the other hand, [33] proposed a Reinforcement Learning approach to find a proper index.
7 Conclusion
In this paper, we propose a Neural Index Search(NIS) approach to automatically tune indexes for a given dataset and workload. The NIS applies the reinforcement learning approach to assemble abstract index blocks into a full-fledged index and tests it against the target workload. The index performance is used as the reward for the learning model to update its strategy. Gradually, the predicted index converges to a fine-tuned structure. In theory, our NIS can simulate many existing index structures, such as B\(^+\)-tree index, Hash index and Skip List index. It can also explore the index structures that have never been examined. We also propose an incremental learning approach to support progressive updates of NIS. In our experiments, the index generated by NIS achieves a comparable performance to existing state-of-the-art index structures. Future and ongoing work include building a learning-based approach for selecting column(s) to index and extending our results to multi-dimensional index structures.
Notes
Single-step reward requires that only one parameter is predicted each time. However, such a reward cannot be obtained, because we must establish the whole index structure before we can deploy it on the database.
References
Zhang C, Zhang Y, Zhang W, Lin X (2013) Inverted linear quadtree: efficient top k spatial keyword search. In: 29th IEEE Int Conf Data Eng, pp 901–912
Cong G, Jensen CS, Wu D (2009) Efficient retrieval top-k most relevant spatial web objects. PVLDB 2(1):337–348
Wang X, Zhang Y, Zhang W, Lin X, Wang W (2015) Ap-tree: efficiently support continuous spatial-keyword queries over stream. In: 31st IEEE Int Conf Data Eng, pp 1107–1118
O’Donoghue B, Munos R, Kavukcuoglu K, Mnih V (2017) Combining policy gradient and q-learning. In: 5th Int Conf Learn Representations
Kraska T, Beutel A, Chi EH, Dean J, Polyzotis N (2018) The case for learned index structures. In: Proc 2018 Int Conf Manag of Data, pp 489–504
Zoph B, Le QV (2017) Neural architecture search with reinforcement learn. In: 5th Int Conf Learn Representations
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O (2017) Proximal policy optimization algorithms, CoRR, vol. abs/1707.06347
Tai KS, Socher R, Manning CD (2015) Improved semantic representations from tree-structured long short-term memory networks. In: Proc 53rd Ann Meeting Assoc for Comput Linguistics and the 7th Int Joint Conf Natural Lang. Process. Asian Federation of Natural Lang. Process., pp 1556–1566
Kipf A, Marcus R, van Renen A, Stoian M, Kemper A, Kraska T, Neumann T (2019) Sosd: a benchmark for learned indexes. NeurIPS Workshop Mach Learn for Syst
Leis V, Kemper A, Neumann T (2013) The adaptive radix tree: artful indexing for main-memory databases. In: 29th IEEE Int Conf Data Eng, pp 38–49
Kim C, Chhugani J, Satish N, Sedlar E, Nguyen AD, Kaldewey T, Lee VW, Brandt SA, Dubey P (2010) FAST: fast architecture sensitive tree search modern cpus and gpus. In: Proc ACM SIGMOD Int Conf Manag of Data, pp 339–350
Wang Z, Pavlo A, Lim H, Leis V, Zhang H, Kaminsky M, Andersen DG (2018) Building a bw-tree takes more than just buzz words. In: Proc 2018 Int Conf Manag of Data, pp 473–488
Ferragina P, Vinciguerra G (2020) The pgm-index: a fully-dynamic compressed learned index with provable worst-case bounds. Proc VLDB Endow 13(8):1162–1175
Pavlo A, Angulo G, Arulraj J, Lin H, Lin J, Ma L, Menon P, Mowry T, Perron M, Quah I, Santurkar S, Tomasic A, Toor S, Aken DV, Wang Z, Wu Y, Xian R, Zhang T (2017) Self-driving database management systems. In: Conf Innov Data Syst, Research
Zhang B, Aken DV, Wang J, Dai T, Jiang S, Lao J, Sheng S, Pavlo A, Gordon GJ (2018) A demonstration ottertune automatic database manag. System tuning service. PVLDB 11(12):1910–1913
Pavlo A, Butrovich M, Joshi A, Ma L, Menon P, Aken DV, Lee L, Salakhutdinov R (2019) External vs. internal: an essay machine learning agents for autonomous database management systems. IEEE Data Eng Bull, pp 32–46
Zhang J, Liu Y, Zhou K, Li G, Xiao Z, Cheng B, Xing J, Wang Y, Cheng T, Liu L, Ran M, Li Z (2019) An end-to-end automatic cloud database tuning system using deep reinforcement learning. In: Proc 2019 Int Conf Manag of Data, pp 415–432
Li G, Zhou X, Li S, Gao B (2019) Qtune: a query-aware database tuning system with deep reinforcement learning. PVLDB 12(12):2118–2130
Krishnan S, Yang Z, Goldberg K, Hellerstein JM, Stoica I (2018) Learning to optimize join queries with deep reinforcement learning, CoRR, vol. abs/1808.03196
Yu X, Li G, Chai C, Tang N (2020) Reinforcement learning with tree-lstm for join order selection. In: 36th IEEE Int Conf Data Eng, IEEE pp 1297–1308
Trummer I, Wang J, Maram D, Moseley S, Jo S, Antonakakis J (2019) Skinnerdb: regret-bounded query evaluation via reinforcement learning. In: Proc 2019 Int Conf Manag of Data, pp 1153–1170
Marcus RC, Negi P, Mao H, Zhang C, Alizadeh M, Kraska T, Papaemmanouil O, Tatbul N (2019) Neo: a learned query optimizer. PVLDB 12(11):1705–1718
Woltmann L, Hartmann C, Thiele M, Habich D, Lehner W (2019) Cardinality estimation with local deep learning models. In: Proc Second Int Workshop Exploiting Artif Intell Techn for Data Manag, pp 5:1–5:8
Yang Z, Liang E, Kamsetty A, Wu C, Duan Y, Chen X, Abbeel P, Hellerstein JM, Krishnan S, Stoica I (2019) Selectivity estimation with deep likelihood models. CoRR, vol abs/1905.04278
Sun J, Li G (2019) An end-to-end learning-based cost estimator. Proc VLDB Endow 13(3):307–319
Kipf A, Kipf T, Radke B, Leis V, Boncz PA, Kemper A (2019) Learned cardinalities: estimating correlated joins with deep learning. In: 9th Biennial Conf Innovative Data Syst, Research
Kraska T, Alizadeh M, Beutel A, Chi EH, Kristo A, Leclerc G, Madden S, Mao H, Nathan V (2019) Sagedb: a learned database system. In: 9th Biennial Conf Innovative Data Syst, Research
Marcus R, Zhang E, Kraska T (2020) Cdfshop: exploring and optimizing learned index structures. In: Proc 2020 Int Conf Manag of Data. ACM, pp 2789–2792
Galakatos A, Markovitch M, Binnig C, Fonseca R, Kraska T (2019) Fiting-tree: a data-aware index structure. In: Proc 2019 Int Conf Manag of Data. ACM, pp 1189–1206
Ding J, Minhas UF, Yu J, Wang C, Do J, Li Y, Zhang H, Chandramouli B, Gehrke J, Kossmann D, Lomet DB, Kraska T (2020) ALEX: an updatable adaptive learned index. In: Proc 2020 Int Conf Manag of Data. ACM, pp 969–984
Kipf A, Marcus R, van Renen A, Stoian M, Kemper A, Kraska T, Neumann T (2020) Radixspline: a single-pass learned index. In: Proc Third Int Workshop Exploiting Artif Intell Techn for Data Manag. ACM, pp 5:1–5:5
Lan H, Bao Z, Peng Y (2020) An index advisor using deep reinforcement learning,” in CIKM ’20: the 29th ACM International conference on information and knowledge management, virtual event, Ireland, d’Aquin M, Dietze S, Hauff C, Curry E, Cudré-Mauroux P, Eds. ACM, 2020, pp 2105–2108. [Online]. Available: https://doi.org/10.1145/3340531.3412106
Acknowledgements
This work was supported by the Key Research Program of Zhejiang Province [Grant Numbers 2021C01109] and the Fundamental Research Funds for Alibaba Group through Alibaba Innovative Research (AIR) Program.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wu, S., Li, Y., Zhu, H. et al. Dynamic Index Construction with Deep Reinforcement Learning. Data Sci. Eng. 7, 87–101 (2022). https://doi.org/10.1007/s41019-022-00186-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41019-022-00186-4